Abstract
Coastal areas face severe corrosion issues, posing significant risks and economic losses to equipment, personnel, and the environment. YOLO v5, known for its speed, accuracy, and ease of deployment, has been employed for the rapid detection and identification of marine corrosion. However, corrosion images often feature complex characteristics and high variability in detection targets, presenting significant challenges for YOLO v5 in recognizing and extracting corrosion features. To improve the detection performance of YOLO v5 for corrosion image features, this study investigates two enhanced models: EfficientViT-NWD-YOLO v5 and Gold-NWD-YOLO v5. These models specifically target improvements to the backbone and neck structures of YOLO v5, respectively. The performance of these models for corrosion detection is analyzed in comparison with both YOLO v5 and NWD-YOLO v5. The evaluation metrics including precision, recall, F1-score, Frames Per Second (FPS), pre-processing time, inference time, non-maximum suppression time (NMS), and confusion matrix were used to evaluate the detection performance. The results indicate that the Gold-NWD-YOLO v5 model shows significant improvements in precision, recall, F1-score, and accurate prediction probability. However, it also increases inference time and NMS time, and decreases FPS. This suggests that while the modified neck structure significantly enhances detection performance in corrosion images, it also increases computational overhead. On the other hand, the EfficientViT-NWD-YOLO v5 model shows slight improvements in precision, recall, F1-score, and accurate prediction probability. Notably, it significantly reduces inference and NMS time, and greatly improves FPS. This indicates that modifications to the backbone structure do not notably enhance corrosion detection performance but significantly improve detection speed. From the application perspective, YOLO v5 and NWD-YOLO v5 are suitable for routine corrosion detection applications. Gold-NWD-YOLO v5 is better suited for scenarios requiring high precision in corrosion detection, while EfficientViT-NWD-YOLO v5 is ideal for applications needing a balance between speed and accuracy. The findings can guide decision making for corrosion health monitoring for critical infrastructure in coastal areas.
1. Introduction
Coastal structures, such as port facilities, offshore platforms, and coastal bridges, often face harsh marine environments, including salt spray, wave impact, and microbial activity. These factors accelerate the corrosion of structures. Corrosion leads to significant economic losses and can cause equipment failure, resulting in toxic leaks, fires, and explosions [1,2]. Accurate and efficient detection methods help quickly identify potential corrosion issues in structures, preventing structural failures and disasters [3,4].
Many researchers have utilized image recognition technology to detect corrosion, employing methods such as traditional color space detection [5,6], metal corrosion area calculations [7,8,9], region classification [10], and morphology analysis [11]. Recent advancements in artificial intelligence, particularly machine learning and deep learning, have introduced new approaches for corrosion detection and evaluation [12,13,14,15,16]. Machine vision, a branch of artificial intelligence, uses algorithms and statistical models to recognize patterns and make predictions based on training datasets, enabling systems to learn and improve performance [17,18]. Numerous studies have applied machine vision in metal corrosion detection, significantly advancing detection, morphology analysis, and identification due to developments in computer vision algorithms [19,20,21]. The increasing application of deep learning in machine vision has also expanded its use in corrosion research. Common methods include convolutional neural networks (CNNs), U-Net, Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs). CNNs excel in image processing and pattern recognition, effectively extracting features and identifying corrosion areas [22,23]. U-Net, widely used for image segmentation, enables the precise segmentation and quantitative analysis of corrosion areas [23,24]. RNNs capture long-term dependencies in time-series data, making them useful for predicting corrosion behavior under varying conditions [25]. Additionally, researchers have combined traditional machine learning algorithms, such as Random Forest and Support Vector Machines, with CNNs to enhance corrosion detection and prediction accuracy [26].
With the development of deep learning technology, the “You Only Look Once” (YOLO) algorithm has gained significant attention and rapid development due to its notable advantages in speed and accuracy. Introduced by Redmon et al. in 2016, YOLO is a real-time object detection algorithm and a single-stage detection method [27]. Over time, it has evolved into multiple versions, from YOLO v1 to YOLO v9 [28]. Although the more advanced YOLO series algorithms, including YOLO v6, v7, v8, and v9, demonstrate better results in image detection and recognition tasks, YOLO v5 still has some obvious advantages as a basic model. For example, YOLO v5’s lightweight design and fast inference capabilities make it suitable for real-time detection in resource-constrained environments. The training and deployment process for YOLO v5 is relatively straightforward, allowing users to easily adjust the model to fit specific datasets and thereby improve recognition accuracy. YOLO v5’s simpler architecture makes it easier for users to debug and understand model behavior. Furthermore, YOLO v5 has been extensively tested and validated, with a more mature framework that is well suited for rapid experimentation and improvement. Additionally, YOLO v5 excels in small object detection tasks, and its relatively low computational complexity allows it to maintain a good balance between performance and speed when hardware resources are limited. Thus, YOLO v5 is widely applied due to its speed, accuracy, and ease of deployment. Recently, YOLO v5 has shown excellent performance in corrosion detection, particularly for pipelines, bridges, ships, and other structures or equipment. YOLO v5’s design makes it user-friendly and adaptable to various training and deployment scenarios. It supports 16-bit floating-point precision, which reduces memory usage and improves training speed without sacrificing accuracy, making it particularly beneficial for large datasets [29]. Compared to traditional CNN, U-Net, and RNN, YOLO v5 exhibits higher real-time performance and better detection accuracy in image recognition. However, YOLO v5 has some limitations. To further enhance its performance and adapt to various application needs, researchers have focused on improving its model structure. These improvements mainly target the backbone, neck, head, and loss functions of YOLO v5. The backbone and neck components are particularly important due to their significant advantages in multi-scale feature fusion and overall model performance enhancement. Consequently, optimizing and refining the backbone and neck parts of the model has become the primary direction for improving the traditional YOLO v5 model [30].
The backbone network, serving as the feature extraction component of YOLO v5, significantly impacts its detection performance. By improving the backbone network, YOLO v5’s detection effectiveness can be enhanced [31]. Addressing YOLO v5’s limitations in small object detection, Benjumea et al. proposed YOLO-Z, which improves the YOLO v5 architecture to enhance its ability to detect small objects [32]. Gong et al. introduced the Swin Transformer and attention mechanisms into YOLO v5, improving its performance in detecting small objects in satellite images [33]. Considering the need to deploy models on resource-constrained devices, researchers have introduced model compression techniques to create lightweight models without compromising performance. Jani et al. reviewed YOLO v5’s model compression methods, discussing techniques such as quantization, pruning, and distillation, and analyzed their effectiveness in various application scenarios [34]. Ren et al. proposed YOLO v5-R, which optimizes YOLO v5’s structure for lightweight real-time detection, reducing computational costs while maintaining high detection accuracy [35]. Additionally, some researchers have introduced attention mechanisms to enhance YOLO v5’s accuracy and efficiency in small object detection and post-compression scenarios. Sun et al. proposed a hybrid attention mechanism-optimized YOLO v5 model, incorporating channel and spatial attention to improve the model’s feature extraction capability and detection performance [36].
Recent improvements to the neck component of YOLO v5 primarily focus on feature fusion, lightweight design, and multi-scale detection. Wang et al. (2023) introduced image enhancement techniques and adaptive threshold segmentation methods, proposing an improved YOLO v5 algorithm for object detection in low-light environments [27]. Zhou et al. (2023) proposed Small Target-YOLO v5, which integrates multi-scale feature fusion and attention mechanisms to detect small targets in drone aerial images [37]. Shan et al. (2023) adopted new data augmentation methods and optimized loss functions, presenting an improved YOLO v5 algorithm to enhance detection accuracy under varying lighting conditions and complex backgrounds [38]. Mei and Chen (2023) proposed an improved lightweight submarine target detection algorithm based on the YOLO v5 architecture, employing MobileNetV3 feature pyramids and C3_DS modules to reduce computational complexity while improving detection accuracy [39]. Wang et al. (2023) introduced depth-wise separable convolutions and an improved C2f_DG module into the backbone network, proposing an ML-YOLO v5-based insulator defect detection algorithm [40]. Liu et al. (2023) developed a lightweight object detection algorithm, BiGA-YOLO, for autonomous driving scenarios by incorporating Ghost-Hardswish convolution modules, coordinate attention mechanisms, and replacing the PANet structure with a BiFPN structure [41].
In addition to improvements in the backbone and neck components, researchers have also focused on enhancing the head component of YOLO v5 to improve detection performance. Wang et al. (2024) proposed an improved YOLO v5 algorithm that combines the CoordConv module, which is applied for real-time fish yield prediction [42]. Zhu et al. (2021) introduced a Transformer Prediction Head, resulting in the TPH-YOLO v5 model suitable for complex scenes captured by drones [43]. Wan et al. (2023) developed the YOLO-HR model by incorporating a multi-head strategy and hybrid attention modules for target detection in high-resolution remote sensing images [44]. Li et al. (2023) proposed the GBH-YOLO v5 model, which includes Ghost convolution, BottleNeckCSP structure, and a small object prediction head to enhance the accuracy and speed of photovoltaic panel defect detection [45]. Moreover, some researchers have focused on improving the loss function of the traditional YOLO v5 model to enhance the detection accuracy and computational speed. Huang et al. (2023) proposed an improved YOLO v5 model by replacing the traditional CIOU (Complete Intersection over Union) loss function with Focal EIOU (Extended Intersection over Union), achieving a 4.3% increase in detection accuracy [46]. Zhang and Liu (2024) addressed small object detection issues by improving the loss function and optimizing the network structure, resulting in an enhanced YOLO v5 algorithm with better detection accuracy in complex backgrounds [47]. Jin et al. (2021) introduced Distributed Focal Loss (DFL) in the YOLO v5 model, combining multi-scale feature extraction and attention mechanisms to improve performance in small object detection [48]. Jung and Choi (2022) proposed an improved YOLO v5 algorithm by optimizing the loss function and incorporating various attention mechanisms to enhance detection performance in low-light and complex backgrounds [49].
Although there have been numerous mature studies and applications focused on improving YOLO v5, there are still certain limitations in terms of accuracy, speed, complexity, and generalization capability. Some improved models, such as those incorporating the SPP module and lightweight neck designs, have optimized computational load to some extent but still face issues with excessive parameters. In particular, the infrastructure in marine environments presents diverse and complex corrosion features, ranging from small pitting to extensive uniform corrosion, making it challenging to detect these corrosion characteristics quickly and accurately. Different models perform variably on specific datasets, and given the complex corrosion characteristics of marine infrastructure, it is necessary to study the YOLO v5 model in combination with specific corrosion feature data. This will help explore the application effects of various improvement methods in metal corrosion detection. Therefore, this study aims to investigate the detection performance and effectiveness of improved YOLO v5 models in marine metal corrosion detection, focusing on improvements to the backbone and neck structures. In addition, this study also tries to give preliminary recommendations for the application of an improved YOLO v5 model in corrosion feature detection tasks based on the evaluation results. To investigate the effects of enhancing the backbone structure on the performance of the YOLO v5 model, an EfficientViT module was introduced to form a new model called EfficientViT-NWD-YOLO v5. Additionally, to examine how improvements to the neck structure influence YOLO v5’s performance, we utilized the GOLD-NWD-YOLO v5 model proposed in our previous study [50] which aimed at validating the detection capabilities of the proposed model and analyzing the corrosion protection effects of different coatings. The study could be helpful in providing guidance for the application and development of YOLO v5 object detection algorithms in marine metal corrosion detection.
2. Materials and Methods
2.1. Research Framework
This study utilizes natural environment corrosion data from the Zhoushan seawater station, provided by the National Materials Corrosion and Protection Data Center of China, to construct a corrosion-labeled image dataset using data processing techniques including data augmentation techniques and image annotation techniques. The labeled corrosion image dataset is used to train and validate the proposed model. Please note that the corrosion image data utilized for model learning and training in this study is identical to the dataset used in our previous research [50]. Consequently, we will not provide details on data collection, processing, and annotation here. For more information, please refer to study [50].
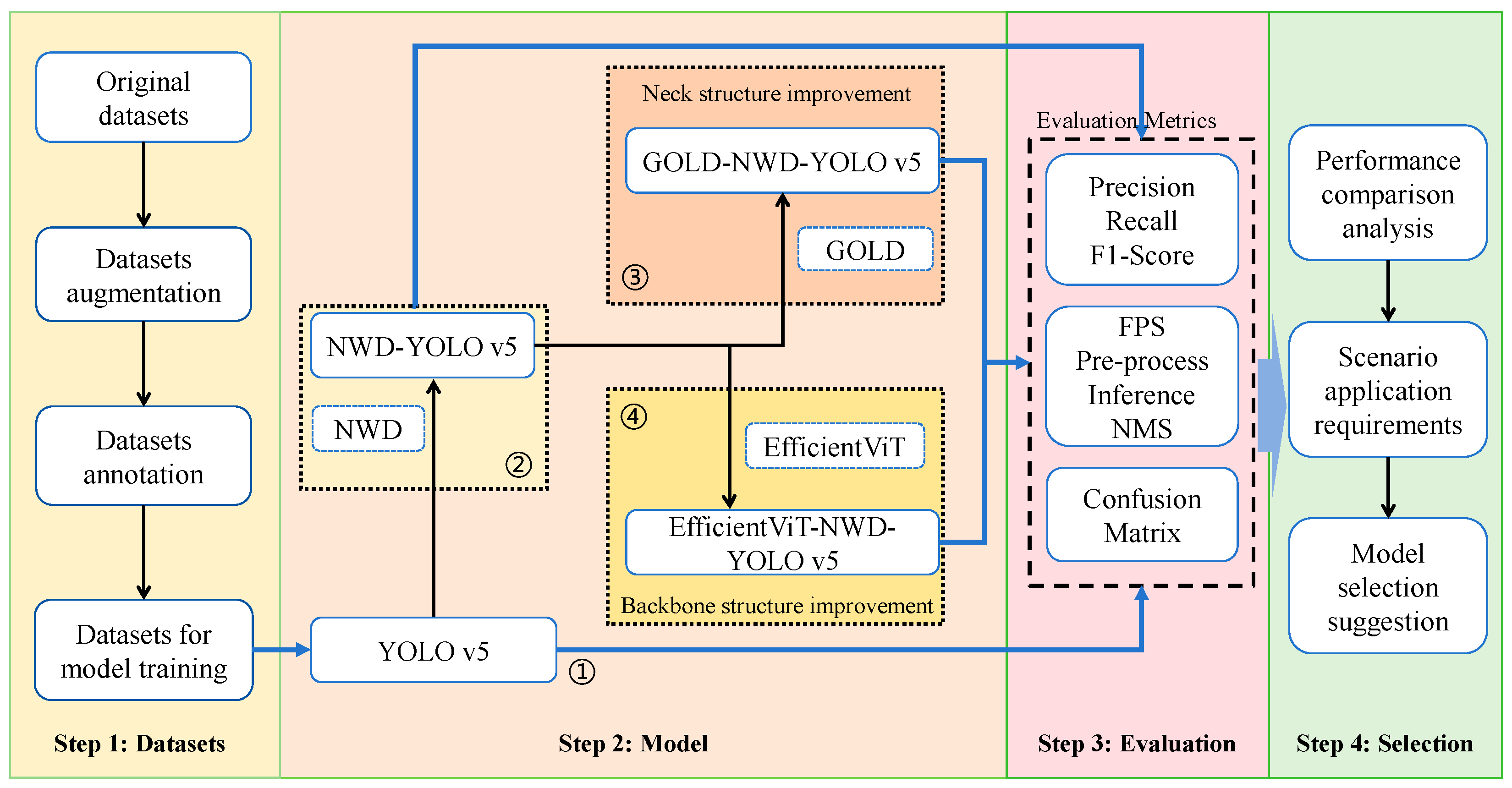
As mentioned above, this study primarily aims to explore how to enhance the YOLO v5 model from the backbone and neck perspectives. To investigate the effects of enhancing the backbone structure on the performance of the YOLO v5 model, EfficientViT was introduced, along with a lighter version named EfficientViT-NWD-YOLO v5. Furthermore, to assess how improvements to the neck structure influence the performance of YOLO v5, the GOLD-NWD-YOLO v5 model from a previous study was utilized, which is an improved model by enhancing neck structure. To evaluate the performance characteristics of the model, a comparative analysis of these two models against the traditional YOLO v5 model and another basic model, NWD-YOLO v5, was conducted. Figure 1 illustrates the basic framework of the study.
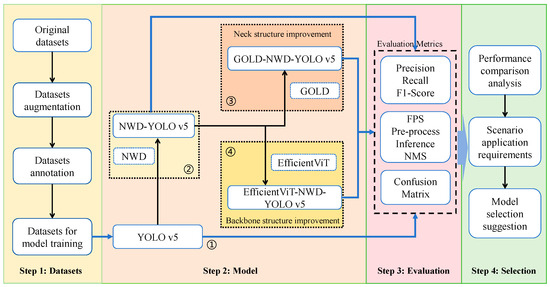
Figure 1.
Research flow chart.
2.2. Model Improvements
YOLO v5 is known for its impressive speed and accuracy, making it particularly suitable for real-time applications. Its architecture features three main components: the backbone, which utilizes CSPNet (Cross Stage Partial Networks) for efficient feature extraction; the neck, which employs PANet (Path Aggregation Network) to enhance feature fusion across scales; and the head, responsible for predicting bounding boxes and class scores. The network architecture of the traditional YOLO v5 can be found in the previous research work [50]. In the context of corrosion detection, YOLO v5 can be trained on datasets containing images of corroded surfaces, enabling it to identify and localize corrosion in real time. This capability is invaluable for infrastructure inspection, maintenance planning, and enhancing safety by allowing for timely interventions based on accurate corrosion assessments.
In the YOLO v5 model architecture, the optimization of bounding boxes is primarily achieved using the Complete Intersection over Union (CIoU) loss function. The CIoU loss function addresses the localization instability associated with traditional IoU loss by considering both the intersection over the union of the bounding boxes and the distance between their center points. Despite its advantages, the CIoU loss function still faces challenges in detecting small objects. For tiny targets, even a minor positional deviation of the bounding box can result in a significant decrease in IoU, leading to inaccurate label assignments. In contrast, for normally sized targets, the effect of bounding box positional deviations on IoU is relatively minimal, as the position changes only discretely. Consequently, there is a need to refine the bounding box optimization process to enhance IoU sensitivity for small targets, thereby improving the accuracy of label assignments.
The Normalized Gaussian Wasserstein Distance (NWD) loss function introduces an anchor-free strategy that directly predicts the position and size of the target, thereby eliminating the adaptability issues commonly associated with traditional anchor designs. Furthermore, the feature extraction network has been enhanced in both width and depth to better capture corrosion features, particularly the intricate details of small target corrosion areas. By modeling the bounding boxes as Gaussian distributions and calculating the Wasserstein distance between these distributions, the NWD loss function facilitates a more stable and balanced training process, ultimately improving the model’s performance in detecting small targets. The detailed calculation of the NWD loss function can be found in reference [50].
The resulting NWD-YOLO v5 model not only optimizes the process of quantifying differences between bounding boxes but also effectively captures fine details of small targets, improving the detection accuracy for small objects. Additionally, by considering information from all the targets in the image, it enhances the overall understanding of the relationship between small targets and other objects. However, the NWD-YOLO v5 model also has some limitations. For instance, the model’s computational complexity is relatively high, which can lead to increased training time. Furthermore, the model requires a more complex feature extraction network to fully leverage its advantages, which might limit its use in resource-constrained applications.
To address the issues and enhance model performance, typical approaches involve making overall or localized improvements to the model. The most common strategies include improving the neck or backbone structures of the model. In the YOLO v5 architecture, the neck module enhances the model’s ability to recognize small targets through multi-scale feature fusion, thereby increasing robustness when handling complex scenes. Conversely, the backbone module employs deeper network structures to capture richer feature information, improving the model’s sensitivity to detailed features. For the enhanced YOLO v5 model that focuses on improving the neck structure, the GOLD-NWD-YOLO v5 model was used and further details regarding this model can be found in [50].
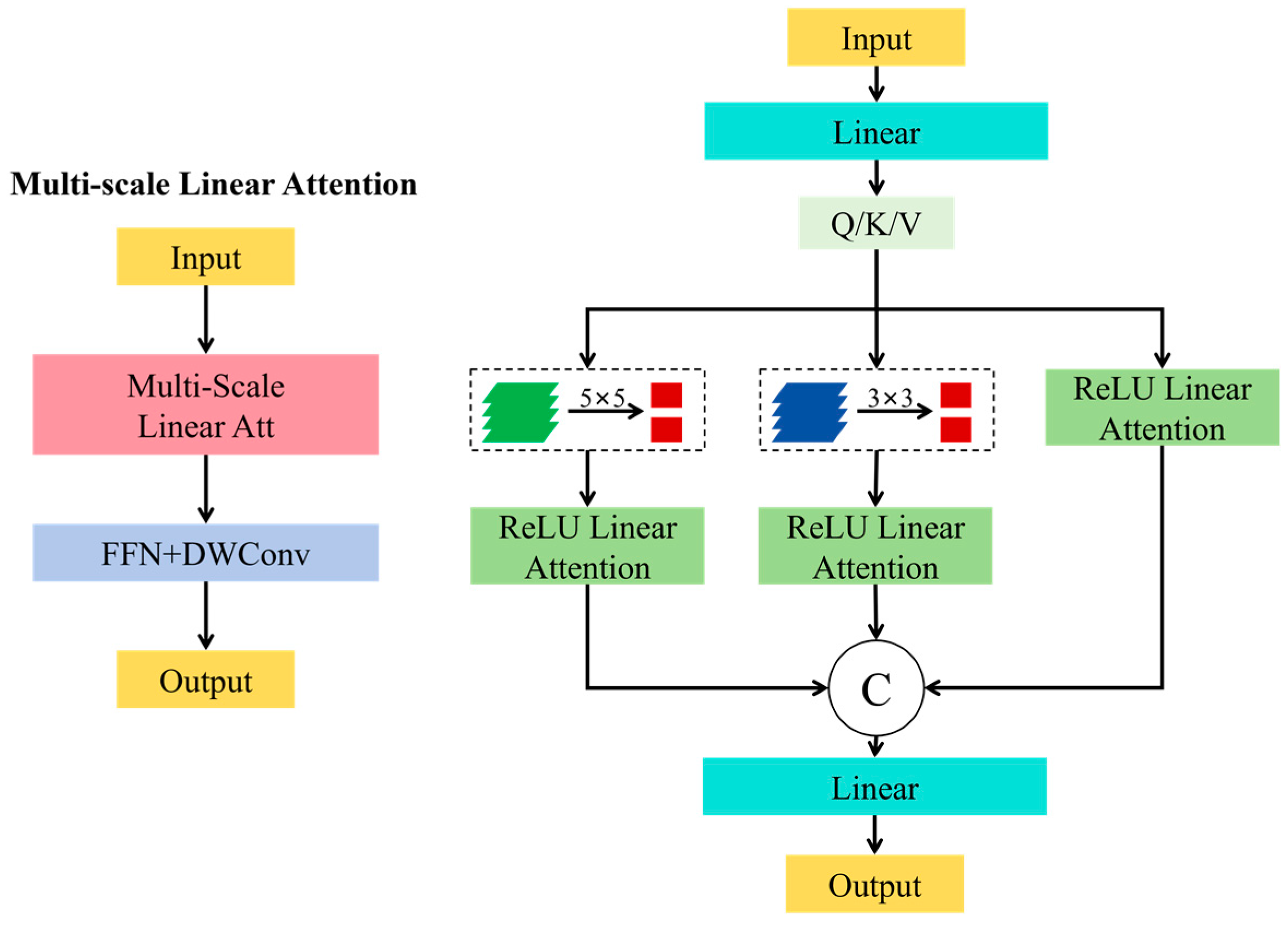
Based on the NWD-YOLO v5 model, this study introduces the EfficientViT for high-resolution dense prediction according to [51], resulting in a new, improved model named EfficientViT-NWD-YOLO v5 which focuses on the improvement of the backbone of the YOLO v5 model. Unlike the existing high-resolution dense prediction models that rely on extensive SoftMax attention, inefficient large-kernel convolutions, or complex topologies, this improvement model includes a multi-scale linear attention module. This module achieves global receptive fields and multi-scale learning without compromising hardware efficiency. Specifically, a lightweight ReLU linear attention mechanism was used here. To further enhance its ability to capture detailed information, convolution operations are integrated to strengthen the ReLU linear attention. This is achieved by embedding deep convolution layers within each feed-forward neural network (FFN) layer.
Figure 2 (left) shows the core architecture of EfficientViT, which combines the multi-scale linear attention module and the feed-forward neural network integrated with deep convolution (i.e., FFN+DWConv). The multi-scale linear attention is responsible for understanding contextual information, while the FFN+DWConv focuses on capturing details and local information. Figure 2 (right) illustrates the specific construction modules of the EfficientViT architecture. The input image data are processed by a linear projection layer to generate Q/K/V vectors. These vectors first undergo lightweight convolution operations for small-scale convolution kernel aggregation, forming multi-scale vectors. They are then processed by ReLU linear attention and aggregated through concatenation operations, and ultimately sent to the linear projection layer for deep feature fusion.
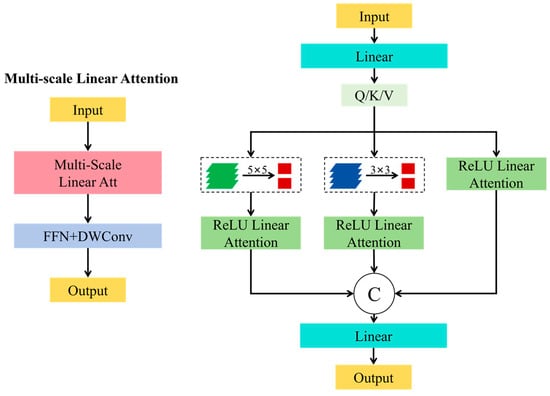
Figure 2.
Multi-scale linear attention (left) and EfficientViT modules (right).
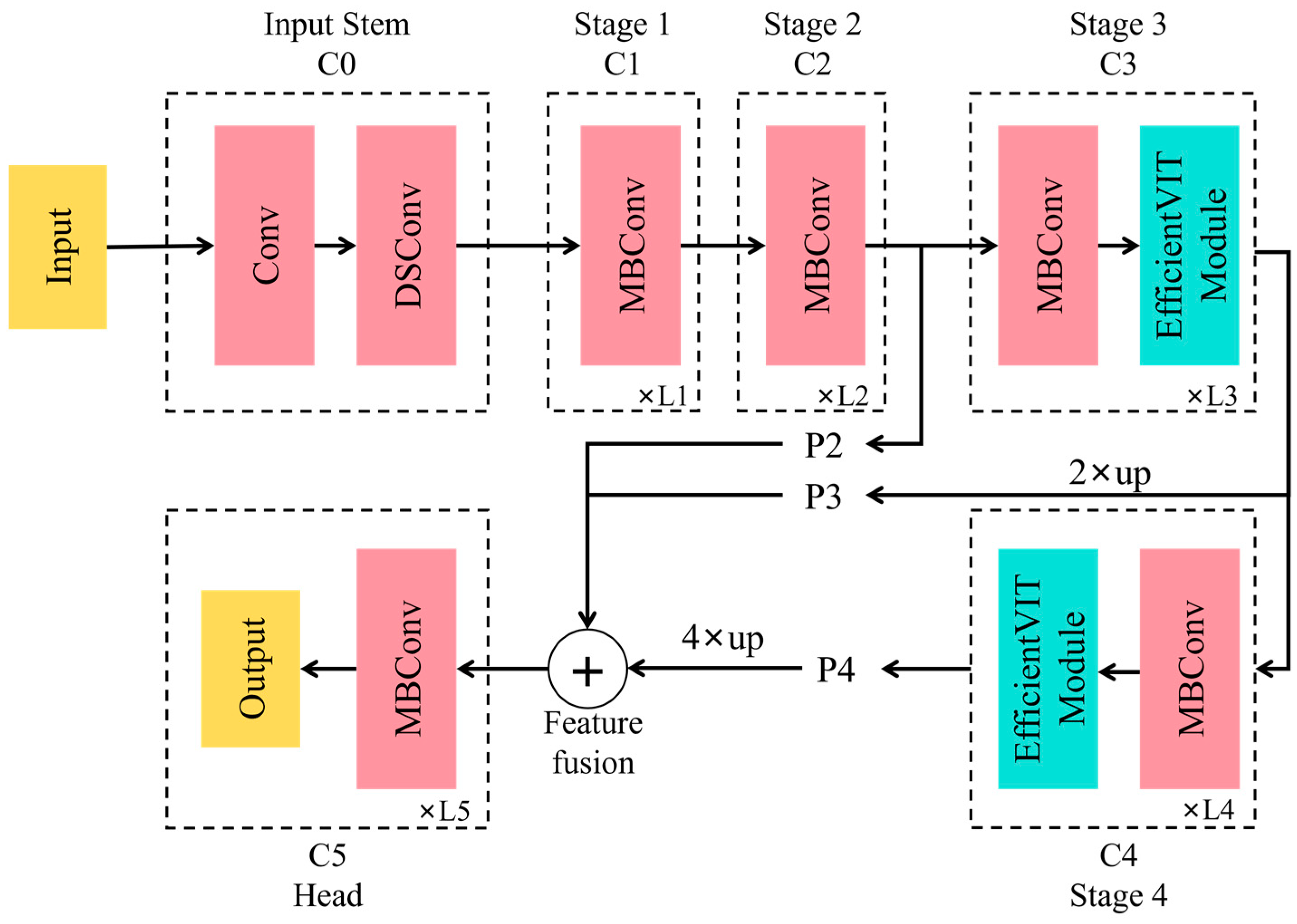
Figure 3 illustrates the overall architecture of EfficientViT-NWD-YOLO v5. Its backbone adopts a standard layout, including an input layer and four stages, which progressively reduce the feature map size while increasing the number of channels. The EfficientViT modules are inserted in the third and fourth stages, utilizing MBConv blocks with a stride of 2 for feature map downsampling. This structure ensures that the backbone network effectively extracts contextual information from images and performs excellently in dense prediction tasks.
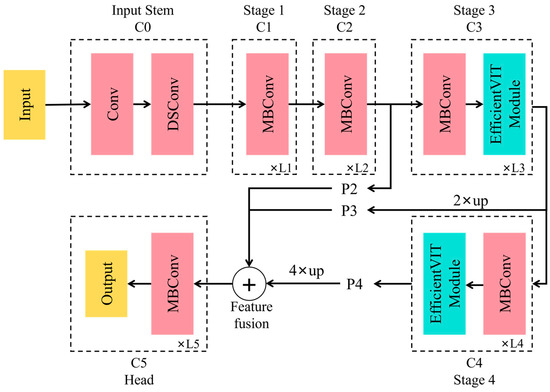
Figure 3.
Architecture of EfficientViT-NWD-YOLO v5.
Specifically, the outputs from stages 2, 3, and 4 (i.e., P2, P3, and P4) form a feature map pyramid. These feature maps are then adjusted in the spatial and channel dimensions through 1 × 1 convolution and standard upsampling techniques such as bilinear or bicubic upsampling. Next, additional operations are used for feature fusion, ensuring that information from all the stages is fully utilized and transmitted to the head structure of the network. The head includes several MBConv blocks and output layers for prediction and upsampling.
Therefore, the models ultimately used for comparative analysis in this study are YOLO v5, NWD-YOLO v5, Gold-NWD-YOLO v5, and EfficientViT-NWD-YOLO v5. Among these, YOLO v5 and NWD-YOLO v5 serve as baseline models to validate the improvement effects of the two models. Gold-NWD-YOLO v5 was proposed in the literature [50] and serves as the main comparison model for the EfficientViT-NWD-YOLO v5 model introduced in this study, with some performance evaluation results referencing the findings from the literature [50]. By comparing the performance of these four models in the corrosion image feature detection task, this study analyzes the corrosion feature detection effects of the two improvement methods on the YOLO v5 and NWD-YOLO v5 models.
2.3. Evaluation Metrics
To evaluate the performance of the GOLD-NWD-YOLO v5 model and the newly proposed EfficientViT-NWD-YOLO v5 model, this study compares them against the YOLO v5 model and the NWD-YOLO v5 model. The evaluation metrics used include precision, recall, F1-score, Frames Per Second (FPS), pre-processing time, inference time, non-maximum suppression time, and the prediction probability from the confusion matrix.
Precision refers to the proportion of true positive detections among all the predicted positive instances. It reflects the ability of models to accurately predict positive cases. A precision of 0 means that all the positive predictions made by the model are incorrect, while a precision of 1 indicates that all the positive predictions are correct. High precision indicates that the model has a low false positive rate, meaning that a high proportion of the predicted positives are actual positives. Recall measures the proportion of true positive detections among all the actual positive instances. It indicates the model’s ability to identify positive cases. A higher recall means the model effectively identifies most of the actual positive samples. F1-score is the harmonic means of precision and recall, providing a single metric that considers both precision and recall. It evaluates the ability of models to maintain a balance between precision and recall.
In the field of image processing, in addition to the traditional evaluation metrics mentioned above, FPS (Frames Per Second) is another important performance indicator. FPS measures the speed at which a system processes input frames. Here, FPS specifically evaluates the speed of an image processing system or algorithm in handling continuous sequences of images. The range and significance of FPS can vary depending on the specific image processing application.
FPS is directly linked to the real-time performance of algorithms and the user experience of applications. Different application scenarios have varying FPS requirements. When designing and evaluating image processing systems, it is essential to consider the specific needs of the task and choose appropriate technologies and algorithms to achieve the desired FPS. Thus, FPS can be used to verify the efficiency of the model’s recognition capabilities. Table 1 introduces the basic range of FPS and the corresponding application scenarios. To analyze the comprehensive performance of the model, this study considers the components of FPS, including pre-processing time (PreT, in ms), inference time (InferT, in ms), and non-maximum suppression time (NMST, in ms). Pre-processing time refers to the duration required for the system to convert raw input data into a format suitable for model processing. The shorter the pre-processing time, the faster the system can enter the inference stage, thereby improving overall FPS. Inference time is the time needed for the model to perform forward propagation calculations. Shorter inference times directly enhance the real-time performance of the system, significantly boosting FPS. NMST refers to the time used in the post-processing stage to eliminate overlapping detection boxes, ensuring that each target has only one optimal detection box.

Table 1.
Basic range of FPS and the corresponding application scenarios.
Equation (1) reflects the functional relationship between FPS and its components.
Additionally, this study uses a confusion matrix as a performance evaluation metric. Specifically, the corrosion prediction probability derived from the confusion matrix is primarily used to assess the model’s detection performance. The confusion matrix aligns the model’s predictive outcomes with the actual labels, delineating them into four principal categories: true positives (TPs), false positives (FPs), true negatives (TNs), and false negatives (FNs). It provides valuable insight into the model’s predictive capabilities, highlighting not only accurate predictions but also the range of misclassifications. This level of detail helps uncover the nuances of prediction errors, thereby revealing opportunities to refine model strategies for improved accuracy.
3. Results
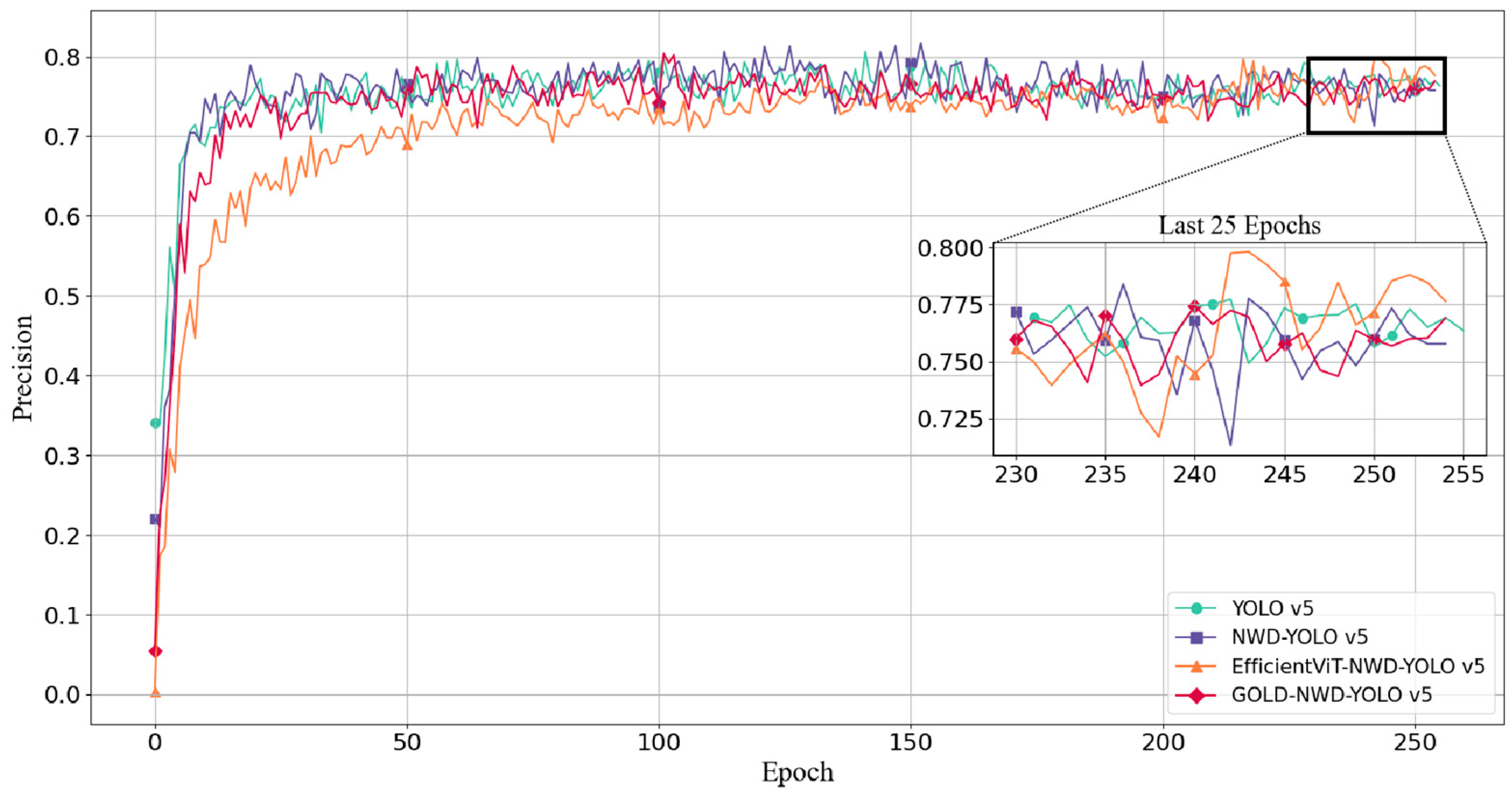
Figure 4 shows the changes in detection precision across epochs for the four models. It can be observed that the traditional YOLO v5 and NWD-YOLO v5 models exhibit almost no significant difference in convergence speed. Gold-NWD-YOLO v5 converges relatively slower, and EfficientViT-NWD-YOLO v5 has the slowest convergence, likely due to its more complex backbone structure. Notably, all four models reach a relatively stable precision after 50 epochs, and especially at 200 epochs, the precision remains consistent. Therefore, this study compared and analyzed the precision metrics of the four models based on the values at 255 epochs.
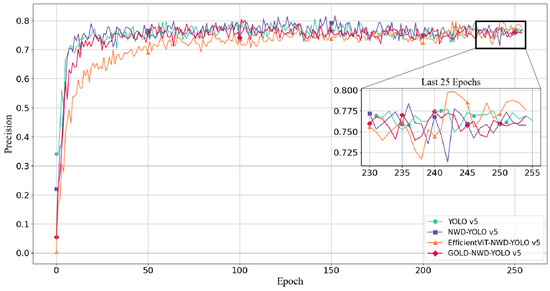
Figure 4.
Precision changes with epoch for the four models.
The evaluation results for the four models including YOLO v5, NWD-YOLO v5, Gold-NWD-YOLO v5 (proposed in [50]), and EfficientViT-NWD-YOLO v5 (proposed in this study) were obtained at the epoch of 250 and shown in Table 2.
Table 2.
Evaluation metric results.
According to the precision results shown in Table 2, the YOLO v5 model has a precision of 0.741, meaning 74.1% of its positive predictions are correct. The NWD-YOLO v5 model also has a precision of 0.741, suggesting that modifying the CIoU loss function to NWD has a negligible impact on precision with the corrosion image dataset used in this study. However, the improved model may show enhancements in other metrics, such as a 2.6% increase in the F1-score. The Gold-NWD-YOLO v5 model achieved a precision of 0.778, representing a 3.7% improvement over the YOLO v5. The EfficientViT-NWD-YOLO v5 model has a precision of 0.744, slightly lower than Gold-NWD-YOLO v5 but still a 3% improvement over YOLO v5 and NWD-YOLO v5. Although the precision increase is modest, the EfficientViT-NWD-YOLO v5 demonstrates better computational speed, making it more suitable for real-time corrosion monitoring applications.
Recall evaluates the model’s ability to identify all the relevant corrosion instances in the dataset. From the recall perspective, YOLO v5 has a recall of 0.66, indicating that it correctly identifies 66% of all the actual positive instances. NWD-YOLO v5 shows an improvement with a recall of 0.69, a 3% increase over YOLO v5, demonstrating better performance in identifying relevant corrosion instances. Gold-NWD-YOLO v5 achieves the highest recall at 0.71 among all the models, ensuring fewer missed detections and making it suitable for high-precision corrosion detection applications where low miss rates are critical. EfficientViT-NWD-YOLO v5 has a recall of 0.67, which, although lower than Gold-NWD-YOLO v5, still shows reliable performance. This model strikes a balance between detection performance and computational speed, making it ideal for real-time corrosion monitoring applications that require a balance between recognition capability and processing speed.
The F1-scores of YOLO v5, NWD-YOLO v5, and Gold-NWD-YOLO v5 show an increasing trend, with values of 0.697, 0.715, and 0.742, respectively. This indicates that improvements to the loss function and neck structure can enhance the F1-score, thereby increasing the overall balance between precision and recall. As a result, these models are better suited for corrosion detection applications. The EfficientViT-NWD-YOLO v5 model has an F1-score of 0.697, reflecting that its overall balance between precision and recall remains essentially unchanged compared to the YOLO v5 model.
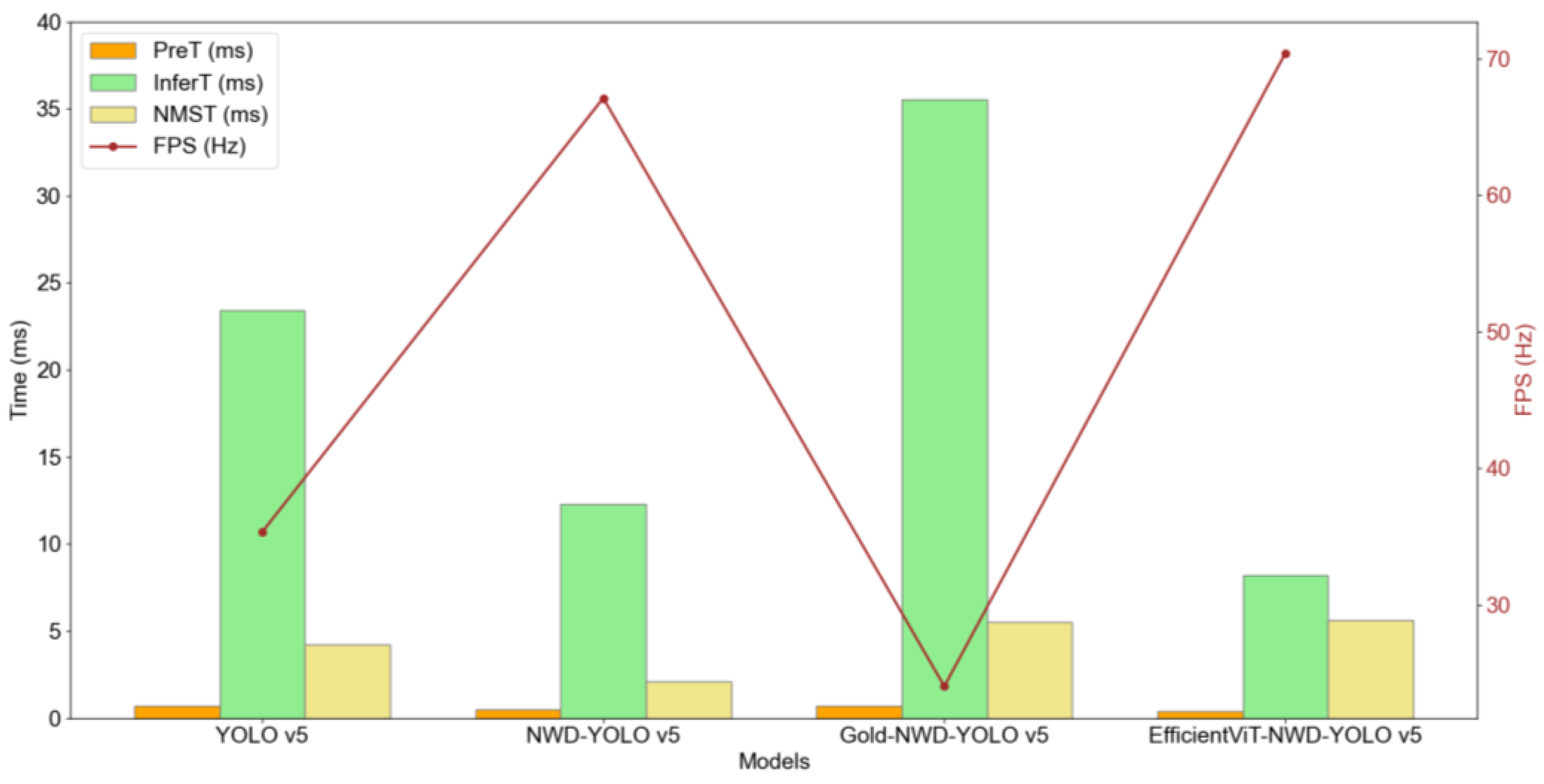
As shown in Figure 5, among the four models, EfficientViT-NWD-YOLO v5 achieves the highest FPS at 70.4 Hz, followed by NWD-YOLO v5 at 67.1 Hz. In contrast, YOLO v5 and Gold-NWD-YOLO v5 have FPS values of 35 Hz and 24 Hz, respectively. This indicates that EfficientViT-NWD-YOLO v5 and NWD-YOLO v5 significantly improve processing speed. Higher FPS allows models to process corrosion images faster, making them more suitable for corrosion detection applications that require high processing speeds.
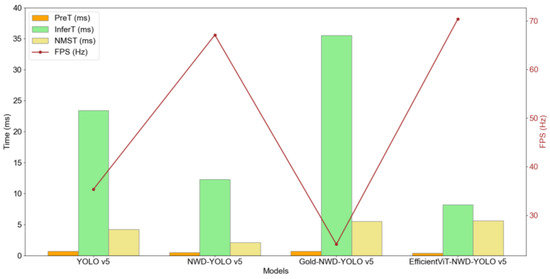
Figure 5.
FPS results of the four models.
Pre-processing time refers to the time required to prepare the data before model inference. YOLO v5 and Gold-NWD-YOLO v5 both have a pre-processing time of 0.7 milliseconds (ms), while NWD-YOLO v5 has a pre-processing time of 0.5 ms. EfficientViT-NWD-YOLO v5 has the fastest pre-processing time at 0.4 ms, indicating a significant improvement in processing speed.
Inference time measures the duration required for the model to make predictions after receiving the input. YOLO v5 has an inference time of 23.4 ms. NWD-YOLO v5 has an inference time of 12.3 ms, indicating that the introduction of the NWD loss function has improved the inference speed of the traditional model. Gold-NWD-YOLO v5 has the longest inference time at 35.5 ms, making it less suitable for real-time processing in corrosion detection scenarios. EfficientViT-NWD-YOLO v5 has the shortest inference time at 8.2 ms, demonstrating that the EfficientViT architecture significantly enhances the inference speed of the traditional model.
NMS time is the duration required to eliminate redundant bounding boxes. The NMS times for YOLO v5, NWD-YOLO v5, Gold-NWD-YOLO v5, and EfficientViT-NWD-YOLO v5 are 4.2 ms, 2.1 ms, 5.5 ms, and 5.6 ms, respectively. Among the four models, NWD-YOLO v5 has the shortest NMS time, while EfficientViT-NWD-YOLO v5 has the longest. This indicates that introducing the NWD loss function in the YOLO v5 effectively reduces NMS time. However, improvements to the neck and backbone structures tend to increase the NMS time.
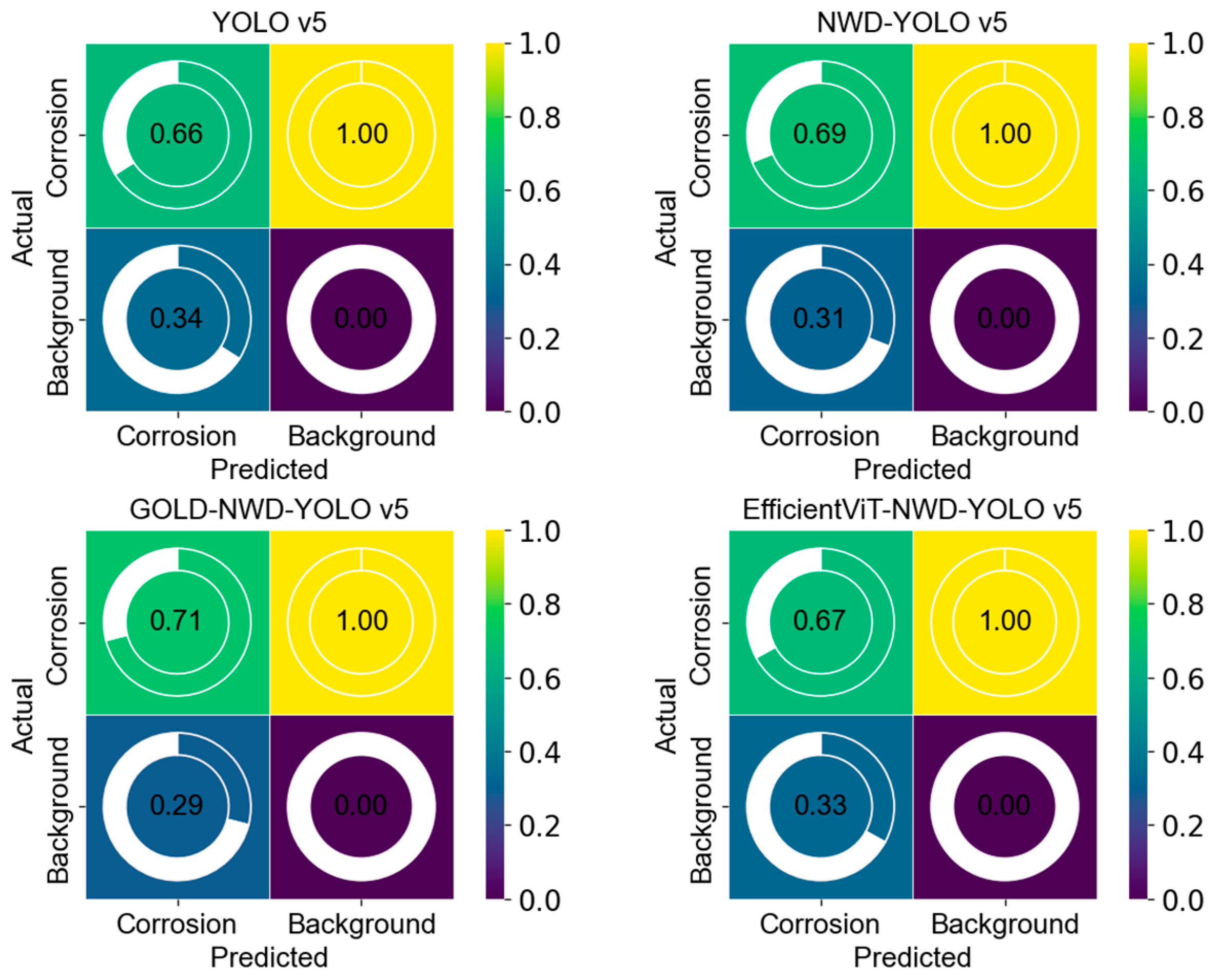
A confusion matrix was used to reveal the performance differences in each model in classifying “Corrosion” and “Background”. The prediction probability reflects the model’s confidence in its predictions. Figure 6 shows the confusion matrix results for the four models. The corrosion prediction probabilities for YOLO v5, NWD-YOLO v5, Gold-NWD-YOLO v5, and EfficientViT-NWD-YOLO v5 are 0.66, 0.69, 0.71, and 0.67, respectively. These results indicate that the four models have similar accuracy and reliability. Comparatively, Gold-NWD-YOLO v5 performs best in high-confidence corrosion detection applications, followed by NWD-YOLO v5, EfficientViT-NWD-YOLO v5, and YOLO v5.
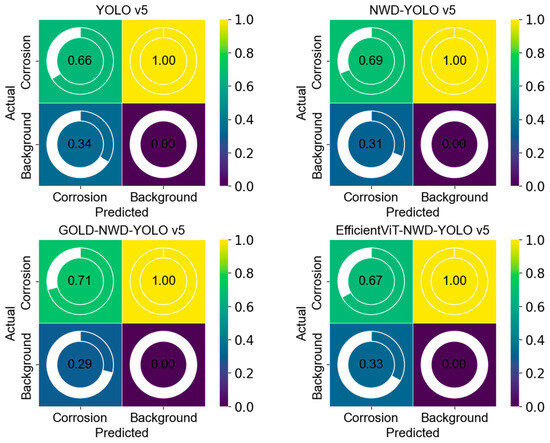
Figure 6.
Confusion matrix results of the four models.
4. Discussion
The comparison results show that improvements to the YOLO v5 model can significantly enhance detection performance on corrosion images. However, the performance improvements vary depending on the modification method. Compared to the YOLO v5 model, the NWD-YOLO v5 model maintains the same precision but shows increases in recall and F1-score. Additionally, it reduces both inference and NMS times, increases FPS, and improves the accuracy of prediction probabilities. The results indicate that the model’s performance on corrosion detection can be enhanced by improving the loss function.
Compared to the YOLO v5 and NWD-YOLO v5 models, the Gold-NWD-YOLO v5 model shows significant enhancements in precision, recall, F1-score, and prediction probability. However, the model’s inference time and NMS time have increased, and the FPS has decreased. This indicates that while the modification to the model’s neck structure improves detection performance on corrosion images, it also extends the model’s computation time. The introduction of a more complex feature fusion strategy in the modified neck structure has enhanced the model’s ability to integrate features at different scales, thereby improving its perceptual capability. Additionally, to address the need for detecting smaller targets in corrosion images, the model includes more feature layers, which capture information across various scales and enhance detection performance. However, the adoption of a more complex feature fusion strategy and additional feature layers has also increased the model’s computational complexity, parameter count, and the overhead associated with multi-scale processing. As a result, this has led to a reduction in the model’s FPS and an increase in both the computation and NMS times. This aligns with the expected outcomes given the added complexity.
Compared to the YOLO v5 model, the EfficientViT-NWD-YOLO v5 model also shows improvements in precision, recall, F1-score, and prediction probability, but these enhancements are not substantial. In addition, it shows a decrease in recall, F1-score, and prediction probability compared to NWD-YOLO v5 and Gold-NWD-YOLO v5. However, the model demonstrates a significant reduction in the inference time and NMS time, and the FPS has notably increased. Compared to YOLO V5, NWD-YOLO v5, and Gold-NWD-YOLO v5, the EfficientViT-NWD-YOLO v5 model demonstrates improvements in processing speed of 99.4%, 4.9%, and 193.3%, respectively. This suggests that while the modifications to the backbone structure did not significantly improve the model’s detection performance, they substantially enhanced the model’s processing speed. The primary reason for these improvements is the introduction of the EfficientViT architecture, which emphasizes lightweight and efficient design. By using fewer parameters and computational resources while maintaining relatively high feature extraction capabilities, the EfficientViT architecture contributes to better detection efficiency. Additionally, EfficientViT incorporates optimized convolution operations and efficient self-attention mechanisms, leading to significant gains in computational efficiency. However, the effectiveness of feature extraction with EfficientViT may not differ greatly from that of the traditional convolutional neural networks. As a result, for complex corrosion image scenarios, the improvements in detection performance are limited.
Overall, the Gold-NWD-YOLO v5 model excels in high-confidence applications, while the EfficientViT-NWD-YOLO v5 model is advantageous for corrosion detection scenarios that require rapid decision making. Therefore, the choice of the most suitable corrosion detection model can be tailored based on specific needs for accuracy and reliability. In this study, the relatively small size and potential quality issues of the corrosion image dataset meant that differences in detection performance and computational efficiency between the models were not very pronounced. Increasing both the quantity and quality of the training dataset would likely highlight more significant distinctions in model performance and efficiency. Given this, selecting or developing the most appropriate model based on specific application requirements is crucial. For example, although the Gold-NWD-YOLO v5 has longer inference and NMS times with a lower frame rate, it demonstrates superior detection accuracy. This makes it better suited for applications that demand high reliability and precision, such as aerospace and nuclear facilities where high accuracy and confidence in corrosion detection are critical to preventing major accidents caused by minor corrosion issues. Similarly, in critical infrastructure monitoring, such as the corrosion monitoring of key components in bridges, pipelines, and storage tanks, high-confidence and accurate detection performance can provide reliable results for safety management. This helps engineers perform timely maintenance and repairs, extending the lifespan of the infrastructure and preventing potential catastrophic failures.
However, the enhancement of high precision and high confidence also comes with increased computational costs. Therefore, in some application scenarios, choosing a model requires balancing improvements in detection performance with computational complexity. Although the EfficientViT-NWD-YOLO v5 model does not match the Gold-NWD-YOLO v5 model in precision, recall, and the other performance metrics, its shorter preprocessing and inference times, along with a higher FPS (2–3 times that of YOLO v5 and Gold-NWD-YOLO v5), provide it with a significant advantage in scenarios requiring rapid decision making. Additionally, this model demonstrates a good balance between accuracy and recall. Thus, for applications that involve handling large amounts of data and making swift decisions, the EfficientViT-NWD-YOLO v5 model proves to be more practical. For instance, in the routine inspections of infrastructure such as bridges, pipelines, and port facilities, the real-time monitoring of corrosion is crucial for safety. When combined with mobile devices and the drone-based inspections of critical infrastructure, there is a high demand for efficiency and rapid processing capabilities in detection algorithms. Therefore, the EfficientViT-NWD-YOLO v5 model is better suited for such detection needs. In summary, the four models cater to different corrosion detection applications: YOLO v5 and NWD-YOLO v5 are suitable for general corrosion detection, Gold-NWD-YOLO v5 is ideal for high-precision scenarios, and EfficientViT-NWD-YOLO v5 is best for applications requiring a balance between speed and accuracy.
5. Conclusions
This study enhances YOLO v5’s performance in detecting corrosion features by exploring two improved models: EfficientViT-NWD-YOLO v5 and Gold-NWD-YOLO v5. A metal corrosion image dataset from coastal areas was constructed for training and validation. The models focus on enhancements to the backbone and neck structures, respectively, and are compared against the YOLO v5 model and the NWD-YOLO v5 model. Performance metrics such as precision, recall, F1-score, FPS, and the confusion matrix were used for evaluation.
The results show that the enhanced Gold-NWD-YOLO v5 model significantly improves precision, recall, F1-score, and prediction probability but also leads to increased inference and NMS times, resulting in lower FPS. This indicates that while modifications to the neck structure enhance detection performance on corrosion images, they also extend computational times. Conversely, the EfficientViT-NWD-YOLO v5 model offers improvements in precision, recall, F1-score, and prediction probability, although these gains are less pronounced. However, it achieves notable reductions in inference and NMS times and a substantial increase in FPS, suggesting that enhancements to the backbone structure primarily boost processing speed rather than detection accuracy. In practical applications, the Gold-NWD-YOLO v5 model is better suited for scenarios requiring high reliability and accuracy, while the EfficientViT-NWD-YOLO v5 model is ideal for applications that prioritize low computational overhead and high efficiency, such as in mobile or drone-based detection systems.
However, this study compared only two models that improve the backbone and neck structures, respectively, which limits the generalizability of the findings regarding the effects of these enhancements on the YOLO v5 model. In addition, the proposed models also face limitations due to structural improvements and training data quality. Future work should focus on enhancing the quantity and quality of the dataset and further refining model structures such as exploring advanced neck structures (e.g., Feature Pyramid Networks or Path Aggregation Networks), backbone architectures (e.g., EfficientNet, ResNeXt, or Swin Transformer), and innovative loss functions (like Focal Loss). Furthermore, with the recent release of more advanced YOLO series algorithms, including YOLO v6, v7, v8, and the newly launched v9 and v10, future research should explore these versions to assess their performance enhancements and practical applications in metal corrosion image detection tasks.
Author Contributions
Conceptualization, Q.Y. and X.G.; methodology, Q.Y., X.G. and W.L.; software, Y.H. (Yudong Han); validation, Q.Y. and Y.H. (Yudong Han); formal analysis, Q.Y., W.L. and Y.H. (Yudong Han); investigation, Y.H. (Yudong Han) and Y.H. (Yi Han); data curation, Y.H. (Yudong Han) and Y.H. (Yi Han); writing—original draft preparation, Y.H. (Yudong Han); writing—review and editing, X.G., W.L. and Q.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Shanghai Planning Office of Philosophy and Social Science, grant number 2020BGL036.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in this article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors acknowledge the anonymous reviewers for their suggestions that improved the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Groysman, A. Corrosion Risk for Process Safety in the Chemical Industry. Afinidad 2024, 81, 10–24. [Google Scholar] [CrossRef]
- Xia, D.H.; Deng, C.M.; Macdonald, D.; Jamali, S.; Mills, D.; Luo, J.L.; Hu, W. Electrochemical Measurements Used for Assessment of Corrosion and Protection of Metallic Materials in the Field: A Critical Review. J. Mater. Sci. Technol. 2022, 112, 151–183. [Google Scholar] [CrossRef]
- Wright, R.F.; Lu, P.; Devkota, J.; Lu, F.; Ziomek-Moroz, M.; Ohodnicki, P.R., Jr. Corrosion Sensors for Structural Health Monitoring of Oil and Natural Gas Infrastructure: A Review. Sensors 2019, 19, 3964. [Google Scholar] [CrossRef] [PubMed]
- Reddy, M.S.B.; Ponnamma, D.; Sadasivuni, K.K.; Aich, S.; Kailasa, S.; Parangusan, H.; Zarandah, R. Sensors in Advancing the Capabilities of Corrosion Detection: A Review. Sens. Actuators A Phys. 2021, 332, 113086. [Google Scholar] [CrossRef]
- Xiong, J.; Yu, D.; Wang, Q.; Shu, L.; Cen, J.; Liang, Q.; Sun, B. Application of Histogram Equalization for Image Enhancement in Corrosion Areas. Shock Vib. 2021, 2021, 8883571. [Google Scholar] [CrossRef]
- Son, H.; Hwang, N.; Kim, C.; Kim, C. Rapid and Automated Determination of Rusted Surface Areas of a Steel Bridge for Robotic Maintenance Systems. Autom. Constr. 2014, 42, 13–24. [Google Scholar] [CrossRef]
- Zhou, Q.; Ding, S.; Feng, Y.; Qing, G.; Hu, J. Corrosion Inspection and Evaluation of Crane Metal Structure Based on UAV Vision. Signal Image Video Process. 2022, 16, 1701–1709. [Google Scholar] [CrossRef]
- Yu, L.; Yang, E.; Luo, C.; Ren, P. AMCD: An Accurate Deep Learning-Based Metallic Corrosion Detector for MAV-Based Real-Time Visual Inspection. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 8087–8098. [Google Scholar] [CrossRef]
- Jia, Z.; Fu, M.; Zhao, X.; Cui, Z. Intelligent Identification of Metal Corrosion Based on Corrosion-YOLO v5s. Displays 2023, 76, 102367. [Google Scholar] [CrossRef]
- Khayatazad, M.; De Pue, L.; De Waele, W. Detection of Corrosion on Steel Structures Using Automated Image Processing. Dev. Built Environ. 2020, 3, 100022. [Google Scholar] [CrossRef]
- Huang, H.; Jia, C.; Zhao, O.; Guo, L. Local Corrosion Morphology Analysis and Simplification of Low Carbon Steel Plates. Ocean. Eng. 2023, 268, 113372. [Google Scholar] [CrossRef]
- Luo, K.; Kong, X.; Zhang, J.; Hu, J.; Li, J.; Tang, H. Computer Vision-Based Bridge Inspection and Monitoring: A Review. Sensors 2023, 23, 7863. [Google Scholar] [CrossRef] [PubMed]
- Hoang, N.D.; Tran, V.D. Image Processing-Based Detection of Pipe Corrosion Using Texture Analysis and Metaheuristic-Optimized Machine Learning Approach. Comput. Intell. Neurosci. 2019, 2019, 8097213. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Li, X.; Wang, X.V.; Wang, L.; Gao, L. A Review on Recent Advances in Vision-Based Defect Recognition Towards Industrial Intelligence. J. Manuf. Syst. 2022, 62, 753–766. [Google Scholar] [CrossRef]
- Lin, Z.; Zhang, W.; Li, J.; Yang, J.; Han, B.; Xie, P. Application of Artificial Intelligence (AI) in the Area of Corrosion Protection. Anti-Corros. Methods Mater. 2023, 70, 243–251. [Google Scholar]
- Yao, Y.; Yang, Y.; Wang, Y.; Zhao, X. Artificial Intelligence-Based Hull Structural Plate Corrosion Damage Detection and Recognition Using Convolutional Neural Network. Appl. Ocean. Res. 2019, 90, 101823. [Google Scholar] [CrossRef]
- Khan, A.I.; Al-Habsi, S. Machine Learning in Computer Vision. Procedia Comput. Sci. 2020, 167, 1444–1451. [Google Scholar] [CrossRef]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of Deep Learning Approaches Based on Convolutional Neural Networks for Corrosion Detection. Struct. Health Monit. 2018, 17, 1110–1128. [Google Scholar] [CrossRef]
- Fang, X.; Luo, Q.; Zhou, B.; Li, C.; Tian, L. Research Progress of Automated Visual Surface Defect Detection for Industrial Metal Planar Materials. Sensors 2020, 20, 5136. [Google Scholar] [CrossRef]
- Forkan, A.R.M.; Kang, Y.B.; Jayaraman, P.P.; Liao, K.; Kaul, R.; Morgan, G.; Sinha, S. CorrDetector: A Framework for Structural Corrosion Detection from Drone Images Using Ensemble Deep Learning. Expert. Syst. Appl. 2022, 193, 116461. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civil. Infra. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A Review of Vibration-Based Damage Detection in Civil Structures: From Traditional Methods to Machine Learning and Deep Learning Applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Coelho, L.B.; Zhang, D.; Van Ingelgem, Y.; Steckelmacher, D.; Nowé, A.; Terryn, H. Reviewing Machine Learning of Corrosion Prediction in a Data-Oriented Perspective. NPJ Mater. Degrad. 2022, 6, 8. [Google Scholar] [CrossRef]
- Azimi, M.; Eslamlou, A.D.; Pekcan, G. Data-Driven Structural Health Monitoring and Damage Detection Through Deep Learning: State-of-the-Art Review. Sensors 2020, 20, 2778. [Google Scholar] [CrossRef]
- Zhang, J.; Zeng, Y.; Starly, B. Recurrent Neural Networks with Long Term Temporal Dependencies in Machine Tool Wear Diagnosis and Prognosis. SN Appl. Sci. 2021, 3, 442. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Shahzad, D.; Heravi, A.; Qayyum, S.; Akram, J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings 2022, 12, 156. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of YOLO Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLO v1 to YOLO v8 and YOLO-NAS. Mach. Learn. Knowl. Extract. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Zhai, Y.; Wang, W.; Huang, R. A Sewer Pipeline Defect Detection Method Based on Improved YOLO v5. Processes 2023, 11, 2508. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Z.; Yu, H. Enhanced YOLO v5: An Efficient Road Object Detection Method. Sensors 2023, 23, 8355. [Google Scholar] [CrossRef]
- Yang, X.; del Rey Castillo, E.; Zou, Y.; Wotherspoon, L. UAV-Deployed Deep Learning Network for Real-Time Multi-Class Damage Detection Using Model Quantization Techniques. Autom. Constr. 2024, 159, 105254. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving Small Object Detection in YOLO v5 for Autonomous Vehicles. arXiv preprint 2021, arXiv:2112.11798. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, B. Swin-Transformer-Enabled YOLO v5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Jani, M.; Fayyad, J.; Al-Younes, Y.; Najjaran, H. Model Compression Methods for YOLO v5: A Review. arXiv 2023, arXiv:2307.11904. [Google Scholar]
- Ren, J.; Wang, Z.; Zhang, Y.; Liao, L. YOLO v5-R: Lightweight Real-Time Detection Based on Improved YOLO v5. J. Electron. Imaging 2022, 31, 033033. [Google Scholar] [CrossRef]
- Sun, G.; Wang, S.; Xie, J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLO v5. Electronics 2023, 12, 1515. [Google Scholar] [CrossRef]
- Zhou, J.; Su, T.; Li, K.; Dai, J. Small Target-YOLO v5: Enhancing the Algorithm for Small Object Detection in Drone Aerial Imagery Based on YOLO v5. Sensors 2024, 24, 134. [Google Scholar] [CrossRef]
- Shan, C.; Liu, H.; Yu, Y. Research on Improved Algorithm for Helmet Detection Based on YOLO v5. Sci. Rep. 2023, 13, 18056. [Google Scholar] [CrossRef] [PubMed]
- Mei, L.; Chen, Z. An Improved YOLO v5-Based Lightweight Submarine Target Detection Algorithm. Sensors 2023, 23, 9699. [Google Scholar] [CrossRef]
- Wang, T.; Zhai, Y.; Li, Y.; Wang, W.; Ye, G.; Jin, S. Insulator Defect Detection Based on ML-YOLO v5 Algorithm. Sensors 2023, 24, 204. [Google Scholar] [CrossRef]
- Liu, J.; Cai, Q.; Zou, F.; Zhu, Y.; Liao, L.; Guo, F. BiGA-YOLO: A Lightweight Object Detection Network Based on YOLO v5 for Autonomous Driving. Electronics 2023, 12, 2745. [Google Scholar] [CrossRef]
- Wang, L.; Chen, L.Z.; Peng, B.; Lin, Y.T. Improved YOLO v5 Algorithm for Real-Time Prediction of Fish Yield in All Cage Schools. J. Mar. Sci. Eng. 2024, 12, 195. [Google Scholar] [CrossRef]
- Wang, Q.; Feng, W.; Yao, L.; Zhuang, C.; Liu, B.; Chen, L. TPH-YOLO v5-Air: Airport Confusing Object Detection via Adaptively Spatial Feature Fusion. Remote Sens. 2023, 15, 3883. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Wang, S.; Shen, S.; Xu, T.; Lang, X. YOLO-HR: Improved YOLO v5 for Object Detection in High-Resolution Optical Remote Sensing Images. Remote Sens. 2023, 15, 614. [Google Scholar] [CrossRef]
- Li, L.; Wang, Z.; Zhang, T. GBH-YOLO v5: Ghost Convolution with BottleneckCSP and Tiny Target Prediction Head Incorporating YOLO v5 for PV Panel Defect Detection. Electronics 2023, 12, 561. [Google Scholar] [CrossRef]
- Huang, B.; Liu, J.; Liu, X.; Liu, K.; Liao, X.; Li, K.; Wang, J. Improved YOLO v5 Network for Steel Surface Defect Detection. Metals 2023, 13, 1439. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, Y. A Small Target Detection Algorithm Based on Improved YOLO v5 in Aerial Image. PeerJ Comput. Sci. 2024, 10, e2007. [Google Scholar] [CrossRef]
- Jin, Z.; Qu, P.; Sun, C.; Luo, M.; Gui, Y.; Zhang, J.; Liu, H. DWCA-YOLO v5: An Improved Single Shot Detector for Safety Helmet Detection. J. Sens. 2021, 2021, 4746516. [Google Scholar] [CrossRef]
- Jung, H.K.; Choi, G.S. Improved YOLO v5: Efficient Object Detection Using Drone Images Under Various Conditions. Appl. Sci. 2022, 12, 7255. [Google Scholar] [CrossRef]
- Yu, Q.; Han, Y.; Lin, W.; Gao, X. Detection and Analysis of Corrosion on Coated Metal Surfaces Using Enhanced YOLO v5 Algorithm for Anti-Corrosion Performance Evaluation. J. Mar. Sci. Eng. 2024, 12, 1090. [Google Scholar] [CrossRef]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation. arXiv 2023, arXiv:2205.14756. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).