Abstract
This paper explores the transformative potential of Foundation Models (FMs) in agriculture, driven by the need for efficient and intelligent decision support systems in the face of growing global population and climate change. It begins by outlining the development history of FMs, including general FM training processes, application trends and challenges, before focusing on Agricultural Foundation Models (AFMs). The paper examines the diversity and applications of AFMs in areas like crop classification, pest detection, and crop image segmentation, and delves into specific use cases such as agricultural knowledge question-answering, image and video analysis, decision support, and robotics. Furthermore, it discusses the challenges faced by AFMs, including data acquisition, training efficiency, data shift, and practical application challenges. Finally, the paper discusses future development directions for AFMs, emphasizing multimodal applications, integrating AFMs across the agricultural and food sectors, and intelligent decision-making systems, ultimately aiming to promote the digitalization and intelligent transformation of agriculture.
1. Introduction
With the rapid development of Artificial Intelligence (AI) technology, research and application of Foundation Models (FMs) have gradually become a focal point across various fields. In agriculture, traditional AI applications mainly rely on specific Machine Learning (ML) and Deep Learning (DL) technologies [1], such as crop classification and pest detection. However, in recent years, the introduction of FM technology has brought new transformative opportunities to agriculture [2]. These models, which are pre-trained on a large scale and fine-tuned for specific agricultural tasks, can handle multimodal data, including text, images, audio, and video, and have the ability for cross-domain transfer learning. The goal of FMs is to enhance the intelligence level of agricultural production, optimize resource management, improve crop yield and quality, and solve practical problems in agricultural production.
The motivation for writing this paper stems from the urgent need for efficient, intelligent decision-support systems in agriculture. With the increasing global population and the impact of climate change, traditional agriculture faces unprecedented challenges, such as resource wastage, low production efficiency, and environmental issues. Therefore, leveraging advanced FM technologies to improve the intelligent and precise management of agricultural production has significant practical value and broad application prospects. By exploring the application of FMs in agriculture, we can drive the sector toward more precise, efficient, and sustainable practices, addressing the current challenges in agriculture and advancing the digitalization and intelligent transformation of the industry.
We systematically collected 84 relevant publications published between 2019 and 2025, which provided an empirical foundation for this study and identified critical technological gaps in the field of agricultural large models.
This study makes four key contributions to advance AFMs:
- We systematically introduce the development of general-purpose foundation models in computer science, including their technical evolution and core architectures (Figure 1, Table 1 and Table 2), providing essential background for non-computer science researchers to understand these transformative AI technologies.
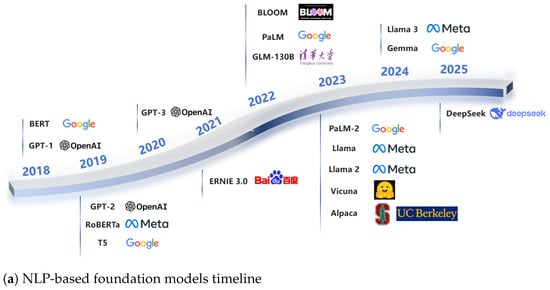
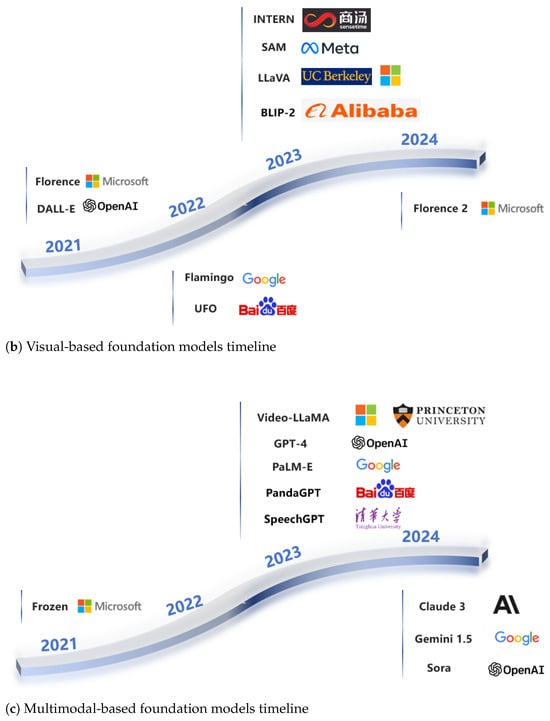 Figure 1. Timeline of existing foundation models (FMs) in recent years, categorized by: (a) NLP-based models; (b) Visual-based models; and (c) Multimodal-based models. Timeline data was extracted from the original papers’ release dates.
Figure 1. Timeline of existing foundation models (FMs) in recent years, categorized by: (a) NLP-based models; (b) Visual-based models; and (c) Multimodal-based models. Timeline data was extracted from the original papers’ release dates. - We comprehensively review existing AFMs and analyze their agricultural applications in knowledge Q&A, disease detection, and decision support (Table 3), offering practical insights for domain experts.
- We identify unique challenges in developing AFMs, including agricultural data heterogeneity, temporal shifts in field conditions, and deployment constraints for smallholder farms.
- We propose future directions emphasizing multimodal integration and intelligent decision systems to bridge AI innovation with agricultural needs.
By synthesizing insights from a large body of research, this work serves as a technical reference for interdisciplinary researchers and an implementation guide for agricultural practitioners.
2. Overview of FM Development
In this section, we provide an overview of the technical background and development history of FMs, examining their historical development, key technological evolution, and significance. This section analyzes the core technologies of FMs, presents the classification of FMs, and offers a reference table that covers different types of FMs and their applications. This section further elaborates on the construction process of FMs, encompassing data processing, model architecture, training optimization, and evaluation. Additionally, it examines the applications of FMs and the challenges associated with them.
2.1. History of FMs
A FM is an artificial intelligence model trained on extensive data with large-scale parameters and complex computational structures [3], typically constructed from deep neural networks [4] and characterized by large-scale parameters, enabling adaptation to a wide range of downstream tasks [5], such as speech recognition, Natural Language Processing (NLP) [6,7,8,9], Computer Vision (CV) [10,11,12,13], and decision-making [14,15]. From a technological perspective, deep neural networks underpin FMs, with both technologies having evolved over decades.
The evolution of machine learning within AI has progressed through distinct phases, beginning with its emergence in the 1990s as a paradigm for automated model building from training data [3] to the recent dominance of DL. While early approaches relied on domain-specific feature engineering for complex tasks in NLP and CV [5], DL’s multi-layered architectures facilitates automated feature extraction, thereby revolutionizing pattern recognition through large-scale datasets and enhanced computational resources [16]. This shift, exemplified by breakthroughs in image recognition [17,18], has achieved superhuman performance in controlled settings [19,20] but faces deployment challenges in practical applications due to interpretability and data quality concerns.
By the end of 2018, the field of NLP was on the verge of another seismic shift, ushering in the era of FMs [5]. Artificial intelligence technology has evolved from small-scale data to big data, from limited models to FMs, and from specialized to general-purpose systems, steadily entering the FM era. Currently, research on FMs is primarily focused on NLP, CV, and multimodal tasks [21]. FMs are classified according to their capacity into NLP-based FMs, vision-based FMs, and multimodal-based FMs. In Figure 1, we outline the evolutionary processes of these three types of FMs in detail.
Large Language Models (LLMs) represent advanced neural architectures characterized by their massive scale, typically comprising billions or more parameters. These extensive models demonstrate unique emergent capabilities that distinguish them from conventional Pre-trained Language Models (PLMs) [22]. Empirical evidence suggests a positive correlation between model scale and performance, with larger architectures exhibiting enhanced sample efficiency and superior task-solving capabilities [23]. Comparative analyses between scaled PLM implementations reveal significant behavioral differences, where expanded models demonstrate remarkable proficiency in addressing complex challenges [24]. A notable manifestation of these emergent properties is evident in GPT-3’s [7] contextual learning capacity, which enables the generation of targeted outputs through text sequence completion without additional parameter optimization, a capability not present in its predecessor, GPT-2 [6].
Large Vision Models (LVMs) represent a significant advancement in CV research. Early approaches in visual pattern recognition primarily relied on basic feature extraction techniques, such as scale-invariant feature transformation and gradient orientation histograms, which were subject to substantial constraints. The landscape transformed dramatically in 2012 when AlexNet’s [17] remarkable performance in the ImageNet competition sparked widespread adoption of Convolutional Neural Networks (CNNs). Subsequent architectural innovations, including VGGNet [25], GoogLeNet [26], and ResNet [27], significantly enhanced the capabilities in image analysis tasks. The proliferation of internet-scale image datasets facilitated the development of advanced detection frameworks, such as Faster R-CNN [28], YOLO [29], and Mask R-CNN [30]. More recently, the integration of Transformer architectures with Generative Adversarial Networks (GANs) has yielded groundbreaking models, such as Vision Transformer(ViT) [31] and DALL-E [32], showcasing exceptional performance in visual understanding and synthesis through self-attention mechanisms.
Multimodal Large Language Models (MLLMs) [33] have emerged as a pivotal advancement in AI research, addressing the limitations of single-modal systems. While LLMs excel in textual tasks and LVMs demonstrate proficiency in visual analysis, both exhibit limited capabilities when processing cross-modal data. MLLMs overcome these limitations by integrating diverse data modalities, including visual, textual, and auditory information, thereby enabling comprehensive multimodal understanding and processing. This technological breakthrough has significantly expanded AI’s capabilities, facilitating sophisticated interpretation and manipulation of heterogeneous data types [33].
To provide a comprehensive overview of the development of FMs, we summarize the key models in NLP, vision, and multimodal domains in Table 1 and Table 2, including their architectures, parameters, and applications.

Table 1.
Overview of popular FMs (Part 1).
Table 1.
Overview of popular FMs (Part 1).
| Model Type | Model Name | Model Creators | Release Year | # Architecture | # Parameters |
|---|---|---|---|---|---|
| NLP-based | GPT-1 [34] | OpenAI | 2018 | Decoder only | 117M |
| GPT-2 [6] | OpenAI | 2019 | Decoder only | 117 M, 345 M, 762 M, 1.5 B | |
| GPT-3 [7] | OpenAI | 2020 | Decoder only | 175 B | |
| GLM-130B [35] | Tsinghua University | 2022 | Encoder–decoder | 130 B | |
| BERT [36] | 2018 | Encoder only | 340 M | ||
| RoBERTa [37] | Meta | 2019 | Encoder only | 340 M | |
| T5 [38] | 2019 | Encoder–decoder | 60 M, 220 M, 770 M, 3 B, 11 B | ||
| Gemma [39] | 2024 | Decoder only | 2 B, 7 B | ||
| PaLM [40] | 2022 | Decoder only | 8 B, 62 B, 540 B | ||
| PaLM-2 [41] | 2023 | Decoder only | 340 B | ||
| BLOOM [42] | BigScience | 2022 | Decoder only | 3 B, 7.1 B, 176 B | |
| ERNIE 3.0 [43] | Baidu | 2021 | Encoder only | 27 M, 75 M, 118 M | |
| Llama [9] | Meta | 2023 | Decoder only | 7 B, 13 B, 33 B, 65 B | |
| Llama 2 [9] | Meta | 2023 | Decoder only | 7 B, 13 B, 34 B, 70 B | |
| Llama 3 [44] | Meta | 2024 | Decoder only | 8 B, 70 B, 400 B | |
| Vicuna [45] | Hugging Face | 2023 | Decoder only | 7 B, 13 B | |
| Alpaca [46] | Stanford and UC Berkeley | 2023 | Decoder only | 7 B | |
| DeepSeek LLM [47] | DeepSeek AI | 2024 | Decoder only | 7 B, 67 B | |
| DeepSeek-V2 [48] | DeepSeek AI | 2024 | Decoder only | 236 B | |
| DeepSeek-V3 [48] | DeepSeek AI | 2024 | Decoder only | 671 B | |
| DeepSeek-R1 [49] | DeepSeek AI | 2025 | Decoder only | 671 B | |
| Vision-based | LLaVA [50] | UC Berkeley and Microsoft | 2023 | Encoder only | 13 B |
| BLIP-2 [51] | Alibaba | 2023 | Encoder only | 12 B | |
| Flamingo [52] | 2022 | Encoder only | 3 B, 9 B, 80 B | ||
| Florence [53] | Microsoft | 2021 | Encoder only | 893 M | |
| Florence 2 [54] | Microsoft | 2024 | Encoder–decoder | 0.2 B, 0.7 B | |
| Segment Anything Model (SAM) [12] | Meta | 2023 | Encoder–decoder | 375 M, 1.25 G, 2.56 G | |
| UFO [55] | Baidu | 2022 | Encoder only | 17 B | |
| INTERN [56] | SenseTime | 2023 | Encoder–decoder | 20 B | |
| DALL·E [32] | OpenAI | 2021 | Encoder–decoder | 12 B | |
| DeepSeek-VL [57] | DeepSeek AI | 2024 | Decoder only | 1.3 B, 7 B | |
| DeepSeek-VL2 [58] | DeepSeek AI | 2024 | Decoder only | 1.0 B, 2.8 B, 4.5 B | |
| Multimodal | GPT-4 [59] | OpenAI | 2023 | Decoder only | 1.8 T |
| Sora [60] | OpenAI | 2024 | Encoder–decoder | - | |
| Claude 3 [61] | Anthropic | 2024 | Decoder only | 20 B, 70 B, 2 T | |
| Video-LLaMA [62] | Princeton & Microsoft | 2023 | Encoder only | - | |
| Gemini 1.5 [63] | 2024 | Decoder only | Nano 1.8 B/3.25 B | ||
| PaLM-E [64] | 2023 | Decoder only | 562 B | ||
| PandaGPT [65] | Baidu | 2023 | Decoder only | - | |
| SpeechGPT [66] | Tsinghua University | 2023 | Decoder only | 13 B | |
| Frozen [67] | Microsoft | 2021 | Decoder only | 7 B |
Table 2.
Overview of Popular FMs (Part 2).
Table 2.
Overview of Popular FMs (Part 2).
| Model Name | I->O Modality | Open Source | Key Applications | Pre-Train Data Scale | Agri-Trained | Agri-Applicable |
|---|---|---|---|---|---|---|
| GPT-1 | Text -> Text | ✓ | Text generation, language modeling | - | × | × |
| GPT-2 | Text -> Text | ✓ | Text generation, language modeling | - | × | × |
| GPT-3 | Text -> Text | ✓ | Text generation, language modeling | 5 G | × | × |
| GLM-130 B | Text -> Text | ✓ | Text generation, question answering | - | × | × |
| BERT | Text -> Text | × | Text generation, question answering, summarization | 570 G | × | × |
| RoBERTa | Text -> Text | ✓ | Language understanding, text classification, NER | - | × | × |
| T5 | Text -> Text | ✓ | Text generation, question answering, summarization | - | × | × |
| Gemma | Text -> Text | ✓ | Multi-language text generation, understanding | 366 B | × | × |
| PaLM | Text -> Text | ✓ | Text generation, summarization, translation | 750 G | × | × |
| PaLM-2 | Text -> Text | ✓ | Text generation, summarization, creative writing | 3 T, 6 T | × | × |
| BLOOM | Text -> Text | ✓ | Text classification, question answering | - | × | × |
| ERNIE 3.0 | Text -> Text | × | Text understanding, knowledge-enhanced tasks | - | × | × |
| Llama | Text -> Text | ✓ | Cross-lingual tasks, text generation | 780 B | × | × |
| Llama 2 | Text -> Text | ✓ | Cross-lingual tasks, text generation | 3.6 T | × | × |
| Llama 3 | Text -> Text | ✓ | Text generation, question answering | 2 T | × | ✓ |
| Vicuna | Text -> Text | ✓ | Chatbot, dialogue systems | - | × | × |
| Alpaca | Text -> Text | ✓ | Text generation, question answering | 1.4 T | × | ✓ |
| DeepSeek LLM | Text -> Text | ✓ | Text generation, question answering | 15 T | × | ✓ |
| DeepSeek-V2 | Text -> Text | ✓ | Chatbot, dialogue systems | 70 K samples | × | × |
| DeepSeek-V3 | Text -> Text | ✓ | Instruction-following tasks | 52 K samples | × | × |
| DeepSeek-R1 | Text -> Text | ✓ | Text generation, dialogue systems | 2T | × | × |
| LLaVA | Image + Text -> Text | ✓ | Vision and language understanding, image captioning | 158 K | × | × |
| BLIP-2 | Image + Text -> Text | ✓ | Visual Question Answering (VQA), image captioning | 129 M | × | ✓ |
| Flamingo | Text + Image -> Text | ✓ | Reasoning, math, code generation | - | × | × |
| Florence | Image -> Image | × | Image recognition, visual understanding | - | × | × |
| Florence 2 | Image -> Image | × | Image recognition, visual understanding | - | × | × |
| Segment Anything Model (SAM) | Image -> Segmentation masks | ✓ | Object segmentation, masking, image manipulation | 1 B | × | ✓ |
| UFO | Image -> Image | × | Industrial visual inspection, object detection | - | × | × |
| INTERN | Image -> Image | × | Image recognition, visual understanding | - | × | × |
| DALL·E | Text -> Image | ✓ | Image generation from text descriptions | - | × | × |
| DeepDeepSeek-VL2Seek-VL | Image + Text -> Text | ✓ | Vision-language tasks | - | × | × |
| Image + Text -> Text | ✓ | Vision-language tasks | - | × | × | |
| GPT-4 | Text + Image -> Text | × | Text generation, image understanding | 1.8 T | × | ✓ |
| Sora | Text -> Video | × | Video generation | - | × | × |
| Claude 3 | Text -> Text | × | Text generation, complex reasoning | - | × | × |
| Video-LLaMA | Video + Text -> Text | ✓ | Video understanding, video captioning | - | × | × |
| Gemini 1.5 | Text + Image -> Text | × | Multimodal understanding | - | × | × |
| PaLM-E | Text + Image -> Text | ✓ | Robotics, multimodal reasoning | - | × | × |
| PandaGPT | Text + Image -> Text | ✓ | Multimodal understanding | - | × | × |
| SpeechGPT | Speech + Text -> Text | ✓ | Speech recognition and synthesis | 60 K h | × | × |
| Frozen | Text + Image -> Text | ✓ | Multimodal learning | - | × | × |
2.2. Process of Building FMs
2.2.1. Data Selection and Processing
Training data play a pivotal role in determining the performance of FMs. Training data can generally be classified into two main categories: general-purpose and domain-specific data. General-purpose data include a wide array of content, such as web pages, books, and conversational text, which is abundant and diverse but often contains noise. Domain-specific data, in contrast, refer to datasets tailored to particular fields, such as scientific papers, code, or multilingual texts, which are essential for refining the model’s capabilities for targeted domains or tasks. Models like BLOOM [42] and PaLM [41] have leveraged such domain-specific datasets to improve performance across a range of languages and domains.
The processing of training data is a fundamental aspect of ensuring high-quality model performance [68]. For general-purpose data, particularly web data, the first step is to filter out low-quality content. This involves removing irrelevant information, such as spam, advertisements, or misleading data. Methods for filtering low-quality data can generally be categorized into classifier-based and heuristic-based approaches. Classifier-based methods, as employed in models such as GPT-3 [7] and PaLM [41], involve training a machine learning classifier to distinguish between high- and low-quality content. Heuristic-based methods, used by models like BLOOM [42], rely on predefined rules or patterns to identify and exclude undesirable data.
Given that web data are vast and heterogeneous, consisting of diverse text formats, topics, and writing styles, preprocessing must also address issues such as duplications and biases. The data must be cleaned and structured to ensure that the remaining content is both relevant and representative of the tasks the model is expected to handle. Another critical step is ensuring data privacy, which involves eliminating Personally Identifiable Information (PII) to comply with regulations such as GDPR [69].
Domain-specific datasets also require careful handling. Scientific literature, for instance, contains complex terminology that must be processed to enable the model to understand domain-specific nuances. Multilingual data present challenges related to diverse grammar rules, syntax, and language-specific structures, necessitating specific preprocessing techniques such as tokenization or translation normalization [70,71,72]. For code generation, it is essential to clean and format code snippets to ensure they can be properly interpreted by the model [73,74].
2.2.2. FMs Architectures
FMs are generally built upon three dominant architectural paradigms: encoder-only, decoder-only, and encoder–decoder models, most of which rely on the Transformer framework as the foundational building block [75].
(1) Encoder Only: Encoder-only architectures, such as BERT [36], are designed for tasks requiring a deep understanding of input sequences, such as named entity recognition, sentence classification, and extractive question answering. These models typically rely on a bidirectional self-attention mechanism, enabling the attention layers to access information across the entire input sequence. Pretraining objectives, such as Masked Language Modeling (MLM), involve corrupting parts of the input sequence and tasking the model with reconstructing it, thereby enhancing the model’s understanding of contextual relationships.
(2) Decoder Only: Decoder-only architectures, exemplified by GPT models [7], are autoregressive and optimized for text generation tasks. In these models, the attention layers can only access preceding tokens in the sequence, enabling them to predict the next token in a stepwise manner. The decoder-only paradigm is particularly suited for tasks such as story generation, conversational AI, and completion-based language modeling.
(3) Encoder–Decoder: Encoder–decoder architectures, such as T5 [38] and BART [76], integrate the strengths of both encoders and decoders. The encoder processes the input sequence in its entirety, while the decoder generates output sequences based on the encoded representation. These models are ideal for sequence-to-sequence tasks, such as machine translation, summarization, and generative question answering. Pretraining objectives often include span corruption, where random spans of text are masked and the model is tasked with reconstructing them.
2.2.3. Training and Optimization
The training of FMs involves addressing challenges related to computational efficiency, model scalability, and task-specific performance. The training process typically consists of two main stages: pre-training on vast amounts of data and fine-tuning to adapt the model to specific tasks. To address these challenges, a range of optimization techniques have been developed to enhance the efficiency and effectiveness of large-scale model training.
(1) Pre-training of FMs: During pre-training, FMs are exposed to vast corpora of unlabeled text, typically employing self-supervised learning techniques. Two common approaches to this process are autoregressive language modeling [77], where the model predicts the next token in a sequence, and masked language modeling [78], where specific tokens are masked, and the model learns to predict them based on the surrounding context. Recently, techniques such as Mixture of Experts (MoE) have emerged, where a sparse set of expert networks is dynamically selected during training to reduce computational overhead, enabling the scaling of both model size and dataset size without a proportional increase in computing costs [79].
(2) Fine-tuning for Task-Specific Adaptation: Fine-tuning [80] is essential for adapting pre-trained models to specific tasks. It can be broadly categorized into two approaches:
- Instruction Tuning: Instruction tuning [81] focuses on enhancing the model’s ability to follow specific instructions across a variety of tasks. This process can be further categorized into full-parameter fine-tuning [82] and Parameter-Efficient Fine-Tuning (PEFT) [83]. Full fine-tuning updates all the parameters in the model to optimize performance for a specific task, but its high computational cost and resource requirements limit its practicality for many use cases. In contrast, PEFT methods achieve task-specific adaptation by updating a small subset of parameters, thereby significantly reducing computational overhead. A notable example of PEFT is LoRA (Low-Rank Adaptation) [84], which applies low-rank matrix approximations to weight updates, further reducing the number of trainable parameters and enhancing scalability.
- Alignment Fine-Tuning: Alignment fine-tuning [24] is designed to refine the model’s behavior to align with human values and expectations. This approach often employs reinforcement learning techniques that incorporate feedback signals to guide the model’s adjustments. A widely used method is Reinforcement Learning with Human Feedback (RLHF) [85], where human-provided feedback, such as preference rankings or annotations, serves as a reward signal for training the model. RLHF has been instrumental in improving the alignment of FMs with user preferences, ensuring that the generated outputs are more relevant and aligned with human expectations. A complementary approach, Reinforcement Learning with AI Feedback (RLAIF) [86], replaces human feedback with AI-generated signals, reducing reliance on human labor while maintaining training efficiency. This approach is particularly valuable for scaling alignment processes in FMs, where collecting human feedback at scale may be impractical.
(3) Optimization Techniques for Enhanced Performance: To further enhance the performance of FMs, Retrieval-Augmented Generation (RAG) [87] has emerged as an effective optimization technique. One of the primary limitations of pre-trained models is their inability to access up-to-date or domain-specific knowledge. RAG addresses this limitation by dynamically retrieving relevant information from external sources, such as search engines or knowledge graphs, and integrating it into the model’s generation process. By integrating retrieval-based information, RAG enhances the relevance of responses, making it a valuable technique for a wide range of applications.
2.2.4. Evaluation Metrics
Evaluating FMs involves using various metrics to assess their performance across different tasks. The following outlines the key methods commonly used for evaluation.
(1) Task-Specific Metrics: Task-specific metrics are efficient and cost-effective, providing a rapid means of evaluating FM performance on defined tasks. Common metrics include ROUGE (Recall-Oriented Understudy for Gisting Evaluation) [88] for text summarization and text generation, which measures recall, precision, and F1 score, and BLEU (Bilingual Evaluation Understudy) [89] for machine translation. These metrics primarily focus on text quality and linguistic accuracy. However, their scope is limited to specific tasks and may not capture nuances such as style, cultural context, or the subtleties of natural language, which are essential for more complex or generalized applications of FMs.
(2) Research Benchmarks: Standardized research benchmarks, such as MMLU (Massive Multitask Language Understanding) [90], GLUE (General Language Understanding Evaluation) [91], and SuperGLUE [92], enable a broad and consistent evaluation of model performance across a variety of tasks and datasets. These benchmarks are useful for quickly assessing foundational model (FM) capabilities, as they cover a wide range of topics and problem domains. However, these benchmarks are not without limitations. Issues such as data contamination (i.e., overlap between benchmark datasets and model training data) [93] and the possibility of “benchmark gaming” (where models are fine-tuned specifically to perform well on these tests) [94] can lead to unreliable assessments. Additionally, these benchmarks are often focused on specific evaluation dimensions, which may not fully capture a model’s versatility or real-world performance across varied tasks.
(3) Model Self-Evaluation: Model self-evaluation enables a pre-trained model to assess the performance of other models by calculating specific metrics, such as perplexity, diversity, and consistency [7]. This method is fast and straightforward, providing an internal mechanism for evaluating generated outputs or model performance. While it is effective for certain applications, such as verifying the accuracy of RAG systems [95], it is not without limitations. For instance, self-evaluation can be resource-intensive and sensitive to the model’s selection criteria and the prompts provided. Moreover, it struggles with tasks that require reasoning or advanced problem-solving, such as step-by-step mathematical reasoning [96].
(4) Human Evaluation: Human evaluation remains the most reliable method for assessing the quality of FMs, particularly in ensuring that their outputs align with human values and expectations. Human evaluators can rank models or evaluate outputs based on subjective criteria, such as coherence, relevance, and overall quality. Common approaches include crowdsourced evaluations [97], where multiple humans evaluate the same model output, and expert evaluations [97], which involve skilled human annotators providing in-depth analysis. While highly reliable, human evaluations are resource-intensive, time-consuming, and expensive, particularly when high-level expertise is required. These evaluations are invaluable for more subjective assessments but may lack efficiency for broader, general-purpose model benchmarking.
2.3. Applications and Challenges of FMs
With the continuous advancement of artificial intelligence, FMs are permeating various industries at an unprecedented speed, demonstrating revolutionary potential and significant application value. However, alongside the numerous innovative opportunities they offer, FMs also face substantial challenges in practical applications, including high computational resource consumption, data privacy and security issues, and limited model interpretability.
2.3.1. Applications of FMs
In recent years, the rapid development of FM technology has showcased its transformative capabilities due to its exceptional semantic understanding, multimodal processing, and logical reasoning skills. These models are profoundly reshaping various vertical domains, such as information retrieval, biotechnology, and autonomous driving. Specifically, in the domain of information retrieval, FMs can capture the true intent behind user queries through deep semantic understanding, thereby enhancing query efficiency, as demonstrated by the work of Mohammad Kachuee et al. [98], who employed query rewriting and expansion to clarify user needs. In biotechnology, FMs have become indispensable tools in scientific research, driving a shift from traditional experiment-driven approaches toward intelligent, data-driven methodologies, as exemplified by DeepMind’s AlphaFold2 [99], which significantly accelerates protein structure prediction and shortens research cycles. In the realm of autonomous driving, while conventional systems rely on multiple independent algorithmic modules, FMs integrate perception, decision-making, and control through deep learning to boost overall system intelligence. For instance, Wang et al. [100] introduced the DriveMLM framework, which achieves closed-loop autonomous driving by standardizing decision states and employing multimodal modeling. Furthermore, FMs are finding applications in smart cities, film production, intelligent education, and robotics [101]. In summary, as FM technology continues to break traditional industry boundaries, it is poised to fundamentally transform production methods and daily lives, delivering unprecedented efficiency and possibilities.
2.3.2. Challenges of FMs
Challenge 1: Computational Resource and Training Duration
The primary challenge of FMs lies in their high computational resource demands during both training and inference [102]. Training these models requires immense computational power, heavily dependent on high-performance GPUs or TPUs, and imposes strict requirements on the scale and performance of computing infrastructure. Moreover, the enormous number of parameters and the need to store intermediate computation results significantly increase memory requirements, presenting notable challenges for hardware configurations. The high computational cost restricts the widespread application of FMs. It also affects their efficient deployment and sustainable operation. Additionally, the iterative parameter optimization process can span several weeks or even months, demanding substantial computational resources, time, and meticulous debugging to gradually achieve the desired performance targets. Consequently, enhancing computational efficiency and reducing resource consumption through algorithm optimization, hardware acceleration, and model compression has become a critical research focus in artificial intelligence.
Challenge 2: Data Privacy and Security
FMs typically require massive datasets for optimal performance, often containing sensitive user information [103]. Inadequate protection mechanisms can lead to data breaches and severe security risks. Furthermore, during both training and inference, data may be susceptible to adversarial attacks or malicious tampering, which can compromise the model’s accuracy and robustness. Such issues not only threaten user privacy but also undermine the model’s credibility and its effectiveness in practical applications, thereby posing significant challenges to the broad deployment and long-term development of AI systems.
Challenge 3: Model Interpretability and Transparency
Given that FMs often comprise billions of parameters, their complex decision-making processes and prediction outputs are difficult to interpret directly [24]. This lack of interpretability poses significant challenges, particularly in fields requiring high transparency and trust, such as medical diagnosis and financial risk management, where interpretability is fundamental for user confidence, regulatory compliance, and practical deployment. The opaque nature of these models may lead to user skepticism regarding their outputs, thereby limiting their application in critical tasks. Moreover, insufficient interpretability hinders error analysis and performance optimization, complicating the identification and correction of potential biases. Although both academia and industry have intensified research into enhancing the interpretability of FMs, achieving a balance between maintaining high performance and improving transparency remains a pressing challenge.
3. FMs in Agriculture
This section investigates the development, diversity, and applications of FMs within the agricultural domain. Figure 2 delineates the construction process of AFMs. We analyze various FMs utilized for tasks such as text classification, disease detection, and image segmentation. These models employ state-of-the-art architectures, including Transformer-based models and multimodal systems that integrate both text and image data. Furthermore, we explore optimization strategies and pre-training techniques tailored for specific agricultural applications. This section offers a comprehensive overview of key models and their contributions to agricultural research and practical applications. These advancements underscore the growing diversity in model architectures and their adaptability to various agricultural challenges, which will be further explored in the following subsections.
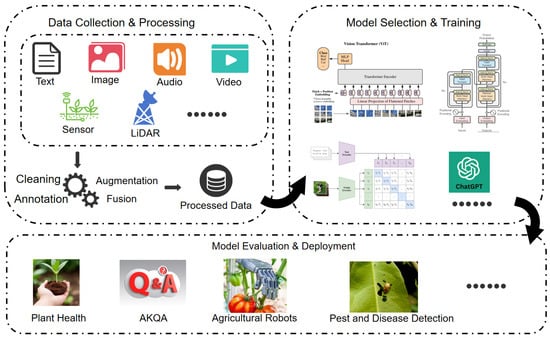
Figure 2.
Development process of AFMs, divided into three main stages: data collection and processing, model selection and training, and model evaluation and deployment.
The implementation of AFMs must address the fundamental dichotomy between smallholder and industrial-scale farming systems. Current research reveals that most AFM architectures follow distinct technological pathways for these operational scales due to divergent infrastructure requirements and economic realities. Smallholder systems, representing over 80% of global farms, require specialized models emphasizing three critical characteristics: offline functionality for connectivity-challenged environments, minimal hardware dependencies, and extreme cost efficiency. These constraints have driven innovations like WhatsApp-based advisory platforms and TinyML implementations capable of operating on low-power edge devices, which achieve 70–80% accuracy at radically reduced deployment costs [104,105]. In contrast, industrial agricultural operations employ high-accuracy (>90%) cloud-based AFMs that process terabytes of multispectral drone and IoT sensor data through sophisticated transformer architectures. This approach requires substantial infrastructure investments in 5G networks and computing resources. This technological bifurcation reflects underlying socioeconomic realities—where smallholder systems prioritize accessibility and resilience, industrial operations optimize for precision at scale through capital-intensive solutions [106].
Table 3 summarizes some of the current AFMs. The emergence of AFMs began in 2022, with one of the earliest models being AgriBERT [107], which utilizes the BERT architecture and is primarily used for tasks such as text classification and generation on agricultural journals and USDA datasets. AgriBERT was pre-trained from scratch using a standard Masked Language Modeling (MLM) objective, where 15% of tokens in input sentences were randomly masked, and the model learned to predict them based on contextual information. The training corpus consisted of 46,446 food and agriculture-related journal articles (311 million tokens, 2.39 million words) rigorously cleaned to remove URLs, emails, and non-ASCII characters, supplemented by WikiText-103 and Penn Treebank datasets for linguistic diversity. As technological advancements occurred, the complexity of model architectures and tasks increased, leading to the introduction of new architectures such as ViT and RoBERTa, which offer stronger support for agricultural tasks involving both images and text.
The validation and processing of agricultural data begins with collecting multi-source texts (such as journal articles and extension materials) and converting them into standardized formats. This is followed by data cleaning to remove noise including garbled characters, non-UTF-8 characters, and the standardization of punctuation and capitalization. When constructing question-answering datasets, documents are filtered according to paragraph-length criteria to divide into training, validation, and test sets. Annotation tools are then employed to generate QA pairs where answers must precisely match source text segments without paraphrasing while ensuring diverse question types. Quality control is implemented through phased supervision by domain experts, including collaborative annotation with regular sampling checks during the annotation phase and consistency validation during evaluation. The inter-annotator agreement is quantified using both Cohen’s Kappa and F1 scores, with the latter (reaching 0.86 in AgXQA1.1) proving more reliable for scenarios with multiple potential answers, thereby ensuring high data quality and task suitability [108].
Table 3.
Overview of agricultural models and tasks.
Table 3.
Overview of agricultural models and tasks.
| Model Name | Year | Architecture | Dataset | Pre-training Method | Fine-tuning Method | Input → Output |
|---|---|---|---|---|---|---|
| AgriBERT ([107]) | 2022 | BERT | Agricultural journals, USDA datasets | MLM trained from scratch | Adding external knowledge, fine-tuning | Text → classification labels, generated text |
| ITLMLP ([109]) | 2023 | ViT-S/16 or ViT-B/16, CLIP | Cucumber, Apple, PlantVillage datasets | Image–text multimodal pre-training | Transfer pre-training, fine-tuning classification head | Image, text, labels → disease category labels |
| AgRoBERTa ([108]) | 2024 | RoBERTa | Agricultural promotion corpus, AgXQA dataset | MLM pre-trained on AEC 1.1 | Traditional fine-tuning, LoRA fine-tuning | Text → answer text |
| ChatAgri ([110]) | 2023 | GPT3.5 (Transformer architecture) | Amazon Food, PestObserver, Agri-News, etc. | Pre-trained on ChatGPT results | Multiple prompt strategies and answer alignment strategies for fine-tuning | Text → classification labels |
| PLLaMa ([111]) | 2024 | Based on LLaMa-2 (Transformer architecture) | Plant science academic papers, RedPajama dataset | Continued pre-training on plant science corpus | Fine-tuned on 1030 instructions | Text → question answers |
| Chains-BERT ([112]) | 2023 | BERT | Agricultural information database, Shandong farm management dataset | Transfer learning, training on unlabeled data | Contrastive learning based on text matching, semi-supervised learning | Text → classification labels, generated text |
| SAM ([113]) | 2023 | ViT | Cage-free chicken dataset, broiler chicken dataset | - | - | Images → segmentation results, bounding box info (tracking) |
| SAM ([114]) | 2023 | ViT | Leaf counting and segmentation challenge dataset | - | - | Image → segmentation masks |
| WDLM ([115]) | 2024 | Transformer-based VLM | Wheat disease dataset, CGIAR dataset | Utilized pre-trained VLM results | LoRA fine-tuning, fine-tuned on disease dataset | Image, text prompts → disease classification, treatment suggestions |
Building on the discussion of various AFMs, we now explore specific applications of FMs in agriculture, examining how they contribute to solving real-world agricultural challenges. These applications span several key areas, including Agricultural Knowledge Question Answering (AKQA), agricultural image and video analysis, agricultural decision-making, and agricultural robots and automation. Through case studies, we will explore the transformative potential of FMs in enhancing decision-making processes, improving crop management practices [116], advancing pest and disease detection, and driving the automation of farming tasks. By integrating large-scale data processing, NLP, and advanced CV techniques, FMs are playing a pivotal role in revolutionizing agricultural practices, rendering them more efficient and sustainable. Each of the following subsections will highlight the contributions, challenges, and future prospects of FMs in these domains.
(1) Agricultural Knowledge Question Answering: Systems leverage large-scale agricultural data and NLP technologies to provide automated, accurate responses to agriculture-related queries. These systems integrate domain expertise to offer scientific support and decision-making guidance for farmers, researchers, and agricultural workers. Core functionalities include information retrieval, which extracts relevant answers from agricultural literature and expert knowledge, and automatic answer generation, which uses NLP models to deliver concise and precise responses. AKQA systems have significantly improved access to agricultural information, particularly in resource-scarce regions, reducing reliance on experts and enhancing daily farming practices. Applications span crop cultivation, pest management, and soil management, providing farmers with actionable insights.
Foundation language models have demonstrated remarkable success in AKQA. For example, large language models have demonstrated significant potential in agricultural applications, with performance varying substantially based on model architecture and augmentation techniques. In evaluations of the Certified Crop Advisor (CCA) certification exams, GPT-4 achieved a 93% accuracy rate when enhanced with RAG, representing a 14-point improvement over its baseline performance of 79% without retrieval augmentation. The comparative analysis revealed consistent performance hierarchies across model types, with GPT-4 outperforming GPT-3.5 (88% with RAG, 64% without) and substantially surpassing smaller models like Llama2-70B (81% with RAG, 55% without) and Llama2-13B (70% with RAG, 47% without), demonstrating how model scale and knowledge retrieval techniques collectively enhance agricultural question-answering capabilities. These results underscore the transformative potential of large language models in agricultural education and decision support, particularly when combining advanced architectures with domain-specific knowledge augmentation. Similarly, ChatAgri, based on ChatGPT, excels in agricultural text classification, particularly in crop cultivation and pest management tasks, outperforming traditional fine-tuning methods [110]. Chains-BERT combines BERT with semi-supervised and contrastive learning, enabling efficient question answering with minimal labeled data, making it highly adaptable to agricultural scenarios. The model achieves this through an innovative dual-encoder architecture, featuring a fixed feature extractor and trainable model that employs contrastive learning to optimize sentence representations. By augmenting this framework with Bi-LSTM layers for label-chain modeling and incorporating semi-supervised techniques like proxy labeling and consistency regularization, Chains-BERT effectively leverages both labeled and unlabeled agricultural data. Experimental results demonstrate its superior performance, achieving an 86.5 Micro-F1 score on the CAIL2018 dataset—a 5.5-point improvement over vanilla BERT. The model also exhibits strong generalization capabilities, outperforming baseline BERT by 3.25 F1 points on SQuAD 2.0, validating its effectiveness beyond agricultural domains [112]. In China, models like ’Hou Ji’ and ’Shennong Model 2.0’ have advanced AKQA by integrating IoT and multimodal reasoning, supporting diverse agricultural domains [111,117]. Additionally, VQA methods are emerging in crop disease diagnosis, combining image and text data for decision-making [118]. These advancements highlight the transformative potential of foundation models in AKQA, bridging gaps in agricultural knowledge dissemination.
(2) Agricultural Image and Video Analysis: Powered by CV and DL, this analysis play a crucial role in crop health monitoring, pest detection, and yield prediction. Visual Foundation Models (VFMs) process image and video data to provide accurate, real-time insights, enhancing agricultural intelligence. Traditional methods, such as molecular biology, are often time-consuming and invasive, whereas image-based approaches improve efficiency and reduce crop damage. For example, preprocessing techniques for night vision images have enhanced accuracy in apple harvesting robots [119]. Recent advancements include multispectral and hyperspectral imaging (MSI/HSI), which enable real-time monitoring of plant health and early disease detection [120,121,122].
VFMs are increasingly replacing traditional CNN models in crop disease diagnosis. The Wheat Disease Language Model (WDLM), for example, combines SAM and reasoning chains to isolate disease features in complex field environments, offering precise treatment recommendations [115]. Remote sensing data from drones and satellites further extend the application of VFMs, enabling large-scale crop health monitoring and pest identification [123,124]. VQA methods, such as multimodal feature fusion for fruit tree diseases, integrate image and text data to provide diagnostic support in areas lacking expert resources [118]. These technologies highlight the growing potential of VFMs in improving agricultural efficiency and sustainability.
(3) Agricultural Decision-Making: This entails complex decisions, such as crop selection, planting schedules [125], irrigation, and pest control, which directly impact productivity and sustainability. FMs enhance decision-making processes by providing data-driven insights and predictions [126]. For example, deep neural networks and GANs analyze historical yield data, weather patterns, and soil conditions to predict crop yields accurately [127,128]. These predictions enable farmers to optimize resource use and maximize productivity.
In pest and disease control, FMs analyze crop images to detect issues early, even during latent stages, reducing pesticide use and improving sustainability [129,130]. Intelligent systems like ’The Farmer Chatbot’ provide real-time advice on plant protection, weather, and soil conditions, leveraging large datasets for accurate recommendations [131]. In livestock farming, FMs classify disease-causing pathogens and monitor animal health, improving resource allocation and welfare [132,133]. Additionally, FMs address climate change challenges by analyzing weather data and recommending adaptive strategies such as crop variety selection and water management [134]. Supply chain optimization is another key application, where FMs forecast demand and streamline production processes [135,136]. Despite their potential, challenges remain, including the need for real-time processing and user-friendly interfaces, which future research must address.
(4) Agricultural Robots and Automation: These technologies significantly enhance productivity by replacing manual labor with intelligent systems capable of crop monitoring, pest control, and harvesting. These robots integrate CV, DL, and sensing technologies to perform tasks such as precision fertilization and disease detection [137,138]. However, traditional systems face limitations in real-time data processing, prompting the adoption of FMs to improve scalability and efficiency.
FMs enable advanced functionalities in agricultural robots. For example, drone systems equipped with FMs monitor crop growth and predict yields in real time, while ground robots perform complex tasks like harvesting and sorting [139]. The SAM processes thermal images for crop segmentation and yield prediction, while the TAM enhances long-term disease monitoring [12,140]. Despite their advantages, FMs require significant computational resources, limiting their applicability in real-time scenarios [141]. Future research should focus on optimizing hardware and reducing resource consumption to fully realize the potential of FMs in agricultural automation.
4. Challenges of AFMs
This section discusses the challenges associated with the AFMs. It explores the complexity and heterogeneity of agricultural data, the difficulties in data acquisition, and the phenomenon of data shift. Additionally, it examines the practical implementation challenges faced when applying AFMs in real-world agricultural settings. Furthermore, this section underscores the necessity for advanced techniques to foster the advancement of AFMs. It provides insights into these challenges and potential solutions that will facilitate the effective application and expansion of FMs within the agricultural sector.
4.1. Diversity and Heterogeneity of Agricultural Data
Agricultural data are characterized by high diversity and heterogeneity [142], which is reflected not only in the types and sources of the data but also in their multifaceted impact on agricultural production, management decisions, and research [143]. With the rapid advancement of emerging technologies, such as precision agriculture and smart agriculture, agricultural data play an increasingly pivotal role in enhancing agricultural productivity, optimizing resource allocation, and mitigating environmental burdens. However, the complexity of agricultural data, coupled with their diversity and heterogeneity, renders them particularly challenging to utilize effectively in AFMs.
Firstly, the diversity of agricultural data sources constitutes a key factor contributing to data heterogeneity. Data can be collected through various channels, including weather stations, satellite remote sensing [144], drones, and IoT sensors. The formats, accuracy, and update frequencies of data from different sources vary, necessitating that FMs handle and integrate information from multiple data sources. For instance, climate data from weather stations and satellite remote sensing not only include indicators such as temperature and humidity but may also encompass additional factors, including wind speed and precipitation, which influence agricultural production. Soil data are typically collected through field testing or sensor monitoring, encompassing indicators such as pH levels, humidity, and organic matter content. Remote sensing data, obtained through satellite [145] or drone imagery, offer novel insights into agricultural practices.
Secondly, the application domains of agricultural data further illustrate their heterogeneity. Various types of data are often closely associated with specific tasks in agricultural production [146]. For example, climate data are essential for crop growth prediction, agricultural climate modeling, and disaster warning, whereas soil data play a pivotal role in soil management and crop planting decisions [147]. Remote sensing data facilitate crop monitoring, agricultural pest detection, and land use analysis, while water resource data are directly linked to irrigation management and water resource optimization [148]. Through precise crop growth monitoring and pest prediction [149], farmers can make more scientifically informed decisions regarding fertilization and irrigation. Each type of data possesses unique importance and distinct application scenarios.
Table 4 presents various types of data, their sources, and applicable fields in agriculture, thereby showcasing the diversity and heterogeneity inherent in agricultural data. Each data type can influence the outcomes of downstream tasks and may directly determine the efficacy of agricultural decisions. Consequently, effectively integrating these heterogeneous data sources and enabling FMs to comprehend and utilize this diverse information represents a significant challenge currently confronting AFMs.
Table 4.
Overview of agricultural data sources and types.
Although the prospects for employing FMs in agriculture are promising, realizing this goal presents considerable challenges. The complexity and diversity of data necessitate the development of algorithms capable of managing heterogeneous data, alongside substantial amounts of labeled data and efficient data fusion methods to enhance the model’s generalization capabilities. Extracting meaningful information from multidimensional, multi-source data, eliminating noise, and constructing accurate agricultural models remain pressing challenges for researchers and practitioners.
4.2. Agricultural Data Acquisition
The challenges associated with acquiring agricultural data primarily arise from the complexity and decentralization of agriculture itself, particularly in developing countries and certain major agricultural nations where agricultural activities continue to rely on traditional, low-tech methods. The pervasive reliance on these traditional methods has resulted in the decentralization of agricultural production, and management systems have yet to achieve full automation. Consequently, data collection becomes particularly challenging. Agricultural production encompasses numerous factors, including soil, climate, water, fertilizers, crop cultivation, sunlight, and others. Each of these data points may exhibit significant variability due to regional differences, crop types, and climatic changes. Furthermore, the collection of these data faces dual challenges related to technology and funding, particularly in remote areas where data collection often necessitates substantial manual labor. Given the diversity and timeliness of agricultural data, the process is often time-consuming and labor-intensive.
Even in advanced agricultural nations, the standardization, unification, and accuracy of data collection continue to pose significant challenges. For instance, models for agricultural pests and diseases are frequently constrained by data quality and availability [150], and existing climate data regarding crop damage prediction face the challenge of becoming outdated [151,152]. To address this challenge, technological innovations, such as the introduction of Unmanned Aerial Vehicles (UAVs) [153] and IoT devices [154], alongside data collection methods like remote sensing and crowdsourcing [155], help mitigate some difficulties associated with traditional data collection. Nonetheless, challenges related to data privacy and ownership remain unresolved [156,157].
In this context, emerging technologies, such as GANs and self-supervised learning, have opened new avenues for agricultural data acquisition and utilization. Specifically, GANs and self-supervised learning techniques have demonstrated promising potential in enhancing data labeling efficiency and data generation. These techniques can simulate and generate data that are challenging to obtain in real-world scenarios, thereby providing additional data support for training agricultural models. These emerging technologies not only improve the efficiency of data acquisition but may also partially address issues such as data labeling and data scarcity [158,159].
Table 5 summarizes different sources of agricultural data acquisition and their associated challenges. It lists various data sources (such as satellite remote sensing, drone imagery, ground sensors, etc.), the types of data, acquisition methods, time frequencies, advantages, and challenges. By summarizing these data acquisition methods, we can better understand the strengths and weaknesses of each and provide more rational options and decision support for data collection in the agricultural sector.
Table 5.
Overview of agricultural data types [160].
Overall, the acquisition of agricultural data faces multifaceted challenges. These challenges stem not only from the complexity of agriculture itself but also from technological and resource limitations. While existing technologies have alleviated these issues to some extent, achieving comprehensive and efficient data collection still requires overcoming legal and ethical issues such as data privacy and ownership while promoting technological innovation and openness in data sharing.
4.3. Agricultural Data Shift
Agricultural data shift refers to the significant discrepancies in data encountered during the training and deployment stages of models in agricultural applications. These shifts may arise from various factors, including environmental changes across different regions and seasons, differences in crop types, varying soil conditions, and diverse agricultural practices. Due to these environmental variations, the distribution of agricultural data can change substantially, impacting the performance and generalization ability of models. Table 6 summarizes the three main types of agricultural data shifts.
Table 6.
Types of agricultural data shift and their manifestations.
Label shift pertains to changes in the distribution of labels across different time periods or environments. For instance, crop yields are influenced by climate and environmental factors, resulting in fluctuations in yield labels for crops across various years or regions. Some crops may experience yield reductions or even fail to grow due to extreme weather conditions, thereby affecting the stability of labels [164].
Data shifts in agriculture have been confirmed by multiple studies. For example, [165] identified a high correlation between certain land cover categories, such as medium-density residential areas and dense residential areas, or between buildings and water storage tanks. This correlation can lead to confusion in classification models, adversely impacting accuracy. Similarly, [164] observed classification confusion between corn and soybeans, while [163] noted significant confusion among tree crops, summer crops, and vegetable cultivation. In the context of plant phenotype recognition, [166,167] highlighted challenges in distinguishing between different plant phenotypes during growth stage transitions, as the appearance of plants changes gradually. This includes not only the slow transition of plant surface features but also variations in climate, soil types, and field management practices, leading to significant differences in data feature distribution over time. Regarding fruit counting, [168,169] found that occlusion, height differences, and unstable lighting conditions are primary factors affecting accuracy. The similarity in color between fruits and leaves exacerbates this issue, diminishing model performance and suggesting that environmental changes can induce shifts in both feature and label data, thereby affecting the generalization ability of models. Furthermore, studies by [170,171] and [172] have examined the differentiation between weeds and crops, particularly concerning features such as shape, texture, color, and position. Due to the similarities between weeds and crops, especially when weeds obscure crops, models often struggle to classify them accurately. This situation is closely related to data distribution shifts, as the same weed may present different features in various environments, impacting classification performance.
Research indicates that data shifts in agriculture can significantly affect model performance, potentially leading to a sharp decline in effectiveness. For example, [114] demonstrated that applying FMs to zero-shot leaf segmentation tasks resulted in poor model performance, likely due to data distribution shifts. To address these challenges, researchers have proposed several solutions, including multi-task learning, continual learning, and distillation techniques to mitigate performance declines caused by data shifts [173].
To effectively tackle agricultural data shifts, scholars have suggested various strategies and methods. These include multi-task learning and continual learning, which enable models to adapt to new data distributions during training, thereby enhancing their generalization ability [173]; domain adaptation techniques, where domain-adaptive models can transfer learned knowledge from training data to different environments, reducing the impact of data shifts [174]; and data augmentation and mixing techniques, which generate diverse training data, particularly in terms of climate, soil, and crop types, effectively bolstering the robustness of models to mitigate data shifts.
4.4. Time Lag Issues
The time lag issue in agricultural data presents a significant challenge. Crop growth cycles influenced by seasonal and climatic variations cause training data for AFMs to gradually lose relevance [2]. Post-deployment, time-series data may become outdated due to changing environmental conditions, leading to prediction deviations [175]. In agricultural vehicular networks, transmission delays between mobile units can compromise decision-making with stale data, particularly affecting real-time applications like GPS navigation. For agricultural robots performing time-sensitive tasks (e.g., harvesting, pest control), processing delays > 200 ms directly impact accuracy and yield, exacerbated by foundation models’ computational demands [176].
Delay-Tolerant Networks (DTNs) address transmission delays in remote areas, as demonstrated by PotatoScanner’s store-carry-forward approach [177]. For robotics, DTN–edge computing hybrids maintain real-time responsiveness in large fields, while model pruning/quantization reduces inference latency for harvesting operations [178].
Time series analysis and dynamic modeling help accommodate agricultural data’s temporal dependencies [179]. Lightweight Transformer architectures now balance accuracy and efficiency for real-time field automation [180], while continual learning maintains model relevance.
4.5. Practical Deployment Challenges
The operational deployment of AFMs faces fundamental technical constraints that manifest differently across farm scales. While current automation systems like Kenya’s FarmBot demonstrate basic inclusivity for smallholders through compressed vision models [181], the integration of full-fledged FMs in low-connectivity environments remains constrained by substantial computational demands. Recent breakthroughs in extreme model compression show promise—binary transformers achieve 99% size reduction while retaining 80% original accuracy in controlled settings, potentially enabling localized FM deployment [182]. However, even distilled models confront memory limitations, as ViT-base architectures require >1.7GB memory, while edge devices typically offer <512 MB RAM, forcing difficult tradeoffs between functionality and accessibility [130].
In real-world operating conditions, these challenges become more acute. Agricultural data streams exhibit inherent asynchrony (e.g., 15–300 ms latency between visual and sensor inputs), which significantly degrades decision accuracy without temporal alignment modules—a particular concern for transformer-based multimodal agricultural foundation models where self-attention mechanisms are temporally sensitive. For smallholder farmers, this complexity is addressed through accessible “Model-as-a-Service” platforms rather than local deployment. Farmers can simply upload field photos via mobile apps to access cloud-based FM APIs. These solutions feature carefully designed interfaces with voice input and visual output to build trust in AI recommendations while employing progressive deployment strategies, starting with basic tasks before advancing to complex decision support. This approach democratizes access to advanced FM capabilities without requiring expensive infrastructure, though it introduces 40–60% higher cloud dependency costs compared to industrial on-premise solutions [183].
5. Development Directions for AFMs
The ongoing advancement and deployment of AFMs signify a transformative phase for the agricultural sector. Future iterations of these models are expected to exhibit enhanced capabilities that extend beyond conventional text and image processing to encompass comprehensive multimodal integration. By leveraging their inherent multimodal architecture, next-generation AFMs will effectively synthesize heterogeneous data streams, including video feeds, audio recordings, and sensor outputs. This technological evolution promises to catalyze unprecedented levels of intelligent automation across agricultural systems, facilitating more sophisticated decision-making frameworks and operational optimization.
To fully grasp the potential of AFMs, it is essential to explore their development from multiple perspectives. The following sections will delve into the key areas where AFMs are anticipated to make significant impacts: leveraging multimodal data, integrating AFMs across the agricultural and food sectors, enhancing intelligent decision-making systems, and addressing ongoing technical development and talent training challenges. Each of these aspects will be discussed in detail to provide a comprehensive understanding of how AFMs are poised to revolutionize agriculture.
5.1. Leveraging Multimodal FMs in Agriculture
Future AFMs should expand beyond traditional text and image modalities to harness emerging technological capabilities. This multimodal expansion forms the technical foundation for cross-domain integration across agricultural supply chains. Recent studies demonstrate the untapped potential of multimodal integration in agriculture: video analytics enable real-time crop monitoring during critical growth stages [184,185], while audio signal processing shows promise in non-destructive quality assessment [186,187].
The intrinsic value of multimodal data lies in their ability to bridge discrete phases of the agricultural value chain. For instance, combining harvest-stage audio ripeness data with growth-period visual analytics allows AFMs to predict post-harvest storage requirements and optimal market timing [188]. Such temporal–spatial data fusion enables vertically integrated decision-making, from field management to logistics optimization.
This technological convergence directly addresses supply chain fragmentation challenges. By fusing complementary data streams—from spectral signatures to temporal growth patterns—multimodal AFMs can synchronize production data with downstream processing parameters (e.g., matching harvest quality metrics to storage facility conditions). The resulting closed-loop intelligence system not only optimizes field-level production efficiency but also enhances the resilience of agricultural supply networks through data-driven coordination [189].
5.2. Integrating AFMs Across the Agricultural and Food Sectors
Agriculture is intrinsically linked to the entire food production and supply chain [190], and the development of AFMs is poised to drive technological advancements across various stages of this chain. Beyond the food industry, AFMs will play a critical role in optimizing agricultural production, improving resource management, and enhancing decision-making processes from crop planting to food processing and distribution.
In the agricultural production phase, AFMs can integrate data from diverse sources, such as soil sensors, weather stations, and crop health monitoring systems, providing real-time insights and predictive analytics for farmers. Recent research demonstrates that multimodal fusion techniques are critical for handling heterogeneous agricultural data. For instance, the Rice-Fusion framework combines CNN-processed leaf images (200 × 200 × 3 RGB) with MLP-analyzed agro-meteorological data (temperature, humidity, NPK values) through feature-level concatenation. This early fusion approach aligns temporal sensor readings (minute-level) with daily drone images via timestamp synchronization, achieving 95.31% disease diagnosis accuracy—a 12.8% improvement over unimodal models. The framework further addresses modality disparities by normalizing sensor data (min–max scaling) and image pixels (0–1 range) before fusion, ensuring compatibility between numerical and visual features [191]. These models can guide farmers in making informed decisions regarding irrigation, pest control, and fertilization, ultimately improving crop yields and minimizing resource waste. Furthermore, AFMs can assist in monitoring the effects of climate change on crop growth, enabling proactive strategies to adapt to shifting environmental conditions.
In the food processing sector, AFMs can facilitate quality control and traceability [192,193], enabling real-time tracking of food from farm to table. By incorporating AFMs into food safety monitoring systems, producers can swiftly identify potential contamination risks and ensure compliance with food safety standards. This seamless integration across agricultural and food production stages will enhance the transparency of food supply chains, which is crucial for fostering consumer trust [194].
Moreover, AFMs can significantly improve supply chain management by predicting demand fluctuations [195], optimizing logistics, and reducing waste. For instance, predictive models could forecast crop availability and help align supply with market demand, leading to more efficient food distribution and minimizing food loss.
In the future, the integration of AFMs with other models across different sectors in the agricultural and food industries will create a mutually reinforcing ecosystem. This cross-sector collaboration will elevate the intelligence of agriculture, food production, logistics, and quality assurance systems, ultimately ensuring the sustainability, safety, and efficiency of the entire food supply chain [184,196].
5.3. Intelligent Decision-Making Systems Based on AFMs
AFMs possess immense potential for enhancing intelligent decision-making, particularly in areas such as crop planting, pest management, irrigation, and fertilization [197]. By analyzing multi-source data, AFMs can facilitate intelligent decision-making and predictions, enabling farmers to make more precise management choices. For instance, intelligent planting and breeding decision systems can integrate sensor data, environmental information, and agricultural expertise to automatically provide farmers with scientifically grounded recommendations [196]. As FMs are increasingly applied across various agricultural domains, the future of agricultural production is set to advance toward greater precision, automation, and efficiency.
Future development of AFM-based decision systems will follow a phased technical roadmap, with an initial focus on lightweight mobile applications delivering basic agricultural guidance through model compression, intermediate development of distributed learning architectures for cross-regional knowledge sharing and cost optimization, and ultimately evolving into self-adaptive intelligent decision systems. Implementation will incorporate data governance protocols, tiered service models, and farmer-centric interface design to ensure equitable access across farm scales, progressively bridging the digital divide in agricultural intelligence adoption.
6. Conclusions
This paper provides a comprehensive overview of the development, applications, and challenges of FMs in agriculture, with a particular focus on AFMs. Through an in-depth exploration of the history, key technologies, and architectures of FMs, this work highlights the transformative potential of these models in revolutionizing agricultural practices. The paper also offers valuable insights into the process of building FMs, encompassing data selection, model architecture design, training and optimization, and evaluation metrics.
In addition to examining the fundamental aspects of FMs, this paper delves into their specific applications in agriculture, including agricultural knowledge question-answering, image and video analysis [198], decision support systems, and agricultural robotics and automation. It further explores the unique challenges posed by the agricultural domain, such as data diversity, acquisition issues, data shifts, time lags, and concerns regarding data privacy and ownership. Through this detailed analysis, this paper elucidates how AFMs can address these challenges, ultimately advancing the digitalization and intelligent transformation of the agricultural sector.
The development directions for AFMs have been outlined in this paper, emphasizing the importance of leveraging multimodal FMs to enhance decision-making processes in agriculture. The integration of AFMs across the agricultural and food sectors promises to optimize resource management and food supply chain systems, while the advancement of intelligent decision-making systems will further improve the precision, efficiency, and automation of agricultural production. Additionally, ongoing technical developments and talent training are identified as critical factors for the future success and widespread adoption of AFMs in agriculture.
By summarizing the state-of-the-art research and providing a clear roadmap for future directions, this paper aims to contribute to the further development of agricultural intelligence, helping to propel the sector toward more sustainable and efficient practices. The application of AFMs, coupled with continuous advancements in technology and expertise, will play a crucial role in ensuring global food security and achieving ecological balance in agricultural production.
Author Contributions
Conceptualization, S.Y. and Q.M.; methodology, S.Y.; investigation, S.Y., X.Z., Y.X. and C.S.; writing—original draft preparation, S.Y.; writing—review and editing, S.Y. and Q.M.; visualization, S.Y., X.Z., Y.X. and C.S.; supervision, Q.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Project of Faculty of Agricultural Engineering of Jiangsu University under Grant NGXB20240101.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Botero-Valencia, J.; García-Pineda, V.; Valencia-Arias, A.; Valencia, J.; Reyes-Vera, E.; Mejia-Herrera, M.; Hernández-García, R. Machine Learning in Sustainable Agriculture: Systematic Review and Research Perspectives. Agriculture 2025, 15, 377. [Google Scholar] [CrossRef]
- Li, J.; Xu, M.; Xiang, L.; Chen, D.; Zhuang, W.; Yin, X.; Li, Z. Foundation models in smart agriculture: Basics, opportunities, and challenges. Comput. Electron. Agric. 2024, 222, 109032. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S. On the Opportunities and Risks of Foundation Models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10684–10695. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Kang, M.; Zhu, J.Y.; Zhang, R.; Park, J.; Shechtman, E.; Paris, S.; Park, T. Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10124–10134. [Google Scholar]
- Reed, S.; Zolna, K.; Parisotto, E.; Colmenarejo, S.G.; Novikov, A.; Barth-Maron, G.; Gimenez, M.; Sulsky, Y.; Kay, J.; Springenberg, J.T.; et al. A generalist agent. arXiv 2022, arXiv:2205.06175. [Google Scholar]
- Team, A.A.; Bauer, J.; Baumli, K.; Baveja, S.; Behbahani, F.; Bhoopchand, A.; Bradley-Schmieg, N.; Chang, M.; Clay, N.; Collister, A.; et al. Human-timescale adaptation in an open-ended task space. arXiv 2023, arXiv:2301.07608. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 485–508. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Madani, A.; Arnaout, R.; Mofrad, M.; Arnaout, R. Fast and accurate view classification of echocardiograms using deep learning. NPJ Digit. Med. 2018, 1, 6. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Zhu, H.; Qin, S.; Su, M.; Lin, C.; Li, A.; Gao, J. Harnessing large vision and language models in agriculture: A review. arXiv 2024, arXiv:2407.19679. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S. A survey on large language models: Applications, challenges, limitations, and practical usage. Authorea Preprints 2023, 3. [Google Scholar]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on machine Learning, Virtual, 18–24 July 2021; PMLR: Birmingham, UK, 2021; pp. 8821–8831. [Google Scholar]
- Wu, J.; Gan, W.; Chen, Z.; Wan, S.; Philip, S.Y. Multimodal large language models: A survey. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2247–2256. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 14 January 2025).
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. GLM-130B: An Open Bilingual Pre-trained Model. In Proceedings of the 11th International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Team, G.; Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; et al. Gemma: Open models based on gemini research and technology. arXiv 2024, arXiv:2403.08295. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Luccioni, A.S.; Viguier, S.; Ligozat, A.-L. Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model. J. Mach. Learn. Res. 2023, 24, 1–15. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Chiang, W.L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J.E.; et al. Vicuna: An Open-Source Chatbot Impressing gpt-4 with 90%* Chatgpt Quality. 2023. Available online: https://vicuna.lmsys.org (accessed on 14 April 2023).
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Alpaca: A strong, replicable instruction-following model. Stanf. Cent. Res. Found. Model. 2023, 3, 7. Available online: https://crfm.stanford.edu/2023/03/13/alpaca.html (accessed on 15 May 2024).
- Bi, X.; Chen, D.; Chen, G.; Chen, S.; Dai, D.; Deng, C.; Ding, H.; Dong, K.; Du, Q.; Fu, Z.; et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv 2024, arXiv:2401.02954. [Google Scholar]
- Liu, A.; Feng, B.; Wang, B.; Wang, B.; Liu, B.; Zhao, C.; Dengr, C.; Ruan, C.; Dai, D.; Guo, D.; et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv 2024, arXiv:2405.04434. [Google Scholar]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2024, 36, 1–8. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: Birmingham, UK, 2023; pp. 19730–19742. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Yuan, L.; Chen, D.; Chen, Y.L.; Codella, N.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A new foundation model for computer vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Xiao, B.; Wu, H.; Xu, W.; Dai, X.; Hu, H.; Lu, Y.; Zeng, M.; Liu, C.; Yuan, L. Florence-2: Advancing a unified representation for a variety of vision tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4818–4829. [Google Scholar]
- Xi, T.; Sun, Y.; Yu, D.; Li, B.; Peng, N.; Zhang, G.; Zhang, X.; Wang, Z.; Chen, J.; Wang, J.; et al. UFO: Unified feature optimization. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 472–488. [Google Scholar]
- Shao, J.; Chen, S.; Li, Y.; Wang, K.; Yin, Z.; He, Y.; Teng, J.; Sun, Q.; Gao, M.; Liu, J.; et al. Intern: A new learning paradigm towards general vision. arXiv 2021, arXiv:2111.08687. [Google Scholar]
- Lu, H.; Liu, W.; Zhang, B.; Wang, B.; Dong, K.; Liu, B.; Sun, J.; Ren, T.; Li, Z.; Yang, H.; et al. Deepseek-vl: Towards real-world vision-language understanding. arXiv 2024, arXiv:2403.05525. [Google Scholar]
- Wu, Z.; Chen, X.; Pan, Z.; Liu, X.; Liu, W.; Dai, D.; Gao, H.; Ma, Y.; Wu, C.; Wang, B.; et al. DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding. arXiv 2024, arXiv:2412.10302. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Liu, Y.; Zhang, K.; Li, Y.; Yan, Z.; Gao, C.; Chen, R.; Yuan, Z.; Huang, Y.; Sun, H.; Gao, J.; et al. Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv 2024, arXiv:2402.17177. [Google Scholar]
- Anthropic, A. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card 2024, 1. [Google Scholar]
- Zhang, H.; Li, X.; Bing, L. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Singapore, 2023; pp. 543–553. [Google Scholar]
- Team, G.; Georgiev, P.; Lei, V.I.; Burnell, R.; Bai, L.; Gulati, A.; Tanzer, G.; Vincent, D.; Pan, Z.; Wang, S.; et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv 2024, arXiv:2403.05530. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. PaLM-E: An Embodied Multimodal Language Model. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: Cambridge, MA, USA, 2023; Volume 202, pp. 8469–8488. Available online: https://arxiv.org/pdf/2303.03378 (accessed on 14 January 2025).
- Su, Y.; Lan, T.; Li, H.; Xu, J.; Wang, Y.; Cai, D. PandaGPT: One Model To Instruction-Follow Them All. In Proceedings of the 1st Workshop on Taming Large Language Models: Controllability in the era of Interactive Assistants! Prague, Czech Republic, 12 September 2023; pp. 11–23. Available online: https://arxiv.org/pdf/2305.16355 (accessed on 14 January 2025).
- Zhang, D.; Li, S.; Zhang, X.; Zhan, J.; Wang, P.; Zhou, Y.; Qiu, X. SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 15757–15773. Available online: https://arxiv.org/pdf/2305.11000 (accessed on 14 January 2025).
- Tsimpoukelli, M.; Menick, J.L.; Cabi, S.; Eslami, S.; Vinyals, O.; Hill, F. Multimodal few-shot learning with frozen language models. Adv. Neural Inf. Process. Syst. 2021, 34, 200–212. [Google Scholar]
- Liu, Y.; Zhu, G.; Zhu, B.; Song, Q.; Ge, G.; Chen, H.; Qiao, G.; Peng, R.; Wu, L.; Wang, J. Taisu: A 166m large-scale high-quality dataset for chinese vision-language pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 16705–16717. [Google Scholar]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Online, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. Available online: https://arxiv.org/pdf/1508.07909 (accessed on 14 January 2025).
- Schuster, M.; Nakajima, K. Japanese and korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 5149–5152. [Google Scholar]
- Kudo, T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 66–75. Available online: https://arxiv.org/pdf/1804.10959 (accessed on 14 January 2025).
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.D.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-level code generation with alphacode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://arxiv.org/pdf/1706.03762 (accessed on 14 January 2025).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. Adv. Neural Inf. Process. Syst. 2015, 28, 5110–5118. [Google Scholar]
- Felsten, G.; Wasserman, G.S. Visual masking: Mechanisms and theories. Psychol. Bull. 1980, 88, 329. [Google Scholar] [CrossRef] [PubMed]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Palais des Congrès Neptune, Toulon, France, 24–26 April 2017. [Google Scholar]
- Han, Z.; Gao, C.; Liu, J.; Zhang, J.; Zhang, S.Q. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. Trans. Mach. Learn. Res. 2024. Available online: https://arxiv.org/pdf/2403.14608 (accessed on 14 January 2025).
- Zhang, S.; Dong, L.; Li, X.; Zhang, S.; Sun, X.; Wang, S.; Li, J.; Hu, R.; Zhang, T.; Wu, F.; et al. Instruction tuning for large language models: A survey. arXiv 2023, arXiv:2308.10792. [Google Scholar]
- Lv, K.; Yang, Y.; Liu, T.; Guo, Q.; Qiu, X. Full Parameter Fine-tuning for Large Language Models with Limited Resources. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2024; Available online: https://arxiv.org/pdf/2306.09782 (accessed on 14 January 2025).
- Mangrulkar, S.; Gugger, S.; Debut, L.; Belkada, Y.; Paul, S.; Bossan, B. Peft: State-of-the-Art Parameter-Efficient Fine-Tuning Methods. 2022. Available online: https://github.com/huggingface/peft (accessed on 14 January 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv 2022, arXiv:2204.05862. [Google Scholar]
- Lee, H.; Phatale, S.; Mansoor, H.; Lu, K.R.; Mesnard, T.; Ferret, J.; Bishop, C.; Hall, E.; Carbune, V.; Rastogi, A. Rlaif: Scaling Reinforcement Learning from Human Feedback with AI Feedback. 2023. Available online: https://arxiv.org/pdf/2309.00267 (accessed on 14 January 2025).
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, H. Retrieval-augmented generation for large language models: A survey. arXiv 2023, arXiv:2312.10997. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; Steinhardt, J. Measuring Mathematical Problem Solving With the MATH Dataset. Sort 2021, 2, 1–5. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. Superglue: A stickier benchmark for general-purpose language understanding systems. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://arxiv.org/pdf/1905.00537 (accessed on 14 January 2025).
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Raji, I.D.; Denton, E.; Bender, E.M.; Hanna, A.; Paullada, A. AI and the Everything in the Whole Wide World Benchmark. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022) Datasets and Benchmarks Track, Virtual, 28 November–9 December 2022; Available online: https://arxiv.org/pdf/2111.15366 (accessed on 14 January 2025).
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Snow, R.; O’connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and fast–but is it good? Evaluating non-expert annotations for natural language tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 25–27 October 2008; pp. 254–263. [Google Scholar]
- Kachuee, M.; Ahuja, S.; Kumar, V.; Xu, P.; Liu, X. Improving Tool Retrieval by Leveraging Large Language Models for Query Generation. In Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, Abu Dhabi, United Arab Emirates, 19–24 January 2025; pp. 29–38. [Google Scholar]
- Jumper, J.M.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xie, J.; Hu, C.; Zou, H.; Fan, J.; Tong, W.; Wen, Y.; Wu, S.; Deng, H.; Li, Z.; et al. DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving. arXiv 2023, arXiv:2312.09245. [Google Scholar]
- Wu, Q.; Gu, J. Design and research of robot visual servo system based on artificial intelligence. Agro Food Ind. Tech 2017, 28, 125–128. [Google Scholar]
- Tu, X.; He, Z.; Huang, Y.; Zhang, Z.H.; Yang, M.; Zhao, J. An overview of large AI models and their applications. Vis. Intell. 2024, 2, 34. [Google Scholar] [CrossRef]
- Pan, X.; Zhang, M.; Ji, S.; Yang, M. Privacy Risks of General-Purpose Language Models. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1314–1331. [Google Scholar]
- Touch, V.; Tan, D.K.; Cook, B.R.; Li Liu, D.; Cross, R.; Tran, T.A.; Utomo, A.; Yous, S.; Grunbuhel, C.; Cowie, A. Smallholder farmers’ challenges and opportunities: Implications for agricultural production, environment and food security. J. Environ. Manag. 2024, 370, 122536. [Google Scholar] [CrossRef] [PubMed]
- Ray, P.P. A review on TinyML: State-of-the-art and prospects. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1595–1623. [Google Scholar] [CrossRef]
- Klerkx, L.; Jakku, E.; Labarthe, P. A review of social science on digital agriculture, smart farming and agriculture 4.0: New contributions and a future research agenda. NJAS-Wagening. J. Life Sci. 2019, 90, 100315. [Google Scholar] [CrossRef]
- Rezayi, S.; Liu, Z.; Wu, Z.; Dhakal, C.; Ge, B.; Zhen, C.; Liu, T.; Li, S. AgriBERT: Knowledge-Infused Agricultural Language Models for Matching Food and Nutrition. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022; pp. 5150–5156. [Google Scholar]
- Kpodo, J.; Kordjamshidi, P.; Nejadhashemi, A.P. AgXQA: A benchmark for advanced Agricultural Extension question answering. Comput. Electron. Agric. 2024, 225, 109349. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, L.; Yuan, Y.; Sun, G. Cucumber disease recognition with small samples using image-text-label-based multi-modal language model. Comput. Electron. Agric. 2023, 211, 107993. [Google Scholar] [CrossRef]
- Zhao, B.; Jin, W.; Del Ser, J.; Yang, G. ChatAgri: Exploring potentials of ChatGPT on cross-linguistic agricultural text classification. Neurocomputing 2023, 557, 126708. [Google Scholar] [CrossRef]
- Yang, X.; Gao, J.; Xue, W.; Alexandersson, E. Pllama: An open-source large language model for plant science. arXiv 2024, arXiv:2401.01600. [Google Scholar]
- Huang, Y.; Liu, J.; Lv, C. Chains-BERT: A High-Performance Semi-Supervised and Contrastive Learning-Based Automatic Question-and-Answering Model for Agricultural Scenarios. Appl. Sci. 2023, 13, 2924. [Google Scholar] [CrossRef]
- Yang, X.; Dai, H.; Wu, Z.; Bist, R.; Subedi, S.; Sun, J.; Lu, G.; Li, C.; Liu, T.; Chai, L. Sam for poultry science. arXiv 2023, arXiv:2305.10254. [Google Scholar]
- Williams, D.; Macfarlane, F.; Britten, A. Leaf only SAM: A segment anything pipeline for zero-shot automated leaf segmentation. Smart Agric. Technol. 2024, 8, 100515. [Google Scholar] [CrossRef]
- Zhang, K.; Ma, L.; Cui, B.; Li, X.; Zhang, B.; Xie, N. Visual large language model for wheat disease diagnosis in the wild. Comput. Electron. Agric. 2024, 227, 109587. [Google Scholar] [CrossRef]
- Chauhdary, J.N.; Li, H.; Jiang, Y.; Pan, X.; Hussain, Z.; Javaid, M.; Rizwan, M. Advances in Sprinkler Irrigation: A Review in the Context of Precision Irrigation for Crop Production. Agronomy 2023, 14, 47. [Google Scholar] [CrossRef]
- Mohamed, T.M.K.; Gao, J.; Tunio, M. Development and experiment of the intelligent control system for rhizosphere temperature of aeroponic lettuce via the Internet of Things. Int. J. Agric. Biol. Eng. 2022, 15, 225–233. [Google Scholar]
- Kuska, M.T.; Wahabzada, M.; Paulus, S. Ai-Chatbots for Agriculture-Where Can Large Language Models Provide Substantial Value? Comput. Electron. Agric. 2024, 221, 108924. [Google Scholar] [CrossRef]
- Jia, W.; Zheng, Y.; Zhao, D.; Yin, X.; Liu, X.; Du, R. Preprocessing method of night vision image application in apple harvesting robot. Int. J. Agric. Biol. Eng. 2018, 11, 158–163. [Google Scholar] [CrossRef]
- Sun, J.; Jiang, S.; Mao, H.; Wu, X.; Li, Q. Classification of black beans using visible and near infrared hyperspectral imaging. Int. J. Food Prop. 2016, 19, 1687–1695. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, L.; Wu, H.; Li, L. Advanced agricultural disease image recognition technologies: A review. Inf. Process. Agric. 2022, 9, 48–59. [Google Scholar] [CrossRef]
- Martínez-Peña, R.; Castillo-Gironés, S.; Álvarez, S.; Vélez, S. Tracing pistachio nuts’ origin and irrigation practices through hyperspectral imaging. Curr. Res. Food Sci. 2024, 9, 100835. [Google Scholar] [CrossRef] [PubMed]
- Solangi, K.A.; Siyal, A.A.; Wu, Y.; Abbasi, B.; Solangi, F.; Lakhiar, I.A.; Zhou, G. An assessment of the spatial and temporal distribution of soil salinity in combination with field and satellite data: A case study in Sujawal District. Agronomy 2019, 9, 869. [Google Scholar] [CrossRef]
- Ganeshkumar, C.; David, A.; Sankar, J.G.; Saginala, M. Application of drone Technology in Agriculture: A predictive forecasting of Pest and disease incidence. In Applying Drone Rechnologies and Robotics for Agricultural Sustainability; IGI Global: New York, NY, USA, 2023; pp. 50–81. [Google Scholar]
- Lu, E.; Xu, L.; Li, Y.; Tang, Z.; Ma, Z. Modeling of working environment and coverage path planning method of combine harvesters. Int. J. Agric. Biol. Eng. 2020, 13, 132–137. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, Z.; Han, Z.; Sun, W.; He, L. A Decision-Making System for Cotton Irrigation Based on Reinforcement Learning Strategy. Agronomy 2023, 14, 11. [Google Scholar] [CrossRef]
- Akkem, Y.; Biswas, S.K.; Varanasi, A. A comprehensive review of synthetic data generation in smart farming by using variational autoencoder and generative adversarial network. Eng. Appl. Artif. Intell. 2024, 131, 107881. [Google Scholar] [CrossRef]
- Iatrou, M.; Karydas, C.; Tseni, X.; Mourelatos, S. Representation learning with a variational autoencoder for predicting nitrogen requirement in rice. Remote. Sens. 2022, 14, 5978. [Google Scholar] [CrossRef]
- Mittal, A.; Gupta, H. A Systematic Literature Survey on Generative Adversarial Network Based Crop Disease Identification. In Proceedings of the 2021 International Conference on Technological Advancements and Innovations (ICTAI), Tashkent, Uzbekistan, 10–12 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 394–399. [Google Scholar]
- Barman, U.; Sarma, P.; Rahman, M.; Deka, V.; Lahkar, S.; Sharma, V.; Saikia, M.J. Vit-SmartAgri: Vision transformer and smartphone-based plant disease detection for smart agriculture. Agronomy 2024, 14, 327. [Google Scholar] [CrossRef]
- Momaya, M.; Khanna, A.; Sadavarte, J.; Sankhe, M. Krushi–the farmer chatbot. In Proceedings of the 2021 International Conference on Communication information and Computing Technology (ICCICT), Mumbai, India, 25–27 June 2021; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Mattila, M. Synthetic Image Generation Using GANs: Generating Class Specific Images of Bacterial Growth. 2021. Available online: https://www.diva-portal.org/smash/get/diva2:1564297/FULLTEXT01.pdf (accessed on 14 January 2025).
- Tai, C.Y.; Wang, W.J.; Huang, Y.M. Using time-series generative adversarial networks to synthesize sensing data for pest incidence forecasting on sustainable agriculture. Sustainability 2023, 15, 7834. [Google Scholar] [CrossRef]
- Bouteska, A.; Sharif, T.; Bhuiyan, F.; Abedin, M.Z. Impacts of the changing climate on agricultural productivity and food security: Evidence from Ethiopia. J. Clean. Prod. 2024, 449, 141793. [Google Scholar] [CrossRef]
- Kollia, I.; Stevenson, J.; Kollias, S. Ai-enabled efficient and safe food supply chain. Electronics 2021, 10, 1223. [Google Scholar] [CrossRef]
- Fernandes, E.A.; Sarries, G.A.; Mazola, Y.T.; Lima, R.C.; Furlan, G.N.; Bacchi, M.A. Machine learning to support geographical origin traceability of Coffea Arabica. Adv. Artif. Intell. Mach. Learn. Res. 2022, 2, 273–287. [Google Scholar] [CrossRef]
- Yang, Q.; Du, X.; Wang, Z.; Meng, Z.; Ma, Z.; Zhang, Q. A review of core agricultural robot technologies for crop productions. Comput. Electron. Agric. 2023, 206, 107701. [Google Scholar] [CrossRef]
- Jin, Y.; Liu, J.; Xu, Z.; Yuan, S.; Li, P.; Wang, J. Development status and trend of agricultural robot technology. Int. J. Agric. Biol. Eng. 2021, 14, 1–19. [Google Scholar] [CrossRef]
- Pazhanivelan, S.; Kumaraperumal, R.; Shanmugapriya, P.; Sudarmanian, N.; Sivamurugan, A.; Satheesh, S. Quantification of biophysical parameters and economic yield in cotton and rice using drone technology. Agriculture 2023, 13, 1668. [Google Scholar] [CrossRef]
- Yang, J.; Gao, M.; Li, Z.; Gao, S.; Wang, F.; Zheng, F. Track anything: Segment anything meets videos. arXiv 2023, arXiv:2304.11968. [Google Scholar]
- Liu, Y.; Hou, J.; Li, C.; Wang, X. Intelligent soft robotic grippers for agricultural and food product handling: A brief review with a focus on design and control. Adv. Intell. Syst. 2023, 5, 2300233. [Google Scholar] [CrossRef]
- Zhou, J.; Li, P.; Wang, J.; Fu, W. Growth, photosynthesis, and nutrient uptake at different light intensities and temperatures in lettuce. HortScience 2019, 54, 1925–1933. [Google Scholar] [CrossRef]
- Wei, L.; Yang, H.; Niu, Y.; Zhang, Y.; Xu, L.; Chai, X. Wheat biomass, yield, and straw-grain ratio estimation from multi-temporal UAV-based RGB and multispectral images. Biosyst. Eng. 2023, 234, 187–205. [Google Scholar] [CrossRef]
- Awais, M.; Li, W.; Hussain, S.; Cheema, M.J.M.; Li, W.; Song, R.; Liu, C. Comparative evaluation of land surface temperature images from unmanned aerial vehicle and satellite observation for agricultural areas using in situ data. Agriculture 2022, 12, 184. [Google Scholar] [CrossRef]
- Cui, X.; Han, W.; Zhang, H.; Dong, Y.; Ma, W.; Zhai, X.; Zhang, L.; Li, G. Estimating and mapping the dynamics of soil salinity under different crop types using Sentinel-2 satellite imagery. Geoderma 2023, 440, 116738. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Y.; Wu, L.; Xu, L.; Xu, C.; Liang, D.; Ding, Y.; Zhang, Y.; Wang, J.; Li, G. The Yield-forming role of nitrogen in rice in the growing seasons with variable thermal conditions. Agronomy 2023, 13, 313. [Google Scholar] [CrossRef]
- Raza, A.; Saber, K.; Hu, Y.; Ray, R.L.; Ziya Kaya, Y.; Dehghanisanij, H.; Kisi, O.; Elbeltagi, A. Modelling reference evapotranspiration using principal component analysis and machine learning methods under different climatic environments. Irrig. Drain. 2023, 72, 945–970. [Google Scholar] [CrossRef]
- Zhu, X.; Chikangaise, P.; Shi, W.; Chen, W.H.; Yuan, S. Review of intelligent sprinkler irrigation technologies for remote autonomous system. Int. J. Agric. Biol. Eng. 2018, 11, 1. [Google Scholar] [CrossRef]
- Chen, X.; Hassan, M.M.; Yu, J.; Zhu, A.; Han, Z.; He, P.; Chen, Q.; Li, H.; Ouyang, Q. Time series prediction of insect pests in tea gardens. J. Sci. Food Agric. 2024, 104, 5614–5624. [Google Scholar] [CrossRef] [PubMed]
- Yang, N.; Yuan, M.; Wang, P.; Zhang, R.; Sun, J.; Mao, H. Tea diseases detection based on fast infrared thermal image processing technology. J. Sci. Food Agric. 2019, 99, 3459–3466. [Google Scholar] [CrossRef]
- Jones, J.W.; Antle, J.M.; Basso, B.; Boote, K.J.; Conant, R.T.; Foster, I.; Godfray, H.C.J.; Herrero, M.; Howitt, R.E.; Janssen, S.; et al. Toward a new generation of agricultural system data, models, and knowledge products: State of agricultural systems science. Agric. Syst. 2017, 155, 269–288. [Google Scholar] [CrossRef]
- Donatelli, M.; Magarey, R.D.; Bregaglio, S.; Willocquet, L.; Whish, J.P.; Savary, S. Modelling the impacts of pests and diseases on agricultural systems. Agric. Syst. 2017, 155, 213–224. [Google Scholar] [CrossRef]
- Qin, W.C.; Qiu, B.J.; Xue, X.Y.; Chen, C.; Xu, Z.F.; Zhou, Q.Q. Droplet deposition and control effect of insecticides sprayed with an unmanned aerial vehicle against plant hoppers. Crop. Prot. 2016, 85, 79–88. [Google Scholar] [CrossRef]
- Elsherbiny, O.; Gao, J.; Ma, M.; Guo, Y.; Tunio, M.H.; Mosha, A.H. Advancing lettuce physiological state recognition in IoT aeroponic systems: A meta-learning-driven data fusion approach. Eur. J. Agron. 2024, 161, 127387. [Google Scholar] [CrossRef]
- Zhang, S.; Xue, X.; Chen, C.; Sun, Z.; Sun, T. Development of a low-cost quadrotor UAV based on ADRC for agricultural remote sensing. Int. J. Agric. Biol. Eng. 2019, 12, 82–87. [Google Scholar] [CrossRef]
- Xu, J.; Gu, B.; Tian, G. Review of agricultural IoT technology. Artif. Intell. Agric. 2022, 6, 10–22. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl. Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative adversarial networks (GANs) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 2022, 200, 107208. [Google Scholar] [CrossRef]
- Li, J.; Chen, D.; Qi, X.; Li, Z.; Huang, Y.; Morris, D.; Tan, X. Label-efficient learning in agriculture: A comprehensive review. Comput. Electron. Agric. 2023, 215, 108412. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Wiles, O.; Gowal, S.; Stimberg, F.; Rebuffi, S.-A.; Ktena, I.; Dvijotham, K.D.; Cemgil, A.T. A fine-grained analysis on distribution shift. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 25–29 April 2022. [Google Scholar]
- Chawla, S.; Singh, N.; Drori, I. Quantifying and alleviating distribution shifts in foundation models on review classification. In Proceedings of the NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications, Online, 13 December 2021. [Google Scholar]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land cover classification via multitemporal spatial data by deep recurrent neural networks. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 1685–1689. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Luus, F.P.; Salmon, B.P.; Van den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Yalcin, H. Plant phenology recognition using deep learning: Deep-Pheno. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Taghavi Namin, S.; Esmaeilzadeh, M.; Najafi, M.; Brown, T.B.; Borevitz, J.O. Deep phenotyping: Deep learning for temporal phenotype/genotype classification. Plant Methods 2018, 14, 1–14. [Google Scholar] [CrossRef]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting apples and oranges with deep learning: A data-driven approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3626–3633. [Google Scholar]
- Dyrmann, M.; Mortensen, A.K.; Midtiby, H.S.; Jørgensen, R.N. Pixel-wise classification of weeds and crops in images by using a fully convolutional neural network. In Proceedings of the International Conference on Agricultural Engineering, Aarhus, Denmark, 26–29 June 2016; pp. 26–29. [Google Scholar]
- Dyrmann, M.; Jørgensen, R.N.; Midtiby, H.S. RoboWeedSupport-Detection of weed locations in leaf occluded cereal crops using a fully convolutional neural network. Adv. Anim. Biosci. 2017, 8, 842–847. [Google Scholar] [CrossRef]
- Xinshao, W.; Cheng, C. Weed seeds classification based on PCANet deep learning baseline. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 408–415. [Google Scholar]
- Wang, H.; Vasu, P.K.A.; Faghri, F.; Vemulapalli, R.; Farajtabar, M.; Mehta, S.; Rastegari, M.; Tuzel, O.; Pouransari, H. Sam-clip: Merging vision foundation models towards semantic and spatial understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 3635–3647. [Google Scholar]
- Cvejoski, K.; Sánchez, R.J.; Ojeda, C. The future is different: Large pre-trained language models fail in prediction tasks. arXiv 2022, arXiv:2211.00384. [Google Scholar]
- Xu, M.; Park, J.E.; Lee, J.; Yang, J.; Yoon, S. Plant disease recognition datasets in the age of deep learning: Challenges and opportunities. Front. Plant Sci. 2024, 15, 1452551. [Google Scholar] [CrossRef] [PubMed]
- Mahmud, M.S.A.; Abidin, M.S.Z.; Emmanuel, A.A.; Hasan, H.S. Robotics and automation in agriculture: Present and future applications. Appl. Model. Simul. 2020, 4, 130–140. [Google Scholar]
- Gernert, B.; Schlichter, J.; Wolf, L. PotatoScanner–A mobile delay tolerant wireless sensor node for smart farming applications. In Proceedings of the 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini Island, Greece, 29–30 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 106–113. [Google Scholar]
- Kondo, S.; Yoshimoto, N.; Nakayama, Y. Farm Monitoring System with Drones and Optical Camera Communication. Sensors 2024, 24, 6146. [Google Scholar] [CrossRef]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Nabaei, S.H.; Zheng, Z.; Chen, D.; Heydarian, A. Multimodal Data Integration for Sustainable Indoor Gardening: Tracking Anyplant with Time Series Foundation Model. arXiv 2025, arXiv:2503.21932. [Google Scholar]
- Murdyantoro, B.; Atmaja, D.S.E.; Rachmat, H. Application design of farmbot based on Internet of Things (IoT). Int. J. Adv. Sci. Eng. Inf. Technol. 2019, 9, 1163–1170. [Google Scholar] [CrossRef]
- Stock, P.; Fan, A.; Graham, B.; Grave, E.; Gribonval, R.; Jegou, H.; Joulin, A. Training with quantization noise for extreme model compression. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Muslim, A.B.; Nordemann, F.; Tönjes, R. Analysis of methods for prioritizing critical data transmissions in agricultural vehicular networks. In Proceedings of the 2020 16th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Thessaloniki, Greece, 12–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 80–85. [Google Scholar]
- Tzachor, A.; Devare, M.; King, B.; Avin, S.; Ó hÉigeartaigh, S. Responsible artificial intelligence in agriculture requires systemic understanding of risks and externalities. Nat. Mach. Intell. 2022, 4, 104–109. [Google Scholar] [CrossRef]
- Chandrasiri, C.; Kiridena, S.; Dharmapriya, S.; Kulatunga, A.K. Adoption of Multi-Modal Transportation for Configuring Sustainable Agri-Food Supply Chains in Constrained Environments. Sustainability 2024, 16, 7601. [Google Scholar] [CrossRef]
- Alexander, C.S.; Yarborough, M.; Smith, A. Who is responsible for ‘responsible AI’?: Navigating challenges to build trust in AI agriculture and food system technology. Precis. Agric. 2024, 25, 146–185. [Google Scholar] [CrossRef]
- Besik, D.; Nagurney, A.; Dutta, P. An integrated multitiered supply chain network model of competing agricultural firms and processing firms: The case of fresh produce and quality. Eur. J. Oper. Res. 2023, 307, 364–381. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral technique combined with deep learning algorithm for detection of compound heavy metals in lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, X.; Aheto, J.H.; Wang, C.; Ernest, B.; Tian, X.; He, P.; Chang, X.; Wang, C. Application of volatile and spectral profiling together with multimode data fusion strategy for the discrimination of preserved eggs. Food Chem. 2021, 343, 128515. [Google Scholar] [CrossRef]
- Wang, H.; Gu, J.; Wang, M. A review on the application of computer vision and machine learning in the tea industry. Front Sustain. Food Syst. 2023, 7, 1172543. [Google Scholar] [CrossRef]
- Patil, R.R.; Kumar, S. Rice-fusion: A multimodality data fusion framework for rice disease diagnosis. IEEE Access 2022, 10, 5207–5222. [Google Scholar] [CrossRef]
- You, J.; Li, D.; Wang, Z.; Chen, Q.; Ouyang, Q. Prediction and visualization of moisture content in Tencha drying processes by computer vision and deep learning. J. Sci. Food Agric. 2024, 104, 5486–5494. [Google Scholar] [CrossRef]
- Huang, X.; Lv, R.; Wang, S.; Aheto, J.H.; Dai, C. Integration of computer vision and colorimetric sensor array for nondestructive detection of mango quality. J. Food Process. Eng. 2018, 41, e12873. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, C.; Li, H.; Xia, H. Design and Evaluation of A Control System for The Fertigation Device. J. ASABE 2022, 65, 1293–1302. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, M.; Xu, B.; Guo, Z. Intelligent quality control of gelatinous polysaccharide-based fresh products during cold chain logistics: A review. Food Biosci. 2024, 62, 105081. [Google Scholar] [CrossRef]
- Mai, G.; Huang, W.; Sun, J.; Song, S.; Mishra, D.; Liu, N.; Gao, S.; Liu, T.; Cong, G.; Hu, Y.; et al. On the opportunities and challenges of foundation models for geospatial artificial intelligence. ACM Trans. Spat. Algorithms Syst. 2024, 10, 1–46. [Google Scholar] [CrossRef]
- Li, W.; Zhang, C.; Ma, T.; Li, W. Estimation of summer maize biomass based on a crop growth model. Emir. J. Food Agric. (EJFA) 2021, 33, 742–750. [Google Scholar] [CrossRef]
- Shen, Y.; Gao, J.; Jin, Z. Research on Acoustic Signal Identification Mechanism and Denoising Methods of Combine Harvesting Loss. Agronomy 2024, 14, 1816. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).