

Intelligent Surface Recognition for Autonomous Tractors Using Ensemble Learning with BNO055 IMU Sensor Data

Abstract
:1. Introduction
2. Materials and Methods
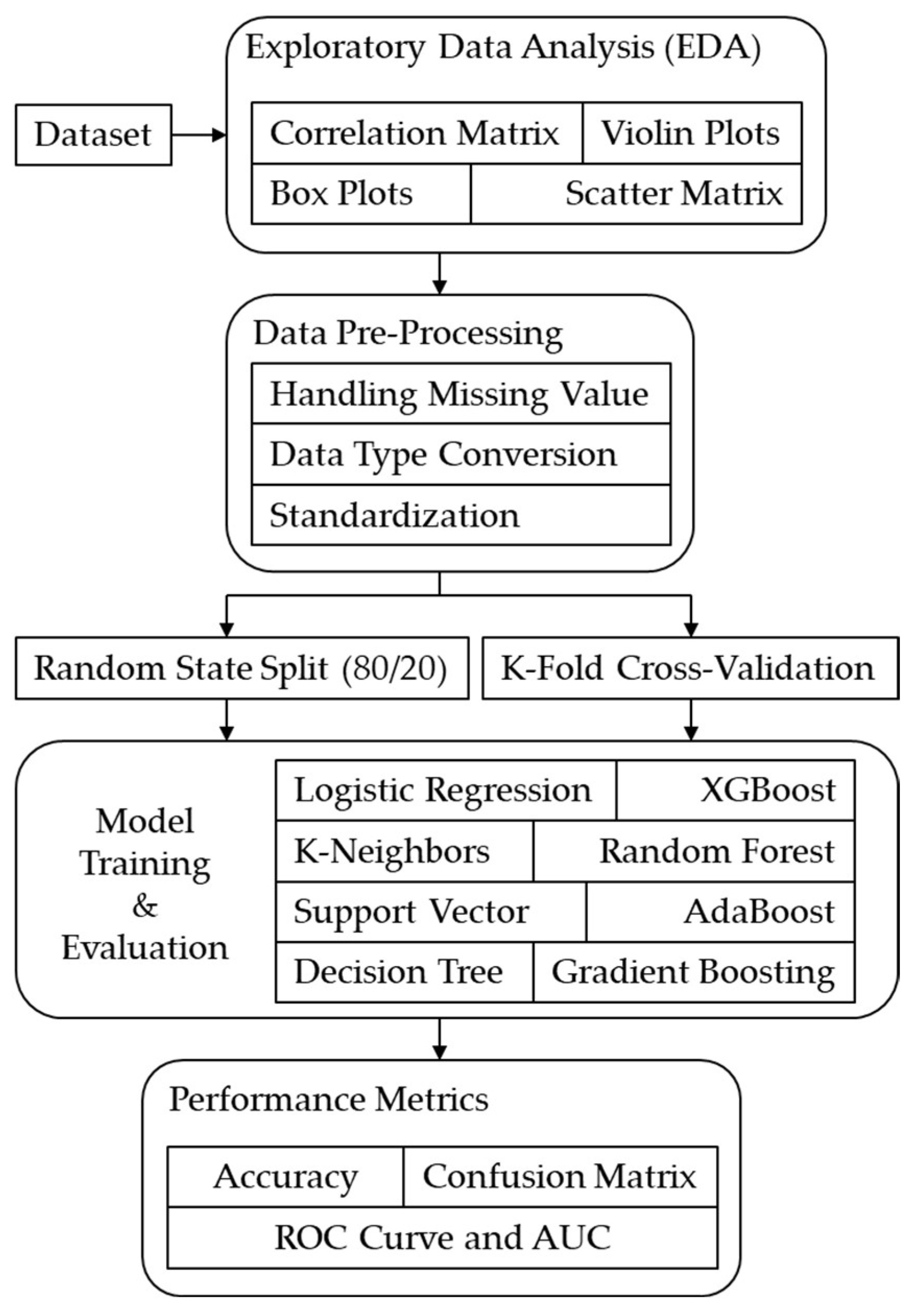
2.1. Research Overview
2.2. Data Collection and Field Testing
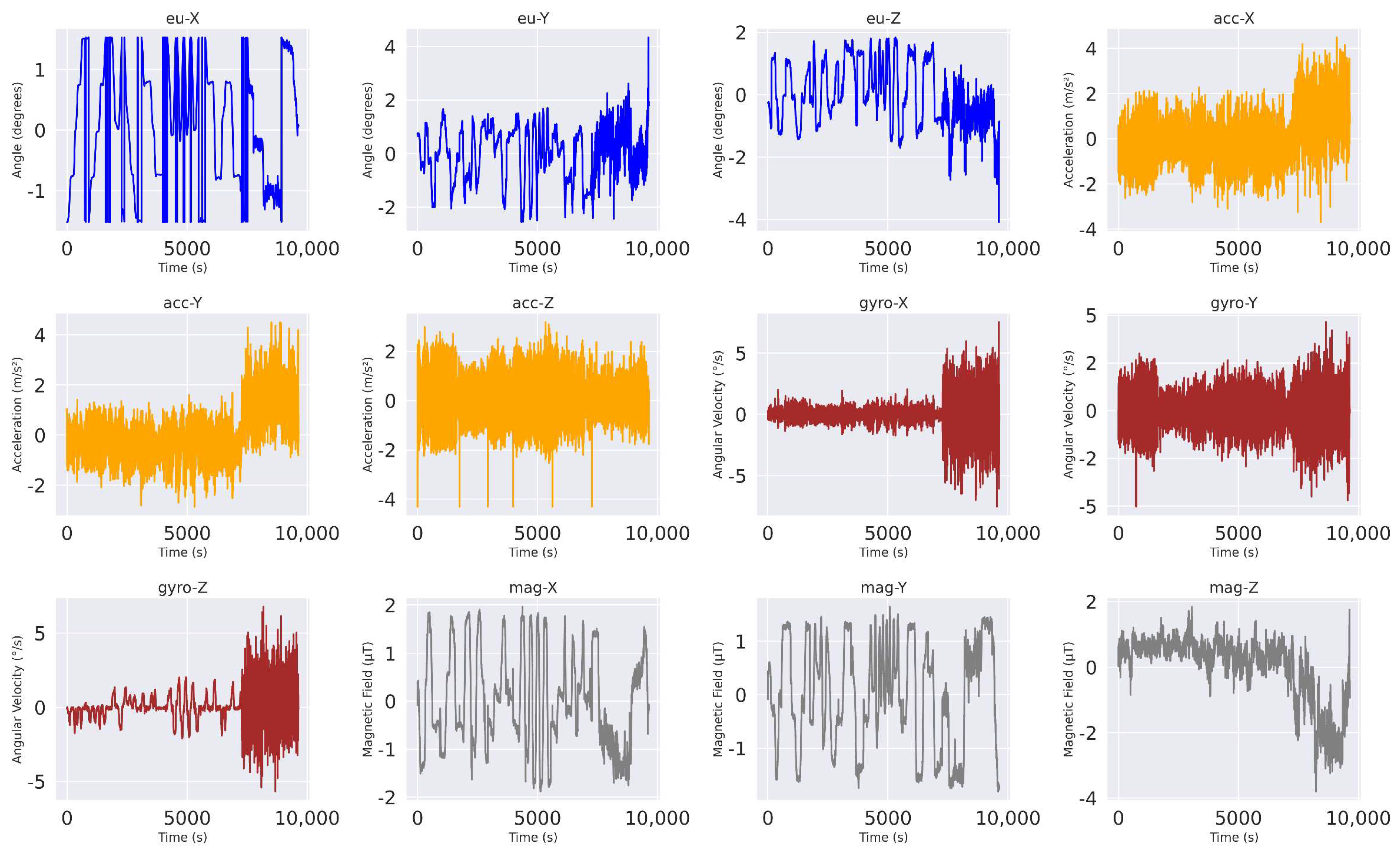
2.3. Data Description
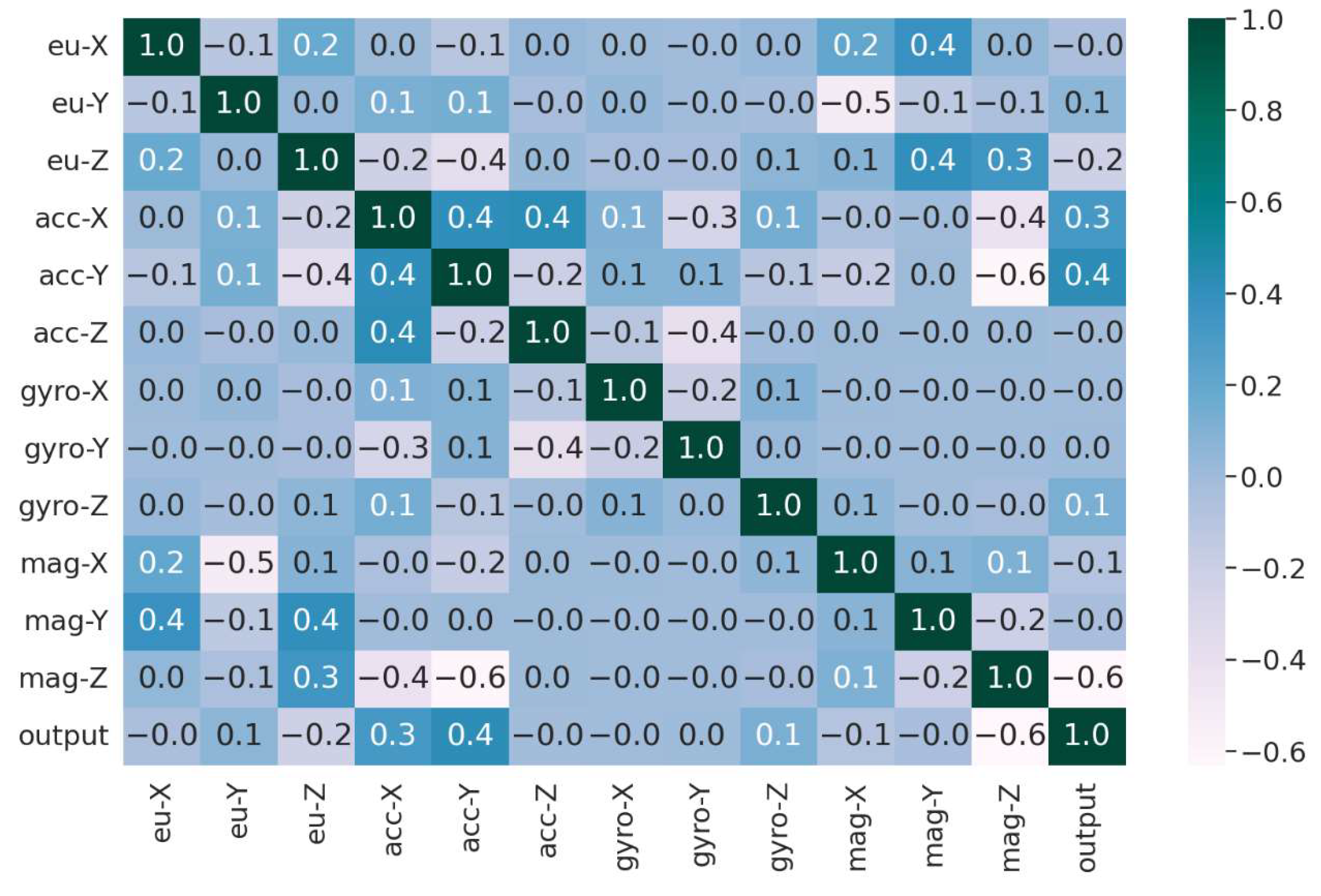
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qu, J.; Zhang, Z.; Qin, Z.; Guo, K.; Li, D. Applications of Autonomous Navigation Technologies for Unmanned Agricultural Tractors: A Review. Machines 2024, 12, 218. [Google Scholar] [CrossRef]
- Xie, B.; Jin, Y.; Faheem, M.; Gao, W.; Liu, J.; Jiang, H.; Cai, L.; Li, Y. Research Progress of Autonomous Navigation Technology for Multi-Agricultural Scenes. Comput. Electron. Agric. 2023, 211, 107963. [Google Scholar] [CrossRef]
- Gil, G.; Casagrande, D.E.; Cortés, L.P.; Verschae, R. Why the Low Adoption of Robotics in the Farms? Challenges for the Establishment of Commercial Agricultural Robots. Smart Agric. Technol. 2023, 3, 100069. [Google Scholar] [CrossRef]
- Shi, J.; Bai, Y.; Diao, Z.; Zhou, J.; Yao, X.; Zhang, B. Row Detection BASED Navigation and Guidance for Agricultural Robots and Autonomous Vehicles in Row-Crop Fields: Methods and Applications. Agronomy 2023, 13, 1780. [Google Scholar] [CrossRef]
- Vrochidou, E.; Oustadakis, D.; Kefalas, A.; Papakostas, G.A. Computer Vision in Self-Steering Tractors. Machines 2022, 10, 129. [Google Scholar] [CrossRef]
- Roshanianfard, A.; Noguchi, N.; Okamoto, H.; Ishii, K. A Review of Autonomous Agricultural Vehicles (The Experience of Hokkaido University). J. Terramech. 2020, 91, 155–183. [Google Scholar] [CrossRef]
- Samatas, G.G.; Pachidis, T.P. Inertial Measurement Units (IMUs) in Mobile Robots over the Last Five Years: A Review. Designs 2022, 6, 17. [Google Scholar] [CrossRef]
- Oliver, M.A. Progress in Precision Agriculture Series Editor; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Loukatos, D.; Petrongonas, E.; Manes, K.; Kyrtopoulos, I.V.; Dimou, V.; Arvanitis, K.G. A Synergy of Innovative Technologies towards Implementing an Autonomous Diy Electric Vehicle for Harvester-Assisting Purposes. Machines 2021, 9, 82. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Zhao, W.; Li, T.; Qi, B.; Nie, Q.; Runge, T. Terrain Analytics for Precision Agriculture with Automated Vehicle Sensors and Data Fusion. Sustainability 2021, 13, 2905. [Google Scholar] [CrossRef]
- Lu, E.; Xue, J.; Chen, T.; Jiang, S. Robust Trajectory Tracking Control of an Autonomous Tractor-Trailer Considering Model Parameter Uncertainties and Disturbances. Agriculture 2023, 13, 869. [Google Scholar] [CrossRef]
- Adab, H.; Morbidelli, R.; Saltalippi, C.; Moradian, M.; Ghalhari, G.A.F. Machine Learning to Estimate Surface Soil Moisture from Remote Sensing Data. Water 2020, 12, 3223. [Google Scholar] [CrossRef]
- Ge, G.; Shi, Z.; Zhu, Y.; Yang, X.; Hao, Y. Land Use/Cover Classification in an Arid Desert-Oasis Mosaic Landscape of China Using Remote Sensed Imagery: Performance Assessment of Four Machine Learning Algorithms. Glob. Ecol. Conserv. 2020, 22, e00971. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine Learning Applications for Precision Agriculture: A Comprehensive Review. IEEE Access 2021, 9, 4843–4873. [Google Scholar] [CrossRef]
- Mohinur Rahaman, M.; Azharuddin, M. Wireless Sensor Networks in Agriculture through Machine Learning: A Survey. Comput. Electron. Agric. 2022, 197, 106928. [Google Scholar] [CrossRef]
- Singh, A.; Nawayseh, N.; Singh, H.; Dhabi, Y.K.; Samuel, S. Internet of Agriculture: Analyzing and Predicting Tractor Ride Comfort through Supervised Machine Learning. Eng. Appl. Artif. Intell. 2023, 125, 106720. [Google Scholar] [CrossRef]
- Buya, S.; Tongkumchum, P.; Owusu, B.E. Modelling of Land-Use Change in Thailand Using Binary Logistic Regression and Multinomial Logistic Regression. Arab. J. Geosci. 2020, 13, 437. [Google Scholar] [CrossRef]
- Mazumder, B.; Khan, M.S.I.; Mohi Uddin, K.M. Biorthogonal Wavelet Based Entropy Feature Extraction for Identification of Maize Leaf Diseases. J. Agric. Food Res. 2023, 14, 100756. [Google Scholar] [CrossRef]
- Kok, Z.H.; Mohamed Shariff, A.R.; Alfatni, M.S.M.; Khairunniza-Bejo, S. Support Vector Machine in Precision Agriculture: A Review. Comput. Electron. Agric. 2021, 191, 106546. [Google Scholar] [CrossRef]
- Reddy, K.S.P.; Roopa, Y.M.; Kovvada Rajeev, L.N.; Nandan, N.S. IoT Based Smart Agriculture Using Machine Learning. In Proceedings of the Second International Conference on Inventive Research in Computing Applications (ICIRCA-2020), Coimbatore, India, 15–17 July 2020; pp. 130–134. [Google Scholar]
- Wang, H.; Yilihamu, Q.; Yuan, M.; Bai, H.; Xu, H.; Wu, J. Prediction Models of Soil Heavy Metal(Loid)s Concentration for Agricultural Land in Dongli: A Comparison of Regression and Random Forest. Ecol. Indic. 2020, 119, 106801. [Google Scholar] [CrossRef]
- Huber, F.; Yushchenko, A.; Stratmann, B.; Steinhage, V. Extreme Gradient Boosting for Yield Estimation Compared with Deep Learning Approaches. Comput. Electron. Agric. 2022, 202, 107346. [Google Scholar] [CrossRef]
- Li, Y.; Guo, Y.; Gong, L.; Liu, C. Harvesting Route Detection and Crop Height Estimation Methods for Lodged Farmland Based on AdaBoost. Agriculture 2023, 13, 1700. [Google Scholar] [CrossRef]
- Mariadass, D.A.L.; Moung, E.G.; Sufian, M.M.; Farzamnia, A. Extreme Gradient Boosting (XGBoost) Regressor and Shapley Additive Explanation for Crop Yield Prediction in Agriculture. In Proceedings of the 2022 12th International Conference on Computer and Knowledge Engineering, ICCKE 2022, Mashhad, Iran, 17–18 November 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; pp. 219–224. [Google Scholar]
- Grygar, T.M.; Radojičić, U.; Pavlů, I.; Greven, S.; Nešlehová, J.G.; Tůmová, Š.; Hron, K. Exploratory Functional Data Analysis of Multivariate Densities for the Identification of Agricultural Soil Contamination by Risk Elements. J. Geochem. Explor. 2024, 259, 107416. [Google Scholar] [CrossRef]
- Dash, C.S.K.; Behera, A.K.; Dehuri, S.; Ghosh, A. An Outliers Detection and Elimination Framework in Classification Task of Data Mining. Decis. Anal. J. 2023, 6, 100164. [Google Scholar] [CrossRef]
- Kebonye, N.M. Exploring the Novel Support Points-Based Split Method on a Soil Dataset. Measurement 2021, 186, 110131. [Google Scholar] [CrossRef]
- Lyu, Z.; Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Nguyen, A. Back-Propagation Neural Network Optimized by K-Fold Cross-Validation for Prediction of Torsional Strength of Reinforced Concrete Beam. Materials 2022, 15, 1477. [Google Scholar] [CrossRef]
- Vu, H.L.; Ng, K.T.W.; Richter, A.; An, C. Analysis of Input Set Characteristics and Variances on K-Fold Cross Validation for a Recurrent Neural Network Model on Waste Disposal Rate Estimation. J. Environ. Manag. 2022, 311, 114869. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Matthews Correlation Coefficient (MCC) Should Replace the ROC AUC as the Standard Metric for Assessing Binary Classification. BioData Min. 2023, 16, 4. [Google Scholar] [CrossRef]
- Valero-Carreras, D.; Alcaraz, J.; Landete, M. Comparing Two SVM Models through Different Metrics Based on the Confusion Matrix. Comput. Oper. Res. 2023, 152, 106131. [Google Scholar] [CrossRef]
- Rachakonda, A.R.; Bhatnagar, A. ARatio: Extending Area under the ROC Curve for Probabilistic Labels. Pattern Recognit. Lett. 2021, 150, 265–271. [Google Scholar] [CrossRef]
- Zou, M.; Djokic, S.Z. A Review of Approaches for the Detection and Treatment of Outliers in Processing Wind Turbine and Wind Farm Measurements. Energies 2020, 13, 4228. [Google Scholar] [CrossRef]
- Ribeiro, R.P.; Moniz, N. Imbalanced Regression and Extreme Value Prediction. Mach. Learn. 2020, 109, 1803–1835. [Google Scholar] [CrossRef]
- Veloso, M. Machine Learning for Autonomous Vehicle Road Condition Analysis. J. AI Healthc. Med. 2023, 3, 141–159. [Google Scholar]
- Jamal, A.; Zahid, M.; Tauhidur Rahman, M.; Al-Ahmadi, H.M.; Almoshaogeh, M.; Farooq, D.; Ahmad, M. Injury Severity Prediction of Traffic Crashes with Ensemble Machine Learning Techniques: A Comparative Study. Int. J. Inj. Contr. Saf. Promot. 2021, 28, 408–427. [Google Scholar] [CrossRef] [PubMed]
- Reina, G.; Milella, A.; Rouveure, R.; Nielsen, M.; Worst, R.; Blas, M.R. Ambient Awareness for Agricultural Robotic Vehicles. Biosyst. Eng. 2016, 146, 114–132. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output ID | Scenario | Track | Surface | Longitude | Latitude |
|---|---|---|---|---|---|
| 0 | Scenario 1 | Around | Asphalt | 14.134466 | 100.610301 |
| 1 | Scenario 2 | Around | Gravel | 14.134458 | 100.609802 |
| 2 | Scenario 3 | Zigzag | Gravel | 14.134458 | 100.609802 |
| 3 | Scenario 4 | Around | Concrete + Gravel | 14.132445 | 100.613033 |
| 4 | Scenario 5 | Zigzag | Concrete + Gravel | 14.132445 | 100.613033 |
| 5 | Scenario 6 | Around | Soil + Grass | 14.135185 | 100.611764 |
| 6 | Scenario 7 | Zigzag | Soil + Grass | 14.135185 | 100.611764 |
| eu-X | eu-Y | eu-Z | acc-X | acc-Y | acc-Z | gyro-X | gyro-Y | gyro-Z | mag-X | mag-Y | mag-Z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 9646 | 9646 | 9646 | 9646 | 9646 | 9646 | 9646 | 9644 | 9644 | 9644 | 9644 | 9644 |
| mean | 179.46 | −3.51 | 1.56 | −0.49 | −1.09 | 9.49 | 0.01 | 0.03 | 0.57 | 2.05 | 2.15 | −3.32 |
| std | 117.85 | 4.68 | 5.98 | 0.83 | 1.04 | 2.20 | 6.61 | 11.80 | 11.26 | 24.25 | 24.90 | 5.53 |
| min | 0.00 | −15.50 | −22.87 | −3.58 | −4.08 | 0.00 | −49.87 | −59.43 | −63.43 | −43.68 | −43.00 | −24.37 |
| 25% | 84.12 | −6.87 | −3.00 | −1.07 | −1.85 | 7.94 | −2.43 | −7.62 | −3.31 | −15.75 | −17.51 | −4.50 |
| 50% | 181.31 | −2.93 | 0.50 | −0.51 | −1.22 | 9.40 | 0.00 | 0.18 | 0.062 | 0.00 | 3.37 | −1.25 |
| 75% | 272.62 | 0.12 | 7.68 | 0.02 | −0.49 | 10.99 | 2.37 | 7.75 | 4.87 | 18.25 | 24.75 | 0.18 |
| max | 360.00 | 16.81 | 12.56 | 3.25 | 3.62 | 16.52 | 49.87 | 54.81 | 76.75 | 49.68 | 43.00 | 6.87 |
| ML | K-Fold Cross-Validation | Random State (80/20) |
|---|---|---|
| LR | 0.5354623361705697 | 0.5598755832037325 |
| KNN | 0.902738234288185 | 0.9015033696215656 |
| SVC | 0.921713247678478 | 0.9248315189217211 |
| DT | 0.9539603539769708 | 0.9574909279419388 |
| RF | 0.9850687475935114 | 0.9875583203732504 |
| GB | 0.963190084084588 | 0.9606013478486263 |
| ADAB | 0.4706558985048043 | 0.44841886988076723 |
| XGB | 0.9873498297443046 | 0.9885951270088128 |
| Scenario | Track | Surface | Accuracy (%) |
|---|---|---|---|
| Scenario 1 | Around | Asphalt | 96.21 |
| Scenario 2 | Around | Gravel | 98.51 |
| Scenario 3 | Zigzag | Gravel | 98.94 |
| Scenario 4 | Around | Concrete + Gravel | 96.09 |
| Scenario 5 | Zigzag | Concrete + Gravel | 96.44 |
| Scenario 6 | Around | Soil + Grass | 98.52 |
| Scenario 7 | Zigzag | Soil + Grass | 97.97 |
| Average Accuracy | 97.53 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thavitchasri, P.; Maneetham, D.; Crisnapati, P.N. Intelligent Surface Recognition for Autonomous Tractors Using Ensemble Learning with BNO055 IMU Sensor Data. Agriculture 2024, 14, 1557. https://doi.org/10.3390/agriculture14091557
Thavitchasri P, Maneetham D, Crisnapati PN. Intelligent Surface Recognition for Autonomous Tractors Using Ensemble Learning with BNO055 IMU Sensor Data. Agriculture. 2024; 14(9):1557. https://doi.org/10.3390/agriculture14091557
Chicago/Turabian StyleThavitchasri, Phummarin, Dechrit Maneetham, and Padma Nyoman Crisnapati. 2024. "Intelligent Surface Recognition for Autonomous Tractors Using Ensemble Learning with BNO055 IMU Sensor Data" Agriculture 14, no. 9: 1557. https://doi.org/10.3390/agriculture14091557
APA StyleThavitchasri, P., Maneetham, D., & Crisnapati, P. N. (2024). Intelligent Surface Recognition for Autonomous Tractors Using Ensemble Learning with BNO055 IMU Sensor Data. Agriculture, 14(9), 1557. https://doi.org/10.3390/agriculture14091557