
LA-DeepLab V3+: A Novel Counting Network for Pigs


Abstract
:1. Introduction
- (1)
- The current DeepLab V3+ semantic segmentation framework has too many network layers and slow speed. Thus, by embedding the attention module based on rows and columns into the backbone network, we can achieve the lightweight and fast network computing efficiency that the traditional semantic segmentation algorithm and other attention modules do not have;
- (2)
- In view of the problem of detail information loss in semantic segmentation algorithms, a recursive cascade mechanism is introduced to supplement the detail information of the unit input feature graph to the output feature graph. This approach better integrates the high-level semantic information into the low-level high-resolution feature graph, improving the segmentation accuracy;
- (3)
- This study integrates deep learning models and attention mechanisms, and it preliminarily achieves the application of complex image inventory of pigs.
2. Materials and Methods
2.1. Self-Built Datasets
2.2. Experimental Design
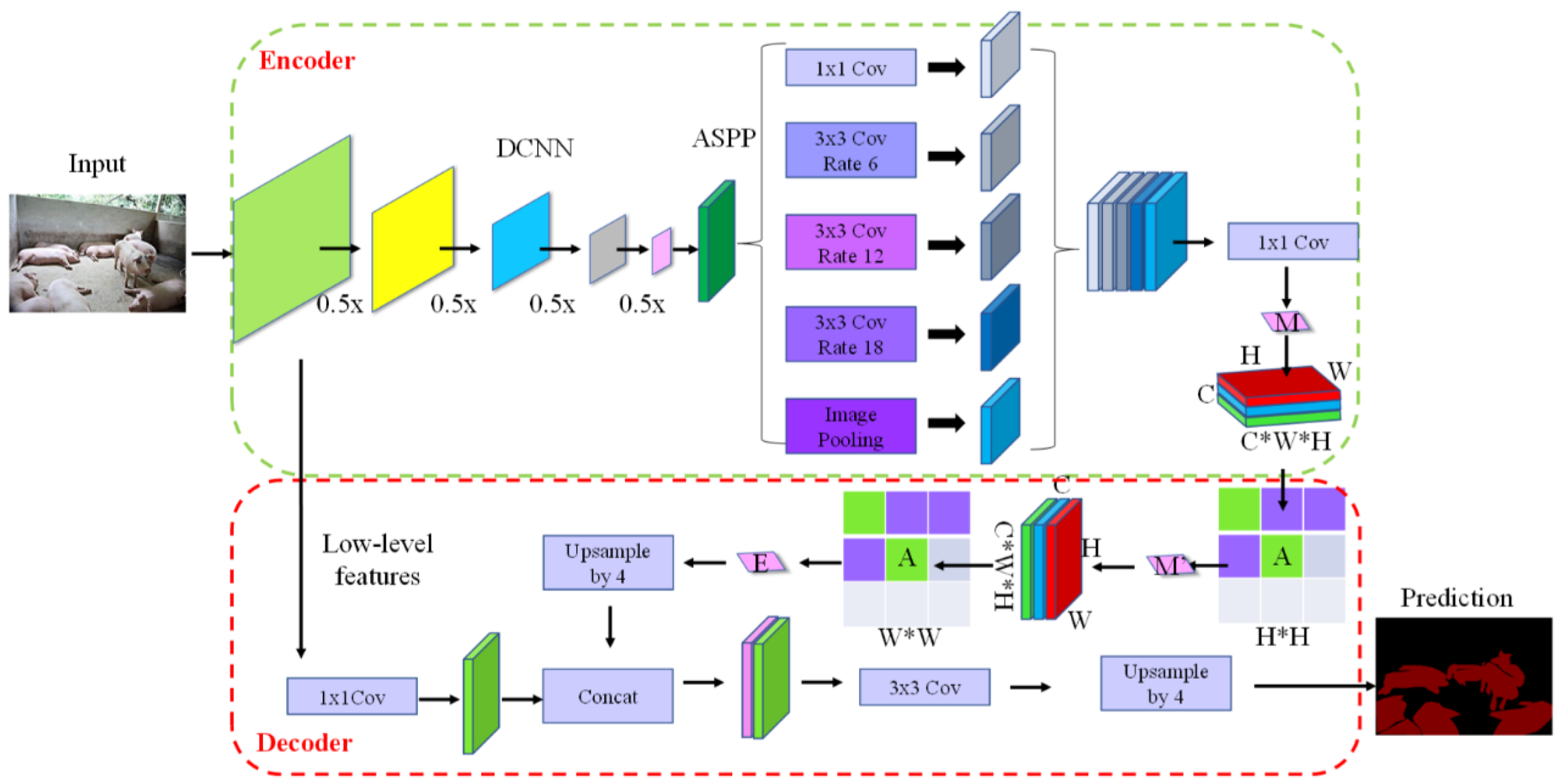
2.3. Improved Light Attention DeepLab V3+ Method
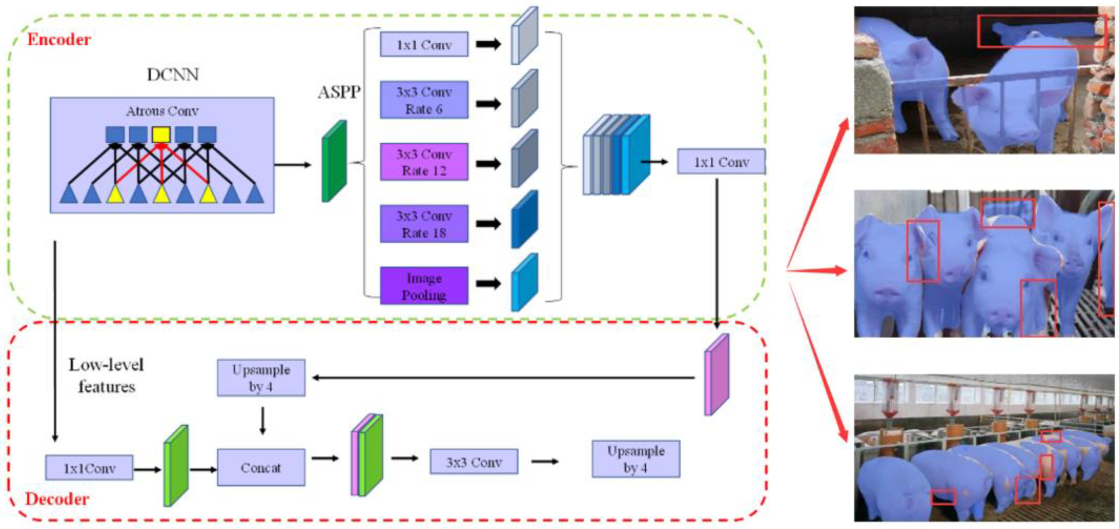
2.3.1. Original DeepLab V3+ Model Analysis
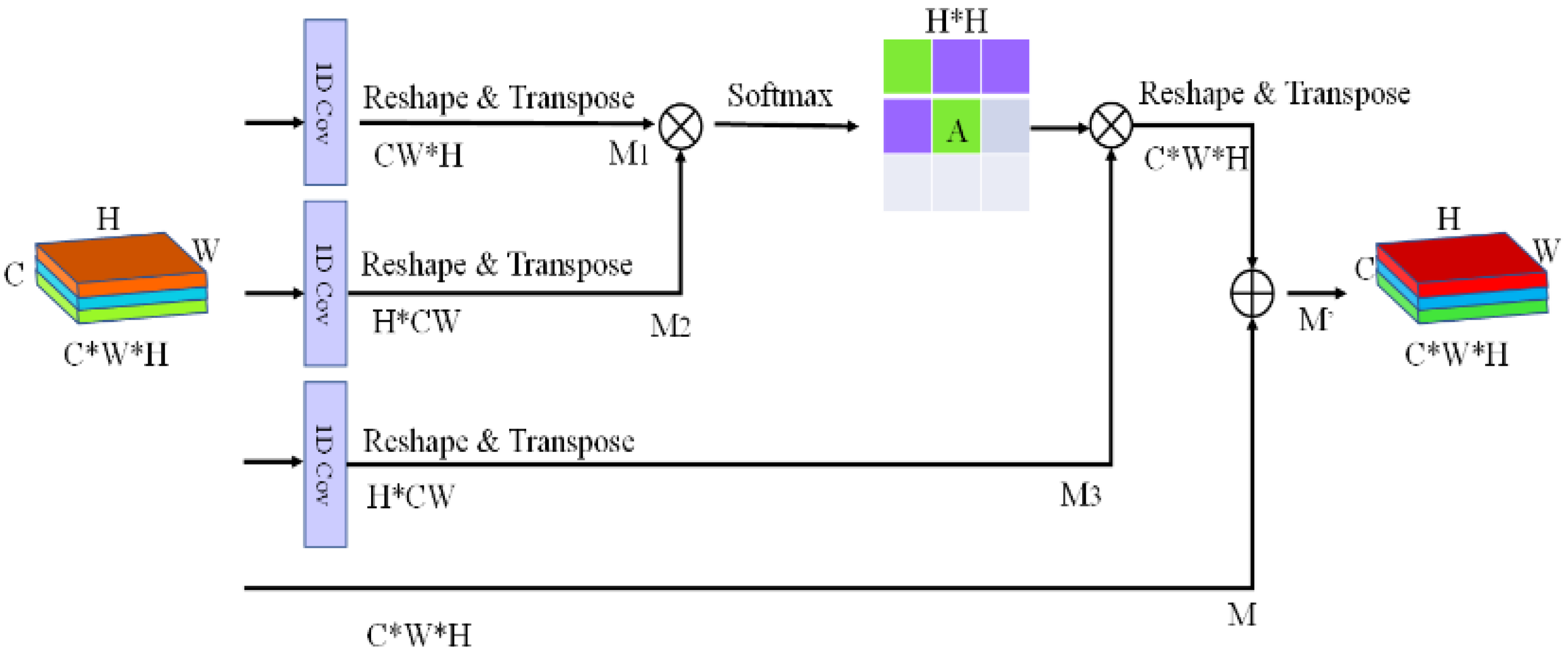
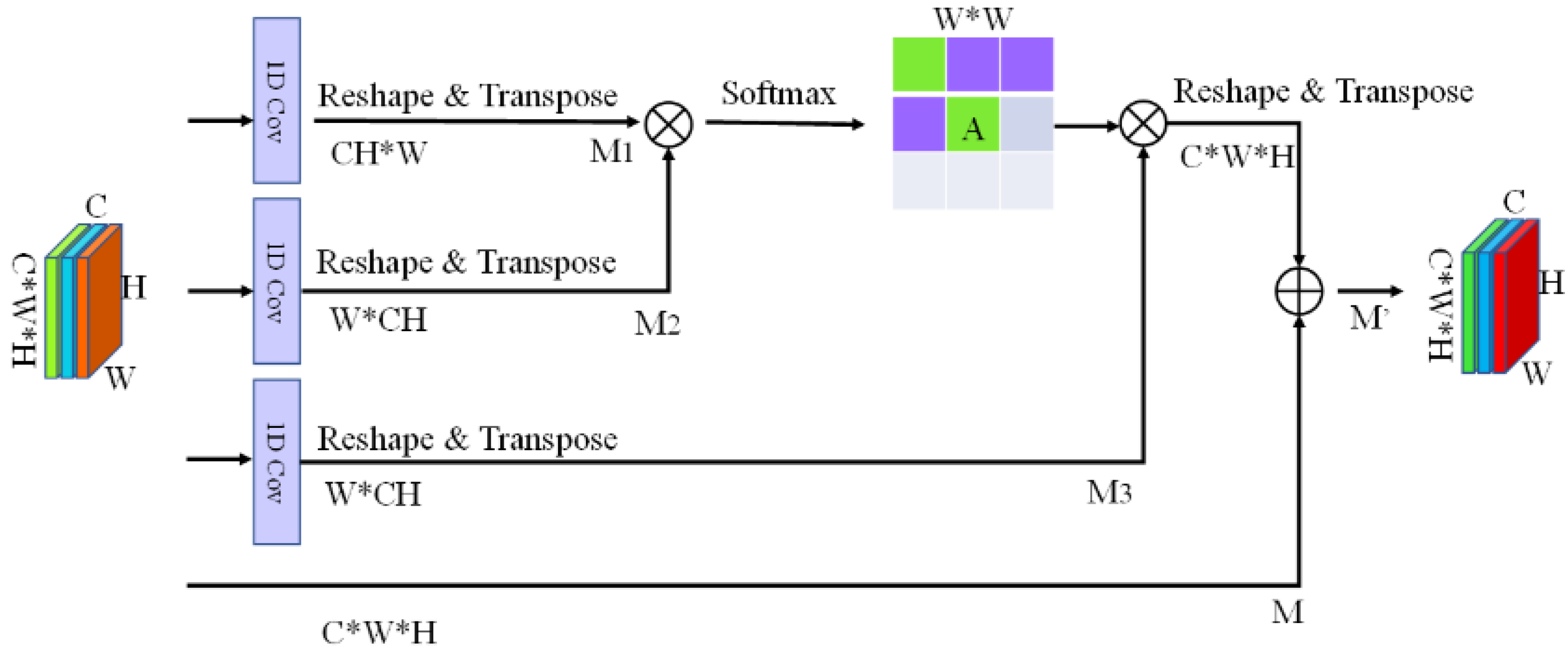
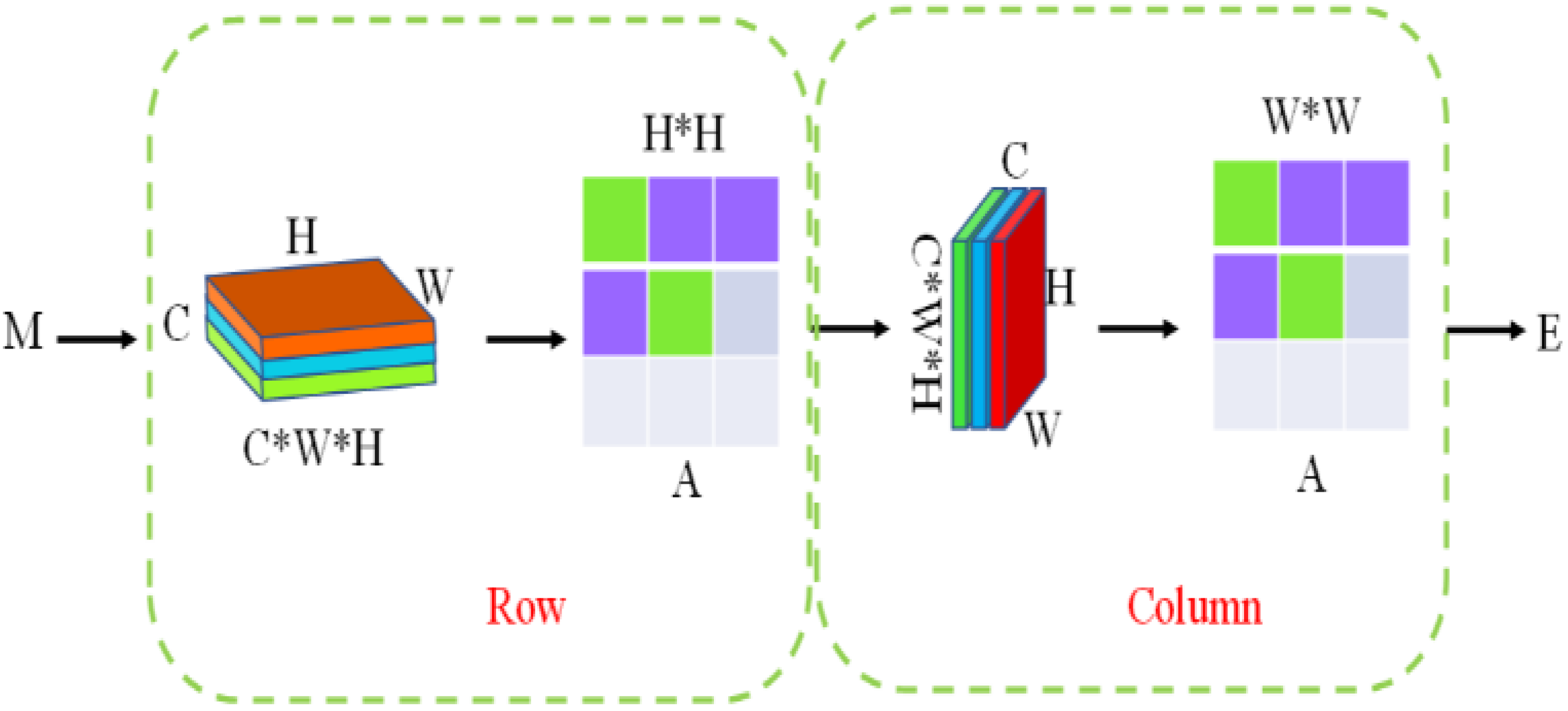
2.3.2. Lightweight Attention Mechanism
2.3.3. Improved Network Model
3. Results
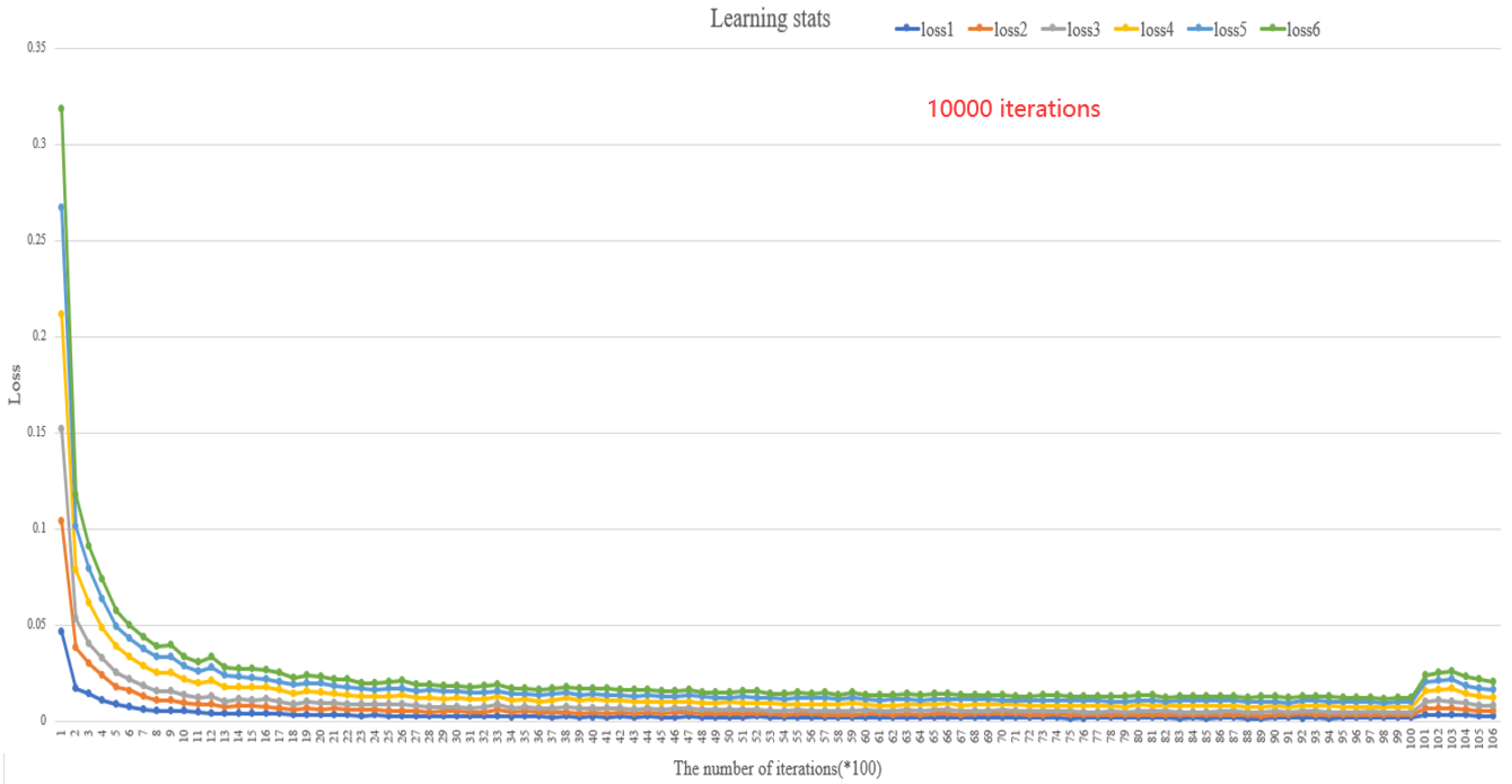
3.1. Model Training Experiment
3.2. Segmentation Experiment
3.2.1. Qualitative Comparative Analysis
3.2.2. Quantitative Comparative Analysis
3.2.3. Generalization Experiment
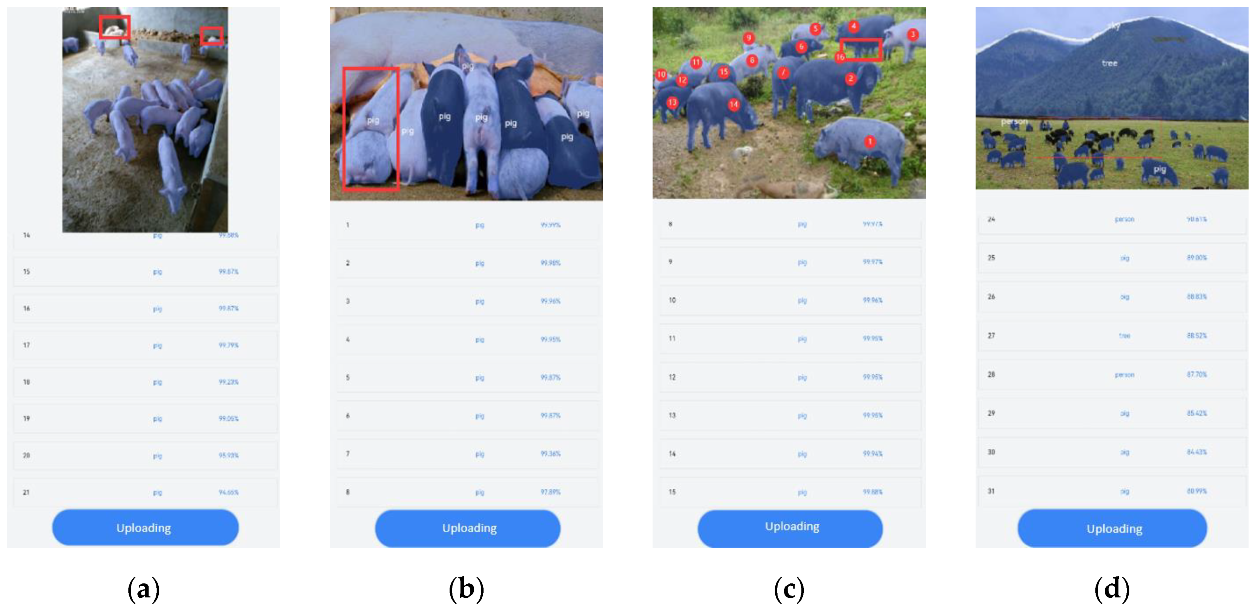
3.3. Model Deployment and Visual Counting Applications
4. Discussion
4.1. Analysis of Each Model
4.2. Analysis of Improved Segmentation Methods
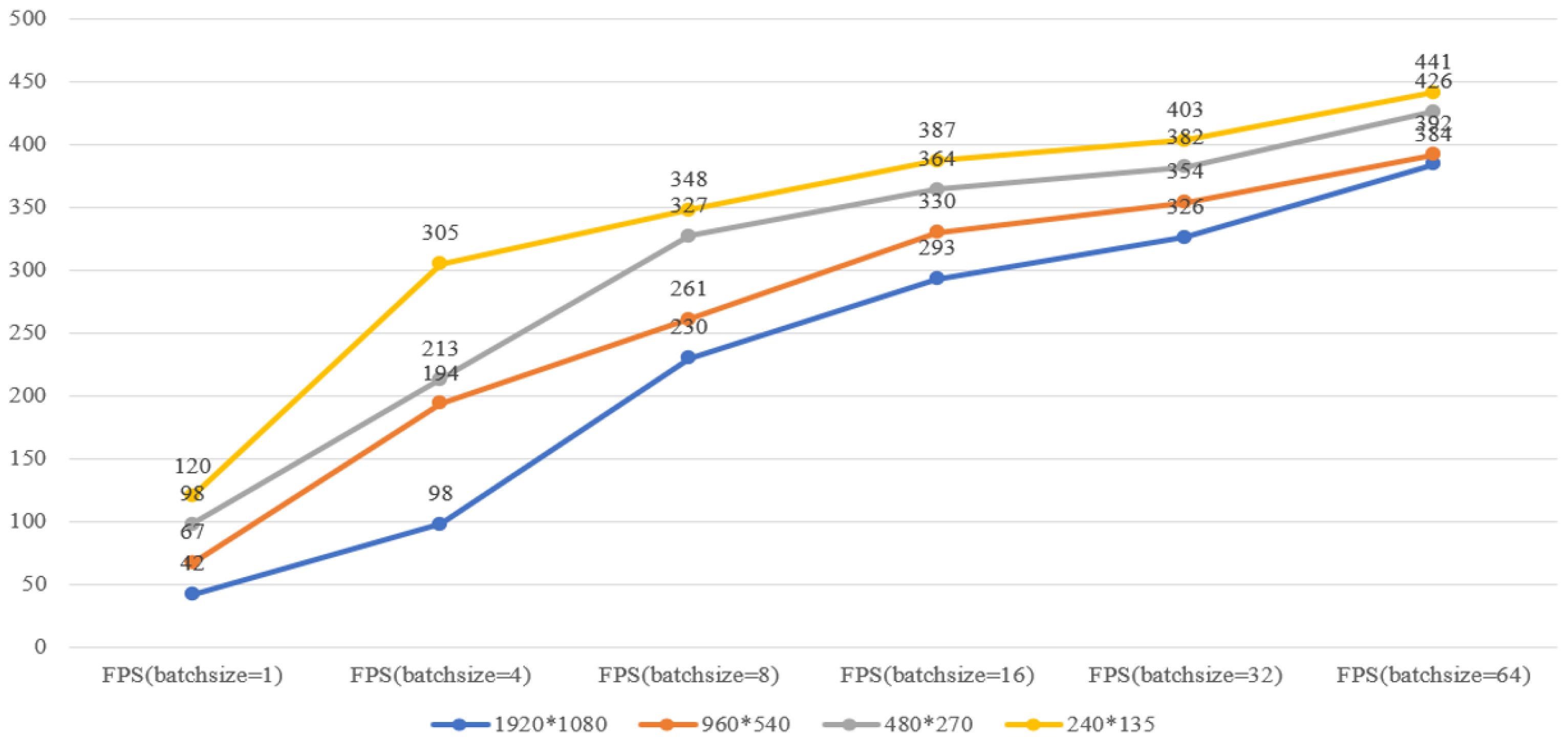
4.3. Pressure Test of the Counting Application System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, A.; Huang, H.; Zheng, C.; Zhu, X.; Yang, X.; Chen, P. High-accuracy image segmentation for lactating sows using a fully convolutional network. Biosyst. Eng. 2018, 176, 36–47. [Google Scholar] [CrossRef]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic individual pig detection and tracking in pig farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Yan, Y.; Chen, S. Multi-scale generative adversation network based pedestrian reidentification method for occlusion. J. Softw. 2020, 31, 1943–1958. [Google Scholar]
- Zhao, Y.; Rao, Y.; Dong, S. A review of deep learning target detection methods. J. Image Graph. 2020, 25, 629–654. [Google Scholar]
- Yan, H.; Lu, H.; Ye, M. Segmentation of pulmonary nodules by sobel operator and mask R-CNN. J. Chin. Comput. Syst. 2020, 41, 161–165. [Google Scholar]
- Tian, Q.; Meng, Y. Image semantic segmentation based on convolutional neural network. J. Chin. Comput. Syst. 2020, 41, 1302–1313. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 764–773. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Li, J.T. A survey on algorithm research of scene parsing based on deep learn. J. Comput. Res. Dev. 2020, 57, 859–875. [Google Scholar]
- Peng, X.; Yin, Z.; Yang, Z. Deeplab_v3_plus-net for Image Semantic Segmentation with Channel Compression. In Proceedings of the IEEE 20th International Conference on Communication Technology, Nanning, China, 28–31 October 2020. [Google Scholar]
- Guo, L.; Zhang, T.S.; Sun, W.Z. Image Semantic Description Algorithm with Integrated Spatial Attention Mechanism. Laser Optoelectron. Prog. 2021, 58, 1210030. [Google Scholar]
- Lou, T.; Yang, H.; Hu, Z. Grape cluster detection and segmentation based on deep convolutional network. J. Shanxi Agric. Univ. Nat. Sci. Ed. 2020, 40, 109–119. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent Models of Visual Attention. Adv. Neural Inf. Processing Syst. 2014, 3, 27. [Google Scholar]
- Wang, F.; Jiang, M.; Chen, Q. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A. Context Encoding for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7151–7160. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Wang, J.; Peng, C. Learning a Discriminative Feature Network for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1857–1866. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S. Attention Is All You Need in Speech Separation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-Attention Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning, Vancouver, BC, Canada, 13 December 2019; pp. 7354–7363. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Everingham, M.; Eslami, S.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | P | R | AP | F1-Score | MIoU |
| FCNNs | 71.60% | 68.46% | 51.43% | 0.69 | 62.21% |
| U-Net | 74.46% | 68.66% | 56.04% | 0.71 | 62.64% |
| SegNet | 78.04% | 62.66% | 65.39% | 0.69 | 68.52% |
| DenseNet | 76.14% | 68.94% | 72.70% | 0.72 | 73.98% |
| DeepLab v3+ | 84.10% | 74.75% | 75.88% | 0.79 | 70.51% |
| LA-DeepLab v3+ (single tag) | 86.04% | 75.06% | 78.67% | 0.80 | 76.31% |
| LA-DeepLab v3+ (multiple tags) | 88.36% | 70.03% | 76.75% | 0.78 | 74.62% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Su, J.; Wang, L.; Lu, S.; Li, L. LA-DeepLab V3+: A Novel Counting Network for Pigs. Agriculture 2022, 12, 284. https://doi.org/10.3390/agriculture12020284
Liu C, Su J, Wang L, Lu S, Li L. LA-DeepLab V3+: A Novel Counting Network for Pigs. Agriculture. 2022; 12(2):284. https://doi.org/10.3390/agriculture12020284
Chicago/Turabian StyleLiu, Chengqi, Jie Su, Longhe Wang, Shuhan Lu, and Lin Li. 2022. "LA-DeepLab V3+: A Novel Counting Network for Pigs" Agriculture 12, no. 2: 284. https://doi.org/10.3390/agriculture12020284
APA StyleLiu, C., Su, J., Wang, L., Lu, S., & Li, L. (2022). LA-DeepLab V3+: A Novel Counting Network for Pigs. Agriculture, 12(2), 284. https://doi.org/10.3390/agriculture12020284