
Research on Visual Perception for Coordinated Air–Sea through a Cooperative USV-UAV System

Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. YOLOX
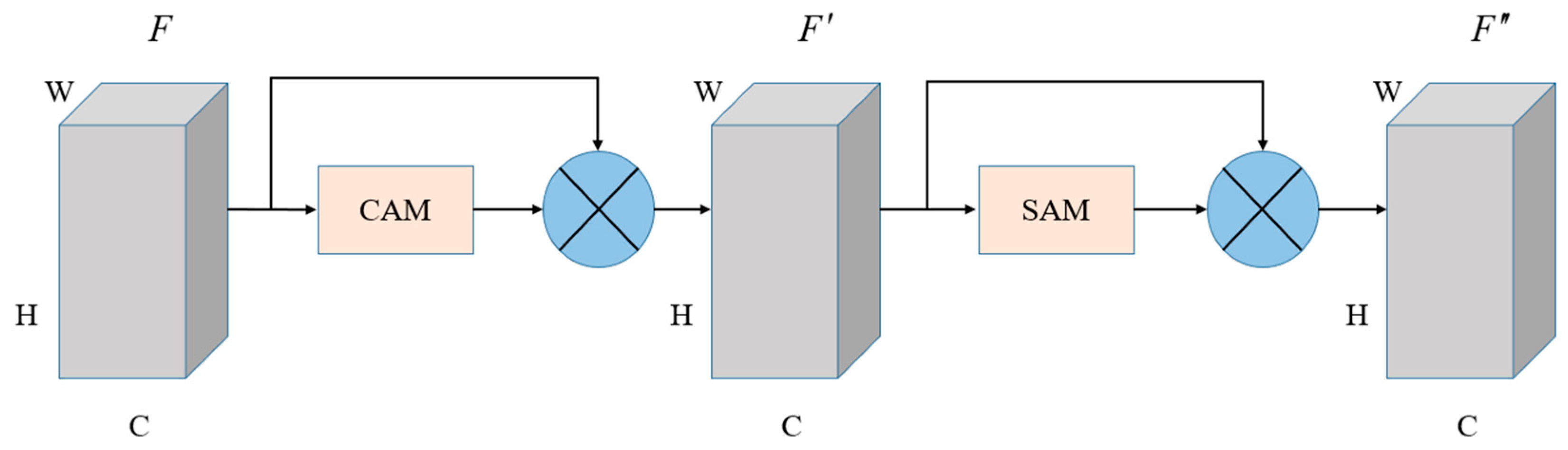
3.2. PIDNet
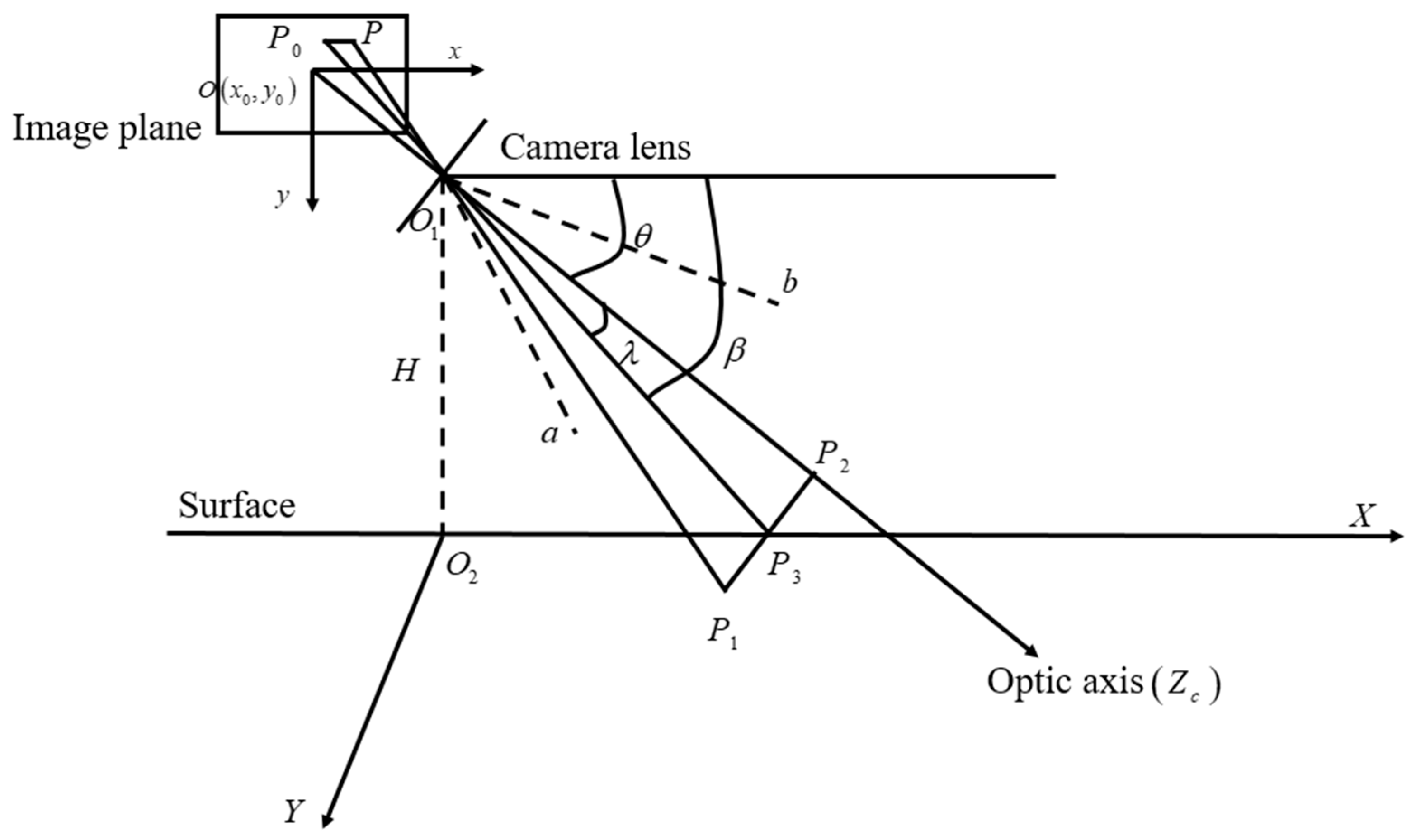
3.3. Monocular Vision Scale–Distance by USVs
4. Experimental Setup
4.1. Data Processing
4.2. Experimental Platform
4.3. Evaluation Criteria
5. Results Analysis
5.1. Multi-Target Recognition
5.2. Semantic Segmentation
5.3. Stereo Distance Measurement
6. Conclusions
- The cooperative platform utilizes the YOLOX model to carry out a range of sea detection tasks, including ship recognition, various obstacle detection, and the identification of individuals. The findings of the YOLOX study demonstrate the versatility and effectiveness of the collaborative USV-UAV system, and provides improved detection accuracy and increased detection speed compared to other mainstream methods;
- The PIDNet model is firstly used to handle the semantic segmentation of sea and air. Compared to other approaches, the results indicate that PIDNet has a significant degree of effectiveness in distinguishing between areas that can be navigated and those that cannot be navigated on complex water surfaces. This offers dependable technical assistance for the autonomous navigation of USVs, relying on visual inputs. The PIDNet model also has a strong ability to detect the sea–skyline in different environmental conditions;
- The application of distance measurements based on monocular camera vision is used to range the distance between the USV and its targets. The results show that this method can effectively estimate the distance of obstacles. Nevertheless, the findings also suggest that, as the distance from the obstruction rises, the precision of the anticipated outcomes will correspondingly deteriorate. Hence, in instances where USVs exhibit high velocities, the utilization of visual ranging technology in isolation is inadequate for ensuring the safety of these USVs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shao, G.; Ma, Y.; Malekian, R.; Yan, X.; Li, Z. A novel cooperative platform design for coupled USV-UAV systems. IEEE Trans. Ind. Inf. 2019, 15, 4913–4922. [Google Scholar] [CrossRef]
- Anderson, K.; Gaston, K.J. Lightweight unmanned aerial vehicles will revolutionize spatial ecology. Front. Ecol. Environ. 2013, 11, 138–146. [Google Scholar] [CrossRef] [PubMed]
- Woellner, R.; Wagner, T.C. Saving species, time, and money: Application of unmanned aerial vehicles (UAVs) for monitoring of an endangered alpine river specialist in a small nature reserve. Biol. Conserv. 2019, 233, 162–175. [Google Scholar] [CrossRef]
- Campbell, S.; Naeem, W.; Irwin, G.W. A review on improving the autonomy of unmanned surface vehicles through intelligent collision avoidance maneuvers. Ann. Rev. Control 2012, 36, 267–283. [Google Scholar] [CrossRef]
- Murphy, P.P.; Steimle, E.; Griffin, C.; Cullins, C.; Hall, M.; Pratt, K. Cooperative use of unmanned sea surface and micro aerial vehicles at Hurricane Wilma. J. Field Robot. 2008, 25, 164–180. [Google Scholar] [CrossRef]
- Mostafa, M.Z.; Khater, H.A.; Rizk, M.R.; Bahasan, A.M. GPS/DVL/MEMS-INS smartphone sensors integrated method to enhance USV navigation system based on adaptive DSFCF. IET Radar Sonar Navig. 2018, 13, 1616–1627. [Google Scholar] [CrossRef]
- Han, J.; Cho, Y.; Kim, J.; Kim, J.; Son, N.-S.; Kim, S.Y. Autonomous collision detection and avoidance for ARAGON USV: Development and field tests. J. Field Robot. 2020, 37, 987–1002. [Google Scholar] [CrossRef]
- Ma, H.; Smart, E.; Ahmed, A.; Brown, D. Radar Image-Based Positioning for USV Under GPS Denial Environment. IEEE Trans. Intell. Transp. Syst. 2018, 19, 72–80. [Google Scholar] [CrossRef]
- Almeida, C.; Franco, T.; Ferreira, H.; Martins, A.; Santos, R.; Almeida, J.M.; Carvalho, J.; Silva, E. Radar based collision detection developments on USV ROAZ II. In Proceedings of the OCEANS 2009—EUROPE, Bremen, Germany, 11–14 May 2009; pp. 1–6. [Google Scholar]
- Zhang, J.Y.; Su, Y.M.; Liao, Y.L. Unmanned surface vehicle target tracking based on marine radar. In Proceedings of the 2011 International Conference on Computer Science and Service System (CSSS), Nanjing, China, 27–29 June 2011; pp. 1872–1875. [Google Scholar]
- Han, J.; Cho, Y.; Kim, J. Coastal SLAM with marine radar for USV operation in GPS-restricted situations. IEEE J. Ocean. Eng. 2019, 44, 300–309. [Google Scholar] [CrossRef]
- Esposito, J.M.; Graves, M. An algorithm to identify docking locations for autonomous surface vessels from 3-D Li DAR scans. In Proceedings of the IEEE International Conference on Technologies for Practical Robot Applications, Woburn, MA, USA, 14–15 April 2014; pp. 1–6. [Google Scholar]
- Su, L.; Yin, Y.; Liu, Z. Small surface targets detection based on omnidirectional sea-sky-line extraction. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 September 2014; pp. 4732–4736. [Google Scholar]
- Tao, M.; Jie, M. A sea-sky line detection method based on line segment detector and Hough transform. In Proceedings of the 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; pp. 700–703. [Google Scholar]
- Kristan, M.; Perš, J.; Sulič, V.; Kovačič, S. A graphical model for rapid obstacle image-map estimation from unmanned surface vehicles. In Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 391–406. [Google Scholar]
- Wang, H.; Mou, X.; Mou, W.; Yuan, S.; Ulun, S.; Yang, S.; Shin, B.-S. Vision based long range object detection and tracking for unmanned surface vehicle. In Proceedings of the 2015 IEEE 7th International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Siem Reap, Cambodia, 15–17 July 2015; pp. 101–105. [Google Scholar]
- Shi, B.; Zhou, H. Marine Object Recognition Based on Deep Learning. In Proceedings of the International Conference on Computer, Network, Communication and Information Systems (CNCI 2019), Qingdao, China, 27–29 March 2019. [Google Scholar]
- Song, X.; Jiang, P.; Zhu, H. Research on Unmanned Vessel Surface Object Detection Based on Fusion of SSD and Faster-RCNN. In Proceedings of the Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3784–3788. [Google Scholar]
- Zhan, W.; Xiao, C.; Wen, Y.; Zhou, C.; Yuan, H.; Xiu, S.; Zhang, Y.; Zou, X.; Liu, X.; Li, Q. Autonomous visual perception for unmanned surface vehicle navigation in an unknown environment. Sensors 2019, 19, 2216. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Chen, G. Autonomous and cooperative control of UAV cluster with multi agent reinforcement learning. Aeronaut. J. 2020, 126, 932–951. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, W.; Zhang, Z.; Luo, K.; Liu, J. Cooperative Control of UAV Cluster Formation Based on Distributed Consensus. In Proceedings of the 2019 IEEE 15th International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019; pp. 788–793. [Google Scholar]
- Li, J.; Zhang, G.; Li, B. Robust adaptive neural cooperative control for the USV-UAV based on the LVS-LVA guidance principle. J. Mar. Sci. Eng. 2022, 10, 51. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Lu, T.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.K.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Towaki, T.; David, A.; Varun, J.; Sanja, F. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Pei, X.Y. Autonomous Navigation Technology of Unmanned Surface Vehicle; Shanghai Maritime University: Shanghai, China, 2015. [Google Scholar]
- Zhao, M.H.; Wang, J.H.; Zheng, X.; Zhang, S.J.; Zhang, C. Monocular vision based water-surface target distance measurement method for unmanned surface vehicles. Transducer Microsyst. Technol. 2021, 40, 47–54. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Versions |
|---|---|
| System Environment | Windows 10 64-bit |
| CPU | Intel(R) Core (TM) i9-9980XE |
| GPU | NVIDIA GTX 2080Ti |
| Python | 3.6.0 |
| Pytorch | 1.5.0 |
| Model | FPS | AP50(%) |
|---|---|---|
| SSD | 52 | 79.9 |
| CenterNet | 57 | 81.5 |
| YOLO V3 | 51 | 83.6 |
| YOLO V4 | 46 | 84.1 |
| YOLO V5 | 47 | 82.7 |
| YOLOX | 42 | 90.3 |
| Networks | Params (M) | MIOU (%) | PA (%) | FPS |
|---|---|---|---|---|
| U-Net | 34.0 | 79.82 | 80.81 | 9 |
| Refine-Net | 55.1 | 81.63 | 84.26 | 15 |
| DeepLab | 44.3 | 87.22 | 89.13 | 30 |
| PIDNet | 29.5 | 91.08 | 94.32 | 40 |
| Real Distance (m) | Camera Height (m) | Pitch Angle (Degree) | Test Distance (m) | Relative Error (%) |
|---|---|---|---|---|
| 5.08 | 2.13 | 18 | 4.92 | −3.1 |
| 2.32 | 20 | 5.05 | −0.5 | |
| 2.51 | 22 | 5.11 | 0.5 | |
| 10.25 | 2.13 | 18 | 11.12 | 8.4 |
| 2.32 | 20 | 10.94 | 6.7 | |
| 2.51 | 22 | 10.44 | 1.8 | |
| 15.18 | 2.13 | 18 | 16.12 | 6.1 |
| 2.32 | 20 | 15.88 | 4.6 | |
| 2.51 | 22 | 16.30 | 7.3 | |
| 22.41 | 2.13 | 18 | 24.18 | 7.8 |
| 2.32 | 20 | 25.02 | 11.6 | |
| 2.51 | 22 | 23.44 | 4.5 | |
| 35.20 | 2.13 | 18 | 39.14 | 11.9 |
| 2.32 | 20 | 38.52 | 9.4 | |
| 2.51 | 22 | 37.80 | 7.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.; Liu, D.; Du, J.-H.; Li, Y.-Z. Research on Visual Perception for Coordinated Air–Sea through a Cooperative USV-UAV System. J. Mar. Sci. Eng. 2023, 11, 1978. https://doi.org/10.3390/jmse11101978
Cheng C, Liu D, Du J-H, Li Y-Z. Research on Visual Perception for Coordinated Air–Sea through a Cooperative USV-UAV System. Journal of Marine Science and Engineering. 2023; 11(10):1978. https://doi.org/10.3390/jmse11101978
Chicago/Turabian StyleCheng, Chen, Dong Liu, Jin-Hui Du, and Yong-Zheng Li. 2023. "Research on Visual Perception for Coordinated Air–Sea through a Cooperative USV-UAV System" Journal of Marine Science and Engineering 11, no. 10: 1978. https://doi.org/10.3390/jmse11101978
APA StyleCheng, C., Liu, D., Du, J.-H., & Li, Y.-Z. (2023). Research on Visual Perception for Coordinated Air–Sea through a Cooperative USV-UAV System. Journal of Marine Science and Engineering, 11(10), 1978. https://doi.org/10.3390/jmse11101978