
Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR





Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Model structure
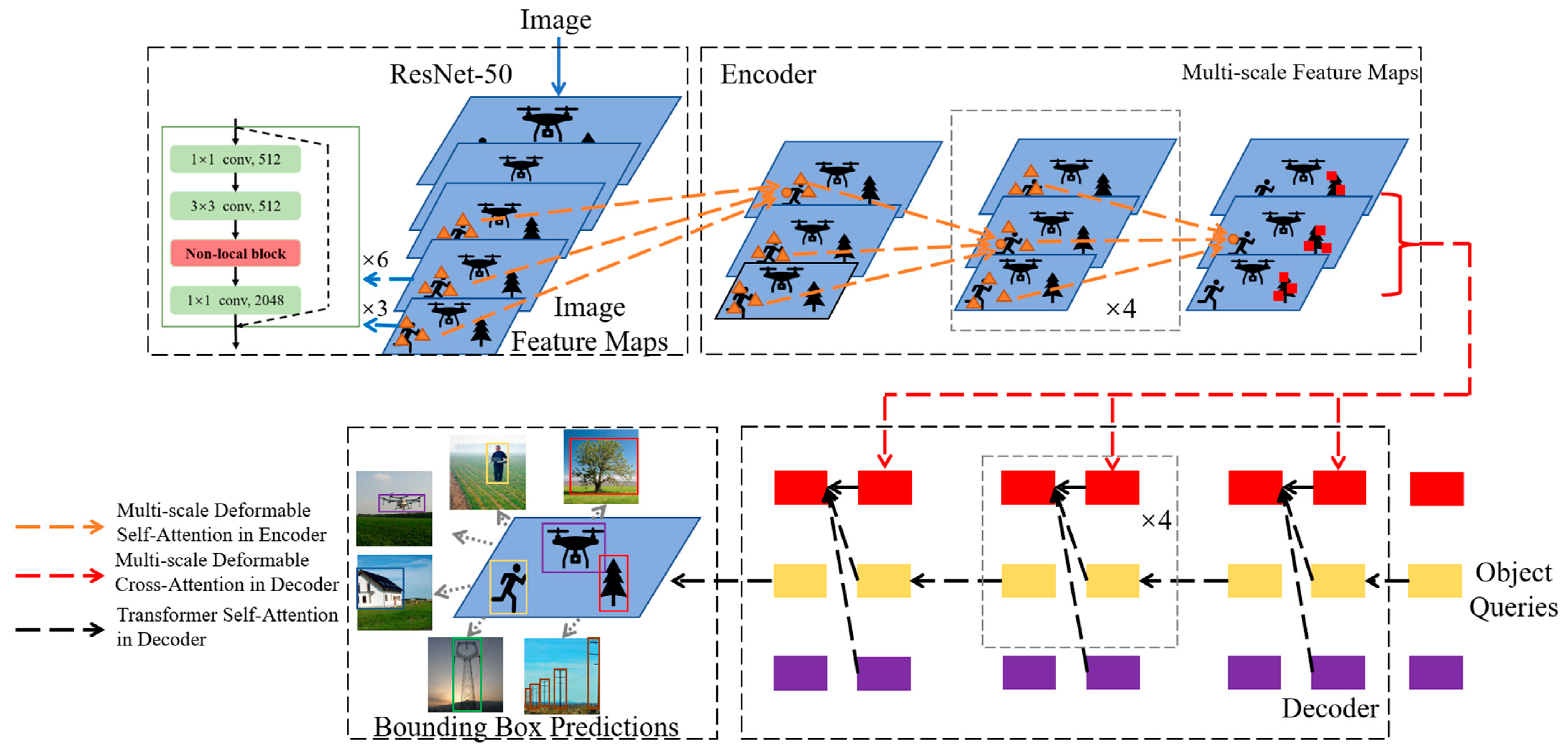
2.2.1. Deformable DETR
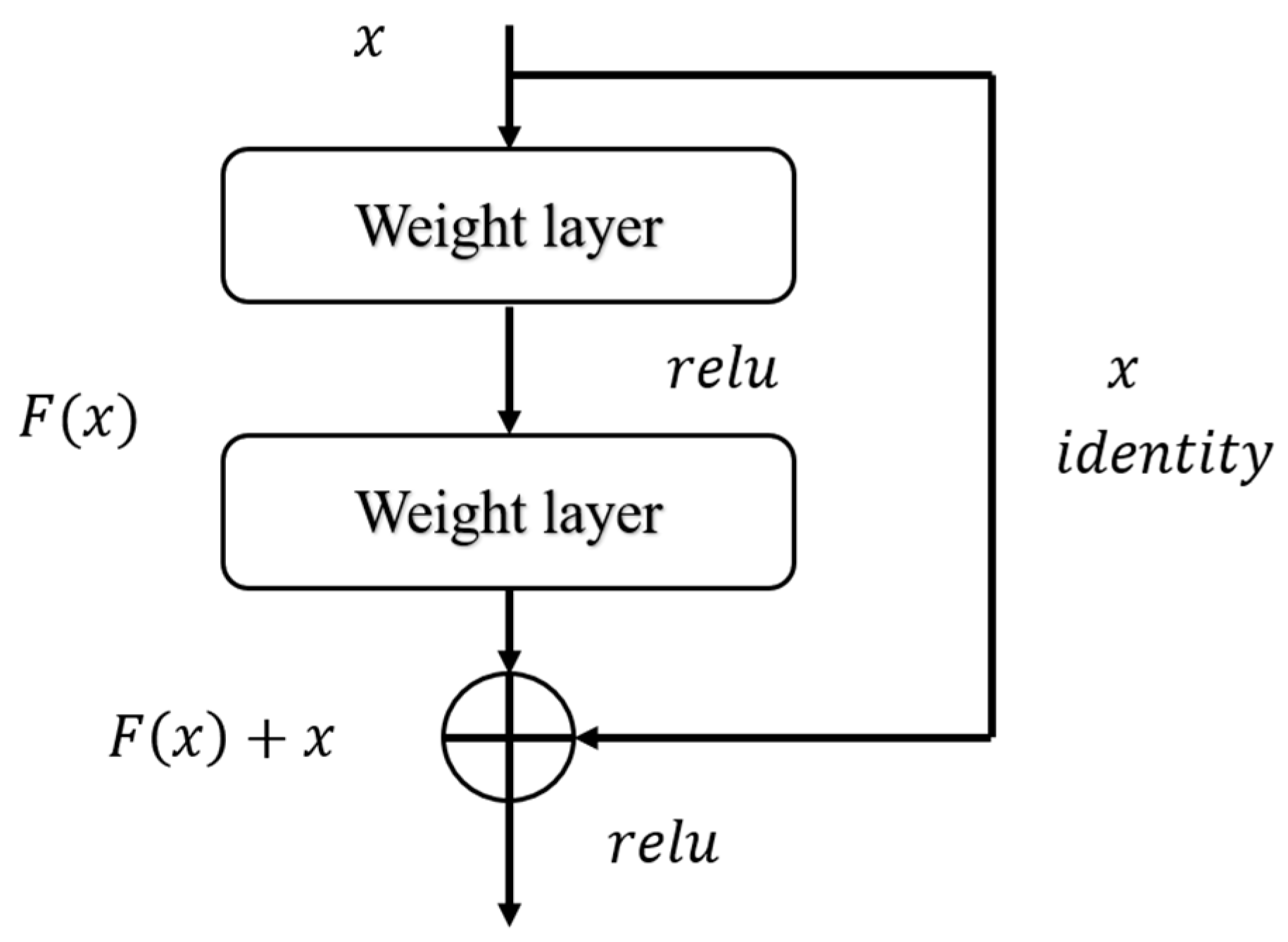
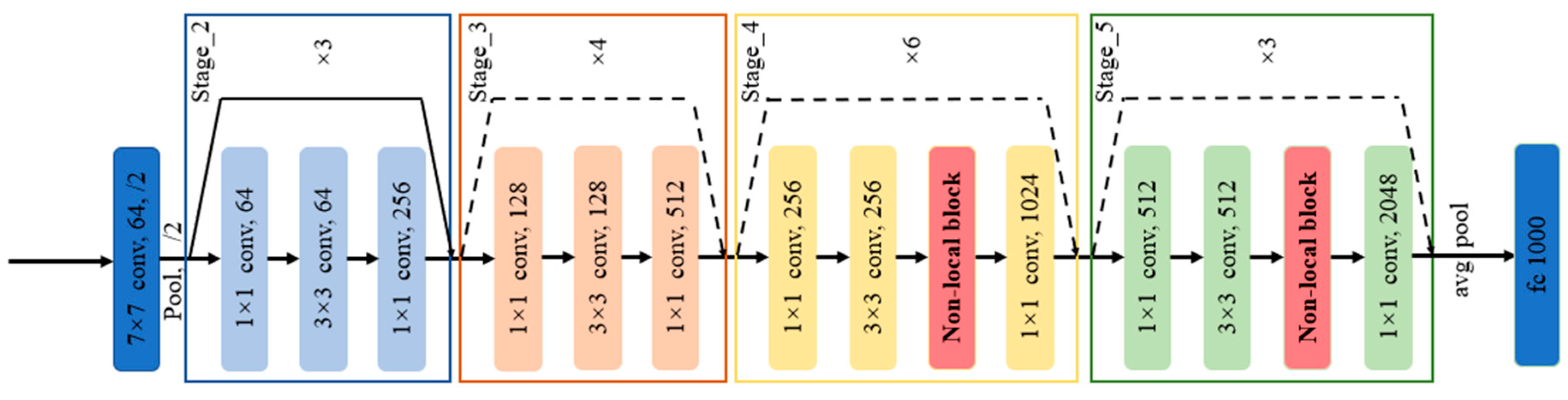
2.2.2. ResNet
2.2.3. Non-Local Neural Networks
2.2.4. Non-Local Deformable DETR
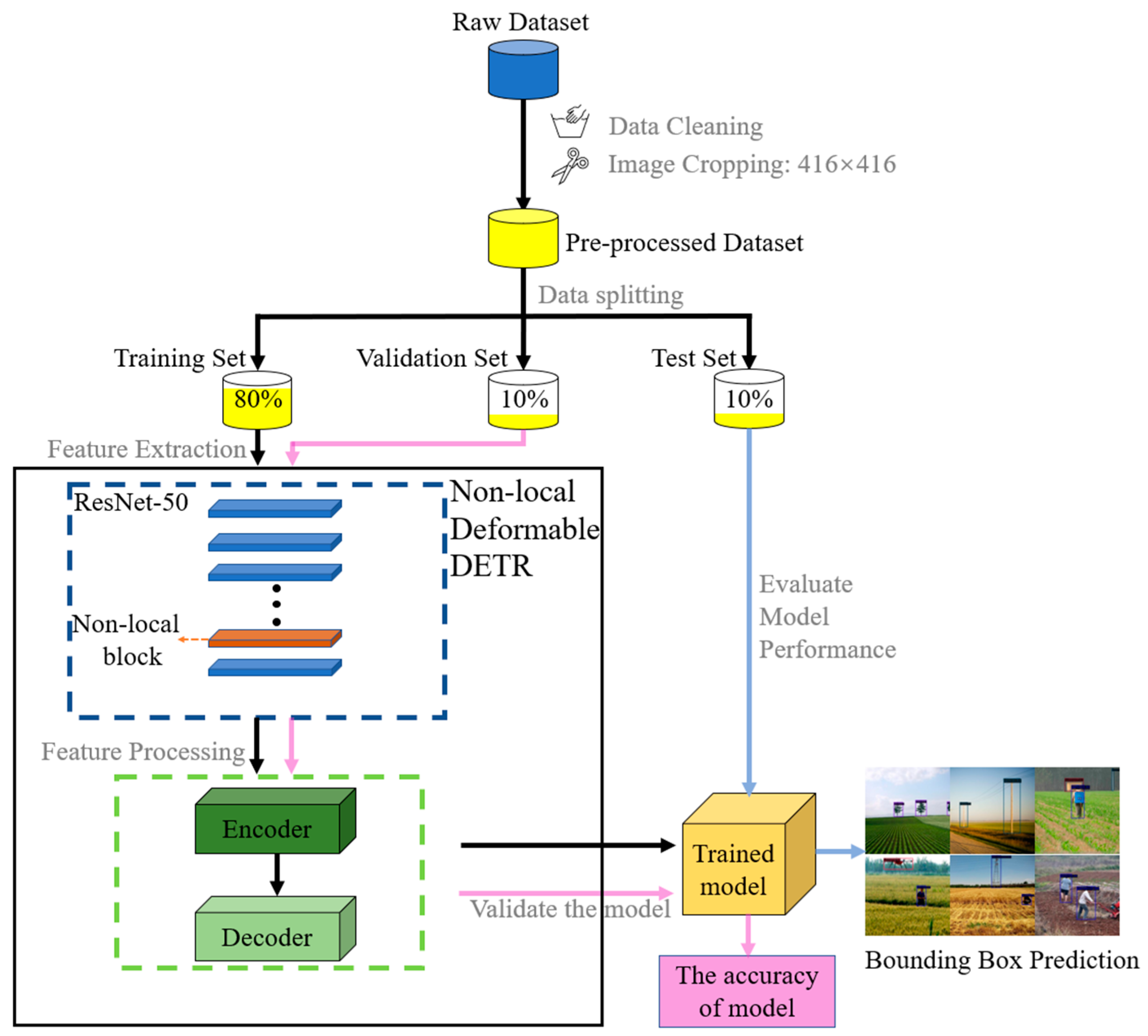
2.3. The Overview of Data Flow
2.4. Evaluation Metrics
3. Results and Discussion
3.1. Implementaion Details
3.2. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maes, W.H.; Steppe, K. Perspectives for remote sensing with unmanned aerial vehicles in precision agriculture. Trends Plant Sci. 2019, 24, 152–164. [Google Scholar] [CrossRef]
- Radoglou-Grammatikis, P.; Sarigiannidis, P.; Lagkas, T.; Moscholios, L. A compilation of UAV applications for precision agriculture. Comput. Netw. 2020, 172, 107148. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Guo, S.; Li, J.; Yao, W.; Hu, X.; Wei, X.; Long, B.; Wu, H.; Li, H. Optimization of the factors affecting droplet deposition in rice fields by rotary unmanned aerial vehicles (UAVs). Precis. Agric. 2021, 22, 1918–1935. [Google Scholar] [CrossRef]
- Xue, X.; Lan, Y.; Sun, Z.; Chang, C.; Hoffmann, W.C. Develop an unmanned aerial vehicle based automatic aerial spraying system. Comput. Electron. Agric. 2016, 128, 58–66. [Google Scholar] [CrossRef]
- Wang, D.; Li, W.; Liu, X.; Li, N.; Zhang, C. UAV environmental perception and autonomous obstacle avoidance: A deep learning and depth camera combined solution. Comput. Electron. Agric. 2020, 175, 105523. [Google Scholar] [CrossRef]
- Park, J.; Cho, N. Collision avoidance of hexacopter UAV based on LiDAR data in dynamic environment. Remote Sens. 2020, 12, 975. [Google Scholar] [CrossRef] [Green Version]
- Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sens. 2022, 14, 3824. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Liu, J.; Xie, S.; Luo, J. Real-Time Monocular Obstacle Detection Based on Horizon Line and Saliency Estimation for Unmanned Surface Vehicles. Mob. Netw. Appl. 2021, 26, 1372–1385. [Google Scholar] [CrossRef]
- Barry, A.J.; Florence, P.R.; Tedrake, R. High-speed autonomous obstacle avoidance with pushbroom stereo. J. Field Robot. 2018, 35, 52–68. [Google Scholar] [CrossRef]
- Falanga, D.; Kleber, K.; Scaramuzza, D. Dynamic obstacle avoidance for quadrotors with event cameras. Sci. Robot. 2020, 5, eaaz9712. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhao, N.; Zhou, L.; Wang, M.; Yang, L.; Fang, H.; He, Y.; Liu, Y. Vision-based moving obstacle detection and tracking in paddy field using improved yolov3 and deep SORT. Sensors 2020, 20, 4082. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J. Obstacle Detection and Safely Navigate the Autonomous Vehicle from Unexpected Obstacles on the Driving Lane. Sensors 2020, 20, 4719. [Google Scholar] [CrossRef]
- Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A review of deep learning in multiscale agricultural sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October –2 November 2019; pp. 593–602. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the 36th International Conference on Machine Learning PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Katsuki, F.; Constantinidis, C. Bottom-up and top-down attention: Different processes and overlapping neural systems. Neuroscientist 2014, 20, 509–521. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Alex, G.; Kavukcuoglu, K. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 2204–2212. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, J.; Wang, J.; Tian, Q.; Gao, W.; Zhang, S. Global-local temporal representations for video person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3958–3967. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, L. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Xiamen, China, 8–11 November 2021; pp. 10347–10357. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yang, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional positional encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7262–7272. [Google Scholar]
- Lin, L.; Fan, H.; Xu, Y.; Ling, H. Swintrack: A simple and strong baseline for transformer tracking. arXiv 2021, arXiv:2112.00995. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Zhang, Y.; Li, X.; Liu, C.; Shuai, B.; Zhu, Y.; Brattoli, B.; Chen, H.; Marsic, I.; Tighe, J. Vidtr: Video transformer without convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13577–13587. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, Y.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 367–376. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12175–12185. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- wkentaro/labelme-Image Polygonal Annotation with Python. Available online: https://github.com/wkentaro/labelme (accessed on 19 November 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
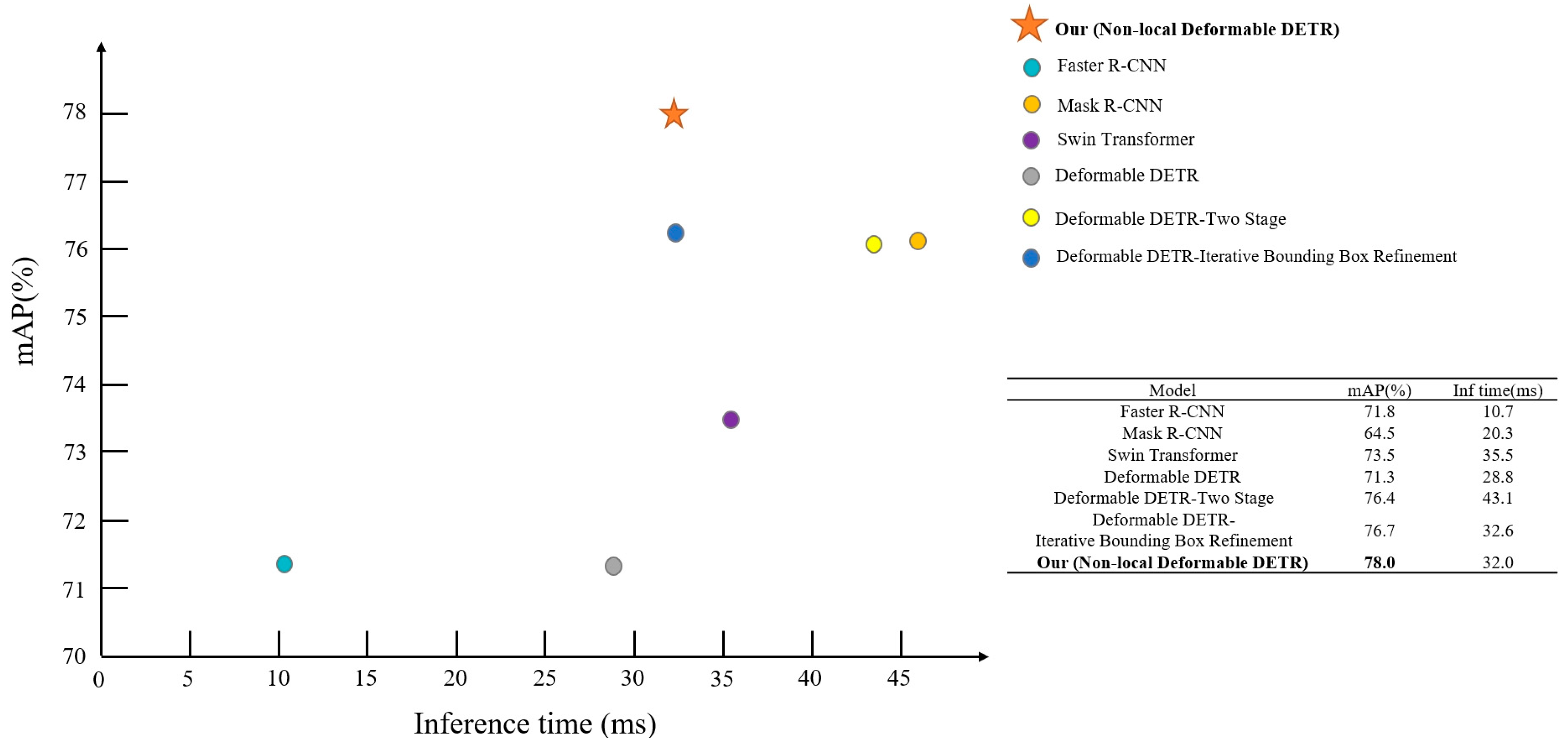
| Model | Bounding Box | Parameters (Million) | Inference Time (ms) | |||||
|---|---|---|---|---|---|---|---|---|
| mAP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) | |||
| Faster R-CNN | 71.8 | 91.6 | 83.8 | 46.6 | 73.4 | 79.8 | 41.15 | 10.7 |
| Mask R-CNN | 64.5 | 85.8 | 77.6 | 27.8 | 67.9 | 76.7 | 43.77 | 20.3 |
| Swin Transformer | 73.5 | 92.1 | 85.1 | 45.5 | 74.8 | 82.2 | 68.71 | 35.5 |
| Deformable DETR | 71.3 | 92.5 | 81.0 | 35.0 | 73.3 | 80.6 | 39.82 | 28.8 |
| Deformable DETR-Iterative Bounding Box Refinement | 76.7 | 93.3 | 84.2 | 43.8 | 77.7 | 86.4 | 40.50 | 32.6 |
| Deformable DETR-Two Stage | 76.4 | 93.4 | 83.7 | 53.5 | 77.7 | 84.6 | 40.81 | 43.1 |
| Non-local Deformable DETR | 78.0 | 94.5 | 85.5 | 48.2 | 79.0 | 85.2 | 42.86 | 32.0 |
| Model | AP (Bounding Box) | |||||
|---|---|---|---|---|---|---|
| UAVs (%) | Building (%) | Power-Tower (%) | Person (%) | Tree (%) | Wire Pole (%) | |
| Faster R-CNN | 85.5 | 66.3 | 78.2 | 69.9 | 76.5 | 54.4 |
| Mask R-CNN | 81.0 | 63.1 | 64.6 | 65.5 | 72.6 | 40.1 |
| Swin Transformer | 85.5 | 69.5 | 77.8 | 74.8 | 76.9 | 56.4 |
| Deformable DETR | 86.0 | 68.7 | 79.1 | 70.9 | 72.6 | 50.7 |
| Deformable DETR-Iterative Bounding Box Refinement | 90.6 | 75.9 | 82.2 | 76.7 | 79.5 | 55.6 |
| Deformable DETR-Two Stage | 89.7 | 73.0 | 80.9 | 77.5 | 76.9 | 60.5 |
| Non-local Deformable DETR | 90.2 | 75.8 | 83.1 | 78.2 | 78.5 | 62.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Li, Z.; Du, X.; Ma, Z.; Liu, X. Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR. Agriculture 2022, 12, 1983. https://doi.org/10.3390/agriculture12121983
Wang D, Li Z, Du X, Ma Z, Liu X. Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR. Agriculture. 2022; 12(12):1983. https://doi.org/10.3390/agriculture12121983
Chicago/Turabian StyleWang, Dashuai, Zhuolin Li, Xiaoqiang Du, Zenghong Ma, and Xiaoguang Liu. 2022. "Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR" Agriculture 12, no. 12: 1983. https://doi.org/10.3390/agriculture12121983
APA StyleWang, D., Li, Z., Du, X., Ma, Z., & Liu, X. (2022). Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR. Agriculture, 12(12), 1983. https://doi.org/10.3390/agriculture12121983