
A Back Propagation Neural Network Model for Postharvest Blueberry Shelf-Life Prediction Based on Feature Selection and Dung Beetle Optimizer

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials and Experimental Program
2.2. Measurement of Quality Indicators for Blueberries during Shelf Life
2.2.1. Color Characteristics
2.2.2. Weight Loss Rate
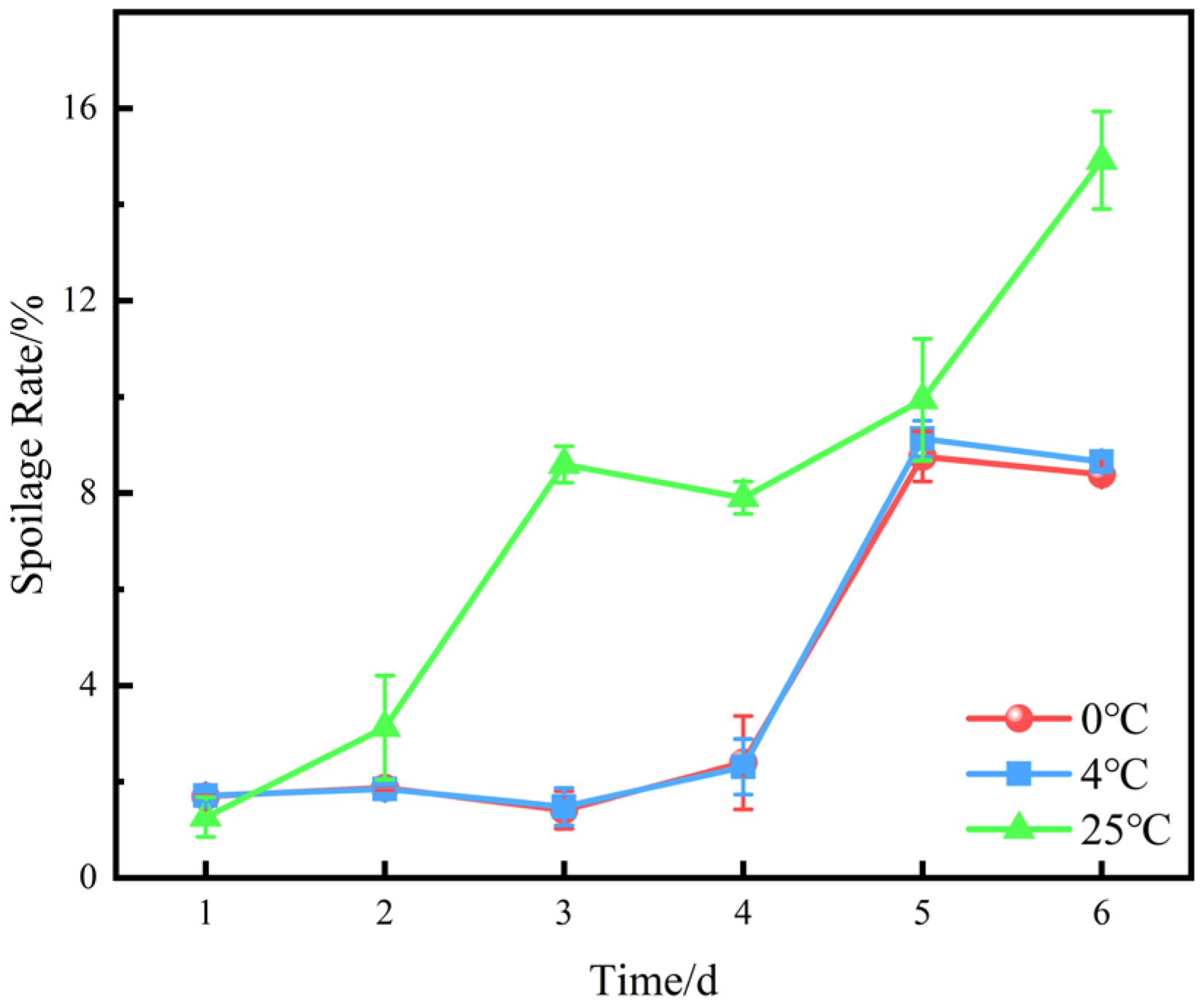
2.2.3. Spoilage Rate
2.2.4. Diameter, Length, and Fruit Shape Index
2.2.5. Texture Parameters
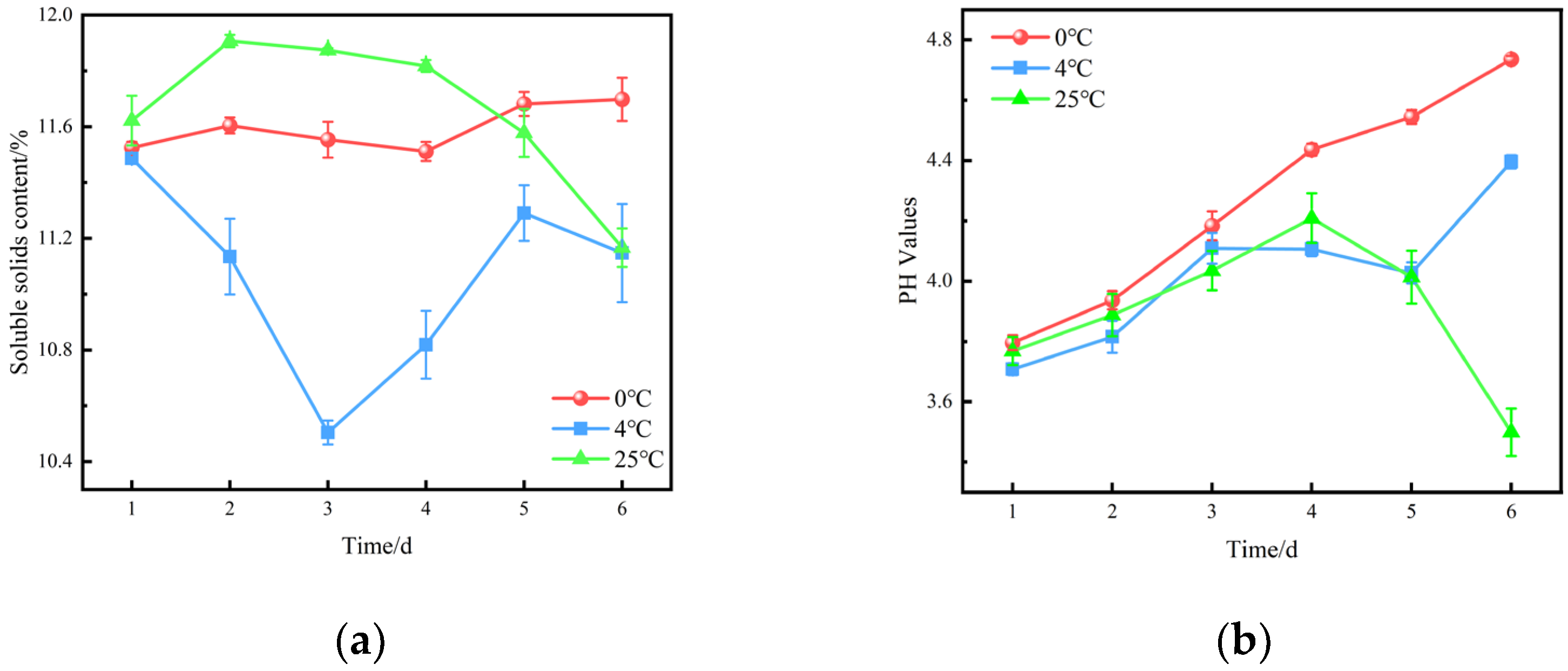
2.2.6. Soluble Solids Content, Titratable Acid Content, and Solid to Acid Ratio
2.2.7. PH Values
2.2.8. Vitamin C
2.2.9. Anthocyanins
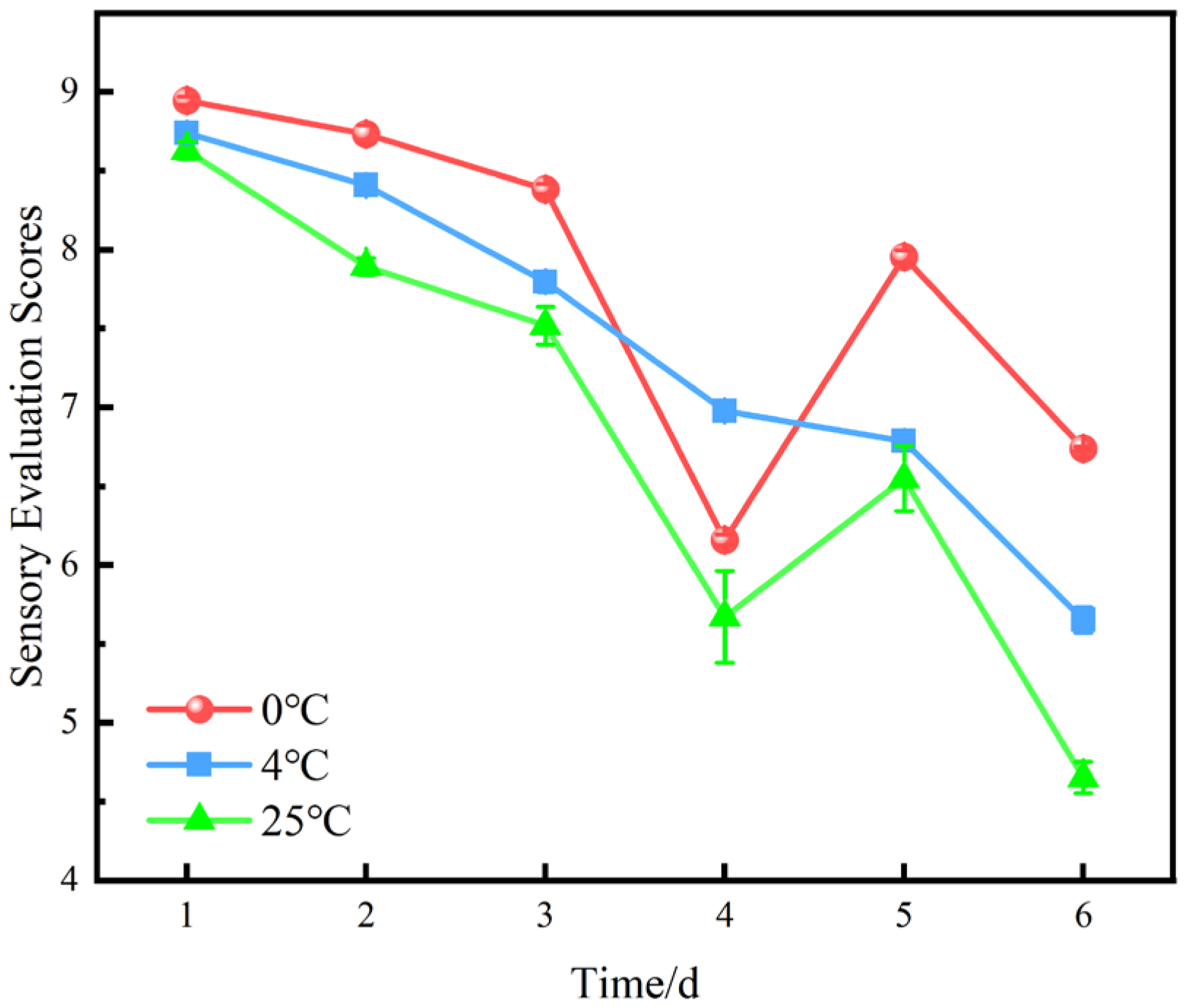
2.2.10. Sensory Evaluation
2.3. Data Processing
2.3.1. Normalization Process
2.3.2. The MRMR Algorithm
2.4. Construction of the Blueberry Shelf-Life Prediction Model
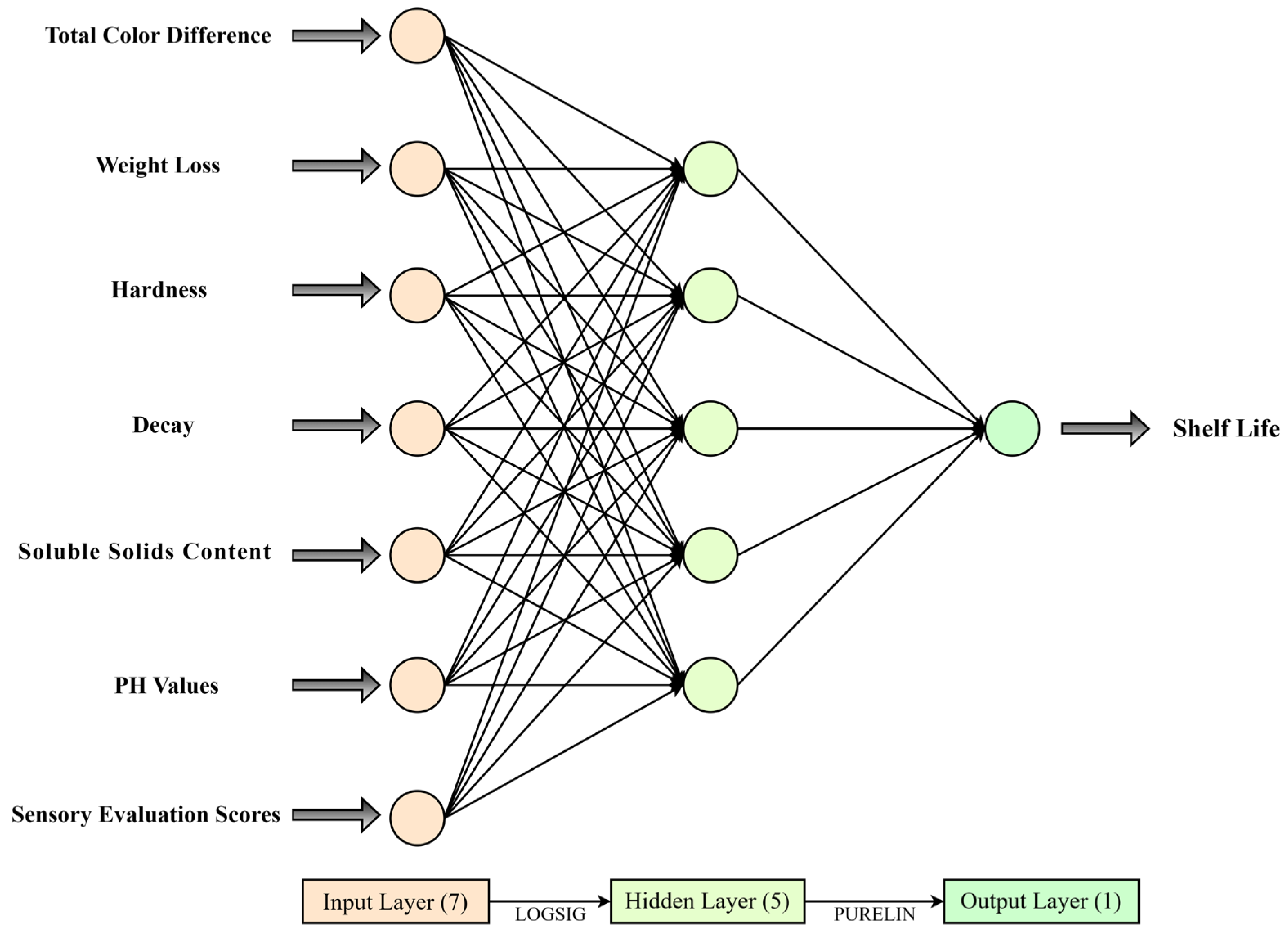
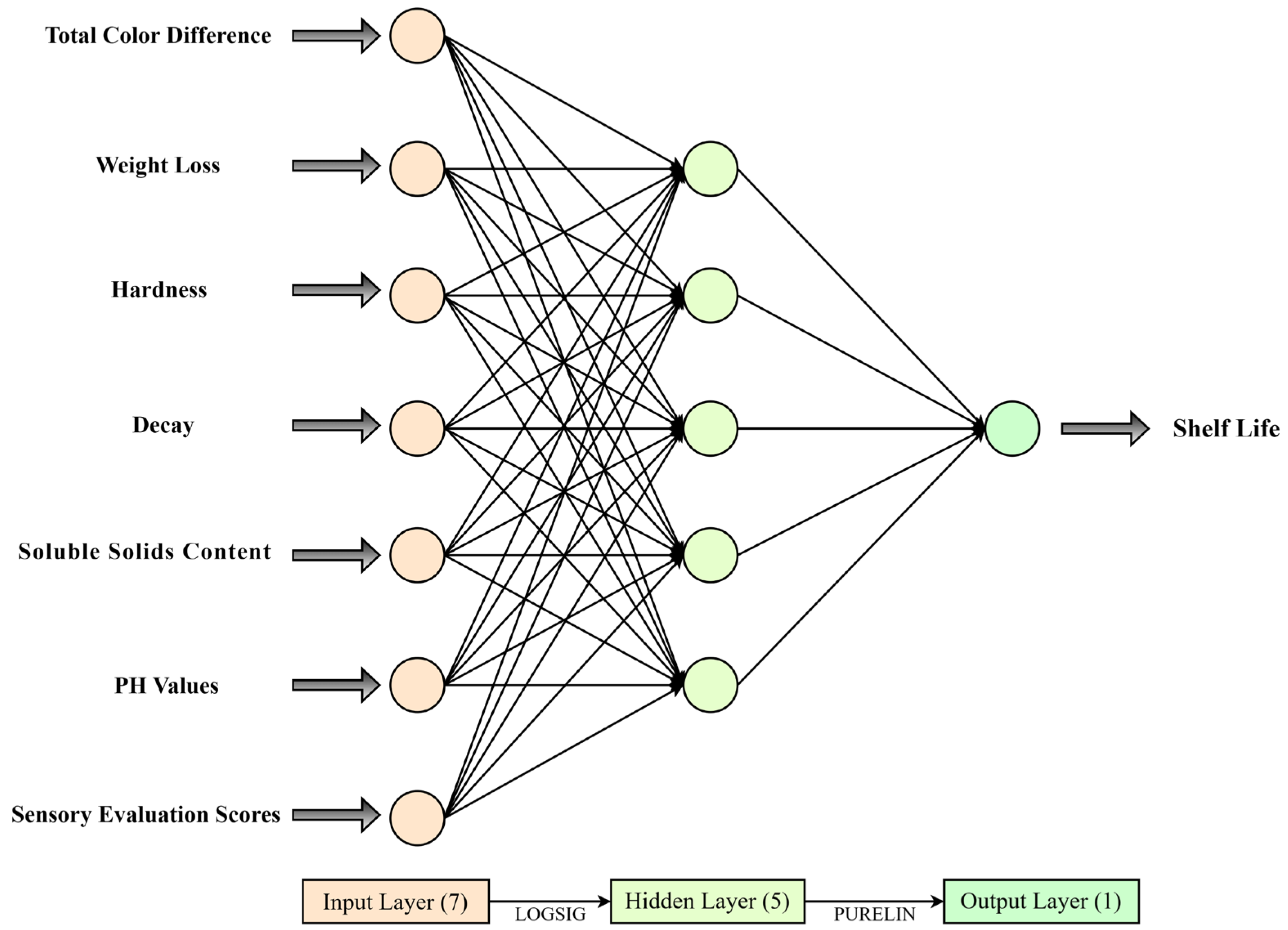
2.4.1. The BPNN Model
2.4.2. The GDEDBO Model
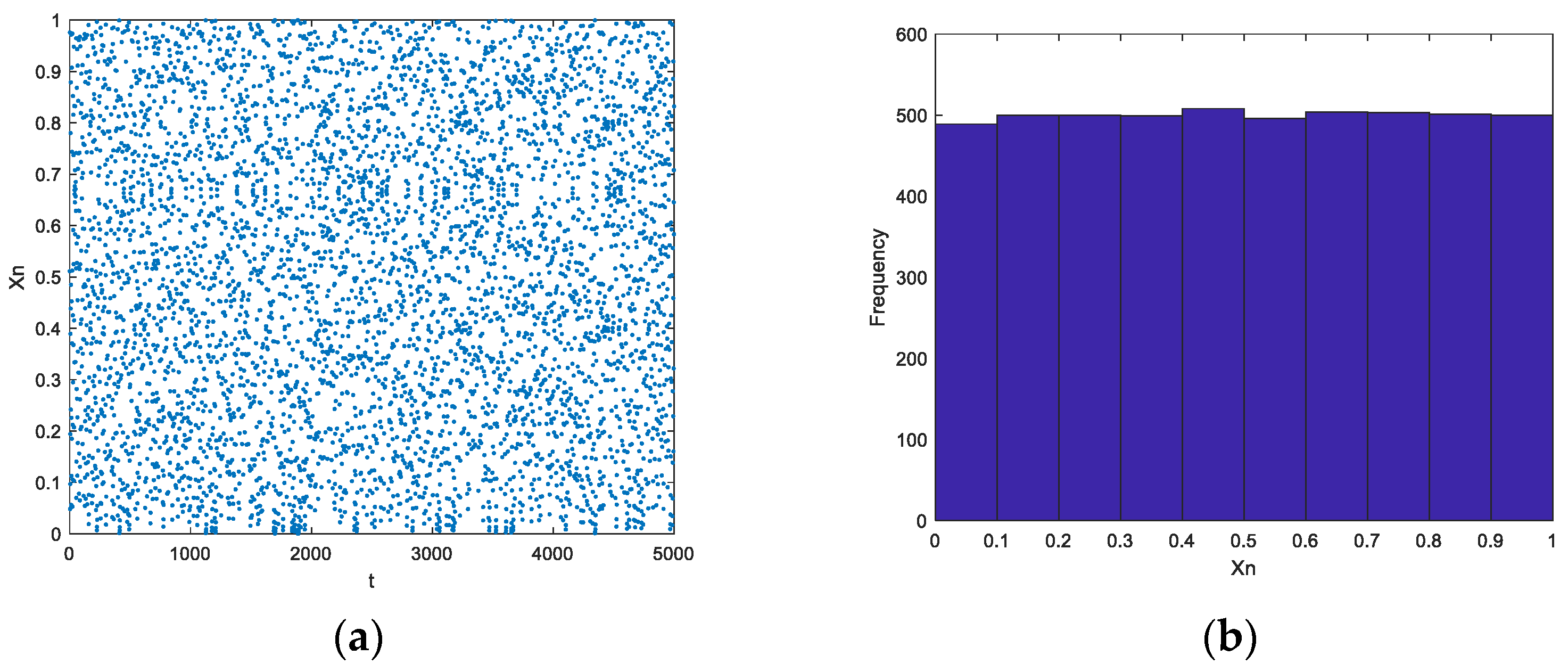
Chaotic Mapping
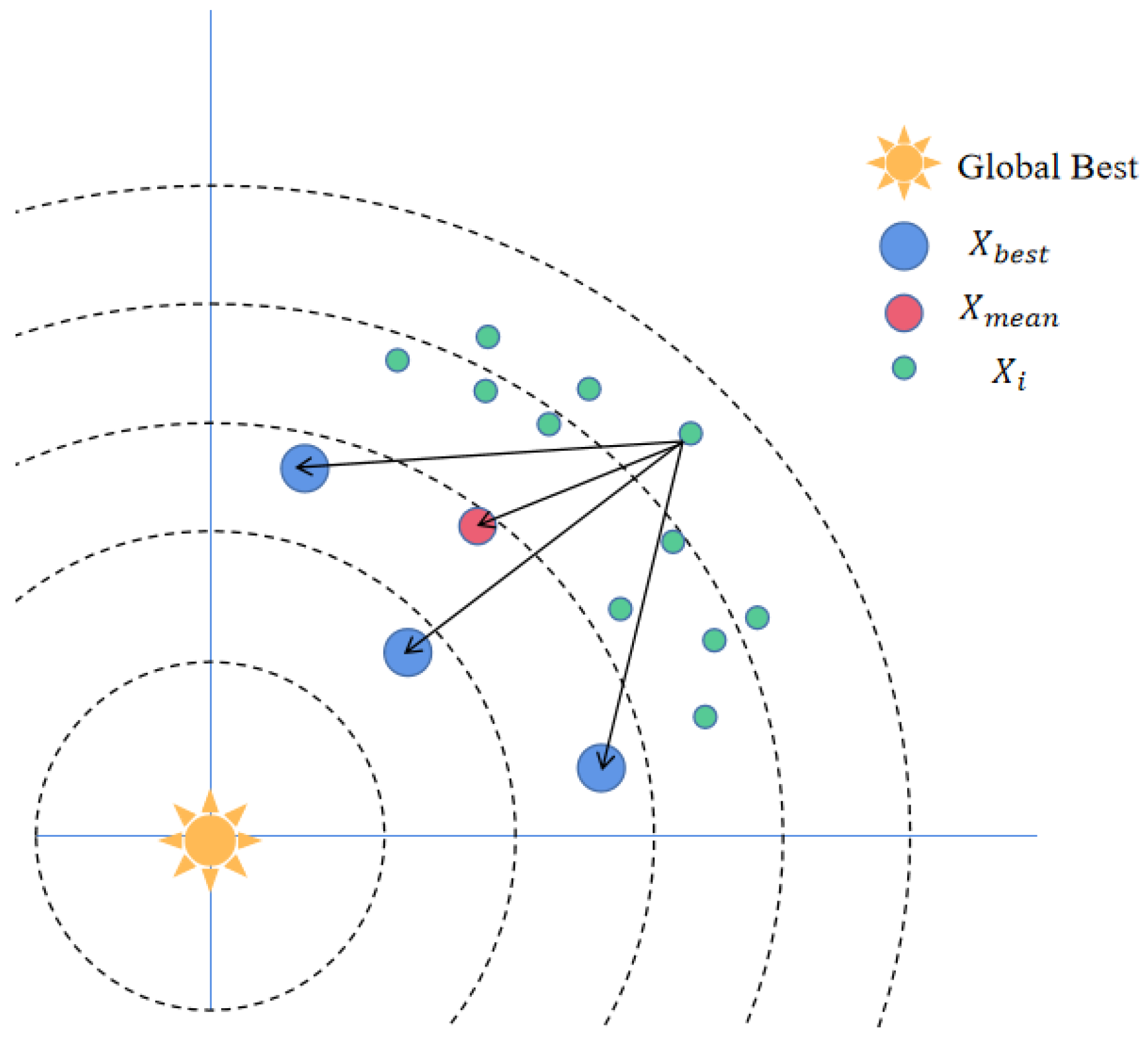
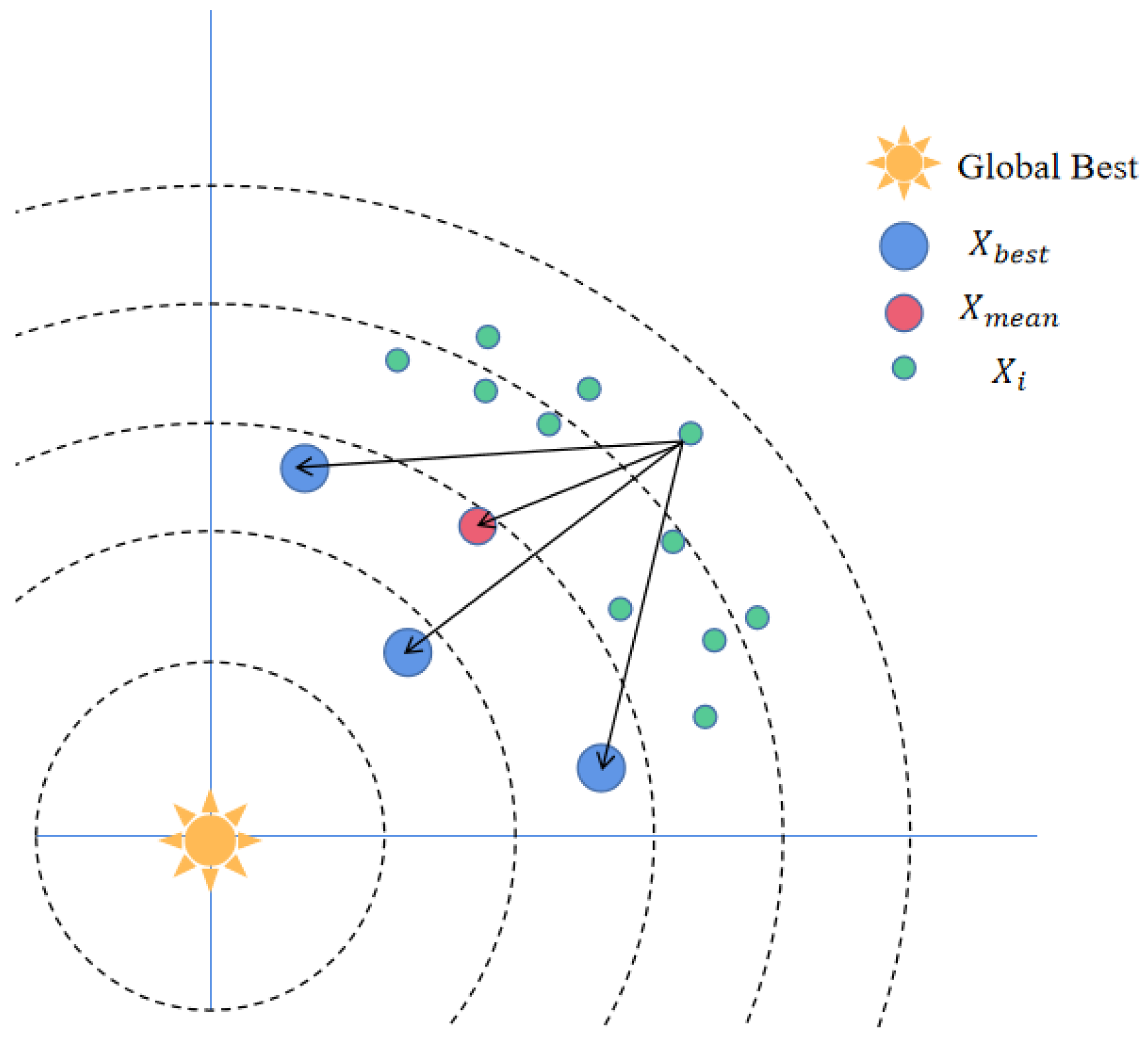
Elite Pool Strategy
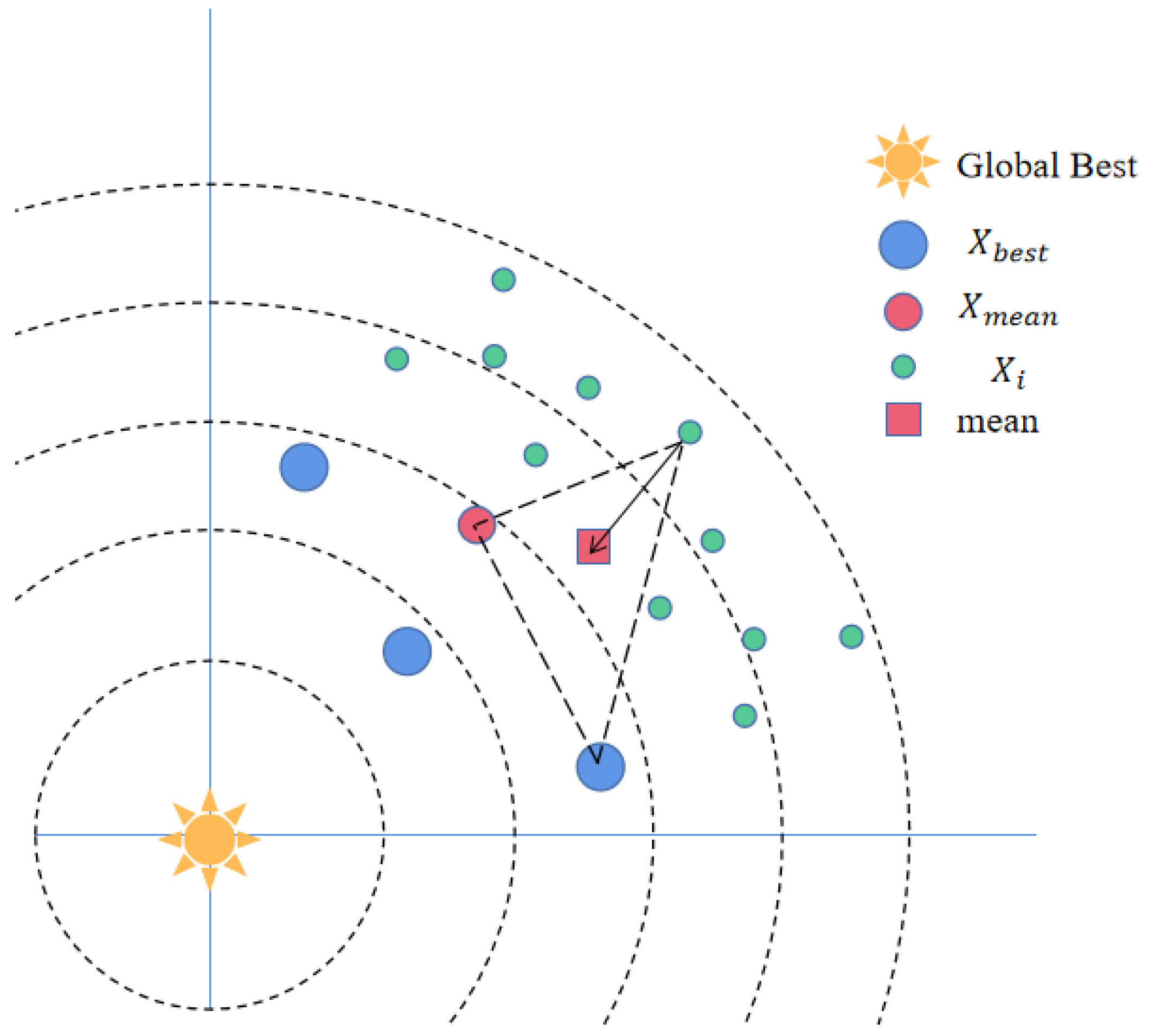
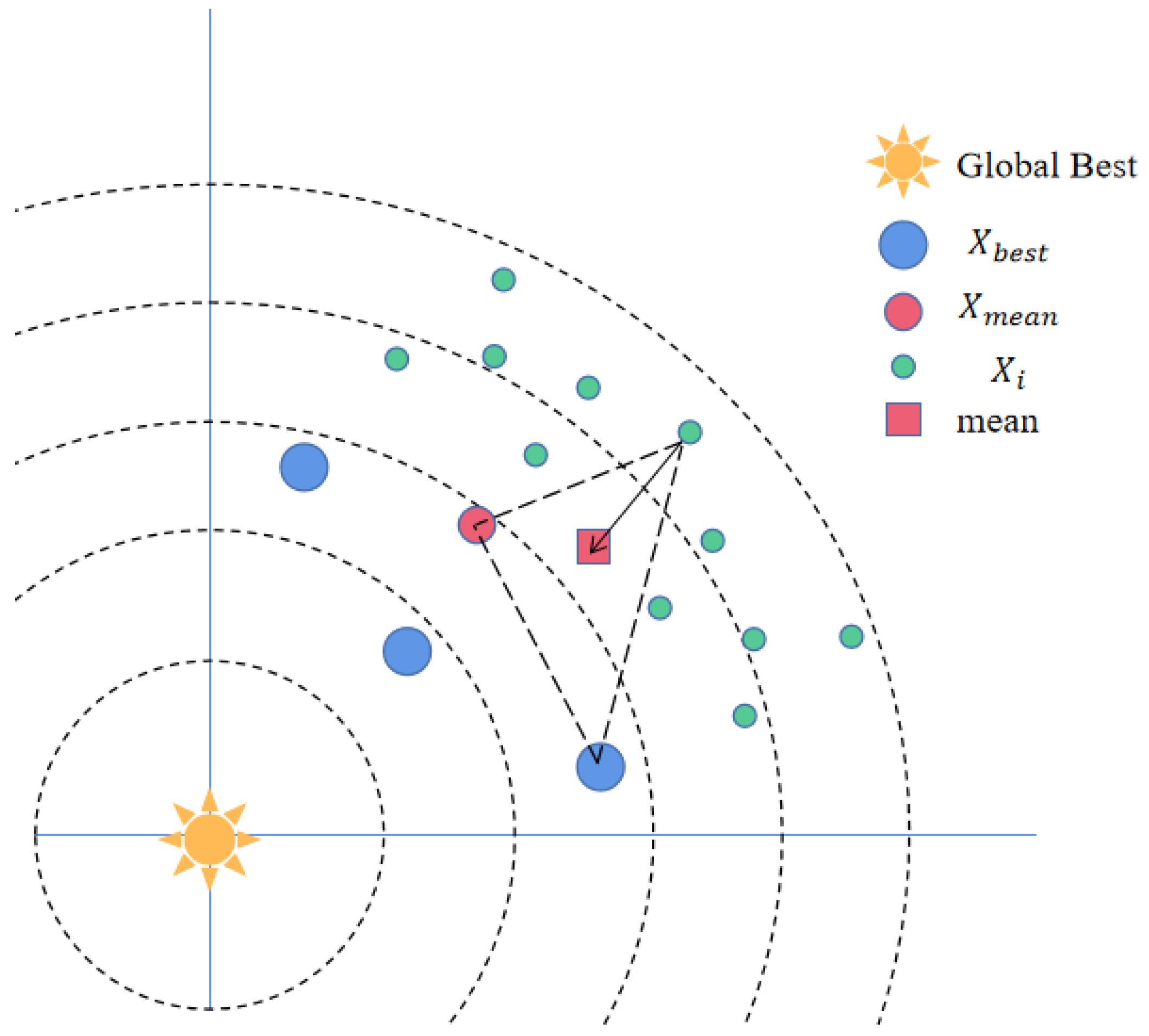
Gaussian Distribution Estimation Strategy
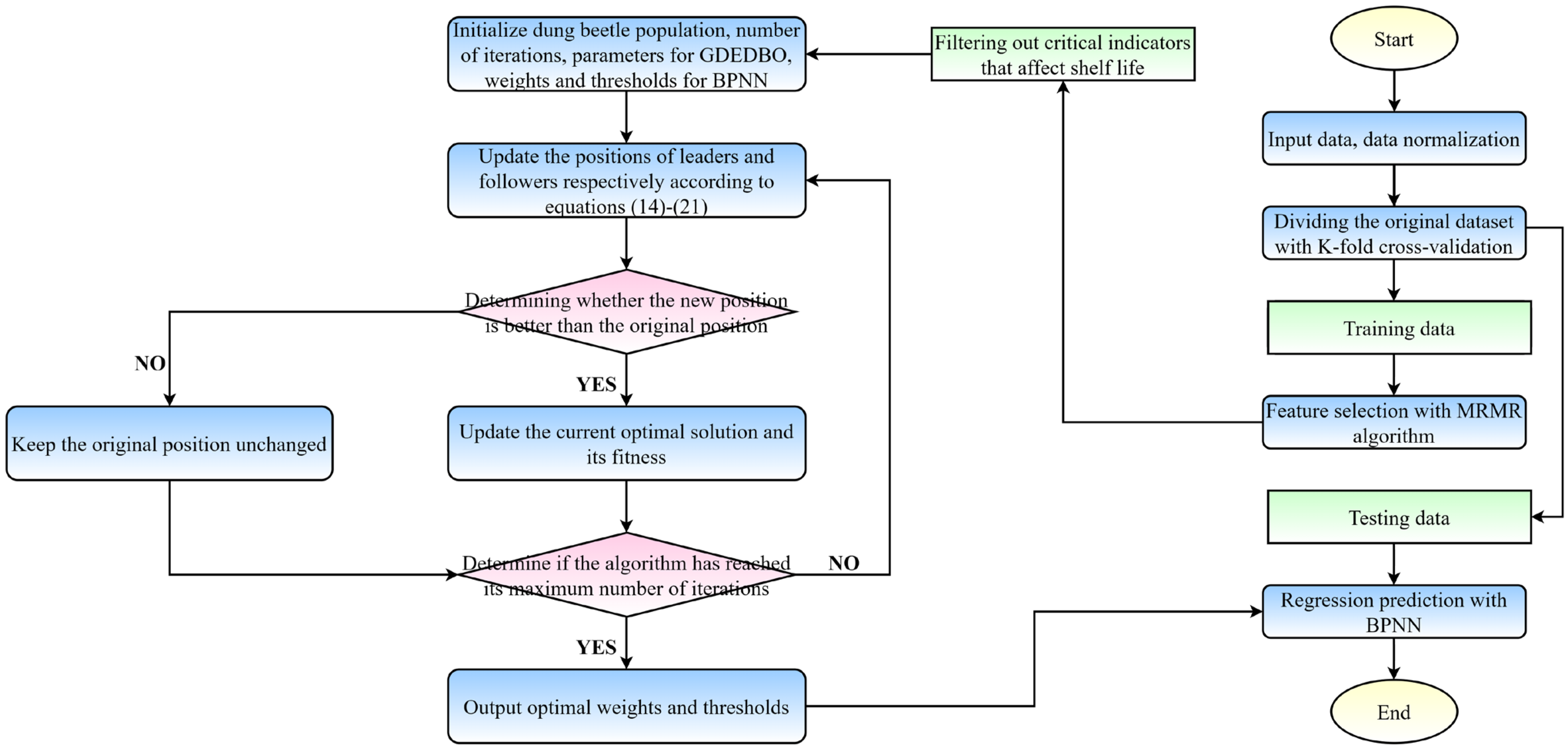
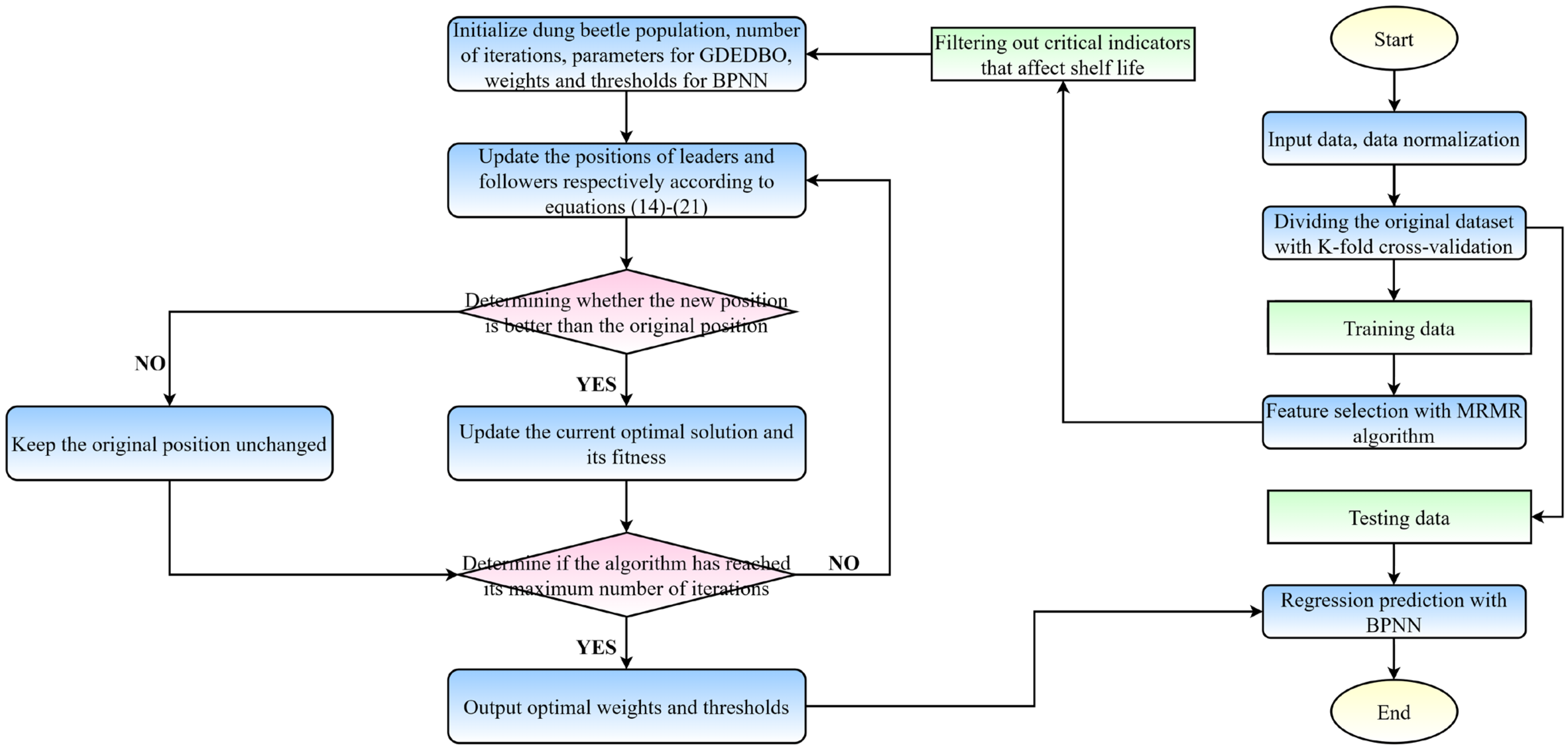
2.4.3. The MRMR-GDEDBO-BPNN Model
- (1)
- Feature selection: The MRMR algorithm was used to select the key factors for predicting the shelf life of blueberries as input. This algorithm reduced the feature dimensionality by filtering out redundant features that could affect the model prediction accuracy;
- (2)
- The GDEDBO model: To address the problems of the original DBO, this paper proposes three improvement strategies. First, tent chaotic mapping was introduced to initialize the dung beetle population and increase its diversity. Second, enhancing the diversity of leaders by introducing an elite pool strategy to improve the exploration performance of the algorithm; and third, using the Gaussian distribution estimation (GDE) strategy to use dominant population information to adjust the search direction to guide the population to better evolution;
- (3)
- The GDEDBO-BPNN model: The GDEDBO-BPNN used the GDEDBO to optimize the parameter weights and thresholds of the BPNN and updated the and of the BPNN by continuously updating the positions of the dung beetles until the global best position, i.e., the optimal solution, was found;
- (4)
- Forecasting model and evaluation of results: The MRMR-GDEDBO-BPNN model predicted the shelf life of blueberries, using the physicochemical and quality indicators selected by the MRMR algorithm as input parameters and selecting different evaluation indicators to evaluate the prediction results. Figure 4 shows the flow chart of the MRMR-GDEDBO-BPNN model.
3. Experimental Simulation and Analysis
3.1. Development and Exploration Capacity Assessment
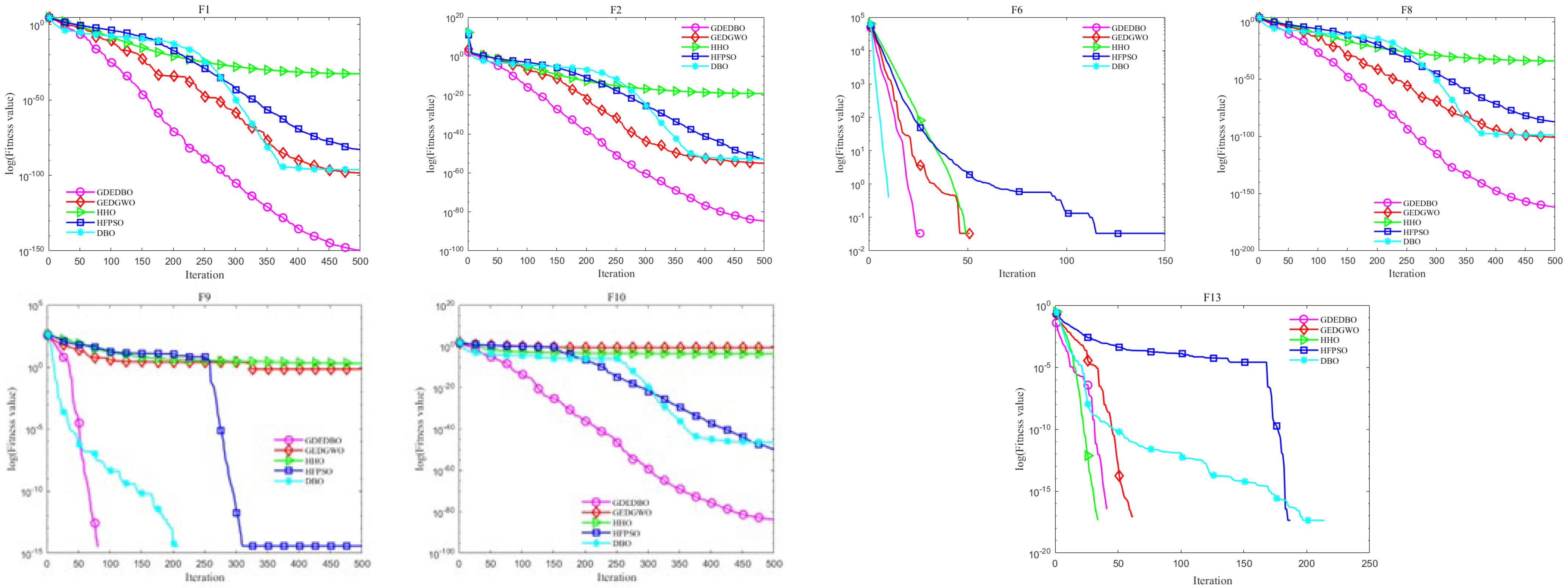
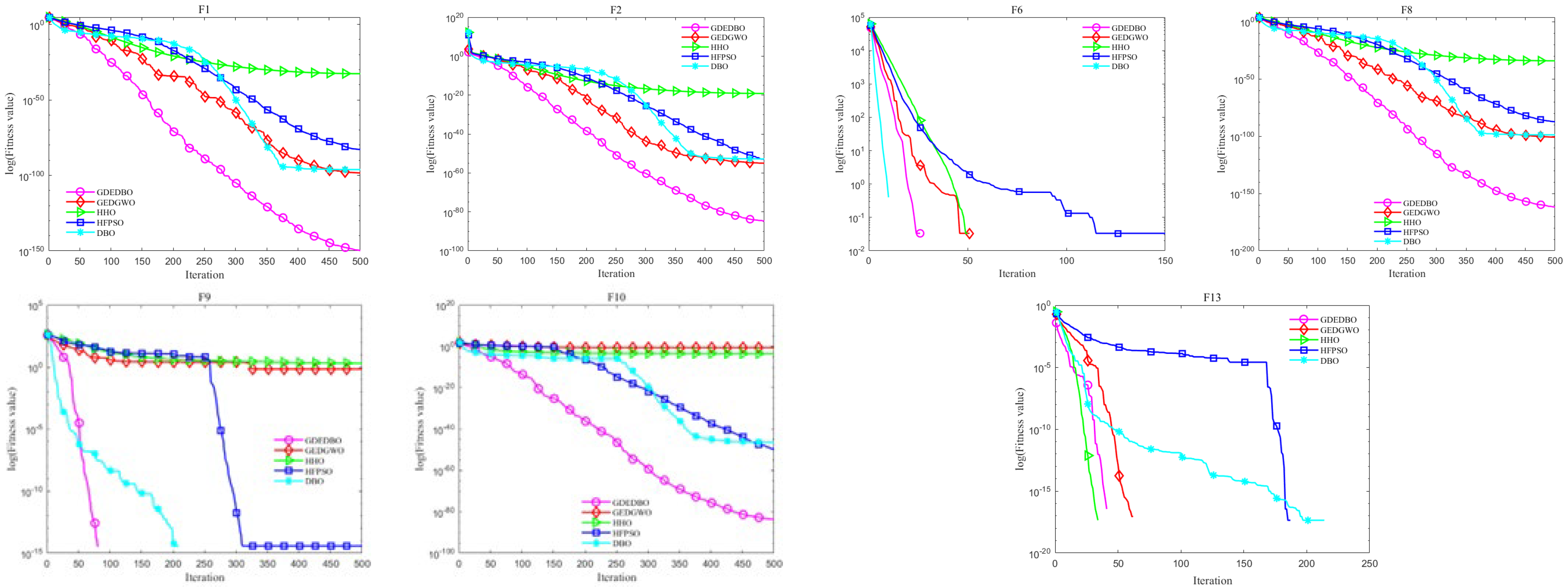
3.2. Convergence Curve Analysis
3.3. Wilcoxon Rank Sum Test
4. Model Parameter Settings and Evaluation Criteria
4.1. Model Parameter Settings
4.1.1. The Baseline Model
4.1.2. The BPNN Model
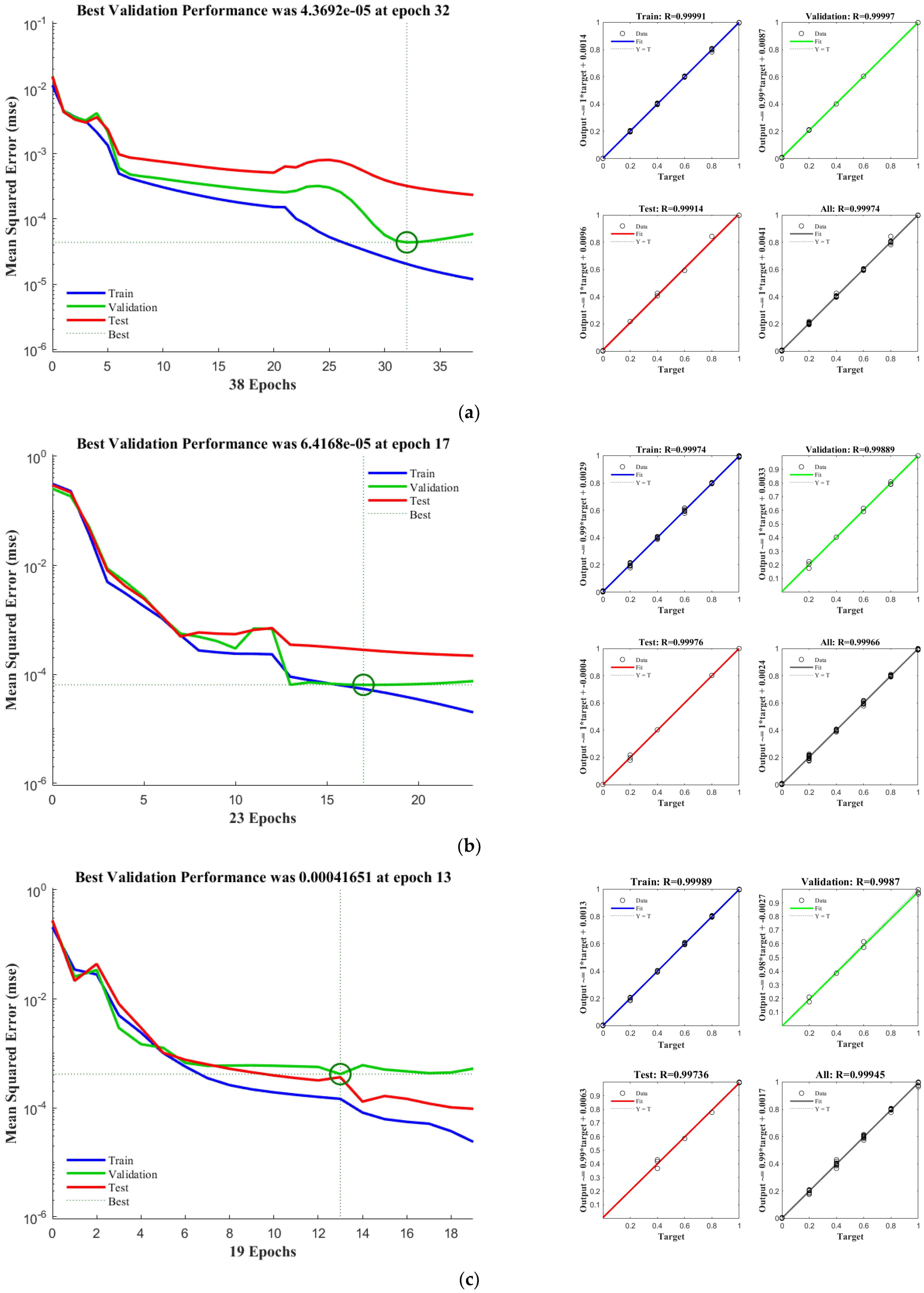
Choice of Network Functions
Selection of Topologies
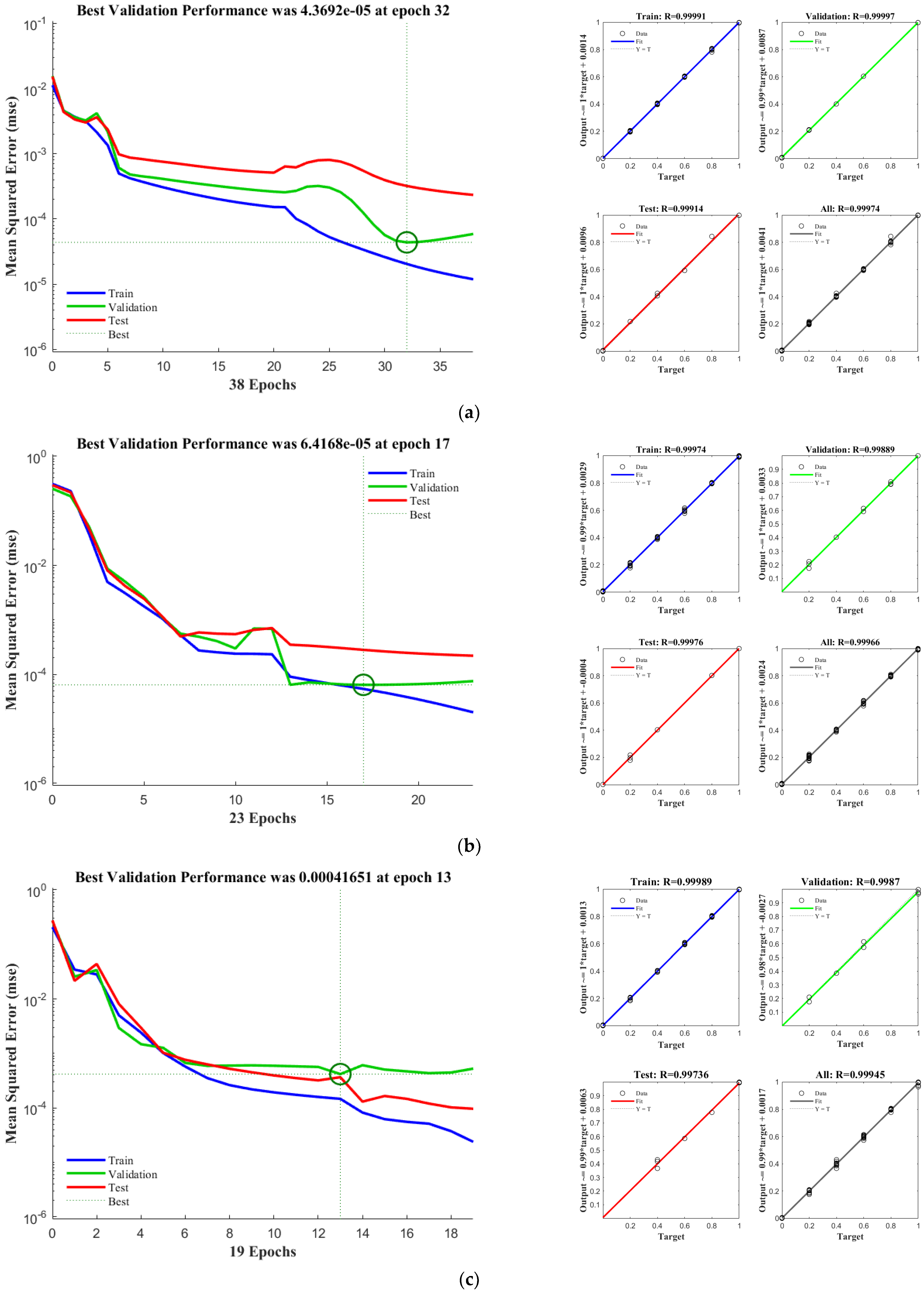
Network Training
4.2. Model Evaluation
4.2.1. K-Fold Cross-Validation
4.2.2. Evaluation Indicators
5. Results
5.1. Trends in Quality Indicators of Blueberries at Different Storage Temperatures
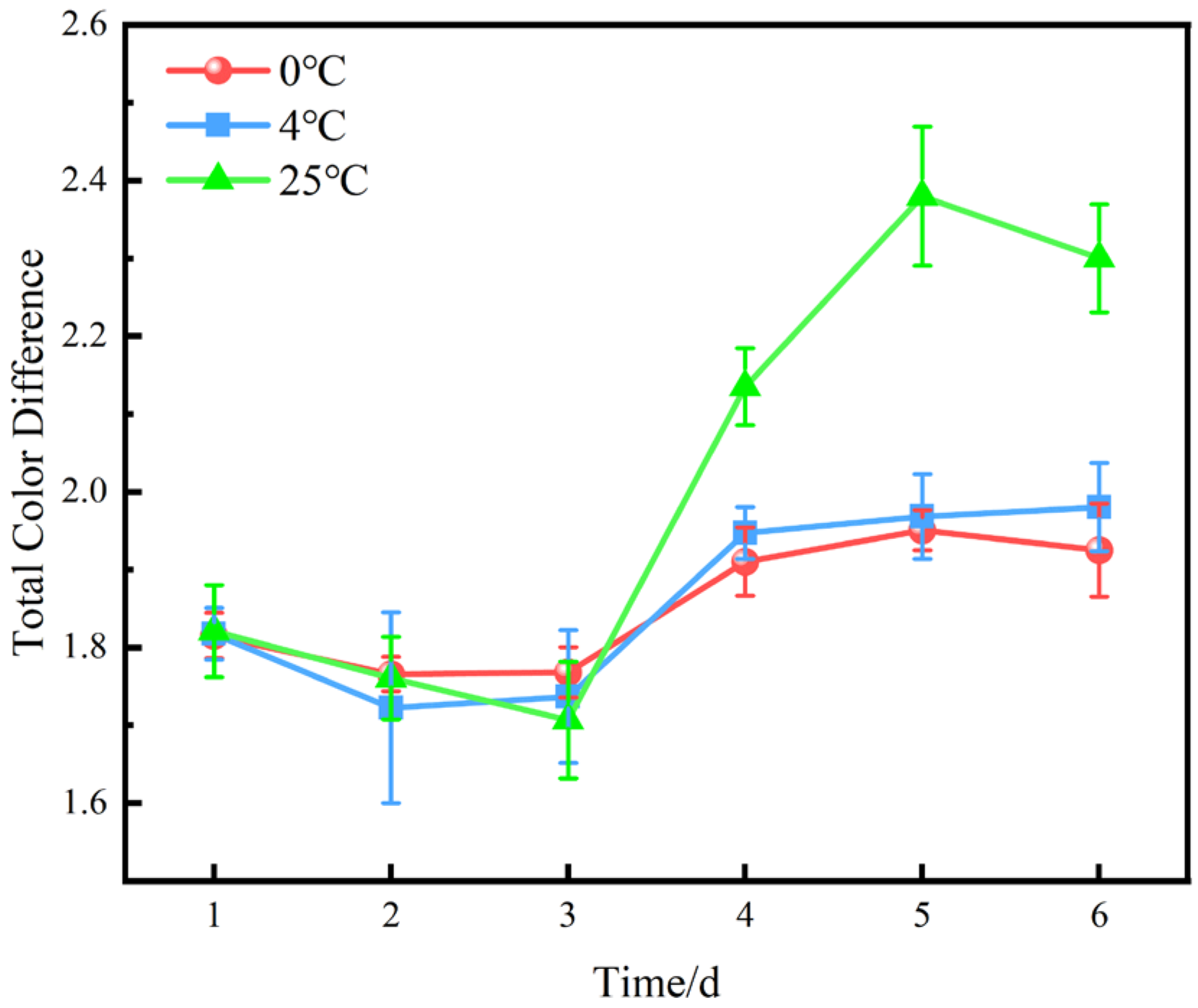
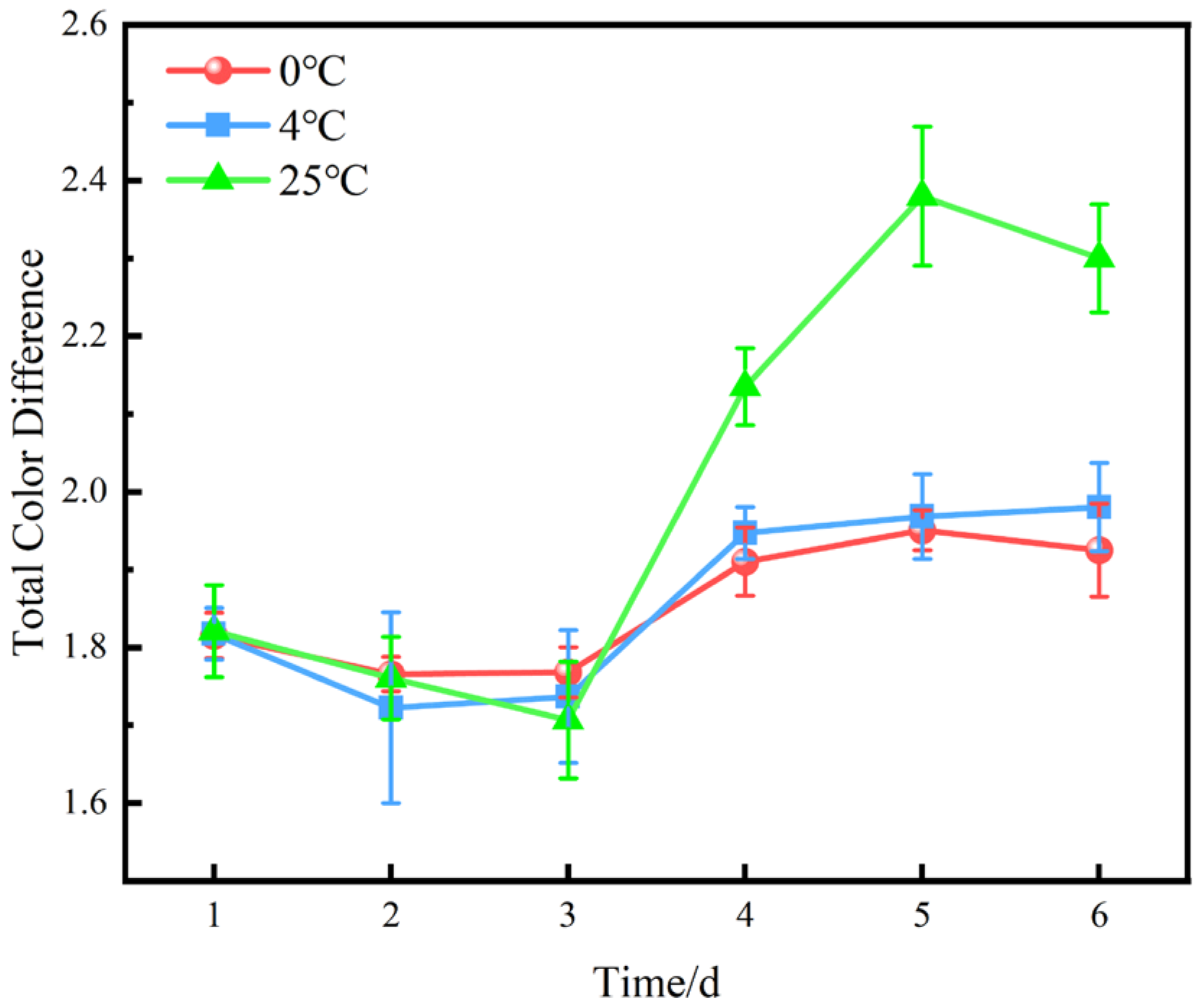
5.1.1. Total Color Difference
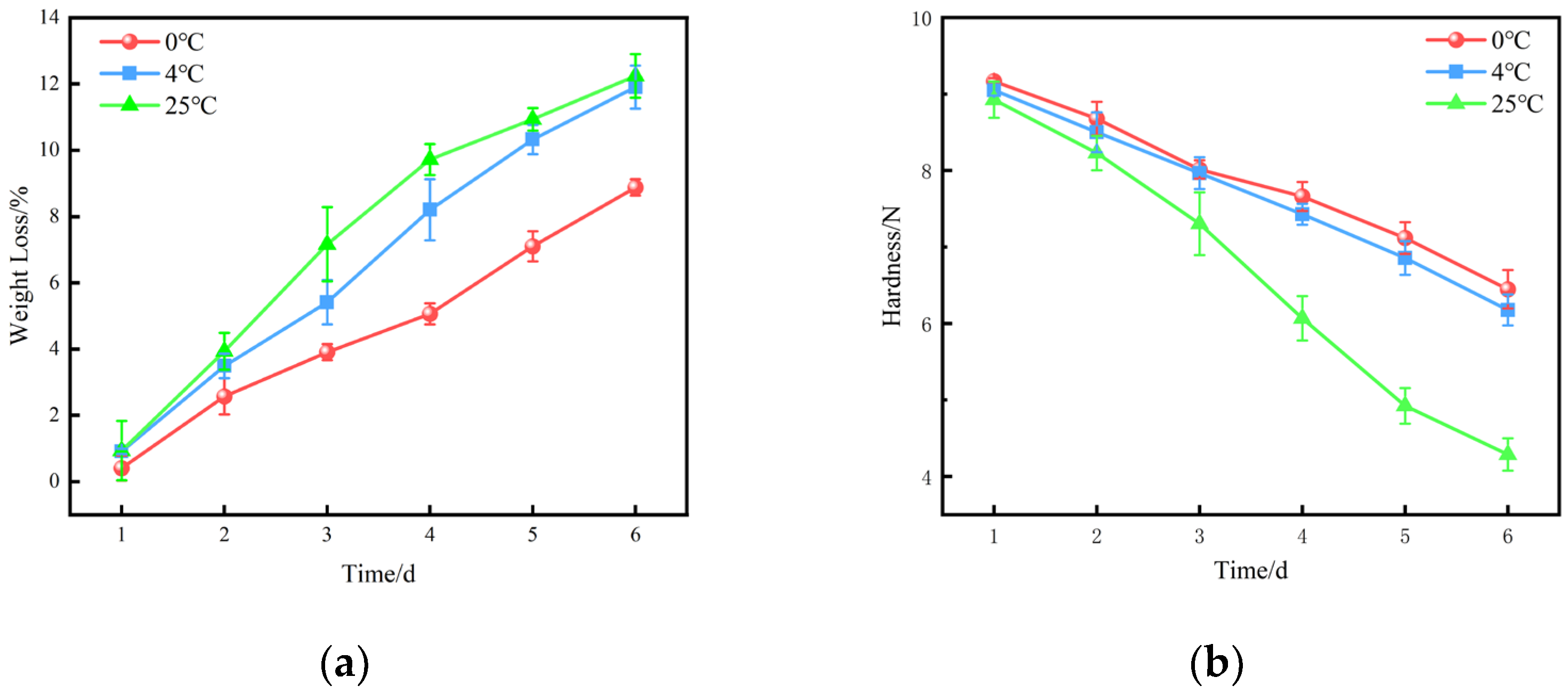
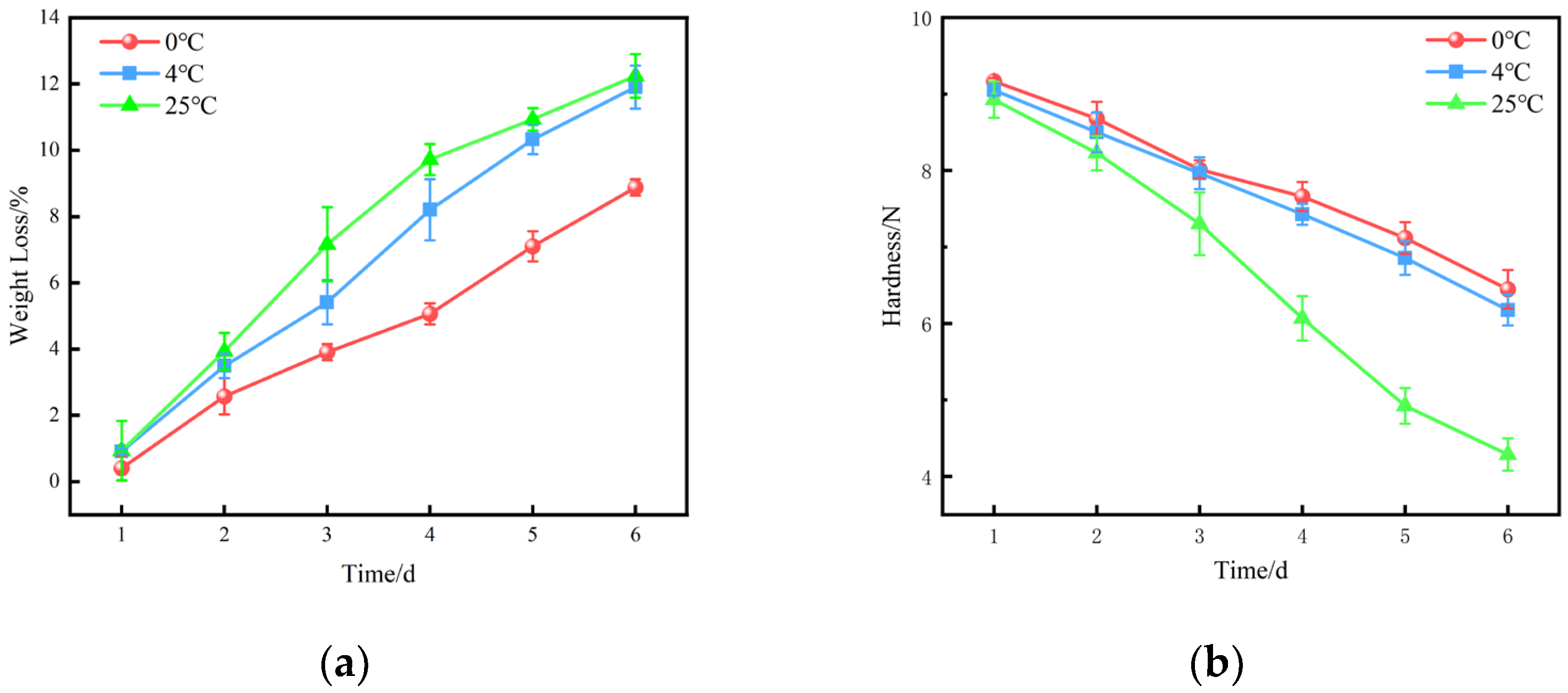
5.1.2. Weight Loss and Hardness
5.1.3. Spoilage Rate
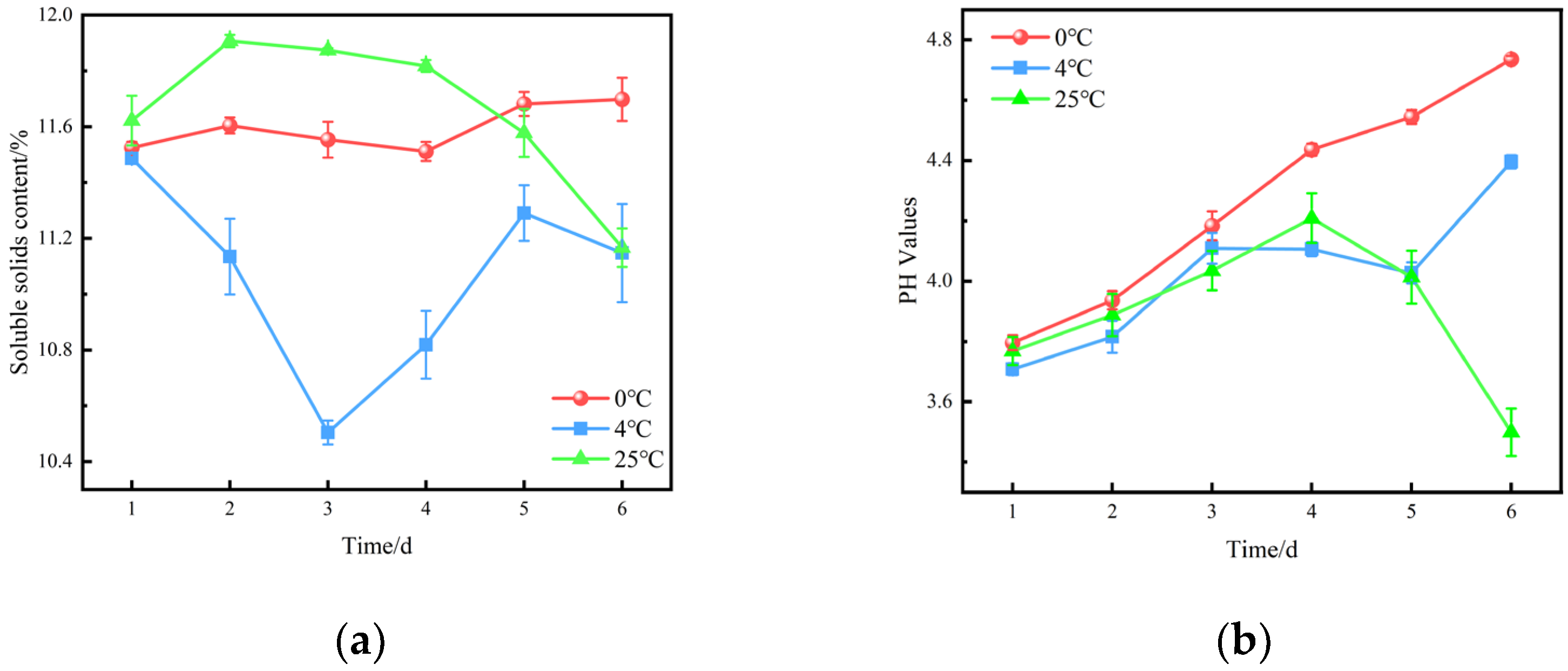
5.1.4. Soluble Solids Content and pH Values
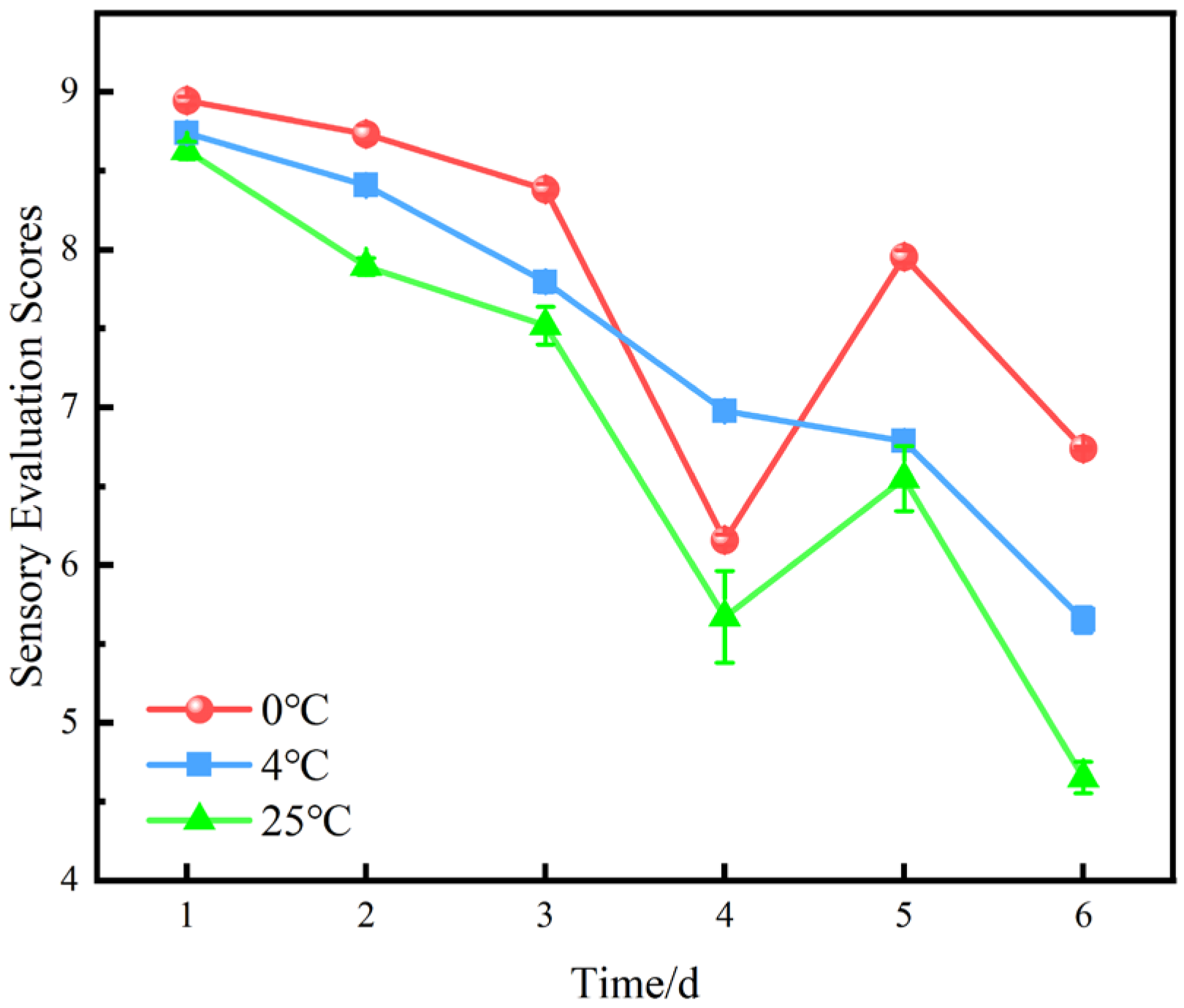
5.1.5. Sensory Evaluation Scores
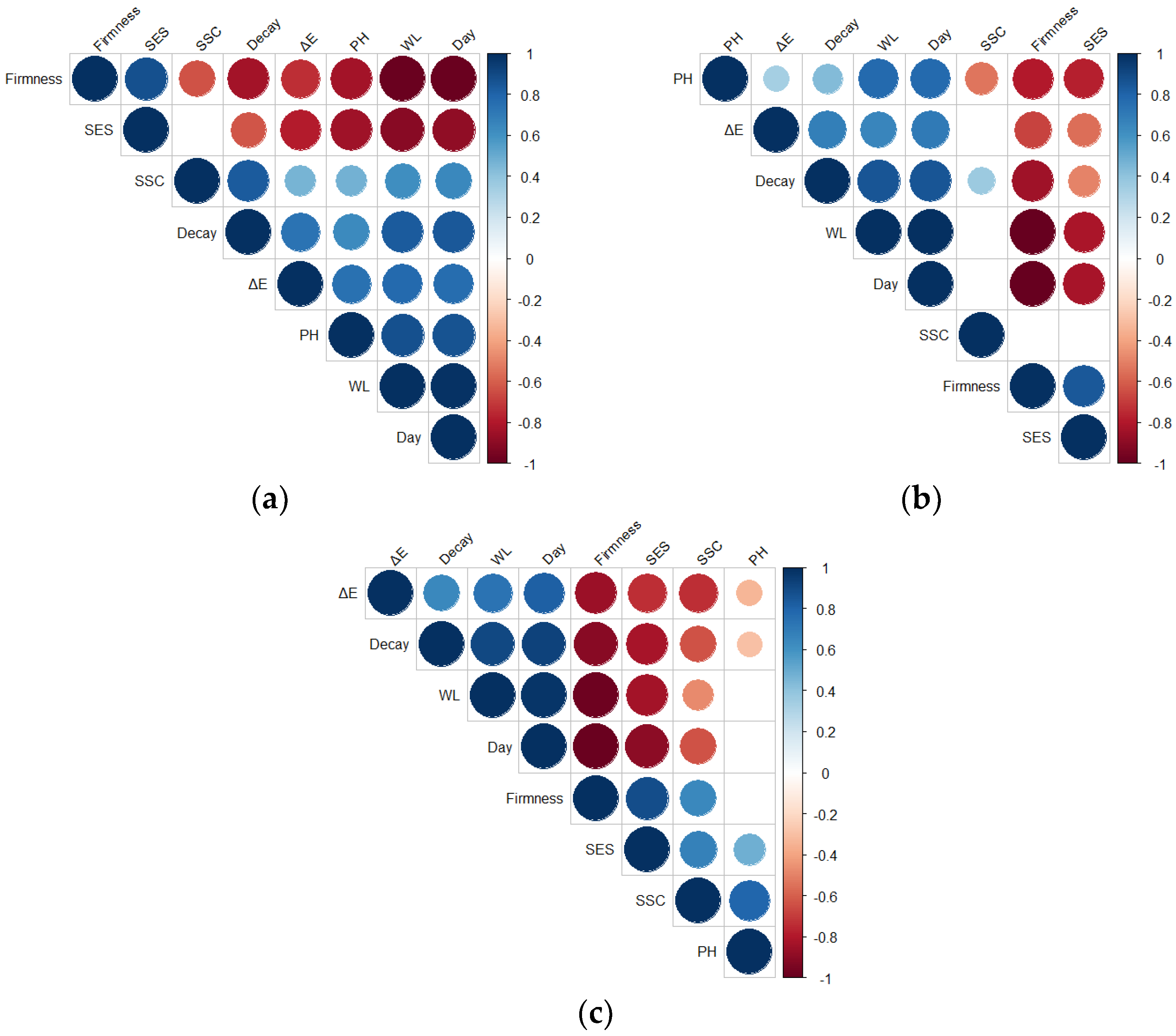
5.2. Pearson’s Correlation Analysis
5.3. Model Performance Comparison Analysis
- (1)
- Compared with the benchmark model, the MRMR-GDEDBO-BPNN model proposed in this paper performed the best, with its MAE, MSE, MAPE, and R2 of 0.0304, 0.0014, 1.1379%, and 0.9995, respectively, significantly outperforming the other models;
- (2)
- Compared with the MLR, ANN, and SVR models, the BPNN model reduced the MAE, MSE, and MAPE values by 56.13–60.02%, 99.54–99.60%, and 35.68–51.71%, respectively. Compared with MRMR-MLR, MRMR-ANN, and MRMR-SVR models, the MRMR-BPNN model reduced the MAE, MSE, and MAPE values by 74.83–78.25%, 99.62–99.69%, and 39.47–43.38%, respectively. These results indicate that the BPNN model had better prediction performance than other models, regardless of feature selection, indicating that the BPNN model has a stronger fitting and generalization ability for the dataset in this paper. The possible reasons are as follows: The MLR model may fail to capture the nonlinear features and complex relationships of the data, leading to large prediction errors [29]. The BPNN model can fit the data more accurately than the ANN model because the BPNN model uses the structure of a multilayer perceptron to learn the high-order features and complex relationships of the data, while the ANN model only uses the structure of a single-layer perceptron. The SVR model is a regression model based on support vector machines, which seeks the optimal hyperplane by maximizing the margin, but the data may not be linearly separable in reality, and the SVR model may not capture the true pattern of the data, resulting in large prediction errors [30];
- (3)
- Compared with the conventional BPNN model, the DBO-BPNN model decreased the MAE and MAPE values by 10.88% and 29.81%, respectively, and increased the R2 value by 1.09%. This indicates that optimizing the weights and thresholds of BPNN with DBO can significantly improve the prediction performance of the neural network. Compared with MRMR-BPNN, the MAE, MSE, and MAPE values of the MRMR-GDEDBO-BPNN model decreased by 74.11%, 26.32%, and 88.40%, respectively, and increased the R2 value by 2.25%, further demonstrating the importance of optimizing the weights and thresholds of BPNN;
- (4)
- Compared with DBO-BPNN, the GDEDBO-BPNN model decreased the MAE, MSE, and MAPE values by 18.68%, 35.14%, and 21.25%, respectively, indicating that the prediction results of the GDEDBO-BPNN model were closer to the actual values and verifying the effectiveness of the improved strategy proposed in this study;
- (5)
- Compared with MLR, ANN, SVR, and BPNN, after feature selection, their MAE, MSE, and MAPE values decreased by 7.20–49.51%, 4.70–32.14%, and 3.34–20.61%, respectively. Compared with GDEDBO-BPNN, the MAE, MSE, and MAPE values of the MRMR-GDEDBO-BPNN model after feature selection decreased by 81.96%, 96.55%, and 79.72%, respectively, and the R2 value increased by 1.15%. This indicates that feature selection can improve the prediction accuracy of the model by effectively reducing redundant features.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 25 °C | 4 °C | 0 °C | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAPE | R2 | MAE | MSE | MAPE | R2 | MAE | MSE | MAPE | R2 | |
| MLR | 0.6088 | 0.7353 | 22.3812% | 0.8588 | 0.6452 | 0.6717 | 21.0512% | 0.8602 | 0.5816 | 0.7081 | 21.0245% | 0.8716 |
| ANN | 0.5807 | 0.6420 | 19.2673% | 0.8607 | 0.5650 | 0.6263 | 17.6226% | 0.8777 | 0.5493 | 0.6106 | 17.5959% | 0.8947 |
| SVR | 0.5738 | 0.6589 | 18.4095% | 0.8771 | 0.5519 | 0.637 | 16.1159% | 0.8929 | 0.5300 | 0.6151 | 17.3324% | 0.9087 |
| MRMR-MLR | 0.5673 | 0.6505 | 18.8400% | 0.8689 | 0.5585 | 0.6317 | 16.8693% | 0.8853 | 0.5397 | 0.6129 | 16.6905% | 0.9017 |
| MRMR-ANN | 0.5507 | 0.6420 | 16.2673% | 0.8807 | 0.5071 | 0.6037 | 16.2406% | 0.8851 | 0.5027 | 0.5819 | 16.2139% | 0.8895 |
| MRMR-SVR | 0.5349 | 0.5654 | 18.0642% | 0.8904 | 0.5007 | 0.5312 | 17.3591% | 0.9013 | 0.4665 | 0.4970 | 15.7850% | 0.9122 |
| BPNN | 0.2862 | 0.0049 | 15.3267% | 0.9516 | 0.2226 | 0.0035 | 13.9958% | 0.9630 | 0.2325 | 0.0028 | 10.1526% | 0.9721 |
| MRMR-BPNN | 0.1955 | 0.0084 | 13.9324% | 0.9574 | 0.1798 | 0.0026 | 12.2877% | 0.9744 | 0.1174 | 0.0019 | 9.8137% | 0.9775 |
| DBO-BPNN | 0.2259 | 0.0906 | 10.7300% | 0.9639 | 0.2040 | 0.0611 | 8.4364% | 0.9797 | 0.2072 | 0.0626 | 7.1264% | 0.9827 |
| MRMR-DBO-BPNN | 0.1248 | 0.0548 | 5.0646% | 0.9793 | 0.1183 | 0.0401 | 5.0379% | 0.9837 | 0.1158 | 0.0401 | 3.5118% | 0.9893 |
| GDEDBO-BPNN | 0.1313 | 0.0737 | 6.4364% | 0.9724 | 0.2071 | 0.0631 | 5.7313% | 0.9833 | 0.1685 | 0.0406 | 5.6121% | 0.9881 |
| MRMR-GDEDBO-BPNN | 0.1013 | 0.0253 | 3.0083% | 0.9910 | 0.0671 | 0.0077 | 2.3654% | 0.9971 | 0.0304 | 0.0014 | 1.1379% | 0.9995 |
- (1)
- The prediction accuracy of the MRMR-GDEDBO-BP model for blueberry shelf life was the highest, with a prediction error within 3.27%, meeting the needs of shelf-life prediction;
- (2)
- The prediction error increased with the increase in blueberry storage temperature, which may be due to the fact that the higher the temperature, the stronger the respiration and transpiration of blueberries, resulting in quality decline and shelf-life reduction acceleration, thus increasing the model error. It can be concluded that 0 °C is the best storage temperature for blueberries during their shelf life.
6. Discussion
- (1)
- Species differences. The quality change patterns and shelf life of fruits are influenced by their species characteristics, such as moisture content, antioxidant capacity, cell wall structure, sugar-acid ratio, etc. Generally speaking, fruits with higher moisture content, stronger antioxidant capacity, more stable cell wall structure, and a moderate sugar-acid ratio have better quality and a longer shelf life. According to previous studies, ‘Liberty’ blueberry is a high-quality variety with high moisture content (about 85%), strong antioxidant capacity (about 13.8 mmol/100 g), stable cell wall structure (about 0.5%), and a moderate sugar-acid ratio (about 15.6) [25]. However, ‘Rustenburg’ navel orange is a low-quality variety with low moisture content (about 60%), weak antioxidant capacity (about 2.4 mmol/100 g), unstable cell wall structure (about 1.2%), and a high sugar-acid ratio (about 25.4) [30];
- (2)
- Improper feature selection. Owoyemi et al. did not perform feature selection and might have redundant features. Zhang et al. used PLS to select features, but this method only considered the linear correlation between features and responses without considering the redundancy and nonlinearity among features. However, the MRMR algorithm used in this paper could simultaneously consider relevance, redundancy, and nonlinearity among features. Therefore, it obtained higher prediction accuracy;
- (3)
- Limitations of the models themselves. Owoyemi et al.’s XGBoost model had problems such as sensitivity to noise and outliers, overfitting, tedious hyperparameter tuning, etc., which affected its generalization ability. Zhang et al. used PLS to build the quality change and shelf-life prediction models of apples, but PLS assumed a linear relationship between features and responses, while there might be a nonlinear relationship in reality. They also used ANN to optimize the parameters of the PLS model, but ANN was prone to falling into local optima and was sensitive to parameter selection. However, the BPNN model used in this paper could handle nonlinear and high-dimensional data and used the GDEDBO algorithm to optimize its parameters to avoid falling into local optima and minimize prediction error. Therefore, it obtained more satisfactory prediction results.
7. Conclusions
- (1)
- Feature selection helps improve the prediction accuracy of shelf-life models;
- (2)
- Optimizing the weights and thresholds of the BPNN with DBO helps enhance the prediction performance of the neural network;
- (3)
- To overcome the limitations of the original DBO algorithm, this paper proposes the GDEDBO model. It uses tent chaotic mapping to initialize the population and increase its diversity. It enhances the diversity of leaders by introducing an elite pool strategy to improve the exploration performance of the algorithm. Moreover, it adjusts the search direction by means of a Gaussian distribution estimation strategy, effectively coordinating the algorithm’s global and local search capabilities and strengthening the algorithm’s late-stage optimization search capability. The GDEDBO is evaluated with four meta-heuristic algorithms, including DBO, on 14 benchmark functions. The results show that GDEDBO exhibits good outperformance for both unimodal and multimodal functions, verifying the effectiveness of the improved strategy and being highly competitive with other meta-heuristic algorithms;
- (4)
- This paper proposed the MRMR-GDEDBO-BPNN model, which uses seven critical factors (hardness, weight loss rate, spoilage rate, total color difference, soluble solids content, pH values, and sensory evaluation scores) filtered by the MRMR algorithm as input variables to establish shelf-life prediction models at three temperatures of 0 °C, 4 °C, and 25 °C, respectively. The results show that compared with the original BPNN, the values of MAE, MSE, and MAPE of the MRMR-GDEDBO-BPNN model are reduced by 86.92%, 50%, and 88.79%, respectively, and the value of is increased by 2.82%. This indicates that the BPNN model with feature selection by the MRMR algorithm and optimization by the GDEDBO model significantly improved the shelf-life prediction accuracy;
- (5)
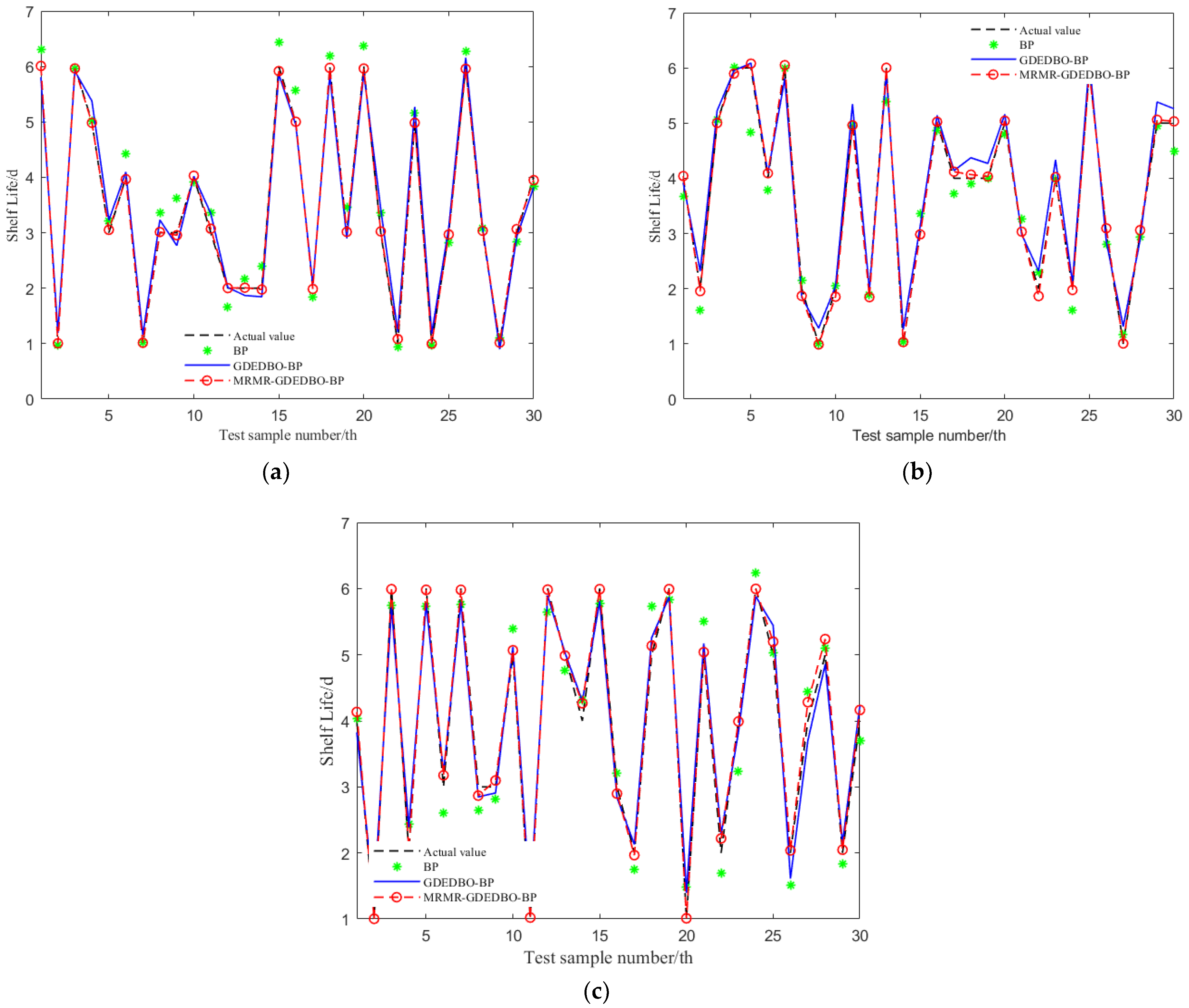
- This paper compares the optimal prediction models of shelf life at three storage temperatures, as shown in Table 9. It can be seen from Table 9 that the optimal prediction models at three temperatures are all MRMR-GDEDBO-BPNN models, whose optimal topological structures are all 7–5−1, and the activation function combinations are all LOGSIG-PURELIN. By comparing the prediction accuracy of models at three different temperatures, it can be concluded that the prediction accuracy of shelf-life models at 0 °C and 4 °C is higher than that at 25 °C, and 0 °C is higher than 4 °C. This may be due to the fact that the higher the temperature, the stronger the respiration and transpiration of blueberries, which leads to a faster rate of quality decline and shelf-life shortening, thus increasing the error of the prediction model. It can be concluded that 0 °C is the optimum storage temperature for blueberries during their shelf life;
- (6)
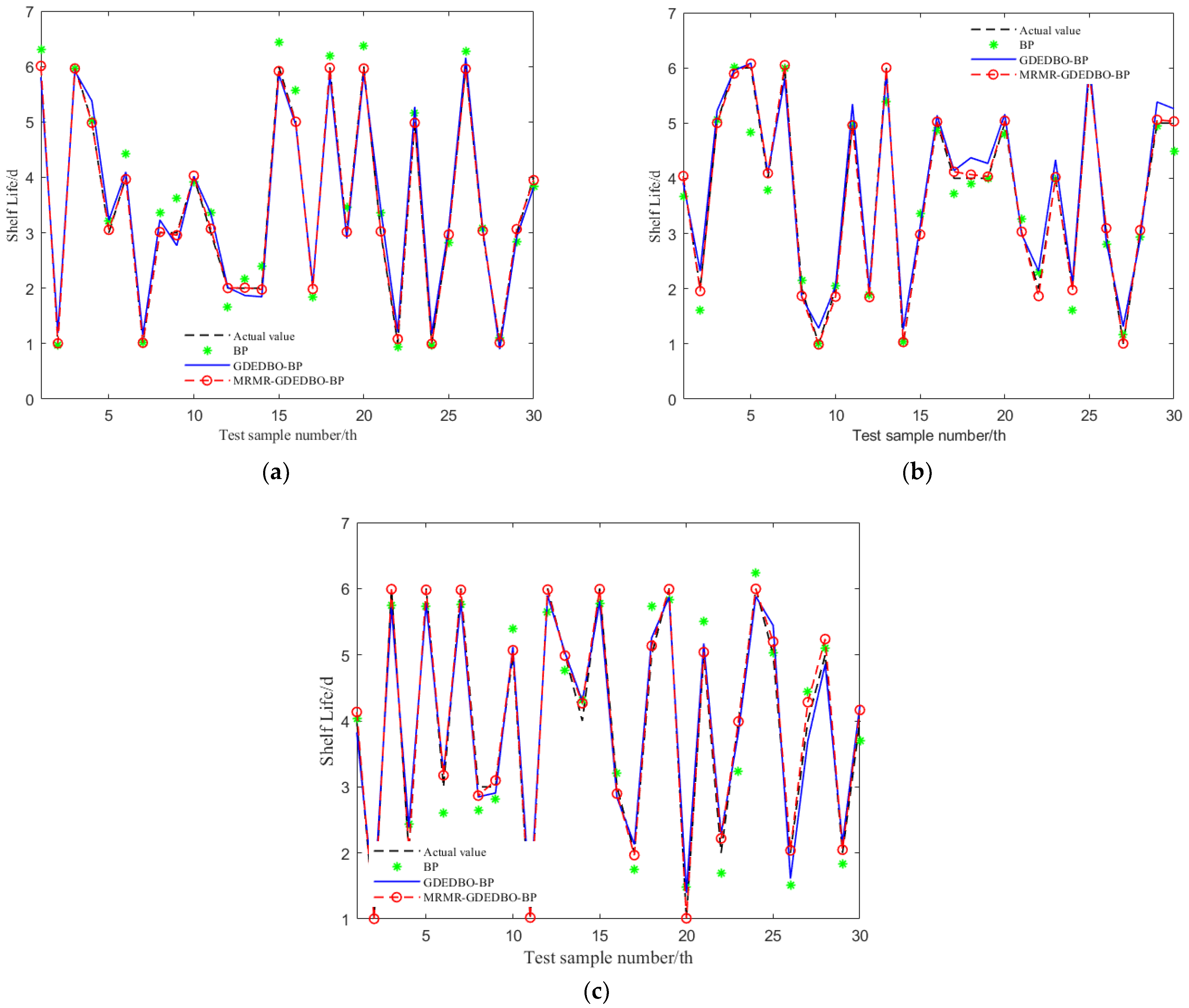
- This paper compares the shelf life at three storage temperatures with a sensory evaluation score of six as the end point of shelf life. The results are shown in Figure 11. It can be seen from Figure 11 that the shelf lives of this variety of blueberries at 0 °C, 4 °C, and 25 °C are 5.99 days, 5.35 days, and 3.67 days, respectively.
- (1)
- To train and test the proposed shelf-life prediction model on multiple varieties or genotypes of blueberries, to verify its applicability in evaluating other varieties or genotypes, and to compare its prediction performance with other models or methods;
- (2)
- To extend the proposed shelf-life prediction model to predict the shelf-life of other crops (such as fruits, vegetables, etc.) and explore their similarities and differences among different crops.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Zhu, X.; Hou, Y.; Pan, Y.; Shi, L.; Li, X. Effects of harvest maturity stage on postharvest quality of winter jujube (Zizyphus jujuba Mill. cv. Dongzao) fruit during cold storage. Sci. Hortic. 2021, 277, 109778. [Google Scholar] [CrossRef]
- Matrose, N.A.; Obikeze, K.; Belay, Z.A.; Caleb, O.J. Plant extracts and other natural compounds as alternatives for post-harvest management of fruit fungal pathogens: A review. Food Biosci. 2021, 41, 100840. [Google Scholar] [CrossRef]
- Han, J.W.; Zuo, M.; Zhu, W.Y.; Zuo, J.H.; Lü, E.L.; Yang, X.T. A comprehensive review of cold chain logistics for fresh agricultural products: Current status, challenges, and future trends. Trends Food Sci. Technol. 2021, 109, 536–551. [Google Scholar] [CrossRef]
- Mesías, F.; Martín, A.; Hern’andez, A. Consumers’ growing appetite for natural foods: Perceptions towards the use of natural preservatives in fresh fruit. Food Res. Int. 2021, 150, 110749. [Google Scholar] [CrossRef]
- Wang, H.; Zheng, Y.; Shi, W. Comparison of Arrhenius model and artificial neuronal network for predicting quality changes of frozen tilapia (Oreochromis niloticus). Food Chem. 2022, 372, 131268. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, D.; Ren, X. Quality changes and shelf-life prediction model of postharvest apples using partial least squares and artificial neural network analysis. Food Chem. 2022, 394, 133526. [Google Scholar] [CrossRef]
- Fan, X.; Jin, Z.; Liu, Y. Effects of super-chilling storage on shelf-life and quality indicators of Coregonus peled based on proteomics analysis. Food Res. Int. 2021, 143, 110229. [Google Scholar] [CrossRef]
- Huang, W.; Wang, X.; Zhang, J. Improvement of blueberry freshness prediction based on machine learning and multi-source sensing in the Cold Chain Logistics. Food Control 2023, 145, 109496. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, Y. Predicting the Mechanical Properties of Heat-Treated Woods Using Optimization-Algorithm-Based BPNN. Forests 2023, 14, 935. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 2022, 79, 7305–7336. [Google Scholar] [CrossRef]
- Obsie, E.Y.; Qu, H.; Drummond, F. Wild blueberry yield prediction using a combination of computer simulation and machine learning algorithms. Comput. Electron. Agric. 2020, 178, 105778. [Google Scholar] [CrossRef]
- Li, Y.; Chu, X.; Fu, Z. Shelf-life prediction model of postharvest table grape using optimized radial basis function (RBF) Neural Network. Br. Food J. 2019, 121, 2919–2936. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Rivera, S.; Giongo, L.; Cappai, F. Blueberry firmness—A review of the textural and mechanical properties used in quality evaluations. Postharvest Biol. Technol. 2022, 192, 112016. [Google Scholar] [CrossRef]
- Yu, S.; Lan, H.; Li, X. Prediction method of shelf life of damaged Korla fragrant pears. J. Food Process Eng. 2021, 44, e13902. [Google Scholar] [CrossRef]
- Lian, S.; Sun, J.; Wang, Z. A block cipher based on a suitable use of the chaotic standard map. Chaos Solitons Fractals 2005, 26, 117–129. [Google Scholar] [CrossRef]
- Wu, Q. A self-adaptive embedded chaotic particle swarm optimization for parameters selection of Wv-SVM. Expert Syst. Appl. 2011, 38, 184–192. [Google Scholar] [CrossRef]
- Ibrahim, B.A. A hybrid firefly and particle swarm optimization algorithm for computationally expensive numerical problems. Appl. Soft Comput. 2018, 6, 232–249. [Google Scholar]
- Wang, X.F.; Zhao, H.; Han, T. A grey wolf optimizer using Gaussian estimation of distribution and its application in the multi-UAV multi-target urban tracking problem. Appl. Soft Comput. 2019, 78, 240–260. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- Reed, R.; Marks, R.J., II. Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks; MIT Press: Cambridge, UK, 1999. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wong, T.T.; Yeh, P.Y. Reliable Accuracy Estimates from k-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
- Dragišić Maksimović, J.; Milivojević, J.; Djekić, I.; Radivojević, D.; Veberič, R.; Mikulič Petkovšek, M. Changes in quality characteristics of fresh blueberries: Combined effect of cultivar and storage conditions. J. Food Compos. Anal. 2022, 111, 104597. [Google Scholar] [CrossRef]
- Mokrzycki, W.S.; Tatol, M. Colour difference ΔE—A survey. Mach. Graph. Vis. 2011, 20, 383–412. [Google Scholar]
- Singh, B.; Suri, K.; Shevkani, K. Enzymatic Browning of Fruit and Vegetables: A Review. In Enzymes in Food Technology; Springer: Singapore, 2018; pp. 63–78. [Google Scholar] [CrossRef]
- Ates, U.; Islam, A.; Ozturk, B. Changes in Quality Traits and Phytochemical Components of Blueberry (Vaccinium Corymbosum Cv. Bluecrop) Fruit in Response to Postharvest Aloe Vera Treatment. Int. J. Fruit Sci. 2022, 22, 303–316. [Google Scholar] [CrossRef]
- Ktenioudaki, A.; O’Donnell, C.P.; Emond, J.P. Blueberry Supply Chain: Critical steps impacting fruit quality and application of a boosted regression tree model to predict weight loss. Postharvest Biol. Technol. 2021, 179, 111590. [Google Scholar] [CrossRef]
- Owoyemi, A.; Porat, R.; Lichtern, A. Large-scale, high-throughput phenotyping of the postharvest storage performance of ‘rustenburg’ navel oranges and the development of shelf-life prediction models. Foods 2022, 11, 1840. [Google Scholar] [CrossRef]
- Piechowiak, T.; Grzelak-Błaszczyk, K.; Sójka, M.; Skóra, B.; Balawejder, M. Quality and antioxidant activity of highbush blueberry fruit coated with starch-based and gelatine-based film enriched with Cinnamon Oil. Food Control 2022, 138, 109015. [Google Scholar] [CrossRef]


| Number | Age | Gender | Class |
|---|---|---|---|
| 1 | 24 | Female | Master’s degree |
| 2 | 35 | Male | Lecturer |
| 3 | 21 | Female | Undergraduate |
| 4 | 30 | Male | PhD |
| 5 | 27 | Female | Assistant Researcher |
| 6 | 32 | Male | Associate Professor |
| 7 | 18 | Female | Undergraduate |
| 8 | 58 | Male | Professor |
| 9 | 23 | Female | Master’s degree |
| 10 | 47 | Male | Fellow |
| Sensory Indicators | Scoring Criteria | Score | |
|---|---|---|---|
| Tier 1 Indicators | Secondary Indicators | ||
| Appearance | Glossy rind | Bright, evenly colored fruit with a glossy surface | 9 |
| Bright fruit, largely uniform in color, with a shiny surface | 7–8 | ||
| Basically uniform color, increased waxy layer, reduced lustre, slightly glossy surface | 4–6 | ||
| Dull surface of the fruit, uneven color, no luster on the surface | 1–3 | ||
| Water loss | Normal, smooth surface of the fruit, no wrinkling, no elasticity when pressed lightly by hand, no deformation of the fruit | 9 | |
| Slight water loss, no surface wrinkling, elastic when pressed with the hand, slightly wrinkled skin, no deformation of the fruit | 7–8 | ||
| Moderate water loss; slight surface wrinkling of the fruit; the wrinkling intensifies when lightly pressed with the hand; the fruit is lightly deformed and inelastic | 4–6 | ||
| Heavy water loss, with obvious surface wrinkling of the fruit, which is severely deformed and inelastic when lightly pressed by hand. | 1–3 | ||
| Weightlessness | Full fruit with little weight loss | 9 | |
| Slight loss of weight; small area of ruffling or crumpling around the fruit abscission site | 7–8 | ||
| Moderate weight loss; with a medium area of pericarp crinkling or folding around the fruit abscission site | 5–6 | ||
| Severe weight loss, with large areas of skin crinkling or folding around the fruit abscission site | 3–4 | ||
| Blueberries almost crumpled into dried blueberries, or whole fruit crumpled to resemble mulberries | 1–2 | ||
| Degree of decay | Fruit surface are free of mold spots | 9 | |
| 1–3 mold spots on the surface of the fruit | 7–8 | ||
| 25–50% of the fruit area decayed | 4–6 | ||
| Fruit surface decay greater than 50% of the fruit area | 1–3 | ||
| Flavor | Scent | Honeyed, richly scented, no bad odor | 9 |
| Slightly fragrant, slightly light odor, no bad smell | 7–8 | ||
| Has an inconspicuous aroma of fruit and no other odor | 5–6 | ||
| No fruit aroma, slight other odor | 3–4 | ||
| No aroma of fruit, bad odor, moldy smell | 1–2 | ||
| Sweetness and acidity | Intense and sweet | 9 | |
| Sweeter | 7–8 | ||
| Moderate | 5–6 | ||
| More acidic | 3–4 | ||
| Very sour | 1–2 | ||
| Taste | Brittleness | Very fluffy | 1–2 |
| Fluffy | 3–4 | ||
| Moderate | 5–6 | ||
| Crisp | 7–8 | ||
| Very crisp | 9 | ||
| Chewiness | Very poor palatability | 1–2 | |
| Poor palatability | 3–4 | ||
| Moderate | 5–6 | ||
| Good palatability | 7–8 | ||
| Very good palatability | 9 | ||
| Tightness | Very low | 1–2 | |
| Relatively low | 3–4 | ||
| Moderate | 5–6 | ||
| High | 7–8 | ||
| Very high | 9 | ||
| Function | Dim | Range | |
|---|---|---|---|
| = | 30/50/100 | [−100,100] | 0 |
| = + | 30/50/100 | [−10,10] | 0 |
| = | 30/50/100 | [−100,100] | 0 |
| = | 30/50/100 | [−100,100] | 0 |
| = | 30/50/100 | [−30,30] | 0 |
| = | 30/50/100 | [−100,100] | 0 |
| = + | 30/50/100 | [−100,100] | 0 |
| = | 30/50/100 | [−5,10] | 0 |
| = | 30/50/100 | [−5.12,5.12] | 0 |
| = | 30/50/100 | [−10,10] | 0 |
| = = 1 , for all = | 30/50/100 | [−50,50] | 0 |
| = 0.1 | 30/50/100 | [−50,50] | 0 |
| = | 30/50/100 | [−100,100] | 0 |
for all | 30/50/100 | [−10,10] | 0 |
| Algorithms | Parameters Settings |
|---|---|
| HFPSO | , , , , |
| GEDGWO | , , |
| HHO | , |
| DBO | , , |
| GDEDBO | , , , |
| F | Index | HFPSO | GEDGWO | HHO | DBO | GDEDBO |
|---|---|---|---|---|---|---|
| F1 | Best | 1.67 × 10−95 | 2.25 × 10−181 | 7.22 × 10−35 | 1.81 × 10−115 | 3.02 × 10−210 |
| Mean | 2.55 × 10−83 | 4.32 × 10−113 | 6.42 × 10−33 | 1.31 × 10−99 | 9.59 × 10−159 | |
| STD | 1.20 × 10−82 | 2.37 × 10−112 | 1.69 × 10−32 | 5.51 × 10−99 | 5.25 × 10−158 | |
| F2 | Best | 4.85 × 10−62 | 1.16 × 10−85 | 3.85 × 10−21 | 4.97 × 10−62 | 2.26 × 10−109 |
| Mean | 3.92 × 10−54 | 6.14 × 10−61 | 6.55 × 10−20 | 8.26 × 10−53 | 4.20 × 10−83 | |
| STD | 1.89 × 10−53 | 2.35 × 10−60 | 4.77 × 10−20 | 3.59 × 10−52 | 2.81 × 10−82 | |
| F3 | Best | 6.29 × 103 | 5.73 × 10−149 | 2.27 × 10−11 | 1.01 × 10−110 | 1.42 × 10−191 |
| Mean | 2.45 × 104 | 9.90 × 10−45 | 9.65 × 10−8 | 6.46 × 10−79 | 1.22 × 10−115 | |
| STD | 9.33 × 103 | 7.00 × 10−44 | 3.94 × 10−7 | 4.57 × 10−78 | 7.98 × 10−115 | |
| F4 | Best | 2.99 × 10−6 | 4.31 × 10−84 | 2.69 × 10−9 | 2.57 × 10−57 | 1.96 × 10−102 |
| Mean | 3.70 × 101 | 3.15 × 10−53 | 1.88 × 10−8 | 7.21 × 10−48 | 4.12 × 10−68 | |
| STD | 2.88 × 101 | 2.23 × 10−52 | 1.33 × 10−8 | 4.23 × 10−47 | 2.31 × 10−67 | |
| F5 | Best | 2.69 × 101 | 1.00 × 10−6 | 2.52 × 101 | 2.45 × 101 | 2.44 × 101 |
| Mean | 2.75 × 101 | 3.01 × 10−3 | 2.67 × 101 | 2.52 × 101 | 2.50 × 101 | |
| STD | 4.83 × 10−1 | 3.32 × 10−3 | 7.85 × 10−1 | 7.38 × 10−1 | 3.28 × 10−1 | |
| F6 | Best | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 |
| Mean | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | |
| STD | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | |
| F7 | Best | 2.01 × 10−88 | 1.92 × 10−155 | 5.23 × 10−29 | 4.29 × 10−113 | 1.38 × 10−196 |
| Mean | 9.19 × 10−77 | 1.16 × 10−111 | 2.88 × 10−27 | 1.03 × 10−93 | 3.10 × 10−152 | |
| STD | 4.61 × 10−76 | 6.14 × 10−111 | 4.91 × 10−27 | 5.39 × 10−93 | 1.30 × 10−151 | |
| F8 | Best | 2.51 × 10−93 | 2.02 × 10−163 | 9.38 × 10−37 | 2.78 × 10−118 | 3.58 × 10−202 |
| Mean | 2.98 × 10−83 | 2.30 × 10−110 | 7.05 × 10−35 | 2.29 × 10−103 | 7.34 × 10−160 | |
| STD | 1.63 × 10−82 | 1.26 × 10−109 | 1.25 × 10−34 | 6.75 × 10−103 | 3.86 × 10−159 | |
| F9 | Best | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 |
| Mean | 1.89 × 10−15 | 4.61 × 10−1 | 3.15 × 100 | 0.00 × 100 | 0.00 × 100 | |
| STD | 1.04 × 10−14 | 2.19 × 100 | 4.36 × 100 | 0.00 × 100 | 0.00 × 100 | |
| F10 | Best | 1.60 × 10−60 | 1.08 × 10−80 | 3.31 × 10−20 | 1.02 × 10−61 | 8.18 × 10−112 |
| Mean | 8.12 × 10−1 | 1.48 × 10−1 | 3.65 × 10−2 | 1.36 × 10−46 | 6.70 × 10−85 | |
| STD | 4.45 × 100 | 8.11 × 10−1 | 1.97 × 10−1 | 7.47 × 10−46 | 2.51 × 10−84 | |
| F11 | Best | 1.02 × 10−3 | 8.84 × 10−9 | 6.30 × 10−1 | 2.45 × 10−11 | 2.87 × 10−6 |
| Mean | 1.38 × 10−2 | 2.60 × 10−6 | 3.25 × 10−2 | 3.54 × 10−4 | 2.27 × 10−5 | |
| STD | 2.42 × 10−2 | 2.49 × 10−6 | 2.23 × 10−2 | 1.40 × 10−3 | 3.04 × 10−5 | |
| F12 | Best | 2.67 × 10−2 | 5.18 × 10−10 | 9.78 × 10−2 | 1.87 × 10−5 | 2.84 × 10−7 |
| Mean | 2.30 × 10−1 | 1.03 × 10−1 | 3.90 × 10−1 | 1.33 × 10−2 | 3.52 × 10−5 | |
| STD | 1.71 × 10−1 | 7.80 × 10−2 | 2.10 × 10−1 | 3.04 × 10−2 | 3.61 × 10−5 | |
| F13 | Best | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 |
| Mean | 1.83 × 10−5 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | |
| STD | 7.91 × 10−5 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | |
| F14 | Best | 5.81 × 10−2 | 4.27 × 10−9 | 5.43 × 10−1 | 1.60 × 10−4 | 2.03 × 10−8 |
| Mean | 4.71 × 10−1 | 1.19 × 10−1 | 1.03 × 100 | 1.04 × 10−2 | 5.43 × 10−5 | |
| STD | 4.66 × 10−1 | 1.14 × 10−1 | 2.56 × 10−1 | 2.72 × 10−2 | 6.87 × 10−5 |
| Functions | HFPSO | GEDGWO | HHO | DBO |
|---|---|---|---|---|
| F1 | 7.07 × 10−18 | 7.07 × 10−18 | 7.07 × 10−18 | 9.54 × 10−18 |
| F2 | 7.07 × 10−18 | 1.08 × 10−17 | 7.07 × 10−18 | 7.07 × 10−18 |
| F3 | 7.07 × 10−18 | 1.99 × 10−12 | 7.07 × 10−18 | 7.07 × 10−18 |
| F4 | 7.07 × 10−18 | 1.32 × 10−14 | 7.07 × 10−18 | 7.07 × 10−18 |
| F5 | 3.02 × 10−11 | 3.01 × 10−11 | 3.01 × 10−11 | 3.01 × 10−11 |
| F6 | N/A | N/A | N/A | N/A |
| F7 | 3.01 × 10−11 | 3.69 × 10−11 | 3.02 × 10−11 | 3.02 × 10−11 |
| F8 | 3.01 × 10−11 | 1.33 × 10−10 | 3.02 × 10−11 | 3.02 × 10−11 |
| F9 | 3.34 × 10−1 | 8.15 × 10−2 | 1.84 × 10−10 | N/A |
| F10 | 3.02 × 10−11 | 3.02 × 10−11 | 3.02 × 10−11 | 3.02 × 10−11 |
| F11 | 3.02 × 10−11 | 8.48 × 10−9 | 3.02 × 10−11 | 1.69 × 10−9 |
| F12 | 1.96 × 10−10 | 8.66 × 10−5 | 4.08 × 10−11 | 8.89 × 10−10 |
| F13 | 1.61 × 10−1 | N/A | N/A | N/A |
| F14 | 3.02 × 10−11 | 1.22 × 10−2 | 3.02 × 10−11 | 4.08 × 10−11 |
| +/=/− | 11/3/0 | 12/2/0 | 12/2/0 | 11/3/0 |
| Models | Optimal Combination of Parameters |
|---|---|
| SVR | {‘C’: 1, ‘epsilon’: 0.5, ‘kernel’: ‘linear’} |
| ANN | {‘activation’: ‘tanh’, ‘alpha’: 0.0001, ‘hidden_layer_sizes’: (5), ‘learning_rate’: ‘adaptive’, ‘learning_rate_init’: 0.01, ‘solver’: ‘sgd’} |
| Temperature | Model | Neuron Configuration | Topology | Hidden and Output Activations | Test | |||
|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAPE | R² | |||||
| 0 °C | BPNN | (6,7) | 23–6–7–1 | LOGSIG-PURELIN | 0.2325 | 0.0028 | 0.0981 | 0.9721 |
| MRMR-BPNN | 6 | 7–6–1 | LOGSIG-PURELIN | 0.1174 | 0.0019 | 0.1015 | 0.9775 | |
| DBO-BPNN | (7,9) | 23–7–9–1 | LOGSIG-TANSIG | 0.2072 | 0.0626 | 0.0713 | 0.9827 | |
| MRMR-DBO-BPNN | 5 | 7–5–1 | LOGSIG-PURELIN | 0.1158 | 0.0401 | 0.0351 | 0.9893 | |
| GDEDBO-BPNN | (8,8) | 23–8–8–1 | PURELIN-LOGSIG | 0.1685 | 0.0406 | 0.0561 | 0.9881 | |
| MRMR-GDEDBO-BPNN | 5 | 7–5–1 | LOGSIG-PURELIN | 0.0304 | 0.0014 | 0.0114 | 0.9995 | |
| 4 °C | BPNN | (6,7) | 23–6–7–1 | LOGSIG-PURELIN | 0.2226 | 0.0035 | 0.1400 | 0.9630 |
| MRMR-BPNN | 6 | 7–6–1 | LOGSIG-PURELIN | 0.1798 | 0.0026 | 0.1229 | 0.9744 | |
| DBO-BPNN | (8,8) | 23–8–8–1 | POSLIN-PURELIN | 0.2040 | 0.0611 | 0.0844 | 0.9797 | |
| MRMR-DBO-BPNN | 5 | 7–5–1 | LOGSIG-TANSIG | 0.1183 | 0.0401 | 0.0504 | 0.9837 | |
| GDEDBO-BPNN | (7,9) | 23–7–9–1 | TANSIG-PURELIN | 0.2071 | 0.0631 | 0.0573 | 0.9833 | |
| MRMR-GDEDBO-BPNN | 5 | 7–5–1 | LOGSIG-PURELIN | 0.0671 | 0.0077 | 0.0237 | 0.9971 | |
| 25 °C | BPNN | (8,8) | 23–8–8–1 | LOGSIG-PURELIN | 0.2862 | 0.0049 | 0.1533 | 0.9516 |
| MRMR-BPNN | 8 | 7–7–1 | LOGSIG-PURELIN | 0.1955 | 0.0084 | 0.1393 | 0.9574 | |
| DBO-BPNN | (9,7) | 23–9–7–1 | LOGSIG-PURELIN | 0.2259 | 0.0906 | 0.1073 | 0.9639 | |
| MRMR-DBO-BPNN | 9 | 7–7–1 | LOGSIG-PURELIN | 0.1248 | 0.0548 | 0.0506 | 0.9793 | |
| GDEDBO-BPNN | (9,9) | 23–8–8–1 | POSLIN-PURELIN | 0.1313 | 0.0737 | 0.0644 | 0.9724 | |
| MRMR-GDEDBO-BPNN | 5 | 7–5–1 | LOGSIG-PURELIN | 0.1013 | 0.0253 | 0.0301 | 0.9910 |
| Actual Shelf-Life/d | Predicted Shelf-Life/d | 0 °C | 4 °C | 25 °C | |||||
|---|---|---|---|---|---|---|---|---|---|
| BP | GDEDBO-BP | MRMR- GDEDBO-BP | BP | GDEDBO-BP | MRMR- GDEDBO-BP | BP | GDEDBO-BP | MRMR- GDEDBO-BP | |
| 1 | 1.1285 | 1.0238 | 1.0049 | 1.2882 | 1.0759 | 1.0095 | 1.3616 | 1.3128 | 1.0112 |
| 2 | 1.9468 | 2.0151 | 1.9926 | 1.8944 | 2.1021 | 1.9359 | 1.8428 | 2.1134 | 2.0654 |
| 3 | 3.2360 | 3.1095 | 3.0223 | 3.0919 | 2.9635 | 3.0429 | 2.8186 | 2.9526 | 3.0092 |
| 4 | 4.0608 | 3.9774 | 3.9812 | 4.1867 | 3.8431 | 4.0615 | 4.1677 | 3.9444 | 3.9759 |
| 5 | 5.2478 | 5.1979 | 4.9893 | 4.8434 | 5.1551 | 5.0225 | 5.2524 | 5.1477 | 5.1123 |
| 6 | 6.2575 | 5.9098 | 5.9638 | 5.7328 | 5.9729 | 5.9884 | 5.8174 | 5.8207 | 5.9867 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Zhu, Y.; Liu, Z.; Feng, G.; Diao, P.; Wang, H.; Fu, S.; Lv, S.; Zhang, C. A Back Propagation Neural Network Model for Postharvest Blueberry Shelf-Life Prediction Based on Feature Selection and Dung Beetle Optimizer. Agriculture 2023, 13, 1784. https://doi.org/10.3390/agriculture13091784
Zhang R, Zhu Y, Liu Z, Feng G, Diao P, Wang H, Fu S, Lv S, Zhang C. A Back Propagation Neural Network Model for Postharvest Blueberry Shelf-Life Prediction Based on Feature Selection and Dung Beetle Optimizer. Agriculture. 2023; 13(9):1784. https://doi.org/10.3390/agriculture13091784
Chicago/Turabian StyleZhang, Runze, Yujie Zhu, Zhongshen Liu, Guohong Feng, Pengfei Diao, Hongen Wang, Shenghong Fu, Shuo Lv, and Chen Zhang. 2023. "A Back Propagation Neural Network Model for Postharvest Blueberry Shelf-Life Prediction Based on Feature Selection and Dung Beetle Optimizer" Agriculture 13, no. 9: 1784. https://doi.org/10.3390/agriculture13091784
APA StyleZhang, R., Zhu, Y., Liu, Z., Feng, G., Diao, P., Wang, H., Fu, S., Lv, S., & Zhang, C. (2023). A Back Propagation Neural Network Model for Postharvest Blueberry Shelf-Life Prediction Based on Feature Selection and Dung Beetle Optimizer. Agriculture, 13(9), 1784. https://doi.org/10.3390/agriculture13091784