Abstract
Quality inspection is a pivotal component in the intelligent sorting of Astragalus membranaceus (Huangqi), a medicinal plant of significant pharmacological importance. To improve the precision and efficiency of assessing the quality of Astragalus slices, we present the FA-SD-YOLO model, an innovative advancement over the YOLOv8n architecture. This model introduces several novel modifications to enhance feature extraction and fusion while reducing computational complexity. The FA-SD-YOLO model replaces the conventional C2f module with the C2F-F module, developed using the FasterNet architecture, and substitutes the SPPF module with the Adaptive Inverted Fusion (AIFI) module. These changes markedly enhance the model’s feature fusion capabilities. Additionally, the integration of the SD module into the detection head optimizes parameter efficiency while improving detection performance. Performance evaluation highlights the superiority of the FA-SD-YOLO model. It achieves accuracy and recall rates of 88.6% and 89.6%, outperforming the YOLOv8n model by 1.8% and 1.3%, respectively. The model’s F1 score reaches 89.1%, and the mean average precision (mAP) improves to 93.2%, reflecting increases of 1.6% and 2.4% over YOLOv8n. These enhancements are accompanied by significant reductions in model size and computational cost: the parameter count is reduced to 1.58 million (a 47.3% reduction), and the FLOPS drops to 4.6 G (a 43.2% reduction). When compared with other state-of-the-art models, including YOLOv5s, YOLOv6s, YOLOv9t, and YOLOv11n, the FA-SD-YOLO model demonstrates superior performance across key metrics such as accuracy, F1 score, mAP, and FLOPS. Notably, it achieves a remarkable recognition speed of 13.8 ms per image, underscoring its efficiency and suitability for real-time applications. The FA-SD-YOLO model represents a robust and effective solution for the quality inspection of Astragalus membranaceus slices, providing reliable technical support for intelligent sorting machinery in the processing of this important medicinal herb.
1. Introduction
Astragalus (Huangqi), a widely used herb in traditional Chinese medicine, is known for its diverse pharmacological properties, including anti-fatigue, antioxidant, and immune-enhancing effects [1,2,3]. During the quality sorting of Astragalus slices, traditional methods often rely on manual labor, which, while effective in ensuring quality, is labor-intensive and time-consuming. Existing color sorters for traditional Chinese medicine (TCM) materials are capable of performing preliminary screening of Astragalus slices. However, these systems are typically based on basic recognition of color and shape, which limits their accuracy. This is particularly problematic for slices that resemble healthy Astragalus but exhibit underlying defects, such as rot, which can be difficult to detect through simple color-based sorting. As a result, the overall effectiveness of the sorting process is compromised. With the rapid advancements in deep learning and intelligent detection technologies, there is a growing need for the development of more efficient and precise algorithms to facilitate the creation of automated sorting systems for Astragalus slices.
Deep learning is a cutting-edge technology with superior capabilities for feature learning and extraction, outperforming traditional machine learning algorithms in many applications [4,5]. Its impact on traditional Chinese medicine (TCM) detection has been transformative, with an increasing number of deep learning models being applied to the identification and quality assessment of medicinal materials. For example, Q. Xue and colleagues developed an internal defect detection model for ginseng using the Faster R-CNN algorithm, enabling X-ray systems to intelligently detect and sort red ginseng based on internal defects, achieving a mean average precision of 95% [6]. Laiali Almazaydeh and collaborators applied the Mask R-CNN algorithm for the identification and detection of over 30 types of herbs, achieving an average accuracy of 95.7% [7]. Zhao P. and colleagues proposed a VGG-16-based herbal medicine identification model to assist in recognizing traditional Chinese medicinal materials [8]. Additionally, Liu S. and team utilized GoogleNet for plant identification in TCM, achieving TOP-1 and TOP-5 accuracy rates of 67.4% and 92.4%, respectively [9].
The YOLO (You Only Look Once) series of algorithms are widely recognized in deep learning for their effectiveness in real-time object detection. These algorithms uniquely integrate feature extraction and classification into a single, unified process, which has made them indispensable in image recognition tasks. YOLO is particularly known for its rapid detection capabilities, allowing for real-time analysis while maintaining high accuracy. As a result, YOLO and its enhanced versions have been increasingly applied to the detection of traditional Chinese medicinal materials. For instance, Teng Y. and colleagues employed the YOLOv5 model with the CBAM attention mechanism to identify Fritillaria ussuriensis, achieving a detection accuracy of 91.32% [10]. Similarly, Gao S. and collaborators applied the YOLOv3 model for recognition tasks involving various traditional Chinese medicinal disks, achieving an average detection accuracy of 96% [11]. Geng T. and his team utilized the lightweight YOLOv5s network to analyze microscopic images of honeysuckle, achieving a mean average precision (mAP) of 0.81 at a threshold of 0.5, demonstrating the model’s effectiveness in recognizing microscopic features of TCM materials [12]. Moreover, Hongxu Zhang and his group focused on red ginseng detection by developing a YOLOv5s model based on hyperspectral imaging, successfully differentiating between various parts of red ginseng, with recognition rates of 96.79% for the rhizome and 95.94% for the main root [13].
In the field of deep learning, research into traditional Chinese medicinal materials has predominantly focused on the classification and identification of different herbs, as well as preliminary assessments of their quality. Given the significant variations among different types of medicinal materials, these authors often found it relatively straightforward to distinguish and identify them. However, research into detailed quality inspection within the same category of materials remains limited. This is especially true for Astragalus membranaceus, where the application of deep learning techniques has been relatively underdeveloped. In the quality inspection of Astragalus slices, the high degree of similarity between certain samples presents a significant challenge, complicating the task of effectively distinguishing between healthy and defective slices.
This study employs the YOLOv8 model for the quality inspection of Astragalus slices and introduces a novel quality inspection method based on the FA-SD-YOLO model. The main contributions of this paper are as follows:
- (1)
- The C2F-F module, which combines the FasterNet module with C2f, is integrated into the YOLOv8n model. This modification reduces FLOPS (Floating Point Operations Per Second) while maintaining the model’s capability to accurately detect the quality of Astragalus slices.
- (2)
- The AIFI module is used in place of the SPPF module, allowing the YOLOv8n model to better focus on key detection features of the target objects (the Astragalus slices), thus improving detection accuracy.
- (3)
- To further reduce FLOPS, the YOLOv8n head network is replaced with the SD module.
In comparison to the YOLOv8n model, the FA-SD-YOLO model reduces the number of parameters while enhancing detection performance for Astragalus slice quality, providing crucial technical support for sorting equipment used in the quality assessment of Astragalus slices.
2. Materials and Methods
2.1. Image Enhancement and Construction of Datasets
This study focused on Gansu Astragalus slices as the research subject and utilized a Hikvision camera (model MV-CB013-20UC-B) to capture images. The camera has a resolution of 1.3 megapixels, and the image collection height was set at 20 cm. A total of 1158 images of Astragalus slices were collected, which were then divided into three sets: a training set (814 images, 75%), a validation set (171 images, 15%), and a test set (173 images, 15%). All images were annotated using LabelImg software. To align with the practical requirements for quality screening, the slices were categorized into five types: Normal, Rot, Special-shaped (SS), Special-shaped_Rot (SR), and Stem.
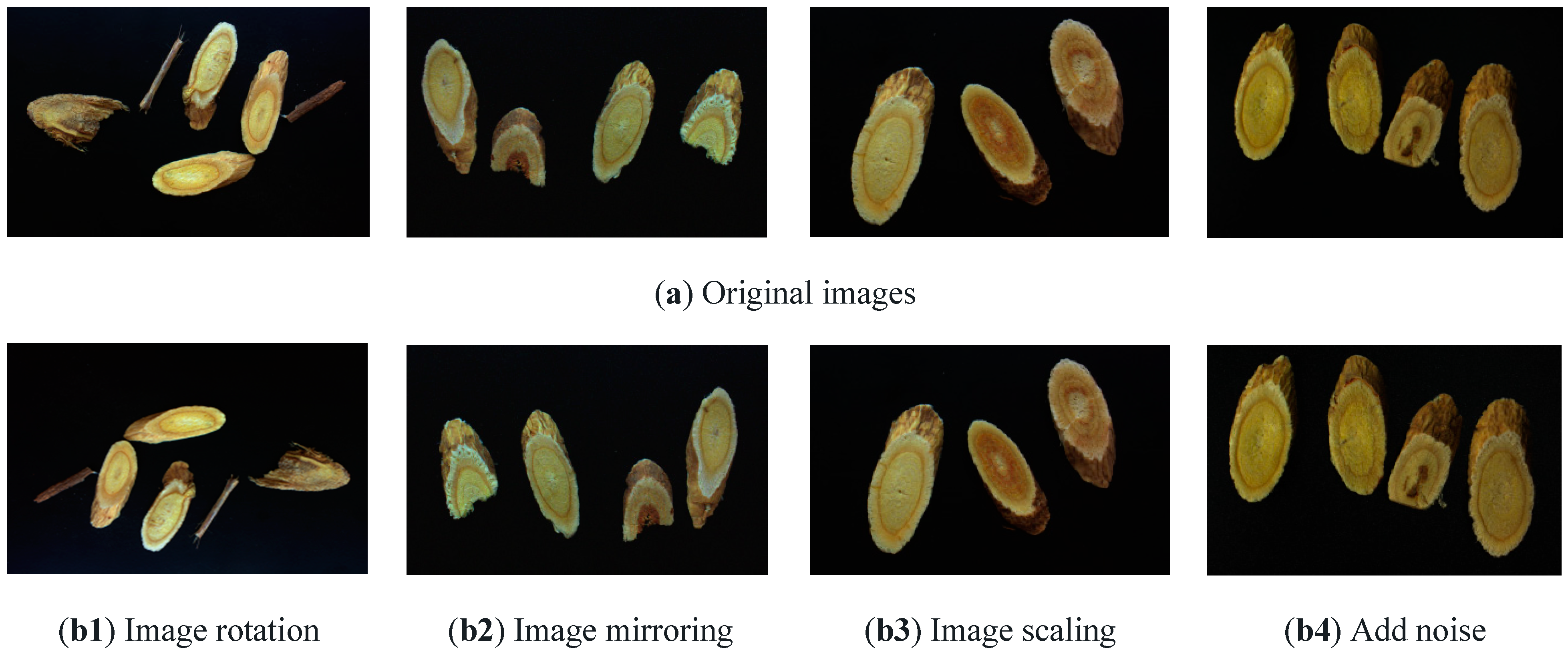
In this study, image enhancement techniques were applied to a subset of the training set images to increase the number of training samples. Four augmentation methods were used: rotation, flipping, scaling, and noise addition (Gaussian noise and salt-and-pepper noise). As a result, the number of training samples was increased from 814 to 1220. The image augmentation process is illustrated in Figure 1. The original training set consisted of 814 images, from which 406 images were randomly selected and divided equally into three groups. The first group was subjected to a rotation operation, with angles randomly selected as 90° or 180°. The second group underwent a mirror operation. In the third group, a scaling operation was performed with a scaling factor randomly selected as 0.8 or 1.2. These enhancements generated an additional 306 images. The enhanced images were then combined with the original 814 to give a total of 1220 images in the training set. Noise (Gaussian or pretzel) was then randomly added to the training set images with a 50% probability of noise inclusion.
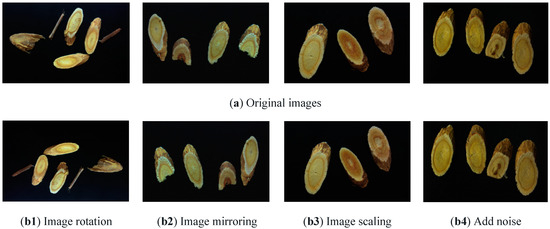
Figure 1.
Image enhancement.
2.2. Construction of the Astragalus membranaceus Slice Detection Model
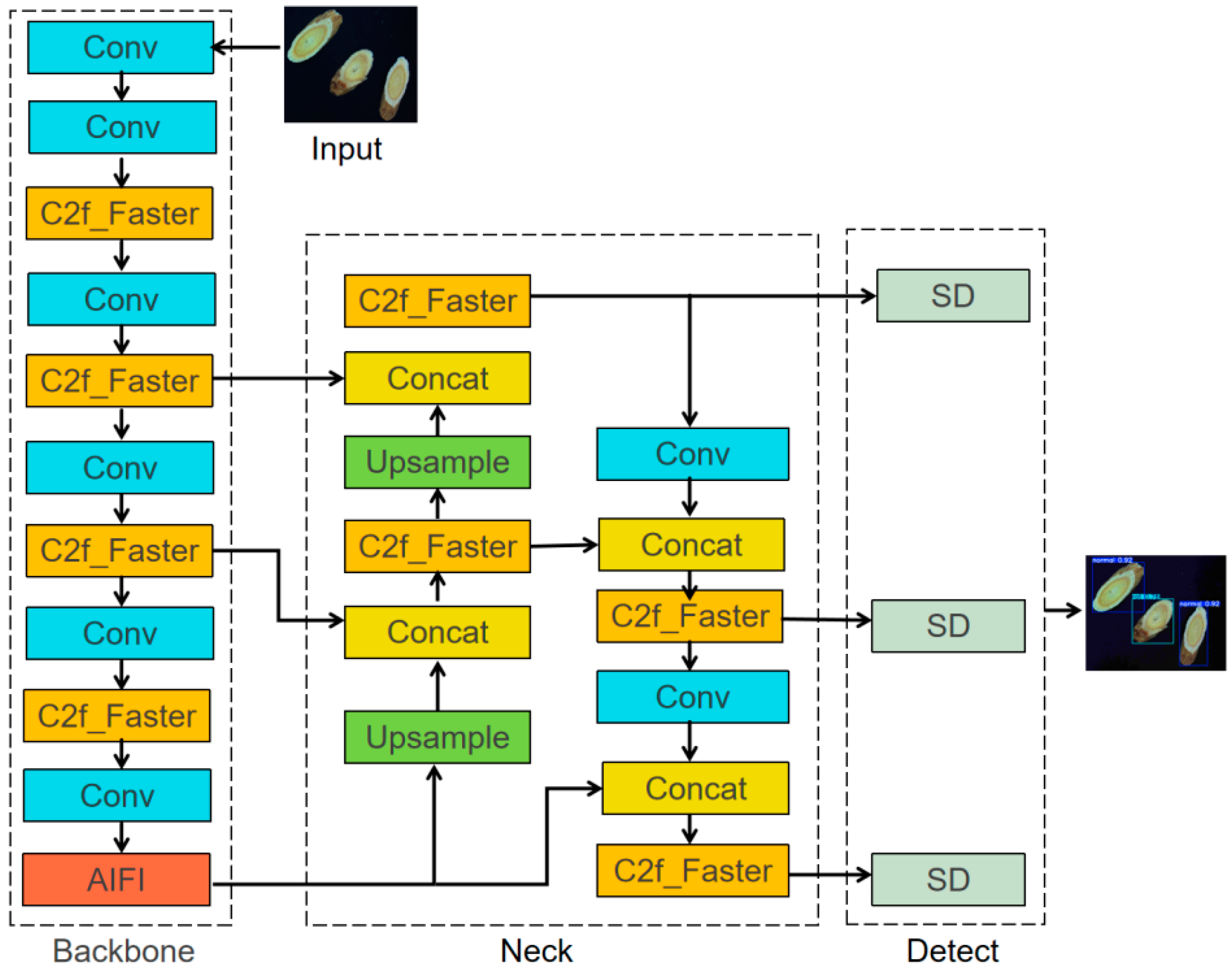
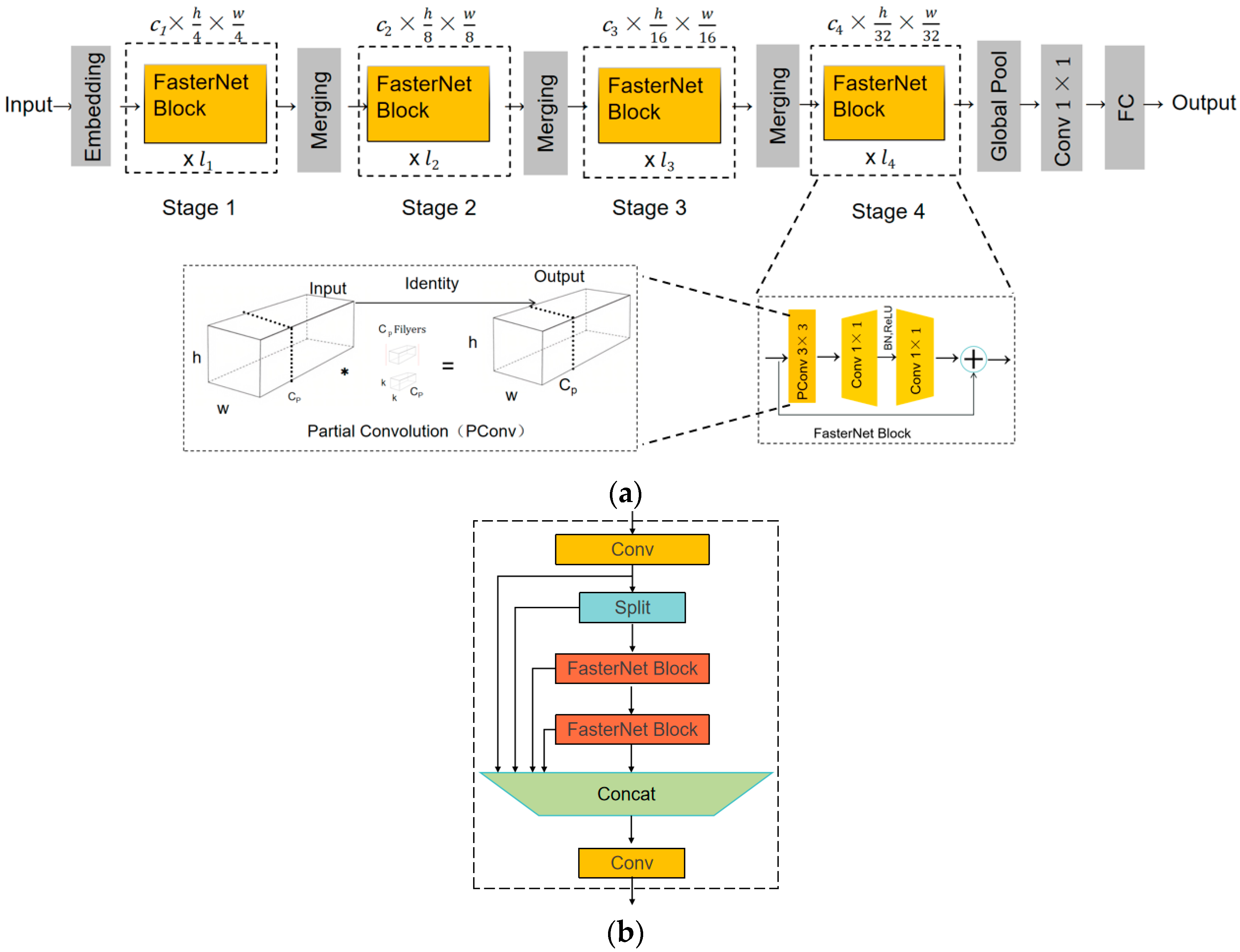
This study introduces an innovative improvement to the YOLOv8n model by proposing the FA-SD-YOLO model, with its structure depicted in Figure 2. The FasterNet module was combined with C2f to form the C2f-F module, and different insertion points of the C2f-F module within the model were analyzed to identify the optimal configuration for performance enhancement. Additionally, the SPPF module was replaced with the AIFI module to enhance feature extraction and representation capabilities. In the sensor head of the model, the original sensor head was substituted with the SD module. These modifications not only improve the model’s ability to detect the quality of Astragalus slices but also significantly reduce the number of parameters and computational complexity.
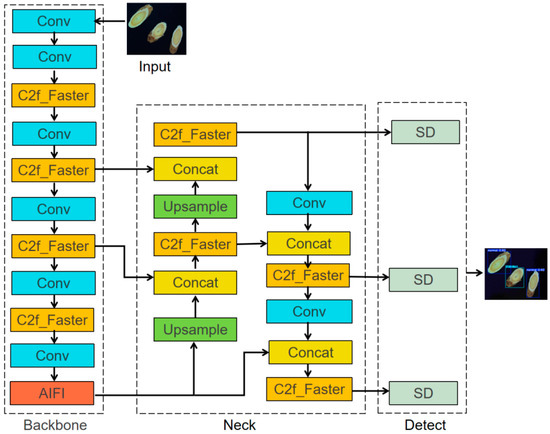
Figure 2.
Structure of FA-SD-YOLO model.
2.2.1. YOLOv8 Model
The target detection network of YOLOv8 consists of three main components: the backbone, neck, and head. The backbone employs the C2f module to extract deep features from the image, which has fewer parameters than the C3 module used in YOLOv5 while delivering superior feature extraction performance. The neck utilizes a PAN-FPN structure, which fuses features from different stages to enhance feature representation. The head includes both detection and classification components that output the detection results [14]. Additionally, YOLOv8 incorporates an anchorless framework and an adaptive NMS (Non-Maximum Suppression) algorithm, which reduce the need for extensive hyperparameter tuning and optimize detection accuracy, thereby minimizing missed detections.
2.2.2. Structure of the C2f-F Module
The FasterNet network, as illustrated in Figure 3a, is a deep learning architecture designed to reduce model size and inference time while maintaining accuracy. The core concept is to decrease the number of floating point operations through a PCon convolutional structure. FasterNet consists of four stages, each preceded by either an embedding layer for downsampling and channel augmentation (using a 4 × 4 standard convolution with a stride of 4) or a merging layer (using a 2 × 2 standard convolution with a stride of 2). Each stage is composed of multiple FasterNet modules [15]. The output layer of the network includes a global average pooling layer, a 1 × 1 convolutional layer, and a fully connected layer [15]. The FasterNet modules themselves are constructed using a PConv layer followed by two 1 × 1 convolutional layers, forming what is known as the inverse residual block. This block enhances feature expressiveness by expanding the number of channels in the intermediate layers. PConv (partial convolution) performs convolutional operations on a partial subset of the input channels, leaving the rest of the channels unchanged. This selective convolution approach reduces computational overhead compared with traditional convolution, effectively minimizing computational redundancy and improving overall efficiency.
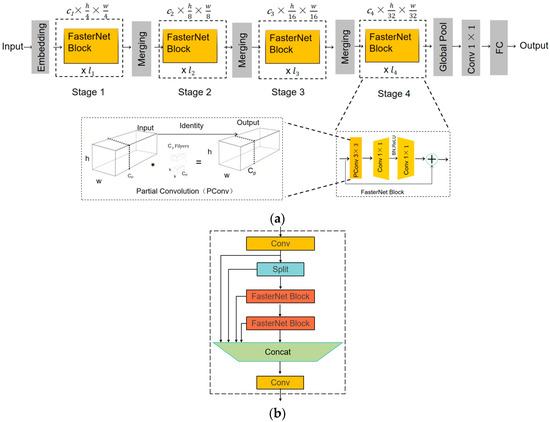
Figure 3.
(a) FasterNet model structure. (b) C2F-F structure.
Embedding the FasterNet Block module into the C2f module forms the C2f-F module (Figure 3b), which reduces computational load and memory access, thereby improving the model’s operational speed. In the C2f-F module, image features are first extracted through a convolutional layer. These features are then passed into a Split layer, where they are divided into two branches. One branch of features flows directly into the Concat module, while the other branch is processed through two consecutive FasterNet Blocks.
Each FasterNet Block consists of a PConv convolutional layer, several additional convolutional layers, and a residual connection. When features enter the PConv layer, only a subset of the channels undergoes convolution, while the remaining channels are left unchanged. This selective convolution strategy significantly reduces computational complexity. The residual connection structure adds the input features to those processed by the PConv layer and the two convolutional layers, mitigating the gradient vanishing problem during network training. The features processed by the two FasterNet Blocks are then concatenated with the features that were passed directly through the Concat module, resulting in a richer feature representation. Finally, the output features of the C2f-F module are obtained after passing through a convolutional layer. The C2f-F module reduces redundant computations and increases processing speed, all while maintaining the network’s detection capability.
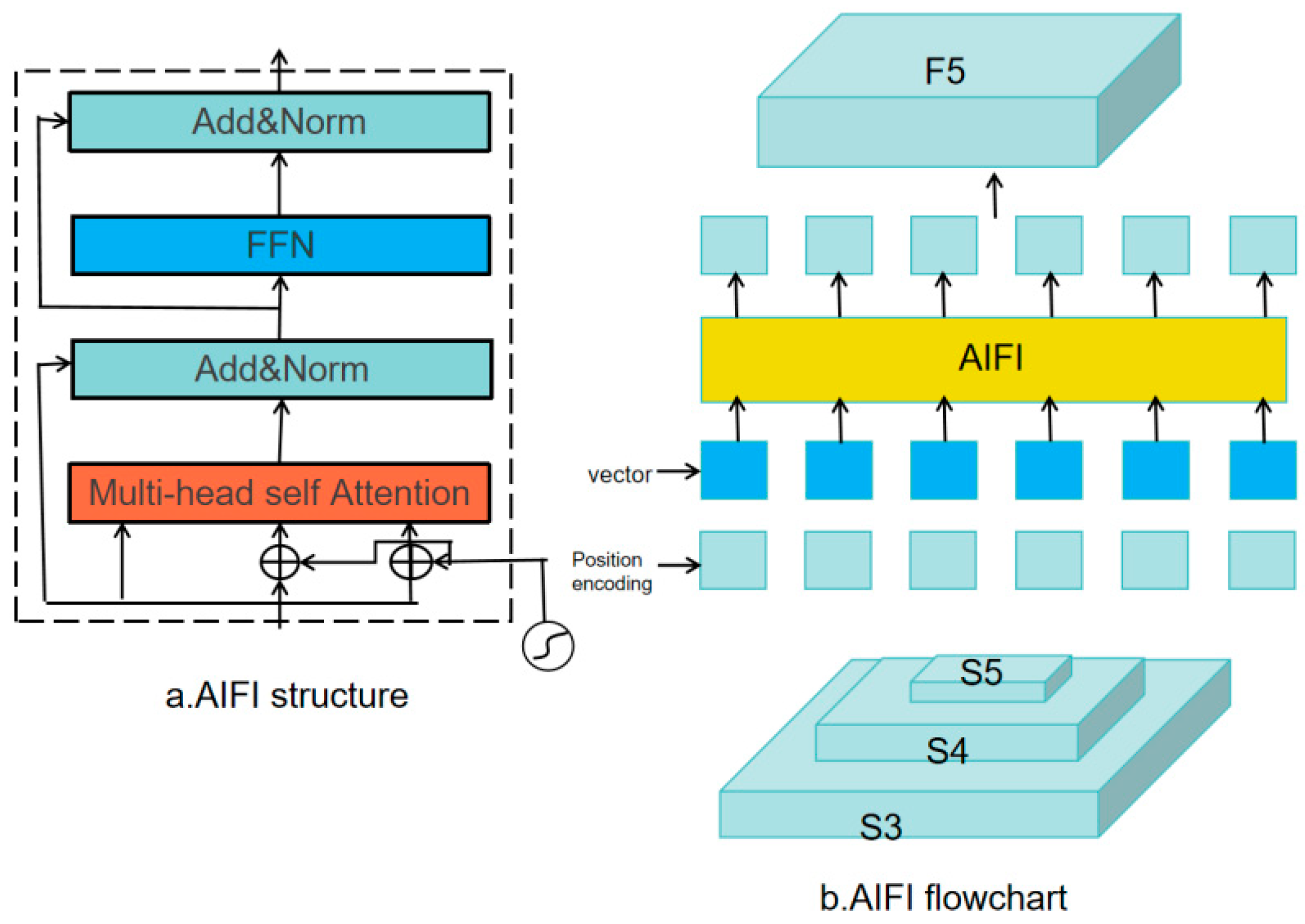
2.2.3. Construction of AIFI and Focal Modulation Modules
AIFI (Attention-based Intra-scale Feature Interaction) is a scale-intrinsic interaction module that leverages attention mechanisms to enhance the efficiency and effectiveness of feature extraction. Its primary goal is to improve the network’s ability to focus on relevant features by facilitating rich fusion among features within the same scale. This process enables the model to capture finer-grained information and enhances its ability to discriminate between object features [16].
The architecture of AIFI is illustrated in Figure 4, with the corresponding equations detailed in Formulas 1–2. Initially, the two-dimensional feature maps derived from layer S5 are projected into a high-dimensional space, where they are processed by the AIFI module. This module integrates a multi-head self-attention mechanism (as described in Formula 3) consisting of several independent attention heads. Each head focuses on different information subspaces, allowing the model to capture diverse feature interactions. The outputs of these heads are then combined with the original input through a residual connection, followed by layer normalization to ensure precise modeling of the intricate interactions within the input sequence. The refined features are then passed through a feedforward neural network (FFN) for further nonlinear transformation. After another round of layer normalization, the module generates attention scores. These scores are then transformed back into a two-dimensional format, denoted as F5. The RT-DETR proposal suggests that deeper features from S5 contain more semantically rich information, which is particularly useful for distinguishing objects. In contrast, the shallower features from S3 and S4 contain less semantic information. Thus, applying the encoder solely to S5 features not only reduces computational complexity but also maintains detection performance with minimal compromise.
where Q, K, and V represent the three vectors of queries, keys, and values; h is the number of heads of attention, and Wo is the output transformation matrix.
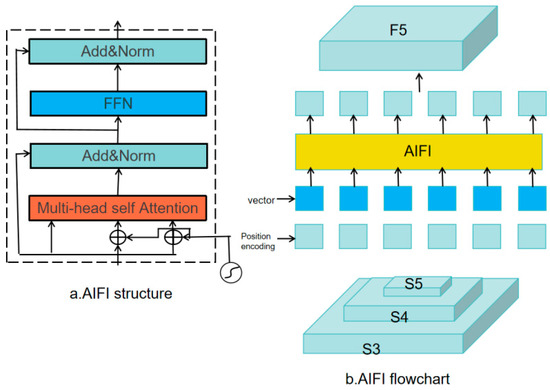
Figure 4.
AIFI module structure.
The integration of the AIFI module into the YOLOv8 model enhances its capabilities by enabling contextual fusion, feature enhancement, and attention focusing. The AIFI module effectively integrates global contextual information from images using an attention mechanism, allowing the model to understand the relationships between spatially distant regions. This is crucial for image recognition tasks, in which understanding such relationships improves detection accuracy. The features processed by the attention mechanism and the feedforward neural network contain richer semantic information, which boosts both the accuracy and robustness of the detection model. Compared with traditional convolutional neural networks, the attention mechanism in AIFI excels at handling long-range dependencies, enabling the model to better understand the overall structure of the target object, even when it appears in different regions of the image. Furthermore, the structure of AIFI allows the model to focus on the most important areas of the image, improving the detection of relevant features. Additionally, the AIFI module incorporates position encoding, which integrates spatial location information into the features, helping the model distinguish between features in different locations and thereby enhancing target localization accuracy.
Focal Modulation is a novel attention mechanism designed to replace traditional self-attention (SA) mechanisms, aiming to enhance network performance in object detection tasks [17]. The module consists of three key components: (1) hierarchical contextual information extraction through depth-wise convolutions, which capture both short-term and long-term dependencies; (2) gated aggregation, in which visual context is selectively pooled based on the content of each token; and (3) injection of the aggregated information into the query, achieved through either pointwise multiplication or affine transformations [18].
In this study, the AIFI and Focal Modulation modules were used to replace the SPPF module, capitalizing on their ability to automatically learn the correlations between features. To further optimize feature extraction, convolutional layers (Conv) were added before the AIFI and Focal Modulation modules to capture local features. This combination is designed to significantly enhance the detection accuracy for targets of varying sizes.
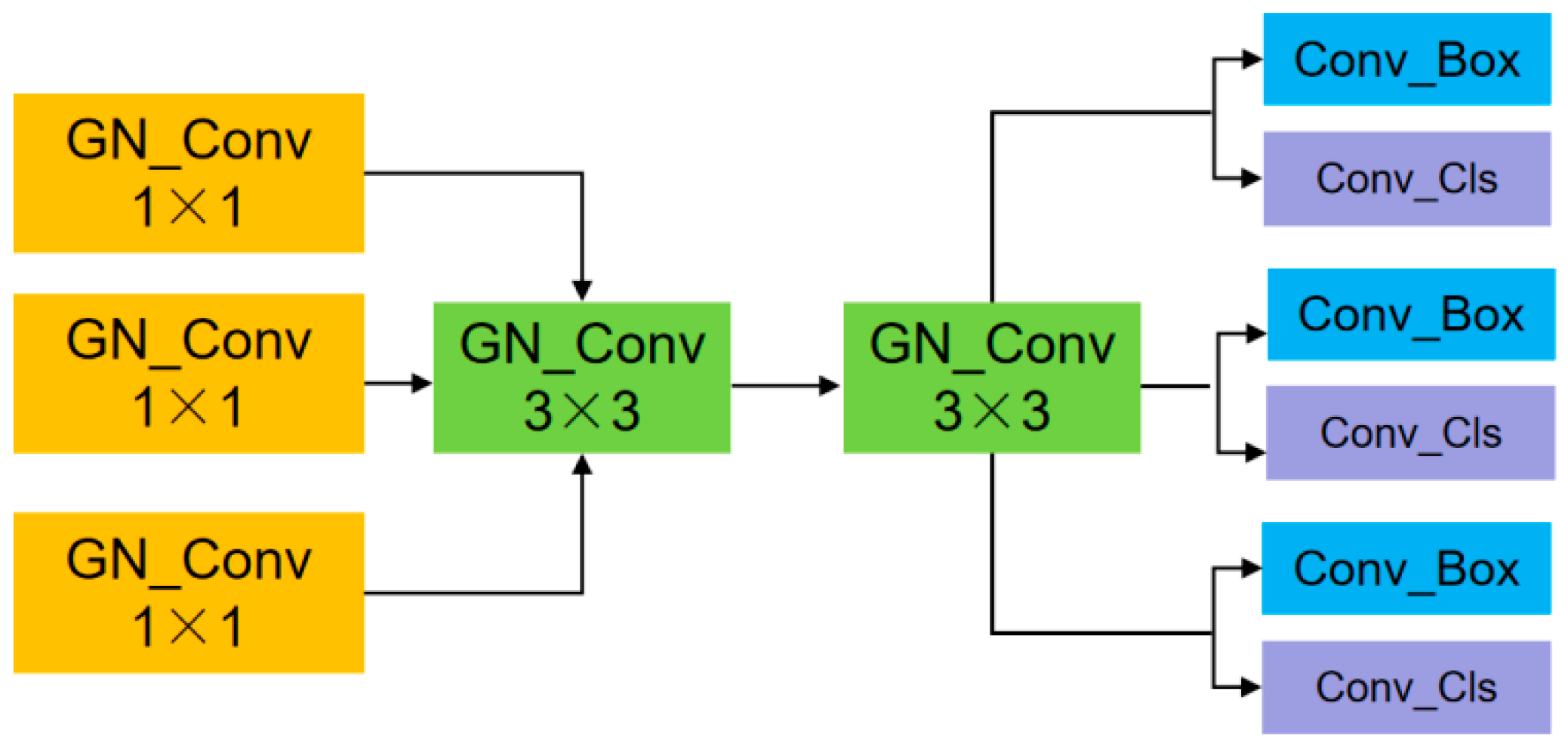
2.2.4. Construction of SD Module
Group Normalization (GN) is a normalization technique used in deep learning to address the limitations of Batch Normalization (BN), particularly when dealing with small batch sizes. The process involves dividing the input features into subsets based on the channel dimensions and then computing the mean and standard deviation for each subset independently. The statistical information obtained from these calculations was used to normalize the elements within each subset [19].
Shared convolution refers to the practice in deep convolutional neural networks in which multiple convolutional layers use the same convolutional kernel weights, enabling the network to extract consistent features across different locations. This approach reduces the model’s parameter count through weight sharing, thereby improving computational efficiency [20]. The benefits of shared convolution include mitigating the risk of overfitting, reducing model size, accelerating training speed, and enhancing performance under limited computational resources. Additionally, it helps the network acquire more stable feature representations at different levels.
This study employed a shared convolutional module (SD module) as the detection head of the model (see Figure 5). Initially, different features pass through 1×1 convolutional layers with GP-N, followed by two shared 3 × 3 convolutional layers, also with GP-N. After processing through these layers, the output from each part was passed to a Conv_Box layer and a Conv_Cls layer.
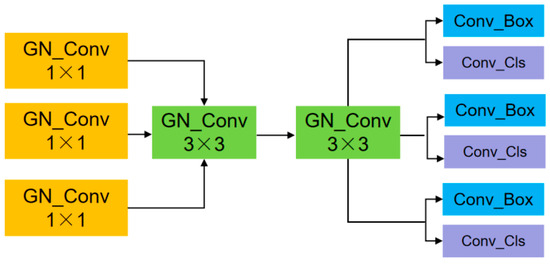
Figure 5.
SD module structure.
2.3. Experimental Platform
This study used the Linux operating system with an NVIDIA P40 GPU. The primary software included Python 3.8, Torch 1.24.0, CUDA 12.0, and cuDNN 8.6. The input image size for the network was 640 × 640 × 3 pixels. The learning rate was set to 0.01, with a batch size of 32 and a total of 200 epochs. All models were trained using the same dataset and hyperparameters.
2.4. Evaluation Indicators
In this study, in order to comprehensively evaluate the performance of the model, we used the following assessment metrics: the F1 score and the average accuracy under the 0.5 threshold (mAP@0.5). The specific formulas are shown below.
where TP is true positive, FP is false positive, FN is false negative, and C is the number of categories.
In addition to the above evaluation metrics, the speed and computational complexity of the model were also evaluated using the following indicators: image recognition speed (ms/img), FLOPs, and number of parameters. The formulas for these are as follows:
where F is the convolution kernel size, I is the number of input channels, O is the number of output channels, and H and W are the feature map height and width, respectively.
The stability evaluation index of the model adopts standard deviation and coefficient of variation, and the formula is as follows:
where is the standard deviation, CVCV is the coefficient of variation, is the sample mean, and k is the number of samples.
3. Results and Analysis
3.1. YOLOv8 Models and Performance Comparison
The scales parameter in the YOLOv8 architecture defines the various model sizes and complexities, where the depth and width parameters control the model’s depth and width, respectively. Specifically, there are five YOLOv8 variants, ranging from small to large. For quality detection of the Huangqislices, the Huangqi slice dataset was used to evaluate the performance of the YOLOv8 model. As shown in Table 1, the mAP values across the YOLOv8 models show slight variations. The YOLOv8l model achieves the highest mAP at 91.4%, while the YOLOv8n model has a mAP of 90.8%, which is 0.6% lower. Notably, the YOLOv8n model has the lowest parameter count (3,006,623) and floating point operations (FLOPS) count (8.1 G) among the five models, indicating that it achieves higher detection accuracy with a smaller model size and reduced computational complexity. Based on these findings, this study aimed to make further improvements to the YOLOv8n model, optimizing it for the real-time requirements of Huangqi slice detection.

Table 1.
YOLOv8 models performance comparison.
3.2. Effect of Different C2f-F Module Positions on Model Performance
The C2f-F module was used to replace the C2f module in both the backbone and neck networks of the YOLOv8n model to evaluate its impact on model performance. Position 1 refers to replacing the original C2f module with the C2f-F module in the backbone network, while Position 2 indicates the replacement of the C2f module with the C2f-F module in the neck network. Position 1 + 2 represents the replacement of the C2f module with the C2f-F module in both the backbone and neck networks of the YOLOv8n model. The details of the results are provided in Table 2.
Table 2.
Comparison of performance when C2f-F modules are used in different positions.
The introduction of the C2f-F module at different positions in the YOLOv8 model enhanced both the mAP and reduced the model size and FLOPS, though there was some fluctuation in the F1 score. The results indicate that, compared with the base model, the model with the C2f-F module introduced at Position 1 experienced a 1.0% decrease in the F1 score, while its mAP increased by 0.8%. At Position 2, the F1 score decreased by 1.2%, but the mAP improved by 1.4%. The model with the C2f-F module introduced at both Position 1 and Position 2 showed the smallest drop in F1 score (0.3%) and the most significant improvement in mAP (1.5%), achieving a total mAP of 92.3%, the best average performance across multiple categories. Additionally, the Position 1 + 2 model had the smallest size at 4.61 MB, a reduction of 1.34 MB from the original model, and the lowest FLOPS at 6.3 G, a reduction of 1.8 G from the original. These results validate the effectiveness of the C2f-F module in model lightweighting.
3.3. Performance of Different Modules Replacing SPPF
In the YOLOv8n model, the SPPF module is responsible for fusing features at different scales to enhance the model’s recognition capabilities. To explore more effective feature extraction methods, this study tested two replacement strategies: the first involves using the AIFI module, which adaptively integrates feature information and optimizes feature representation; the second involves introducing the Focal Modulation module, which improves the model’s ability to detect key targets by dynamically adjusting the focus of feature maps. Both modules were introduced in place of the SPPF module to evaluate their impact on the detection performance of the YOLOv8n model. The experimental results are presented in Table 3.
Table 3.
Comparison performance of AIFI and Focal Modulation.
The F1 score of the AIFI model was 87.2%, a decrease of 0.3% compared with the original model. However, the mAP increased to 92.9%, an improvement of 2.1% over the original model, and both model size and FLOPS were slightly lower. In contrast, the Focal Modulation model had an F1 score of 86.9%, a decrease of 0.6% compared with the original, but the mAP improved to 92.6%, a gain of 1.8%. Both model size and FLOPS were slightly higher than the original model. When comparing the two, the AIFI model outperformed the Focal Modulation model, with a 0.3% higher F1 score and a 0.3% higher mAP. Additionally, the AIFI model had a model size and FLOPS that were 0.35 MB and 0.2 G lower, respectively. Based on these results, the AIFI module was selected to replace the SPPF module in the YOLOv8n model, as it enhanced feature extraction capabilities while reducing computational load.
3.4. Ablation Test
Ablation testing was employed to examine the impact of specific substructures or training methods on model performance. In this study, based on the YOLOv8n model, the C2F-F module was introduced to replace the C2F module in both the backbone and neck networks, aiming to enhance feature fusion capabilities and improve computational speed. The AIFI module was used to replace the SPPF module in the backbone network to boost the model’s recognition ability. Additionally, the SD module was incorporated to replace the recognition head of the YOLOv8n model, with the goal of reducing model parameters and increasing recognition speed.
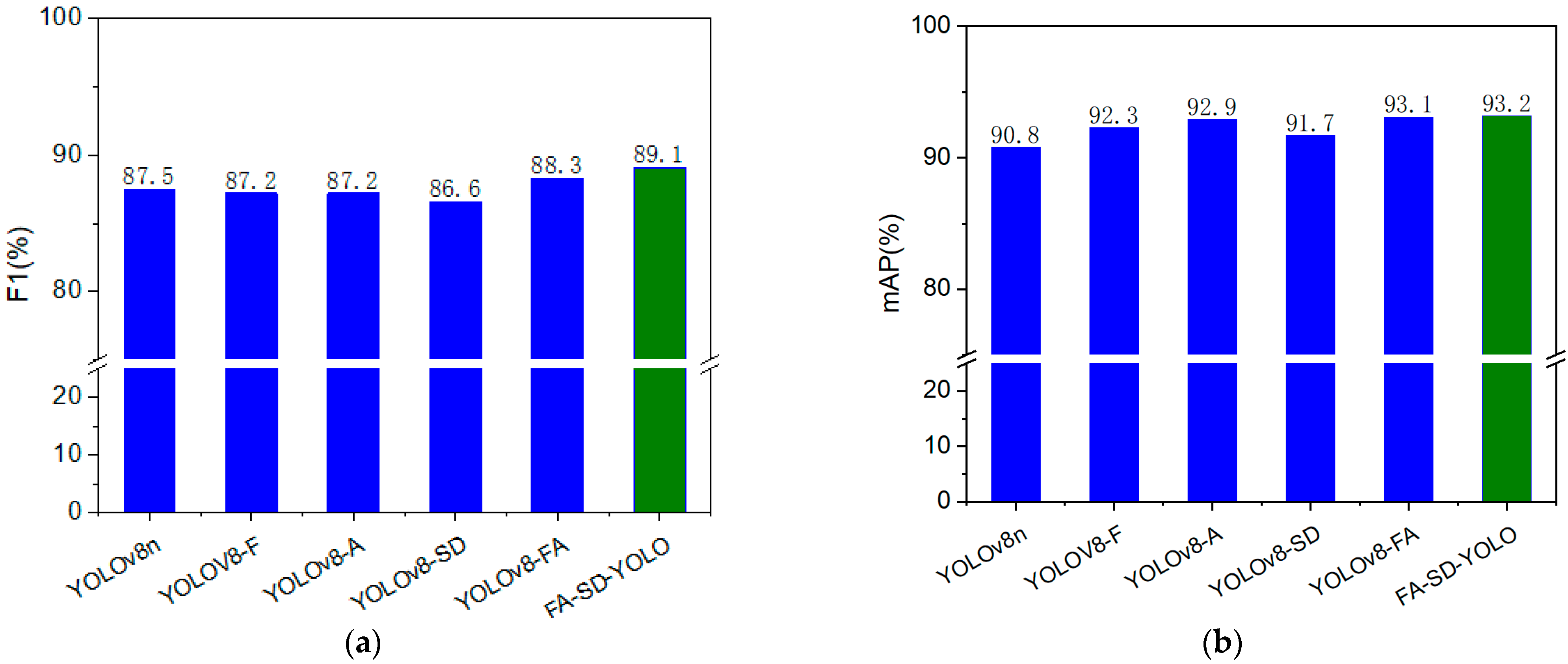
In this study, ablation tests were conducted to compare the performance of various upgraded models. YOLOv8-F refers to the model in which the C2f-F module replaces the C2f module. YOLOv8-A denotes the model in which the AIFI module replaces the SPPF module in the backbone network. YOLOv8-SD represents the model in which the SD module replaces the detection head. YOLOv8-FA is the model in which the C2f-F module replaces the C2f module, and the AIFI module replaces the SPPF module in the backbone network. Finally, FA-SD-YOLO refers to the model in which the C2f-F module replaces the C2f module, the AIFI module replaces the SPPF module in the backbone network, and the SD module replaces the detection head. The results are presented in Table 4 and Figure 6.
Table 4.
Ablation test results.
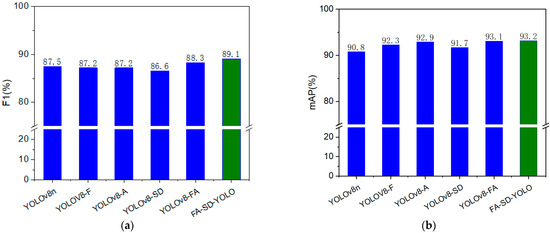
Figure 6.
(a) Bar charts of F1 values for different models. (b) Bar charts of mAP values for different models.
The YOLOv8-F model, compared with the YOLOv8n model, shows a slight improvement in accuracy and mAP, increasing by 0.1% and 1.5%, respectively. However, there is a small decline in recall rate and F1 score, which decreased by 1.1% and 0.3%, respectively. In contrast, the YOLOv8-A model exhibits a different trend: while accuracy and the F1 score drop slightly, the recall rate and mAP see notable improvements, increasing by 0.8% and 2.1%, respectively. Both models demonstrate a common enhancement in mAP, highlighting the effectiveness of the YOLOv8-F and YOLOv8-A modules in improving detection performance across all categories. The YOLOv8-FA model, by combining the strengths of the C2f-F and AIFI modules, delivers a more significant overall performance boost. Compared with the YOLOv8n model, the YOLOv8-FA model shows improvements in precision, F1 score, and mAP, with increases of 3.3%, 0.8%, and 2.3%, respectively. These gains reflect an enhancement in the model’s capabilities. However, the recall rate decreases by 1.7%, suggesting that while the YOLOv8-FA model excels in several key metrics, there is still room for further improvement in recall. When comparing the FA-SD-YOLO model to the YOLOv8n model, significant differences emerge. Specifically, the F1 scores for the Rot, SR, and Stem categories in the FA-SD-YOLO model improve by 1.0%, 6.8%, and 0.4%, respectively, with the SR category showing the most notable improvement. In contrast, the Normal and SS categories experience slight declines in F1 scores by 0.4% and 0.3%, respectively—however, these reductions are minimal and can be seen as minor fluctuations. Additionally, the FA-SD-YOLO model outperforms the YOLOv8n model in terms of AP values across several categories: Normal, Rot, SS, SR, and Stem, with increases of 0.5%, 2.0%, 1.8%, 7.3%, and 0.3%, respectively. The most significant improvement is seen in the SR category. The FA-SD-YOLO model also improves precision by 1.8%, recall rate by 1.3%, overall F1 score by 1.6%, and mAP by 2.4%. In summary, the FA-SD-YOLO model outperforms the YOLOv8n model on multiple key performance indicators, demonstrating the effectiveness and validity of the proposed model improvements.
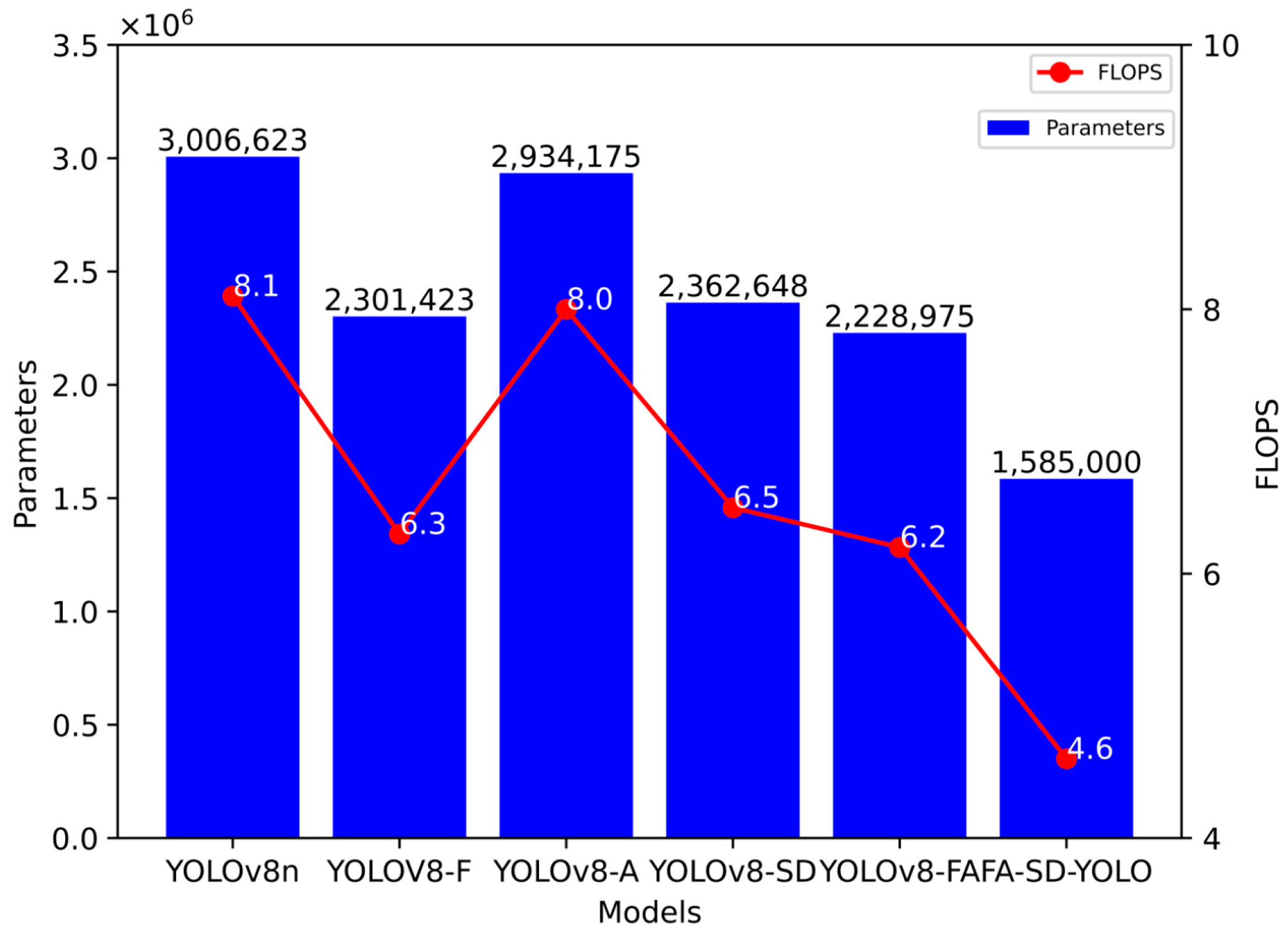
Figure 7 presents the parameters and FLOPS of the models used in the ablation experiment. Compared with the YOLOv8n model, the YOLOv8-F, YOLOv8-SD, and YOLOv8-FA models exhibit a reduction in both the number of parameters and FLOPS, indicating that the C2f-F and SD modules effectively contribute to model lightweighting. The YOLOv8-A model shows only a marginal reduction in parameters and FLOPS relative to the YOLOv8n model. However, the FA-SD-YOLO model stands out with the lowest number of parameters and FLOPS, recording 1,585,000 parameters and 4.6 G FLOPS, representing a reduction of 47.3% in parameters and 43.2% in FLOPS compared with the original YOLOv8n model. This emphasizes the lightweight nature of the improved models, showcasing their efficiency.
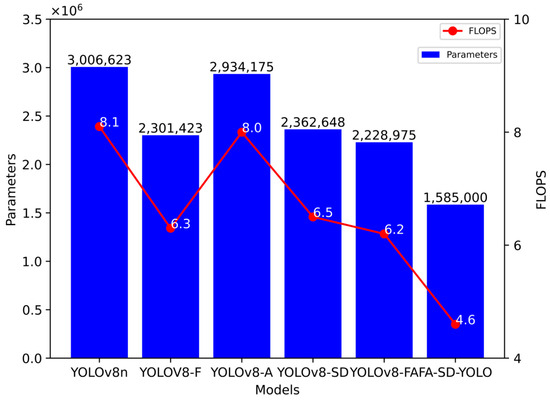
Figure 7.
Number of parameters and FLOPS for different models.
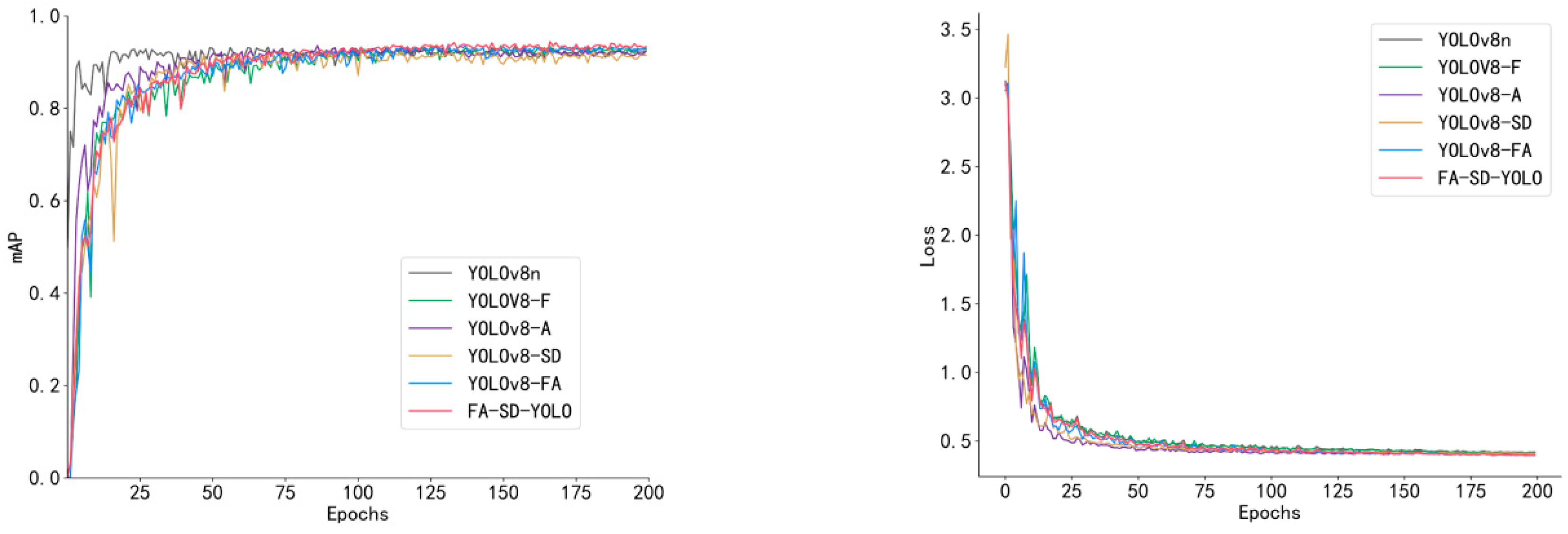
Figure 8 illustrates the curves for the mean accuracy (mAP) and loss function during the ablation experiments on the validation set. All six models began to converge and stabilize gradually after 50 epochs. The YOLOv8n model’s mAP reached its peak early and then plateaued, while the FA-SD-YOLO model exhibited a slightly higher mAP than the other models after approximately 80 epochs. The loss curves of all six models show a similar trend, but the FA-SD-YOLO model’s loss remained slightly lower in the later stages of training. These results highlight that the optimization strategies implemented in this study have significantly enhanced the performance of the model.
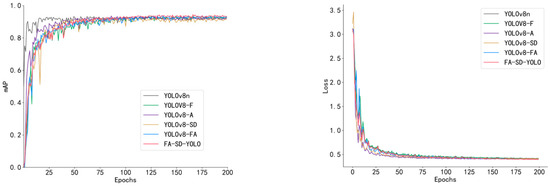
Figure 8.
MAP and loss curves of the ablation test model.
Figure 9 presents the detection results for three Huangqi slice images, as evaluated by the six models. In Image 1, all six models successfully identified the targets with no errors. For Image 2, the YOLOv8n model made one detection error, while the other models maintained accurate detection performance. In Image 3, the YOLOv8n, YOLOv8-A, and YOLOv8-SD models each made one detection error, whereas the remaining models correctly identified all targets. The specific errors are highlighted with a red ‘×’ to indicate the incorrectly detected parts.
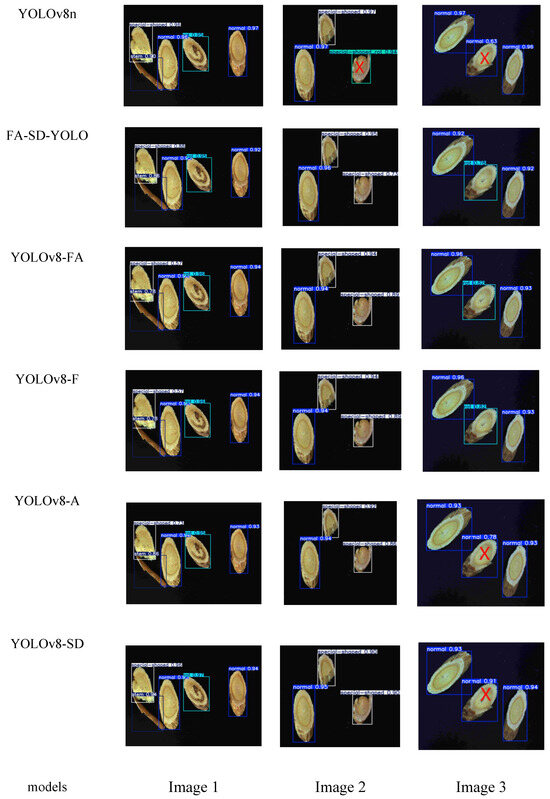
Figure 9.
Image detection results of different models.
In order to further assess the performance and stability of the YOLOv8n baseline model and the FA-SD-YOLO model, a 5-fold cross-validation method was used to train and validate the two models, and a test set was used to assess the stability of the models using the standard deviation and coefficient of variation. The smaller the standard deviation, the narrower the range of fluctuation in the model’s assessment index values. The coefficient of variation can eliminate the influence of data size, reacting only to the relative degree of data dispersion—the smaller the coefficient of variation, the better the consistency of the model’s assessment indexes’ numerical performance and the more stable the model becomes. The specific results are shown in Table 5. The average precision, average recall, average F1, and average mAP of the YOLOv8n model are 82.8%, 85.4%, 84.1%, and 89.3%, respectively. The average precision, average recall, average F1, and average mAP of the FA-SD-YOLO model are 86.4%, 85.1%, 85.9%, and 91.2%, respectively, where the average precision, average F1, and average mAP are 3.6%, 1.8% and 1.9% higher than those of the YOLOv8n model, respectively. This result verified that the performance of FA-SD-YOLO for the quality detection of Astragalus tablets was due to the YOLOv8n model. In addition, the FA-SD-YOLO model was lower than the YOLOv8n model in terms of precision, standard deviation of the F1 score, and mAP, although the standard deviation of recall was slightly increased. Similarly, the FA-SD-YOLO model was lower than the YOLOv8n model in terms of the coefficients of variation for precision, F1 score, and mAP, while the coefficients of variation for recall increased slightly. A comprehensive analysis of the model cross-validation results showed that the FA-SD-YOLO model was superior to YOLOv8n in all assessment metrics, and the overall stability was also better than that of YOLOv8n.
Table 5.
Model evaluation results and stability results.
3.5. Quality Analysis Results of Astragalus membranaceus Slices by Different Detection Models
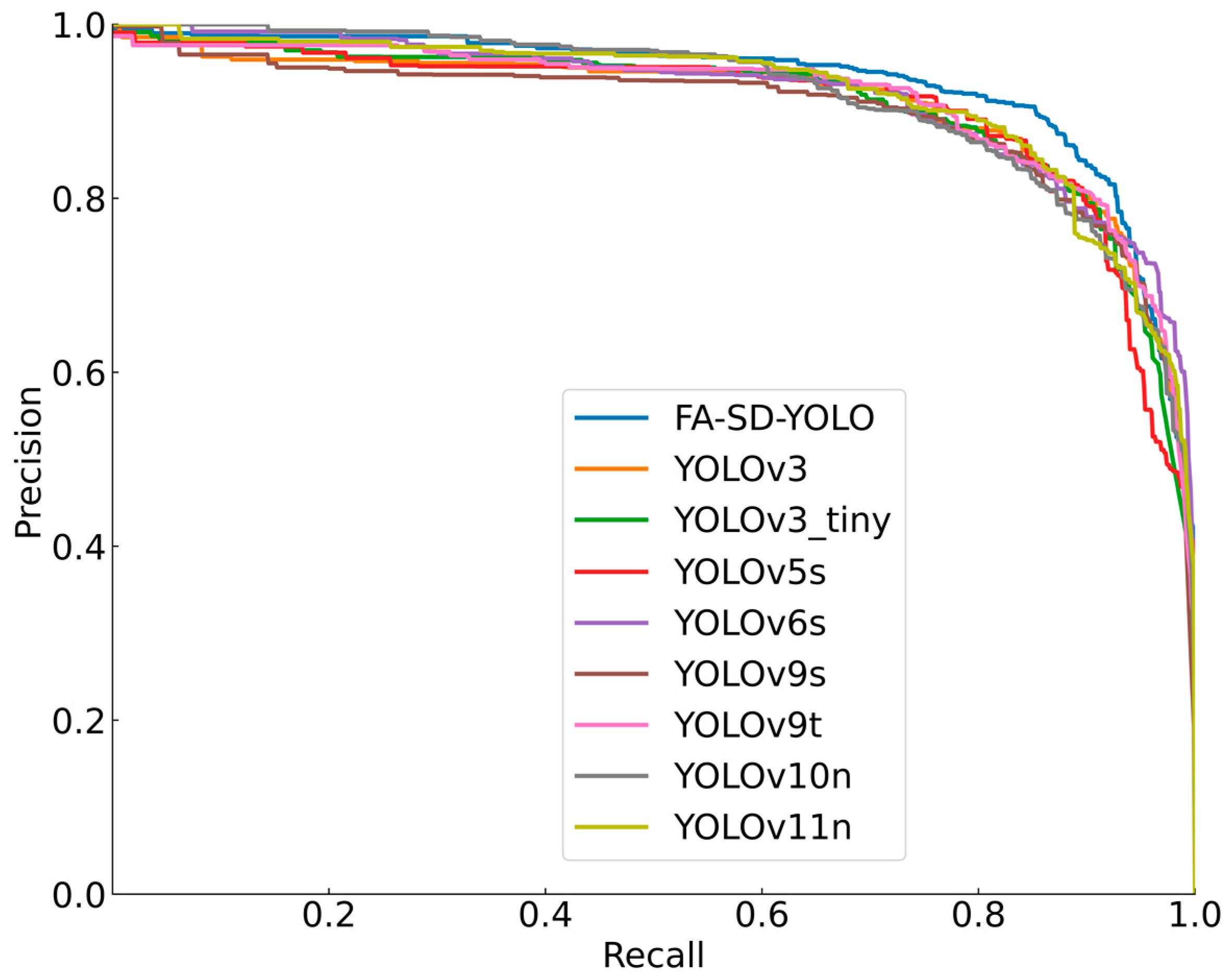
To further validate the performance of the improved model, this study compared the FA-SD-YOLO with several other models, including YOLOv3-tiny, YOLOv3, YOLOv5s, YOLOv6s, YOLOv9t, YOLOv9n, YOLOv10n, and YOLOv11n. The precision-recall (P-R) curves of these models are shown in Figure 10, where the FA-SD-YOLO model stands out with the largest area under the P-R curve, indicating the highest mean average precision (mAP). Specific detection results are presented in Table 6, where the FA-SD-YOLO model demonstrates superior precision, F1 score, and mAP compared with the other models. Its recall rate is tied with the YOLOv5s model for first place. In terms of detection speed, the FA-SD-YOLO model excels with a detection time of 13.8 ms per image, which is 0.3 ms faster than YOLOv5s and 1.4 ms faster than YOLOv9s. However, it is slightly slower than YOLOv9t (by 0.5 ms) and YOLOv6s (by 0.2 ms). The YOLOv3-tiny model achieves the fastest detection speed but performs relatively weakly across other evaluation metrics. Additionally, the FA-SD-YOLO model has significantly lower FLOPS (4.6 G), which is 24.3%, 1.6%, 29.1%, 38.9%, 60.5%, 17.2%, 70.7%, and 73.0% of the FLOPS of the YOLOv3-tiny, YOLOv3, YOLOv5s, YOLOv6s, YOLOv9t, YOLOv9s, YOLOv10n, and YOLOv11n models, respectively. In conclusion, the FA-SD-YOLO model strikes a balance between high detection accuracy and reduced computational complexity, making it well suited for efficient Astragalus quality inspection tasks. This provides a solid foundation for its deployment in Astragalus quality sorting equipment.
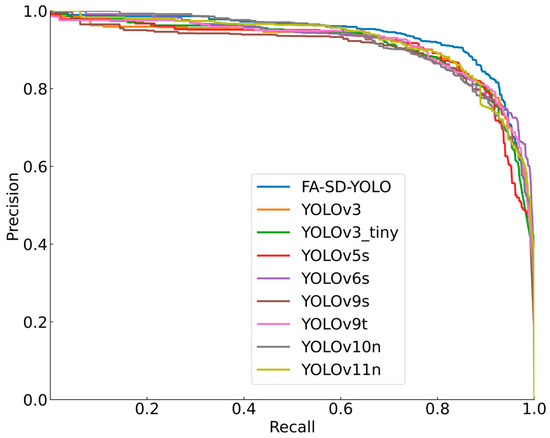
Figure 10.
P-R curves of test sets for different models.
Table 6.
Analysis of the detection results of the different models.
4. Discussion
This study utilized the FasterNet, AIFI, and SD modules to optimize the performance and parameter efficiency of the YOLOv8n model for Astragalus slice quality inspection. The results indicate that both the FasterNet and AIFI modules are particularly effective in reducing parameter computation and enhancing feature representation. These modules have been applied in various detection tasks across different domains. For example, Shi Lei and colleagues combined the FasterNet network with the Swin Transformer module to form the FSST model, achieving rapid and accurate identification of wheat growth stages [21]. Yang Q and others employed the FasterNet network as the backbone for the YOLOv7n model in underwater target detection, optimizing the loss function to improve the efficiency of feature space extraction in complex environments [22].
The AIFI module, a core component of the DETR model, enhances the model’s ability to process both local and global information by integrating attention mechanisms. Its incorporation into various image detection models has proven effective. For instance, Xie M and colleagues introduced the AIFI module into the YOLOv5 model, leveraging self-attention to improve the recognition rate of tire defects [23]. These studies collectively highlight the significant application potential of the FasterNet and AIFI modules in the field of image detection.
Quality inspection serves as a crucial safeguard for the intelligent sorting of Astragalus slices, facilitating the automatic and precise screening of these slices. This process enhances production efficiency and ensures consumer safety. Presently, the quality sorting of Astragalus slices in China predominantly relies on manual operations, which are labor-intensive and time-consuming. Research in the realm of Astragalus slice quality detection is still in its nascent stages. The integration and application of advanced models, such as FasterNet and AIFI, in this field are still in their infancy. Additionally, there is a paucity of research exploring the use of traditional machine learning and deep learning algorithms for the quality inspection of Astragalus slices, with only two relevant studies identified. Zhang Lei and colleagues have conducted preprocessing, including enhancement and normalization, on images of Gansu Astragalus slices [24]. They utilized linear classifiers to classify the integrated features of color and texture. This research employed traditional feature extraction and design, which may be susceptible to factors such as background and light source, affecting model accuracy. Zhang BingZheng proposed a DT-SVM classifier traditional target detection algorithm for classifying five types of Astragalus slices: normal, hollow, cracked, petiole, and fibrous [25]. Based on attention mechanisms, he introduced an improved YOLOX-s detection algorithm. The model achieved an overall sorting accuracy rate of 84.33% and a detection speed of 2.27 slices per second. However, this model’s detection speed was relatively low and did not address the removal of rotten Astragalus slices. Astragalus is prone to rot during its growth cycle due to environmental influences, and incomplete slices may also be produced during machine slicing. Consequently, the removal of rotten and incomplete Astragalus slices is a vital task. The FA-SD-YOLO model developed in this study can detect normal, rotten, incomplete, and incomplete_rot Astragalus slices and stems, providing a reference and viability for the application of deep learning models in the intelligent sorting of Astragalus. The mAP of the proposed FA-SD-YOLO model reached 93.2%, and the detection speed achieved 13.8 milliseconds per image. However, when employing the model for Astragalus slice quality detection, it was observed that Astragalus slices categorized as Normal, Rot, and Stem were predominantly correctly identified, while slices categorized as special-shaped and special-shaped_rot were occasionally misclassified. This may be attributed to the high similarity between special-shaped Astragalus slices and special-shaped_rot slices, which complicates the identification process. Therefore, future research should focus on developing a more comprehensive Astragalus slice quality detection model.
5. Conclusions
In this study, a dataset comprising images of Huangqi (Astragalus) slices was developed, and five YOLOv8 models of varying sizes (n, s, m, l, and x) were evaluated. The results revealed negligible differences in the mean average precision (mAP) values among these models. Consequently, the YOLOv8n model was selected as the base and enhanced by replacing the original C2F module with the C2F-F module and the SPPF module with the AIFI module to improve feature fusion and extraction capabilities. Additionally, a novel detection head, the SD module, was introduced to reduce the model’s computational complexity. Ablation experiments were conducted to validate the enhanced model’s effectiveness. The key findings are summarized below:
- (1)
- By combining the FasterNet module with the C2F module to create the C2F-F module as a substitute for the original C2F module and examining the impact of the C2F-F module’s placement (in the backbone, neck, or both) on model performance, the experiments showed that incorporating the C2F-F module in both the backbone and neck networks resulted in a 1.5% increase in mean average precision (mAP). Although there was a slight 0.3% decrease in the F1 score, the computational complexity (FLOPS) was reduced by 1.8 G, demonstrating that the FasterNet module effectively reduces computational requirements while maintaining detection performance.
- (2)
- The study aimed to investigate the effects of replacing the SPPF module with the AIFI module and the Focused Modulation module on detection efficiency. The research showed that substituting the SPPF module with the AIFI module enhanced model performance, with the mAP reaching 92.9%, while FLOPS decreased by 0.1 G. These results highlight the AIFI module’s effectiveness in facilitating feature enhancement. When both the C2F-F and AIFI modules were integrated into the model, the F1 score and mAP achieved were 88.3% and 93.1%, respectively, thereby improving the model’s detection performance for the quality of Astragalus membranaceus slices.
- (3)
- The integration of the FasterNet module, the AIFI module, and the SD module into the YOLOv8n model resulted in the FA-SD-YOLO model, which demonstrated excellent performance in the quality detection of Huangqi slices. The accuracy and recall rates of the new model were 88.6% and 89.6%, respectively, while the F1 score and mAP were 89.1% and 93.2%, respectively. Compared with the original YOLOv8n model, the accuracy rate increased by 1.8%, the recall rate by 1.3%, the F1 score by 1.6%, and the mAP by 2.4%, while the FLOPS decreased by 43.2%, fully demonstrating the FA-SD-YOLO model’s effectiveness in enhancing detection capabilities.
- (4)
- Comparative analysis with various mainstream object recognition models (including YOLOv3 tiny, YOLOv3, YOLOv5s, YOLOv6s, YOLOv09t, YOLOv9n, YOLOv10n, and YOLOv11n) revealed that the FA-SD YOLO model required only 13.8 ms per image for recognition speed, with FLOPS of only 4.6 G, significantly lower than the other six models compared, and it also had the highest mAP value.
The FA-SD-YOLO model proposed in this study achieved the highest F1 score and mAP, striking a balance between speed and model complexity, meeting the requirements for fast and accurate detection of Huangqi slices. It provides reliable technical support for the intelligent sorting equipment of Huangqi slices.
Author Contributions
F.Z.: writing—original draft, modeling, methodology, investigation, data curation. J.Z.: review, funding acquisition. Q.L.: investigation. C.L.: methodology. S.Z.: graphic visualization. M.L.: formal analysis, review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This study was sponsored by Heilongjiang Provincial Department of Science and Technology Project, with the grant number No. 2022C03062, and the APC was funded by Fan Zhao.
Institutional Review Board Statement
This study does not involve research on humans or animals, therefore, it does not require approval from an ethics committee.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, B.; Ji, C.; Chen, X.; Cui, L.; Bi, Z.; Wan, Y.; Xu, J. Protective effect of astragaloside IV against matrix metalloproteinase-1 expression in ultraviolet-irradiated human dermal fibroblasts. Arch. Pharm. Res. 2011, 34, 1553–1560. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wang, C.; Li, W.; Chen, J. Hyperspectral image classification by AdaBoost weighted composite kernel extreme learning machines. Neurocomputing 2018, 275, 1725–1733. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, B.; Li, L.; Si, Y.; Chang, M.; Ma, S.; Li, R.; Wang, Y.; Zhang, Y. Efficacy of Modified Huangqi Chifeng decoction in alleviating renal fibrosis in rats with IgA nephropathy by inhibiting the TGF-β1/Smad3 signaling pathway through exosome regulation. J. Ethnopharmacol. 2022, 285, 114795. [Google Scholar] [CrossRef] [PubMed]
- Dai, G.; Fan, J.; Dewi, C. ITF-WPI: Image and text based cross-modal feature fusion model for wolfberry pest recognition. Comput. Electron. Agric. 2023, 212, 108129. [Google Scholar] [CrossRef]
- Dai, G.; Tian, Z.; Fan, J.; Sunil, C.; Dewi, C. DFN-PSAN: Multi-level deep information feature fusion extraction network for interpretable plant disease classification. Comput. Electron. Agric. 2024, 216, 108481. [Google Scholar] [CrossRef]
- Xue, Q.; Miao, P.; Miao, K.; Yu, Y.; Li, Z. An online automatic sorting system for defective Ginseng Radix et Rhizoma Rubra using deep learning. Chin. Herb. Med. 2023, 15, 447–456. [Google Scholar] [CrossRef] [PubMed]
- Almazaydeh, L.; Alsalameen, R.; Elleithy, K. Herbal leaf recognition using mask-region convolutional neural network (Mask r-Cnn). J. Theor. Appl. Inf. Technol. 2022, 100, 3664–3671. [Google Scholar]
- Zhao, P. Explore the identification of Chinese herbal medicine based on the VGG-16 model. Appl. Comput. Eng. 2023, 4, 645–650. [Google Scholar] [CrossRef]
- Liu, S.; Chen, W.; Li, Z.; Dong, X. Chinese Herbal Classification Based on Image Segmentation and Deep Learning Methods; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Teng, Y.; Zhao, W.; Han, Y.; Wang, Y.S.; Wang, S.; Song, J. Improved CBAM Fritillaria Ussuriensis Detection Model Based on YOLOv5. Chin. Agric. Mach. Equip. 2023, 8–12. Available online: https://xueshu.baidu.com/usercenter/paper/show?paperid=1r3m0830w76n0850ry000ad0f1048877&site=xueshu_se (accessed on 12 October 2024).
- Gao, S.; Zhou, Z.; Huang, X.; Gao, L.; Bian, H. Intelligent Identification of Traditional Chinese Medicine Decoction Pieces Based on Deep Learning Algorithms. J. Chin. Med. Mater. 2023, 46, 57–61. [Google Scholar] [CrossRef]
- Tian, G.; Li, X.; Wu, Y.; Liu, A.; Zhang, Y.; Ma, Y.; Guo, W.; Sun, X.; Fu, B.; Li, D. Recognition effect of models based on different microscope objectives. In Proceedings of the 3rd International Symposium on Artificial Intelligence for Medicine Sciences, Amsterdam, The Netherlands, 13–15 October 2022; pp. 133–141. [Google Scholar] [CrossRef]
- Zhang, H.; Pan, Y.; Liu, X.; Chen, Y.; Gong, X.; Zhu, J.; Yan, J.; Zhang, H. Recognition of the rhizome of red ginseng based on spectral-image dual-scale digital information combined with intelligent algorithms. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 297, 122742. [Google Scholar] [CrossRef] [PubMed]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Yang, J.; Li, C.; Dai, X.; Yuan, L.; Gao, J. Focal modulation networks. Adv. Neural Inf. Process. Syst. 2022, 35, 4203–4217. [Google Scholar]
- Ashraf, T.; Bin Afzal Mir, F.; Gillani, I.A. TransFed: A way to epitomize Focal Modulation using Transformer-based Federated Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 554–563. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Meng, Y.; Jin, D.; Liu, G.; Xu, S.; Han, J.; Shi, D. Text detection with kernel-sharing dilated convolutions and attention-guided FPN. Opt. Precis. Eng. 2021, 29, 13. [Google Scholar] [CrossRef]
- Shi, L.; Lei, J.; Wang, J.; Yang, C.; Liu, Z.; Xi, L.; Xiong, S. Lightweight Wheat Growth Stage Identification Model Based on Improved FasterNet. Trans. Chin. Soc. Agric. Mach. 2024, 55, 226–234. [Google Scholar] [CrossRef]
- Yang, Q.; Meng, H.; Gao, G.D. A real-time object detection method for underwater complex environments based on FasterNet-YOLOv7. J. Real-Time Image Process. 2024, 21, 8.1–8.14. [Google Scholar] [CrossRef]
- Xie, M.; Bian, H.; Jiang, C.; Zheng, Z.; Wang, W. An Improved YOLOv5 Algorithm for Tyre Defect Detection. Electronics 2024, 13, 2207. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Guo, K.; Wang, B.; Wang, H. Study on the algorithm of quality grade classification of Radix Astragali in Gansu. J. Northwest Norm. Univ. 2023, 59, 58–64. [Google Scholar] [CrossRef]
- Zhang, B. Development of an Online Detection and Sorting System for the Appearance Quality of Astragalus Decoction; Beijing Forestry University: Beijing, China, 2022. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).