Abstract
Recent attempts to classify adult-onset diabetes using only six diabetes-related variables (GAD antibody, age at diagnosis, BMI, HbA1c, and homeostatic model assessment 2 estimates of b-cell function and insulin resistance (HOMA2-B and HOMA2-IR)) showed that diabetes can be classified into five clusters, of which four correspond to type 2 diabetes (T2DM). Here, we classified nondiabetic individuals to identify risk clusters for incident T2DM to facilitate the refinement of prevention strategies. Of the 1167 participants in the population-based Iwaki Health Promotion Project in 2014 (baseline), 868 nondiabetic individuals who attended at least once during 2015–2019 were included in a prospective study. A hierarchical cluster analysis was performed using four variables (BMI, HbA1c, and HOMA2 indices). Of the four clusters identified, cluster 1 (n = 103), labeled as “obese insulin resistant with sufficient compensatory insulin secretion”, and cluster 2 (n = 136), labeled as “low insulin secretion”, were found to be at risk of diabetes during the 5-year follow-up period: the multiple factor-adjusted HRs for clusters 1 and 2 were 14.7 and 53.1, respectively. Further, individuals in clusters 1and 2 could be accurately identified: the area under the ROC curves for clusters 1and 2 were 0.997 and 0.983, respectively. The risk of diabetes could be better assessed on the basis of the cluster that an individual belongs to.
1. Introduction
Type 2 diabetes (T2DM) increases the risks of serious physical and mental health problems, and its prevalence is increasing worldwide [1,2]. Therefore, the identification of individuals at risk of developing T2DM is important. To this end, biological markers may be of use in clinical settings, regardless of whether they show causal relationships or merely an association with T2DM. However, currently, no effective markers other than those directly related to glucose metabolism, such as glucose concentrations and glycated substrates, are used in clinical practice [3]. Although such markers are an undoubtedly effective means of predicting incident diabetes, they are not useful in assessing the T2DM status classification, which will occur in the future.
Since T2DM is a heterogeneous disorder of the glucose metabolism that is characterized by both insulin resistance and pancreatic β-cell dysfunction [4,5], the pathophysiology associated with the development of T2DM and the clinical characteristics of individuals with T2DM vary substantially from person to person. To evaluate such differences in the underlying condition in individuals with diabetes, a cluster analysis of six variables (glutamate decarboxylase antibody (GAD-Ab), age at diagnosis, HbA1c, BMI, and homeostatic model assessment 2 estimates of b-cell function and insulin resistance (HOMA2-B and HOMA2-IR)) has recently been conducted, and this identified five clusters with distinct clinical characteristics and outcomes, such as diabetic complications [6]. Of these five clusters, one seemed to correspond to type 1 diabetes, and the other four seemed to correspond to T2DM. Since then, various other studies have similarly shown that T2DM can be classified at least into four groups, labeled as severe insulin-deficient diabetes (SIDD), severe insulin-resistant diabetes (SIRD), mild obesity-related diabetes (MOD), and mild age-related diabetes (MARD) [6,7,8,9,10,11,12,13,14,15,16,17,18]. In addition, individuals in these T2DM clusters have been shown to be at different risks of diabetic complications and to have differences in their glycemic response, with particular benefits of certain antidiabetic drugs for particular clusters [6,8,9,10,11,12,16,17,18]. Thus, T2DM can be classified into four groups, which necessitate differing therapeutic approaches. However, it is unclear whether nondiabetic individuals could be similarly classified. If so, individuals at risk of diabetes could be evaluated more precisely with respect to their underlying pathophysiology, which should help suggest the most appropriate means of preventing T2DM.
Therefore, in the present study, we classified nondiabetic individuals in the general Japanese population by hierarchical clustering analyses using four variables: HbA1c, BMI, HOMA2-B, and HOMA2-IR. Furthermore, we evaluated the risk of incident diabetes in each group during a 5-year follow-up period, along with the factors related to the development of diabetes in each cluster. The findings of the present study suggest a means of precisely evaluating individuals at risk of diabetes, permitting the targeted provision of healthcare services for the prevention of T2DM.
2. Methods
2.1. Study Sample
Participants were recruited from the residents aged ≥20 years living in the Iwaki area, Japan, through a public announcement (the Iwaki Health Promotion Project: Iwaki study). The Iwaki study is aimed to prevent lifestyle-related diseases and prolong lifespans, and no inclusion and exclusion criteria were set [19,20,21]. The Iwaki study is conducted annually in the Iwaki area of the city of Hirosaki in Aomori Prefecture, Northern Japan. Of the 1167 individuals who participated in the Iwaki study in 2014, 979 individuals attended the follow-up examinations at various intervals until 2019. Of these participants, 19 with an incomplete dataset and 74 with diabetes were excluded. After these exclusions, 886 individuals (327 men and 559 women) aged 53.8 ± 14.6 years remained for inclusion in the present study. The mean duration of follow-up was 4.9 years.
This study was approved by the Ethics Committee of the Hirosaki University School of Medicine (No. 2014-014, 2014-377-1, 2016-028-1, 2021-030, 2018-063, and 2019-009) and was conducted in accordance with the principles of the Declaration of Helsinki. Written informed consent was obtained from all the participants.
2.2. Parameters Measured
Blood samples were collected in the morning from a peripheral vein of fasted participants. Urine samples were also collected in the morning. The following parameters were measured: height; body weight; BMI; percentage body fat (fat (%)); fasting blood glucose (FBG); fasting serum C-peptide; glycated hemoglobin (HbA1c); systolic and diastolic blood pressure; serum low-density lipoprotein (LDL)-cholesterol, triglyceride (TG), high-density lipoprotein (HDL)-cholesterol, uric acid, urea nitrogen, and creatinine concentrations; and urinary albumin and creatinine concentrations (uACR). Fat (%) was measured using the bioelectricity impedance method with a Tanita MC-190 body composition analyzer (Tanita Corp., Tokyo, Japan). HbA1c (%) is expressed as the National Glycohemoglobin Standardization Program value. Laboratory testing was performed in a commercial laboratory (LSI Medience Co., Tokyo, Japan), according to the reagent manufacturer’s protocols. Pancreatic β-cell function (B) and insulin resistance (IR) were evaluated using the updated Homeostatic model assessment (HOMA2) via the HOMA 2 Calculator (©Oxford University 2004 (available at www.dtu.ox.ac.uk/homacalculator/download.php) by inserting the serum C-peptide and blood glucose concentrations. The incidence and/or treatment of diabetes was identified using a questionnaire. DM was defined based on the criteria of the Japan Diabetes Society published in 2010: FBG ≥ 126 mg/dL [22]. In participants in whom the FBG concentration was not measured, diabetes was defined using an HbA1c of ≥6.5%. Participants receiving treatment for diabetes were also considered to have diabetes. Hypertension was defined using a blood pressure of ≥140/90 mmHg or current treatment for hypertension. Hyperlipidemia was defined using an LDL-cholesterol of ≥140 mg/dL, a TG of ≥150 mg/dL, or current treatment for hyperlipidemia. Alcohol consumption (current or not) and smoking (never, past, or current smoker) habits were recorded using questionnaires.
2.3. Statistical Analysis
Data are presented as means ± SDs. Statistical significance of differences in values among groups (parametric) and case–control associations among groups (nonparametric) were assessed using the analysis of covariance (ANOVA) with Tukey’s post-hoc analyses and the χ2 test, respectively. Statistical significance of differences in parametric and nonparametric values for participants in each cluster at baseline and at the onset of diabetes were assessed using the paired t-test and McNemar’s test, respectively. Based on their HbA1c, BMI, HOMA2-B, and HOMA2-IR, the participants were grouped by hierarchical clustering into four major clusters, and the risk of diabetes in each cluster was evaluated using Kaplan–Meier and multivariate Cox proportional hazard regression analyses. Cox proportional hazard regression models were used to calculate hazard ratios (HRs) for incident diabetes at baseline after adjustment for multiple possible confounding factors, including age and gender. Receiver operating characteristic (ROC) curves were plotted to determine the optimal cut-off values for each cluster at baseline. The values that yielded the highest sensitivities and specificities were determined as the cut-off values. Prior to statistical analysis, HOMA-IR, TG concentrations, and uACR were log-transformed (log10) to approximate a normal distribution. p < 0.05 was considered to represent statistical significance. All analyses were performed using JMP version 16.0 (SAS Institute Japan Ltd., Tokyo, Japan).
3. Results
3.1. Clinical Characteristics of the Participants at the Baseline
The clinical characteristics of the participants at baseline are shown in Table 1. The mean age of the participants was 53.8 ± 14.6. Although the national prevalence of hypertension and hyperlipidemia for nondiabetic individuals has not been reported, the prevalence of hypertension (42.1%) and hyperlipidemia (36.5%) measured appeared to not be substantially different from those of the general Japanese population: the national prevalence of hypertension reported by the Japanese government in 2014 were 36.2% and 26.8% for men and women of ≥20 years of age, respectively; and the prevalence of hyperlipidemia reported in other areas of Japan was also similar [23,24,25,26].

Table 1.
Clinical characteristics of the study subjects.
3.2. Cluster Analysis Using Four Variables
Since only nondiabetic individuals were included, two variables (glutamate decarboxylase antibody and age at diagnosis) out of the six original variables reported previously were not used for the present cluster analysis. Therefore, on the basis of HbA1c, BMI, HOMA2-B, and HOMA2-IR, the participants were grouped by hierarchical clustering into four major clusters (Table 2 and Figure 1). Cluster 1 (n = 103 (11.6%)) was characterized by high BMI, insulin resistance, high insulin secretion, an abnormal lipid profile, and higher kidney damage and was labeled as “obese insulin resistant with sufficient compensatory insulin secretion” (IR-SIS). Cluster 2 (n = 136 (15.3%)) was characterized by low insulin secretion and dysglycemia and was labeled as “low insulin secretion” (Low-IS). Cluster 3 (n = 314 (35.4%)) was characterized by normal BMI and a generally healthy metabolic profile and was labeled as “non-obese healthy”. Cluster 4 (n = 333 (37.6%)) was characterized by a low BMI and a generally healthy metabolic profile and was labelled as “lean healthy”.
Table 2.
Cluster characteristics.
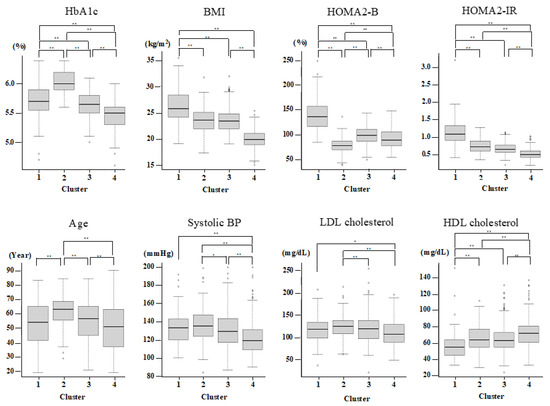
Figure 1.
Cluster characteristics. The characteristics of HbA1c, BMI, HOMA2-IR, HOMA2-B, Age, sBP, LDL, and HDL-cholesterol for each cluster. p < 0.05 and <0.01 are indicated by * and **, respectively.
3.3. Risk of Diabetes Associated with Clusters
The risk of incident diabetes for each cluster was then examined. During the 5-year follow-up period of the study, 38 (4.3%) of the participants developed diabetes. The numbers who developed diabetes during this period were 8/103 (7.8%), 28/136 (20.6%), 0/314 (0.0%), and 2/333 (0.6%), for clusters 1–4, respectively. An analysis using the Kaplan–Meier method showed a significantly higher risk of diabetes in clusters 1 and 2 (log rank p < 0.001) (Figure 2). Cox’s proportional hazard regression model analysis also showed the effects of being in clusters 1 and 2 on the risk of incident diabetes (hazard ratio (HR) (95% confidence interval (CI)) vs. being in clusters 3 or 4: 25.8 (5.5–121.6) and 72.0 (17.2–302.3), respectively) (Table 3). After further adjustment for multiple possible confounding factors (age, gender, sBP, LDL-c, HDL-c, SUN, Cre, SUA, and alcohol drinking and smoking habits), being in clusters 1 and 2 remained a risk factor for incident diabetes (HR and 95% CI: 14.2 (2.9–70.4) and 53.2 (12.4–227.5), respectively) (Table 3).
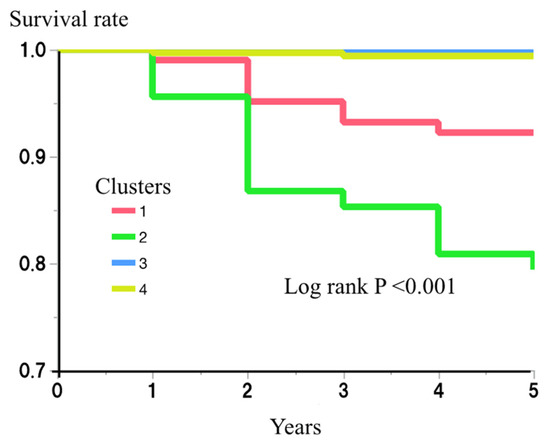
Figure 2.
Risk of clusters for incident diabetes.
Table 3.
Risk of each cluster for incident diabetes.
The risk of each cluster for incident diabetes during the 5-year follow-up period was then examined using the Kaplan–Meier method. The differences among the clusters were assessed using log-rank test. p < 0.05 was considered to represent statistical significance.
3.4. Cut-Off Values of the Four Variables for the Identification of Participants Belonging to Clusters 1 and 2
Next, to identify participants belonging to clusters 1 and 2 or at risk of diabetes in a standard clinical setting, we determined the optimal cut-off values of the four variables used for the cluster analysis. Logistic regression analyses showed that someone in cluster 1 could be identified using three of the four variables (the p-values for HbA1c, BMI, HOMA2-B, and HOMA2-IR were 0.104, <0.001, <0.001, and <0.001, respectively), while someone in cluster 2 could also be identified using three of the four variables (p-values for HbA1c, BMI, HOMA2-B, and HOMA2-IR were <0.001, 0.041, <0.001, and 0.856, respectively). Therefore, ROC curve analyses using the corresponding variables were performed to determine the optimal cut-off values for the identification of individuals belonging to clusters 1 and 2 (Figure 3). For cluster 1, BMI ≥ 21.72 kg/m2, HOMA2-B ≥83.8, and HOMA2-IR ≥1.38 were found to be the optimal cut-off values (area under the ROC curve (AUC): 0.997, sensitivity: 1.000, and specificity: 0.976), and for cluster 2, HbA1c >5.8%, BMI ≥20.43 kg/m2, and HOMA2-B ≤80.9 were found to be the optimal cut-off values (AUC: 0.983, sensitivity: 0.985, specificity: 0.892).
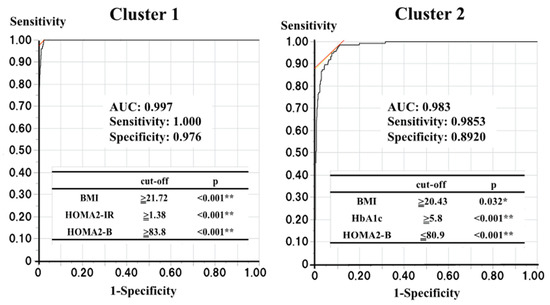
Figure 3.
The optimal cut-off values to find the subjects belonging to clusters 1 and 2. p < 0.05 and <0.01 are indicated by * and **, respectively.
ROC curve analyses with those each corresponding three variables were performed to determine the optimal cut-off values for the finding the subjects belonging to the clusters 1 and 2.
3.5. Changes in the Clinical Characteristics of the Participants in Clusters 1 and 2 between Baseline and the Onset of Diabetes
Since clinical characteristics of the participants in clusters 1 and 2 at the baseline were very different, the factors predisposed toward the development of diabetes in each cluster may be different. Therefore, we next evaluated the changes in the clinical characteristics in the participants in clusters 1 and 2 between the baseline and the onset of diabetes (Table 4). The participants in cluster 1 who developed diabetes showed a decline of compensatory increased insulin secretion (from 129.9 ± 26.4 to 99.2 ± 20.3, p = 0.029), without a concomitant decrease in insulin resistance (from 1.47 ± 0.39 to 1.84 ± 0.98, p = 0.340) during the follow-up period, while the participants in cluster 2 who developed diabetes showed a significant increase in insulin resistance (from 0.84 ± 0.20 to 1.18 ± 0.49, p < 0.001), along with a modest decrease in insulin secretion (from 72.9 ± 17.4 to 64.6 ± 18.8, p = 0.005).
Table 4.
Changes in the clinical characteristics from baseline to diabetes onset in clusters 1 and 2.
4. Discussion
In the present study of nondiabetic Japanese participants, we identified two distinct groups who are at risk of incident diabetes using a cluster analysis of four variables (HbA1c, BMI, HOMA2-B, and HOMA2-IR). Thus, in addition to T2DM being a heterogenous disease, we have shown that those at risk of diabetes are also heterogenous in their characteristics. Of the two groups found to be at risk of diabetes, participants in cluster 1 (IR-SIS) were not dysglycemic and therefore would not be identified to be at risk of incident diabetes over the relatively short period of 5 years in a standard clinical setting. In contrast, the participants in cluster 2, although not diabetic, showed dysglycemia and therefore would be more readily assessed as being at risk of diabetes. Dysglycemia is a well-known marker of diabetes risk. However, although the risk of diabetes associated with dysglycemia, defined as HbA1c 5.8~6.4%, was very high (HR (95% CI): 12.2 (4.3–35.3), p < 0.001), it appeared to be lower than that for cluster 2 (HR (95% CI): 53.1 (12.4–227.5), p < 0.001), suggesting that being in cluster 2 is a superior predictor of diabetes than dysglycemia alone. In addition, the ROC analysis showed that the two groups could be evaluated highly reliably using only the cut-off values for the three corresponding variables (AUCs of 0.9970 and 0.9831 for clusters 1 and 2, respectively). Thus, using only four commonly measured variables, two distinct groups at risk of diabetes within the following 5 years can be accurately identified, at least in the Japanese population.
Moreover, because individuals at risk of incident diabetes can be divided into two groups with differing clinical characteristics and predisposing factors, healthcare can be tailored to individuals according to the group to which they belong. In other words, individuals in clusters 1 or 2 should both be eligible for more intensive healthcare, but the specific measures instituted should be determined by the cluster to which they belong.
As described, cluster 1 was characterized by high BMI, insulin resistance, high insulin secretion, an abnormal lipid profile, and higher kidney damage, and it was labeled as “obese insulin resistant with sufficient compensatory insulin secretion” (IR-SIS). Bearing the facts in mind, the participants in cluster 1 who developed diabetes showed declines in the compensatory increased insulin secretion (from 129.9 ± 26.4 to 99.2 ± 20.3, p = 0.029), without a concomitant decrease in insulin resistance (change from 1.47 ± 0.39 to 1.84 ± 0.98, p = 0.340) during the 5-year follow-up period. Interestingly, the ROC analysis, which was used to determine the cut-off values for each of the variables defining cluster 1, revealed that individuals with high insulin secretion (HOMA2-B ≥83.8), moderate-to-high BMI (≥21.72), and high insulin resistance (HOMA2-IR ≥1.3831) can be allocated to cluster 1. In other words, higher, rather than lower, insulin secretion is a predictor of being in cluster 1. These findings suggest that excessive insulin secretion in compensation for insulin resistance may be followed by a rapid decline in insulin secretion. A recent cluster analysis using six variables (glutamate decarboxylase antibody, age at diagnosis, HbA1c, BMI, HOMA2-B, and HOMA2-IR) showed four T2DM clusters with distinctly different clinical characteristics and outcomes, such as diabetic complications [6,7,8,9,10,11,12,13,14,15,16,17,18]. If the characteristics of cluster 1 at the onset of diabetes are compared with those of the four T2DM clusters previously described, cluster 1 appears to be similar to MOD, which has been shown to be associated with the lowest risk of diabetic complications of the four defined clusters [6,8,9,10,11,12,16,17,18]. This implies that individuals in cluster 1 are at risk of incident diabetes, but if they do develop diabetes, their risks of developing diabetes-related complications may be low. Taken together, these findings suggest that the healthcare for individuals in cluster 1 should focus on obesity reduction, with the aim of reducing insulin resistance and avoiding the decline in compensatory increased insulin secretion.
Cluster 2 was characterized by low insulin secretion and dysglycemia and was labeled as “low insulin secretion” (Low-IS). The participants in cluster 2 who developed diabetes showed significant increases in insulin resistance (from 0.84 ± 0.20 to 1.18 ± 0.49, p < 0.001), along with a modest decrease in insulin secretion (from 72.9 ± 17.4 to 64.6 ± 18.8, p = 0.005) during the 5-year follow-up period. However, ROC curve analyses to define optimal cut-off values for the variables predicting cluster 2 revealed that HbA1c >5.8, BMI ≥20.43, and HOMA2-B ≤80.9 were the values. Namely, insulin resistance did not predict being in cluster 2. Taken together, these findings suggest that a slow decline in insulin secretion over a period of 5 years, coupled with a modest increase in insulin resistance and low insulin secretion at baseline, may lead to the development of diabetes. Therefore, to maintain adequate insulin secretion, healthcare should be focused on preventing an increase in blood glucose concentrations for individuals in cluster 2. In addition, as for cluster 1, we also compared the characteristics of cluster 2 at the onset of diabetes to those of the four T2DM clusters previously reported and found that cluster 2 is similar to MARD, which has been shown to have the highest prevalence but the lowest risk of diabetic complications among the four T2DM clusters reported in most previous studies [6,8,9,10,11,12,16,17,18,27]. This implies that individuals in cluster 2 are at higher risk of incident diabetes, but their risk of subsequently developing diabetes complications may be low, at least over a 5-year period.
As described, most of the participants who developed T2DM during the 5-year follow-up period could be classified as either MOD (21.6%) or MARD (75.7%). Although ethnic differences in the frequencies of the T2DM clusters previously reported have been reported, these high frequencies of MOD and MARD are inconsistent with those reported previously [27,28]. Even in a study of a Japanese sample, the frequencies of the SIDD, SIRD, MOD, and MARD clusters were reported to be 19.0, 7.2, 28.9, and 39.5, respectively [10]. The individuals classified in the present study were those who developed T2DM during a 5-year follow-up period and therefore could only have had T2DM for a short period of time. Furthermore, a comparison of the characteristics of the participant in clusters 1 and 2 at the onset of T2DM with those of individuals defined as SIRD and SIDD suggests that they may be at least at risk of SIRD and SIDD, respectively, in the future. Taking these findings together, it seems that the participants in cluster 1 are at risk of becoming MOD in the near future and may be at risk of becoming SIRD in the distant future, whereas the participants in cluster 2 are at risk of becoming MARD in the near future and may be at risk of becoming SIDD at the distant future. This may explain the high frequencies of MOD and MARD observed in the present study. However, further analysis with a longer follow-up and more subjects is awaited to test this hypothesis.
This study was conducted in the thought that the risk of incident T2DM could be more precisely assessed by cluster analysis than by analysis with a single variable. To ensure such a thought, we also analyzed the risk of incident T2DM for BMI in the study sample, since BMI is a well-known risk factor for incident T2DM and could be a suitable example for such an analysis. BMI was found to be associated with the risk for incident T2DM (HR: 1.15 per 1 kg/m2, p = 0.007). The analysis using the optimal cutoff value for BMI (23.187) showed that the multiple factors adjusted HR for those at risk based on the BMI was 3.15 (p = 0.003). In addition, further adjustments with the HbA1c and HOMA2 indices made the association insignificant (HR: 1.83, p = 0.171). Furthermore, the multiple factors adjusted HR for those at risk based on the cutoff values of BMI 25 kg/m2 and 30 kg/m2 were 2.00 (p = 0.047) and 2.15 (p = 0.312), respectively. These values were clearly lower than those of clusters 1 and 2 observed in the present cluster analysis. Similarly, the multiple factors adjusted HR for those at risk based on the cutoff values of FBG 92 mg/dl and 110 mg/dl were 10.86 (p < 0.001) and 23.64 (p < 0.001), respectively, clearly lower than that of cluster 2 observed in the present cluster analysis. These findings may indicate that a cluster analysis with several variables such as HbA1c, BMI, and HOMA2 indices together may more accurately assess the risk of incident T2DM than each variable alone.
The present study had several strengths and limitations. With regard to its strengths, we studied a sample from the general population and accounted for multiple factors that could have confounded the statistical analyses. Furthermore, the study had a longitudinal component, as well as a cross-sectional one, which permitted us to evaluate the relationships between the clusters and incident diabetes. As for the limitations, firstly, we recruited the participants from a health promotion study rather than from among people attending health check-ups, and therefore, the participants may have been relatively health-conscious. Consistent with this, the proportion of women in the study was high (63.1%). However, in contrast, the participants may not be so healthy, since the prevalence of hypertension and hyperlipidemia seems to be somewhat higher. In addition, since the participation rate was not so high (1167/11,292: 10.3%), a selection bias may exist. However, as shown in the results, since the prevalence of hypertension and hyperlipidemia does not seem to differ substantially from the general Japanese population, the bias may not be so substantial. Secondly, we did not measure the GAD-Ab, and therefore, individuals predisposed toward type 1 diabetes may have been misevaluated. However, none of the participants developed type 1 diabetes during the 5-year follow-up period, and therefore, this is a remote possibility. In addition, the 5-year follow-up period may have been too short for this kind of longitudinal study. However, during the follow-up period, significant differences between the groups were identified, and therefore, it seemed to be sufficient for the present analysis. Thirdly, only four variables were used in the cluster analysis. Including more variables, such as family history or genetic background, would improve the sensitivity and specificity of the risk assessment for incident T2DM. In fact, a recent study using multiple variables, including genetic factors, showed that pre-diabetics could be classified into six clusters, of which the clusters with a genetically higher risk of T2DM were at a higher risk of incident diabetes than the other clusters [29]. Therefore, future analyses with more variables, such as family history or genetic background, are awaited. However, we believe the value of this study is that it assessed the risk of incident T2DM quite accurately using only four common variables.
In conclusion, we classified nondiabetic individuals selected from the general Japanese population by hierarchical clustering analyses using four variables that are commonly measured in the standard clinical setting and identified two distinct groups that are at risk of incident diabetes during the subsequent 5 years: IR-SIS and Low-IS. Furthermore, we evaluated the factors related to the development of diabetes in each cluster at risk of incident diabetes. The findings have implications for how individuals at risk of diabetes should be evaluated and how appropriately healthcare should be targeted toward individuals for the prevention of diabetes.
Author Contributions
R.I., S.M., M.D., and K.I. designed the study. R.I., S.M, and M.D. analyzed and interpreted the data. M.D. wrote the manuscript. Y.N., S.O., A.T. (Ayumi Tamura), K.H., A.T. (Akihide Terada), J.T., M.Y, K.M.W., Y.K., Y.T., and K.I. contributed to data acquisition. Y.N., S.O., A.T. (Ayumi Tamura), K.H., A.T. (Akihide Terada), J.T., and M.Y. contributed to data interpretation. R.I., S.M, Y.T., and K.I. take responsibility for the integrity and the accuracy of the data. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Center of Innovation Program from the Japan Science and Technology Agency (JPMJCE1302 and JPMJCA2201).
Institutional Review Board Statement
This present study was approved by the Ethics Committee of the Hirosaki University School of Medicine (No. 2014-014, 2014-377-1, 2016-028-1, 2021-030, 2018-063, and 2019-009) and was conducted according to principles of the Declaration of Helsinki.
Informed Consent Statement
Written informed consent was obtained from all the participants.
Data Availability Statement
All data generated or analyzed during this study are included in the published article.
Acknowledgments
We thank Mark Cleasby for editing a draft of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- UK Prospective Diabetes Study Group. Cost effectiveness analysis of improved blood pressure control in hypertensive patients with type 2 diabetes: UKPDS 40. BMJ 1998, 317, 720–726. [Google Scholar] [CrossRef]
- Lam, D.W.; LeRoith, D. The worldwide diabetes epidemic. Curr. Opin. Endocrinol. Diabetes Obes. 2012, 19, 93–96. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association Professional Practice Committee. Classification and Diagnosis of Diabetes: Standards of Medical Care in Diabetes—2022. Diabetes Care 2022, 45 (Suppl. 1), S17–S38. [Google Scholar] [CrossRef] [PubMed]
- Stumvoll, M.; Goldstein, B.J.; van Haeften, T.W. Type 2 diabetes: Principles of pathogenesis and therapy. Lancet 2005, 365, 1333–1346. [Google Scholar] [CrossRef]
- DeFronzo, R.A. Pathogenesis of type 2 diabetes mellitus. Med. Clin. N. Am. 2004, 88, 787–835. [Google Scholar] [CrossRef] [PubMed]
- Ahlqvist, E.; Storm, P.; Käräjämäki, A.; Martinell, M.; Dorkhan, M.; Carlsson, A.; Vikman, P.; Prasad, R.B.; Aly, D.M.; Almgren, P.; et al. Novel subgroups of adult-onset diabetes and their association with outcomes: A data-driven cluster analysis of six variables. Lancet Diabetes Endocrinol. 2018, 6, 361–369. [Google Scholar] [CrossRef]
- Zou, X.; Zhou, X.; Zhu, Z.; Ji, L. Novel subgroups of patients with adult-onset diabetes in Chinese and US populations. Lancet Diabetes Endocrinol. 2019, 7, 9–11. [Google Scholar] [CrossRef]
- Dennis, J.M.; Shields, B.M.; Henley, W.E.; Jones, A.G.; Hattersley, A.T. Disease progression and treatment response in data-driven subgroups of type 2 diabetes compared with models based on simple clinical features: An analysis using clinical trial data. Lancet Diabetes Endocrinol. 2019, 7, 442–451. [Google Scholar] [CrossRef]
- Zaharia, O.P.; Strassburger, K.; Strom, A.; Bönhof, G.J.; Karusheva, Y.; Antoniou, S.; Bódis, K.; Markgraf, D.F.; Burkart, V.; Müssig, K.; et al. Risk of diabetes-associated diseases in subgroups of patients with recent-onset diabetes: A 5-year follow-up study. Lancet Diabetes Endocrinol. 2019, 7, 684–694. [Google Scholar] [CrossRef]
- Tanabe, H.; Saito, H.; Kudo, A.; Machii, N.; Hirai, H.; Maimaituxun, G.; Tanaka, K.; Masuzaki, H.; Watanabe, T.; Asahi, K.; et al. Factors Associated with Risk of Diabetic Complications in Novel Cluster-Based Diabetes Subgroups: A Japanese Retrospective Cohort Study. J. Clin. Med. 2020, 9, 2083. [Google Scholar] [CrossRef]
- Kahkoska, A.R.; Geybels, M.S.; Klein, K.R.; Kreiner, F.F.; Marx, N.; Nauck, M.A.; Pratley, R.E.; Wolthers, B.O.; Buse, J.B. Validation of distinct type 2 diabetes clusters and their association with diabetes complications in the DEVOTE, LEADER and SUSTAIN-6 cardiovascular outcomes trials. Diabetes Obes. Metab. 2020, 22, 1537–1547. [Google Scholar] [CrossRef] [PubMed]
- Xing, L.; Peng, F.; Liang, Q.; Dai, X.; Ren, J.; Wu, H.; Yang, S.; Zhu, Y.; Jia, L.; Zhao, S. Clinical Characteristics and Risk of Diabetic Complications in Data-Driven Clusters Among Type 2 Diabetes. Front. Endocrinol. (Lausanne) 2021, 12, 617628. [Google Scholar] [CrossRef] [PubMed]
- Aoki, Y.; Hamrén, B.; Clegg, L.E.; Stahre, C.; Bhatt, D.; Raz, I.; Scirica, B.M.; Oscarsson, J.; Carlsson, B. Assessing reproducibility and utility of clustering of patients with type 2 diabetes and established CV disease (SAVOR -TIMI 53 trial). PLoS ONE 2021, 16, e0259372. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yang, S.; Cao, C.; Yan, X.; Zheng, L.; Zheng, L.; Da, J.; Tang, X.; Ji, L.; Yang, X.; et al. Validation of the Swedish Diabetes Re-Grouping Scheme in Adult-Onset Diabetes in China. J. Clin. Endocrinol. Metab. 2020, 105, dgaa524. [Google Scholar] [CrossRef]
- Lugner, M.; Gudbjörnsdottir, S.; Sattar, N.; Svensson, A.M.; Miftaraj, M.; Eeg-Olofsson, K.; Eliasson, B.; Franzén, S. Comparison between data-driven clusters and models based on clinical features to predict outcomes in type 2 diabetes: Nationwide observational study. Diabetologia 2021, 64, 1973–1981. [Google Scholar] [CrossRef]
- Wang, W.; Pei, X.; Zhang, L.; Chen, Z.; Lin, D.; Duan, X.; Fan, J.; Pan, Q.; Guo, L. Application of new international classification of adult-onset diabetes in Chinese inpatients with diabetes mellitus. Diabetes Metab. Res. Rev. 2021, 37, e3427. [Google Scholar] [CrossRef]
- Bello-Chavolla, O.Y.; Bahena-López, J.P.; Vargas-Vázquez, A.; Antonio-Villa, N.E.; Márquez-Salinas, A.; Fermín-Martínez, C.A.; Rojas, R.; Mehta, R.; Cruz-Bautista, I.; Hernández-Jiménez, S.; et al. Clinical characterization of data-driven diabetes subgroups in Mexicans using a reproducible machine learning approach. BMJ Open Diabetes Res. Care 2020, 8, e001550. [Google Scholar] [CrossRef]
- Xiong, X.F.; Yang, Y.; Wei, L.; Xiao, Y.; Li, L.; Sun, L. Identification of two novel subgroups in patients with diabetes mellitus and their association with clinical outcomes: A two-step cluster analysis. J. Diabetes Investig. 2021, 12, 1346–1358. [Google Scholar] [CrossRef]
- Daimon, M.; Kamba, A.; Murakami, H.; Takahashi, K.; Otaka, H.; Makita, K.; Yanagimachi, M.; Terui, K.; Kageyama, K.; Nigawara, T.; et al. Association Between Pituitary-Adrenal Axis Dominance Over the Renin-Angiotensin-Aldosterone System and Hypertension. J. Clin. Endocrinol. Metab. 2016, 101, 889–897. [Google Scholar] [CrossRef]
- Kamba, A.; Daimon, M.; Murakami, H.; Otaka, H.; Matsuki, K.; Sato, E.; Tanabe, J.; Takayasu, S.; Matsuhashi, Y.; Yanagimachi, M.; et al. Association between Higher Serum Cortisol Levels and Decreased Insulin Secretion in a General Population. PLoS ONE 2016, 11, e0166077. [Google Scholar] [CrossRef]
- Nakaji, S.; Ihara, K.; Sawada, K.; Parodi, S.; Umeda, T.; Takahashi, I.; Murashita, K.; Kurauchi, S.; Tokuda, I. Social innovation for life expectancy extension utilizing a platform-centered system used in the Iwaki health promotion project: A protocol paper. SAGE Open Med. 2021, 9, 20503121211002606. [Google Scholar] [CrossRef] [PubMed]
- Committee of the Japan Diabetes Society on the Diagnostic Criteria of Diabetes Mellitus; Seino, Y.; Nanjo, K.; Tajima, N.; Kadowaki, T.; Kashiwagi, A.; Araki, E.; Ito, C.; Inagaki, N.; Iwamoto, Y.; et al. Report of the committee on the classification and diagnostic criteria of diabetes mellitus. J. Diabetes Investig. 2010, 1, 212–228. [Google Scholar] [CrossRef] [PubMed]
- Ministry of Health, Labour and Welfare, Japan. National Health and Nutrition Survey 2014. Available online: https://www.mhlw.go.jp/file/04-Houdouhappyou-10904750-Kenkoukyoku-Gantaisakukenkouzoushinka/0000117311.pdf (accessed on 2 March 2022).
- Daimon, M.; Oizumi, T.; Saitoh, T.; Kameda, W.; Hirata, A.; Yamaguchi, H.; Ohnuma, H.; Igarashi, M.; Tominaga, M.; Kato, T. Decreased serum levels of adiponectin are a risk factor for the progression to type 2 diabetes in the Japanese Population: The Funagata study. Diabetes Care 2003, 26, 2015–2020. [Google Scholar] [CrossRef] [PubMed]
- Hata, J.; Ninomiya, T.; Hirakawa, Y.; Nagata, M.; Mukai, N.; Gotoh, S.; Fukuhara, M.; Ikeda, F.; Shikata, K.; Yoshida, D.; et al. Secular trends in cardiovascular disease and its risk factors in Japanese: Half-century data from the Hisayama Study (1961–2009). Circulation 2013, 128, 1198–1205. [Google Scholar] [CrossRef]
- Fujiwara, T.; Saitoh, S.; Takagi, S.; Ohnishi, H.; Ohata, J.; Takeuchi, H.; Isobe, T.; Chiba, Y.; Katoh, N.; Akasaka, H.; et al. Prevalence of asymptomatic arteriosclerosis obliterans and its relationship with risk factors in inhabitants of rural communities in Japan: Tanno-Sobetsu study. Atherosclerosis 2004, 177, 83–88. [Google Scholar] [CrossRef]
- Varghese, J.S.; Narayan, K.M.V. Ethnic differences between Asians and non-Asians in clustering-based phenotype classification of adult-onset diabetes mellitus: A systematic narrative review. Prim. Care Diabetes 2022, 16, 853–856. [Google Scholar] [CrossRef]
- Ke, C.; Venkat Narayan, K.M.; Chan, J.C.N.; Jha, P.; Shah, B.R. Pathophysiology, phenotypes and management of type 2 diabetes mellitus in Indian and Chinese populations. Nat. Rev. Endocrinol. 2022, 18, 413–432. [Google Scholar] [CrossRef]
- Wagner, R.; Heni, M.; Tabák, A.G.; Machann, J.; Schick, F.; Randrianarisoa, E.; de Angelis, M.H.; Birkenfeld, A.L.; Stefan, N.; Peter, A.; et al. Pathophysiology-based subphenotyping of individuals at elevated risk for type 2 diabetes. Nat. Med. 2021, 27, 49–57. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).