1. Introduction
Rice is one of the essential food crops in China, with a wide planting area. Diseases and insect pests are critical factors affecting rice yield and quality in rice production; thus, it is essential to obtain the treatment methods of rice-related problems quickly and accurately in the planting process. With the rapid development of the internet era, questions asking, answering, and discussion in the online question-and-answer (Q&A) community [
1], it has become an essential way to seek answers and meet their own information needs. The “China agricultural technology promotion information platform” is a comprehensive service platform specialized in providing an agricultural technology Q&A community, expert guidance, online learning, achievement delivery, and knowledge exchange, among others, which plays a vital role in helping farmers find solutions to problems. The Rice-related Q&A community has accumulated a large number of users and content, and it has produced a large number of low-quality texts, which has dramatically affected users’ efficiency in retrieving satisfactory answers. Therefore, improving the performance of answer quality prediction has become particularly important. The challenge of redundancy, sparsity [
2], and the poor standardization of agricultural texts leads to inaccurate text feature extraction and the difficulty in determining the relationship between features. The critical technical link to realize an intelligent agricultural Q&A community is to detect the correct answer from the candidate answer text dataset and return it to the user quickly, automatically, and accurately. Traditional answer selection [
3] relies on manual screening and it is challenging to process text data efficiently. Due to human feature selection, it does not automatically and accurately judge the correct answer from a large amount of agricultural text data. Therefore, deep learning [
4] and natural language processing technology [
5] to realize the intelligent selection of rice-related question answers is a significant problem to be solved by the “China agricultural technology promotion information platform”.
In recent years, deep neural networks have made remarkable achievements in many natural language processing tasks, including answer selection. The core problem is to obtain distinctive semantic features from question-and-answer sentences with deep neural networks. Lei et al. [
6] proposed an answer selection model based on a CNN (Convolutional Neural Networks) [
7], to extract semantic information from question-and-answer sentences, map them into low-dimensional distributed representation vectors, and learn a semantic matching function, semantic matching of question-and-answer pairs. Severyn et al. [
8] also proposed an answer selection model based on a CNN, which simultaneously learns the intermediate representation and final representation of question-and-answer pairs to generate a more refined semantic representation of question-and-answer pairs for semantic similarity matching. Kalchbrenner et al. [
9] proposed a DCNN (Dynamic Convolutional Neural Network) for answer selection. To accurately present the semantic information in question-and-answer sentences, the DCNN adopts a multi-layer wide convolution and dynamic K-MAX pooling operation, which retains the word order information in the sentence and the relative position between words and can dynamically deal with question-and-answer pairs of different lengths. Compared with the traditional statistical learning model, the performance based on a CNN has been significantly improved. However, a single CNN cannot effectively extract the contextual semantic correlation information in question-and-answer pairs, which is vital for selecting the most suitable answer from the answer sequence. Some models use RNNs (Recurrent Neural Networks) for answer selection tasks. Wang et al. [
10] obtained semantic representations of different granularities in the text through an RNN. Then, they extracted their semantic matching information from the semantic interaction information of different granularities in the question-and-answer text to calculate the semantic matching degree of the question-and-answer pairs. Wang et al. [
11] applied the stacked bi-directional LSTM (Long Short-Term Memory) [
12] network to capture the forward and backward context information from the question-and-answer sentence. Cai et al. [
13] used the bi-directional LSTM network to extract question-and-answer features at various scales. It used three different similarity matrix learning models to obtain the overall similarity of question-and-answer pairs from the local feature similarity.
With the good performance of the attention mechanism [
14] in the sentence representation task, researchers applied it to the answer selection task. Tan et al. [
15] proposed QA-LSTM-CNN with attention, where the sentence vector representation obtained through the LSTM-CNN network is taken into the attention network. The attention distribution of different units in the sentence vector, and sentence correlation information were obtained. Secondly, there are also different methods and strategies in applying attention mechanisms. Santos et al. [
16] proposed the attention pooling networks and the concept of attention pooling. In the case of pairwise sorting or classification with the neural network, the attention pooling can perceive the current input pair, so the information from two input items can directly affect the calculation represented by each other. The target task is regarded as a three-tuple similarity solution in the answer selection task. After the pre-training model [
17] was proposed, researchers fine-tuned it to solve the downstream target tasks, and its efficiency has been verified to a great extent. Thirdly, the researchers also optimized the pre-training model under a large corpus, only used as the underlying language representation structure to obtain sentence representation, and combined it with other network structures to model the target task [
18].
However, mainstream neural networks have recently focused more on the representation of sentence interaction, which have their shortcomings in the expression of model performance. This paper proposed an effective method to solve the problem of incomplete sentence representation and sentence interaction. To solve the problem of incomplete sentence representation, this paper embedded the word vector into the sentence representation by using a twelve-layer Chinese Bert pre-training model [
19]. The word vector was generated by the pre-training language model containing some contextual semantic information. Secondly, this paper also introduced a dynamic attention mechanism to filter the irrelevant information in the sentence vector to understand the sentence vector better. To solve the problem of insufficient information interaction between sentences, this paper introduced a multi-Strategy matching strategy in the matching layer. The obtained sentence vectors interact with each other through two different matching strategies to better capture the semantic correlation information between question and candidate answer. The main work of this paper is as follows:
A method based on dynamic attention mechanisms and multi-strategy matching was proposed.
The pre-training model was cleverly transferred to the context embedding layer, which provides a new idea of sentence pair representation.
The dynamic attention mechanism can effectively screen the irrelevant information in sentence representation and improve sentence expression.
The model introduced two matching strategies to capture the interaction between the question and candidate answer fully.
5. Conclusions
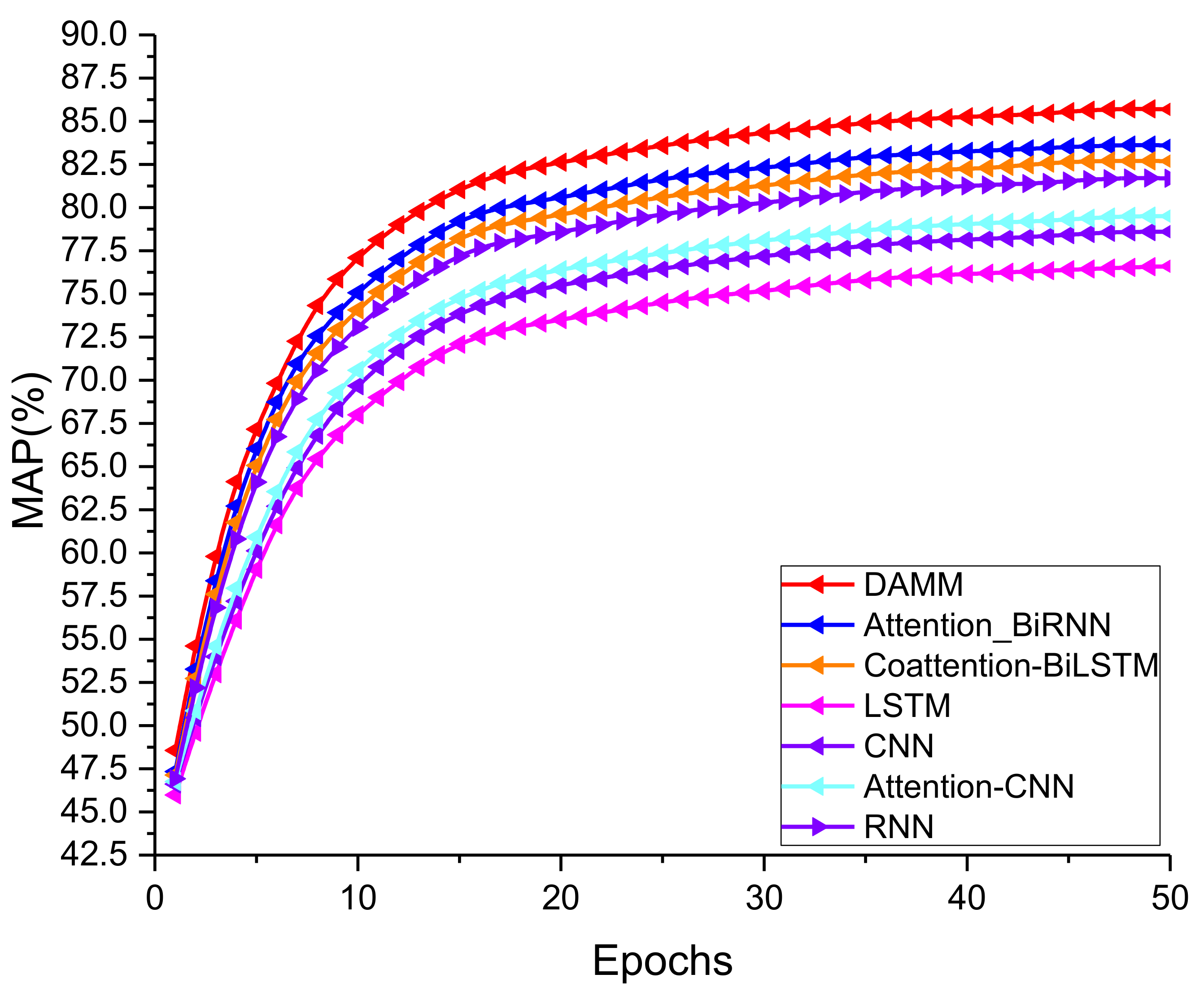
In this paper, a dynamic attention mechanism and multi-Strategy matching model was proposed to complete the rice-related answer selection task. The model combined the advantages of the pre-training model in language representation. At the same time, a dynamic attention mechanism was introduced to remove some irrelevant and redundant information to obtain sentence representation efficiently. Secondly, multi-Strategy matching was introduced to compare different units between sentences, and the semantic association between target sentences was fully obtained. The experimental results showed that the overall performance of the proposed model was better than that of the baseline model. In addition, the model proposed in this paper can be applied not only to answer selection tasks but also to matching and sorting tasks—for example, automatic question answering, machine reading comprehension, and dialogue system. Currently, this paper migrated the trained Bert pre-training model because there is an out-of-vocabulary (OOV) problem in the text field that cannot be ignored. In future work, we will first train the Elmo model on our dataset and embed the new word vector representation obtained from the training into the context embedding layer; we will explore the influence of the corpus knowledge field on word vector representation. In addition, we will further explore the impact of other existing pre-training models on downstream processing tasks, such as general pre-training (GPT) and universal language model fine-tuning (ULMFIT), which are currently well used; and then analyze and study the representation mechanism, applicable scenarios, and migration strategies of the language model. Finally, we will also explore the matching strategy of deep interaction between sentences.






{kind=link}
{kind=link}
{kind=link}
{kind=link}