1. Introduction
Glaucoma is an optic neuropathy of asymptomatic progression and characteristic visual field loss that can lead to total and irreversible blindness. It is estimated that in 2013, 64.3 million people aged 40 to 80 years were diagnosed with glaucoma, and this number is expected to increase to 76 million by 2020 and 111.8 million by 2040 [
1]. In most cases, the disease has a slow and asymptomatic evolution. At the time of diagnosis, many patients have already had some degree of visual damage with varying degrees of disability for work and activities of daily living. The situation worsens with a lack of specialists and equipment, and many cases may be under-reported. Therefore, there is a need to popularize glaucoma screening through cheaper techniques that serve many people. Early diagnosis and treatment can delay the progression of glaucomatous disease. Currently, it is estimated that half of all glaucoma patients remain undiagnosed. Detecting this substantial number of undiagnosed patients is a significant challenge [
2].
In recent years, deep learning techniques have demonstrated the potential to solve complex problems involving images and medical domains, such as automated glaucoma screening. For example, in visual field examination, deep learning has been shown to differentiate between normal visual fields and those with pre-perimetric glaucoma [
3]. Still, the scope of glaucoma screening using these techniques is not yet defined.
In medicine, the use of artificial intelligence (AI), through deep learning techniques, has shown potential for population screening and reducing glaucoma progression in patients waiting for help from professionals, facilitating populations’ access to early diagnoses, especially in more distant locations, which standardizes diagnostic results and even decreases diagnostic divergence between specialists. However, AI offers only one reference for a clinical diagnosis. Thus, medical specialists will always be responsible for diagnosis and treatment [
4]. In other medical areas, deep learning methodologies are used to segment lungs, brain, cell mitosis, prediction of development, progression of myopia [
4], and diagnostics in the digestive system. So far, in ophthalmology, two AI algorithms have been approved by the FDA for clinical use. One is IDX-DR, which can detect diabetic retinopathy (DR), and the other is Viz.AI, which analyzes images for indicators associated with a stroke [
4].
Color fundus photography (CFP) is a cost-effective and non-invasive way to analyze the retina [
5,
6]. CFPs are considered a significant element in glaucoma screening in clinical practice and deep learning methodologies. Public databases contain a set of color photographs used for training deep learning (DL) algorithms intended to screen for various retinal pathologies such as diabetic retinopathy, diabetic macular edema, and glaucoma. In clinical practice, CFPs are analyzed with other clinical data such as intraocular pressure measurements (IOP), automated perimetry, and optical coherence tomography (OCT) to diagnose glaucoma. However, large-scale population screening programs based on traditional clinical methodologies are not employed, as they are uneconomic [
7]. In addition, they can generate many false positives, creating a burden on public health infrastructure and a harmful condition on the patient’s quality of life until the glaucoma diagnosis is ruled out [
8].
Public databases have diverse characteristics that make it difficult to correlate data. For example, some databases present the optic disc (OD) segmentation and cupping made by experts and grouped into sets of “normal” and “glaucomatous” papillae based on appearance. Others give classifications based on patient chart data and show evolving stages of glaucoma, i.e., an early, moderate, and severe glaucoma group.
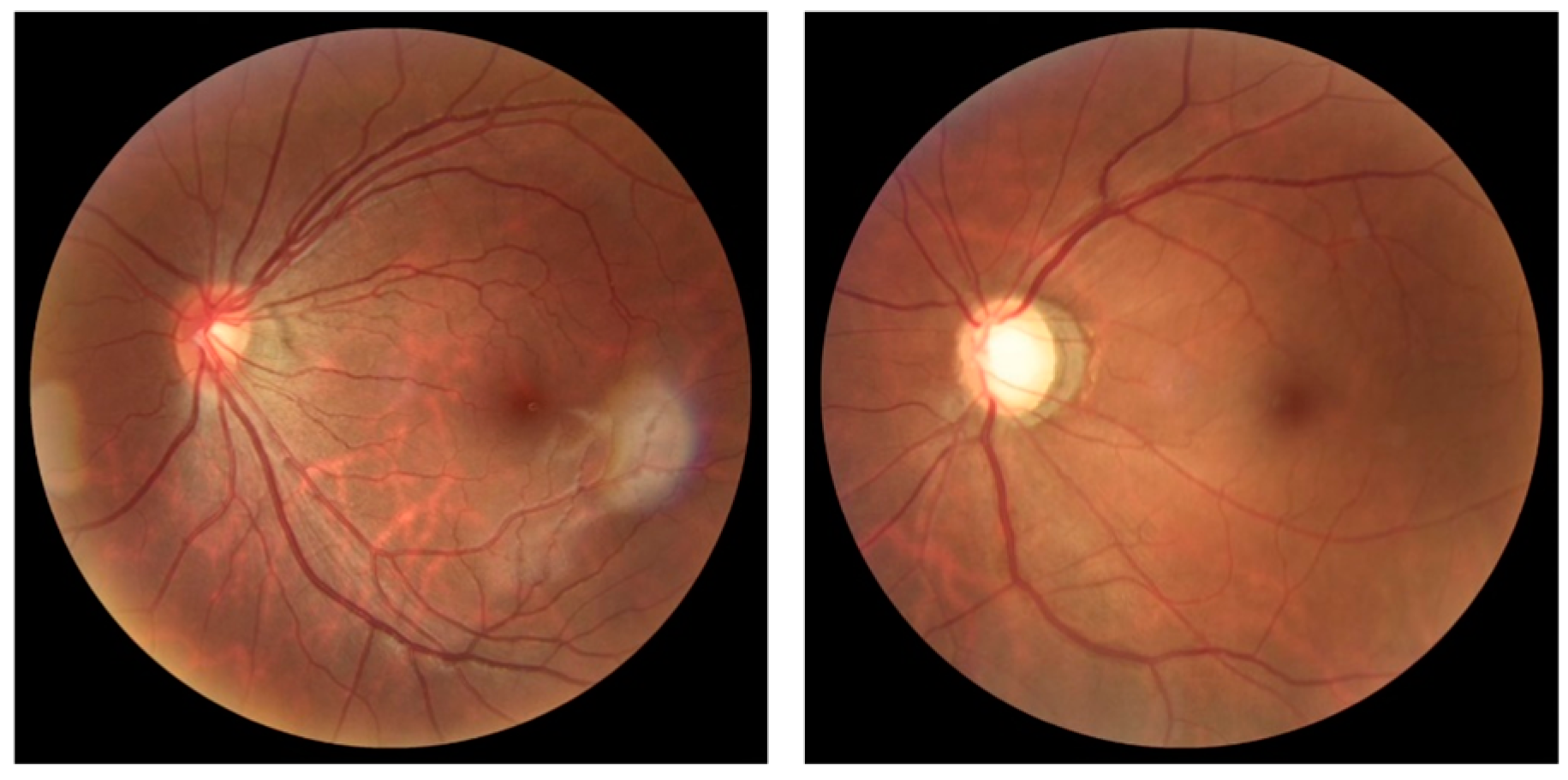
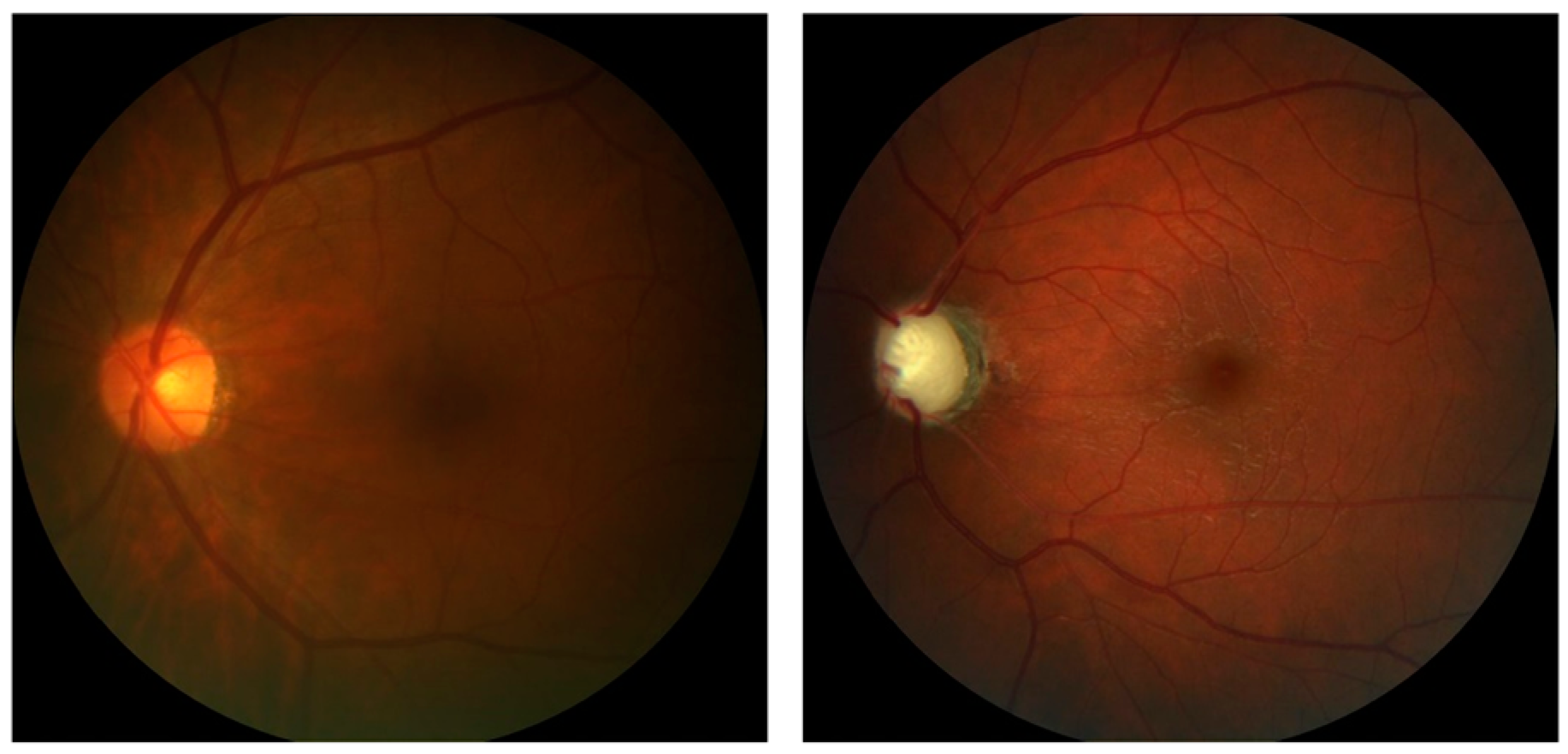
Other retinal pathologies concomitant with glaucoma should be evaluated in clinical practice. The specialist can diagnose them through clinical data or examination findings. Color retinography is an element of immense importance for diagnostic aid and will undoubtedly demand an excellent function of the algorithms to embrace a more comprehensive diagnostic range.
In the development of deep learning databases and architectures, a significant research effort is being made to introduce tools for the segmentation of the OD and the optic cup in CFPs and to identify glaucoma cases based on clinical features [
9,
10,
11]. However, the approaches used in different databases cannot be adequately compared due to the lack of a single validation protocol [
8] and the limited size of the available datasets. In addition, the absence of large-scale glaucoma imaging datasets has hampered the rapid deployment of DL techniques to detect the pathology [
12] and the lack of a strategy for marking papillae and excavation boundaries (BENCHMARK) and hinders uniform comparison of existing methods [
8].
The optic papilla region includes several anatomical variations considered normal in the population. In addition to spatial and non-overlapping differences between the images of right and left papillae, these variations include the insertion of the nerve in the eye, the size, and excavation of the papilla, vascular emergence, pigmentation, and the peripapillary region. Many variables may be presented as different fingerprints in a population capable of influencing the training and the results of neural networks. Therefore, there is a requirement to constantly update the datasets and establish protocols for the images integrated with clinical data and ancillary tests. In addition, there is a need to define the training and validation set of the public databases, develop automated tools for segmentation and classification of the CFP to reduce data deficiency, and ensure more reliable results for effective glaucoma detection. Public databases adapt to these requirements through the challenges for segmentation and classification as in REFUGE and, more recently, another challenge, “Artificial Intelligence for RObust Glaucoma Screening” (AIROGS).
This study aims to analyze the gold standard public databases for glaucoma analysis and offer recommendations to improve their contributions to the learning of neural networks showing significant advances for automated screening of glaucomatous papillae. It is divided into five main topics: a few fundamentals of glaucoma, deep learning in the context of artificial intelligence, fundamentals of the existing public databases for the study of the retina, and fundamentals considered the gold standard for the study of glaucoma. Finally, various recommendations will be analyzed to improve existing databases and those used in the future.
3. Fundamentals of Deep Learning in the Context of AI
Some fundamentals of deep learning within artificial intelligence will be analyzed, with an emphasis on application, the challenges of large-scale application, and ways of applying DL architectures in automated glaucoma classification.
As a subarea of artificial intelligence, machine learning (ML) algorithms deal with large datasets such as thousands of images, facilitating the resolution of problems that would be impractical through classical statistical analysis. In turn, deep learning is a sub-area of machine learning that operates data analysis through the representation of successive layers (neural networks) inspired by the human brain. Each layer could filter specific properties and select more relevant characteristics that have significant applications in medical diagnosis problems, allowing complex representations to be learned and divided into intermediate spaces (layers). Deep learning has demonstrated a vast applicability potential in the medical area by improving image accuracy, processing, and identification of diagnostic relevant features in radiographic images, tomography, ultrasonography, histological analysis of organs and tissues, and photographic analysis images. Deep learning can identify features within a complex structure in large datasets using multiple intermediate layers positioned between the input and output layers (as seen in
Figure 2), allowing each layer to learn to transform its input signal to the next layer. It has shown considerable utility in discovering intricate structures in complex data such as medical images. The key to the successful operation of these methods is having enough data to train and evaluate the system. Furthermore, the validation of these methods requires a reference standard that can be used for comparison, i.e., having public retinography databases that satisfy several requirements, which should also be clearly defined [
19].
The deep learning workflow can be defined in three steps: (1) pre-processing of image data; (2) model training, model validation, and testing; and (3) evaluation. Pre-processing includes noise reduction, feature selection and extraction from the image, and data normalization. A model to be trained is initially divided into three sets: training data, validation, and testing. The training set allows the model to learn to fit the data parameters of the classifier. The validation set prevents overfitting. The test set is used to evaluate the performance of the trained model. The data provided by the public databases will be used in the training step of the deep learning algorithms. For best results, the data need to be dependable and offered in a sufficient quantity to train and evaluate the system.
3.1. Challenges in Applying Deep Learning on a Large Scale
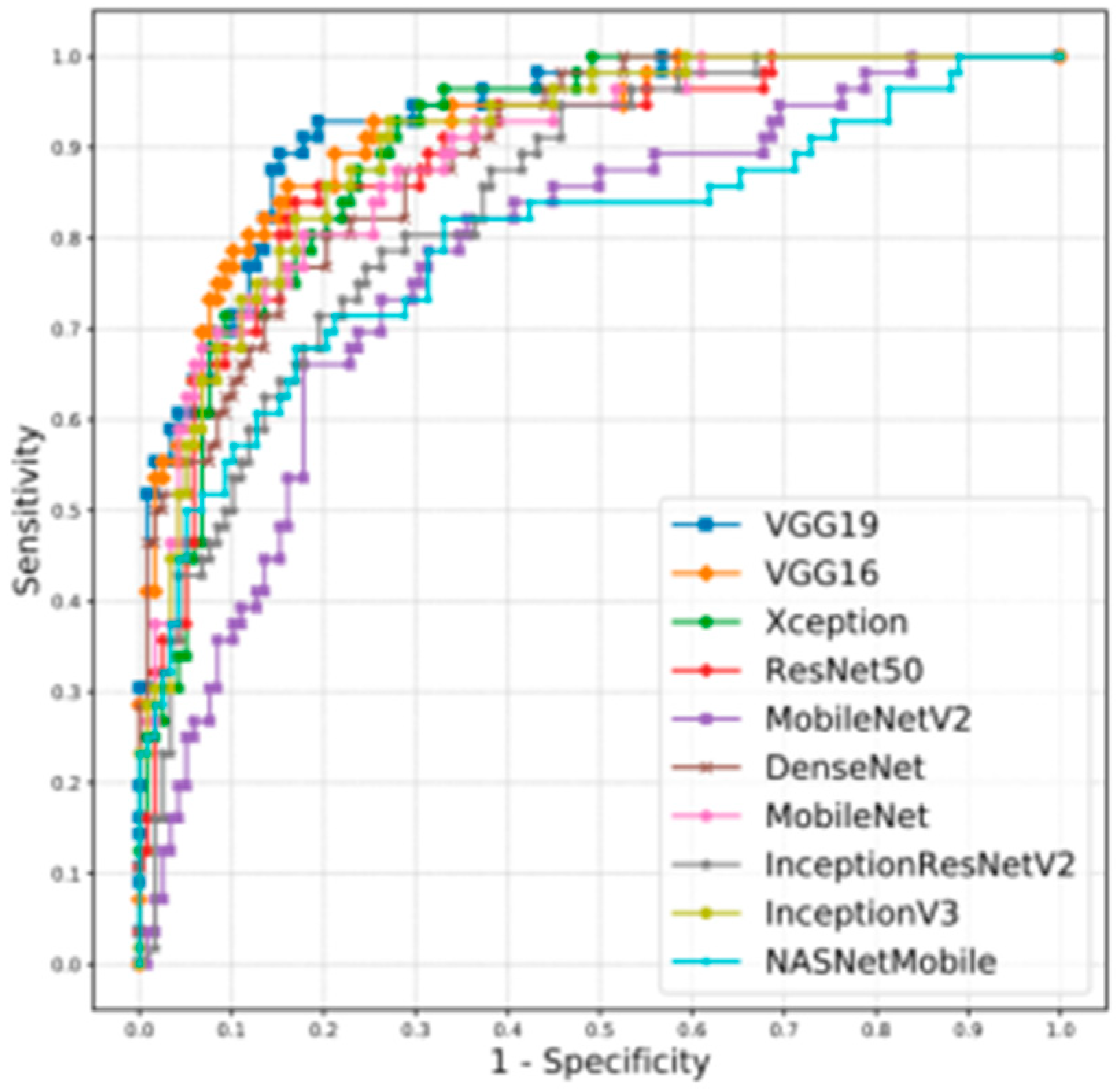
Many of the main challenges for problem-solving through DL architectures are generated by protocol deficiencies in defining public databases. If the databases do not appropriately train the networks, it may be misleading to networks’ responses. Gold standard public databases such as DRIHTI-GS, RIM-ONE DL, and REFUGE offer a reduced dataset and few data for training/testing. For example, data are classified into glaucoma and non-glaucoma groups based on imaging alone in the case of the RIM-ONE DL database, and there is no information on which clinical bases the clinical classification used in the DRISHT-GS1 and REFUGE databases were based. Furthermore, no public database presents images of the papillae of both eyes. The lack of standardized strategies makes it difficult to compare existing methods [
8].
According to [
4], automated DL techniques may provide false negative results from ocular diseases such as optic neuropathy coexisting with pathological myopia, retinal detachment, and senile macular degeneration. False-positive results arise from other ocular conditions, including increased physiological cupping. In addition, other challenges affect the accuracy of diagnostic results and represent obstacles in large-scale applications of AI technology, such as few standardized sets for training, a limited number of datasets with low anatomical representativeness of normal and glaucomatous papillae, and differences in the quality of images used in different countries, regions, and medical institutions. This inevitably affects the accuracy of image analysis, which may represent a higher computational expense and produce inaccurate results, especially in the early stages of the disease that require the analysis of peripapillary fibers. Furthermore, AI cannot provide the physician or other users with the rationale for the diagnosis. There is no explanation for why the differences exist or the pathological basis of the differences that could affect physicians’ acceptance of these devices in clinical applications. The bases do not show images of the right and left eyes of the same patient, an element widely used in clinical practice for the comparison of cup size because of the asymmetric feature in disease progression.
3.2. Automated Classification of Glaucoma
Automated recognition of glaucomatous papillae in CFPs by DL techniques can be performed in two ways: by directly recognizing glaucomatous features in the optic papilla by DL architectures and by segmenting the disc and excavation of the optic papilla. Existing DL approaches are based on adaptations of supervised DL techniques [
8], i.e., techniques capable of “automatically learning” features by analyzing large training sets of segmented images [
20] not offered by databases. Through deep learning classifiers, multiple retinal vascular diseases may be distinguished with an accuracy above 80% and may be a valuable instrument in areas with a shortage of ophthalmic care [
21].
3.2.1. Classification of Glaucoma Directly through Deep Learning Architectures
Automated glaucoma classification directly by DL architectures classifies an input image as glaucoma or non-glaucoma based on the visual characteristics of the optic papilla and the segmentation of the optical disc and cupping. It can be divided into methods based on image similarity, manual techniques, transfer learning methods, and OD limitation.
DL methods produce glaucoma diagnosis through image similarity. They need a large dataset for learning networks. Historical and clinical data extracted from the medical consultation can complement DL model features and give reasons for neglected diagnosis results [
22].
Manually handcrafted methods used for excavation/disc segmentation are used for feature extraction techniques and ML classifiers using supervised or unsupervised techniques [
9,
10,
11]. However, they exhibit limited accuracy due to the inability to characterize the onset of disease.
Transfer learning methods are based on pre-trained architectures with non-medical data. They use weights learned from ImageNet. Russakovsky et al. [
23] and Gómez-Valverde et al. [
13] applied a set with more than 14,000 images to train these networks, although at the cost of lower performance [
8].
Methods with OD and OC restriction restrict the analysis area to the OD affected by glaucoma. Limiting the image of the optic papilla allows a better exploration of its features and results in better learning performance of the automated models than at full size but determines a substantial restriction in the field of view of the networks and hinders their ability to learn alternative features of other regions [
24]. However, it determines a substantial restriction in the field of view of networks. Furthermore, it hinders their ability to learn alternative characteristics of other regions, for example, the analysis of areas of atrophy of peripapillary fibers, limiting the early diagnosis of glaucoma.
3.2.2. Classification of Glaucoma by Disc Segmentation and Cupping
Excavation segmentation from a retinal image is challenging due to the lack of depth view in 2D images but is relevant because it helps assess glaucomatous damage to the optic nerve head (ONH) [
10]. Furthermore, the papilla region has several anatomical variabilities that are considered normal. It can be interpreted as a false positive by neural networks, such as oblique insertion of the optic nerve, more prominent papillae, and peripapillary atrophies myopia. Most methods use techniques to locate the optic papilla area and then crop the images around it [
25,
26,
27,
28,
29]. It avoids false positives in regions containing severe illumination artifacts and improves the analysis of the optic papilla but does not differentiate it from other structures of the eye fundus. The precise delineation of the OD is especially difficult in pathological changes such as peripapillary atrophies or hemorrhages [
9,
11]. Large vessels in the OD area lack depth information in the CFP [
8].
6. Discussion
Analysis of the results and recommendations will be made to improve the databases and make cross-sectional annotations in the dataset feasible. The public databases’ main limitations and the results’ clinical implications are discussed below.
The bases RIM-ONE-DL [
19], DRISHTI-GS [
53], and REFUGE [
8] have proved to be beneficial for the automated study of the papilla by including the following features: classification between normal and glaucoma eyes, segmentation of the OD, and excavation and differentiation of the test and training groups. The DRISHTI-GS database contains images with the centralized optic papilla and a periphery of about 30 degrees around the papilla. It allows the visualization of the excavation features and sectorial defects in the fiber layers, an element considered in early classification. The REFUGE database includes groups of normal and glaucoma eyes pre-classified based on the evaluation of the patient’s clinical records (not in the presentation), including fundus images, ocular pressure measurements, OCT images, and visual field, with images of glaucoma eyes corresponding to patients with reproducible glaucomatous damage. Only REFUGE and RIM-ONE DL meet the additional requirements of offering images from different cameras and clear training and test data [
8]. Only the REFUGE database was classified based on clinical records or subsidiary examinations.
A synopsis of the main advantages and disadvantages of the gold standard public databases used in glaucoma is shown in
Table 12.
As analyzed in Trucco et al. [
35], the lack of predefined partitions in training and test sets induces a chaotic practical application of existing data that affects the direct comparison of the performance of existing methods, making it difficult to conclude which features are more appropriate to solve each task.
6.1. Recommendations to Improve the Databases
The recommendations for improving the databases suggest a set of protocols to avoid errors in training and make the training of DL nets closer to reality.
Data should be continually updated to encompass the normal and pathological anatomical diversities of the fundus of the eye.
There should be a more representative dataset including a diversity of ethnicities, comorbidities, genders, and ages; comparative photographs of both eyes; and color fundus photographs with varying qualities.
A percentage of glaucoma cases should be maintained that is similar to that expected in a population-screening scenario estimated to be between 1% and 2% in the general population, reaching 6% to 7% after 70 years [
59].
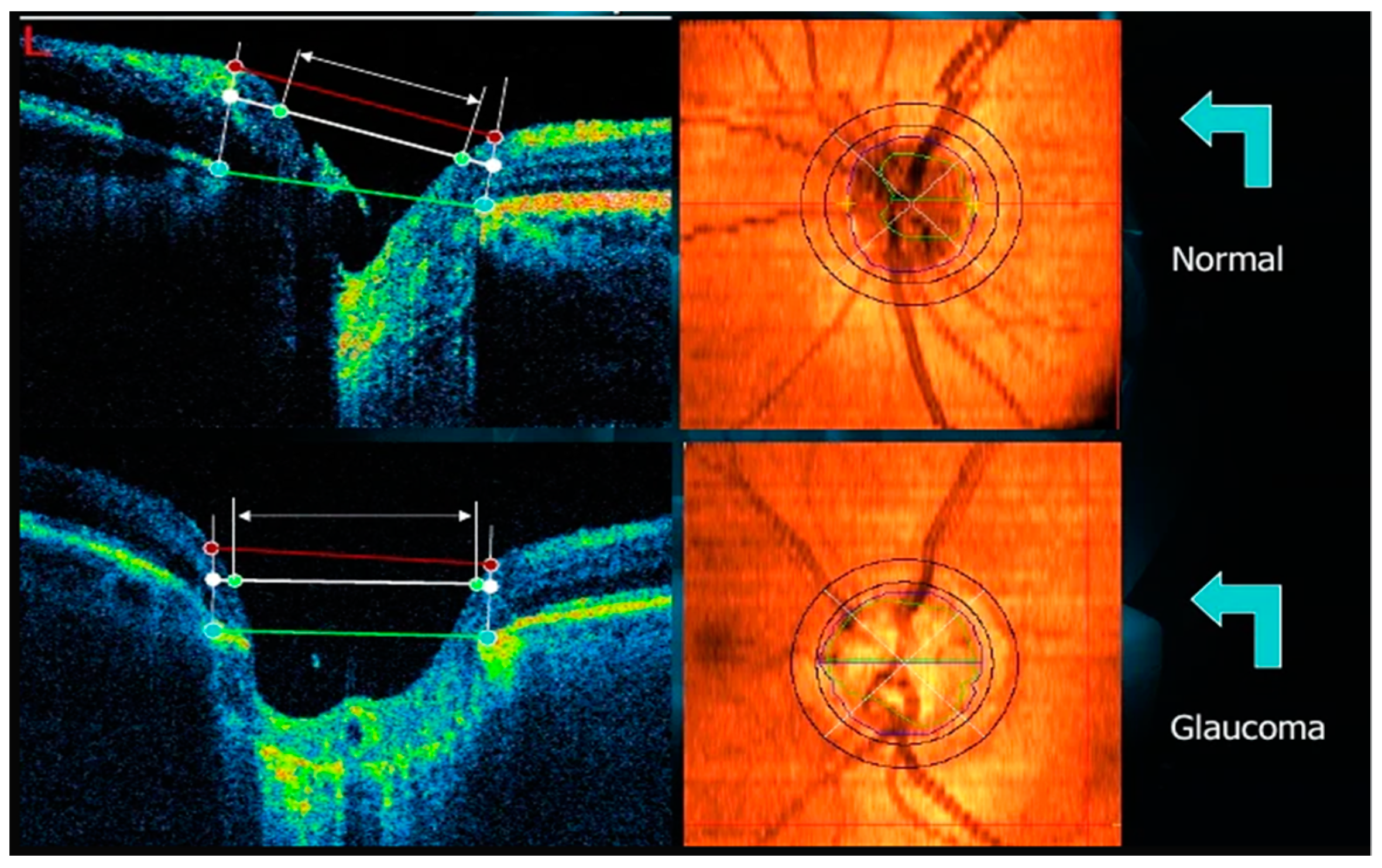
Manual disc and cupping segmentations and binary ground truth classifications performed from CFPs should consider cupping depth information from OCT scans, which provide cross-sectional retinal images (and thus depth information) and reference Bruch’s membrane, which is considered to be the best anatomical delimitation of the OD, and serves as a reference for one of the most recent measurements of the number of retinal nerve fibers (BMO-MRW) [
60]. The complementarity of CFP and OCT for automated glaucoma screening still needs to be explored.
Protocols should be made available for the analysis of medical records used as the basis for glaucoma/non-glaucoma binary classification to allow other comorbidities that may accompany glaucoma to be addressed.
6.2. How Public Databases Can Contribute
The databases can contribute to more reliable and accurate results for the training/testing groups, increasing the accuracy of the screening results of the DL networks regarding the segmentation and binary classification of the normal/glaucomatous papilla through images.
6.3. Feasibility of Annotating across All Datasets
Cross-sectional annotation of datasets using homogeneous protocols could increase the available data and improve the network results. Therefore, to validate a cross-sectional annotation, the images should be repositioned and submitted to homogeneous criteria of disc segmentation and cupping, and a re-analysis of the binary classification between normal/glaucomatous papillae based on clinical data and ancillary tests such as visual field and OCT should be performed, since the analysis by image similarity increases the number of false positives, as reported. The grouping of images with irregularities not yet visible at the inner border of the neural layer but with corresponding initial perimetric alterations would bring advantages in the early diagnosis. Sets of betterand worse-quality images obtained by different cameras in distinct locations and populations could be used in the training of neural networks as parameters closer to reality. Another point of divergence for the network is the presentation of the right papilla image and how the networks would interpret the sample of the left papilla since the papillae of the two eyes do not overlap spatially. Another factor is that the databases cannot be matched as they use different strategies. Protocols with an approach closer to the real world would provide greater sampling security.
6.4. Notch Detection
No single parameter would bring a diagnostic confirmation of glaucoma. Some parameters such as ocular hypertension and glaucomatous papilla features, including enlarged cupping, are factors for suspecting the disease. The diagnostic certainty of glaucoma consists in the correspondence between the glaucomatous part of the papilla with an alteration in the visual field in that region. The same reasoning can be applied to the presence of a notch. This is a feature that can be considered suspicious. Still, it is not pathognomonic of glaucoma by itself, as it may be only an image noise that does not represent a region of neural damage. The detection of a (small) notch correlated with the visual field may be a goal to be pursued by AI as far as it facilitates early diagnosis.
6.5. Limitations of Public Databases
Retinal image pigmentation can undergo a few changes in different ethnicities and influence the performance of others.
The percentage of glaucoma cases in the REFUGE, DRIHST-GS1, and RIM-ONE datasets is higher than expected in a screening setting.
Including only high-quality photographs makes applying the proposed methods in real screening scenarios challenging.
Manual OD/OC segmentations performed from CFPs may be ill-defined.
Better binary ground truth classifications follow two-dimensional patterns for delineating OD/OC.
Color photographs do not match data from analyzed medical records and do not allow a broader approach to other comorbidities that may accompany glaucoma.
6.6. Clinical Implications and Future of Databases
Reliable results obtained within a dataset presented in one database may not necessarily reflect the same results in other databases subjected to the same learning values considering heterogeneous protocols (as cited). The automated systems can detect suspected glaucoma cases from fundus photographs as long as they follow some previously analyzed protocols. At the moment, this is still an open question. Although challenges such as REFUGE are moving in a more realistic direction, we do not yet know the significance of the answers that AI could provide in a population setting. With technological development continuously transforming, fundus cameras are improving portability and ease of use, as well as the use of defined protocols. It is hoped to expand the use of AI to diagnose and follow the progression of glaucomatous disease, remembering that the modality of early imaging in databases is still pending due to the subtle manifestation of the initial stages of disease images.
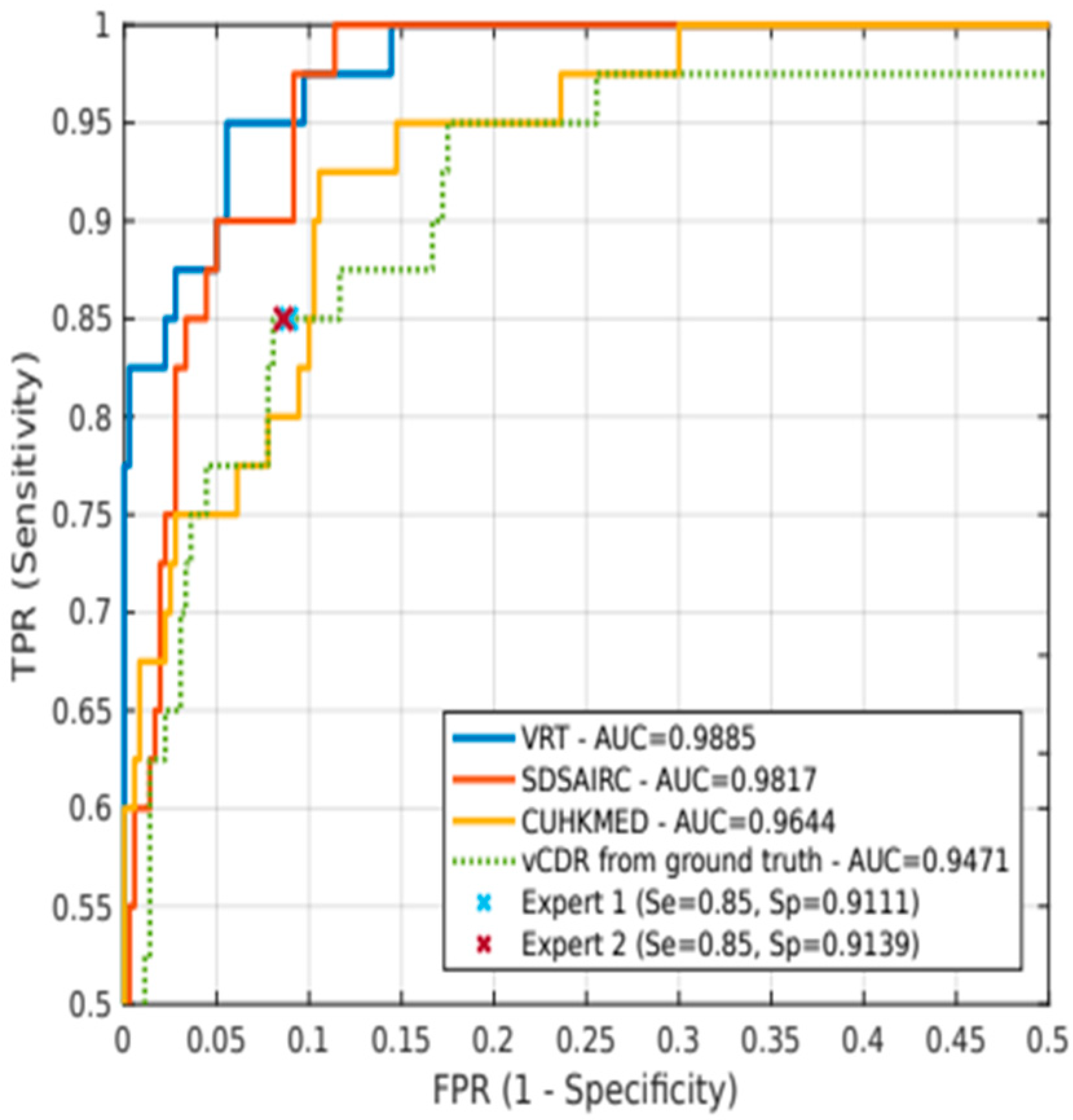
We saw that some of the proposed models were able to identify glaucoma with a focus on a few biometric features of the optic papilla, such as the disc-to-cavity ratio in REFUGE and the notch in DRISHT-GS1. We have seen that the REFUGE challenge results also seem to indicate that the use of vCDR may be a feature of greater importance than others, such as ONH hemorrhages, sectorial atrophies, or RNFL defects. Based on vCDR, as a probability of glaucoma, sensitivity and specificity values were statistically equivalent to those obtained using ground truth. Perhaps these parameters alone do not diagnose the disease but may have importance as single screening factors. However, we may incur errors by basing the binary classification on only a few features. Therefore, it is essential to have a conveniently classified sample of data.
In the REFUGE challenge, the top-performing teams complemented ONH measurements by DL models. We can significantly outperform expert diagnosis of glaucoma, with increases in sensitivity of up to 10% [
8]. Although these results are limited to a specific population, we can still argue that these deep learning models can identify complementary features that are invisible to the naked eye and are essential to ensure a more accurate disease diagnosis.
Other metrics derived from relative OD/OC shapes have recently outperformed vCDR in the diagnostic process, such as the rim-to-disc ratio [
61]. However, some clinical guidelines, such as the European Glaucoma Society 2017 [
62], do not recommend vCDR to classify patients, as several healthy discs may have large vCDR. Instead, the focus is on neuroretinal rim thickness (ISNT rule) and the degree of vCDR symmetry between eyes. In any case, vCDR is still a relevant parameter (it reached an AUC of 0.9471 in the test set for glaucoma classification). In addition, other ophthalmological parameters such as ocular pressure; the asymmetry between the papillae; the presence, size, and location of ONH hemorrhages; or the presence and size of retinal fiber layer defects can help analyze disease progression in each patient visit to ensure more reliable predictions.
Retinal evaluation by CFPs allows for the cost-effective assessment of glaucoma. Although OCT better highlights the excavation and fiber layer damage and provides a three-dimensional view of the retina, its large-scale use is economically unfeasible. Other markers used alone to make transverse scans and quantify the thickness of the RNFL or the size of the excavation have proven to be financially unviable and alone do not confirm the diagnosis. Thus, the development of DL methods for glaucoma screening must integrate CFPs analysis and glaucoma biomarkers.
Therefore, we recommend a database with more robust data following some protocols that allow the integration between datasets that may encompass CFPs obtained from multi-population centers, with the segmentation of the OD and cupping and images of both eyes, with diversified image quality, divided into well-defined training/test/validation groups, presenting structured binary classifications using clinical criteria that allow division into groups of papillae with early to severe glaucoma, besides the possibility of analyzing other retinal comorbidities evaluation through methods.
7. Conclusions
Public databases form the training and learning base for automated screening performed by deep learning architectures. Of the various databases used in ophthalmology, many are most helpful in diagnosing diabetic retinopathy, senile macular degeneration, and glaucoma. Among the bases used for glaucoma, the gold standards RIM-ONE DL, DRISHTI-GS1, and REFUGE are the most useful because they present segmentations of the disc and the excavation drawn by specialists and present classifications of normal papillae and those with glaucoma based on images, clinical data, and ancillary tests. Its disadvantages are the heterogeneous photographic quality, varied sizes and positioning of the image, and lack of images of both eyes. It would be advantageous to develop a protocol capable of performing population screening for glaucoma and diagnosing early forms of the disease and other retinal comorbidities in the medical context. Therefore, we suggest that the database data be continually updated and reclassified based on image segmentation and using clinical data and ancillary tests to provide more robust data to public databases and make the results more dependable.
Deep learning architectures could be made more dependable by using other clinical biomarkers, symptoms, eye pressure, family, and personal history to make DL models closer to the real thing and to make the results more accurate.
Future Work
We suggest the inclusion of clinical parameters such as notch (neural portion defects), CDR measurements as performed in the DRISHT-GS1 database, images with pre-perimetric defects, images with non-glaucomatous peri-papillary changes (myopic degeneration, peri-papillary atrophy), and continual updating of images to encompass rare diagnoses and avoid false positives.
The possibility of including the simultaneous screening of other retinal pathologies concomitant to glaucoma in DL networks in clinical practice should be screened by specialists through clinical data or be diagnosed as an examination finding. In this case, color retinography is significant in diagnostic aid and will certainly demand an excellent function of the public databases and algorithms to embrace a more comprehensive diagnostic range.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}