Aiding the Diagnosis of Diabetic and Hypertensive Retinopathy Using Artificial Intelligence-Based Semantic Segmentation



Abstract
:1. Introduction
2. Related Works
2.1. Vessel Segmentation Based on Conventional Handcrafted Local Features
2.2. Vessel Segmentation Using Machine Learning or Deep Learning (CNN)
3. Contribution
- -
- Vess-Net performs semantic segmentation to detect retinal vessels without the requirement of conventional pre-processing.
- -
- Vess-Net guarantees dual-stream spatial information flow inside and outside the encoder–decoder.
- -
- Vess-Net’s internal residual skip path (IRSP) ensures feature re-use policy in order to compensate for spatial loss created by the continuous convolution process.
- -
- Vess-Net’s outer residual skip path (ORSP) is designed to provide direct spatial edge information from the initial layer of encoder to the end of decoder. Moreover, the direct information flow pushes the Vess-Net to converge faster (in just 15 epochs with 3075 iterations).
- -
- Vess-Net utilizes the benefits of both identity and non-identity mappings for outer and inner residual connections, respectively
- -
- For fair comparison with other research results, the trained Vess-Net models and algorithms are made publicly available in [56].
4. Proposed Method
4.1. Overview of Proposed Architecture
4.2. Retinal Blood Vessel Segmentation Using Vess-Net
4.2.1. Vess-Net Encoder
4.2.2. Vess-Net Decoder
5. Experimental Results
5.1. Experimental Data and Environment
5.2. Data Augmentation
5.3. Vess-Net Training
5.4. Testing of Proposed Method
5.4.1. Vess-Net Testing for Retinal Vessel Segmentation
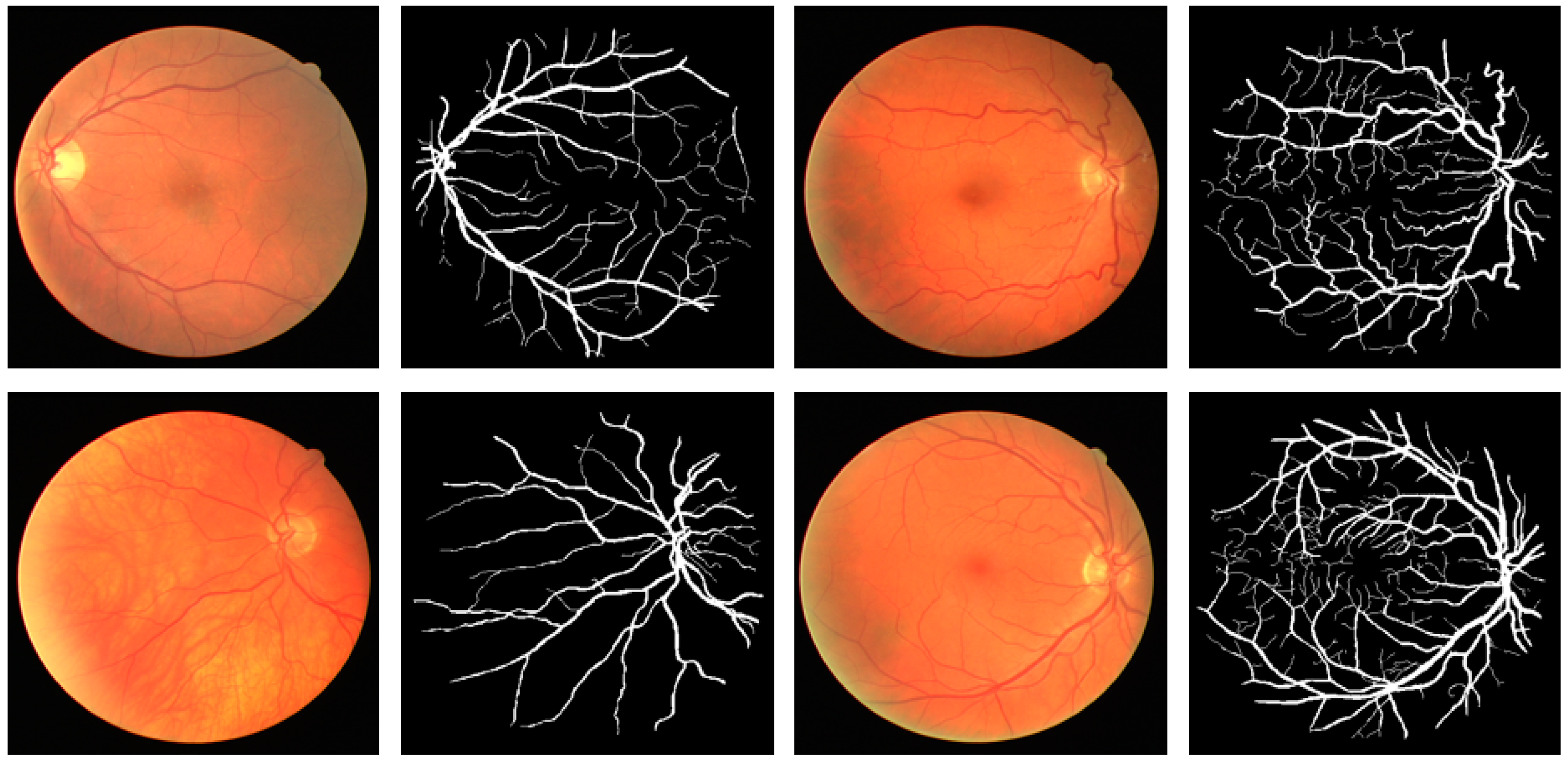
5.4.2. Vessel Segmentation Results by Vess-Net
5.4.3. Comparison of Vess-Net with Previous Methods
5.4.4. Vessel Segmentation with Other Open Datasets Using Vess-Net
6. Detection of Diabetic or Hypertensive Retinopathy
7. Discussion
- -
- Vess-Net is empowered by IRSPs and ORSPs, which enables the network to provide high accuracy with few convolution layers (only 16).
- -
- With provision of direct spatial edge information, the network is pushed to converge rapidly, i.e., in only 15 epochs (3075 iterations).
- -
- Vess-Net is designed in a way that it maintains the minimal feature map size at 27 × 27 (as shown in Table 3), which is sufficient to represent tiny vessels that are created due to diabetic retinopathy.
8. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Braović, M.; Božić-Štulić, D.; Stipaničev, D. A review of image processing and deep learning based methods for automated analysis of digital retinal fundus images. In Proceedings of the 3rd International Conference on Smart and Sustainable Technologies, Split, Croatia, 26–29 June 2018; pp. 1–6. [Google Scholar]
- Dervenis, N.; Coleman, A.L.; Harris, A.; Wilson, M.R.; Yu, F.; Anastasopoulos, E.; Founti, P.; Pappas, T.; Kilintzis, V.; Topouzis, F. Factors associated with retinal vessel diameters in an elderly population: The Thessaloniki eye study. Invest. Ophthalmol. Vis. Sci. 2019, 60, 2208–2217. [Google Scholar] [CrossRef] [PubMed]
- Tawfik, A.; Mohamed, R.; Elsherbiny, N.M.; DeAngelis, M.M.; Bartoli, M.; Al-Shabrawey, M. Homocysteine: A potential biomarker for diabetic retinopathy. J. Clin. Med. 2019, 8, 121. [Google Scholar] [CrossRef] [PubMed]
- Granado-Casas, M.; Castelblanco, E.; Ramírez-Morros, A.; Martín, M.; Alcubierre, N.; Martínez-Alonso, M.; Valldeperas, X.; Traveset, A.; Rubinat, E.; Lucas-Martin, A.; et al. Poorer quality of life and treatment satisfaction is associated with diabetic retinopathy in patients with type 1 diabetes without other advanced late complications. J. Clin. Med. 2019, 8, 377. [Google Scholar] [CrossRef] [PubMed]
- Youssif, A.A.-H.A.-R.; Ghalwash, A.Z.; Ghoneim, A.A.S.A.-R. Optic disc detection from normalized digital fundus images by means of a vessels’ direction matched filter. IEEE Trans. Med. Imaging 2008, 27, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Debayle, J.; Presles, B. Rigid image registration by general adaptive neighborhood matching. Pattern Recognit. 2016, 55, 45–57. [Google Scholar] [CrossRef]
- Trucco, E.; Azegrouz, H.; Dhillon, B. Modeling the tortuosity of retinal vessels: Does caliber play a role? IEEE Trans. Biomed. Eng. 2010, 57, 2239–2247. [Google Scholar] [CrossRef]
- Smart, T.J.; Richards, C.J.; Bhatnagar, R.; Pavesio, C.; Agrawal, R.; Jones, P.H. A study of red blood cell deformability in diabetic retinopathy using optical tweezers. In Proceedings of the SPIE Nanoscience + Engineering-Optical Trapping and Optical Micromanipulation XII, San Diego, CA, USA, 9–13 August 2015; p. 954825. [Google Scholar]
- Laibacher, T.; Weyde, T.; Jalali, S. M2U-Net: Effective and efficient retinal vessel segmentation for resource-constrained environments. arXiv 2019, arXiv:physics/1811.07738v3. [Google Scholar]
- Irshad, S.; Akram, M.U. Classification of retinal vessels into arteries and veins for detection of hypertensive retinopathy. In Proceedings of the Cairo International Biomedical Engineering Conference, Cairo, Egypt, 11–13 December 2014; pp. 133–136. [Google Scholar]
- Cheung, C.Y.L.; Zheng, Y.; Hsu, W.; Lee, M.L.; Lau, Q.P.; Mitchell, P.; Wang, J.J.; Klein, R.; Wong, T.Y. Retinal vascular tortuosity, blood pressure, and cardiovascular risk factors. Ophthalmology 2011, 118, 812–818. [Google Scholar] [CrossRef]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. Blood vessel segmentation methodologies in retinal images—A survey. Comput. Methods Programs Biomed. 2012, 108, 407–433. [Google Scholar] [CrossRef]
- Han, Z.; Yin, Y.; Meng, X.; Yang, G.; Yan, X. Blood vessel segmentation in pathological retinal image. In Proceedings of the IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 960–967. [Google Scholar]
- Alam, M.; Le, D.; Lim, J.I.; Chan, R.V.P.; Yao, X. Supervised machine learning based multi-task artificial intelligence classification of retinopathies. J. Clin. Med. 2019, 8, 872. [Google Scholar] [CrossRef]
- Faust, O.; Hagiwara, Y.; Hong, T.J.; Lih, O.S.; Acharya, U.R. Deep learning for healthcare applications based on physiological signals: A review. Comput. Methods Programs Biomed. 2018, 161, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Karim, R.; Kim, Y. A two-stage big data analytics framework with real world applications using spark machine learning and long short-term memory network. Symmetry 2018, 10, 485. [Google Scholar] [CrossRef]
- Peek, N.; Combi, C.; Marin, R.; Bellazzi, R. Thirty years of artificial intelligence in medicine (AIME) conferences: A review of research themes. Artif. Intell. Med. 2015, 65, 61–73. [Google Scholar] [CrossRef] [PubMed]
- Hamet, P.; Tremblay, J. Artificial intelligence in medicine. Metabolism 2017, 69, 36–40. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.Y.; Hsieh, M.H.; Lin, C.L.; Hsieh, M.J.; Hsu, W.H.; Lin, C.C.; Hsu, C.Y.; Kao, C.H. Artificial intelligence prediction model for the cost and mortality of renal replacement therapy in aged and super-aged populations in Taiwan. J. Clin. Med. 2019, 8, 995. [Google Scholar] [CrossRef] [PubMed]
- Owais, M.; Arsalan, M.; Choi, J.; Mahmood, T.; Park, K.R. Artificial intelligence-based classification of multiple gastrointestinal diseases using endoscopy videos for clinical diagnosis. J. Clin. Med. 2019, 8, 986. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.H.; Liu, W.X. Identifying degenerative brain disease using rough set classifier based on wavelet packet method. J. Clin. Med. 2018, 7, 124. [Google Scholar] [CrossRef] [PubMed]
- Owais, M.; Arsalan, M.; Choi, J.; Park, K.R. Effective diagnosis and treatment through content-based medical image retrieval (CBMIR) by using artificial intelligence. J. Clin. Med. 2019, 8, 462. [Google Scholar] [CrossRef] [PubMed]
- Akram, M.U.; Khan, S.A. Multilayered thresholding-based blood vessel segmentation for screening of diabetic retinopathy. Eng. Comput. 2013, 29, 165–173. [Google Scholar] [CrossRef]
- Fraz, M.M.; Welikala, R.A.; Rudnicka, A.R.; Owen, C.G.; Strachan, D.P.; Barman, S.A. QUARTZ: Quantitative analysis of retinal vessel topology and size—An automated system for quantification of retinal vessels morphology. Expert Syst. Appl. 2015, 42, 7221–7234. [Google Scholar] [CrossRef]
- Kar, S.S.; Maity, S.P. Blood vessel extraction and optic disc removal using curvelet transform and kernel fuzzy c-means. Comput. Biol. Med. 2016, 70, 174–189. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhao, J.; Yang, J.; Liu, Y.; Zhao, Y.; Zheng, Y.; Xia, L.; Wang, Y. Saliency driven vasculature segmentation with infinite perimeter active contour model. Neurocomputing 2017, 259, 201–209. [Google Scholar] [CrossRef] [Green Version]
- Pandey, D.; Yin, X.; Wang, H.; Zhang, Y. Accurate vessel segmentation using maximum entropy incorporating line detection and phase-preserving denoising. Comput. Vis. Image Underst. 2017, 155, 162–172. [Google Scholar] [CrossRef]
- Neto, L.C.; Ramalho, G.L.B.; Neto, J.F.S.R.; Veras, R.M.S.; Medeiros, F.N.S. An unsupervised coarse-to-fine algorithm for blood vessel segmentation in fundus images. Expert Syst. Appl. 2017, 78, 182–192. [Google Scholar] [CrossRef]
- Sundaram, R.; KS, R.; Jayaraman, P.; Venkatraman, B. Extraction of blood vessels in fundus images of retina through hybrid segmentation approach. Mathematics 2019, 7, 169. [Google Scholar] [CrossRef]
- Zhao, Y.; Rada, L.; Chen, K.; Harding, S.P.; Zheng, Y. Automated vessel segmentation using infinite perimeter active contour model with hybrid region information with application to retinal images. IEEE Trans. Med. Imaging 2015, 34, 1797–1807. [Google Scholar] [CrossRef]
- Jiang, Z.; Yepez, J.; An, S.; Ko, S. Fast, accurate and robust retinal vessel segmentation system. Biocybern. Biomed. Eng. 2017, 37, 412–421. [Google Scholar] [CrossRef]
- Rodrigues, L.C.; Marengoni, M. Segmentation of optic disc and blood vessels in retinal images using wavelets, mathematical morphology and Hessian-based multi-scale filtering. Biomed. Signal. Process. Control 2017, 36, 39–49. [Google Scholar] [CrossRef]
- Sazak, Ç.; Nelson, C.J.; Obara, B. The multiscale bowler-hat transform for blood vessel enhancement in retinal images. Pattern Recognit. 2019, 88, 739–750. [Google Scholar] [CrossRef]
- Chalakkal, R.J.; Abdulla, W.H. Improved vessel segmentation using curvelet transform and line operators. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Honolulu, HI, USA, 12–15 November 2018; pp. 2041–2046. [Google Scholar]
- Wahid, F.F.; Raju, G. A dual step strategy for retinal thin vessel enhancement/extraction. In Proceedings of the Amity International Conference on Artificial Intelligence, Dubai, UAE, 4–6 February 2019; pp. 666–671. [Google Scholar]
- Akyas, A.T.U.; Abhin, J.A.; Geo, J.G.; Santhosh, K.B.V. Automated system for retinal vessel segmentation. In Proceedings of the 2nd International Conference on Inventive Communication and Computational Technologies, Coimbatore, India, 20–21 April 2018; pp. 717–722. [Google Scholar]
- Zhang, J.; Chen, Y.; Bekkers, E.; Wang, M.; Dashtbozorg, B.; Romeny, B.M.; Ter, H. Retinal vessel delineation using a brain-inspired wavelet transform and random forest. Pattern Recognit. 2017, 69, 107–123. [Google Scholar] [CrossRef]
- Tan, J.H.; Acharya, U.R.; Bhandary, S.V.; Chua, K.C.; Sivaprasad, S. Segmentation of optic disc, fovea and retinal vasculature using a single convolutional neural network. J. Comput. Sci. 2017, 20, 70–79. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.; Zou, B.; Zhao, R.; Cui, J.; Duan, X.; Chen, Z.; Liang, Y. Retinal vessel segmentation in colour fundus images using extreme learning machine. Comput. Med. Imaging Graph. 2017, 55, 68–77. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jiang, X.; Ren, J. Blood vessel segmentation from fundus image by a cascade classification framework. Pattern Recognit. 2019, 88, 331–341. [Google Scholar] [CrossRef]
- Tuba, E.; Mrkela, L.; Tuba, M. Retinal blood vessel segmentation by support vector machine classification. In Proceedings of the 27th International Conference Radioelektronika, Brno, Czech Republic, 19–20 April 2017; pp. 1–6. [Google Scholar]
- Savelli, B.; Bria, A.; Galdran, A.; Marrocco, C.; Molinara, M.; Campilho, A.; Tortorella, F. Illumination correction by dehazing for retinal vessel segmentation. In Proceedings of the 30th International Symposium on Computer-Based Medical Systems, Thessaloniki, Greece, 22–24 June 2017; pp. 219–224. [Google Scholar]
- Girard, F.; Kavalec, C.; Cheriet, F. Joint segmentation and classification of retinal arteries/veins from fundus images. Artif. Intell. Med. 2019, 94, 96–109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, K.; Zhang, Z.; Niu, X.; Zhang, Y.; Cao, C.; Xiao, F.; Gao, X. Retinal vessel segmentation of color fundus images using multiscale convolutional neural network with an improved cross-entropy loss function. Neurocomputing 2018, 309, 179–191. [Google Scholar] [CrossRef]
- Fu, H.; Xu, Y.; Lin, S.; Wong, D.W.K.; Liu, J. DeepVessel: Retinal vessel segmentation via deep learning and conditional random field. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 132–139. [Google Scholar]
- Soomro, T.A.; Afifi, A.J.; Gao, J.; Hellwich, O.; Khan, M.A.U.; Paul, M.; Zheng, L. Boosting sensitivity of a retinal vessel segmentation algorithm with convolutional neural network. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Sydney, Australia, 29 November–1 December 2017; pp. 1–8. [Google Scholar]
- Guo, S.; Gao, Y.; Wang, K.; Li, T. Deeply supervised neural network with short connections for retinal vessel segmentation. arXiv 2018, arXiv:physics/1803.03963v1. [Google Scholar] [CrossRef] [PubMed]
- Chudzik, P.; Al-Diri, B.; Calivá, F.; Hunter, A. DISCERN: Generative framework for vessel segmentation using convolutional neural network and visual codebook. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Honolulu, HI, USA, 18–21 July 2018; pp. 5934–5937. [Google Scholar]
- Hajabdollahi, M.; Esfandiarpoor, R.; Najarian, K.; Karimi, N.; Samavi, S.; Soroushmeh, S.M.R. Low complexity convolutional neural network for vessel segmentation in portable retinal diagnostic devices. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2785–2789. [Google Scholar]
- Yan, Z.; Yang, X.; Cheng, K.T. A three-stage deep learning model for accurate retinal vessel segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 1427–1436. [Google Scholar] [CrossRef]
- Soomro, T.A.; Hellwich, O.; Afifi, A.J.; Paul, M.; Gao, J.; Zheng, L. Strided U-Net model: Retinal vessels segmentation using dice loss. In Proceedings of the Digital Image Computing: Techniques and Applications, Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl. Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef] [Green Version]
- Leopold, H.A.; Orchard, J.; Zelek, J.S.; Lakshminarayanan, V. PixelBNN: Augmenting the PixelCNN with batch normalization and the presentation of a fast architecture for retinal vessel segmentation. J. Imaging 2019, 5, 26. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Z.; Ren, Q.; Xu, Y.; Yu, Y. Dense U-net based on patch-based learning for retinal vessel segmentation. Entropy 2019, 21, 168. [Google Scholar] [CrossRef]
- Feng, S.; Zhuo, Z.; Pan, D.; Tian, Q. CcNet: A cross-connected convolutional network for segmenting retinal vessels using multi-scale features. Neurocomputing 2019. [Google Scholar] [CrossRef]
- Dongguk Vess-Net Model with Algorithm. Available online: https://drive.google.com/open?id=1a27G7sLXSKhdHt7gPqcEYyYJ1gq_mnCL (accessed on 4 September 2019).
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 636–644. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K.R. FRED-Net: Fully residual encoder–decoder network for accurate iris segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust iris segmentation using densely connected fully convolutional networks in the images by visible light and near-infrared light camera sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [PubMed]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- GeForce GTX TITAN X Graphics Processing Unit. Available online: https://www.geforce.com/hardware/desktop-gpus/geforce-gtx-titan-x/specifications (accessed on 4 July 2019).
- MATLAB R2019a. Available online: https://ch.mathworks.com/products/new_products/latest_features.html (accessed on 4 July 2019).
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef] [PubMed]
- Hoover, A.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Image 2000, 19, 203–210. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Methods | Strength | Weakness |
|---|---|---|---|
| Using handcrafted local features | Vessel segmentation using thresholding [23,24,28,29,31,33,34,35,36] | Simple method to approximate vessel pixels | False points detected when vessel pixel values are closer to background |
| Fuzzy-based segmentation [25] | Performs well with uniform pixel values | Intensive pre-processing is required to intensify blood vessels’ response | |
| Active contours [26,30] | Better approximation for detection of real boundaries | Iterative and time-consuming processes are required | |
| Vessel tubular properties-based method [32] | Good estimation of vessel-like structures | Limited by pixel discontinuities | |
| Line detection-based method [27] | Removing background helps reduce false skin-like pixels | ||
| Using features based on machine learning or deep learning | Random forest classifier-based method [37] | Lighter method to classify pixels | Various transformations needed before classification to form features |
| Patch-based CNN [38,42] | Better classification | Training and testing require long processing time | |
| SVM-based method [41] | Lower training time | Use of pre-processing schemes with several images to produce feature vector | |
| Extreme machine-learning [39] | Machine learning with many discriminative features | Morphology and other conventional approaches are needed to produce discriminative features | |
| Mahalanobis distance classifier [40] | Simple procedure for training | Pre-processing overhead is still required to compute relevant features | |
| U-Net-based CNN for semantic segmentation [43] | U-Net structure preserves the boundaries well | Gray scale pre-processing is required | |
| Multi-scale CNN [44,47] | Better learning due to multi-receptive fields | Tiny vessels not detected in certain cases | |
| CNN with CRFs [45] | CNN with few layers provides faster segmentation | CRFs are computationally complex | |
| SegNet-inspired method [46] | Encoder and decoder architecture provides a uniform structure of network layers | Use of PCA to prepare data for training | |
| CNN with visual codebook [48] | 10-layer CNN for correlation with ground truth representation | No end-to-end system for training and testing | |
| CNN with quantization and pruning [49] | Pruned convolutions increase the efficiency of the network | Fully connected layers increase the number of trainable parameters | |
| Three-stage CNN-based deep-learning method [50] | Fusion of multi-feature image provides powerful representation | Usage of three CNNs requires more computational power and cost | |
| Modified U-Net with dice loss [51] | Dice loss provides good results with unbalanced classes | Use of PCA to prepare data for training | |
| Deformable U-Net-based method [52] | Deformable networks can adequately accommodate geometric variations of data | Patch-based training and testing is time-consuming | |
| PixelBNN [53] | Pixel CNN is famous for predicting pixels with spatial dimensions | Use of CLAHE for pre-processing | |
| Dense U-Net-based method [54] | Dense block is good for alleviating vanishing gradient problem | Patch-based training and testing is time-consuming | |
| Cross-connected CNN (CcNet) [55] | Cross-connections of layers empower features | Complex architecture with pre-processing | |
| Vess-Net (this work) | Robust segmentation with fewer layers | Augmented data necessary to fully train network |
| Method | Other Architectures | Vess-Net |
|---|---|---|
| ResNet [58] | Residual skip path between adjacent layers only | Skip connections between adjacent layers and directly between the encoder and decoder |
| All variants use 1 × 1 convolution bottleneck layer | 1 × 1 convolution is used only in non-identity residual paths in combination with BN | |
| No index information with max-pooling layers | Index information between max-pooling and max-unpooling layers used to maintain feature size and location | |
| One fully connected layer for classification network | Fully convolutional network (FCN) for semantic segmentation, so fully connected layers not used | |
| Average pooling at the end in place of max-pooling in each block | Max-pooling in each encoder block and max-unpooling in each decoder block | |
| IrisDenseNet [62] | Total of 26 (3 × 3) convolutional layers | Total of 16 (3 × 3) convolutional layers |
| Uses dense connectivity inside each dense block via feature concatenation in just encoder | Uses residual connectivity via element-wise addition | |
| Different number of convolutional layers: first two blocks have two convolutional layers and other blocks have three | Same number of convolutional layers (two layers) in each block of encoder and decoder | |
| No dense connectivity inside decoder | Uses connectivity inside and between the encoder and decoder | |
| FRED-Net [61] | Only uses residual connectivity between adjacent layers | Uses residual connectivity between adjacent layers in encoder and decoder and residual connectivity outside encoder and decoder |
| No outer residual skip paths for direct spatial edge information flow | Inner and outer residual connections for information flow | |
| Total of 6 skip connections inside the encoder and decoder | 10 residual skip connections in encoder and decoder | |
| Only non-identity mapping for residual connections | Non-identity mapping for inner residual connections (Stream 1) and identity mapping for outer residual connections (Stream 2) | |
| Only uses post-activation because ReLU activation is used after element-wise addition | Uses the pre-activation and post-activation as ReLU is used before and after the element-wise addition |
| Block | Name/Size | Number of Filters | Output Feature Map Size (Width × Height × Number of Channels) | Number of Trainable Parameters (Econ + BN) |
|---|---|---|---|---|
| ECB-1 | ECon-1_1 **/3 × 3 × 3 To decoder (ORSP-1) | 64 | 447 × 447 × 64 | 1792 + 128 |
| ECon-1_2 **/3 × 3 × 64 | 64 | 36,928 + 128 | ||
| Pooling-1 | Pool-1/2 × 2 | - | 223 × 223 × 64 | - |
| ECB-2 | ECon-2_1 **/3 × 3 × 64 To decoder (ORSP-2) | 128 | 223 × 223 × 128 | 73,856 + 256 |
| IRSP-1 */1 × 1 × 64 | 128 | 8320 + 256 | ||
| ECon-2_2 */3 × 3 × 128 | 128 | 147,584 + 256 | ||
| Add-1 (ECon-2_2* + IRSP-1 *) | - | - | ||
| Pooling-2 | * Pool-2/2 × 2 | - | 111 × 111 × 128 | - |
| ECB-3 | ECon-3_1 **/3 × 3 × 128 To decoder (ORSP-3) | 256 | 111 × 111 × 256 | 295,168 + 512 |
| IRSP-2 */1 × 1 × 128 | 256 | 33,024 + 512 | ||
| ECon-3_2 */3 × 3 × 256 | 256 | 590,080 + 512 | ||
| Add-2 (ECon-3_2 * + IRSP-2 *) | - | - | ||
| Pooling-3 | * Pool-3/2×2 | - | 55 × 55 × 256 | - |
| ECB-4 | ECon-4_1 **/3 × 3 × 256 To decoder (ORSP-4) | 512 | 55 × 55 × 512 | 1,180,160 + 1024 |
| IRSP-3 */1 × 1 × 256 | 512 | 131,584 + 1024 | ||
| ECon-4_2 */3 × 3 × 512 | 512 | 2,359,808 + 1024 | ||
| Add-3 (ECon-4_2 * + IRSP-3 *) | - | - | ||
| Pooling-4 | * Pool-4/2 × 2 | - | 27 × 27 × 512 | - |
| Block | Name/Size | Number of Filters | Output Feature Map Size (Width × Height × Number of Channels) | Number of Trainable Parameters (DCon + BN) |
|---|---|---|---|---|
| Un-pooling-4 | Unpool-4 | - | 55 × 55 × 512 | - |
| DCB-4 | DCon-4_2 **/3 × 3 × 512 | 512 | 2,359,808 + 1024 | |
| ORSP-4 from encoder ECon-4_1 ** Add-4 (DCon-4_2 ** + ECon-4_1 **) | - | - | ||
| IRSP-4 */1 × 1 × 512 | 256 | 55 × 55 × 256 | 131,328 + 512 | |
| DCon-4_1 */3 × 3 × 512 | 256 | 1,179,904 + 512 | ||
| Add-5 (DCon-4_1 * + IRSP-4 *) | - | - | ||
| Unpooling-3 | * Unpool-3 | - | 111 × 111 × 256 | - |
| DCB-3 | DCon-3_2 **/3 × 3 × 256 | 256 | 590,080 + 512 | |
| ORSP-3 from encoder ECon-3_1 ** Add-6 (DCon-3_2 ** + ECon-3_1 **) | - | - | ||
| IRSP-5 */1 × 1 × 256 | 128 | 111 × 111 × 128 | 32,896 + 256 | |
| DCon-3_1 **/3 × 3 × 256 | 128 | - | ||
| Add-7 (DCon-3_1 * + IRSP-5 *) | - | - | ||
| Unpooling-2 | * Unpool-2 | - | 223 × 223 × 128 | - |
| DCB-2 | DCon-2_2 **/3 × 3 × 128 | 128 | 147,584 + 256 | |
| ORSP-2 from encoder ECon-2_1 ** Add-8 (DCon-2_2 ** + ECon-2_1 **) | - | - | ||
| IRSP-6 */1 × 1 × 128 | 64 | 223 × 223 × 64 | 8256 + 128 | |
| DCon-2_1 **/3 × 3 × 128 | 64 | 73,792 + 128 | ||
| Add-9 (DCon-3_1 * + IRSP-6*) | - | - | ||
| Unpooling-1 | * Unpool-1 | - | 447 × 447 × 64 | - |
| DCB-1 | DConv-1_2 **/3 × 3 × 64 | 64 | 36,928 + 128 | |
| ORSP-1 from encoder ECon-1_1 ** Add-10(DConv-1_2 **+ ECon-1_1 **) | - | - | ||
| DConv-1_1 **/3 × 3 × 64 | 2 | 447 × 447 × 2 | 1154 + 4 |
| Type | Method | Se | Sp | AUC | Acc |
|---|---|---|---|---|---|
| Handcrafted local feature-based methods | Akram et al. [23] | - | - | 96.32 | 94.69 |
| Fraz et al. [24] | 74.0 | 98.0 | - | 94.8 | |
| Kar et al. [25] | 75.48 | 97.92 | - | 96.16 | |
| Zhao et al. (without Retinex) [26] | 76.0 | 96.8 | 86.4 | 94.6 | |
| Zhao et al. (with Retinex) [26] | 78.2 | 97.9 | 88.6 | 95.7 | |
| Pandey et al. [27] | 81.06 | 97.61 | 96.50 | 96.23 | |
| Neto et al. [28] | 78.06 | 96.29 | - | 87.18 | |
| Sundaram et al. [29] | 69.0 | 94.0 | - | 93.0 | |
| Zhao et al. [30] | 74.2 | 98.2 | 86.2 | 95.4 | |
| Jiang et al. [31] | 83.75 | 96.94 | - | 95.97 | |
| Rodrigues et al. [32] | 71.65 | 98.01 | - | 94.65 | |
| Sazak et al. [33] | 71.8 | 98.1 | - | 95.9 | |
| Chalakkal et al. [34] | 76.53 | 97.35 | - | 95.42 | |
| Akyas et al. [36] | 74.21 | 98.03 | - | 95.92 | |
| Learned/deep feature-based methods | Zhang et al. (without post-processing) [37] | 78.95 | 97.01 | - | 94.63 |
| Zhang et al. (with post-processing) [37] | 78.61 | 97.12 | - | 94.66 | |
| Tan et al. [38] | 75.37 | 96.94 | - | - | |
| Zhu et al. [39] | 71.40 | 98.68 | - | 96.07 | |
| Wang et al. [40] | 76.48 | 98.17 | - | 95.41 | |
| Tuba et al. [41] | 67.49 | 97.73 | - | 95.38 | |
| Girard et al. [43] | 78.4 | 98.1 | 97.2 | 95.7 | |
| Hu et al. [44] | 77.72 | 97.93 | 97.59 | 95.33 | |
| Fu et al. [45] | 76.03 | - | - | 95.23 | |
| Soomro et al. [46] | 74.6 | 91.7 | 83.1 | 94.6 | |
| Guo et al. [47] | 78.90 | 98.03 | 98.02 | 95.60 | |
| Chudzik et al. [48] | 78.81 | 97.41 | 96.46 | - | |
| Yan et al. [50] | 76.31 | 98.20 | 97.50 | 95.38 | |
| Soomro et al. [51] | 73.9 | 95.6 | 84.4 | 94.8 | |
| Jin et al. [52] | 79.63 | 98.00 | 98.02 | 95.66 | |
| Leopold et al. [53] | 69.63 | 95.73 | 82.68 | 91.06 | |
| Wang et al. [54] | 79.86 | 97.36 | 97.40 | 95.11 | |
| Feng et al. [55] | 76.25 | 98.09 | 96.78 | 95.28 | |
| Vess-Net (this work) | 80.22 | 98.1 | 98.2 | 96.55 |
| Type | Method | Se | Sp | AUC | Acc |
|---|---|---|---|---|---|
| Handcrafted local feature-based methods | Fraz et al. [24] | 72.2 | 74.1 | - | 94.6 |
| Pandey et al. [27] | 81.06 | 95.30 | 96.33 | 94.94 | |
| Sundaram et al. [29] | 71.0 | 96.0 | - | 95.0 | |
| Learned/deep feature-based methods | Zhang et al. (without post-processing) [37] | 77.86 | 96.94 | - | 94.97 |
| Zhang et al. (with post-processing) [37] | 76.44 | 97.16 | - | 95.02 | |
| Wang et al. [40] | 77.30 | 97.92 | - | 96.03 | |
| Fu et al. [45] | 71.30 | - | - | 94.89 | |
| Yan et al. [50] | 76.41 | 98.06 | 97.76 | 96.07 | |
| Jin et al. [52] | 81.55 | 97.52 | 98.04 | 96.10 | |
| Leopold et al. [53] | 86.18 | 89.61 | 87.90 | 89.36 | |
| Vess-Net (this work) | 82.06 | 98.41 | 98.0 | 97.26 |
| Type | Method | Se | Sp | AUC | Acc |
|---|---|---|---|---|---|
| Handcrafted local feature-based methods | Akram et al. [23] | - | - | 97.06 | 95.02 |
| Fraz et al. [24] | 75.54 | 97.6 | - | 95.3 | |
| Kar et al. (normal cases) [25] | 75.77 | 97.88 | - | 97.30 | |
| Kar et al. (abnormal cases) [25] | 75.49 | 96.99 | - | 97.41 | |
| Zhao et al. (without Retinex) [26] | 76.6 | 97.72 | 86.9 | 94.9 | |
| Zhao et al. (with Retinex) [26] | 78.9 | 97.8 | 88.5 | 95.6 | |
| Pandey et al. [27] | 83.19 | 96.23 | 95.47 | 94.44 | |
| Neto et al. [28] | 83.44 | 94.43 | - | 88.94 | |
| Zhao et al. [30] | 78.0 | 97.8 | 87.4 | 95.6 | |
| Jiang et al. [31] | 77.67 | 97.05 | - | 95.79 | |
| Sazak et al. [33] | 73.0 | 97.9 | - | 96.2 | |
| Learned/deep feature-based methods | Zhang et al. (without post-processing) [37] | 77.24 | 97.04 | - | 95.13 |
| Zhang et al. (with post-processing) [37] | 78.82 | 97.29 | - | 95.47 | |
| Wang et al. [40] | 75.23 | 98.85 | - | 96.40 | |
| Hu et al. [44] | 75.43 | 98.14 | 97.51 | 96.32 | |
| Fu et al. [45] | 74.12 | - | - | 95.85 | |
| Soomro et al. [46] | 74.8 | 92.2 | 83.5 | 94.8 | |
| Chudzik et al. [48] | 82.69 | 98.04 | 98.37 | - | |
| Hajabdollahi et at. (CNN) [49] | 78.23 | 97.70 | - | 96.17 | |
| Hajabdollahi et at. (Quantized CNN) [49] | 77.92 | 97.40 | - | 95.87 | |
| Hajabdollahi et at. (Pruned-quantized CNN) [49] | 75.99 | 97.57 | - | 95.81 | |
| Yan et al. [50] | 77.35 | 98.57 | 98.33 | 96.38 | |
| Soomro et al. [51] | 74.8 | 96.2 | 85.5 | 94.7 | |
| Jin et al. [52] | 75.95 | 98.78 | 98.32 | 96.41 | |
| Leopold et al. [53] | 64.33 | 94.72 | 79.52 | 90.45 | |
| Wang et al. [54] | 79.14 | 97.22 | 97.04 | 95.38 | |
| Feng et al. [55] | 77.09 | 98.48 | 97.0 | 96.33 | |
| Vess-Net (this work) | 85.26 | 97.91 | 98.83 | 96.97 |
| Method | Se | Sp | AUC | Acc |
|---|---|---|---|---|
| Vess-Net (this work) | 81.13 | 96.21 | 97.4 | 95.11 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arsalan, M.; Owais, M.; Mahmood, T.; Cho, S.W.; Park, K.R. Aiding the Diagnosis of Diabetic and Hypertensive Retinopathy Using Artificial Intelligence-Based Semantic Segmentation. J. Clin. Med. 2019, 8, 1446. https://doi.org/10.3390/jcm8091446
Arsalan M, Owais M, Mahmood T, Cho SW, Park KR. Aiding the Diagnosis of Diabetic and Hypertensive Retinopathy Using Artificial Intelligence-Based Semantic Segmentation. Journal of Clinical Medicine. 2019; 8(9):1446. https://doi.org/10.3390/jcm8091446
Chicago/Turabian StyleArsalan, Muhammad, Muhammad Owais, Tahir Mahmood, Se Woon Cho, and Kang Ryoung Park. 2019. "Aiding the Diagnosis of Diabetic and Hypertensive Retinopathy Using Artificial Intelligence-Based Semantic Segmentation" Journal of Clinical Medicine 8, no. 9: 1446. https://doi.org/10.3390/jcm8091446
APA StyleArsalan, M., Owais, M., Mahmood, T., Cho, S. W., & Park, K. R. (2019). Aiding the Diagnosis of Diabetic and Hypertensive Retinopathy Using Artificial Intelligence-Based Semantic Segmentation. Journal of Clinical Medicine, 8(9), 1446. https://doi.org/10.3390/jcm8091446