
Methodological and Statistical Considerations for Cross-Sectional, Case–Control, and Cohort Studies

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Methods
3. The Proper Classification of Analytical Observational Studies
4. Key Points for Correctly Classifying a Study
4.1. In Cross-Sectional Studies, Exposure and Outcome Are Identified Simultaneously
4.2. In Cross-Sectional Studies, There Is Neither Prospective nor Retrospective Follow-Up
4.3. In Case–Control Studies, the Study Population Is Selected Based on the Outcomes
4.4. Cohort Studies Compare Study Groups Based on the Risk Factor
4.5. How to Differentiate between a Retrospective Cohort and a Case–Control Study?
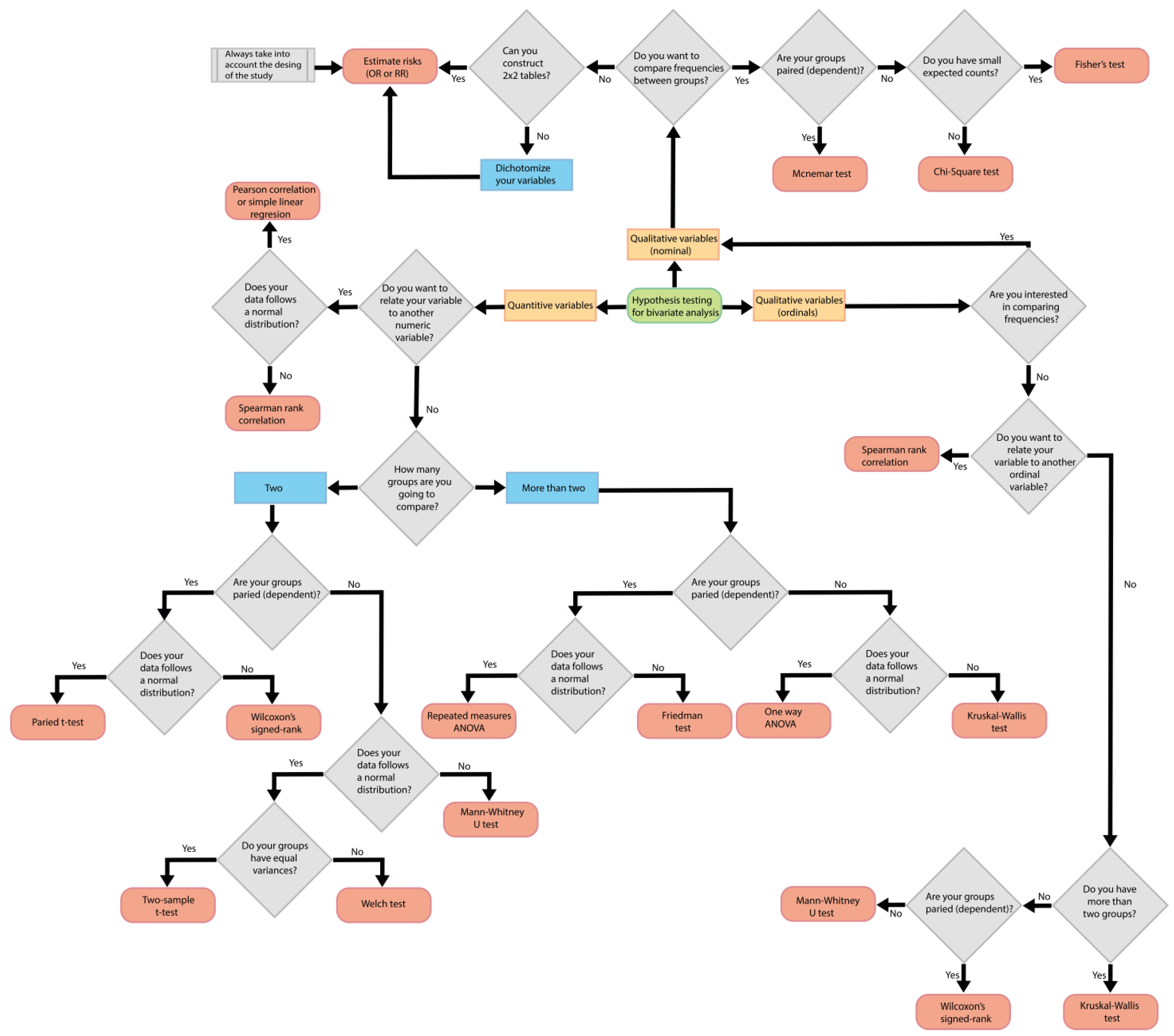
5. Statistical Considerations in Analytical Observational Studies
- Identify the type of variables.
- Determine if the statistical test involves comparing between groups or intends to find the relationship with another variable.
- Determine if measurements will be taken in different groups or if repeated measurements will be taken in the same group over time.
- Establish the number of groups being compared.
- Identify the distribution of the data.
- Define the type of study.
5.1. Identify the Type of Variables
5.2. Determine If the Statistical Test Involves Comparing between Groups or Intends to Find the Relationship with Another Variable
5.3. Determine If Measurements Will Be Taken in Different Groups or If Repeated Measurements Will Be Taken in the Same Group over Time
5.4. Establish the Number of Groups Being Compared
5.5. Identify the Distribution of the Data
5.6. Define the Type of Study
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Epidemiology Is a Science of High Importance. Nat. Commun. 2018, 9, 1703. [CrossRef] [PubMed]
- Belbasis, L.; Bellou, V. Introduction to Epidemiological Studies. In Genetic Epidemiology; Humana Press: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Bos, D.; Ikram, M.A. Research Aims in Clinical Medicine: Description, Identification, or Explanation. World Neurosurg. 2022, 161, 240–244. [Google Scholar] [CrossRef] [PubMed]
- Ranganathan, P.; Aggarwal, R. Study Designs: Part 3—Analytical Observational Studies. Perspect. Clin. Res. 2019, 10, 91–94. [Google Scholar] [CrossRef] [PubMed]
- Shreffler, J.; Huecker, M.R. Types of Variables and Commonly Used Statistical Designs. Available online: https://www.ncbi.nlm.nih.gov/books/NBK557882/ (accessed on 27 February 2024).
- von Elm, E.; Altman, D.G.; Egger, M.; Pocock, S.J.; Gøtzsche, P.C.; Vandenbroucke, J.P. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) Statement: Guidelines for Reporting Observational Studies. Lancet 2007, 370, 1453–1457. [Google Scholar] [CrossRef] [PubMed]
- Cuschieri, S. The STROBE Guidelines. Saudi J. Anaesth. 2019, 13, S31–S34. [Google Scholar] [CrossRef] [PubMed]
- Irani, M.; Hassanzadeh Bashtian, M.; Khadivzadeh, T.; Ebrahimipour, H.; Asghari Nekah, S.M. Weaknesses in the Reporting of Cross-Sectional Studies in Accordance with the STROBE Report (The Case of Congenital Anomaly among Infants in Iran): A Review Article. Iran J. Public Health 2018, 47, 1796–1804. [Google Scholar] [PubMed]
- Nair, S.; Yean, C.; Yoo, J.; Leff, J.; Delphin, E.; Adams, D.C. Reasons for article retraction in anesthesiology: A comprehensive analysis. Can. J. Anaesth. 2020, 67, 57–63. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Kamel, M.; Jin, Y.; Xu, M.K.; Mbuagbaw, L.; Samaan, Z.; Levine, M.A.; Thabane, L. Exploring the characteristics, global distribution and reasons for retraction of published articles involving human research participants: A literature survey. J. Multidiscip. Healthc. 2018, 11, 39–47. [Google Scholar] [CrossRef] [PubMed]
- Hill, H.Z.; Pitt, J.H. Failure to Replicate: A Sign of Scientific Misconduct? Publications 2014, 2, 71–82. [Google Scholar] [CrossRef]
- LeBrun, D.G.; Bido, J.; Kocher, M.S.; Baldwin, K.D.; Fabricant, P.D. Misclassification of Case–Control Studies in the Orthopedic Literature Is Common: A Bibliometric Analysis. HSS J. 2020, 16, 366–371. [Google Scholar] [CrossRef]
- Esene, I.N.; Mbuagbaw, L.; Dechambenoit, G.; Reda, W.; Kalangu, K.K. Misclassification of Case-Control Studies in Neurosurgery and Proposed Solutions. World Neurosurg. 2018, 112, 233–242. [Google Scholar] [CrossRef] [PubMed]
- Kicielinski, K.P.; Dupépé, E.B.; Gordon, A.S.; Mayo, N.E.; Walters, B.C. What Isn’t a Case-Control Study? Neurosurgery 2019, 84, 993–999. [Google Scholar] [CrossRef] [PubMed]
- Mayo, N.; Goldberg, M. When Is a Case-Control Study Not a Case-Control Study? J. Rehabil. Med. 2009, 41, 209–216. [Google Scholar] [CrossRef] [PubMed]
- Grimes, D.A. “Case-Control” Confusion. Obstet. Gynecol. 2009, 114, 1284–1286. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Cheng, Z. Cross-Sectional Studies. Chest 2020, 158, S65–S71. [Google Scholar] [CrossRef] [PubMed]
- Capili, B. Cross-Sectional Studies. AJN Am. J. Nurs. 2021, 121, 59–62. [Google Scholar] [CrossRef] [PubMed]
- Setia, M. Methodology Series Module 3: Cross-Sectional Studies. Indian J. Dermatol. 2016, 61, 261–264. [Google Scholar] [CrossRef] [PubMed]
- Tamhane, A.R.; Westfall, A.O.; Burkholder, G.A.; Cutter, G.R. Prevalence Odds Ratio versus Prevalence Ratio: Choice Comes with Consequences. Stat. Med. 2016, 35, 5730–5735. [Google Scholar] [CrossRef] [PubMed]
- Biernikiewicz, M.; Sobieszczańska, M.; Szuster, E.; Pawlikowska-Gorzelańczyk, A.; Janocha, A.; Rożek-Piechura, K.; Rusiecka, A.; Gebala, J.; Okrzymowska, P.; Kałka, D. Erectile Dysfunction as an Obesity-Related Condition in Elderly Men with Coronary Artery Disease. J. Clin. Med. 2024, 13, 2087. [Google Scholar] [CrossRef]
- Bell, A. Cross-Sectional and Longitudinal Studies. In Research Methods in the Social Sciences: An A-Z of Key Concepts; Oxford University Press: Oxford, UK, 2021; pp. 72–76. [Google Scholar]
- Kim, S. Cross-Sectional and Longitudinal Studies. In Encyclopedia of Gerontology and Population Aging; Springer International Publishing: Cham, Switzerland, 2021; pp. 1251–1255. [Google Scholar]
- Elsevier Scopus. Available online: https://www.scopus.com/search/form.uri?display=basic#basic (accessed on 6 February 2024).
- Pan, X. Repeated Cross-Sectional Design. In Encyclopedia of Gerontology and Population Aging; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–5. [Google Scholar]
- Bann, D.; Wright, L.; Goisis, A.; Hardy, R.; Johnson, W.; Maddock, J.; McElroy, E.; Moulton, V.; Patalay, P.; Scholes, S.; et al. Investigating Change across Time in Prevalence or Association: The Challenges of Cross-Study Comparative Research and Possible Solutions. Discov. Soc. Sci. Health 2022, 2, 18. [Google Scholar] [CrossRef]
- Siller, A.; Seekircher, L.; Astl, M.; Tschiderer, L.; Wachter, G.A.; Penz, J.; Pfeifer, B.; Huber, A.; Gaber, M.; Schennach, H.; et al. Anti-SARS-CoV-2 IgG Seroprevalence in Tyrol, Austria, among 28,768 Blood Donors between May 2022 and March 2023. Vaccines 2024, 12, 284. [Google Scholar] [CrossRef] [PubMed]
- Carlson, M.D.A.; Morrison, R.S. Study Design, Precision, and Validity in Observational Studies. J. Palliat. Med. 2009, 12, 77–82. [Google Scholar] [CrossRef] [PubMed]
- Ramji, S. Study Design: Observational Studies. Indian Pediatr. 2022, 59, 493–498. [Google Scholar] [CrossRef] [PubMed]
- Mann, C.J. Observational Research Methods. Research Design II: Cohort, Cross Sectional, and Case-Control Studies. Emerg. Med. J. 2003, 20, 54–60. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Perez, N.; Echezarreta-Ruiz, O.; Alegria-Lertxundi, I.M.; de Pancorbo, M.; Olasagasti, F.; Eguiraun, H.; Arroyo-Izaga, M. Relationships between Meat and Fish Consumption, N-Acetyltransferase 2 Genotypes, and Colorectal Cancer Risk: A Case–Control Study in the Basque Country. Proceedings 2023, 91, 358. [Google Scholar]
- Sato, Y.; Nakaya, N.; Kuriyama, S.; Nishino, Y.; Tsubono, Y.; Tsuji, I. Meat Consumption and Risk of Colorectal Cancer in Japan: The Miyagi Cohort Study. Eur. J. Cancer Prev. 2006, 15, 211–218. [Google Scholar] [CrossRef]
- Goldbohm, R.A.; van den Brandt, P.A.; van ’t Veer, P.; Brants, H.A.; Dorant, E.; Sturmans, F.; Hermus, R.J. A Prospective Cohort Study on the Relation between Meat Consumption and the Risk of Colon Cancer. Cancer Res. 1994, 54, 718–723. [Google Scholar]
- Willett, W.C.; Stampfer, M.J.; Colditz, G.A.; Rosner, B.A.; Speizer, F.E. Relation of Meat, Fat, and Fiber Intake to the Risk of Colon Cancer in a Prospective Study among Women. N. Engl. J. Med. 1990, 323, 1664–1672. [Google Scholar] [CrossRef]
- Hatchell, A.C.; Farrokhyar, F.; Choi, M. The Misconception of Case-Control Studies in the Plastic Surgery Literature: A Literature Audit. Plast. Reconstr. Surg. 2017, 139, 1356e–1363e. [Google Scholar] [CrossRef]
- Dey, T.; Mukherjee, A.; Chakraborty, S. A Practical Overview of Case-Control Studies in Clinical Practice. Chest 2020, 158, S57–S64. [Google Scholar] [CrossRef]
- Thiese, M.S. Observational and Interventional Study Design Types; an Overview. Biochem. Med. 2014, 24, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Kattan, M.W. Cohort Studies. Chest 2020, 158, S72–S78. [Google Scholar] [CrossRef] [PubMed]
- Song, J.W.; Chung, K.C. Observational Studies: Cohort and Case-Control Studies. Plast. Reconstr. Surg. 2010, 126, 2234–2242. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.A.; Taino, A.; Facchinetti, P.; Rossi, V.; Ruggiero, D.; Berra, S.; Blanda, G.; Flor, N.; Cogliati, C.; Colombo, R. Venous Thromboembolism Management throughout the COVID-19 Era: Addressing Acute and Long-Term Challenges. J. Clin. Med. 2024, 13, 1825. [Google Scholar] [CrossRef] [PubMed]
- Mellado-García, E.; Díaz-Rodríguez, L.; Cortés-Martín, J.; Sánchez-García, J.C.; Piqueras-Sola, B.; Macías, J.C.H.; Rivas Ruiz, F.; Rodríguez-Blanque, R. Comparative Analysis of Therapeutic Showers and Bathtubs for Pain Management and Labor Outcomes—A Retrospective Cohort Study. J. Clin. Med. 2024, 13, 3517. [Google Scholar] [CrossRef] [PubMed]
- Tsinopoulou, V.R.; Kotanidou, E.P.; Athanasiadis, N.; Bacopoulou, F.; Stefanaki, C.; Fidani, L.; Galli-Tsinopoulou, A.; Christoforidis, A. Earlier Menarche in Greek Girls Born by Caesarean Section: A Case–Control Study. J. Clin. Med. 2024, 13, 3452. [Google Scholar] [CrossRef]
- Bacchetti, P. Peer Review of Statistics in Medical Research: The Other Problem. BMJ 2002, 324, 1271–1273. [Google Scholar] [CrossRef]
- Greenwood, D.C.; Freeman, J.V. How to Spot a Statistical Problem: Advice for a Non-Statistical Reviewer. BMC Med. 2015, 13, 270. [Google Scholar] [CrossRef] [PubMed]
- Proctor, D.M.; Dada, N.; Serquiña, A.; Willett, J.L.E. Problems with Peer Review Shine a Light on Gaps in Scientific Training. mBio 2023, 14, e03183-22. [Google Scholar] [CrossRef]
- Kongjam, P.; Jeyaseelan, L.; Chaijaroenkul, W.; Na-Bangchang, K. Systematic Analysis of the Application and Inappropriate Use/Misuse of Statistics in Cholangiocarcinoma Research in Southeast Asia. Asian Pac. J. Cancer Prev. 2020, 21, 275–280. [Google Scholar] [CrossRef]
- Scales, C.D.; Norris, R.D.; Peterson, B.L.; Preminger, G.M.; Dahm, P. Clinical Research and Statistical Methods in the Urology Literature. J. Urol. 2005, 174, 1374–1379. [Google Scholar] [CrossRef] [PubMed]
- LeBrun, D.G.; Tran, T.; Wypij, D.; Kocher, M.S. How Often Do Orthopaedic Matched Case-Control Studies Use Matched Methods? A Review of Methodological Quality. Clin. Orthop. Relat. Res. 2019, 477, 655–662. [Google Scholar] [CrossRef] [PubMed]
- Jupiter, D.C. A Variety of Variables. J. Foot Ankle Surg. 2014, 53, 124–125. [Google Scholar] [CrossRef] [PubMed]
- McHugh, M.L. The Chi-Square Test of Independence. Biochem. Med. 2013, 23, 143–149. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Lee, W. Does McNemar’s Test Compare the Sensitivities and Specificities of Two Diagnostic Tests? Stat. Methods Med. Res 2017, 26, 142–154. [Google Scholar] [CrossRef] [PubMed]
- Amiri, S.; Modarres, R. Comparison of Tests of Contingency Tables. J. Biopharm. Stat. 2017, 27, 784–796. [Google Scholar] [CrossRef] [PubMed]
- Mircioiu, C.; Atkinson, J. A Comparison of Parametric and Non-Parametric Methods Applied to a Likert Scale. Pharmacy 2017, 5, 26. [Google Scholar] [CrossRef] [PubMed]
- Simon, S.D. Understanding the Odds Ratio and the Relative Risk. J. Androl. 2001, 22, 533–536. [Google Scholar] [CrossRef]
- Yan, F.; Robert, M.; Li, Y. Statistical Methods and Common Problems in Medical or Biomedical Science Research. Int. J. Physiol. Pathophysiol. Pharmacol. 2017, 9, 157–163. [Google Scholar]
- Kim, T.K. T Test as a Parametric Statistic. Korean J. Anesthesiol. 2015, 68, 540. [Google Scholar] [CrossRef]
- Guo, S.; Zhong, S.; Zhang, A. Privacy-Preserving Kruskal–Wallis Test. Comput. Methods Programs Biomed. 2013, 112, 135–145. [Google Scholar] [CrossRef] [PubMed]
- Twomey, P.J.; Kroll, M.H. How to Use Linear Regression and Correlation in Quantitative Method Comparison Studies. Int. J. Clin. Pract. 2008, 62, 529–538. [Google Scholar] [CrossRef] [PubMed]
- Eberly, L.E. Correlation and Simple Linear Regression. In Topics in Biostatistics; Humana Press: New York, NY, USA, 2007; pp. 143–164. [Google Scholar]
- Divine, G.; Norton, H.J.; Hunt, R.; Dienemann, J. A Review of Analysis and Sample Size Calculation Considerations for Wilcoxon Tests. Anesth. Analg. 2013, 117, 699–710. [Google Scholar] [CrossRef] [PubMed]
- Misra, D.P.; Zimba, O.; Gasparyan, A.Y. Statistical Data Presentation: A Primer for Rheumatology Researchers. Rheumatol. Int. 2021, 41, 43–55. [Google Scholar] [CrossRef] [PubMed]
- Royston, P. Which Measures of Skewness and Kurtosis Are Best? Stat. Med. 1992, 11, 333–343. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, A. Conoce Tus Datos: Evaluación de La Normalidad de Variables Continuas y Estrategias Para Tratar Con Distribuciones No Normales. Med. Clin. 2020, 154, 142–145. [Google Scholar] [CrossRef] [PubMed]
- Habibzadeh, F. Data Distribution: Normal or Abnormal? J. Korean Med. Sci. 2024, 39, e35. [Google Scholar] [CrossRef] [PubMed]
- Bajwa, S.J. Basics, Common Errors and Essentials of Statistical Tools and Techniques in Anesthesiology Research. J. Anaesthesiol. Clin. Pharmacol. 2015, 31, 547. [Google Scholar] [CrossRef] [PubMed]
- Antay-Bedregal, D.; Camargo-Revello, E.; Alvarado, G.F. Associated Factors vs Risk Factors in Cross-Sectional Studies. Patient Prefer. Adherence 2015, 2015, 1635–1636. [Google Scholar] [CrossRef]
- Viera, A.J. Odds Ratios and Risk Ratios: What’s the Difference and Why Does It Matter? South. Med. J. 2008, 101, 730–734. [Google Scholar] [CrossRef]
- Tenny, S.; Hoffman, M. Odds Ratio. Available online: https://www.ncbi.nlm.nih.gov/books/NBK431098/ (accessed on 5 March 2024).
- Tenny, S.; Hoffman, M. Relative Risk. Available online: https://www.ncbi.nlm.nih.gov/books/NBK430824/ (accessed on 5 March 2024).

{kind=link}
| Author and Year of Publication | Main Results |
|---|---|
| LeBrun, D. G., 2020 [12] | A total of 339 articles were identified and classified as case–control studies from 75 orthopedic journals. It was found that 227 were misclassified. The designs most commonly confused with case–control studies were cross-sectional and cohort studies. |
| Esene, I. N., 2018 [13] | Of 224 articles initially classified as case–control studies and published in 31 neurosurgery journals, it was determined that 91 of them were not actually case–control studies. Most of the incorrectly labeled studies corresponded to retrospective cohorts. |
| Kicielinski, K., 2019 [14] | Out of 125 articles classified as case–control studies and published in neurosurgery journals, it was observed that 79 were incorrectly labeled, with cross-sectional studies being the most commonly confused. |
| Mayo, N. E., 2009 [15] | Out of 86 articles classified as case–control studies published in rehabilitation journals, it was discovered that 56 of them were actually cross-sectional studies, and 13 were intervention studies. |
| Grimes D. A., 2009 [16] | In four journals, it was identified that out of 124 articles classified as case–control studies, 30% were mislabeled. The majority of mislabeled studies were actually retrospective cohorts |
| Year | Prospective Cross-Sectional | Retrospective Cross-Sectional |
|---|---|---|
| 2023 | 136 | 423 |
| 2022 | 147 | 382 |
| 2021 | 136 | 337 |
| 2020 | 125 | 239 |
| 2019 | 106 | 221 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Guerrero, E.E.; Guillén-Medina, M.R.; Márquez-Sandoval, F.; Vera-Cruz, J.M.; Gallegos-Arreola, M.P.; Rico-Méndez, M.A.; Aguilar-Velázquez, J.A.; Gutiérrez-Hurtado, I.A. Methodological and Statistical Considerations for Cross-Sectional, Case–Control, and Cohort Studies. J. Clin. Med. 2024, 13, 4005. https://doi.org/10.3390/jcm13144005
Pérez-Guerrero EE, Guillén-Medina MR, Márquez-Sandoval F, Vera-Cruz JM, Gallegos-Arreola MP, Rico-Méndez MA, Aguilar-Velázquez JA, Gutiérrez-Hurtado IA. Methodological and Statistical Considerations for Cross-Sectional, Case–Control, and Cohort Studies. Journal of Clinical Medicine. 2024; 13(14):4005. https://doi.org/10.3390/jcm13144005
Chicago/Turabian StylePérez-Guerrero, Edsaúl Emilio, Miryam Rosario Guillén-Medina, Fabiola Márquez-Sandoval, José María Vera-Cruz, Martha Patricia Gallegos-Arreola, Manuel Alejandro Rico-Méndez, José Alonso Aguilar-Velázquez, and Itzae Adonai Gutiérrez-Hurtado. 2024. "Methodological and Statistical Considerations for Cross-Sectional, Case–Control, and Cohort Studies" Journal of Clinical Medicine 13, no. 14: 4005. https://doi.org/10.3390/jcm13144005