
Non-Destructive Detection of Chicken Freshness Based on Electronic Nose Technology and Transfer Learning





Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Materials
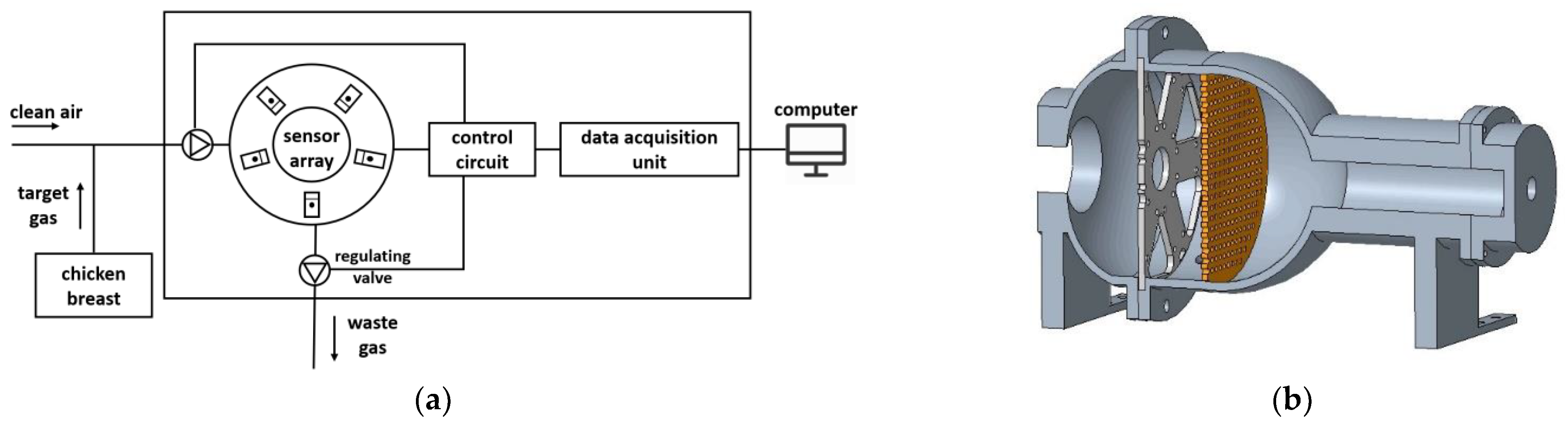
2.2. Electronic Nose Device and Collection of Odor Data
2.3. Computing Platforms
2.4. Data Processing
2.4.1. Data Calibration
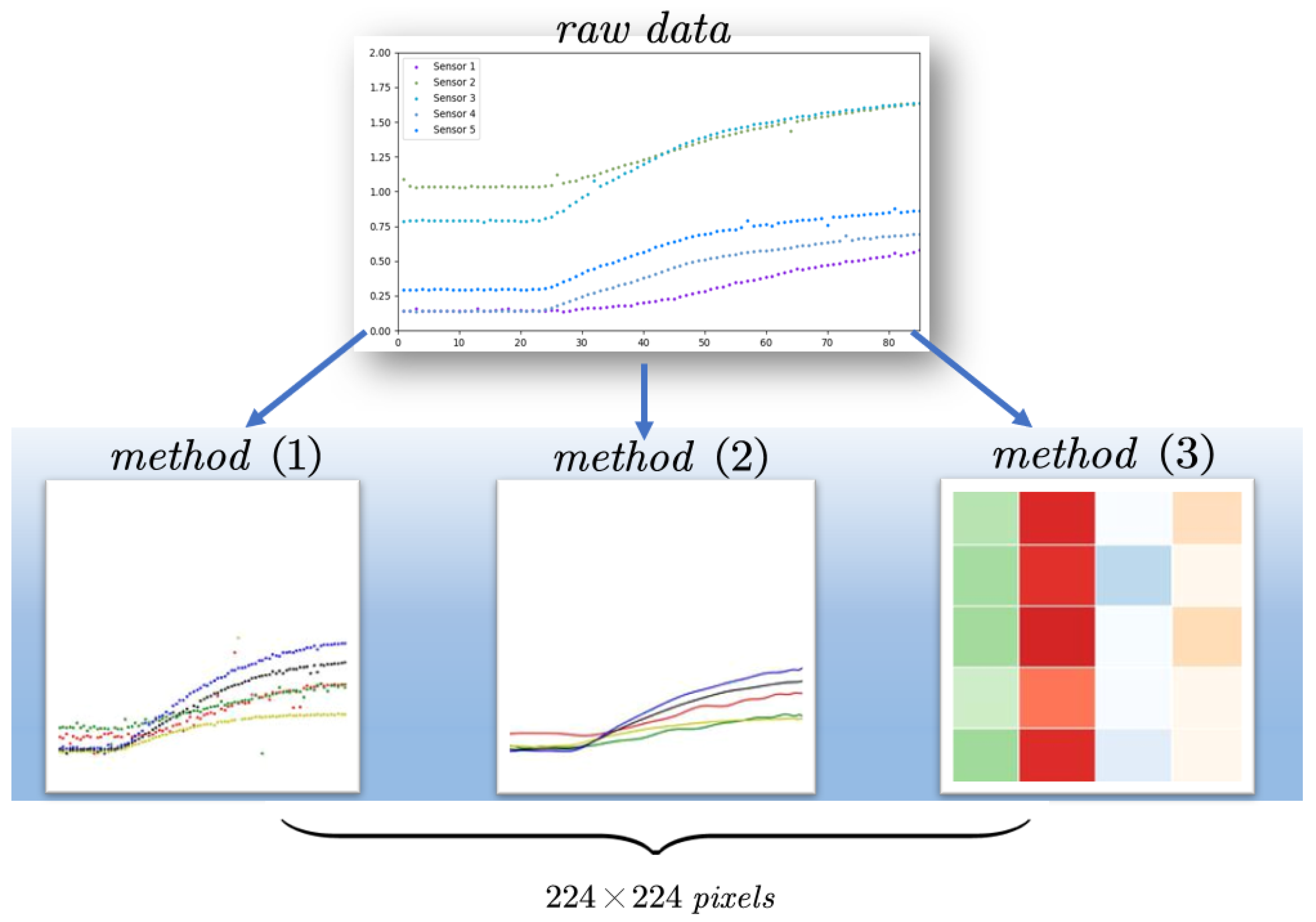
2.4.2. Input Images Preparation for Deep Learning Models
- (1)
- Transformation into image based on the raw discrete data;
- (2)
- Conversion to image based on fitted data;
- (3)
- Extraction of feature data from the fitted curve into image.
Method 1: Transformation of Raw Data into Input Images
Method 2: Fitting the Curve to the Input Image
Method 3: Eigenvalue Mapping to Color Matrix Images
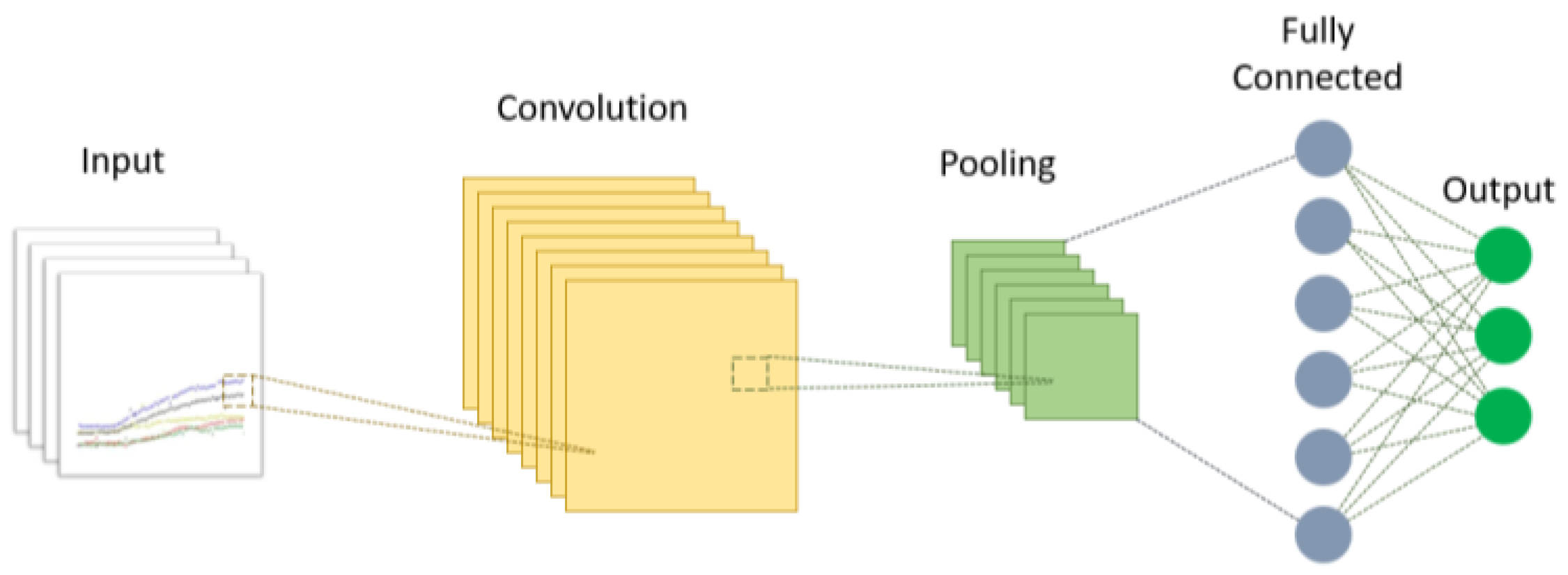
2.5. Deep Convolutional Neural Network Model Construction
2.5.1. AlexNet
2.5.2. GoogLeNet
2.5.3. ResNet50
2.5.4. Transfer Learning
3. Results and Discussion
3.1. Experimental Setup
3.2. Influence of the Input Pattern of the Deep Transfer Model
3.3. Comparison of Experimental Training Results
3.4. Effect of Training Set Size on Model Performance
3.5. Influence of Network Parameters
- (1)
- Effect of Batch Size on results
- (2)
- Effect of Batch Size on results
- (3)
- Impact of different optimizers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, H.; Chen, Q.; Zhao, J.; Wu, M. Nondestructive detection of total volatile basic nitrogen (TVB-N) content in pork meat by integrating hyperspectral imaging and colorimetric sensor combined with a nonlinear data fusion. LWT 2015, 63, 268–274. [Google Scholar] [CrossRef]
- Rodtong, S.; Nawong, S.; Yongsawatdigul, J. Histamine accumulation and histamine-forming bacteria in Indian anchovy (Stolephorus indicus). Food Microbiol. 2005, 22, 475–482. [Google Scholar] [CrossRef]
- Rukchon, C.; Nopwinyuwong, A.; Trevanich, S.; Jinkarn, T.; Suppakul, P. Development of a food spoilage indicator for monitoring freshness of skinless chicken breast. Talanta 2014, 130, 547–554. [Google Scholar] [CrossRef] [PubMed]
- Khulal, U.; Zhao, J.; Hu, W.; Chen, Q. Intelligent evaluation of total volatile basic nitrogen (TVB-N) content in chicken meat by an improved multiple level data fusion model. Sens. Actuators B Chem. 2017, 238, 337–345. [Google Scholar] [CrossRef]
- Korel, F.; Luzuriaga, D.; Balaban, M. Objective Quality Assessment of Raw Tilapia (Oreochromis niloticus) Fillets Using Electronic Nose and Machine Vision. J. Food Sci. 2001, 66, 1018–1024. [Google Scholar] [CrossRef]
- Chen, Q.; Hui, Z.; Zhao, J.; Ouyang, Q. Evaluation of chicken freshness using a low-cost colorimetric sensor array with AdaBoost–OLDA classification algorithm. LWT 2014, 57, 502–507. [Google Scholar] [CrossRef]
- Du, C.-J.; Sun, D.-W. Learning techniques used in computer vision for food quality evaluation: A review. J. Food Eng. 2006, 72, 39–55. [Google Scholar] [CrossRef]
- Xiong, Z.; Sun, D.-W.; Pu, H.; Xie, A.; Han, Z.; Luo, M. Non-destructive prediction of thiobarbituricacid reactive substances (TBARS) value for freshness evaluation of chicken meat using hyperspectral imaging. Food Chem. 2015, 179, 175–181. [Google Scholar] [CrossRef]
- Kandpal, L.M.; Lee, H.; Kim, M.S.; Mo, C.; Cho, B.-K. Hyperspectral Reflectance Imaging Technique for Visualization of Moisture Distribution in Cooked Chicken Breast. Sensors 2013, 13, 13289–13300. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Z.; Sun, D.-W.; Pu, H.; Gao, W.; Dai, Q. Applications of emerging imaging techniques for meat quality and safety detection and evaluation: A review. Crit. Rev. Food Sci. Nutr. 2017, 57, 755–768. [Google Scholar] [CrossRef]
- Pérez-Palacios, T.; Antequera, T.; Durán, M.L.; Caro, A.; Rodríguez, P.G.; Palacios, R. MRI-based analysis of feeding background effect on fresh Iberian ham. Food Chem. 2011, 126, 1366–1372. [Google Scholar] [CrossRef]
- Taheri-Garavand, A.; Fatahi, S.; Shahbazi, F.; De La Guardia, M. A nondestructive intelligent approach to real-time evaluation of chicken meat freshness based on computer vision technique. J. Food Process Eng. 2019, 42, e13039. [Google Scholar] [CrossRef]
- Antequera, T.; Caballero, D.; Grassi, S.; Uttaro, B.; Perez-Palacios, T. Evaluation of fresh meat quality by Hyperspectral Imaging (HSI), Nuclear Magnetic Resonance (NMR) and Magnetic Resonance Imaging (MRI): A review. Meat Sci. 2021, 172, 108340. [Google Scholar] [CrossRef]
- Tan, J.; Xu, J. Applications of electronic nose (e-nose) and electronic tongue (e-tongue) in food quality-related properties determination: A review. Artif. Intell. Agric. 2020, 4, 104–115. [Google Scholar] [CrossRef]
- Shi, H.; Zhang, M.; Adhikari, B. Advances of electronic nose and its application in fresh foods: A review. Crit. Rev. Food Sci. Nutr. 2018, 58, 2700–2710. [Google Scholar] [CrossRef]
- Wang, Y.; Diao, J.; Wang, Z.; Zhan, X.; Zhang, B.; Li, N.; Li, G. An optimized deep convolutional neural network for dendrobium classification based on electronic nose. Sens. Actuators A: Phys. 2020, 307, 111874. [Google Scholar] [CrossRef]
- Liu, Q.; Hu, X.; Cheng, X.; Ye, M.; Li, F. Gas Recognition under Sensor Drift by Using Deep Learning. Int. J. Intell. Syst. 2015, 30, 907–922. [Google Scholar] [CrossRef]
- Peng, P.; Zhao, X.; Pan, X.; Ye, W. Gas Classification Using Deep Convolutional Neural Networks. Sensors 2018, 18, 157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.; Yu, C.; Xiao, K.; Zhao, X. A New Method of Mixed Gas Identification Based on a Convolutional Neural Network for Time Series Classification. Sensors 2019, 19, 1960. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramcharan, A.; Baranowski, K.; McCloskey, P.; Ahmed, B.; Legg, J.; Hughes, D.P. Deep Learning for Image-Based Cassava Disease Detection. Front. Plant Sci. 2017, 8, 1852. [Google Scholar] [CrossRef] [Green Version]
- Arsalane, A.; El Barbri, N.; Tabyaoui, A.; Klilou, A.; Rhofir, K.; Halimi, A. An embedded system based on DSP platform and PCA-SVM algorithms for rapid beef meat freshness prediction and identification. Comput. Electron. Agric. 2018, 152, 385–392. [Google Scholar] [CrossRef]
- Vivek, K.; Subbarao, K.; Routray, W.; Kamini, N.; Dash, K.K. Application of Fuzzy Logic in Sensory Evaluation of Food Products: A Comprehensive Study. Food Bioprocess Technol. 2020, 13, 1–29. [Google Scholar] [CrossRef]
- Ge, Q.; Tang, X.; Fan, Y.; Ma, L.; Jia, X.; Gu, R.; Wei, J.; Gao, Y. Effect of refrigeration temperature on texture characteristics of fresh chicken and determination of freshness index. J. Food Saf. Qual. 2018, 9, 6483–6488. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J.; Zhou, P.; Li, W.; Zhang, X.; Fu, Z. Progress and Prospects of Studies of Chilled Chicken Meat Quality and Shelf Life. Mod. Food Sci. Technol. 2017, 33, 328–340. [Google Scholar] [CrossRef]
- Freeman, L.R.; Silverman, G.J.; Angelini, P.; Merritt, C.; Esselen, W.B. Volatiles produced by microorganisms isolated from refrigerated chicken at spoilage. Appl. Environ. Microbiol. 1976, 32, 222–231. [Google Scholar] [CrossRef] [Green Version]
- Klein, D.; Maurer, S.; Herbert, U.; Kreyenschmidt, J.; Kaul, P. Detection of Volatile Organic Compounds Arising from Chicken Breast Filets Under Modified Atmosphere Packaging Using TD-GC/MS. Food Anal. Methods 2018, 11, 88–98. [Google Scholar] [CrossRef]
- Zou, X.; Wang, C.; Luo, M.; Ren, Q.; Liu, Y.; Zhang, S.; Bai, Y.; Meng, J.; Zhang, W.; Su, S.W. Design of Electronic Nose Detection System for Apple Quality Grading Based on Computational Fluid Dynamics Simulation and K-Nearest Neighbor Support Vector Machine. Sensors 2022, 22, 2997. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Liu, T.; Ye, L.; Ueland, M.; Forbes, S.L.; Su, S.W. A novel data pre-processing method for odour detection and identification system. Sens. Actuators A Phys. 2019, 287, 113–120. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.Y.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–31 June 2016. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Dawei, W.; Limiao, D.; Jiangong, N.; Jiyue, G.; Hongfei, Z.; Zhongzhi, H. Recognition pest by image-based transfer learning. J. Sci. Food Agric. 2019, 99, 4524–4531. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | External Quality | Internal Quality | Physical and Chemical Indicators |
|---|---|---|---|
| Level 1 | The pieces are intact, free from defects, elastic, not sticky, with good skin adhesion, normal and even meat color, with the normal fresh chicken aroma | Myogenic fibers are in a relaxed state; the meat is tender and can be eaten normally. | pH value ≤ 6.0 TVB-N content ≤ 15 mg/100 g |
| Level 2 | The pieces are relatively intact, generally elastic, slightly dry in appearance, with average flesh adhesion, dark and uneven color, and no particular odor | The chicken shrinks and becomes tough, with a slight loss of tenderness. | pH value > 6.5 TVB-N content 15~30 mg/100 g |
| Level 3 | Pieces are fragmented, dark in color, dry, sticky, and smelly on the surface | Chicken is rotten inside and should not be eaten. | pH value > 6.7 TVB-N content > 30 mg/100 g |
| Array Number | Detection of Gases | Model | Detection Range (‰) |
|---|---|---|---|
| Sensor 1 | VOC, hydrogen sulfide, ammonia | TGS2602 | 0.001~0.030 |
| Sensor 2 | Hydrogen sulfide | MQ136 | 0.05~5.00 |
| Sensor 3 | Ammonia | MQ137 | 0.005~0.100 |
| Sensor 4 | Ammonia, hydrogen sulfide | MQ135 | 0.03~0.30 |
| Sensor 5 | Formaldehyde | MQ138 | 0.05~1.00 |
| Classification Algorithms | Relevant Parameters |
|---|---|
| Support Vector Machines (SVM) | Penalty parameter c = 2.0; kernel: “RBF”; |
| Random Forest (RF) | Feature selection criterion: Gini Min_samples_split:5 |
| K Nearest Neighbors (KNN) | K neighbors:5 |
| GoogLeNet | Initial learning rate: 0.0001. MaxEpochs:3; MiniBatchSize:10; Optimization algorithm: SGDM |
| AlexNet | |
| ResNet |
| Method | GoogLeNet | AlexNet | ResNet |
|---|---|---|---|
| Method 1 | 99.10% | 98.90% | 99.33% |
| Method 2 | 99.03% | 99.70% | 99.40% |
| Method 3 | 90.22% | 92.91% | 96.67% |
| Algorithms | SVM | RF | KNN |
|---|---|---|---|
| Accuracy | 94.33% | 94.01% | 92.08% |
| Learning Rate | 0.001 | 0.0001 | 0.0005 | |
|---|---|---|---|---|
| GoogLeNet | Method 1 | 95.78% | 99.10% | 92.22% |
| Method 2 | 98.89% | 99.03% | 96.44% | |
| Method 3 | 81.23% | 90.22% | 88.89% | |
| AlexNet | Method 1 | 33.33% | 98.90% | 33.33% |
| Method 2 | 33.33% | 99.70% | 33.33% | |
| Method 3 | 33.33% | 92.91% | 86.11% | |
| ResNet | Method 1 | 97.56% | 99.33% | 98.89% |
| Method 2 | 99.26% | 99.40% | 98.89% | |
| Method 3 | 94.78% | 96.67% | 96.67% |
| Optimizers | Adam | SDGM | 0.0005 | |
|---|---|---|---|---|
| GoogLeNet | Method 1 | 91.33% | 99.10% | 76.22% |
| Method 2 | 97.78% | 99.03% | 93.11% | |
| Method 3 | 62.67% | 90.22% | 45.78% | |
| AlexNet | Method 1 | 98.33% | 98.90% | 98.44% |
| Method 2 | 98.89% | 99.70% | 98.89% | |
| Method 3 | 93.33% | 92.91% | 84.89% | |
| ResNet | Method 1 | 98.89% | 99.33% | 99.33% |
| Method 2 | 99.56% | 99.40% | 99.56% | |
| Method 3 | 97.11% | 96.67% | 95.56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Y.; Li, Y.; Wang, C.; Shi, H.; Wang, S.; Yong, C.; Gong, Y.; Zhang, W.; Zou, X. Non-Destructive Detection of Chicken Freshness Based on Electronic Nose Technology and Transfer Learning. Agriculture 2023, 13, 496. https://doi.org/10.3390/agriculture13020496
Xiong Y, Li Y, Wang C, Shi H, Wang S, Yong C, Gong Y, Zhang W, Zou X. Non-Destructive Detection of Chicken Freshness Based on Electronic Nose Technology and Transfer Learning. Agriculture. 2023; 13(2):496. https://doi.org/10.3390/agriculture13020496
Chicago/Turabian StyleXiong, Yunwei, Yuhua Li, Chenyang Wang, Hanqing Shi, Sunyuan Wang, Cheng Yong, Yan Gong, Wentian Zhang, and Xiuguo Zou. 2023. "Non-Destructive Detection of Chicken Freshness Based on Electronic Nose Technology and Transfer Learning" Agriculture 13, no. 2: 496. https://doi.org/10.3390/agriculture13020496
APA StyleXiong, Y., Li, Y., Wang, C., Shi, H., Wang, S., Yong, C., Gong, Y., Zhang, W., & Zou, X. (2023). Non-Destructive Detection of Chicken Freshness Based on Electronic Nose Technology and Transfer Learning. Agriculture, 13(2), 496. https://doi.org/10.3390/agriculture13020496