
Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Hyperspectral Image Acquisition and Correction
2.3. Region of Interest (ROI) Identification
2.4. Chemometric Methods
2.4.1. Principal Component Analysis
2.4.2. Data Preprocessings
2.4.3. Feature Selection
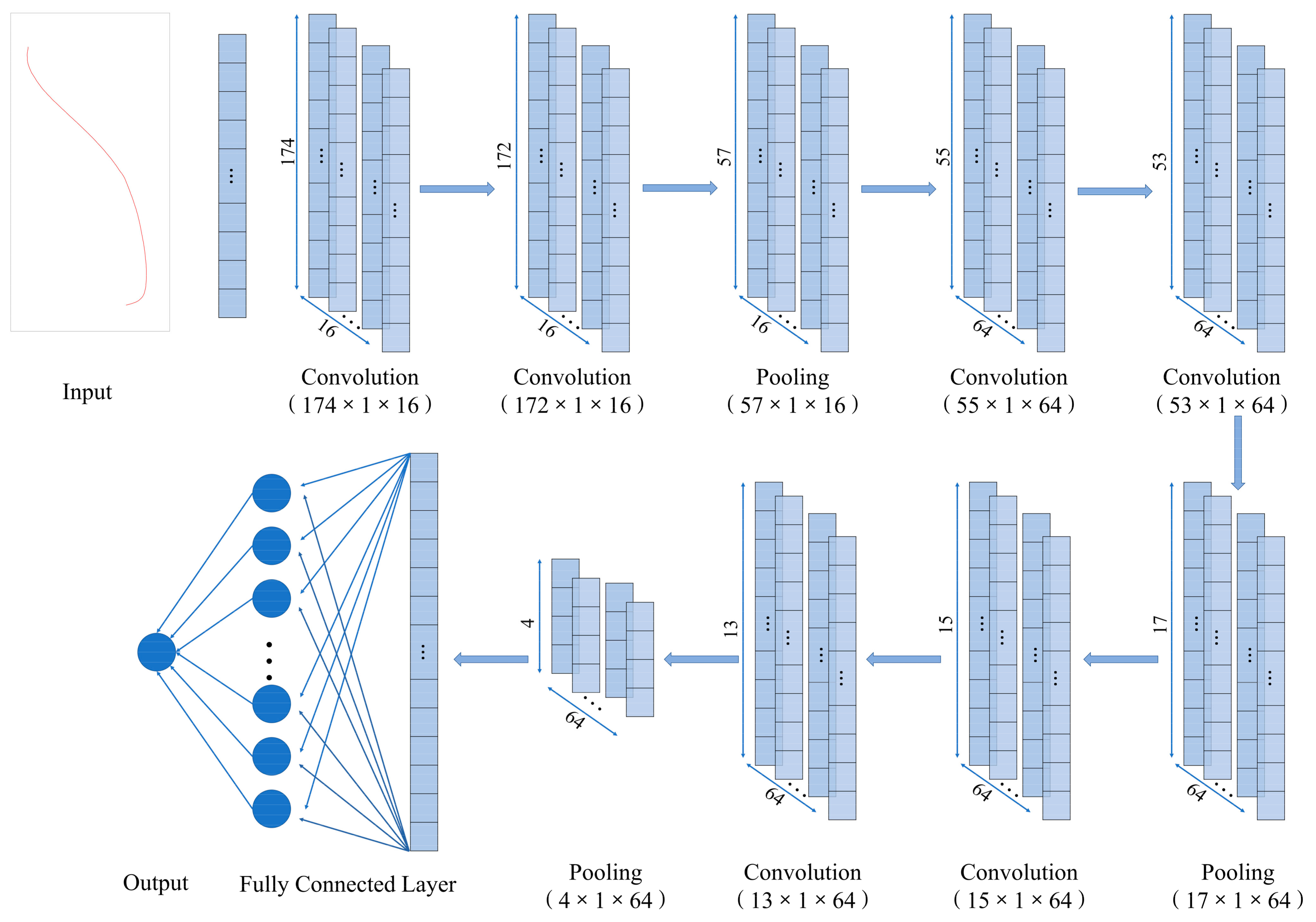
2.4.4. Modeling Methods
2.4.5. Models Assessment
3. Results and Discussion
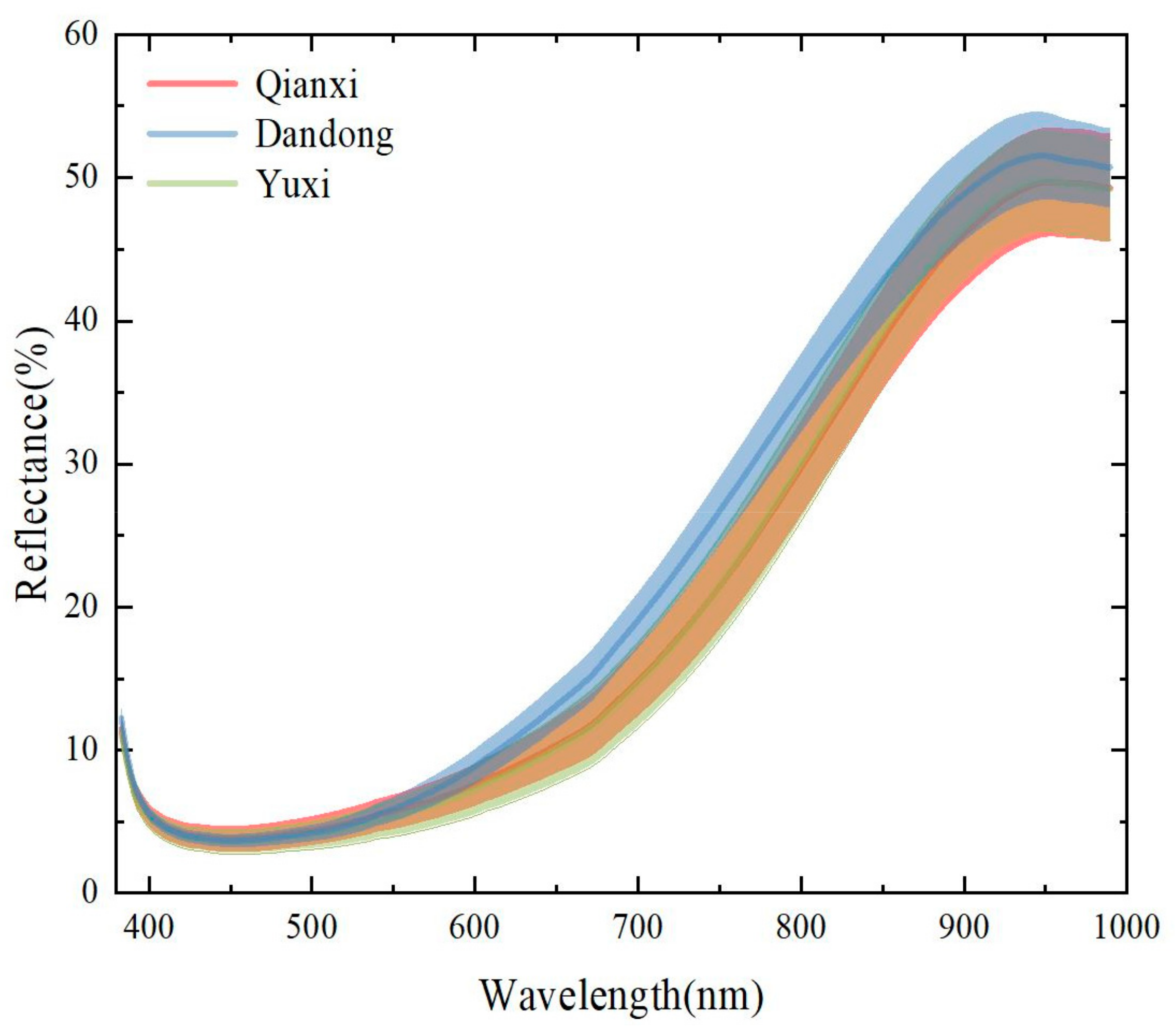
3.1. Overview of the Spectra
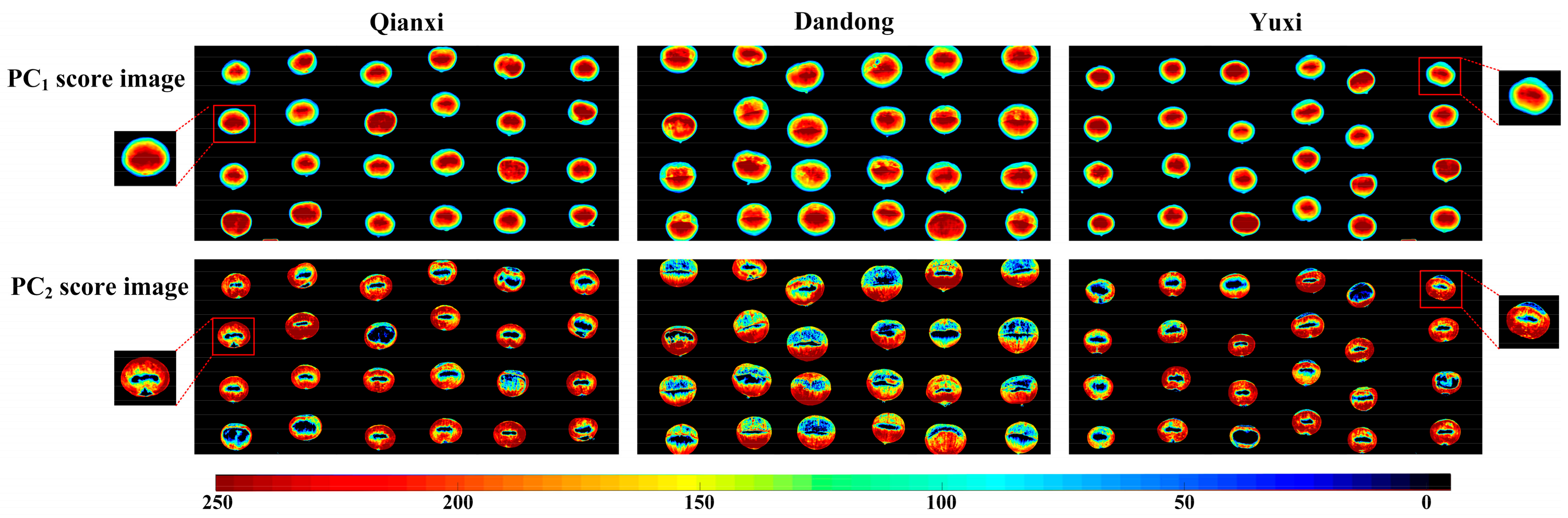
3.2. PCA Score Plot
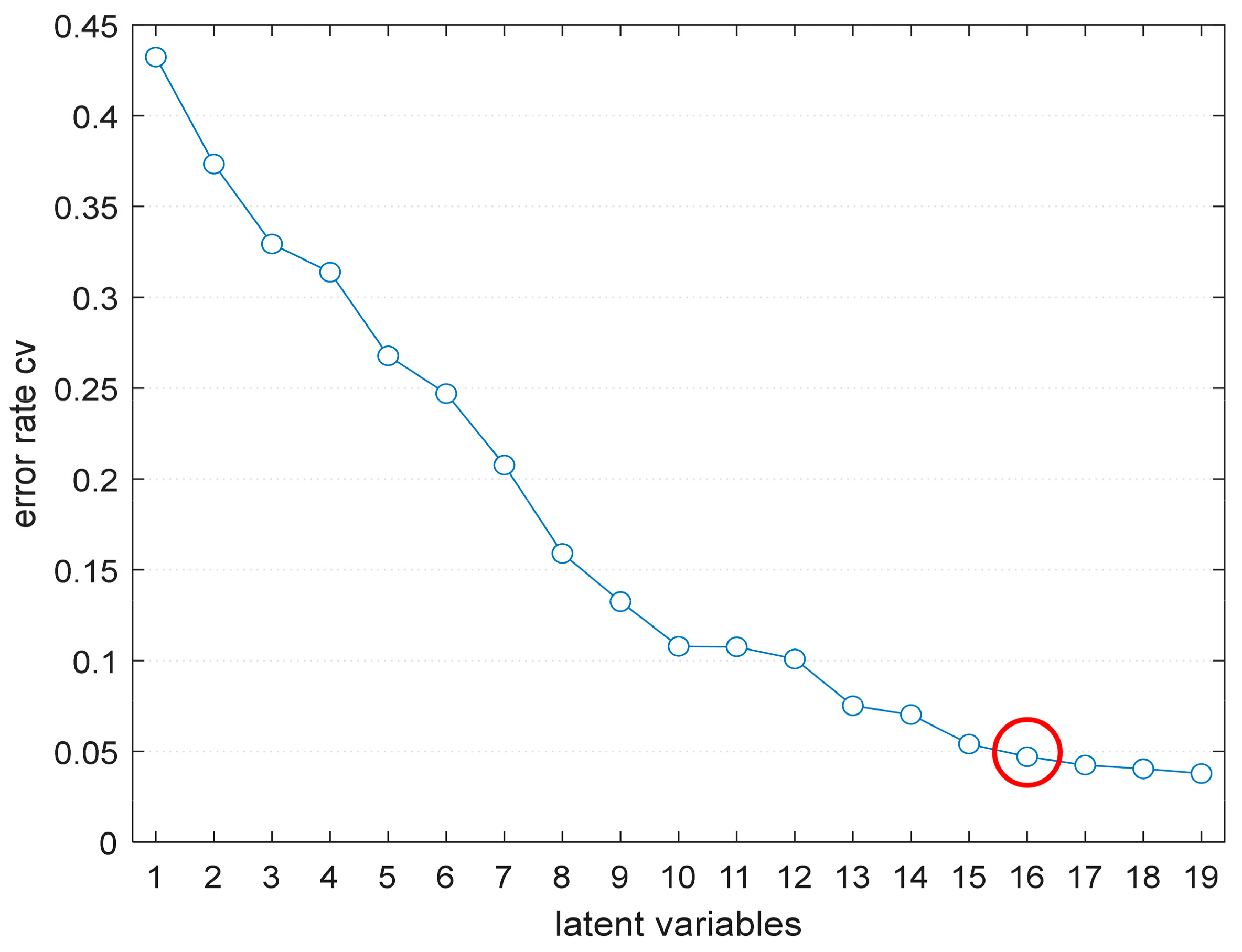
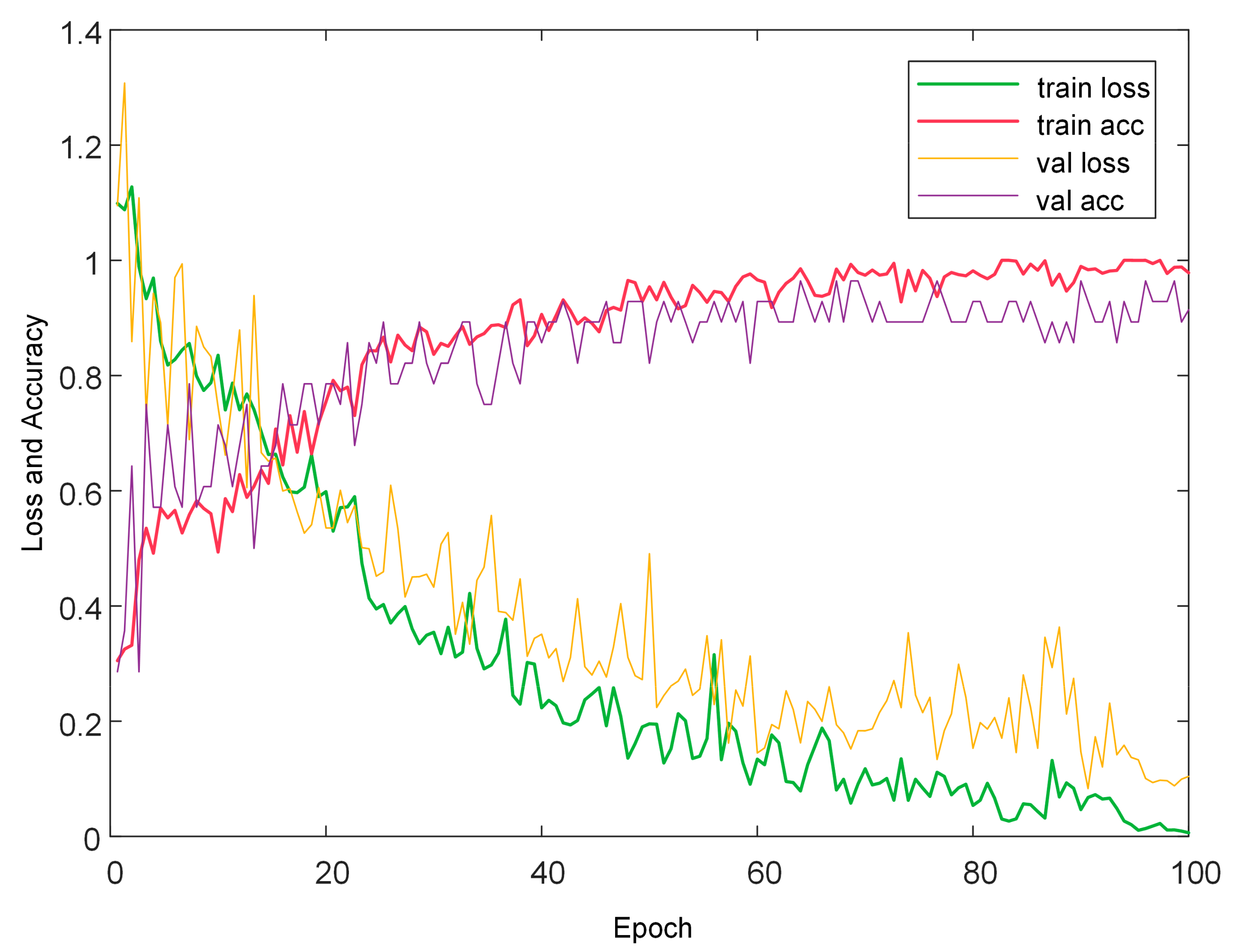
3.3. Analysis of Classification Model Based on Full Spectra
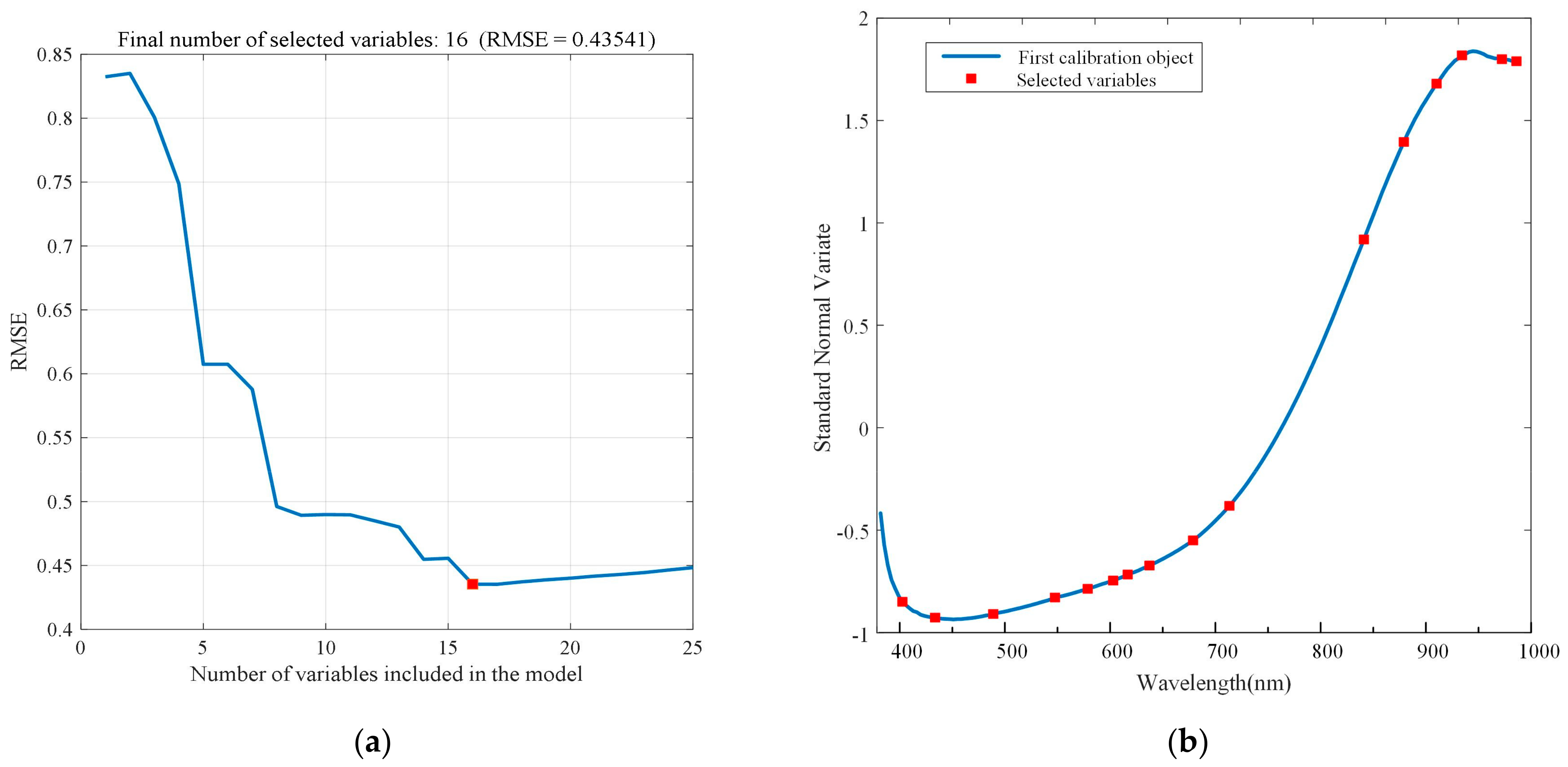
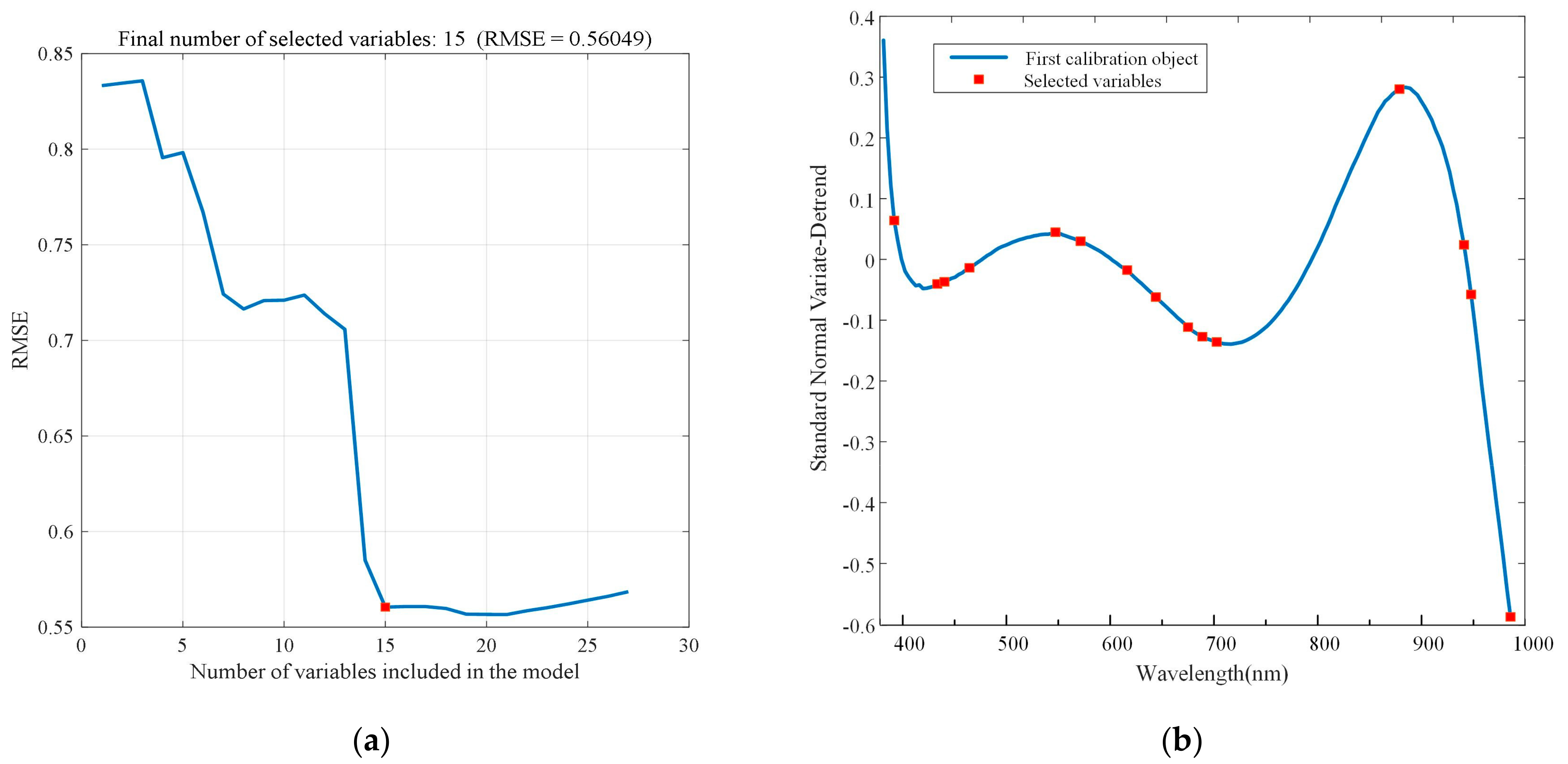
3.4. Characteristic Wavelengths Selection
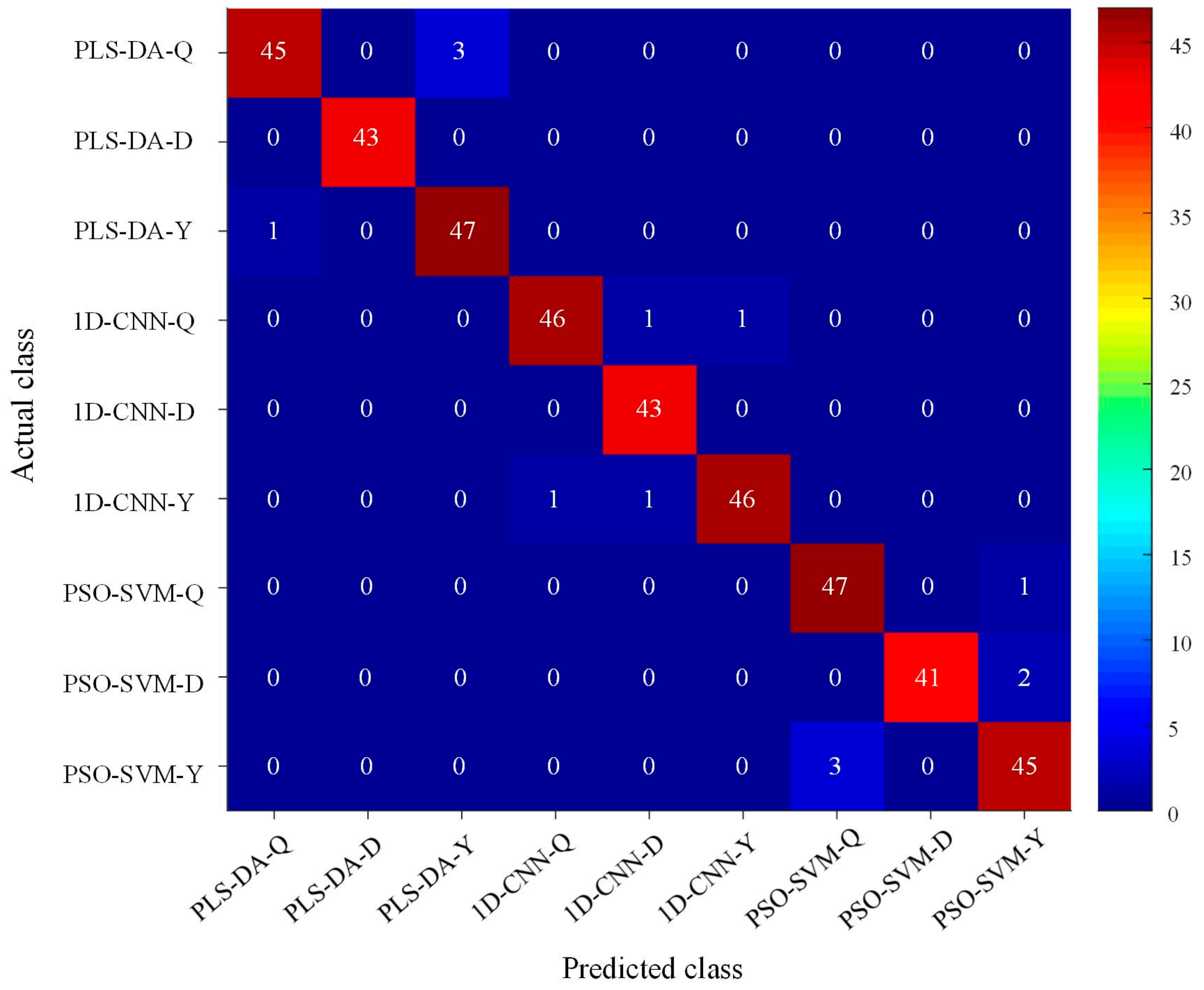
3.5. Classification Models on Characteristic Wavelengths
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiao, J.; Gu, C.; Zhu, D.; Wen, X.; Zhou, Q.; Huang, Y. Effects of low relative humidity on respiratory metabolism and energy status revealed new insights on “calcification” in chestnut (Castanea mollissima Bl. cv. ‘Youli’) during postharvest shelf life. Sci. Hortic. 2021, 289, 110473. [Google Scholar] [CrossRef]
- De Vasconcelos, M.C.B.M.; Bennett, R.N.; Rosa, E.A.S.; Ferreira-Cardoso, J.V. Composition of European chestnut (Castanea sativa Mill.) and association with health effects: Fresh and processed products. J. Sci. Food Agric. 2010, 90, 1578–1589. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Zhang, P.; Guo, M.; Li, M.; Wang, L.; Adeel, M.; Shakoor, N.; Rui, Y. Effects of age on mineral elements, amino acids and fatty acids in Chinese chestnut fruits. Eur. Food Res. Technol. 2021, 247, 2079–2086. [Google Scholar] [CrossRef]
- FAO. Food and Agriculture Data. Available online: http://www.fao.org/faostat/zh/#data/QC (accessed on 10 January 2021).
- Han, J.C.; Wang, G.P.; Kong, D.J.; Liu, Q.X.; Zhang, X.Y. Genetic diversity of Chinese chestnut (Castanea mollissima) in Hebei. Acta Hortic. 2007, 760, 573–577. [Google Scholar] [CrossRef]
- Jeon, H.N.; Park, H.W.; Kim, D.-H. Comparative analysis of gallic acid content by chestnut varieties. J. Korea Acad.-Ind. Coop. Soc. 2020, 21, 362–368. [Google Scholar] [CrossRef]
- Krist, S.; Unterweger, H.; Bandion, F.; Buchbauer, G. Volatile compound analysis of SPME headspace and extract samples from roasted Italian chestnuts (Castanea sativa Mill.) using GC-MS. Eur. Food Res. Technol. 2004, 219, 470–473. [Google Scholar] [CrossRef]
- Cirlini, M.; Dall’Asta, C.; Silvanini, A.; Beghe, D.; Fabbri, A.; Galaverna, G.; Ganino, T. Volatile fingerprinting of chestnut flours from traditional Emilia Romagna (Italy) cultivars. Food Chem. 2012, 134, 662–668. [Google Scholar] [CrossRef] [PubMed]
- Park, S.H.; Noh, S.H.; McCarthy, M.J.; Kim, S.M. Internal quality evaluation of chestnut using nuclear magnetic resonance. Int. J. Food Eng. 2021, 17, 57–63. [Google Scholar] [CrossRef]
- Correia, P.; Cruz-Lopes, L.; Beirao-da-Costa, L. Morphology and structure of chestnut starch isolated by alkali and enzymatic methods. Food Hydrocoll. 2012, 28, 313–319. [Google Scholar] [CrossRef]
- Kan, L.; Li, Q.; Xie, S.; Hu, J.; Wu, Y.; Ouyang, J. Effect of thermal processing on the physicochemical properties of chestnut starch and textural profile of chestnut kernel. Carbohydr. Polym. 2016, 151, 614–623. [Google Scholar] [CrossRef]
- Zhang, D.; Feng, X.; Xu, C.; Xia, D.; Liu, S.; Gao, S.; Zheng, F.; Liu, Y. Rapid discrimination of Chinese dry-cured hams based on Tri-step infrared spectroscopy and computer vision technology. Spectrochim. Acta Part A 2020, 228, 117842. [Google Scholar] [CrossRef] [PubMed]
- Srinuttrakul, W.; Mihailova, A.; Islam, M.D.; Liebisch, B.; Maxwell, F.; Kelly, S.D.; Cannavan, A. Geographical differentiation of Hom Mali rice cultivated in different regions of Thailand using FTIR-ATR and NIR spectroscopy. Foods 2021, 10, 1951. [Google Scholar] [CrossRef] [PubMed]
- Marquez, C.; Isabel Lopez, M.; Ruisanchez, I.; Pilar Callao, M. FT-Raman and NIR spectroscopy data fusion strategy for multivariate qualitative analysis of food fraud. Talanta 2016, 161, 80–86. [Google Scholar] [CrossRef] [PubMed]
- Biancolillo, A.; Luca, S.D.; Bassi, S.; Roudier, L.; Marini, F. Authentication of an Italian PDO hazelnut (“Nocciola Romana”) by NIR spectroscopy. Environ. Sci. Pollut. Res. 2018, 25, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Manfredi, M.; Robotti, E.; Quasso, F.; Mazzucco, E.; Marengo, E. Fast classification of hazelnut cultivars through portable infrared spectroscopy and chemometrics. Spectrochim. Acta Part A 2018, 189, 427–435. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, L.C.; Morais, C.L.M.; Lima, K.M.G.; Leite, G.W.P.; Oliveira, G.S.; Casagrande, I.P.; Santos Neto, J.P.; Teixeira, G.H.A. Using intact nuts and near infrared spectroscopy to classify macadamia cultivars. Food Anal. Method. 2018, 11, 1857–1866. [Google Scholar] [CrossRef] [Green Version]
- Arndt, M.; Drees, A.; Ahlers, C.; Fischer, M. Determination of the geographical origin of walnuts (Juglans regia L.) using Near-Infrared spectroscopy and chemometrics. Foods 2020, 9, 1860. [Google Scholar] [CrossRef] [PubMed]
- Nogalesbueno, J.; Feliz, L.; Bacabocanegra, B.; Rato, A.E. Comparative study on the use of three different near infrared spectroscopy recording methodologies for varietal discrimination of walnuts. Talanta 2019, 206, 120189. [Google Scholar] [CrossRef] [PubMed]
- Moscetti, R.; Berhe, D.H.; Agrimi, M.; Haff, R.P.; Liang, P.; Ferri, S.; Monarca, D.; Massantini, R. Pine nut species recognition using NIR spectroscopy and image analysis. J. Food Eng. 2021, 292, 110357. [Google Scholar] [CrossRef]
- Huang, Y.; Si, W.; Chen, K.; Sun, Y. Assessment of tomato maturity in different layers by spatially resolved spectroscopy. Sensors 2020, 20, 7229. [Google Scholar] [CrossRef]
- Ni, C.; Li, Z.Y.; Zhang, X.; Sun, X.Y.; Huang, Y.P.; Zhao, L.; Zhu, T.T.; Wang, D.Y. Online sorting of the film on cotton based on deep learning and hyperspectral imaging. IEEE Access 2020, 8, 93028–93038. [Google Scholar] [CrossRef]
- Huang, Y.P.; Yang, Y.T.; Sun, Y.; Zhou, H.Y.; Chen, K.J. Identification of apple varieties using a multichannel hyperspectral imaging system. Sensors 2020, 20, 5120. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety identification of single rice seed using hyperspectral imaging combined with convolutional neural network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef] [Green Version]
- Vresak, M.; Olesen, M.H.; Gislum, R.; Bavec, F.; Jorgensen, J.R. The use of image-spectroscopy technology as a diagnostic method for seed health testing and variety identification. PLoS ONE 2016, 11, e0152011. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.D.; Mi, C.X.; Wu, N.; Liu, F.; He, Y. Rapid classification of wheat grain varieties using hyperspectral imaging and chemometrics. Appl. Sci. 2019, 9, 4119. [Google Scholar] [CrossRef] [Green Version]
- Kamruzzaman, M.; Barbin, D.; ElMasry, G.; Sun, D.W.; Allen, P. Potential of hyperspectral imaging and pattern recognition for categorization and authentication of red meat. Innov. Food Sci. Emerg. Technol. 2012, 16, 316–325. [Google Scholar] [CrossRef]
- Steinbrener, J.; Posch, K.; Leitner, R. Hyperspectral fruit and vegetable classification using convolutional neural networks. Comput. Electron. Agr. 2019, 162, 364–372. [Google Scholar] [CrossRef]
- Qin, J.W.; Vasefi, F.; Hellberg, R.S.; Akhbardeh, A.; Isaacs, R.B.; Yilmaz, A.G.; Hwang, C.S.; Baek, I.; Schmidt, W.F.; Kim, M.S. Detection of fish fillet substitution and mislabeling using multimode hyperspectral imaging techniques. Food Control 2020, 114, 107234. [Google Scholar] [CrossRef]
- Baek, I.; Kim, M.S.; Cho, B.-K.; Mo, C.; Barnaby, J.Y.; McClung, A.M.; Oh, M. Selection of optimal hyperspectral wavebands for detection of discolored, diseased rice seeds. Appl. Sci. 2019, 9, 1027. [Google Scholar] [CrossRef] [Green Version]
- Mo, C.; Kim, G.; Lim, J.; Kim, M.S.; Cho, H.; Cho, B.-K. Detection of lettuce discoloration using hyperspectral reflectance imaging. Sensors 2015, 15, 29511–29534. [Google Scholar] [CrossRef] [Green Version]
- Xuan, G.; Gao, C.; Shao, Y.; Wang, X.; Wang, Y.; Wang, K. Maturity determination at harvest and spatial assessment of moisture content in okra using Vis-NIR hyperspectral imaging. Postharvest Biol. Technol. 2021, 180, 111597. [Google Scholar] [CrossRef]
- Rajkumar, P.; Wang, N.; Elmasry, G.; Raghavan, G.S.V.; Gariepy, Y. Studies on banana fruit quality and maturity stages using hyperspectral imaging. J. Food Eng. 2012, 108, 194–200. [Google Scholar] [CrossRef]
- Chu, X.; Wang, W.; Ni, X.Z.; Li, C.Y.; Li, Y.F. Classifying maize kernels naturally infected by fungi using near-infrared hyperspectral imaging. Infrared Phys. Technol. 2020, 105, 103242. [Google Scholar] [CrossRef]
- Chen, S.Y.; Chang, C.Y.; Ou, C.S.; Lien, C.T. Detection of insect damage in green coffee beans using VIS-NIR hyperspectral imaging. Remote Sens. 2020, 12, 2348. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.S.; Lin, F.C.; Su, Z.Z.; Yuan, K.P.; Zhao, Y.Y.; He, Y.; Zhang, C. Detection of oil chestnuts infected by blue mold using Near-Infrared hyperspectral imaging combined with artificial neural networks. Sensors 2018, 18, 1944. [Google Scholar] [CrossRef] [Green Version]
- Park, S.H.; Lim, K.T.; Lee, H.; Lee, S.H.; Sang, H.N. Prediction of soluble solids content of chestnut using VIS/NIR spectroscopy. J. Biosyst. Eng. 2013, 38, 185–191. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, D.D.; Tu, S.Y.; Xiao, H.; Zhang, B.; Sun, Y.; Pan, L.Q.; Tu, K. Quantitative visualization of fungal contamination in peach fruit using hyperspectral imaging. Food Anal. Methods 2020, 13, 1262–1270. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L.M.; Cheng, F. Classification of frozen corn seeds using hyperspectral VIS/NIR reflectance imaging. Molecules 2019, 24, 149. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.C.; Zhao, F.; Dong, J.L. Nondestructive measurement of soluble solids content of kiwifruits using Near-Infrared hyperspectral imaging. Food Anal. Methods 2016, 9, 38–47. [Google Scholar] [CrossRef]
- Amanah, H.Z.; Wakholi, C.; Perez, M.; Faqeerzada, M.A.; Tunny, S.S.; Masithoh, R.E.; Choung, M.G.; Kim, K.H.; Lee, W.H.; Cho, B.K. Near-Infrared Hyperspectral Imaging (NIR-HSI) for nondestructive prediction of anthocyanins content in black rice seeds. Appl. Sci. 2021, 11, 4841. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard normal variate transformation and De-Trending of Near-Infrared diffuse reflectance spectra. Appl. Spectrosc. 2016, 43, 772–777. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, T.; Li, Z.; Ni, C. Non-destructive testing of moisture and nitrogen content in pinus massoniana seedling leaves with NIRS based on MS-SC-CNN. Appl. Sci. 2021, 11, 2754. [Google Scholar] [CrossRef]
- Xiao, Q.L.; Bai, X.L.; He, Y. Rapid screen of the color and water content of fresh-cut potato tuber slices using hyperspectral imaging coupled with multivariate analysis. Foods 2020, 9, 94. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Esteva, S.; Knadel, M.; Kucheryavskiy, S.; de Jonge, L.W.; Rubaek, G.H.; Hermansen, C.; Heckrath, G. Combining Laser-Induced breakdown spectroscopy (LIBS) and visible Near-Infrared spectroscopy (Vis-NIRS) for soil phosphorus determination. Sensors 2020, 20, 5419. [Google Scholar] [CrossRef]
- Andersen, A.H.; Rayens, W.S.; Liu, Y.; Smith, C.D. Partial least squares for discrimination. Magn. Reson. Imaging 2012, 30, 446–452. [Google Scholar] [CrossRef] [Green Version]
- Perez, N.F.; Ferre, J.; Boque, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Patel, H.; Upla, K.P. A shallow network for hyperspectral image classification using an autoencoder with convolutional neural network. Multimed. Tools. Appl. 2021, 1–20. [Google Scholar] [CrossRef]
- Sellami, A.; Tabbone, S. Deep neural networks-based relevant latent representation learning for hyperspectral image classification. Pattern Recogn. 2021, 121, 108224. [Google Scholar] [CrossRef]
- Yang, S.; Li, C.; Mei, Y.; Liu, W.; Liu, R.; Chen, W.; Han, D.; Xu, K. Determination of the geographical origin of coffee beans using terahertz spectroscopy combined with machine learning methods. Front. Nutr. 2021, 8, 680627. [Google Scholar] [CrossRef]
- Wang, Q.; Zhao, W.F.; Ren, J.D. Intrusion detection algorithm based on image enhanced convolutional neural network. J. Intell. Fuzzy Syst. 2021, 41, 2183–2194. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yang, Q.F.; Zhang, H.J.; Xia, J.; Zhang, X.L. Evaluation of magnetic resonance image segmentation in brain low-grade gliomas using support vector machine and convolutional neural network. Quant. Imag. Med. Surg. 2021, 11, 300–316. [Google Scholar] [CrossRef]
- Huang, K.; Wang, H.J.; Xu, H.R.; Wang, J.P.; Ying, Y.B. NIR spectroscopy based on least square support vector machines for quality prediction of tomato juice. Spectrosc. Spect. Anal. 2009, 29, 931–934. [Google Scholar] [CrossRef]
- Li, Y.; Via, B.K.; Young, T.; Li, Y.X. Visible-Near Infrared spectroscopy and chemometric methods for wood density prediction and origin/species identification. Forests 2019, 10, 1078. [Google Scholar] [CrossRef] [Green Version]
- Li, X.X.; Bi, S.H.; Zhang, Y.H.; Shen, T.; IEEE. SVM-based apple classification of soluble solids content by Near-infrared spectroscopy. In Proceedings of the 31st Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 4001–4005. [Google Scholar]
- Kurosaki, K.; Wu, R.; Uesawa, Y. A toxicity prediction tool for potential agonist/antagonist activities in molecular initiating events based on chemical structures. Int. J. Mol. Sci. 2020, 21, 7853. [Google Scholar] [CrossRef]
- Doheny, E.P.; Walsh, C.; Foran, T.; Greene, B.R.; Fan, C.W.; Cunningham, C.; Kenny, R.A. Falls classification using tri-axial accelerometers during the five-times-sit-to-stand test. Gait Posture 2013, 38, 1021–1025. [Google Scholar] [CrossRef]
- Duan, G.H.; Zhang, J.C.; Zhang, S.P. Assessment of landslide susceptibility based on multiresolution image segmentation and geological factor ratings. Int. J. Environ. Res. Public Health 2020, 17, 7863. [Google Scholar] [CrossRef] [PubMed]
- Li, B.C.; Hou, B.L.; Zhou, Y.; Zhao, M.T.; Zhang, D.W.; Hong, R.J. Detection of waxed chestnuts using visible and Near-Infrared hyper-spectral imaging. Food Sci. Technol. Res. 2016, 22, 267–277. [Google Scholar] [CrossRef] [Green Version]
- Imbao, J.; van Bokhoven, J.A.; Clark, A.; Nachtegaal, M. Elucidating the mechanism of heterogeneous Wacker oxidation over Pd-Cu/zeolite Y by transient XAS. Nat. Commun. 2020, 11, 1118. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Sun, D.W. Application of visible and near infrared hyperspectral imaging for non-invasively measuring distribution of water-holding capacity in salmon flesh. Talanta 2013, 116, 266–276. [Google Scholar] [CrossRef]
- Bobelyn, E.; Serban, A.S.; Nicu, M.; Lammertyn, J.; Nicolai, B.M.; Saeys, W. Postharvest quality of apple predicted by NIR-spectroscopy: Study of the effect of biological variability on spectra and model performance. Postharvest Biol. Technol. 2010, 55, 133–143. [Google Scholar] [CrossRef]
- Kukreti, S.; Cerussi, A.; Tromberg, B.; Gratton, E. Intrinsic tumor biomarkers revealed by novel double-differential spectroscopic analysis of near-infrared spectra. J. Biomed. Opt. 2007, 12, 020509. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.S.; Zhang, C.; Bao, Y.D.; Gao, P.; He, Y. Variety identification of raisins using Near-Infrared hyperspectral imaging. Molecules 2018, 23, 2907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.; Song, X.L.; Qiu, Z.J.; He, Y. Mapping of TBARS distribution in frozen-thawed pork using NIR hyperspectral imaging. Meat Sci. 2016, 113, 92–96. [Google Scholar] [CrossRef]
- Wang, Y.J.; Li, T.H.; Li, L.Q.; Ning, J.M.; Zhang, Z.Z. Evaluating taste-related attributes of black tea by micro-NIRS. J. Food Eng. 2021, 290, 110181. [Google Scholar] [CrossRef]
- Su, W.H.; Yang, C.; Dong, Y.; Johnson, R.; Steffenson, B.J. Hyperspectral imaging and improved feature variable selection for automated determination of deoxynivalenol in various genetic lines of barley kernels for resistance screening. Food Chem. 2021, 343, 128507. [Google Scholar] [CrossRef]
- Peng, X.X.; Wu, W.Y.; Zheng, Y.Y.; Sun, J.Y.; Hu, T.G.; Wang, P. Correlation analysis of land surface temperature and topographic elements in Hangzhou, China. Sci. Rep. 2020, 10, 10451. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Deleted Layer | Accuracy (%) | ||
|---|---|---|---|
| Calibration Set | Cross-Validation Set | Prediction Set | |
| None | 97.84 | 91.38 | 92.81 |
| C7, C8, S9 | 94.96 | 92.12 | 89.92 |
| C4, C5, S6, C7, C8, S9 | 64.03 | 60.48 | 56.83 |
| Layer | Type | Feature Map | Kernel Size | Stride | Padding | Size | Activation Function |
|---|---|---|---|---|---|---|---|
| In | Input | 1 | … | … | … | 176 × 1 × 1 | … |
| Conv1 | Convolution | 16 | 3 × 1 | 1 | 0 | 174 × 1 × 16 | … |
| Conv2 | Convolution | 16 | 3 × 1 | 1 | 0 | 172 × 1 × 16 | tanh |
| S3 | Max pooling | 16 | 3 × 1 | 1 | 0 | 57 × 1 × 16 | … |
| Conv 4 | Convolution | 64 | 3 × 1 | 1 | 0 | 55 × 1 × 64 | … |
| Conv 5 | Convolution | 64 | 3 × 1 | 1 | 0 | 53 × 1 × 64 | tanh |
| S6 | Max pooling | 64 | 3 × 1 | 1 | 0 | 17 × 1 × 64 | … |
| Conv 7 | Convolution | 64 | 3 × 1 | 1 | 0 | 15 × 1 × 64 | … |
| Conv 8 | Convolution | 64 | 3 × 1 | 1 | 0 | 13 × 1 × 64 | tanh |
| S9 | Max pooling | 64 | 3 × 1 | 1 | 0 | 4 × 1 × 64 | … |
| FC10 | Flatten | … | … | … | … | 256 × 1 | … |
| FC11 | Fully connected | … | … | … | … | 3 × 1 | softmax |
| Out | Output | … | … | … | … | 3 × 1 | … |
| Batch Size | Accuracy (%) | ||
|---|---|---|---|
| Calibration Set | Cross-Validation Set | Prediction Set | |
| 1 | 97.84 | 91.38 | 92.81 |
| 8 | 95.68 | 91.04 | 89.93 |
| 16 | 99.64 | 86.63 | 88.49 |
| 32 | 92.81 | 82.76 | 82.73 |
| Modeling Methods | Preprocessings | Accuracy (%) | Parameters | ||
|---|---|---|---|---|---|
| Calibration Set | Cross-Validation Set | Prediction Set | |||
| PLS-DA | None | 97.84 | 94.96 | 95.68 | LVs = 16 |
| SNV | 99.28 | 98.20 | 97.12 | LVs = 18 | |
| SNV-detrend | 97.84 | 96.04 | 94.96 | LVs = 14 | |
| Normalization | 97.48 | 95.32 | 94.96 | LVs = 15 | |
| SG-1der | 98.56 | 95.32 | 94.96 | LVs = 16 | |
| SG-2der | 100 | 84.89 | 84.17 | LVs = 19 | |
| 1D-CNN | None | 97.84 | 91.38 | 92.81 | / |
| SNV | 97.12 | 83.52 | 95.68 | / | |
| SNV-detrend | 99.64 | 93.13 | 97.12 | / | |
| Normalization | 98.56 | 82.42 | 91.37 | / | |
| SG-1der | 96.40 | 92.49 | 88.49 | / | |
| SG-2der | 100 | 75.61 | 93.53 | / | |
| PSO-SVM | None | 98.20 | 84.17 | 89.93 | / |
| SNV | 96.04 | 91.73 | 95.68 | / | |
| SNV-detrend | 97.84 | 92.81 | 95.68 | / | |
| Normalization | 97.12 | 84.17 | 92.09 | / | |
| SG-1der | 80.22 | 77.70 | 79.86 | / | |
| SG-2der | 73.38 | 66.91 | 71.22 | / | |
| Preprocessings | Number | Selected Wavelengths (nm) |
|---|---|---|
| SNV | 16 | 402.5, 431.5, 483.7, 540, 570.2, 593.9, 607.5, 628, 669.3, 704.1, 835.7, 875.7, 908.6, 934.5, 975.4, 990.4 |
| SNV-detrend | 15 | 392.9, 431.5, 438, 460.8, 540, 563.5, 607.5, 634.8, 665.8, 679.7, 693.6, 875.7, 941.9, 949.3, 990.4 |
| Preprocessings | Number | Selected Wavelengths (nm) |
|---|---|---|
| SNV | 15 | 460.8, 473.8, 523.4, 526.7, 530, 533.3, 536.7, 546.7, 570.2, 573.6, 577, 583.7, 669.3, 686.7, 697.1 |
| SNV-detrend | 18 | 421.8, 460.8, 467.3, 473.8, 523.4, 526.7, 530, 533.3, 570.2, 573.6, 577, 669.3, 686.7, 756.9, 908.6, 912.3, 945.6, 971.7 |
| Modeling Methods | Feature Selection | Number | LVs | Accuracy (%) | Computing Time (s) | ||
|---|---|---|---|---|---|---|---|
| Calibration | Cross-Validation | Prediction | |||||
| PLS-DA | FULL | 176 | 18 | 99.28 | 98.2 | 97.12 | 5.19 |
| SPA | 16 | 13 | 98.2 | 97.84 | 97.12 | 3.51 | |
| CARS | 15 | 10 | 95.32 | 93.88 | 93.53 | 3.39 | |
| PSO-SVM | FULL | 176 | \ | 97.84 | 92.81 | 95.68 | 771.01 |
| SPA | 15 | \ | 96.76 | 91.37 | 95.68 | 349.42 | |
| CARS | 18 | \ | 96.76 | 94.24 | 96.4 | 238.21 | |
| 1D-CNN | FULL | 176 | \ | 99.64 | 93.13 | 97.12 | 35.32 |
| Actual Class | Predicted Class | |||||
|---|---|---|---|---|---|---|
| SPA-PLS-DA | 1D-CNN | |||||
| Qianxi | Dandong | Yuxi | Qianxi | Dandong | Yuxi | |
| Qianxi | 48 | 0 | 0 | 46 | 1 | 1 |
| Dandong | 0 | 42 | 1 | 0 | 43 | 0 |
| Yuxi | 2 | 1 | 45 | 1 | 1 | 46 |
| Sen a (%) | 100 | 97.67 | 93.75 | 95.83 | 100 | 95.83 |
| Spe b (%) | 97.80 | 98.96 | 98.90 | 98.90 | 97.92 | 98.90 |
| Kappa | 0.95677 | 0.95681 | ||||
| Acc c (%) | 97.12 | 97.12 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Jiang, H.; Jiang, X.; Shi, M. Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm. Agriculture 2021, 11, 1274. https://doi.org/10.3390/agriculture11121274
Li X, Jiang H, Jiang X, Shi M. Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm. Agriculture. 2021; 11(12):1274. https://doi.org/10.3390/agriculture11121274
Chicago/Turabian StyleLi, Xingpeng, Hongzhe Jiang, Xuesong Jiang, and Minghong Shi. 2021. "Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm" Agriculture 11, no. 12: 1274. https://doi.org/10.3390/agriculture11121274
APA StyleLi, X., Jiang, H., Jiang, X., & Shi, M. (2021). Identification of Geographical Origin of Chinese Chestnuts Using Hyperspectral Imaging with 1D-CNN Algorithm. Agriculture, 11(12), 1274. https://doi.org/10.3390/agriculture11121274