
A Highland Barley Crop Extraction Method Based on Optimized Feature Combination of Multiple Phenological Sentinel-2 Images

Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Source and Preprocessing
2.3. Sample Data
2.4. Methods
2.4.1. Feature Set Construction
2.4.2. Principal Component Analysis (PCA)
2.4.3. GrayScale Covariance Matrix
2.4.4. Random Forest Algorithm
- (1)
- Construction, calibration, and variables of the random forest model
- (2)
- Crop information extraction and classification
- (3)
- Importance discrimination of characteristic variables
2.4.5. Accuracy Assessment
3. Results
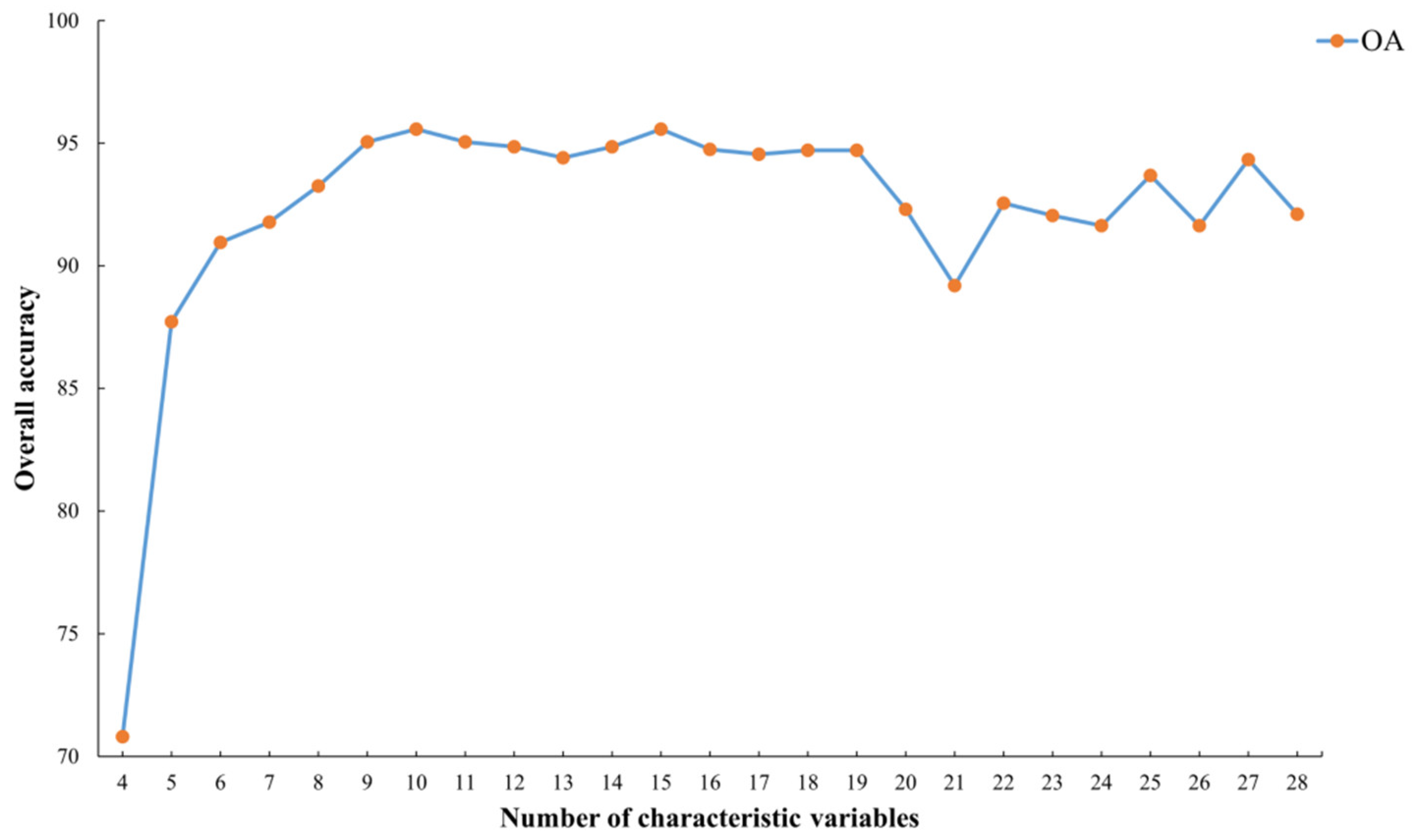
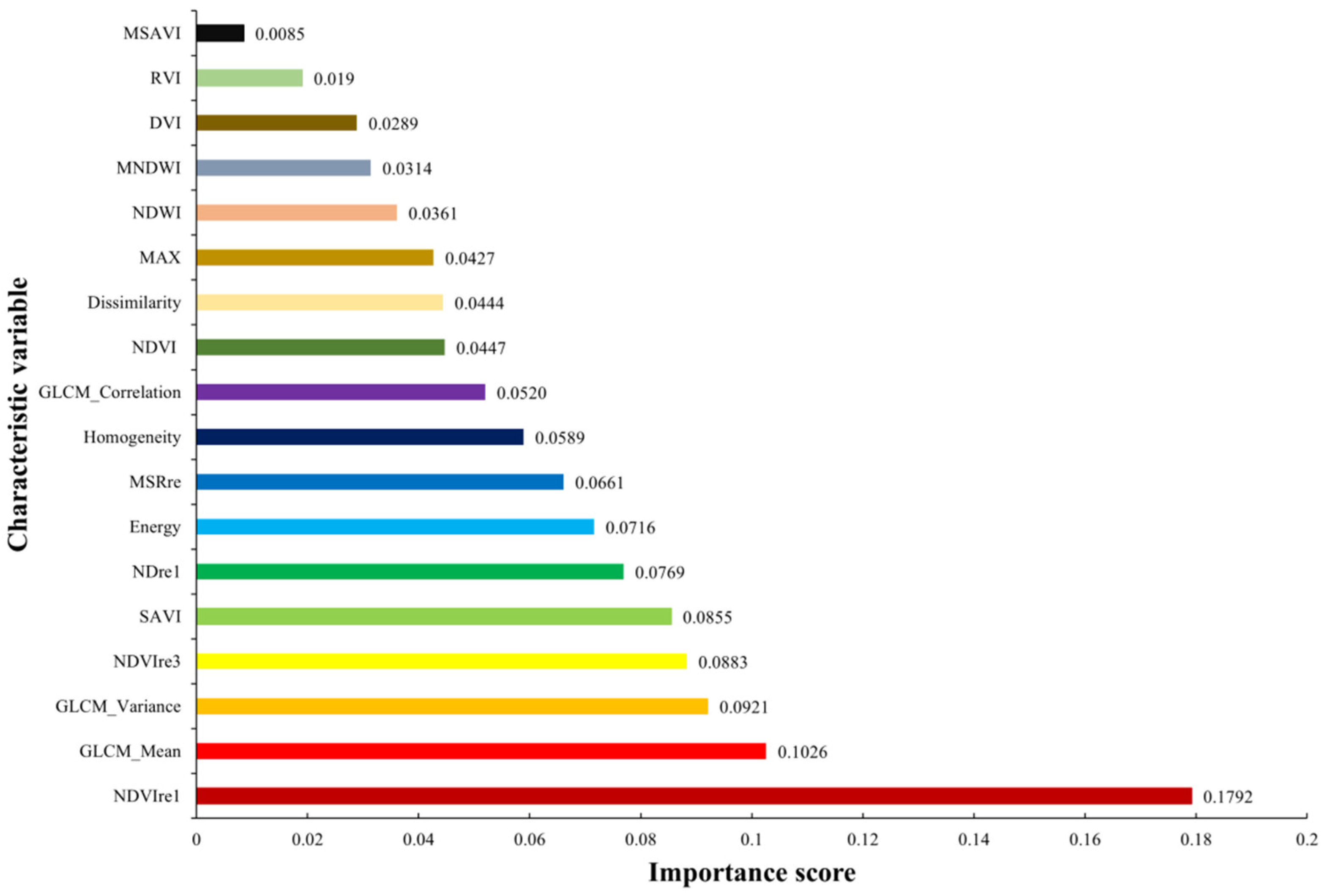
3.1. Importance Ranking of Characteristic Variables
3.2. The Optimal Combination of Crop Classification Characteristics in Different Phenological Periods
3.3. Analysis of Spatial Distribution of Highland Barley in Different Time Phases
4. Discussion
5. Conclusion
- (1)
- The overall classification accuracy of information extraction was better after feature optimization and the combination of multitemporal image data. The optimal phenological periods for highland barley extraction were the jointing stage and the milk ripening stage. For highland barley crops, the overall accuracy at the jointing stage was 92.56%, with a kappa coefficient of 0.86. The overall accuracy at the milk ripening stage was 91.55%, with a kappa coefficient of 0.84.
- (2)
- The importance score of the red edge index based on the Sentinel-2 image data was higher in the feature selection combination. The red edge index had a higher contribution rate in the process of crop information extraction and classification.
- (3)
- The five characteristic variables—GLCM_Mean, RVI, homogeneity, MAX, and GLCM_Correlation—were applicable to the information extraction of crops in Chengbei District and played a very important role in the classification of different phenological periods. These five characteristic variables were stable and universal throughout the process of crop extraction.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, B.; Xiao, L. Research on Crop intelligent Image Recognition and Classification Based on Convolution Neural Network. J. Agric. Mech. Res. 2023, 45, 20–23, 29. [Google Scholar]
- Yang, C.; Liu, H.H.; Zhang, C. UAV Hyperspectral Remote Sensing Image Crop Fine Classification Based on SVM and RF. Henan Sci. 2020, 38, 1987–1995. [Google Scholar]
- Liang, H.H. Research on crop classification based on UAV hyperspectral remote sensing image. China S. Agric. Mach. 2022, 53, 38–41. [Google Scholar]
- Zhang, R.H. Study on Field Crop Extraction based on UAV Visible Light Image and Random Forest Model. Hortic. Seed 2023, 43, 99–101. [Google Scholar]
- Cheng, T.; Xing, X.C.; Chen, C. Sugarcane planting range extraction based on multi temporal remote sensing images. Sci. Surv. Mapp. 2023, 48, 137–143. [Google Scholar]
- Bao, J.W.; Wu, L.T.Y.; Che, Y.W.; Liu, Z.H.; Liu, Z.X. Research on crop planting structure extraction methods based on GF-6 images. J. N. Agric. 2023, 51, 112–121. [Google Scholar]
- Yan, J.Z.; Zhang, M.; Zhang, S.Y. Information Extraction of Main Crops in Eastern Qinghai Province Based on GEE Platform and MODIS NDVI Time Series. J. S. Univ. Nat. Sci. Ed. 2023, 45, 55–64. [Google Scholar]
- Liu, J.W. Research on Extraction of Crop Spatial Planting Structure Based on Sentinel-2 Data. Geomat. Spat. Inf. Technol. 2022, 45, 62–64. [Google Scholar]
- Xie, Y.; Wang, J.N.; Liu, Y. Research on Winter Wheat Planting Area Identification Method Based on Sentinel-1/2 Data Feature Optimization. Trans. Chin. Soc. Agric. Mach. 2024, 55, 231–241. [Google Scholar]
- Shi, F.F.; Lei, C.M.; Xiao, J.S.; Li, F.; Shi, M.M. Classification of Crops in Complicated Topography Area Based on Multisource Remote Sensing Data. Geogr. Geo-Inf. Sci. 2018, 34, 49–55+2. [Google Scholar]
- Faqe Ibrahim, G.R.; Azad, R.; Haidi, A. Improving Crop Classification Accuracy with Integrated Sentinel-1 and Sentinel-2 Data: A Case Study of Barley and Wheat. J. Geovis. Spat. Anal. 2023, 7, 22. [Google Scholar] [CrossRef]
- Bao, J.W.; Yu, L.F.; Wulantuya; Xu, H.; Wuyundeji; Yu, W.Z. Research on crop remote sensing recognition method based on a random forest method—Take some areas of Arun Banner as an example. J. N. Agric. 2020, 48, 129–134. [Google Scholar]
- Chen, J.; Li, H.; Liu, Y.F.; Chang, Z.; Han, W.J.; Liu, S.S. Crops identification based on Sentinel-2 data with multi-feature optimization. Remote Sens. Nat. Resour. 2023, 35, 292–300. [Google Scholar]
- Zhang, L.; Gong, Z.N.; Wang, Q.W.; Jin, D.D.; Wang, X. Wetland mapping of Yellow River Delta wetlands based on multi-feature optimization of Sentinel-2 images. Natl. Remote Sens. Bull. 2019, 23, 313–326. [Google Scholar] [CrossRef]
- Fabian, L.; Grégory, D. Defining the Spatial Resolution Requirements for Crop Identification Using Optical Remote Sensing. Remote Sens. 2014, 6, 9034–9063. [Google Scholar] [CrossRef]
- José, M.; Peña, B.; Moffatt, K.N.; Richard, E.P.; Johan, S. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar]
- Zhang, M.; Wu, B.F.; Yu, M.Z.; Zou, W.T.; Zheng, Y. Crop Condition Assessment with Adjusted NDVI Using the Uncropped Arable Land Ratio. Remote Sens. 2014, 6, 5774–5794. [Google Scholar] [CrossRef]
- Fernández-Manso, A.; Fernández-Manso, O.; Quintano, C. SENTINEL-2A red-edge spectral indices suitability for discriminating burn severity. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 170–175. [Google Scholar] [CrossRef]
- He, Z.N.; Jing, M.; Han, H.T.; Liu, P.; Ji, F.; Chen, M.L. Sparse principal component analysis-random forest algorithm combined with optimized spectroscopy for identification of soil surface oil species. Chin. J. Anal. Lab. 2024, 3, 1–9. [Google Scholar]
- Zhou, Z.H. Machine Learning: Development and Future. Commun. China Comput. Soc. 2017, 13, 44–51. [Google Scholar]
- Li, X.D. Water quality assessment based on principal component analysis and water quality identification index: Taking Dongshan County of Fujian Province as an example. Jilin Geol. 2022, 41, 57–65. [Google Scholar]
- Haralick, R.M. Statistical and structural approaches to texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Wang, L.X.; Shi, Z.T.; Xi, W.F.; Li, G.Z.; Yang, Z.R. Research on Extraction of Bedrock Landslide Texture Feature Based on Gray Co-occurrence Matrix. Urban Geotech. Investig. Surv. 2023, 2, 187–192. [Google Scholar]
- Iverson, L.R.; Prasad, A.M.; Matthews, S.N.; Peters, M. Estimating potential habitat for 134 eastern US tree species under six climate scenarios. For. Ecol. Manag. 2008, 254, 390–406. [Google Scholar] [CrossRef]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ou, D.J. Hyperspectral Remote Sensing Image Classification Based on Multi-Classifier Fusion. Master’s Thesis, Shandong University, Jinan, China, 2019. [Google Scholar]
- Sun, R.X.; Shen, M.S.; Hu, Y.W.; Xu, Q.T.; Zhang, J.J. Effect of Grass Belt Distribution on Runoff and Sediment Yield Under Simulated Rainfall. J. Soil Water Conserv. 2022, 36, 22–29. [Google Scholar]
- Yang, Y.G.; Liu, P.; Zhang, H.B.; Zhang, W.Z. Research on GF-2 Image Classification Based on Feature Optimization Random Forest Algorithm. Spacecr. Recovery Remote Sens. 2022, 43, 115–126. [Google Scholar]
- Tao, L.; Hu, Z.L. Crop planting structure identification based on Sentinel-2A data in hilly region of middle and lower reaches of Yangtze River. Bull. Surv. Mapp. 2021, 7, 39–43. [Google Scholar] [CrossRef]
- Huang, Q.Y.; Li, L.; Xue, P.; Ying, G.W. Main Crop Classification Based on Multi-temporal Sentinel-2 Data in Chengdu Plain. Geomat. Spat. Inf. Technol. 2024, 47, 65–68. [Google Scholar]
- Rashmi, S.; Kumar, S.G. Crop classification in a heterogeneous agricultural environment using ensemble classifiers and single-date Sentinel-2A imagery. Geocarto Int. 2019, 36, 2141–2159. [Google Scholar]
- Wang, L.J.; Guo, Y.; He, J.; Wang, L.M.; Zhang, X.W.; Liu, T. Classification Method by Fusion of Decision Tree and SVM Based on Sentinel-2A Image. Trans. Chin. Soc. Agric. Mach. 2018, 49, 146–153. [Google Scholar]
- Saini, R.; Ghosh, K.S. Crop classification on single date Sentinel-2 imagery using random forest and suppor vector machine. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 683–688. [Google Scholar] [CrossRef]
- Jiang, Y.R.; Ye, J.; Xie, Z.L.; Li, X.H. Rape planting extraction based on phenological characteristics analysis of time series Sentinel-2 images. J. Chengdu Univ. Technol. Sci. Technol. Ed. 2024, 4, 15–28. [Google Scholar]
- Song, Y.B.; Xiao, C.; Zhao, Y.F.; Wang, Y.C. Research on crop remote sensing classification method based on growth spatio-temporal information. China S. Agric. Mach. 2023, 54, 49–51. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bands | Central Wavelength (nm) | Bandwidth (nm) | Resolution (m) |
|---|---|---|---|
| B1: Coast/aerosol band | 443 | 20 | 60 |
| B2: Blue band | 490 | 65 | 10 |
| B3: Green band | 560 | 35 | 10 |
| B4: Red band | 665 | 30 | 10 |
| B5: Vegetation red edge (band 1) | 705 | 15 | 20 |
| B6: Vegetation red edge (band 2) | 740 | 15 | 20 |
| B7: Vegetation red edge (band 3) | 783 | 20 | 20 |
| B8: Near-infrared band (wide) | 842 | 115 | 10 |
| B8A: Near-infrared band (narrow) | 865 | 20 | 20 |
| B9: Water vapor band | 945 | 20 | 60 |
| B10: Cirrus band | 1375 | 20 | 60 |
| B11: Short-wave infrared (band 1) | 1610 | 90 | 20 |
| B12: Short-wave infrared (band 2) | 2190 | 180 | 20 |
| Image Date | 0616 | 0706 | 0726 | 0811 | 0825 |
|---|---|---|---|---|---|
| Phenological period of highland barley | Jointing stage | Heading stage | Flowering stage | Milk ripening stage | Maturity stage |
| Characteristic Variable Set | Characteristic Variable | Explanation/Calculation Formula | Main References |
|---|---|---|---|
| Spectral Signature | Band | B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12 | -- |
| Texture Features | Angular Second Moment (ASM) | -- | |
| Contrast | -- | ||
| Dissimilarity | -- | ||
| Energy | -- | ||
| Entropy | -- | ||
| Homogeneity | -- | ||
| MAX | -- | ||
| GLCM_Correlation | -- | ||
| GLCM_Mean | -- | ||
| GLCM_Variance | -- | ||
| Vegetation Index | Normalized Difference Vegetation Index (NDVI) | [15,16,17] | |
| Ratio Vegetation Index (RVI) | |||
| Difference Vegetation Index (DVI) | |||
| Modified Soil-Adjusted Vegetation Index (MSAVI) | |||
| Soil-Adjusted Vegetation Index (SAVI) | |||
| Water Index | Normalized Difference Water Index (NDWI) | ||
| Modified Normalized Difference Water Index (MNDWI) | |||
| Red Edge Index | Red Edge Normalized Difference Vegetation Index (RNDVI) | [18] | |
| Red Edge Chlorophyll Index (CIre) | |||
| Modified Simple Ratio Red Edge Index (MSRre) | |||
| Red Edge Normalized Difference Vegetation Index 1 (NDVIre1) | |||
| Red Edge Normalized Difference Vegetation Index 2 (NDVIre2) | |||
| Red Edge Normalized Difference Vegetation Index 3 (NDVIre3) | |||
| Red Edge Normalized Difference 1 (NDre1) | |||
| Red Edge Normalized Difference 2 (NDre2) |
| Principal Component Analysis | Contribution Rate |
|---|---|
| PCA_1 | 83.5% |
| PCA_2 | 9.8% |
| PCA_3 | 4.5% |
| Phenophase | Optimal Combination of Features |
|---|---|
| Jointing Stage | PCA_1, PCA_2, PCA_3, NDVIre1, GLCM_Variance, NDVIre3, SAVI, NDre1, Energy, MSRre, Homogeneity, GLCM_Correlation, NDVI, Dissimilarity, MAX, NDWI, MNDWI, DVI, RVI, MSAVI |
| Heading Stage | PCA_1, PCA_2, PCA_3, NDVIre1, GLCM_Mean, GLCM_Variance, NDVIre3, SAVI, NDre1, Energy, MSRre, Homogeneity, GLCM_Correlation, NDVI, Dissimilarity, MAX, NDWI, MNDWI, DVI, RVI, MSAVI |
| Flowering Stage | PCA_1, PCA_2, PCA_3, GLCM_Mean, NDVIre1, GLCM_Correlation, CIre, MSRre, GLCM_Variance, Homogeneity, Contrast, RVI, NDWI, MNDWI, ASM, MAX, SAVI, Dissimilarity |
| Milk Ripening Stage | PCA_1, PCA_2, PCA_3, RNDVI, GLCM_Mean, GLCM_Variance, NDre1, GLCM_Correlation, Entropy, NDVIre3, RVI, Homogeneity, MAX, Energy, ASM, NDVIre2, NDre2, DVI, NDVI, NDVIre1 |
| Maturity Stage | PCA_1, PCA_2, PCA_3, NDre1, RNDVI, GLCM_Mean, MNDWI, GLCM_Correlation, NDWI, RVI, NDVIre3, MAX, Entropy, CIre, Energy, Homogeneity, MSAVI, SAVI, DVI |
| Phenophase | Jointing Stage | Heading Stage | Flowering Stage | Milk Ripening Stage | Maturity Stage | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Evaluation Index | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) |
| Highland Barley | 89.65 | 88.53 | 90.24 | 82.51 | 91.86 | 82.80 | 95.87 | 86.39 | 93.85 | 87.51 |
| Other Crops | 48.36 | 77.18 | 30.77 | 50.16 | 37.68 | 45.61 | 40.77 | 45.21 | 30.14 | 67.46 |
| Mountainous Areas | 96.07 | 95.64 | 95.42 | 94.87 | 93.69 | 95.94 | 93.92 | 96.59 | 93.61 | 94.14 |
| Urban Areas | 99.09 | 84.47 | 95.70 | 91.95 | 98.79 | 91.06 | 98.48 | 91.17 | 99.61 | 79.31 |
| Water Bodies | 94.96 | 100.00 | 98.05 | 100.00 | 98.70 | 100.00 | 91.38 | 100.00 | 90.73 | 100.00 |
| OA (%) | 92.56 | 90.90 | 90.74 | 91.55 | 90.51 | |||||
| Kappa | 0.86 | 0.82 | 0.82 | 0.84 | 0.82 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Pan, K.; Zhang, L.; He, X.; Wang, L.; Guo, B. A Highland Barley Crop Extraction Method Based on Optimized Feature Combination of Multiple Phenological Sentinel-2 Images. Agriculture 2024, 14, 1466. https://doi.org/10.3390/agriculture14091466
Wu X, Pan K, Zhang L, He X, Wang L, Guo B. A Highland Barley Crop Extraction Method Based on Optimized Feature Combination of Multiple Phenological Sentinel-2 Images. Agriculture. 2024; 14(9):1466. https://doi.org/10.3390/agriculture14091466
Chicago/Turabian StyleWu, Xiaogang, Kaiwen Pan, Lin Zhang, Xiulin He, Longhao Wang, and Bing Guo. 2024. "A Highland Barley Crop Extraction Method Based on Optimized Feature Combination of Multiple Phenological Sentinel-2 Images" Agriculture 14, no. 9: 1466. https://doi.org/10.3390/agriculture14091466