
Underwater Reverberation Suppression via Attention and Cepstrum Analysis-Guided Network
 , , , and
, , , and
Abstract
:1. Introduction
2. Theory and Methods
2.1. Active Sonar Observation Signal Model
2.1.1. Reverberation Model
- Changes in the sound velocity caused by temperature, pressure, and other factors are not considered. Thus, the sound trajectories are all straight lines;
- Only the sound absorption effect and the spherical expansion effect of sound waves are considered, while other attenuation effects are ignored;
- The reverberant scattering units are uniformly distributed in distance, azimuth, and elevation;
- The scatterers are uniformly distributed in the entire scattering unit at any given moment, and the density of the scatterer is large enough;
- The pulse width is short enough that the propagation effect within the scattering units is negligible;
- No multiple scattering.
2.1.2. Target Echo Highlight Model
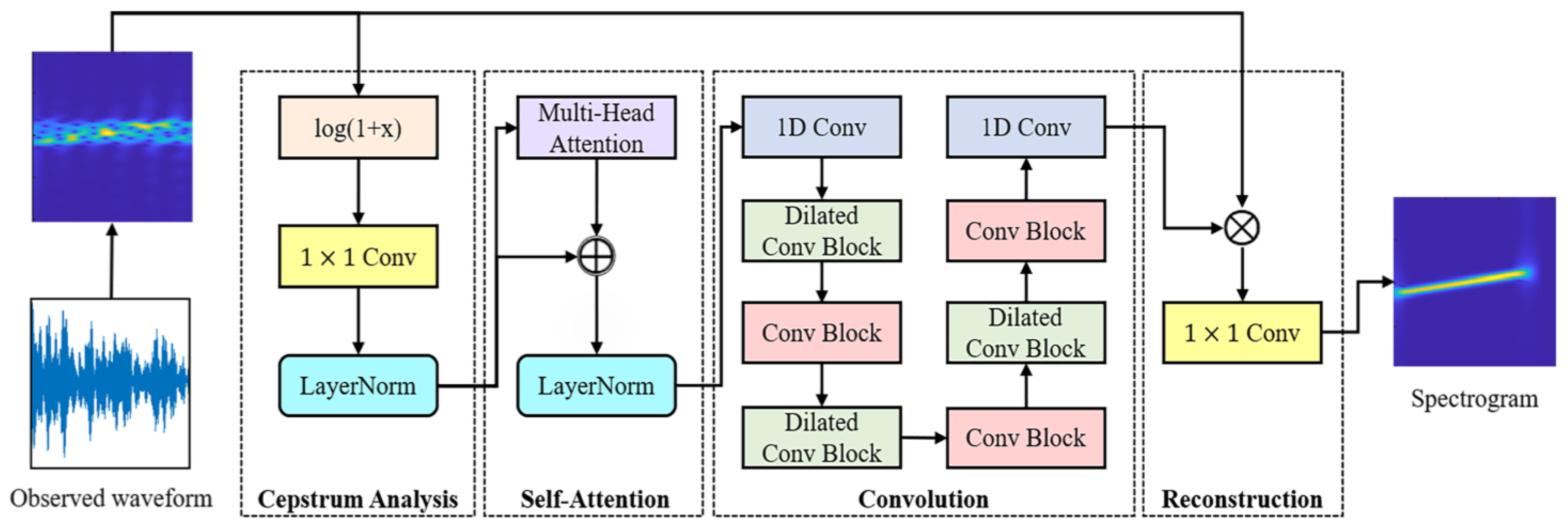
2.2. Proposed Method
2.2.1. Joint Time–Frequency Domain Processing
2.2.2. Cepstrum Analysis Module
2.2.3. Self-Attention Module
2.2.4. Convolution Module
2.2.5. Reconstruction Module
2.2.6. Loss Function
3. Data and Implementation
3.1. Dataset
3.1.1. Training Dataset
3.1.2. Test Dataset
3.2. Implementation Detail
4. Results
4.1. Evaluation Metrics
4.2. Evaluation Results
5. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Etter, P.C. Underwater Acoustic Modeling and Simulation, 5th ed.; CRC Press: Boca Raton, FL, USA, 2018; pp. 275–314. ISBN 978-0-429-22538-3. [Google Scholar]
- Wang, Y.; He, Y.; Wang, J.; Shi, Z. Comb Waveform Optimisation with Low Peak-to-average Power Ratio via Alternating Projection. IET Radar Sonar Navig. 2018, 12, 1012–1020. [Google Scholar] [CrossRef]
- Cox, H.; Lai, H. Geometric Comb Waveforms for Reverberation Suppression. In Proceedings of the 1994 28th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 31 October–2 November 1994; Volume 2, pp. 1185–1189. [Google Scholar] [CrossRef]
- Doisy, Y.; Deruaz, L.; van IJsselmuide, S.P.; Beerens, S.P.; Been, R. Reverberation Suppression Using Wideband Doppler-Sensitive Pulses. IEEE J. Ocean. Eng. 2008, 33, 419–433. [Google Scholar] [CrossRef]
- Collins, T. Active Sonar Pulse Design, 1st ed.; University of Birmingham: Birmingham, UK, 1996; pp. 97–119. [Google Scholar]
- Hague, D.A.; Buck, J.R. The Generalized Sinusoidal Frequency Modulated Waveform for High Duty Cycle Active Sonar. In Proceedings of the 2014 48th Asilomar Conference on Signals, Pacific Grove, CA, USA, 2–5 November 2014; pp. 148–152. [Google Scholar] [CrossRef]
- Soli, J.; Hickman, G. Co-Prime Comb Signals for Active Sonar. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Yue, L.; Liang, H.; Duan, T.; Dai, Z. A Reverberation Suppression Method Based on the Joint Design of a PTFM Waveform and Receiver Filter. Entropy 2022, 24, 1707. [Google Scholar] [CrossRef] [PubMed]
- Jaffer, A.G. Constrained Partially Adaptive Space-Time Processing for Clutter Suppression. In Proceedings of the 1994 28th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 31 October–2 November 1994; Volume 1, pp. 671–676. [Google Scholar] [CrossRef]
- Mio, K.; Chocheyras, Y.; Doisy, Y. Space Time Adaptive Processing for Low Frequency Sonar. In Proceedings of the OCEANS 2000 MTS/IEEE Conference and Exhibition, Conference Proceedings (Cat. No.00CH37158), Providence, RI, USA, 11–14 September 2000; Volume 2, pp. 1315–1319. [Google Scholar] [CrossRef]
- Li, W.; Ma, X.; Zhu, Y.; Yang, J.; Hou, C. Detection in Reverberation Using Space Time Adaptive Prewhiteners. J. Acoust. Soc. Am. 2008, 124, EL236–EL242. [Google Scholar] [CrossRef] [PubMed]
- Sasi, N.M.; Sathidevi, P.S.; Pradeepa, R.; Gopi, S. A Low Complexity STAP for Reverberation Cancellation in Active Sonar Detection. In Proceedings of the 2010 IEEE Sensor Array and Multichannel Signal Processing Workshop, Jerusalem, Israel, 4–7 October 2010; pp. 245–248. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, S.; Hao, C. A Novel Adaptive Reverberation Suppression Method for Moving Active Sonar. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 831–835. [Google Scholar] [CrossRef]
- Xing, G.; Cai, Z. Ocean Reverberation Suppressing by Direct Data Domain Based STAP. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing, Beijing, China, 21–25 October 2012; pp. 2085–2088. [Google Scholar] [CrossRef]
- Cohen, L. Time-Frequency Distributions-a Review. Proc. IEEE 1989, 77, 941–981. [Google Scholar] [CrossRef]
- Choi, H.-I.; Williams, W.J. Improved Time-Frequency Representation of Multicomponent Signals Using Exponential Kernels. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 862–871. [Google Scholar] [CrossRef]
- Li, X.; Xia, Z. Research of Underwater Bottom Object and Reverberation in Feature Space. J. Marine. Sci. Appl. 2013, 12, 235–239. [Google Scholar] [CrossRef]
- Kay, S.; Salisbury, J. Improved Active Sonar Detection Using Autoregressive Prewhiteners. J. Acoust. Soc. Am. 1990, 87, 1603–1611. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Meng, X. Morphological characteristics separation of underwater target echo and reverberation in time and frequency domain. Acta Acust. 2017, 42, 169–177. [Google Scholar] [CrossRef]
- Virtanen, T. Monaural Sound Source Separation by Nonnegative Matrix Factorization with Temporal Continuity and Sparseness Criteria. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1066–1074. [Google Scholar] [CrossRef]
- Mohammadiha, N.; Smaragdis, P.; Leijon, A. Supervised and Unsupervised Speech Enhancement Using Nonnegative Matrix Factorization. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 2140–2151. [Google Scholar] [CrossRef]
- Lee, S.; Lim, J. Reverberation Suppression Using Non-Negative Matrix Factorization to Detect Low-Doppler Target with Continuous Wave Active Sonar. EURASIP J. Adv. Sig. Process. 2019, 2019, 11. [Google Scholar] [CrossRef]
- Kim, G.; Lee, K.; Lee, S. Linear Frequency Modulated Reverberation Suppression Using Non-Negative Matrix Factorization Methods, Dechirping Transformation and Modulo Operation. IEEE Access 2020, 8, 110720–110737. [Google Scholar] [CrossRef]
- Kim, G.; Lee, S. Reverberation Suppression Method for Active Sonar Systems Using Non-Negative Matrix Factorization with Pre-Trained Frequency Basis Matrix. IEEE Access 2021, 9, 148060–148075. [Google Scholar] [CrossRef]
- Jia, H.; Li, X. Underwater Reverberation Suppression Based on Non-Negative Matrix Factorisation. J. Sound Vib. 2021, 506, 116166. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9908, pp. 630–645. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement. arXiv 2020, arXiv:2008.00264. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A Regression Approach to Speech Enhancement Based on Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 7–19. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Wang, D.; Woods, W.S.; Merks, I.; Zhang, T. Learning Spectral Mapping for Speech Dereverberation and Denoising. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 982–992. [Google Scholar] [CrossRef]
- Borgstrom, B.J.; Brandstein, M.S. The Speech Enhancement via Attention Masking Network (SEAMNET): An End-to-End System for Joint Suppression of Noise and Reverberation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 515–526. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, D.; Xu, B.; Zhang, T. Monaural Speech Dereverberation Using Temporal Convolutional Networks with Self Attention. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1598–1607. [Google Scholar] [CrossRef]
- Zou, B.; Wang, X.; Feng, W.; Zhu, H.; Lu, F. DU-CG-STAP Method Based on Sparse Recovery and Unsupervised Learning for Airborne Radar Clutter Suppression. Remote Sens. 2022, 14, 3472. [Google Scholar] [CrossRef]
- Kou, S.; Feng, X.; Huang, H.; Bi, Y. A Space-Time Adaptive Processing Method Based on Sparse Reconstruction of Reverberation Interference. JNWPU 2020, 38, 1179–1187. [Google Scholar] [CrossRef]
- Chen, W.; Xie, W.; Wang, Y. Short-Range Clutter Suppression for Airborne Radar Using Sparse Recovery and Orthogonal Projection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3500605. [Google Scholar] [CrossRef]
- Shang, Z.; Huo, K.; Liu, W.; Sun, Y.; Wang, Y. Knowledge-Aided Covariance Estimate via Geometric Mean for Adaptive Detection. Digit. Signal Process. 2020, 97, 102616. [Google Scholar] [CrossRef]
- Zhu, G.; Song, Z.; Yin, J.; Liu, B.; Liu, J. Extracting target highlight feature based on low-rank matrix recovery in reverberation background. Acta Acust. 2019, 44, 471–479. [Google Scholar] [CrossRef]
- Kazimierski, W.; Zaniewicz, G. Determination of Process Noise for Underwater Target Tracking with Forward Looking Sonar. Remote Sens. 2021, 13, 1014. [Google Scholar] [CrossRef]
- Wawrzyniak, N.; Stateczny, A. MSIS Image Postioning in Port Areas with the Aid of Comparative Navigation Methods. Polish Marit. Res. 2017, 24, 32–41. [Google Scholar] [CrossRef]
- Liu, B.; Huang, Y.; Chen, W.; Lei, J. Principles of Underwater Acoustics, 3rd ed.; Science China Press: Beijing, China, 2019; pp. 217–261. ISBN 978-7-03-063011-7. [Google Scholar]
- Tang, W. Highlight model of echoes from sonar targets. Acta Acust. 1994, 19, 92–100. [Google Scholar] [CrossRef]
- Zheng, F.; Zhang, G.; Song, Z. Comparison of Different Implementations of MFCC. J. Comput. Sci. Technol. 2001, 16, 582–589. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | 1D CNN Layer | Layer-Norm | Activation | Block in Figure 1 | |||
|---|---|---|---|---|---|---|---|
| Kernel Size | Input Channels | Output Channels | Dilation | ||||
| 1 | 3 | 256 | 512 | 1 | ✗ | ReLU | 1D Conv |
| 2 | 3 | 512 | 512 | 2 | ✓ | ReLU | Dilated Conv Block |
| 3 | 3 | 512 | 512 | 2 | ✓ | ReLU | |
| 4 | 3 | 512 | 512 | 1 | ✓ | ReLU | Conv Block |
| 5 | 3 | 512 | 512 | 1 | ✓ | ReLU | |
| 6 | 3 | 512 | 512 | 2 | ✓ | ReLU | Dilated Conv Block |
| 7 | 3 | 512 | 512 | 2 | ✓ | ReLU | |
| 8 | 3 | 512 | 512 | 1 | ✓ | ReLU | Conv Block |
| 9 | 3 | 512 | 512 | 1 | ✓ | ReLU | |
| 10 | 3 | 512 | 512 | 2 | ✓ | ReLU | Dilated Conv Block |
| 11 | 3 | 512 | 512 | 2 | ✓ | ReLU | |
| 12 | 3 | 512 | 512 | 1 | ✓ | ReLU | Conv Block |
| 13 | 3 | 512 | 512 | 1 | ✓ | ReLU | |
| 14 | 3 | 512 | 256 | 1 | ✗ | ReLU | 1D Conv |
| Item | Training Dataset | Test Dataset |
|---|---|---|
| Target | 3 targets contain 1, 2, and 3 highlights, respectively | |
| Transmitted Signal | 3 (frequency) × 4 (bandwidth) × 3 (pulse width) = 36 | 3 (frequency) × 3 (bandwidth) × 3 (pulse width) = 27 |
| Target Echo Signal | 36 for each target | 27 for each target |
| Reverberation | 10 for each target | 3 for each target |
| Observed Signal | 36 × 3 × 10 × 5 (SRRs) = 5400 | 27 × 3 × 3 × 5 (SRRs) = 1215 |
| Methods | PSNR | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Number of Highlights | 1 | 2 | 3 | ||||||
| Input | 23.94 | 24.39 | 24.10 | 23.00 | 23.32 | 23.31 | 22.88 | 22.91 | 23.06 |
| Baseline system | 31.58 | 31.76 | 31.11 | 29.61 | 29.69 | 29.47 | 28.36 | 28.24 | 27.89 |
| Cepstrum Analysis | 32.01 | 32.68 | 31.78 | 30.20 | 30.39 | 30.24 | 29.15 | 28.90 | 28.74 |
| Self-Attention | 32.43 | 32.69 | 32.09 | 30.43 | 30.68 | 30.48 | 29.71 | 29.36 | 29.34 |
| Methods | PSNR | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Number of Highlights | 1 | 2 | 3 | ||||||
| Input | 23.94 | 24.39 | 24.10 | 23.00 | 23.32 | 23.31 | 22.88 | 22.91 | 23.06 |
| NMF * | 27.24 | 27.56 | 27.12 | 23.34 | 23.40 | 23.29 | 21.90 | 21.84 | 21.83 |
| ACANet * | 32.43 | 32.69 | 32.09 | 30.43 | 30.68 | 30.48 | 29.71 | 29.36 | 29.34 |
| Methods | PSNR | SRR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Input | 18.55 | 19.68 | 22.25 | 26.12 | 30.58 | −9.2 | −3.98 | 1.22 | 6.41 | 11.6 |
| NMF * | 21.81 | 22.64 | 24.37 | 25.73 | 26.28 | −5.94 | −1.01 | 3.34 | 6.03 | 7.3 |
| ACANet * | 26.59 | 26.29 | 27.49 | 30.32 | 32.94 | −1.17 | 2.64 | 6.46 | 10.61 | 13.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Y.; Wu, X.; Wang, H.; He, X.; Hao, C.; Wang, Z.; Hu, Q. Underwater Reverberation Suppression via Attention and Cepstrum Analysis-Guided Network. J. Mar. Sci. Eng. 2023, 11, 313. https://doi.org/10.3390/jmse11020313
Hao Y, Wu X, Wang H, He X, Hao C, Wang Z, Hu Q. Underwater Reverberation Suppression via Attention and Cepstrum Analysis-Guided Network. Journal of Marine Science and Engineering. 2023; 11(2):313. https://doi.org/10.3390/jmse11020313
Chicago/Turabian StyleHao, Yukun, Xiaojun Wu, Huiyuan Wang, Xinyi He, Chengpeng Hao, Zirui Wang, and Qiao Hu. 2023. "Underwater Reverberation Suppression via Attention and Cepstrum Analysis-Guided Network" Journal of Marine Science and Engineering 11, no. 2: 313. https://doi.org/10.3390/jmse11020313