
Lightweight-Improved YOLOv5s Model for Grape Fruit and Stem Recognition


Abstract
1. Introduction
2. Materials and Methods
2.1. Image Acquisition and Augmentation
2.2. Image Annotation
2.3. Lightweight Improvement of YOLOv5s
2.3.1. YOLOv5s Model
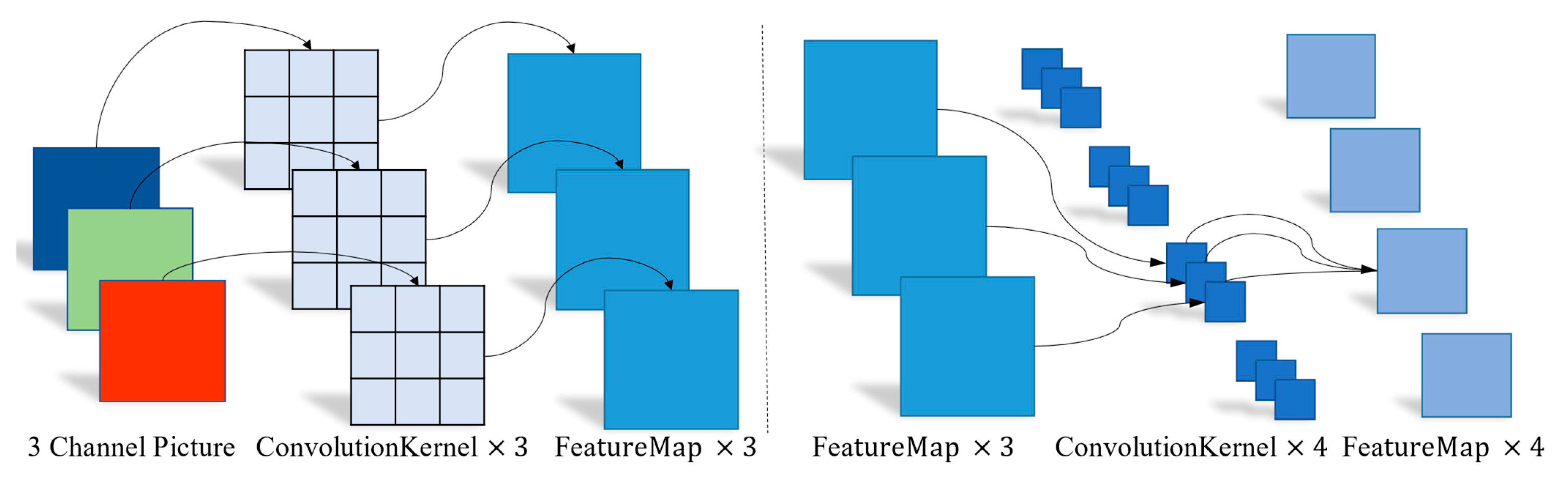
2.3.2. Ghost Module for CSP Improvement
2.3.3. Depthwise Separable Convolution for Improved Convolutional Layers
2.4. Training and Evaluation
2.4.1. Training Platform
2.4.2. Model Training
2.4.3. Model Validation and Testing
3. Results
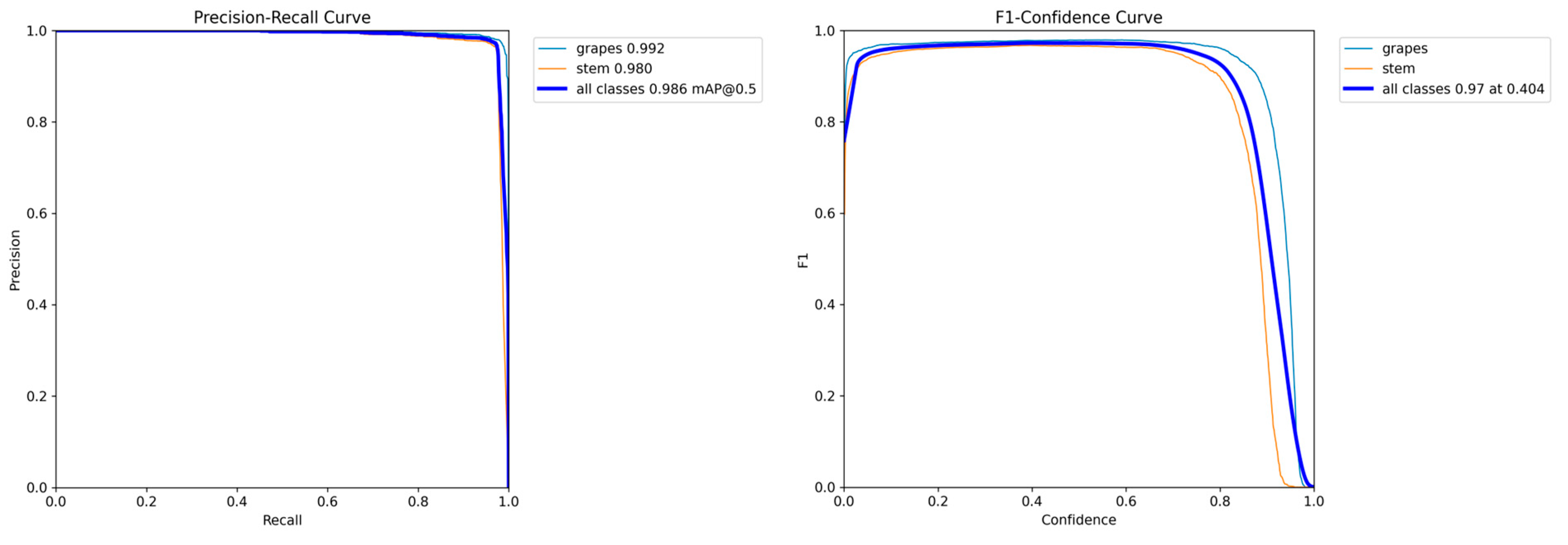
3.1. The Performance of Lightweight-Improved YOLOv5s
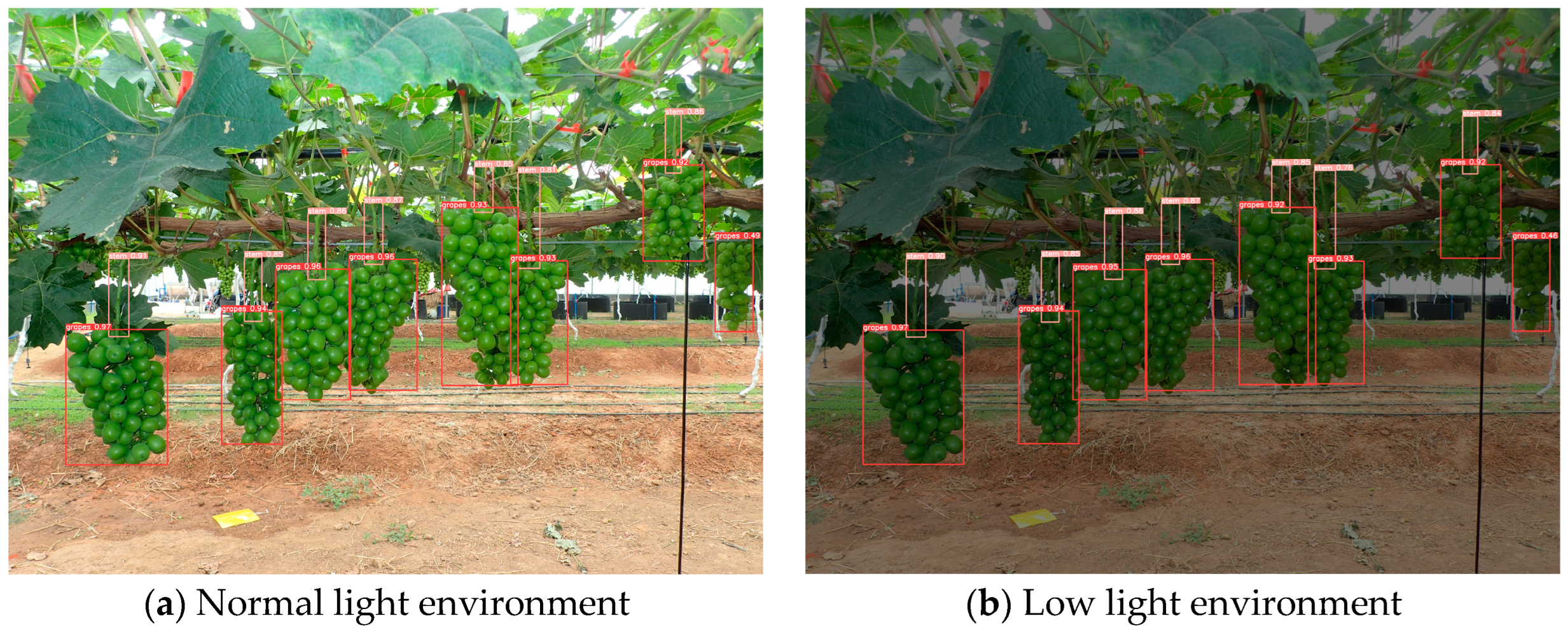
3.2. Comparison of Recognition Results via Different Object Detection Models
3.3. Speed Comparison on Different CPUs
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Feng, Q.; Li, T.; Xie, F.; Liu, C.; Xiong, Z. Advance of target visual information acquisition technology for fresh fruit robotic harvesting: A review. Agronomy 2022, 12, 1336. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Lv, Z.; Yang, C.; Lin, P.; Chen, F.; Hong, J. Identification and experimentation of overlapping honeydew in natural scene images. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 158–167. [Google Scholar]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Huang, Z.; Zhou, H.; Wang, C.; Lian, G. Three-dimensional perception of orchard banana central stock enhanced by adaptive multi-vision technology. Comput. Electron. Agric. 2020, 174, 105508. [Google Scholar] [CrossRef]
- Syazwani, R.W.N.; Asraf, H.M.; Amin, M.A.M.S.; Dalila, N.K.A. Automated image identification, detection and fruit counting of top-view pineapple crown using machine learning. Alex. Eng. J. 2022, 61, 1265–1276. [Google Scholar] [CrossRef]
- Lei, W.; Lu, J. Visual localization of picking points in grape picking robots. J. Jiangsu Agric. 2020, 36, 1015–1021. [Google Scholar]
- Luo, L.; Zou, X.; Xiong, J.; Zhang, Y.; Peng, H.; Lin, G. Automatic positioning of grape picking robot picking points under natural environment. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2015, 31, 14–21. [Google Scholar]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, J.; Li, B.; Xu, C. Localization method of tomato bunch picking point identification based on RGB-D information fusion and target detection. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 143–152. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Fu, L.; Majeed, Y.; Zhang, X.; Karkee, M.; Zhang, Q. Faster R–CNN–based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting. Biosyst. Eng. 2020, 197, 245–256. [Google Scholar] [CrossRef]
- Yan, J.; Zhao, Y.; Zhang, L.; Su, X.; Liu, H.; Zhang, F.; Fan, W.; He, L. Improved Faster-RCNN for identifying prickly pear fruits under natural environment. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2019, 35, 144–151. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Xu, Z.; Jia, R.; Sun, H.; Liu, Q.; Cui, Z. Light-YOLOv3: Fast method for detecting green mangoes in complex scenes using picking robots. Appl. Intell. 2020, 50, 4670–4687. [Google Scholar] [CrossRef]
- Qiu, C.; Tian, G.; Zhao, J.; Liu, Q.; Xie, S.; Zheng, K. Grape Maturity Detection and Visual Pre-Positioning Based on Improved Yolov4. Electronics 2022, 11, 2677. [Google Scholar] [CrossRef]
- Huang, M.; Wu, Y. GCS-YOLOV4-Tiny: A lightweight group convolution network for multi-stage fruit detection. Math. Biosci. Eng. 2023, 20, 241–268. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Sun, M.; Ding, X.; Li, Y.; Zhang, G.; Shi, G.; Li, W. A method based on YOLOv4+HSV for tomato identification at maturity. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 183–190. [Google Scholar]
- Chen, S.; Zou, X.; Zhou, X.; Xiang, Y.; Wu, M. Study on fusion clustering and improved YOLOv5 algorithm based on multiple occlusion of Camellia oleifera fruit. Comput. Electron. Agric. 2023, 206, 107706. [Google Scholar] [CrossRef]
- Duan, J.; Wang, Z.; Zou, X.; Yuan, H.; Huang, G.; Yang, Z. Identification of banana spikes and their bottom fruit axis positioning using improved YOLOv5. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 122–130. [Google Scholar]
- Li, K.; Wang, J.; Jalil, H.; Wang, H. A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Comput. Electron. Agric. 2023, 204, 107534. [Google Scholar] [CrossRef]
- Sun, H.; Wang, B.; Xue, J. YOLO-P: An efficient method for pear fast detection in complex orchard picking environment. Front. Plant Sci. 2023, 13, 1089454. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wu, P.; Zu, S.; Xu, D.; Zhang, Y.; Dong, Z. A farming recognition method for tomato flower and fruit thinning based on improved SSD lightweight neural network. China Cucurbits Veg. 2021, 34, 38–44. [Google Scholar]
- Li, S.; Hu, D.; Gao, S.; Lin, J.; An, X.; Zhu, M. Real-time classification detection of citrus based on improved SSD. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2019, 35, 307–313. [Google Scholar]
- Sun, Y.; Zhang, D.; Guo, X.; Yang, H. Lightweight algorithm for apple detection based on an improved YOLOv5 model. Plants 2023, 12, 3032. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A real-time apple targets detection method for picking robot based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, R.; Zhang, H.; Yin, C.; Xia, Y.; Fu, M.; Fu, W. Dragon fruit detection in natural orchard environment by integrating lightweight network and attention mechanism. Front. Plant Sci. 2022, 13, 1040923. [Google Scholar] [CrossRef]
- Ren, R.; Sun, H.; Zhang, S.; Wang, N.; Lu, X.; Jing, J.; Xin, M.; Cui, T. Intelligent Detection of lightweight “Yuluxiang” pear in non-structural environment based on YOLO-GEW. Agronomy 2023, 13, 2418. [Google Scholar] [CrossRef]
- Chen, J.; Ma, A.; Huang, L.; Su, Y.; Li, W.; Zhang, H.; Wang, Z. GA-YOLO: A lightweight YOLO model for dense and occluded grape target detection. Horticulturae 2023, 9, 443. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–25 July 2017; pp. 2117–2125. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zou, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtually, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 6848–6856. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–25 July 2017; pp. 1251–1258. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I 14; Springer International Publishing: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Zhao, J.; Hu, Q.; Li, B.; Xie, Y.; Lu, H.; Xu, S. Research on an Improved Non-Destructive Detection Method for the Soluble Solids Content in Bunch-Harvested Grapes Based on Deep Learning and Hyperspectral Imaging. Appl. Sci. 2023, 13, 6776. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Number of Pictures | Number of Targets | P (%) | R (%) | Map (%) | F1 (%) |
|---|---|---|---|---|---|---|
| Grapes | 452 | 1737 | 97.1 | 98.5 | 99.2 | 97.8 |
| Stems | 452 | 1392 | 96.5 | 96.8 | 98.0 | 96.6 |
| Total | 452 | 3129 | 96.8 | 97.7 | 98.6 | 97.2 |
| Model | P (%) | R (%) | F1 (%) | mAP (%) | Weight (MB) | Frame Rate (FPS) |
|---|---|---|---|---|---|---|
| YOLOv5s | 95.8 | 97.9 | 96.8 | 98.6 | 14.9 | 154 |
| YOLOv5m | 94.8 | 96.7 | 95.7 | 97.0 | 42.2 | 80 |
| YOLOv5l | 94.5 | 96.5 | 95.5 | 96.8 | 92.8 | 55 |
| YOLOv5x | 95.4 | 96.5 | 96.0 | 97.3 | 173.1 | 31 |
| YOLOv7-tiny | 94.9 | 95.5 | 95.2 | 97.8 | 12.3 | 161 |
| Faster-RCNN | 97.6 | 97.4 | 97.5 | 97.6 | 330.2 | 20 |
| SSD | 88.7 | 95.0 | 91.7 | 88.7 | 106.0 | 25 |
| Our Model | 96.8 | 97.7 | 97.2 | 98.6 | 5.8 | 221 |
| CPU | Number of Cores | Threads | Basic Frequency (GHz) | Detection Time (ms) | Frame Rate (FPS) | Original Model Frame Rate (FPS) |
|---|---|---|---|---|---|---|
| Intel® Core TM i7-11700K | 8 | 16 | 3.60 | 23.9 | 41.9 | 32.0 |
| AMD RyzenTM7 5800H | 8 | 16 | 3.20 | 94.9 | 10.5 | 9.0 |
| Intel® Core TM i5-8500 | 6 | 6 | 3.00 | 100.7 | 9.9 | 8.2 |
| Intel® Core TM i5-10210U | 4 | 8 | 1.60 | 155.6 | 6.4 | 4.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Yao, X.; Wang, Y.; Yi, Z.; Xie, Y.; Zhou, X. Lightweight-Improved YOLOv5s Model for Grape Fruit and Stem Recognition. Agriculture 2024, 14, 774. https://doi.org/10.3390/agriculture14050774
Zhao J, Yao X, Wang Y, Yi Z, Xie Y, Zhou X. Lightweight-Improved YOLOv5s Model for Grape Fruit and Stem Recognition. Agriculture. 2024; 14(5):774. https://doi.org/10.3390/agriculture14050774
Chicago/Turabian StyleZhao, Junhong, Xingzhi Yao, Yu Wang, Zhenfeng Yi, Yuming Xie, and Xingxing Zhou. 2024. "Lightweight-Improved YOLOv5s Model for Grape Fruit and Stem Recognition" Agriculture 14, no. 5: 774. https://doi.org/10.3390/agriculture14050774
APA StyleZhao, J., Yao, X., Wang, Y., Yi, Z., Xie, Y., & Zhou, X. (2024). Lightweight-Improved YOLOv5s Model for Grape Fruit and Stem Recognition. Agriculture, 14(5), 774. https://doi.org/10.3390/agriculture14050774