1. Introduction
Amanita is a large fungus, which is an important part of natural medicine resources. At present, using the characteristics of amatoxins to control and treat tumors is a promising method [
1,
2,
3].
Amanita muscaria is a famous hallucinogenic mushroom, which can be used to develop special drugs for anesthesia and sedation [
4]. In terms of biological control, the toxins contained in
Amanita albicans and
Amanita muscaria have certain trapping and killing effects on insects or agricultural pests [
3,
5]. At present, there is no artificially cultivated
Amanita, the amatoxins needed in scientific research can only be extracted from fruit bodies collected in the field [
6,
7,
8]. Moreover, due to the lack of knowledge and ability to identify poisonous mushrooms, there are a number of cases of poisoning death from eating wild mushrooms every year [
9,
10,
11,
12,
13]. In Europe, 95% of mushroom poisoning deaths are caused by poisonous
Amanita [
14,
15]. Therefore, it is necessary to accurately classify and identify them both in terms of use value and poisoning prevention.
Many researchers have contributed to the classification of mushrooms. For example, Ismail [
16] studied the characteristics of mushrooms, such as the shape, surface and color of the cap, roots and stems, and used the principal component analysis (PCA) algorithm to select the best features for the classification experiment using the decision tree (DT) algorithm. Pranjal Maurya [
17] used a support vector machine (SVM) classifier to distinguish edible and poisonous mushrooms, with an accuracy of 76.6%. Xiao [
18] used the Shuf-fleNetV2 model to quickly identify the toxicity of wild bacteria. The accuracy of the model is 55.18% for Top-1 and 93.55% for Top-5. Chen [
19] used the Keras platform to build a convolutional neural network (CNN) for end-to-end model training and migrated to the Android end to realize mushroom recognition on the mobile end, but the recognition effect of his model was poor. Preechasuk J [
20] proposed a new model of classifying 45 types of mushrooms including edible and poisonous mushrooms by using a technique of CNN, which gives the results of 0.78, 0.73 and 0.74 of precision, recall and F1 score, respectively. Dong J [
21] proposed a CNN model that can detect qualified and three common types of substandard enoki mushroom caps and achieved 98.35% accuracy. However, this model is suitable for few types of mushrooms, and the cap must be detected.
Since the method based on the visual attention mechanism [
22,
23] can locate the distinguishable areas in the image without additional annotation information, it has been widely used in the field of fine-grained classification of images in recent years. At present, the mainstream attention mechanism can be divided into the following three types: channel attention, spatial attention and self-attention.
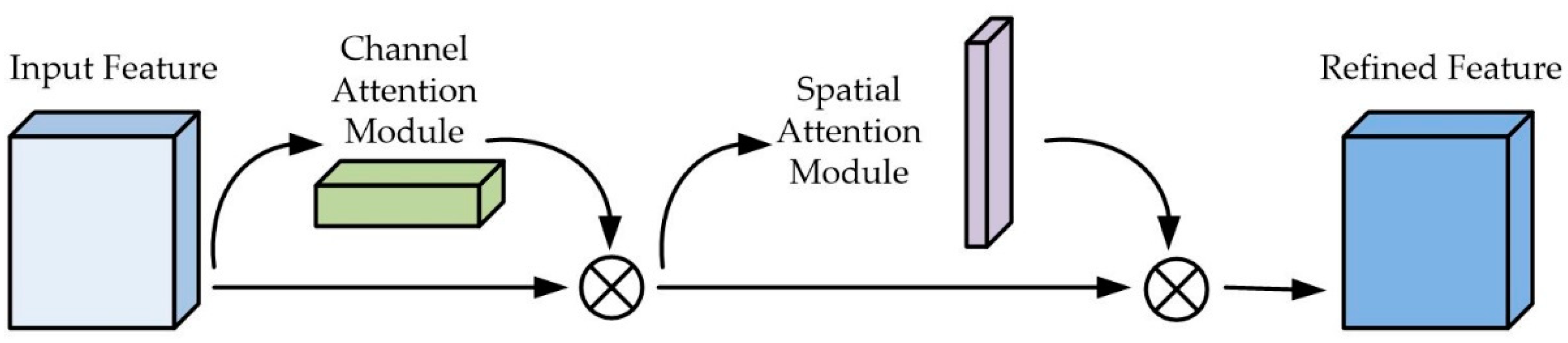
Channel attention aims to show the correlation between different channels. In a convolutional neural network, each image is initially represented by three channels (R, G, B) [
24]. After different convolution kernels are processed, each channel will generate a new channel with different information. Channel attention automatically obtains the importance of each feature channel through network learning, and finally assigns different weight coefficients to each channel. It can achieve the purpose of strengthening important channels and suppressing non-important channels.
Spatial Attention is designed to enhance the spatial characteristics of expression of critical areas. DeepMind designed a Spatial Transformer Layer (STL) to realize spatial invariance [
25,
26]. Its principle is to transform the spatial information in the original picture into another space and retain the key information through STL. Then, generate a weight mask for each position and weigh the output. This method can enhance the specific target area of interest while weakening the irrelevant background area to extract the key information.
Self-attention reduces the dependence on external information and uses the inherent information within the feature to interact with attention as much as possible [
27,
28]. However, the disadvantage of this method is that every point must capture global contextual information, which will cause a lot of computational complexity and memory capacity, and the information on the channel is not considered.
In this paper, a method of CNN combined with an attention mechanism is proposed to solve the problem of difficult classification and identification of Amanita. The specific contributions and innovations are as follows:
- (1)
A self-built Amanita dataset that is 3219 Amanita images obtained from the Internet and divided.
- (2)
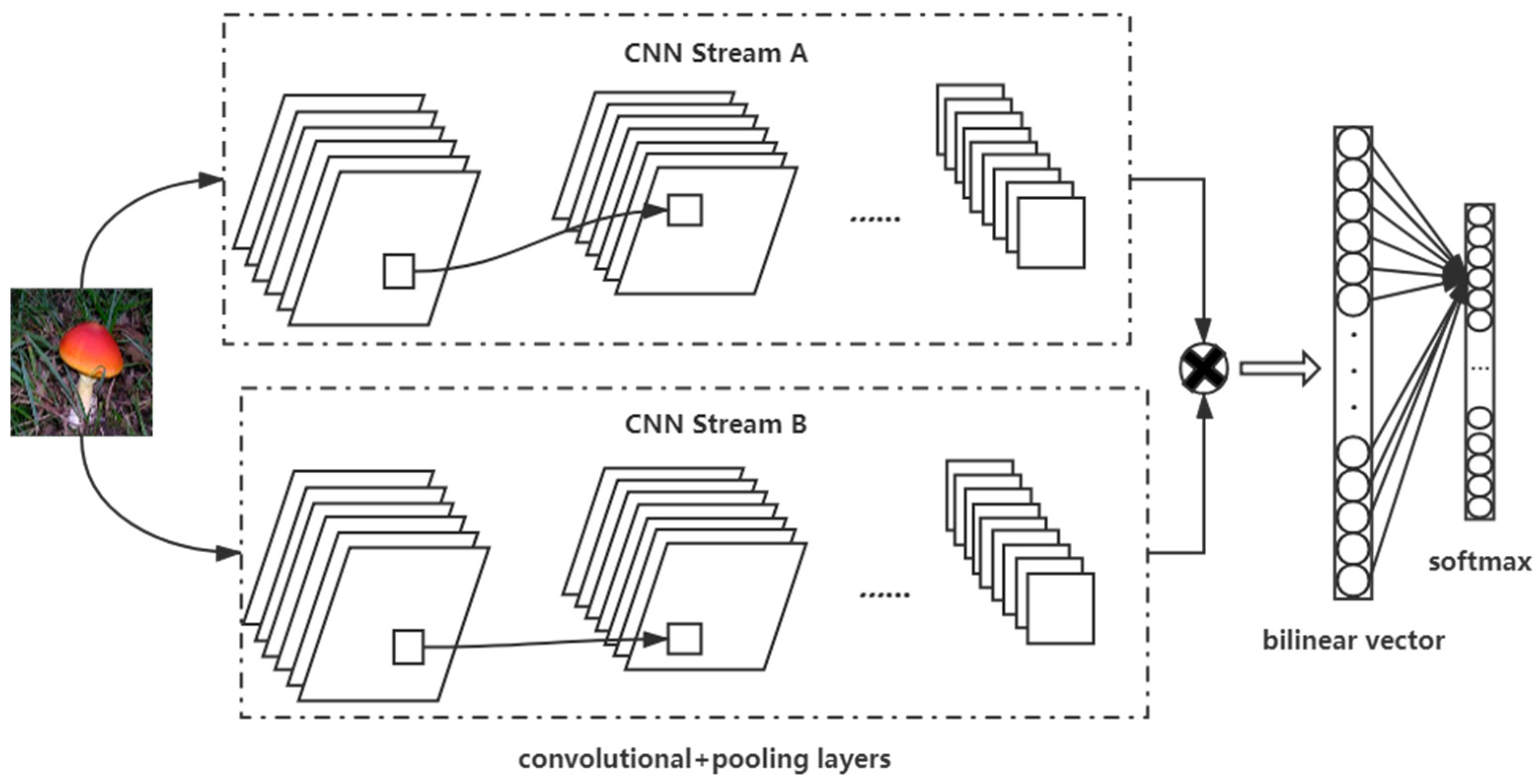
The Bilinear convolutional neural networks model was built and fine-tuned to make the model more suitable for the dataset.
- (3)
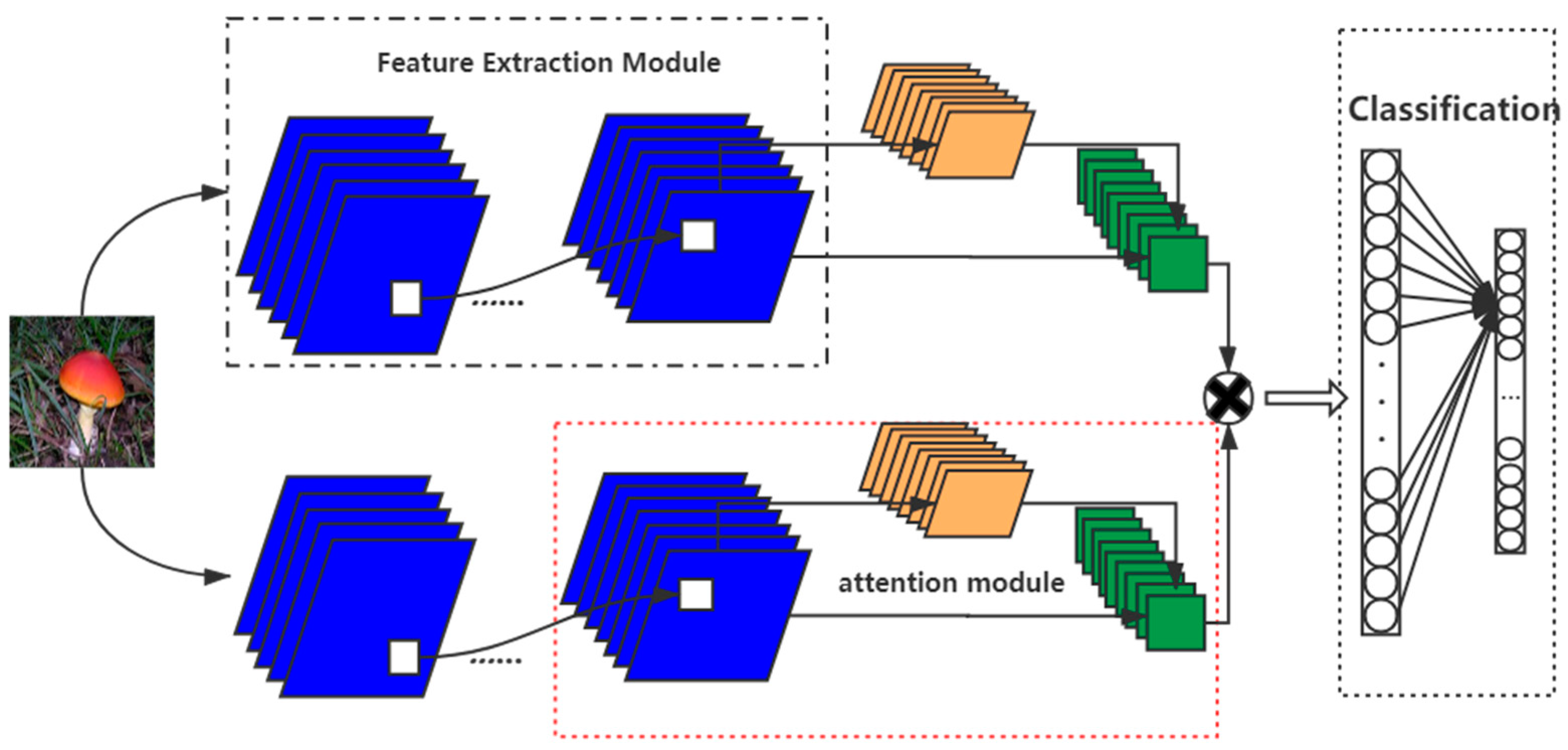
The Bilinear convolutional neural networks model is combined with the attention mechanism to improve the model. This method can quickly obtain the most effective information.
3. Experimental Results and Discussion
3.1. Model Training
In this paper, the experimental environment is on the Google Colaboratory platform, which uses Tesla K80 GPU resources. The programming environment is Python3, and the framework structure is Keras 2.1.6 and Tensorflow 1.6.
The specific model training steps are as follows:
A batch of Amanita pictures (32 pictures) were randomly loaded from the training dataset for subsequent data processing.
Preprocess the image to change the image size to 224 × 224 × 3. Then, put it through the Tensorflow2.0 built-in ImageDataGenerator for data enhancement.
Load the model (such as EfficientNet-B4) and fine-tune the model. Change the fully connected layer to a custom layer and modify the Softmax layer to seven layers according to the number of classifications required. In this paper, different layers are frozen according to the different models, and the method of transfer learning [
45] is used to perform pre-training with Imagenet weights.
Before training the model, it is necessary to set the hyperparameters and optimizers related to the network structure. Pass the training dataset pictures (as shown in
Figure 7) to the neural network for training. Among them, the feature map of the first convolutional layer (as shown in
Figure 8), after one round of model training, obtains the loss and accuracy of the training dataset.
This experiment is to avoid overtraining the network. An early stopping strategy is set, and the loss is verified by monitoring the training process. When the verification loss does not change within five rounds or the model training reaches the preset value, the model will stop training.
3.2. Comparison of Modeling Methods
In order to verify the performance of the model, we compared the proposed model with other CNN models on the dataset. The structure and parameters of these models are shown in
Table 3.
In this paper, the steps of the comparison experiment are: (1) Use the VGGnet model with 16 layers (VGG-16) [
46], the Residual Network with 50 layers (ResNet-50) [
47], compare these two network models with EfficientNet-B4. (2) Combine the bilinear model to build a bilinear EfficientNet-B4, compare the bilinear VGG-16 model (B-CNN(VGG-16, VGG-16)) and the B-CNN(VGG-16, ResNet-50) model. (3) Add an attention mechanism to the model, conduct a comparative experiment, and discuss the effect of adding an attention mechanism.
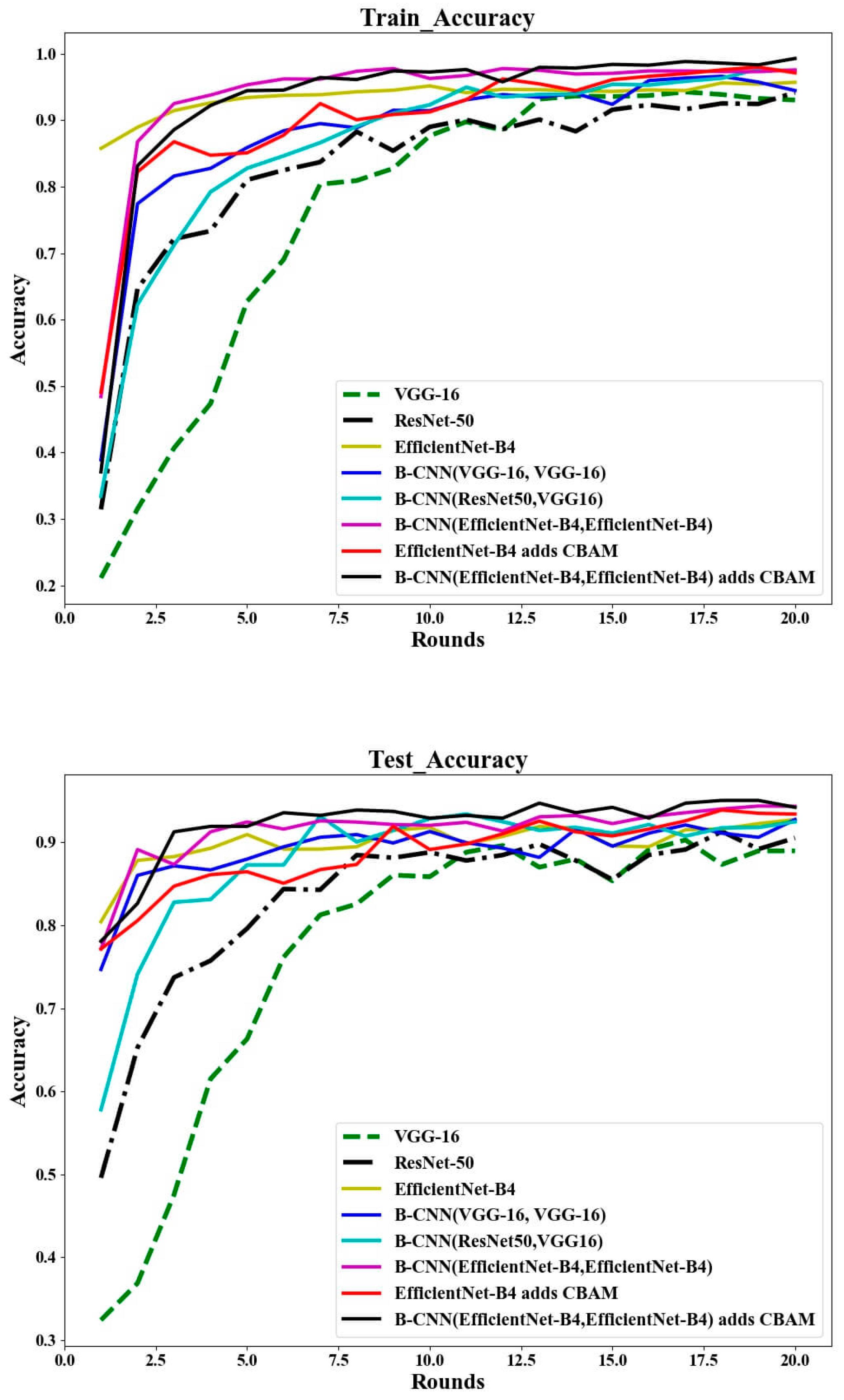
Figure 9 shows the changes in loss and accuracy during training and testing.
Table 4 compares the results of different methods. The comprehensive chart can be used to draw the following conclusions:
- (1)
The EfficientNet-B4 is superior to VGG-16 and Resnet-50 in terms of accuracy, model parameters and model size.
- (2)
On this basis, the bilinear structure was studied and used, and it was found that B-CNN(VGG-16, ResNet-50) has good accuracy. However, it has the largest number of parameters in the model used, and the size of the model is also very large. However, Bilinear EfficientNet-B4 has a good performance in accuracy, model size and number of parameters.
- (3)
For EfficientNet-B4 (accuracy rate is 92.76%), after adding the attention mechanism, its accuracy rate is 93.53%, which improves the accuracy rate by 0.77%; after combining the bilinear structure and attention mechanism, its accuracy rate is 95.2%, an increase of 1.77%. In general, adding an attention mechanism to the model will increase the accuracy by about 1% and can reduce the time by 0.5 s.
In addition, by comparing the first five rounds of training and testing in
Figure 9, it can be found that the accuracy of the test is slightly higher than that of the training. The main reason is that the network is initialized with pre-trained weights. Therefore, the model has better feature extraction capabilities in the first few rounds of testing.
3.3. Model Test Results
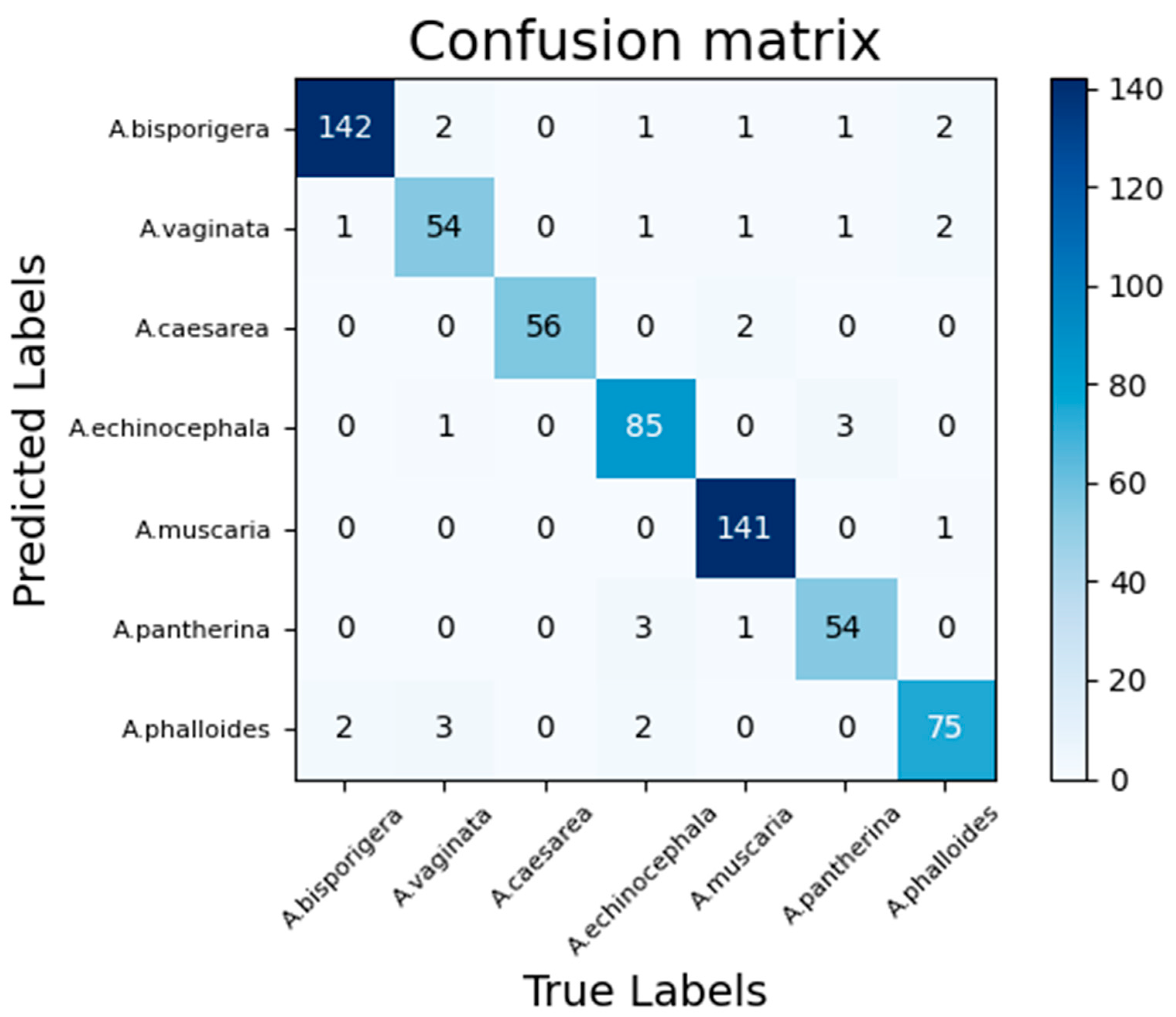
Not all objects are equally difficult to classify, so it is necessary to observe the accuracy of each category and the confusion between categories. In the test dataset, there are 638 pictures, and the Bilinear EfficientNet-B4 with the attention model is used to obtain the confusion matrix as shown in
Figure 10.
It can be seen from
Figure 10 that it is difficult to classify among the three types of
Amanita vaginata,
Amanita bisporigera and
Amanita phalloides, resulting in the lowest accuracy and recall rate of
Amanita vaginata. Observing the dataset found that there are three main reasons:
- (1)
Amanita vaginata and pure white Amanita bisporigera are similar in shape and feature, except for the difference in color on the surface of the fungus cap. The shapes of Amanita vaginata, Amanita bisporigera and Amanita phalloides are very similar in their juvenile period.
- (2)
Some pictures of Amanita vaginata are overexposed and the pictures are white. At this time, the characteristics are very similar to Amanita bisporigera, so part of Amanita vaginata is classified as Amanita bisporigera.
- (3)
The base of this category in the test dataset is not large.
In addition, the accuracy and recall rate of Amanita muscaria reached 1.0 and 0.959, indicating that this model is most suitable for identifying this type of Amanita.
In order to test the robustness of the classifier, we used other types of mushroom pictures and non-mushroom pictures for classification. Since the unknown class is not added to the data set at the beginning of training, when the classifier classifies an unknown category, it will be forced to be classified as a class in the data set. Therefore, the robustness of the model can be identified according to the probability of the unknown class classification.
The test results of non-mushrooms are shown in
Table 5. Combining the classification results with the data set pictures, it can be found that when, the shape is different from the
Amanita, it will be divided according to the color of the object. For example, when a white cat image is used for the classification test, the test result is
Amanita bisporigera. This is because the color of
Amanita bisporigera is white. However, its predicted value is 53%. Using seven kinds of pictures for classification, it can be found that the predicted value is relatively low (<55%).
Common edible fungi were used for classification prediction and the test results are shown in
Table 6. We can see that when using other mushroom images for classification, their predicted values are generally higher than those in
Table 5. This is because they have a higher degree of similarity in appearance. However, in general, when we use the pictures of the
Amanita species in the data set for classification prediction, the prediction probability is often more than 97%. Therefore, when the prediction probability is less than a certain value, we can treat the prediction result as an unknown class.
4. Conclusions
In this paper, eight different convolutional neural networks are used to classify seven different Amanita species. In order to select Amanita suitable for growing in the wild environment, the speed and accuracy of eight classification models were compared. These results show that the classifier based on deep learning is quite suitable for Amanita classification.
In this paper, we used simple models (VGG, ResNet, EfficientNet) for classification and found that the accuracy of these models is not particularly good. Therefore, the Bilinear Networks model is proposed. After building the B-CNN, we found that, although the accuracy of the model has improved, the size of the model is larger and the training time is longer. Therefore, we chose to add an attention mechanism to the model to improve the speed and accuracy of model training.
After comprehensive comparison of models, we found that the best model is B-CNN (EfficientNet-B4, EfficientNet-B4) which adds CBAM. After training, the accuracy of the training set is 99.3%, and the accuracy of the test set is 95.2%, which can solve the problem of difficult image classification of Amanita in the complex environment of the wild to a certain extent. It can provide a certain basis for future classification and identification of mushrooms with high similarity, and its model size is 130 MB. The presented model processed pictures in 4.56 s, which facilitates its application in mobile devices.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















