



Fuel Consumption Prediction Models Based on Machine Learning and Mathematical Methods

 ,
, 


Abstract
:1. Introduction
2. Related Work
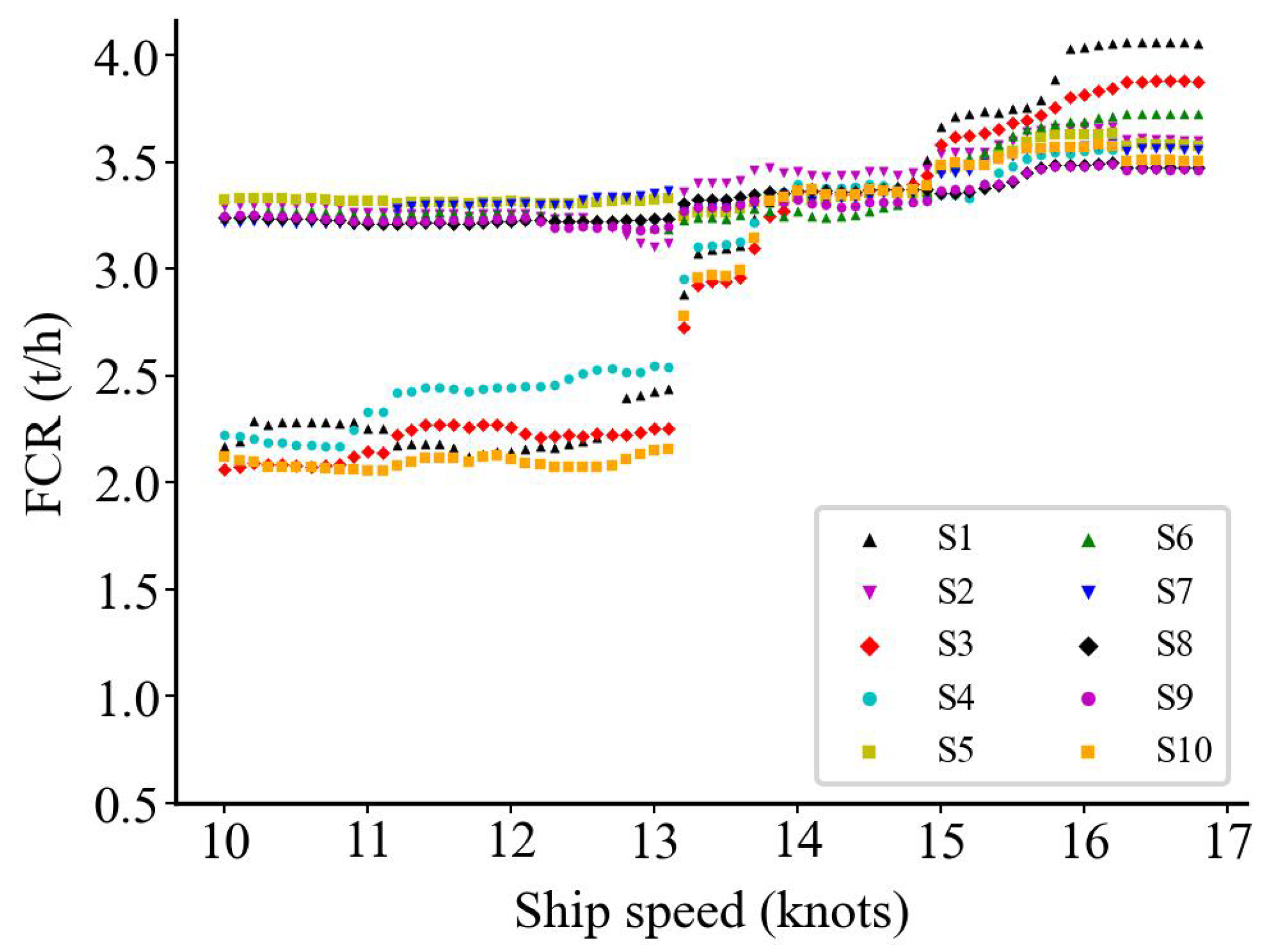
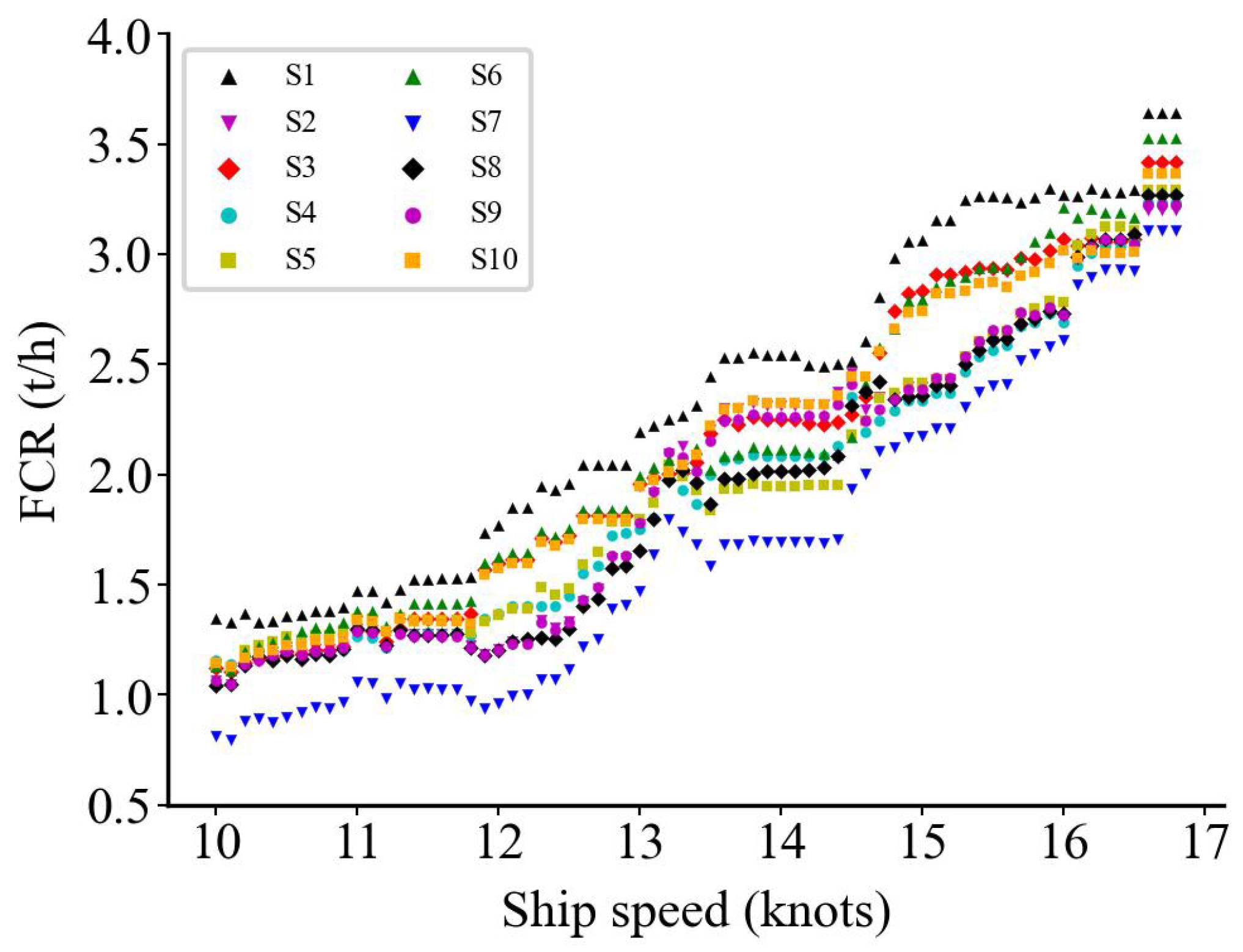
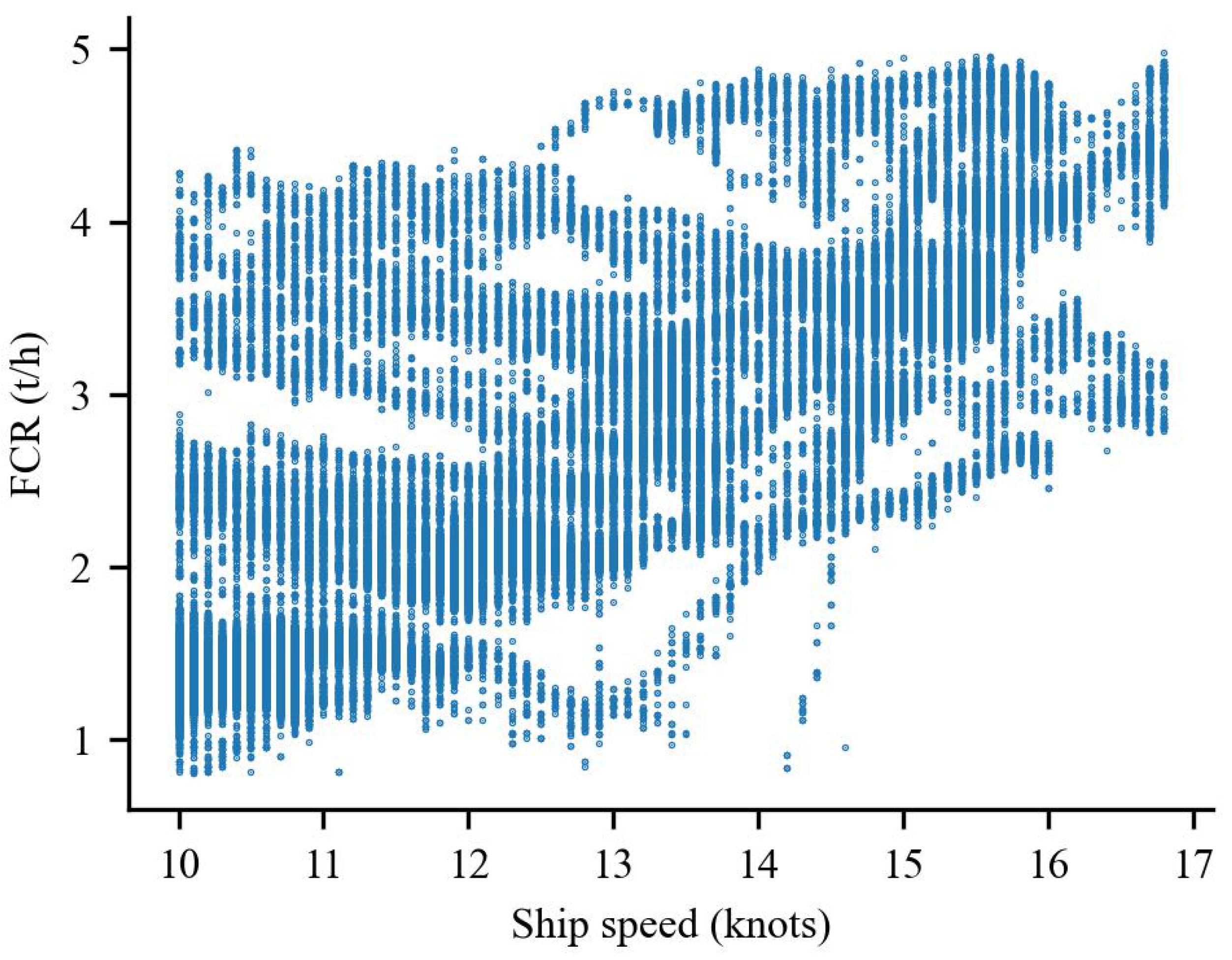
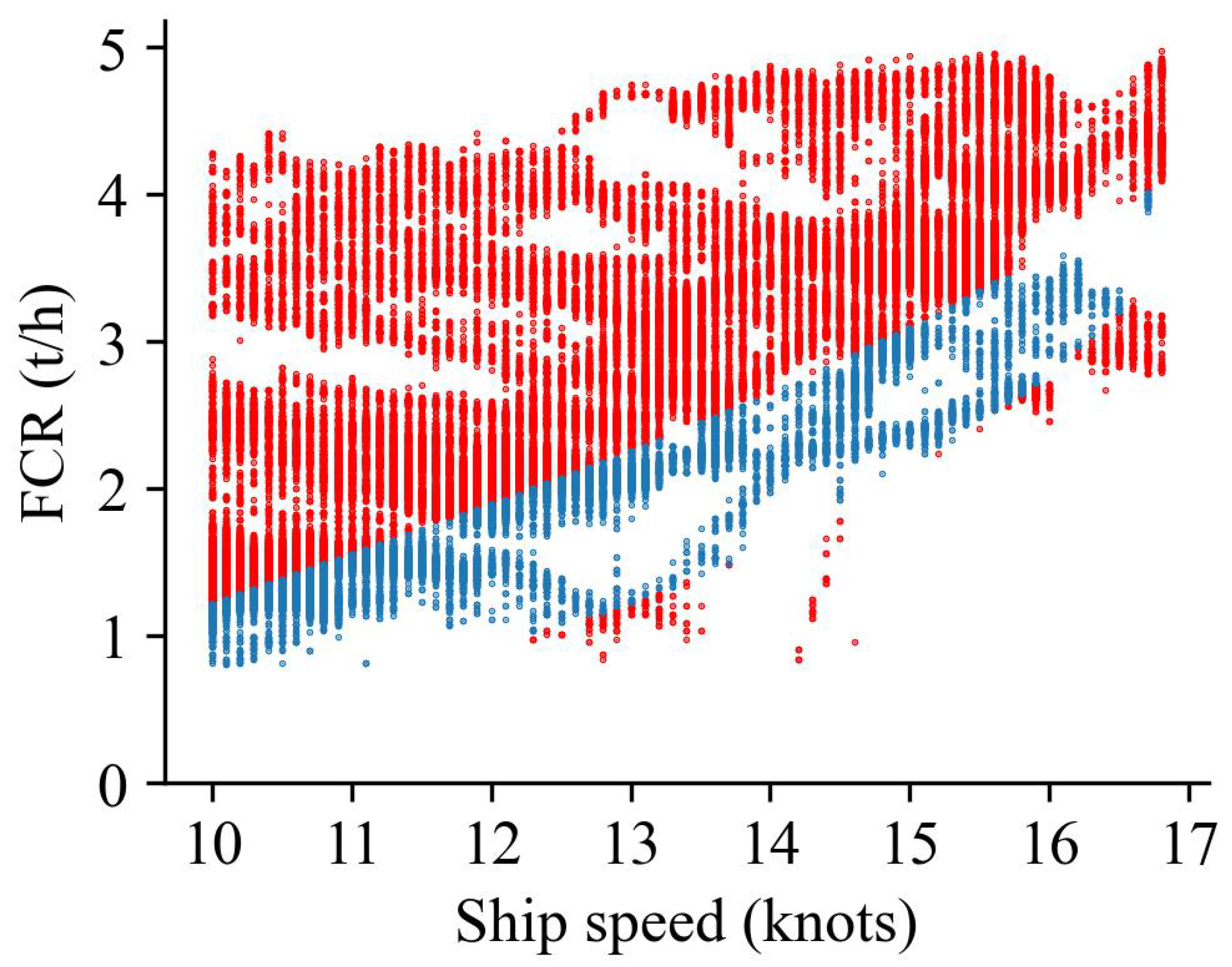
3. Data Description and Preprocessing
4. Fuel Consumption Prediction Models
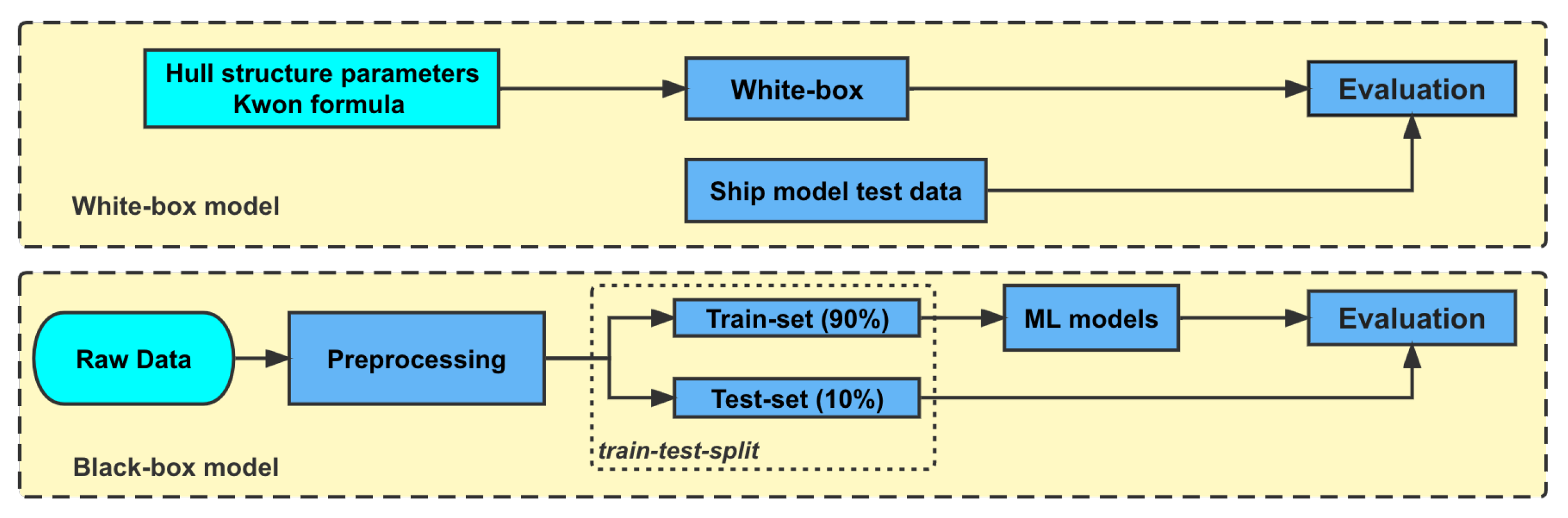
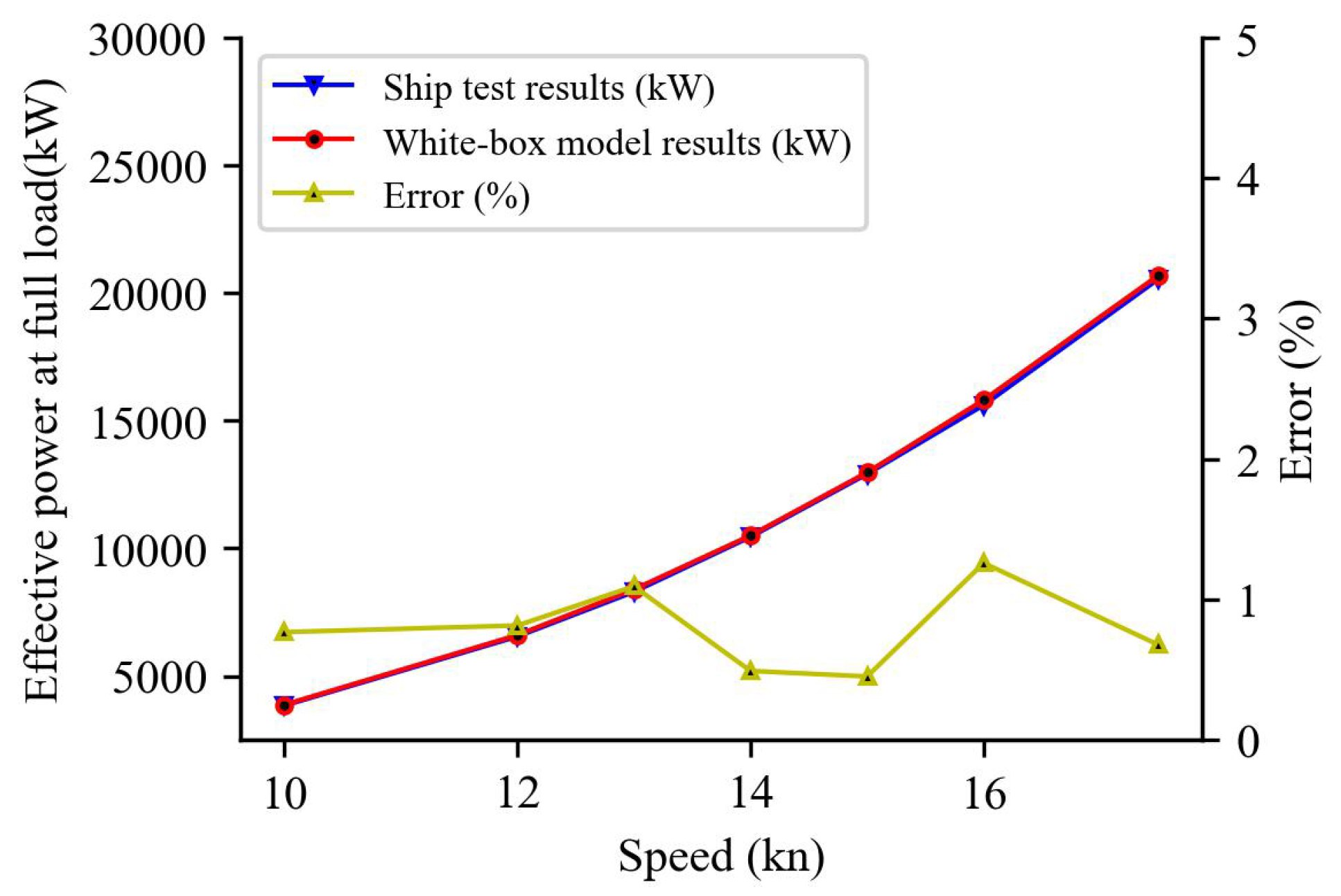
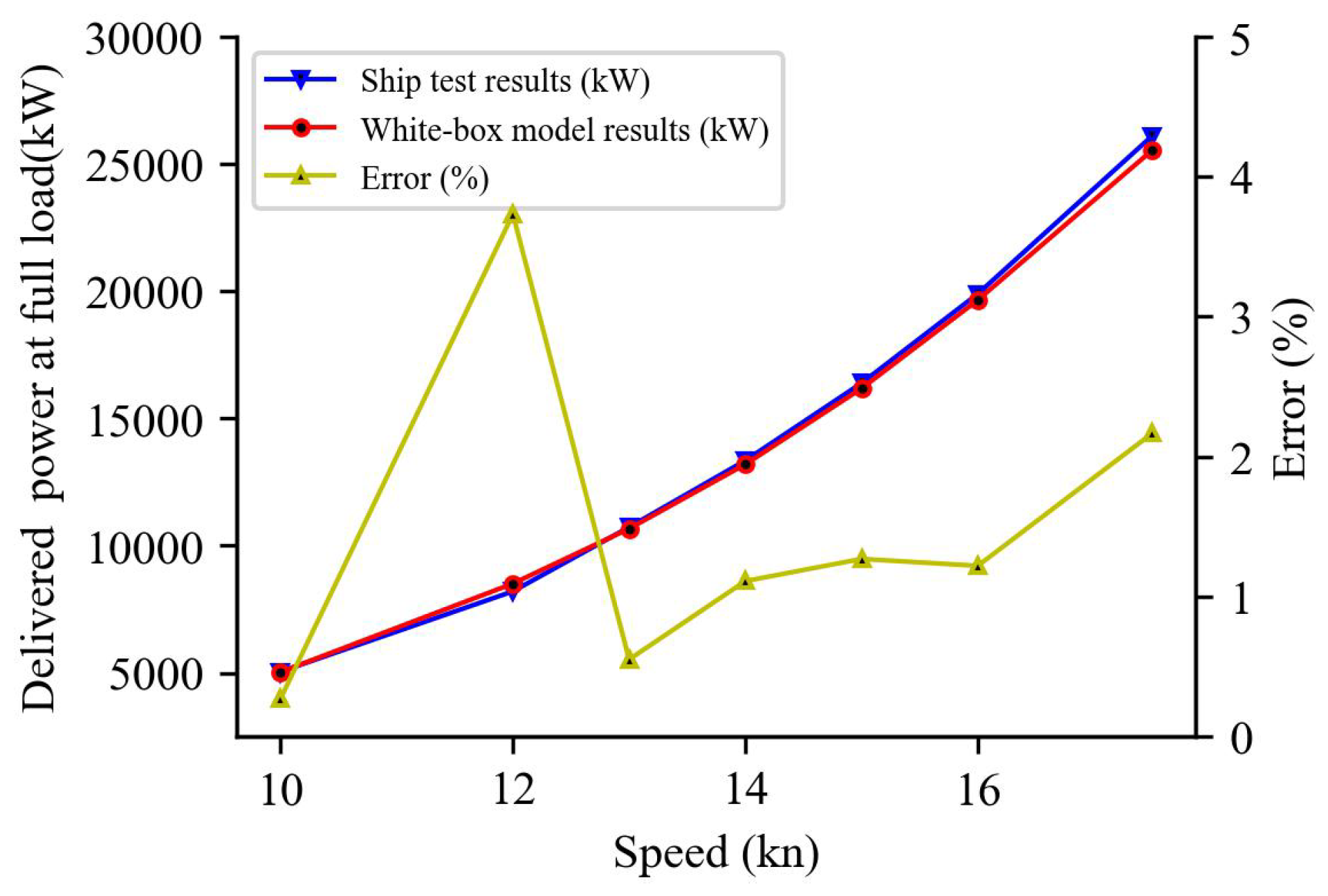
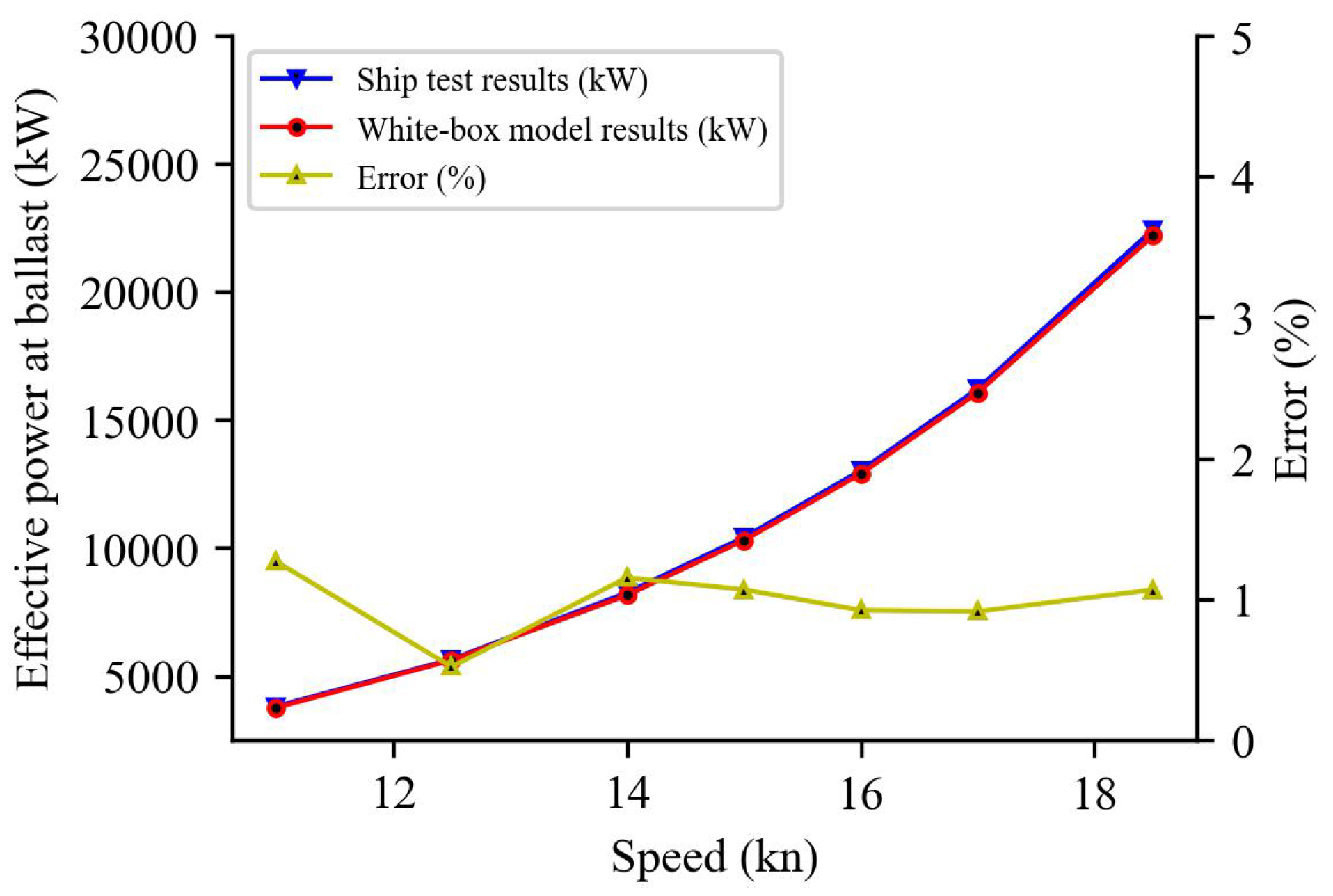
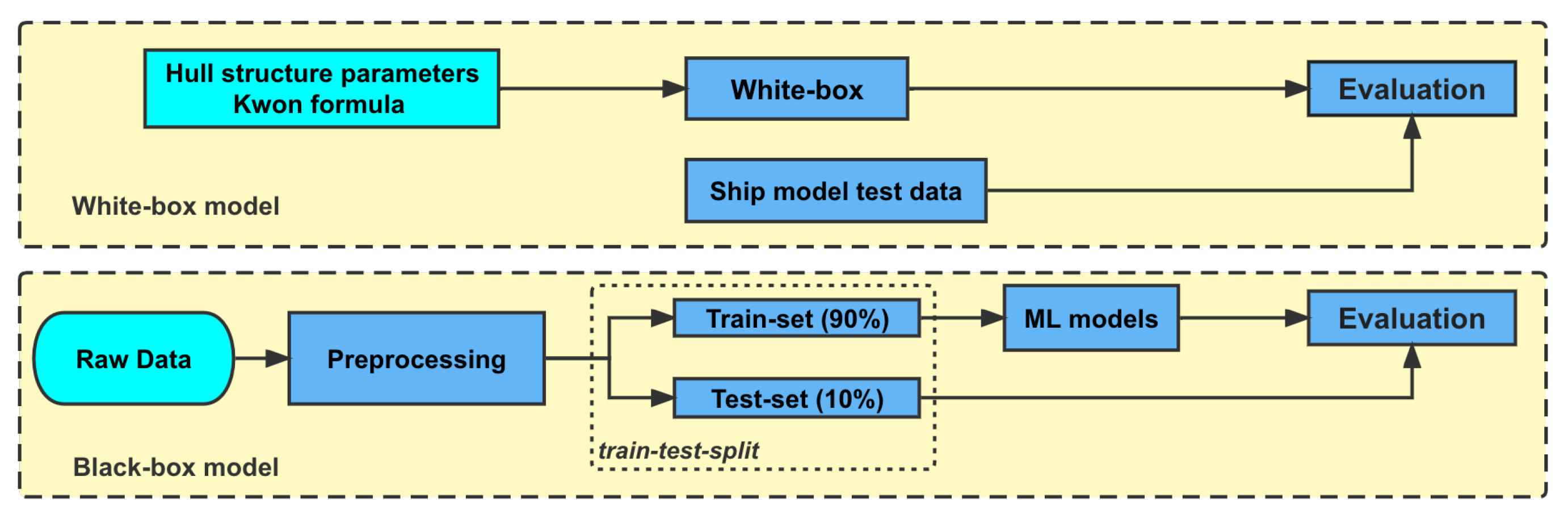
4.1. White-Box Model
4.2. Black-Box Model
- (1)
- Strong interpretability: The tree-based algorithms can provide each feature’s importance and have strong interpretability. In comparison, ANN is brutal in explaining the contribution of each feature.
- (2)
- Fast training speed: RF and XGBoost can be processed in parallel, and the training speed is fast. In contrast, ANN requires iterative optimization of the backpropagation algorithm, and the training speed is relatively slow.
- (3)
- Strong robustness: RF and XGBoost are relatively robust to outliers and noise and are not easily affected by extreme values. In contrast, ANN is sensitive to outliers and noise and requires data preprocessing.
- (4)
- Can handle high-dimensional data: Random Forest and XGBoost can handle high-dimensional data very well, and the problem of dimensionality disaster is challenging. In contrast, ANN requires dimensionality reduction when dealing with high-dimensional data.
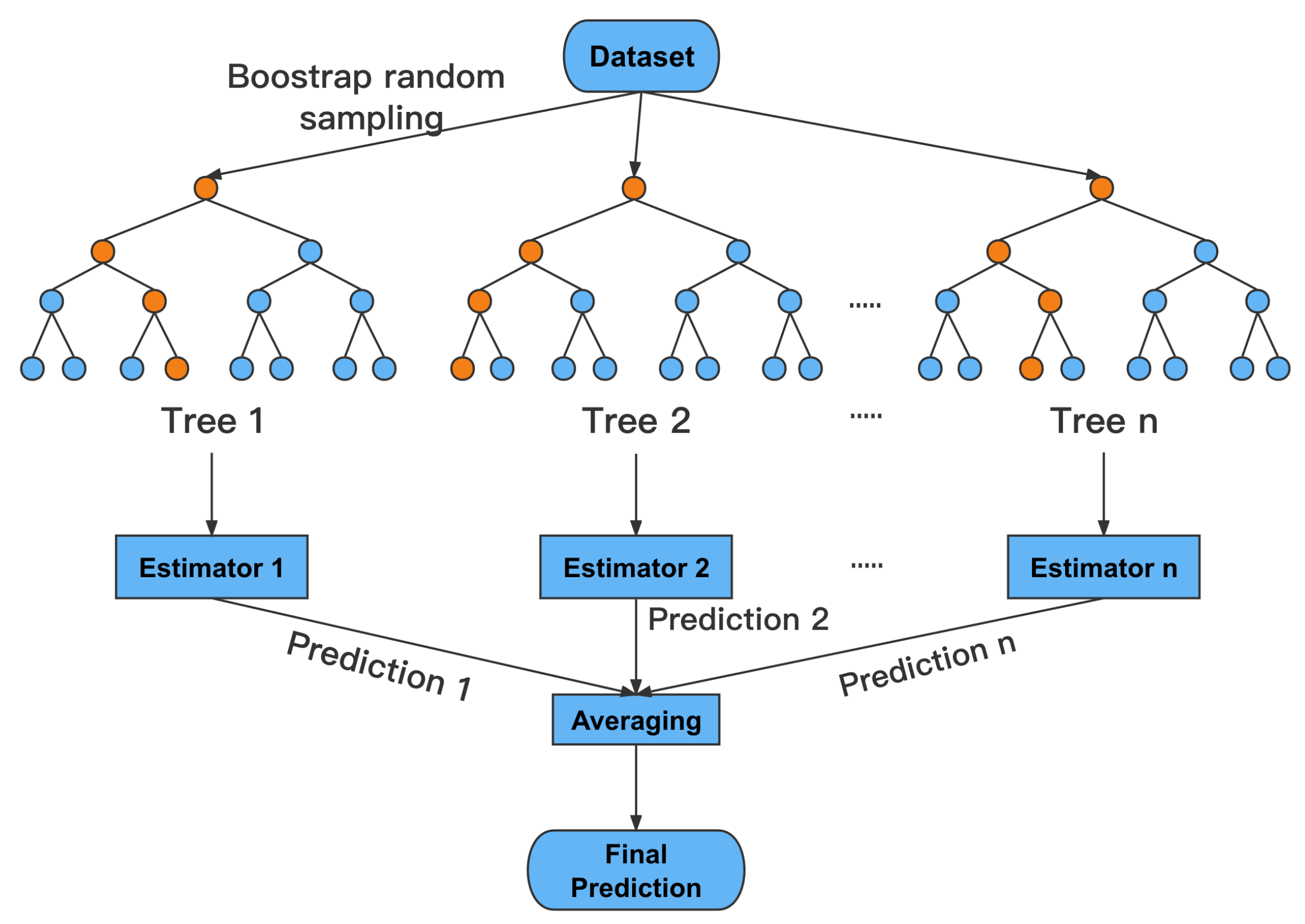
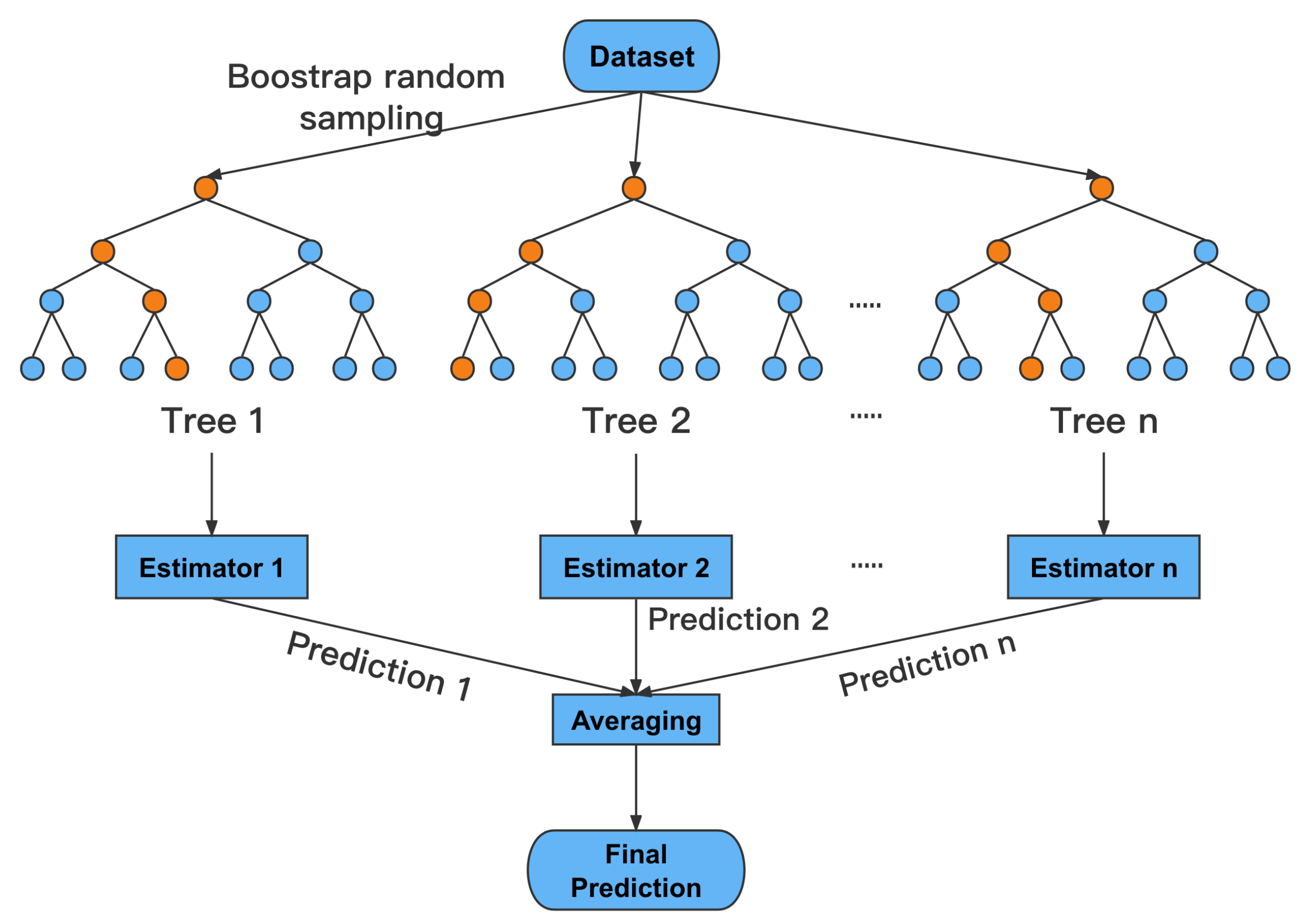
4.2.1. RF Model
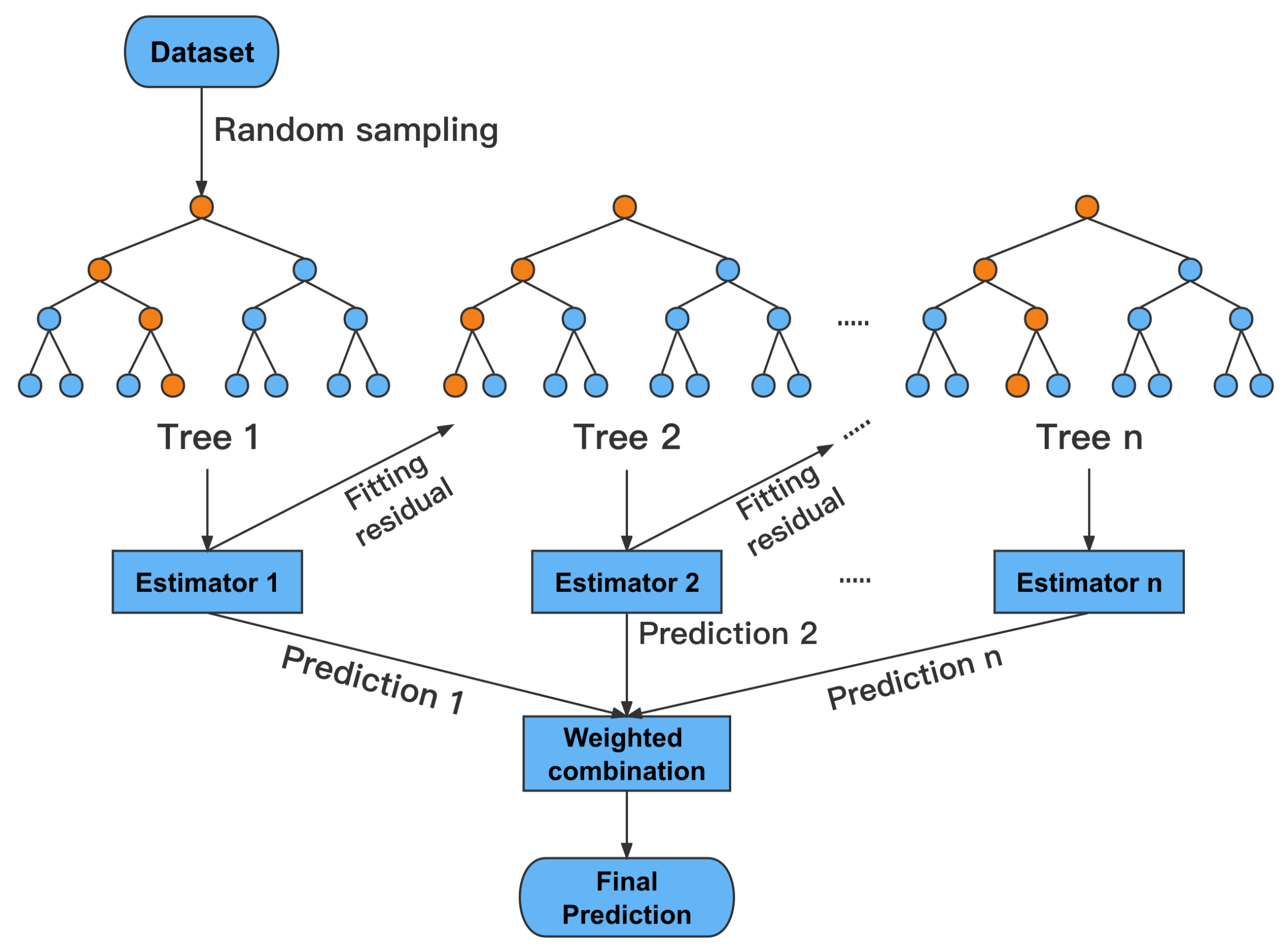
4.2.2. Xgboost Model
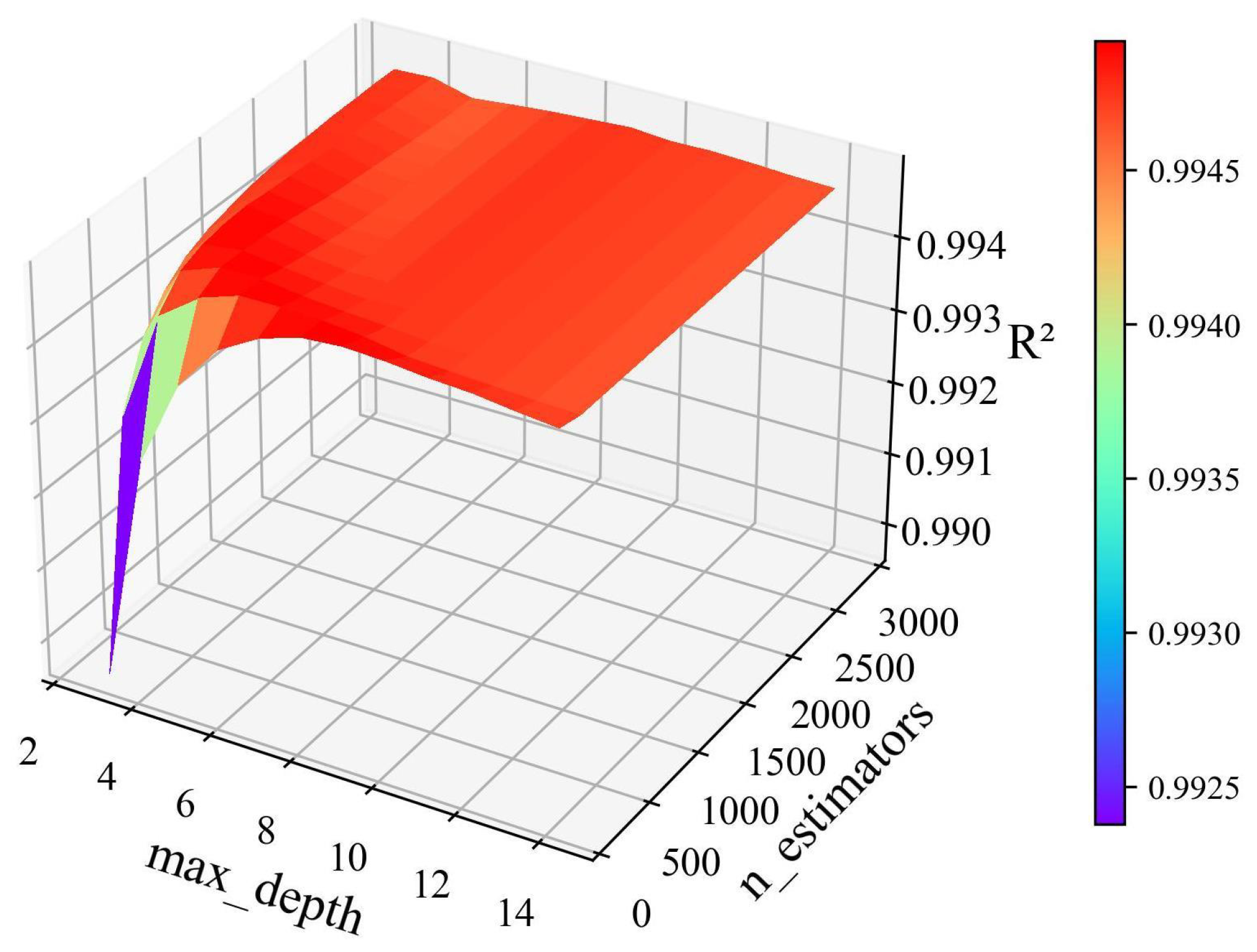
4.2.3. Hyperparameter Optimization (HPO)
4.3. Black-Box Model Cleaning Method
5. Results
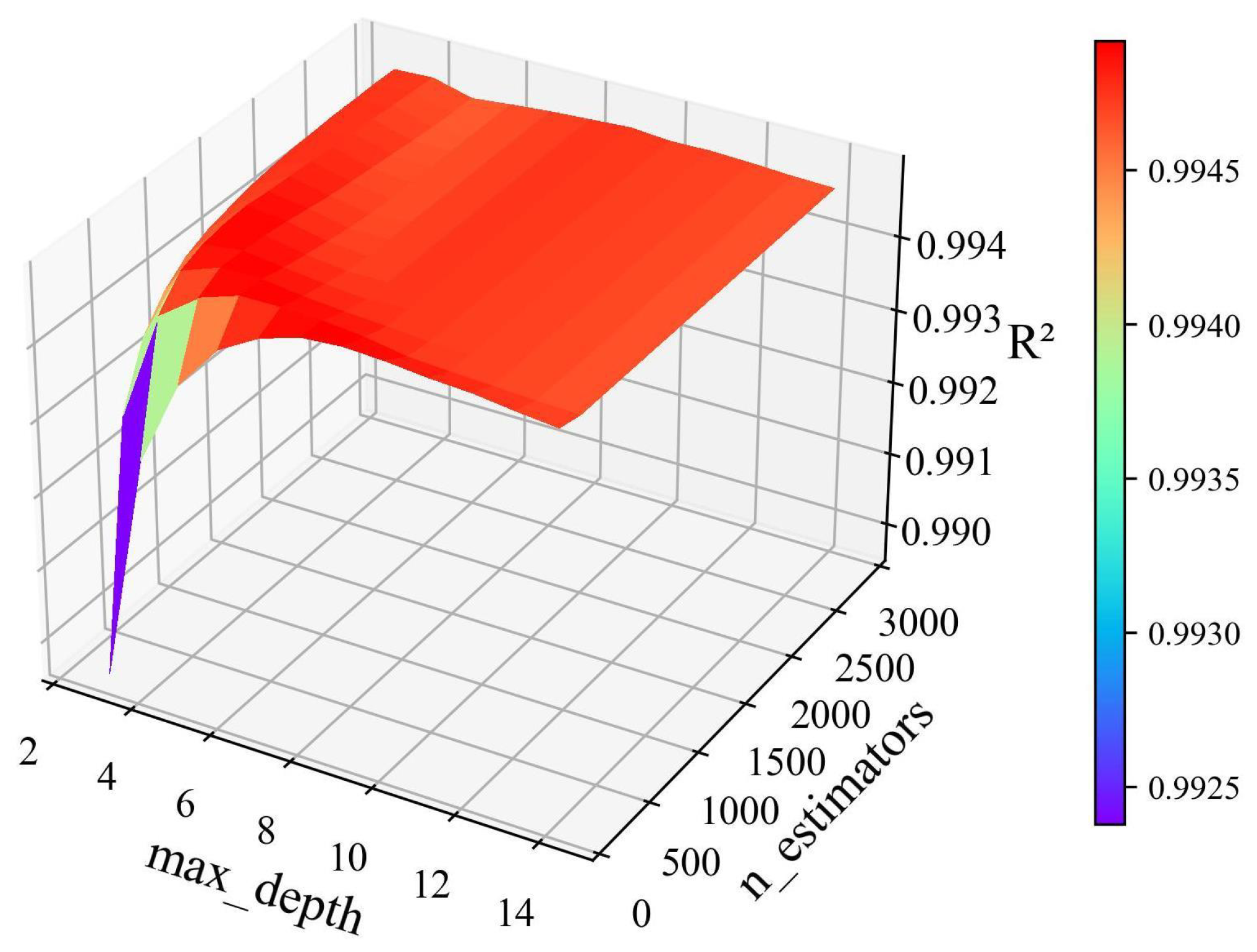
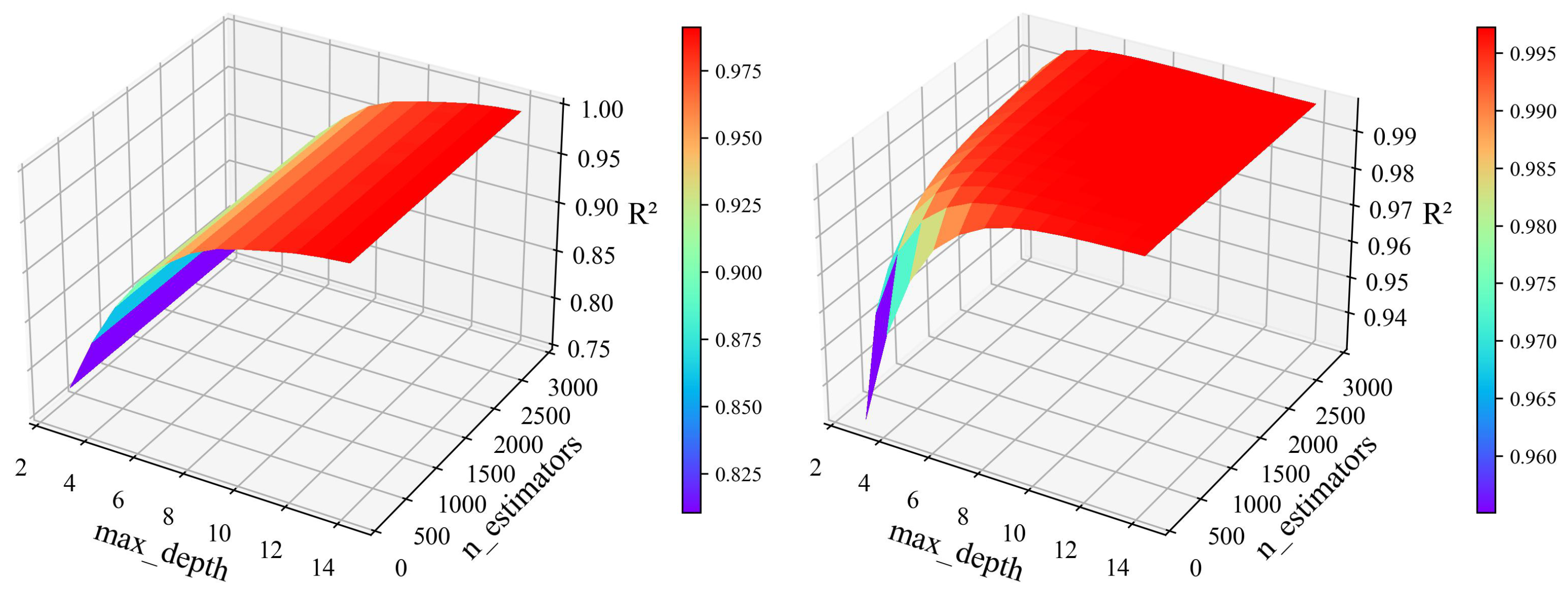
5.1. HPO Results
5.2. Model Evaluation Results
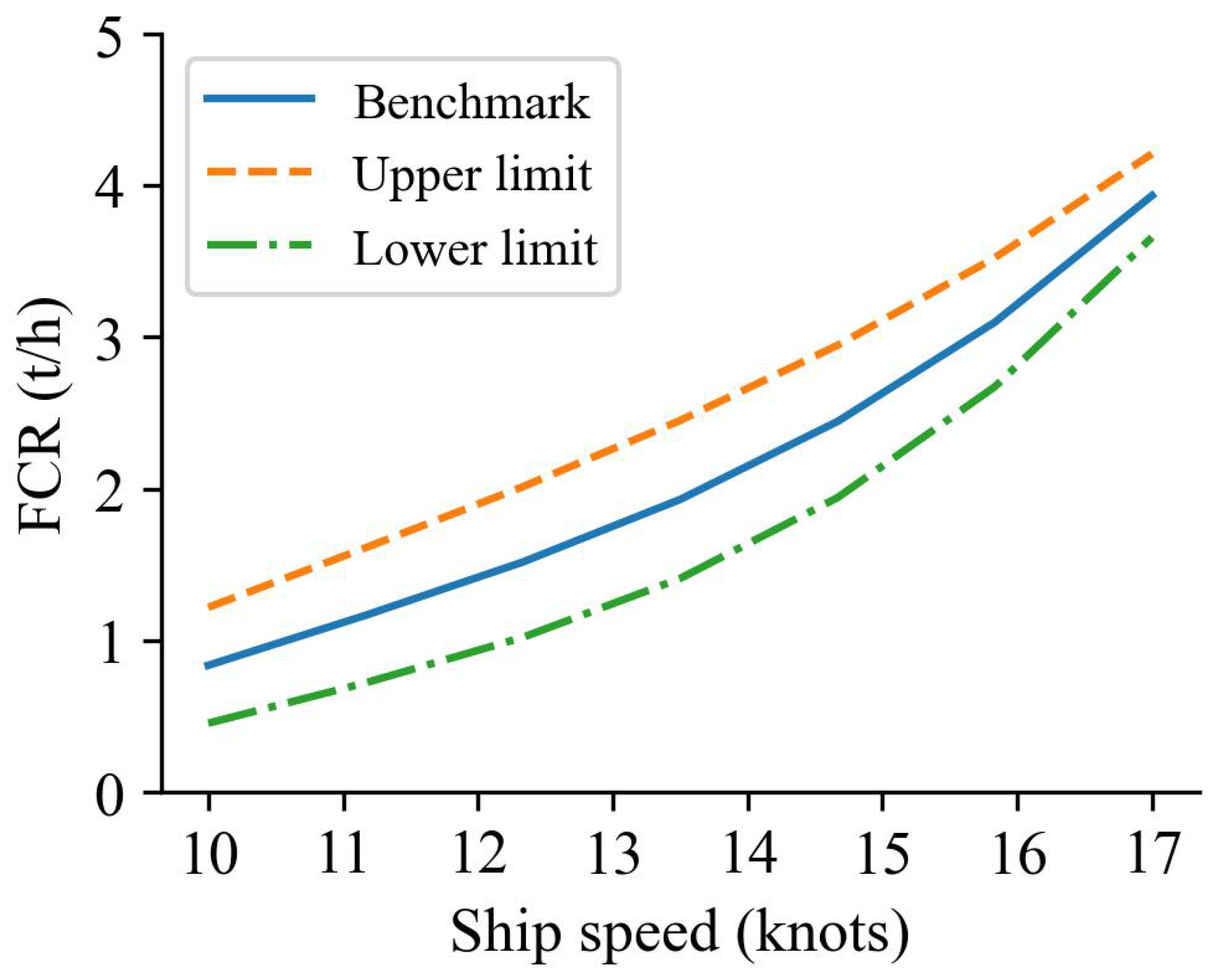
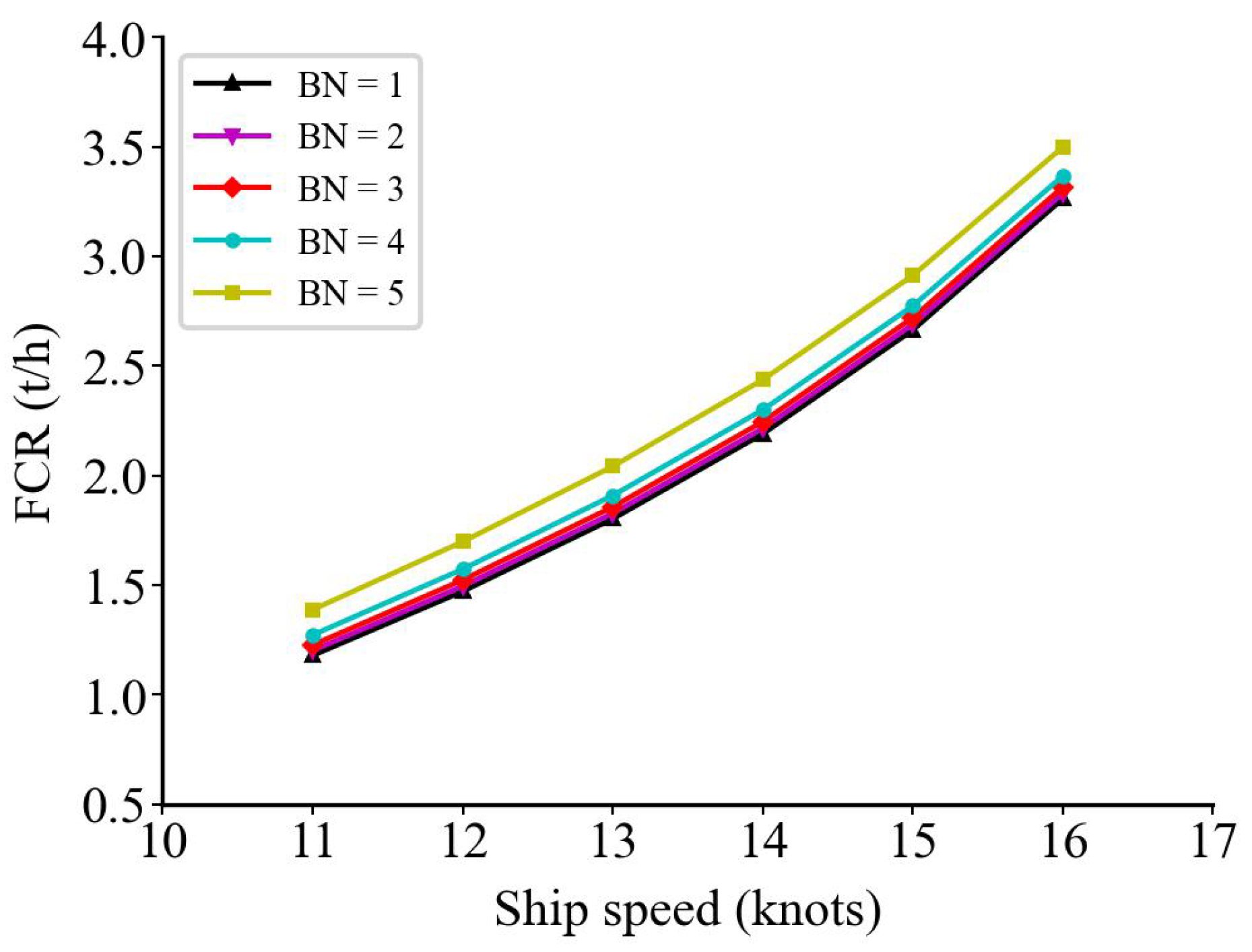
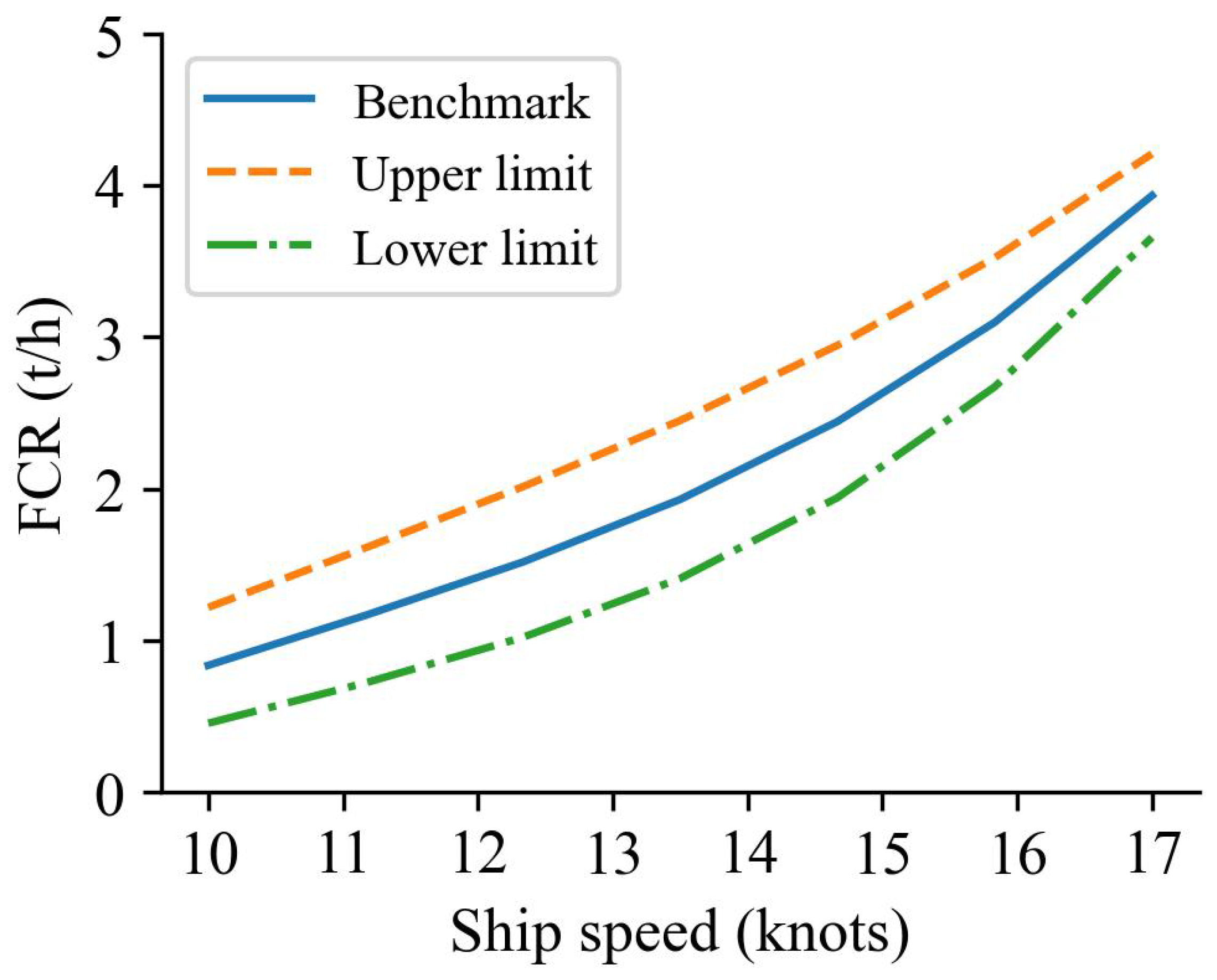
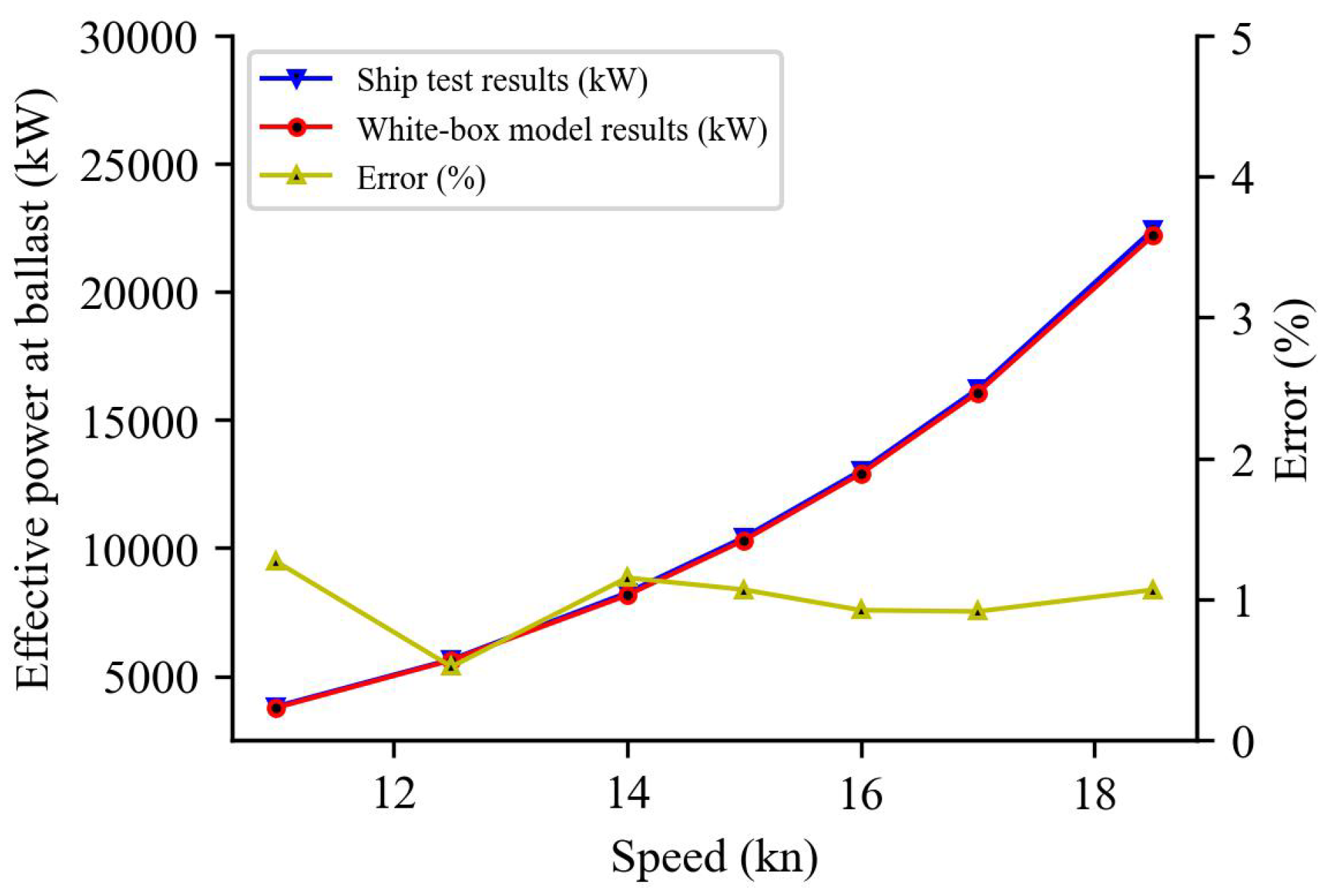
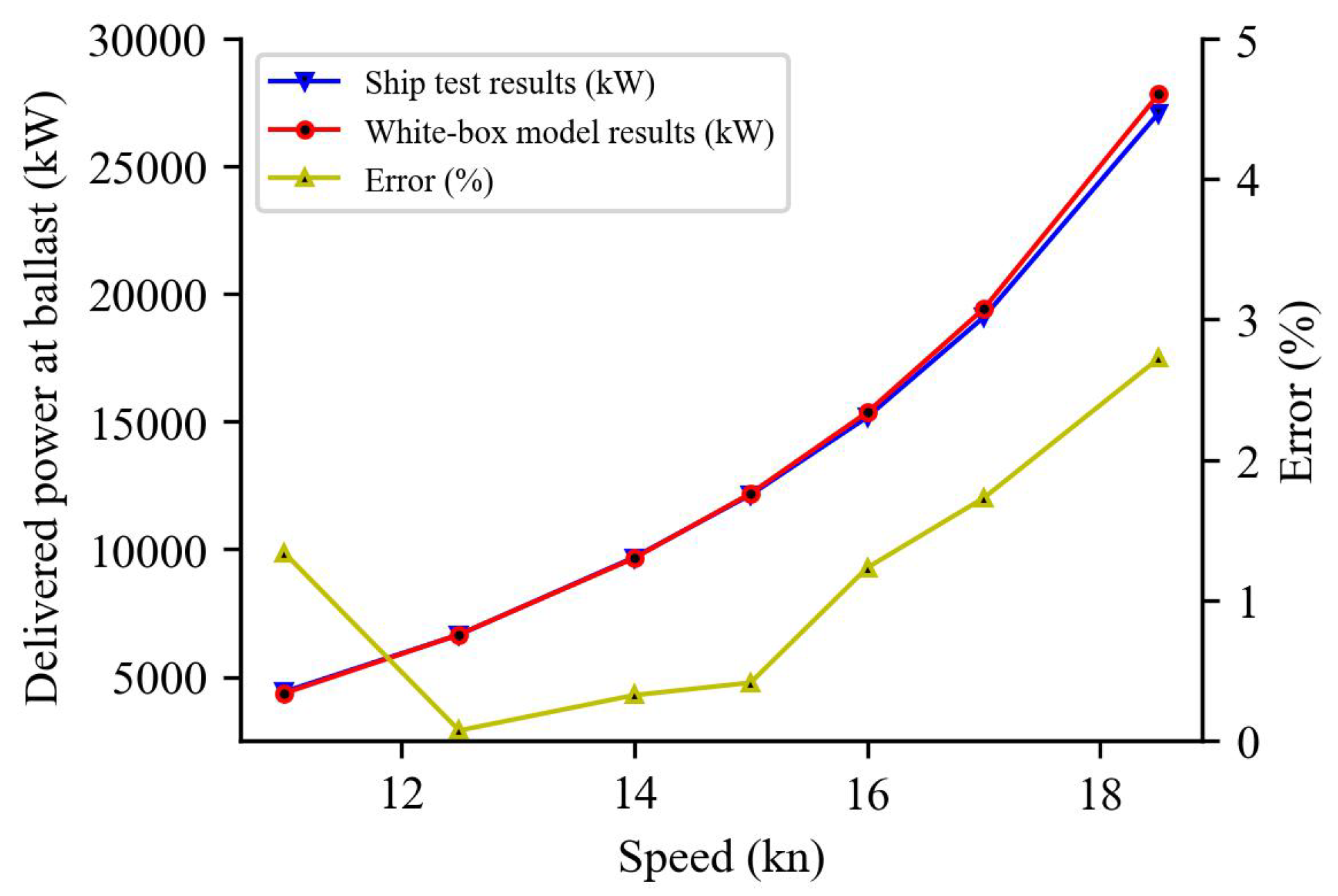
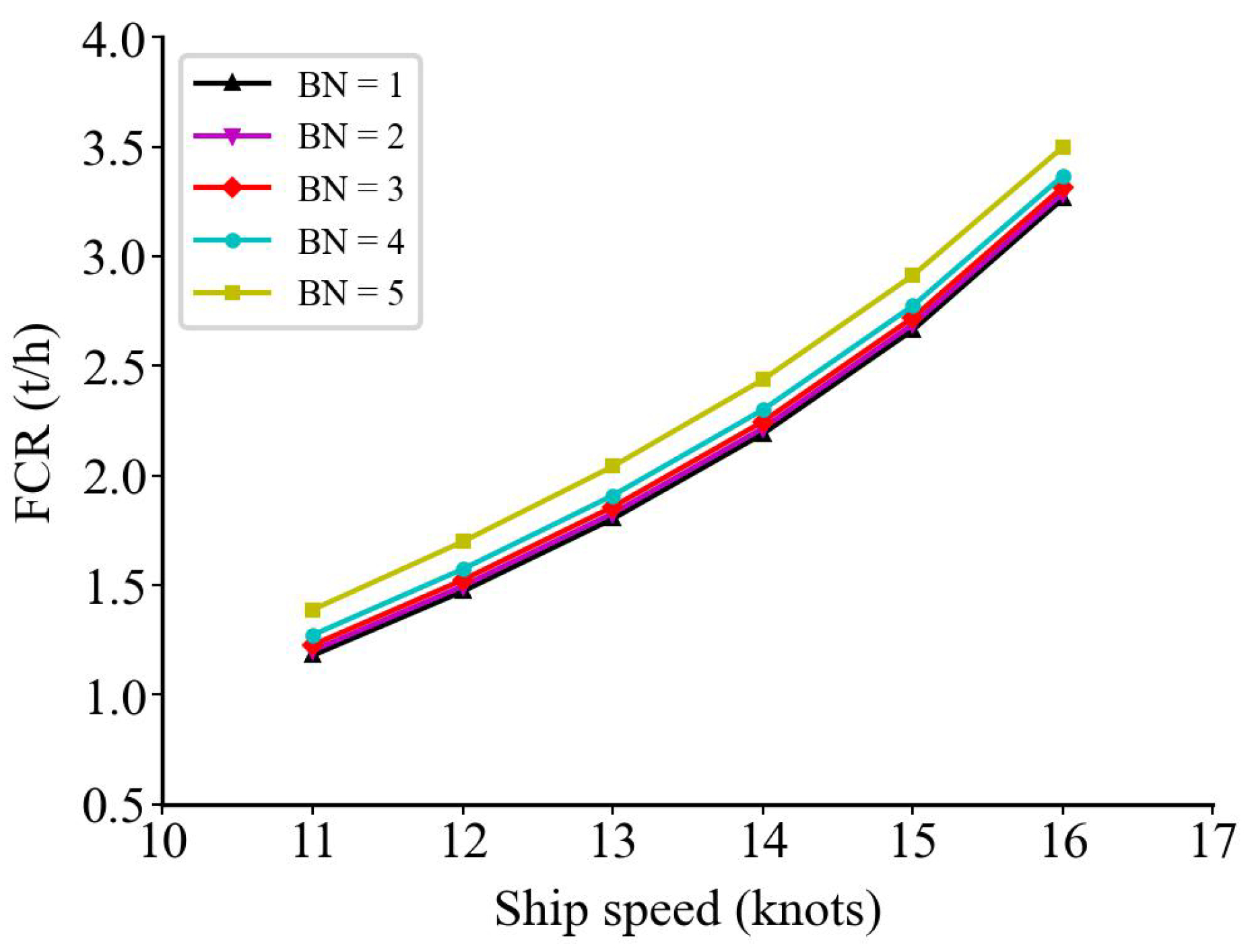
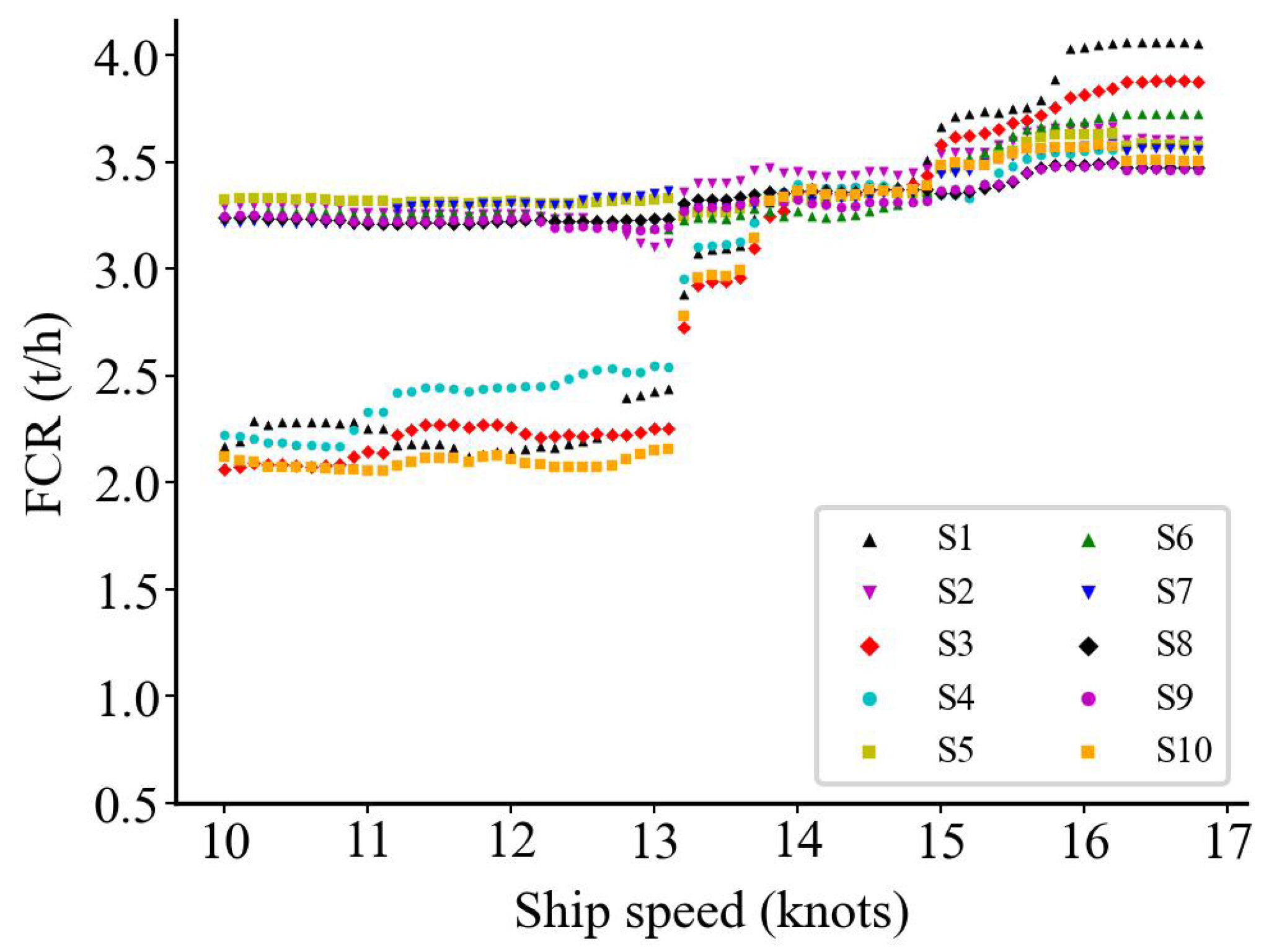
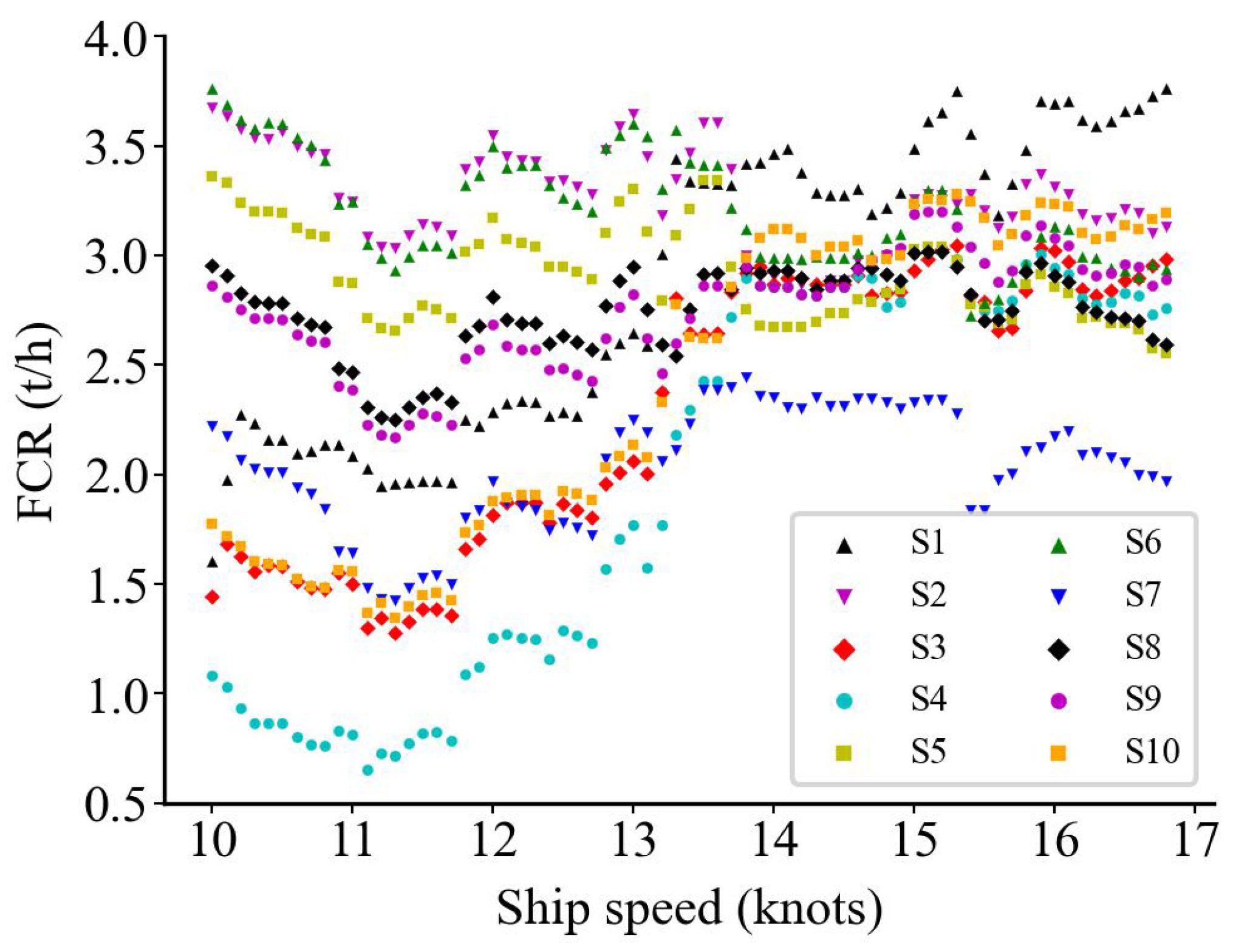
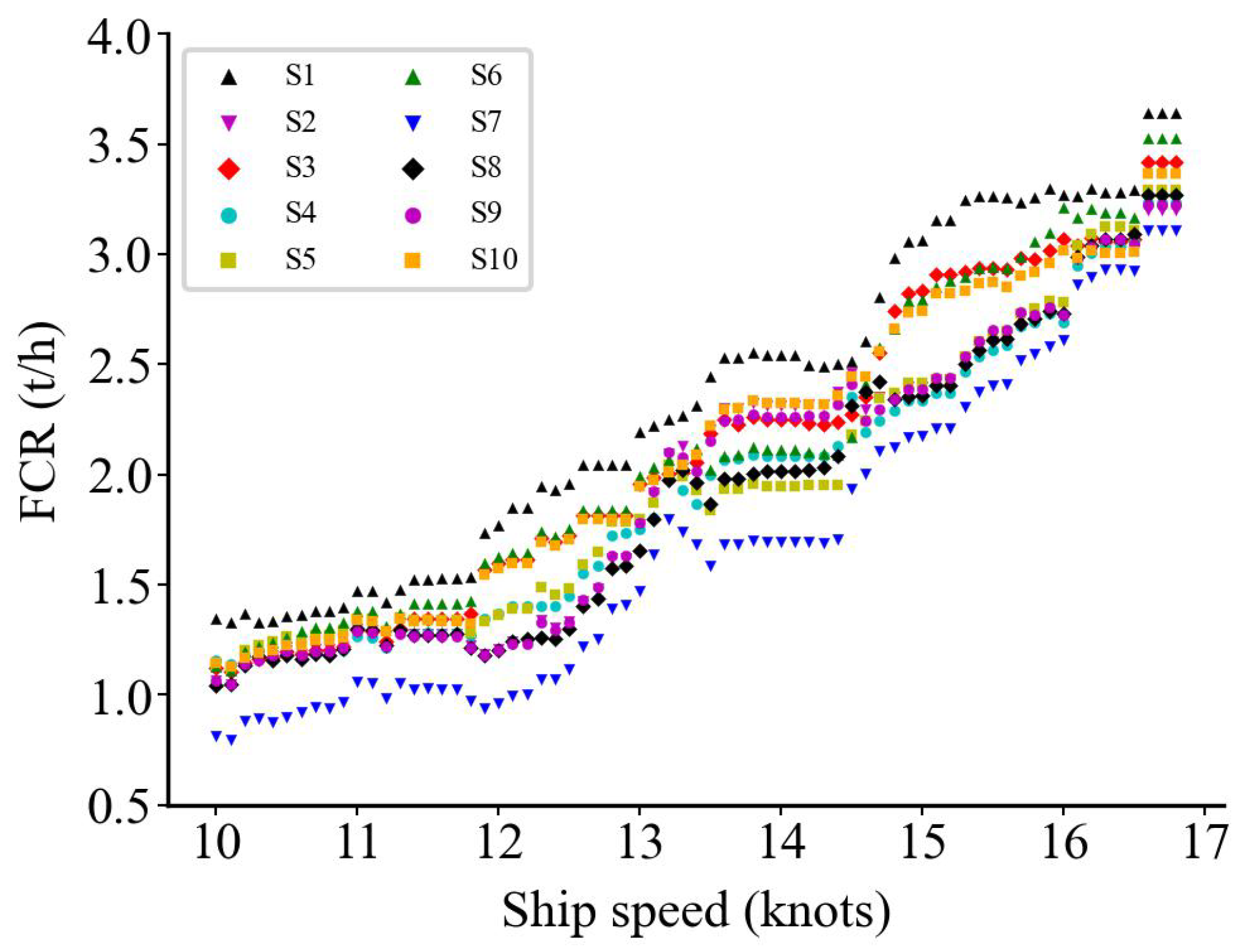
5.3. Model Prediction Results
6. Discussion and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IMO. Fourth IMO Greenhouse Gas Study 2020; International Maritime Organization: London, UK, 2020. [Google Scholar]
- IEA. International Shipping; International Energy Agency: Paris, France, 2022. [Google Scholar]
- ITF. Reducing shipping greenhouse gas emissions: Lessons from port-based incentives. In Proceedings of the International Transport Forum and Organisation for Economic Cooperation and Development, Paris, France, 1–2 March 2018. [Google Scholar]
- Joung, T.H.; Kang, S.G.; Lee, J.K.; Ahn, J. The IMO initial strategy for reducing Greenhouse Gas (GHG) emissions, and its follow-up actions towards 2050. J. Int. Marit. Saf. Environ. Aff. Shipp. 2020, 4, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Fang, Z.; Fu, X.; Liu, J.; Chen, J. Literature review on emission control-based ship voyage optimization. Transp. Res. Part D Transp. Environ. 2021, 93, 102768. [Google Scholar] [CrossRef]
- Han, P. Data-Driven Methods for Decision Support in Smart Ship Operations; NTNU: Geilo, Norway, 2022. [Google Scholar]
- Tay, Z.Y.; Hadi, J.; Chow, F.; Loh, D.J.; Konovessis, D. Big data analytics and machine learning of harbour craft vessels to achieve fuel efficiency: A review. J. Mar. Sci. Eng. 2021, 9, 1351. [Google Scholar] [CrossRef]
- Rudzki, K.; Tarelko, W. A decision-making system supporting selection of commanded outputs for a ship’s propulsion system with a controllable pitch propeller. Ocean. Eng. 2016, 126, 254–264. [Google Scholar] [CrossRef]
- Li, X.; Sun, B.; Jin, J.; Ding, J. Speed Optimization of Container Ship Considering Route Segmentation and Weather Data Loading: Turning Point-Time Segmentation Method. J. Mar. Sci. Eng. 2022, 10, 1835. [Google Scholar] [CrossRef]
- Haranen, M.; Pakkanen, P.; Kariranta, R.; Salo, J. White, grey and black-box modelling in ship performance evaluation. In Proceedings of the 1st Hull Performence & Insight Conference (HullPIC), Turin, Italy, 13–15 April 2016; pp. 115–127. [Google Scholar]
- Fan, A.; Yang, J.; Yang, L.; Wu, D.; Vladimir, N. A review of ship fuel consumption models. Ocean. Eng. 2022, 264, 112405. [Google Scholar] [CrossRef]
- Wei, N.; Yin, L.; Li, C.; Li, C.; Chan, C.; Zeng, F. Forecasting the daily natural gas consumption with an accurate white-box model. Energy 2021, 232, 121036. [Google Scholar] [CrossRef]
- Lu, R.; Turan, O.; Boulougouris, E.; Banks, C.; Incecik, A. A semi-empirical ship operational performance prediction model for voyage optimization towards energy efficient shipping. Ocean. Eng. 2015, 110, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Venturini, G.; Iris, Ç.; Kontovas, C.A.; Larsen, A. The multi-port berth allocation problem with speed optimization and emission considerations. Transp. Res. Part D Transp. Environ. 2017, 54, 142–159. [Google Scholar] [CrossRef] [Green Version]
- Yan, R.; Wang, S.; Psaraftis, H.N. Data analytics for fuel consumption management in maritime transportation: Status and perspectives. Transp. Res. Part E Logist. Transp. Rev. 2021, 155, 102489. [Google Scholar] [CrossRef]
- Li, X.; Sun, B.; Zhao, Q.; Li, Y.; Shen, Z.; Du, W.; Xu, N. Model of speed optimization of oil tanker with irregular winds and waves for given route. Ocean. Eng. 2018, 164, 628–639. [Google Scholar] [CrossRef]
- Angelini, G.; Muggiasca, S.; Belloli, M. A Techno-Economic Analysis of a Cargo Ship Using Flettner Rotors. J. Mar. Sci. Eng. 2023, 11, 229. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Perera, L.P. Handling big data in ship performance and navigation monitoring. In Proceedings of the Smart Ship Technology, London, UK, 24–25 January 2017; pp. 89–97. [Google Scholar]
- Perera, L.P.; Mo, B.; Kristjánsson, L.A. Identification of optimal trim configurations to improve energy efficiency in ships. IFAC-PapersOnLine 2015, 48, 267–272. [Google Scholar] [CrossRef]
- Bialystocki, N.; Konovessis, D. On the estimation of ship’s fuel consumption and speed curve: A statistical approach. J. Ocean. Eng. Sci. 2016, 1, 157–166. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Wang, K.; Yuan, Y.; Jiang, X.; Negenborn, R.R. Energy-efficient shipping: An application of big data analysis for optimizing engine speed of inland ships considering multiple environmental factors. Ocean. Eng. 2018, 169, 457–468. [Google Scholar] [CrossRef]
- Maleki, N.; Rahmani, A.M.; Conti, M. MapReduce: An infrastructure review and research insights. J. Supercomput. 2019, 75, 6934–7002. [Google Scholar] [CrossRef]
- Du, Y.; Meng, Q.; Wang, S.; Kuang, H. Two-phase optimal solutions for ship speed and trim optimization over a voyage using voyage report data. Transp. Res. Part B Methodol. 2019, 122, 88–114. [Google Scholar] [CrossRef]
- Yan, R.; Wang, S.; Du, Y. Development of a two-stage ship fuel consumption prediction and reduction model for a dry bulk ship. Transp. Res. Part E Logist. Transp. Rev. 2020, 138, 101930. [Google Scholar] [CrossRef]
- Smith, T.; Aldous, L.; Bucknall, R. Noon Report Data Uncertainty; UCL: London, UK, 2013. [Google Scholar]
- Coraddu, A.; Oneto, L.; Baldi, F.; Anguita, D. Vessels fuel consumption forecast and trim optimisation: A data analytics perspective. Ocean. Eng. 2017, 130, 351–370. [Google Scholar] [CrossRef]
- Cheng, X.; Li, G.; Skulstad, R.; Chen, S.; Hildre, H.P.; Zhang, H. A neural-network-based sensitivity analysis approach for data-driven modeling of ship motion. IEEE J. Ocean. Eng. 2019, 45, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Jeon, M.; Noh, Y.; Shin, Y.; Lim, O.; Lee, I.; Cho, D. Prediction of ship fuel consumption by using an artificial neural network. J. Mech. Sci. Technol. 2018, 32, 5785–5796. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, X.; Tong, L.; Yang, R.; Shen, B. Research on Multi-Objective Energy Efficiency Optimization Method of Ships Considering Carbon Tax. J. Mar. Sci. Eng. 2023, 11, 82. [Google Scholar] [CrossRef]
- Kee, K.K.; Simon, B.Y.L.; Renco, K.H.Y. Prediction of ship fuel consumption and speed curve by using statistical method. J. Comput. Sci. Comput. Math 2018, 8, 19–24. [Google Scholar] [CrossRef] [Green Version]
- Soner, O.; Akyuz, E.; Celik, M. Use of tree based methods in ship performance monitoring under operating conditions. Ocean. Eng. 2018, 166, 302–310. [Google Scholar] [CrossRef]
- Papandreou, C.; Ziakopoulos, A. Predicting VLCC fuel consumption with machine learning using operationally available sensor data. Ocean. Eng. 2022, 243, 110321. [Google Scholar] [CrossRef]
- Gkerekos, C.; Lazakis, I.; Theotokatos, G. Machine learning models for predicting ship main engine Fuel Oil Consumption: A comparative study. Ocean. Eng. 2019, 188, 106282. [Google Scholar] [CrossRef]
- Lang, X.; Wu, D.; Mao, W. Comparison of supervised machine learning methods to predict ship propulsion power at sea. Ocean. Eng. 2022, 245, 110387. [Google Scholar] [CrossRef]
- El Mekkaoui, S.; Benabbou, L.; Caron, S.; Berrado, A. Deep Learning-Based Ship Speed Prediction for Intelligent Maritime Traffic Management. J. Mar. Sci. Eng. 2023, 11, 191. [Google Scholar] [CrossRef]
- Karagiannidis, P.; Themelis, N.; Zaraphonitis, G.; Spandonidis, C.; Giordamlis, C. Ship fuel consumption prediction using artificial neural networks. In Proceedings of the Annual Meeting of Marine Technology Conference Proceedings, Athens, Greece, 26–27 November 2019; pp. 46–51. [Google Scholar]
- Christos, S.C.; Panagiotis, T.; Christos, G. Combined multi-layered big data and responsible AI techniques for enhanced decision support in Shipping. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 669–673. [Google Scholar]
- Sanil, A.P. Principles of Data Mining; Taylor & Francis: Abingdon, UK, 2003. [Google Scholar]
- Alexandropoulos, S.A.N.; Kotsiantis, S.B.; Vrahatis, M.N. Data preprocessing in predictive data mining. Knowl. Eng. Rev. 2019, 34. [Google Scholar] [CrossRef] [Green Version]
- Carlton, J. Marine Propellers and Propulsion; Butterworth-Heinemann: Oxford, UK, 2018. [Google Scholar]
- Kwon, Y. Speed loss due to added resistance in wind and waves. Nav Archit 2008, 3, 14–16. [Google Scholar]
- Townsin, R.; Kwon, Y. Approximate Formulae for the Speed Loss Due to Added Resistance in Wind and Waves; TRB: Washington, DC, USA, 1983. [Google Scholar]
- Molland, A.F.; Turnock, S.R.; Hudson, D.A. Ship Resistance and Propulsion; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Raschka, S.; Liu, Y.H.; Mirjalili, V.; Dzhulgakov, D. Machine Learning with PyTorch and Scikit-Learn: Develop Machine Learning and Deep Learning Models with Python; Packt Publishing Ltd.: Birmingham, UK, 2022. [Google Scholar]
- Cui, Z.; Du, D.; Zhang, X.; Yang, Q. Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data. J. Mar. Sci. Eng. 2022, 10, 1749. [Google Scholar] [CrossRef]
- Hu, Z.; Zhou, T.; Osman, M.T.; Li, X.; Jin, Y.; Zhen, R. A novel hybrid fuel consumption prediction model for ocean-going container ships based on sensor data. J. Mar. Sci. Eng. 2021, 9, 449. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Dong, H.; He, D.; Wang, F. SMOTE-XGBoost using Tree Parzen Estimator optimization for copper flotation method classification. Powder Technol. 2020, 375, 174–181. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Wang, W.; Shao, L.; Ling, H.; Porikli, F. Dynamical Hyperparameter Optimization via Deep Reinforcement Learning in Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1515–1529. [Google Scholar] [CrossRef] [PubMed]
- Yokoyama, A.; Yamaguchi, N. Optimal hyperparameters for random forest to predict leakage current alarm on premises. In Proceedings of the 2019 International Conference on Power, Energy and Electrical Engineering (PEEE 2019), London, UK, 19–21 December 2019; E3S Web of Conferences. EDP Sciences. 2020; Volume 152, p. 03003. [Google Scholar] [CrossRef]
- Carlton, J. Chapter 12—Resistance and Propulsion. In Marine Propellers and Propulsion, 4th ed.; Carlton, J., Ed.; Butterworth-Heinemann: Oxford, UK, 2019; pp. 313–365. [Google Scholar] [CrossRef]
- Babicz, J. Encyclopedia of Ship Technology; Wärtsilä Corporation: Helsinki, Finland, 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| V (knots) | Wind (knots) | Wind () | D (m) | D (m) | T (m) | Wave (m) | Wave () | FCR (tons/h) | |
|---|---|---|---|---|---|---|---|---|---|
| Count | 147,845 | 147,845 | 147,845 | 147,845 | 147,845 | 147,845 | 147,845 | 147,845 | 147,845 |
| Mean | 13.14 | 9.42 | 84.49 | 18.80 | 17.23 | 1.57 | 0.37 | 192.57 | 2.78 |
| Std | 1.92 | 5.23 | 44.46 | 2.92 | 4.22 | 1.44 | 0.25 | 30.53 | 0.97 |
| Min | 10.00 | 0.00 | 0.00 | 11.83 | 7.17 | −0.64 | 0.12 | 133.20 | 0.81 |
| 25% | 11.5 | 5.40 | 54.70 | 19.11 | 16.30 | 0.65 | 0.17 | 200.02 | 2.03 |
| 50% | 13.20 | 8.60 | 79.50 | 20.30 | 19.46 | 0.91 | 0.24 | 204.49 | 2.77 |
| 75% | 14.90 | 11.90 | 112.00 | 20.40 | 19.69 | 2.29 | 0.35 | 211.72 | 3.51 |
| Max | 16.80 | 25.60 | 180.00 | 20.70 | 20.03 | 5.55 | 0.85 | 218.20 | 4.98 |
| Models | Execution Time | Resources |
|---|---|---|
| RF | 9.15 h | 8-core M2 CPU, 24GB RAM |
| XGBoost | 15.04 h |
| XGBoost | RF | |
|---|---|---|
| MSE | 0.0022 | 0.0074 |
| RMSE | 0.0467 | 0.0861 |
| MAE | 0.0308 | 0.0494 |
| MAPE | 1.3268 | 2.0949 |
| 0.9977 | 0.9922 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| RF | 0.9923 | 0.9922 | 0.9920 | 0.9926 | 0.9924 | 0.9923 | 0.9918 | 0.9922 | 0.9921 | 0.9917 |
| XGBoost | 0.9976 | 0.9978 | 0.9978 | 0.9976 | 0.9976 | 0.9976 | 0.9978 | 0.9975 | 0.9979 | 0.9979 |
| XGBoost | |
|---|---|
| MSE | 0.0018 |
| RMSE | 0.0423 |
| MAE | 0.0296 |
| MAPE | 1.7461 |
| 0.9954 |
| No. | T (m) | (m) | (m) | () | (knots) | (m) | () |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 22 | 18 | 56.3 | 5.8 | 0.12 | 30.7 |
| 2 | 4 | 22 | 18 | 128.5 | 13.6 | 0.54 | 45.9 |
| 3 | 4 | 22 | 18 | 48.9 | 12.1 | 0.20 | 78.9 |
| 4 | 4 | 22 | 18 | 162.3 | 14.6 | 0.25 | 59.6 |
| 5 | 4 | 22 | 18 | 146.3 | 18.3 | 0.38 | 153.9 |
| 6 | 4 | 22 | 18 | 65.4 | 21.3 | 0.48 | 153.8 |
| 7 | 4 | 22 | 18 | 175.3 | 22.9 | 0.67 | 198.8 |
| 8 | 4 | 22 | 18 | 170.3 | 16.3 | 0.83 | 37.3 |
| 9 | 4 | 22 | 18 | 140.3 | 15.2 | 0.79 | 67.2 |
| 10 | 4 | 22 | 18 | 100.6 | 10.6 | 0.25 | 87.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Sun, B.; Li, X.; Olsson, T.; Maleki, N.; Ahlgren, F. Fuel Consumption Prediction Models Based on Machine Learning and Mathematical Methods. J. Mar. Sci. Eng. 2023, 11, 738. https://doi.org/10.3390/jmse11040738
Xie X, Sun B, Li X, Olsson T, Maleki N, Ahlgren F. Fuel Consumption Prediction Models Based on Machine Learning and Mathematical Methods. Journal of Marine Science and Engineering. 2023; 11(4):738. https://doi.org/10.3390/jmse11040738
Chicago/Turabian StyleXie, Xianwei, Baozhi Sun, Xiaohe Li, Tobias Olsson, Neda Maleki, and Fredrik Ahlgren. 2023. "Fuel Consumption Prediction Models Based on Machine Learning and Mathematical Methods" Journal of Marine Science and Engineering 11, no. 4: 738. https://doi.org/10.3390/jmse11040738
APA StyleXie, X., Sun, B., Li, X., Olsson, T., Maleki, N., & Ahlgren, F. (2023). Fuel Consumption Prediction Models Based on Machine Learning and Mathematical Methods. Journal of Marine Science and Engineering, 11(4), 738. https://doi.org/10.3390/jmse11040738