
Multi-Feature Fusion Recognition and Localization Method for Unmanned Harvesting of Aquatic Vegetables

 ,
,
Abstract
1. Introduction
- We have developed a dataset of Brasenia schreberi that encompasses diverse lighting conditions and complex occlusions, consisting of 1500 images, which filled the blank of this aquatic vegetable sample;
- We have made lightweight enhancements to the recognition algorithm by designing a C3-GS cross-stage module and replacing the convolution module. Additionally, we have added a 160 × 160 detector head and introduced the Focal EIoU loss function as an evaluation metric. This not only effectively reduces computational costs but also maintains detection accuracy;
- We have designed a comprehensive vision-based harvesting scheme that integrates RGB and depth data to furnish precise three-dimensional coordinates for harvesting points, thus enabling autonomous harvesting.
2. Materials and Methods
2.1. Technical Analysis
2.1.1. Analysis of Platform Elements
2.1.2. Analysis of Environmental Elements
2.1.3. Summary of Technical Difficulties
- Under the current limited computational conditions, it is necessary to consider the detection accuracy and real-time performance of the target recognition algorithm so as to meet the two key indexes of precise identification and picking efficiency in the actual picking task;
- The pond picking environment of Brasenia schreberi is quite different from the land or indoor environment. The interference caused by light changes becomes more serious due to the reflection of water’s surface. The light adaptability of target recognition algorithm needs to be strengthened;
- The growth density of Brasenia schreberi is high, with frequent overlapping occlusion, resulting in the loss of some target information and occasional missing detection. It is essential to enhance the feature extraction capability of the target recognition algorithm to decrease the missing detection rate.
2.2. Visual Program
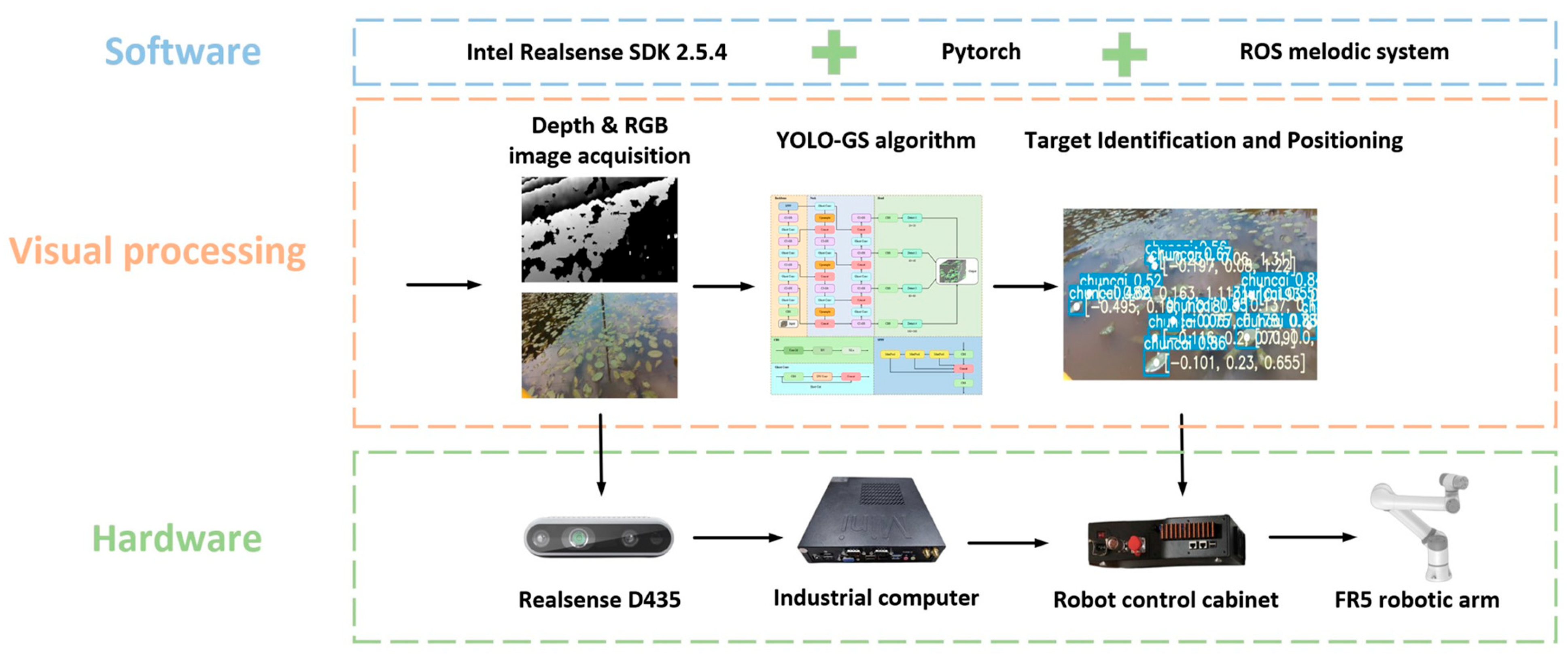
2.2.1. Hardware and Software Framework
- (1)
- To meet the extended operational demands of the unmanned picking platform, it is essential to control the overall power consumption. While maintaining the manipulator and boat’s regular operation, the visual algorithm must lower its computational expenses to run effectively on the industrial computer;
- (2)
- In the pond environment, there are interference factors such as water surface reflection and overlapping occlusion. These factors need to be optimized at the algorithm level in order to reduce the missed detection rate in special cases.
- Software part: The software used is based on Ubuntu 18.04 system (Canonical Group Ltd., London, UK), covering the depth camera software Intel Realsense SDK (Intel Corp, Santa Clara, CA, USA), ROS system (Open Robotics, Mountain View, CA, USA), and the YOLO-GS target recognition algorithm based on PyTorch deep learning framework (Facebook, Menlo Park, CA, USA);
- Hardware part: It is mainly composed of D435 depth camera (Intel Corp, Santa Clara, CA, USA), industrial computer (TexHoo, Guangzhou, China), FR5 robot controller, and robotic arm (FAIRINO, Suzhou, China);
- Visual processing stage: Initially, the D435 camera is utilized to capture the RGB and depth data of Brasenia schreberi. Subsequently, the data are sent to the YOLO-GS algorithm running on the industrial computer. The YOLO-GS algorithm enhances the feature extraction capability and recognition accuracy of multi-scale Brasenia schreberi targets in complex environments by utilizing the newly developed C3-GS module and detection head structure. This optimization leads to a significant reduction in computational load and parameters, enabling precise identification of Brasenia schreberi targets. Upon completion of target recognition, the RGB and depth feature information is fused to pinpoint the central picking location of Brasenia schreberi. Finally, the picking location data are converted into the 3D coordinates of the manipulator coordinate system through the coordinate transformation matrix. These coordinates are then transmitted to the robot controller within the ROS system, facilitating actual picking.
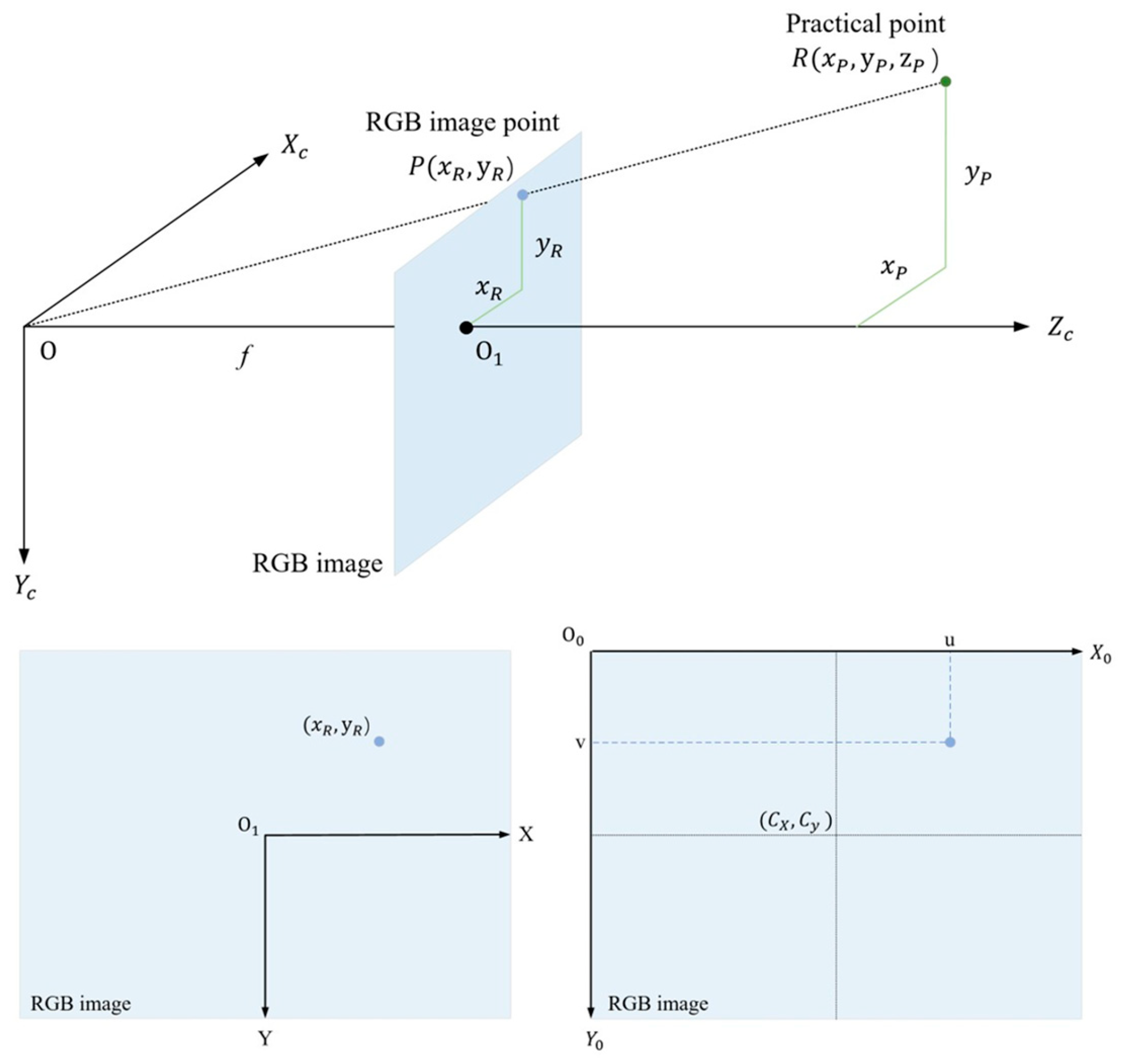
2.2.2. Depth Camera-Based Picking Point Localization
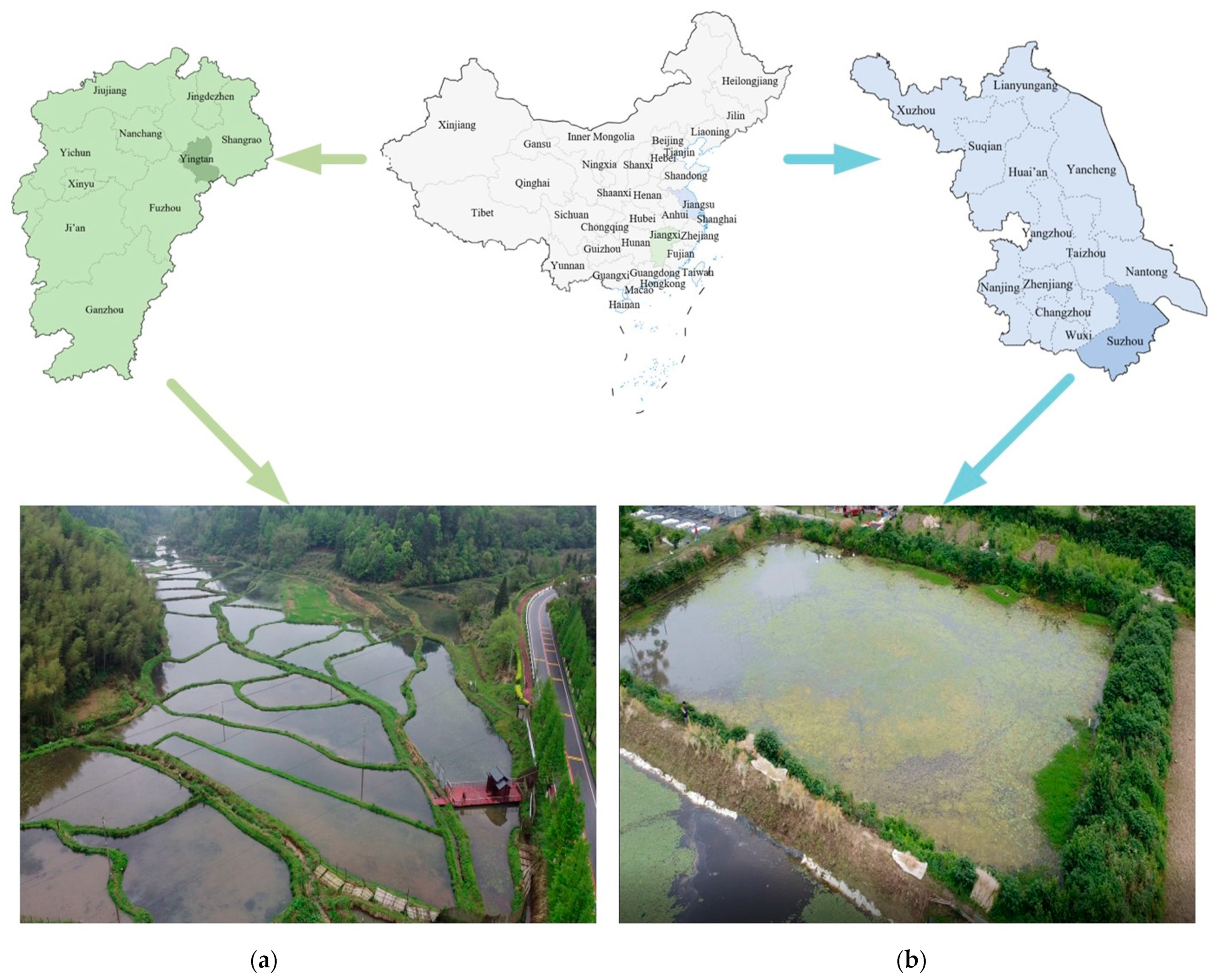
2.3. Data Set Construction
2.3.1. Data Collection and Labelling
2.3.2. Data Enhancement
2.4. Modelling Improvements
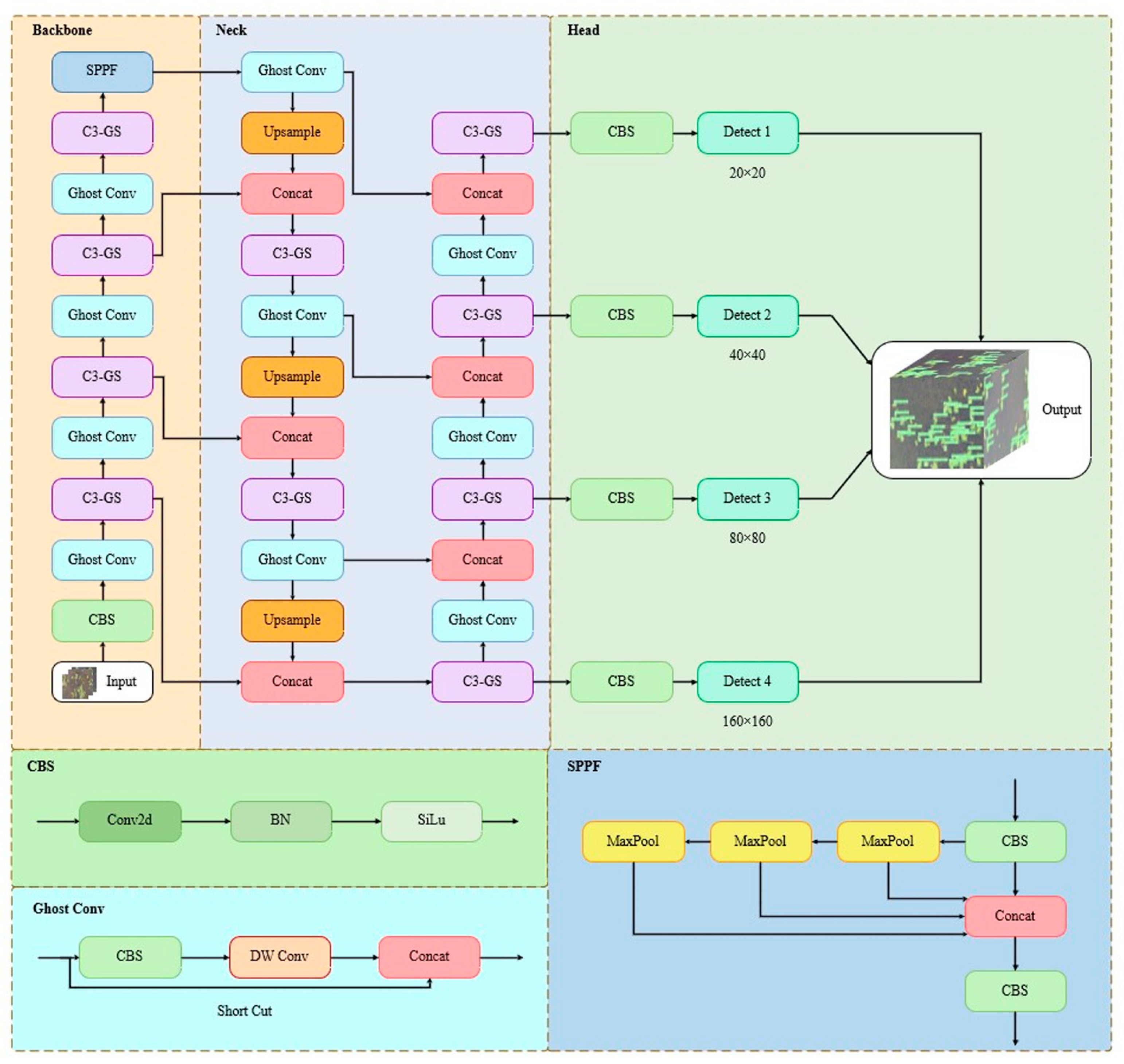
2.4.1. Network Framework for the Improved Algorithm YOLO-GS
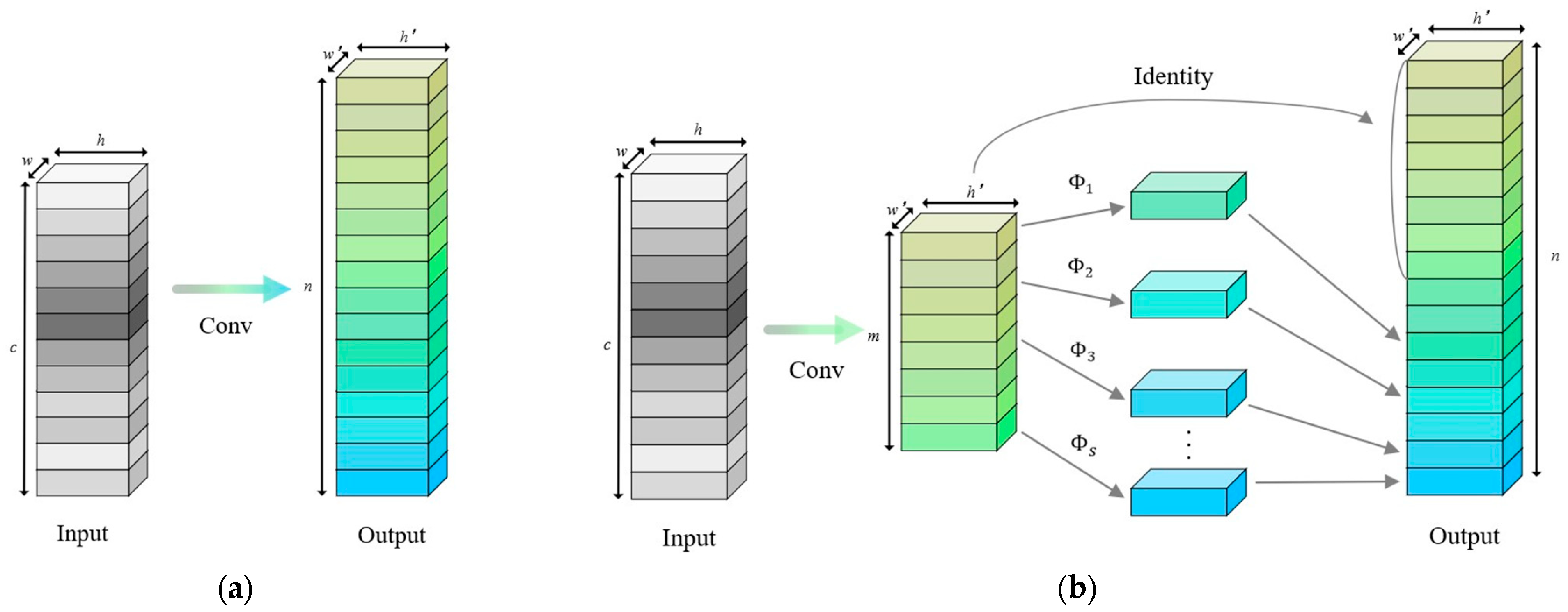
2.4.2. Convolution Module Improvements
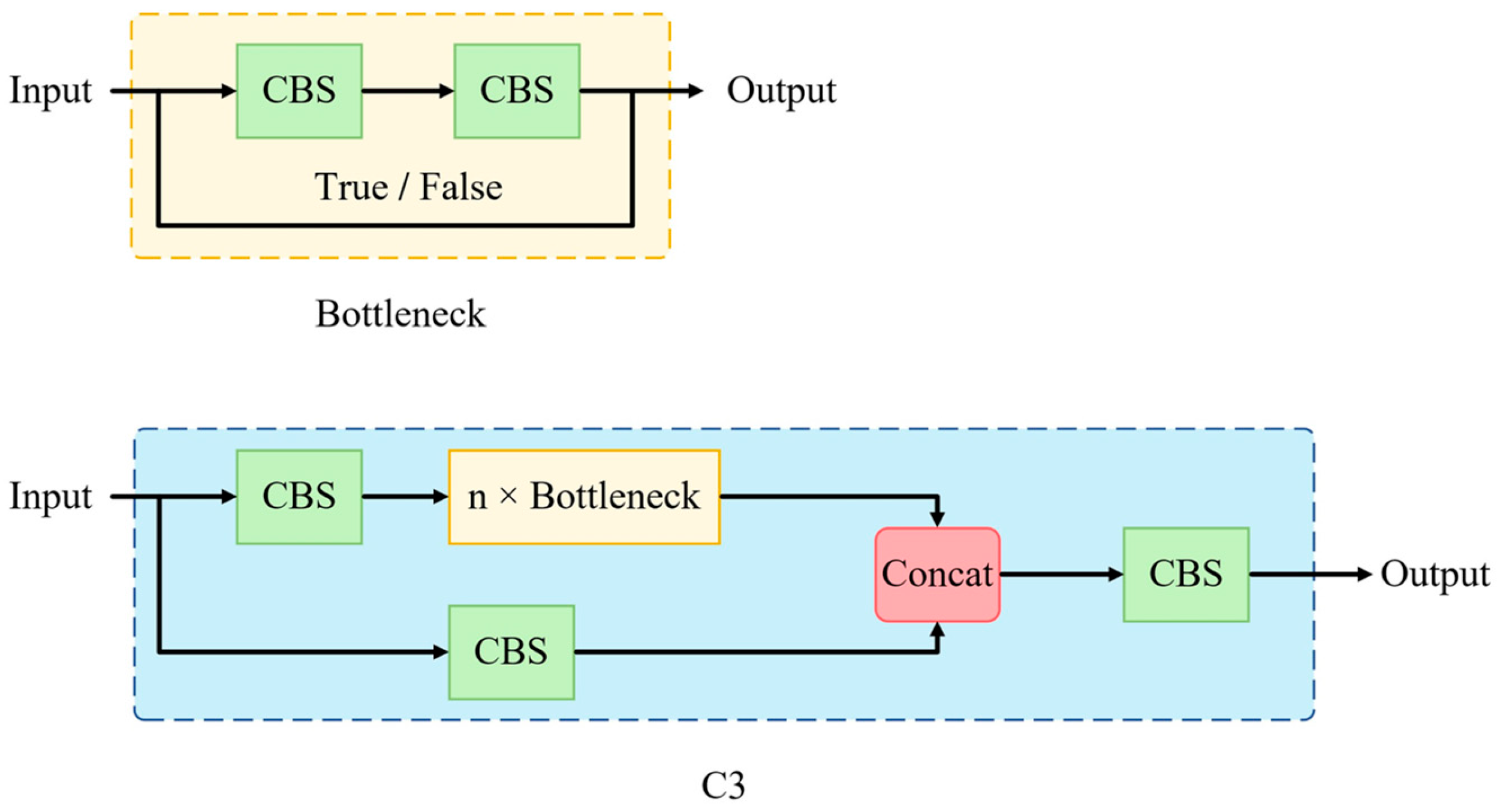
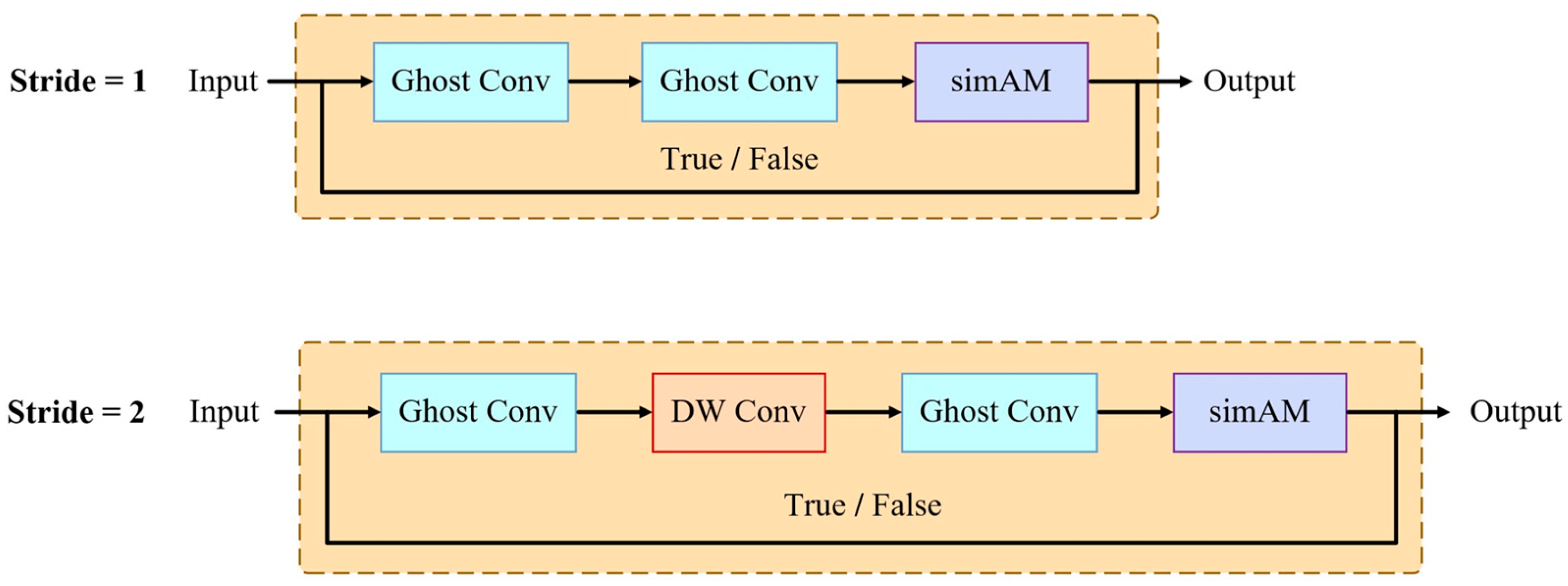
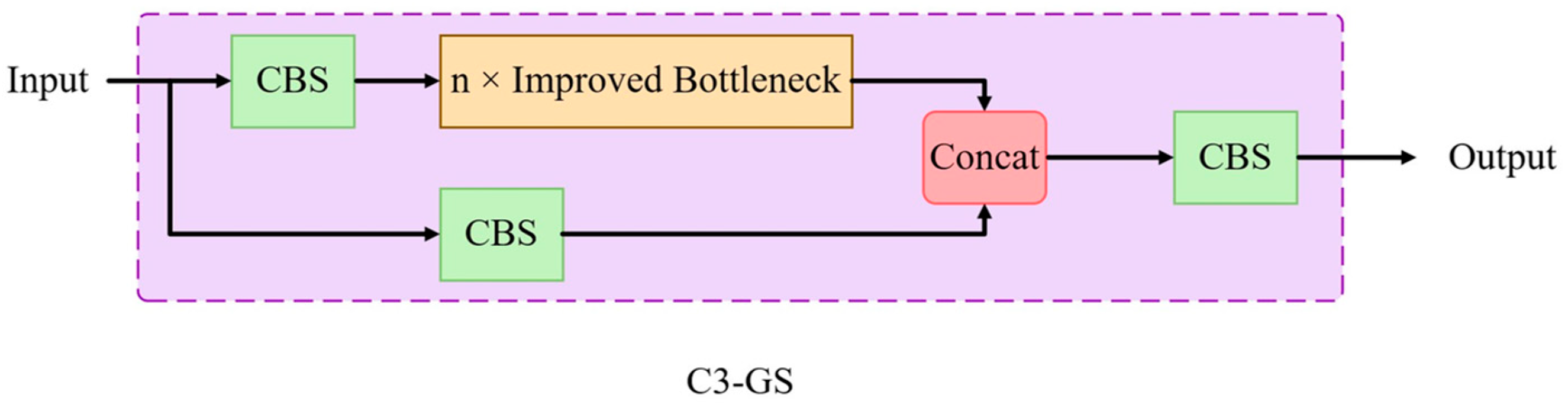
2.4.3. C3-GS: A Lightweight Cross-Stage Module
2.4.4. Detection Head Improvements
2.4.5. Loss Function
2.5. Model Training
2.5.1. Training Environment and Model Configuration
2.5.2. Evaluation Indicators
3. Results and Discussion
3.1. Visualization of Feature Maps
3.2. Comparison of YOLOv5s and YOLO-GS Detection Results
3.3. Ablation Experiments
3.4. Performance Comparison of Different Models
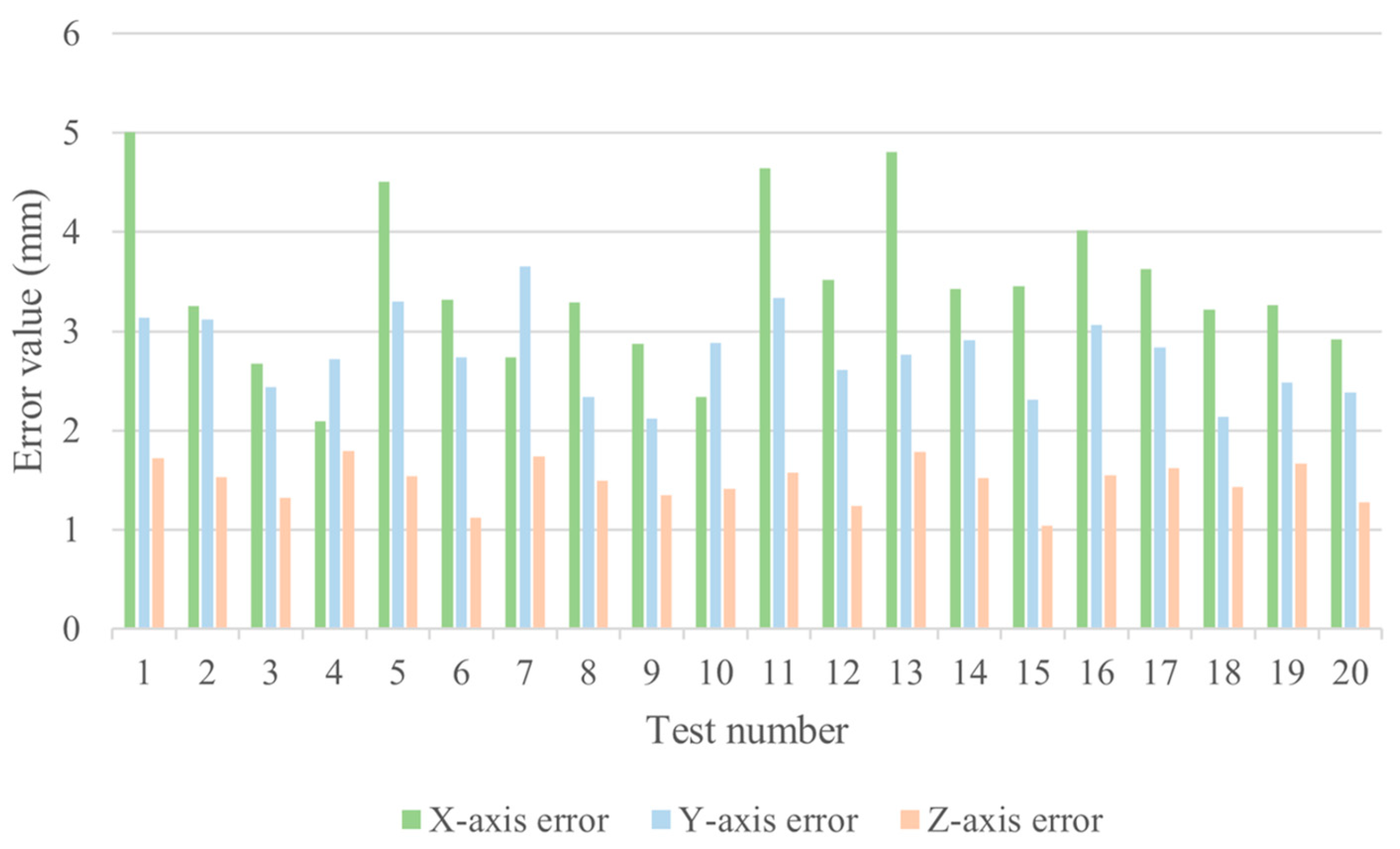
3.5. Picking Point Localisation Experiments Combined with Depth Camera
- Activate the RealSense D435 camera to continuously acquire RGB and depth image information;
- The RGB image information is passed to the YOLO-GS algorithm deployed on the industrial controller for recognition;
- The YOLO-GS algorithm starts interacting with the depth camera in real time, aligning the depth image with the RGB image;
- When a harvestable target (distance less than 1.0 m) enters the camera’s field of view, the identification frame is drawn in real time, and the coordinates of its center point in the RGB image are obtained;
- Map the coordinates of the RGB image to the depth image to obtain the corresponding depth coordinate , and generate the target-point coordinates in the camera coordinate system, as shown in Figure 17;
- Calculate the coordinate difference between the target-point coordinates and the practical picking point, take the absolute value, and finally obtain the error in each direction on the X-axis, Y-axis, and Z-axis.
4. Conclusions
- Further expand the data set. On the one hand, the Brasenia schreberi are classified according to the growth period, and the distinction between fresh Brasenia schreberi and aging Brasenia schreberi is made so as to achieve more refined picking operations. On the other hand, the roots, leaves, and buds of vegetables are used for different purposes. When picking, classification should be realized according to different picking purposes, and the data sets should be made for different parts of Brasenia schreberi;
- Expand the application. The identification and positioning method proposed in this paper can also be used in the field of crop monitoring and analysis. Combined with the improved counting program, it can monitor the growth status of crops in the designated area in real time and provide information support for fertilization and pesticide application in agricultural production activities;
- On the basis of the target recognition and positioning method we studied, we will analyze the harvesting cost of aquatic vegetables from the perspective of economy and efficiency, compared with manual picking and picking methods based on other algorithm frameworks, and explore the scheme of unmanned harvesting of aquatic vegetables with the best comprehensive cost.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Peter, K.V. Potential of Aquatic Vegetables in the Asian Diet. In Proceedings of the Seaveg, High Value Vegetables in Southeast Asia: Production, Supply & Demand, Chiang Mai, Thailand, 24–26 January 2012; pp. 210–215. [Google Scholar]
- Yang, C.; Zhang, X.; Seago, J.L., Jr.; Wang, Q. Anatomical and Histochemical Features of Brasenia schreberi (Cabombaceae) Shoots. Flora 2020, 263, 151524. [Google Scholar] [CrossRef]
- Liu, G.; Feng, S.; Yan, J.; Luan, D.; Sun, P.; Shao, P. Antidiabetic Potential of Polysaccharides from Brasenia schreberi Regulating Insulin Signaling Pathway and Gut Microbiota in Type 2 Diabetic Mice. Curr. Res. Food Sci. 2022, 5, 1465–1474. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Yi, C.; Zhang, C.; Pan, F.; Xie, C.; Zhou, W.; Zhou, C. Effects of Light Quality on Leaf Growth and Photosynthetic Fluorescence of Brasenia schreberi Seedlings. Heliyon 2021, 7, e06082. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Li, J.; Wang, N.; Zou, X.; Zou, S. The Complete Chloroplast Genome Sequence of Brasenia schreberi (Cabombaceae). Mitochondrial DNA Part B 2019, 4, 3842–3843. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Luan, D.; Ning, K.; Shao, P.; Sun, P. Ultrafiltration Isolation, Hypoglycemic Activity Analysis and Structural Characterization of Polysaccharides from Brasenia schreberi. Int. J. Biol. Macromol. 2019, 135, 141–151. [Google Scholar] [CrossRef] [PubMed]
- Otsu, N. Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Lowe, D.G.; Lowe, D.G. Distinctive Image Features from Scale-Invariant Key-Points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. A K-Means Clustering Algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An Efficient K-Means Clustering Algorithm: Analysis and Implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Leavers, V.F. Shape Detection in Computer Vision Using the Hough Transform; Springer: New York, NY, USA, 1992. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Benalcázar, M.E. Machine Learning for Computer Vision: A Review of Theory and Algorithms. RISTI—Rev. Iber. De Sist. E Tecnol. Inf. 2019, E19, 608–618. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Geoffrey Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Attri, I.; Awasthi, L.K.; Sharma, T.P.; Rathee, P. A Review of Deep Learning Techniques Used in Agriculture. Ecol. Inform. 2023, 77, 102217. [Google Scholar] [CrossRef]
- Li, W.; Zheng, T.; Yang, Z.; Li, M.; Sun, C.; Yang, X. Classification and Detection of Insects from Field Images Using Deep Learning for Smart Pest Management: A Systematic Review. Ecol. Inform. 2021, 66, 101460. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Jocher, G. YOLOv5 by Ultralytics; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Jin, X.; Jiao, H.; Zhang, C.; Li, M.; Zhao, B.; Liu, G.; Ji, J. Hydroponic Lettuce Defective Leaves Identification Based on Improved YOLOv5s. Front. Plant Sci. 2023, 14, 1242337. [Google Scholar] [CrossRef]
- Hajam, M.A.; Arif, T.; Khanday, A.M.U.D.; Neshat, M. An Effective Ensemble Convolutional Learning Model with Fine-Tuning for Medicinal Plant Leaf Identification. Information 2023, 14, 618. [Google Scholar] [CrossRef]
- Yadav, S.; Sengar, N.; Singh, A.; Singh, A.; Dutta, M.K. Identification of Disease Using Deep Learning and Evaluation of Bacteriosis in Peach Leaf. Ecol. Inform. 2021, 61, 101247. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Yang, M.; Wang, G.; Zhao, Y.; Hu, Y. Optimal Training Strategy for High-Performance Detection Model of Multi-Cultivar Tea Shoots Based on Deep Learning Methods. Sci. Hortic. 2024, 328, 112949. [Google Scholar] [CrossRef]
- Yang, J.; Chen, Y. Tender Leaf Identification for Early-Spring Green Tea Based on Semi-Supervised Learning and Image Processing. Agronomy 2022, 12, 1958. [Google Scholar] [CrossRef]
- Chaivivatrakul, S.; Moonrinta, J.; Chaiwiwatrakul, S. Convolutional Neural Networks for Herb Identification: Plain Background and Natural Environment. Int. J. Adv. Sci. Eng. Inf. Technol. 2022, 12, 1244–1252. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, J.; Wang, S.; Shen, J.; Yang, K.; Zhou, X. Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network. Agriculture 2022, 12, 1083. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Z.; Zhang, Y.; Zhou, J.; Wu, J.; Li, P. Real-Time Detection and Location of Potted Flowers Based on a ZED Camera and a YOLO V4-Tiny Deep Learning Algorithm. Horticulturae 2022, 8, 21. [Google Scholar] [CrossRef]
- Li, Y.; Wang, W.; Guo, X.; Wang, X.; Liu, Y.; Wang, D. Recognition and Positioning of Strawberries Based on Improved YOLOv7 and RGB-D Sensing. Agriculture 2024, 14, 624. [Google Scholar] [CrossRef]
- Hu, T.; Wang, W.; Gu, J.; Xia, Z.; Zhang, J.; Wang, B. Research on Apple Object Detection and Localization Method Based on Improved YOLOX and RGB-D Images. Agronomy 2023, 13, 1816. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, J.; Wang, J.; Cai, L.; Jin, Y.; Zhao, S.; Xie, B. Realtime Picking Point Decision Algorithm of Trellis Grape for High-Speed Robotic Cut-and-Catch Harvesting. Agronomy 2023, 13, 1618. [Google Scholar] [CrossRef]
- Zhang, G.; Tian, Y.; Yin, W.; Zheng, C. An Apple Detection and Localization Method for Automated Harvesting under Adverse Light Conditions. Agriculture 2024, 14, 485. [Google Scholar] [CrossRef]
- Luo, G. Some Issues of Depth Peception and Three Dimention Reconstruction from Binocular Stereo Vision. Ph.D. Thesis, Central South University, Changsha, China, 2012. [Google Scholar]
- Kaur, P.; Khehra, B.S.; Pharwaha, A.P.S. Color Image Enhancement Based on Gamma Encoding and Histogram Equalization. Mater. Today Proc. 2021, 46, 4025–4030. [Google Scholar] [CrossRef]
- Li, S.; Bi, X.; Zhao, Y.; Bi, H. Extended Neighborhood-Based Road and Median Filter for Impulse Noise Removal from Depth Map. Image Vis. Comput. 2023, 135, 104709. [Google Scholar] [CrossRef]
- Dou, H.-X.; Lu, X.-S.; Wang, C.; Shen, H.-Z.; Zhuo, Y.-W.; Deng, L.-J. Patchmask: A Data Augmentation Strategy with Gaussian Noise in Hyperspectral Images. Remote Sens. 2022, 14, 6308. [Google Scholar] [CrossRef]
- Zhao, R.; Han, Y.; Zhao, J. End-to-End Retinex-Based Illumination Attention Low-Light Enhancement Network for Autonomous Driving at Night. Comput. Intell. Neurosci. 2022, 2022, 4942420. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
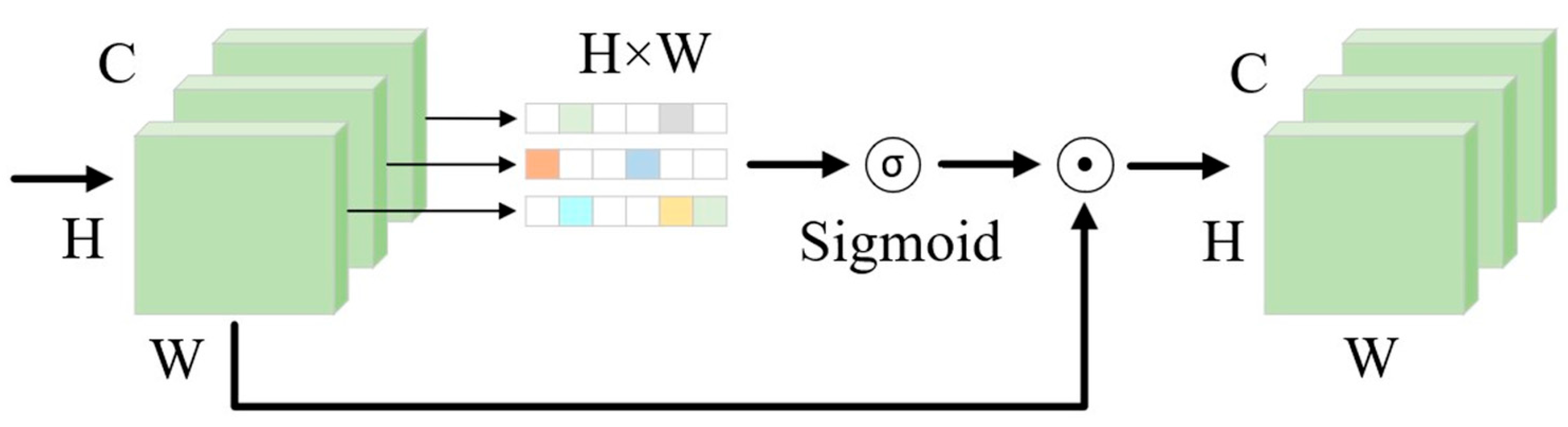
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- He, J.; Erfani, S.M.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. arXiv 2021, arXiv:2110.13675. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO V3-Tiny: Object Detection and Recognition Using One Stage Improved Model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-Time Object Detection Method Based on Improved YOLOv4-Tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Details |
|---|---|
| GPU | Nvidia GeForce RTX2080ti × 2 (Nvidia Corp, Santa Clara, CA, USA) |
| CPU | Intel Xeon Silver E5-4216 (Intel Corp, Santa Clara, CA, USA) |
| Operating system | Windows server 2012r (Microsoft Corp, Redmond, WA, USA) |
| Python | 3.7.13 |
| CUDA | 10.1 |
| Pytorch | 1.7.0 |
| Hyperparameters | Details |
|---|---|
| Epochs | 600 |
| Image Size | 640 × 640 |
| Batch size | 16 |
| Optimizer | SGD |
| Momentum | 0.937 |
| Initial learning rate | 0.01 |
| Scene | Model | True Quantity | Correctly Identified | Missed | ||
|---|---|---|---|---|---|---|
| Amount | Rate (%) | Amount | Rate (%) | |||
| General scenes | YOLOv5s | 32 | 27 | 84.4 | 5 | 15.6 |
| YOLO-GS | 31 | 96.9 | 1 | 3.1 | ||
| Densely distributed scenes | YOLOv5s | 66 | 58 | 87.9 | 8 | 12.1 |
| YOLO-GS | 64 | 97.0 | 2 | 3.0 | ||
| Brightly lit scenes | YOLOv5s | 67 | 46 | 68.7 | 21 | 31.3 |
| YOLO-GS | 63 | 94.0 | 4 | 6.0 | ||
| Model | Ghost Conv | C3-GS | 4-Head | Precision | Recall | F1-Score | mAP@0.5 | Weight Size (MB) | GFLOPS |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | × | × | × | 89.9 | 87.5 | 88.7 | 92.9 | 14.1 | 15.8 |
| Model 1 | √ | × | × | 88.5 | 90.2 | 89.3 | 94.7 | 11.3 | 13.4 |
| Model 2 | × | √ | × | 88.9 | 90.6 | 89.7 | 94.1 | 9.69 | 10.4 |
| Model 3 | × | × | √ | 88.9 | 90.4 | 89.6 | 94.9 | 14.3 | 18.5 |
| Model 4 | √ | √ | × | 89.0 | 90.0 | 89.5 | 94.9 | 7.39 | 8.0 |
| Model 5 | × | √ | √ | 89.1 | 91.1 | 90.1 | 95.7 | 10.2 | 12.2 |
| Model 6 | √ | × | √ | 88.9 | 90.8 | 89.8 | 95.5 | 12.0 | 15.9 |
| Model 7 | √ | √ | √ | 89.2 | 90.3 | 89.7 | 95.6 | 7.95 | 9.5 |
| Model | Precision | Recall | F1-Score | mAP@0.5 |
|---|---|---|---|---|
| Model 7-CIoU | 89.2 | 90.3 | 89.7 | 95.6 |
| Model 7-EIoU | 88.5 | 91.1 | 89.8 | 95.5 |
| Model 7-NWD | 90.6 | 87.5 | 89.0 | 95.3 |
| Model 7-alphaIoU | 87.0 | 92.2 | 89.5 | 95.4 |
| Model 7-SIoU | 88.9 | 90.2 | 89.5 | 95.4 |
| Model 7-Focal EIoU | 89.1 | 89.5 | 89.3 | 95.7 |
| Models | Precision/% | Recall/% | F1/% | mAP@0.5 | Parameters (M) | Weight Size (MB) | GFLOPS | Detect Speed (FPS) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 89.9 | 87.5 | 88.7 | 92.9 | 7.01 | 14.1 | 15.8 | 24.9 |
| YOLOv6s | 80.7 | 87.1 | 83.8 | 95.0 | 18.5 | 38.7 | 45.2 | 23.1 |
| YOLOv7 | 89.0 | 91.6 | 90.3 | 95.8 | 36.5 | 71.3 | 103.2 | 6.6 |
| YOLOv4 | 89.9 | 82.9 | 86.3 | 94.8 | 63.9 | 245 | 141.9 | 3.7 |
| YOLOv4-tiny | 87.5 | 82.5 | 84.9 | 91.7 | 5.9 | 23 | 16.2 | 20.4 |
| YOLOv3 | 89.4 | 84.8 | 87.0 | 92.5 | 61.5 | 117 | 154.5 | 5.8 |
| YOLOv3-tiny | 88.9 | 85.7 | 87.3 | 90.1 | 8.7 | 36.6 | 12.9 | 25.3 |
| SSD | 84.7 | 81.9 | 83.3 | 91.0 | 23.6 | 90.6 | 136.6 | 4.5 |
| Faster-RCNN | 63.5 | 90.9 | 74.8 | 83.8 | 136.7 | 521.0 | 200.8 | 0.8 |
| YOLO-GS | 89.1 | 89.5 | 89.3 | 95.7 | 3.75 | 7.95 | 9.5 | 28.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, X.; Shi, L.; Yang, W.; Ge, H.; Wei, X.; Ding, Y. Multi-Feature Fusion Recognition and Localization Method for Unmanned Harvesting of Aquatic Vegetables. Agriculture 2024, 14, 971. https://doi.org/10.3390/agriculture14070971
Guan X, Shi L, Yang W, Ge H, Wei X, Ding Y. Multi-Feature Fusion Recognition and Localization Method for Unmanned Harvesting of Aquatic Vegetables. Agriculture. 2024; 14(7):971. https://doi.org/10.3390/agriculture14070971
Chicago/Turabian StyleGuan, Xianping, Longyuan Shi, Weiguang Yang, Hongrui Ge, Xinhua Wei, and Yuhan Ding. 2024. "Multi-Feature Fusion Recognition and Localization Method for Unmanned Harvesting of Aquatic Vegetables" Agriculture 14, no. 7: 971. https://doi.org/10.3390/agriculture14070971
APA StyleGuan, X., Shi, L., Yang, W., Ge, H., Wei, X., & Ding, Y. (2024). Multi-Feature Fusion Recognition and Localization Method for Unmanned Harvesting of Aquatic Vegetables. Agriculture, 14(7), 971. https://doi.org/10.3390/agriculture14070971