


Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model

Abstract
:1. Introduction
2. Materials and Methods
2.1. Bayberry Image Collection
2.2. Data Annotation and Augmentation
2.3. YOLOv7-Tiny Object Detection Network
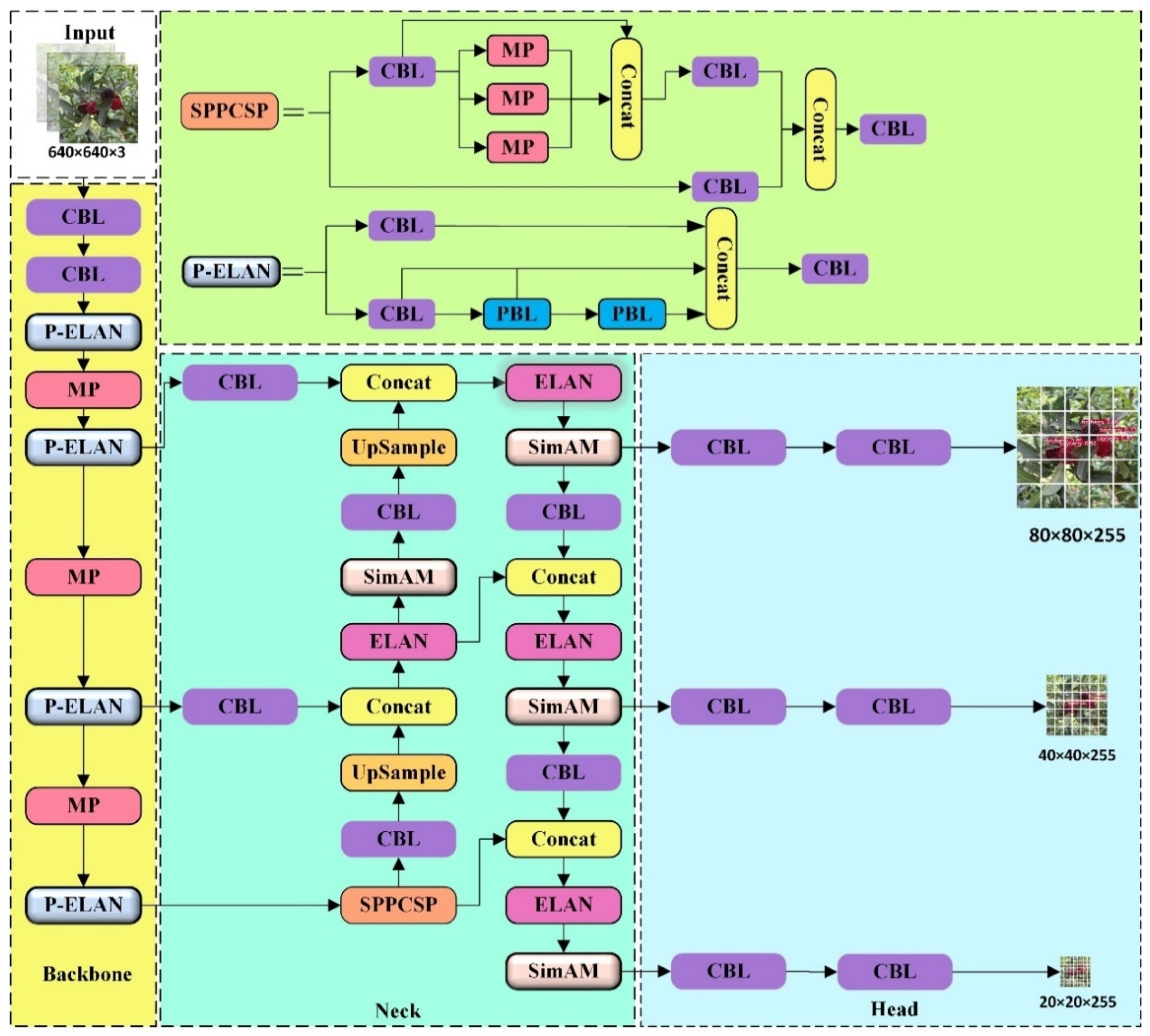
2.4. Improvement of the YOLOv7-Tiny Network Model
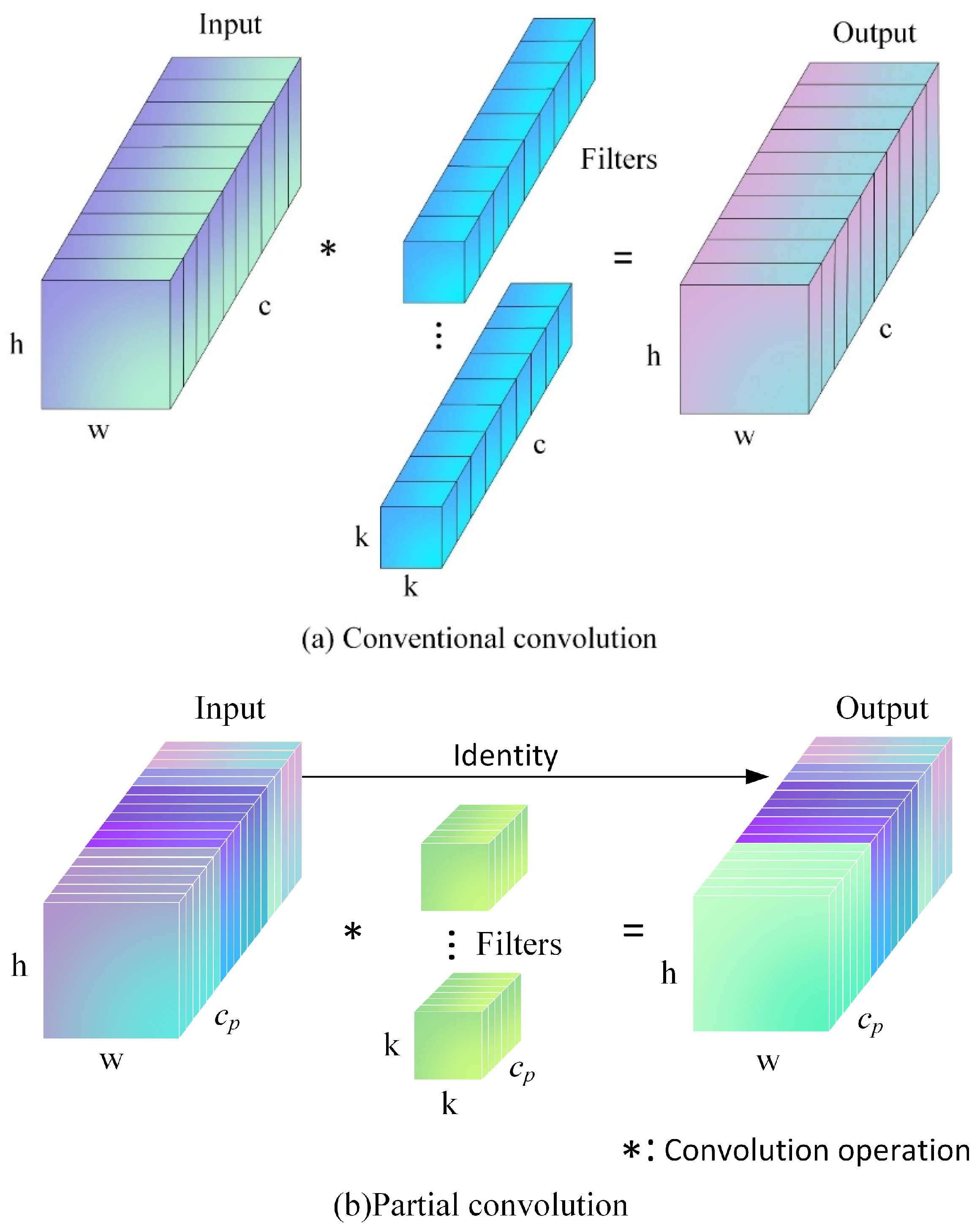
2.4.1. Improvement of the Backbone Network
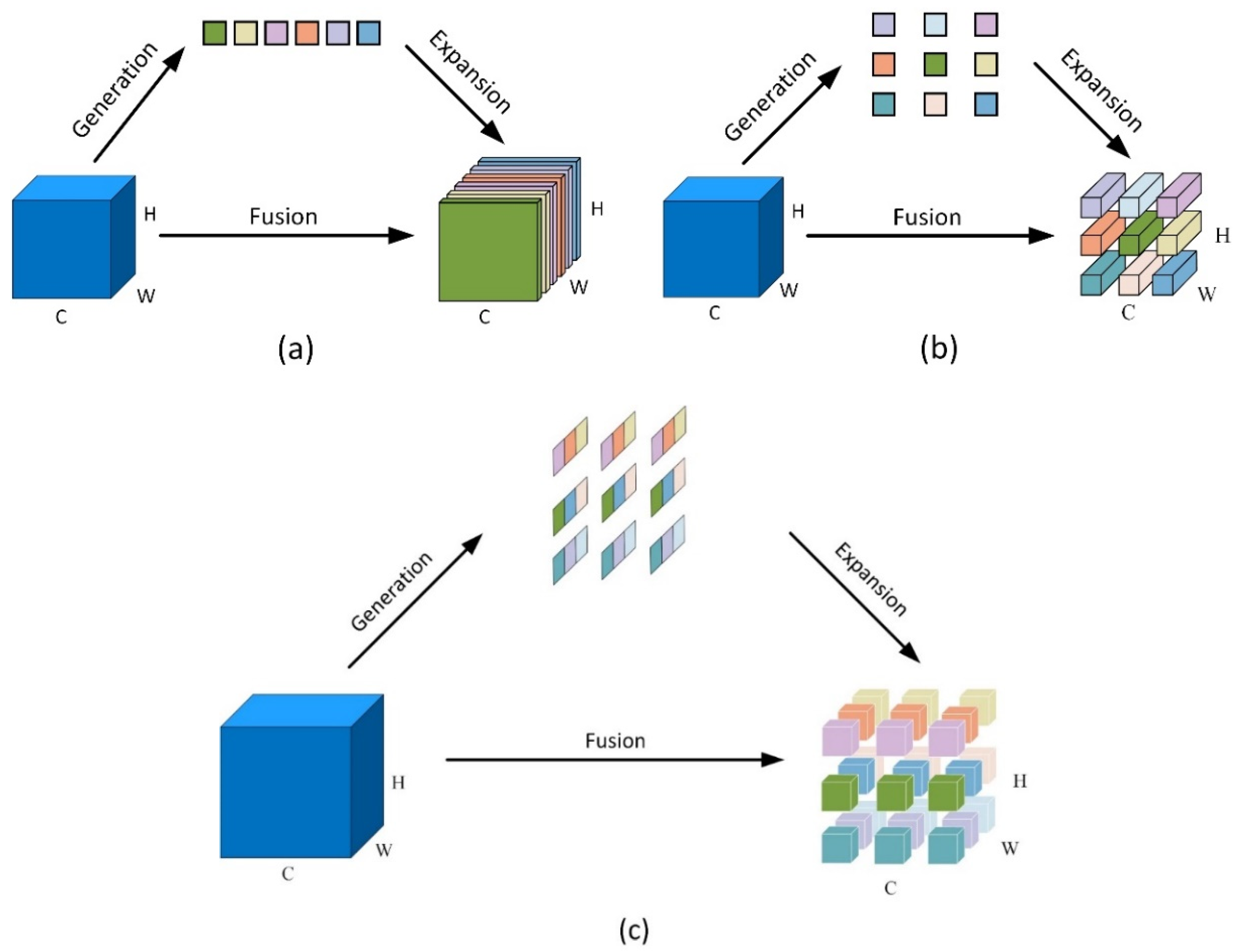
2.4.2. Neck Improvement
2.4.3. Loss Function Improvement
2.4.4. Experimental Process and Proposed Algorithm
2.5. Model Training
2.5.1. Training Platform and Parameter Settings
2.5.2. Evaluation Metrics
3. Results
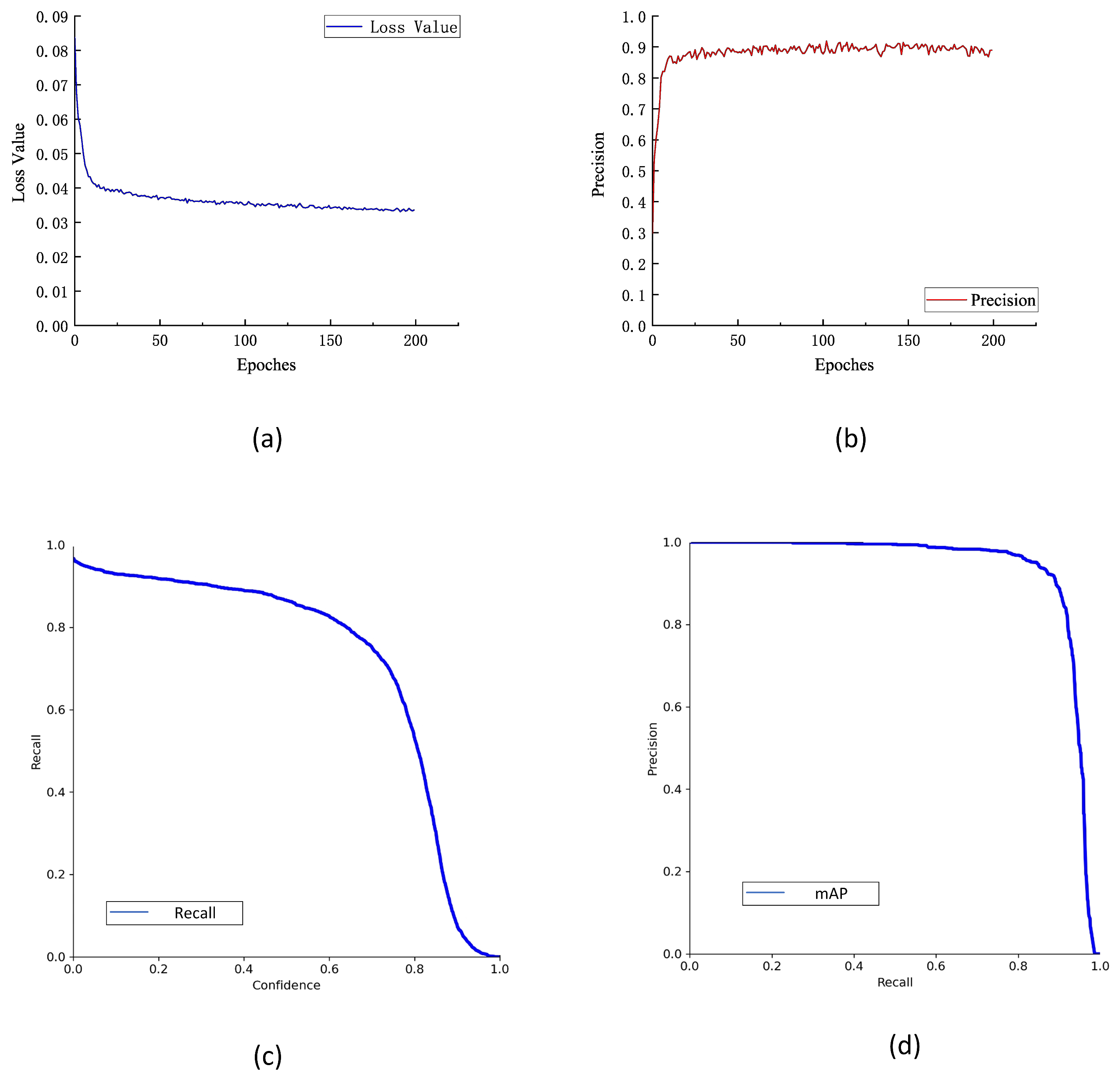
3.1. Training Results
3.2. Comparative Study of Attention Mechanisms
3.3. Ablation Experiment
3.4. Comparative Study of Different Networks
3.5. Harvesting Robot Model Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, C.; Feng, C.; Li, X.; Xu, C.; Sun, C.; Chen, K. Analysis of expressed sequence tags from Chinese bayberry fruit (Myrica rubra Sieb. and Zucc.) at different ripening stages and their association with fruit quality development. Int. J. Mol. Sci. 2013, 14, 3110–3123. [Google Scholar] [CrossRef] [PubMed]
- Ge, S.; Wang, L.; Ma, J.; Jiang, S.; Peng, W. Biological analysis on extractives of bayberry fresh flesh by GC–MS. Saudi J. Biol. Sci. 2018, 25, 816–818. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, H.; Zhang, X.; Gao, P.; Xu, Z.; Huang, X. An object detection method for bayberry trees based on an improved YOLO algorithm. Int. J. Digit. Earth 2023, 16, 781–805. [Google Scholar] [CrossRef]
- Hoshyarmanesh, H.; Dastgerdi, H.R.; Ghodsi, M.; Khandan, R.; Zareinia, K. Numerical and experimental vibration analysis of olive tree for optimal mechanized harvesting efficiency and productivity. Comput. Electron. Agric. 2017, 132, 34–48. [Google Scholar] [CrossRef]
- Ni, H.; Zhang, J.; Zhao, N.; Wang, C.; Lv, S.; Ren, F.; Wang, X. Design on the winter jujubes harvesting and sorting device. Appl. Sci. 2019, 9, 5546. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhu, Z.; Ye, Y.; Qian, M. Continuous picking of yellow peaches with recognition and collision-free path. Comput. Electron. Agric. 2023, 214, 108273. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Ma, Z.; Chen, M.; Zhong, Y.; Deng, F.; Li, M. Computer vision-based high-quality tea automatic plucking robot using Delta parallel manipulator. Comput. Electron. Agric. 2021, 181, 105946. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Li, J.; Xiong, J. In-field citrus detection and localisation based on RGB-D image analysis. Biosyst. Eng. 2019, 186, 34–44. [Google Scholar] [CrossRef]
- Wu, G.; Li, B.; Zhu, Q.; Huang, M.; Guo, Y. Using color and 3D geometry features to segment fruit point cloud and improve fruit recognition accuracy. Comput. Electron. Agric. 2020, 174, 105475. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.; Gao, T.; Fang, Y.; Chen, T. A novel SSD-based detection algorithm suitable for small object. IEICE Trans. Inf. Syst. 2023, 106, 625–634. [Google Scholar] [CrossRef]
- Zhang, Z.; Shi, R.; Xing, Z.; Guo, Q.; Zeng, C. Improved faster region-based convolutional neural networks (R-CNN) model based on split attention for the detection of safflower filaments in natural environments. Agronomy 2023, 13, 2596. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Sheng, B.; Li, P.; Yang, P.; Feng, D.D.; Qi, J. Automatic detection and classification system of domestic waste via multimodel cascaded convolutional neural network. IEEE Trans. Ind. Inform. 2022, 18, 163–173. [Google Scholar] [CrossRef]
- Dai, L.; Sheng, B.; Chen, T.; Wu, Q.; Liu, R.; Cai, C.; Wu, L.; Yang, D.; Hamzah, H.; Liu, Y.; et al. A deep learning system for predicting time to progression of diabetic retinopathy. Nat. Med. 2024, 30, 584–594. [Google Scholar] [CrossRef] [PubMed]
- Dai, L.; Wu, L.; Li, H.; Cai, C.; Wu, Q.; Kong, H.; Liu, R.; Wang, X.; Hou, X.; Liu, Y.; et al. A deep learning system for detecting diabetic retinopathy across the disease spectrum. Nat. Commun. 2021, 12, 3242. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Liu, Y.; Ren, H.; Zhang, Z.; Men, F.; Zhang, P.; Wu, D.; Feng, R. Research on multi-cluster green persimmon detection method based on improved Faster RCNN. Front. Plant Sci. 2023, 14, 1177114. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 779–788. [Google Scholar]
- Ji, W.; Gao, X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple target recognition method in complex environment based on improved YOLOv4. J. Food Process Eng. 2021, 44, e13866. [Google Scholar] [CrossRef]
- Cao, Z.; Yuan, R. Real-Time detection of mango based on improved YOLOv4. Electronics 2022, 11, 3853. [Google Scholar] [CrossRef]
- Sun, L.; Hu, G.; Chen, C.; Cai, H.; Li, C.; Zhang, S.; Chen, J. Lightweight apple detection in complex orchards using YOLOV5-PRE. Horticulturae 2022, 8, 1169. [Google Scholar] [CrossRef]
- Li, T.; Sun, M.; He, Q.; Zhang, G.; Shi, G.; Ding, X.; Lin, S. Tomato recognition and location algorithm based on improved YOLOv5. Comput. Electron. Agric. 2023, 208, 107759. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Wang, J. RDE-YOLOv7: An improved model based on yolov7 for better performance in detecting dragon fruits. Agronomy 2023, 13, 1042. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A Multiscale lightweight and efficient model based on YOLOv7: Applied to citrus orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Qian, M.; Chen, Q.; Sun, F.; Pan, J. An improved YOLOv5 model: Application to mixed impurities detection for walnut kernels. Foods 2023, 12, 624. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, F.; Lv, C.; Dong, L.; Li, X.; Guo, P.; Zhao, B. Development of effective model for non-destructive detection of defective kiwifruit based on graded lines. Front. Plant Sci. 2023, 14, 1170221. [Google Scholar] [CrossRef]
- Huang, P.; Wang, S.; Chen, J.; Li, W.; Peng, X. Lightweight model for pavement defect detection based on improved YOLOv7. Sensors 2023, 23, 7112. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Lin, X.; Sun, S.; Huang, W.; Sheng, B.; Li, P.; Feng, D.D. EAPT: Efficient attention pyramid transformer for image processing. IEEE Trans. Multimedia 2023, 25, 50–61. [Google Scholar] [CrossRef]
- Ma, J.; Lu, A.; Chen, C.; Ma, X.; Ma, Q. YOLOv5-lotus: An efficient object detection method for lotus seedpod in a natural environment. Comput. Electron. Agric. 2023, 206, 107635. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Y. SA-Net: Shuffle attention for deep convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Mosaic | 100% probability |
| Fliplr | 50% probability |
| Mixup | 15% probability |
| HSV_Hue | 0.015 fraction |
| HSV_Saturation | 0.7 fraction |
| HSV_Value | 0.4 fraction |
| Model | mAP (%) | Recall (%) | Model Size (MB) |
|---|---|---|---|
| YOLOv7 | 91.9 | 94.5 | 73.1 |
| YOLOv7-tiny | 93.7 | 96.3 | 11.9 |
| YOLOv7x | 92.5 | 94.6 | 138.7 |
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| Image Size | 640 × 640 | Momentum | 0.937 |
| Batch Size | 4 | Box loss gain | 0.05 |
| Epochs | 200 | Cls loss gain | 0.3 |
| Learning Rate | 0.01 | Obj loss gain | 0.7 |
| Model | Precision (%) | Recall (%) | mAP (/%) |
|---|---|---|---|
| YOLOv7-tiny | 83.4 | 96.3 | 93.7 |
| +CBAM | 85.2 | 97.0 | 94.1 |
| +CA | 84.1 | 96.5 | 93.7 |
| +SA | 85.0 | 97.0 | 93.9 |
| +SimAM | 85.3 | 97.2 | 93.8 |
| SIoU | SimAM | PConv | Precision (%) | Recall (%) | mAP (%) | Model Size (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| 83.4 | 96.3 | 93.7 | 11.9 | 6.58 | |||
| √ | 84.8 | 96.5 | 93.8 | 11.9 | 6.58 | ||
| √ | 85.3 | 97.2 | 93.8 | 11.9 | 6.58 | ||
| √ | 86.2 | 97.1 | 93.3 | 9.1 | 4.8 | ||
| √ | √ | 87.9 | 97.3 | 93.9 | 11.9 | 6.58 | |
| √ | √ | √ | 88.1 | 97.6 | 93.4 | 9.0 | 4.8 |
| Model | Precision (%) | Recall (%) | mAP (%) | Model Size (MB) |
|---|---|---|---|---|
| Faster-RCNN | 62.1 | 91.1 | 90.1 | 108.7 |
| YOLOv3-tiny | 85.4 | 94.1 | 87.8 | 16.9 |
| YOLOv5-m | 83.4 | 97.2 | 93.9 | 41.2 |
| YOLOv6-n | 81.6 | 97.1 | 93.2 | 10.2 |
| YOLOv7-tiny | 83.4 | 96.3 | 93.7 | 11.9 |
| Ours | 88.1 | 97.6 | 93.4 | 9.0 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Display Card | Nvidia RTX 1050 | System | Ubuntu18.04 |
| Camera | Intel D435 | Framework | PyTorch 1.10 |
| Robot Arm | AUBO-i5 | Python | 3.8 |
| Video Memory | 8 G | Image Size | 640 × 640 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Qian, M.; Zhang, X.; Zhu, J. Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model. Agriculture 2024, 14, 1725. https://doi.org/10.3390/agriculture14101725
Chen Z, Qian M, Zhang X, Zhu J. Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model. Agriculture. 2024; 14(10):1725. https://doi.org/10.3390/agriculture14101725
Chicago/Turabian StyleChen, Zhenlei, Mengbo Qian, Xiaobin Zhang, and Jianxi Zhu. 2024. "Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model" Agriculture 14, no. 10: 1725. https://doi.org/10.3390/agriculture14101725
APA StyleChen, Z., Qian, M., Zhang, X., & Zhu, J. (2024). Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model. Agriculture, 14(10), 1725. https://doi.org/10.3390/agriculture14101725