
Named Entity Recognition for Crop Diseases and Pests Based on Gated Fusion Unit and Manhattan Attention

Abstract
:1. Introduction
- This study uses a gated fusion unit to perform a weighted fusion of the output of RoBERTa with the output of BiLSTM to ensure that the information flow of the model does not depend on a single feature representation. The feature selection function of the gating mechanism also allows the model to select more important or more relevant features according to different input situations, which enhances the model’s ability to adapt to specific situations.
- This study introduces a novel Manhattan attention mechanism that measures the similarity between the query matrix (Q) and key matrix (K) by calculating their Manhattan distance, which has been shown to outperform traditional dot-product attention.
- This study incorporates adversarial training to learn more robust feature representations, enhancing the model’s performance when faced with unfamiliar inputs.
2. Model Structure
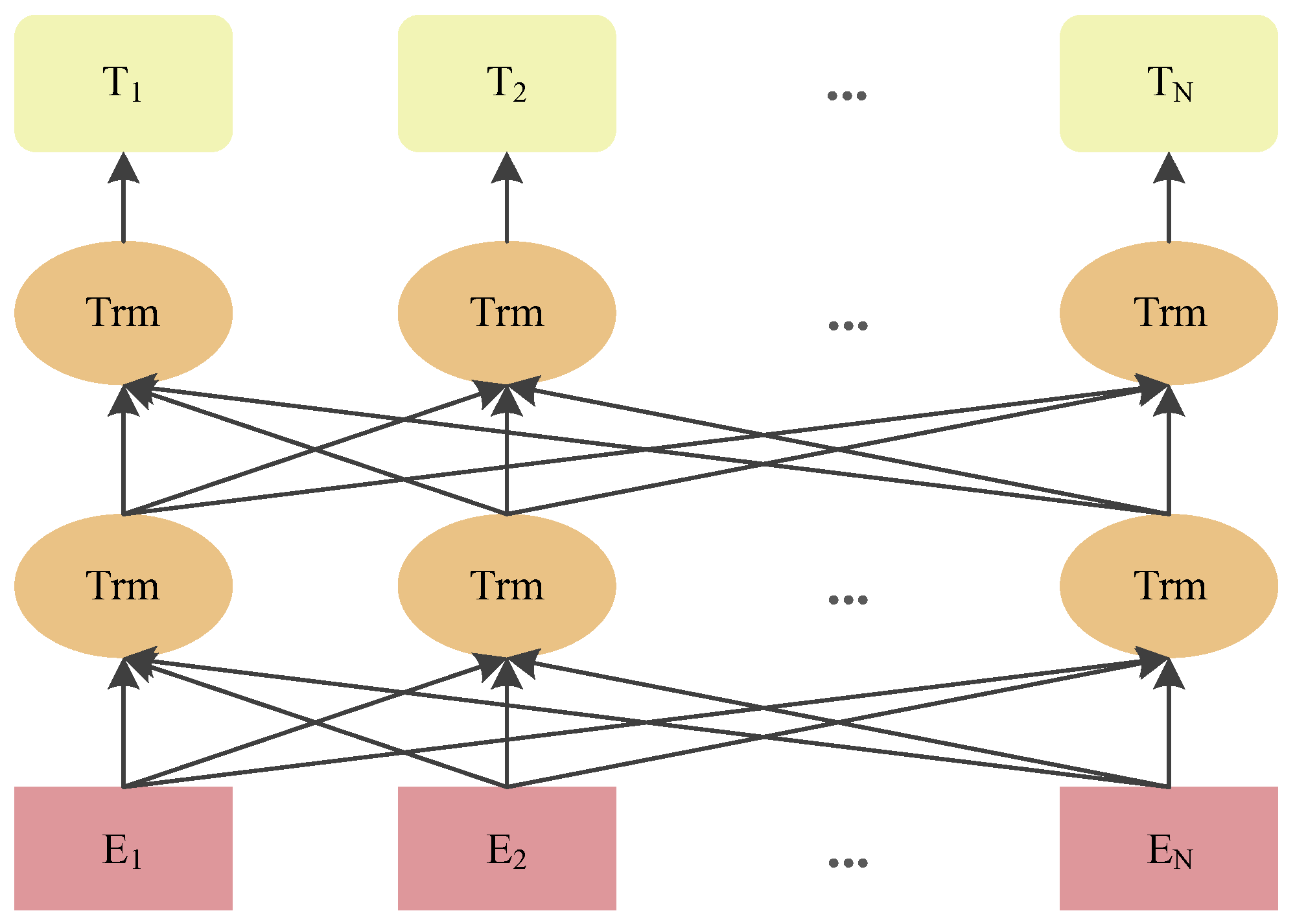
2.1. RoBERTa Pre-Trained Model
2.2. Adversarial Training
- Calculate the original loss and gradient. First, perform forward propagation on the input sample and calculate its loss . Subsequently, perform backward propagation on the loss function to compute the gradient of the loss, considering the input sample.
- Generate the adversarial perturbation: Calculate the perturbation vector based on the gradient of the embedding representation of the input sample, as shown in Equation (1).where denotes the perturbation size. The perturbation vector is then added to the embedding representation of the current input sample to obtain the adversarial sample .
- Calculate the adversarial loss and gradient: Perform forward propagation on the adversarial sample to calculate its loss . Subsequently, perform backward propagation on the loss function to compute the gradient of the adversarial loss relative to the input sample, and add this gradient to the original gradient from step (1).
- Restore the original embedding: Return the embedding of the input sample to its original state from Step (1) to ensure that the parameter updates are not affected by adversarial perturbation.
- Based on the accumulated gradients, update the model parameters to enhance the model’s robustness to both the original and adversarial samples.
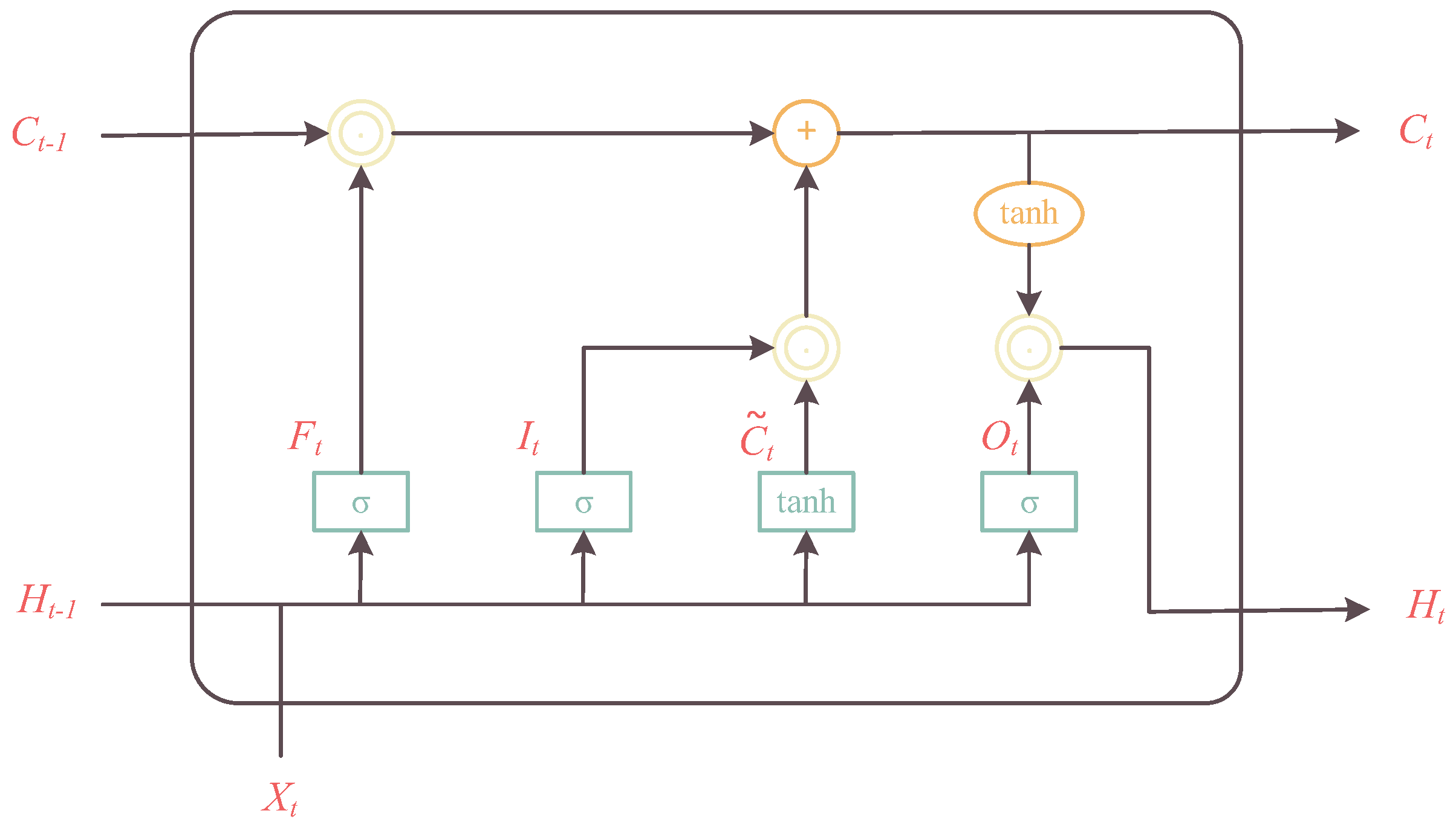
2.3. BiLSTM
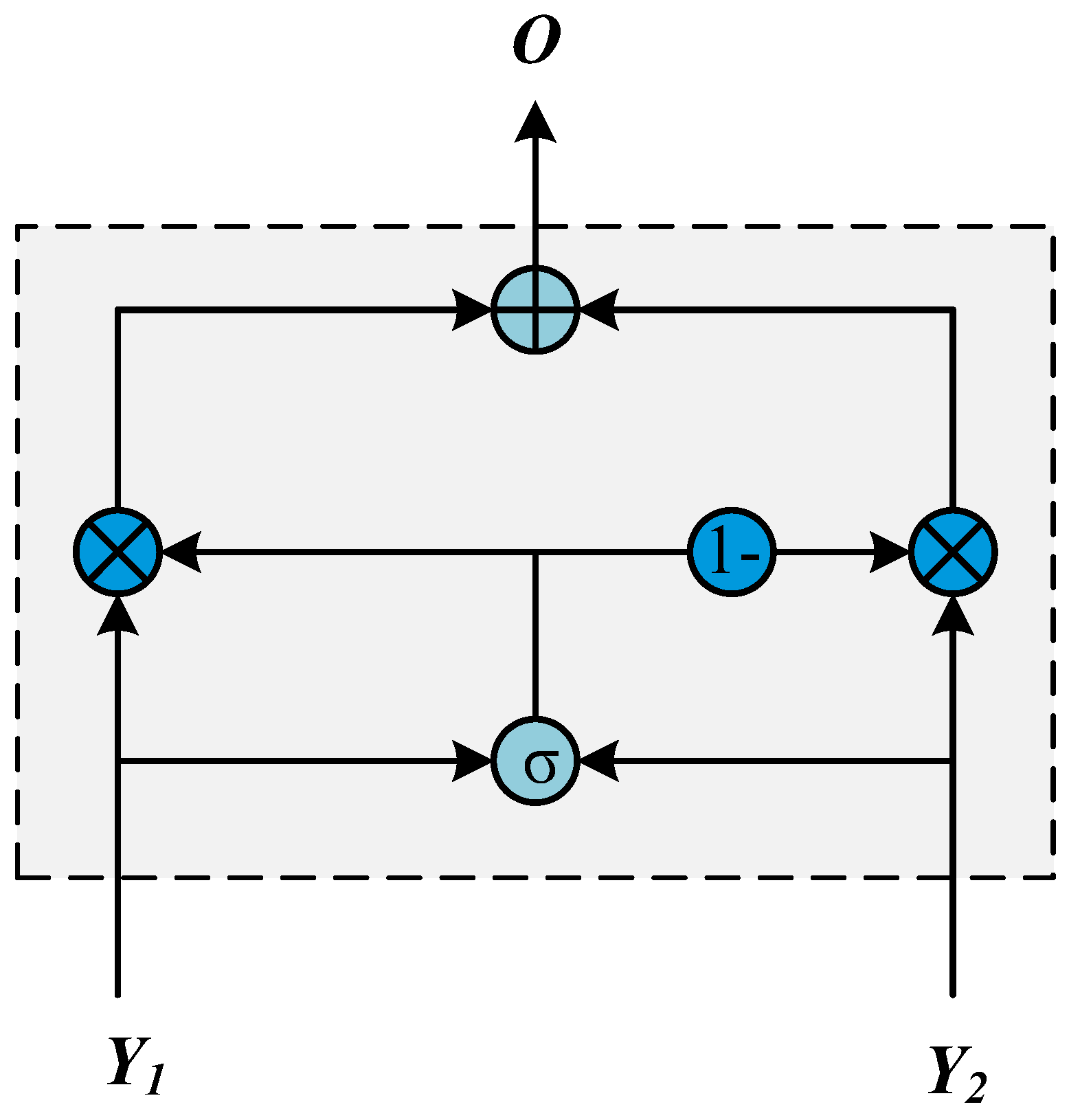
2.4. Gated Fusion Unit
2.5. Attention Mechanism
2.5.1. Limitations of the Dot-Product Attention Mechanism
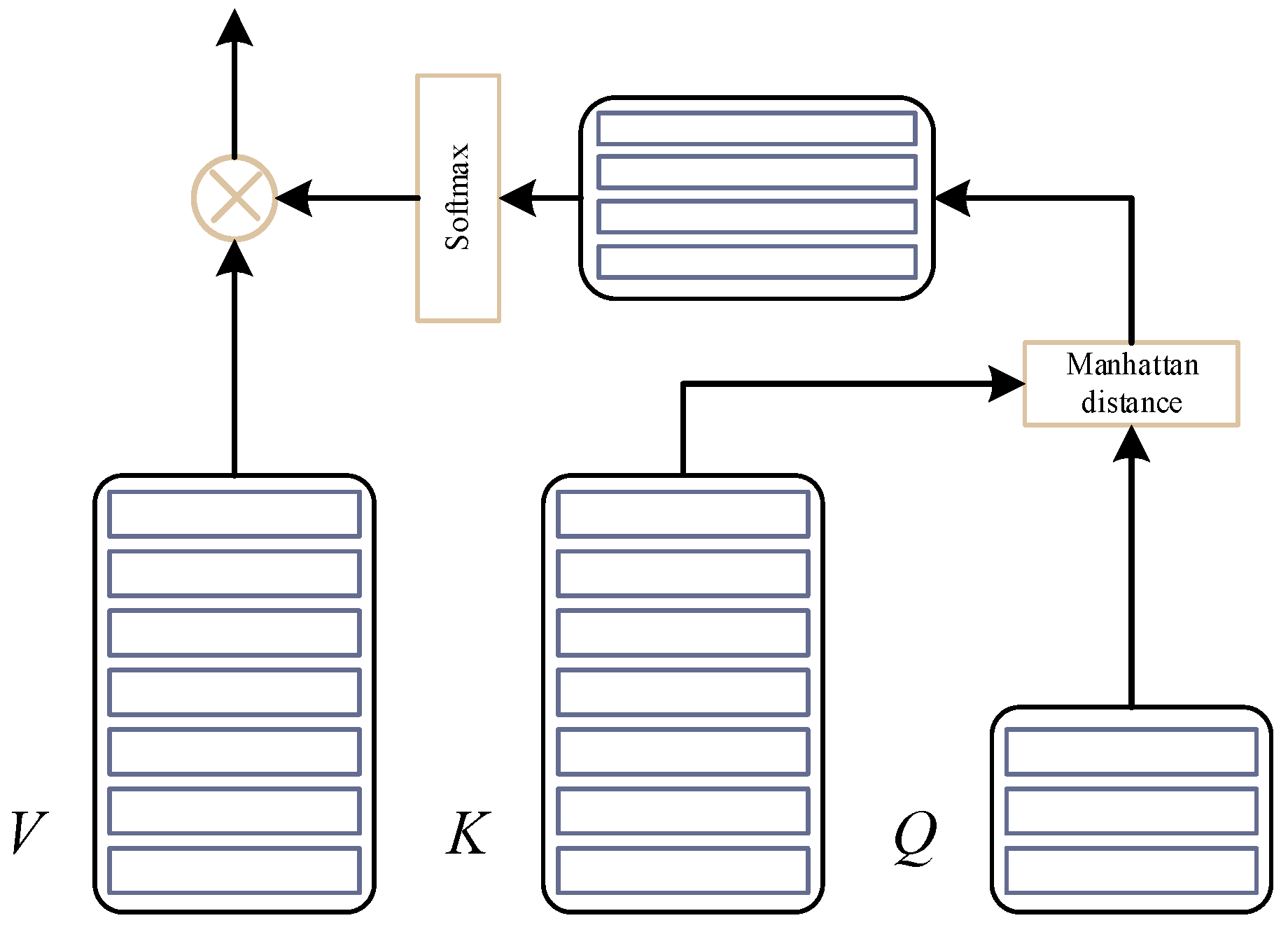
2.5.2. Manhattan Attention Mechanism
2.6. CRF
3. Experiments and Analysis
3.1. Dataset
3.2. Experimental Setup
3.3. Analysis of Experimental Results
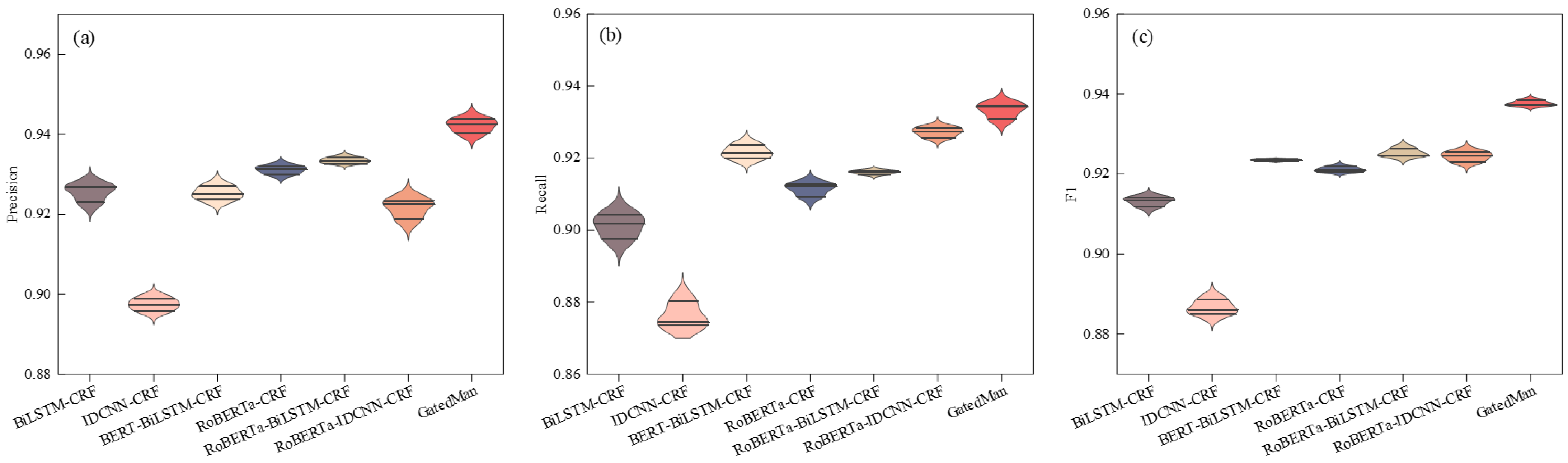
3.3.1. Comparison of Different Model Performances
- By comparing the two groups of models, BiLSTM-CRF with IDCNN-CRF and RoBERT-IDCNN-CRF with RoBERT-BiLSTM-CRF, it can be observed that the models using BiLSTM as the encoder generally perform better, indicating that BiLSTM provides more powerful contextual semantic understanding capabilities, making it more suitable for text-processing tasks.
- The introduction of pre-trained models enhanced performance. This improvement is due to the pre-trained models having learned abundant linguistic rules and knowledge from extensive text pre-training, which aids the current NER task. The pre-trained models also offer better model initialization parameters, enhancing the model’s generalization capability.
- The proposed GatedMan model outperformed the other models in all three metrics, proving its effectiveness.
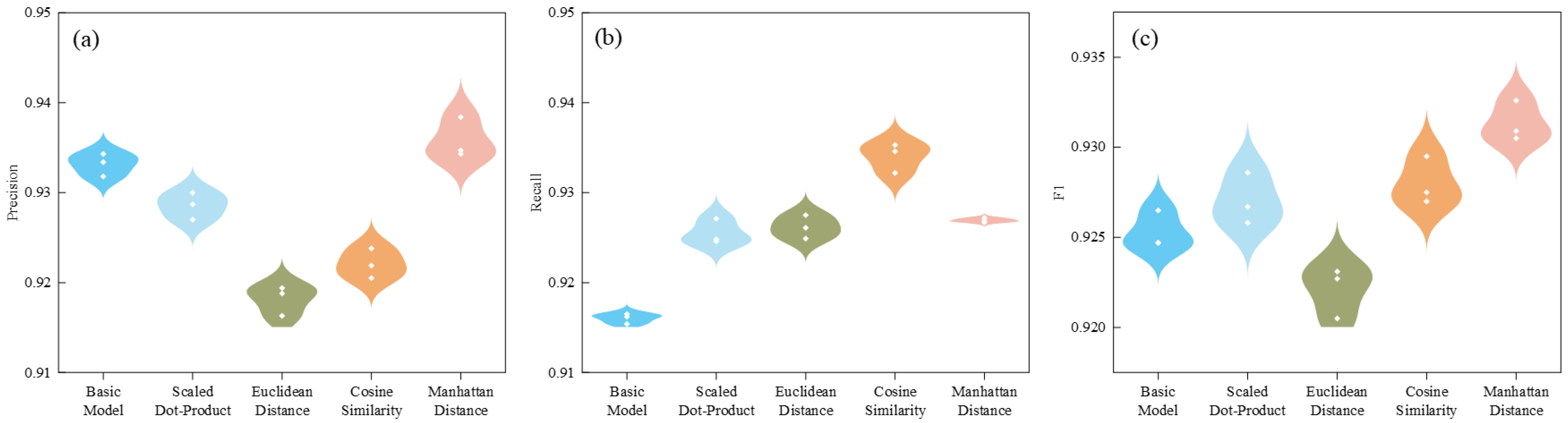
3.3.2. Comparison of Different Evaluation Mechanisms’ Performances
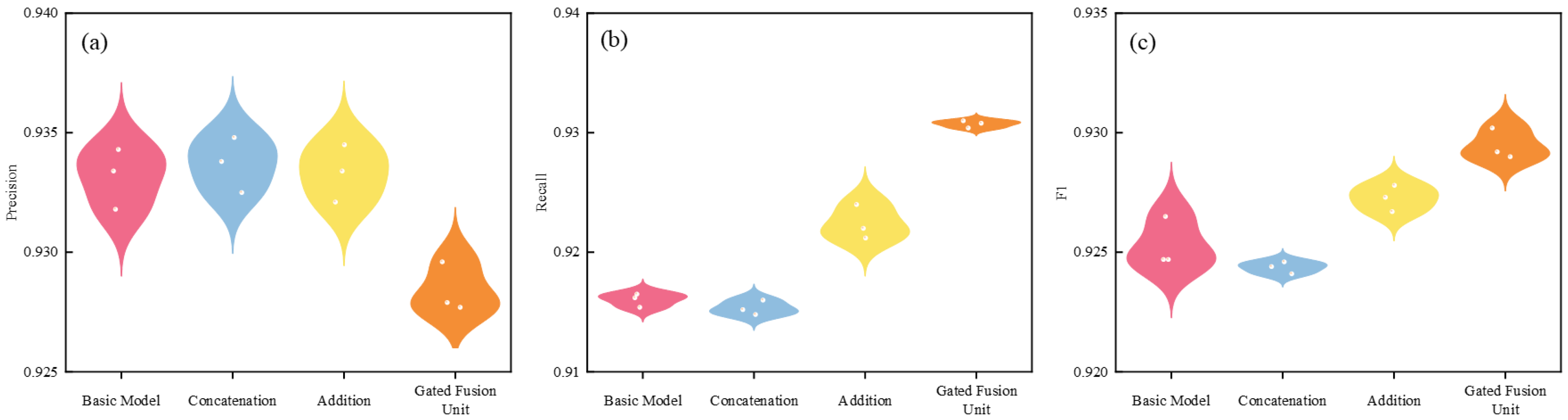
3.3.3. Comparison of Different Feature Fusion Methods’ Performances
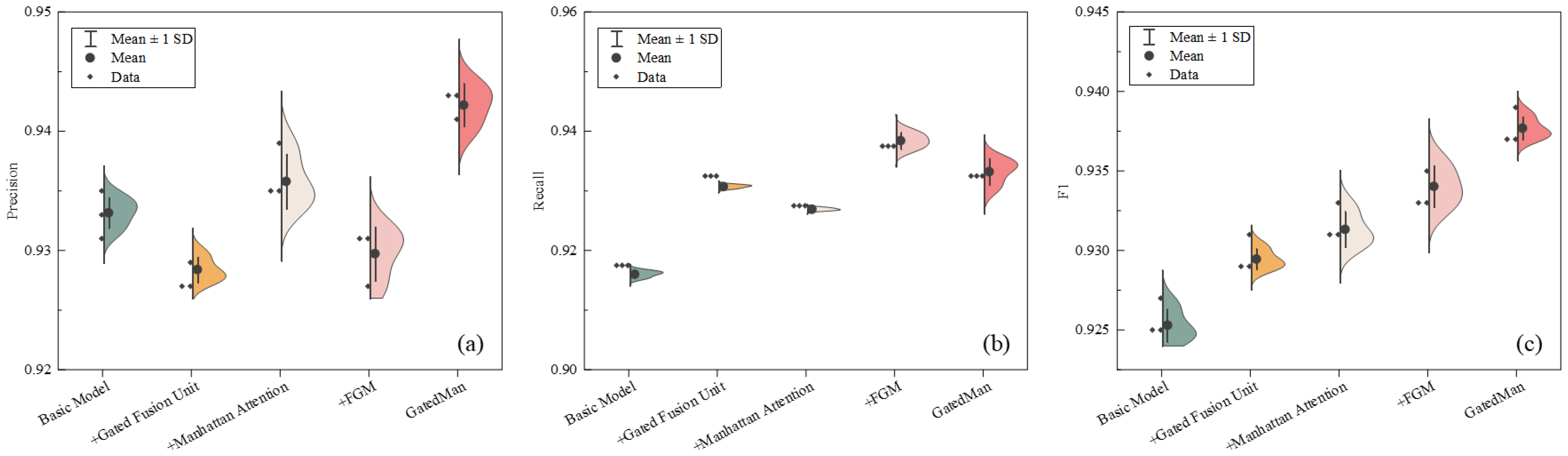
3.3.4. Ablation Study
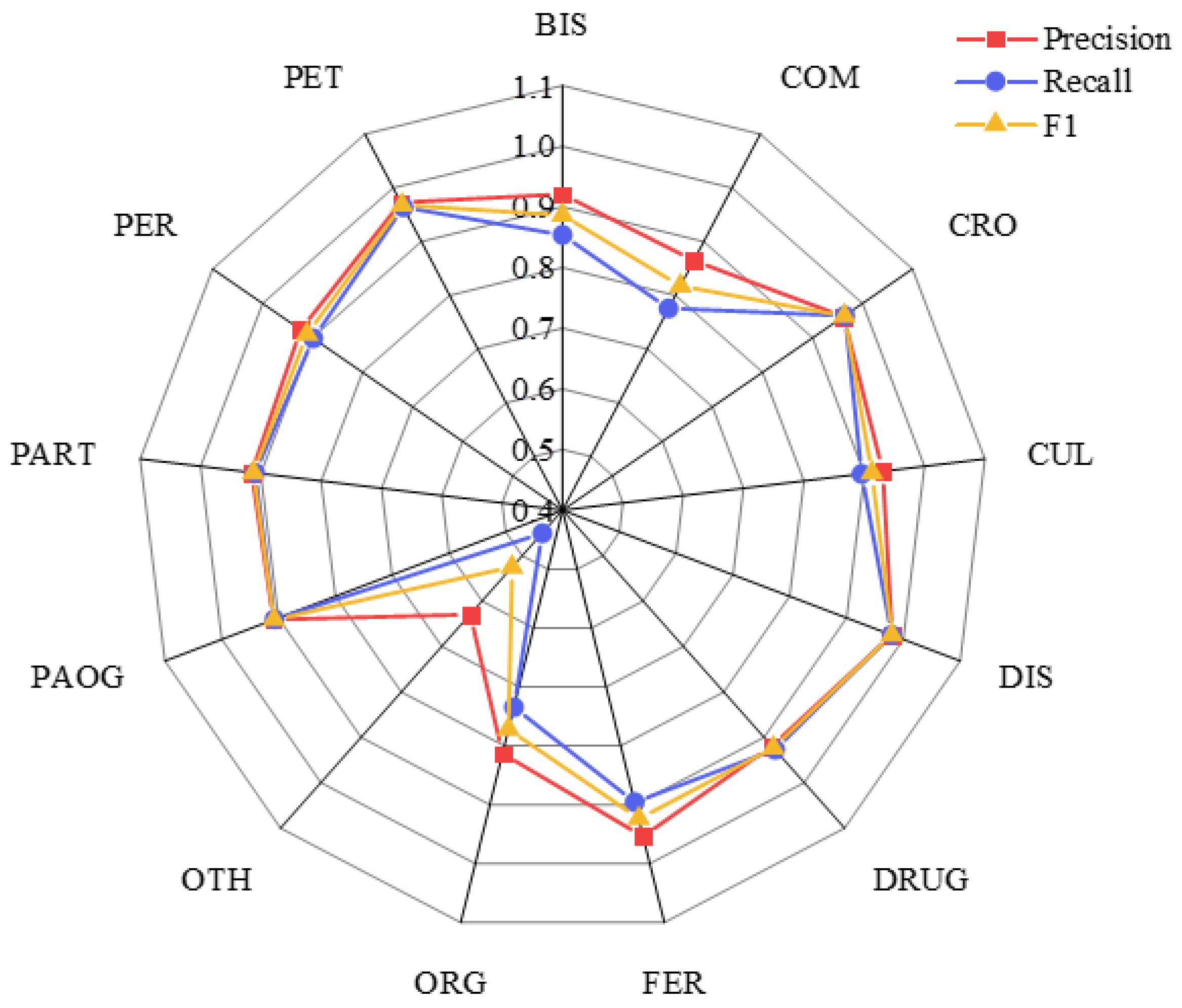
3.3.5. Results of Entity Recognition
3.3.6. Validation of Model Generalizability
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, W.T.; Hu, Z.L. Survey of agricultural knowledge graph. Comput. Eng. Appl. 2024, 60, 63–76. [Google Scholar]
- Malarkodi, C.S.; Lex, E.; Devi, S.L. Named entity recognition for the agricultural domain. Res. Comput. Sci. 2016, 117, 121–132. [Google Scholar]
- Li, X.; Wei, X.H.; Jia, L.; Chen, X.; Liu, L.; Zhang, Y.E. Recognition of crops, diseases and pesticides named entities in Chinese based on conditional random fields. Trans. Chin. Soc. Agric. Mach. 2017, 48, 178–185. [Google Scholar]
- Zhao, P.F.; Wang, W.; Liu, H.; Han, M. Recognition of the agricultural named entities with multifeature fusion based on ALBERT. IEEE Access 2022, 10, 98936–98943. [Google Scholar] [CrossRef]
- Zhang, D.M.; Zheng, G.; Liu, H.B.; Ma, X.M.; Xi, L. AWdpCNER: Automated Wdp Chinese named entity recognition from wheat diseases and pests text. Agriculture 2023, 13, 1220. [Google Scholar] [CrossRef]
- Zhang, L.L.; Nie, X.L.; Zhang, M.M.; Gu, M.Y.; Geissen, V.; Ritsema, C.J.; Niu, D.D.; Zhang, H.M. Lexicon and attention-based named entity recognition for kiwifruit diseases and pests: A deep learning approach. Front. Plant Sci. 2022, 13, 1053449. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.C.; Lu, S.H.; Tang, Z.; Bai, Z.; Diao, L.; Zhou, H.; Li, L. CG-ANER: Enhanced contextual embeddings and glyph features-based agricultural named entity recognition. Comput. Electron. Agric. 2022, 194, 106776. [Google Scholar] [CrossRef]
- Wu, K.J.; Xu, L.Q.; Li, X.X.; Zhang, Y.H.; Yue, Z.Y.; Gao, Y.J.; Chen, Y.Q. Named entity recognition of rice genes and phenotypes based on BiGRU neural networks. Comput. Biol. Chem. 2024, 108, 107977. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.H.; Ott, M.; Goyal, N.; Du, J.F.; Joshi, M.; Chen, D.Q.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Miyato, T.; Dai, A.M.; Goodfellow, I. Adversarial training methods for semi-supervised text classification. arXiv 2016, arXiv:1605.07725. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yao, X.C.; Hao, X.; Liu, R.; Li, L.; Guo, X.C. AgCNER, the first large-scale Chinese named entity recognition dataset for agricultural diseases and pests. Sci. Data 2024, 11, 769. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.X.; Sun, M.Z.; Zhang, W.H.; Xie, G.Q.; Jiang, Y.X.; Li, X.L.; Shi, Z.X. DAE-NER: Dual-channel attention enhancement for Chinese named entity recognition. Comput. Speech Lang. 2023, 85, 101581. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, K.; Wang, H.W.; Li, M.Z.; Pan, J.G. Chinese named-entity recognition via self-attention mechanism and position-aware influence propagation embedding. Data Knowl. Eng. 2022, 139, 101983. [Google Scholar] [CrossRef]
- Liu, J.X.; Cheng, J.R.; Peng, X.; Zhao, Z.L.; Tang, X.Y.; Sheng, V.S. MSFM: Multi-view semantic feature fusion model for Chinese named entity recognition. KSII Trans. Internet Inf. Syst. 2022, 16, 1833–1848. [Google Scholar]
- Dong, Y.F.; Bai, J.M.; Wang, L.Q.; Wang, X. Chinese named entity recognition combining prior knowledge and glyph features. J. Comput. Appl. 2024, 44, 702–708. [Google Scholar]
- Jia, Y.Z.; Xu, X.B. Chinese Named Entity Recognition Based on CNN-BiLSTM-CRF. In Proceedings of the IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 1–4. [Google Scholar]
- Zhang, N.X.; Li, F.; Xu, G.; Zhang, W.K.; Yu, H.F. Chinese NER using dynamic meta-embeddings. IEEE Access 2019, 7, 64450–64459. [Google Scholar] [CrossRef]
- Li, J.T.; Meng, K. MFE-NER: Multi-feature fusion embedding for Chinese named entity recognition. arXiv 2021, arXiv:2109.07877. [Google Scholar]
- Han, X.K.; Yue, Q.; Chu, J.; Shi, W.L.; Han, Z. Chinese named entity recognition based on attention-enhanced lattice Transformer. J. Xiamen Univ. Nat. Sci. 2022, 61, 1062–1071. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tags | Abbr. | Proportion | Example |
|---|---|---|---|
| Pest | PET | 22.17% | Coccinellidae, locust |
| Disease | DIS | 13.47% | Potato wart, rice blast |
| Crop | CRO | 20.38% | Rice, wheat, apple |
| Drug | DRUG | 12.08% | Prometryn, pendimethalin |
| Cultivar | CUL | 5.86% | Kexin No.1, Quanyou 822 |
| Fertilizer | FER | 0.51% | Nitrogen fertilizer, potash fertilizer |
| Pathogens | PAOG | 2.25% | Phytophthora infestans |
| Period | PER | 10.84 | Flower period, heading date |
| Part | PART | 8.63% | Tuber, leaf, brain |
| Company | COM | 0.34% | Yuan Longping High-Tech Agriculture Co., Ltd., Changsha, China |
| Organization | ORG | 1.44% | Academy of Agricultural Sciences |
| Biosystematic | BIS | 0.89% | Peronosporales, Noctuidae |
| Other | OTH | 1.14% | Insecticide, viral disease |
| Sentence | Label |
|---|---|
| The Cnaphalocrocis medinalis is showing an outbreak trend. | O/B-PET/I-PET/O/O/O/O/O |
| Usually, the disease starts from the lower leaves of the plant. | O/O/O/O/O/O/O/O/P-PARTO/O/O |
| Matsumura is an important pest on soybeans in Northeast China. | B-PET/O/O/O/O/O/B-CRO/O/O/O |
| The insect lurks as a larva inside the glume shell. | O/O/O/O/O/B-PER/O/O/B-PART/I-PART |
| Parameter | Value |
|---|---|
| Learning rate | 5 × 10−5 |
| Batch size | 32 |
| Optimizer | Adam |
| Epoch | 30 |
| LSTM hidden size | 256 |
| Dropout | 0.1 |
| Datasets | Models | P/% | R/% | F1/% |
|---|---|---|---|---|
| Peoples_daily | DAE-NER (Liu et al. [13]) | 92.17 | 90.63 | 91.40 |
| SAGNet (Zhang et al. [14]) | 89.44 | 80.79 | 84.90 | |
| MSFM (Liu et al. [15]) | 82.21 | 86.66 | 87.43 | |
| PKGF (Dong et al. [16]) | 94.35 | 93.06 | 93.70 | |
| GatedMan | 94.69 | 93.58 | 94.13 | |
| MSRA | CNN-BiLSTM-CRF (Jia et al. [17]) | 91.63 | 90.56 | 91.09 |
| DAE-NER (Liu et al. [13]) | 92.73 | 90.15 | 91.42 | |
| DEM (Zhang et al. [18]) | 90.59 | 91.15 | 90.87 | |
| MFE-NER (Li et al. [19]) | 93.32 | 86.83 | 89.96 | |
| GatedMan | 94.36 | 93.60 | 93.98 | |
| Resume | DAE-NER (Liu et al. [13]) | 96.92 | 95.18 | 96.04 |
| MSFM (Liu et al. [15]) | 96.08 | 94.79 | 95.43 | |
| MFE-NER (Li et al. [19]) | 95.76 | 95.71 | 95.73 | |
| AELT (HAN et al. [20]) | 95.80 | 96.06 | 95.93 | |
| GatedMan | 97.23 | 95.82 | 96.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, W.; Wen, X.; Hu, Z. Named Entity Recognition for Crop Diseases and Pests Based on Gated Fusion Unit and Manhattan Attention. Agriculture 2024, 14, 1565. https://doi.org/10.3390/agriculture14091565
Tang W, Wen X, Hu Z. Named Entity Recognition for Crop Diseases and Pests Based on Gated Fusion Unit and Manhattan Attention. Agriculture. 2024; 14(9):1565. https://doi.org/10.3390/agriculture14091565
Chicago/Turabian StyleTang, Wentao, Xianhuan Wen, and Zelin Hu. 2024. "Named Entity Recognition for Crop Diseases and Pests Based on Gated Fusion Unit and Manhattan Attention" Agriculture 14, no. 9: 1565. https://doi.org/10.3390/agriculture14091565