
Real-Time Relative Positioning Study of an Underwater Bionic Manta Ray Vehicle Based on Improved YOLOx

 , , and
, , and 
Abstract
:1. Introduction
2. Design of Visual Positioning System for the UBMRV
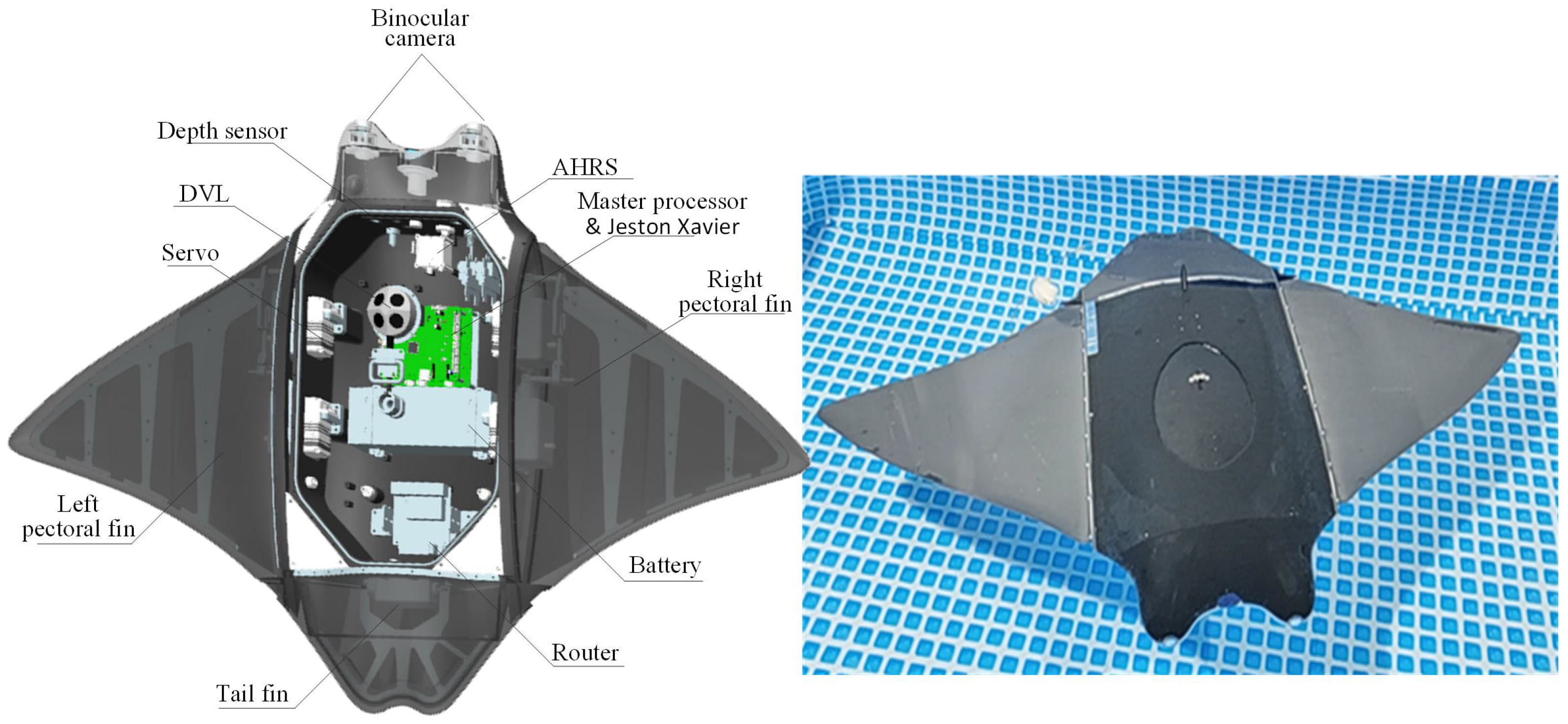
2.1. Description of the UBMRV
2.2. Description of Relative Positioning System Based on Binocular Camera
2.2.1. Object Detection Module
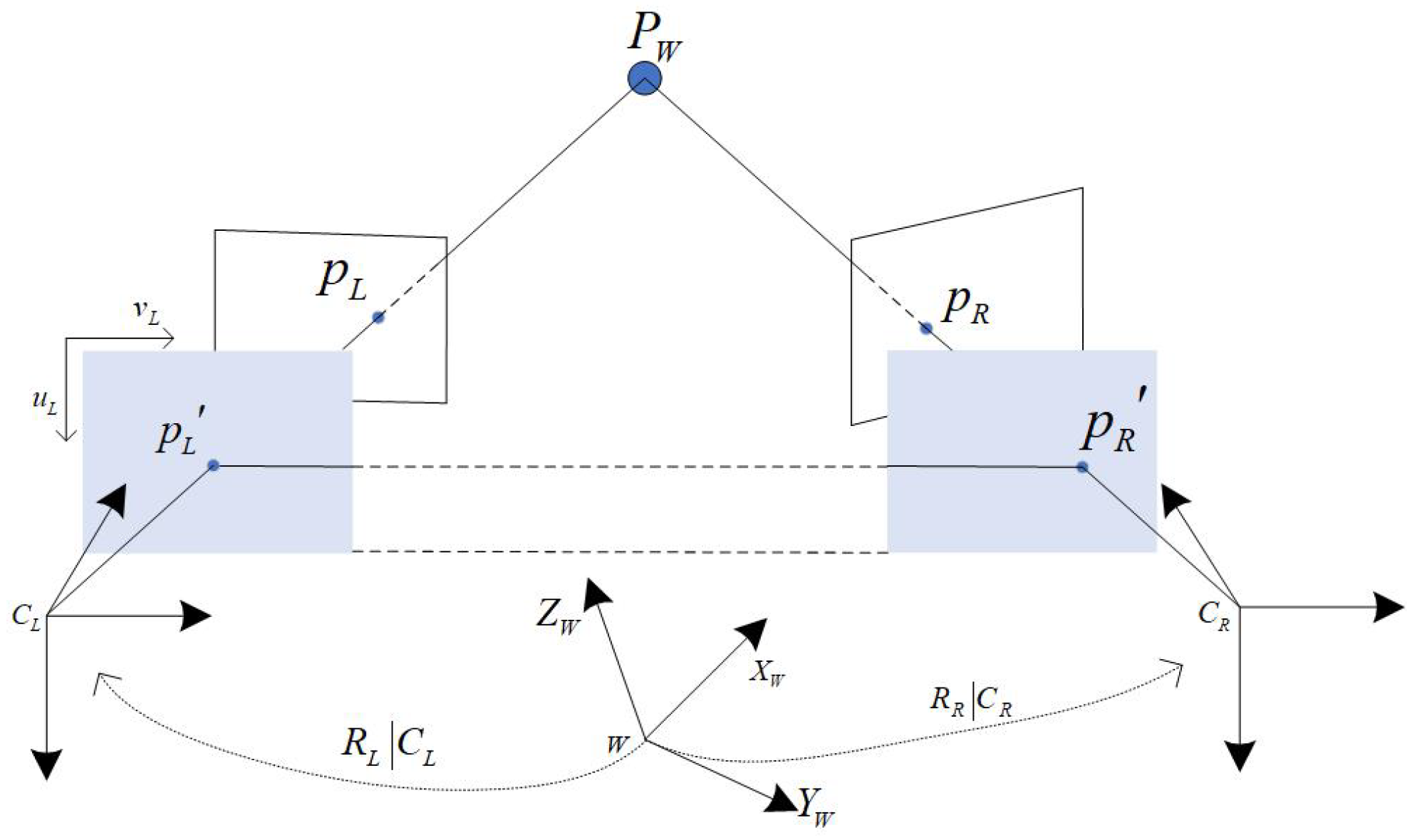
2.2.2. Relative Distance and Bearing Estimation Module
3. Design of the UBMRV Positioning Algorithm Based on Improved YOLOx
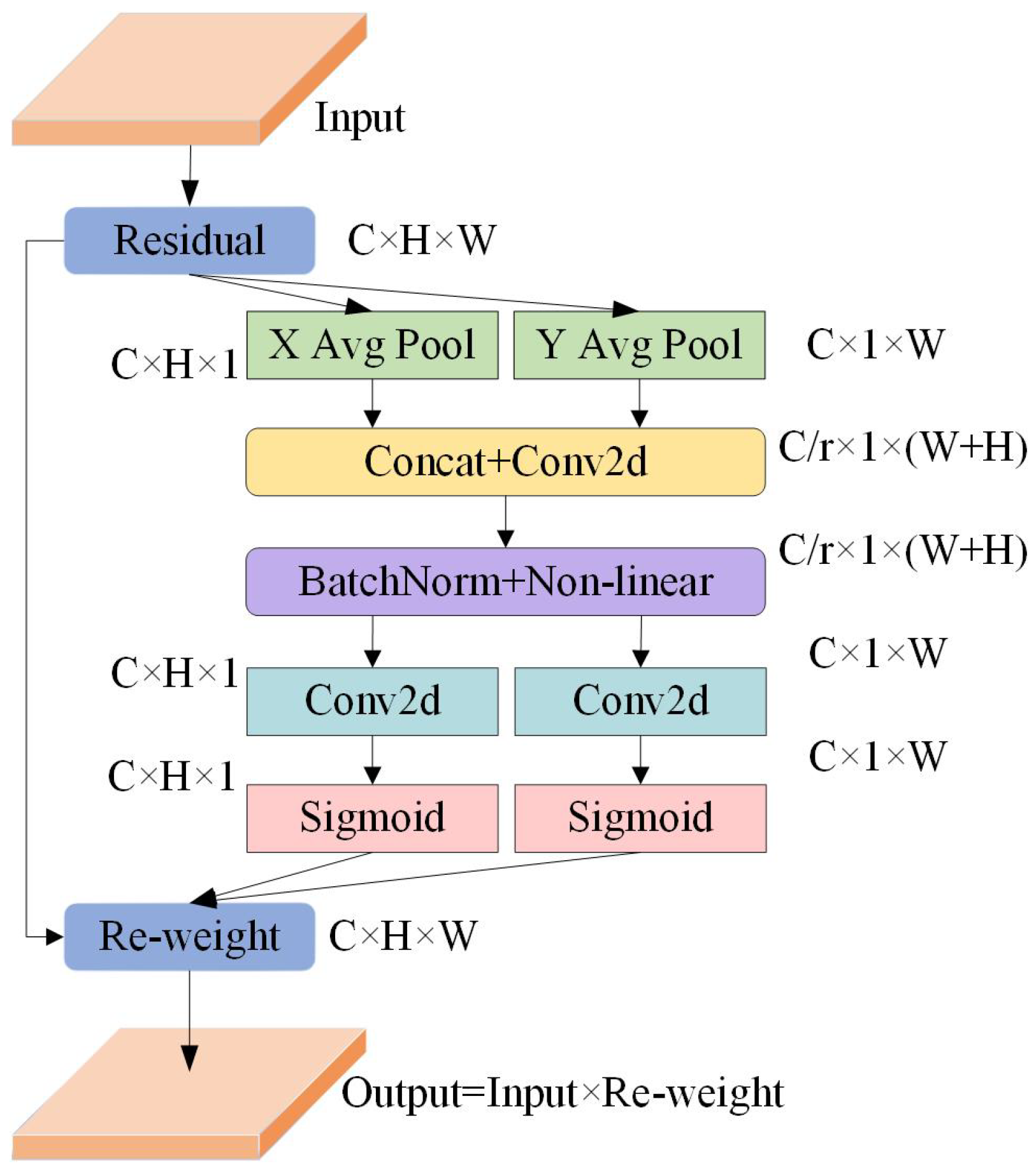
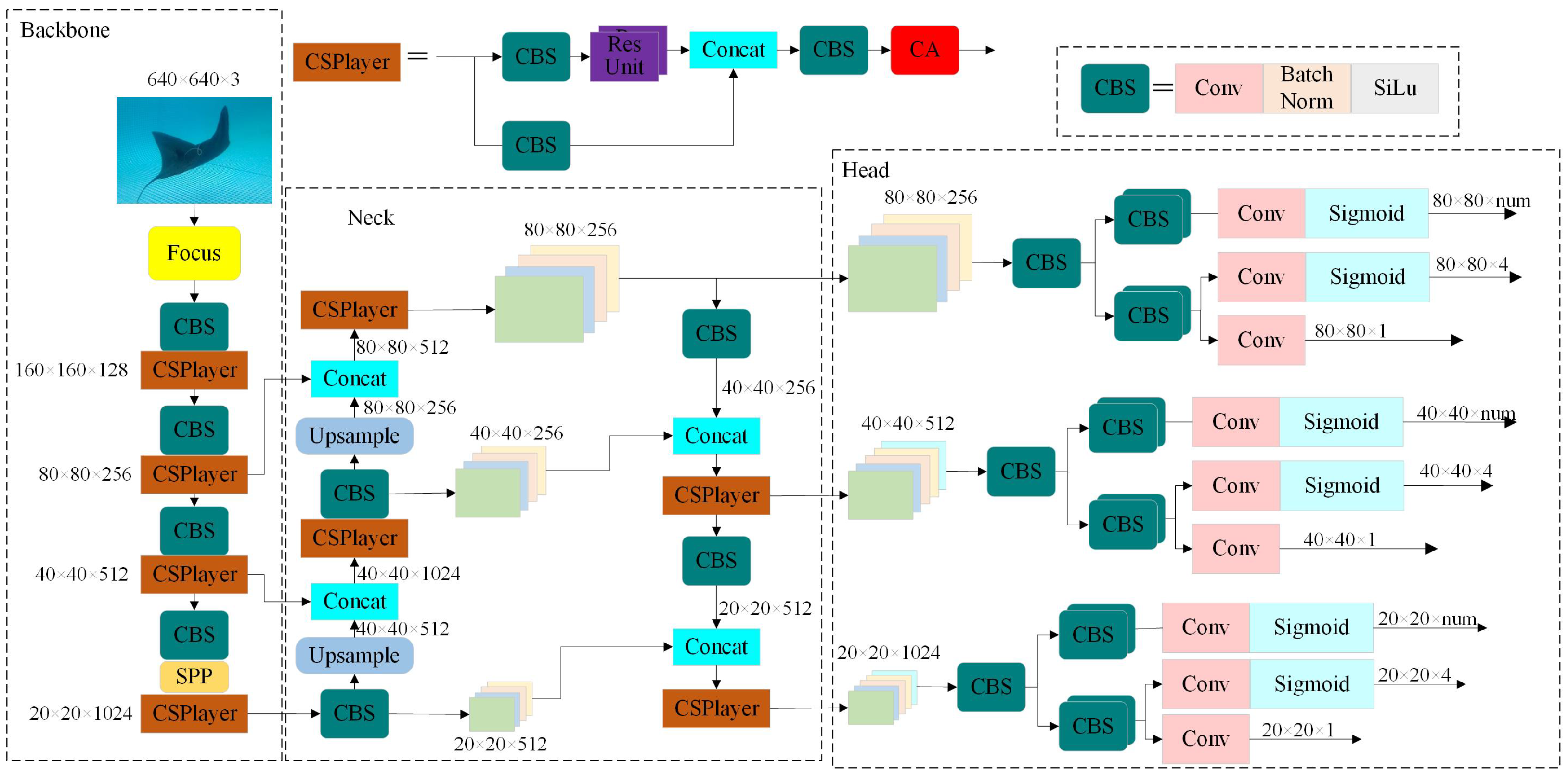
3.1. Improved YOLOx Network Design
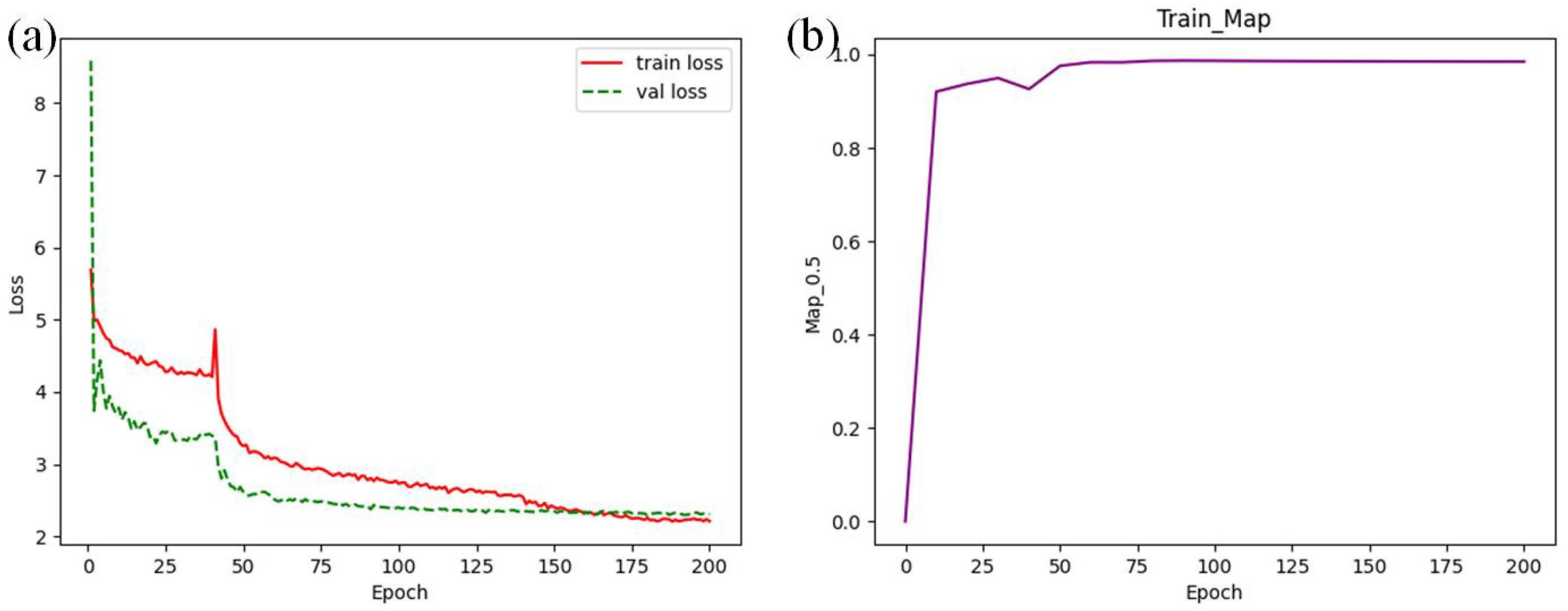
3.2. Model Training and Testing
3.3. Relative Distance and Bearing Estimation Based on Binocular Camera
4. Experiment and Analysis
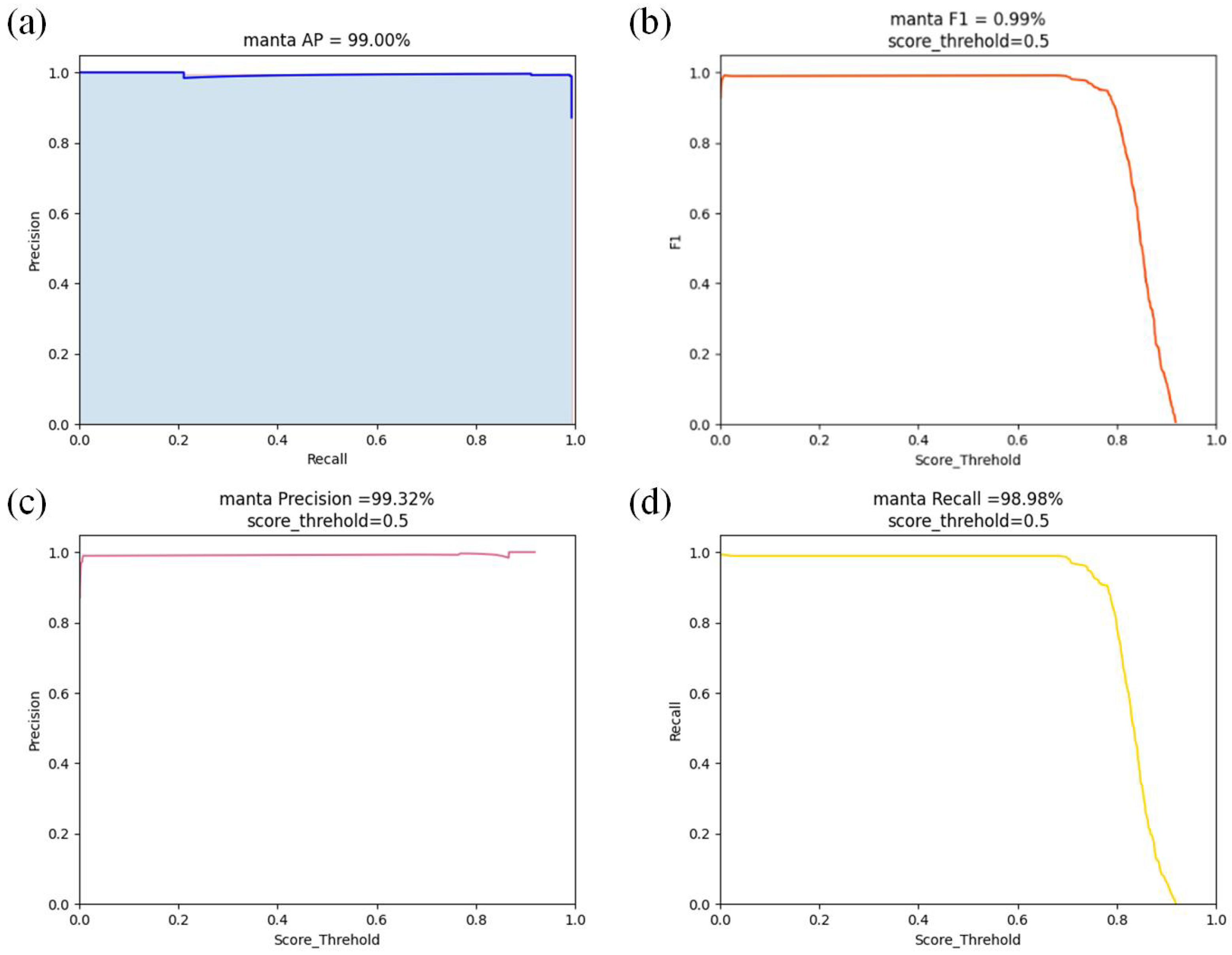
4.1. The UBMRV Object Detection Experiment
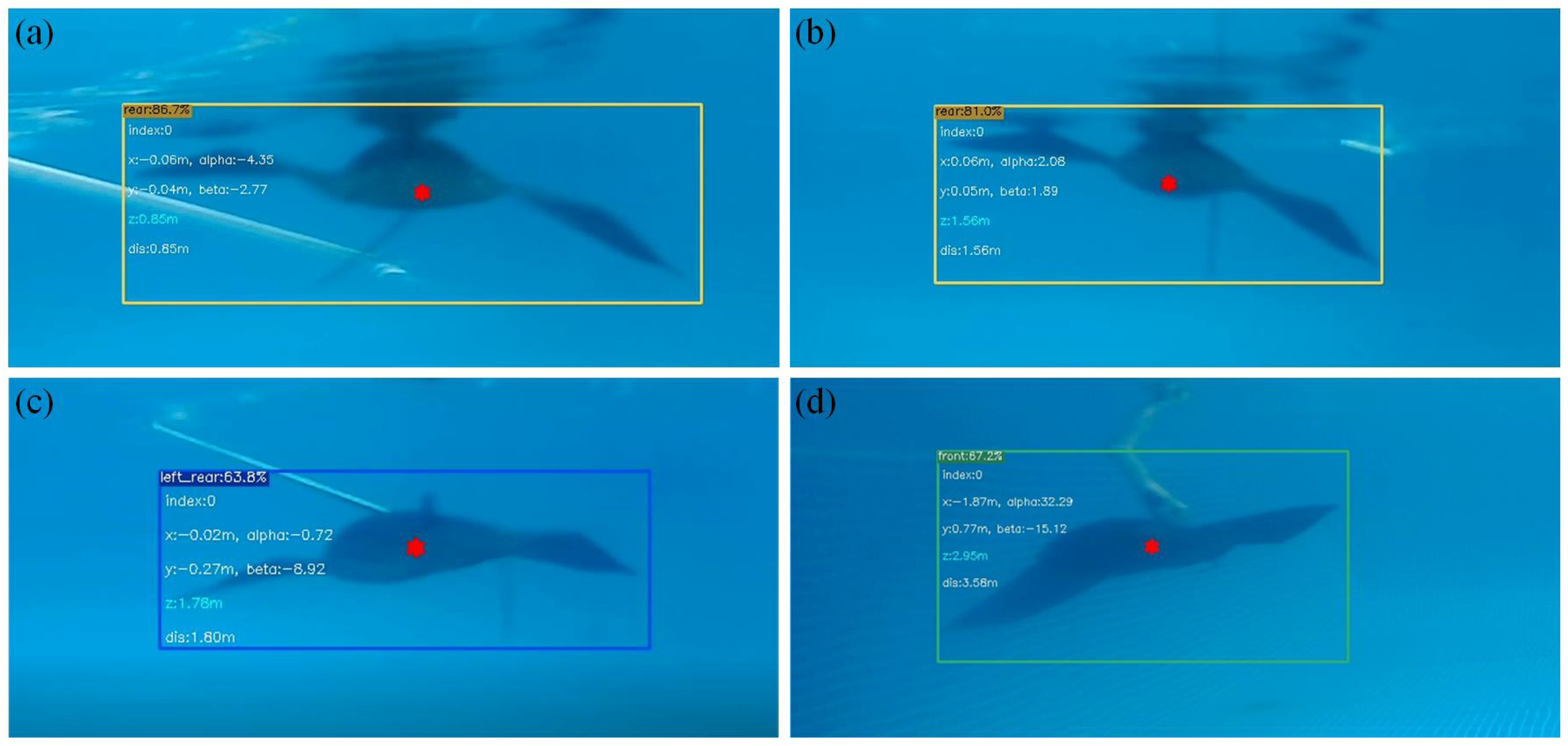
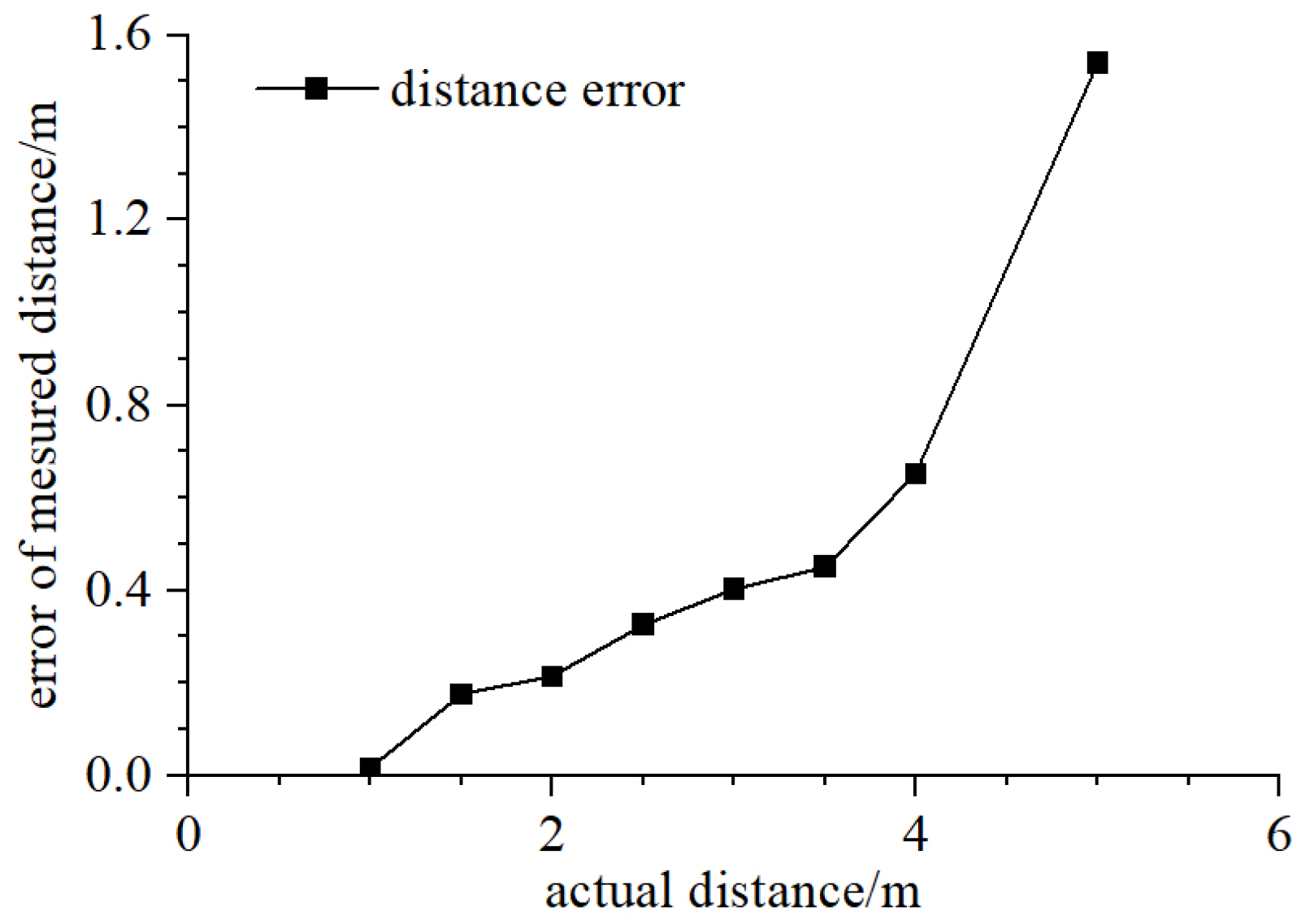
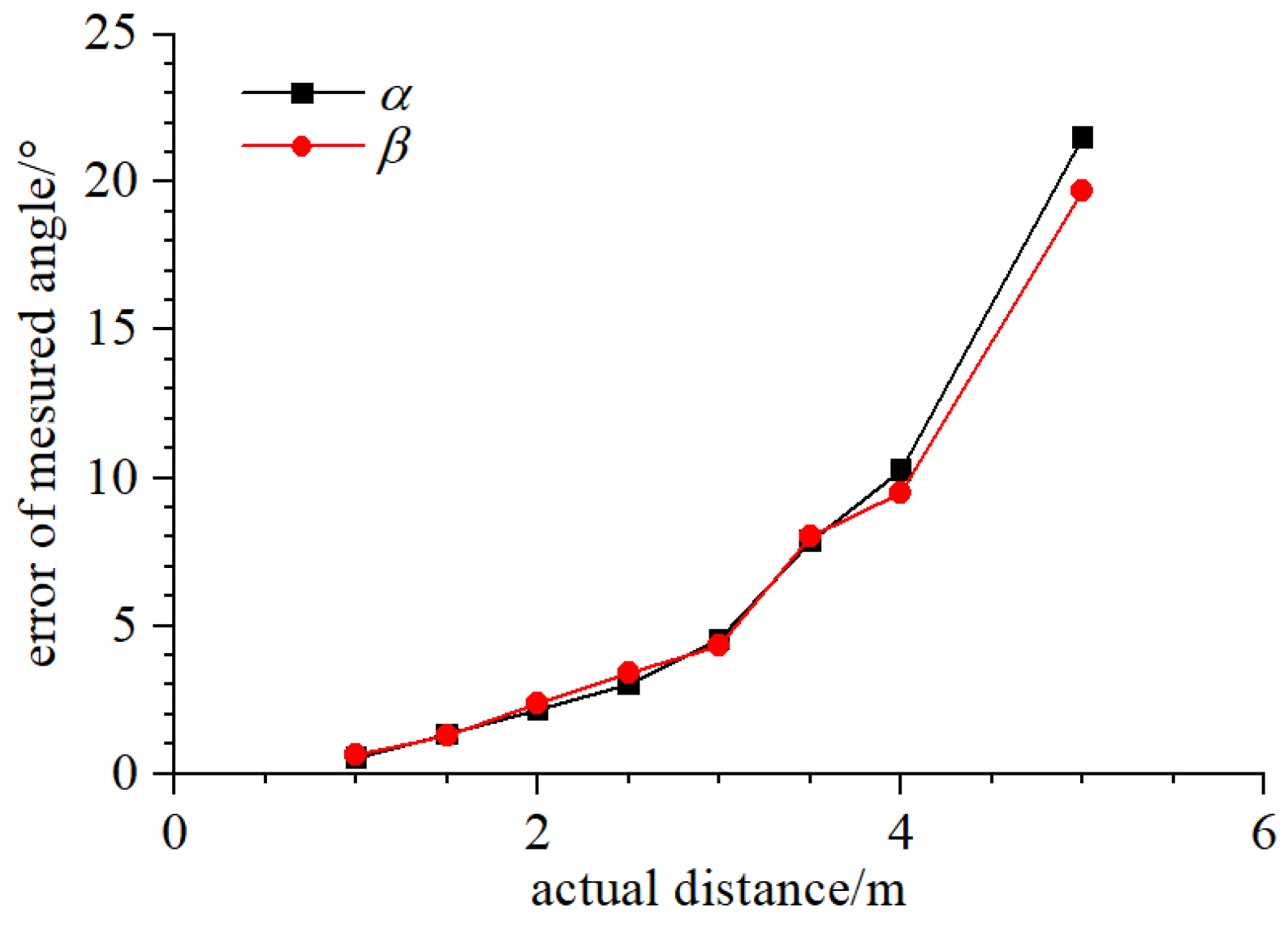
4.2. Experiment on Relative Distance and Bearing Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yuh, J. Design and control of autonomous underwater robots: A survey. Auton. Robot. 2000, 8, 7–24. [Google Scholar] [CrossRef]
- Alam, K.; Ray, T.; Anavatti, S.G. Design optimization of an unmanned underwater vehicle using low-and high-fidelity models. IEEE Trans. Syst. Man, Cybern. Syst. 2015, 47, 2794–2808. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, D.; Pan, G. Computational model construction and analysis of the hydrodynamics of a Rhinoptera Javanica. IEEE Access 2020, 8, 30410–30420. [Google Scholar] [CrossRef]
- He, J.; Cao, Y.; Huang, Q.; Cao, Y.; Tu, C.; Pan, G. A New Type of Bionic Manta Ray Robot. In Proceedings of the IEEE Global Oceans 2020: Singapore–US Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–6. [Google Scholar]
- Cao, Y.; Ma, S.; Xie, Y.; Hao, Y.; Zhang, D.; He, Y.; Cao, Y. Parameter Optimization of CPG Network Based on PSO for Manta Ray Robot. In Proceedings of the International Conference on Autonomous Unmanned Systems, Changsha, China, 24–26 September 2021; pp. 3062–3072. [Google Scholar]
- Ryuh, Y.S.; Yang, G.H.; Liu, J.; Hu, H. A school of robotic fish for mariculture monitoring in the sea coast. J. Bionic Eng. 2015, 12, 37–46. [Google Scholar] [CrossRef]
- Chen, Y.L.; Ma, X.W.; Bai, G.Q.; Sha, Y.; Liu, J. Multi-autonomous underwater vehicle formation control and cluster search using a fusion control strategy at complex underwater environment. Ocean Eng. 2020, 216, 108048. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zhang, S.; Li, J.; Yang, C.; Yang, Y.; Hu, X. Vision-based UAV Positioning Method Assisted by Relative Attitude Classification. In Proceedings of the 2020 5th International Conference on Mathematics and Artificial Intelligence, Chengdu, China, 10–13 April 2020; pp. 154–160. [Google Scholar]
- Feng, J.; Yao, Y.; Wang, H.; Jin, H. Multi-AUV terminal guidance method based on underwater visual positioning. In Proceedings of the 2020 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 13–16 October 2020; pp. 314–319. [Google Scholar]
- Chi, W.; Zhang, W.; Gu, J.; Ren, H. A vision-based mobile robot localization method. In Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 2703–2708. [Google Scholar]
- Xu, J.; Dou, Y.; Zheng, Y. Underwater target recognition and tracking method based on YOLO-V3 algorithm. J. Chin. Intertial Technol. 2020, 28, 129–133. [Google Scholar]
- Zhai, X.; Wei, H.; He, Y.; Shang, Y.; Liu, C. Underwater Sea Cucumber Identification Based on Improved YOLOv5. Appl. Sci. 2022, 12, 9105. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, preprint. arXiv:2107.08430. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Karami, E.; Prasad, S.; Shehata, M. Image matching using SIFT, SURF, BRIEF and ORB: Performance comparison for distorted images. arXiv 2017, preprint. arXiv:1710.02726. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE 2011 International Conference on Computer Vision, Washington, DC, USA, 20–25 June 2011; pp. 2564–2571. [Google Scholar]
- Shu, C.W.; Xiao, X.Z. ORB-oriented mismatching feature points elimination. In Proceedings of the 2018 IEEE International Conference on Progress in Informatics and Computing (PIC), Suzhou, China, 14–16 December 2018; pp. 246–249. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Training Time (Hour) | Detection Rate (fps) |
|---|---|---|---|
| YOLOx | 98.98% | 2.0 | 58 |
| YOLOx+CA | 99.32% | 2.3 | 56 |
| Relative Distance | 1 m | 1.5 m | 2 m | 2.5 m | 3 m | 3.5 m | 4 m | 5 m |
| Effective detection rate | 100% | 100% | 100% | 100% | 95% | 80% | 70% | 40% |
| Averaged effective detection rate | 85.625% | |||||||
| Influence speed | 25 fps | |||||||
| Relative Distance | 1 m | 1.5 m | 2 m | 2.5 m | 3 m | 3.5 m | 4 m | 5 m |
| Distance error | 0.0164 m | 0.1751 m | 0.2132 m | 0.3274 m | 0.4039 m | 0.4518 m | 0.6512 m | 1.5386 m |
| Total time | 0.2 s–0.25 s | |||||||
| Actual Location (cm) | (20,30,100) | (−35,40,145) | (40,15,200) | (40,−100,230) | (100,60,280) |
| bearing error | 0.532 | 1.320 | 2.156 | 3.047 | 4.539 |
| bearing error | 0.635 | 1.286 | 2.381 | 3.408 | 4.328 |
| Actual location (cm) | (−240,−15,270) | (400,20,150) | (250,10,430) | ||
| bearing error | 7.863 | 10.267 | 21.485 | ||
| bearing error | 8.034 | 9.485 | 19.690 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Zhang, L.; Zhu, Y.; Liu, L.; Huang, Q.; Cao, Y.; Pan, G. Real-Time Relative Positioning Study of an Underwater Bionic Manta Ray Vehicle Based on Improved YOLOx. J. Mar. Sci. Eng. 2023, 11, 314. https://doi.org/10.3390/jmse11020314
Zhao Q, Zhang L, Zhu Y, Liu L, Huang Q, Cao Y, Pan G. Real-Time Relative Positioning Study of an Underwater Bionic Manta Ray Vehicle Based on Improved YOLOx. Journal of Marine Science and Engineering. 2023; 11(2):314. https://doi.org/10.3390/jmse11020314
Chicago/Turabian StyleZhao, Qiaoqiao, Lichuan Zhang, Yuchen Zhu, Lu Liu, Qiaogao Huang, Yong Cao, and Guang Pan. 2023. "Real-Time Relative Positioning Study of an Underwater Bionic Manta Ray Vehicle Based on Improved YOLOx" Journal of Marine Science and Engineering 11, no. 2: 314. https://doi.org/10.3390/jmse11020314
APA StyleZhao, Q., Zhang, L., Zhu, Y., Liu, L., Huang, Q., Cao, Y., & Pan, G. (2023). Real-Time Relative Positioning Study of an Underwater Bionic Manta Ray Vehicle Based on Improved YOLOx. Journal of Marine Science and Engineering, 11(2), 314. https://doi.org/10.3390/jmse11020314