
Machine Learning Prediction Model to Predict Length of Stay of Patients Undergoing Hip or Knee Arthroplasties: Results from a High-Volume Single-Center Multivariate Analysis

 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Data Extraction
2.3. Data Selection and Inclusion Criteria
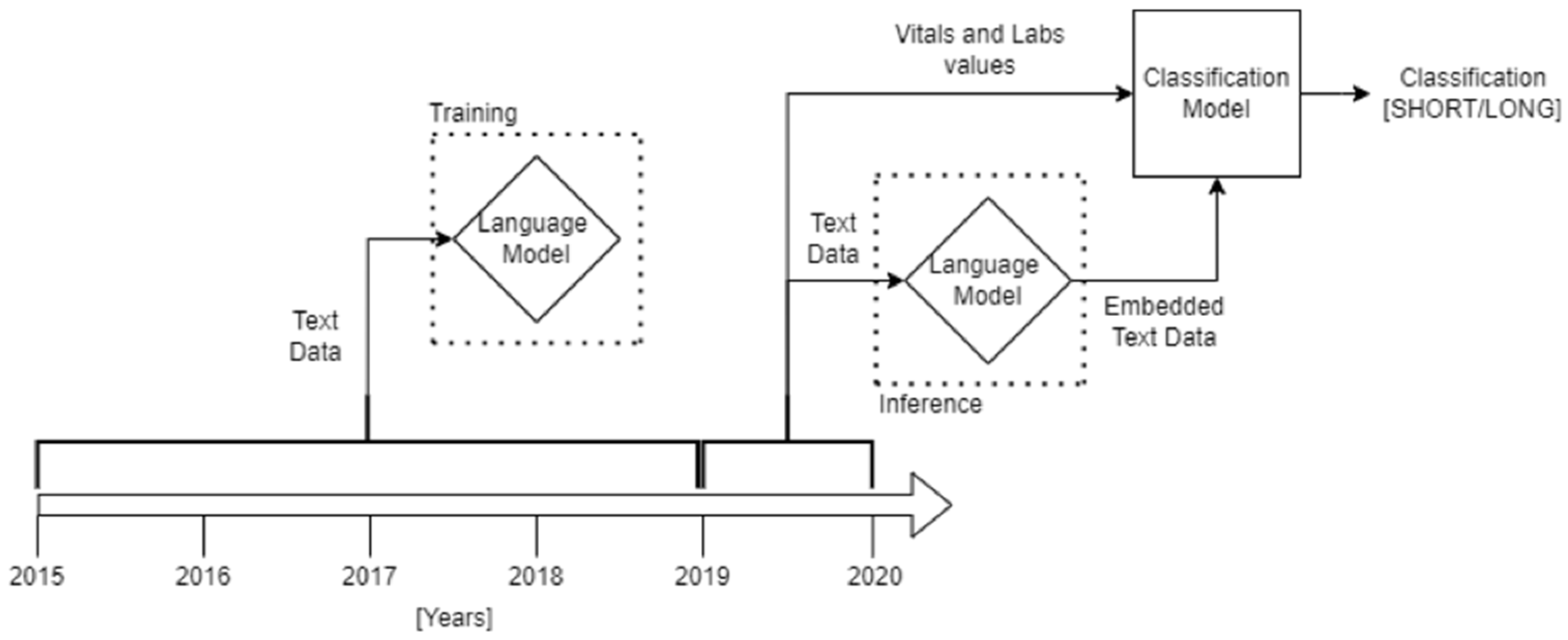
2.4. Methods
- Pandas 1.0.1 [20]: importing and managing data.
- Numpy 1.18.1 [21]: array manipulation and scientific computation.
- Scikit-learn 1.0.0 [22]: definition, training, and validation of machine learning and statistical models.
- Tensorflow 2.0.0 [23]: definition, training, and validation of transformer autoencoder.
- Matplotlib 3.1.3 [24]: plotting models’ performances.
2.5. Text Pre-Processing
2.6. Classification
2.7. Statistical Analysis
3. Results
3.1. Dataset and Univariate Analysis
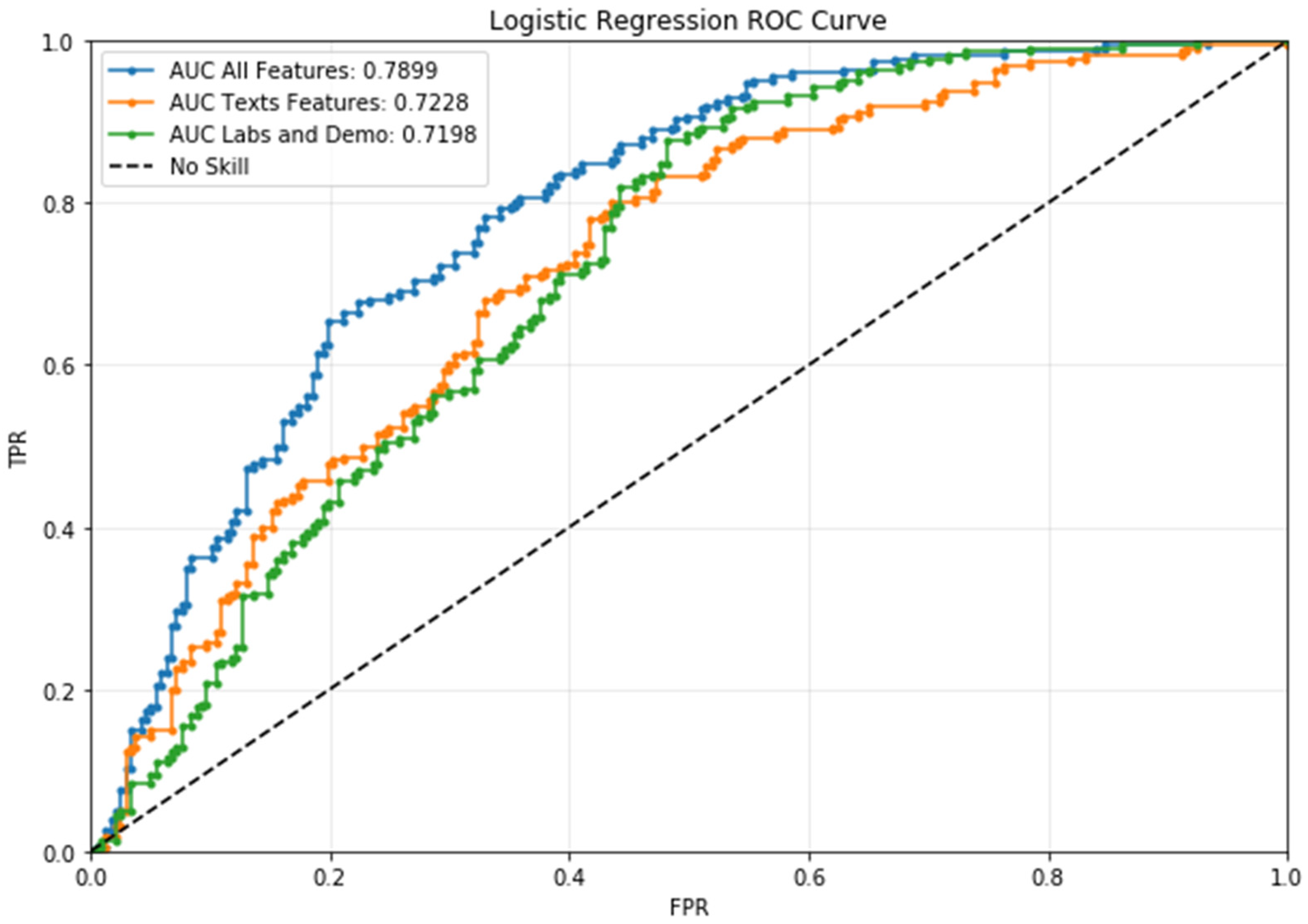
3.2. Classification
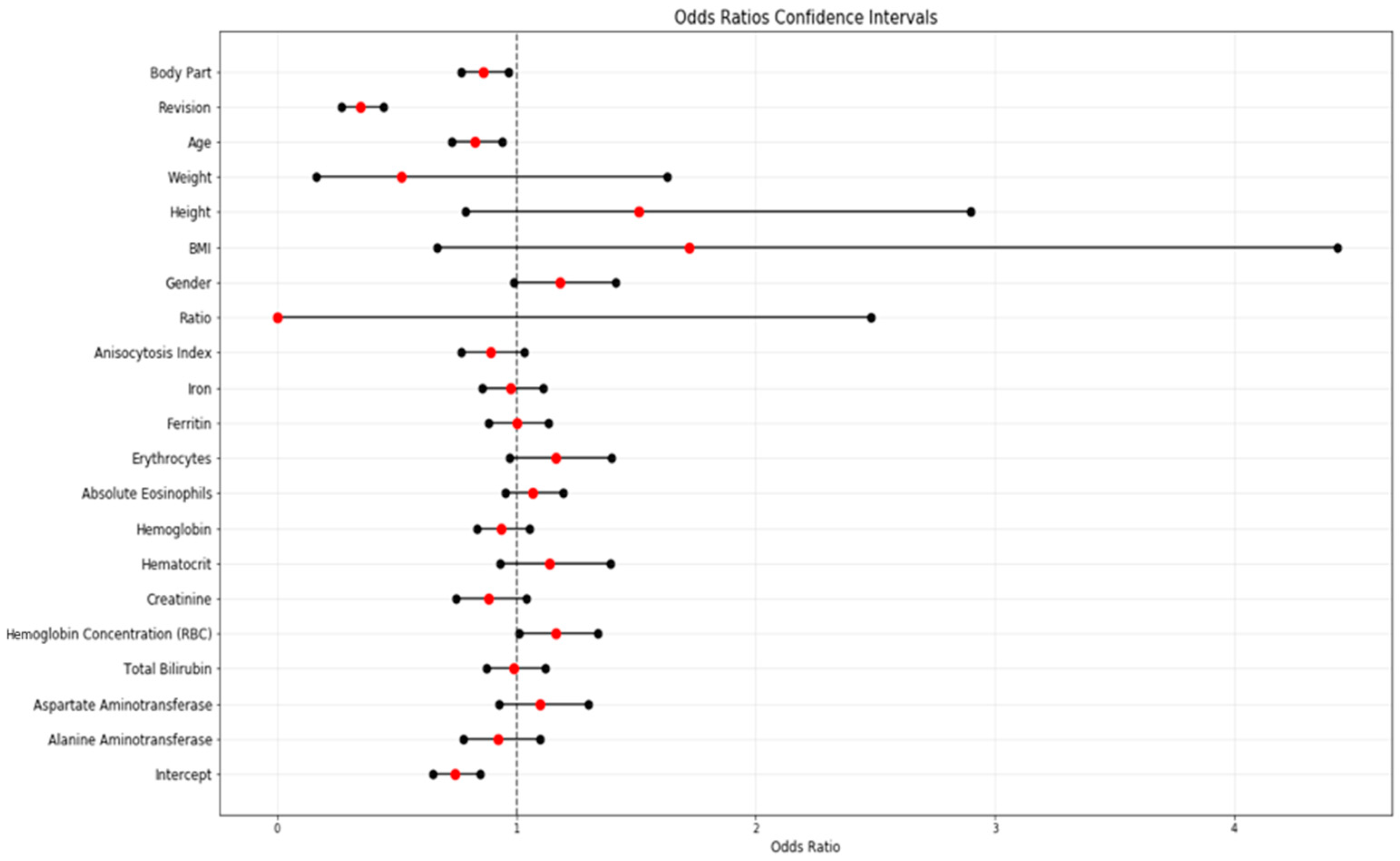
3.3. Multivariate Analysis
4. Discussion
5. Limitations of the Study and Future Plans
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Konopka, J.F.; Lee, Y.-Y.; Su, E.P.; McLawhorn, A.S. Quality-Adjusted Life Years After Hip and Knee Arthroplasty: Health-Related Quality of Life After 12,782 Joint Replacements. JBJS Open Access 2018, 3, e0007. [Google Scholar] [CrossRef] [PubMed]
- Benedetta Report Annuale RIAP 2021 e Compendio. Available online: https://riap.iss.it/riap/it/attivita/report/2022/10/27/report-annuale-riap-2021/ (accessed on 11 June 2023).
- Torre, M.; Romanini, E.; Zanoli, G.; Carrani, E.; Luzi, I.; Leone, L.; Bellino, S. Monitoring Outcome of Joint Arthroplasty in Italy: Implementation of the National Registry. Joints 2017, 5, 70–78. [Google Scholar] [CrossRef]
- Husted, H.; Solgaard, S.; Hansen, T.B.; Søballe, K.; Kehlet, H. Care Principles at Four Fast-Track Arthroplasty Departments in Denmark. Dan. Med. Bull. 2010, 57, A4166. [Google Scholar] [PubMed]
- Kehlet, H. Fast-Track Hip and Knee Arthroplasty. Lancet 2013, 381, 1600–1602. [Google Scholar] [CrossRef] [PubMed]
- Frassanito, L.; Vergari, A.; Nestorini, R.; Cerulli, G.; Placella, G.; Pace, V.; Rossi, M. Enhanced Recovery after Surgery (ERAS) in Hip and Knee Replacement Surgery: Description of a Multidisciplinary Program to Improve Management of the Patients Undergoing Major Orthopedic Surgery. Musculoskelet. Surg. 2020, 104, 87–92. [Google Scholar] [CrossRef]
- Mayfield, C.K.; Haglin, J.M.; Levine, B.; Valle, C.D.; Lieberman, J.R.; Heckmann, N. Medicare Reimbursement for Hip and Knee Arthroplasty from 2000 to 2019: An Unsustainable Trend. J. Arthroplast. 2020, 35, 1174–1178. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402. [Google Scholar] [CrossRef]
- Embi, P.J.; Kaufman, S.E.; Payne, P.R.O. Biomedical Informatics and Outcomes Research: Enabling Knowledge-Driven Health Care. Circulation 2009, 120, 2393–2399. [Google Scholar] [CrossRef]
- Cafri, G.; Li, L.; Paxton, E.W.; Fan, J. Predicting Risk for Adverse Health Events Using Random Forest. J. Appl. Stat. 2018, 45, 2279–2294. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.-Z. Deep Learning for Health Informatics. IEEE J. Biomed. Health Inform. 2017, 21, 4–21. [Google Scholar] [CrossRef]
- Navarro, S.M.; Wang, E.Y.; Haeberle, H.S.; Mont, M.A.; Krebs, V.E.; Patterson, B.M.; Ramkumar, P.N. Machine Learning and Primary Total Knee Arthroplasty: Patient Forecasting for a Patient-Specific Payment Model. J. Arthroplast. 2018, 33, 3617–3623. [Google Scholar] [CrossRef] [PubMed]
- Biron, D.R.; Sinha, I.; Kleiner, J.E.; Aluthge, D.P.; Goodman, A.D.; Sarkar, I.N.; Cohen, E.; Daniels, A.H. A Novel Machine Learning Model Developed to Assist in Patient Selection for Outpatient Total Shoulder Arthroplasty. J. Am. Acad. Orthop. Surg. 2020, 28, e580–e585. [Google Scholar] [CrossRef] [PubMed]
- Etzel, C.M.; Veeramani, A.; Zhang, A.S.; McDonald, C.L.; DiSilvestro, K.J.; Cohen, E.M.; Daniels, A.H. Supervised Machine Learning for Predicting Length of Stay After Lumbar Arthrodesis: A Comprehensive Artificial Intelligence Approach. J. Am. Acad. Orthop. Surg. 2022, 30, 125–132. [Google Scholar] [CrossRef]
- Anis, H.K.; Strnad, G.J.; Klika, A.K.; Zajichek, A.; Spindler, K.P.; Barsoum, W.K.; Higuera, C.A.; Piuzzi, N.S.; Group, C.C.O.A. Developing a Personalized Outcome Prediction Tool for Knee Arthroplasty. Bone Jt. J. 2020, 102-B, 1183–1193. [Google Scholar] [CrossRef] [PubMed]
- Ramkumar, P.N.; Karnuta, J.M.; Navarro, S.M.; Haeberle, H.S.; Scuderi, G.R.; Mont, M.A.; Krebs, V.E.; Patterson, B.M. Deep Learning Preoperatively Predicts Value Metrics for Primary Total Knee Arthroplasty: Development and Validation of an Artificial Neural Network Model. J. Arthroplast. 2019, 34, 2220–2227.e1. [Google Scholar] [CrossRef]
- Ramkumar, P.N. Development and Validation of a Machine Learning Algorithm After Primary Total Hip Arthroplasty: Applications to Length of Stay and Payment Models. J. Arthroplast. 2019, 34, 632–637. [Google Scholar] [CrossRef]
- Gabriel, R.A.; Sharma, B.S.; Doan, C.N.; Jiang, X.; Schmidt, U.H.; Vaida, F. A Predictive Model for Determining Patients Not Requiring Prolonged Hospital Length of Stay After Elective Primary Total Hip Arthroplasty. Anesth. Analg. 2019, 129, 43–50. [Google Scholar] [CrossRef]
- Greenstein, A.S.; Teitel, J.; Mitten, D.J.; Ricciardi, B.F.; Myers, T.G. An Electronic Medical Record–Based Discharge Disposition Tool Gets Bundle Busted: Decaying Relevance of Clinical Data Accuracy in Machine Learning. Arthroplast. Today 2020, 6, 850–855. [Google Scholar] [CrossRef]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and Statistical Modeling with Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 92–96. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization 2017. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- van Buuren, S.; Groothuis-Oudshoorn, K. Mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Mann, H.B.; Whitney, D.R. On a Test of Whether One of Two Random Variables Is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Student. The Probable Error of a Mean. Biometrika 1908, 6, 1–25. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Pearson, K.X. On the Criterion That a given System of Deviations from the Probable in the Case of a Correlated System of Variables Is Such that It Can Be Reasonably Supposed to Have Arisen from Random Sampling. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 50, 157–175. [Google Scholar] [CrossRef]
- Cox, D.R. The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Fletcher, R. Practical Methods of Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Moldovan, F. Bone Cement Implantation Syndrome: A Rare Disaster Following Cemented Hip Arthroplasties—Clinical Considerations Supported by Case Studies. J. Pers. Med. 2023, 13, 1381. [Google Scholar] [CrossRef]
- Podmore, B.; Hutchings, A.; Skinner, J.A.; MacGregor, A.J.; van der Meulen, J. Impact of Comorbidities on the Safety and Effectiveness of Hip and Knee Arthroplasty Surgery. Bone Jt. J. 2021, 103-B, 56–64. [Google Scholar] [CrossRef] [PubMed]
- Masaracchio, M.; Hanney, W.J.; Liu, X.; Kolber, M.; Kirker, K. Timing of Rehabilitation on Length of Stay and Cost in Patients with Hip or Knee Joint Arthroplasty: A Systematic Review with Meta-Analysis. PLoS ONE 2017, 12, e0178295. [Google Scholar] [CrossRef] [PubMed]
- Padegimas, E.M.; Verma, K.; Zmistowski, B.; Rothman, R.H.; Purtill, J.J.; Howley, M. Medicare Reimbursement for Total Joint Arthroplasty: The Driving Forces. J. Bone Jt. Surg. 2016, 98, 1007–1013. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Long | Short | p-Value | ||
|---|---|---|---|---|
| Patients, n | 795 | 722 | ||
| Admissions, n | 812 | 729 | ||
| Age, mean (SD) | 67.0 (12.9) | 63.8 (10.9) | <0.001 | |
| BMI, mean (SD) | 27.4 (5.0) | 27.7 (4.5) | 0.260 | |
| Height, mean (SD) | 165.7 (9.8) | 167.7 (9.2) | <0.001 | |
| Weight, mean (SD) | 75.6 (16.3) | 78.2 (15.3) | 0.001 | |
| Gender, n (%) | Female | 503 (61.9) | 364 (49.9) | <0.001 |
| Male | 309 (38.1) | 365 (50.1) | ||
| Alanine aminotransferase, mean (SD) | 19.2 (11.1) | 21.2 (12.3) | 0.001 | |
| Aspartate aminotransferase, mean (SD) | 21.4 (7.5) | 22.3 (10.8) | 0.041 | |
| Total bilirubin, mean (SD) | 0.7 (0.3) | 0.7 (0.3) | 0.030 | |
| RBC hemoglobin concentration, mean (SD) | 33.1 (0.8) | 33.3 (0.8) | <0.001 | |
| Creatinin, mean (SD) | 0.8 (0.4) | 0.8 (0.2) | <0.001 | |
| Hematocrit, mean (SD) | 41.8 (3.8) | 43.2 (3.7) | <0.001 | |
| Hemoglobin, mean (SD) | 7.5 (2.0) | 7.7 (2.0) | <0.001 | |
| Absolute eosinophils, mean (SD) | 0.2 (0.1) | 0.2 (0.1) | 0.044 | |
| Erythrocytes, mean (SD) | 4.6 (0.5) | 4.8 (0.4) | <0.001 | |
| Ferritin, mean (SD) | 96.2 (89.3) | 108.1 (89.6) | 0.009 | |
| Iron, mean (SD) | 80.9 (30.1) | 86.5 (29.8) | <0.001 | |
| INR, mean (SD) | 1.1 (0.2) | 1.0 (0.1) | <0.001 | |
| Anisocytosis index, mean (SD) | 14.3 (1.3) | 14.0 (1.2) | <0.001 | |
| Ratio, mean (SD) | 1.1 (0.2) | 1.0 (0.1) | <0.001 | |
| Revision, n (%) | No | 641 (78.9) | 722 (99.0) | <0.001 |
| Yes | 171 (21.1) | 7 (1.0) | ||
| Body part, n (%) | Hip | 639 (78.7) | 530 (72.7) | 0.007 |
| Knee | 173 (21.3) | 199 (27.3) | ||
| Marital status, n (%) | Five | 11 (1.4) | 3 (0.4) | 0.283 |
| Four | 2 (0.2) | 1 (0.1) | ||
| One | 6 (0.7) | 4 (0.5) | ||
| Six | 560 (69.0) | 481 (66.0) | ||
| Three | 2 (0.2) | 1 (0.1) | ||
| Two | 60 (7.4) | 59 (8.1) | ||
| Unknown | 171 (21.1) | 180 (24.7) |
| Long | Short | |||||||
|---|---|---|---|---|---|---|---|---|
| F1 Score | Precision | Recall | Support | F1 Score | Precision | Recall | Support | |
| Complete | 0.709251 | 0.741935 | 0.679325 | 237.0 | 0.720339 | 0.691057 | 0.752212 | 226.0 |
| Texts | 0.656319 | 0.691589 | 0.624473 | 237.0 | 0.673684 | 0.642570 | 0.707965 | 226.0 |
| Others | 0.642082 | 0.660714 | 0.624473 | 237.0 | 0.645161 | 0.627615 | 0.663717 | 226.0 |
| Macro Avg. | Weighted Avg. | |||||||
|---|---|---|---|---|---|---|---|---|
| F1 Score | Precision | Recall | Support | F1 Score | Precision | Recall | Support | |
| Complete | 0.714795 | 0.716496 | 0.715769 | 463.0 | 0.714663 | 0.717101 | 0.714903 | 463.0 |
| Texts | 0.665002 | 0.66708 | 0.666219 | 463.0 | 0.664795 | 0.667662 | 0.665227 | 463.0 |
| Others | 0.643622 | 0.644165 | 0.644095 | 463.0 | 0.643585 | 0.644558 | 0.643629 | 463.0 |
| Feature | Coefficients | Standard Errors | W Values | p > |z| | Odds Ratio | [0.025] | [0.975] | |
|---|---|---|---|---|---|---|---|---|
| 0 | Intercept | −0.2990 | 0.0680 | −4.3950 | <0.0001 | 0.7416 | 0.6490 | 0.8473 |
| 1 | Alanine aminotransferase | −0.0785 | 0.0870 | −0.9060 | 0.3650 | 0.9245 | 0.7796 | 1.0964 |
| 2 | Aspartate aminotransferase | 0.0931 | 0.0860 | 1.0860 | 0.2780 | 1.0976 | 0.9273 | 1.2991 |
| 3 | Total bilirubin | −0.0111 | 0.0630 | −0.1760 | 0.8600 | 0.9890 | 0.8741 | 1.1189 |
| 4 | Mean corpuscular hemoglobin concentration (MCHC) | 0.1503 | 0.0720 | 2.0910 | 0.0370 | 1.1622 | 1.0092 | 1.3383 |
| 5 | RBC hemoglobin concentration | −0.1261 | 0.0850 | −1.4880 | 0.1370 | 0.8815 | 0.7462 | 1.0413 |
| 6 | Hematocrit | 0.1303 | 0.1020 | 1.2820 | 0.2000 | 1.1392 | 0.9327 | 1.3913 |
| 7 | Hemoglobin | −0.0647 | 0.0600 | −1.0800 | 0.2800 | 0.9373 | 0.8334 | 1.0543 |
| 8 | Absolute eosinophils | 0.0658 | 0.0570 | 1.1600 | 0.2460 | 1.0680 | 0.9551 | 1.1943 |
| 9 | Erythrocytes | 0.1528 | 0.0930 | 1.6510 | 0.0990 | 1.1651 | 0.9710 | 1,3981 |
| 10 | Ferritin | 0.0012 | 0.0630 | 0.0190 | 0.9850 | 1.0012 | 0.8849 | 1.1328 |
| 11 | Iron | −0.0239 | 0.0670 | −0.3560 | 0.7220 | 0.9764 | 0.8562 | 1.1134 |
| 12 | INR | 8.4158 | 4.9490 | 1.7000 | 0.0890 | 4517.8884 | 0.2769 | 73,724,077.5095 |
| 13 | Anisocytosis index | −0.1163 | 0.0760 | −1.5400 | 0.1240 | 0.8902 | 0.7670 | 1.0332 |
| 14 | Ratio | −8.8155 | 4.9610 | −1.7770 | 0.0760 | 0.0001 | 0.0000 | 2.4795 |
| 15 | Gender | 0.1667 | 0.0910 | 1.8380 | 0.0660 | 1.1814 | 0.9884 | 1.4121 |
| 16 | Marital status—One | −0.0423 | / | 0.0000 | 1.0000 | 0.9586 | 0 | / |
| 17 | Marital status—Two | 0.0191 | / | 0.0000 | 1.0000 | 1.0193 | 0 | / |
| 18 | Marital status—Three | −0.0360 | / | 0.0000 | 1.0000 | 0.9646 | 0 | / |
| 19 | Marital status—Four | −0.0491 | / | 0.0000 | 1.0000 | 0.9521 | 0 | / |
| 20 | Marital status—Five | −0.0973 | / | 0.0000 | 1.0000 | 0.9073 | 0 | / |
| 21 | Marital status—Six | 0.0011 | / | 0.0000 | 1.0000 | 1.0011 | 0 | / |
| 22 | Marital status—Unknown | 0.0257 | / | 0.0000 | 1.0000 | 1.0260 | 0 | / |
| 23 | BMI | 0.5422 | 0.4830 | 1.1220 | 0.2620 | 1.7198 | 0.6673 | 4.4321 |
| 24 | Height | 0.4118 | 0.3330 | 1.2380 | 0.2160 | 1.5095 | 0.7859 | 2.8993 |
| 25 | Weight | −0.6558 | 0.5840 | −1.1220 | 0.2620 | 0.5190 | 0.1652 | 1.6304 |
| 26 | Age | −0.1895 | 0.0640 | −2.9460 | 0.0030 | 0.8274 | 0.7298 | 0.9379 |
| 27 | Revision | −1.0611 | 0.1260 | −8.4100 | <0.0001 | 0.3461 | 0.2703 | 0.4430 |
| 28 | Body Part | −0.1499 | 0.0590 | −2.5560 | 0.0110 | 0.8608 | 0.7668 | 0.9663 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Matteo, V.; Tommasini, T.; Morandini, P.; Savevski, V.; Grappiolo, G.; Loppini, M. Machine Learning Prediction Model to Predict Length of Stay of Patients Undergoing Hip or Knee Arthroplasties: Results from a High-Volume Single-Center Multivariate Analysis. J. Clin. Med. 2024, 13, 5180. https://doi.org/10.3390/jcm13175180
Di Matteo V, Tommasini T, Morandini P, Savevski V, Grappiolo G, Loppini M. Machine Learning Prediction Model to Predict Length of Stay of Patients Undergoing Hip or Knee Arthroplasties: Results from a High-Volume Single-Center Multivariate Analysis. Journal of Clinical Medicine. 2024; 13(17):5180. https://doi.org/10.3390/jcm13175180
Chicago/Turabian StyleDi Matteo, Vincenzo, Tobia Tommasini, Pierandrea Morandini, Victor Savevski, Guido Grappiolo, and Mattia Loppini. 2024. "Machine Learning Prediction Model to Predict Length of Stay of Patients Undergoing Hip or Knee Arthroplasties: Results from a High-Volume Single-Center Multivariate Analysis" Journal of Clinical Medicine 13, no. 17: 5180. https://doi.org/10.3390/jcm13175180
APA StyleDi Matteo, V., Tommasini, T., Morandini, P., Savevski, V., Grappiolo, G., & Loppini, M. (2024). Machine Learning Prediction Model to Predict Length of Stay of Patients Undergoing Hip or Knee Arthroplasties: Results from a High-Volume Single-Center Multivariate Analysis. Journal of Clinical Medicine, 13(17), 5180. https://doi.org/10.3390/jcm13175180