
DGS-YOLOv8: A Method for Ginseng Appearance Quality Detection

 , and
, and
Abstract
:1. Introduction
2. Material Handling and Methods
2.1. Ginseng Image Dataset Acquisition
2.2. Sample Pre-Processing and Creation of Datasets
2.3. YOLOv8 Algorithm and Improvements
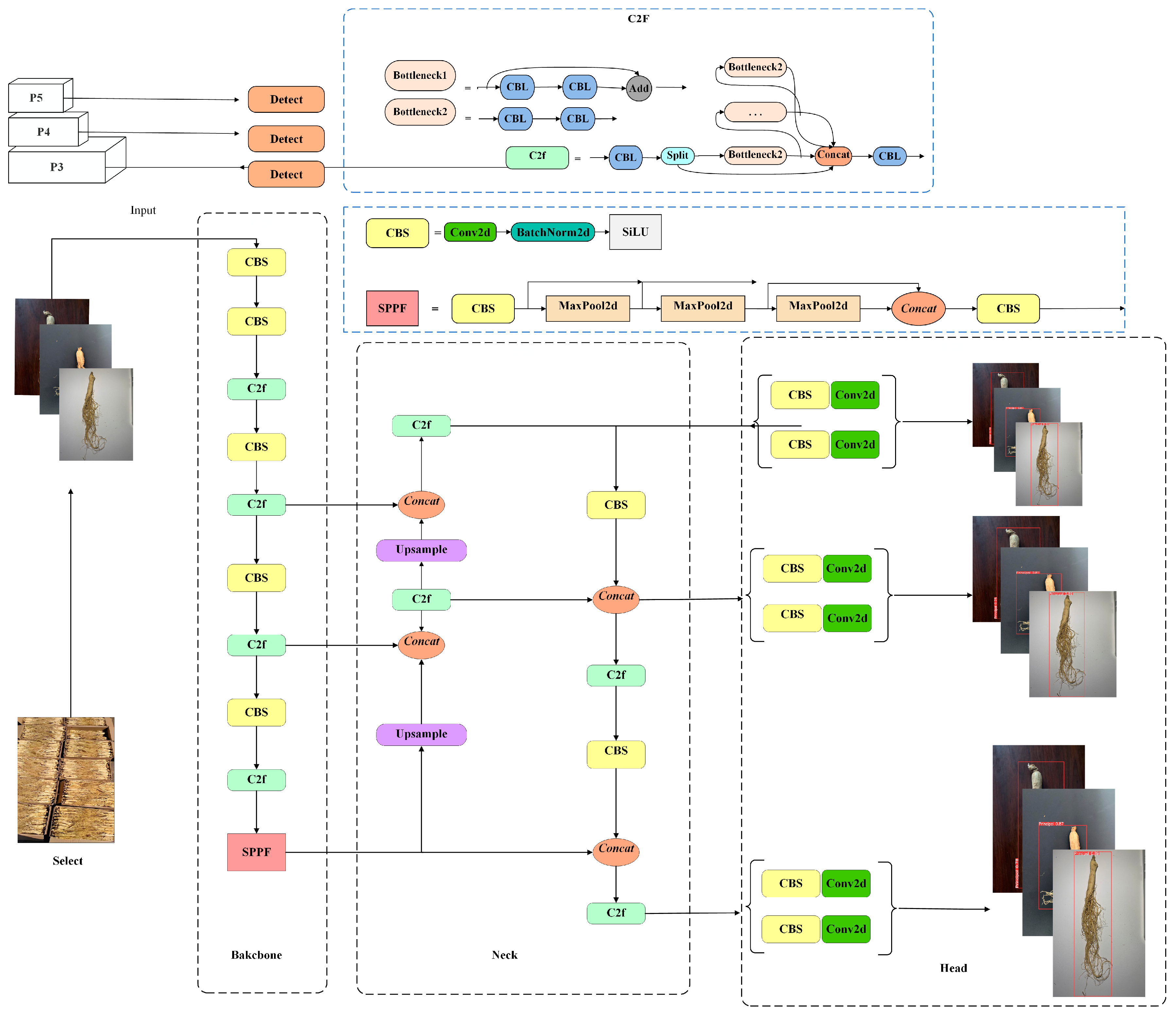
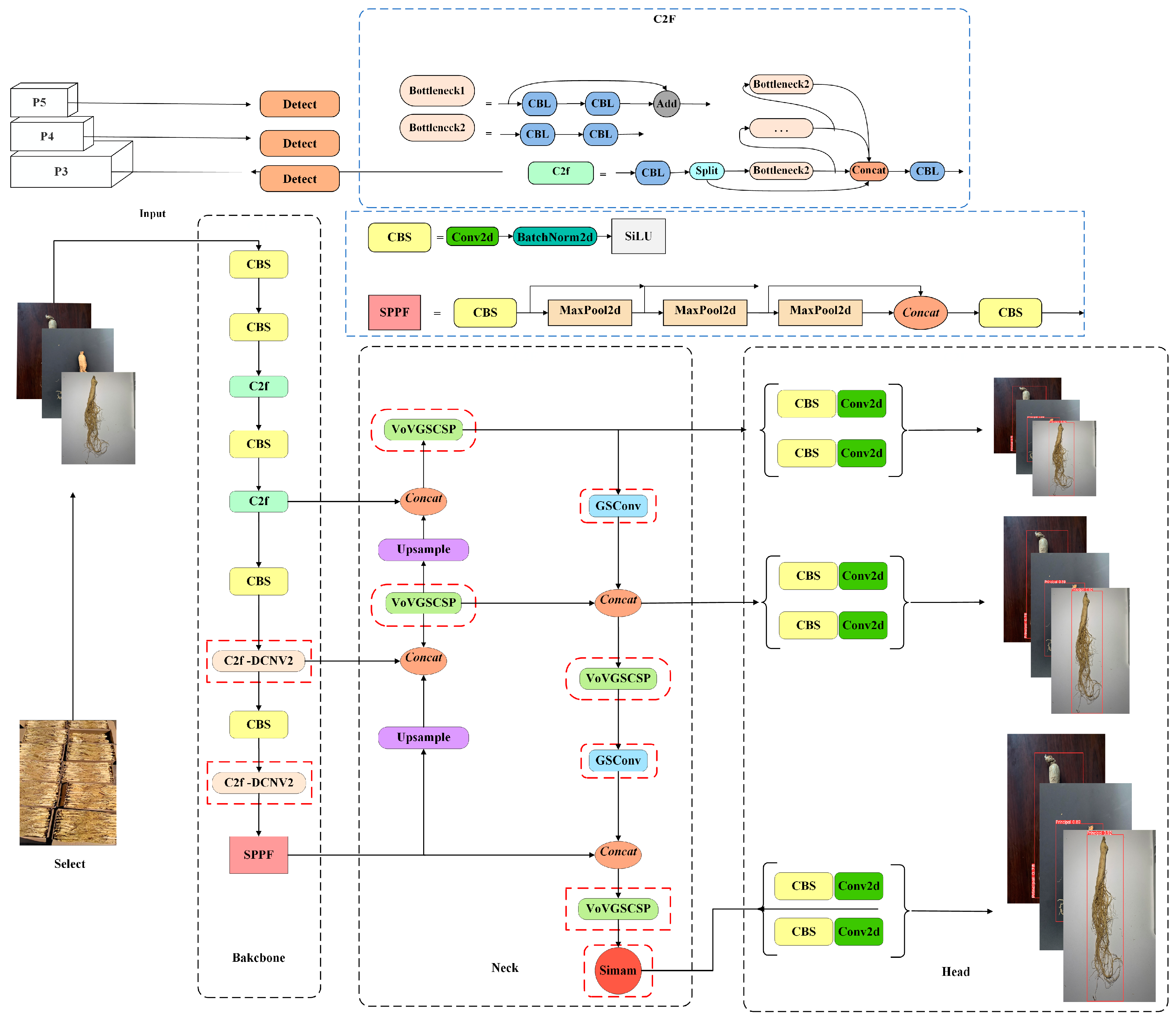
2.3.1. YOLOv8 and DGS-YOLOv8 Network Architecture
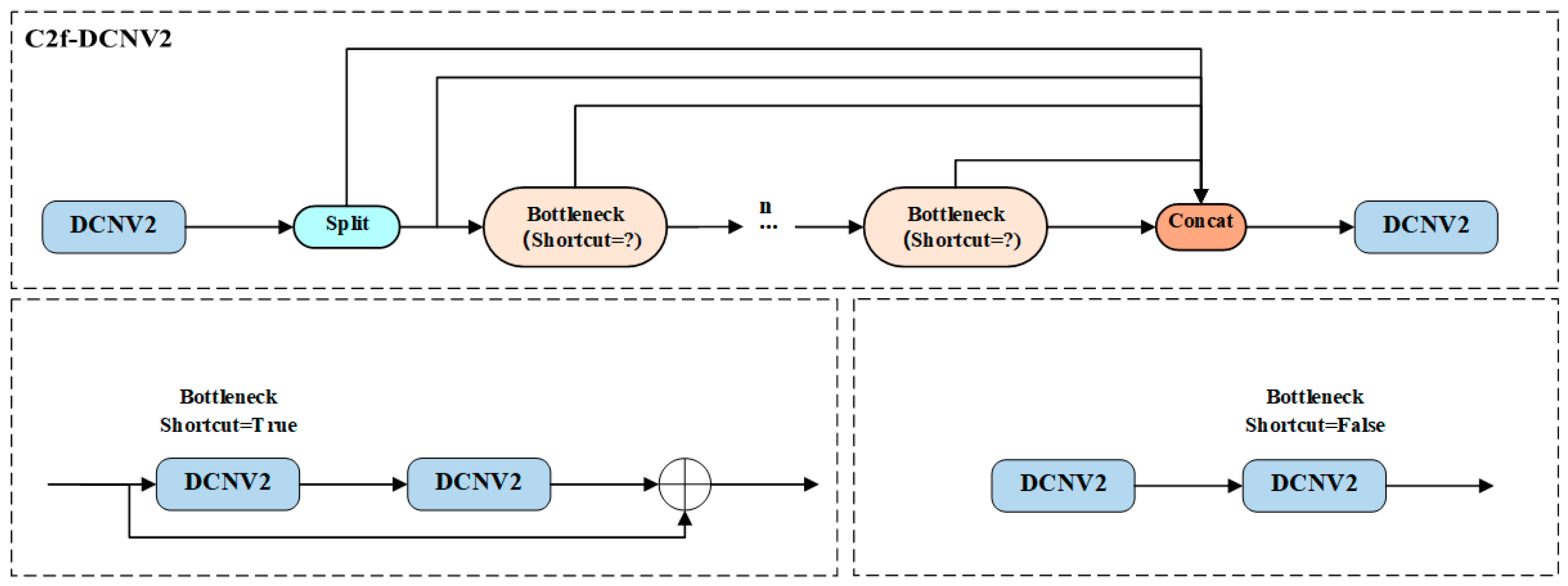
2.3.2. YOLOv8-C2f-DCNv2
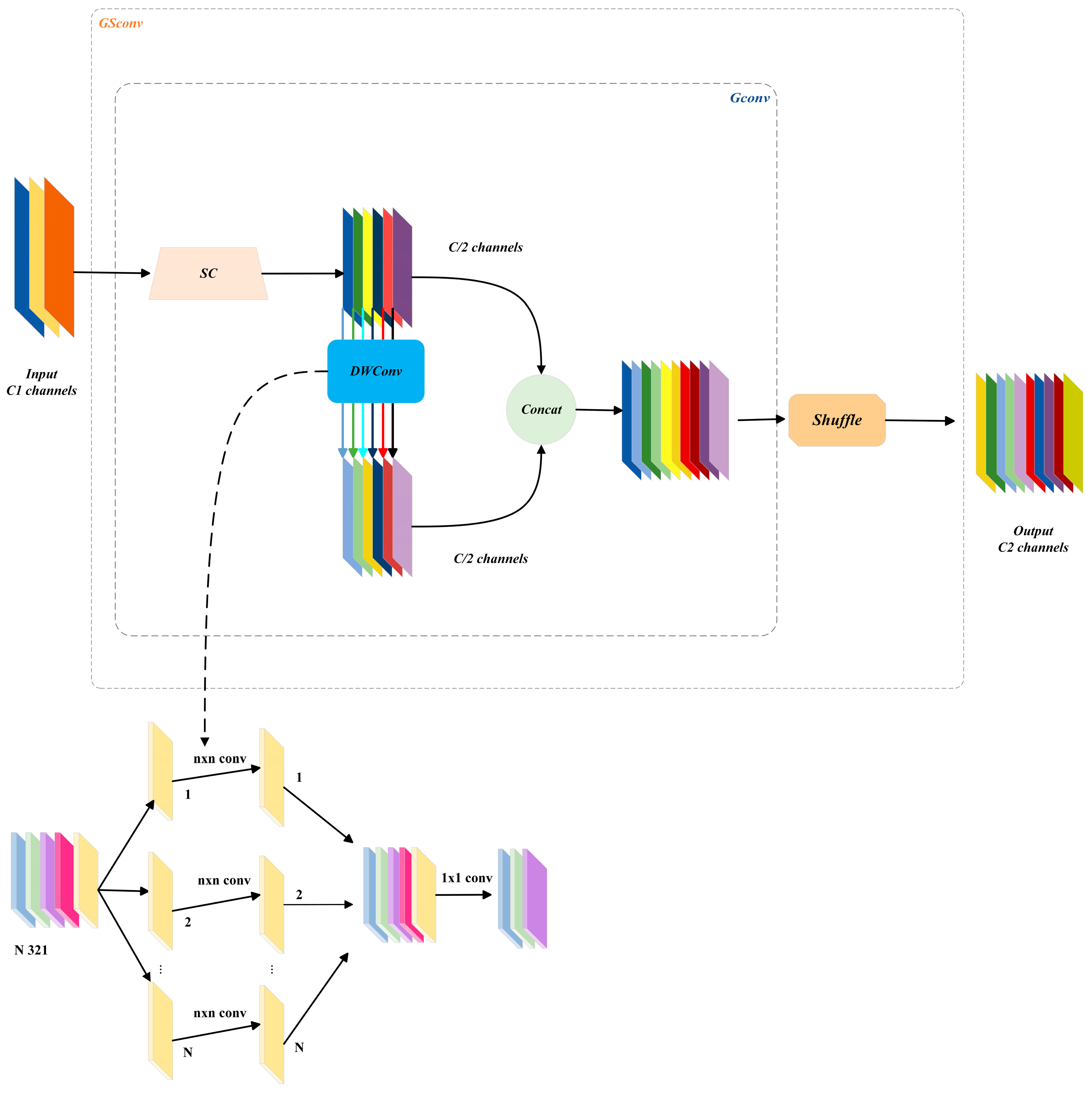
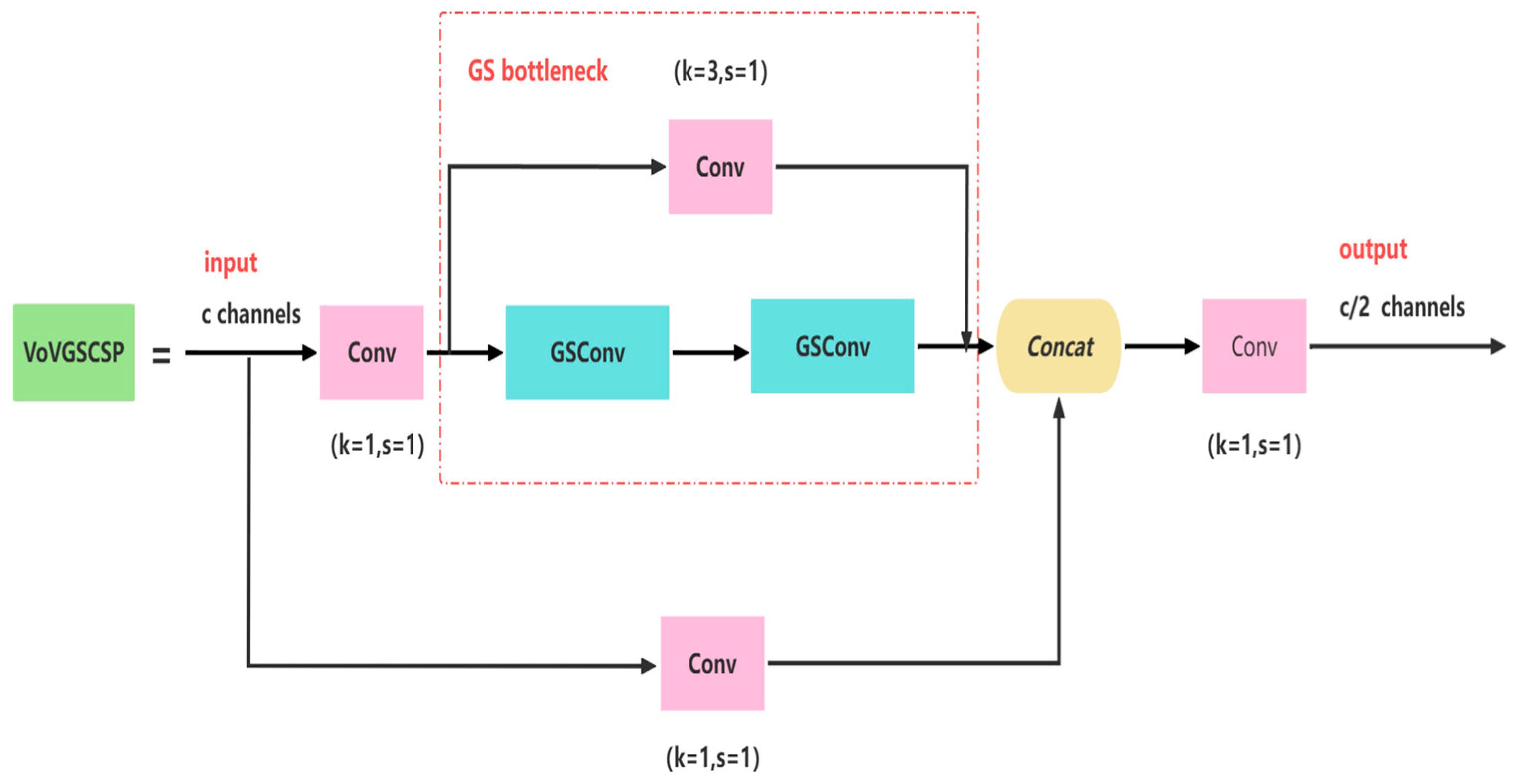
2.3.3. YOLOv8-GSconv
2.3.4. YOLOv8-SimAM (Simple Attention Module)
2.4. Experimental Environment
2.5. Evaluation Criteria
3. Experiments and Analysis of Results
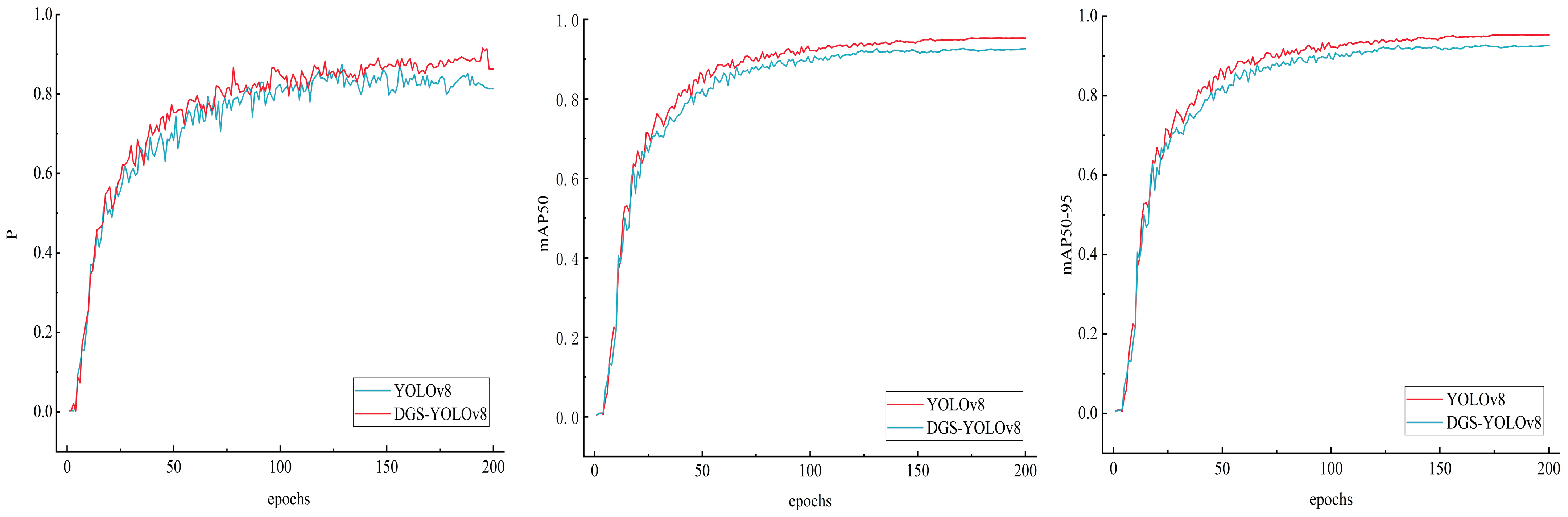
3.1. Experimental Comparison before and after Model Improvement
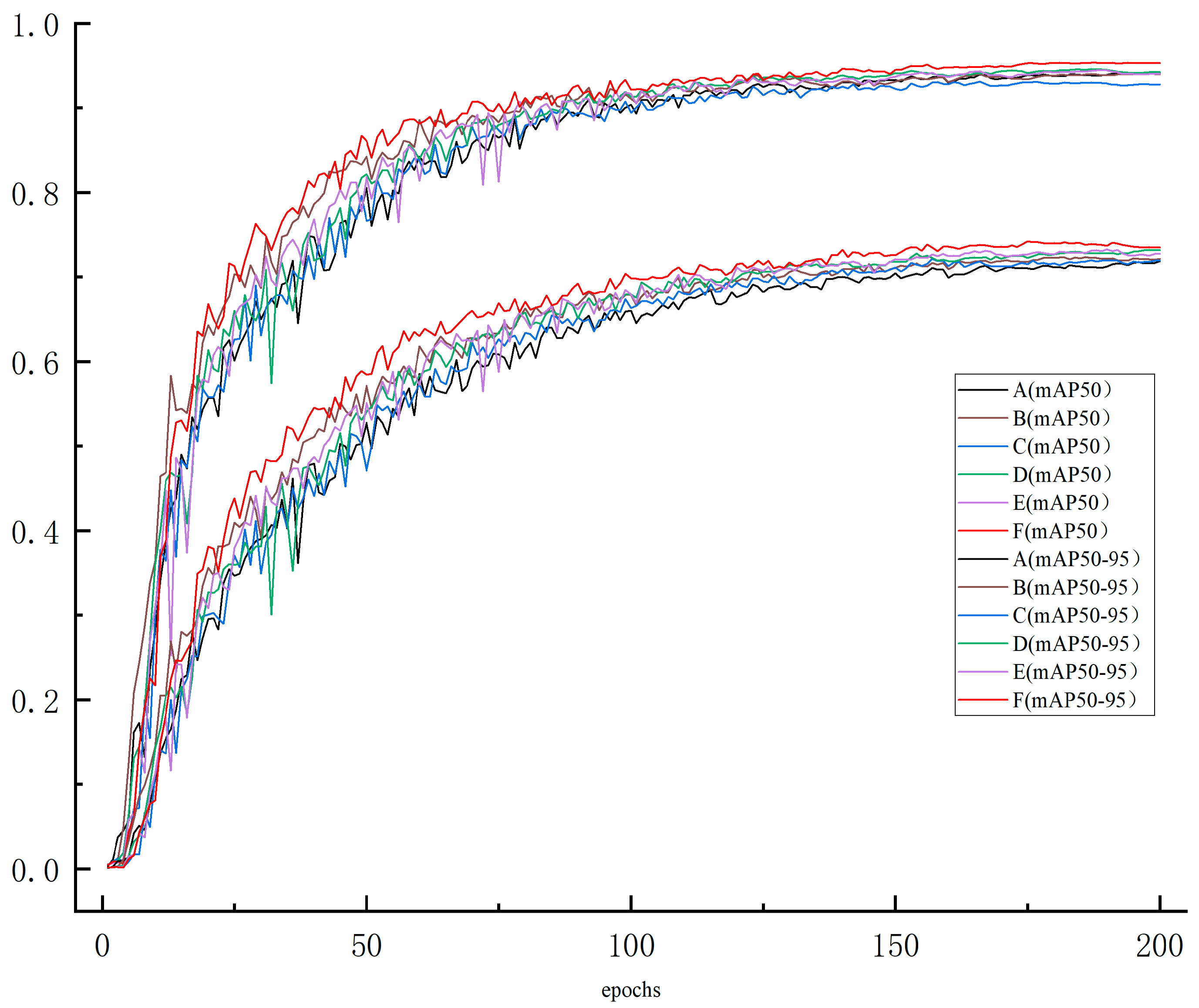
3.2. Ablation Experiment
3.3. Comparison of Results of Different Attention Mechanisms
3.4. Optimal Location of Attention
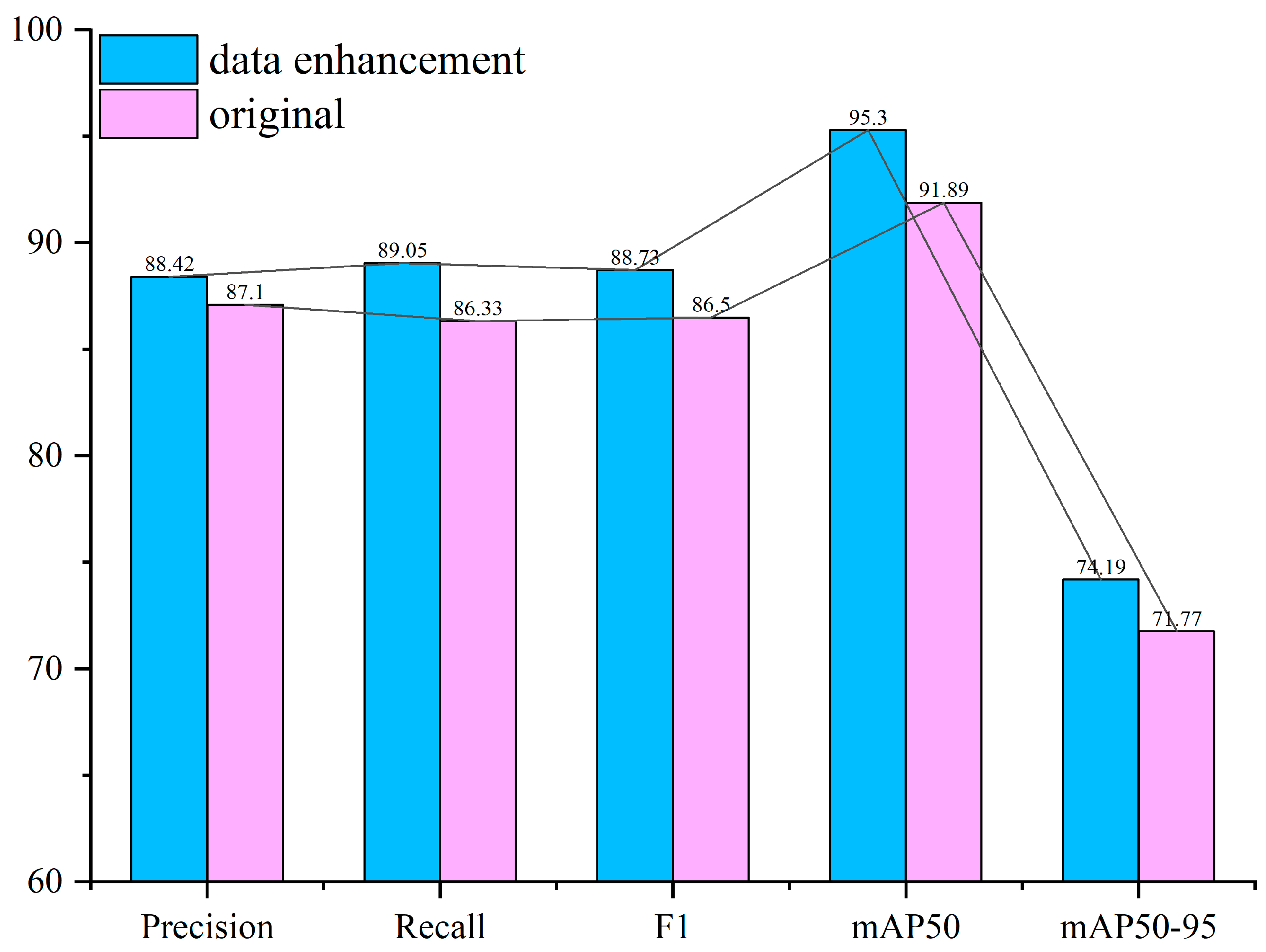
3.5. Comparison before and after Data Enhancement
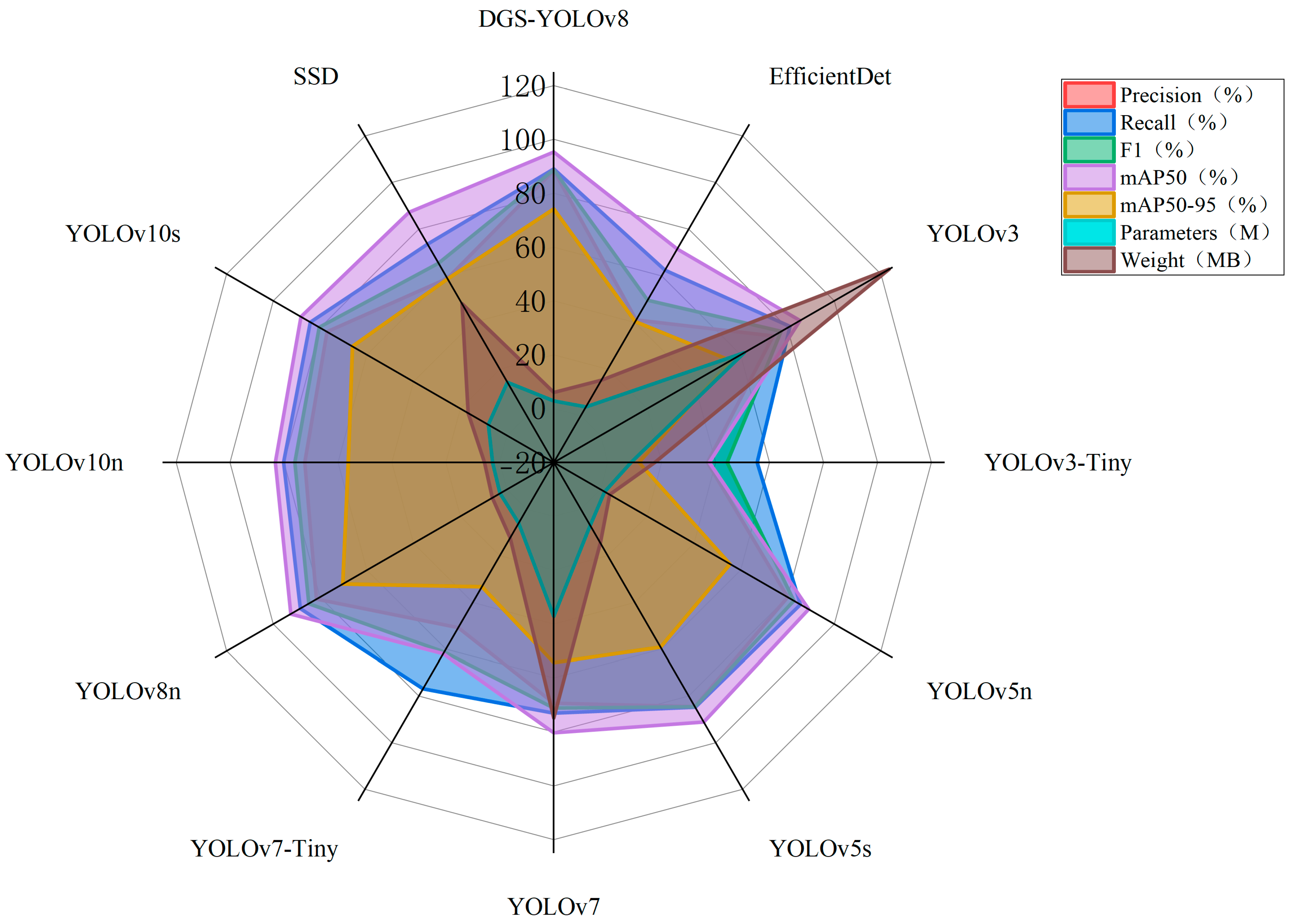
3.6. Comparison Experiment
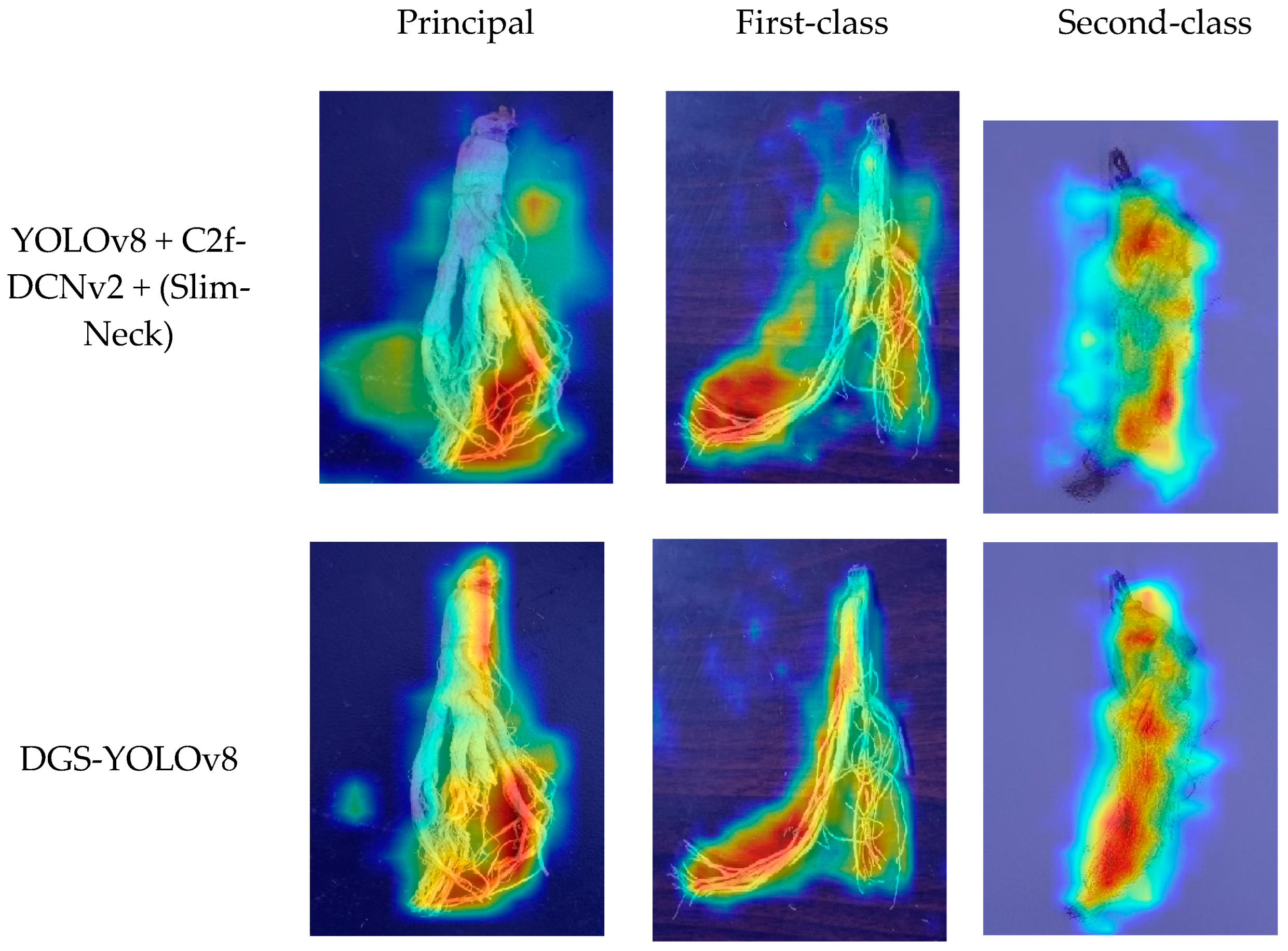
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Hu, J.; Mao, Q.; Liu, C.; He, H.; Hui, X.; Yang, G.; Qu, P.; Lian, W.; Duan, L. Functional compounds of ginseng and ginseng-containing medicine for treating cardiovascular diseases. Front. Pharmacol. 2022, 13, 1034870. [Google Scholar] [CrossRef] [PubMed]
- Loo, S.; Kam, A.; Dutta, B.; Zhang, X.; Feng, N.; Sze, S.K.; Liu, C.-F.; Wang, X.; Tam, J.P. Broad-spectrum ginsentides are principal bioactives in unraveling the cure-all effects of ginseng. Acta Pharm. Sin. B 2024, 14, 653–666. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Tian, X.; Wang, D.; Wang, H. Species authentication of Panax ginseng CA Mey. and ginseng extracts using mitochondrial nad2 intron 4 region. J. Appl. Res. Med. Aromat. Plants 2024, 41, 100554. [Google Scholar]
- Lee, K.-Y.; Shim, S.-L.; Jang, E.-S.; Choi, S.-G. Ginsenoside stability and antioxidant activity of Korean red ginseng (Panax ginseng CA meyer) extract as affected by temperature and time. LWT 2024, 200, 116205. [Google Scholar] [CrossRef]
- Fan, W.; Fan, L.; Wang, Z.; Mei, Y.; Liu, L.; Li, L.; Yang, L.; Wang, Z. Rare ginsenosides: A unique perspective of ginseng research. J. Adv. Res. 2024; in press. [Google Scholar]
- Zhang, Z.; Chen, X.; Zhang, K.; Zhang, R.; Wang, Y. Research on the current situation of ginseng industry and development counter-measures in Jilin Province. J. Jilin Agric. Univ. 2023, 45, 649–655. [Google Scholar]
- Fang, J.; Xu, Z.-F.; Zhang, T.; Chen, C.-B.; Liu, C.-S.; Liu, R.; Chen, Y.-Q. Effects of soil microbial ecology on ginsenoside accumulation in Panax ginseng across different cultivation years. Ind. Crops Prod. 2024, 215, 118637. [Google Scholar] [CrossRef]
- Ye, X.-W.; Li, C.-S.; Zhang, H.-X.; Li, Q.; Cheng, S.-Q.; Wen, J.; Wang, X.; Ren, H.-M.; Xia, L.-J.; Wang, X.-X.; et al. Saponins of ginseng products: A review of their transformation in processing. Front. Pharmacol. 2023, 14, 1177819. [Google Scholar] [CrossRef] [PubMed]
- Ryu, J.Y.; Kim, H.U.; Lee, S.Y. Deep learning improves prediction of drug–drug and drug–food interactions. Proc. Natl. Acad. Sci. USA 2018, 115, E4304–E4311. [Google Scholar] [CrossRef]
- Li, D.; Yang, C.; Yao, R.; Ma, L. Origin Identification of Saposhnikovia divaricata by CNN Embedded with the Hierarchical Residual Connection Block. Agronomy 2023, 13, 1199. [Google Scholar] [CrossRef]
- Kim, M.; Kim, J.; Kim, J.S.; Lim, J.-H.; Moon, K.-D. Automated Grading of Red Ginseng Using DenseNet121 and Image Preprocessing Techniques. Agronomy 2023, 13, 2943. [Google Scholar] [CrossRef]
- Li, D.; Piao, X.; Lei, Y.; Li, W.; Zhang, L.; Ma, L. A Grading Method of Ginseng (Panax ginseng C. A. Meyer) Appearance Quality Based on an Improved ResNet50 Model. Agronomy 2022, 12, 2925. [Google Scholar] [CrossRef]
- Li, D.; Zhai, M.; Piao, X.; Li, W.; Zhang, L. A Ginseng Appearance Quality Grading Method Based on an Improved ConvNeXt Model. Agronomy 2023, 13, 1770. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Chen, X.; Liu, T.; Han, K.; Jin, X.; Wang, J.; Kong, X.; Yu, J. TSP-yolo-based deep learning method for monitoring cabbage seedling emergence. Eur. J. Agron. 2024, 157, 127191. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.; Gao, S.; Deng, Z. Strawberry ripeness detection based on YOLOv8 algorithm fused with LW-Swin Transformer. Comput. Electron. Agric. 2023, 215, 108360. [Google Scholar] [CrossRef]
- Liu, Z.; Rasika, D.; Abeyrathna, R.M.; Mulya Sampurno, R.; Massaki Nakaguchi, V.; Ahamed, T. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Ma, L.; Yu, Q.; Yu, H.; Zhang, J. Maize Leaf Disease Identification Based on YOLOv5n Algorithm Incorporating Attention Mechanism. Agronomy 2023, 13, 521. [Google Scholar] [CrossRef]
- Jiang, M.; Liang, Y.; Pei, Z.; Wang, X.; Zhou, F.; Wei, C.; Feng, X. Diagnosis of breast hyperplasia and evaluation of RuXian-I based on metabolomics deep belief networks. Int. J. Mol. Sci. 2019, 20, 2620. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, Y.; Zhao, Y.; Na, X. Image Classification and Recognition of Medicinal Plants Based on Convolutional Neural Network. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology (ICCT), Tianjin, China, 13–16 October 2021; pp. 1128–1133. [Google Scholar]
- Lu, J.; Wu, W. Fine-grained image classification based on attention-guided image enhancement. Proc. J. Phys. Conf. Ser. 2021, 1754, 012189. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D. ultralytics/yolov5: v7. 0-yolov5 sota realtime instance segmentation. Zenodo 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7347926J/abstract (accessed on 11 August 2024).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Projects | Principal Ginseng | First-Class Ginseng | Second-Class Ginseng |
|---|---|---|---|
| Main Root | Cylindrical-like | ||
| Branch Root | There are 2~3 evident branched roots, and the thickness is more uniform | One to four branches, coarser and finer | |
| Rutabaga | Complete with reed head and ginseng fibrous roots | The reed head and ginseng fibrous roots are more complete | Rutabaga and ginseng with incomplete fibrous roots |
| Groove | Clear grooves | Not unmistakable, distinct groove | Without grooves |
| Diameter Length | ≥3.5 | 3.0–3.49 | 2.5–2.99 |
| Surface | Yellowish-white or grayish-yellow, no water rust, no draw grooves | Yellowish-white or grayish-yellow, light water rust, or with pumping grooves | Yellowish-white or grayish-yellow, slightly more water rust, with pumping grooves |
| Cross-section | Yellowish-white in section, powdery, with resinous tract visible | ||
| Texture | Harder, powdery, non-hollow | ||
| Damage, Scars | No significant injury | Minor injury | More serious |
| Insects, Mildew, Impurities | None | Mild | Presence |
| Section | Section neat, clear | Segment is obvious | Segments are not obvious |
| Springtails | Square or rectangular | Made conical or cylindrical | Irregular shape |
| Weight | 500 g/root or more | 250–500 g/root | 100–250 g/root |
| Level | Number of Original Training Sets | Number of Enhanced Training Sets | Number of Original Validation Sets | Number of Enhanced Training Sets |
|---|---|---|---|---|
| Principal | 339 | 1017 | 85 | 255 |
| First-class | 380 | 1140 | 100 | 300 |
| Second-class | 355 | 1065 | 84 | 252 |
| Parameters | Setup |
|---|---|
| Epochs | 200 |
| Batch Size | 32 |
| Optimizer | SGD |
| Initial Learning Rate | 0.001 |
| Final Learning Rate | 0.001 |
| Momentum | 0.937 |
| Weight-Decay | 5 × 10−4 |
| Close Mosaic | Last ten epochs |
| Images | 640 |
| Workers | 8 |
| Mosaic | 1.0 |
| Level | Model | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| Principal | YOLOv8 | 84.08 | 89.79 | 86.84 | 93.57 | 68.28 |
| DGS-YOLOv8 | 89.33 | 89.8 | 89.56 | 96.47 | 73.01 | |
| First-class | YOLOv8 | 80.43 | 90.63 | 85.23 | 92.29 | 70.35 |
| DGS-YOLOv8 | 85.75 | 91.85 | 88.70 | 94.96 | 73.77 | |
| Second-class | YOLOv8 | 80.18 | 85.12 | 82.7 | 91.85 | 72.48 |
| DGS-YOLOv8 | 90.19 | 85.49 | 87.78 | 94.47 | 75.78 | |
| ALL | YOLOv8 | 81.56 | 88.52 | 84.9 | 92.57 | 70.37 |
| DGS-YOLOv8 | 88.42 | 89.05 | 88.73 | 95.3 | 74.19 |
| YOLOv8n | C2f-DCNv2 | Slim-Neck | Simam | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) | Parameters (M) | Weight (MB) |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | 81.56 | 88.52 | 84.88 | 92.57 | 70.37 | 3.01 | 6.3 | |||
| √ | √ | 84.94 | 88.76 | 86.88 | 93.59 | 72.61 | 3.07 | 6.4 | ||
| √ | √ | 87.79 | 87.53 | 87.68 | 93.74 | 71.8 | 2.80 | 5.9 | ||
| √ | √ | 86.19 | 86.61 | 86.38 | 92.83 | 70.86 | 3.01 | 6.3 | ||
| √ | √ | √ | 86.54 | 88.0 | 87.26 | 93.67 | 72.97 | 2.86 | 6.0 | |
| √ | √ | √ | 84.80 | 87.48 | 86.10 | 92.82 | 71.85 | 3.07 | 6.4 | |
| √ | √ | √ | 84.63 | 89.09 | 86.82 | 94.0 | 71.83 | 2.80 | 5.9 | |
| √ | √ | √ | √ | 88.42 | 89.05 | 88.73 | 95.3 | 74.19 | 2.86 | 6.0 |
| Attention Mechanisms | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|
| NO | 81.56 | 88.52 | 84.88 | 92.57 | 70.37 |
| CBMA | 87.88 | 87.87 | 87.94 | 93.97 | 73.23 |
| CA | 85.62 | 87.05 | 86.30 | 93.27 | 71.63 |
| SE | 87.71 | 87.53 | 87.64 | 94.38 | 73.71 |
| EMA | 83.96 | 89.07 | 86.48 | 93.89 | 72.91 |
| GAM | 86.22 | 88.16 | 87.12 | 93.68 | 72.22 |
| NAM | 85.05 | 87.96 | 86.46 | 95.3 | 74.19 |
| SimAM | 88.42 | 89.05 | 88.73 | 95.3 | 74.19 |
| Experiment | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|
| A | 87.32 | 88.78 | 88.04 | 94.11 | 71.89 |
| B | 84.67 | 88.7 | 86.64 | 93.94 | 72.4 |
| C | 84.8 | 87.7 | 86.23 | 92.98 | 72.13 |
| D | 84.93 | 90.41 | 87.58 | 94.19 | 73.2 |
| E | 83.27 | 90.57 | 86.77 | 94.45 | 73.28 |
| F | 88.42 | 89.05 | 88.73 | 95.3 | 74.19 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) | Parameters (%) | Weight (MB) |
|---|---|---|---|---|---|---|---|
| SSD | 58.9 | 73.61 | 65.44 | 87.3 | 58.7 | 14.34 | 48.1 |
| EfficientDet | 41.1 | 62.41 | 49.56 | 71.51 | 40.44 | 3.87 | 15.3 |
| YOLOv3 | 73.91 | 81.09 | 77.34 | 85.40 | 55.69 | 61.5 | 123.6 |
| YOLOv3-Tiny | 36.91 | 55.37 | 44.28 | 37.62 | 11.59 | 8.67 | 17.5 |
| YOLOv5n | 80.09 | 85.53 | 82.74 | 89.1 | 55.5 | 1.78 | 3.9 |
| YOLOv5s | 84.61 | 84.89 | 84.66 | 91.2 | 59.2 | 7.03 | 14.5 |
| YOLOv7 | 69.31 | 72.97 | 71.10 | 80.31 | 54.3 | 37.21 | 74.8 |
| YOLOv7-Tiny | 50.8 | 76.98 | 61.24 | 62 | 33.31 | 6.02 | 12.3 |
| YOLOv8n | 81.56 | 88.52 | 84.88 | 92.57 | 70.37 | 3.0 | 6.3 |
| YOLOv10n | 72.3 | 80.11 | 75.96 | 83.24 | 56.17 | 2.7 | 5.7 |
| YOLOv10s | 77.02 | 84.19 | 80.36 | 88.21 | 66.2 | 8.07 | 16.6 |
| DGS-YOLOv8 | 88.42 | 89.05 | 88.73 | 95.3 | 74.19 | 2.86 | 6.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; You, H.; Wei, Z.; Li, Z.; Jia, H.; Yu, S.; Zhao, C.; Lv, Y.; Li, D. DGS-YOLOv8: A Method for Ginseng Appearance Quality Detection. Agriculture 2024, 14, 1353. https://doi.org/10.3390/agriculture14081353
Zhang L, You H, Wei Z, Li Z, Jia H, Yu S, Zhao C, Lv Y, Li D. DGS-YOLOv8: A Method for Ginseng Appearance Quality Detection. Agriculture. 2024; 14(8):1353. https://doi.org/10.3390/agriculture14081353
Chicago/Turabian StyleZhang, Lijuan, Haohai You, Zhanchen Wei, Zhiyi Li, Haojie Jia, Shengpeng Yu, Chunxi Zhao, Yan Lv, and Dongming Li. 2024. "DGS-YOLOv8: A Method for Ginseng Appearance Quality Detection" Agriculture 14, no. 8: 1353. https://doi.org/10.3390/agriculture14081353