Abstract
Rising labor costs and a workforce shortage have impeded the development and economic benefits of the global grape industry. Research and development of intelligent grape harvesting technologies is desperately needed. Therefore, rapid and accurate identification of grapes is crucial for intelligent grape harvesting. However, object detection algorithms encounter multiple challenges in unstructured vineyards, such as similar background colors, light obstruction from greenhouses and leaves, and fruit occlusion. All of these factors contribute to the difficulty of correctly identifying grapes. The GrapeDetectNet (GDN), based on the YOLO (You Only Look Once) v5s, is proposed to improve grape detection accuracy and recall in unstructured vineyards. dual-channel feature extraction attention (DCFE) is a new attention structure introduced in GDN. We also use dynamic snake convolution (DS-Conv) in the backbone network. We collected an independent dataset of 1280 images after a strict selection process to evaluate GDN’s performance. The dataset encompasses examples of Shine Muscat and unripe Kyoho grapes, covering a range of complex outdoor situations. The results of the experiment demonstrate that GDN performed outstandingly on this dataset. Compared to YOLOv5s, this model increased metrics such as 2.02% of mAP0.5:0.95, 2.5% of mAP0.5, 1.4% of precision, 1.6% of recall, and 1.5% of F1 score. Finally, we test the method on a grape-picking robot, and the results show that our algorithm works remarkably well in harvesting experiments. The results indicate that the GDN grape detection model in this study exhibits high detection accuracy. It is proficient in identifying grapes and demonstrates good robustness in unstructured vineyards, providing a valuable empirical reference for the practical application of intelligent grape harvesting technology.
1. Introduction
Edible grapes have a variety of applications and are economically beneficial [1]. Global fresh table grape output has expanded quickly in recent years and is expected to reach 27.3 million tons by 2023. However, traditional manual harvesting methods are inefficient [2], costly [3], and labor-intensive [4], making it difficult to meet the growing demand. The development of intelligent harvesting technology for grapes has become an inevitable trend.
Accurate fruit recognition is essential for robots that pick fruit. Fruit recognition methods can be divided into two main types: traditional image processing methods and deep learning methods. Traditional methods, such as the Otsu algorithm [5,6], k-means algorithm [7,8], Hough transform [9,10], and SVM [11,12], have been widely used for fruit recognition. These traditional methods rely on features such as fruit color, shape, texture, and edges [13,14]. However, their ability to recognize fruits in complex scenes is limited, and they are sensitive to factors such as changes in lighting, occlusion, and noise. However, deep learning can automatically extract features from images at a deeper level than traditional image processing techniques, avoiding the laborious process of manual feature extraction and optimization [15].
Due to the artificial intelligence field’s rapid development, deep learning has found extensive applications in agricultural image processing, such as crop disease detection [16,17], weed detection [18], and fruit ripeness detection [19]. Prevalent tasks include image classification, object detection, and image segmentation. Examining the framework structure and principles, object detection frameworks can be broadly categorized into two types: one-stage and two-stage. Two-stage algorithms involve generating a large number of candidate boxes on the input image using methods such as sliding windows or selective search. Each candidate box is then evaluated to determine whether it contains the target object. Representative two-stage algorithms include R-CNN [20], Fast R-CNN [21], and Mask-R-CNN [22], which are frequently employed in fruit detection. Fu et al. [23] proposed a model based on Fast R-CNN for kiwi recognition, which demonstrated good robustness under lighting changes and leaf occlusion. Gao et al. [24] utilized Fast R-CNN to identify apples under four scenarios: no obstruction, leaf obstruction, pipeline obstruction, and fruit obstruction. Jia et al. [25] introduced an apple detection and segmentation method based on Mask-R-CNN, which improved the recognition of overlapping fruits. Two-stage object detection algorithms’ main superiority is their accuracy. But they necessitate producing a lot of candidate boxes, which adds a significant amount of computational overhead and slows down processing. One-stage object detection algorithms typically use a neural network to directly predict the positions and categories of all possible bounding boxes in each image. This approach includes the SSD series [26] and the YOLO series [27], which have the benefits of speed and real-time performance. Han et al. [28], based on the SSD neural network model, applied transfer learning for the recognition of grapefruits, stems, and leaves. Santos et al. [29] compared YOLOv2, YOLOv3, and Mask R-CNN networks in grape detection research. Liu et al. [30] employed YOLOv3 for tomato detection, using circular bounding boxes instead of traditional rectangular ones. Qi et al. [31], based on YOLOv5, conducted lychee detection and calculated the pixel coordinates of picking points.
Although deep learning-based fruit detection has proven successful, inaccurate detection and localization may still occur due to the intricacy of agricultural environments, fluctuations in lighting, and unpredictability such as wind or mechanical hand vibrations during the actual harvesting process [32,33]. The accuracy of detection still needs to be increased, particularly for green grapes that are highly similar to the background. There may still be missing detections and low confidence in the results in cases where fruits overlap or where leaves or greenhouses block light. To solve the problems of low accuracy and missed grapes, this study has improved the YOLOv5 model. In addition, we have built a robot platform for picking grapes that mimics the actual grape harvesting procedure to verify our algorithm.
An overview of the study’s contributions is provided below:
- (1)
- A new attention mechanism, the DCFE attention, is proposed in this work. DCFE combines convolution and multi-head attention, demonstrating its capability to effectively capture both local and global features.
- (2)
- The DCFE attention mechanism and DS-Conv have been incorporated into the YOLOv5 network to improve the model’s capacity to extract features from unstructured vineyards. It has led to a reduction in missed grape detections and an improvement in detection accuracy.
- (3)
- Furthermore, we implemented our algorithm on a grape-picking robot for harvesting experiments, offering solid evidence of the usefulness of the approach in this paper.
2. Materials and Methods
2.1. Data Acquisition and Processing
2.1.1. Data Acquisition
The experimental data collection was conducted in Kunshan City, Jiangsu Province, China (coordinates: 31N, 120E). Kunshan City is a significant area in Jiangsu Province, with a grape cultivation area of approximately 4900 acres, primarily distributed in townships such as Bacheng, Zhangpu, and Huaqiao within Kunshan City. The grape varieties cultivated include Kyoho, Summer Black, and Shine Muscat, among others. For this study, we selected two varieties with high similarity to the background color as the research subjects: Shine Muscat and unripe Kyoho grapes. They both have a bright green appearance similar to the color of leaves, usually oval or ellipsoidal in shape. And they have high economic value and are widely cultivated locally. All images were captured in the same orchard located in Bacheng.
Image collection was conducted in two sessions, each using a RealSense D435i sensor and driven by a laptop. The first collection took place on 11 July 2021. The variety is Sunshine Muscat, the image resolution is 1280 × 720 pixels, and 680 images were collected. The second collection time was 6 July 2023. The species was Kyoho, the image resolution was 1280 × 720 pixels, and 580 images were collected. In total, 1260 grape images were obtained from these two sessions. The grape images are displayed in Figure 1.

Figure 1.
Images of Shine Muscat and Kyoho. (a) Shine Muscat. (b) Kyoho.
2.1.2. Dataset Annotation and Partition
This study utilized the annotation software Labelme 5.0.1 for grape image annotation. We chose to include the stems in our annotation of grapes since they are an integral part of the fruit and their characteristics are critical for recognizing grape identity. The dataset was divided into training and validation sets at a ratio of 8:2 in order to train and validate the model. The specific Grape Dataset information is shown in Table 1.

Table 1.
Information of Grape Dataset.
2.2. GDN (Grape Detection Model)
To increase the precision of grape recognition in unstructured orchard environments, we proposed the GDN grape detection model, which is based on YOLOv5. We present a new attention, DCFE Attention, in the GDN. To extract local and global information from the feature maps, DCFE Attention uses a dual-channel approach that combines convolution and multi-head attention. This enhancement improves feature representation and spatial relationships, consequently elevating the model’s generalization performance. Additionally, we integrate Dynamic Snake Convolution into the C3 module to augment its feature extraction capabilities. By substituting the C3 module in the backbone network with the C3-DS module, we augment the grape detection performance of the model. These innovative enhancements enable our GDN model to attain greater accuracy and robustness in grape detection tasks within unstructured vineyard environments. Finally, we use our algorithm to simulate grape-picking experiments on a grape-harvesting robot to verify its stability and practicality. The specific research technical process is shown in Figure 2.
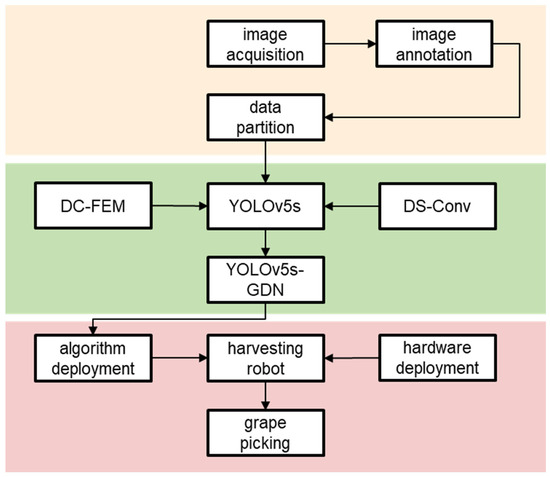
Figure 2.
The technical process. (From top to bottom: Data acquisition; Model improvements; Harvesting experiments).
2.3. Network Architecture of YOLOv5
The YOLOv5 detection model consists of three parts: backbone network, neck network, and head network, as illustrated in Figure 3.
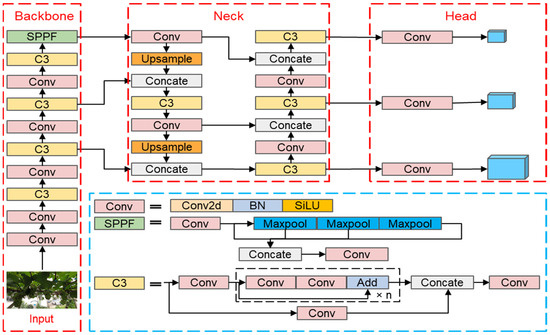
Figure 3.
The network structure of initial YOLOv5. (Consists of three parts: backbone, neck, and head).
The backbone network’s primary task is to extract feature maps of various sizes. It consists of the Conv, C3, and SPPF modules of the YOLOv5 backbone network. A SiLU activation function, a BatchNorm2d layer, and a Conv2d layer made up the structure of the Conv module. The C3 module is a crucial component of the YOLOv5 backbone network, namely the Cross Stage Partial (CSP) bottleneck block [34]. The input feature map must be divided into the main path and the branch path by the C3 module and then merged to obtain a richer and more powerful feature representation. SPPF stands for Spatial Pyramid Pooling Fusion, which is a method that combines Spatial Pyramid Pooling (SPP) and Feature Pyramid Network (FPN); its purpose is to fuse feature maps of different scales for better object detection.
The neck network’s primary role is to combine feature maps with various resolutions and levels. In the YOLOv5 architecture, the neck network consists of a Feature Pyramid Network (FPN) [35] + a Path Aggregation Network (PAN) [36]. The FPN structure performs top-down upsampling to enrich lower-level feature maps. Bottom-up upsampling is carried out by the PAN structure to guarantee that the top-level feature maps have more robust positional information.
The head network is responsible for processing the features extracted from the neck network into actual object detection results. The head network of YOLOv5 is the final layer of the object detection model, is mainly responsible for processing and decoding the features that are taken from the neck network to locate and classify objects.
2.4. Network Architecture of GDN
The GDN Grape Detection Model is an improvement based on YOLOv5. In the backbone network, we enhanced the C3 module by integrating DS-Conv, resulting in the C3-DS module. The backbone network’s feature extraction capacity is enhanced by this integration. In the neck network, we inserted a DCFE Attention to fuse local and global information from the feature maps, further improving the robustness of the model. Simultaneously, this significantly enhances the model’s performance, making it well-suited for grape detection in unstructured orchard environments. The structure of the GDN model is shown in Figure 4.
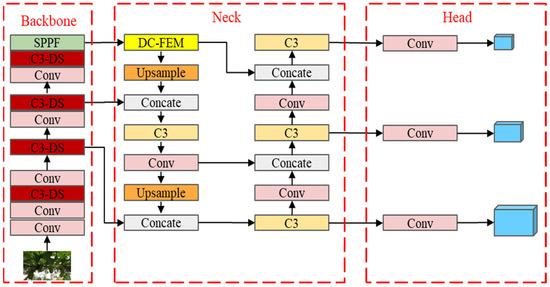
Figure 4.
The network structure of GDN. (Model improvement: The backbone utilizes the C3-DS module to enhance feature extraction capability; the neck employs DCFE Attention to elevate local and global feature importance).
2.4.1. Improvements Based on DCFE Attention
Each element in the input sequence has a weight assigned by the attention mechanism, which multiplies these weights with the corresponding input elements and sums them to obtain a new output [37]. Convolutional kernels sliding on the input are very effective for capturing local information, such as edges or textures in images. Meanwhile, multi-head attention [38] performs exceptionally well in handling tasks involving long sequences.
The integration of global attention and local attention facilitates the comprehensive capture of crucial visual information [39]. Convolution and multi-head attention work together in the DCFE Attention to integrate local and global attention. To extract local information from the input feature maps, the local attention module uses convolution to build a bottleneck structure. In the meantime, the global attention module utilizes positional encoding, patch embedding, and dimension reduction on the input feature maps and then uses multi-head attention to compute global attention. Finally, dimension restoration is carried out. The structure of DCFE attention is illustrated in Figure 5.
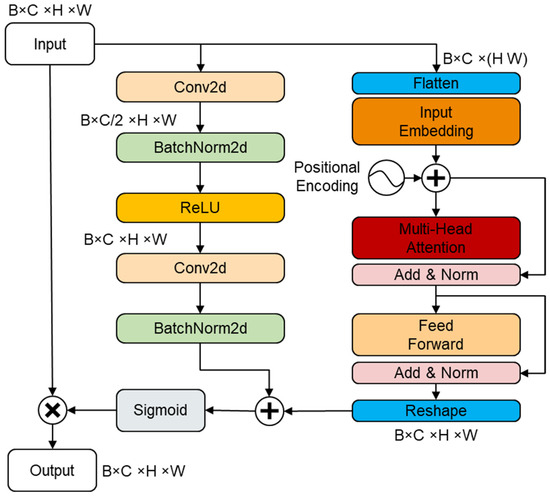
Figure 5.
The structure of DCFE attention.
By applying the sigmoid function, we are able to get weight values (A(X)) for the fusion of local attention (L(X)) and global attention (G(X)). The output feature map X′ is created by applying these weight values to the feature map X through attention operations. The calculation formula is as follows:
where (B) represents Batch Normalization, and (R) represents the ReLU activation function.
where (TE) is the Transformer Encoder layer, ⊗ denotes element-wise multiplication of two feature layers, (PE) is positional encoding, (F) represents flattening the tensor to reduce dimensions, and (RE) is reshaping the tensor to restore dimensions.
where (Sigmoid) is the Sigmoid function, and ⊕ denotes element-wise addition.
2.4.2. Improvements Based on DS-Conv
To improve the feature extraction performance, we used Dynamic Snake Convolution [40]. Compared to traditional convolution, using dynamic deformable convolution kernels allows for better extraction of features with different geometric shapes [41]. The convolution kernel can dynamically change its shape in space to accommodate features in various regions due to dynamic deformable convolution. As a result, the neural network can extract complex features more effectively. It can better capture features with irregular shapes, become more adaptive to variations in input, expand its receptive field, and acquire a wider range of contextual information. Standard convolution and dynamic deformable convolution are illustrated in Figure 6.
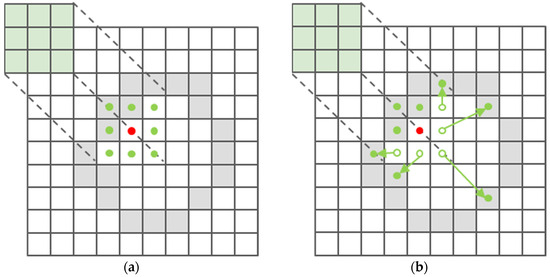
Figure 6.
Standard Convolution and Dynamic Deformable Convolution. (a) Standard Convolution. (b) Dynamic Deformable Convolution.
Dynamic convolution can increase the model’s capacity while maintaining relatively low computational costs, thereby improving model performance [42]. DS-Conv can improve the model’s capacity to extract delicate features (such as grape grain contours, grape stems, and branches). The C3-DS module was created by integrating Dynamic Snake Convolution into the C3 module. This raises the upper limit for feature extraction capabilities in the backbone network significantly, which helps explain why grape detection models in an unstructured orchard are more accurate. The structure of C3-DS is shown in Figure 7.
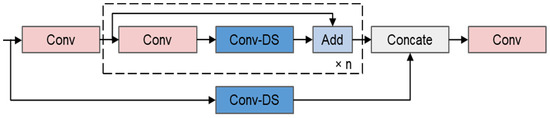
Figure 7.
The structure of C3-DS. (“× n” means the model contains n identical bottleneck structures, which, while keeping the model lightweight, increase the depth and complexity of the network, thus enhancing the model’s ability to detect and localize targets).
2.5. Model Training
Model performance and training efficiency in deep learning training can be impacted by the devices and hyperparameters chosen. Choosing the right hardware—GPU and CPU—can significantly quicken the training process. In terms of hyperparameters, the model’s performance and capacity for generalization are directly impacted by decisions about learning rate, batch size, number of iterations, and optimizer. The specific model training environment and key training parameters are outlined in Table 2 and Table 3.
Table 2.
Model training environment.
Table 3.
Model training hyperparameters.
2.6. Evaluation Metrics
In this study, the precision (P), recall (R), F1 score, mAP0.5, and mAP0.5:0.95 are used to assess the model’s performance [43,44,45]. These metrics are employed to evaluate the model’s overall performance in a comprehensive manner.
where (TP) represents the model correctly predicts a sample as positive, and the true class is indeed positive. (FP) The model incorrectly predicts a sample as positive, but the true class is actually negative. (FN) The model incorrectly predicts a sample as negative, but the true class is actually positive.
where (F1 score) is a comprehensive evaluation metric that combines precision and recall.
where (P(r)) represents the precision-recall curve is a graphical representation of the trade-off between precision (vertical axis) and recall (horizontal axis) for different thresholds in a binary classification model.
where (mAP0.5) refers to the average precision when the Intersection over Union (IOU) threshold is set to 0.5. On the other hand, (mAP0.5:0.95) indicates the average precision as the IOU threshold varies gradually from 0.5 to 0.95.
3. Results
3.1. Visualization of DS-Conv Feature Maps
The visualization of the model’s feature maps enables a comprehensive understanding of the model’s outputs at different hierarchical levels, facilitating our comprehension of the essential features extracted during the learning process. Figure 8 showcases the visualization results of the C3 and C3-DS module feature layers at the fourth layer of the backbone network in both YOLOv5s and GDN models. From the first row of Figure 8, it is clear that the C3-DS module performs exceptionally well at capturing the contour features of grape grains, giving the grains a more rounded appearance. The second row of Figure 8 illustrates that C3-DS captures grapes with greater detail overall, revealing contours between individual grape grains and the cluster as a whole that are more distinct and easily discernible. This is primarily attributed to the deformable convolution’s superior ability to extract nonlinear features, thereby enhancing the model’s recognition capabilities for the intricate details of grapes in complex, unstructured environments.
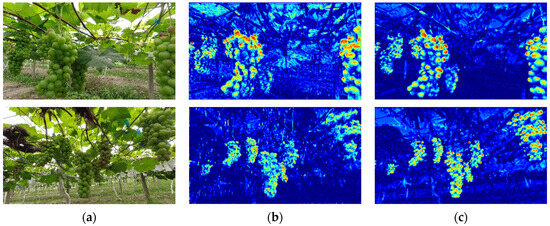
Figure 8.
Visualization results of C3 and C3-DS feature maps. (a) Original Image; (b) C3 Feature Map; (c) C3-DS Feature Map.
3.2. Ablation Experiments
The same dataset and training settings were used in the ablation experiments carried out in this work to examine the effects of two different improvement methods on the model’s efficacy. The experimental results are shown in Table 4. The results show that the model’s performance can be improved by the DCFE and DS-CONV improvement measures in comparison to YOLOv5s. The DCFE attention mechanism excels at capturing contextual information around pixels, resulting in a notable enhancement in the model’s recall (R). Despite a minor decline in model precision (P), an overall assessment of other metrics suggests that this improvement measure is advantageous for the model. The DS-CONV improvement measure enhances YOLOv5s across various metrics by reinforcing the model’s capability to extract features. Combining these two improvement measures, our model exhibits the best performance. Compared to YOLOv5s, the method achieves a 2.2% increase in mAP0.5:0.95, a 2.5% increase in mAP0.5, a 1.4% increase in precision (P), a 1.6% increase in recall (R), and a 1.5% increase in F1 score.
Table 4.
Results of the ablation experiments.
3.3. Performance Comparison of Different Models
We performed a comparative analysis to perform a detailed comparison of the performance differences between the improved GDN network and some currently popular detection networks (SSD_VGG16, YOLOv3_tiny, and YOLOv5s). The data in Table 5 illustrates that our GDN outperformed competitors across various metrics, encompassing mAP0.5:0.95, mAP0.5, precision (P), recall (R), and F1 score. This accomplishment is credited to DS-Conv’s enhanced capability in extracting intricate features, while the DCFE attention mechanism empowers the model to comprehend contextual information within images, thus effectively addressing severe occlusion challenges and enhancing object detection accuracy. The improvement in our parameters has been modest, which is essential for maintaining the real-time inferring speed of the GDN.
Table 5.
Results of different models.
Analysis of Detection Results for YOLOv5s and GDN
To assess our proposed algorithm’s generalization performance in different situations, we conducted assessments using various scenes provided in the dataset. In the first row of Figure 9, we demonstrate that under well-lit conditions and relatively ideal detection conditions, both YOLOv5s and GDN can effectively detect all grapes. However, in the second row of Figure 9, when grapes are occluded, GDN exhibits a stronger recognition effect compared to YOLOv5s. In these cases, YOLOv5s failed to successfully detect grapes that were heavily obscured by the yellow boxes in the image. Finally, in the third row of Figure 9, the results show that in extreme conditions, specifically in densely shaded scenes where sunlight is obstructed by greenhouses and plant leaves, our method demonstrates significant superiority.
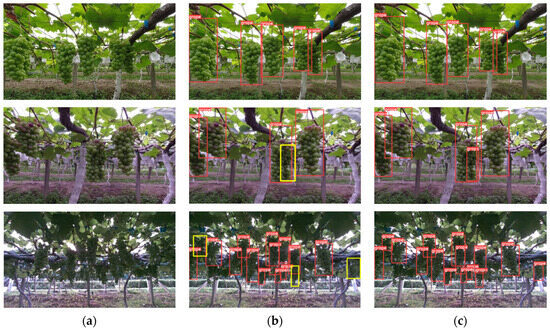
Figure 9.
Grape detection results for YOLOv5s and GDN: (a) Original image; (b) YOLOv5s detection results; (c) GDN detection results. (Red and yellow boxes represent successful detections and missed detections).
3.4. Harvesting Experiments
We established a harvesting platform to conduct harvesting experiments to verify the feasibility of our algorithm. The experimental platform includes an AUBO-i5 robotic arm, an electric scissors as the end effector, a RealSense L515 for the vision system, an NVIDIA GeForce RTX 2080 for the control system, a wheeled mobile platform, and a power system consisting of 12 sets of 24 V, 70 AH lead-acid battery packs. The grape-harvesting robot is illustrated in Figure 10.

Figure 10.
Grape Harvesting Robot.
We deployed our GDN grape detection algorithm on the grape harvesting platform. The harvesting process involves the grape harvesting robot activating the RealSense L515 to capture RGB and depth images. The GDN algorithm is then used to detect grapes entering the field of view. When a harvestable target is identified, the system initiates a binocular recognition and positioning algorithm to identify grapes in the common field of view of the stereo cameras. The three-dimensional coordinates of the grapes are obtained from the depth image, and the end effector is moved to the close-up view for harvesting.
Table 6 documents 20 harvesting instances, demonstrating an average inference time of 1.04 s per harvest, a mean total harvesting time of 11.84 s, and a harvesting success rate of 90%. The reason for the two failed harvests is due to errors in the calculation of picking point localization based on depth information. Experimental results show that the GDN grape detection algorithm has fast inference speed and accuracy, making it suitable for practical grape harvesting by the harvesting robot.
Table 6.
Harvesting experiment results.
4. Discussion
The manual labor-intensive process of hand-harvesting fruit is associated with substantial costs [46]. Advancing technologies related to grape-picking robots can enhance grape harvesting efficiency, mitigate labor costs and shortages, and bolster the economic viability of the grape industry [47,48,49].
However, in natural settings, grape-picking robots face challenges due to factors such as fluctuations in lighting and obstacles, hindering precise visual positioning. Moreover, distinguishing green grapes poses a greater challenge compared to identifying red grapes [50], making it challenging to achieve accurate real-time detection. Fruit detection algorithms employing deep learning outperform traditional image recognition methods in terms of speed and accuracy, rendering them the predominant approach in practice. YOLOv5 stands out among single-stage detection models due to its superior detection accuracy and rapid detection speed [51], making it highly suitable for real-time grape detection tasks. This study aims to address the challenge of limited grape detection in unstructured vineyards by proposing the GDN grape detection model based on YOLOv5. The GDN model incorporates two innovative techniques, DCFE and DS-CONV, to enhance the accuracy and robustness of grape detection in complex environments.
From Table 4 and Table 5 and Figure 8, it can be concluded that the DCFE attention mechanism and DS-CONV improvement measures are effective, contributing to enhancing the grape detection performance of the model in unstructured orchards. This indicates that the method of using convolutions in DCFE to extract local attention and employing a multi-head attention structure to capture global attention is effective in addressing grape misdetection in complex environments. DS-CONV allows the backbone network to obtain more detailed features. The simultaneous use of both enables GDN to outperform mainstream object detection networks in various metrics. As evident from the actual detection results in Figure 9, compared to YOLOv5, GDN demonstrates better detection performance for occluded fruits and fruits in densely shaded areas, even when object features are challenging to acquire and distinguish in these scenarios. The results in Table 6 demonstrate that the accuracy and speed of our algorithm meet the requirements for intelligent grape harvesting.
Furthermore, this study still has certain limitations. Firstly, the research only involves the grape image recognition part, and algorithms related to depth data processing and picking point localization are not mentioned. Although we have achieved some progress, the relevant algorithms need further refinement. Additionally, the dataset used has a limited number of samples and only includes two grape varieties, making it challenging to achieve satisfactory detection results for other varieties with significant color and shape differences.
In future work, we will integrate depth information to further study grape picking point localization, aiming to achieve rapid and accurate three-dimensional positioning of grape harvesting points. Simultaneously, we will collect grape data from different scenes and varieties to expand our dataset, meeting the grape harvesting needs in various situations.
5. Conclusions
In this study, to solve the problem of limited grape detection in unstructured vineyards, we proposed the GDN grape detection model. Our conclusions are as follows:
- (1)
- Ablation experiments indicate that DCFE enhances the model’s robustness, significantly improving the recall rate in complex scenes. The addition of DS-CONV enhances feature extraction capabilities, thereby improving the model’s precision. The combination of both leads to the maximum performance improvement, with mAP0.5:0.95 increasing by 2.2% and mAP0.5 increasing by 2.5%.
- (2)
- A comparison of several object detection networks and SSD, YOLOv3-tiny, and YOLOv5s reveals that GDN performs much better across a range of metrics. Additionally, we analyzed the performance of the GDN model in different scenarios, including well-lit conditions, occlusion, and poor lighting with dense fruit distribution. The results indicate that, in complex scenes, GDN demonstrates stronger robustness compared to YOLOv5s.
- (3)
- Grape picking experiments demonstrate that our proposed algorithm has an average inference time of 1.04 s and a harvesting success rate of 90%, meeting the requirements for grape picking by the harvesting robot and proving its practicality.
- (4)
- In conclusion, the GDN grape detection model achieves high accuracy and recall in complex environments, making it suitable for practical grape harvesting by harvesting robots. It provides valuable insights for future research on deep learning-based harvesting algorithms.
Author Contributions
Conceptualization, W.W. and Y.S.; methodology, W.W.; coding, W.W.; experiment design, W.W. and W.L.; writing—original draft preparation, W.W.; writing—review and editing, Z.C. and W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by 2022 Xinjiang Uygur Autonomous Region Academician Project (2022LQ02004); 2023 Key Task of the Science and Technology Innovation Engineering Center of the Chinese Academy of Agricultural Sciences (CAAS-CAE-202302); 2023 Key R&D Task of Xinjiang Uygur Autonomous Region (20222101543).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Acknowledgments
We would like to acknowledge the facilities and technical assistance provided by the Institute of Agricultural Resources and Regional Planning.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Roselli, L.; Casieri, A.; De Gennaro, B.C.; Sardaro, R.; Russo, G. Environmental and economic sustainability of table grape production in Italy. Sustainability 2020, 12, 3670. [Google Scholar] [CrossRef]
- Ehsani, R.; Udumala, S. Mechanical Harvesting of Citrus-An overview. Resour. Mag. 2010, 17, 4–6. [Google Scholar]
- Moreno, R.; Torregrosa, A.; Moltó, E.; Chueca, P. Effect of harvesting with a trunk shaker and an abscission chemical on fruit detachment and defoliation of citrus grown under Mediterranean conditions. Span. J. Agric. Res. 2015, 13, 12. [Google Scholar] [CrossRef]
- Yu, Y.; Sun, Z.; Zhao, X.; Bian, J.; Hui, X. Design and implementation of an automatic peach-harvesting robot system. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018; pp. 700–705. [Google Scholar]
- Wei, X.; Jia, K.; Lan, J.; Li, Y.; Zeng, Y.; Wang, C. Automatic method of fruit object extraction under complex agricultural background for vision system of fruit picking robot. Optik 2014, 125, 5684–5689. [Google Scholar] [CrossRef]
- Septiarini, A.; Hamdani, H.; Sauri, M.S.; Widians, J.A. Image processing for maturity classification of tomato using otsu and manhattan distance methods. J. Inform. 2022, 16, 118. [Google Scholar] [CrossRef]
- Sidehabi, S.W.; Suyuti, A.; Areni, I.S.; Nurtanio, I. Classification on passion fruit’s ripeness using K-means clustering and artificial neural network. In Proceedings of the 2018 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 304–309. [Google Scholar]
- Yu, Y.; Velastin, S.A.; Yin, F. Automatic grading of apples based on multi-features and weighted K-means clustering algorithm. Inf. Process. Agric. 2020, 7, 556–565. [Google Scholar] [CrossRef]
- Murillo-Bracamontes, E.A.; Martinez-Rosas, M.E.; Miranda-Velasco, M.M.; Martinez-Reyes, H.L.; Martinez-Sandoval, J.R.; Cervantes-de-Avila, H. Implementation of Hough transform for fruit image segmentation. Procedia Eng. 2012, 35, 230–239. [Google Scholar] [CrossRef][Green Version]
- Lin, G.; Tang, Y.; Zou, X.; Cheng, J.; Xiong, J. Fruit detection in natural environment using partial shape matching and probabilistic Hough transform. Precis. Agric. 2020, 21, 160–177. [Google Scholar] [CrossRef]
- Peng, H.; Shao, Y.; Chen, K.; Deng, Y.; Xue, C. Research on multi-class fruits recognition based on machine vision and SVM. IFAC-Pap. 2018, 51, 817–821. [Google Scholar] [CrossRef]
- Behera, S.K.; Rath, A.K.; Sethy, P.K. Fruit recognition using support vector machine based on deep features. Karbala Int. J. Mod. Sci. 2020, 6, 16. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Vibhute, A.; Bodhe, S.K. Applications of image processing in agriculture: A survey. Int. J. Comput. Appl. 2012, 52, 34–40. [Google Scholar] [CrossRef]
- Khattak, A.; Asghar, M.U.; Batool, U.; Asghar, M.Z.; Ullah, H.; Al-Rakhami, M.; Gumaei, A. Automatic detection of citrus fruit and leaves diseases using deep neural network model. IEEE Access 2021, 9, 112942–112954. [Google Scholar] [CrossRef]
- Nagaraju, M.; Chawla, P.; Upadhyay, S.; Tiwari, R. Convolution network model based leaf disease detection using augmentation techniques. Expert Syst. 2022, 39, e12885. [Google Scholar] [CrossRef]
- Kaur, P.; Harnal, S.; Tiwari, R.; Upadhyay, S.; Bhatia, S.; Mashat, A.; Alabdali, A.M. Recognition of leaf disease using hybrid convolutional neural network by applying feature reduction. Sensors 2022, 22, 575. [Google Scholar] [CrossRef]
- Mishra, A.M.; Harnal, S.; Gautam, V.; Tiwari, R.; Upadhyay, S. Weed density estimation in soya bean crop using deep convolutional neural networks in smart agriculture. J. Plant Dis. Prot. 2022, 129, 593–604. [Google Scholar] [CrossRef]
- Xiao, B.; Nguyen, M.; Yan, W.Q. Fruit ripeness identification using transformers. Appl. Intell. 2023, 53, 22488–22499. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Fu, L.; Feng, Y.; Majeed, Y.; Zhang, X.; Zhang, J.; Karkee, M.; Zhang, Q. Kiwifruit detection in field images using Faster R-CNN with ZFNet. IFAC-Pap. 2018, 51, 45–50. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference (Part I 14), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Han, K.; Xu, M.; Li, S.; Xu, Z.; Ye, H.; Hua, S. Research on Positioning Technology of Facility Cultivation Grape Based on Transfer Learning of SSD MobileNet. In Proceedings of the International Conference on Wireless Communications, Networking and Applications, Wuhan, China, 16–18 December 2022; pp. 600–608. [Google Scholar]
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Qi, X.; Dong, J.; Lan, Y.; Zhu, H. Method for identifying litchi picking position based on YOLOv5 and PSPNet. Remote Sens. 2022, 14, 2004. [Google Scholar] [CrossRef]
- Jimenez, A.; Ceres, R.; Pons, J.L. A survey of computer vision methods for locating fruit on trees. Trans. ASAE 2000, 43, 1911–1920. [Google Scholar] [CrossRef]
- Xiong, J.; Lin, R.; Liu, Z.; He, Z.; Tang, L.; Yang, Z.; Zou, X. The recognition of litchi clusters and the calculation of picking point in a nocturnal natural environment. Biosyst. Eng. 2018, 166, 44–57. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Li, L.; Tang, S.; Deng, L.; Zhang, Y.; Tian, Q. Image caption with global-local attention. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6070–6079. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11030–11039. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference (Part V 13), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Afsah-Hejri, L.; Homayouni, T.; Toudeshki, A.; Ehsani, R.; Ferguson, L.; Castro-García, S. Mechanical harvesting of selected temperate and tropical fruit and nut trees. Hortic. Rev. 2022, 49, 171–242. [Google Scholar]
- Lytridis, C.; Bazinas, C.; Kalathas, I.; Siavalas, G.; Tsakmakis, C.; Spirantis, T.; Badeka, E.; Pachidis, T.; Kaburlasos, V.G. Cooperative Grape Harvesting Using Heterogeneous Autonomous Robots. Robotics 2023, 12, 147. [Google Scholar] [CrossRef]
- Yang, Q.; Du, X.; Wang, Z.; Meng, Z.; Ma, Z.; Zhang, Q. A review of core agricultural robot technologies for crop productions. Comput. Electron. Agric. 2023, 206, 107701. [Google Scholar] [CrossRef]
- Badeka, E.; Karapatzak, E.; Karampatea, A.; Bouloumpasi, E.; Kalathas, I.; Lytridis, C.; Tziolas, E.; Tsakalidou, V.N.; Kaburlasos, V.G. A Deep Learning Approach for Precision Viticulture, Assessing Grape Maturity via YOLOv7. Sensors 2023, 23, 8126. [Google Scholar] [CrossRef]
- Xiong, J.; Liu, Z.; Lin, R.; Bu, R.; He, Z.; Yang, Z.; Liang, C. Green grape detection and picking-point calculation in a night-time natural environment using a charge-coupled device (CCD) vision sensor with artificial illumination. Sensors 2018, 18, 969. [Google Scholar] [CrossRef]
- Niu, K.; Wang, C.; Xu, J.; Yang, C.; Zhou, X.; Yang, X. An Improved YOLOv5s-Seg Detection and Segmentation Model for the Accurate Identification of Forest Fires Based on UAV Infrared Image. Remote Sens. 2023, 15, 4694. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).