1. Introduction
Tomato is one of the most representative crops widely planted in China. Due to the characteristics of tomato planting, it is inevitable to encounter diseases in the process of tomato growth. The impact of various diseases is one of the reasons for tomato yield loss. To avoid the serious economic losses caused by tomato yield loss, early diagnosis is an efficient way to prevent the spread of tomato disease. Therefore, early and accurate diagnosis of tomato diseases is of utmost importance to tomato yield increase and national economic development.
In the old days, the main early diagnosis method of tomato disease was visual examination. However, this method relies on the professional diagnosis experts, non-specialists are highly prone to error while analyzing diseases. Owing to the visual disparity on leaves in the early stage of tomato diseases, analyzing diseases by computer vision is a reliable method for early diagnosis. Over the past decade, a significant amount of research has addressed various methods for tomato disease classification in computer vision systems. These methods measured the discrepancy of leaf images by feature extraction, then visualized the differences with reproducible results. Prior to diagnosis, approaches of computer vision focused on the manual feature extraction. Ropelewska et al. [
1] extracted the texture parameters to discriminate the cultivars of tomatoes. Several classical machine learning methods, such as HoeffdingTree and BayesNet, were also proved to be effective in classification [
2]. The limitation of manual feature extraction methods is the dependence of a reasonable feature-design algorithm. To overcome this challenge, deep learning methods have attracted considerable interest in research, due to their convenience of extracting features from huge data sets instead of hand-crafted features. In addition to the advantage mentioned above, it indicates that deep learning methods could also offer a better accuracy performance [
3,
4,
5].
As one kind of deep learning method, the convolutional neural network (CNN) is inspired by the animal visual cortex, primarily employed for object recognition. Various CNN architectures are proposed and improved for specific tasks. In the field of tomato disease classification, Tm et al. [
6] proposed a CNN classification method to diagnose tomato disease, it offered a better performance than classical machine learning methods. Tan et al. [
7] also compared deep learning methods with classical machine learning methods in tomato disease classification, the experiments of their research indicated that deep learning networks were all better than measured machine learning algorithms. Rangarajan et al. [
8] improved diagnosis precision by applying transfer learning methods on CNN. The attention mechanism has proved to be effective for CNN. The attention-based CNN architectures are proposed in order to provide high-performance discrimination of tomato disease [
9]. Several CNN architectures are designed by lesser parameters [
10], these light-weight CNN architectures could be applied on mobile devices for real-time tomato disease diagnosis.
Most of the previous deep learning methods for tomato disease classification focused on verifying by independent identical distribution (IID) samples, i.e., both the training samples and the testing samples are divided from the same original dataset. However, in real-world diagnosis tasks, the testing dataset tends to be infinite, and most testing samples are provided with out-of-distribution (OOD) samples. The existing study neglected the generalization of the model. The accuracy performance of these proposed state-of-the-art methods may drop steeply when testing by OOD samples, such as images with serious noises or samples from another dataset. The issues mentioned above have attracted a lot of attention from several research as well. Kc et al. [
11] explored the method of VGG architecture could achieve an accuracy of 99.53% on public datasets but dipped to 33.27% in real-world detection tasks. Qiao et al. [
12] observed the accuracy of classification on a database of the Mixed National Institute of Standards and Technology (MNIST) would decrease significantly from 100% to 27.83% by replacing the validation set with Street View House Number (SVHN) dataset. The challenge of OOD generalization must be overcome before deep-learning classification methods translate into practice.
An OOD sample refers to a sample with a significant distribution discrepancy with other samples in its category. In computer vision, the factors which cause the discrepancy include but are not limited to background shifts, corruption shifts, texture shifts and style shifts [
13]. Background shifts mean the change of background, which may bias the prediction of a deep learning method [
14]. Corruption shifts stand for the vicinal impurities mixed in samples, which are caused by different shooting equipment, photograph conditions (i.e., illumination) or image processing (i.e., segmentation) [
15]. Texture shifts refer to the destruction of texture features [
16]. Style shifts often reflect in multiple concept changes such as transforming the image of a real object to a cartoon or painting style [
17]. The OOD Generalization ability of a deep learning classification method is measured by the IID/OOD generalization gap [
18], which can be defined as
where
is the input image and
is the corresponding label.
and
represent the classifier and feature encoder.
,
denote the number of IID and OOD data and
,
.
is the indicator function.
In the real-world diagnosis of tomato disease, background shifts and corruption shifts are relatively common. There have been many methods proposed for background shifts, i.e., image segmentation is an efficient method to improve the generalization performance of background shifts [
19,
20,
21]. However, the work of corruption shifts generalization for tomato disease classification is still at a conceptual stage. Therefore, the major challenge of tomato disease OOD detection is to improve the generalization performance of corruption shifts.
Corruption shifts mainly incorporate image noise, image blur, weather change and digital transformation [
22], all these issues are frequently encountered while diagnosing tomato disease by image in the real world. Recent works for corruption shift generalization focused on data augmentation, domain alignment and adversarial training methods. Data augmentation methods create a larger training set by transformed images [
23] or generative adversarial networks (GAN) images [
24]. The limitation of these methods is the domain of the test dataset tends to be infinite when the model is applied in the real world. It is impossible to expand the training set to contain all the unknown domains. The purpose of domain alignment is to align the distribution of the source domain and target domain [
25]. This method needs to obtain the distribution of target domain samples. However, the distribution of target domain samples is actually unknown in the real world. Adversarial training methods apply perturbation to the training process in order to improve the robustness of the deep learning model. These methods could achieve better prediction performances than standard training approaches on OOD samples [
26,
27,
28]. Nevertheless, compared to standard training approaches, these adversarial training methods perform poorly on IID samples [
29].
In this article, we investigate the corruption shifts generalization of CNN to propose a method for OOD tomato disease classification. The proposed method could improve the classification performance of corruption shifts samples while retaining the high-accuracy performance of the original images. Our main contributions are summarized as follows:
To the best of our knowledge, this is the first study to investigate the corruption shifts’ generalization of tomato disease classification.
We investigated the impacts of attention mechanism on generalization improvement. The channel attention mechanism is improved by using multiple low-frequency components instead of the lowest frequency component. Moreover, depth convolution is applied to reduce the complexity of the mechanism.
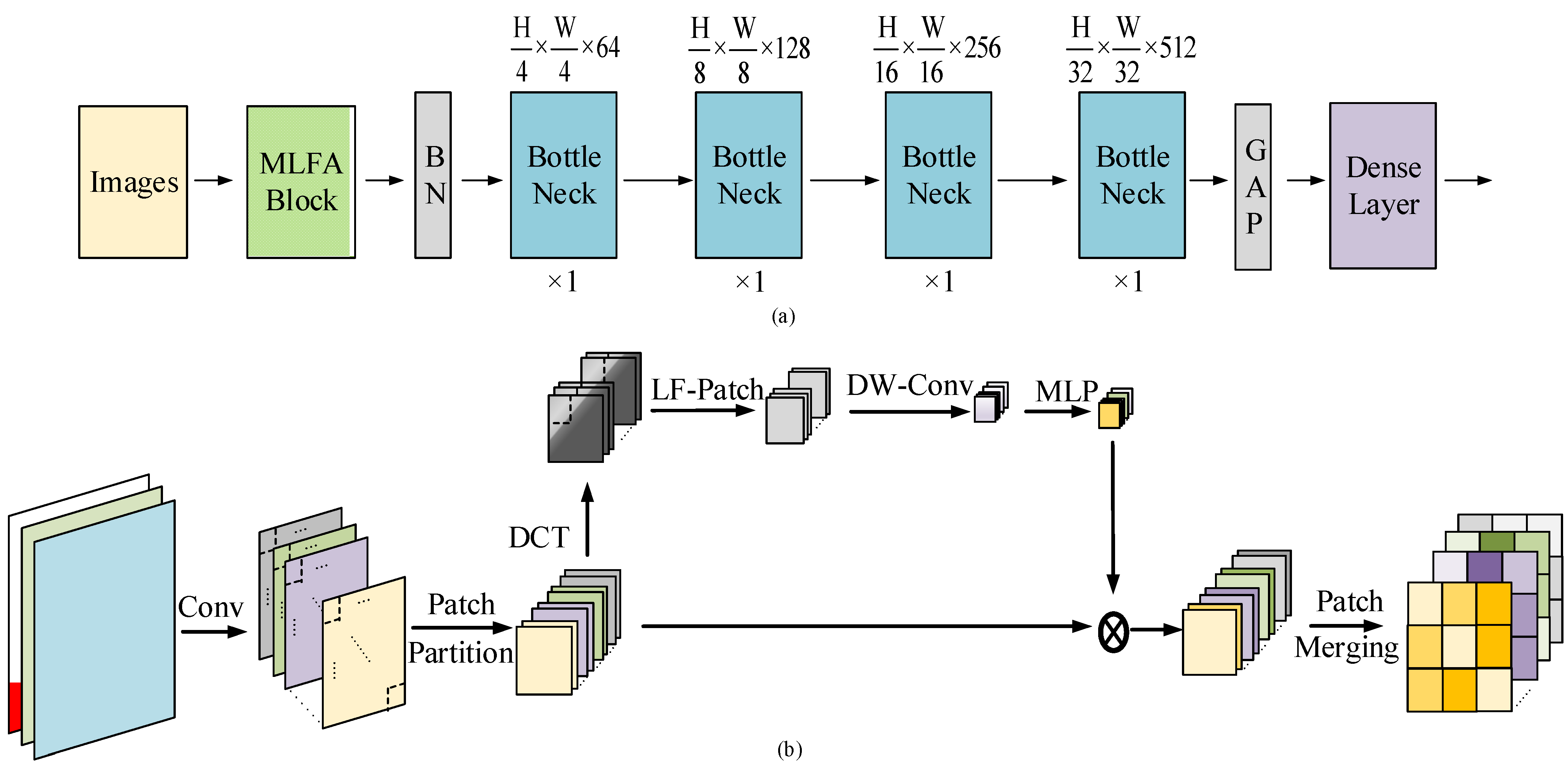
A CNN architecture named multiple low-frequency attention network (MLFAnet) is proposed for tomato disease classification. The experiment result demonstrates that the proposed architecture could consistently improve the performance of generalization ability.
This paper is organized as follows. After the introduction,
Section 2 introduces the dataset, the principle of the method, the proposed MLFA block and the architecture of the proposed MLFAnet.
Section 3 designs the experiments. Then, the results of
Section 3 are discussed in
Section 4. Finally,
Section 5 makes a conclusion of the study.
4. Discussion
The experiment results in
Section 3.1 indicated that for tomato disease classification, both architectures with small-number layers (ResNet-18, VGG-11) and architectures with large-number layers (ResNet-152, VGG-19) could achieve high degrees of accuracy on original samples. As the high-frequency components decreased, the prediction accuracy of low-frequency reconstructed samples reduced more dramatically for the model with large-number layers. It indicated that a deeper model would be biased to neglect the low-frequency components. Low-frequency components are significant to the model’s generalization performance, this discovery could be applied to design a more efficient CNN architecture with reasonable layer depth.
In
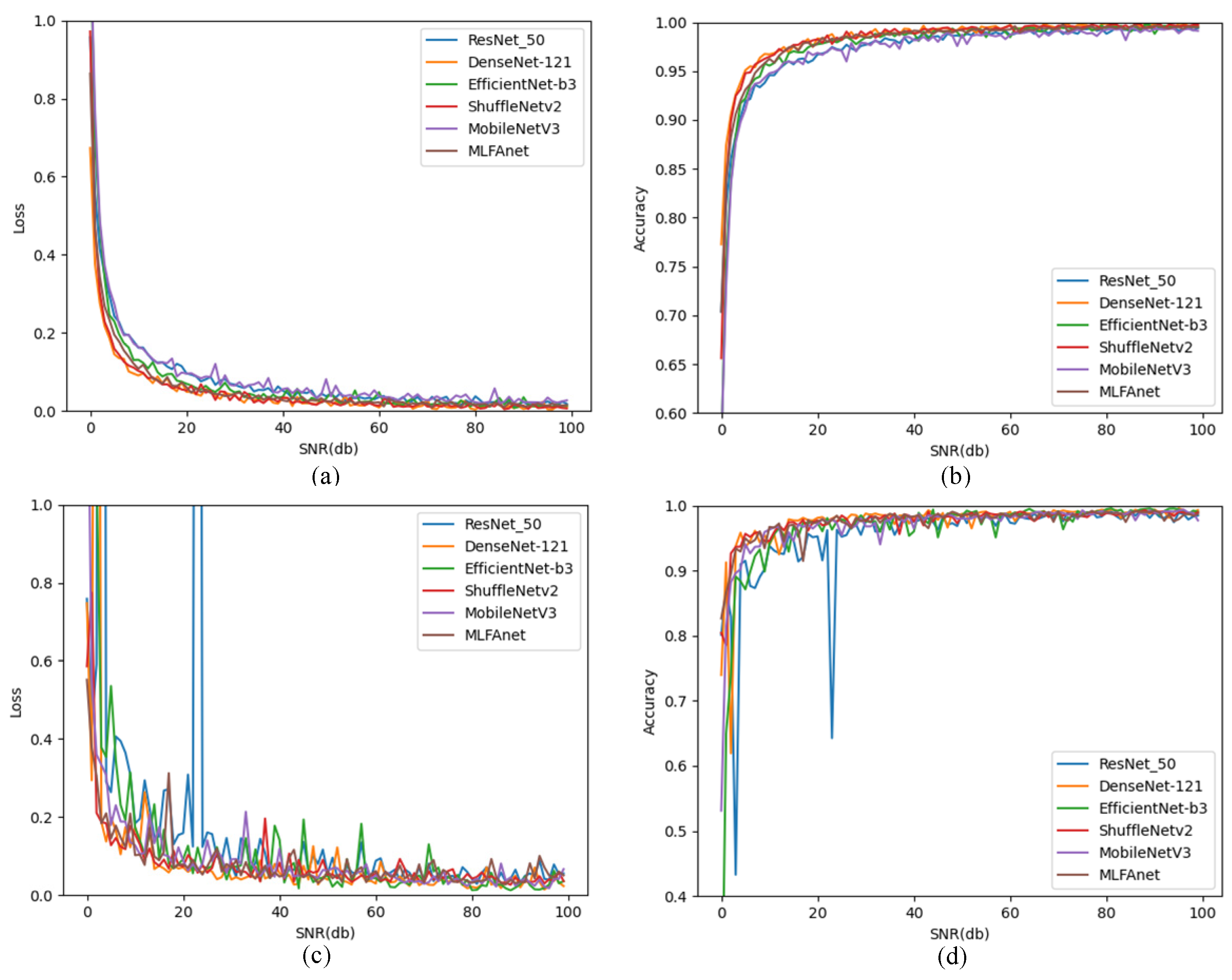
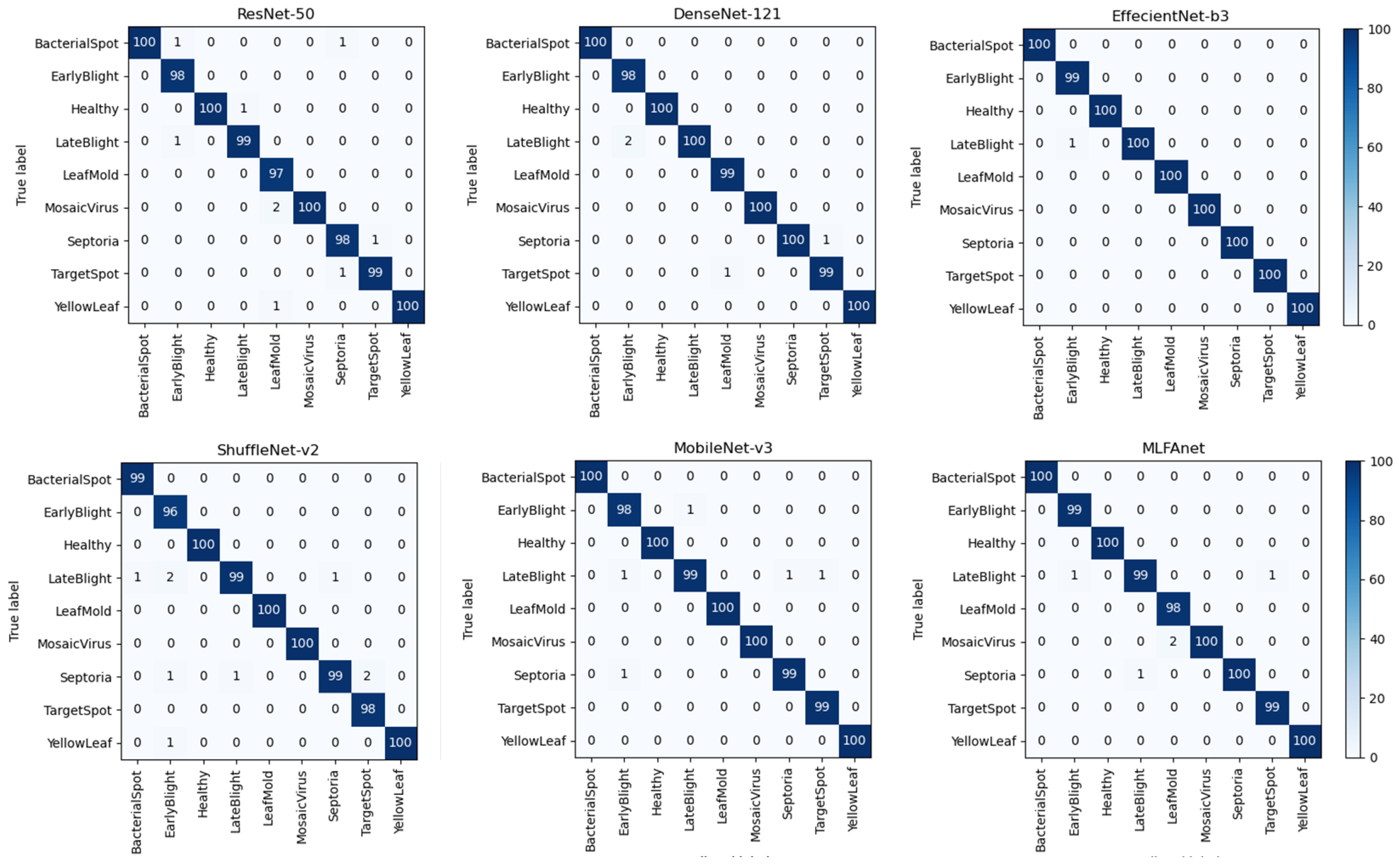
Section 3.2, the accuracy performances indicated that EffecientNet-b3 architecture, which achieved the highest accuracy rate (99.9%) in the original testing set, performed best on the IID tomato disease classification task. The other architectures, with accuracies of more than 99%, achieved excellent classification performance on IID testing samples as well. However, on corruption shifts samples of CLT set, the accuracy performances break down dramatically. It can be calculated in
Table 4 and
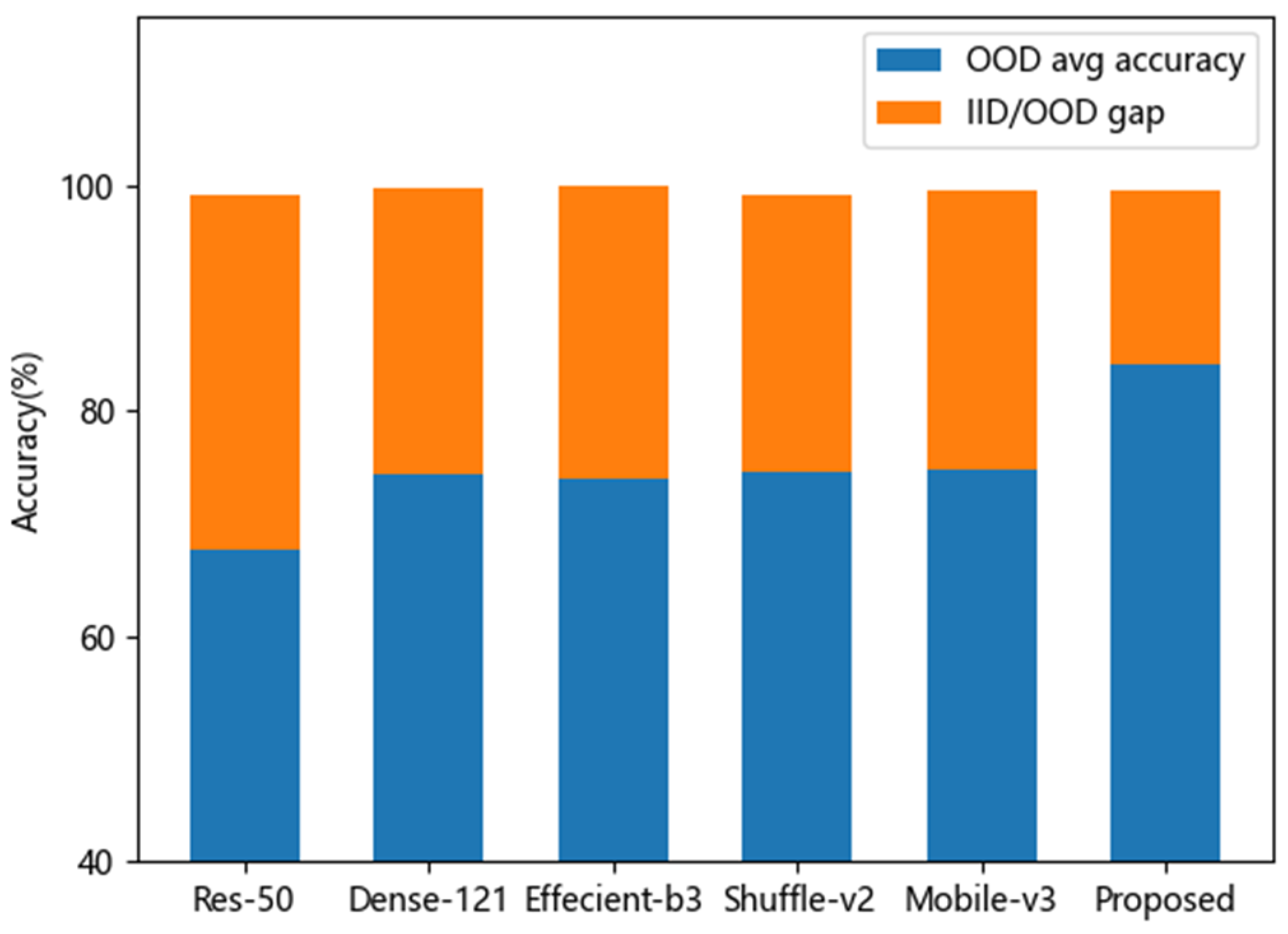
Table 5 that the average accuracy result of EffecientNet-b3 was 74.0%. The generalization gap was 25.9% (the difference value of 99% and 74.0%). The proposed MLFAnet achieved an average accuracy of 84.0% on corruption shifts samples, and the better generalization gap performance was 15.4%. To easily compare the generalization ability between different architectures, visual representations were shown in
Figure 8.
Based on
Figure 8, we could have the following observations. First, the average accuracy performance of our proposed method on corrupted samples classification was better than other conventional CNN architecture, as shown by the blue histogram. Second, the method had a better generalization performance because it achieved the smallest generalization gap, while the accuracy on original IID samples was almost identical to others, as shown by the orange histogram. It illustrates that the prediction model we proposed for tomato disease, which has a stronger generalization ability on corruption shifts samples, is a better fit than previous studies in practical application.
We further explored why our model achieved a strong generalization ability.
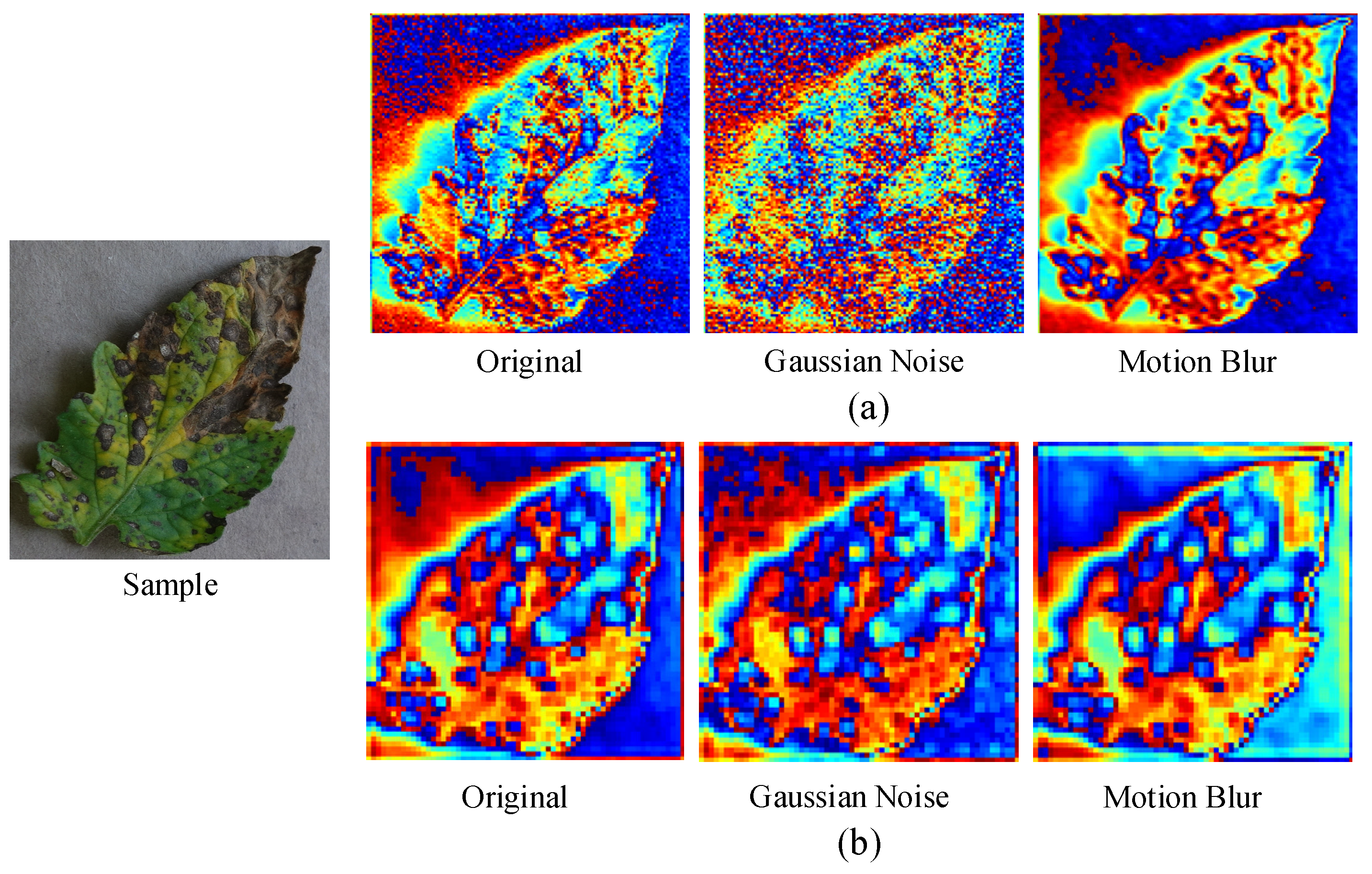
Figure 9 showed the feature maps of the original sample and corruption shifts samples. The kinds of corruption were Gaussian noise and motion blur. The features were the first convolution layer outputs of conventional ResNet-50 architecture and the proposed MLFAnet architecture. It observed that feature maps extracted by ResNet-50 changed sharply as the samples were corrupted by Gaussian noise and motion blur. On the contrary, the diversity among the feature maps was less under the proposed MLFAnet architecture. The example demonstrated that the feature extractor of MLFAnet was more robust on corruption shifts. It helped to improve the accuracy performance of the classifier on corruption shifts samples.
Comprehensive experiments showed that the MLFAnet performed well on benchmarks of corruption shift generalization. Furthermore, the prediction of noise and blur corruption shifts samples, in particular, had a dramatically improved. It indicated that the MLFAnet may provide support for the real-world diagnosis of tomato disease, i.e., it can diagnose the disease accurately from a blur leaf image which is captured by a shaking camera or a moving device. However, when the leaf images are affected by weather corruption and contrast transformation, the classification performance of MLFAnet is not outstanding. It shows that accurate diagnosis of MLFAnet is limited in complex weather conditions.
5. Conclusions
In this work, we investigated the OOD generalization of CNN architectures and proposed an efficient classification method for tomato disease. The method with a better capacity of generalization could diagnose tomato disease more accurately from corruption shifts images while retaining the satisfying classification performance of original images.
From our study and simulation results, we may obtain the following conclusions: (1) CNN may degrade the generalization ability while focusing on high-frequency components. (2) For a basic classification task, such as tomato disease with nine categories, the accuracy precision on IID samples of a shallow CNN architecture is similar to that of DCNN models. However, shallow-layer CNN architecture has a better OOD generalization performance. (3) Results verify the hypothesis that attention mechanisms are capable of improving the generalization performance of deep CNN models. For these reasons, an improved attention algorithm was proposed by calculating the weight of feature maps with multiple low-frequency components, and it has been demonstrated the effectiveness of corruption shifts generalization. Moreover, we provided an efficient CNN method named MLFAnet to improve the generalization on the diagnosis of tomato disease. An interesting question to make further progress would be verifying the effectiveness of MLFAnet on other fruits or vegetables. Though we consider our proposed method is based on a general CNN system, it can be applied to most of the image classification tasks with a high probability. However, extra work and experiments should be designed to prove it for further study.
Our work on corruption shifts sample generalization could scale to the real-world problem, which is left for future investigation.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}