
The Rapid Detection of Trash Content in Seed Cotton Using Near-Infrared Spectroscopy Combined with Characteristic Wavelength Selection
Abstract
:1. Introduction
2. Materials and Methods
2.1. Seed Cotton Samples
2.2. Spectral Preprocessing
2.3. Determination of Trash Content
2.4. Acquisition of FT-NIR Spectra
2.5. Spectral Variable Selection
2.5.1. siPLS Methodology
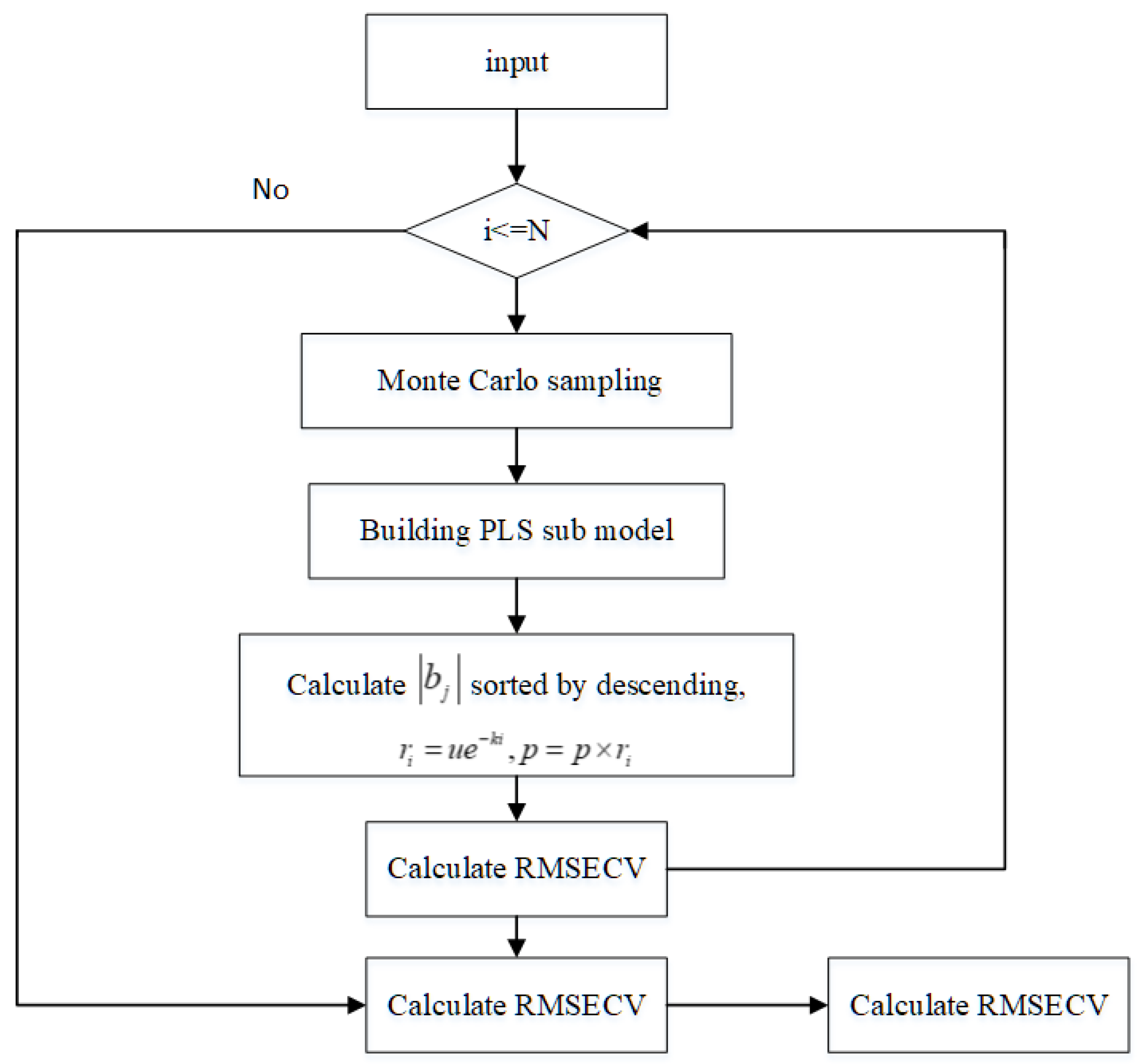
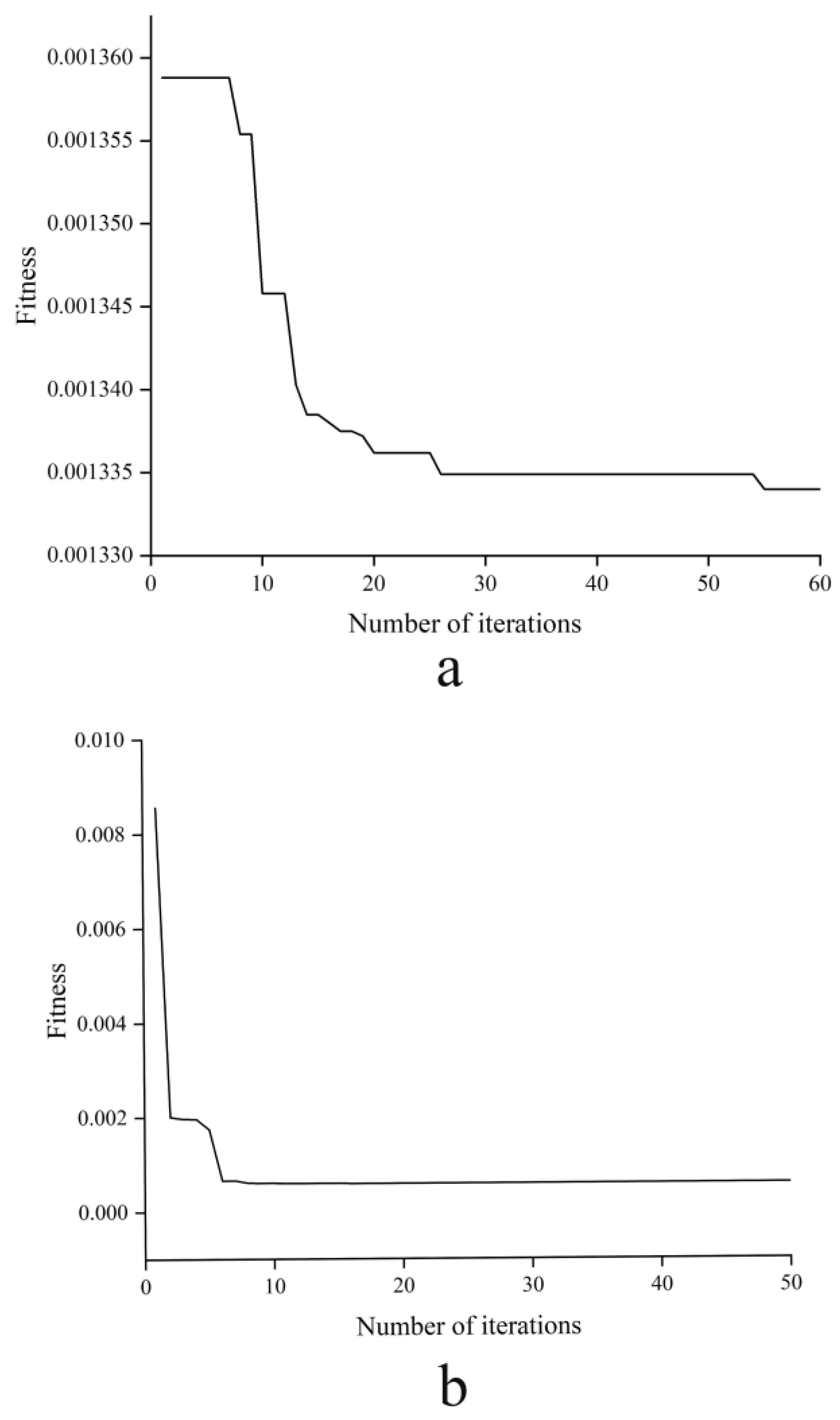
2.5.2. The CARS Algorithm
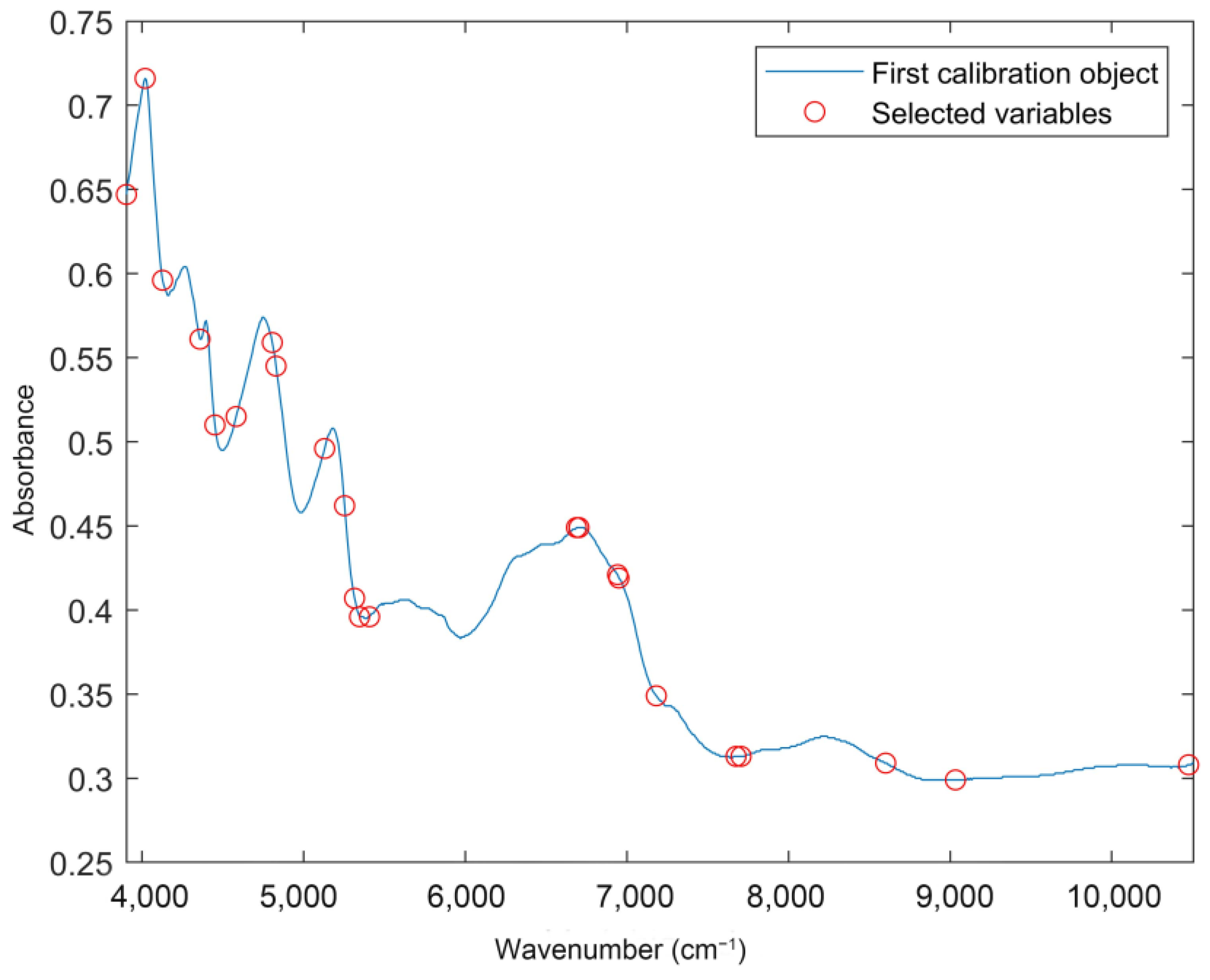
2.5.3. The SPA Algorithm
2.6. Modeling Methods
2.6.1. PLS-Based Regression
2.6.2. SVM-Based Regression
2.7. Model Evaluation
2.8. Software
3. Results and Discussion
3.1. Selection of Characteristic Spectral Wavelengths
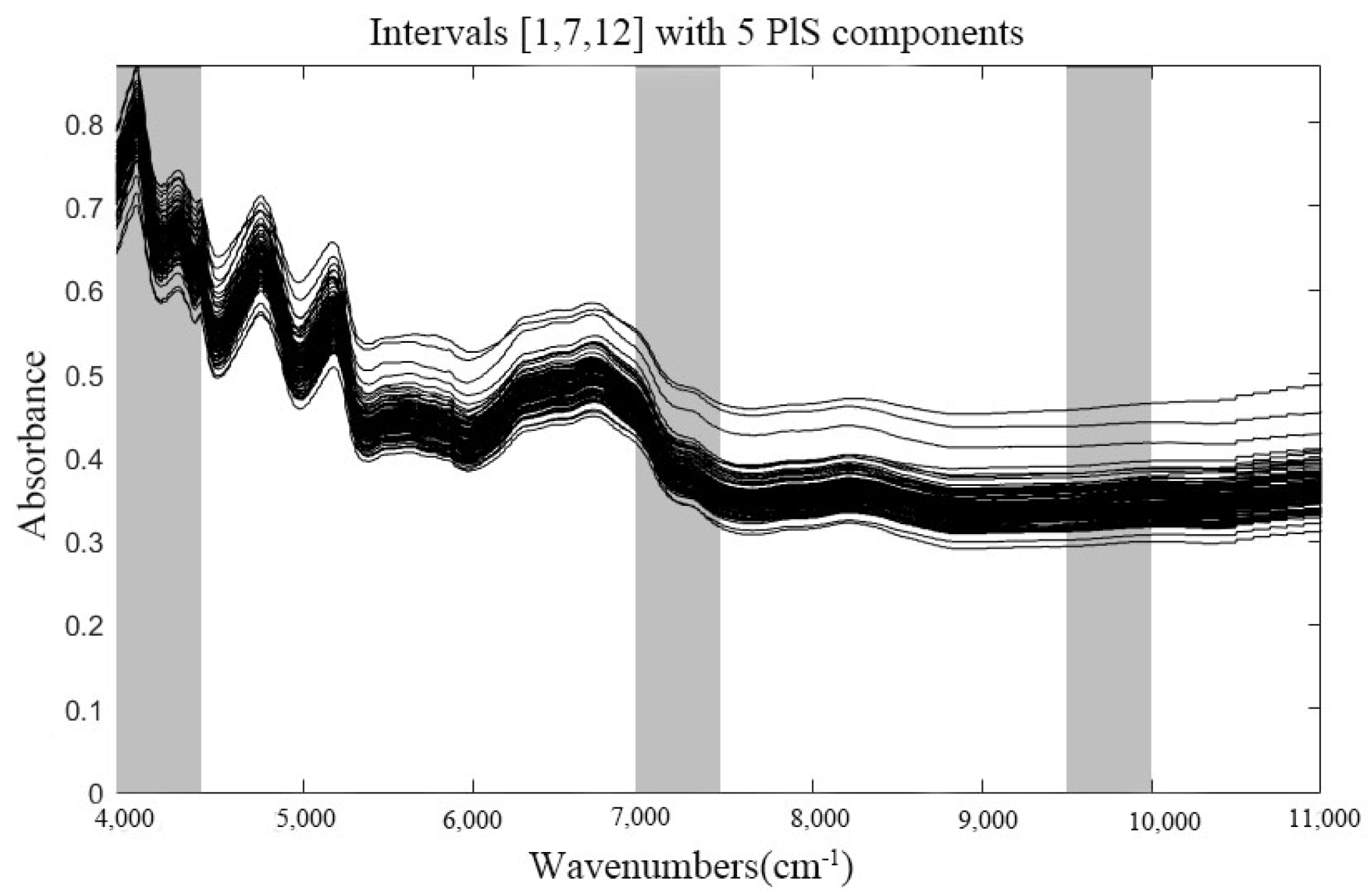
3.1.1. siPLS-Based Feature Interval Selection
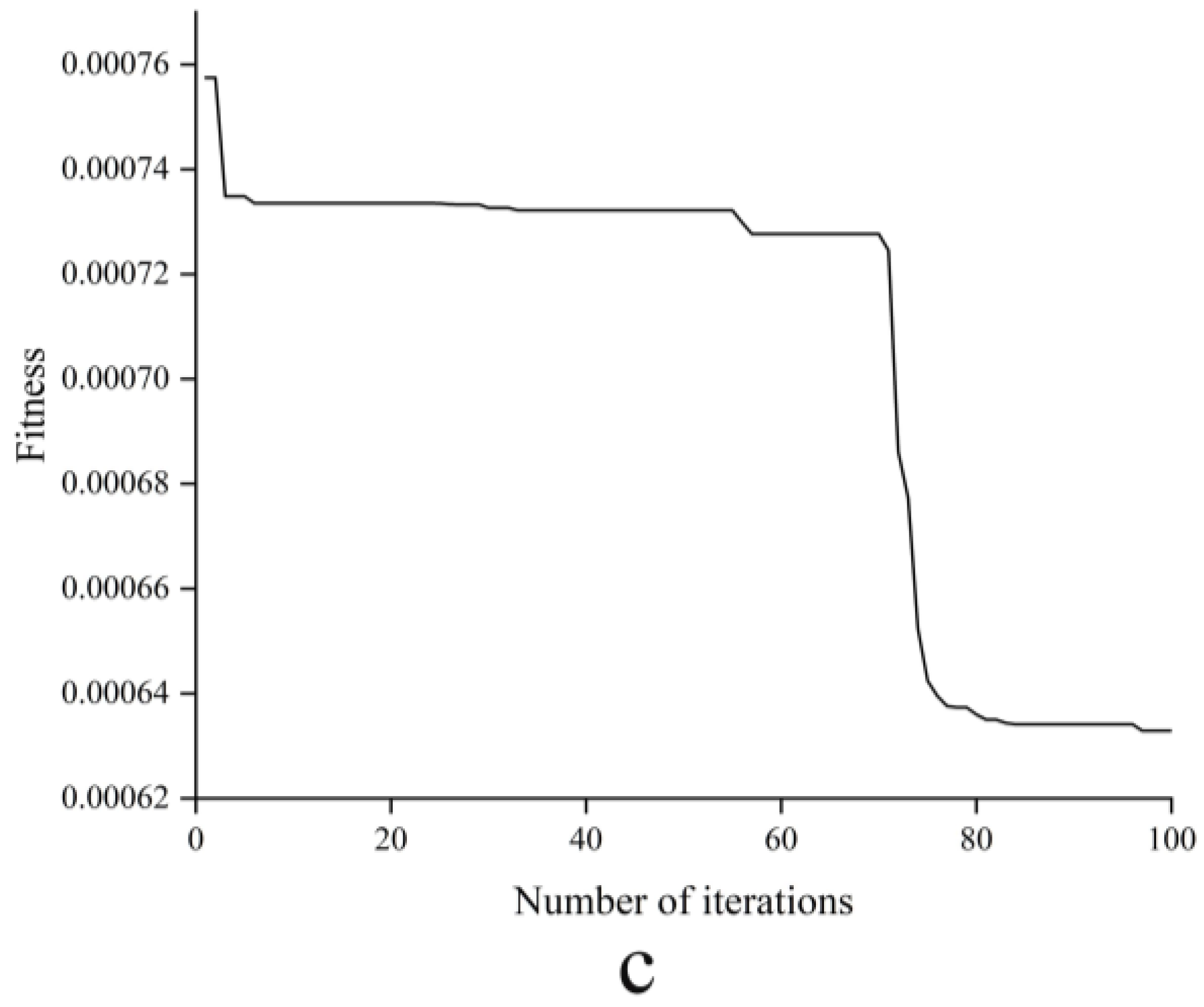
3.1.2. The CARS Algorithm
3.1.3. SPA
3.2. PLS-Based Regression
3.3. SVM- Based Regression
3.3.1. Optimization of SVM Based on GWO, SSA, and BES
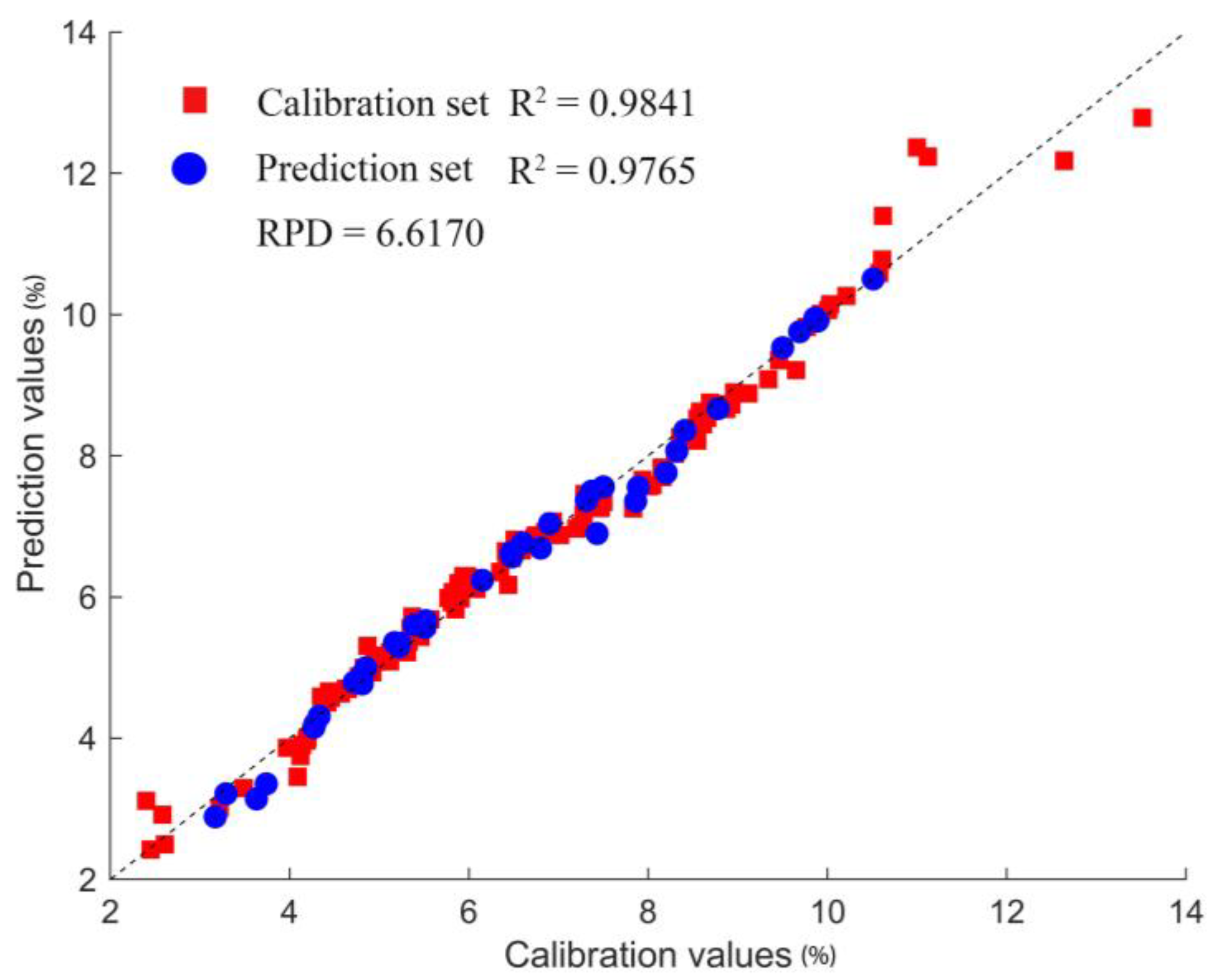
3.3.2. Modeling of Seed Cotton Impurity Prediction
3.3.3. Suggestions for Further Research
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- National Bureau of Statistics of the People’s Republic of China. NSO Announcement on Cotton Production in 2022[EB/OL]. Available online: http://www.stats.gov.cn/sj/zxfb/202302/t20230203_1901689.html (accessed on 26 December 2022).
- Central People’s Government. Xinjiang’s Cotton Mechanized Harvesting Rate Exceeds 80 Percent [EB/OL]. Available online: https://www.gov.cn/xinwen/2022-06/22/content_5697041.htm (accessed on 22 June 2022).
- Wang, X.; Li, D.; Yang, W.; Li, Z. Lint Cotton Pseudo-foreign Fiber Detection Based on Visible Spectrum Computer Vision. Trans. Chin. Soc. Agric. Mach. 2015, 46, 7–14. [Google Scholar]
- Zhou, F.; Ding, T.; Qu, X. Detection of foreign materials in lint cotton with a white-light/fluorescence alternating imaging method. J. Tsinghua University. Sci. Technol. 2010, 50, 1234–1238. [Google Scholar]
- Wan, L.; Pang, Y.; Zhang, R.; Jiang, Y.; Zhang, M.; Song, F.; Chang, J.; Xia, B. Rapid measurement system for the impurity rate of machine-picked seed cotton in acquisition. Trans. Chin. Soc. Agric. Eng. 2021, 37, 182–189. [Google Scholar]
- Zhang, C.; Li, L.; Dong, Q.; Ge, R. Recognition for machine picking seed cotton impurities based on GA-SVM model. Trans. Chin. Soc. Agric. Eng. 2016, 32, 189–196. [Google Scholar]
- Zhang, C.; Li, L.; Dong, Q.; Ge, R. Recognition Method for Machine-harvested Cotton Impurities Based on Color and Shape Features. Trans. Chin. Soc. Agric. Mach. 2016, 47, 28–34. [Google Scholar]
- Wang, H.; Li, H. Classification recognition of impurities in seed cotton based on local binary pattern and gray level co-occurrence matrix. Trans. Chin. Soc. Agric. Eng. 2015, 31, 236–241. [Google Scholar]
- Zhao, X.; Li, D.; Yang, B.; Ma, C.; Zhu, Y.; Chen, H. Feature selection based on improved ant colony optimization for online detection of foreign fiber in cotton. Appl. Soft Comput. 2014, 24, 585–596. [Google Scholar] [CrossRef]
- Mustafic, A.; Li, C.Y.; Haidekker, M. Blue and UV LED-induced fluorescence in cotton foreign matter. J. Biol. Eng. 2014, 8, 29. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, J.; Zeng, C.; Bao, C.; Li, Z.; Zhang, D.; Zhen, F. Rapid detection of protein content in rice based on Raman and near-infrared spectroscopy fusion strategy combined with characteristic wavelength selection. Infrared Phys. Technol. 2023, 129, 104563. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Zhang, Q.; Duan, D.; Chen, L. Establishment of a multi-position general model for evaluation of watercore and soluble solid content in ‘Fuji’ apples using online full-transmittance visible and near infrared spectroscopy. J. Food Compos. Anal. 2023, 117, 105150. [Google Scholar] [CrossRef]
- Fortier, C.A.; Rodgers, J.E.; Cintron, M.S.; Cui, X.; Foulk, J.A. Identification of cotton and cotton trash components by Fourier-transform near-infrared spectroscopy. Text. Res. J. 2010, 81, 230–238. [Google Scholar] [CrossRef]
- Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New approach for rapid estimation of leaf nitrogen, phosphorus, and potassium contents in apple-trees using Vis/NIR spectroscopy based on wavelength selection coupled with machine learning. Comput. Electron. Agric. 2023, 207, 107746. [Google Scholar] [CrossRef]
- Wang, K.; Jiang, Y.; Li, C. Detection and Discrimination of Cotton Foreign Matter Using Push-Broom Based Hyperspectral Imaging: System Design and Capability. PLoS ONE 2015, 10, e0121969. [Google Scholar]
- Chen, M.; Ni, Y.; Jin, C.; Xu, J.; Yuan, W. High spectral inversion of wheat impurities rate for grain combine harvester. Trans. Chin. Soc. Agric. Eng. 2019, 35, 22–29. [Google Scholar]
- Chen, M.; Xu, J.; Jin, C.; Zhang, G.; Ni, Y. Inversion model of soybean impurity rate based on hyperspectral. J. China Agric. Univ. 2019, 24, 160–167. [Google Scholar]
- Wu, M.; Li, Y.; Yuan, Y.; Li, S.; Song, X.; Yin, J. Comparison of NIR and Raman spectra combined with chemometrics for the classification and quantification of mung beans (Vigna radiata L.) of different origins. Food Control 2023, 145, 109498. [Google Scholar] [CrossRef]
- Teye, E.; Huang, X. Novel Prediction of Total Fat Content in Cocoa Beans by FT-NIR Spectroscopy Based on Effective Spectral Selection Multivariate Regression. Food Anal. Methods 2015, 8, 945–953. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X. Quantitative analysis of near infrared spectroscopic data based on dual-band transformation and competitive adaptive reweighted sampling. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 285, 121924. [Google Scholar] [CrossRef]
- Li, Q.; Huang, Y.; Song, X.; Zhang, J.; Min, S. Moving window smoothing on the ensemble of competitive adaptive reweighted sampling algorithm[J]. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 214, 129–138. [Google Scholar]
- Xu, S.; Zhao, Y.; Wang, M.; Shi, X. Determination of rice root density from Vis–NIR spectroscopy by support vector machine regression and spectral variable selection techniques. Catena 2017, 157, 12–23. [Google Scholar] [CrossRef]
- Sarathjith, M.C.; Das, B.S.; Wani, S.P.; Sahrawat, K.L. Variable indicators for optimum wavelength selection in diffuse reflectance spectroscopy of soils. Geoderma 2016, 267, 1–9. [Google Scholar] [CrossRef]
- Vohland, M.; Ludwig, M.; Thiele-Bruhn, S.; Ludwig, B. Determination of soil properties with visible to near- and mid-infrared spectroscopy: Effects of spectral variable selection. Geoderma 2014, 223–225, 88–96. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Bian, X.; Wang, K.; Tan, E.; Diwu, P.; Zhang, F.; Guo, Y. A selective ensemble preprocessing strategy for near-infrared spectral quantitative analysis of complex samples. Chemom. Intell. Lab. Syst. 2020, 197, 103916. [Google Scholar] [CrossRef]
- Jiang, H.; Liu, L.; Chen, Q. Rapid determination of acidity index of peanuts by near-infrared spectroscopy technology: Comparing the performance of different near-infrared spectral models. Infrared Phys. Technol. 2022, 125, 104308. [Google Scholar] [CrossRef]
- Miao, X.; Miao, Y.; Gong, H.; Tao, S.; Chen, Z.; Wang, J.; Chen, Y.; Chen, Y. NIR spectroscopy coupled with chemometric algorithms for the prediction of cadmium content in rice samples. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 257, 119700. [Google Scholar] [CrossRef] [PubMed]
- Zou, X.; Zhao, J.; Povey, M.J.W.; Holmes, M.; Mao, H. Variables selection methods in near-infrared spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar]
- Ma, C.; Shao, X. Continuous Wavelet Transform Applied to Removing the Fluctuating Background in Near-Infrared Spectra. J. Chem. Inf. Comput. Sci. 2004, 44, 907–911. [Google Scholar] [CrossRef]
- GB/T 21397-2002; Cotton Harvesters: Certification and Accreditation Administration. Standardization Administration of the People’s Republic of China: Beijing, China, 2008.
- Wang, L.S.; Wang, R.J. Determination of soil pH from Vis-NIR spectroscopy by extreme learning machine and variable selection: A case study in lime concretion black soil. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 283, 121707. [Google Scholar] [CrossRef]
- Kumar, K. Competitive adaptive reweighted sampling assisted partial least square analysis of excitation-emission matrix fluorescence spectroscopic data sets of certain polycyclic aromatic hydrocarbons. Spectrochem. Acta Part A Mol. Biomol. Spectrosc. 2021, 244, 118874. [Google Scholar] [CrossRef]
- Yang, G.; Li, Y.; Zhen, F.; Xu, Y.; Liu, J.; Li, N.; Sun, Y.; Luo, L.; Wang, M.; Zhang, L. Biochemical methane potential prediction for mixed feedstocks of straw and manure in anaerobic co-digestion. Bioresour. Technol. 2021, 326, 124745. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Yuan, Q.; Wang, Q.D.; Liu, S.; Wu, K. A systematic Chandra study of Sgr A⋆: II. X-ray flare statistics. Mon. Not. R. Astron. Soc. 2018, 473, 306–316. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Jiang, H.; Yuan, W.; Ru, Y.; Chen, Q.; Wang, J.; Zhou, H. Feasibility of identifying the authenticity of fresh and cooked mutton kebabs using visible and near-infrared hyperspectral imaging. Spectrochem. Acta Part A Mol. Biomol. Spectrosc. 2022, 282, 121689. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Zhao, J.; Fang, C.H.; Wang, D. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochem. Acta Part A Mol. Biomol. Spectrosc. 2007, 66, 568–574. [Google Scholar] [CrossRef]
- Li, J.; Huang, W.; Zhao, C.; Zhang, B. A comparative study for the quantitative determination of soluble solids content, pH and firmness of pears by Vis/NIR spectroscopy. J. Food Eng. 2013, 116, 324–332. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Alsattar, H.A.; Zaidan, A.A.; Zaidan, B.B. Novel meta-heuristic bald eagle search optimization algorithm. Artif. Intell. Rev. 2019, 53, 2237–2264. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Li, L.; Jákli, B.; Lu, P.; Ren, T.; Ming, J.; Liu, S.; Wang, S.; Lu, J. Assessing leaf nitrogen concentration of winter oilseed rape with canopy hyperspectral technique considering a non-uniform vertical nitrogen distribution. Ind. Crops Prod. 2018, 116, 1–14. [Google Scholar] [CrossRef]
- Bao, C.; Zeng, C.; Liu, J.; Zhang, D. Rapid detection of talc content in flour based on near-infrared spectroscopy combined with feature wavelength selection. Appl. Opt. 2022, 61, 5790–5798. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PLS Components | Selected Intervals | RMSECV (%) |
|---|---|---|
| 5 | [1,7,12] | 0.3981 |
| 5 | [1,7,9] | 0.3989 |
| 5 | [1,7,14] | 0.3995 |
| 5 | [1,7,13] | 0.4001 |
| 5 | [1,8,13] | 0.4007 |
| 5 | [1,7,11] | 0.4008 |
| 4 | [1,8,9] | 0.4020 |
| 4 | [1,11,12] | 0.4022 |
| 4 | [1,9,10] | 0.4022 |
| 4 | [1,12,13] | 0.4023 |
| Feature Selection | Number of Wavelengths | Modeling Methods | Calibration Set | Prediction Set | RPD | ||
|---|---|---|---|---|---|---|---|
| RMSEC | RMSEP | ||||||
| siPLS | 273 | PLS | 0.9702 | 0.3717 | 0.9273 | 0.5896 | 3.4702 |
| CARS | 55 | 0.9716 | 0.3279 | 0.9643 | 0.5389 | 3.0634 | |
| SPA | 48 | 0.9700 | 0.3706 | 0.9438 | 0.4824 | 3.5236 | |
| siPLS-CARS | 30 | 0.9687 | 0.3773 | 0.9534 | 0.4748 | 4.0613 | |
| siPLS-SPA | 23 | 0.9753 | 0.3289 | 0.9607 | 0.4086 | 3.8976 | |
| CARS-SPA | 9 | 0.9688 | 0.3514 | 0.9698 | 0.4506 | 3.7128 | |
| Feature Selection | Modeling Methods | Calibration Set | Prediction Set | RPD | ||
|---|---|---|---|---|---|---|
| RMSEC | RMSEP | |||||
| siPLS | GWO-SVM | 0.9967 | 0.1228 | 0.9274 | 0.5893 | 3.7621 |
| CARS | 0.9813 | 0.3034 | 0.8979 | 0.6134 | 3.1724 | |
| SPA | 0.9947 | 0.1545 | 0.9198 | 0.6190 | 3.5785 | |
| siPLS-CARS | 0.9973 | 0.1075 | 0.9294 | 0.6234 | 3.8161 | |
| siPLS-SPA | 0.9910 | 0.2002 | 0.9544 | 0.4737 | 4.7506 | |
| CARS-SPA | 0.9692 | 0.3747 | 0.9433 | 0.5240 | 4.2558 | |
| siPLS | SSA-SVM | 0.9971 | 0.1147 | 0.9287 | 0.5832 | 3.7973 |
| CARS | 0.9883 | 0.2414 | 0.9447 | 0.5453 | 4.3125 | |
| SPA | 0.9916 | 0.1927 | 0.9087 | 0.6621 | 3.3541 | |
| siPLS-CARS | 0.9968 | 0.1188 | 0.9437 | 0.5467 | 4.2717 | |
| siPLS-SPA | 0.9841 | 0.2814 | 0.9772 | 0.3355 | 6.7224 | |
| CARS-SPA | 0.9964 | 0.1267 | 0.9551 | 0.4836 | 4.7844 | |
| siPLS | BES-SVM | 0.9980 | 0.0949 | 0.9216 | 0.6134 | 3.6212 |
| CARS | 0.9880 | 0.2315 | 0.9194 | 0.5911 | 3.5710 | |
| SPA | 0.9948 | 0.1412 | 0.9412 | 0.5392 | 4.1824 | |
| siPLS-CARS | 0.9847 | 0.2620 | 0.9708 | 0.3803 | 5.9303 | |
| siPLS-SPA | 0.9869 | 0.2422 | 0.9765 | 0.2900 | 6.6170 | |
| CARS-SPA | 0.9674 | 0.3831 | 0.9785 | 0.2949 | 5.7914 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Guo, J.; Zhang, Z.; Yang, X.; Shi, Y.; Zhou, J. The Rapid Detection of Trash Content in Seed Cotton Using Near-Infrared Spectroscopy Combined with Characteristic Wavelength Selection. Agriculture 2023, 13, 1928. https://doi.org/10.3390/agriculture13101928
Han J, Guo J, Zhang Z, Yang X, Shi Y, Zhou J. The Rapid Detection of Trash Content in Seed Cotton Using Near-Infrared Spectroscopy Combined with Characteristic Wavelength Selection. Agriculture. 2023; 13(10):1928. https://doi.org/10.3390/agriculture13101928
Chicago/Turabian StyleHan, Jing, Junxian Guo, Zhenzhen Zhang, Xiao Yang, Yong Shi, and Jun Zhou. 2023. "The Rapid Detection of Trash Content in Seed Cotton Using Near-Infrared Spectroscopy Combined with Characteristic Wavelength Selection" Agriculture 13, no. 10: 1928. https://doi.org/10.3390/agriculture13101928