


A Semi-Supervised Diffusion-Based Framework for Weed Detection in Precision Agricultural Scenarios Using a Generative Attention Mechanism

 and
and 
Abstract
1. Introduction
- Introduction of diffusion model-based generative cyclic network: This paper is the first to apply a diffusion model to weed detection tasks, designing a semi-supervised diffusion-based generative cyclic network capable of generating high-quality synthetic data. The model improves the realism and diversity of the generated data through cyclic optimization strategies. This approach significantly reduces the reliance on large-scale labeled data.
- Design of a combined generation and detection attention mechanism: A generation attention mechanism is proposed in this paper, which integrates the features generated by the diffusion model into the detection network. By dynamically adjusting the weight distribution, this mechanism enhances the detection model’s ability to express fine-grained features in complex scenes, especially in scenarios where weeds and crops have highly similar appearances.
- Proposal of a new semi-supervised loss function: To optimize the model’s performance with limited labeled data, a new loss function, semi-diffusion loss, is introduced. This function combines the characteristics of supervised and generative learning, effectively balancing the training weights between labeled and generated data, thereby improving the model’s overall robustness and detection accuracy.
2. Related Work
2.1. Supervised Learning
2.2. Semi-Supervised Learning
3. Materials and Methods
3.1. Dataset Collection
3.2. Data Annotation
3.3. Data Augmentation
3.4. Proposed Method
3.4.1. Semi-Supervised Diffusion Weed Detection Network
3.4.2. Semi-Supervised Diffusion Data Generation Loop
3.4.3. Generative Attention Mechanism
- Generative feature embedding module: The generated features are first passed through a convolutional layer to reduce the number of channels to 128 while preserving the spatial dimensions, thereby reducing computational overhead. The embedding process is expressed aswhere represents the embedded features.
- Feature fusion module: Complementary information between the generated features and the real features is captured by computing the attention weight matrix W. The attention weights are computed aswhere denotes the normalized attention weights. The fused features are obtained by weighting the real features and adding the generated features :
- Weighted output module: The fused features are further processed through a convolutional layer to enhance local information and adjust the number of channels to the target dimension :where represents the final fused feature output.
3.4.4. Semi-Diffusion Loss
- Pseudo-labels for unlabeled data are generated by the diffusion model.
- The detection network computes the supervised loss for labeled data and the pseudo-supervised loss for unlabeled data.
- The losses are combined to update the network parameters.
3.5. Evaluation Metrics
4. Results and Discussion
4.1. Results
4.1.1. Baseline
4.1.2. Hardware and Software Platform
4.1.3. Optimizer and Hyperparameters
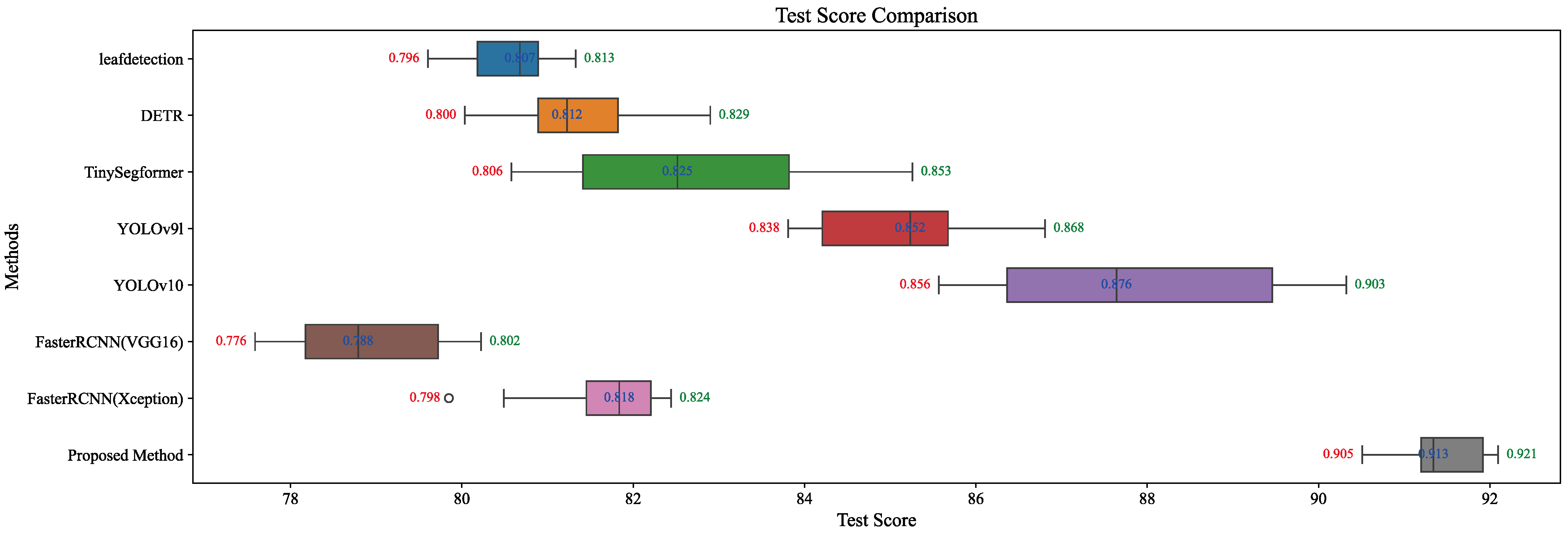
4.1.4. Weed Detection Results
4.1.5. Results Analysis for Different Weed Types Using the Proposed Method
4.1.6. Test on Other Aerial-Based Detection Tasks
4.2. Discussion
4.2.1. Discussion on Different Data Augmentation Methods
4.2.2. Ablation Study on Different Learning Methods
4.3. Exploratory Data Analysis
Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kumar, A.; Sharma, P. Impact of climate variation on agricultural productivity and food security in rural India. Soc. Sci. Res. Netw. 2022. [Google Scholar] [CrossRef]
- Chouhan, G.K.; Verma, J.P.; Jaiswal, D.K.; Mukherjee, A.; Singh, S.; de Araujo Pereira, A.P.; Liu, H.; Abd_Allah, E.F.; Singh, B.K. Phytomicrobiome for promoting sustainable agriculture and food security: Opportunities, challenges, and solutions. Microbiol. Res. 2021, 248, 126763. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, X.; Liu, Y.; Zhou, J.; Huang, Y.; Li, J.; Zhang, L.; Ma, Q. A time-series neural network for pig feeding behavior recognition and dangerous detection from videos. Comput. Electron. Agric. 2024, 218, 108710. [Google Scholar] [CrossRef]
- Esposito, M.; Westbrook, A.S.; Maggio, A.; Cirillo, V.; DiTommaso, A. Neutral weed communities: The intersection between crop productivity, biodiversity, and weed ecosystem services. Weed Sci. 2023, 71, 301–311. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-accuracy detection of maize leaf diseases CNN based on multi-pathway activation function module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Monteiro, A.; Santos, S. Sustainable approach to weed management: The role of precision weed management. Agronomy 2022, 12, 118. [Google Scholar] [CrossRef]
- Adeux, G.; Cordeau, S.; Antichi, D.; Carlesi, S.; Mazzoncini, M.; Munier-Jolain, N.; Bàrberi, P. Cover crops promote crop productivity but do not enhance weed management in tillage-based cropping systems. Eur. J. Agron. 2021, 123, 126221. [Google Scholar] [CrossRef]
- Choudhary, A.K.; Yadav, D.; Sood, P.; Rahi, S.; Arya, K.; Thakur, S.; Lal, R.; Kumar, S.; Sharma, J.; Dass, A.; et al. Post-Emergence herbicides for effective weed management, enhanced wheat productivity, profitability and quality in North-Western Himalayas: A ‘Participatory-Mode’Technology Development and Dissemination. Sustainability 2021, 13, 5425. [Google Scholar] [CrossRef]
- Rai, N.; Zhang, Y.; Ram, B.G.; Schumacher, L.; Yellavajjala, R.K.; Bajwa, S.; Sun, X. Applications of deep learning in precision weed management: A review. Comput. Electron. Agric. 2023, 206, 107698. [Google Scholar] [CrossRef]
- Vasileiou, M.; Kyrgiakos, L.S.; Kleisiari, C.; Kleftodimos, G.; Vlontzos, G.; Belhouchette, H.; Pardalos, P.M. Transforming weed management in sustainable agriculture with artificial intelligence: A systematic literature review towards weed identification and deep learning. Crop Prot. 2024, 176, 106522. [Google Scholar] [CrossRef]
- Upadhyay, A.; Sunil, G.; Zhang, Y.; Koparan, C.; Sun, X. Development and evaluation of a machine vision and deep learning-based smart sprayer system for site-specific weed management in row crops: An edge computing approach. J. Agric. Food Res. 2024, 18, 101331. [Google Scholar] [CrossRef]
- Saleh, A.; Olsen, A.; Wood, J.; Philippa, B.; Azghadi, M.R. Semi-Supervised Weed Detection for Rapid Deployment and Enhanced Efficiency. arXiv 2024, arXiv:2405.07399. [Google Scholar]
- Muvva, V.B.R.; Kumpati, R.; Skarka, W. Efficient Weed Detection Using CNN with an Autonomous Robot. In Proceedings of the 2024 2nd International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 12–14 February 2024; pp. 1–7. [Google Scholar]
- Narayana, C.L.; Ramana, K.V. An efficient real-time weed detection technique using YOLOv7. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 65. [Google Scholar] [CrossRef]
- Li, J.; Chen, D.; Yin, X.; Li, Z. Performance evaluation of semi-supervised learning frameworks for multi-class weed detection. Front. Plant Sci. 2024, 15, 1396568. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Cui, J.; Liu, H.; Han, Y.; Ai, H.; Dong, C.; Zhang, J.; Chu, Y. Weed identification in soybean seedling stage based on optimized Faster R-CNN algorithm. Agriculture 2023, 13, 175. [Google Scholar] [CrossRef]
- Yan, J.; Wang, X. Unsupervised and semi-supervised learning: The next frontier in machine learning for plant systems biology. Plant J. 2022, 111, 1527–1538. [Google Scholar] [CrossRef] [PubMed]
- Garibaldi-Márquez, F.; Flores, G.; Mercado-Ravell, D.A.; Ramírez-Pedraza, A.; Valentín-Coronado, L.M. Weed classification from natural corn field-multi-plant images based on shallow and deep learning. Sensors 2022, 22, 3021. [Google Scholar] [CrossRef] [PubMed]
- Trabucco, B.; Doherty, K.; Gurinas, M.; Salakhutdinov, R. Effective data augmentation with diffusion models. arXiv 2023, arXiv:2302.07944. [Google Scholar]
- Li, Q.; Zhang, Y. Confidential Federated Learning for Heterogeneous Platforms against Client-Side Privacy Leakages. In Proceedings of the ACM Turing Award Celebration Conference 2024, Changsha, China, 5–7 July 2024; pp. 239–241. [Google Scholar]
- Veeragandham, S.; Santhi, H. Optimization enabled Deep Quantum Neural Network for weed classification and density estimation. Expert Syst. Appl. 2024, 243, 122679. [Google Scholar] [CrossRef]
- Belissent, N.; Peña, J.M.; Mesías-Ruiz, G.A.; Shawe-Taylor, J.; Pérez-Ortiz, M. Transfer and zero-shot learning for scalable weed detection and classification in UAV images. Knowl.-Based Syst. 2024, 292, 111586. [Google Scholar] [CrossRef]
- Zhang, F.; Ren, F.; Li, J.; Zhang, X. Automatic stomata recognition and measurement based on improved YOLO deep learning model and entropy rate superpixel algorithm. Ecol. Inform. 2022, 68, 101521. [Google Scholar] [CrossRef]
- Das, S.; Chatterjee, M.; Stephen, R.; Singh, A.K.; Siddique, A. Unveiling the Potential of YOLO v7 in the Herbal Medicine Industry: A Comparative Examination of YOLO Models for Medicinal Leaf Recognition. Int. J. Eng. Res. Technol. 2024, 13. [Google Scholar]
- Adhinata, F.D.; Wahyono; Sumiharto, R. A comprehensive survey on weed and crop classification using machine learning and deep learning. Artif. Intell. Agric. 2024, 13, 45–63. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.; Brohi, S.N. Performance of deep learning vs machine learning in plant leaf disease detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Shorewala, S.; Ashfaque, A.; Sidharth, R.; Verma, U. Weed density and distribution estimation for precision agriculture using semi-supervised learning. IEEE Access 2021, 9, 27971–27986. [Google Scholar] [CrossRef]
- Al-Badri, A.H.; Ismail, N.A.; Al-Dulaimi, K.; Salman, G.A.; Khan, A.; Al-Sabaawi, A.; Salam, M.S.H. Classification of weed using machine learning techniques: A review—challenges, current and future potential techniques. J. Plant Dis. Prot. 2022, 129, 745–768. [Google Scholar] [CrossRef]
- Li, Y.; Chao, X. Semi-supervised few-shot learning approach for plant diseases recognition. Plant Methods 2021, 17, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Moreno, H.; Gómez, A.; Altares-López, S.; Ribeiro, A.; Andújar, D. Analysis of Stable Diffusion-derived fake weeds performance for training Convolutional Neural Networks. Comput. Electron. Agric. 2023, 214, 108324. [Google Scholar] [CrossRef]
- Benchallal, F.; Hafiane, A.; Ragot, N.; Canals, R. ConvNeXt based semi-supervised approach with consistency regularization for weeds classification. Expert Syst. Appl. 2024, 239, 122222. [Google Scholar] [CrossRef]
- Hu, R.; Su, W.H.; Li, J.L.; Peng, Y. Real-time lettuce-weed localization and weed severity classification based on lightweight YOLO convolutional neural networks for intelligent intra-row weed control. Comput. Electron. Agric. 2024, 226, 109404. [Google Scholar] [CrossRef]
- Liu, T.; Jin, X.; Zhang, L.; Wang, J.; Chen, Y.; Hu, C.; Yu, J. Semi-supervised learning and attention mechanism for weed detection in wheat. Crop Prot. 2023, 174, 106389. [Google Scholar] [CrossRef]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Ajayi, O.G.; Ashi, J.; Guda, B. Performance evaluation of YOLO v5 model for automatic crop and weed classification on UAV images. Smart Agric. Technol. 2023, 5, 100231. [Google Scholar] [CrossRef]
- Manikandakumar, M.; Karthikeyan, P. Weed classification using particle swarm optimization and deep learning models. Comput. Syst. Sci. Eng. 2023, 44, 913–927. [Google Scholar] [CrossRef]
- Sunil, G.; Zhang, Y.; Koparan, C.; Ahmed, M.R.; Howatt, K.; Sun, X. Weed and crop species classification using computer vision and deep learning technologies in greenhouse conditions. J. Agric. Food Res. 2022, 9, 100325. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Zhang, Y.; Wa, S.; Zhang, L.; Lv, C. Automatic plant disease detection based on tranvolution detection network with GAN modules using leaf images. Front. Plant Sci. 2022, 13, 875693. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Lv, C. TinySegformer: A lightweight visual segmentation model for real-time agricultural pest detection. Comput. Electron. Agric. 2024, 218, 108740. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Rehman, M.U.; Eesaar, H.; Abbas, Z.; Seneviratne, L.; Hussain, I.; Chong, K.T. Advanced drone-based weed detection using feature-enriched deep learning approach. Knowl.-Based Syst. 2024, 305, 112655. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, M.; Ma, X.; Wu, X.; Wang, Y. High-precision wheat head detection model based on one-stage network and GAN model. Front. Plant Sci. 2022, 13, 787852. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weed Type | Number of Images |
|---|---|
| Setaria viridis | 1591 |
| Xanthium spinosum | 842 |
| Cyclachaena xanthiifolia | 2094 |
| Xanthium italicum | 1796 |
| Amaranthus rudis | 1339 |
| Model | Precision | Recall | Accuracy | mAP@50 | mAP@75 | FPS |
|---|---|---|---|---|---|---|
| leafdetection [40] | 0.83 | 0.80 | 0.81 | 0.82 | 0.80 | 23.1 |
| DETR | 0.84 | 0.82 | 0.83 | 0.84 | 0.82 | 18.9 |
| TinySegformer [41] | 0.86 | 0.84 | 0.85 | 0.86 | 0.84 | 34.7 |
| YOLO v9l | 0.88 | 0.86 | 0.87 | 0.88 | 0.86 | 45.8 |
| YOLO v10l | 0.91 | 0.89 | 0.90 | 0.91 | 0.89 | 43.6 |
| FasterRCNN (VGG16) | 0.81 | 0.79 | 0.80 | 0.81 | 0.79 | 18.9 |
| FasterRCNN (Xception) | 0.84 | 0.82 | 0.82 | 0.84 | 0.80 | 23.5 |
| Proposed Method | 0.94 | 0.90 | 0.92 | 0.92 | 0.91 | 33.5 |
| Weed Type | Precision | Recall | Accuracy | mAP@50 | mAP@75 |
|---|---|---|---|---|---|
| Setaria viridis | 0.97 | 0.93 | 0.95 | 0.95 | 0.94 |
| Xanthium spinosum | 0.95 | 0.91 | 0.93 | 0.93 | 0.92 |
| Cyclachaena xanthiifolia | 0.93 | 0.89 | 0.91 | 0.91 | 0.90 |
| Xanthium italicum | 0.92 | 0.88 | 0.90 | 0.90 | 0.89 |
| Amaranthus rudis | 0.90 | 0.87 | 0.88 | 0.87 | 0.86 |
| Model | Precision | Recall | Accuracy | mAP@50 | mAP@75 | FPS |
|---|---|---|---|---|---|---|
| DETR | 0.70 | 0.71 | 0.70 | 0.68 | 0.65 | 18.9 |
| YOLO v9l | 0.72 | 0.71 | 0.72 | 0.70 | 0.68 | 45.8 |
| YOLO v10l | 0.71 | 0.69 | 0.70 | 0.65 | 0.62 | 43.6 |
| FasterRCNN (VGG16) | 0.67 | 0.61 | 0.63 | 0.65 | 0.61 | 18.9 |
| FasterRCNN (Xception) | 0.67 | 0.62 | 0.64 | 0.65 | 0.62 | 23.5 |
| Proposed Method | 0.75 | 0.72 | 0.72 | 0.72 | 0.69 | 33.5 |
| Augmentation Method | Precision | Recall | Accuracy | mAP@50 | mAP@75 |
|---|---|---|---|---|---|
| No Augmentation | 0.85 | 0.80 | 0.82 | 0.85 | 0.83 |
| CutOut | 0.88 | 0.84 | 0.86 | 0.87 | 0.85 |
| MixUp | 0.90 | 0.86 | 0.88 | 0.89 | 0.87 |
| GridMask | 0.89 | 0.85 | 0.87 | 0.88 | 0.86 |
| CutOut + MixUp + GridMask | 0.94 | 0.90 | 0.92 | 0.92 | 0.91 |
| Model | Precision | Recall | Accuracy | mAP@50 | mAP@75 | FPS |
|---|---|---|---|---|---|---|
| GAN (Semi-Supervised) | 0.72 | 0.69 | 0.71 | 0.71 | 0.70 | 28.5 |
| VAE (Semi-Supervised) | 0.87 | 0.83 | 0.85 | 0.84 | 0.83 | 41.9 |
| Standard Self-Attention | 0.89 | 0.85 | 0.86 | 0.84 | 0.81 | 18.3 |
| CBAM | 0.85 | 0.81 | 0.83 | 0.83 | 0.82 | 31.6 |
| Semi-Supervised Attention | 0.94 | 0.90 | 0.92 | 0.92 | 0.91 | 33.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.; Wang, X.; Cui, Y.; Xu, Y.; Zhou, Y.; Tang, X.; Jiang, C.; Song, Y.; Dong, H.; Yan, S. A Semi-Supervised Diffusion-Based Framework for Weed Detection in Precision Agricultural Scenarios Using a Generative Attention Mechanism. Agriculture 2025, 15, 434. https://doi.org/10.3390/agriculture15040434
Li R, Wang X, Cui Y, Xu Y, Zhou Y, Tang X, Jiang C, Song Y, Dong H, Yan S. A Semi-Supervised Diffusion-Based Framework for Weed Detection in Precision Agricultural Scenarios Using a Generative Attention Mechanism. Agriculture. 2025; 15(4):434. https://doi.org/10.3390/agriculture15040434
Chicago/Turabian StyleLi, Ruiheng, Xuaner Wang, Yuzhuo Cui, Yifei Xu, Yuhao Zhou, Xuechun Tang, Chenlu Jiang, Yihong Song, Hegan Dong, and Shuo Yan. 2025. "A Semi-Supervised Diffusion-Based Framework for Weed Detection in Precision Agricultural Scenarios Using a Generative Attention Mechanism" Agriculture 15, no. 4: 434. https://doi.org/10.3390/agriculture15040434
APA StyleLi, R., Wang, X., Cui, Y., Xu, Y., Zhou, Y., Tang, X., Jiang, C., Song, Y., Dong, H., & Yan, S. (2025). A Semi-Supervised Diffusion-Based Framework for Weed Detection in Precision Agricultural Scenarios Using a Generative Attention Mechanism. Agriculture, 15(4), 434. https://doi.org/10.3390/agriculture15040434