Abstract
The rapid development of artificial intelligence and remote sensing technologies is indispensable for modern agriculture. In orchard environments, challenges such as varying light conditions and shading complicate the tasks of intelligent picking robots. To enhance the recognition accuracy and efficiency of apple-picking robots, this study aimed to achieve high detection accuracy in complex orchard environments while reducing model computation and time consumption. This study utilized the CenterNet neural network as the detection framework, introducing gray-centered RGB color space vertical decomposition maps and employing grouped convolutions and depth-separable convolutions to design a lightweight feature extraction network, Light-Weight Net, comprising eight bottleneck structures. Based on the recognition results, the 3D coordinates of the picking point were determined within the camera coordinate system by using the transformation relationship between the image’s physical coordinate system and the camera coordinate system, along with depth map distance information of the depth map. Experimental results obtained using a testbed with an orchard-picking robot indicated that the proposed model achieved an average precision (AP) of 96.80% on the test set, with real-time performance of 18.91 frames per second (FPS) and a model size of only 17.56 MB. In addition, the root-mean-square error of positioning accuracy in the orchard test was 4.405 mm, satisfying the high-precision positioning requirements of the picking robot vision system in complex orchard environments.
1. Introduction
The fruit-growing industry encounters significant challenges during the annual orchard harvest season, striving to ensure timely delivery of fresh produce to the market. This challenge is particularly pronounced in apple harvesting, a labor-intensive and time-consuming endeavor [1]. Moreover, escalating labor costs exacerbate the inefficiency, expense, and risk associated with manual harvesting [2,3]. Consequently, to enhance agricultural productivity and supplant manual apple picking in orchards, the development of robots capable of autonomous and intelligent operation in orchard environments is crucial [4,5].
Apple-picking robots consist primarily of two key subsystems: the vision system and the picking execution system. Accurate target recognition by the vision system is prerequisite to grasping and picking actions on apple targets. Vision serves as the cornerstone of information perception [6]. The accuracy and efficiency of the vision system, encompassing recognition and localization, profoundly influence the picking execution system, directly impacting picking efficiency. Hence, it has emerged as a pivotal means for robots to perceive their surroundings [7]. In recent decades, propelled by the continual advancement of precision agriculture technology, orchard robots have been increasingly applied in the agricultural domain. However, the practical utilization of highly efficient apple-picking robots remains limited [8]. Despite the availability of diverse exemplary target detection models capable of recognizing various target types, their applicability in specific apple-picking scenarios remains constrained [9]. This constraint can be primarily attributable to the complex natural scenes characteristic of unstructured apple orchards, encompassing fluctuating lighting conditions (e.g., sunny, cloudy, backlit), light obstruction by foliage and fruits, resulting in shadowing on apple surfaces, and fruit overlap, all of which significantly impede accurate identification of apple targets. Consequently, precise target positioning and execution of the picking task are compromised [10]. Enhancing recognition accuracy in complex scenes thus represents the crux and challenge of vision technology for picking robots.
Currently, two primary approaches dominate computer vision: recognition methods grounded in prior knowledge models and data-driven deep learning methods, as illustrated in Figure 1. Model-based recognition algorithms entail direct engagement in target feature engineering, such as constructing features like Scale-Invariant Feature Transform (SIFT), Histogram of Oriented Gradient (HOG), and Speeded Up Robust Features (SURF). These engineered features are then integrated with machine learning principles like the K-means clustering algorithm [11], the region growing method [12], and algorithms such as Support Vector Machines (SVMs) [13], to facilitate classification recognition and semantic segmentation. This enables target recognition amidst complex backgrounds. Such algorithms offer ease of explanation and comprehension, owing to their comprehensive grasp of data and underlying algorithms, thereby facilitating straightforward parameter tuning and model design adjustments [10].
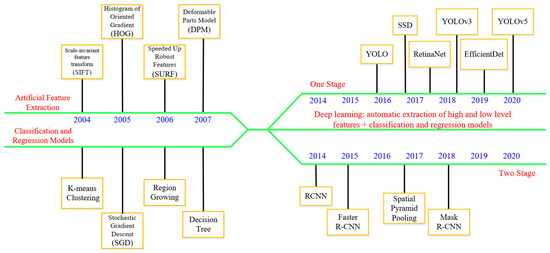
Figure 1.
Evolution of target detection algorithm.
Manickam and Chithra [14] converted RGB color images depicting apple fruits into grayscale representations. Subsequently, they delineated the region of interest within these apple images by applying five distinct fuzzy clustering bins, characterized by overlapping pixel ranges. The selection of the cluster with the maximal pixel count facilitated the computation of the threshold value. Li and Jing [15] proposed an innovative method for apple target recognition grounded in K-Means feature clustering. Operating within the L* a* b color space, this method harnessed K-Means clustering to partition the image, leveraging the *a component to discern the target from the background, thereby enhancing segmentation accuracy. Gill et al. [16] designed an objective function predicated on cross entropy, subsequently employing a teacher-learner-based optimization algorithm to minimize it. This optimization process yielded optimal thresholds at varying levels, subsequently utilized for segmenting red, green, and golden apple images. Zou et al. [17] introduced a pioneering color-index-based approach to apple image segmentation, affording automatic determination of a specific color index pertinent to the image segmentation task. Wang et al. [18] introduced a novel kernel density clustering algorithm (KDC). This algorithm employed a simple linear iterative clustering mechanism to partition the apple image into irregular blocks, thereafter amalgamating approximate pixels within confined regions into superpixel regions. In scenarios characterized by notable disparities between the fruit and background in apple imagery, color information emerged as the most direct discriminator for distinguishing ripe fruit from the background. Nevertheless, akin to the aforementioned studies, notwithstanding the attainment of heightened apple recognition, the intricate natural milieu of orchards poses significant challenges. When light is obstructed by branches, leaves, or other fruits, shadows and light spots are formed on the apple surface, thereby perturbing the extractable or learnable features from the image. Therefore, algorithms must consider the complex characteristics of orchards to further refine algorithmic recognition performance [19].
Existing CNN-based fruit recognition techniques are based on the principle of anchor frame recognition, categorized into one-stage and two-stage modalities. One-stage methodologies bifurcate the fruit recognition problem into two discrete steps: initial generation of candidate regions potentially encompassing fruits by the network, succeeded by the classification of these candidate regions. Networks under this paradigm typically exhibit protracted recognition times, colloquially termed two-stage detection. Representative algorithms encompass RCNN (Regions with CNN features), Fast RCNN, and Faster RCNN [20,21,22]. Rahnemoonfar and Sheppard [23] modified the Inception-ResNet network architecture, quantifying distinct fruits with an average accuracy approaching 91%. However, the discernment accuracy markedly diminishes in instances where fruits overlap or occlude one another. Tong et al. [2] integrated Swin-Transformer and ResNet50 as backbone models with Mask R-CNN and Cascade Mask R-CNN to detect and segment trunks, major branches, and supporting structures within apple trees. Xiong et al. [24] trained the Faster R-CNN network model to recognize citrus fruits, achieving a test accuracy surpassing 85% on the validation set. Identification errors and omissions primarily occur because of the inadequate generalization capability and insensitivity of the model to smaller fruits.
Two-stage recognition directly employs the CNN to ascertain fruit confidence and location, facilitating faster recognition speeds. Representative algorithms include YOLO and SSD [25,26]. In [27], Kang and Chen achieved apple recognition by devising a lightweight backbone network, enabling a recognition time of approximately 0.028s per image. Although this method enhances recognition speed, the size of the Anchor Box must be preset, and the model’s Average Precision (AP) value for apple recognition stands at 85.3%. In [23], Zhao et al. improved the YOLO convolutional neural network to recognize apples, achieving a single-image recognition time of about 0.017s. However, the recognition accuracy for occluded and overlapping apples is 75.15%. Similarly, Tian et al. [28] enhanced the YOLO convolutional neural network, also with a recognition time of around 0.017s, yet encountered a similar accuracy challenge with occluded and overlapping apples. Tian et al. further improved the YOLOv3 algorithm by replacing the feature extraction backbone network with DenseNet for recognizing apples across different growth stages, although recognition in denser scenes remains untested. In [29], Wang et al. proposed a coordinated control strategy for long and short distances. In the long-distance stage, YOLOv5 is combined with the DBSCAN point cloud clustering method to determine the target position; in the short-distance stage, Mask RCNN is used to segment the bifurcated branches, achieving a positioning success rate of 88.46% for the branches, but showing poor learning ability for small bifurcated branches. In [30], Wang et al. used the YOLOv8-Seg model to segment lychee fruits and branches, achieving a success rate of 88% in identifying picking points, with an average positioning error of 2.8511 mm and an average recognition time of 0.082 s.
Network architectures must be designed with lightweight and real-time operation for deployment on robots. Therefore, researchers have favored lightweight networks such as the YOLO family and GhostNet, enhancing detection accuracy while mitigating computational overhead. Zhang et al. [29] proposed an Enhanced YOLOv4, amalgamating GhostNet with a coordinate attention module and depth-separable convolution. This optimization of the neck and YOLO head structure enhances detection accuracy while reducing computational demands. Sekharamantry et al. [30] introduced a Yolov5 architecture that incorporates an adaptive pooling scheme and an attribute enhancement model, elevating feature quality for apple detection amidst complex backgrounds. Additionally, the introduction of a bounding box loss function ensures precise bounding boxes, thereby maximizing detection accuracy. In [31], Chen et al. proposed a series of vision algorithms for picking robots, aimed at motion target estimation, real-time self-localization, and dynamic picking, enabling the robot to operate continuously autonomously. However, it performs poorly at night. In [32], Li et al. introduced the YOLOv7-Litchi algorithm, which integrates channel and spatial attention along with multi-head self-attention from transformers, achieving recall and accuracy rates of 95.9% and 94.6%, respectively. This algorithm is characterized by its fast detection speed and strong robustness. In [33], Shu et al. proposed an algorithm that can correct image colors according to light conditions by calculating the Hue color layer, analyzing the external features and position data of lychee, effectively solving the occlusion problem of neighboring lychees.
Real-time performance constitutes another pivotal metric. By refining network structures—for instance, by substituting standard convolutional modules with lightweight counterparts—and incorporating mechanisms like attention modules and bounding box loss functions, both detection speed and accuracy have seen enhancements. These methods empower robots to swiftly and accurately identify fruit targets in complex environments. Ji et al. [34] devised an apple detection method based on Shufflenetv2-YOLOX, utilizing YOLOX-Tiny and lightweight Shufflenetv2 as the backbone, alongside a convolutional block attention module (CBAM) and an adaptive spatial feature fusion (ASFF) module to bolster detection accuracy. Lee et al. [35] proposed leveraging Rand Augment (RA) to elevate crop detection performance through geometric, photometric, and partial occlusion transformations, thereby optimizing computational efficiency to alleviate burden on mobile platforms. In conclusion, the research and design of intelligent fruit-picking robotic vision systems necessitate the integration of lightweight, real-time, and accurate methodologies to address the demands of modern agriculture, thereby enhancing picking efficiency and reducing costs.
In our prior study, we examined the color attributes and local variations within apple images, constructing feature engineering based on the intrinsic characteristics of the recognition target. Accordingly, a color prior model-based algorithm was developed for apple image recognition, particularly adept at handling variations in lighting and shading, thereby rendering apple recognition more interpretable and comprehensible [10]. However, the segmentation effect is weak when the target is obscured by branches, leaves, or overlapping occlusions. Conventional model-based apple recognition methods often fail in segmenting apples under such conditions, highlighting a common deficiency in these approaches. In our earlier work, we also proposed a framework for further exploration, advocating for the fusion of a prior knowledge-based approaches with the strengths of deep learning methods for a more reasoned explanation and broader applicability. Accordingly, our team leveraged an improved CenterNet neural network model, achieving an average recognition accuracy of 96.26% on one class of the test set (dense scenes, i.e., long-distance scenes), and 92.47% on another class of the test set (scenes characterized by smooth lighting, backlighting, occlusion, and overlapping phenomena), representing a marginal decrease of 3.79% [36]. While transfer learning can potentially address this issue, extreme lighting conditions, whether excessively strong or weak, may adversely affect recognition outcomes [37]. Furthermore, an improved backbone feature extraction network prototype, known as Hourglass, was adopted. Originally devised by the CenterNet designers, the Hourglass network possesses a symmetric structure designed to leverage multi-scale features for recognizing complex target poses [38]. Notably, upsampling and delayed downsampling are followed by convolution, resulting in substantially increased computational load. This network, characterized by its substantial volume, even with a reduced number of layers, remains computationally intensive. Consequently, its utility in orchard detection hinges significantly on hardware capabilities, with discernible trade-offs in loading and operational speed. The suitability of such architectures warrants must be considered carefully because apple recognition encompasses a single category and does not necessitate an overly robust backbone network.
Addressing the challenges posed by complex natural scenes in apple orchards (e.g., variations in lighting, backlighting, occlusions, and overlapping phenomena) on the vision system of picking robots, we propose an apple recognition method based on a color a prior model, building upon previous research. Specifically, we introduce gray-centered colored spatial vertical decomposition maps, leveraging a prior knowledge that these maps can mitigate the impact of light and shadows. By splicing the original map, our aim is to bolster the picking robots’ recognition rates, enabling them to better withstand the challenges posed by complex scenes characterized by light variations, shadows, and occlusions.
Furthermore, to address issues such as slow system response, bulky model size, challenging deployment, and slow loading speeds encountered during the operation of picking robots in orchard settings, we introduce the Light-Weight Net lightweight feature extraction network. Drawing inspiration from the "Objects as Points" concept in human body gesture detection, as well as ideas surrounding grouped convolution and depth-separable convolution, our objective is to develop a recognition model characterized by high detection rates, low computational demands, and a compact footprint, thereby facilitating its deployment within robotic systems.
The subsequent sections of this paper unfold as follows: Section 2 describes the network design process, encompassing dataset acquisition, generation, and augmentation, alongside the conceptualization of the network design and its implementation steps. Section 3 elucidates the experimental findings, including analysis and discussion of the apple localization method leveraging the RealSense D435 depth camera. Section 4 conducts a comparative analysis of the recognition performance of various convolutional neural networks for apple targets, culminating in the establishment of a platform for evaluating the accuracy of the localization method proposed herein in orchard settings. Finally, our conclusions are articulated.
2. Materials and Methods
2.1. Sample Image Acquisition and Data Production
In this study, we focused on the ‘Fuji’ apple as our research subject. Our experiments were conducted at the Baishui Apple Experimental Demonstration Station of Northwest A & F University, situated in Baishui County, Shaanxi Province (109 °E, 35.12 °N), positioned in the transitional zone between the Guanzhong Plain and the Northern Shaanxi Plateau.
Image acquisition took place at the Shaanxi Baishui Apple Mechanized Research Base, where we captured images of red Fuji apples using a Sony FDR-AX45 camera (Sony, New York, NY, USA). The shooting distance ranged from 0.5 m to 1 m, within the reachable range of the robotic arm, with images taken from multiple angles. We collected images under smooth light and backlight conditions at various times throughout the day. Both scenarios encompassed varying degrees of leaf, branch, and overlapping fruit shading. In total, we gathered 3069 apple images, comprising 1550 under smooth light conditions and 1519 under backlight conditions. Based on a prior assumption that vertical decomposition maps can mitigate the impact of light shading, we obtained 3069 light-shading-independent maps.
Using LabelImg annotation software, we drew rectangular boxes around apples in the 3069 apple images, generating corresponding XML files containing annotation information, including the coordinates of each apple target’s real lower-left and upper-right points. During labeling, rectangular boxes were drawn solely on the original image, with the original image and its decomposition counterpart sharing the same XML file. We selected 160 apple images from both the smooth light and backlight datasets, totaling 320 images, for the test set, as depicted in Figure 2. These images included varying degrees of occlusion. The remaining apple images were allocated to the training and validation sets. To enhance model generalization performance, we generated a total of 36,510 images from the remaining 2749 apple images through color, geometric, and noise augmentation. Annotations for the augmented images were identical to those of the original images.

Figure 2.
Apple images in a complex orchard scene: (a) front-lit scene and (b) back-lit scene.
2.2. CenterNet Deep Learning Network Models
CenterNet embraces the concept of “Objects as Points”, which offers a notable advantage over detection algorithms reliant on Anchor Boxes [39]. The CenterNet network preprocesses input images, identifying the center point of the apple after extracting apple features through stacked bottlenecks. It then regresses the width and height of the apple target, along with category and positional deviation information, through point estimation, utilizing maximum pooling to filter key points and generate prediction boxes, as depicted in Figure 3.
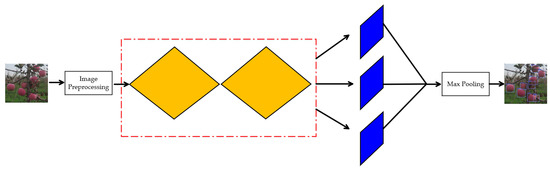
Figure 3.
CenterNet network identification process.
CenterNet locates the target at the center of the apple, simplifying the detection task into a key point prediction problem, thereby achieving high accuracy and speed in recognition. The process of predicting the center point of the apple target entails feeding the apple image into CenterNet. A Gaussian kernel function in the classification network generates a heatmap, which is then forwarded to the classification network for training. The Gaussian kernel distribution function is expressed as Equation (1).
The Gaussian kernel distribution function transforms the apple map into a heatmap, intensively predicting target categories based on labeled image (Ground truth) apple center point information. The heat map assigns scores ranging from 0 to 1 to all potential apple centers, with the smallest error determining the heat map loss Lk as shown in Equation (2). Focal Loss hyperparameters, set to 2 and 4, further enhance algorithm detection accuracy [40].
where N represents the number of apple targets in a single image. x, y denote the real center point coordinates of the apples, and c = 1. α and β are hyperparameters contributed by each point, with α set to 2 and β set to 4. and represent the coordinates of center points on the feature map after 4-fold downsampling.
Because of the 4-fold downsampling resolution change in the heat value feature maps trained in the classification network, the peak point deviates from the Ground truth centroid, impacting the predicted widths and heights of the apples. Therefore, the offset loss and size loss are denoted by Loff and Lsize, respectively [41].
where p represents the true center point of the object; represents the center point after 4-fold downsampling. and represents the offset of the x and y coordinates.
The CenterNet total loss function comprises three components: the heat map loss Lk, the apple width and height dimensions Lsize and the center point Loff, respectively, as depicted in Equation (7)
where αoff represents the weight of the offset loss, set to 1, and βsize represents the weight of dimensional loss, set to 0.1.
2.3. Lightweight Network Design
Typical, deeper and more complex neural networks can extract features at higher abstraction levels, resulting in abundant semantic information, akin to VGG networks [42]. However, increasing network depth often leads to challenges such as excessive computations and gradient explosions [43]. To address these issues, bottleneck structures are employed, where the feature map’s channel count is reduced via a 1 × 1 convolution, followed by a subsequent 1 × 1 convolution to restore the channel count of the output feature map after the primary convolution operation [44]. Additionally, residual learning is applied to enable stacked bottleneck structures to continuously acquire new features [45].
In this study, 8 bottleneck structures were stacked to construct the backbone network, employing a continuous 3 × 3 convolution kernel to deepen the network while maintaining the same field of view as larger convolution kernels. Grouped convolutions and depth-separable convolutions were integrated to reduce network parameters while ensuring accuracy. Through experimentation, various activation functions and hyperparameters were incorporated to finalize the Light-Weight Net network, as depicted in Figure 4.
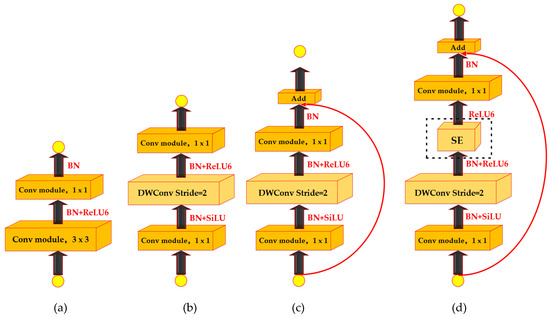
Figure 4.
Light-Weight Net network with a bottleneck structure: (a) BottleNeck 1; (b) BottleNeck 2; (c) BottleNeck 3,7,8; and (d) BottleNeck 4,5,6.
2.3.1. Grouped Convolutional Networks
Grouped convolution enhances model efficiency by reducing model parameters with an increasing number of filter groups. Specifically, grouped convolution with two filter groups halves the parameter count compared to conventional convolution, as illustrated in Figure 5.
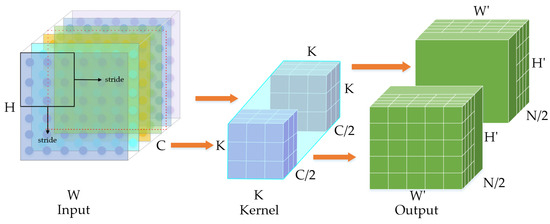
Figure 5.
Grouped Convolution Modules.
Before stacking the bottleneck structure, channels comprising the original input and vertical decomposition maps are grouped for convolution. Feature maps derived from the original and vertical decomposition maps via distinct convolution paths exhibit low coupling between them. The filter group learns channel dimensions with a sparsity of the diagonal structure, allowing convolution kernels with high correlation to be learned in a more structured manner [46], yielding complementary feature maps, as demonstrated in Figure 6.

Figure 6.
Significance of group convolution.
2.3.2. Depthwise Separable Convolutional Networks with Residual Modules
Depthwise separable convolutional networks contribute to lighter and faster models. By employing depthwise separable convolutional parameters, the parameter count can be reduced to approximately 1⁄8 of the number of parameters used in standard convolution. For instance, considering an input of 6 × 6 × 3 and an output of 4 × 4 × 128, standard convolutional computation entails 128 convolutions of size 3 × 3 × 3 shifted 4 × 4 times, totaling 128 × ((3 × 3 × 3) × (4 × 4)) = 128 × 432 = 55,296. In contrast, for a depthwise separable convolutional network, the parameter count is as follows: the first step involves 3 × 3 × 1 convolutions (3) shifted 4 × 4 times, while the second step comprises 1 × 1 × 3 convolutions (128) shifted 4 × 4 times. Consequently, the parameter count is 3 × ((3 × 3 × 1) × (4 × 4)) + 128 × ((1 × 1 × 3) × (4 × 4)) = 6576. This demonstrates an 8.4-fold reduction in the number of parameters with depthwise separable convolutions.
The introduction of residual networks, as proposed in ResNet, enables deeper network layers and more efficient parameters [47]. Hence, shortcut connections (3-layer residual networks with 1 × 1 convolution before and after the 3 × 3 depthwise separable convolution in the middle, facilitating dimensionality reduction and enhancement) are incorporated into the 3rd–8th bottleneck layers. This approach allows the entire network to focus solely on learning the input and output difference components, effectively reducing the parameter count once more for the same number of layers. Consequently, deeper models can be constructed, leveraging increased depth to enhance accuracy and precision, thus simplifying the learning task.
2.3.3. Light Squeeze-and-Excitation Block
The Squeeze-and-Excitation (SE) Block enhances channel attention, assigning greater weight to effective features while reducing the weight of irrelevant ones, thereby enhancing network learning capabilities [48]. Given the abundant information in apple images, including the presence of target apples amidst varying sizes, concentrations, and other distinctive characteristics, SE Blocks can emphasize instance information and suppress non-target features, thereby improving detection accuracy. In our experiment, SE Blocks are integrated into the 4th-6th bottleneck layers, strategically positioned within the model. Additionally, shortcut connections are added to each SE Block to ensure seamless information transmission and enhance the speed and effectiveness of model training, as illustrated in Figure 7.
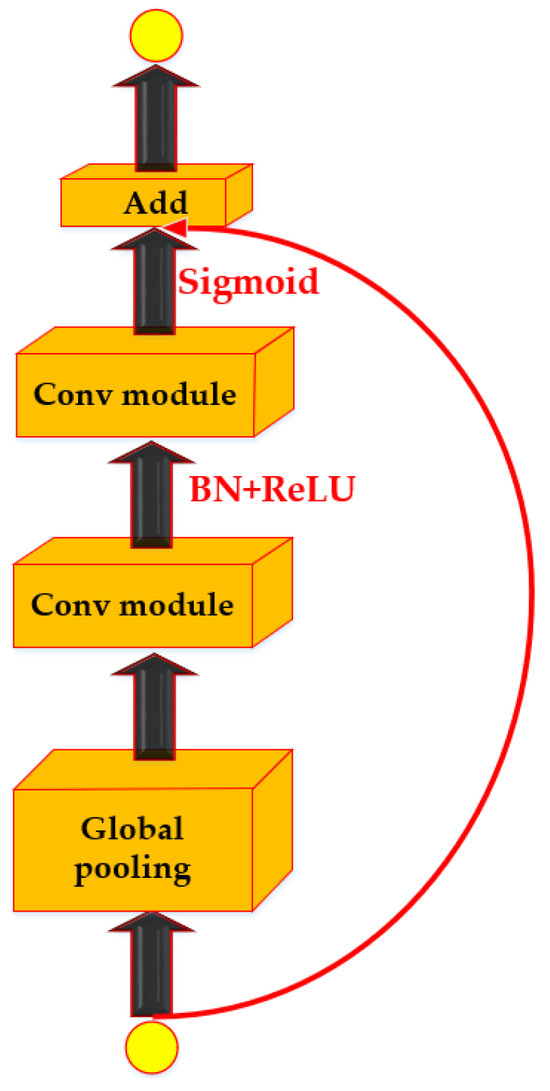
Figure 7.
Light-SE Block.
2.3.4. Integrated Use of Activation Functions SiLU and RELU6
Within the designed Bottleneck, a combination of both SiLU and ReLU6 activation functions is employed for the bottleneck modules, except for the 1st Bottleneck, which is unsuitable for complex operations and thus does not utilize convolution and SiLU. The SiLU activation function is chosen for its properties of lacking an upper bound and lower bound, smoothness, and non-monotonicity, which yield better results than ReLU, particularly in deeper networks [49]. ReLU6 is utilized for two reasons: extensive experimental data indicate no significant difference in accuracy in classification experiments using either ReLU6 or ReLU activation functions. However, from a software deployment perspective, nearly all hardware and software frameworks offer optimized implementations of ReLU6 [50].
The CenterNet network structure based on the Light-Weight Net backbone is depicted in Figure 8.
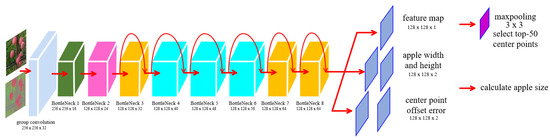
Figure 8.
CenterNet network architecture based on Light-Weight Net.
2.4. Network Model Training
For streamlined integration and deployment of the vision system and other software systems in subsequent stages, the model was trained and tested in the Linux Ubuntu18.04 environment, utilizing an Intel(R) Xeon(R) 5118CPU@2.30GHz 2.29GHz (2 processors), 32GB of running memory, and Nvidia RTX2080TI- graphics card with 11GB. Python 3.7 and PyTorch 1.2 framework were employed for training.
The network training parameters are as follows: the image input size is set to 512 × 512, the initial learning rate is 0.0005, the total number of training sessions is 150, with the learning rate decreasing to 5 × 10−5 and 5 × 10−6 at the 80th and 110th training sessions, respectively. The batch size during training is 64. Considering the advantage of smaller batch size in terms of memory usage, the batch size during testing is set to 1. The loss curve for network training is depicted in Figure 9.
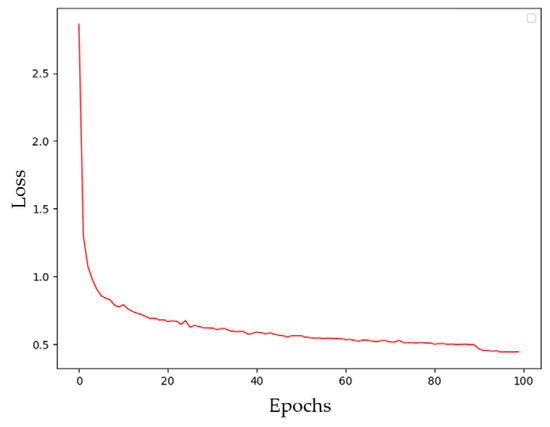
Figure 9.
Loss-value change curve for the number of training sessions.
This subsection evaluates the model from an engineering perspective, quantitatively assessing the model in terms of detection precision, operation speed, and model volume, utilizing Recall, Precision, and Detection Precision AP to evaluate the model’s performance. AP represents the area under the Precision-Recall (PR) curve, with a higher value indicating better category detection. Detection speed refers to the frame rate of detection (FPS) on the dataset, measuring the number of frames per second of the detected image, which is a crucial parameter for real-time applications [51]. Model size and Params serve as evaluation indices of the model’s occupancy of computational and storage resources [52].
2.5. Depth-Camera-Based Approach for Apple Localization
A depth camera, an innovative addition to traditional cameras, measures the distance to the target. Among these, the Intel RealSense D435 (referred to as D435) is notable, boasting an applicable range of 0.2 to 10 m. In modern orchards in Shaanxi Province, with row spacings of 3 to 4 m, the compact size, easy mounting, and high accuracy of the D435 make it suitable as a vision system for picking robots.
The D435 depth camera captures both the color map and depth map of the target apple simultaneously. The trained recognition model calculates the two-dimensional coordinates (x, y) of the apple on the color map and provides the depth value on the depth map, yielding the spatial position of the apple (x, y, z). To meet the requirements of the apple-picking robot vision system, which needs target apple position information under the camera coordinate system, a coordinate transformation relationship is constructed. Firstly, the relationship between the pixel coordinate system and the image coordinate system is established, as depicted in Figure 10. Here, point p represents the two-dimensional coordinates (x, y) of the apple center point identified by the model under the pixel coordinate system Ouv, and Oxy represents the image coordinate system.
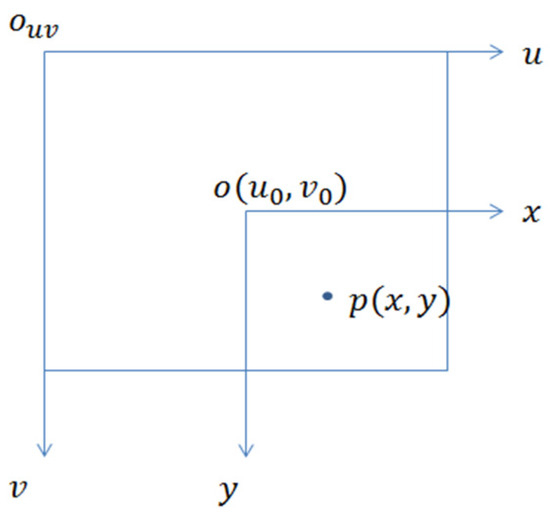
Figure 10.
Image coordinate system and pixel coordinate system.
Equations (9) and (10) can be converted into a matrix subform as follows:
The relationship between the image coordinate system and the camera coordinate system is delineated, as illustrated in Figure 11. Point p represents the two-dimensional coordinates (x, y, z) of the apple center point identified by the model under the camera coordinate system OXcYc. According to the principle of perspective mapping, the projection of point P under the image coordinate system Oxy is p(x, y, z).
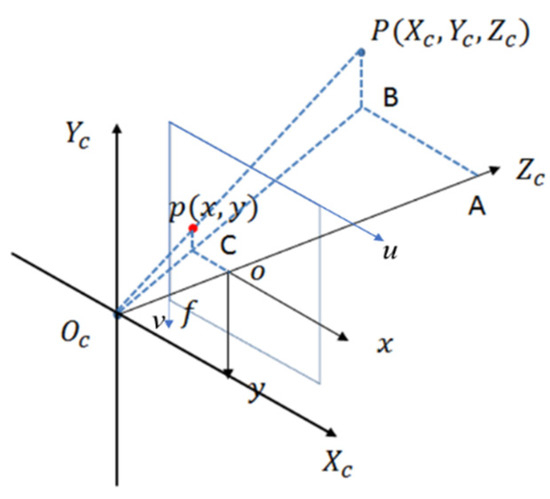
Figure 11.
Camera coordinate system and image coordinate.
Based on Figure 11,
Equation (12) can be converted into homogeneous matrices as shown in Equation (13):
The 3D coordinates of the apple in the camera coordinate system can be determined by acquiring the camera’s internal reference matrix, which necessitates obtaining the calibration matrix. is the depth camera internal reference matrix.
3. Experimental Results and Analysis
3.1. Comparison of the Number of Bottlenecks in the Model on Network Recognition Results
The performances of three different numbers of Bottlenecks with depths set at 6, 8, and 10, denoted as Bottleneck-6, Bottleneck-8, and Bottleneck-10, respectively, were compared to enhance the recognition speed of the network without compromising accuracy. Before determining the number of Bottlenecks, this experiment designed three different numbers of Bottlenecks for performance comparison. The test set consisted of a total of 320 images, with 160 images under front-lit conditions and 160 images under backlit conditions. Table 1 presents the network’s performance on the test set.

Table 1.
Detection results obtained using the Bottleneck backbone network with different numbers.
The Bottleneck-8 backbone network outperforms the other two variants in terms of detection accuracy, model size, and number of parameters. As the number of Bottlenecks increases, the overall detection accuracy and speed decrease, while the model size and number of parameters grow. With Bottleneck-8, the detection accuracy and speed on the test set reach 96.90% and 18.91%, respectively, representing a significant improvement of 7.3% compared to Bottleneck-6. However, there is a slight decrease in detection speed by 0.35. Compared to Bottleneck-10, Bottleneck-8 shows a 1.35% improvement in detection accuracy, with a proportional increase in model size and parameters. Consequently, the network constructed with Bottleneck-8 achieves better recognition speed and accuracy, making it the preferred backbone network structure.
3.2. Camera Internal Parameter Calibration Results
The internal parameter matrix of the camera can be obtained through calibration tests [53]. First, a calibration board is fabricated, and a C++ program is written under the Linux Ubuntu 18.04 environment [48]. The D435 depth camera is connected to a laptop (Lenovo Y7000, Intel Core i7, 16GB RAM, NVIDIA GTX 1660Ti) via USB 3.0. The calibration process is shown in Figure 12, and the calibration results are shown in Figure 13. The specific experimental procedure is as follows:

Figure 12.
Photographs of the calibration plate at different angles.
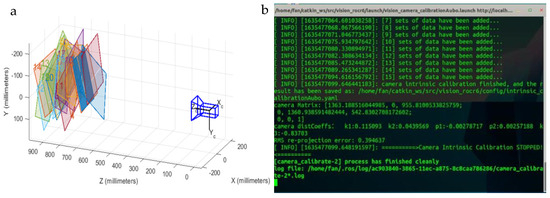
Figure 13.
Calibration board position and calibration results in the camera coordinate system: (a) Calibration board position; (b) Calibration program results.
(1) Fix the camera, ensuring its position and orientation remain unchanged during the calibration process;
(2) Manually rotate the calibration board and run the program once;
(3) After the calibration program successfully captures the image, rotate the calibration board again, ensuring each rotation varies in position and orientation;
(4) Repeat step 3 until 15 rotations are completed, and record the results.
The results using the calibrated internal reference matrix are as follows:
4. Discussion
4.1. Comparison of Identification Results of Different Backbone Networks
The CenterNet detection performance of the Bottleneck-8 constructed backbone network was verified by testing two other backbone networks based on the CenterNet architecture using the same dataset (320 images of apples). This dataset comprised images of apples with varying degrees of occlusion under both smooth light and backlight conditions (160 images each for smooth light and backlight). The comparative networks included Bottleneck-8 without three-channel decomposition plots (Three-channel original image), Tiny Hourglass-24 [36], and DLA-34 [54]. The results are summarized in Table 2.
Table 2.
Detection results of different backbone networks.
The comparison reveals that the six-channel Bottleneck-8 achieves a detection accuracy of 96.80%, only 1.65% higher than Tiny Hourglass-24, but 2.55% higher than the three-channel original image Bottleneck-8, indicating that the addition of vertical decomposition plots significantly improves the model’s accuracy. Although their overall accuracies are comparable, Bottleneck-8 significantly reduces model volume and parameter count by 77%, while increasing detection speed (FPS) by 4.21%, thus excelling in terms of efficiency and real-time performance. On the other hand, the DLA-34 backbone network exhibits a detection accuracy of 92.45% on the test set, which is 3.35% lower than Bottleneck-8. Furthermore, DLA-34 has a larger model size and parameter count, resulting in slower recognition speed compared to the other two backbone networks. Given their shared "Objects as Points" detection strategy, the recognition effects and accuracies of all three networks are relatively similar. Among them, Bottleneck-8 demonstrates superior performance in detection accuracy and speed, with a model size and parameter count more conducive to deployment in robot vision systems.
In actual orchard operations, the movement of the platform will cause changes in the image acquisition environment. To test the recognition performance of the vision model deployed on the picking robot under different conditions, a D435 depth camera stand (made of aluminum) was fixed on a mobile platform (lithium battery-powered tracked vehicle). The height of the depth camera was adjustable, ranging from 1200 mm to 1800 mm, with a shooting distance to the apple tree between 500 mm and 1300 mm, as shown in Figure 14. The D435 depth camera was connected to a laptop (Lenovo Y7000, Intel Core i7, 16GB RAM, NVIDIA GTX 1660Ti) via USB 3.0 and operated in a Linux Ubuntu 18.04 environment. The tests were conducted on a sunny day from 8 am to 6 pm. The specific experimental procedure was as follows:

Figure 14.
Schematic of the Testing Hardware for the Vision System in Orchard Operations of the Picking Robot.
(1) Adjust the aluminum frame to make it level with the ground and shoot the apple tree, recording recognition accuracy, false detections, and missed apples. Repeat the shooting 10 times.
(2) Adjust the aluminum frame to tilt approximately 20° with the ground and shoot the apple tree 10 times after a 2-h interval, making the same recognition records.
(3) Adjust the aluminum frame to shoot the apple tree 10 times each from overhead, left view, and right view, with a 2-h interval between each shooting method, making the same recognition records.
Figure 15 illustrates some detection maps of apple trees captured by the camera at different locations within its field of view, with the camera position shown as a three-dimensional schematic. Table 3 presents the detection results of the camera under various positions, with average accuracy, false detection rate, leakage rate, and F1 score selected as evaluation indexes for the detection accuracy of the network model.
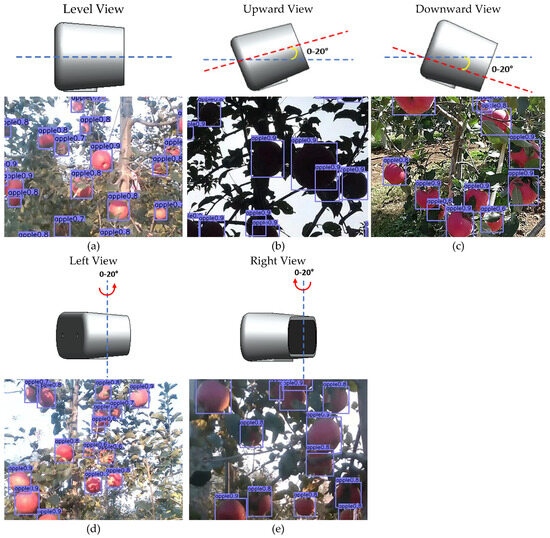
Figure 15.
Recognition results obtained through different photography modes of the camera: (a) Illustration of horizontal shooting mode with D435 depth camera and model recognition results; (b) Illustration of upward shooting mode and model recognition results; (c) Illustration of downward shooting mode and model recognition results. (d) Illustration of leftward shooting mode and model recognition results; (e) Illustration of rightward shooting mode and model recognition results.
Table 3.
Detection results obtained through different camera shooting methods.
Figure 15 demonstrates that the model maintains a consistently high level of recognition accuracy across various camera angles. Recognition accuracy peaks when shooting in flat view and top view, as these angles are less susceptible to sunlight illumination. However, the top view, with its narrower field of view and fewer apple targets, also yields high accuracy. The left-view and right-view shooting modes exhibit comparable recognition accuracies. Elevation shooting mode, tested under backlight conditions, often results in underexposed images with target and background colors closely resembling each other. The experiment found that the model demonstrates good robustness in detecting apples under these lighting conditions. Due to the strong feature extraction capabilities of the deep convolutional neural network, it can autonomously extract and learn different features from both the original and vertically decomposed apple images, thereby overcoming issues related to underexposure of apple targets caused by lighting changes. In smooth light conditions, flat view, left view, and right view photography modes may also produce exposure phenomena, enhancing the brightness of the apple surface and potentially whitening some color features. Moreover, all five shooting methods may encounter situations where fruits are obscured by branches and leaves or where fruits overlap each other. The model performs well in detecting apples when only a portion of the apple surface is covered by branches and leaves in complex scenes. Furthermore, when multiple fruits overlap and cover each other, the model’s detection efficacy improves when the exposed area of the fruits after being covered exceeds half the total area of the fruits.
4.2. Comparison of Recognition Results of Different Algorithms
For fair comparison, the improved CenterNet is compared with the YOLOv5 [55] detection algorithm and EfficientDet-D0 [56] detection algorithm using the same test set (320 images of apples, with 160 images each for smooth light and backlight). The testing hardware is described in Section 2.4, with the average precision (AP) value and frames per second (FPS) serving as evaluation metrics. The network identification results are shown in Figure 16. The data is summarized in Table 4.


Figure 16.
Recognition results of the three algorithms: (a) Proposed algorithm; (b) YOLOv5; (c) Detection Result.
Table 4.
Performance comparison of three object detection networks.
As indicated by the data in Table 4, the CenterNet network based on Bottleneck-8 achieves the highest AP and FPS on the test set. It demonstrates a 6.50% improvement in AP compared to the YOLOv5 network and a 5.37% improvement compared to EfficientDet-D0.
From Figure 16a, it can be seen that the improved CenterNet achieves good recognition results when the fruit is occluded by tree trunks and when the fruits overlap with each other. Figure 16b shows that YOLOv5, due to the need to set Anchor box parameters, exhibits false detections when apples are heavily occluded by branches and leaves. Figure 16c indicates that EfficientDet-D0 has missed detection phenomena when apples are partially obscured by branches at a distance. This is because the network has a noticeable deficiency in detecting small obstructing targets, which leads to an overall decline in detection accuracy. The detection speed is particularly low compared to Bottleneck-8, which is due to its inadequate utilization of system computational resources, resulting in lower detection speeds.
4.3. Localization Results and Analysis of Localization Methods
Orchard localization was validated to determine the accuracy of the model’s recognition and the depth camera’s error-free internal reference matrix. The depth camera is affixed to the picking robot’s mobile platform using a connecting frame. The camera is then activated, and the detection model is run. The camera connects to a laptop through USB3.0 and operates within the Linux Ubuntu18.04 environment, as depicted in Figure 17. The test is carried out at the apple whole mechanization research base, following this specific process:

Figure 17.
Experiment table construction and positioning results example.
(1) The depth camera is turned on to capture images of the apple targets;
(2) The model positioning program is initiated to observe the output 3D coordinates of the apple target’s center point (where z corresponds to the depth map);
(3) The SW-M40 laser range finder measures the distance from the apple’s center point three times consecutively, and the average value is recorded;
(4) The position of the connection frame is adjusted to fix the camera’s position, and the above process is repeated 15 times, with the data recorded.
The true values statistics are obtained using LabelImg software for the pixel coordinates of the apple’s center point in the labeled image box, while the true depth value z is acquired from Step 3. A comparison is made with the predicted coordinates derived from the test, and the results are tabulated in Table 5. To assess the deviation of the predicted center coordinates from the true value, the root mean square error (RMSE) is utilized as the evaluation index.
Table 5.
Results of Apple 3D coordinate positioning.
As indicated by the data in Table 5, the maximum errors in the true three-dimensional coordinates of the apple, compared to the predicted values identified and located by the model, are 2.616 mm, 2.843 mm, and 1.303 mm along the X-, Y-, and Z-axes, respectively. The average errors are 1.047 mm, 1.303 mm, and 7.2 mm, respectively, with the RMSE of the visual system recognition and location being 4.405 mm. The relatively large error in the depth value can be attributed to human measurement inaccuracies, along with a 2 mm error inherent in the laser rangefinder and a 2% measurement error within 2 m for the D435 depth camera. The recognition model proposed in this study effectively handles apple target recognition and location in complex natural orchard environments, providing technical support for subsequent “Eye-to-hand” and “Eye-in-hand” visual control schemes for picking robots.
4.4. Analysis of the Impact of Weather Conditions on Recognition and Localization
To analyze the impact of changing weather conditions on the model’s recognition and localization performance, orchard test experiments were conducted. A total of 15 sets of picking tests were carried out, with 9 sets on sunny days, 3 sets on cloudy days, and 3 sets on overcast days. These tests were designed to verify the adaptability of the picking robot’s vision system to complex environments under different weather conditions.
The results of CenterNet Apple Detection under sunny and overcast conditions are shown in Figure 18. The number of visible fruits within the camera’s vision range and the number of recognized and localized coordinates were recorded. The recognition results of the 15 test sets are summarized in Table 6. The overall recognition and localization accuracy of the picking robot’s vision system was 96.12%. On sunny days, the recognition and localization accuracy was 96.39%, with the proportion of false and missed detections being 5.67%. On cloudy and overcast days, the recognition and localization accuracy increased to 97.46%, with the proportion of false and missed detections decreasing to 3.39%, showing an improvement of 1.07% in accuracy and a reduction of 2.28% in false and missed detections compared to sunny days. The deep convolutional neural network in the model has strong feature extraction capabilities, enabling it to autonomously extract and learn various features from different apple images. This ability helps to overcome issues related to underexposure or overexposure of apple targets caused by changes in lighting conditions (weather).
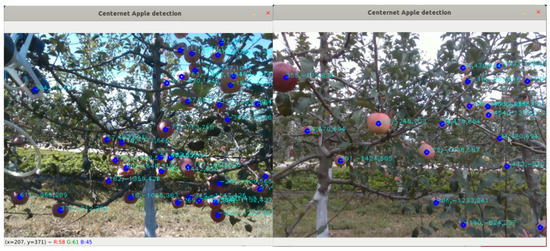
Figure 18.
Examples of apple recognition in sunny and cloudy conditions.
Table 6.
Statistical results of apple-picking visual test.
5. Further Research Perspectives
In this study, we propose a novel method to help robots identify and locate apples in orchards. This method primarily utilizes a prior knowledge-based image processing techniques and a lightweight neural network design. Through this approach, robots can accurately recognize apples under various complex lighting conditions, such as front light, backlight, and cloudy weather, and can quickly process images to improve operational efficiency.
The excellent performance of the proposed method in this study is mainly attributed to two factors: the use of gray-centered vertical decomposition maps to mitigate the impact of illumination and shadows, and the inclusion of a dataset containing various complex scenes. In the future, the most direct research direction that integrates these two factors is to explore advanced image processing algorithms such as Generative Adversarial Networks (GANs). GANs can generate more diverse training data, which will further enhance the robustness and accuracy of the model in complex scenes. GANs, by generating synthetic images similar to real data, can effectively expand the diversity and coverage of the training dataset, thereby improving the model’s robustness and accuracy in different scenarios. Additionally, GANs can simulate different lighting and occlusion conditions, further enhancing the model’s adaptability to complex environments. Therefore, using GANs to generate more diverse training data will help to further improve the model’s performance in complex scenes.
6. Conclusions
This study addresses the challenges of complex natural scenes in modern apple orchards and proposes a real-time recognition and localization method based on an improved CenterNet convolutional neural network. This method offers the following features:
1. Using the CenterNet network as the detection framework, the method incorporates a grayscale center color space vertical decomposition map prior. It employs grouped convolutions and depthwise separable convolutions to design a lightweight backbone network, Light-Weight Net. Adhering to the "point is the target" approach, it directly predicts the apple’s center point and dimensions to facilitate identification.
2. A deep learning environment was established for model training. On the test set, which included scenarios of direct light, backlight, occlusion, and overlap, the model achieved an AP value of 96.80% and an FPS of 18.91, corresponding to an average recognition time per image of 0.053 s. The model size is 17.56 MB. Compared to the YOLOv5 and EfficientDet-D0 models on the same test set, the experimental results demonstrate an AP increase of 6.50% and 5.37%, respectively, and faster average recognition times per image by 0.054 s and 0.013 s, respectively.
3. The study also investigates an apple localization method using the Intel RealSense D435 depth camera, selected as the visual system for the picking robot. By leveraging the transformation relationship between the image physical coordinate system and the camera coordinate system, combined with the distance information from the depth map, the coordinates of the picking point in the camera coordinate system were obtained. Orchard localization experiments revealed a RMSE of 4.405 mm, indicating minimal localization errors. This satisfies the high-precision localization requirements for the picking robot’s visual system in the complex natural scenes of apple orchards.
In summary, the proposed method demonstrates effective apple target recognition and localization, providing robust technical support for the development of advanced visual control systems for picking robots.
Author Contributions
Conceptualization: P.F. and Y.L.; methodology: P.F.; software: J.S. and P.F.; formal analysis: C.Z.; resources: J.S.; data curation: C.Z.; writing—original draft preparation: P.F. and Y.L.; writing—review and editing: J.S. and D.C.; supervision: G.L.; funding acquisition: P.F. and D.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research Program of the Shaanxi Provincial Department of Education (No. 23JP004) and the R&D Program of the Shaanxi Province of China (No. 2024GX-YBXM-104).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to them also being necessary for future essay writing.
Acknowledgments
We express our heartfelt gratitude to the anonymous reviewers for their invaluable feedback and constructive suggestions, which have significantly enhanced the quality of this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ma, L.; Zhao, L.; Wang, Z.; Zhang, J.; Chen, G. Detection and Counting of Small Target Apples under Complicated Environments by Using Improved YOLOv7-tiny. Agronomy 2023, 13, 1419. [Google Scholar] [CrossRef]
- Tong, S.; Yue, Y.; Li, W.; Wang, Y.; Kang, F.; Feng, C. Branch Identification and Junction Points Location for Apple Trees Based on Deep Learning. Remote Sens. 2022, 14, 4495. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J. Deep Learning-Based Apple Detection with Attention Module and Improved Loss Function in YOLO. Remote Sens. 2023, 15, 1516. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Sun, X.; Zheng, Y.; Wu, D.; Sui, Y. Detection of Orchard Apples Using Improved YOLOv5s-GBR Model. Agronomy 2024, 14, 682. [Google Scholar] [CrossRef]
- Lv, J.; Xu, H.; Xu, L.; Gu, Y.; Rong, H.; Zou, L. An image rendering-based identification method for apples with different growth forms. Comput. Electron. Agric. 2023, 211, 108040. [Google Scholar] [CrossRef]
- Li, T.; Xie, F.; Zhao, Z.; Zhao, H.; Guo, X.; Feng, Q. A multi-arm robot system for efficient apple harvesting: Perception, task plan and control. Comput. Electron. Agric. 2023, 211, 107979. [Google Scholar] [CrossRef]
- Jiang, H.; Sun, X.; Fang, W.; Fu, L.; Li, R.; Cheein, F.A.; Majeed, Y. Thin wire segmentation and reconstruction based on a novel image overlap-partitioning and stitching algorithm in apple fruiting wall architecture for robotic picking. Comput. Electron. Agric. 2023, 209, 107840. [Google Scholar] [CrossRef]
- Fan, P.; Lang, G.; Yan, B.; Lei, X.; Guo, P.; Liu, Z.; Yang, F. A Method of Segmenting Apples Based on Gray-Centered RGB Color Space. Remote Sens. 2021, 13, 1211. [Google Scholar] [CrossRef]
- Lv, J.; Ni, H.; Wang, Q.; Yang, B.; Xu, L. A segmentation method of red apple image. Sci. Hortic. 2019, 256, 108615. [Google Scholar] [CrossRef]
- Lakhdar, D.; Abdelkrim, M.; Abdelaziz, O.; Darna, A. Two-stage HOG/SVM for license plate detection and recognition. Indones. J. Electr. Eng. Comput. Sci. 2024, 34, 210–223. [Google Scholar] [CrossRef]
- Zhang, H.; Tang, C.; Sun, X.; Fu, L. A Refined Apple Binocular Positioning Method with Segmentation-Based Deep Learning for Robotic Picking. Agronomy 2023, 13, 1469. [Google Scholar] [CrossRef]
- Manickam, H.; Chithra, P. Segmentation using fuzzy cluster-based thresholding method for apple fruit sorting. IET Image Process. 2021, 14, 4178–4187. [Google Scholar] [CrossRef]
- Li, B.; Jing, X. A Recognition Scheme Based on K-means Feature Clustering for Obscured Apple Object. IOP Conf. Ser. Mater. Sci. Eng. 2020, 740, 012086. [Google Scholar] [CrossRef]
- Gill, H.; Khehra, B. Apple image segmentation using teacher learner based optimization based minimum cross entropy thresholding. Multimed. Tools Appl. 2022, 81, 11005–11026. [Google Scholar] [CrossRef]
- Zou, K.; Ge, L.; Zhou, H.; Zhang, C.; Li, W. An apple image segmentation method based on a color index obtained by a genetic algorithm. Multimed. Tools Appl. 2022, 81, 8139–8153. [Google Scholar] [CrossRef]
- Wang, Z.F.; Jia, W.-K.; Mou, S.H.; Hou, S.J.; Yin, X.; Ji, Z. KDC: A Green Apple Segmentation Method. Guang Pu Xue Yu Guang Pu Fen Xi/Spectrosc. Spectr. Anal. 2021, 41, 2980–2988. [Google Scholar]
- Fan, P.; Lang, G.; Guo, P.; Liu, Z.; Yang, F.; Yan, B.; Lei, X. Multi-Feature Patch-Based Segmentation Technique in the Gray-Centered RGB Color Space for Improved Apple Target Recognition. Agriculture 2021, 11, 273. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the lEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Richfeature hierarchies for accurate object detection and semanticsegmentation. In Proceedings of the lEEE Conference Oncomputer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef]
- Juntao, X.; Zhenhui, Z.; Jiaen, L.; Zhuo, Z.; Bolin, L.; Baoxia, S. Citrus Detection Method in Night Environment Based on Improved YOLO v3 Network. Trans. Chin. Soc. Agric. Mach. 2020, 51, 199–206. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Tian, L.; Zhang, H.; Bin, L.; Zhang, J.; Duan, N.; Yuan, A.; Huo, Y. VMF-SSD: A Novel V-Space based Multi-scale Feature Fusion SSD for Apple Leaf Disease Detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 20, 2016–2028. [Google Scholar] [CrossRef] [PubMed]
- Kang, H.; Chen, C. Fast Implementation of Real-time Fruit Detection in Apple Orchards using Deep Learning. Comput. Electron. Agric. 2019, 168, 105108. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Chen, M.; Chen, Z.; Luo, L.; Tang, Y.; Cheng, J.; Wei, H.; Wang, J. Dynamic visual servo control methods for continuous operation of a fruit harvesting robot working throughout an orchard. Comput. Electron. Agric. 2024, 219, 108774. [Google Scholar] [CrossRef]
- Wang, C.; Li, C.; Han, Q.; Wu, F.; Zou, X. A Performance Analysis of a Litchi Picking Robot System for Actively Removing Obstructions, Using an Artificial Intelligence Algorithm. Agronomy 2023, 13, 2795. [Google Scholar] [CrossRef]
- Wang, H.; Lin, Y.; Xu, X.; Chen, Z.; Wu, Z.; Tang, Y. A Study on Long-Close Distance Coordination Control Strategy for Litchi Picking. Agronomy 2022, 12, 1520. [Google Scholar] [CrossRef]
- Li, C.; Lin, J.; Li, Z.; Mai, C.; Jiang, R.; Li, J. An efficient detection method for litchi fruits in a natural environment based on improved YOLOv7-Litchi. Comput. Electron. Agric. 2024, 217, 108605. [Google Scholar] [CrossRef]
- Shu, Y.; Zheng, W.; Xiong, C.; Xie, Z. Research on the vision system of lychee picking robot based on stereo vision. J. Radiat. Res. Appl. Sci. 2024, 17, 100777. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A Real-Time Apple Targets Detection Method for Picking Robot Based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Lee, G.; Yonrith, P.; Yeo, D.; Hong, A. Enhancing detection performance for robotic harvesting systems through RandAugment. Eng. Appl. Artif. Intell. 2023, 123, 106445. [Google Scholar] [CrossRef]
- Fuzeng, Y.; Xiaoyan, L.; Zhijie, L.; Pan, F.; Bin, Y. Fast Recognition Method for Multiple Apple Targets in Dense Scenes Based on CenterNet. Trans. Chin. Soc. Agric. Mach. 2022, 53, 265–273. [Google Scholar]
- Riehle, D.; Reiser, D.; Griepentrog, H.W. Robust index-based semantic plant/background segmentation for RGB-images. Comput. Electron. Agric. 2020, 169, 105201. [Google Scholar] [CrossRef]
- Shi, T.; Gong, J.; Hu, J.; Zhi, X.; Zhang, W.; Zhang, Y.; Zhang, P.; Bao, G. Feature-Enhanced CenterNet for Small Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 5488. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Zhang, M.; Sun, N.; Zhang, Y.; Zhou, M.; Shen, Y.; Shi, H. A centernet-based direct detection method for mining conveyer belt damage. J. Ambient Intell. Humaniz. Comput. 2023, 14, 4477–4487. [Google Scholar] [CrossRef]
- Sulistyowati, T.; Purwanto, P.; Alzami, F.; Pramunendar, R. VGG16 Deep Learning Architecture Using Imbalance Data Methods For The Detection Of Apple Leaf Diseases. Monet. J. Keuang. Dan Perbank. 2023, 11, 41–53. [Google Scholar] [CrossRef]
- Tey, H.-C.; Chong, L.-Y.; Chin, C. Comparative Analysis of VGG-16 and ResNet-50 for Occluded Ear Recognition. JOIV Int. J. Inform. Vis. 2023, 7, 2247–2254. [Google Scholar] [CrossRef]
- Daquan, Z.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking Bottleneck Structure for Efficient Mobile Network Design. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 680–697. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. AAAI Conf. Artif. Intell. 2016, 31, 4278–4284. [Google Scholar] [CrossRef]
- Wang, B.; Pei, W.; Xue, B.; Zhang, M. Explaining Deep Convolutional Neural Networks for Image Classification by Evolving Local Interpretable Model-agnostic Explanations. arXiv 2022, arXiv:2211.15143. [Google Scholar]
- Wang, Q.; Du, J.; Wu, H.-X.; Pan, J.; Ma, F.; Lee, C.-H. A Four-Stage Data Augmentation Approach to ResNet-Conformer Based Acoustic Modeling for Sound Event Localization and Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 1251–1264. [Google Scholar] [CrossRef]
- Wei, Z. Fire Detection of yolov8 Model based on Integrated SE Attention Mechanism. Front. Comput. Intell. Syst. 2023, 4, 28–30. [Google Scholar] [CrossRef]
- Paul, A.; Bandyopadhyay, R.; Yoon, J.; Geem, Z.W.; Sarkar, R. SinLU: Sinu-Sigmoidal Linear Unit. Mathematics 2022, 10, 337. [Google Scholar] [CrossRef]
- Wang, M.; Ma, H.; Liu, S.; Yang, Z. A novel small-scale pedestrian detection method base on residual block group of CenterNet. Comput. Stand. Interfaces 2023, 84, 103702. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, Y.; Zhang, X.; Wang, X.; Lian, C.; Li, J.; Shan, P.; Fu, C.; Lyu, X.; Li, L.; et al. MobileSAM-Track: Lightweight One-Shot Tracking and Segmentation of Small Objects on Edge Devices. Remote Sens. 2023, 15, 5665. [Google Scholar] [CrossRef]
- Kim, C.; Lee, D. Comparison of Depth Estimation Based on Variable Block Size with Deep Learning Model in Stereo Vision. J. Korea Acad. Ind. Coop. Soc. 2023, 24, 360–365. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, H.; Lin, W.; Chandran, A.; Jing, X. Camera Contrast Learning for Unsupervised Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4096–4107. [Google Scholar] [CrossRef]
- Sun, K.; Zhen, Y.; Zhang, B.; Song, Z. An improved anchor-free object detection method applied in complex scenes based on SDA-DLA34. Multimed. Tools Appl. 2023, 83, 59227–59252. [Google Scholar] [CrossRef]
- Abeyrathna, R.M.R.D.; Nakaguchi, V.; Minn, A.; Ahamed, T. Recognition and Counting of Apples in a Dynamic State Using a 3D Camera and Deep Learning Algorithms for Robotic Harvesting Systems. Sensors 2023, 23, 3810. [Google Scholar] [CrossRef] [PubMed]
- Chu, P.; Li, Z.; Zhang, K.; Chen, D.; Lammers, K.; Lu, R. O2RNet: Occluder-occludee relational network for robust apple detection in clustered orchard environments. Smart Agric. Technol. 2023, 5, 100284. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).