



Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model


Abstract
:1. Introduction
2. Materials and Methods
2.1. Mature Zanthoxylum Image Collection
2.2. Construction of the Dataset
2.3. Network Model Construction
2.3.1. YOLOv5
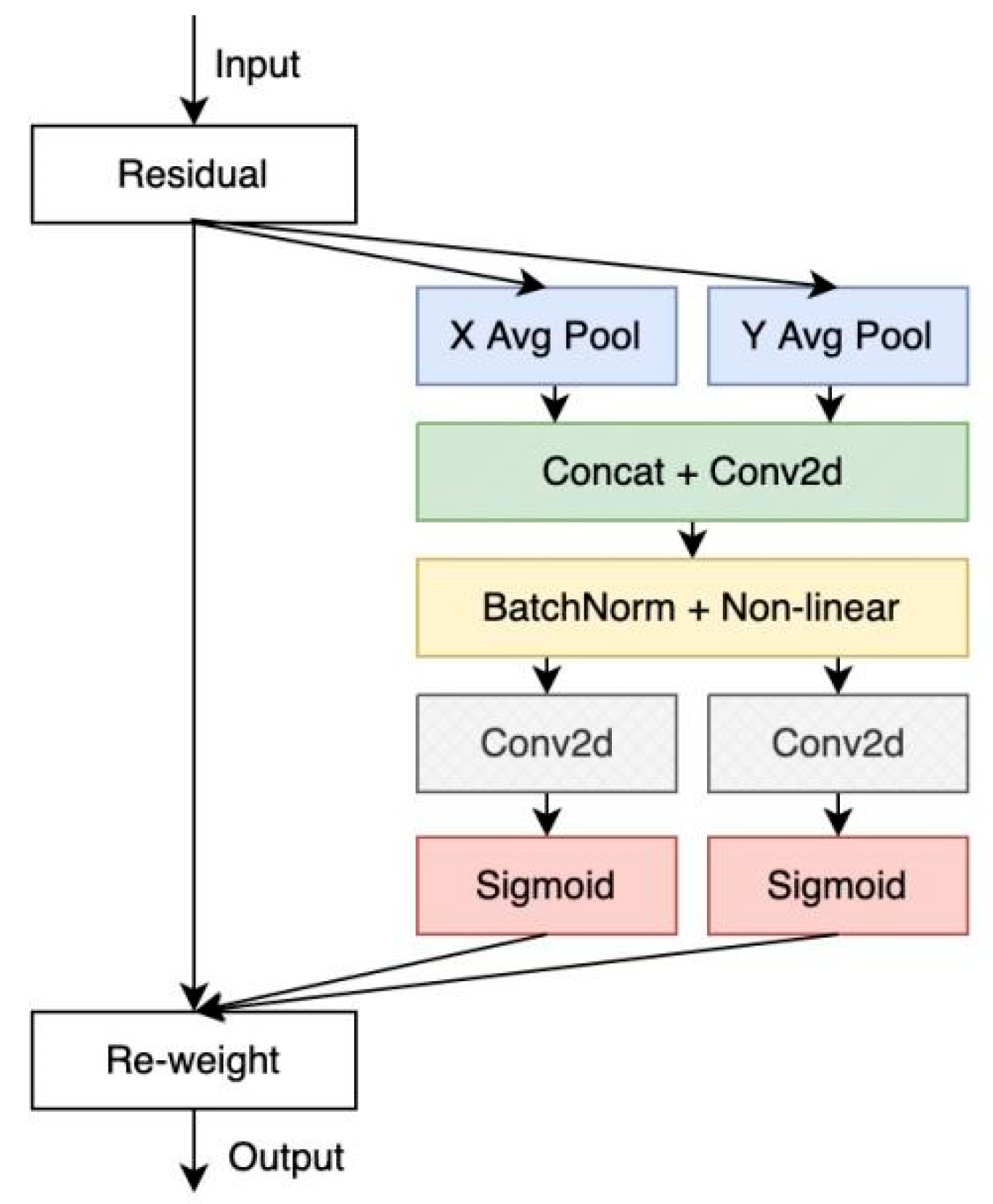
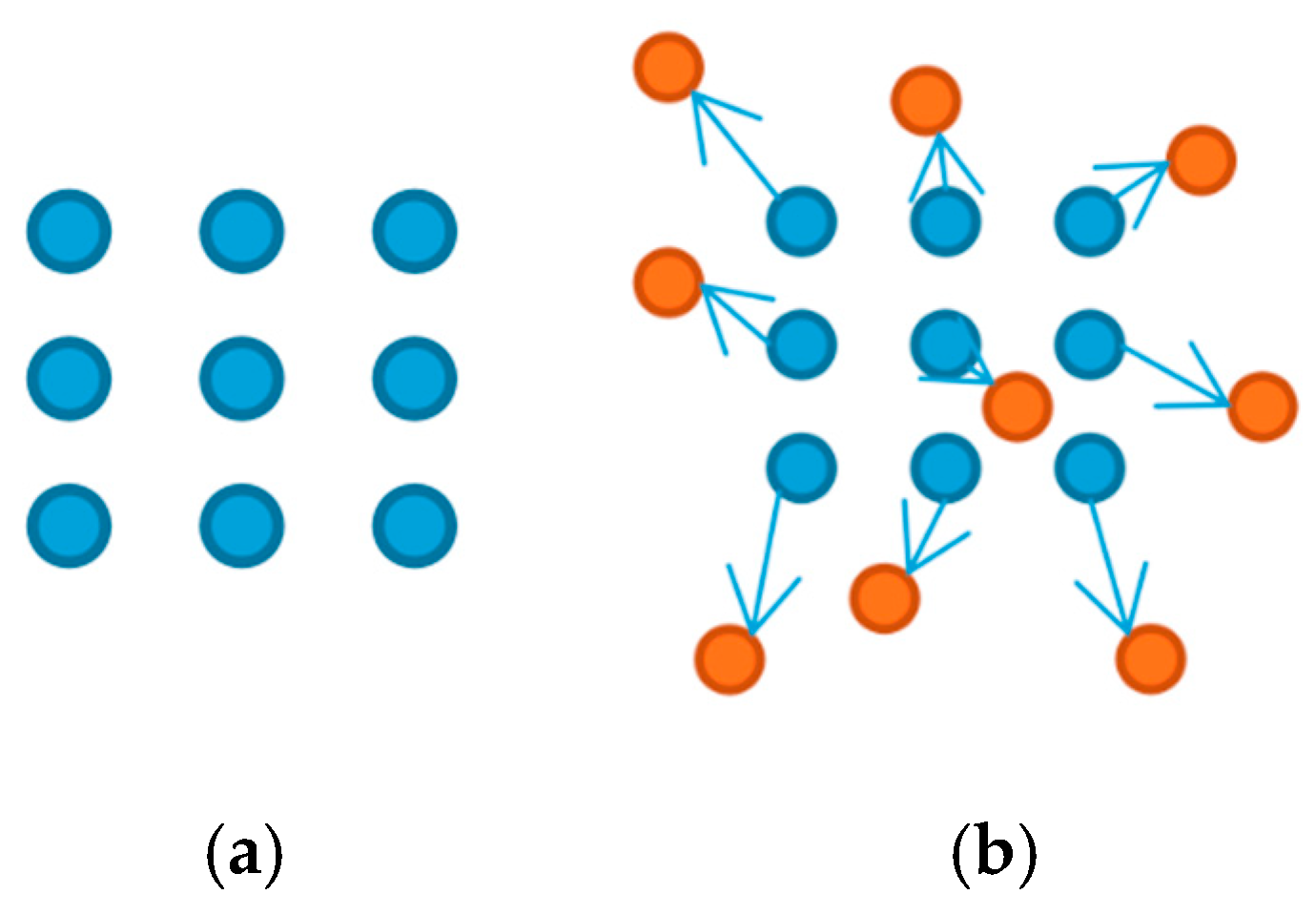
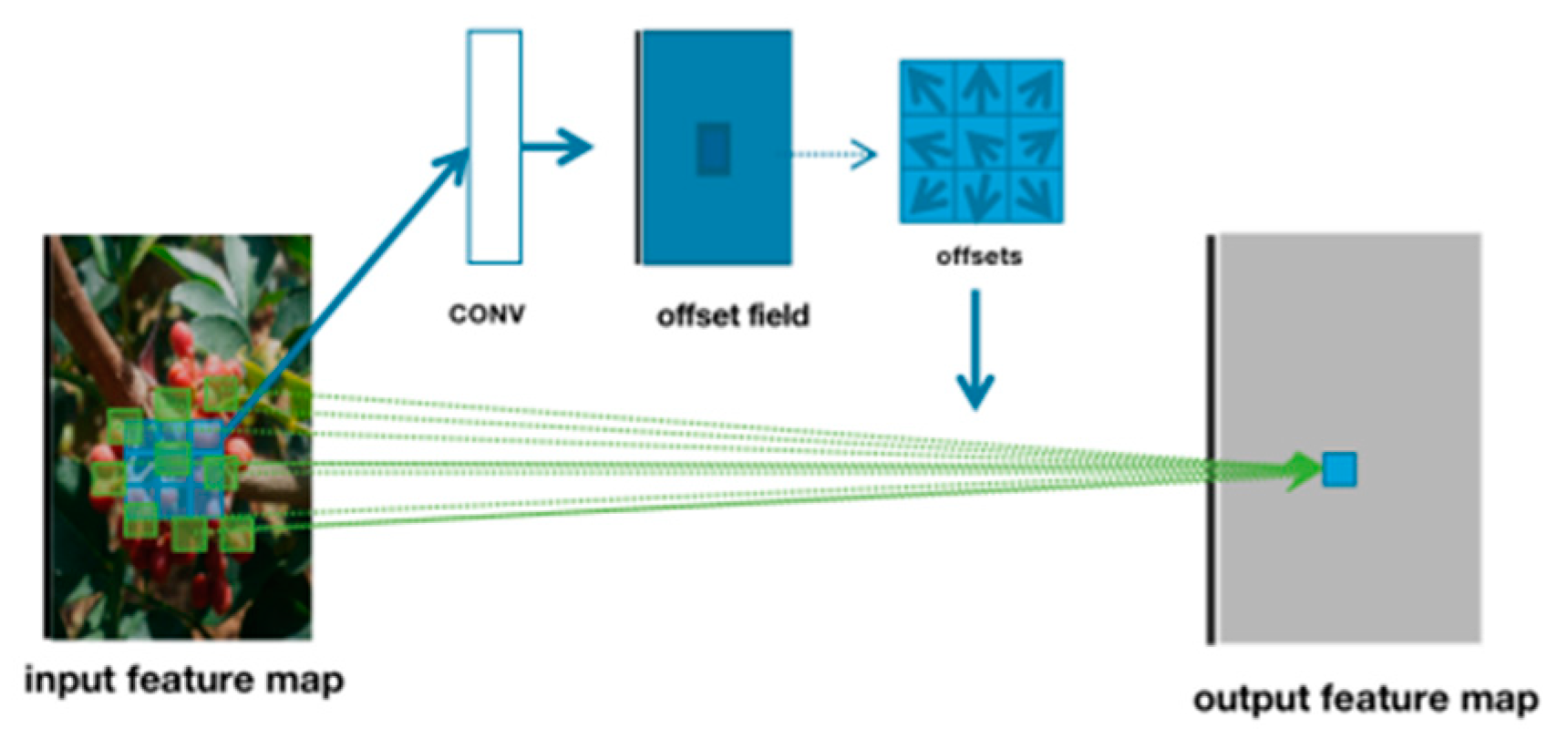
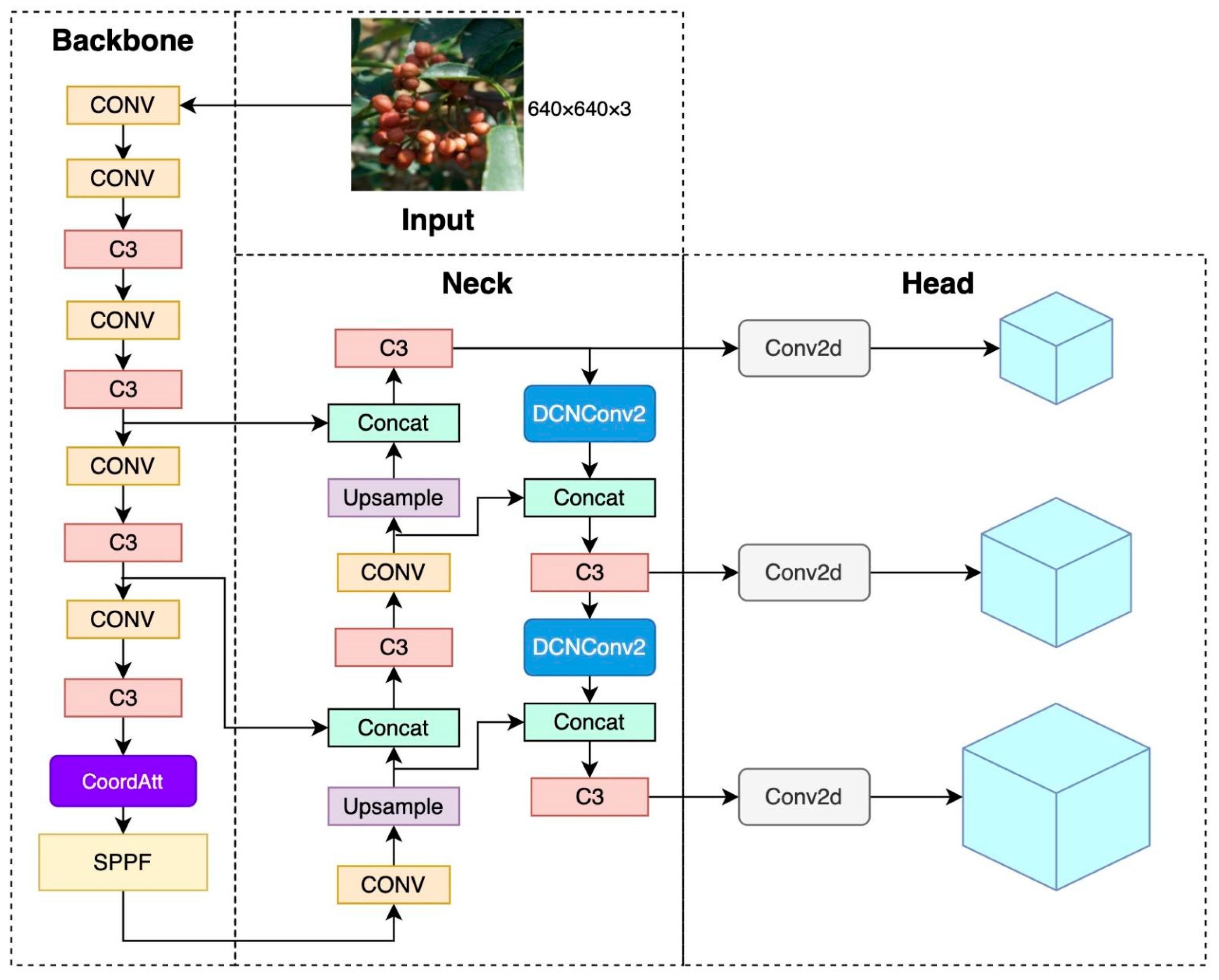
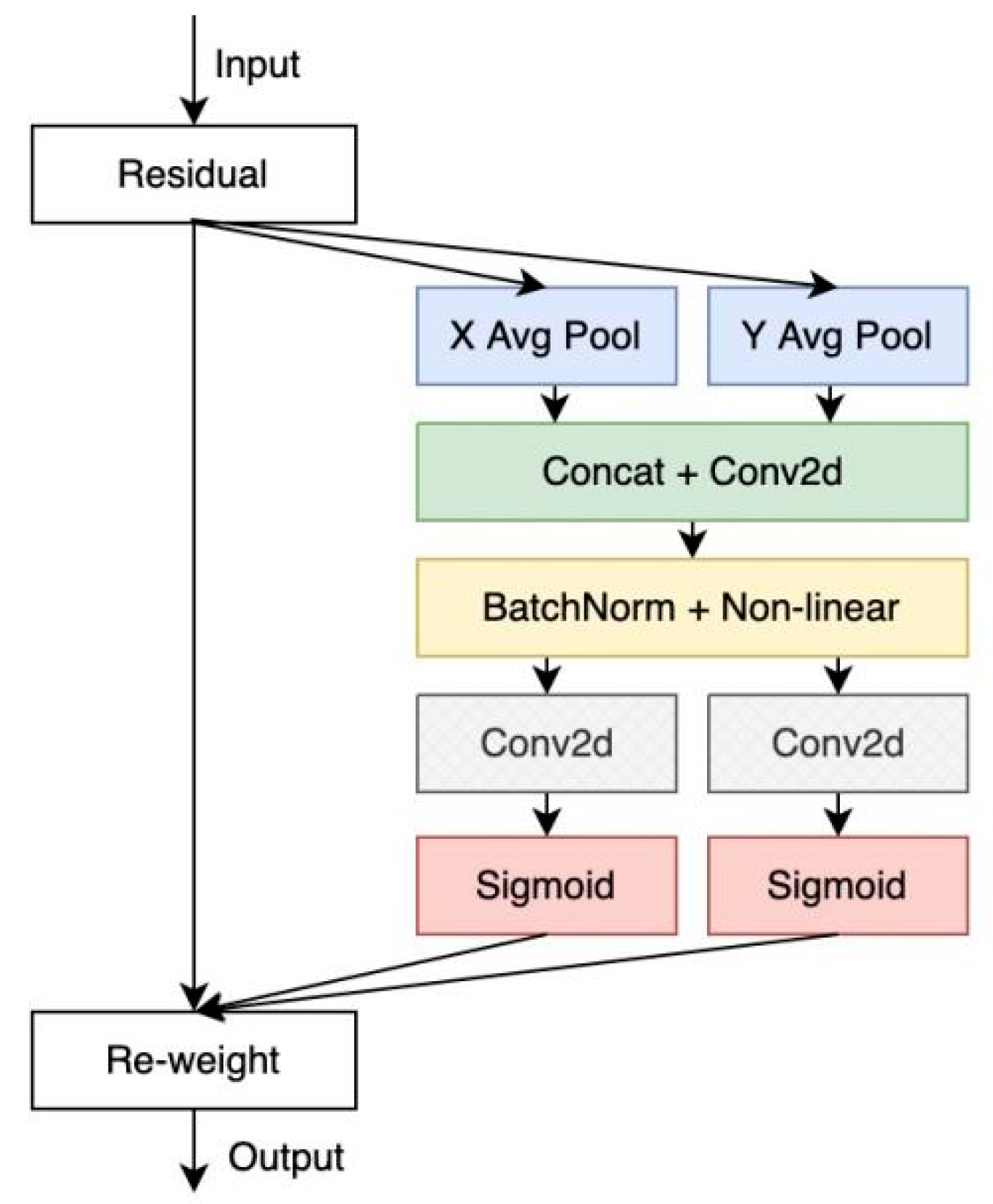
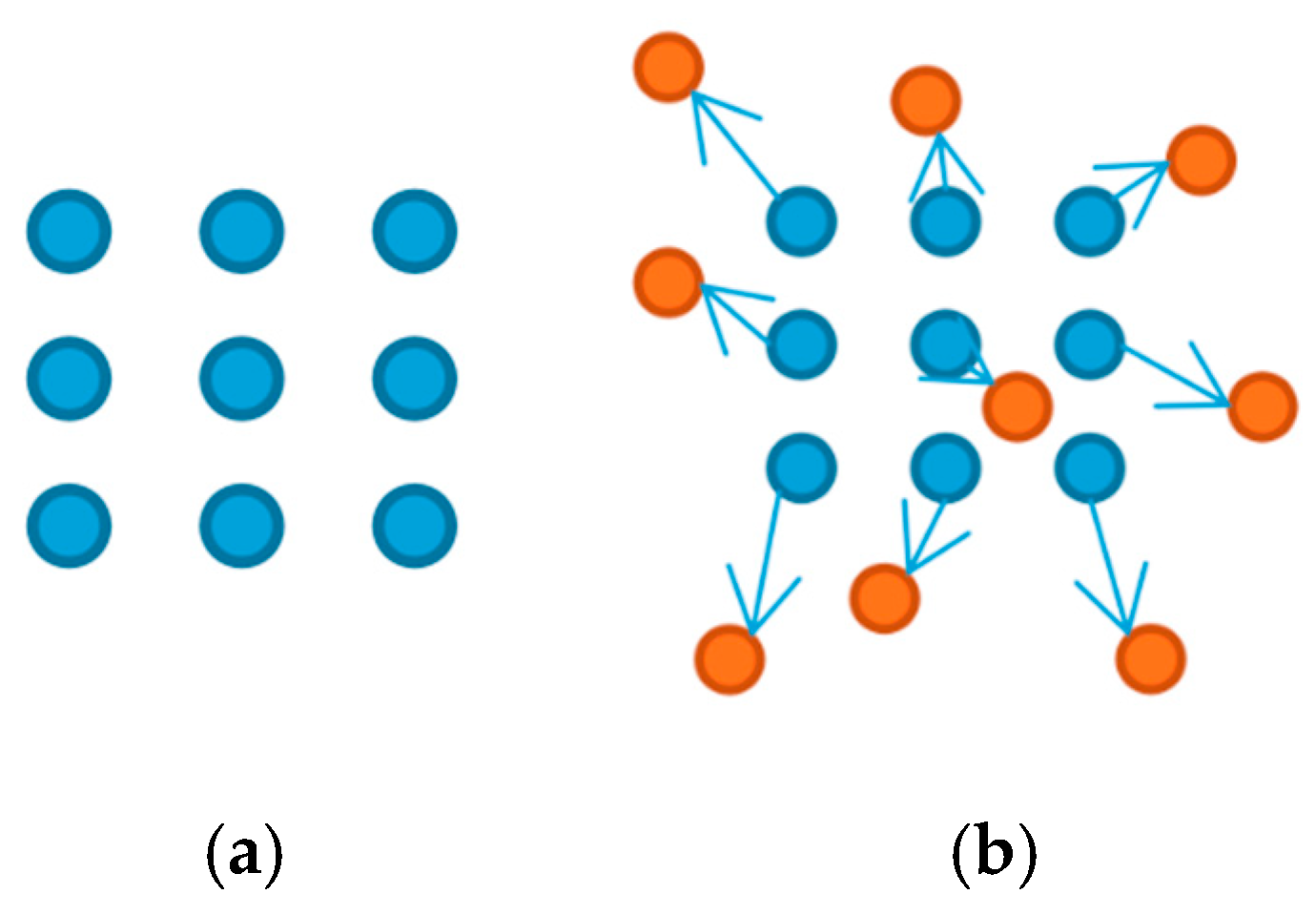
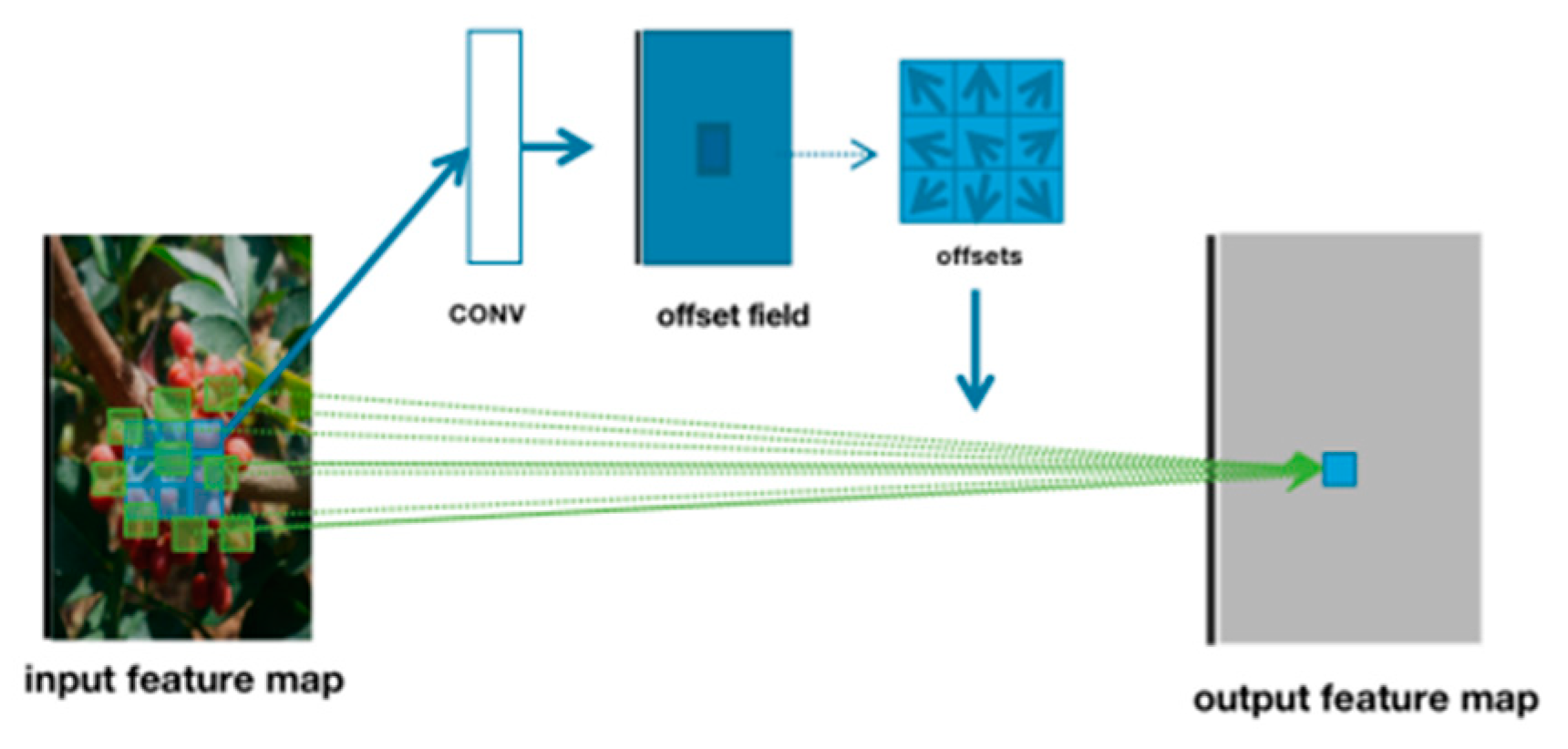
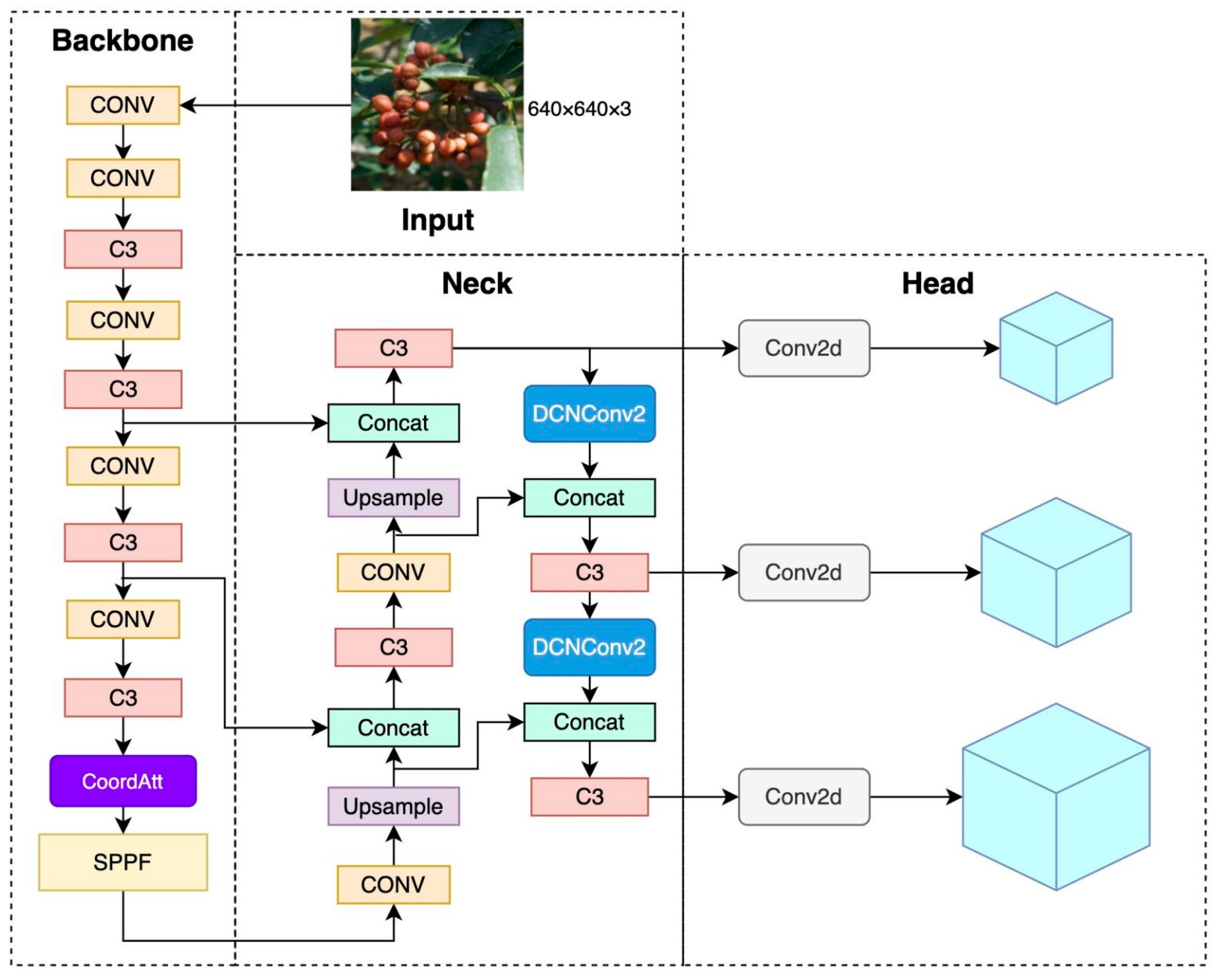
2.3.2. A YOLOv5 Model Incorporating Attention Mechanisms and Deformable Convolutions
3. Experimental Design
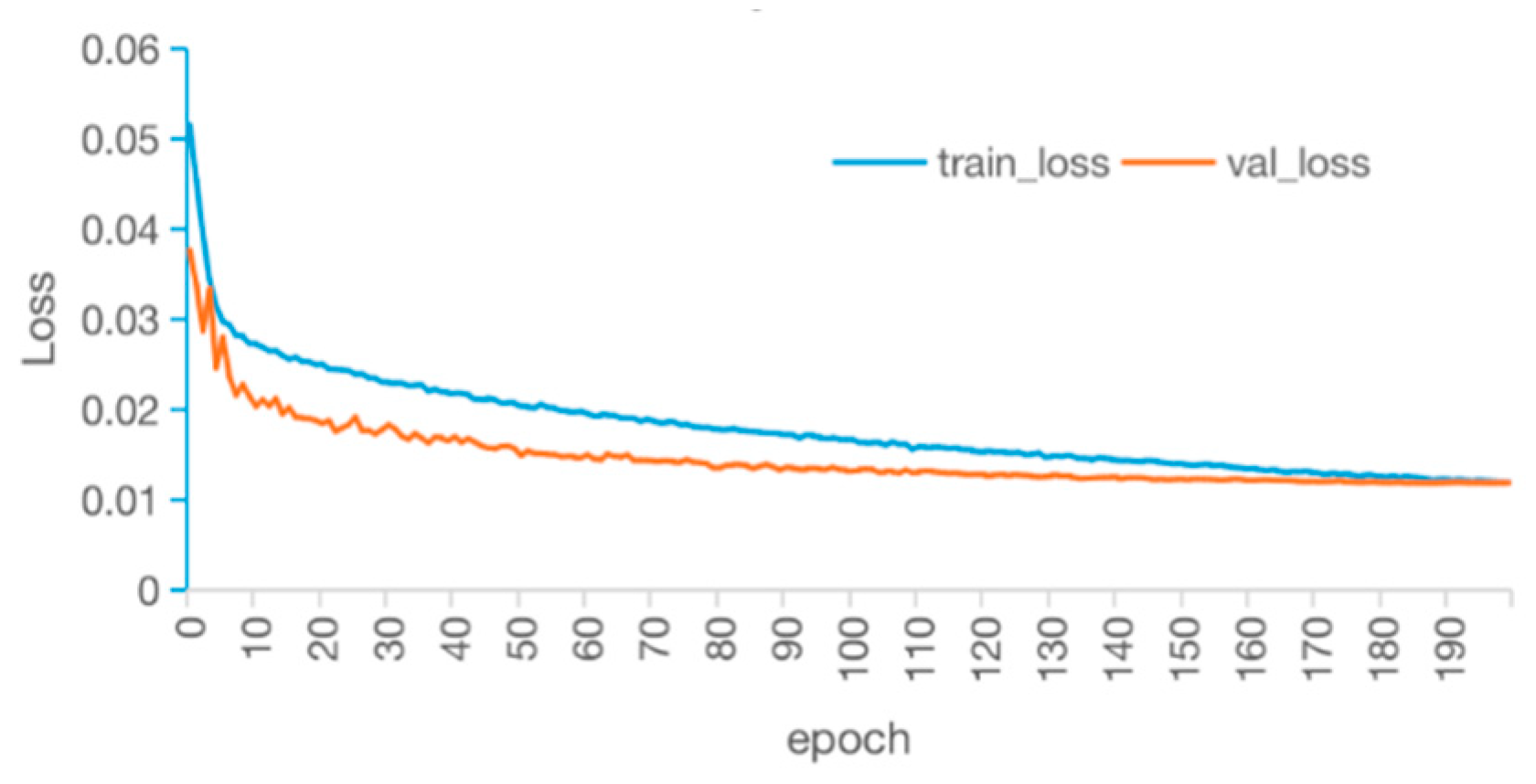
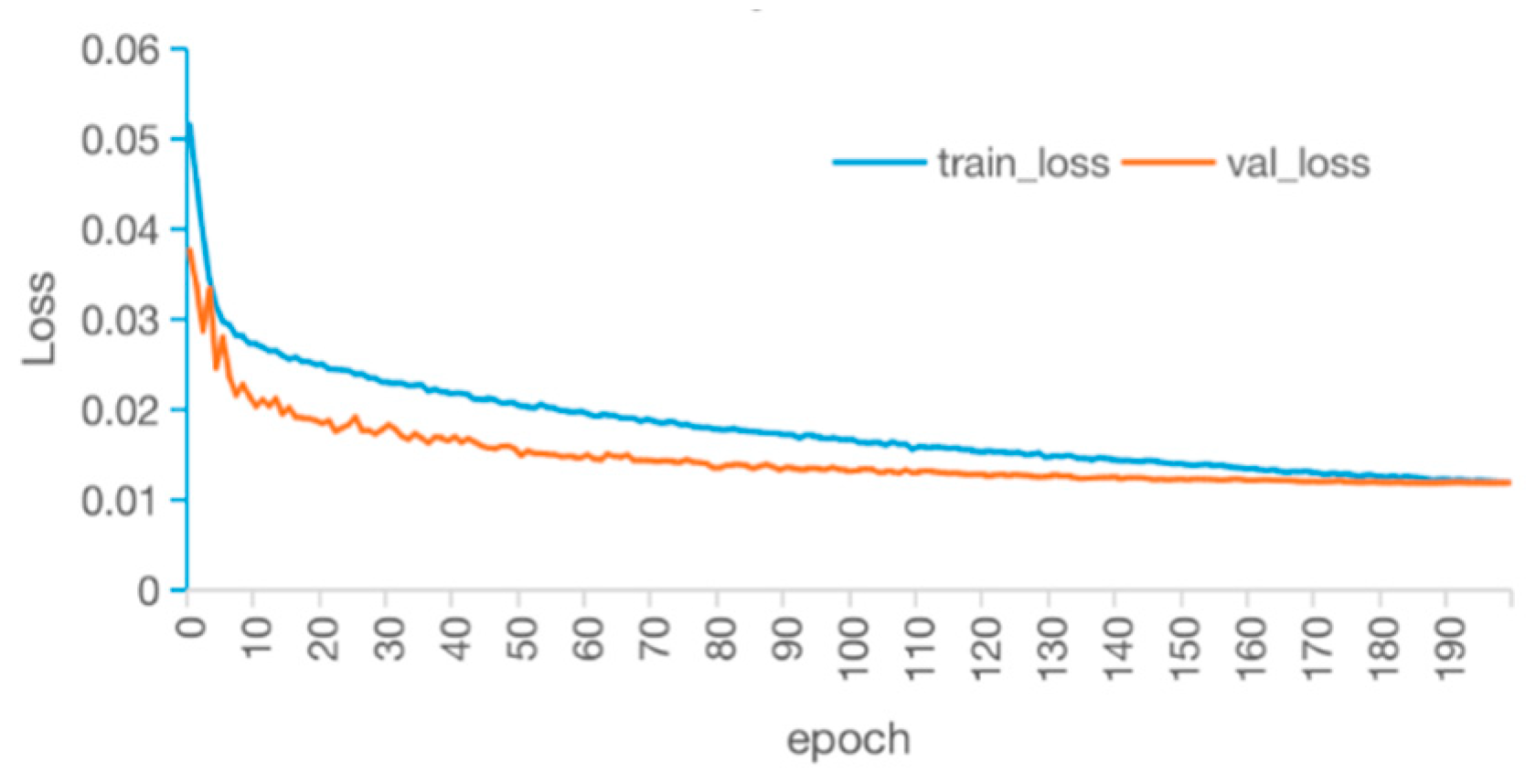
3.1. Model Training
3.1.1. Model Training Parameters
3.1.2. Model Evaluation Index
3.2. Test Platform Construction
4. Results
4.1. Comparative Analysis of Algorithm Optimization Experiment and Results
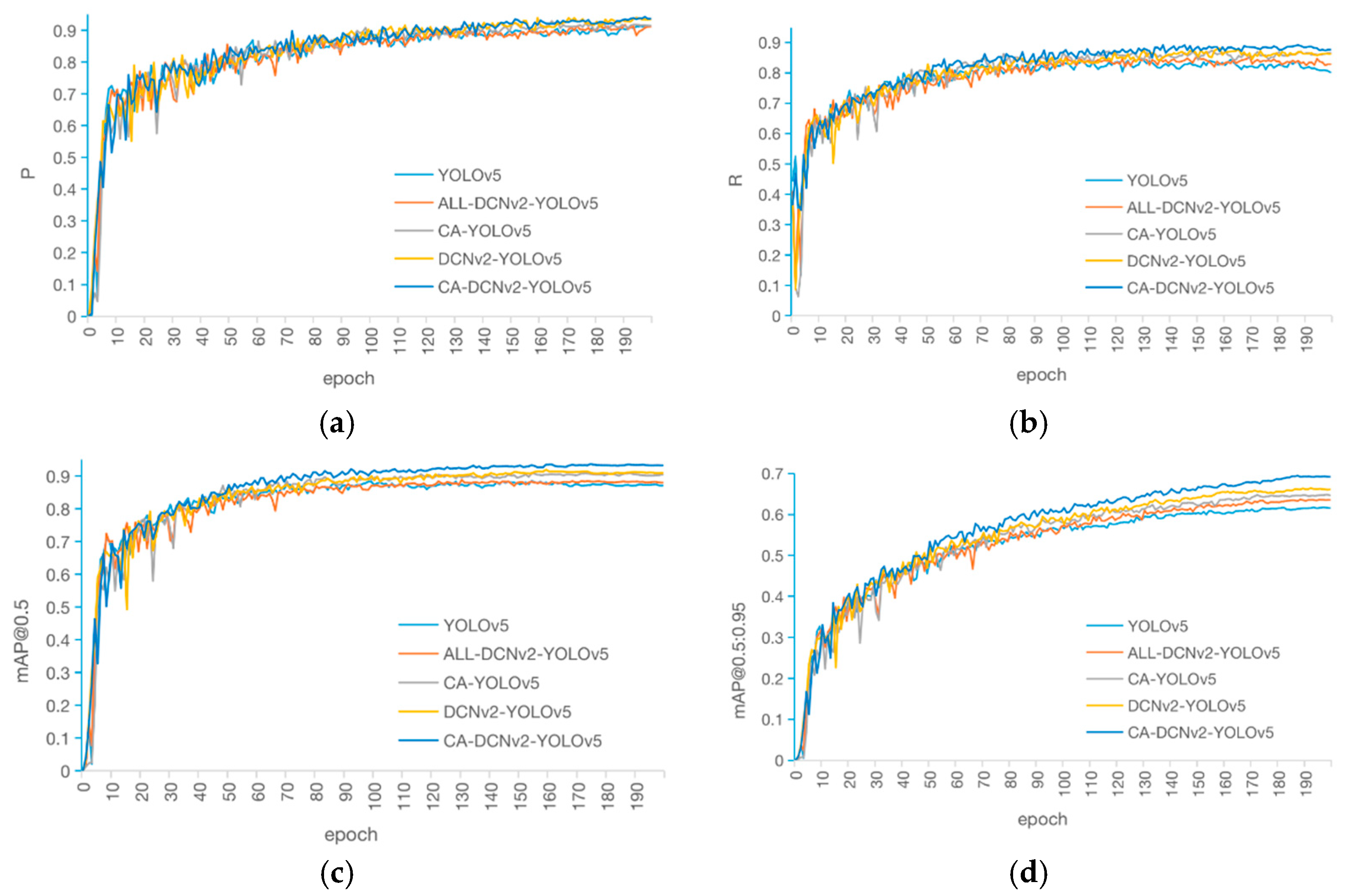
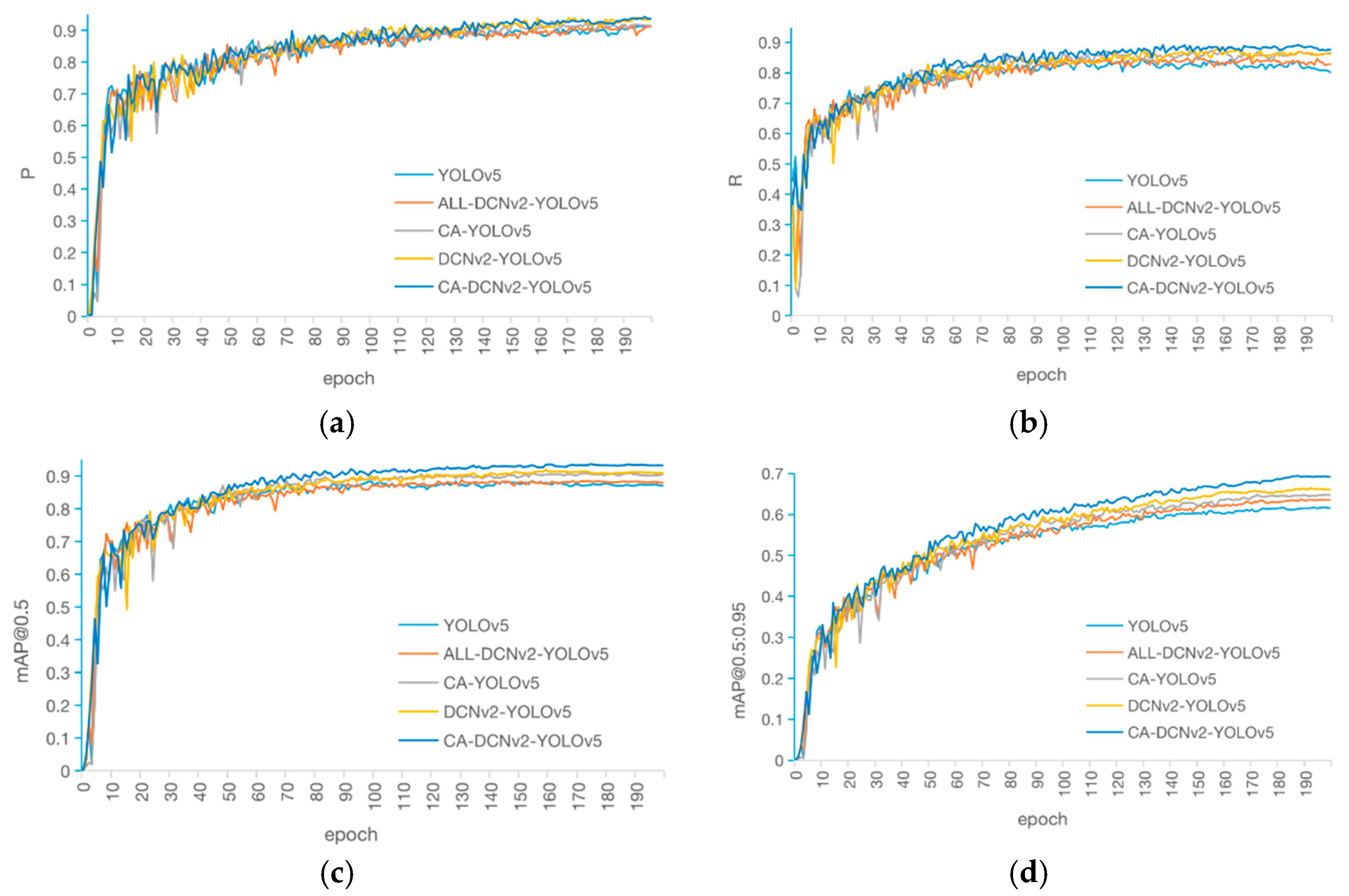
4.1.1. Ablation Study
4.1.2. Comparison of Different Models
4.1.3. Comparison of Model Detection Effect
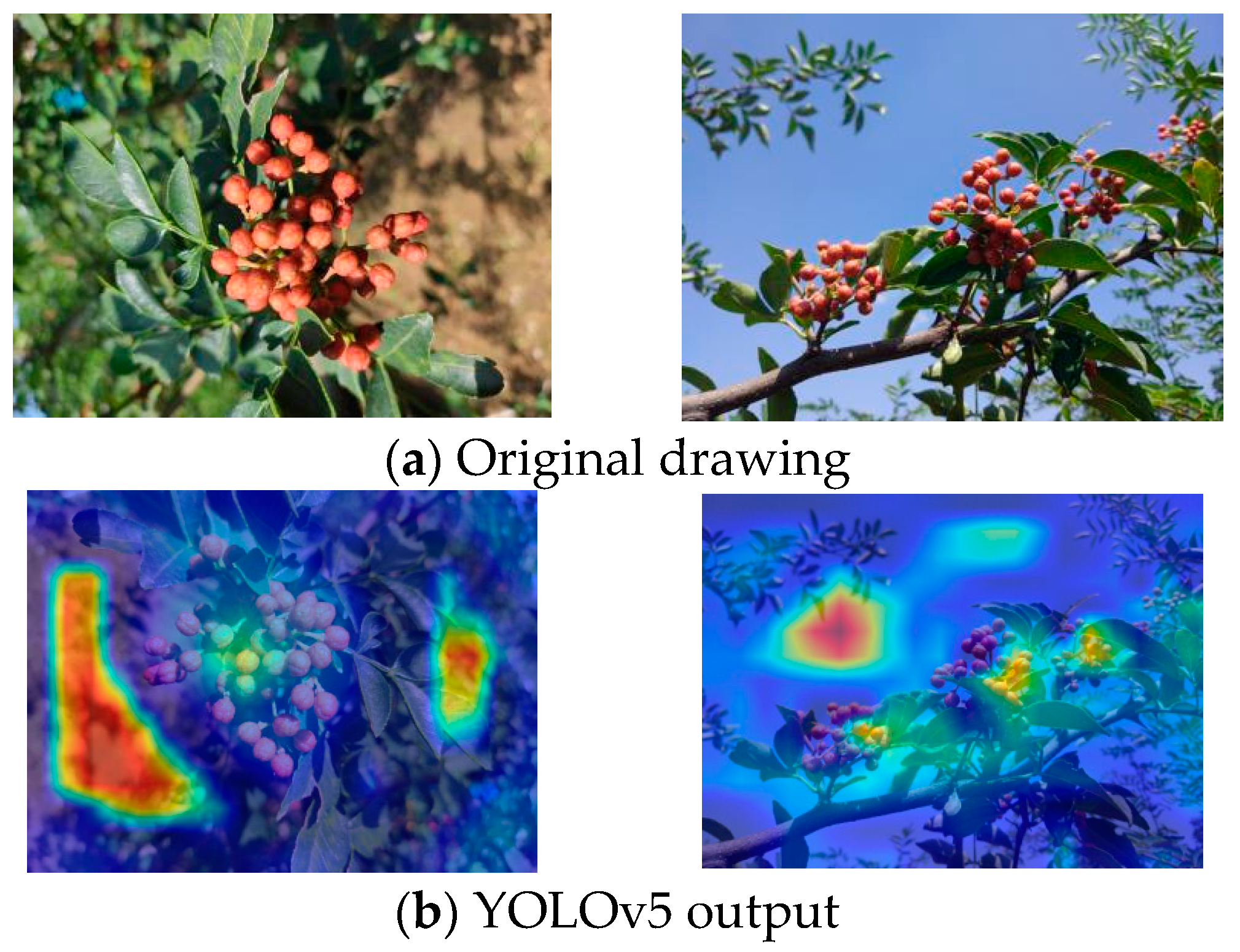
4.1.4. Network Attention Visualization
4.1.5. Model Recognition Performance for Zanthoxylum under Occlusion Conditions
4.2. Field Experiment
5. Discussion
6. Conclusions
- An improved YOLOv5 model was proposed for Zanthoxylum cluster detection in its natural environment by adding the CA attention mechanism module into the backbone network and introducing the deformable convolutional module into the neck. The testing results showed that the improved model had an average accuracy of 93.5% in [email protected] and 69.5% in [email protected]:0.95, which improved by 4.6% and 6.9%, respectively, compared to the original YOLOv5 model, while maintaining the basic detection speed. In addition, the CA-DCNv2-YOLOv5 model proposed in this paper demonstrated a significant performance advantage compared to Faster R-CNN, SSD, and CenterNet.
- The improved YOLOv5 network model was tested on an image dataset that included occlusions of Zanthoxylum. The average precision scores, [email protected] and [email protected]:0.95, improved by 5.4% and 4.7%, respectively, compared to the original YOLOv5 network.
- The improved YOLOv5 network model had a detection speed of approximately 89.3 frames per second on mobile devices, meeting the real-time detection requirements of the Zanthoxylum-harvesting robot.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, K.; Jun, W.; Shang, J.; Li, Y.; Cao, J. Development status and countermeasures of Dahongpao pepper industry in Shantin district, Zaozhuang city. Agric. Dev. Equip. 2021, 6, 47–48. [Google Scholar]
- An, J.; Yang, H.; Lu, W.; Wang, X.; Wang, W. The current situation and development trend of pepper harvesting machinery. Agric. Sci. Technol. Inf. 2019, 6, 57–59. [Google Scholar]
- Li, K. Research and Design of Pepper Harvesting Robot Control System. Master’s Thesis, Lanzhou University of Technology, Lanzhou, China, 2020. [Google Scholar]
- Wan, F.-X.; Sun, H.-B.; Pu, J.; Li, S.-Y.; Zhao, Y.-B.; Huang, X.-P. Design and experiment of comb-air pepper harvester. Agric. Res. Arid. Areas 2021, 39, 219–227+238. [Google Scholar]
- Zheng, T.-Y. Design of electromagnetic pepper harvester. Electr. Autom. 2017, 39, 108–110. [Google Scholar]
- Qi, R.L. Research on Pepper Target Recognition and Positioning Technology Based on Machine Vision. Master’s Thesis, Shaanxi University of Technology, Hanzhong, China, 2020. [Google Scholar] [CrossRef]
- Zhang, J. Target extraction of fruit picking robot vision system. J. Phys. Conf. Ser. 2019, 1423, 012061. [Google Scholar] [CrossRef]
- Tang, S.; Zhao, D.; Jia, W.; Chen, Y.; Ji, W.; Ruan, C. Feature extraction and recognition based on machine vision application in lotus picking robot. In Proceedings of the International Conference on Computer & Computing Technologies in Agriculture, Beijing, China, 27–30 September 2015. [Google Scholar]
- Zhang, Y.M.; Li, J.X. Study on automatic recognition technology of mature pepper fruit. Agric. Technol. Equip. 2019, 1, 4–6. [Google Scholar]
- Yang, P.; Guo, Z.C. Vision recognition and location solution of pepper harvesting robot. J. Hebei Agric. Univ. 2020, 43, 121–129. [Google Scholar] [CrossRef]
- Bai, Q.; Gao, R.; Zhao, C.; Li, Q.; Wang, R.; Li, S. Multi-scale behavior recognition method of cow based on improved YOLOv5s network. J. Agric. Eng. 2022, 38, 163–172. [Google Scholar]
- Hao, J.; Bing, Z.; Yang, S.; Yang, J.; Sun, L. Detection of green walnut with improved YOLOv3 algorithm. J. Agric. Eng. 2022, 38, 183–190. [Google Scholar]
- Cong, P.; Feng, H.; Lv, K.; Zhou, J.; Li, S. MYOLO: A Lightweight Fresh Shiitake Mushroom Detection Model Based on YOLOv3. Agriculture 2023, 13, 392. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, H.; Lawal, O.M.; Lu, X.; Ren, R.; Zhang, S. An Automatic Jujube Fruit Detection and Ripeness Inspection Method in the Natural Environment. Agronomy 2023, 13, 451. [Google Scholar] [CrossRef]
- Phan, Q.-H.; Nguyen, V.-T.; Lien, C.-H.; Duong, T.-P.; Hou, M.T.-K.; Le, N.-B. Classification of Tomato Fruit Using Yolov5 and Convolutional Neural Network Models. Plants 2023, 12, 790. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Peng, J.; Wang, J.; Chen, B.; Jing, T.; Sun, D.; Gao, P.; Wang, W.; Lu, J.; Yetan, R.; et al. Litchi Detection in a Complex Natural Environment Using the YOLOv5-Litchi Model. Agronomy 2022, 12, 3054. [Google Scholar] [CrossRef]
- Cao, Z.; Yuan, R. Real-Time Detection of Mango Based on Improved YOLOv4. Electronics 2022, 11, 3853. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Z.; Luo, L.; Zhu, W.; Chen, J.; Wang, W. SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment. Horticulturae 2021, 7, 492. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement [DB/OL]. arXiv 2018, arXiv:1804.02767v1. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal speed and accuracy of object detection [DB/OL]. arXiv 2020, arXiv:2004. 10934v1. [Google Scholar]
- Yan, B.; Fan, P.; Wang, M.; Shi, S.; Lei, X.; Yang, F. Real-time recognition of apple picking methods based on improved YOLOv5m for harvesting robots. Trans. Chin. Soc. Agric. Mach. 2022, 53, 28–38+59. [Google Scholar]
- Zhang, Z.; Luo, M.; Guo, S.; Liu, G.; Li, S. Cherry fruit detection method in natural scene based on improved YOLOv5. Trans. Chin. Soc. Agric. Mach. 2022, 53 (Suppl. 1), 232–240. [Google Scholar]
- He, B.; Zhang, Y.; Gong, J.; Fu, G.; Zhao, Y. Fast recognition of night greenhouse tomato fruit based on improved YOLO v5. Trans. Chin. Soc. Agric. Mach. 2022, 53, 201–208. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zha, M.; Qian, W.; Yi, W.; Hua, J. A lightweight YOLOv4-Based forestry pest detection method using coordinate attention and feature fusion. Entropy 2021, 23, 1587. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. Comput. Vis. Pattern Recognit. 2017, 9, 334–420. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Park, H.; Paik, J. Pyramid attention upsampling module for object detection. IEEE Access 2022, 10, 38742–38749. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameter |
|---|---|
| CPU | I7-1165G7 |
| Memory | 16GB |
| GPU | RTX2060-6GB |
| System | Ubuntu18.04 |
| Python version | 3.8.13 |
| Pytorch version | 1.12.0 |
| Number | Models | Explain |
|---|---|---|
| 1 | YOLOv5 | YOLOv5s |
| 2 | All-DCNv2-YOLOv5 | The convolutional layers in the backbone network are all replaced with deformable convolutions |
| 3 | CA-YOLOv5 | The CA module is added to the backbone network |
| 4 | DCNv2-YOLOv5 | The neck network introduced DCNv2 |
| 5 | CA-DCNv2-YOLOv5 | The backbone network adds the CA, and the Neck network introduces the DCNv2 |
| 6 | Faster R-CNN | A typical two-stage detection algorithm |
| 7 | SSD [39] | A typical one-stage detection algorithm |
| 8 | CenterNet [40] | A typical one-stage detection algorithm |
| Number | F1 Score | [email protected]/% | [email protected]:0.95/% | Speed/(Frame/s) | Model Size/(M) |
|---|---|---|---|---|---|
| 1 | 0.86 | 88.9 | 62.6 | 97.1 | 14.5 |
| 2 | 0.87 | 88.3 | 63.6 | 82.7 | 14.7 |
| 3 | 0.89 | 90.4 | 64.8 | 97.1 | 14.8 |
| 4 | 0.90 | 91.1 | 66.4 | 95.2 | 14.6 |
| 5 | 0.91 | 93.5 | 69.5 | 95.2 | 14.7 |
| Model | F1 Score | [email protected]/% | [email protected]:0.95/% | Speed/(Frame/s) | Model Size/(M) |
|---|---|---|---|---|---|
| CA-DCNv2-YOLOv5 | 0.91 | 93.5 | 69.5 | 95.2 | 14.7 |
| Faster R-CNN | 0.85 | 85.9 | 55.9 | 16.0 | 113.4 |
| SSD | 0.76 | 79.6 | 40.6 | 98.9 | 95.5 |
| CenterNet | 0.69 | 77.8 | 38.5 | 81.1 | 131 |
| Models | [email protected]/% | [email protected]:0.95/% |
|---|---|---|
| YOLOv5 | 86.5 | 58.9 |
| CA-DCNv2-YOLOv5 | 91.9 | 63.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Xiao, X.; Miao, J.; Tian, B.; Zhao, J.; Lan, Y. Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model. Agriculture 2023, 13, 821. https://doi.org/10.3390/agriculture13040821
Guo J, Xiao X, Miao J, Tian B, Zhao J, Lan Y. Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model. Agriculture. 2023; 13(4):821. https://doi.org/10.3390/agriculture13040821
Chicago/Turabian StyleGuo, Jinkai, Xiao Xiao, Jianchi Miao, Bingquan Tian, Jing Zhao, and Yubin Lan. 2023. "Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model" Agriculture 13, no. 4: 821. https://doi.org/10.3390/agriculture13040821
APA StyleGuo, J., Xiao, X., Miao, J., Tian, B., Zhao, J., & Lan, Y. (2023). Design and Experiment of a Visual Detection System for Zanthoxylum-Harvesting Robot Based on Improved YOLOv5 Model. Agriculture, 13(4), 821. https://doi.org/10.3390/agriculture13040821