Abstract
Corn silage is the main feed in the diet of dairy cows and other ruminant livestock. Silage corn feed is very susceptible to spoilage and corruption due to the influence of aerobic secondary fermentation during the silage process. At present, silage quality testing of corn feed mainly relies on the combination of sensory evaluation and laboratory measurement. The sensory review method is difficult to achieve precision and objectivity, while the laboratory determination method has problems such as cumbersome testing procedures, time-consuming, high cost, and damage to samples. In this study, the external sensory quality grading model for different qualities of silage corn feed was established using hyperspectral data. To explore the feasibility of using hyperspectral data for external sensory quality grading of corn silage, a hyperspectral system was used to collect spectral data of 200 corn silage samples in the 380–1004 nm band, and the samples were classified into four grades: excellent, fair, medium, and spoiled according to the German Agricultural Association (DLG) standard for sensory evaluation of silage samples. Three algorithms were used to preprocess the fodder hyperspectral data, including multiplicative scatter correction (MSC), standard normal variate (SNV), and S–G convolutional smoothing. To reduce the redundancy of the spectral data, variable combination population analysis (VCPA) and competitive adaptive reweighted sampling (CARS) were used for feature wavelength selection, and linear discriminant analysis (LDA) algorithm was used for data dimensionality reduction, constructing random forest classification (RFC), convolutional neural networks (CNN) and support vector machines (SVM) models. The best classification model was derived based on the comparison of the model results. The results show that SNV-LDA-SVM is the optimal algorithm combination, where the accuracy of the calibration set is 99.375% and the accuracy of the prediction set is 100%. In summary, combined with hyperspectral technology, the constructed model can realize the accurate discrimination of the external sensory quality of silage corn feed, which provides a reliable and effective new non-destructive testing method for silage corn feed quality detection.
1. Introduction
Corn silage is made by chopping whole corn plants, including the ears, during the waxy ripening stage. It is then fermented anaerobically in a closed environment, resulting in a palatable, highly digestible, and nutritious feed [1,2]. With the development of society, the demand for meat and dairy products is increasing and the production of ruminants such as dairy cows, beef cattle, and sheep is also developing rapidly, and the demand for silage is increasing [3,4]. Since silage maize feed is very widely available, with the rapid development of the modern livestock industry, livestock after feeding can suffer from diseases such as dysentery and abortion, causing huge economic losses. Therefore, it is important to achieve external sensory quality grading of corn silage.
At present, there are mainly two methods to assess the quality of corn silage; one is the most widely used sensory evaluation method in China; its method is simple, but subjective, requiring a high degree of experience in the determination of personnel, and therefore it cannot accurately identify the quality of corn silage; the other is the laboratory evaluation method; although the detection accuracy is high, this method is based on chemical analysis, so it requires a lot of time, manpower, material and financial resources. Therefore, there is an urgent need to study a fast, non-destructive, and green method for testing and evaluating the quality of silage corn feed.
At present, the methods for detecting the quality of agricultural products are becoming increasingly diverse. Hyperspectral imaging technology, as an emerging non-destructive testing method, has become one of the important means for non-destructive testing of agricultural products. This method involves collecting spectral data or images of agricultural products across different bands, followed by preprocessing, feature extraction, and model establishment to analyze, judge, and evaluate relevant indicators. It can be used for the component analysis and quality grading of agricultural products, and compared to traditional methods, it has the advantages of being fast, safe, and suitable for online testing [5,6]. Therefore, the application of hyperspectral technology is of great significance for advancing the level of research on the quality testing of silage corn feed.
Giorgio Masoero et al. [7] used (near-infrared, NIR) spectroscopy and electronic nose to predict the feasibility of fermentation characteristics of fresh silage. Hetta et al. [8] combined NIR technology with NIR spectroscopy analysis to construct partial least squares regression (PLSR) models for forage quality, morphology, and agronomic traits. Xiao Hong and Tang Kaiting et al. [9,10] conducted experiments on fresh samples of alfalfa silage and established an NIR prediction model for nutrient composition with good results; Jue Zhang et al. [11] used an improved discrete particle swarm algorithm to predict the moisture content of corn silage raw materials and established a PLSR model, and the study concluded that the coefficient of determination of the correction and prediction sets was around 0.8. Zhang et al. [12] used NIR spectroscopy to determine the moisture in maize stover silage, and the results showed that NIR spectroscopy can determine a large amount of moisture in maize stover silage quickly and non-destructively. Mingyue Cao et al. [13] applied PLS to establish a prediction model for the content of silage components and quantified the nutrients such as crude protein in the feed.
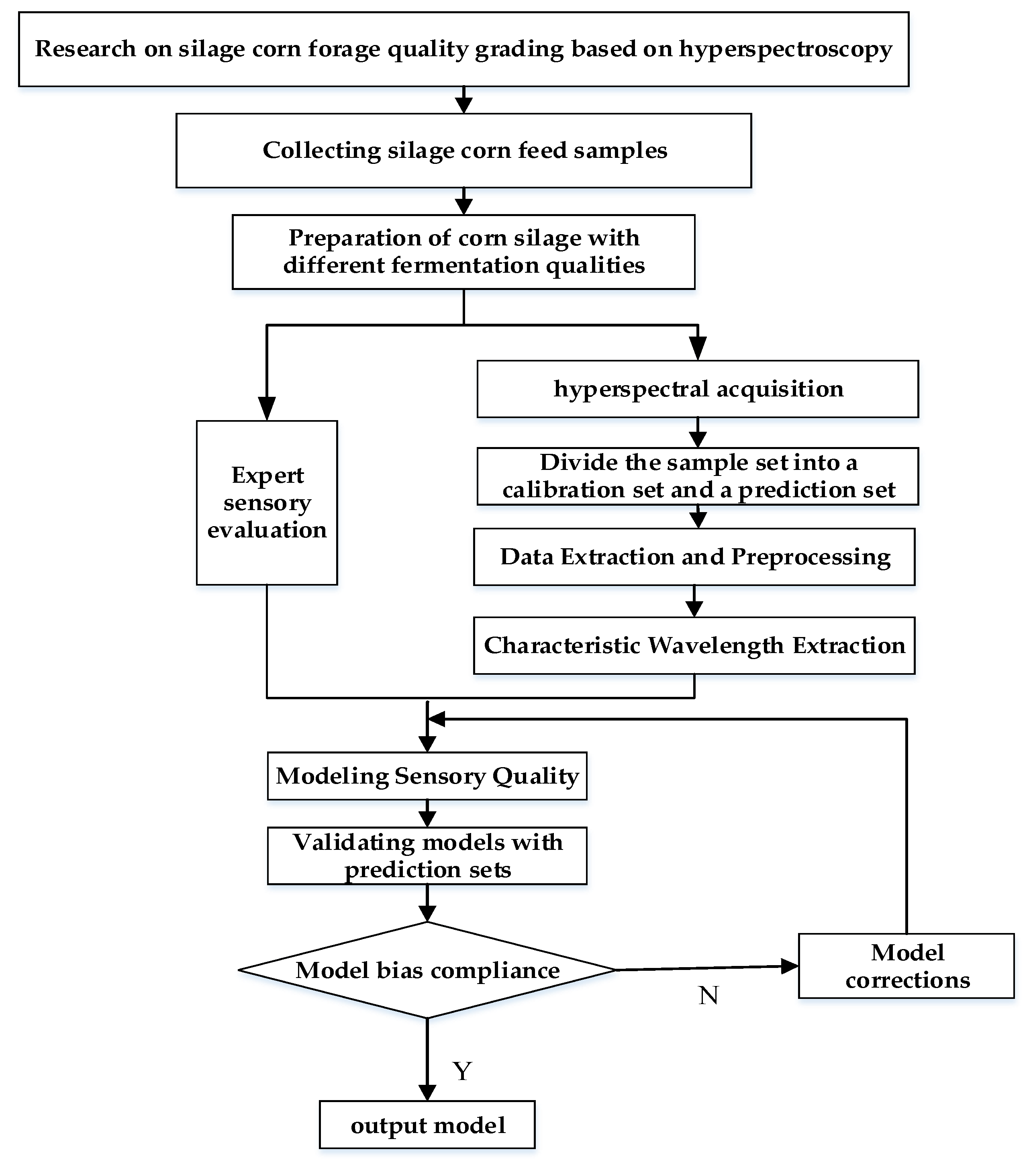
Although silage has been studied by some scholars, little research has been reported on the quality classification of silage maize feeds. In this study, a hyperspectral imaging system was used to collect the spectral data of silage maize feeds, and the external sensory quality classification model of silage maize feeds was established by the chemometric method. The flow chart of this study is shown below (Figure 1 Flow chart).
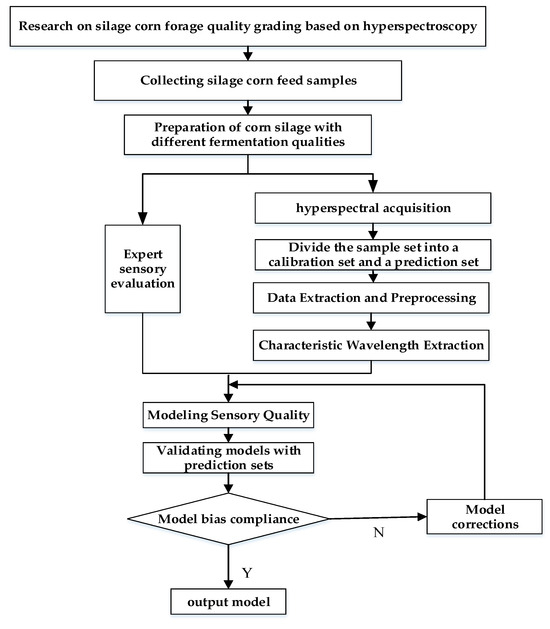
Figure 1.
Flow chart.
2. Materials and Methods
2.1. Sample Preparation
This experiment takes silage maize feed as the research subject, part of which was collected from a cattle farm in Hohhot City, Inner Mongolia, China, in August 2021, and the other part was prepared in the laboratory in September 2021. Of the silage maize material which was harvested in Helinger County, Hohhot City, Inner Mongolia Autonomous Region, China (latitude: 40°38′ N, longitude: 111°82′ E), a total of 1 ton was harvested at the end of the milky ripening period. The silage maize variety was Jingke Silage 301, and the silage maize raw material was cut into 4 cm size and bagged by silage harvester while harvesting in the field; the silage maize and its field harvesting are shown in Figure 2. The cut maize silage material was quickly transported to the laboratory and immediately silaged, divided into two types of silage: silage bags and silage buckets; the size of the silage bags used was 50 cm × 70 cm with 22 wires, and the capacity of the silage buckets was 10 L. The sample preparation is shown in Figure 3. The raw materials were fermented in a closed and anaerobic environment for 45 days to stabilize the silage fermentation and the silage was finished to obtain a sample of corn silage. The samples were classified into four grades according to the DLG (German Agricultural Association Silage Sensory Rating), namely excellent, fair, medium, and spoiled.

Figure 2.
Map of corn silage and field harvest. (a) Corn silage. (b) Field harvest map. (c) Chopped silage corn.

Figure 3.
Sample preparation diagram. (a) Silage bags preparation method. (b) Silage buckets preparation methods.
After the silage was finished, the prepared corn silage was placed in polyethylene vacuum bags using the 9-point sampling method [14]. In order to ensure data accuracy and experimental rigor, it is important to ensure that the samples taken are sufficiently representative and that errors caused by sampling are minimized by removing the top layer of silage bags and silage buckets as well as the edge of the moldy and deteriorated feeds before sampling and sampling layer by layer. A total of 200 samples were collected and labeled separately, and the samples were treated in two ways: intermittent opening and continuous opening. The intermittent opening treatment was to open the bag for 60 min at 12:00 noon every day, and the air in the bag was expelled and sealed after the opening; the continuous opening treatment was to make small holes evenly arranged on the surface of the polyethylene vacuum bag to ensure that the feed could react evenly with the outside air, so that the secondary fermentation could be carried out to obtain different grades of feed samples. In this process, samples were taken on days 0–14 after the two treatments and sensory evaluation were carried out according to the German Agricultural Association sensory evaluation criteria.
2.2. Hyperspectral Data Acquisition
The test instrument is the hyperspectral imaging system of Shanghai Wuling Optoelectronics Technology Co as shown in Figure 4. The system mainly includes hyperspectral imager, CCD camera, halogen lamp, mobile control platform, computer, etc. [15]. The specific parameters of the hyperspectral system are shown in Table 1.

Figure 4.
Hyperspectral imaging system.

Table 1.
Information on the main components of the hyperspectral imaging system.
Before data acquisition, the hyperspectral imager was turned on and preheated for 30 min, then the halogen lamp light sources were turned on in turn, the light sources were adjusted so that the MAX DN value (energy value) of each light source reached the maximum, and the lens position was adjusted so that the position captured by the lens was the center of the experimental platform and all of the Petri dishes were within the range of the capture. The effect of baseline deviation on the spectral curve was eliminated by adjusting the lens position and focusing the spectrometer. In order to eliminate the inhomogeneity of light intensity, as well as the effect of background and dark current, a black and white correction is required before acquiring the hyperspectral images. The correction equation is as in Equation (1):
white corrected sample; Is refers to the spectral intensity reflected from the original sample; ID is the spectral intensity reflected from the reference blackboard; IW is the spectral intensity reflected from the reference whiteboard [16].
During the hyperspectral image acquisition, 50.0 g (accurate to 0.1 g) of corn silage was weighed on an electronic balance (UX6200H, Shimadzu, Kyoto, Japan) and placed in a Petri dish to flatten and compact the top surface, the samples were loaded and placed on the mobile control platform of the hyperspectral imager, the hyperspectral image acquisition software was used to acquire hyperspectral images of the samples at different wavelengths, and three samples were acquired each time. Parallel samples were collected each time.
3. Spectral Data Preprocessing
MATLAB R2018b, The Unscrambler X 10.4, and other software were used to process the silage maize forage spectral data.
Because hyperspectral data are susceptible to instrumental noise, the surrounding environment, and other factors, the spectral information, in addition to containing useful physicochemical information of silage corn feed, also contains interference information such as dark current and light scattering, and there are more burrs in the raw spectral curves of silage corn feed, which have a certain impact on the subsequent modeling.
MSC (Multiplicative Scatter Correction) is mainly used to eliminate the effect of scattering on the spectra, so that the spectra of different samples have a more similar shape and amplitude. The function of SNV (Standard Normal Variate) is to correct the spectral baseline drift and optical range change caused by particle size, scattering, and other physical factors, so as to enhance the comparability of the spectra. S–G (Savitzky–Golay) filtering is often used to smooth the spectrum to remove the noise, while retaining the main features of the spectrum. In order to eliminate the effects caused by the surrounding environment, uneven illumination, and the dark current of the instrument during image acquisition [17], in this study, three algorithms, MSC, SNV, and S–G, are used to preprocess the spectral data.
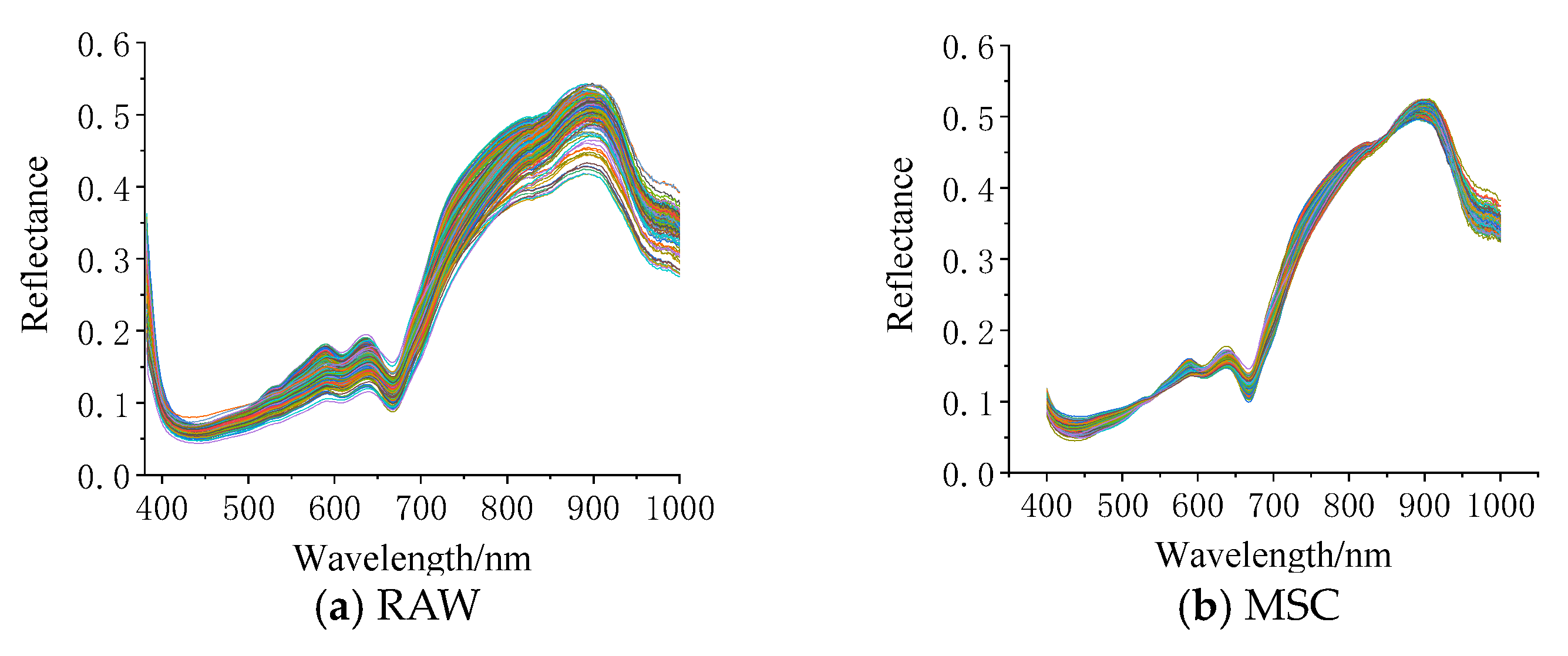
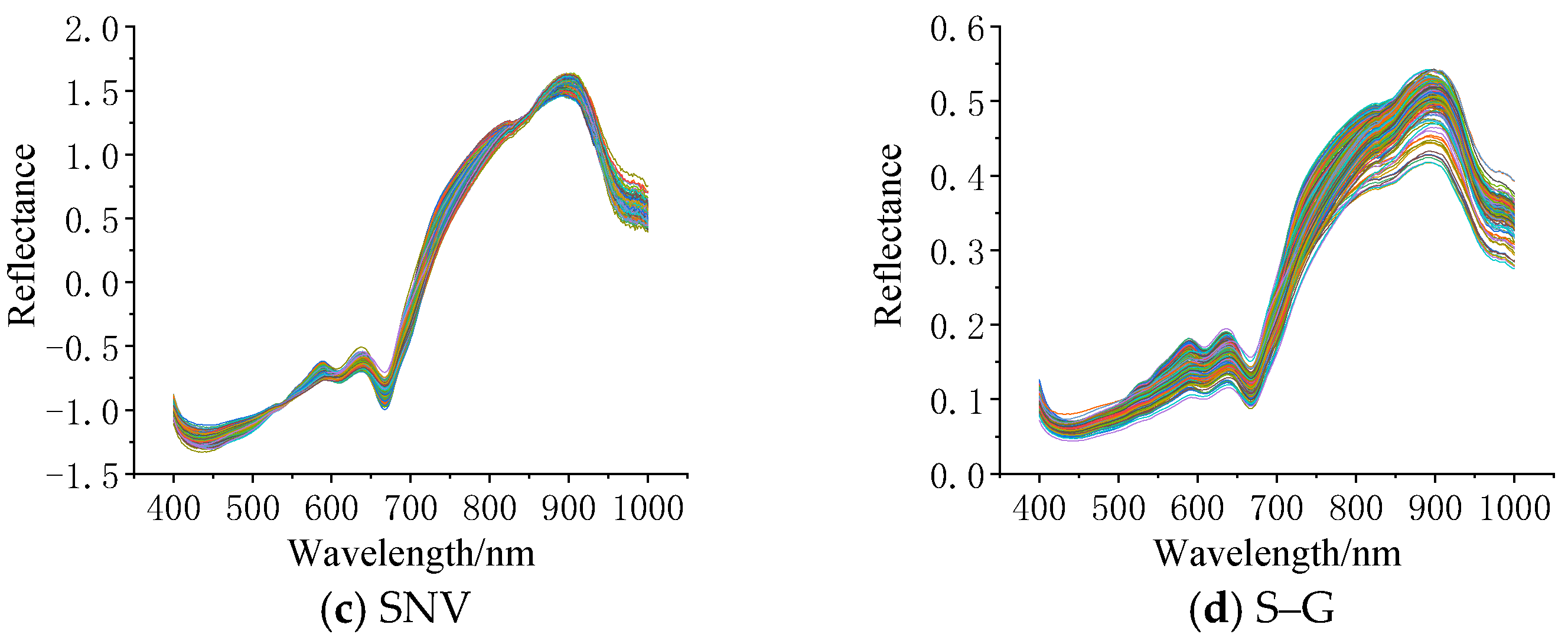
The original hyperspectral curves of silage corn feed and the preprocessed spectral curves are shown in Figure 5a–d. Figure 5a displays the original spectral curves of silage corn feed of different qualities, indicating that the original spectra are significantly affected by noise; Figure 5b shows the spectra after MSC pretreatment, and it can be seen that MSC pretreatment makes the gap between the curves of each hyperspectral data smaller, which indicates that MSC pretreatment can eliminate the scattering phenomenon in the spectra and eliminate the necessary errors; Figure 5c shows the spectra after SNV pretreatment. It can be seen that the effect of SNV preprocessing is similar to that of MSC; Figure 5d shows the spectrum after S–G convolution smoothing preprocessing, and comparing Figure 5a with Figure 5d, it can be found that the spectral curve after S–G convolution smoothing preprocessing is smoother than the original curve. The partial least squares regression (PLSR) model was constructed to optimize the best preprocessing method, and the predicted results are shown in Table 1. From Table 2, it can be seen that the SNV pretreatment is the best, in which the root mean square error of the correction set is 0.0416 and the coefficient of determination is 0.9984, the root mean square error of the prediction set is 0.1273 and the coefficient of determination is 0.9870, and the SNV pretreatment method is used for all subsequent treatments.
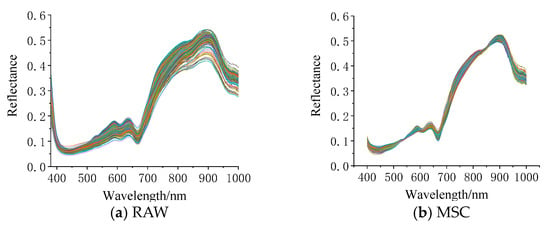
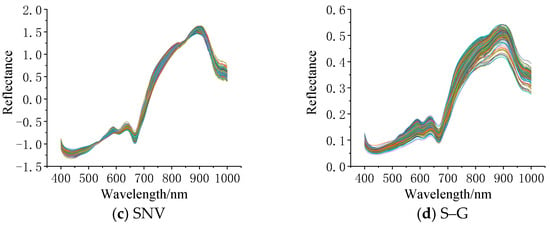
Figure 5.
Preprocessing results graph (each line in the figure represents a sample.).
Table 2.
Full-band PLSR prediction models with different preprocessing methods.
4. Feature Wavelength Extraction and Data Dimensionality Reduction
Hyperspectral data have rich band information, but the overlap of band information will bring redundant data, which may reduce the model classification accuracy.
In order to realize silage corn feed quality classification, this study adopts SNV for spectral data preprocessing to eliminate the influence of noise on spectral acquisition, then uses VCPA and CARS for feature wavelength extraction, and the LDA algorithm for data dimensionality reduction to establish the feed quality classification discriminant model by using only screened-out feature wavelengths, which on the one hand can simplify the model and improve the model running speed, and on the other hand can exclude variables that are not related to or have high correlation with feed quality, so as to obtain a better accuracy and robustness. On the other hand, it can exclude the variables that are not related to feed quality or have low correlation, and then obtain a classification model with better accuracy and robustness.
4.1. Variable Combination Population Analysis (VCPA)
Variable combination population analysis (VCPA) [18,19] is a new variable selection method that uses the idea of model cluster analysis to consider the interaction between variables. The method uses the exponentially decreasing function (EDF) to determine the remaining number of variables and reduce the variable space, and in each EDF run, the binary matrix sampling (BMS) algorithm yields a random combination of variables in each EDF run to generate a cluster of different variable combination subsets and build a submodel from them. The best combination of feature variables is obtained by extracting the optimal 10% submodels with small RMSECV values from the submodel clusters of feature variables and calculating the frequency of all feature variables in the optimal 10% submodels; the higher the frequency, the more important the feature variables are.
When extracting the feature wavelengths from the SNV preprocessed spectra using VCPA, the 5-fold cross-validation method was used, and the number of binary matrix sampling (BMS) runs was set to 1000, and the number of exponentially decreasing function (EDF) runs was set to 50. A total of 11 feature wavelengths were finally filtered out, which were 411, 415, 432, 433, 466, 488, 594, 598, 682, 738, and 996 nm. The number of characteristic wavelengths was reduced from 428 to 11, accounting for 2.6% of the total spectral wavelengths.
4.2. Competitive Adaptive Reweighted Sampling (CARS)
Competitive adaptive reweighted sampling (CARS) is a feature wavelength selection method based on Monte Carlo sampling and regression coefficients in partial least squares regression (PLSR) models, aiming to screen the most competitive wave number combinations. The CARS algorithm calculates the absolute value weights in the regression coefficients by adaptive weighted sampling, removes the points with smaller weights, and the points with larger weights will be used as a new subset, and then the PLSR model is built based on the new subset, and the wavelength corresponding to the PLSR model with the smallest root mean square error of interaction verification (RMSECV) is selected as the characteristic wavelength [20].
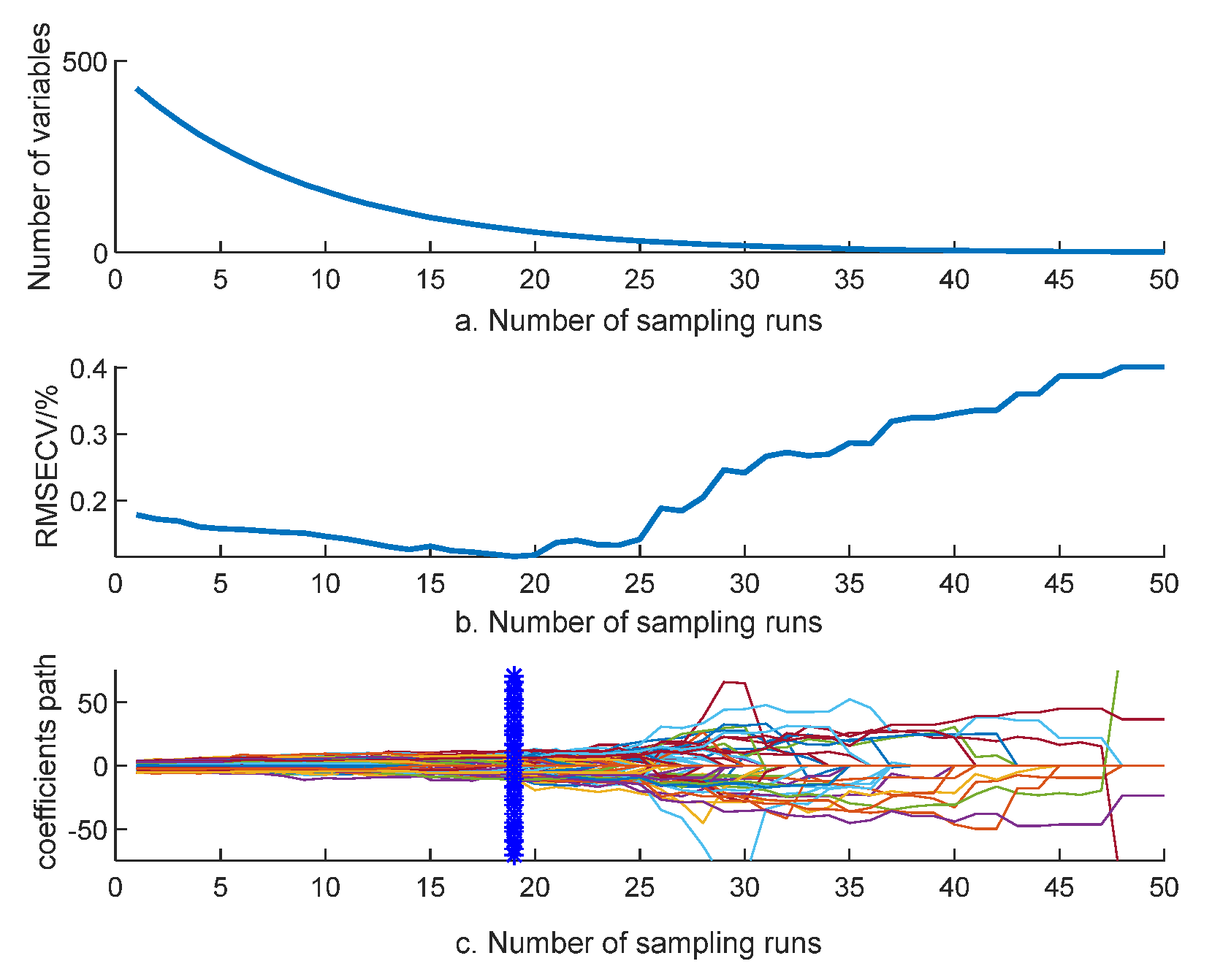
When extracting the feature wavelengths from the SNV preprocessed spectra using the CARS method, the number of Monte Carlo samples is set to 50 and the 5-fold cross-validation method is used [21], and the obtained result plots are shown in Figure 6. As can be seen from the figure, with the increase of sampling times, the number of variables gradually decreases and RMSECV first decreases and then increases, and the value of RMSECV is the lowest at the 19th time, which indicates that the wavelengths with little correlation with feed quality in the silage corn feed spectral data are eliminated during the screening process, and some important parameters are eliminated due to the high selectivity in the screening above 19 times, which causes the error of gradual increase; a total of 43 characteristic wavelengths were screened out, which were 408, 492, 551, 587, 593, 594, 660, 679, 682, 711, 726, 732, 733, 759, 761, 763, 802, 821, 834, 836, 837, 839, 843, 848, 858, 864 876, 879, 882, 897, 899, 900, 905, 906, 909, 923, 939, 943, 948, 951, 955, 970, and 996 nm. The characteristic wavelengths were reduced from the original 428 bands to 43, accounting for 10% of the full spectral bands.
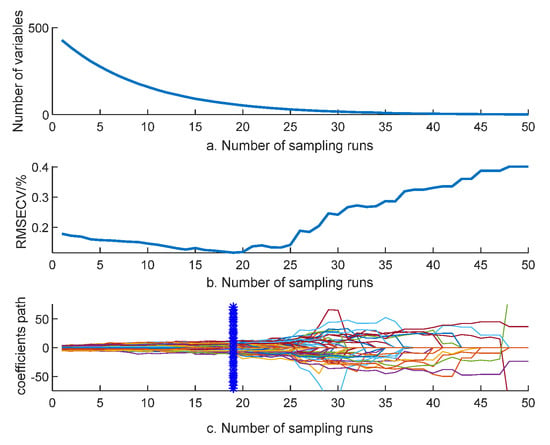
Figure 6.
CARS operation results.
4.3. Linear Discriminant Analysis (LDA)
Linear discriminant analysis (LDA) is a supervised learning dimensionality reduction technique, which uses the discriminant information of sample set to construct intra−class scatter matrix and inter-class scatter matrix , and seeks the optimal projection direction based on this, so that the inter−class scatter of dissimilar data is maximized and the intra−class scatter of similar data is minimized to achieve the sample and which are defined as shown in Equations (1) and (2) [22].
where is the prior probability of the sample of category i; is the j th sample of category i; is the mean of category i; L is the number of categories. represents the projection matrix, then the objective function of LDA can be expressed as Equation (3).
5. Modeling of Silage Maize Feed Classification
5.1. Establishment of RFC Classification Model
The random forest classification (RFC) model uses multiple decision trees for training and enhances the generalization ability of the model by randomly selecting features and data samples. Each decision tree is trained by randomly selecting features and data samples. At classification time, RFC votes the results of multiple decision trees to arrive at the final classification result. The final output is obtained by aggregating the results of each tree, combining several weak classifiers, and voting on the final results using a majority voting mechanism. The final result is obtained by voting or taking the mean value, which gives the whole model effect with higher accuracy and generalization characteristics. The RFC model has high prediction accuracy and noise immunity, and the introduction of randomness avoids the overfitting problem.
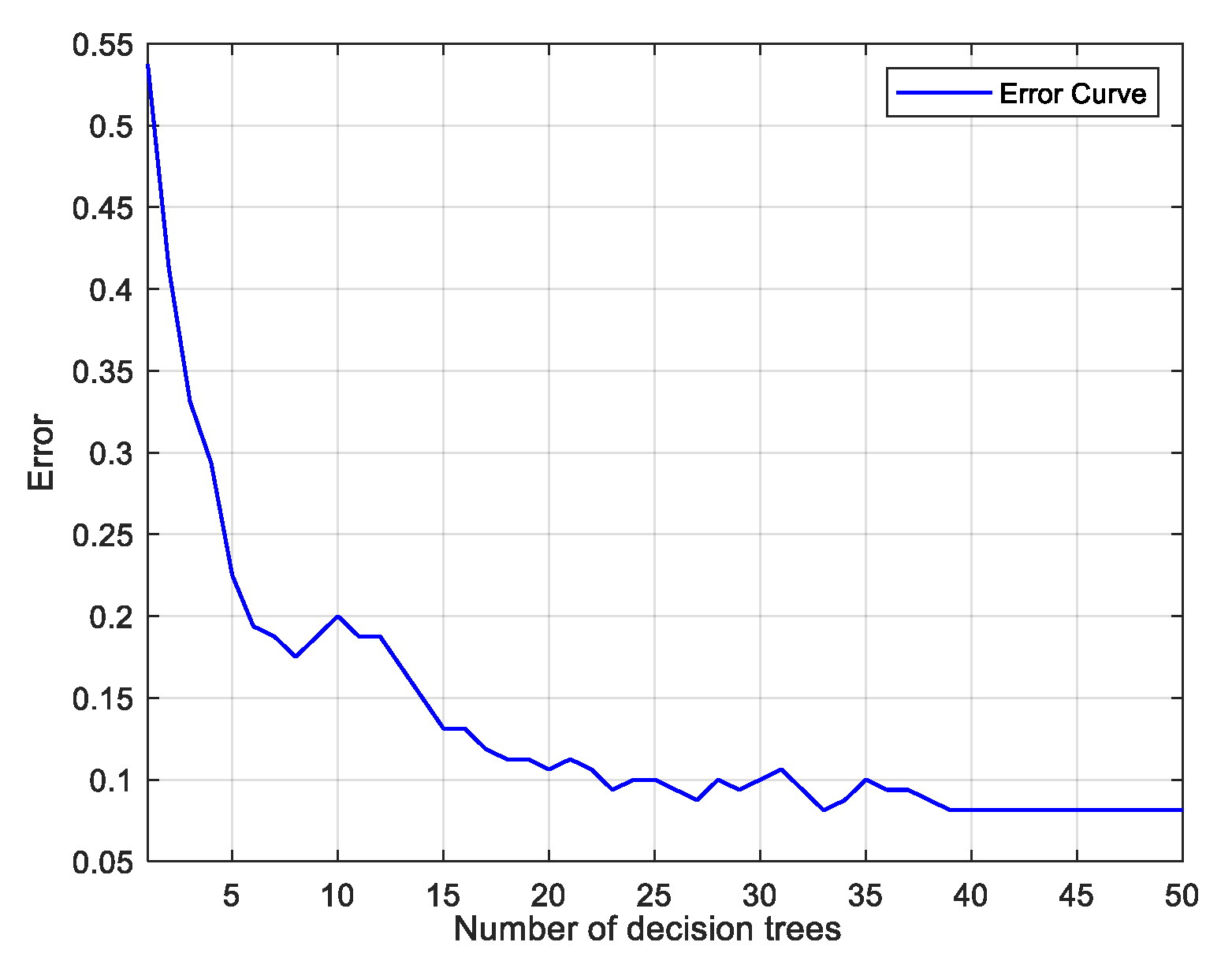
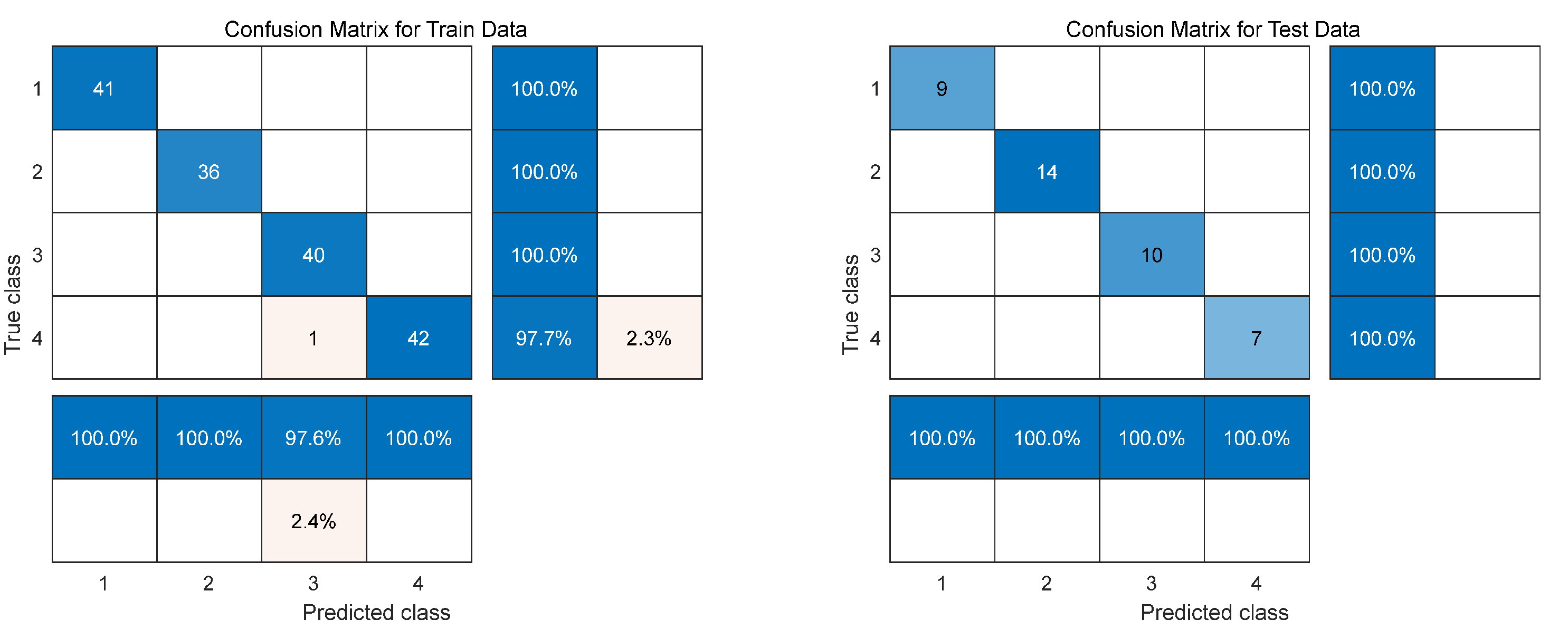
In this study, the number of decision trees in the model is set to 50, and the minimum number of leaves of each decision tree is set to 1. The 200 samples are randomly arranged and divided into correction set and prediction set by 4:1, where the correction set contains 160 samples and the prediction set contains 40 samples. The 11 spectral feature variables selected by the VCPA algorithm and 43 spectral feature variables selected by the CARS algorithm were brought into the RFC classification model, respectively, and the error curves are shown in Figure 7. It can be seen that the error decreases with the increase of the number of decision trees, and when the number of decision trees is 39, the error drops to the lowest and remains basically unchanged. The classification results of the RFC model are shown in Table 3, and from Table 3 it can be seen that the confusion matrix of the correction and prediction sets of the SNV-CARS-RFC model are shown in Figure 8, which shows that there are 50 silage samples of each grade. In the correction set, there are 41 samples with good grades, 36 samples with fair grades, 40 samples with medium grades, and 43 samples with spoilage; in the prediction set, there are 9 samples with good grades, 14 samples with fair grades, 10 samples with medium grades, and 7 samples with spoilage. In the correction set, one sample with the grade of corruption was misclassified as medium. In the prediction set, each class of samples could be accurately classified, and the classification results are shown in Figure 8, which shows that the model classification accuracy is 99.375%, and all samples in the prediction set are accurately discriminated, reaching 100% accuracy.
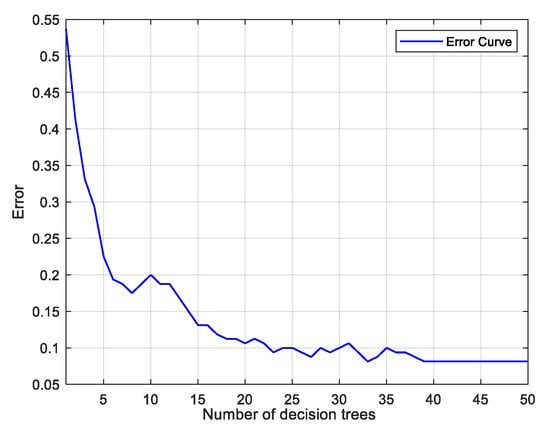
Figure 7.
Error graph.
Table 3.
Accuracy of RFC-based silage maize feed classification model.
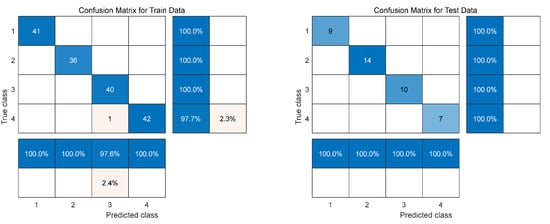
Figure 8.
Confusion matrix diagram.
5.2. CNN Classification Model Building
Convolutional neural network is one of the typical models of deep learning, with convolutional computation and deep structure of feedforward neural network; the basic structure consists of input layer, convolutional layer, activation layer, pooling layer, and fully connected layer [23,24].
In this study, the model consists of two convolutional pooling layers, the size of convolutional kernels is set to 2 × 1, the step size is 2, the number of convolutional kernels is 16 and 32, the maximum pooling layers are set to 2 × 1 and 2 × 2, the step size is 2, a rectified linear unit (RELU) activation function is set in each convolutional layer [25], and gradient descent (Adam) is used as the optimization algorithm. With algorithm (Adam) as the optimization algorithm, the maximum number of iterations is set to 500, the initial learning rate is set to 0.001, and the regularization parameter is set to 0.0001.
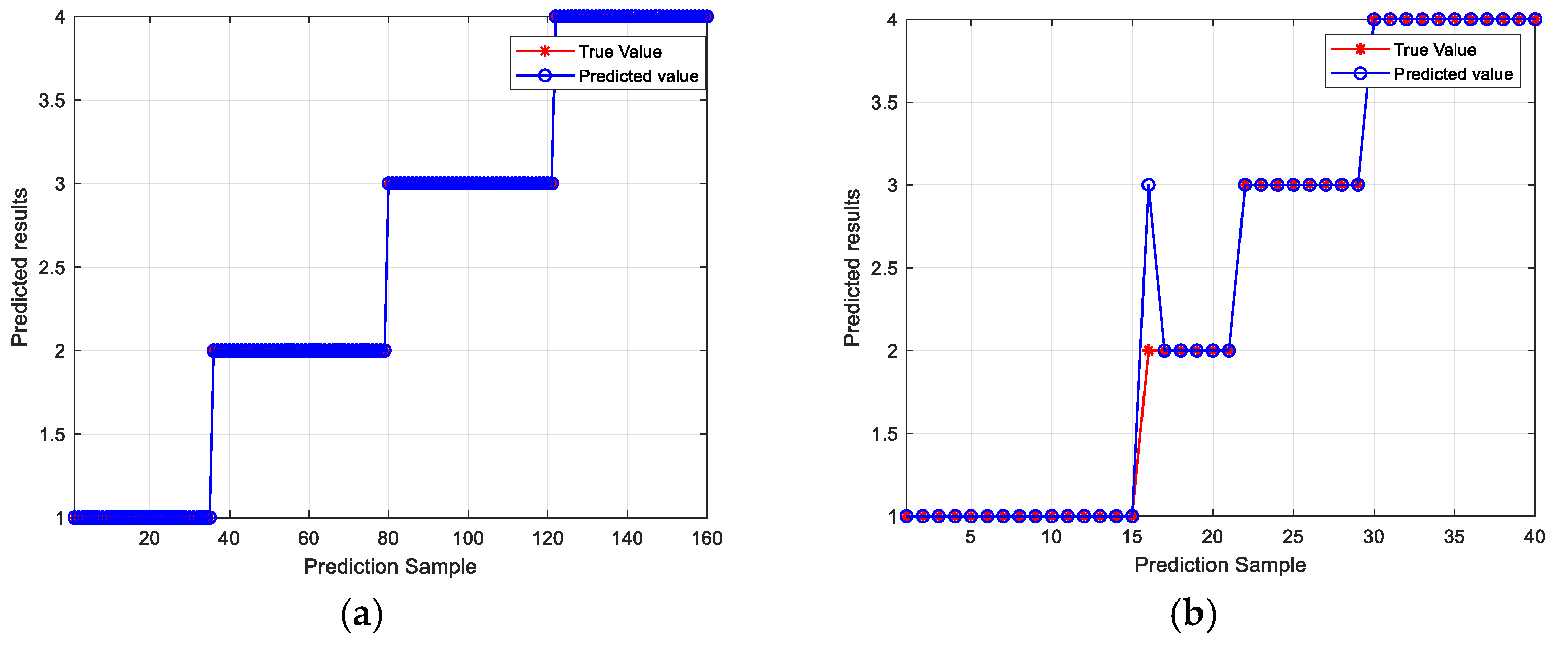
The 200 samples were divided into correction set and prediction set in the ratio of 4:1. The original silage corn feed spectral data, the spectral data after different preprocessing and the data after feature wavelength extraction were imported into the CNN model [26], and the classification results are shown in Table 4. As can be seen from Table 4, the SNV-CNN and SNV-CARS-CNN classification results are the same, with 100% accuracy for the correction set and 97.5% accuracy for the prediction set, but the SNV-CARS-CNN model runs in 38 s, while the SNV-CNN model runs in 128 s, which shows that the SNV-CARS-CNN model has a shorter runtime compared to the SNV-CNN model, which indicates that after feature wavelength extraction, the amount of data is compressed and the model is simplified, thus improving the model’s operation speed. The classification results of the SNV-CARS-CNN model are shown in Figure 9. From Figure 9b, it can be seen that in the test set of the SNV-CARS-CNN model, one secondary sample was misclassified as tertiary, which means that the silage corn feed sample with the grade of still good was misclassified as medium, which may be due to the fact that the values of the feature parameters of still good and medium are relatively similar, which led to the bias of the model when it carried out the classification, which led to the misclassification. Comprehensively comparing the algorithms, the SNV-CARS-CNN model has the best accuracy, and the running time is significantly reduced.
Table 4.
Accuracy of CNN-based classification model for silage maize feed.
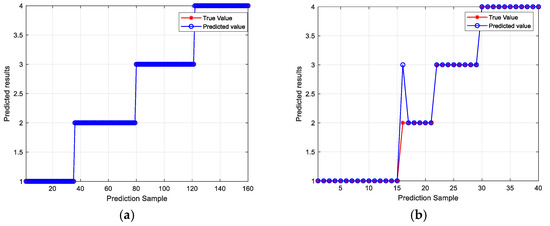
Figure 9.
Graph of SNV-CARS-CNN classification results. (a) Plot of SNV-CARS-CNN calibration set results. (b) Graph of SNV-CARS-CNN prediction set results.
5.3. SVM Classification Model Building
Support vector machines (SVM) can solve linear undifferentiated problems and are particularly suitable for data classification problems [22]. The choice of kernel function type, related parameters c and gamma are key. C is the weight to adjust the interval size and classification accuracy; too high value of c tends to over-adjust, and vice versa; too low value of c will lead to under-adjustment, which in turn affects the generalization effect; gamma value mainly affects the mapping of low-dimensional samples; the larger the value, the less support vectors, and vice versa, the more support vectors.
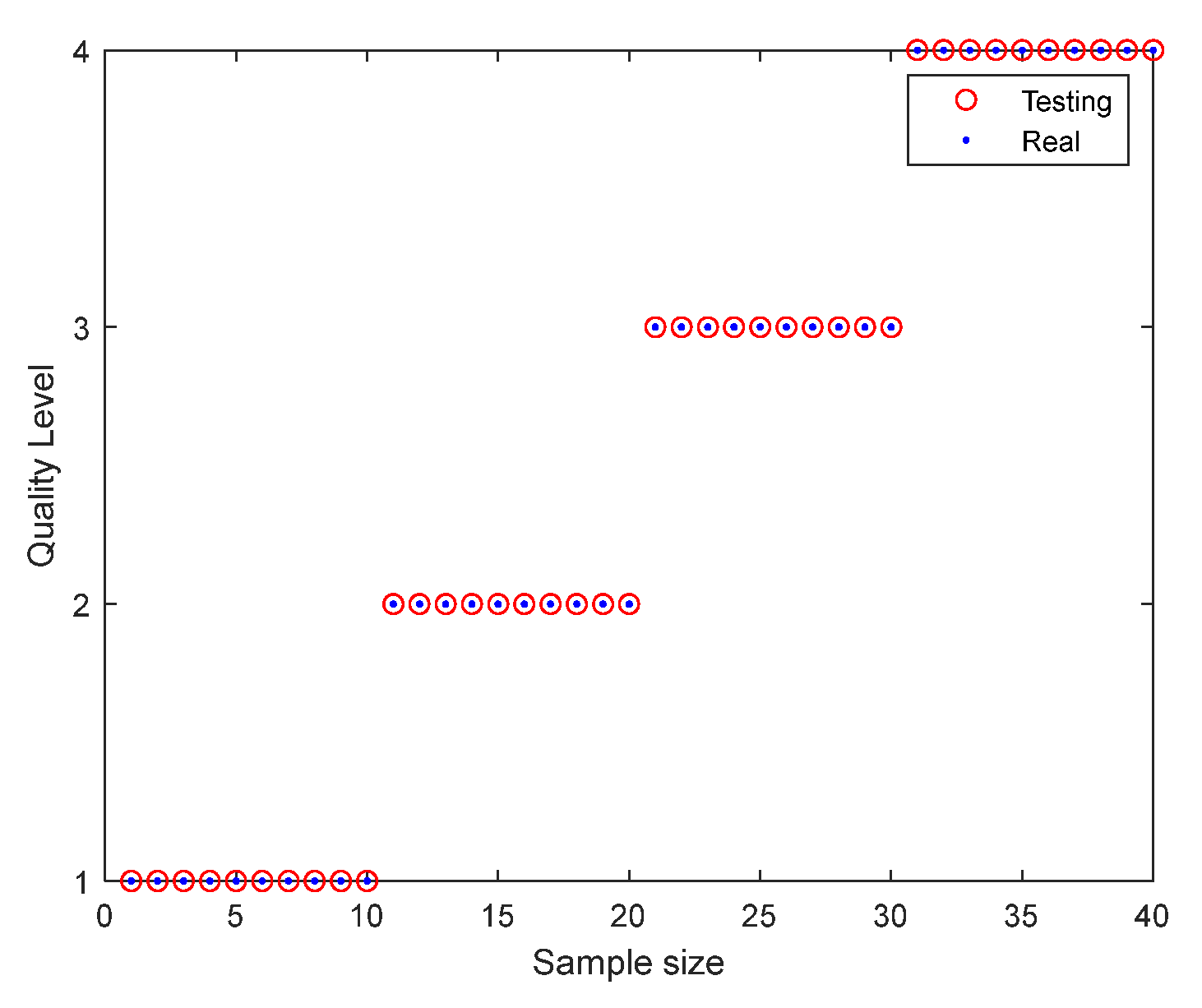
In this study, 200 silage corn feed samples of different quality were divided into calibration and prediction sets in the ratio of 4:1, and Gaussian kernel function (Gaussian) was selected as the kernel function because it has the characteristics of high stability and good model accuracy. The feature wavelengths of the pre-treated silage corn feed spectral data were extracted using CARS and VCPA algorithms, and the LDA algorithm was used for data dimensionality reduction to construct SVM classification models for silage corn feed quality, respectively. Figure 10 shows the graph of SNV-LDA-SVM classification results, and Table 5 shows the classification results of silage corn feed based on SVM models. From Figure 10 and Table 5, it can be seen that the use of SNV as the silage corn feed pretreatment method, using LDA dimensionality reduction and the building SVM classification model, has the best results, which can accurately achieve the quality classification of silage corn feed, where the accuracy of the correction set is 100% and the accuracy of the prediction set is 100%.
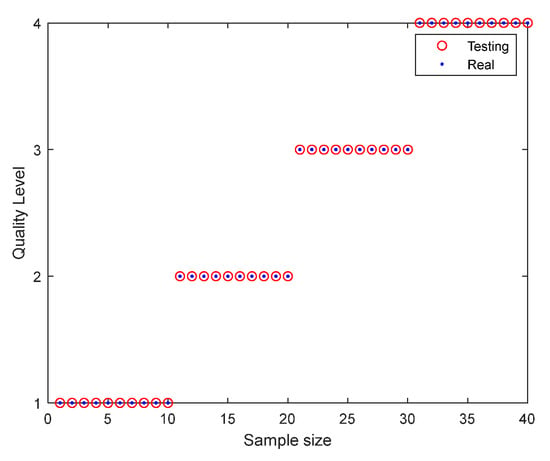
Figure 10.
Graph of SNV-LDA-SVM classification results.
Table 5.
Classification results based on SVM model.
6. Comparison of Model Results
In this study, three classification models, RFC, CNN, and SVM, were used to realize the quality classification of silage corn fodder. In the RFC classification model, the optimal algorithm combination was SNV-CARS-RFC, with 99.375% classification accuracy in the correction set and 100% classification accuracy in the prediction set. In the CNN classification model, the optimal algorithm combination is SNV-CARS-CNN with 100% accuracy in the correction set and 97.5% accuracy in the prediction set. In the SVM classification model, the optimal algorithm combination is SNV-LDA-SVM, the accuracy of the correction set is 100%, and the accuracy of the prediction set is 100%. Comprehensively comparing the above algorithms, SNV-LDA-SVM is the optimal algorithm combination, which can accurately realize the external sensory quality grading of silage corn feed.
7. Discussion
The traditional methods for testing the quality of maize silage are mainly divided into sensory evaluation and laboratory evaluation methods. The sensory evaluation method mainly judges from the three aspects of smell, texture, and color and classifies the maize silage into four grades: good, fair, medium, and spoiled. This method is highly subjective and requires a great deal of experience on the part of the inspectors. The laboratory evaluation method is mainly based on chemical analysis, which evaluates the quality of the samples to be tested by calculating the percentage of organic acids in the silage and combining this with the ammonia nitrogen score. Although the accuracy of this method is high, the process is complicated with a large number of experimental instruments, which requires a large amount of time, manpower, material and financial resources, and the chemical substances produced in the analysis also cause pollution of the environment.
Hyperspectral imaging technology has the advantages of non-destructive, rapid, accurate, multi-parameter simultaneous detection, etc., which can provide comprehensive and objective information for silage maize feed quality assessment, and compared with the traditional quality detection methods, hyperspectral technology can greatly improve the detection efficiency, reduce the detection cost, and reduce the human error, so the adoption of hyperspectral technology to promote the improvement of the research level of silage maize feed quality detection has an advantage. Therefore, the use of hyperspectral technology is of great significance to promote the improvement of silage maize feed quality testing.
Hyperspectral imaging technology can accurately capture the spectral response of silage maize feed at different wavelengths by collecting different wavelength spectral data or images of the samples, and these spectral information contain important indexes such as nutrient composition, moisture content, fermentation quality of the feed, etc. The hyperspectral reflectance curves corresponding to silage maize feeds with different qualities differ to a certain extent. Through preprocessing, characteristic wavelength extraction, and model building, these spectral data can be processed and analyzed, and a mathematical model directly related to feed quality can be established, and then the quality grading of silage corn feed can be completed.
8. Conclusions and Perspectives
In this study, we used a hyperspectral imaging system to collect spectral data of 200 silage maize samples in the 380~1004 nm band. Preprocessing of the hyperspectral data was performed using three algorithms: MSC, SNV and S–G. To reduce the redundancy of spectral data, feature wavelength selection was conducted using CARS and VCPA algorithms, and data dimensionality reduction was achieved using the LDA algorithm. Classification models for both the full and feature bands of the feed were established using RFC, CNN, and SVM models, leading to the determination of the optimal classification model. The experimental results indicate that the use of SNV as a preprocessing method for silage corn feed, combined with LDA for data dimensionality reduction and the establishment of an SVM classification model, yielded the best results, with an accuracy rate of 100% for both the calibration and prediction sets. Consequently, the integration of hyperspectral technology with the SNV-LDA-SVM algorithm can facilitate the external sensory quality grading of silage corn feed, with grading outcomes aligning with the sensory evaluation grades determined by experts according to the DLG standards.
Since the silage maize forage samples for quality grading in this study were all collected from the Inner Mongolia region, the relevant prediction models still need to be verified in terms of robustness and adaptability. For this reason, subsequent studies can be repeated in other silage maize growing regions or products from other provinces and cities in the Inner Mongolia Autonomous Region to increase the number of data, improve the sample variability, and provide data support for constructing and revising the model, which will contribute to the popularization and application of hyperspectral technology in the field of silage maize feed quality testing.
Author Contributions
Conceptualization, M.Z. and M.H.; methodology, M.Z. and M.H.; software, M.Z. and M.H.; validation, M.Z., M.H., H.T. and J.S.; formal analysis, M.H. and H.T.; investigation, J.S.; resources, H.T.; data curation, M.Z., M.H., H.T. and J.S.; writing—original draft preparation, M.Z. and M.H.; writing—review and editing, M.Z. and M.H.; visualization, M.Z. and M.H.; supervision, M.H. and H.T.; project administration, H.T.; funding, M.Z. and M.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (32071893); The Science and Technology Program Project of Inner Mongolia Autonomous Region (2022YFDZ0024).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author; however, since the author has not yet graduated and there is a confidentiality agreement, the disclosure of the data will be considered after graduation.
Conflicts of Interest
Author Mengyu Zhang was employed by the company Xilingol Power Branch of Inner Mongolia Power (Group) Co. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Jin, Y. Notes, problems and countermeasures of whole plant corn silage technology. Anim. Husb. Vet. Sci. Electron. Ed. 2020, 15, 129–130. [Google Scholar]
- Liu, Z.; Liu, Z.; Li, J.; Xie, N.; Qin, W.; Feng, W.; Zhi, J. Analysis of the development status of silage industry in China. Herbology 2020, 251, 70–75. [Google Scholar]
- Gao, Y.; Lin, H. The status of grass economy in the national economy, current situation and its development suggestions. J. Grass Ind. 2015, 24, 141. [Google Scholar] [CrossRef]
- He, L. Identification of silage quality and key factors affecting it. China Livest. Poult. Breed. Ind. 2018, 14, 26–27. [Google Scholar]
- Li, X.; Jiang, H.; Jiang, X.; Gu, H. Research progress on near-infrared spectroscopy and imaging nondestructive testing of woody grain, oil and forest fruit quality. Food Ferment. Ind. 2022, 48, 302–308. [Google Scholar] [CrossRef]
- Mu, H. Research on the Application of Near-Infrared Spectroscopy Technology in the Evaluation of Corn Nutritional Quality and Silage Quality. Bachelor’s Thesis, Inner Mongolia Agricultural University, Hohhot, China, 2008. [Google Scholar]
- Giorgio, M.; Giacomo, S. Development of near infrared (NIR) spect.roscopy and electronic nose (EN) techniques to analyse the conservation quality of farm silages. J. Food Agric. Environ. 2007, 5, 172–177. [Google Scholar]
- Hetta, M.; Mussadiq, Z.; Wallsten, J.; Halling, M.; Swensson, C.; Geladi, P. Prediction of nutritive values, morpHology and agronomic characteristics in forage maize using two applications of NIRS spectrometry. Acta Agric. Scand. Sect. Bsoil Plant Sci. 2017, 67, 326–333. [Google Scholar] [CrossRef]
- Xiao, H.; Ma, F.H.; Wang, F.Q.; Li, Y.; Rong, Y. Study on the near-infrared assessment method of crude ash content of alfalfa silage. Anal. Chem. 2018, 1285–1289. [Google Scholar] [CrossRef]
- Tang, K. Model Development and Application of Portable Near-Infrared Spectrometer for Predicting Alfalfa Hay Quality. Master’s Thesis, Shihezi University, Shihezi, China, 2018. [Google Scholar]
- Zhang, J.; Tian, H.; Zhao, Z.; Zhang, L.; Zhang, J.; Li, F. Hyperspectral detection of water content of silage maize raw materials based on improved discrete particle swarm algorithm. J. Agric. Eng. 2019, 35, 285–293. [Google Scholar]
- Zhang, M.; Zhao, C.; Shao, Q.; Yang, Z.; Zhang, X.; Xu, X.; Hassan, M. Determination of water content in corn stover silage using near-infrared spectroscopy. Int. J. Agric. Biol. Eng. 2019, 12, 143–148. [Google Scholar] [CrossRef]
- Cao, M.Y.; Li, X.; Huang, H.Q.; Lan, J.; Niu, Y.; Lv, J.; Lan, Z. Detection of nutrient composition of silage by near-infrared spectroscopy. Mod. Anim. Husb. 2020, 4, 42–45. [Google Scholar]
- Ren, X. Research on Silage Corn Feed Quality Detection Method Based on Computer Vision; Inner Mongolia Agricultural University: Hohhot, China, 2023. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Tian, H. Remote sensing estimation research of leaf nitrogen in sugar beet based on hyperspectral imaging. J. Zhongshan Univ. Nat. Sci. Ed. 2018, 57, 103–112, (In Chinese with English Abstract). [Google Scholar]
- Sun, J.; Cong, S.; Mao, H.; Wu, X.; Zhang, X.; Wang, P. Hyperspectral-based CARS-ABC-SVR prediction model for leaf moisture in oilseed rape. J. Agric. Eng. 2017, 33, 178–184. [Google Scholar]
- Liu, H.; Wu, X.; Li, D.; Zhang, F.; Zhang, D.; Huang, H. Study on the moisture content of tobacco leaves during picking period based on hyperspectral technology. Chin. J. Agric. Chem. 2021, 42, 157–163. [Google Scholar]
- Song, Y.; Huan, K.; Han, X.; Shi, X.; Zhao, H. Selection of near-infrared spectral variables for wheat proteins based on Monte Carlo variable combination cluster analysis. J. Chang. Univ. Sci. Technol. Nat. Sci. Ed. 2017, 40, 29–35. [Google Scholar]
- Sun, D. Research on Near-Infrared Spectral Analysis Technology of Wheat Quality Based on Model Cluster Analysis. Master’s Thesis, Changchun University of Science and Technology, Changchun, China, 2020. [Google Scholar] [CrossRef]
- Yang, C. Research on Fermentation Quality Information Detection Technology of Black Tea Based on Hyperspectral. Master’s Thesis, Shihezi University, Shihezi, China, 2021. [Google Scholar] [CrossRef]
- Gao, S.; Wang, Q.; Fu, D.; Li, Q. Hyperspectral imaging nondestructive detection of red grape brix and hardness. J. Opt. 2019, 39, 355–364. [Google Scholar]
- Xiong, J.; Qiao, F.; Liu, Z.; Liu, Y.; Hao, B.; Jiang, W.; Xu, L.; Lu, L. Research on rapid nondestructive detection method of shellfish heavy metal contamination based on hyperspectral images. Environ. Eng. 2022, 40, 141–149. [Google Scholar]
- Dai, Q.; Liao, C.; Li, Z.; Song, S.; Xue, X.; Xiong, S. Hyperspectral citrus leaf water content visualization based on CARS-CNN. Spectrosc. Spectr. Anal. 2022, 42, 2848–2854. [Google Scholar]
- Jiang, H. Research and implementation of audio opinion analysis system based on heterogeneous neural network. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2021. [Google Scholar] [CrossRef]
- Li, X.; Ling, Z.; Zou, W. Semi-supervised hyperspectral image classification based on convolutional neural network. J. Electron. Meas. Instrum. 2018, 32, 95–102. [Google Scholar]
- Ji, J.; Li, P.; Jin, X.; Ma, H.; Li, M. Quantitative detection of tomato seedling robustness during spring nursery transplanting based on spectroscopy. Spectrosc. Spectr. Anal. 2022, 42, 1741–1748. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).