Abstract
Background. Leukemic relapse remains the primary cause of treatment failure and death after allogeneic hematopoietic stem cell transplant. Changes in post-transplant donor chimerism have been identified as a predictor of relapse. A better predictive model of relapse incorporating donor chimerism has the potential to improve leukemia-free survival by allowing earlier initiation of post-transplant treatment on individual patients. We explored the use of machine learning, a suite of analytical methods focusing on pattern recognition, to improve post-transplant relapse prediction. Methods. Using a cohort of 63 pediatric patients with acute lymphocytic leukemia (ALL) and 46 patients with acute myeloid leukemia (AML) who underwent stem cell transplant at a single institution, we built predictive models of leukemic relapse with both pre-transplant and post-transplant patient variables (specifically lineage-specific chimerism) using the random forest classifier. Local Interpretable Model-Agnostic Explanations, an interpretable machine learning tool was used to confirm our random forest classification result. Results. Our analysis showed that a random forest model using these hyperparameter values achieved 85% accuracy, 85% sensitivity, 89% specificity for ALL, while for AML 81% accuracy, 75% sensitivity, and 100% specificity at predicting relapses within 24 months post-HSCT in cross validation. The Local Interpretable Model-Agnostic Explanations tool was able to confirm many variables that the random forest classifier identified as important for the relapse prediction. Conclusions. Machine learning methods can reveal the interaction of different risk factors of post-transplant leukemic relapse and robust predictions can be obtained even with a modest clinical dataset. The random forest classifier distinguished different important predictive factors between ALL and AML in our relapse models, consistent with previous knowledge, lending increased confidence to adopting machine learning prediction to clinical management.
1. Introduction
Acute leukemia is the most common form of childhood cancer, accounting for 25% of all cancer before the age of 20; acute lymphoblastic leukemia represents most of the cases at around 80% while acute myeloid leukemia (AML) represents 15 to 20% of all the cases [1,2]. While most patients can be treated with chemotherapy, some require hematopoietic stem cell transplant (HSCT) for durable remission in which leukemia relapse still remains a major cause of treatment failure [3]. Post-transplant donor chimerism has been identified as a predictor of relapse in patients with hematologic malignancies who received HSCT, suggesting the possibility of meaningful relapse surveillance prior to the detection of minimal residual disease [4,5,6,7,8]. The application of these post-transplant chimerism analyses to predict leukemia relapse is limited by the fact that studies mostly correlate relapse to a single selected threshold of chimerism at fixed time points, making it more difficult to apply to individual patients and their own unique risk factors. The ability to forecast more accurately leukemia relapse would likely improve post-transplant outcome by enabling more timely initiation of post-transplant treatment strategies, including hypomethylating agents, targeted therapies like inhibitors of FLT3, Hedgehog and Menin, as well as cellular therapies like donor lymphocyte infusion and allogeneic chimeric antigen receptor T cells [9,10,11,12]. A prediction model that takes account of both pre-transplant risk factors and post-transplant chimerism could help clinicians assess relapse risk and individualize treatment strategies.
One way to achieve a deeper understanding of the complex interaction of multiple risk factors is through the application of machine learning (ML), a suite of data analysis methods which automate analytical model building emphasizing pattern recognition and which has been adopted in hematology [13,14,15,16]. Instead of focusing on making statistical inference to the entire population, ML methods hone in on the structure of the data itself, leading to better pattern recognition [17]. A number of studies have used ML to build predictive models with large datasets; Fuse et al. published their work on using ML to predict leukemia relapse within the first year of HSCT and achieved a highly accurate prediction in cross validation with only seven pretransplant variables [18]. On a larger scale, Shouval et al. reported the European Society for Blood and Marrow Transplantation (EBMT) ML analysis of Day 100 non-relapse mortality and found that only three to five variables were necessary to achieve maximum predictive skill in each model, suggesting that a few high impact variables might be adequate to make accurate predictions for focused clinical questions with ML [19]. While there are increasing numbers of large or “big” datasets, there are many more smaller datasets available from more focused clinical studies. These findings raise the question of whether ML methods, while well suited for “big data”, may also be successfully applied to smaller datasets to extract useful information and build useful predictive models that could complement standard statistical analysis [20,21,22,23]. An obstacle of applying ML in clinical decision making is that these prediction models are often viewed as a “black box” to clinicians. Interpretable machine learning (IML) methods can help illustrate in an intuitive manner on how an ML algorithm learns the relationship between the input variables and the predicted outcome [24,25]. To demonstrate further the potential of ML/IML analysis to extract valid information for focused clinical questions, we used a random forest (RF) classifier, an ML algorithm, to analyze the pattern of post-transplant relapse using pre-transplant variables and post-transplant chimerism in a single-center cohort of patients with ALL and AML undergoing HSCT. Our RF analysis yielded findings consistent with the current knowledge, but was also able to detect different patterns of interactions between the variables in subgroups. IML, specifically Local Interpretable Model-Agnostic Explanations (LIME), was applied to each individual patient and collaborated with our RF analysis, lending more confidence in the RF prediction model [26].
2. Materials & Methods
2.1. Study Design and Data Acquisition
We performed a retrospective archival data analysis using RF classification to produce predictive models of leukemic relapse in post-HSCT setting. Patients with the diagnosis of ALL and AML (confirmed by immunophenotyping and pathology review) undergoing HSCT with at least 18 months of follow-up at Lucile Packard Children’s Hospital (LPCH), a tertiary teaching hospital, from 2012 to 2020 were included in the analysis. As most leukemic relapses occur within the first 2 years post-SCT, patients who relapsed beyond 24 months post-HSCT were excluded from the analysis [27]. This was also due to the paucity of chimerism data beyond the first year of HSCT and the increased number of patients lost to follow up. Patients who had no chimerism data were also excluded. Time-invariant variables included demographics, remission status, inclusion of total body irradiation in the conditioning regimen, clinical diagnosis of the graft-versus-host (GVHD) diseases post-HSCT. Graft source, HLA match, and GVHD prophylaxis were combined as one variable following the principle of dimensionality reduction [28] given our center’s standardized approach—bone marrow grafts (mostly 10/10 HLA match, only five patients had 9/10 HLA matched donors) were given tacrolimus/methotrexate, cord blood grafts were given tacrolimus/mycophenolate, and peripheral blood stem cell grafts were almost exclusively used in haploidentical SCT with ex vivo T-cell depletion. Post-HSCT donor chimerism tests were performed between 1 and 5 times (at approximately 1, 2, 3, 6, and 12-months post-transplant) per patient and used as time-variant variables. Leukemic relapse was defined as detection of leukemic blasts by minimal residual disease flow cytometry and confirmed by the pathology review. Chimerism results at the same time of the leukemic relapse were excluded since they would have correlated 100% with relapse and offer no value in the predictive model.
Post-transplant chimerism was performed with the AmpFLSTR™ Identifiler™ PCR Amplification Kit (Thermo Fisher Scientific, Waltham, MA, USA) which is a multiplex short tandem repeat assay. The test involves amplifying 15 tetranucleotide repeat loci and amelogenin gender determining marker in a single PCR reaction using DNA extracted from peripheral blood/bone marrow aspirate samples, and lineage-specific cell subsets (CD3, CD15, and CD34) isolated from blood/marrow specimens [29]. For isolation of CD34+ cells from peripheral blood or bone marrow, Ficoll–Hypague was first used to isolate the mononuclear cells followed by positive selection of CD34+ cell subset with CD34 monoclonal antibody conjugated to magnetic nanoparticles. The rest of the cell subsets were isolated through positive selection with the corresponding monoclonal antibodies conjugated to magnetic nanoparticles. Based on the differences between recipient and donor STR alleles, the presence and quantitative fractions of recipient/donor chimerism were determined.
Clinical data were collected from an internal database maintained for the Center of International Blood Marrow Transplant Research data submission by the data management team at LPCH and cross checked against source documents in the electronic medical record (EMR). Chimerism data were obtained from EMR and cross checked with the internal HLA laboratory database for accuracy and completeness. All data collected were independently verified by two investigators.
Once the data were verified and cleaned, they were assembled and merged for machine learning. For the analysis, we considered each test to be an independent observation, with any patient-level impact on relapse probability being controlled by the time-invariant variables. Each set of test results is linked to the final relapse outcome for that patient, coded as a ‘1’ for relapse, and ‘0’ for no relapse within the study period. As we excluded any post-relapse test information, our model framework estimates the risk of future relapse, given any test within the 18-month follow-up period.
The institutional review boards of both Stanford (IRB 58403, approval date 5 December 2020) and University of Utah (IRB 00137615, approval date 26 October 2020) approved the study. This study received Stanford and Utah IRB approval for a waiver of informed consent since this was submitted as a retrospective data study.
2.2. Standard Statistical Analysis
Wilcoxon rank sum test was performed on all post-transplant lineage-specific donor chimerism samples, analyzing them collectively as well as at different time points. This was performed to confirm the correlation between mixed chimerism and relapse in our dataset prior to machine learning analysis.
2.3. Machine Learning Analysis
For the relapse dataset, we first created a simple baseline predictive model to compare against the random forest; we defined the baseline model by setting the probability of relapse () for each case as the proportion of relapse cases in the sample dataset. We further used a Monte Carlo approach to assess the uncertainty in this baseline model by repeatedly assigning relapse or non-relapse status to each case based on random draws from a binomial distribution with . This Monte Carlo simulation provided a range of possible outcomes and their probability of occurring for any test.
We then used a random forest to build a predictive model of relapse risk. Model predictive skill was assessed using a nested 5-fold cross-validation. The outer cross-validation loop was used to assess model skill as the area under the curve (AUC) score of the receiver operator characteristic (ROC) curve, a threshold independent metric widely used to test the accuracy of binary predictions, as well as sensitivity and specificity. In addition to this outer cross-validation, we used an inner 5-fold cross-validation to tune the model hyperparameters, including the minimum node size (nodesize), the size of the subset of variables for each split (mtry), and the number of trees (ntree). A stratified sampling approach was used to form all training and testing datasets to ensure that all tests for an individual patient were either in the training or testing dataset. The same approach was used to assess the baseline model to allow comparisons with the random forest results.
Following cross-validation, we built a final random forest model using the full dataset and the parameter values obtained from tuning. This model was then used to estimate feature importance, partial dependencies that show the marginal response of the model, and LIME models. All calculations were carried out using the open-source R statistical language, which provides many add-on packages to facilitate machine learning [30]. Random forests were built using the R package ranger, which allowed the forest to be built using multiple CPU cores, with notable increases in computational time [31]. Cross-validation was carried out using the caret package [32], and LIME models were built using the lime package. Our work contains all pertinent elements of medical AI publication per International Journal of Medical Informatics 2021 guidelines [33].
2.4. Data Sharing
Please contact the corresponding author for the patient data set. Machine learning codes with explanation as well as all subgroup analysis and LIME analysis for every individual patient can be found at https://simonbrewer.github.io/aml_all/ (accessed on 6 July 2024).
3. Results
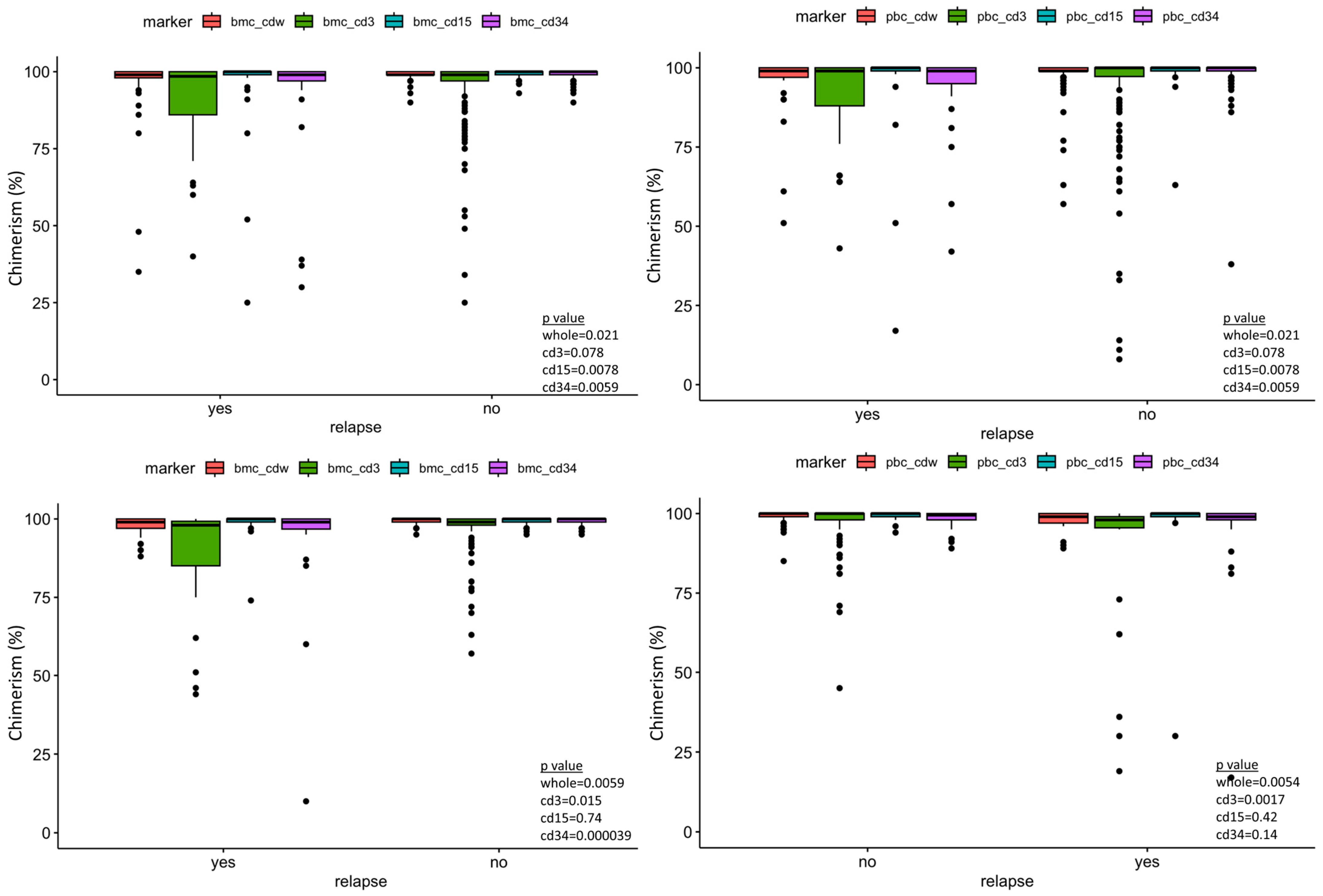
Sixty-three ALL patients and 46 AML patients were included in our data analysis, with a total of 141 tests. Table 1 and Table 2 summarize the variables included in our study. The median and mean days from the last peripheral chimerism to relapse in our study cohort were 63 and 129 days for ALL, and 39 and 132 days for AML, respectively. All patients had minimal residual disease evaluation by flow cytometry on the same days of the chimerism testing. Wilcoxon rank sum test demonstrated statistical significance between peripheral blood and marrow donor chimerism between the relapse vs. no-relapse group in both the ALL and AML cohort (Figure 1).

Table 1.
Patient and transplantation characteristics.
Table 2.
Chimerism data, TX-transplant.
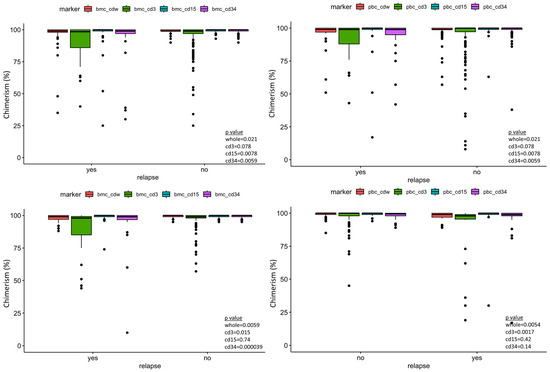
Figure 1.
Box plot of the post-transplant lineage-specific donor chimerism showing significant difference of peripheral blood CD34 donor chimerism between relapse and no-relapse, taking all measurements together as well at the different time points post-transplant. Bmc—bone marrow chimerism, pbc—peripheral blood chimerism, cdw—whole. Top left panel—ALL bone marrow chimerism. Top right panel—ALL peripheral blood chimerism. Bottom left—AML bone marrow chimerism. Bottom right—AML peripheral blood chimerism.
We observed a drop-off in the post-HSCT chimerism testing for both ALL and AML cohorts starting at the 6-month time points and significantly less at the 12-month time points. Table 2 shows, for ALL, only 62% of peripheral blood and 68% of bone marrow chimerism data (defined as the number of available chimerism measurements/the number of expected chimerism measurements of the surviving cohort at specific time point) at 6 months post SCT while even less is available at 12 months (PB 37%, BM 22%). A similar pattern was observed on the AML cohort as well—PB 50%, BM 67% at the 6-month time point; PB 37%, BM 41% at the 12-month time point. This is partially attributed to deaths from other causes and relapses. The missing chimerism data are likely to have minimal impact on the model given that most of the relapses occur within 300 days (12 out of 14 ALL relapses and 10 out of 13 from AML as shown in Table 1).
Hyperparameter tuning of the random forest resulted in the following values: mtry (number of variables randomly chosen for each split) = 8; nodesize (minimum node size for partitioning) = 4; ntree (total number of trees built) = 500. Model accuracy was first assessed using the out-of-bag (OOB) error rate estimate, based on the samples excluded in each bootstrap iteration. The OOB rate was 8% for the ALL cohort and 14% for the AML cohort, which supported strongly the validity of our models. The results of the cross-validation process showed that a random forest model using these hyperparameter values achieves 85% accuracy, 85% sensitivity, 89% specificity for ALL and 81% accuracy, 75% sensitivity, and 100% specificity for AML at predicting relapses within 24 months post-HSCT in cross validation. This represented a significant improvement over the baseline Monte Carlo simulation model, which has sensitivity similar to the incidence of relapse in our patient cohorts.
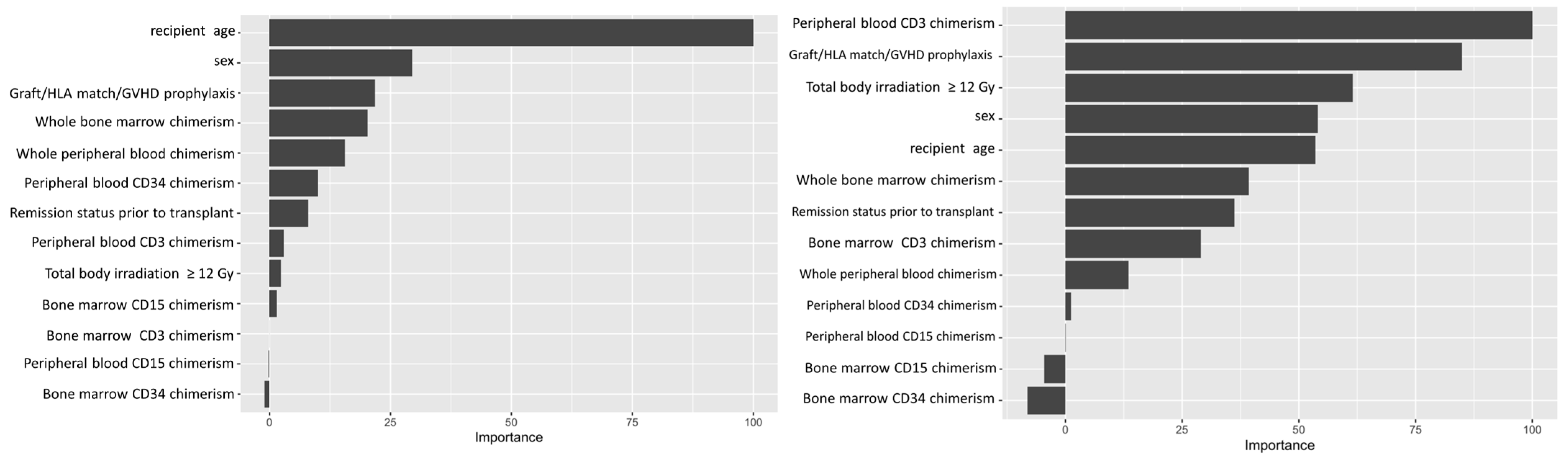
Variable importance values were estimated using a final random forest model based on the full dataset and the selected hyperparameter values, and ranked based on the relative importance of the different variables. The importance value of different variables is conventionally normalized to the most important variable, which is expressed as 100. This allows easy visualization of relative strengths of the variables tested. For the ALL cohort, our analysis showed recipient age as the most important predictive feature amongst the variables we tested, while whole blood or marrow chimerism was the most important post-transplant variable. For AML, peripheral CD3 chimerism was the most important variable (Figure 2).
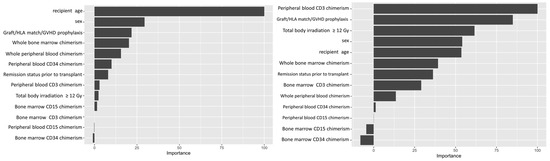
Figure 2.
Variable importance plot. Left panel shows variable importance for ALL. Right panel shows variable importance for AML. Recipient age at time of transplant was the most important variable (or feature) in the random forest classification for leukemic relapse for ALL. Peripheral CD3 donor chimerism was the most important variable for AML.
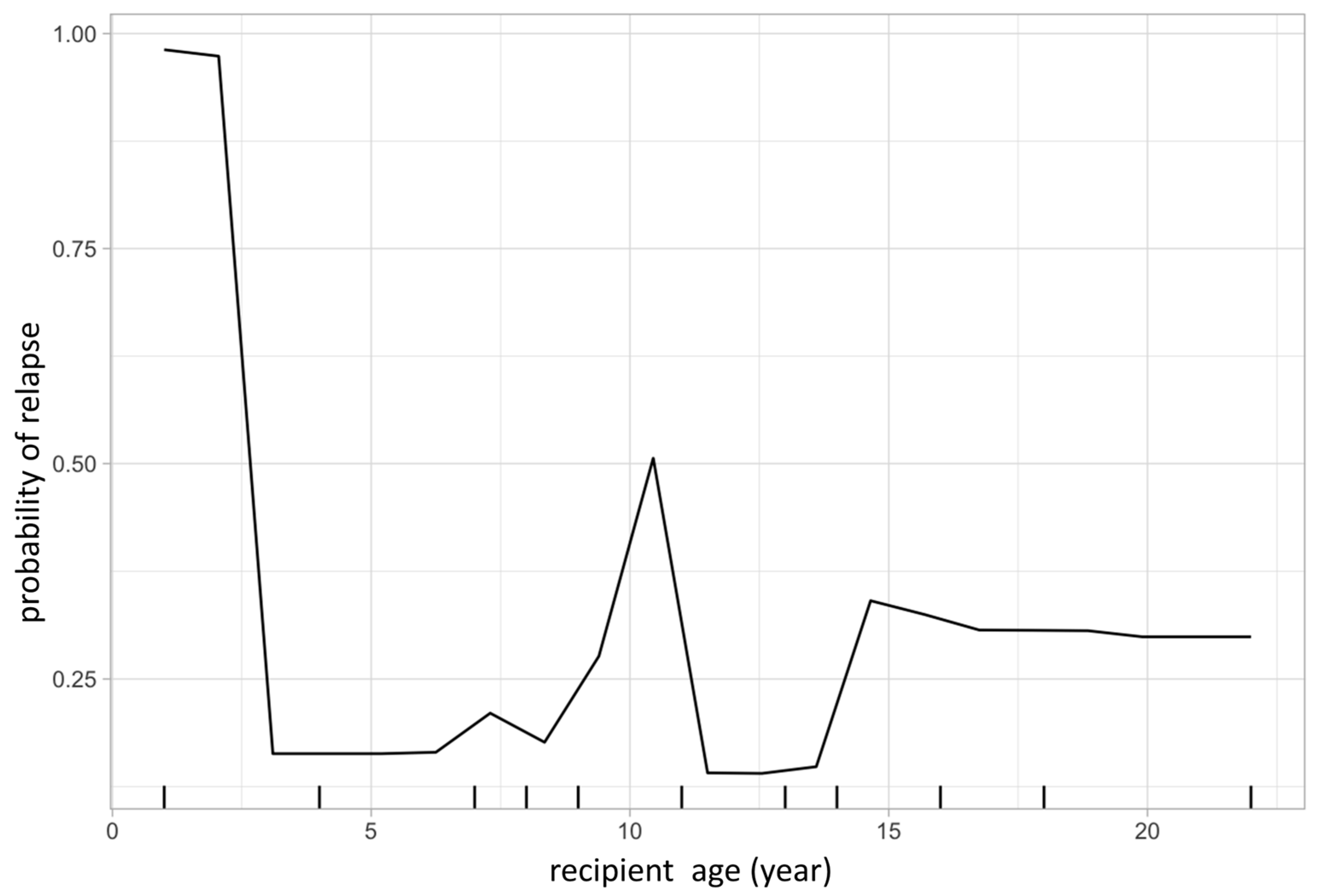
The same model was then used to calculate partial dependency plots (PDPs) for the highest ranked variables from the importance analysis. The PDP of the probability of relapse to recipient age at transplant is shown in Figure 3, and the PDP of peripheral blood chimerism of various lineages in Figure 4. The age PDP identified the highest risk of relapse in patients less than 2-years old in our cohort (reflecting the very high-risk infant ALL patients) and higher relapse risk in teenage/adolescent patients in ALL.
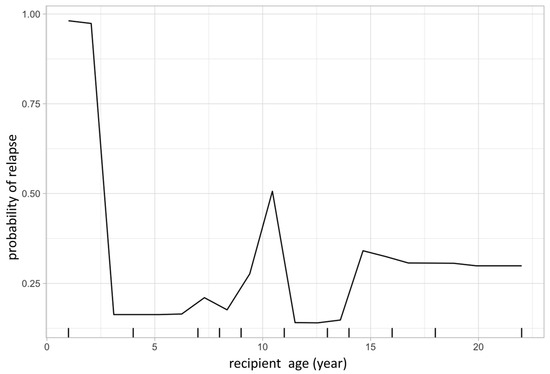
Figure 3.
Partial dependence plot visualizes the relationship of a given variable (feature) to leukemic relapse. In this figure, X-axis represents recipient age at transplant and Y-axis represents the probability of leukemic relapse as predicted by the random forest classification. Recipient age at transplant shows a bimodal distribution with younger patients having lower risk of relapse except those less than 1-year old, representing the very high-risk infantile leukemia.
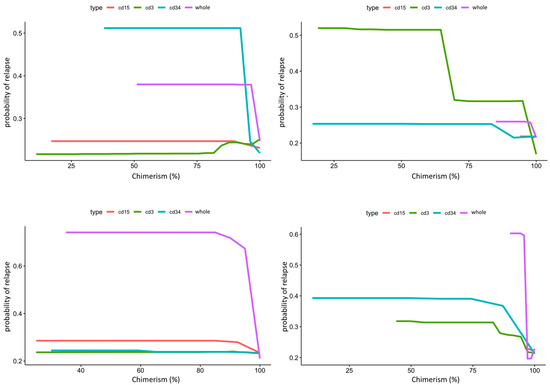
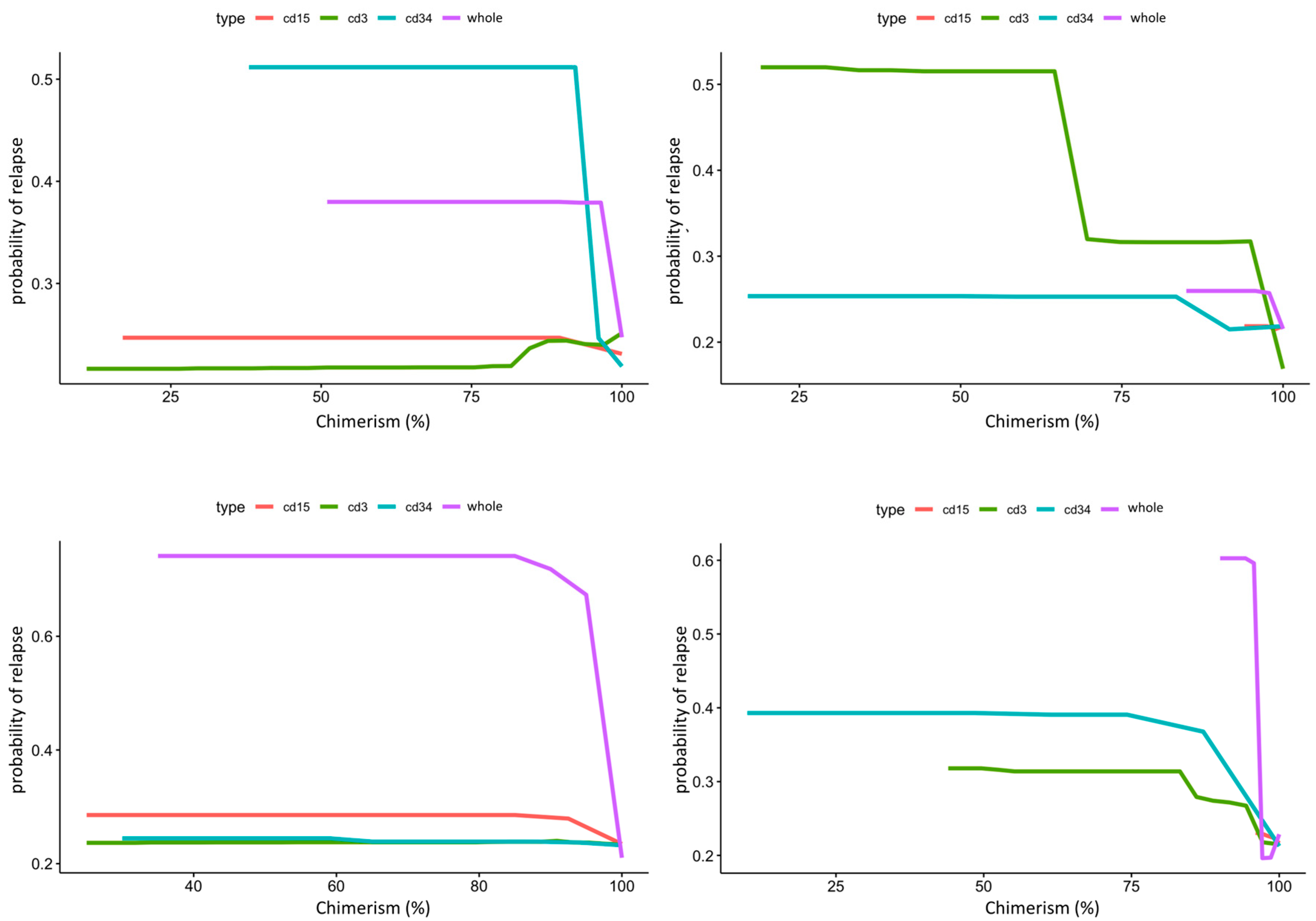
Figure 4.
Composite partial dependence plot of CD3, CD15, CD34, and whole peripheral/marrow blood donor chimerism to leukemic relapse. In this figure, X-axis represents lineage specific donor chimerism at transplant and Y-axis represents the probability of leukemic relapse. Top panel shows peripheral blood chimerism partial dependence for ALL on the left and AML on the right. CD34 chimerism below 95% dramatically increases risk of relapse for ALL, while CD3 chimerism below 95% dramatically increases risk of relapse for AML. Bottom panel shows bone marrow chimerism partial dependence for ALL on the left and AML on the right. Whole marrow chimerism below 95% greatly increases risk of relapse for both ALL and AML.
PDPs for the lineage specific peripheral blood chimerism showed an increase in relapse risk with decreases of all lineages, but large differences in the scale response, indicating that CD34 was most impactful at predicting relapse, despite its relatively small proportion (0.01 to 0.1%) in the peripheral blood [29]. Notably, this exhibited a threshold effect at 95% donor chimerism where <95% confers significantly increased relapse risk. In contrast, age did not have a large impact in risk of relapse in AML. PB CD3 chimerism showed a similar threshold at 95%. Of note, whole marrow chimerism was most predictive of relapse compared to lineage specific chimerism in both ALL and AML patients with a threshold of 95% (Figure 4).
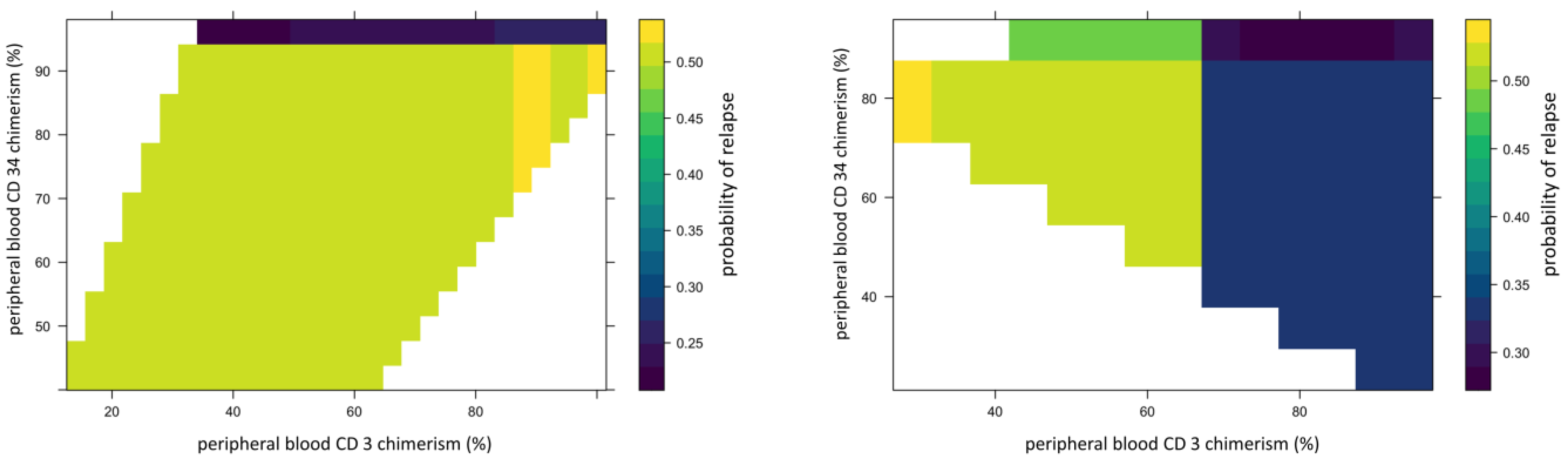
We used 2-dimensional PDPs to illustrate the interaction between two continuous variables. These illustrated changes in relapse risk are shown as a heatmap, with the color scale indicating the probability of relapse for pairwise combinations of two selected variables. The interaction between peripheral blood CD34 and CD3 chimerism (Figure 5) showed that the 95% threshold of CD34 chimerism values far outweighs the effect of changes in CD3 chimerism in ALL and vice versa in AML.
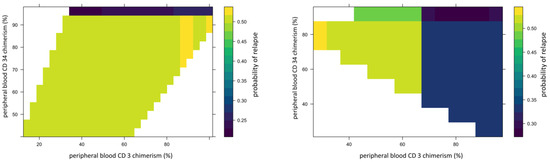
Figure 5.
Example of 2D partial dependence plot showing interaction between peripheral blood CD34 donor and CD3 chimerism. In this figure, X-axis represents peripheral blood CD34 donor chimerism and Y-axis represents peripheral blood CD3 donor chimerism. The heat map scale represents updated probability of relapse combining the two variables. The left panel shows in ALL, >95%. Peripheral blood CD34 donor chimerism lowers the probability of relapse for recipient regardless of donor CD3 chimerism. The right panel shows stronger impact of donor CD3 chimerism than donor CD34 on risk of relapse in AML.
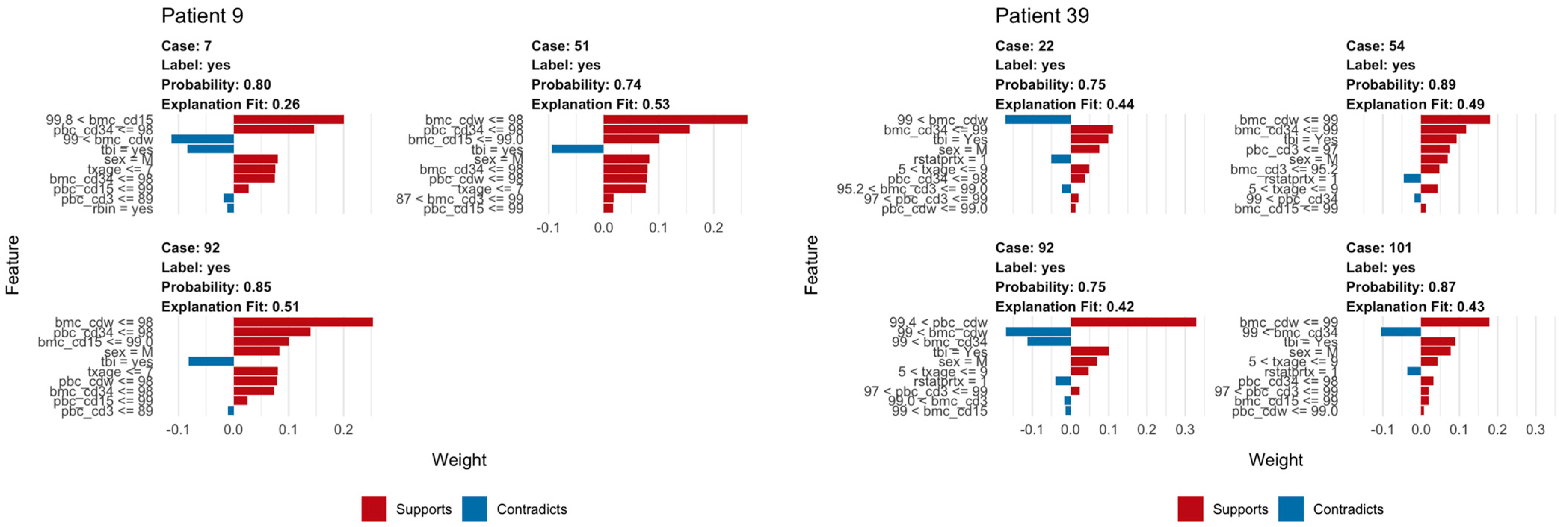
We used LIME plots to illustrate how the random forest model makes predictions for an individual, helping to identify how the specific characteristics of an individual increase or decrease the probability of predicted relapse. As the random forest model captured both non-linearities in the data and interactions between variables, the impact of these characteristics may vary strongly between individuals. For example, an individual’s age might correspond to a region of the partial dependency where the response changes very little, so a change in the patient’s age would have little impact on the overall prediction. As a result, other variables were able to dominate and inform the prediction. In each plot, the bars show whether the value of a variable decreases (red) or increases (blue) the risk of relapse. In a given example, the overall predicted probability or relapse is given above each figure and increases slightly and is expressed in probability (Figure 6).
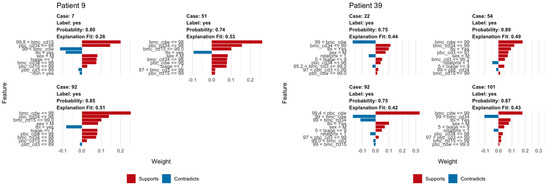
Figure 6.
Example of LIME analysis. The left panel shows LIME analysis for a patient with ALL; note TBI in conditioning regimen consistently acts as opposing factor for relapse. The right panel shows how similar LIME reveals the logic of the random forest classifier in making a prediction of relapse in a patient with AML including whole bone marrow chimerism below 99% and peripheral blood CD3 chimerism below 93%.
The explanation fit indicates how well the LIME analysis explains the model predictions for that individual; lower values indicate that the results should be interpreted with caution. Our LIME analysis has explanation fit up to 0.5 for both ALL and AML, indicating the LIME can explain about 50% of the RF model. The LIME analysis for consistently selected TBI = ‘yes’, having a positive effect at decreasing relapse risk for ALL patients, in contrast with the variable importance scores (Figure 2), where TBI was only ranked ninth, far behind age, the most important variable. This indicated that while the presence or absence of TBI has relatively little predictive power for the entire cohort, it may be highly important for individual patients.
4. Discussion
A major obstacle of applying ML in the clinical setting is that it can often be viewed by clinicians in terms of “black box” models, in which the ML algorithm make predictions in an unknown fashion, leading to skepticism. On the contrary, ML methods can actually provide information about datasets both “globally” and “locally” in an intuitive manner, and we argue that this information can be used to supplement traditional assessment methods, even with small datasets. While many ML algorithms can be used to make a predictive model, we selected the random forest classifier to build our predictive model since it is based on decision tree analysis, which is easy to understand intuitively. Variable importance values were estimated using a final random forest model based on the full dataset and the selected hyperparameter values, and ranked based on the relative importance of the different variables. Partial dependence allows us to visualize how the probability of relapse varies across the range of values for any variable, illustrating how the ML can capture different types of response, including linear, non-linear, or threshold. By calculating the partial dependency for two variables, we can further visualize how the model captures interactions between variables and that these interactions can also be non-linear. It is important to note that while we restricted our results to first-order interactions, the model includes higher order interactions (e.g., the influence of variable x3 on the interaction between x1 and x2) [34]. These plots showed the nuance of the different variables and their interactions to relapse risk, which was the basis of improved prediction.
In contrast to the “global” view provided by variable importance and partial dependence, IML, e.g., LIME, shows how predictions are made “locally” or for individual cases. This provides another check on the logic of the machine learning prediction, and helps to identify the factors that are most relevant to an individual prediction, and the extent to which they increase or decrease the relapse risk as well as to how confident we can be with any individual prediction. While the LIME analysis did not create the same variable importance as RF, it identified many of the same important variables as RF, which increased our confidence in the RF model. This again highlights the nonlinearity and interactions captured by the model, and allows us to appreciate better the main drivers of a given case which may be different between cases, and notably, different from what is the most important variable for the population. Our analysis suggests PB CD34 donor chimerism might warrant further investigation for pediatric patients with ALL for relapse surveillance. PB CD3 chimerism might be valuable in AML patients post-HSCT; however, the brisker pace of AML relapse makes disease surveillance challenging, regardless.
The RF classifier dramatically improved relapse prediction within 24 months post-HSCT in the context of our dataset. Our model is far from being perfect and as it is based on a small sample size and a modest number of variables, it is difficult to know how well this would generalize to a patient population outside of our institution. However, the goal of our study was not meant to create a definitive or generally applicable prediction model, but instead to demonstrate the rationale of adopting ML/IML more broadly to improve patient care and add more value to existing data and knowledge, even within a single institution. It is worth noting that during our study, the analytical results changed as we included more patient data, further illustrating the adaptable, learning nature of ML. ML methods offer a highly flexible approach for working with complex datasets, including low n, high p data, in which the number of variables or features is greater than the number of observations. The addition of more objective measures including biomarkers and biopsy finding for GVHD and immune reconstitution could further improve our model as these events have strong biological relevance to leukemic relapse. Similarly, pharmacokinetic data of conditioning chemotherapy (ATG, busulfan) and pre-transplant next generation sequencing minimal residual disease testing have recently been shown to play a bigger role in relapse and can also be incorporated into our existing model [35,36]. Furthermore, inclusion of pre-transplant chemotherapy treatment data, specifically salvaged treatment used to achieve remission prior to SCT, will likely further improve our model and shed more light on the optimal salvage strategy. ML analysis is potentially a useful and complementary approach to standard statistical methods on clinical studies constrained by smaller patient sample size or under powered [37]. The common perception of “large” sample size is requisite for validity or applicability in ML and should be re-evaluated. The dataset should be appropriate for the clinical challenge and might not necessarily need to be large or with highly granular details but, more importantly, relevant. Machine learning is not only for “big data”, but can also be applied to smaller datasets, which may be more appropriate to answer more focused questions, particularly with rare diseases and less common medical challenges.
Author Contributions
D.S. designed and performed the research, collected the data, analyzed the data, and wrote the paper. G.S. verified the data. B.M.Z. performed the chimerism testing. S.C.B. designed and performed the research, contributed vital analytical tools, analyzed the data, and wrote the paper. D.S. and S.C.B. contributed equally to this study. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The institutional review boards of both Stanford (IRB 58403, approval date 5 December 2020) and University of Utah (IRB 00137615, approval date 26 October 2020) approved the study.
Informed Consent Statement
This study received Stanford and Utah IRB approval for a waiver of informed consent since this was submitted as a retrospective data study.
Data Availability Statement
Please contact the corresponding author for the patient data set. Machine learning codes with explanation as well as all subgroup analysis and LIME analysis for every individual patient can be found at https://simonbrewer.github.io/aml_all/ (accessed on 6 July 2024).
Acknowledgments
We thank Robertson Parkman and Kenneth Weinberg (Stanford University) for providing critical feedback on the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- De Rooij, J.D.; Zwaan, C.M.; van den Heuvel-Eibrink, M. Pediatric AML: From Biology to Clinical Management. J. Clin. Med. 2015, 4, 127–149. [Google Scholar] [CrossRef] [PubMed]
- Ward, E.; DeSantis, C.; Robbins, A.; Kohler, B.; Jemal, A. Childhood and adolescent cancer statistics, 2014. CA Cancer J. Clin. 2014, 64, 83–103. [Google Scholar] [CrossRef] [PubMed]
- Styczyński, J.; Tridello, G.; Koster, L.; Iacobelli, S.; van Biezen, A.; van der Werf, S.; Mikulska, M.; Gil, L.; Cordonnier, C.; Ljungman, P.; et al. Death after hematopoietic stem cell transplantation: Changes over calendar year time, infections and associated factors. Bone Marrow Transplant. 2020, 55, 126–136. [Google Scholar] [CrossRef]
- Broglie, L.; Helenowski, I.; Jennings, L.J.; Schafernak, K.; Duerst, R.; Schneiderman, J.; Tse, W.; Kletzel, M.; Chaudhury, S. Early mixed T-cell chimerism is predictive of pediatric AML or MDS relapse after hematopoietic stem cell transplant. Pediatr. Blood Cancer 2017, 64, e26493. [Google Scholar] [CrossRef] [PubMed]
- Kinsella, F.A.; Inman, C.F.; Gudger, A.; Chan, Y.T.; Murray, D.J.; Zuo, J.; McIlroy, G.; Nagra, S.; Nunnick, J.; Holder, K.; et al. Very early lineage-specific chimerism after reduced intensity stem cell transplantation is highly predictive of clinical outcome for patients with myeloid disease. Leuk. Res. 2019, 83, 106173. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.C.; Saliba, R.M.; Rondon, G.; Chen, J.; Charafeddine, Y.; Medeiros, L.J.; Alatrash, G.; Andersson, B.S.; Popat, U.; Kebriaei, P.; et al. Mixed T Lymphocyte Chimerism after Allogeneic Hematopoietic Transplantation Is Predictive for Relapse of Acute Myeloid Leukemia and Myelodysplastic Syndromes. Biol. Blood Marrow Transplant. 2015, 21, 1948–1954. [Google Scholar] [CrossRef] [PubMed]
- Preuner, S.; Peters, C.; Potschger, U.; Daxberger, H.; Fritsch, G.; Geyeregger, R.; Schrauder, A.; von Stackelberg, A.; Schrappe, M.; Bader, P.; et al. Risk assessment of relapse by lineage-specific monitoring of chimerism in children undergoing allogeneic stem cell transplantation for acute lymphoblastic leukemia. Haematologica 2016, 101, 741–746. [Google Scholar] [CrossRef] [PubMed]
- Thompson, P.A.; Stingo, F.; Keating, M.J.; Wierda, W.G.; O’Brien, S.M.; Estrov, Z.; Ledesma, C.; Rezvani, K.; Qazilbash, M.; Shah, N.; et al. Long-term follow-up of patients receiving allogeneic stem cell transplant for chronic lymphocytic leukaemia: Mixed T-cell chimerism is associated with high relapse risk and inferior survival. Br. J. Haematol. 2017, 177, 567–577. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.J.; Savani, B.N.; Mohty, M.; Gorin, N.C.; Labopin, M.; Ruggeri, A.; Schmid, C.; Baron, F.; Esteve, J.; Giebel, S.; et al. Post-remission strategies for the prevention of relapse following allogeneic hematopoietic cell transplantation for high-risk acute myeloid leukemia: Expert review from the Acute Leukemia Working Party of the European Society for Blood and Marrow Transplantation. Bone Marrow Transplant. 2019, 54, 519–530. [Google Scholar]
- DeFilipp, Z.; Langston, A.A.; Chen, Z.; Zhang, C.; Arellano, M.L.; El Rassi, F.; Flowers, C.R.; Kota, V.K.; Al-Kadhimi, Z.; Veldman, R.; et al. Does Post-Transplant Maintenance Therapy with Tyrosine Kinase Inhibitors Improve Outcomes of Patients with High-Risk Philadelphia Chromosome-Positive Leukemia? Clin. Lymphoma Myeloma Leuk. 2016, 16, 466–471.e461. [Google Scholar] [CrossRef]
- Yan, C.H.; Liu, Q.F.; Wu, D.P.; Zhang, X.; Xu, L.P.; Zhang, X.H.; Wang, Y.; Huang, H.; Bai, H.; Huang, F.; et al. Prophylactic Donor Lymphocyte Infusion (DLI) Followed by Minimal Residual Disease and Graft-versus-Host Disease-Guided Multiple DLIs Could Improve Outcomes after Allogeneic Hematopoietic Stem Cell Transplantation in Patients with Refractory/Relapsed Acute Leukemia. Biol. Blood Marrow Transplant. 2017, 23, 1311–1319. [Google Scholar] [PubMed]
- Lankester, A.C.; Locatelli, F.; Bader, P.; Rettinger, E.; Egeler, M.; Katewa, S.; Pulsipher, M.A.; Nierkens, S.; Schultz, K.; Handgretinger, R.; et al. Will post-transplantation cell therapies for pediatric patients become standard of care? Biol. Blood Marrow Transplant. 2015, 21, 402–411. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. Boosting and Additive Trees. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Hastie, T., Tibshirani, R., Friedman, J., Eds.; Springer: New York, NY, USA, 2009; pp. 337–387. [Google Scholar]
- Shouval, R.; Fein, J.A.; Savani, B.; Mohty, M.; Nagler, A. Machine learning and artificial intelligence in haematology. Br. J. Haematol. 2021, 192, 239–250. [Google Scholar] [CrossRef] [PubMed]
- Muhsen, I.N.; Shyr, D.; Sung, A.D.; Hashmi, S.K. Machine Learning Applications in the Diagnosis of Benign and Malignant Hematological Diseases. Clin. Hematol. Int. 2021, 3, 13–20. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Smith, J.; Keerthi, D.; Li, C.; Sun, Y.; Mothi, S.S.; Shyr, D.C.; Spitzer, B.; Harris, A.C.; Chatterjee, A.; et al. Longitudinal clinical data improve survival prediction after hematopoietic cell transplantation using machine learning. Blood Adv. 2024, 8, 686–698. [Google Scholar] [CrossRef] [PubMed]
- Powers, S.; Qian, J.; Jung, K.; Schuler, A.; Shah, N.H.; Hastie, T.; Tibshirani, R. Some methods for heterogeneous treatment effect estimation in high dimensions. Stat. Med. 2018, 37, 1767–1787. [Google Scholar] [CrossRef] [PubMed]
- Fuse, K.; Uemura, S.; Tamura, S.; Suwabe, T.; Katagiri, T.; Tanaka, T.; Ushiki, T.; Shibasaki, Y.; Sato, N.; Yano, T.; et al. Patient-based prediction algorithm of relapse after allo-HSCT for acute Leukemia and its usefulness in the decision-making process using a machine learning approach. Cancer Med. 2019, 8, 5058–5067. [Google Scholar] [CrossRef]
- Shouval, R.; Labopin, M.; Unger, R.; Giebel, S.; Ciceri, F.; Schmid, C.; Esteve, J.; Baron, F.; Gorin, N.C.; Savani, B.; et al. Prediction of Hematopoietic Stem Cell Transplantation Related Mortality- Lessons Learned from the In-Silico Approach: A European Society for Blood and Marrow Transplantation Acute Leukemia Working Party Data Mining Study. PLoS ONE 2016, 11, e0150637. [Google Scholar] [CrossRef]
- Zhang, Y.; Ling, C. A strategy to apply machine learning to small datasets in materials science. NPJ Comput. Mater. 2018, 4, 25. [Google Scholar] [CrossRef]
- Caiafa, C.F.; Sun, Z.; Tanaka, T.; Marti-Puig, P.; Solé-Casals, J. Machine Learning Methods with Noisy, Incomplete or Small Datasets. Appl. Sci. 2021, 11, 4132. [Google Scholar] [CrossRef]
- Koppe, G.; Meyer-Lindenberg, A.; Durstewitz, D. Deep learning for small and big data in psychiatry. Neuropsychopharmacology 2021, 46, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Shaikhina, T.; Lowe, D.; Daga, S.; Briggs, D.; Higgins, R.; Khovanova, N. Machine Learning for Predictive Modelling based on Small Data in Biomedical Engineering. IFAC-PapersOnLine 2015, 48, 469–474. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Kumarakulasinghe, N.B.; Blomberg, T.; Liu, J.; Leao, A.S.; Papapetrou, P. Evaluating Local Interpretable Model-Agnostic Explanations on Clinical Machine Learning Classification Models. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020. [Google Scholar]
- Kaphan, E.; Bettega, F.; Forcade, E.; Labussière-Wallet, H.; Fegueux, N.; Robin, M.; De Latour, R.P.; Huynh, A.; Lapierre, L.; Berceanu, A.; et al. Late relapse after hematopoietic stem cell transplantation for acute leukemia: A retrospective study by SFGM-TC. Transplant. Cell Ther. 2023, 29, 362.e1–362.e12. [Google Scholar] [CrossRef] [PubMed]
- Ray, P.; Reddy, S.S.; Banerjee, T. Various dimension reduction techniques for high dimensional data analysis: A review. Artif. Intell. Rev. 2021, 54, 3473–3515. [Google Scholar] [CrossRef]
- Jelic, T.M.; Estalilla, O.C.; Vos, J.A.; Harvey, G.; Stricker, C.J.; Adelanwa, A.O.; Khalid, A.; Plata, M.J. Flow Cytometric Enumeration of Peripheral Blood CD34+ Cells Predicts Bone Marrow Pathology in Patients with Less Than 1% Blasts by Manual Count. J. Blood Med. 2023, 14, 519–535. [Google Scholar] [CrossRef]
- RCoreTeam. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org (accessed on 30 November 2023).
- Esplin, I.N.D.; Berg, J.A.; Sharma, R.; Allen, R.C.; Arens, D.K.; Ashcroft, C.R.; Bairett, S.R.; Beatty, N.J.; Bickmore, M.; Bloomfield, T.J.; et al. Genome Sequences of 19 Novel Erwinia amylovora Bacteriophages. Genome Announc. 2017, 5, e00931-17. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 26. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A. The need to separate the wheat from the chaff in medical informatics: Introducing a comprehensive checklist for the (self)-assessment of medical AI studies. Int. J. Med. Inform. 2021, 153, 104510. [Google Scholar] [CrossRef]
- Friedman, J.H.; Popescu, B.E. Predictive Learning via Rule Ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Admiraal, R.; Nierkens, S.; A de Witte, M.; Petersen, E.J.; Fleurke, G.-J.; Verrest, L.; Belitser, S.V.; Bredius, R.G.M.; Raymakers, R.A.P.; Knibbe, C.A.J.; et al. Association between anti-thymocyte globulin exposure and survival outcomes in adult unrelated haemopoietic cell transplantation: A retrospective, pharmacodynamic cohort analysis. Lancet Haematol. 2017, 4, e183–e191. [Google Scholar] [CrossRef]
- Pulsipher, M.A.; Han, X.; Maude, S.L.; Laetsch, T.W.; Qayed, M.; Rives, S.; Boyer, M.W.; Hiramatsu, H.; Yanik, G.A.; Driscoll, T.; et al. Next-Generation Sequencing of Minimal Residual Disease for Predicting Relapse after Tisagenlecleucel in Children and Young Adults with Acute Lymphoblastic Leukemia. Blood Cancer Discov. 2022, 3, 66–81. [Google Scholar] [CrossRef]
- Bzdok, D.; Altman, N.; Krzywinski, M. Statistics versus machine learning. Nat. Methods 2018, 15, 233–234. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).