

Vulnerability of Clean-Label Poisoning Attack for Object Detection in Maritime Autonomous Surface Ships


Abstract
:1. Introduction
2. Background
2.1. Literature Review
2.2. Contribution of This Paper
3. Theory: Clean-Label Poisoning Attack
- Data collection: An attacker first gathers information about the target model and its training dataset. This can be achieved using public datasets or datasets with distributions similar to those of the target model.
- Poison sample selection: An attacker selects a subset of data points to modify or from which to create new instances. The choice of sample depends on the attacker’s goal, such as targeting a specific class or introducing a specific type of error.
- Data manipulation: An attacker subtly manipulates the selected data points to create poisoned instances. These manipulations can include adding, removing, or modifying features to make the instances appear legitimate while still affecting the learning process of the model.
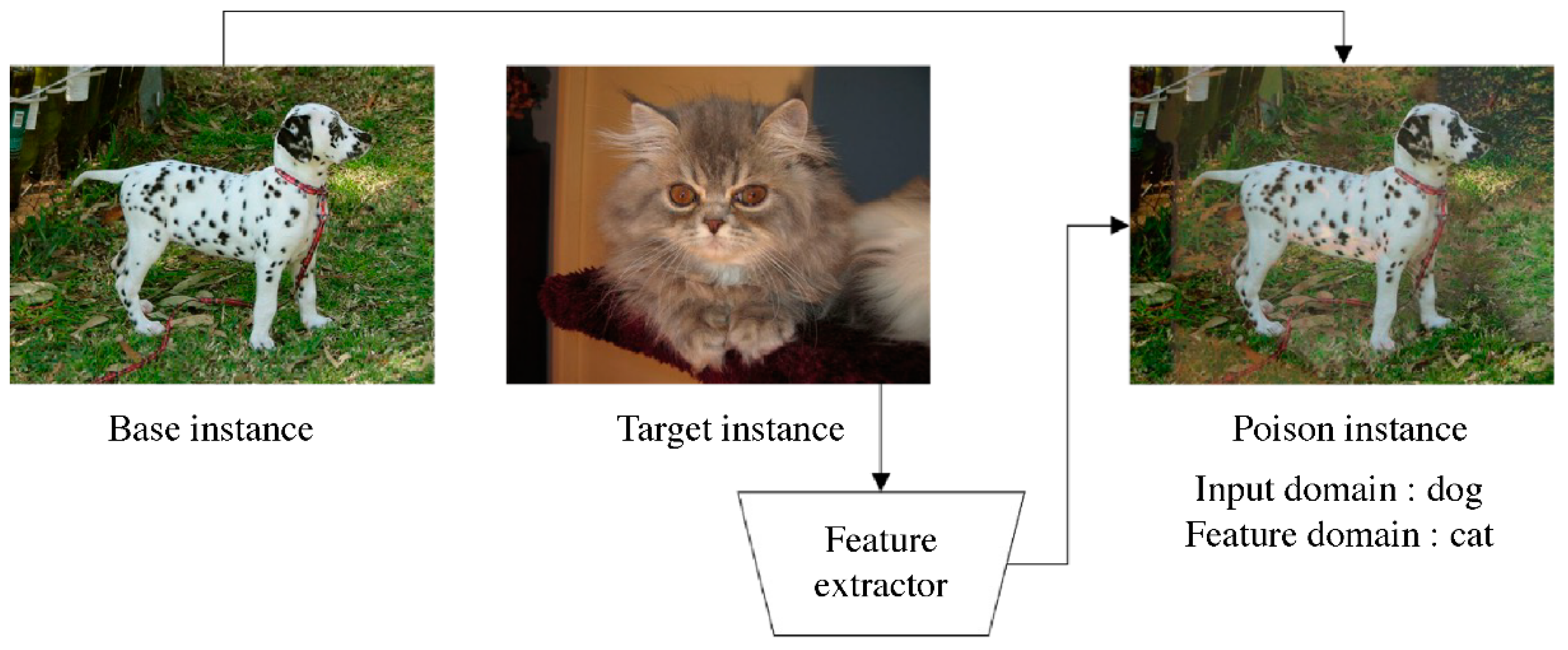
- Injection of poisoned data: The attacker injects manipulated data points into the target model’s training dataset. This can be achieved through various ways, for instance, by compromising the data collection process, infiltrating the data storage system, or leveraging insider access. An attacker can deploy poisoned data or move to the next step and deploy a poisoned model. As shown in Figure 1, the algorithm generates a poisoned instance by extracting the features of the target cat image and applying them to the base dog image. In the input domain, which is visible to the human eye, the instance appears to be a dog, but in the feature domain, which is perceived by AI, the instance appears to be a cat.
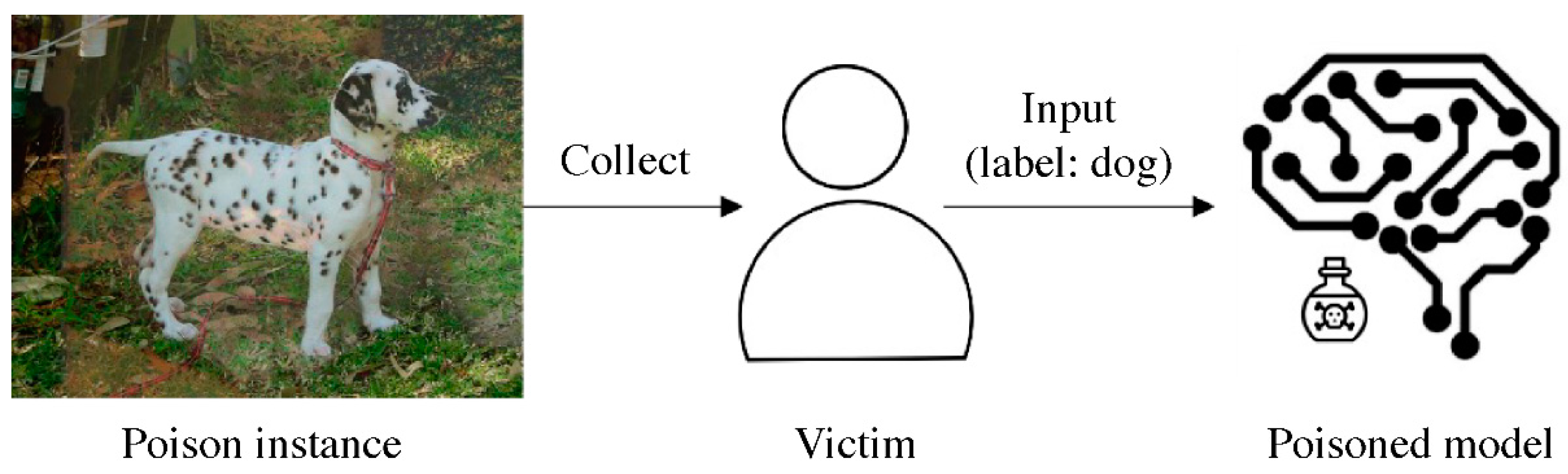
- Model retraining: The target model is retrained with the poisoned dataset by incorporating poisoned instances into its learning process. This typically results in degraded performance or specific errors depending on the attacker’s goals. As shown in Figure 2, the victim collects the poisoned instance, and because there are no apparent anomalies in the image, it is unsuspectingly labeled as a dog and trains the model. In this example, the poisoned instance is exaggerated for the sake of understanding; however, in reality, it is nearly indistinguishable from the base instance.
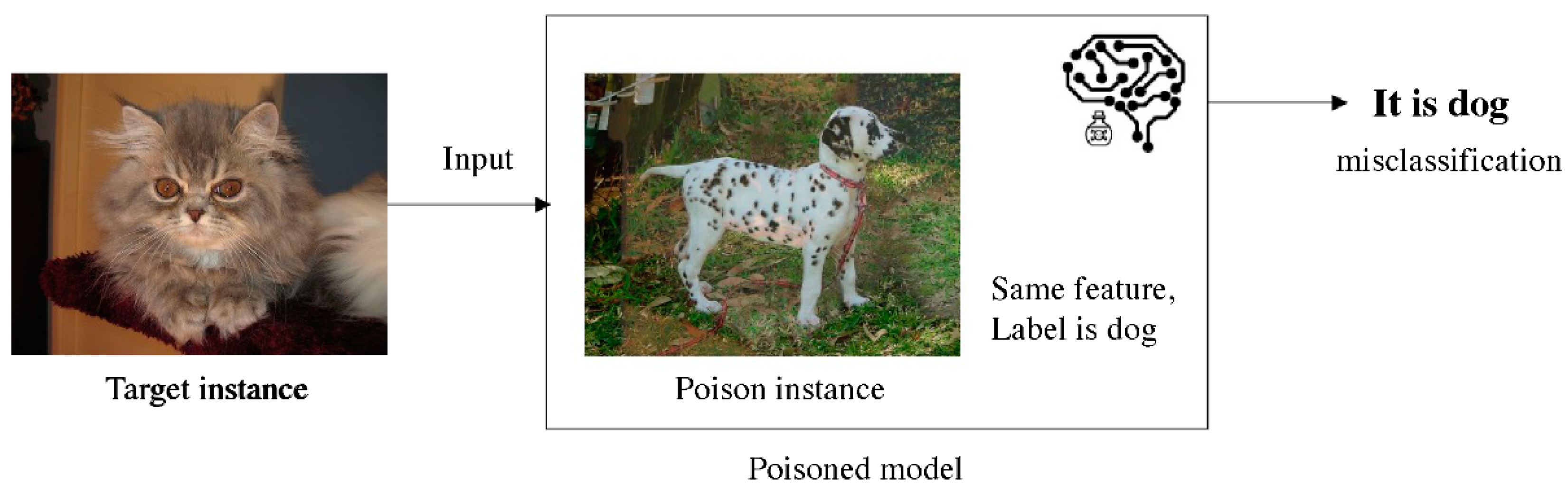
- Exploiting the compromised model: Once the model has been retrained, the attacker exploits the compromised model for their purposes. This can involve causing misclassifications, bypassing security measures, or altering the model’s behavior in other malicious ways. As shown in Figure 3, when an attacker inputs the target instance into the poisoned model, it is classified as the same class as the poisoned instance because they share similar features. Because the label of the poisoned instance is “dog,” the target instance is also classified as “dog,” resulting in misclassification.
4. Methodology
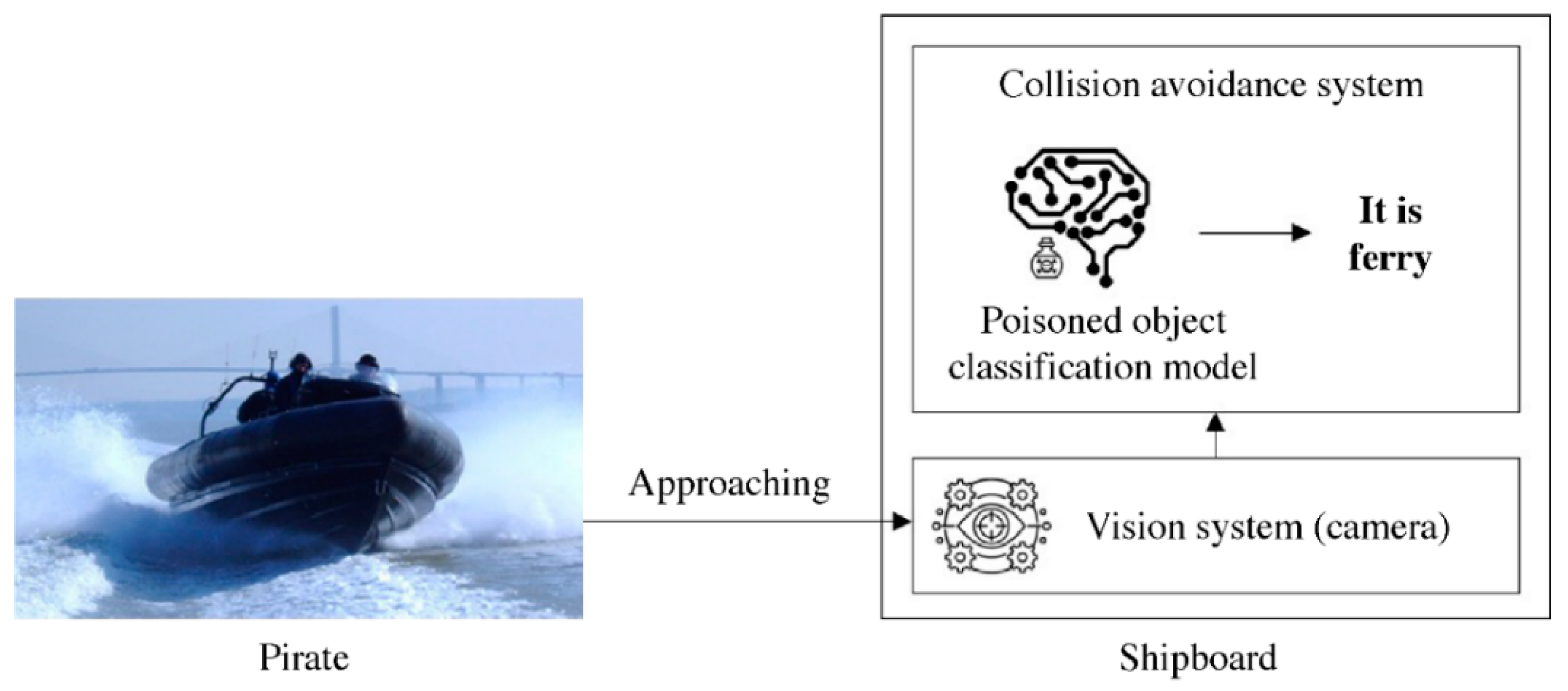
4.1. Proposed Hypothetical Scenario
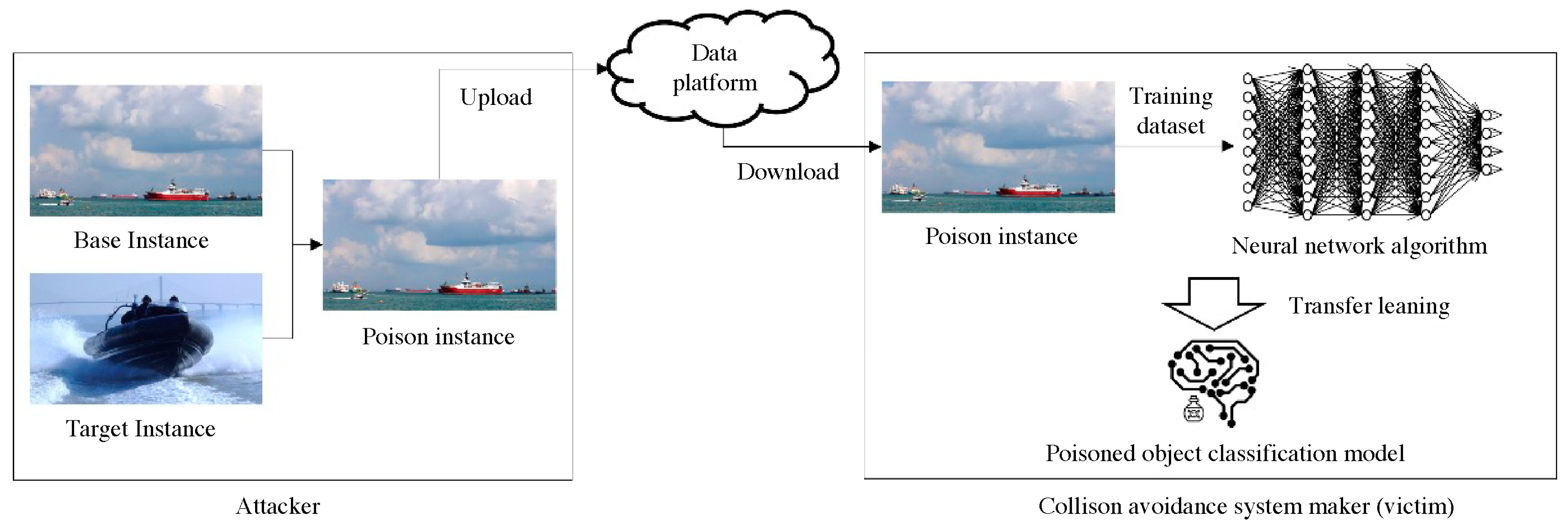
- An attacker captures scenes of a ferry approaching the target vessels for piracy purposes.
- A poisoning image is generated using the clean-label poisoning algorithm with the base image of a boat for each frame of the captured video.
- The attacker uploads the dataset pretending that it is a new trustworthy dataset for object detection.
- The collision avoidance system developer (victim) unknowingly trains their model using the poisoned dataset, which appears normal to the human eye and produces high accuracy during training.
- 5.
- The collision avoidance system, which includes a poisoned-object detection model, is installed on a ship and operates normally.
- 6.
- The pirate uses a boat to approach the target vessel in a real, similar location to the captured scenes.
- 7.
- The poisoned-object detection model is triggered by the poison image and misclassifies the approaching boat as a ferry, thereby failing to detect a boat.
- 8.
- Through this clean-label poisoning attack, the collision avoidance system fails to detect the approaching boat, potentially rendering the target vessel vulnerable to piracy.
4.2. Validation of the Proposed Scenario
5. Results: Experimental Clean-Label Poisoning Attack
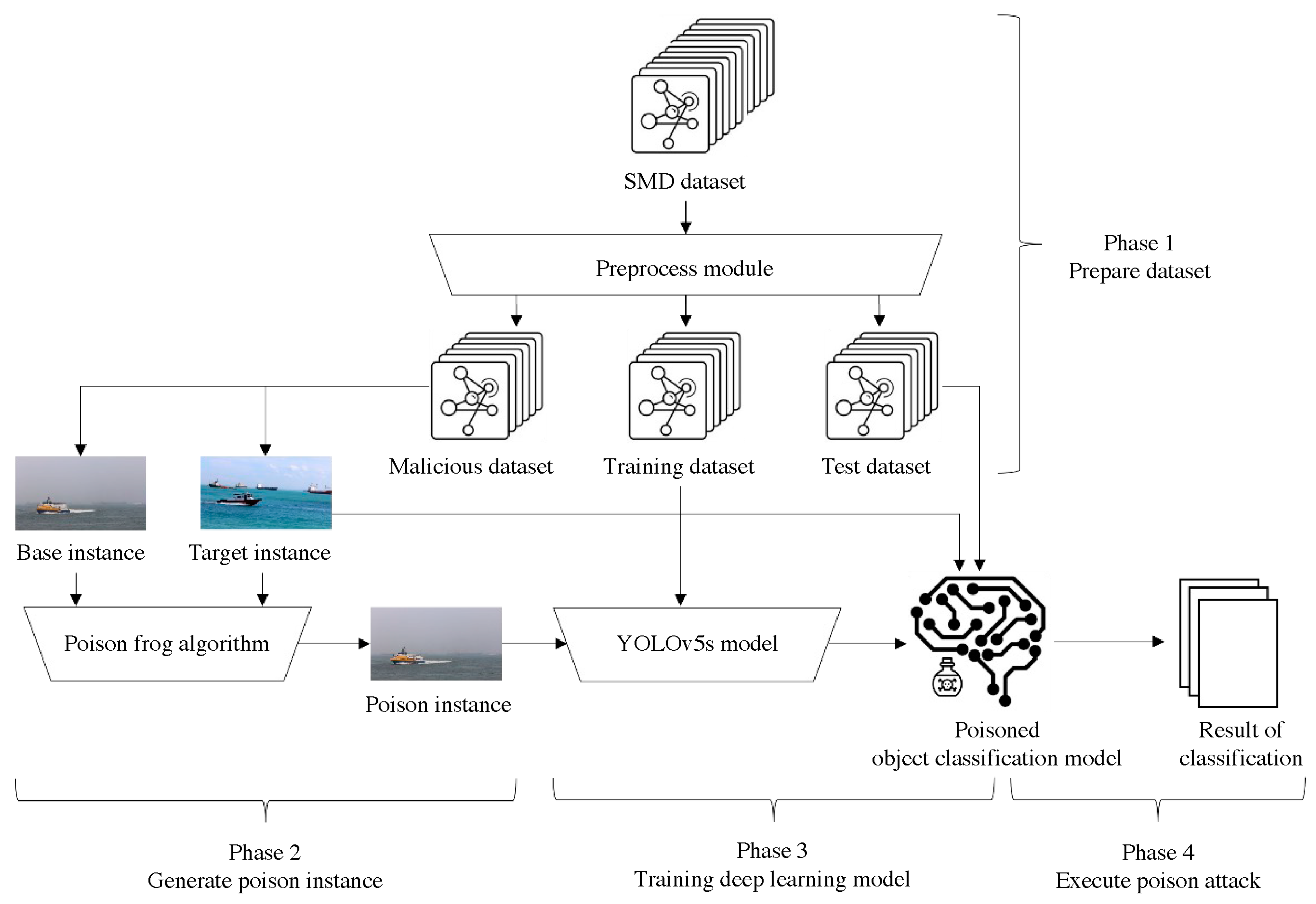
5.1. Dataset Preparation
5.2. Poison Instance Generation
5.3. Deep-Learning Model and Attack Execution
5.4. Result Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akdağ, M.; Solnør, P.; Johansen, T.A. Collaborative collision avoidance for maritime autonomous surface ships: A review. Ocean Eng. 2022, 250, 110920. [Google Scholar] [CrossRef]
- Xu, H.; Moreira, L.; Guedes Soares, C.G. Maritime autonomous vessels. J. Mar. Sci. Eng. 2023, 11, 168. [Google Scholar] [CrossRef]
- Liu, C.; Chu, X.; Wu, W.; Li, S.; He, Z.; Zheng, M.; Zhou, H.; Li, Z. Human–machine cooperation research for navigation of maritime autonomous surface ships: A review and consideration. Ocean Eng. 2022, 246, 110555. [Google Scholar] [CrossRef]
- Qiao, Y.; Yin, J.; Wang, W.; Duarte, F.; Yang, J.; Ratti, C. Survey of deep learning for autonomous surface vehicles in marine environments. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3678–3701. [Google Scholar] [CrossRef]
- Wang, L.; Wu, Q.; Liu, J.; Li, S.; Negenborn, R. State-of-the-art research on motion control of maritime autonomous surface ships. J. Mar. Sci. Eng. 2019, 7, 438. [Google Scholar] [CrossRef] [Green Version]
- Jorge, V.A.M.; Granada, R.; Maidana, R.G.; Jurak, D.A.; Heck, G.; Negreiros, A.P.F.; Dos Santos, D.H.; Gonçalves, L.M.G.; Amory, A.M. A survey on unmanned surface vehicles for disaster robotics: Main challenges and directions. Sensors 2019, 19, 702. [Google Scholar] [CrossRef] [Green Version]
- Cho, S.; Orye, E.; Visky, G.; Prates, V. Cybersecurity Considerations in Autonomous Ships; NATO Cooperative Cyber Defence Centre of Excellence: Tallinn, Estonia, 2022. [Google Scholar]
- ISO/IEC. TR 24028; Information Technology—Artificial Intelligence—Overview of Trustworthiness in Artificial Intelligence. ISO: Geneva, Switzerland, 2020.
- Rekavandi, A.M.; Xu, L.; Boussaid, F.; Seghouane, A.-K.; Hoefs, S.; Bennamoun, M. A Guide to Image and Video based Small Object Detection using Deep Learning: Case Study of Maritime Surveillance. arXiv 2022, arXiv:2207.12926. [Google Scholar]
- Shao, Z.; Lyu, H.; Yin, Y.; Cheng, T.; Gao, X.; Zhang, W.; Jing, Q.; Zhao, Y.; Zhang, L. Multi-scale object detection model for autonomous ship navigation in maritime environment. J. Mar. Sci. Eng. 2022, 10, 1783. [Google Scholar] [CrossRef]
- Yao, Z.; Chen, X.; Xu, N.; Gao, N.; Ge, M. LiDAR-based simultaneous multi-object tracking and static mapping in nearshore scenario. Ocean Eng. 2023, 272, 113939. [Google Scholar] [CrossRef]
- Yang, H.; Xiao, J.; Xiong, J.; Liu, J. Rethinking YOLOv5 with feature correlations for unmanned surface vehicles. In Proceedings of the 2022 International Conference on Autonomous Unmanned Systems (ICAUS 2022); Springer Nature: Singapore, 2023; pp. 753–762. [Google Scholar] [CrossRef]
- Wróbel, K.; Gil, M.; Krata, P.; Olszewski, K.; Montewka, J. On the use of leading safety indicators in maritime and their feasibility for Maritime Autonomous Surface Ships. Proc. Inst. Mech. Eng. Part O 2023, 237, 314–331. [Google Scholar] [CrossRef]
- Li, X.; Oh, P.; Zhou, Y.; Yuen, K.F. Operational risk identification of maritime surface autonomous ship: A network analysis approach. Transp. Policy 2023, 130, 1–14. [Google Scholar] [CrossRef]
- Akpan, F.; Bendiab, G.; Shiaeles, S.; Karamperidis, S.; Michaloliakos, M. Cybersecurity challenges in the maritime sector. Network 2022, 2, 123–138. [Google Scholar] [CrossRef]
- Ben Farah, M.A.; Ukwandu, E.; Hindy, H.; Brosset, D.; Bures, M.; Andonovic, I.; Bellekens, X. Cyber security in the maritime industry: A systematic survey of recent advances and future trends. Information 2022, 13, 22. [Google Scholar] [CrossRef]
- Walter, M.J.; Barrett, A.; Walker, D.J.; Tam, K. Adversarial AI testcases for maritime autonomous systems. AI Comput. Sci. Robot. Technol. 2023, 2, 1–29. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Steinhardt, J.; Koh, P.W.; Liang, P.S. Certified defenses for data poisoning attacks. Adv. Neural Inf. Process. Syst. 2017, 30, 3517–3529. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. Available online: https://arxiv.org/abs/1412.6572 (accessed on 28 May 2023).
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar] [CrossRef] [Green Version]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2018, arXiv:1706.06083. [Google Scholar]
- Turner, A.; Tsipras, D.; Madry, A. Clean-label backdoor attacks. In Proceedings of the ICLR 2019 Conference, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Saha, A.; Subramanya, A.; Pirsiavash, H. Hidden trigger backdoor attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11957–11965. [Google Scholar] [CrossRef]
- Zhao, S.; Ma, X.; Zheng, X.; Bailey, J.; Chen, J.; Jiang, Y.-G. Clean-label backdoor attacks on video recognition models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14431–14440. [Google Scholar] [CrossRef]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Zhu, C.; Huang, W.R.; Li, H.; Taylor, G.; Studer, C.; Goldstein, T. Transferable clean-label poisoning attacks on deep neural nets. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Aghakhani, H.; Meng, D.; Wang, Y.-X.; Kruegel, C.; Vigna, G. Bullseye polytope: A scalable clean-label poisoning attack with improved transferability. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 6–10 September 2021; Volume 2021. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. In Proceedings of the 29th International Conference on Machine Learning (ICML-12), Edinburgh, UK, 26 June–1 July 2012; pp. 1467–1474. [Google Scholar]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.P.; Tygar, J.D. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar] [CrossRef]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses against adversarial examples. In Proceedings of the 2017 Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 281–292. [Google Scholar]
- Yerlikaya, F.A.; Bahtiyar, Ş. Data poisoning attacks against machine learning algorithms. Expert Syst. Appl. 2022, 208, 118101. [Google Scholar] [CrossRef]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. In Proceedings of the 6th International Conference on Learning Representations (ICLR’18), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xiao, H.; Biggio, B.; Brown, G.; Fumera, G.; Eckert, C.; Roli, F. Is feature selection secure against training data poisoning? In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1224–1235. [Google Scholar]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-H.; Kim, N.; Park, Y.W.; Won, C.S. Object detection and classification based on YOLO-V5 with improved maritime dataset. J. Mar. Sci. Eng. 2023, 10, 377. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Original data points x and their true labels y; target model with parameters θ, loss function L(θ, x, y) |
| Output | Poisoned datapoints x* |
| Algorithm | 1. Find poisoned datapoints x* that minimize the distance to the original datapoints while maximizing the model’s loss on the target test point: min_x* D(x, x*) subject to min_θ L(θ, x*, y*) where D(x, x*) denotes a distance metric between the original datapoints x and the poisoned datapoints x*. |
| 2. Compute the gradient of the inner optimization problem with respect to the poisoned datapoints using the implicit function theorem: ∇_x* L(θ*, x*, y*) = −H(θ*, x*, y*)−1 * J(θ*, x*, y*) where θ* denotes the optimal model parameters, H(θ*, x*, y*) denotes the Hessian matrix of the loss function, and J(θ*, x*, y*) denotes the Jacobian matrix of the loss function with respect to the poisoned datapoints. | |
| 3. Iteratively update the poisoned datapoints using the computed gradient: x*^(t + 1) = x*^(t) − α * ∇_x* L(θ*, x*^(t), y*) where x*^(t) denotes the poisoned datapoints at iteration t, α denotes the learning rate, and ∇_x* L(θ*, x*^(t), y*) denotes the computed gradient. | |
| 4. Repeat steps 2 and 3 until convergence or a predefined number of iterations. | |
| 5. Inject the generated poisoned datapoints x* into the training dataset and retrain the target model. |
| Class | Class Identifier | Number of Objects |
|---|---|---|
| Boat | 1 | 14,021 |
| Vessel/ship | 2 | 125,872 |
| Ferry | 3 | 3431 |
| Kayak | 4 | 3798 |
| Buoy | 5 | 3657 |
| Sailboat | 6 | 1926 |
| Others | 7 | 24,993 |
| Class | Precision | Recall | mAP@0.5 |
|---|---|---|---|
| All | 0.894 | 0.797 | 0.858 |
| Boat | 0.992 | 0.886 | 0.937 |
| Vessel/ship | 0.894 | 0.941 | 0.960 |
| Ferry | 0.833 | 0.862 | 0.855 |
| Kayak | 0.737 | 0.467 | 0.590 |
| Buoy | 1.000 | 0.789 | 0.895 |
| Sailboat | 0.902 | 1.000 | 0.995 |
| Others | 0.901 | 0.630 | 0.772 |
| Source | Input Images | Not Detected | Misclassified |
|---|---|---|---|
| MVI_1469_VIS.avi | 528 | 2 | 0 |
| MVI_1470_VIS.avi | 168 | 0 | 168 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.; Lee, S. Vulnerability of Clean-Label Poisoning Attack for Object Detection in Maritime Autonomous Surface Ships. J. Mar. Sci. Eng. 2023, 11, 1179. https://doi.org/10.3390/jmse11061179
Lee C, Lee S. Vulnerability of Clean-Label Poisoning Attack for Object Detection in Maritime Autonomous Surface Ships. Journal of Marine Science and Engineering. 2023; 11(6):1179. https://doi.org/10.3390/jmse11061179
Chicago/Turabian StyleLee, Changui, and Seojeong Lee. 2023. "Vulnerability of Clean-Label Poisoning Attack for Object Detection in Maritime Autonomous Surface Ships" Journal of Marine Science and Engineering 11, no. 6: 1179. https://doi.org/10.3390/jmse11061179
APA StyleLee, C., & Lee, S. (2023). Vulnerability of Clean-Label Poisoning Attack for Object Detection in Maritime Autonomous Surface Ships. Journal of Marine Science and Engineering, 11(6), 1179. https://doi.org/10.3390/jmse11061179