
Soybean–Corn Seedling Crop Row Detection for Agricultural Autonomous Navigation Based on GD-YOLOv10n-Seg




Abstract
1. Introduction
- (1)
- Establishing a field crop row image dataset under the soybean–corn compound planting mode;
- (2)
- Establishing a crop row segmentation model of soybean–corn crop rows based on the improved YOLOv10n-segmentation algorithm;
- (3)
- Generating the crop row lines based on the segmentation results;
- (4)
- Testing the accuracy of the crop row line generation results.
2. Materials and Methods
2.1. Image Acquisition and Dataset Construction
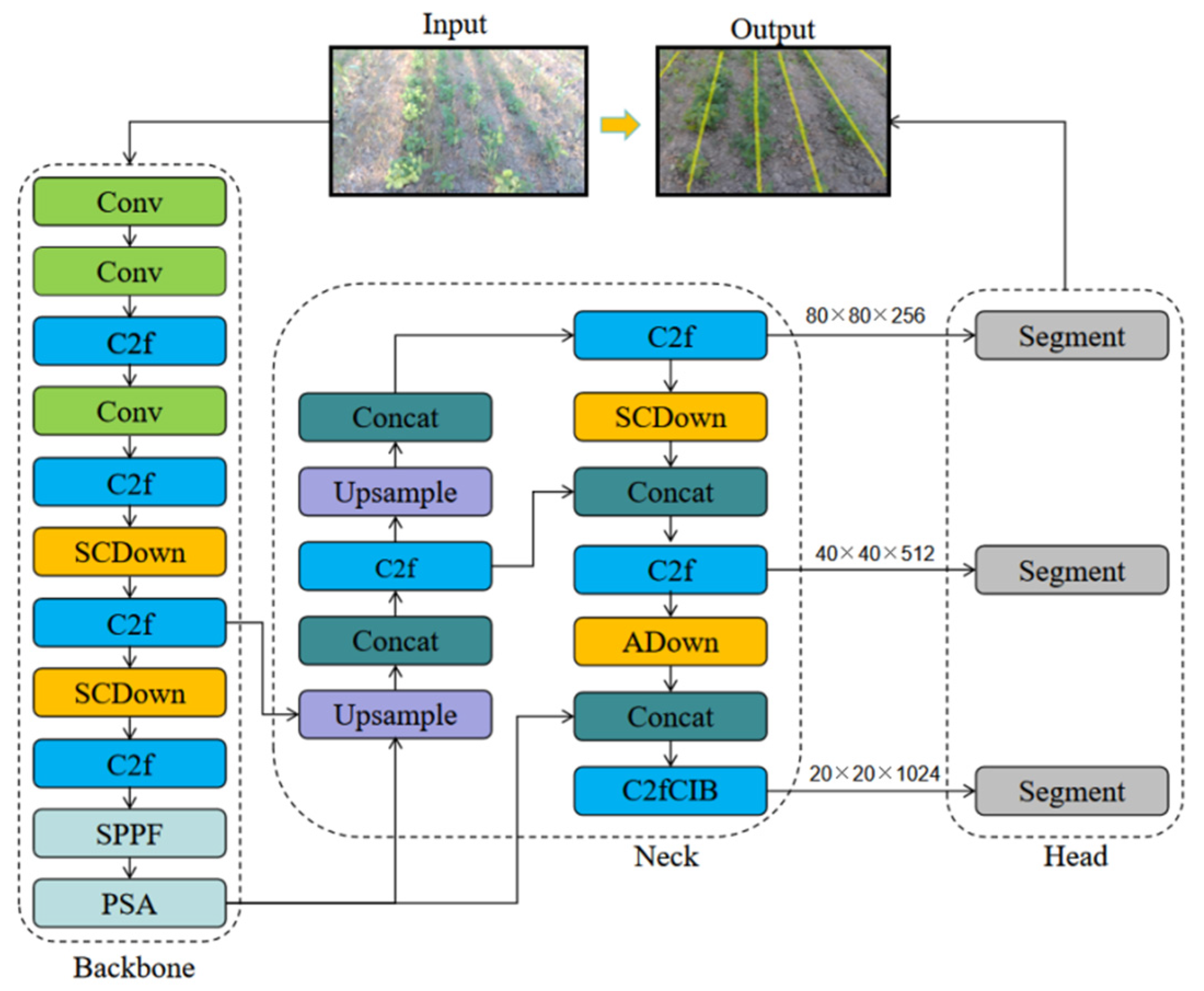
2.2. Crop Row Detection Model
- (1)
- Real-time performance: YOLOv10 is a new real-time target detection method developed by researchers at Tsinghua University that addresses the shortcomings of previous versions of YOLO in terms of post-processing and model architecture. By eliminating non-maximum suppression (NMS) and optimizing various model components, YOLOv10 achieves high recognition performance while significantly reducing computational consumption [38].
- (2)
- Lightweight design: Considering the requirement of reducing computational consumption in resource-constrained environments, we chose YOLOv10n-segmentation (YOLOv10n-seg) as the baseline algorithm. This model has the smallest number of parameters and GFlops among the YOLOv10 algorithms, allowing it to significantly reduce computational consumption while maintaining high performance.
- (3)
- Segmentation capability: YOLOv10n-seg integrates instance segmentation functionality, allowing for the direct generation of crop row masks without additional post-processing steps. When performing instance segmentation operations, YOLOv10n-seg first detects objects using a target detector and then passes the detected objects to the instance segmentation detector to generate a segmentation mask for each object. This approach not only identifies the location of the objects but also obtains their exact shapes, which effectively improves the speed of the segmentation, resulting in a high real-time performance.
2.2.1. Label Visualization
- (1)
- Providing region proposals for the segmentation head;
- (2)
- Constraining mask predictions within biologically plausible areas.
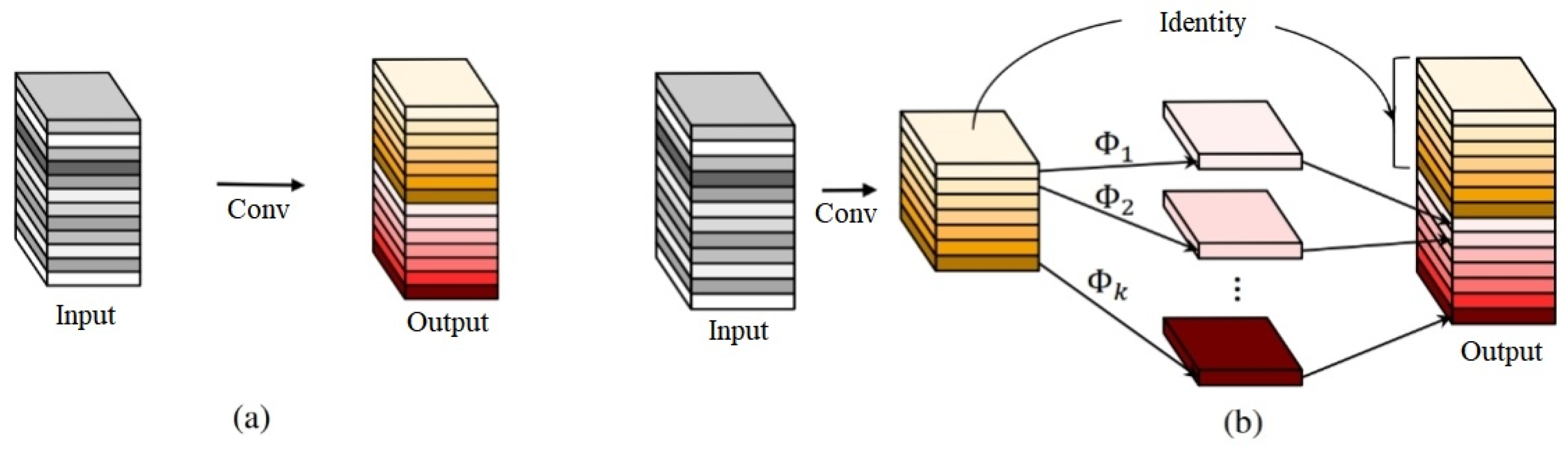
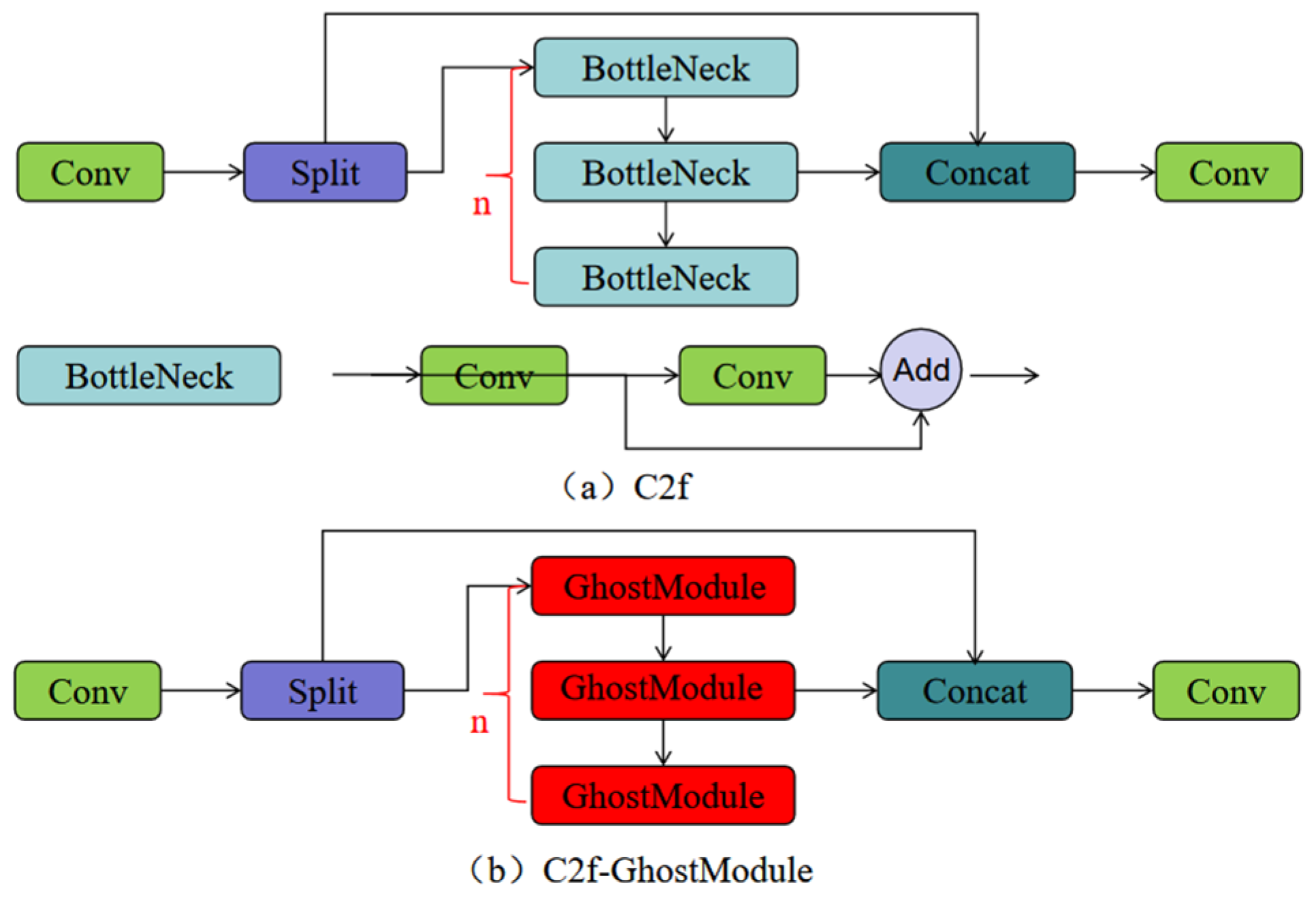
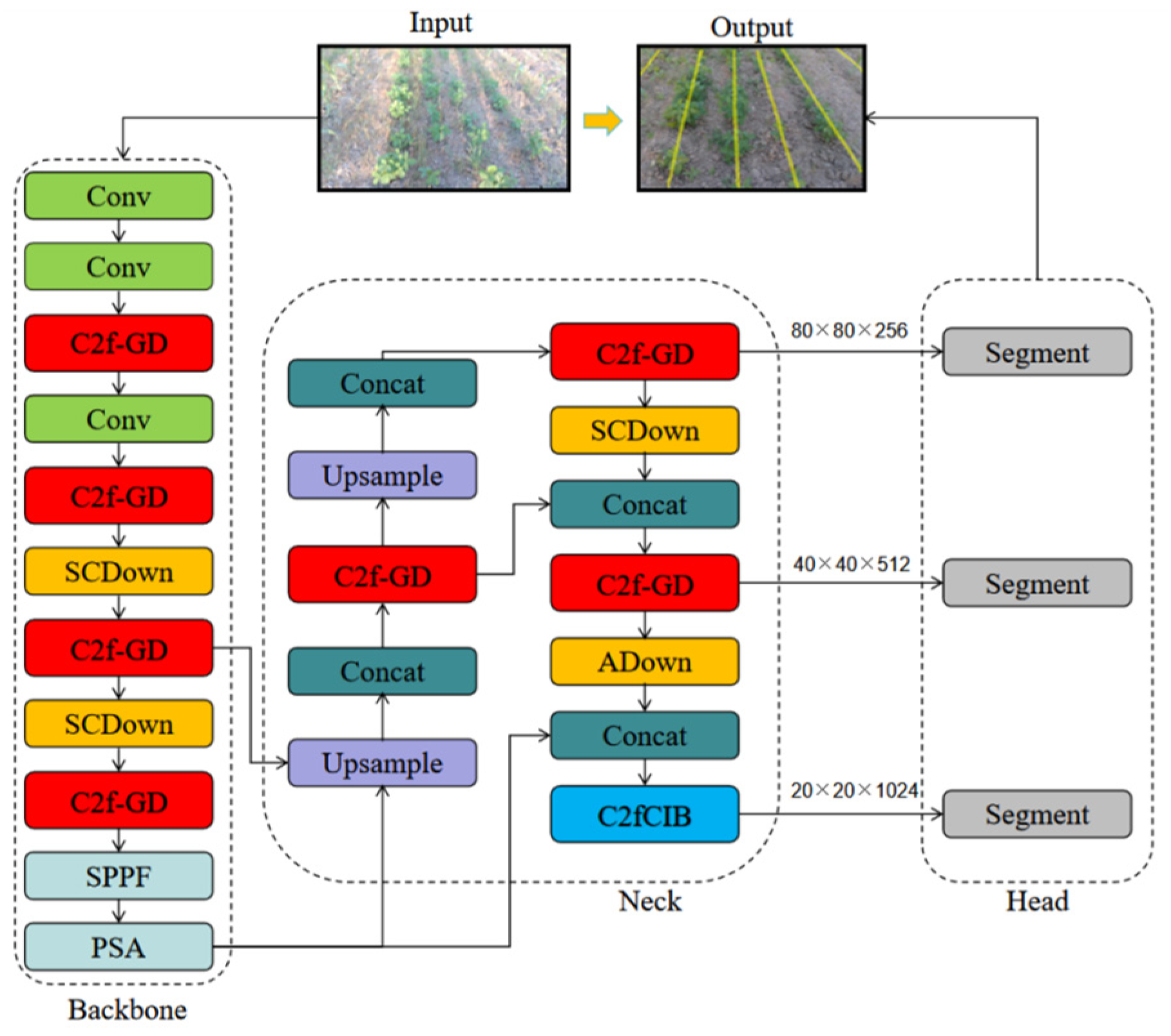
2.2.2. C2f Improvements Based on GhostModule
2.2.3. Improved GhostModule Based on DynamicConv
2.2.4. Model Performance Evaluation Indices
2.3. Crop Row Line Fitting and Test
2.3.1. Crop Row Line Fitting
- (1)
- Data pre-processing: centering the mask data of all crop row scattergrams and subtracting each coordinate point from the average value of all points to ensure that the data are centered at the origin;
- (2)
- Construct covariance matrix: after calculating the covariance matrix of the centered data, this matrix reflects the magnitude of variance in each direction;
- (3)
- Solve for eigenvalues and eigenvectors: calculating the eigenvalues of the covariance matrix and the corresponding eigenvectors, which point out the main direction of the data distribution;
- (4)
- Extract the principal component straight line: Choosing the eigenvector corresponding to the largest eigenvalue as the direction of the fitted straight line. The straight line leading to this direction through the data center point is the required fitted straight line;
- (5)
- Calculate and plot the result: according to the direction of the obtained fitted straight line and the original center point, plot the straight line and calculate the projection of each scatter point to the straight line so as to verify the fitting effect of the straight line.
2.3.2. Test of Crop Row Line Extraction Effect
3. Results
3.1. Performance of Segmentation Model
3.1.1. Performance of YOLOv10n-Seg Model
3.1.2. Performance of the Improved Model Based on GhostModule
3.1.3. Performance of the Improved Model Based on DynamicConv-GhostModule
- (1)
- DynamicConv operations: the introduced dynamic convolution adapted kernel weights per input, adding minor computational overhead.
- (2)
- Enhanced feature representation: while GhostModule reduced parameters, DynamicConv increased the model adaptability, trading off some speed for improved accuracy.
3.1.4. Comparison with Other Segmentation Algorithms
3.2. Crop Row Line Fitting Results
4. Discussion
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, X.T.; Xi, X.B.; Chen, M.; Huang, S.J.; Jin, Y.F.; Zhang, R.H. Development Status of Soybean-Corn Strip Intercropping Technology and Equipment. Jiangsu Agric. Sci. 2023, 51, 36–45, (In Chinese with English Abstract). [Google Scholar]
- Gerrish, J.B.; Stockman, G.C.; Mann, L.; Hu, G. Path-finding by image processing in agricultural field operations. SAE Trans. 1986, 95, 540–554. [Google Scholar]
- Li, D.; Li, B.; Long, S.; Feng, H.; Wang, Y.; Wang, J. Robust detection of headland boundary in paddy fields from continuous RGB-D images using hybrid deep neural networks. Comput. Electron. Agric. 2023, 207, 107713. [Google Scholar]
- Rabab, S.; Badenhorst, P.; Chen, Y.P.P.; Daetwyler, H.D. A template-free machine vision-based crop row detection algorithm. Precis. Agric. 2021, 22, 124–153. [Google Scholar]
- Mousazadeh, H. A technical review on navigation systems of agricultural autonomous off-road vehicles. J. Terra Mech. 2013, 50, 211–232. [Google Scholar]
- Winterhalter, W.; Fleckenstein, F.; Dornhege, C.; Burgard, W. Localization for precision navigation in agricultural fields—Beyond crop row following. J. Field Robot. 2021, 38, 429–451. [Google Scholar]
- Gao, G.; Xiao, K.; Jia, Y. A spraying path planning algorithm based on colourdepth fusion segmentation in peach orchards. Comput. Electron. Agric. 2020, 173, 105412. [Google Scholar]
- Rivera, G.; Porras, R.; Florencia, R.; Sánchez-Solís, J.P. LiDAR applications in precision agriculture for cultivating crops: A review of recent advances. Comput. Electron. Agric. 2023, 207, 107737. [Google Scholar]
- Zhang, S.; Ma, Q.; Cheng, S.; An, D.; Yang, Z.; Ma, B.; Yang, Y. Crop Row Detection in the Middle and Late Periods of Maize under Sheltering Based on Solid State LiDAR. Agriculture 2022, 12, 2011. [Google Scholar] [CrossRef]
- Tsiakas, K.; Papadimitriou, A.; Pechlivani, E.M.; Giakoumis, D.; Frangakis, N.; Gasteratos, A.; Tzovaras, D. An Autonomous Navigation Framework for Holonomic Mobile Robots in Confined Agricultural Environments. Robotics 2023, 12, 146. [Google Scholar] [CrossRef]
- Farhan, S.M.; Yin, J.; Chen, Z.; Memon, M.S. A Comprehensive Review of LiDAR Applications in Crop Management for Precision Agriculture. Sensors 2024, 24, 5409. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Chen, B.; Zhang, Z.; Li, H.; Zhang, M. Applications of machine vision in agricultural robot navigation: A review. Comput. Electron. Agric. 2022, 198, 107085. [Google Scholar]
- Li, X.; Su, J.H.; Yue, Z.C.; Wang, S.C.; Zhou, H.B. Extracting navigation line to detect the maize seedling line using median-point Hough transform. Trans. Chin. Soc. Agric. Eng. 2022, 38, 167–174, (In Chinese with English Abstract). [Google Scholar]
- Bawden, O.; Kulk, J.; Russell, R.; McCool, C.; English, A.; Dayoub, F.; Lehnert, C.F.; Perez, T. Robot for weed species plant-specific management. J. Field Robot. 2017, 34, 1179–1199. [Google Scholar]
- Lan, T.; Li, R.L.; Zhang, Z.H.; Yu, J.G.; Jin, X.J. Analysis on research status and trend of intelligent agricultural weeding robot. Comput. Meas. Control. 2021, 29, 1–7, (In Chinese with English Abstract). [Google Scholar]
- Zhang, W.; Miao, Z.; Li, N.; He, C.; Sun, T. Review of Current Robotic Approaches for Precision Weed Management. Curr. Robot. Rep. 2022, 3, 139–151. [Google Scholar]
- Jørgensen, R.N.; Sørensen, C.A.; Pedersen, J.M.; Havn, I.; Jensen, K.; Søgaard, H.T.; Sørensen, L.B. HortiBot: A System Design of a Robotic Tool Carrier for High-tech Plant Nursing. Agric. Eng. Int. CIGR J. 2007, 9, 14075959. [Google Scholar]
- Bai, Y.H.; Zhang, B.H.; Xu, N.M.; Zhou, J.; Shi, J.Y.; Diao, Z.H. Vision-based navigation and guidance for agricultural autonomous vehicles and robots: A review. Comput. Electron. Agric. 2023, 205, 107584. [Google Scholar]
- Zhou, Y.; Yang, Y.; Zhang, B.L.; Wen, X.; Yue, X.; Chen, L. Autonomous detection of crop rows based on adaptive multi-ROI in maize fields. Int. J. Agric. Biol. Eng. 2021, 14, 1934–6344. [Google Scholar]
- Søgaard, H.T.; Olsen, H.J. Determination of crop rows by image analysis without segmentation. Comput. Electron. Agric. 2003, 38, 141–158. [Google Scholar]
- Li, M.; Zhang, M.; Meng, Q. Rapid detection method of agricultural machinery visual navigation baseline based on scanning filtering. Trans. Chin. Soc. Agric. Eng. 2013, 29, 41–47, (In Chinese with English Abstract). [Google Scholar]
- Montalvo, M.; Pajares, G.; Guerrero, J.M.; Romeo, J.; Guijarro, M.; Ribeiro, A.; Ruz, J.J.; Cruz, J.M. Automatic detection of crop rows in maize fields with high weeds pressure. Expert Syst. Appl. 2012, 39, 11889–11897. [Google Scholar]
- Yu, Y.; Bao, Y.; Wang, J.; Chu, H.; Zhao, N.; He, Y.; Liu, Y. Crop Row Segmentation and Detection in Paddy Fields Based on Treble-Classification Otsu and Double-Dimensional Clustering Method. Remote Sens. 2021, 13, 901. [Google Scholar] [CrossRef]
- Leemans, V.; Destain, M.F. Line cluster detection using a variant of the Hough transform for culture row localisation. Image Vis. Comput. 2006, 24, 541–550. [Google Scholar]
- Yang, X.; Li, X. Research on Autonomous Driving Technology Based on Deep Reinforcement Learning. Netw. Secur. Technol. Appl. 2021, 1, 136–138. [Google Scholar]
- Hwang, J.H.; Seo, J.W.; Kim, J.H.; Park, S.; Kim, Y.J.; Kim, K.G. Comparison between Deep Learning and Conventional Machine Learning in Classifying Iliofemoral Deep Venous Thrombosis upon CT Venography. Diagnostics 2022, 12, 274. [Google Scholar] [CrossRef]
- Niu, S.; Liu, Y.; Wang, J.; Song, H. A Decade Survey of Transfer Learning (2010–2020). Trans. Artif. Intell. 2020, 1, 151–166. [Google Scholar]
- Zhao, C.; Wen, C.; Lin, S.; Guo, W.; Long, J. A method for identifying and detecting tomato flowering period based on cascaded convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2020, 36, 143–152, (In Chinese with English Abstract). [Google Scholar]
- Hu, R.; Su, W.H.; Li, J.L.; Peng, Y.K. Real-time lettuce-weed localization and weed severity classification based on lightweight YOLO convolutional neural networks for intelligent intra-row weed control. Comput. Electron. Agric. 2024, 226, 109404. [Google Scholar]
- Wen, C.J.; Chen, H.R.; Ma, Z.Y.; Zhang, T.; Yang, C.; Su, H.Q.; Chen, H.B. Pest-YOLO: A model for large-scale multi-class dense and tiny pest detection and counting. Front. Plant Sci. 2022, 13, 973985. [Google Scholar]
- Li, J.; Yin, J.; Deng, L. A robot vision navigation method using deep learning in edge computing environment. EURASIP J. Adv. Signal Process. 2021, 22, 1–20. [Google Scholar]
- Adhikari, S.P.; Kim, G.; Kim, H. Deep Neural Network-based System for Autonomous Navigation in Paddy Field. IEEE Access 2020, 8, 71272–71278. [Google Scholar]
- Ponnambalam, V.R.; Bakken, M.; Moore, R.J.D.; Gjevestad, J.G.O.; From, P.J. Autonomous Crop Row Guidance Using Adaptive Multi-ROI in Strawberry Fields. Sensors 2020, 20, 5249. [Google Scholar] [CrossRef] [PubMed]
- Bah, M.; Hafiane, A.; Canals, R. CRowNet: Deep Network for Crop Row Detection in UAV Images. IEEE Access 2020, 8, 5189–5200. [Google Scholar]
- Ruan, Z.; Chang, P.; Cui, S.; Luo, J.; Gao, R.; Su, Z. A precise crop row detection algorithm in complex farmland for unmanned agricultural machines. Biosyst. Eng. 2023, 232, 1–12. [Google Scholar]
- Gong, H.; Zhuang, W.; Wang, X. Improving the maize crop row navigation line recognition method of YOLOX. Front. Plant Sci. 2024, 15, 1338228. [Google Scholar]
- Liu, H.; Xiong, W.; Zhang, Y. YOLO-CORE: Contour Regression for Efficient Instance Segmentation. Mach. Intell. Res. 2023, 20, 716–728. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.H.; Chen, K.; Lin, Z.J.; Han, J.G.; Ding, G.G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Systems 2024, 37, 107984–108011. [Google Scholar]
- Li, X.G.; Zhao, W.; Zhao, L.L. Extraction algorithm of the center line of maize row in case of plants lacking. Trans. Chin. Soc. Agric. Eng. 2021, 37, 203–210, (In Chinese with English Abstract). [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Yan, H.W.; Wang, Y. UAV Object Detection Model Based on Improved Ghost Module. J. Phys. Conf. Ser. 2022, 2170, 012013. [Google Scholar]
- Yang, L.; Cai, H.; Luo, X.; Wu, J.; Tang, R.; Chen, Y.; Li, W. A lightweight neural network for lung nodule detection based on improved ghost module. Quant. Imaging Med. Surg. 2023, 13, 4205–4221. [Google Scholar] [PubMed]
- Chen, Y.; Li, J.; Sun, K.; Zhang, Y. A lightweight early forest fire and smoke detection method. J. Supercomput. 2024, 80, 9870–9893. [Google Scholar]
- Han, K.; Wang, Y.H.; Guo, J.Y.; Wu, E.H. ParameterNet: Parameters Are All You Need for Large-scale Visual Pretraining of Mobile Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11027–11036. [Google Scholar]
- Yang, Y.; Zhang, B.L.; Zha, J.Y.; Wen, X.; Chen, L.Q.; Zhang, T.; Dong, X.; Yang, X.J. Real-time extraction of navigation line between corn rows. Trans. Chin. Soc. Agric. Eng. 2020, 36, 162–171, (In Chinese with English Abstract). [Google Scholar]
- Silva, R.D.; Cielniak, G.; Wang, G.; Gao, J. Deep learning-based crop row detection for infield navigation of agri-robots. J. Field Robot. 2022, 41, 2299–2321. [Google Scholar]
- Lin, S.J.; Chen, Q.; Chen, J.J. Ridge-furrow Detection in Glycine Max Farm Using Deep Learning. In Proceedings of the 2020 International Conference on Pervasive Artificial Intelligence (ICPAI), Taipei, Taiwan, 3–5 December 2020; pp. 183–187. [Google Scholar]
- Fu, D.B.; Chen, Z.Y.; Yao, Z.Q.; Liang, Z.P.; Cai, Y.H.; Liu, C.; Tang, Z.Y.; Lin, C.X.; Feng, X.; Qi, L. Vision-based trajectory generation and tracking algorithm for maneuvering of a paddy field robot. Comput. Electron. Agric. 2024, 226, 109368. [Google Scholar]
- Yang, R.; Zhai, Y.; Zhang, J.; Zhang, H.; Tian, G.; Zhang, J.; Huang, P.; Li, L. Potato Visual Navigation Line Detection Based on Deep Learning and Feature Midpoint Adaptation. Agriculture 2022, 12, 1363. [Google Scholar] [CrossRef]
- Cao, M.; Tang, F.; Ji, P.; Ma, F. Improved Real-Time Semantic Segmentation Network Model for Crop Vision Navigation Line Detection. Front. Plant Sci. 2022, 13, 898131. [Google Scholar]
- Chen, X.J.; Wang, C.X.; Zhu, D.Q.; Liu, X.L.; Zou, Y.; Zhang, S.; Liao, J. Detection of rice seedling row lines based on YOLO convolutional neural network. Jiangsu J. Agric. Sci. 2020, 04, 930–935, (In Chinese with English Abstract). [Google Scholar]
- Guo, X.Y.; Xue, X.Y. Extraction of navigation lines for rice seed field based on machine vision. J. Chin. Agric. Mech. 2021, 42, 197–201, (In Chinese with English Abstract). [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| Operation System | Windows 10 Professional Workstation Edition |
| CPU | Intel i5 13600KF (Intel, Santa Clara, CA, USA) |
| GPU | NVIDIA GTX4070ti 12GB (Nvidia, Santa Clara, CA, USA) |
| Acceletate Environment | Window 10 Profession |
| Python | 3.8 |
| Pytorch | 2.0.1 |
| Cuda | 11.8 |
| Cudnn | 8.9.1 |
| Data Annotation Tools | Labelme |
| Model | MPA /% | MIoU /% | MRecall /% | Speed /FPS | GFlops | Parameters /Million | Model Size /mb | Remarks |
|---|---|---|---|---|---|---|---|---|
| YOLOv10n -seg | 58.18 | 42.04 | 59.00 | 149.54 | 11.7 | 2.84 | 5.75 | Baseline |
| G-YOLO-v10n -seg | 58.71 | 41.11 | 56.82 | 147.45 | 9.7 | 2.21 | 4.58 | +GhostModule |
| GD-YOLO-v10n -seg | 60.76 | 43.04 | 58.63 | 120.19 | 9.6 | 2.28 | 4.70 | +GhostModule +DynamicConv |
| Model | MPA/% | MIoU/% | MRecall/% | Speed/FPS | Model Size/mb |
|---|---|---|---|---|---|
| GD-YOLO-v10n-seg | 60.76 | 43.04 | 58.63 | 120.19 | 4.70 |
| YOLOv10n-seg | 58.18 | 42.04 | 59.00 | 149.54 | 5.75 |
| YOLOv12n-seg | 56.71 | 41.29 | 59.11 | 110.43 | 5.81 |
| YOLOv11n-seg | 57.98 | 41.55 | 58.41 | 134.05 | 5.76 |
| YOLOv9t-seg | 57.15 | 41.75 | 59.34 | 103.67 | 6.61 |
| YOLOv8n-seg | 56.50 | 41.50 | 59.52 | 158.42 | 6.48 |
| YOLOv6n-seg | 55.26 | 40.43 | 58.87 | 172.83 | 8.65 |
| YOLOv5n-seg | 57.35 | 41.32 | 58.35 | 164.41 | 5.55 |
| U-Net | 54.49 | 37.39 | 52.81 | 8.58 | 94.9 |
| DeepLabv3+ | 53.65 | 40.31 | 60.42 | 7.91 | 22.4 |
| Algorithms | Accuracy/% | Line Angular Deviation/° | Speed/FPS |
|---|---|---|---|
| PCA | 95.08 | 1.75 | 61.47 |
| OLSs | 94.67 | 1.88 | 61.31 |
| RANSAC | 93.83 | 1.99 | 34.65 |
| Algorithm | Target Crop | Speed/FPS | Reference |
|---|---|---|---|
| GD-YOLOv10n-seg | soybean, corn | 61.47 (total) | ours |
| U-Net-based | potato | 1.9 (total) | [50] |
| E-Net-based | sugar beet | 17 (recognition) | [51] |
| YOLOX-based | corn | 23.8 (total) | [36] |
| YOLO-based | paddy | ≤25 (total) | [52] |
| RGB-based | paddy | 5 (total) | [53] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, T.; Le, F.; Cai, C.; Jin, Y.; Xue, X.; Cui, L. Soybean–Corn Seedling Crop Row Detection for Agricultural Autonomous Navigation Based on GD-YOLOv10n-Seg. Agriculture 2025, 15, 796. https://doi.org/10.3390/agriculture15070796
Sun T, Le F, Cai C, Jin Y, Xue X, Cui L. Soybean–Corn Seedling Crop Row Detection for Agricultural Autonomous Navigation Based on GD-YOLOv10n-Seg. Agriculture. 2025; 15(7):796. https://doi.org/10.3390/agriculture15070796
Chicago/Turabian StyleSun, Tao, Feixiang Le, Chen Cai, Yongkui Jin, Xinyu Xue, and Longfei Cui. 2025. "Soybean–Corn Seedling Crop Row Detection for Agricultural Autonomous Navigation Based on GD-YOLOv10n-Seg" Agriculture 15, no. 7: 796. https://doi.org/10.3390/agriculture15070796
APA StyleSun, T., Le, F., Cai, C., Jin, Y., Xue, X., & Cui, L. (2025). Soybean–Corn Seedling Crop Row Detection for Agricultural Autonomous Navigation Based on GD-YOLOv10n-Seg. Agriculture, 15(7), 796. https://doi.org/10.3390/agriculture15070796