
Machine Learning Predicts 30-Day Outcome among Acute Myeloid Leukemia Patients: A Single-Center, Retrospective, Cohort Study


 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Materials and Methods
3. Results
3.1. D30 Prediction by ML
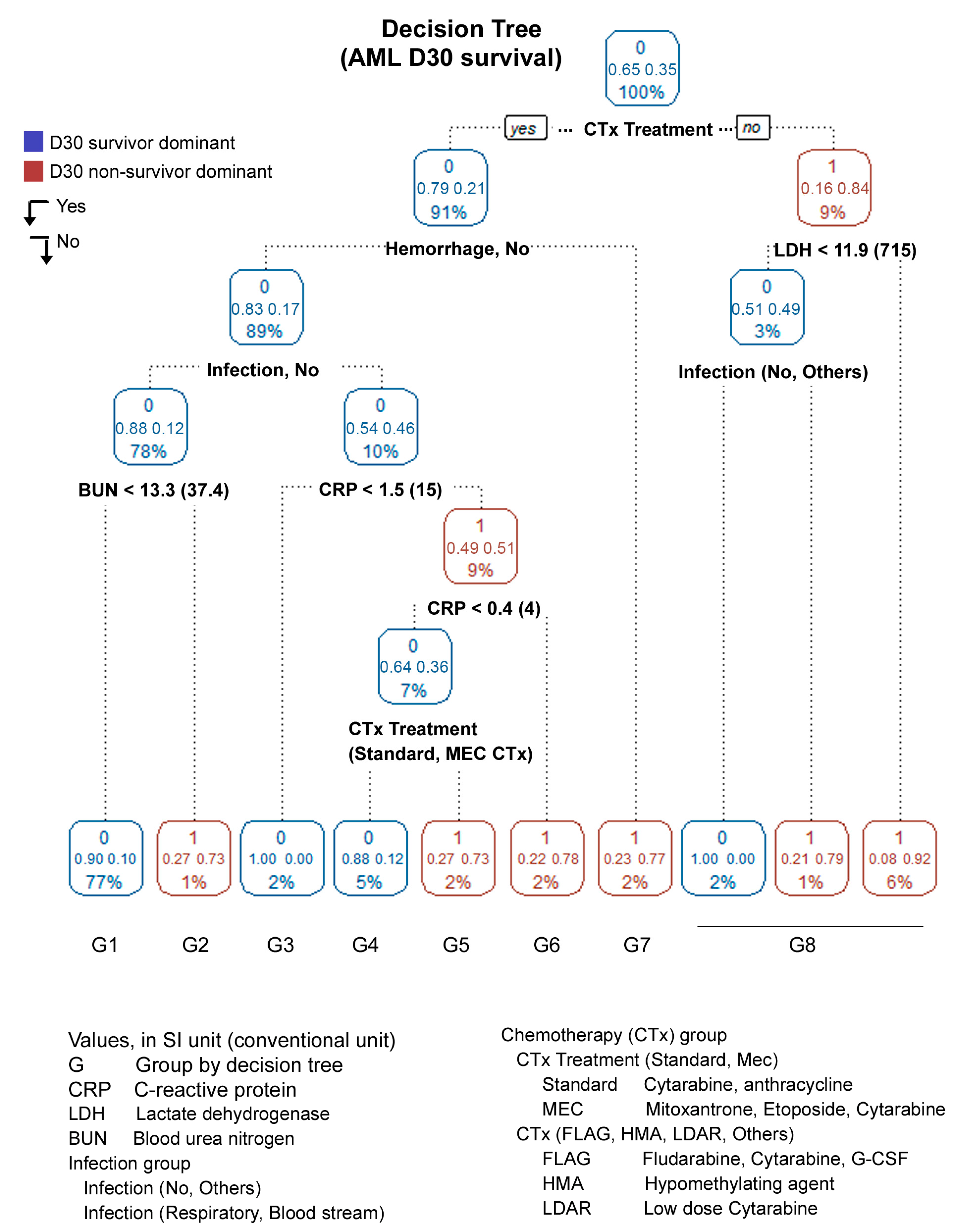
3.2. Decision Tree (DT)
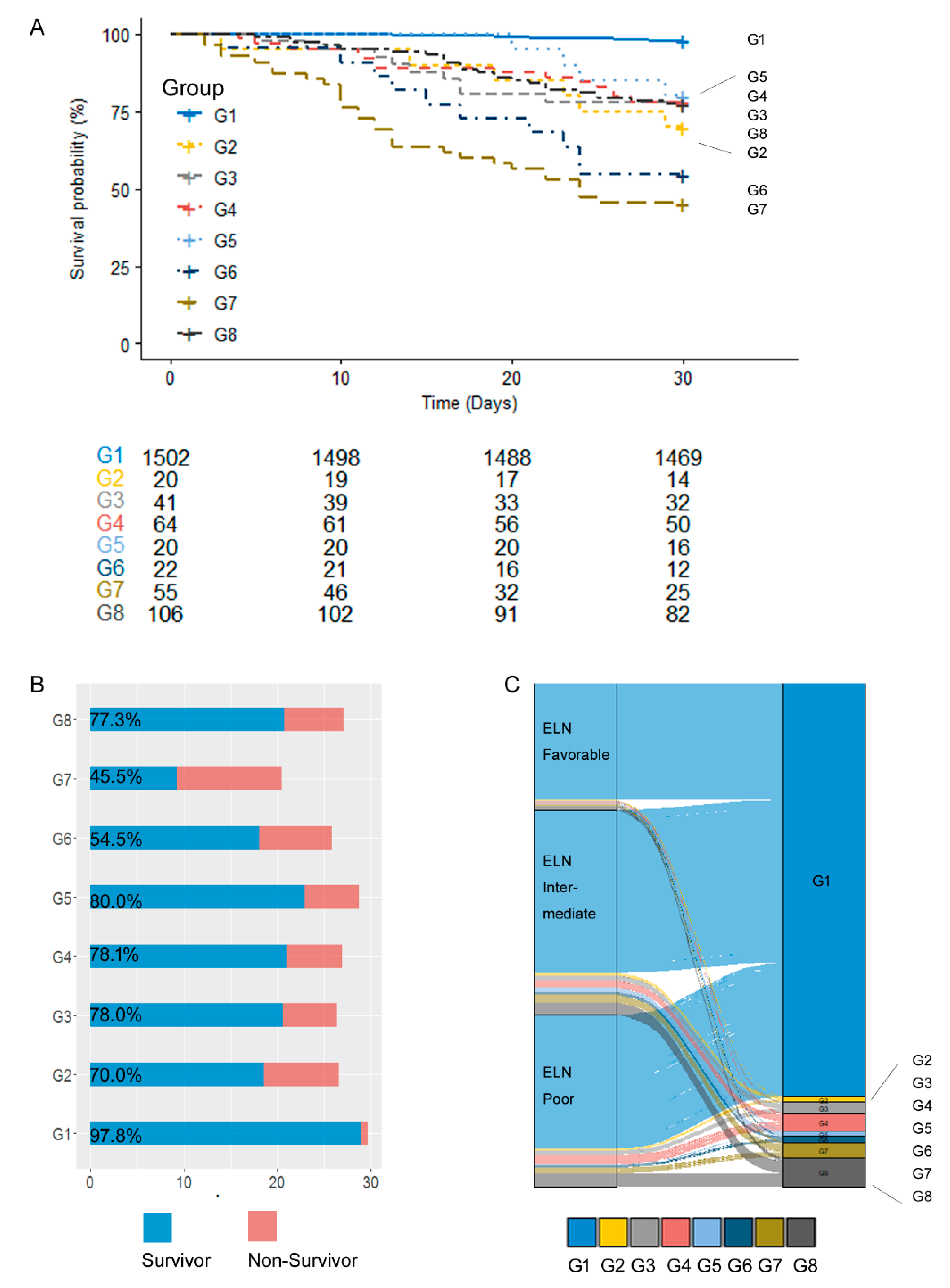
3.3. Prognosis
3.4. Prediction of Hemorrhage
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arber, D.A.; Orazi, A.; Hasserjian, R.P.; Borowitz, M.J.; Calvo, K.R.; Kvasnicka, H.-M.; Wang, S.A.; Bagg, A.; Barbui, T.; Branford, S.; et al. International Consensus Classification of Myeloid Neoplasms and Acute Leukemias: Integrating morphologic, clinical, and genomic data. Blood 2022, 140, 1200–1228. [Google Scholar] [CrossRef]
- Khoury, J.D.; Solary, E.; Abla, O.; Akkari, Y.; Alaggio, R.; Apperley, J.F.; Bejar, R.; Berti, E.; Busque, L.; Chan, J.K.C.; et al. The 5th edition of the World Health Organization Classification of Haematolymphoid Tumours: Myeloid and Histiocytic/Dendritic Neoplasms. Leukemia 2022, 36, 1703–1719. [Google Scholar] [CrossRef]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics, 2023. CA Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Konopleva, M.; DiNardo, C.D.; Borthakur, G.; Loghavi, S.; Tang, G.; Daver, N.; Pemmaraju, N.; Jabbour, E.; Rausch, C.R.; et al. Urgent cytoreduction for newly diagnosed acute myeloid leukemia patients allows acquisition of pretreatment genomic data and enrollment on investigational clinical trials. Am. J. Hematol. 2022, 97, 885–894. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Park, S.; Yoon, J.-H.; Cho, B.-S.; Kim, H.-J.; Lee, S.; Kim, D.-W.; Chung, N.-G.; Cho, B.; Kim, K.B.; et al. The factors influencing clinical outcomes after leukapheresis in acute leukaemia. Sci. Rep. 2021, 11, 6426. [Google Scholar] [CrossRef] [PubMed]
- Kantarjian, H.; Kadia, T.; DiNardo, C.; Daver, N.; Borthakur, G.; Jabbour, E.; Garcia-Manero, G.; Konopleva, M.; Ravandi, F. Acute myeloid leukemia: Current progress and future directions. Blood Cancer J. 2021, 11, 41. [Google Scholar] [CrossRef]
- Huerga-Domínguez, S.; Villar, S.; Prósper, F.; Alfonso-Piérola, A. Updates on the Management of Acute Myeloid Leukemia. Cancers 2022, 14, 4756. [Google Scholar] [CrossRef] [PubMed]
- Yoon, J.-H.; Kim, H.-J.; Kwak, D.-H.; Min, G.J.; Park, S.-S.; Jeon, Y.-W.; Lee, S.-E.; Cho, B.-S.; Eom, K.-S.; Kim, Y.-J.; et al. Comparison of the effects of early intensified induction chemotherapy and standard 3+7 chemotherapy in adult patients with acute myeloid leukemia. Blood Res. 2017, 52, 174–183. [Google Scholar] [CrossRef]
- DiNardo, C.D.; Erba, H.P.; Freeman, S.D.; Wei, A.H. Acute myeloid leukaemia. Lancet 2023, 401, 2073–2086. [Google Scholar] [CrossRef]
- Lachowiez, C.A.; Reville, P.K.; Kantarjian, H.; Jabbour, E.; Borthakur, G.; Daver, N.; Loghavi, S.; Furudate, K.; Xiao, L.; Pierce, S.; et al. Venetoclax combined with induction chemotherapy in patients with newly diagnosed acute myeloid leukaemia: A post-hoc, propensity score-matched, cohort study. Lancet Haematol. 2022, 9, e350–e360. [Google Scholar] [CrossRef] [PubMed]
- Stubbins, R.J.; Francis, A.; Kuchenbauer, F.; Sanford, D. Management of Acute Myeloid Leukemia: A Review for General Practitioners in Oncology. Curr. Oncol. 2022, 29, 6245–6259. [Google Scholar] [CrossRef] [PubMed]
- Bhansali, R.S.; Pratz, K.W.; Lai, C. Recent advances in targeted therapies in acute myeloid leukemia. J. Hematol. Oncol. 2023, 16, 29. [Google Scholar] [CrossRef] [PubMed]
- Mohty, R.; El Hamed, R.; Brissot, E.; Bazarbachi, A.; Mohty, M. New drugs before, during, and after hematopoietic stem cell transplantation for patients with acute myeloid leukemia. Haematologica 2023, 108, 321–341. [Google Scholar] [CrossRef] [PubMed]
- Turkalj, S.; Radtke, F.A.; Vyas, P. An Overview of Targeted Therapies in Acute Myeloid Leukemia. Hemasphere 2023, 7, e914. [Google Scholar] [CrossRef]
- Sasaki, K.; Kadia, T.; Begna, K.; DiNardo, C.D.; Borthakur, G.; Short, N.J.; Jain, N.; Daver, N.; Jabbour, E.; Garcia-Manero, G.; et al. Prediction of early (4-week) mortality in acute myeloid leukemia with intensive chemotherapy. Am. J. Hematol. 2022, 97, 68–78. [Google Scholar] [CrossRef]
- Kusuda, M.; Nakasone, H.; Nakamura, Y.; Kawamura, M.; Takeshita, J.; Kawamura, S.; Yoshino, N.; Misaki, Y.; Yoshimura, K.; Matsumi, S.; et al. Very early death within 30 days after diagnosis in patients with acute myeloid leukemia. Int. J. Hematol. 2023, 117, 198–205. [Google Scholar] [CrossRef]
- Mendes, F.R.; da Silva, W.F.; da Costa Bandeira de Melo, R.; Silveira, D.R.A.; Velloso, E.D.R.P.; Rocha, V.; Rego, E.M. Predictive factors associated with induction-related death in acute myeloid leukemia in a resource-constrained setting. Ann. Hematol. 2022, 101, 147–154. [Google Scholar] [CrossRef]
- Hastie, T. The Element of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Sarkar, D. R Machine Learning by Example; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Lantz, B. Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Chang, H.-H.; Chiang, J.-H.; Wang, C.-S.; Chiu, P.-F.; Abdel-Kader, K.; Chen, H.; Siew, E.D.; Yabes, J.; Murugan, R.; Clermont, G.; et al. Predicting Mortality Using Machine Learning Algorithms in Patients Who Require Renal Replacement Therapy in the Critical Care Unit. J. Clin. Med. 2022, 11, 5289. [Google Scholar] [CrossRef]
- Dequen, G.; Guérin, J.-L.; Elbattah, M.; Viton, F. Multi-channel ConvNet Approach to Predict the Risk of in-Hospital Mortality for ICU Patients. In Proceedings of the 1st International Conference on Deep Learning Theory and Applications, Paris, France, 8–10 July 2020; pp. 98–102. [Google Scholar]
- Park, S.-S.; Lee, J.C.; Byun, J.M.; Choi, G.; Kim, K.H.; Lim, S.; Dingli, D.; Jeon, Y.-W.; Yahng, S.-A.; Shin, S.-H.; et al. ML-based sequential analysis to assist selection between VMP and RD for newly diagnosed multiple myeloma. Npj. Precis. Oncol. 2023, 7, 46. [Google Scholar] [CrossRef]
- Awada, H.; Durmaz, A.; Gurnari, C.; Kishtagari, A.; Meggendorfer, M.; Kerr, C.M.; Kuzmanovic, T.; Durrani, J.; Shreve, J.; Nagata, Y.; et al. Machine learning integrates genomic signatures for subclassification beyond primary and secondary acute myeloid leukemia. Blood 2021, 138, 1885–1895. [Google Scholar] [CrossRef]
- Döhner, H.; Estey, E.; Grimwade, D.; Amadori, S.; Appelbaum, F.R.; Büchner, T.; Dombret, H.; Ebert, B.L.; Fenaux, P.; Larson, R.A.; et al. Diagnosis and management of AML in adults: 2017 ELN recommendations from an international expert panel. Blood 2017, 129, 424–447. [Google Scholar] [CrossRef]
- Cazzola, M. Introduction to a review series: The 2016 revision of the WHO classification of tumors of hematopoietic and lymphoid tissues. Blood 2016, 127, 2361–2364. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Liaw, A.W.M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Tianqi Chen, C.G. XGBoost: A Scalable Tree Boosting System. arXiv 2016, arXiv:1603.02754v3. [Google Scholar]
- Kuhn, M.Q.R. C50: C5.0 Decision Trees and Rule-Based Models, R Package Version 0.1.8. 2023. Available online: https://topepo.github.io/C5.0/ (accessed on 22 August 2023).
- Wien, T. e1071: Misc Functions of the Department of Statistics, Probability Theory Group. 2017. Available online: https://CRAN.R-project.org/package=e1071 (accessed on 23 January 2023).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Majka, M. High Performance Implementation of the Naive Bayes Algorithm. 2022. Available online: https://github.com/majkamichal/naivebayes (accessed on 25 March 2023).
- Terry Therneau EJA, Mayo Foundation. rpart: Recursive Partitioning and Regression Trees. 2022. Available online: https://github.com/bethatkinson/rpart (accessed on 21 January 2023).
- Mrózek, K.; Kohlschmidt, J.; Blachly, J.S.; Nicolet, D.; Carroll, A.J.; Archer, K.J.; Mims, A.S.; Larkin, K.T.; Orwick, S.; Oakes, C.C.; et al. Outcome prediction by the 2022 European LeukemiaNet genetic-risk classification for adults with acute myeloid leukemia: An Alliance study. Leukemia 2023, 37, 788–798. [Google Scholar] [CrossRef] [PubMed]
- Gernsheimer, T.B.; Brown, S.P.; Triulzi, D.J.; Key, N.S.; El Kassar, N.; Herren, H.; Poston, J.N.; Boyiadzis, M.; Reeves, B.N.; Selukar, S.; et al. Prophylactic tranexamic acid in patients with hematologic malignancy: A placebo-controlled, randomized clinical trial. Blood 2022, 140, 1254–1262. [Google Scholar] [CrossRef] [PubMed]
- Khaldoyanidi, S.; Nagorsen, D.; Stein, A.; Ossenkoppele, G.; Subklewe, M. Immune Biology of Acute Myeloid Leukemia: Implications for Immunotherapy. J. Clin. Oncol. 2021, 39, 419–432. [Google Scholar] [CrossRef] [PubMed]
- Price, T.H.; Boeckh, M.; Harrison, R.W.; McCullough, J.; Ness, P.M.; Strauss, R.G.; Nichols, W.G.; Hamza, T.H.; Cushing, M.M.; King, K.E.; et al. Efficacy of transfusion with granulocytes from G-CSF/dexamethasone-treated donors in neutropenic patients with infection. Blood 2015, 126, 2153–2161. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.; Cho, H.S.; Yoon, J.-H.; Cho, B.S.; Kim, H.-J.; Lee, D.-G.; Jekarl, D.W.; Kim, M.; Oh, E.-J.; Park, Y.-J.; et al. Risk stratification by 30-day prognostic factors of clinical outcomes after granulocyte transfusion in acute myeloid leukemia: A single-center retrospective study. PLoS ONE 2022, 17, e0273827. [Google Scholar] [CrossRef] [PubMed]
- Garg, A.; Gupta, A.; Mishra, A.; Singh, M.; Yadav, S.; Nityanand, S. Role of granulocyte transfusions in combating life-threatening infections in patients with severe neutropenia: Experience from a tertiary care centre in North India. PLoS ONE 2018, 13, e0209832. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D30 Survivor | D30 Non-Survivor | p | ||
|---|---|---|---|---|
| n | n = 1700 (%) | n = 130 (%) | ||
| Age | 1830 | 50.6 ± 15.5 | 60.1 ± 14.2 | <0.001 * |
| Sex | 1830 | 0.084 | ||
| Female | 781 (45.9) | 49 (37.7) | ||
| Male | 919 (54.1) | 81 (62.3) | ||
| Diagnosis a | 1830 | <0.001 * | ||
| BCR/ABL | 7 (0.4) | 0 (0.0) | ||
| CBFB_MYH11 | 66 (3.8) | 3 (2.3) | ||
| CEBPA | 72 (4.2) | 1 (0.7) | ||
| DEK/NUP | 12 (0.7) | 0 (0.0) | ||
| FLT3 | 151 (8.8) | 17 (13.1) | ||
| GATA2/MECOM | 14 (0.8) | 2 (1.5) | ||
| KMT2A | 63 (3.7) | 4 (3.1) | ||
| MRC | 145 (8.5) | 11 (8.4) | ||
| NOS | 594 (34.9) | 54 (34.9) | ||
| NPM1 | 130 (7.6) | 3 (2.3) | ||
| NPM1-FLT3 | 38 (2.2) | 2 (1.5) | ||
| RUNX1_RUNXT1 | 181 (10.6) | 4 (3.1) | ||
| TAML | 11 (0.6) | 2 (1.5) | ||
| Secondary AML | 34 (2.0) | 5 (3.8) | ||
| AML MRC | 182 (10.7) | 22 (16.9) | ||
| Induction | 1830 | <0.001 * | ||
| No CTx | 95 (5.6) | 71 (54.6) | ||
| Standard CTx | 1307 (76.9) | 34 (26.2) | ||
| FLAG CTx | 40 (2.4) | 3 (2.3) | ||
| HMA | 120 (7.1) | 13 (10) | ||
| LDAC | 67 (3.9) | 7 (5.4) | ||
| MEC | 64 (3.8) | 2 (1.5) | ||
| Others | 7 (0.4) | 0 (0.0) | ||
| Hemorrhage | 1830 | <0.001 * | ||
| No | 1675 (98.5) | 100 (76.9) | ||
| Yes | 25 (1.5) | 30 (23.1) | ||
| Infection | <0.001 * | |||
| No | 1482 (88.6) | 58 (45.3) | ||
| Respiratory | 146 (8.7) | 56 (43.8) | ||
| Bloodstream | 8 (0.5) | 9 (7.0) | ||
| Others | 36 (2.2) | 5 (3.9) | ||
| Cytogenetics | 1626 | <0.001 * | ||
| Normal | 698 (41.1) | 43 (33.1) | ||
| One abnormality | 395 (23.2) | 20 (15.4) | ||
| Two abnormalities | 164 (9.6) | 6 (4.6) | ||
| Complex | 261 (15.4) | 39 (30.0) | ||
| No data | 182 (10.7) | 22 (16.9) | ||
| ELN classification | 1626 | <0.001 * | ||
| Favorable | 449 (26.5) | 11 (8.4) | ||
| Intermediate | 695 (40.9) | 53 (40.8) | ||
| Poor | 365 (22.0) | 48 (36.9) | ||
| No data | 182 (10.7) | 22 (16.9) | ||
| Comorbidity | 1830 | <0.001 * | ||
| Others | 1679 (98.8) | 119 (91.5) | ||
| Renal disease | 21 (1.2) | 11 (8.5) |
| D30 Survivor | D30 Non-Survivor | p | |
|---|---|---|---|
| (n = 1700) | (n = 130) | ||
| WBC (×109) | 35.3 ± 64.0 | 55.2 ± 85.6 | 0.010 * |
| RBC (×1012) | 2.8 ± 0.6 | 2.8 ± 0.6 | 0.463 |
| Hemoglobin (g/dL) a | 9.0 ± 1.7 | 8.7 ± 1.7 | 0.060 |
| Hematocrit (%) a | 26.9 ± 8.3 | 25.6 ± 4.9 | 0.008 * |
| Platelet (×109) | 75.5 ± 79.0 | 75.3 ± 99.5 | 0.978 |
| Neutrophil (%) | 20.1 ± 20.2 | 16.4 ± 18.5 | 0.046 * |
| Lymphocyte (%) | 34.2 ± 27.2 | 26.0 ± 25.5 | 0.001 * |
| Monocyte (%) | 9.9 ± 15.8 | 16.1 ± 24.1 | 0.005 * |
| Eosinophil (%) | 0.7 ± 2.0 | 0.3 ± 1.3 | 0.004 * |
| Basophil (%) | 0.2 ± 1.0 | 0.3 ± 1.1 | 0.519 |
| Blast (%) | 39.0 ± 29.9 | 41.5 ± 31.7 | 0.356 |
| ANC (×109) a | 3.0 ± 6.7 | 3.6 ± 6.3 | 0.318 |
| RDW | 16.0 ± 2.0 | 16.2 ± 2.2 | 0.192 |
| MCV (fL) | 95.5 ± 7.1 | 92.9 ± 6.8 | <0.001 * |
| MCH (pg) a | 32.2 ± 2.6 | 31.6 ± 2.6 | 0.012 * |
| MCHC (%) | 33.7 ± 1.3 | 34.0 ± 1.5 | 0.016 * |
| PT (s) a | 13.3 ± 1.8 | 14.7 ± 2.3 | <0.001 * |
| APTT (s) | 30.1 ± 6.3 | 33.3 ± 7.3 | <0.001 * |
| FDP (mcg/mL) | 12.6 ± 17.9 | 24.1 ± 27.0 | <0.001 * |
| Fibrinogen (g/L) a | 9.8 ± 2.8 | 9.36 ± 3.69 | 0.545 |
| D-dimer (nmol/L) | 25.4 ± 41.1 | 49.2 ± 60.7 | <0.001 * |
| Glucose (mmol/L) | 6.8 ± 2.2 | 7.8 ± 2.9 | <0.001 * |
| BUN (mg/dL) | 5.0 ± 2.4 | 7.2 ± 2.2 | <0.001 * |
| Creatinine (mg/dL) | 70.7 ± 35.3 | 97.2 ± 88.4 | 0.003 |
| Protein (g/L) a | 66.0 ± 7.0 | 63.0 ± 7.0 | <0.001 * |
| Albumin (g/L) | 37.0 ± 5.0 | 34.0 ± 5.0 | <0.001 * |
| AST (uKat/L) | 0.5 ± 0.6 | 0.8 ± 1.0 | 0.004 * |
| ALT (ukat/L) | 0.6 ± 0.8 | 0.7 ± 0.8 | 0.093 |
| ALP (ukat/L) | 1.2 ± 0.8 | 1.7 ± 1.6 | <0.001 * |
| Bilirubin (umol/L) | 11.9 ± 8.5 | 17.1 ± 11.9 | <0.001 * |
| Direct Bilirubin (umol/L) | 5.1 ± 3.4 | 8.5 ± 10.6 | <0.001 * |
| Uric acid (mmol.L) | 0.3 ± 0.1 | 0.4 ± 0.2 | 0.002 |
| Calcium (mmol/L) | 2.1 ± 0.2 | 2.1 ± 0.2 | 0.004 |
| Phosphorus (mmol/L) | 1.2 ± 0.3 | 1.1 ± 0.5 | 0.453 |
| Sodium (mmol/L) | 139.8 ± 3.2 | 138.3 ± 3.9 | <0.001 * |
| Potassium (mmol/L) | 3.9 ± 0.5 | 3.9 ± 0.5 | 0.678 |
| Chloride (mmol/L) | 103.6 ± 3.4 | 147.0 ± 6.5 | 0.330 |
| LDH (ukat/L) | 21.9 ± 28.6 | 37.2 ± 50.4 | 0.001 * |
| CPK (ukat/L) | 1.4 ± 4.3 | 1.8 ± 3.3 | 0.301 |
| Amylase (ukat/L) | 1.11 ± 0.7 | 1.1 ± 0.7 | 0.440 |
| Magnesium (mmol/L) | 0.9 ± 0.1 | 0.9 ± 0.1 | 0.494 |
| ESR (mm/h) | 33.1 ± 25.7 | 33.1 ± 26.9 | 0.999 |
| CRP (mg/L) | 42.0 ± 62.0 | 75.0 ± 78.0 | <0.001 |
| Accuracy | 95% CI | Sensitivity | 95% CI | Specificity | 95% CI | |
|---|---|---|---|---|---|---|
| Multivariable LR, initial | 89.5 | 0.873–0.914 | 3.2 | 0.004–0.113 | 95.6 | 0.941–0.969 |
| Multivariable LR, six features | 87.8 | 0.855–0.899 | 4.3 | 0.009–0.122 | 94.6 | 0.929–0.961 |
| SVM, initial | 93.3 | 0.915–0.948 | 0 | 0.000–0.059 | 100 | 0.996–1.000 |
| SVM, six features, un-tuned | 91.1 | 0.801–0.928 | 14.7 | 0.070–0.262 | 96.4 | 0.111–0.393 |
| SVM, six features, tuned | 93.3 | 0.915–0.948 | 0 | 0.000–0.059 | 100 | 0.996–1.000 |
| Naïve Bayesian, initial | 89.7 | 0.868–0.911 | 34.4 | 0.227–0.477 | 92.9 | 0.910–0.946 |
| Naïve Bayesian, six features | 91.4 | 0.893–0.931 | 37.7 | 0.256–0.510 | 95.1 | 0.935–0.965 |
| Random Forest, initial | 94.7 | 0.931–0.961 | 26.2 | 0.158–0.391 | 99.6 | 0.990–0.999 |
| Random Forest, six features | 93.7 | 0.920–0.952 | 39.3 | 0.271–0.527 | 97.6 | 0.964–0.986 |
| Random Forest, six features, tuned | 93.3 | 0.915–0.948 | 36.1 | 0.242–0.494 | 97.4 | 0.961–0.984 |
| Decision Tree, initial | 93.6 | 0.918–0.951 | 29.5 | 0.185–0.426 | 98.2 | 0.971–0.990 |
| Decision Tree, six features | 90.6 | 0.885–0.924 | 70.4 | 0.885–0.924 | 92.1 | 0.885–0.924 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.; Han, J.H.; Kim, J.K.; Yoo, J.; Yoon, J.-H.; Cho, B.S.; Kim, H.-J.; Lim, J.; Jekarl, D.W.; Kim, Y. Machine Learning Predicts 30-Day Outcome among Acute Myeloid Leukemia Patients: A Single-Center, Retrospective, Cohort Study. J. Clin. Med. 2023, 12, 5940. https://doi.org/10.3390/jcm12185940
Lee H, Han JH, Kim JK, Yoo J, Yoon J-H, Cho BS, Kim H-J, Lim J, Jekarl DW, Kim Y. Machine Learning Predicts 30-Day Outcome among Acute Myeloid Leukemia Patients: A Single-Center, Retrospective, Cohort Study. Journal of Clinical Medicine. 2023; 12(18):5940. https://doi.org/10.3390/jcm12185940
Chicago/Turabian StyleLee, Howon, Jay Ho Han, Jae Kwon Kim, Jaeeun Yoo, Jae-Ho Yoon, Byung Sik Cho, Hee-Je Kim, Jihyang Lim, Dong Wook Jekarl, and Yonggoo Kim. 2023. "Machine Learning Predicts 30-Day Outcome among Acute Myeloid Leukemia Patients: A Single-Center, Retrospective, Cohort Study" Journal of Clinical Medicine 12, no. 18: 5940. https://doi.org/10.3390/jcm12185940
APA StyleLee, H., Han, J. H., Kim, J. K., Yoo, J., Yoon, J.-H., Cho, B. S., Kim, H.-J., Lim, J., Jekarl, D. W., & Kim, Y. (2023). Machine Learning Predicts 30-Day Outcome among Acute Myeloid Leukemia Patients: A Single-Center, Retrospective, Cohort Study. Journal of Clinical Medicine, 12(18), 5940. https://doi.org/10.3390/jcm12185940