1. Introduction
A percutaneous bone conduction device (BCD) is a viable solution for patients with a conductive or mixed hearing loss (HL) [
1,
2,
3], or with single-sided deafness [
4]. A BCD comprises of a sound processor fixated with a skin-penetrating abutment on a titanium implant (fixture) anchored in the skull. The sound processor converts sounds into mechanical vibrations that are transferred through abutment, implant, and skull to the cochlea.
By default, the effective gain of a BCD, defined as the bone conduction threshold minus the aided threshold [
5], rarely results in a complete closure of the air-bone gap. For example, in patients with conductive losses and average BC thresholds of 10 or 20 dB HL, an effective gain was found of −6 dB [
6] or −7 dB [
7], respectively. These findings were corroborated by [
5], showing negative effective gain values in patients with average bone conduction thresholds at 1, 2, and 4 kHz, up to 25 dB HL. It is thus worth investigating whether increasing gain relative to a default BCD target-gain prescription is beneficial to the listener. Given the small headroom of BCD devices for frequencies below 1 kHz [
8], and the relatively small contribution of low frequencies to speech intelligibility [
9], we decided to increase gain only for frequencies above 1 kHz.
The benefits of percutaneous BCDs have been clearly demonstrated using speech intelligibility measurements [
10,
11], and retrospective questionnaires such as the Speech Spatial Qualities (SSQ) [
11,
12] or the Abbreviated Profile of Hearing Aid Benefit (APHAB) [
10,
13,
14,
15]. However, independent data on real-life patient outcomes and limitations beyond listening tests in simulated real-world environments are lacking [
16].
Methods of evaluating listening benefits from BCDs are currently limited to laboratory settings or retrospective reports, which hinders investigations into real-life and context-specific benefits. Well-controlled listening tests do provide reliable data, but often lack validity, as actual real-life listening conditions can be vastly different from those inside the laboratory. Typically, laboratory testing of hearing abilities reaches its ceiling at negative or close to zero SNRs [
17,
18,
19], whereas real-world SNRs are rarely negative [
20,
21,
22,
23]. For example, Wu et al. [
22] report that 63% of their recorded real-world SNRs were between 4- and 14-dB; Smeds et al. [
20] reported a mode in the distribution of real-world SNRs between 2- and 6-dB. In contrast to laboratory-based listening tests, self-reports and questionnaires, such as the aforementioned SSQ and APHAB, have high face validity [
24,
25]. However, with retrospective self-reports, subjects need to memorize their experiences with certain listening situations, dating back days, weeks, or even months. This delayed recall may bias overall judgements, as subjects tend to put more emphasis on recent experiences [
26]. Additionally, when answering questionnaires, listeners need to aggregate and generalize experiences across various listening situations. Detailed contextual information of their experiences with specific listening situations, i.e., the ‘auditory ecology’ [
27], will get lost. Therefore, both listening tests and self-reports may not appropriately reflect real-world performance [
24,
28], and the retrospective nature of questionnaires prevents assessments of day-to-day changes (i.e., acclimatization) in the listening experience [
29].
An alternative to using traditional self-reports is the sampling of real-world experiences in situ, referred to as experience sampling or ecological momentary assessment (EMA) [
30]. With the EMA approach, listener experiences are captured on a wearable device, e.g., a smartphone, in real time. The EMA methodology has been shown to be feasible for hearing aid evaluation [
31] in exploring daily effects of tinnitus [
32], exploring benefits from hearing aid noise management [
33], and characterizing hearing problems of hearing aid users in everyday life [
26]. In parallel to the EMA, selected parameters of the ambient acoustic environment, i.e., the ‘soundscape’, can be logged in real-time with the smartphone-connected hearing device. The combination of listener experiences and acoustical data provides insights into listener-specific problems in daily life [
34,
35]. Although several studies have reported on everyday listening experiences of hearing aid users [
26,
31], only a few previous studies have employed statistical modelling of EMA responses with real-time acoustical data [
36,
37,
38] in order to identify targeted context-specific benefits.
The aim of this study is to evaluate whether a group of unilaterally fitted BCD users will benefit from custom high-frequency amplification, in addition to a standard prescription, under both real-life and laboratory conditions. Specifically, two listening programs differing only in high-frequency gain above 1.1 kHz are contrasted, and context-specific real-life outcomes are investigated with statistical modeling of in situ subjective listening experiences (EMAs), with real-time data logging of the ambient acoustic environment. The real-life outcomes are compared to traditional speech reception tests and retrospective questionnaires about listening experiences.
In supporting analyses, data logs of BCD volume control and day-to-day changes in EMAs are assessed. The latter is important for understanding acclimatization effects [
29], by establishing how subjects’ listening experience changes with days of use, while the former might provide insights into subjects’ behavioral patterns. Specifically, while the target-gain prescription is fixed among the subjects, volume control usage across the trial period might reveal individual needs for additional and personalized fine-tuning.
2. Methods and Materials
2.1. Subjects
This study was designed to include twenty experienced BCD users, all with an air-bone gap of at least 20 dB and BC thresholds on the fitted side better than 45 dB HL. While we originally aimed to include 20 subjects, due to COVID-19 ‘lockdown’ measures we closed this study after including 19 subjects. At their first visit, all subjects gave their informed consent to participate in the study. Subject characteristics are shown in
Table 1. The group was comprised of 8 females and 11 males with a median age of 47 years (range: 19–72 years). Seventeen subjects had about 5 years of experience with an earlier Ponto BCD (Oticon Medical, Askim, Sweden), whereas subjects 8 and 12 had 2 and 4 months of experience, respectively. The average bone conduction threshold at the fitted side was 20.9 dB HL (range: 3.8–36.3 dB HL).
Ten subjects (1, 3, 4, 8, 9, 10, 11, 14, 15, 18) had a bilateral conductive or mixed HL due to chronic suppurative otitis media (CSOM), and two subjects (5, 13) had a bilateral conductive loss due to congenital atresia. Five subjects had a unilateral HL due to CSOM (2, 6, 7, 12, 17). On the contralateral side, two subjects had normal hearing (2, 12), two subjects had a sensorineural HL (6, 7), and one subject had no contralateral hearing (17). Subjects 16 and 19 had a unilateral HL due to congenital atresia, with normal hearing on the contralateral side.
2.2. Devices
All subjects were fitted with a new Ponto 4 BCD with two listening programs. At the first visit, pure-tone thresholds were measured with a clinical audiometer (Interacoustics Equinox, Assens, Denmark) using TDH-39 headphones and a B-71 bone conductor, and BC in situ thresholds were measured with the BCD. From the BCD threshold, a default listening program (P
d) was created with the Genie Medical fitting software (Oticon Medical). This default program was copied to a custom program (P
c), and its gain settings were modified using an Excel worksheet implementing the following rule:
with G
0 = default gain for a 0-dB HL BC threshold.
Thus, both programs had identical gain settings for frequencies below 1.1 kHz, corresponding to the prescription of the Genie Medical fitting program. In Pd this prescription was also used for the higher frequencies, whereas in Pc an input-independent (linear) gain prescription (Equation (1)) was used with a modified third-gain rationale. The programs Pc and Pd were randomly assigned as listening program 1 or 2 in the BCD.
The rationale in Pc resulted in at least 5 dB more gain for frequencies above 1.1 kHz than with Pd, across all subjects. The average 1–4 kHz gain for input levels of 50, 65, and 80 dB SPL was 3.0, 7.2, and 11.7 dB higher for Pc than for Pd, respectively.
2.3. Experimental Procedure
2.3.1. EMA Field Test
During a 4-week trial period (actual days of testing varied, see
Table 2), subjects used the Ponto 4 BCD connected via Bluetooth to an iPhone, with an iOS research app from Oticon Medical for changing the listening program and volume (using 2.5-dB steps), for logging their in situ EMA responses, and for storing acoustical data of the momentary listening environment. Subjects without an iPhone received a loaner iPhone for the trial period.
For the trial period, Pc was randomly assigned as program 1 or 2. Subjects were encouraged to change the listening program as often as practically feasible. Upon changing the listening program, users were prompted to respond to a five-question EMA on a continuous scale: (1) How do you rate loudness? (2) How do you rate sound quality? (3) How suitable is this program for this environment? (4) Did you listen to speech? If yes: (5) How do you rate speech intelligibility? Henceforward, the four EMA questions are referred to as “Sound quality”, “Program suitability”, “Loudness”, and “Speech understanding”, respectively.
2.3.2. Follow-Up Laboratory Tests and Questionnaires
At the second visit (i.e., end of the trial), speech perception in quiet and noisy environments was measured for both listening programs. Speech-in-quiet was measured with NVA-monosyllabic word lists, comprising 11 consonant-vocal-consonant syllables per sublist [
39]. The sublists were presented at 40, 50, 60, and 70 dB SPL in free field with speech from the front. No contralateral masking was applied, mimicking real-life device use. The speech reception threshold (SRT) was calculated from the performance-intensity curve by interpolating levels that yielded scores just below and above 50%. Speech perception in a noisy environment was measured with the sentence material of Plomp and Mimpen [
40], with both speech and 65 dBA noise presented from the front. The SRT in the noisy environment was measured with an adaptive ‘one up, one down’ procedure with 2-dB steps, as suggested by [
40].
In addition, overall experiences with both programs were probed with “The Abbreviated Profile of Hearing Aid Benefit” (APHAB) [
41] and “The Speech, Spatial and Qualities of Hearing Scale” (SSQ) [
42] questionnaires, as well as with a proprietary preference questionnaire, using five-point Likert scales for clarity, loudness, and overall preferred listening program. The APHAB [
41] is a 24-item questionnaire for assessing hearing problems in daily life. The frequency of problems listeners had with communication or loud noises were scored on four subscales: ease of communication (EC), background noise (BN), reverberation (RV), and aversiveness of loud sounds (AV). The SSQ [
42] is a 49-item self-assessment of hearing disability in situations typical of real life. It comprises 14 items on speech hearing (speech), 17 items on spatial hearing (spatial), and 18 items on quality of sound (quality). All questionnaires were administered at the second session for the aided condition in order to obtain a direct comparison of both listening programs. At the end of this visit, the experimenter retrieved all logged data from the iPhone, comprising both the acoustical data by the BCD and the subject’s EMAs for further off-line analysis.
All users decided to keep their BCD. The BCD was programmed according to the subject’s preferences, the research app was removed from the iPhone, and the standard Oticon ON app for controlling the device and Bluetooth sound streaming was installed on the subject’s smartphone.
2.4. Data Logging and Data Pre-Processing
A time-stamped sound pressure level (SPL) and signal-to-noise (SNR) estimate, together with an acoustic analysis classifying the listening environment as ‘Quiet’, ‘Noise’, Speech’, and ‘Speech in Noise’ (soundscape), were logged and stored on the iPhone every 80 s of BCD wear time as long as the iPhone had a Bluetooth connection with the BCD. All measures are available in standard commercial Ponto 4 BCDs, and the acoustic data are similar to those logged by standard Oticon Op S behind-the-ear hearing aids (see Christensen et al., 2019 and Christensen et al., 2021 [
23,
43] for more details about the acoustic data). In brief, momentary sound input was recorded by two calibrated microphones situated in the hearing device and sensitive to sound across a frequency range of 0–10 kHz. The SPL is the level output estimate from a low-pass infinite impulse response filter with a time constant of 63 ms. The SNR was computed as the difference between a bottom tracker (noise floor), which was implemented with a dynamic attack time of 1–5 s and a release time of 30 ms, and the SPL (for an illustration, see Figure 10.3 in [
44]).
To obtain robust estimates of the ambient sound environment associated with self-reported listening experiences and BCD usage, each logged EMA and volume change (irrespective of listening program) were associated with the average of the three prior logged acoustic data samples. Thus, short-term sound exposure was associated to changes in both volume and ratings of the two listening programs. Note that since the BCD automatically sets the volume to 0 on reset and program change, all logged volume changes to level 0 were excluded from further analysis.
Observations were predominantly classified as belonging to either Quiet or Speech soundscapes (37.6% and 36.9%, respectively), with observations in Speech in Noise and Noise being sparse (18.3% and 7.3%, respectively). To increase statistical power, and given the high degree of overlap between Speech in Noise and Noise in terms of other acoustical characteristics [
23], we collapsed these two soundscapes prior to further analysis (henceforward called Noisy Speech or Noise).
2.5. Statistical Analysis
We applied linear mixed-effect (LME) modelling to associate EMA ratings with days of BCD usage, to associate ambient sound levels (SNR and SPL) with volume adjustments, and to predict EMA ratings based on soundscape data and listening program. In addition, random effects were included to adjust the models for contextual confounds. For the first case, inter-individual variability in offsets and slopes were adjusted for by including a random term for subject ID. For the second case, the random effect structure was expanded to also include offsets due to time (i.e., hour of the day). Lastly, for the third case, the random effects structure additionally included days of usage offsets (i.e., acclimatization effect), and offsets due to volume setting.
The listening program and soundscape categorical predictors were contrasted against baseline conditions Pd and Quiet, respectively, and LME models were compared using likelihood-ratio tests to ensure optimal model fit.
We used t-tests or Kruskal–Wallis and Wilcoxon signed-rank tests (when normality could not be assumed) for additional paired or un-paired comparisons, and all statistical analysis were performed in R (version 3.6.1, “The R Foundation for Statistical Computing”, Vienna, Austria), with packages “nlme” for LME modelling, “stargazer” for regression coefficient statistical evaluation, and “coin” for Wilcoxon signed-rank tests.
3. Results
3.1. Standard Measures of Hearing Performance
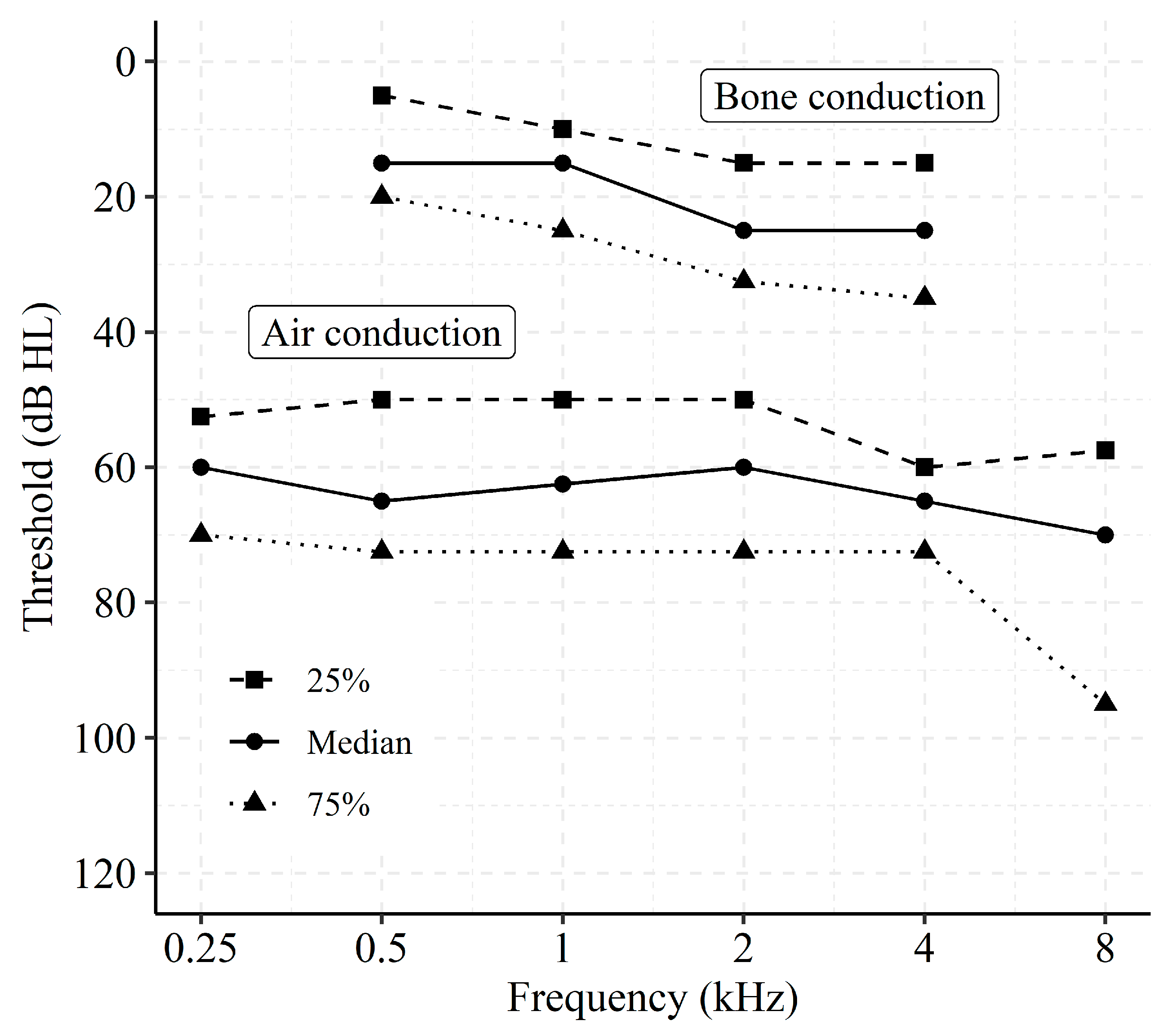
Figure 1 shows the distribution of air conduction thresholds and masked bone conduction thresholds for the fitted side, expressed in 25%, 50%, and 75% percentiles. Averaged across all subjects, the pure-tone average threshold at 0.5, 1, 2, and 4 kHz was 63.4 dB HL for air conduction and 20.9 dB HL for bone conduction.
At the second visit, speech-in-quiet was measured with frontal speech for both listening programs with NVA monosyllables [
39]. For the default program, the average SRT of 39.1 dB SPL (±1.4 dB, mean standard error) was significantly higher than the SRT of 36.9 ± 1.3 dB SPL for the custom program (paired
t-test;
t = 2.86, df = 18;
p = 0.01). The signal-to-noise ratios for sentences [
39] with frontal speech and 65 dBA frontal noise were −4.2 dB and −3.9 dB for the default and custom programs, respectively. This difference was not significant (paired
t-test;
t = 1.32, df = 18;
p > 0.05).
At the second visit, subjects filled in APHAB and SSQ questionnaires for the aided conditions. Mean scores of the APHAB questionnaire for the domains ease of communication (EC), background noise (BN), reverberation (RV), and aversiveness of loud sounds (AV) were 21.2 ± 2.8, 39.4 ± 3.6, 32.0 ± 3.6, and 39.1 ± 5.3 for the default program and 23.7 ± 4.3, 42.1 ± 4.6, 32.5 ± 4.2, and 44.9 ± 6.0 for the custom program, respectively. For the SSQ questionnaire, mean scores for speech, spatial, and sound quality were 6.4 ± 0.3, 5.1 ± 0.6, and 7.1 ± 0.3 for the default program and 6.2 ± 0,4, 5.2 ± 0.5, and 7.0 ± 0.3 for the custom program, respectively. The APHAB and SSQ scores were not significantly different for the two listening programs (paired t-test; APHAB EC: t = 0.59, BN: t = 0.70, RV: t = 0.16, AV t = 2.11; SSQ Speech t = 1.53, Spatial t = 0.30, Quality t = 1.29; df = 16; p > 0.05).
Data from a retrospective questionnaire using five-point Likert scales for the overall preferred listening program revealed that 9 out of 18 subjects (data missing from one subject) preferred the default program, 6 preferred the custom program, and 3 did not have a preference.
3.2. Data Logging and In Situ Reports
The total amount of logged data (usage, acoustic data, and EMAs) per subject is summarized in
Table 2. On average, data were logged for approximately 50% of the total BCD up-time (see
Table 2, right column). Both the amount of data logging and the number of EMAs differed for the two listening programs, but the differences were not significant (Wilcoxon signed-rank tests; z = −1.65,
p = 0.10, and z = −1.75,
p = 0.08, respectively).
We also investigated when and in which contexts EMAs were submitted.
Figure 2A shows density plots of the SPLs encountered by each subject when performing EMAs. It shows that subjects varied in their auditory ecology—that is, some subjects were exposed to challenging and loud environments (e.g., subject 5 and 10), whereas others predominantly submitted EMAs in quiet conditions (e.g., subject 8 and 12). Across all subjects, the 25, 50, and 75% percentiles of encountered SNRs were 3.2, 7.5, and 14.1 dB when performing EMAs, and 1.5, 4.3, and 10.4 dB during normal usage times, respectively. In addition, most EMAs were performed in Quiet and Speech environments (see
Figure 2B and
Table 2), and those EMAs were skewed towards later times of the day (afternoon/early evening). In contrast, EMAs submitted in more challenging listening conditions were predominantly made around morning/noon. These patterns align well with what would be expected from normal device usage; that is, the BCD were predominantly used in Quiet and Speech environments (36% and 38% of total use time—see
Table 2). A strong correlation between the relative amount of submitted EMAs and relative usage per soundscape indicate that, indeed, subjects in the current study completed EMAs in proportion to the time spent in these environments (Pearson’s product-moment correlation,
t(55) = 7.45,
r = 0.71,
p < 0.001). Thus, the listening environments associated with EMAs were comparable to the listening environments during periods without EMAs.
Lastly, since all subjects were new to the Ponto 4 BCD, we expect a certain acclimatization to the BCD, as has been reported for new users of BTE hearing aids [
29]. The grand average EMA rating for “Sound quality” was 5.8 (SD = 2.0) on the very first day of testing. This number increased to 7.11 (SD = 1.8) on the last day of testing, representing a 22.6% increase due to acclimatization.
Figure 3A shows average EMA ratings per question and per day since day one of the study, corrected for inter-individual variance in EMA scores (i.e., z-score transformed). Notably, ratings of “Sound quality” and “Program suitability” increased beginning around 17 days of use. We quantified the acclimatization effect by regressing (using LME modelling) EMA ratings for each question with number of days from day one of the study and allowed for random slopes and offsets per subject. The resulting regression coefficients (shown in
Figure 3B) indicate significantly increasing ratings for “Sound quality” (P
d:
β = 0.037, 95% CI = (0.008–0.067),
p = 0.013; P
c:
β = 0.036, 95% CI = (0.013–0.060),
p = 0.002), and “Program suitability” (P
d:
β = 0.041, 95% CI = (0.013–0.070),
p = 0.004; P
c:
β = 0.046, 95% CI = (0.023–0.069),
p < 0.001) with days of use. This effect did not differ significantly between the listening programs.
Comparing In Situ with Retrospective Preference Reports
In situ EMAs for each subject and listening program were averaged across time and EMA questions to represent “overall in situ preferences” (i.e., thereby disregarding specific listening conditions). In this respect, the overall preference refers to the average rating of “Sound quality”, “Speech understanding”, and “Program suitability” when conversation was indicated, and otherwise to the average rating of only “Sound quality” and “Program suitability” when subjects indicated that no conversation was taking place.
Figure 4 displays the overall in situ preference as difference scores (i.e., mean preference for P
d minus mean preference for P
c) on the
x-axis against the retrospective preference on the
y-axis. The in situ preference was slightly higher for P
d (mean difference = 0.14, SD = 1.06), albeit not significantly different (Wilcoxon paired signed-rank test, z = −1.33,
p = 0.18). Moreover, “Loudness” ratings were higher for P
c than for P
d (mean difference = −0.47, SD = 1.13), but this difference was also not significant (Wilcoxon paired signed-rank test, z = 1.73,
p = 0.08).
Notably, the in situ overall preference aligned well with the retrospective preference reports. However, four subjects (4, 6, 8, and 14) did not exhibit a clear in situ preference compared to in the retrospective reports, and one subject (9) exhibited a slightly higher overall in situ preference for Pd while preferring Pc at the retrospective follow-up questionnaire.
3.3. Insights from Volume Control Logs
We hypothesized that volume control logging reveals behavioral insights in support of the EMA evaluation of listening experiences with the BCD listening programs. Thus, we investigated whether volume control differed among the two listening programs in terms of overall level usage and level changes.
The volume control varied considerably among subjects and listening programs (see
Figure 5A). Some subjects did not use volume control at all (e.g., subject 6), whereas others preferred to generally use lower (e.g., subject 5) or higher (e.g., subject 13) volume levels compared to the default setting (0 dB volume setting). In addition, more volume changes to levels above 0 were made for P
d (see
Figure 5B). In total, 1026 volume adjustments (mean = 54, SD = 71) were made during the EMA trial period.
To quantify volume control, a linear-mixed effect (LME) model was applied to predict volume level changes from listening program and acoustic data. This tested whether subjects actively used the volume control (i.e., reacted to changes in the listening environments) and whether this behavior could potentially differentiate between the two listening programs. The applied LME model is described by:
with fixed effect regression coefficients,
to
, and random effects offsets
and
. Note that the acoustic predictors SPL and SNR were centered and scaled prior to modeling, which means that the intercept predicts the volume for the observed grand mean SPL and SNR.
The regression coefficients in
Table 3 show that volume changes were overall 0.74 step lower for P
c compared to P
d when evaluated at the mean observed levels of SNR and SPL. In addition, subjects preferred a lower volume when SPL increased, but a higher volume when SNR increased. A significant interaction between SPL and listening program indicates that this volume sensitivity was more pronounced with P
c than with P
d. This pattern was not driven by SPL and SNR being inversely correlated, since variance inflation factors post modeling were low (2.2 for SPL and 2.9 for SNR). Instead, the pattern indicates that ambient SPL (e.g., related to loudness perception) and ambient SNR (e.g., related to signal perception) modulated changes in volume preference, and that subjects were more sensitive towards change in SPL when using the high-frequency gain program.
The LME model explained 48.8% of the variance in all volume changes. Out of this, 3.7% of the variance was contributed by the fixed effects (SPL, SNR and listening program) alone, whereas individual differences (i.e., different average volume per subject) captured 43.8% of the total explained variance. The remaining explained variance was captured by hourly fluctuations in volume changes.
3.4. Statistical Modeling of In Situ Reports
Average in situ ratings (
Figure 4) and retrospective APHAB and SSQ scores did not reveal any significant differences in listening experience with the two listening programs. However, as highlighted in the previous section and shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5, inter-individual (e.g., device usage, volume control) and contextual factors (e.g., time of day, sound environments) contributed to variance in EMA ratings. Thus, averaging across time, subjects, and listening environments might mask differences in listening experiences with the two listening programs. Therefore, in this section, EMA ratings are assessed while considering contextual factors.
In
Figure 6, boxplots of the average EMAs for each subject (individually scaled and centered) are shown stratified by soundscape and listening program. Across soundscapes, P
c was rated higher than P
d on “Loudness” (P
c: M = 0.17, 95% CI = 0.15; P
d: M = −0.16, 95% CI = 0.13), but lower on the “Sound quality” (P
c: M = −0.02, 95% CI = 0.15; P
d: M = 0.16, 95% CI = 0.11) and “Program suitability” (P
c: M = −0.03, 95% CI = 0.12; P
d: M = −0.17, 95% CI = 0.10) questions.
For the “Speech understanding” question, Pc was again rated higher than Pd but only for Quiet and Noisy Speech or Noise soundscapes. For the Speech soundscape, “Speech understanding” was rated slightly higher with Pc than Pd (Pc: M = 0.13, 95% CI = 0.16; Pd: M = 0.00, 95% CI = 0.19).
To allow for statistical testing and targeted context-dependent evaluation of in situ listening preferences (
Figure 6), individual ratings of each EMA question were modelled using linear-mixed effect (LME) models, adjusted for variance due to inter-individual baseline offsets and sensitivity towards soundscapes, time-of-day, days since study start, and volume setting. Another advantage of using LME models for EMA data is that the modelling outcomes are appropriately weighted by sample sizes, which differed among the subjects (
Table 2) and listening conditions (
Figure 2).
The fixed-effects independent variables for LME modelling were listening program (P
d vs. P
c), soundscape, and the interaction between the two. The associated regression coefficients are presented in
Table 4.
At baseline levels, the marginal effects indicate that “Program suitability” ratings were higher in the Speech compared to the Quiet soundscape with Pd. In addition, ratings of “Loudness” were higher with Pc than with Pd in the Quiet (baseline) soundscape. The significant interactions between soundscape and listening program suggest that “Sound quality”, “Speech understanding”, and “Program suitability” were all rated lower with Pc than with Pd in Noisy Speech or Noise soundscapes. In addition, the higher rating of “Loudness” with Pc was also present in Speech soundscapes but not in Noisy Speech or Noise soundscapes.
In summary, LME modeling revealed that the additional high-frequency gain in the custom listening program yielded higher ratings of “Loudness” for Quiet and Speech soundscapes and lower ratings of “Sound quality”, “Speech understanding”, and “Program suitability” for the more challenging Speech in Noise and Noise soundscapes.
We also checked whether adjusting for volume, time, and day in the LME models was warranted. That is, we assessed whether these contextual factors affected how ratings were performed in the trial period. Each fitted model was compared to more simple models that only adjusted for inter-individual differences in EMAs. In all cases, adding the additional contextual parameters as co-regressors significantly improved model fits when testing with likelihood ratio tests (Loudness: dAIC = 10, Chi2(2) = 16.10, p = 0.001; Sound quality: dAIC = 74, Chi2(2) = 79.88, p < 0.001; Speech understanding dAIC = 60, Chi2(2) = 66.37, p < 0.001; Program suitability dAIC = 49, Chi2(2) = 55.10 p < 0.001).
4. Discussion
Differences in listening abilities and experiences with two BCD listening programs were investigated in a heterogeneous sample of 19 unilaterally fitted subjects. The listening programs differed only in high-frequency gain. Laboratory measures of speech reception thresholds revealed a significant benefit of the additional high-frequency gain in the speech-in-quiet condition, but not for the speech-in-noise condition. Moreover, retrospective preference ratings with the SSQ and APHAB questionnaires did not reveal significant differences in listening experiences with the two listening programs. However, Ecological Momentary Assessments (EMAs) combined with data logging of the auditory ecology of subjects identified distinct patterns in listening experiences. The additional high-frequency gain resulted in higher “Loudness” ratings in quiet and pure speech listening environments. On the other hand, the default prescribed listening program was rated higher on “Sound quality”, “Speech understanding”, and “Program suitability” when in noisy speech or noise conditions. These findings suggest that additional high-frequency gain can be beneficial for speech understanding, but only in quiet and ideal listening conditions driven by an increased audibility (i.e., higher “Loudness” rating). In fact, EMA data indicated that additional high-frequency gain resulted in real-world listening experiences that were judged as too loud, even for the pure speech soundscape. Thus, the data do not provide evidence for the hypothesized benefit in speech recognition from the availability of more high-frequency speech cues [
9,
43,
45]. Instead, the results suggest that real-life experiences should be considered more closely when fitting high-frequency amplification in BCD users.
Subjects tended to use the volume control differently with the two programs and used overall lower levels of volume with the custom gain program, most likely to compensate for the additional high-frequency gain. By analyzing volume control logs, we were able to identify global patterns of volume control. Specifically, we found that subjects preferred to change to higher levels of volume when in optimal listening environments (i.e., high SNR), whereas lower levels of volume were activated when the sound pressure levels increased and vice versa. In addition, volume preferences depended on the listening program, with higher volumes being preferred for the default compared to the custom high-frequency gain program. This corroborates well with the documented increase in loudness perception when using the high-frequency gain program. However, strong inter-individual differences in volume control were evident. That is, some subjects consistently changed to higher or lower volume levels than the default level (see
Figure 5, e.g., subject 5 and 8), independent of listening program. The inter-individual differences in volume control were not explained by HL characteristics (
Table 1). Instead, abnormal volume control (i.e., more often choosing a level different than the default) might indicate an insufficient fitting—that is, a fitting with consistently too little or too much gain according to an individual’s needs and listening preferences.
A possible explanation for the discrepancy between benefits of custom high-frequency gain in the laboratory versus in real-world could be because of the difference in testing hearing at threshold levels (i.e., small or negative SNRs and low SPLs) and relating listening experiences to supra-threshold listening conditions (i.e., real-world conditions). The documented SRTs, which were statistically different between the two listening programs, were 39.1 dB SPL for P
c and 36.9 dB SPL for P
d. These levels are much lower than the ones faced in real life [
34,
44], and lower than the levels associated with EMA submissions in the current study (See
Figure 2). In addition, the encountered real-world SNRs vastly differ from those during laboratory testing. In fact, only 6.8% of the recorded SNRs during normal BCD usage in the current study had levels less than zero, and the 25% and 75% quantiles were 1.5- and 10.4-dB SNR, respectively. Furthermore, the subjects encountered slightly higher SNRs when performing EMAs compared to periods of normal BCD usage (median SNR when performing EMA was 7.5 dB, and 4.3 dB for normal BCD usage). Thus, the additional high-frequency gain expected to aid in speech perception was most likely not necessary in everyday usage, since SNRs were favorable.
A possible solution for increasing real-world speech perception by increasing high-frequency gain would be to implement fast acting compression on the acoustic sources and take the ambient SNR into account [
46]. Compression in the custom high-frequency gain program would have reduced high-level gain differences between both listening programs, and it would have reduced effects of device saturation for high-level inputs.
The relatively high real-world SNRs documented in our study are comparable to those found in previous studies [
20,
22,
23]. This indicates that despite differences in recording equipment, SNR estimates in the current study derived directly from the BCDs are valid. In addition, the distributions of EMAs per soundscape and time of day (
Figure 2B) are comparable to those previously found in studies using the EMA methodology to assess behind-the-ear (BTE) hearing aid benefits [
35]. This suggests that the distributions are shaped from normal device usage patterns (e.g., Speech in Noise soundscapes naturally occurring more often during noon/midday activities), and that usage patterns are similar among BTE and BCD users. The current study therefore validates the use of EMAs for evaluating listening experiences in BCD users and expands upon previous work by including behavioral insights from data logging to support the EMA outcomes. Crucially, data logging ensures that confounding factors can be adjusted for when modeling the EMA reports. For example, ecological behavior will entail user changes in volume control (e.g.,
Figure 5), which if not adjusted for, will skew the EMA modeling outcomes and produce worse model fits.
Besides providing evidence of everyday listening experiences, the current study shows that EMA data can help track day-to-day acclimatization to hearing device features. None of the subjects in the current study had prior experience with the Ponto 4 BCD, and a certain acclimatization would therefore be expected [
29].
Figure 3 shows that acclimatization (i.e., change in EMA rating per day) is especially pronounced in questions of “Sound quality” and suitability of the listening program, whereas there were no significant effects of acclimatization in ratings of “Loudness” or “Speech understanding”. Thus, retrospective questionnaires targeting multiple dimensions of listening experiences will inevitably be differently affected by the level of acclimatization achieved and the time point at which such questionnaires are given. Moreover, as the test-retest reliability of EMAs has been found to be high [
47], any acclimatization effect identified by day-to-day changes in EMAs reflects real changes in listening experiences.
In summary, our current findings highlight the potential of supporting traditional outcome measures of assistive hearing technology with ecologically valid EMA and real-world data logging. Outcome measures from laboratory tests typically target threshold hearing abilities under artificial conditions, whereas real-world EMA and data logging assess both on-the-spot subjective listening experiences and objective dimensions of hearing health behavior (e.g., sound exposure, volume/program control, device usage times), which are important for interpretation of EMA ratings.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}