
A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline
 , ,
, ,
Abstract
:1. Introduction
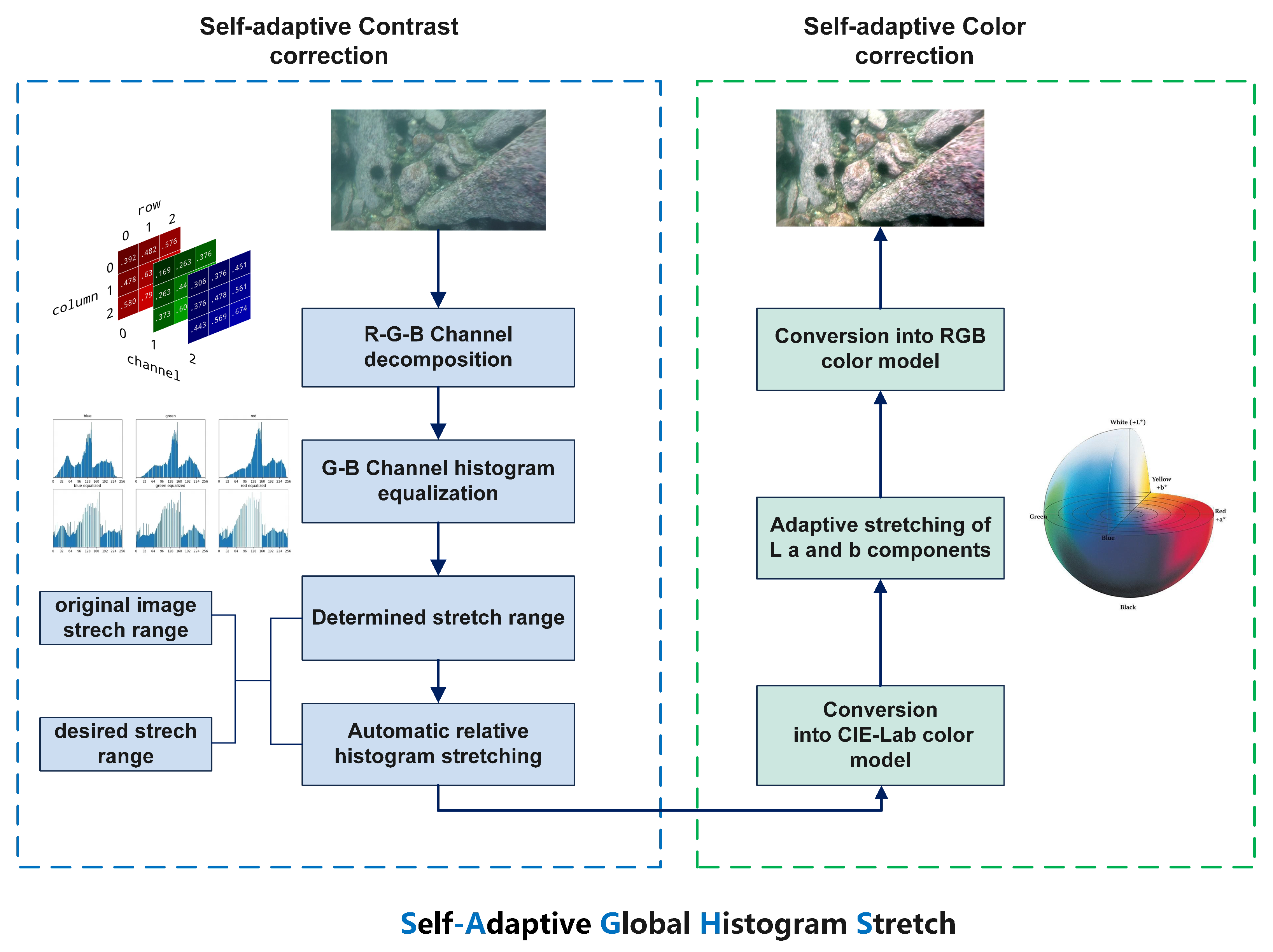
- The correction of bluish and greenish backgrounds and low contrast using an improved global histogram stretching method that dynamically adjusts the histogram stretching coefficient, for which a detailed linear function and framework were built;
- The integration of a convolutional block attention module (CBAM) into CSPDarknet53 to enhance the features of small, overlapping, and occluded objects. In particular, the CBAM mechanism can be employed to improve the contrast between an object and the surrounding environment and refine redundant information that is produced by the Focus function;
- The use of a simple and efficient connection between the attention mechanism and object detection algorithm for the first time. The CBAM module was added to the Focus module of the backbone network to reduce the model burden as much as possible while ensuring the desired detection accuracy of the improved algorithm.
2. Related Work
2.1. Underwater Image Enhancement (UIE) Methods
2.2. Attention Mechanisms
2.3. Underwater Object Detection Algorithms
3. Methodology
3.1. Self-Adaptive Histogram Stretching Algorithm
3.1.1. Self-Adaptive Contrast Correction Module
| Algorithm 1 The self-adaptive global histogram stretching algorithm. |
|
3.1.2. Self-Adaptive Color Correction Module
3.2. Convolutional Block Attention Module Mechanism (CBAM)
3.2.1. Channel Attention Module
3.2.2. Spatial Attention Module
3.3. Enhanced YOLOv5 Network
3.3.1. YOLOv5 Object Detection Algorithm
3.3.2. Improved YOLOv5 Backbone Network
4. Experimental Configuration
4.1. Dataset
- Low resolution: the textural feature information of aquatic organisms is lost in low-quality images, which makes it more difficult to recognize creatures with comparable features;
- Motion blur: since the dataset was obtained from video clipping, motion blur was inevitable due to the movement of the sampling robot. In low light conditions, there are few differences between the morphologies of underwater creatures;
- Color cast and low contrast: as color and contrast are affected by the propagation properties of underwater light, images in underwater datasets mostly have blue-green backgrounds with low contrast, which makes certain creatures, such as scallops, easy to confuse with the background;
- Small and/or occluded target organisms: the density of underwater creatures is high and mutual, which results in a serious loss of texture information for occluded creatures.
4.2. Experiment Details
4.3. Evaluation Indicators
4.4. Results and Discussion
4.4.1. Image Preprocessing Experiments
4.4.2. Object Detection Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yeh, C.H.; Lin, C.H.; Kang, L.W.; Huang, C.H.; Wang, C. Lightweight Deep Neural Network for Joint Learning of Underwater Object Detection and Color Conversion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-World Underwater Enhancement: Challenges, Benchmarks, and Solutions Under Natural Light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Sun, X.; Liu, J.; Yang, X.; Zhou, C. Composited FishNet: Fish Detection and Species Recognition From Low-Quality Underwater Videos. IEEE Trans. Image Process. 2021, 30, 4719–4734. [Google Scholar] [CrossRef] [PubMed]
- van de Weijer, J.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2007, 16, C2. [Google Scholar] [CrossRef] [PubMed]
- Provenzi, E.; Gatta, C.; Fierro, M.; Rizzi, A. A Spatially Variant White-Patch and Gray-World Method for Color Image Enhancement Driven by Local Contrast. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1757–1770. [Google Scholar] [PubMed]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. Graph. Gems 1994, 474–485. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; Vleeschouwer, C.D.; Bekaert, P. Color Balance and Fusion for Underwater Image Enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [PubMed]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, T.; Dong, J.; Yu, H. Underwater Image Enhancement via Extended Multi-Scale Retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Drews, P.; Nascimento, E.R.; Botelho, S.; Campos, M. Underwater Depth Estimation and Image Restoration Based on Single Images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.-T.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, Z.; Tong, L.; Liu, Z.; Zhao, A.; Zhang, Q.; Dong, J.; Zhou, H. Perceptual Underwater Image Enhancement With Deep Learning and Physical Priors. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3078–3092. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Fabbri, C.; Jahidul Islam, M.; Sattar, J. Enhancing Underwater Imagery using Generative Adversarial Networks. arXiv 2018, arXiv:1801.04011. [Google Scholar]
- Ye, X.; Li, Z.; Sun, B.; Wang, Z.; Fan, X. Deep Joint Depth Estimation and Color Correction From Monocular Underwater Images Based on Unsupervised Adaptation Networks. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3995–4008. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- FeI, W.; Jiang, M.; Chen, Q.; Yang, S.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast accurate fish detection and recognition of underwater images with Fast R-CNN. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Hao, J.; Yang, Z. Accelerating fish detection and recognition by sharing CNNs with objectness learning. In Proceedings of the OCEANS 2016—Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Li, X.; Cui, Z. Deep residual networks for plankton classification. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, H.; Zhou, H.; Yang, X.; Zhang, L.; Qi, L.; Zang, A.Y. Faster R-CNN for marine organisms detection and recognition using data augmentation. Neurocomputing 2019, 337, 372–384. [Google Scholar] [CrossRef]
- Fan, B.; Chen, W.; Cong, Y.; Tian, J. Dual Refinement Underwater Object Detection Network. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 275–291. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | mAP = 0.5 | mAP = 0.5:0.95 | |
|---|---|---|---|---|
| YOLOv5s | 0.823 | 0.689 | 0.729 | 0.42 |
| YOLOv5l | 0.811 | 0.704 | 0.742 | 0.427 |
| Faster RCNN | N/A | N/A | 0.664 | N/A |
| YOLOv5s + SAGHS | 0.781↓ | 0.737↑ | 0.753↑ | 0.417↓ |
| YOLOV5s + CBAM | 0.837↑ | 0.762↑ | 0.792↑ | 0.451↑ |
| Holothurian | Echinus | Scallop | Starfish | |
|---|---|---|---|---|
| Faster RCNN | 0.715 | 0.855 | 0.712 | 0.823 |
| YOLOv5s | 0.685 | 0.802 | 0.701 | 0.753 |
| YOLOv5s + SAGHS | 0.79 | 0.918 | 0.823 | 0.893 |
| YOLOV5s + CBAM | 0.827 | 0.934 | 0.823 | 0.91 |
| Parameter | FPS | Backbone Layer | |
|---|---|---|---|
| YOLOv5s | 7,074,330 | 125 | 283 |
| YOLOv5s + SAGHS | 7,074,330 | 125 | 283 |
| YOLOV5s + CBAM | 7,074,940 | 91 | 293 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhuang, Y.; Jia, P.; Wu, C.; Xu, H.; Liu, Z. A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline. J. Mar. Sci. Eng. 2022, 10, 1204. https://doi.org/10.3390/jmse10091204
Liu Z, Zhuang Y, Jia P, Wu C, Xu H, Liu Z. A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline. Journal of Marine Science and Engineering. 2022; 10(9):1204. https://doi.org/10.3390/jmse10091204
Chicago/Turabian StyleLiu, Zheng, Yaoming Zhuang, Pengrun Jia, Chengdong Wu, Hongli Xu, and Zhanlin Liu. 2022. "A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline" Journal of Marine Science and Engineering 10, no. 9: 1204. https://doi.org/10.3390/jmse10091204