
Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset



Abstract
:1. Introduction
- (i)
- We have improved the existing SMD dataset by removing noisy labels and fixing the bounding boxes. It is expected that the improved dataset of the SMD-Plus will be used as a benchmark dataset for the detection and classification of objects in maritime environments.
- (ii)
- In addition to the YOLO-V5 augmentation techniques, we proposed the Online Copy & Paste and Mix-up methods for the SMD-Plus. Our Online Copy & Paste scheme has significantly improved the classification performance for the minority classes, thus alleviating the class-imbalance problem in the SMD-Plus.
- (iii)
- The ground truth table for the SMD-Plus and the results of the detection and classification are open to the public and may be downloaded from the following website (accessed on 2 March 2022): https://github.com/kjunhwa/Singapore-Maritime-Dataset-Plus.
2. Related Work
2.1. Maritime Dataset
2.2. Object Detection Models
3. Improved SMD: SMD-Plus
- (i)
- ‘Swimming person’ class is empty and is deleted;
- (ii)
- Non-ship ‘Flying bird and plane’ class is deleted;
- (iii)
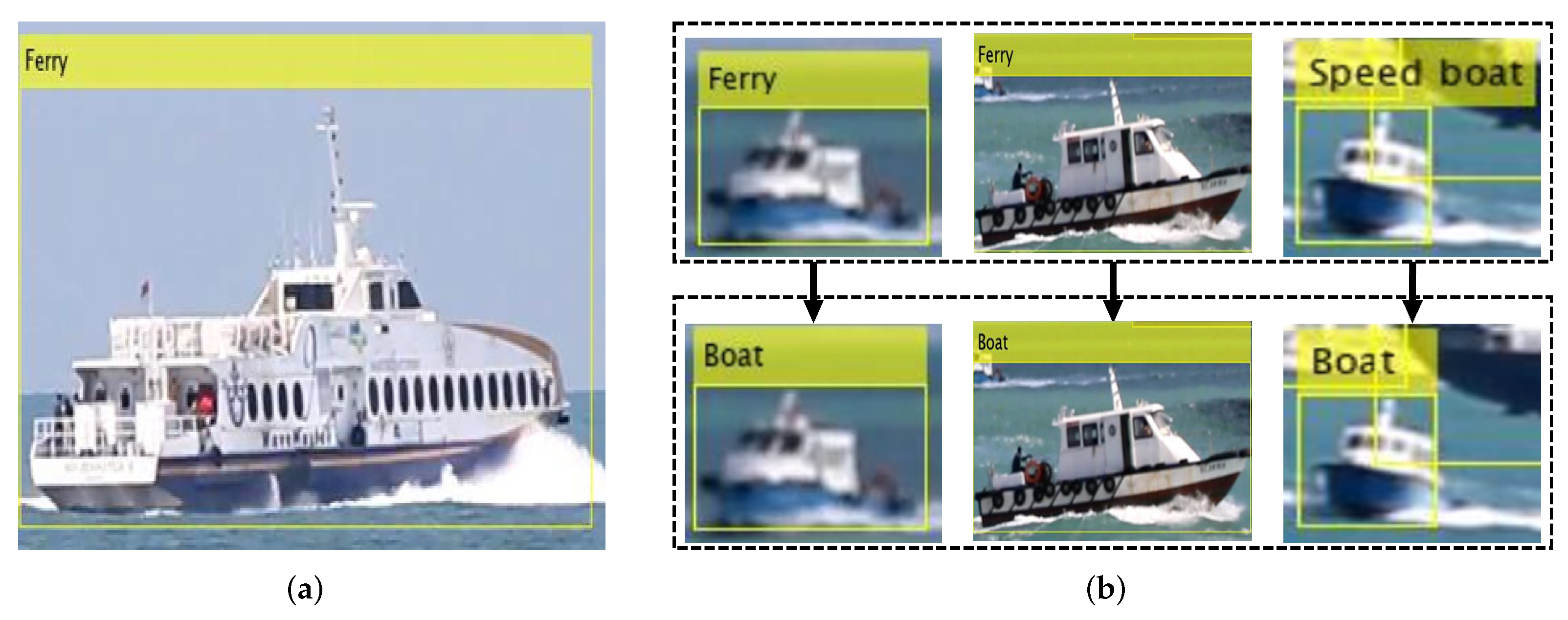
- Visually similar classes of ‘Speed boat’ and ‘Boat’ are merged;
- (iv)
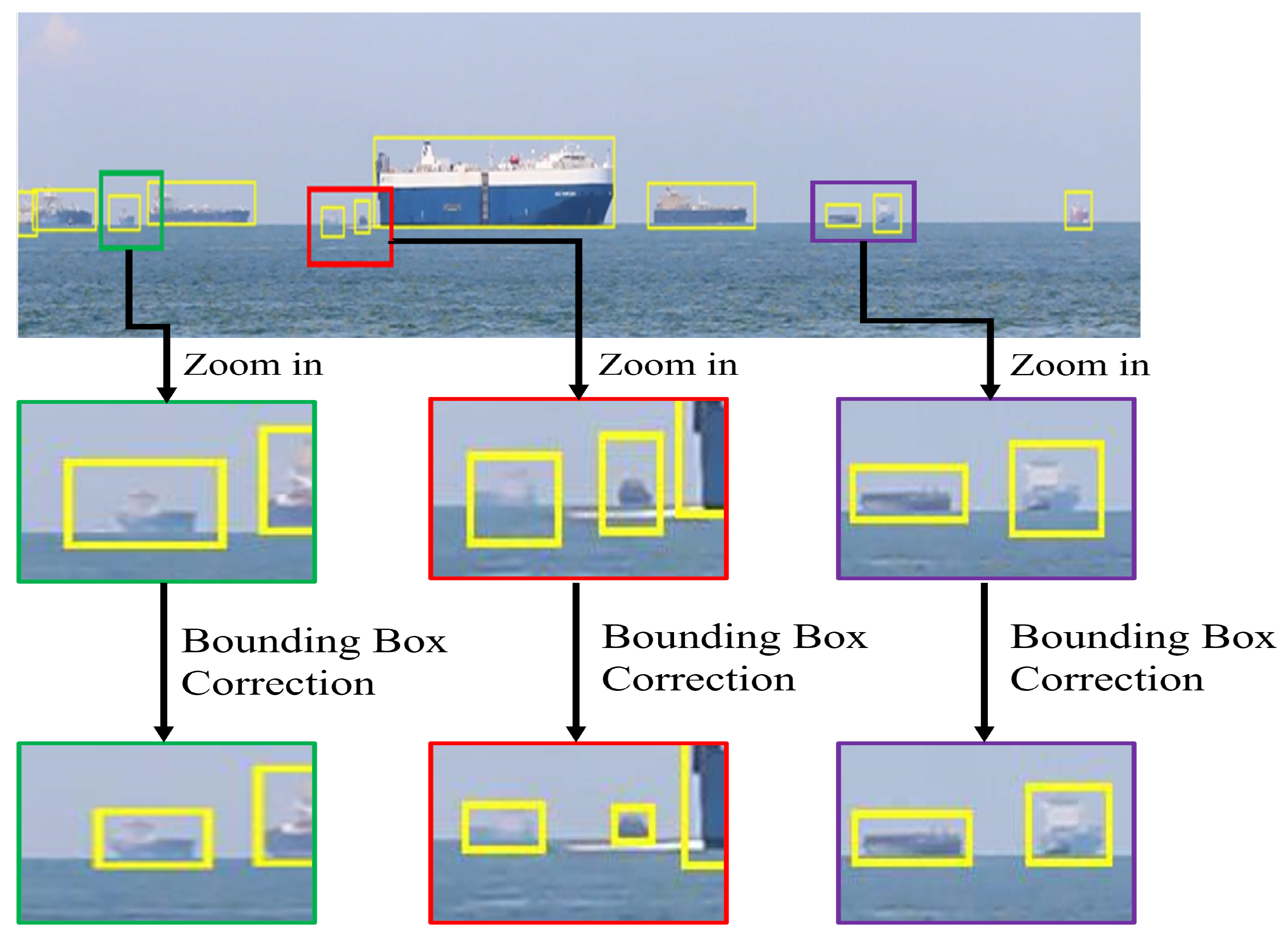
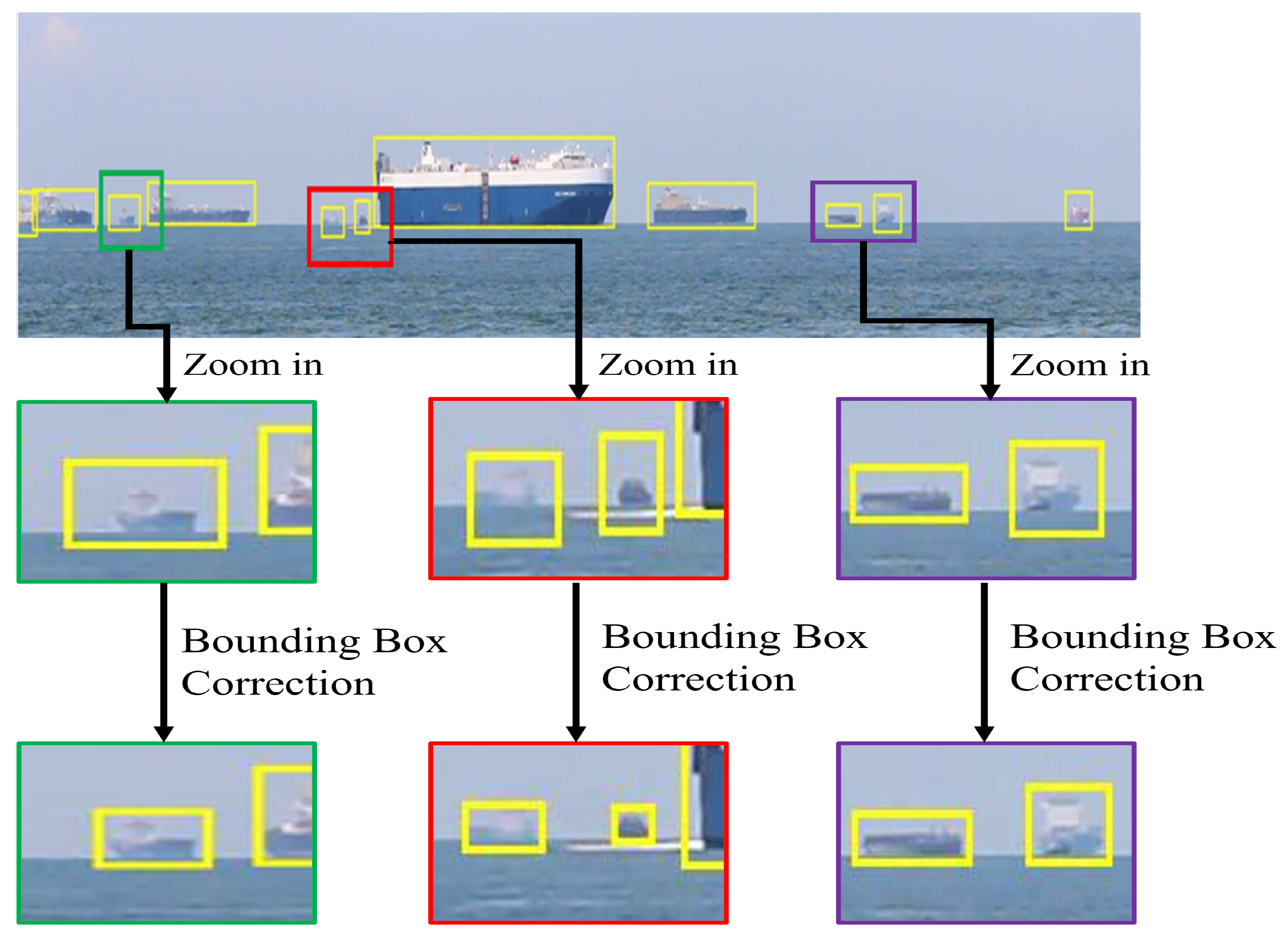
- Bounding boxes of the original SMD are tightened;
- (v)
- Some of the missing bounding boxes in ‘Kayak’ are added;
- (vi)
- According to our redefinitions for the ‘Ferry’ and ‘Other’ classes, some of the misclassified objects in them are corrected.
4. Data Augmentation for YOLO-V5
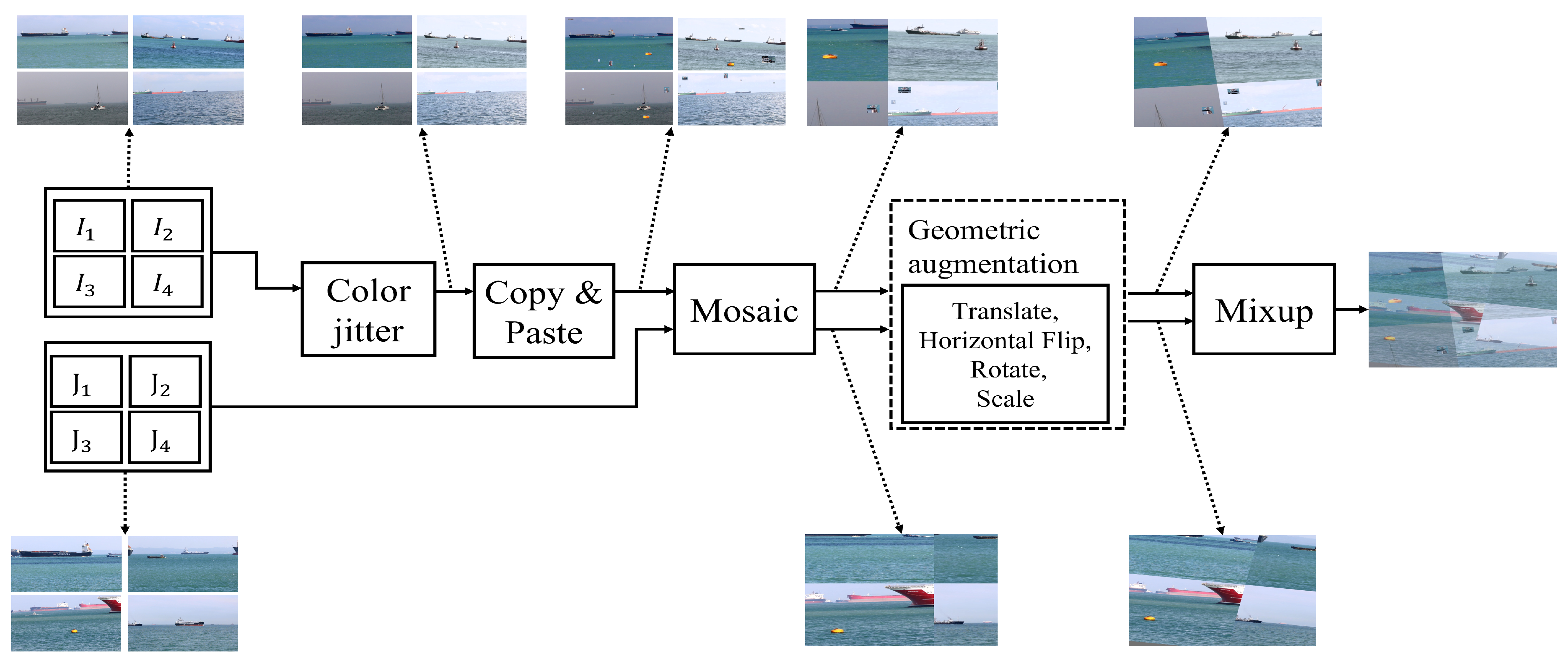
4.1. Copy & Paste Augmentation
4.2. Mix-up Augmentation
4.3. Basic Augmentations from YOLO-V5
5. Experiment Results
- For color jittering: hue ranges from 0 to 0.015; saturation, from 0 to 0.7; and brightness, from 0 to 0.4;
- The probability of generating a mosaic is 0.5;
- Translate shifts range from 0 to 0.1;
- The probability of a horizontal flip is 0.5;
- Random rotation within angles from −10 to +10 degrees;
- Random scaling in the range of 0.5×∼1.5×.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Shim, S.; Cho, G.C. Lightweight semantic segmentation for road-surface damage recognition based on multiscale learning. IEEE Access 2020, 8, 102680–102690. [Google Scholar] [CrossRef]
- Yuan, Y.; Islam, M.S.; Yuan, Y.; Wang, S.; Baker, T.; Kolbe, L.M. EcRD: Edge-cloud Computing Framework for Smart Road Damage Detection and Warning. IEEE Internet Things J. 2020, 8, 12734–12747. [Google Scholar] [CrossRef]
- Li, X.; Lai, S.; Qian, X. DBCFace: Towards Pure Convolutional Neural Network Face Detection. IEEE Trans. Circuits Syst. Video Technol. 2021; early access. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Lei, Z.; Li, S.Z. Refineface: Refinement neural network for high performance face detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4008–4020. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Yap, K.H.; Kot, A.C.; Duan, L. Jdnet: A joint-learning distilled network for mobile visual food recognition. IEEE J. Sel. Top. Signal Process. 2020, 14, 665–675. [Google Scholar] [CrossRef]
- Won, C.S. Multi-scale CNN for fine-grained image recognition. IEEE Access 2020, 8, 116663–116674. [Google Scholar] [CrossRef]
- Moosbauer, S.; Konig, D.; Jakel, J.; Teutsch, M. A benchmark for deep learning based object detection in maritime environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 916–925. [Google Scholar]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Gao, M.; Shi, G.; Li, S. Online Prediction of Ship Behavior with Automatic Identification System Sensor Data Using Bidirectional Long Short-Term Memory Recurrent Neural Network. Sensors 2018, 18, 4211. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gundogdu, E.; Solmaz, B.; Yücesoy, V.; Koc, A. Marvel: A large-scale image dataset for maritime vessels. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 165–180. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Shin, H.C.; Lee, K.I.; Lee, C.E. Data augmentation method of object detection for deep learning in maritime image. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 463–466. [Google Scholar]
- Nalamati, M.; Sharma, N.; Saqib, M.; Blumenstein, M. Automated Monitoring in Maritime Video Surveillance System. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- YOLO-V5. Available online: ultralytics/yolov5:V3.0 (accessed on 13 August 2020).
- Qiao, D.; Liu, G.; Lv, T.; Li, W.; Zhang, J. Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey. J. Mar. Sci. Eng. 2021, 9, 397. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, J.; Zheng, X.; Wen, J.; Rao, L.; Zhao, J. Maritime Visible Image Classification Based on Double Transfer Method. IEEE Access 2020, 8, 166335–166346. [Google Scholar] [CrossRef]
- Bloisi, D.D.; Iocchi, L.; Pennisi, A.; Tombolini, L. ARGOS-Venice Boat Classification. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SMD | SMD-Plus | ||
|---|---|---|---|
| Class | Objects(#) | Class | Objects(#) |
| Boat | 1499 | Boat | 14,021 |
| Speed Boat | 7961 | ||
| Vessel/Ship | 117,436 | Vessel/Ship | 125,872 |
| Ferry | 8588 | Ferry | 3431 |
| Kayak | 4308 | Kayak | 3798 |
| Buoy | 3065 | Buoy | 3657 |
| Sail Boat | 1926 | Sail Boat | 1926 |
| Others | 12,564 | Others | 24,993 |
| Flying bird and plane | 650 | Removed | - |
| Swimming Person | 0 | Removed | - |
| Set | Subset | Video Name | Condition | Number of Objects | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| c1 | c2 | c3 | c4 | c5 | c6 | c7 | Total | ||||
| Train (37) | OnShore (28) | MVI_1451 | Hazy | 329 | 0 | 2524 | 337 | 0 | 0 | 0 | 3190 |
| MVI_1452 | Hazy | 0 | 0 | 1020 | 0 | 0 | 340 | 339 | 1609 | ||
| MVI_1470 | Daylight | 0 | 266 | 1862 | 302 | 0 | 0 | 20 | 2450 | ||
| MVI_1471 | Daylight | 0 | 299 | 1723 | 433 | 0 | 0 | 58 | 2513 | ||
| MVI_1478 | Daylight | 0 | 0 | 1431 | 477 | 0 | 477 | 516 | 2901 | ||
| MVI_1479 | Daylight | 0 | 0 | 824 | 237 | 0 | 0 | 57 | 1118 | ||
| MVI_1481 | Daylight | 0 | 409 | 1227 | 1002 | 0 | 0 | 409 | 3047 | ||
| MVI_1482 | Daylight | 0 | 0 | 1362 | 1059 | 0 | 0 | 24 | 2445 | ||
| MVI_1483 | Daylight | 0 | 0 | 897 | 0 | 0 | 0 | 0 | 897 | ||
| MVI_1484 | Daylight | 0 | 0 | 687 | 687 | 0 | 0 | 1374 | 2748 | ||
| MVI_1485 | Daylight | 0 | 104 | 832 | 104 | 0 | 0 | 0 | 1040 | ||
| MVI_1486 | Daylight | 0 | 630 | 5032 | 630 | 0 | 0 | 0 | 6292 | ||
| MVI_1578 | Dark/twilight | 0 | 0 | 3030 | 0 | 0 | 0 | 505 | 3535 | ||
| MVI_1582 | Dark/twilight | 0 | 0 | 7560 | 540 | 0 | 0 | 540 | 8640 | ||
| MVI_1583 | Dark/twilight | 0 | 0 | 2510 | 502 | 0 | 0 | 97 | 3109 | ||
| MVI_1584 | Dark/twilight | 0 | 0 | 6456 | 881 | 0 | 0 | 3228 | 10,565 | ||
| MVI_1609 | Daylight | 505 | 0 | 5555 | 443 | 3115 | 0 | 505 | 10,123 | ||
| MVI_1610 | Daylight | 0 | 0 | 1086 | 974 | 0 | 543 | 0 | 2603 | ||
| MVI_1619 | Daylight | 0 | 0 | 2365 | 0 | 0 | 0 | 473 | 2838 | ||
| MVI_1612 | Daylight | 0 | 0 | 2069 | 154 | 0 | 0 | 261 | 2484 | ||
| MVI_1617 | Daylight | 0 | 0 | 4309 | 0 | 0 | 0 | 2163 | 6472 | ||
| MVI_1620 | Daylight | 0 | 0 | 2008 | 0 | 0 | 0 | 1151 | 3159 | ||
| MVI_1622 | Daylight | 214 | 0 | 618 | 0 | 0 | 0 | 236 | 1068 | ||
| MVI_1623 | Daylight | 522 | 0 | 1528 | 0 | 0 | 0 | 1044 | 3094 | ||
| MVI_1624 | Daylight | 431 | 0 | 1482 | 0 | 0 | 0 | 0 | 1913 | ||
| MVI_1625 | Daylight | 0 | 0 | 5066 | 0 | 0 | 0 | 4694 | 9760 | ||
| MVI_1626 | Daylight | 0 | 0 | 2854 | 0 | 0 | 0 | 2605 | 5459 | ||
| MVI_1627 | Daylight | 0 | 0 | 2975 | 595 | 0 | 0 | 813 | 4383 | ||
| OnBoard (9) | MVI_0788 | Daylight | 0 | 0 | 796 | 0 | 0 | 0 | 0 | 796 | |
| MVI_0789 | Daylight | 0 | 0 | 88 | 119 | 0 | 0 | 11 | 218 | ||
| MVI_0790 | Daylight | 0 | 14 | 70 | 5 | 0 | 0 | 8 | 97 | ||
| MVI_0792 | Daylight | 0 | 0 | 604 | 0 | 0 | 0 | 100 | 704 | ||
| MVI_0794 | Daylight | 292 | 0 | 0 | 0 | 0 | 0 | 0 | 292 | ||
| MVI_0795 | Daylight | 510 | 0 | 0 | 0 | 0 | 0 | 0 | 510 | ||
| MVI_0796 | Daylight | 0 | 0 | 504 | 0 | 0 | 0 | 0 | 504 | ||
| MVI_0797 | Daylight | 0 | 0 | 1129 | 0 | 0 | 0 | 113 | 1242 | ||
| MVI_0801 | Daylight | 0 | 0 | 596 | 275 | 0 | 0 | 43 | 914 | ||
| Test (14) | OnShore (12) | MVI_1469 | Daylight | 0 | 600 | 3600 | 941 | 0 | 0 | 600 | 5741 |
| MVI_1474 | Daylight | 0 | 1335 | 3560 | 890 | 0 | 0 | 3560 | 9345 | ||
| MVI_1587 | Dark/twilight | 0 | 0 | 6000 | 600 | 0 | 0 | 586 | 7186 | ||
| MVI_1592 | Dark/twilight | 0 | 0 | 2850 | 0 | 683 | 0 | 0 | 3533 | ||
| MVI_1613 | Daylight | 0 | 0 | 5750 | 0 | 0 | 0 | 904 | 6654 | ||
| MVI_1614 | Daylight | 0 | 0 | 5464 | 582 | 0 | 0 | 934 | 6980 | ||
| MVI_1615 | Dark/twilight | 0 | 0 | 3277 | 0 | 0 | 566 | 566 | 4409 | ||
| MVI_1644 | Daylight | 0 | 0 | 1008 | 0 | 0 | 0 | 756 | 1764 | ||
| MVI_1645 | Daylight | 0 | 0 | 3210 | 0 | 0 | 0 | 0 | 3210 | ||
| MVI_1646 | Daylight | 0 | 0 | 4610 | 0 | 0 | 0 | 373 | 4533 | ||
| MVI_1448 | Hazy | 165 | 0 | 3624 | 1590 | 0 | 0 | 19 | 5398 | ||
| MVI_1640 | Daylight | 302 | 0 | 1756 | 0 | 0 | 0 | 38 | 2096 | ||
| OnBoard (2) | MVI_0799 | Daylight | 161 | 0 | 379 | 0 | 0 | 0 | 40 | 580 | |
| MVI_0804 | Daylight | 0 | 0 | 484 | 0 | 0 | 0 | 980 | 1464 | ||
| Min Rectangle Area | Max Rectangle Area | |
|---|---|---|
| Small object | ||
| Medium object | ||
| Large object |
| Dataset | Network | mAP(0.5) | mAP(0.5:0.95) |
|---|---|---|---|
| SMD | YOLO-V4 | 0.704 | 0.297 |
| YOLO-V5-S | 0.772 | 0.386 | |
| YOLO-V5-M | 0.750 | 0.403 | |
| YOLO-V5-L | 0.766 | 0.407 | |
| SMD-Plus | YOLO-V4 | 0.847 | 0.428 |
| YOLO-V5-S | 0.898 | 0.522 | |
| YOLO-V5-M | 0.867 | 0.528 | |
| YOLO-V5-L | 0.878 | 0.527 |
| Dataset | Network | Object Class | mAP | mAP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | (0.5) | (0.5:0.95) | ||
| SMD | YOLO-V4 | - | 0.0205 | 0.657 | 0.271 | - | 0.148 | - | 0.00223 | 0.000 | - | 0.186 | 0.0807 |
| YOLO-V5-S | - | 0.0285 | 0.657 | 0.249 | - | 0.379 | - | 0.00671 | 0.000 | - | 0.22 | 0.0903 | |
| YOLO-V5-M | - | 0.0627 | 0.706 | 0.249 | - | 0.0538 | - | 0.0213 | 0.000 | - | 0.182 | 0.0817 | |
| YOLO-V5-L | - | 0.0879 | 0.678 | 0.357 | - | 0.594 | - | 0.11 | 0.000 | - | 0.304 | 0.128 | |
| Dataset | Copy & Paste | Network | Object Class | P | R | mAP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c1 | c2 | c3 | c4 | c5 | c6 | c7 | 0.5 | 0.5 | 0.5 | 0.5:0.95 | |||
| SMD-Plus | None | YOLO-V4 | 0.160 | 0.622 | 0.868 | 0.632 | 0.00995 | 0.995 | 0.274 | 0.476 | 0.566 | 0.509 | 0.258 |
| YOLO-V5-S | 0.372 | 0.691 | 0.827 | 0.569 | 0.00573 | 0.995 | 0.089 | 0.716 | 0.517 | 0.507 | 0.254 | ||
| YOLO-V5-M | 0.588 | 0.882 | 0.816 | 0.615 | 0.00063 | 0.97 | 0.111 | 0.741 | 0.513 | 0.569 | 0.298 | ||
| YOLO-V5-L | 0.673 | 0.789 | 0.846 | 0.571 | 0.0123 | 0.995 | 0.131 | 0.803 | 0.505 | 0.574 | 0.286 | ||
| Online | YOLO-V4 | 0.172 | 0.539 | 0.868 | 0.721 | 0.114 | 0.995 | 0.243 | 0.486 | 0.621 | 0.522 | 0.308 | |
| YOLO-V5-S | 0.471 | 0.864 | 0.869 | 0.549 | 0.162 | 0.995 | 0.123 | 0.650 | 0.536 | 0.576 | 0.291 | ||
| YOLO-V5-M | 0.588 | 0.706 | 0.842 | 0.607 | 0.259 | 0.991 | 0.123 | 0.709 | 0.486 | 0.588 | 0.338 | ||
| YOLO-V5-L | 0.714 | 0.806 | 0.828 | 0.582 | 0.232 | 0.995 | 0.147 | 0.811 | 0.534 | 0.615 | 0.33 | ||
| Offline | YOLO-V4 | 0.217 | 0.445 | 0.881 | 0.647 | 0.108 | 0.995 | 0.172 | 0.481 | 0.610 | 0.495 | 0.284 | |
| YOLO-V5-S | 0.475 | 0.386 | 0.887 | 0.603 | 0.0985 | 0.994 | 0.152 | 0.582 | 0.482 | 0.514 | 0.291 | ||
| YOLO-V5-M | 0.49 | 0.809 | 0.852 | 0.603 | 0.0592 | 0.995 | 0.169 | 0.724 | 0.788 | 0.568 | 0.309 | ||
| YOLO-V5-L | 0.618 | 0.789 | 0.847 | 0.667 | 0.0319 | 0.995 | 0.231 | 0.688 | 0.541 | 0.597 | 0.316 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Kim, N.; Park, Y.W.; Won, C.S. Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. J. Mar. Sci. Eng. 2022, 10, 377. https://doi.org/10.3390/jmse10030377
Kim J-H, Kim N, Park YW, Won CS. Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. Journal of Marine Science and Engineering. 2022; 10(3):377. https://doi.org/10.3390/jmse10030377
Chicago/Turabian StyleKim, Jun-Hwa, Namho Kim, Yong Woon Park, and Chee Sun Won. 2022. "Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset" Journal of Marine Science and Engineering 10, no. 3: 377. https://doi.org/10.3390/jmse10030377
APA StyleKim, J.-H., Kim, N., Park, Y. W., & Won, C. S. (2022). Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. Journal of Marine Science and Engineering, 10(3), 377. https://doi.org/10.3390/jmse10030377