

Data-Driven Prediction of Maximum Settlement in Pipe Piles under Seismic Loads

 ,
,  ,
, 

Abstract
1. Introduction
2. Methodology
2.1. Data Collecting
2.2. Data Preparation
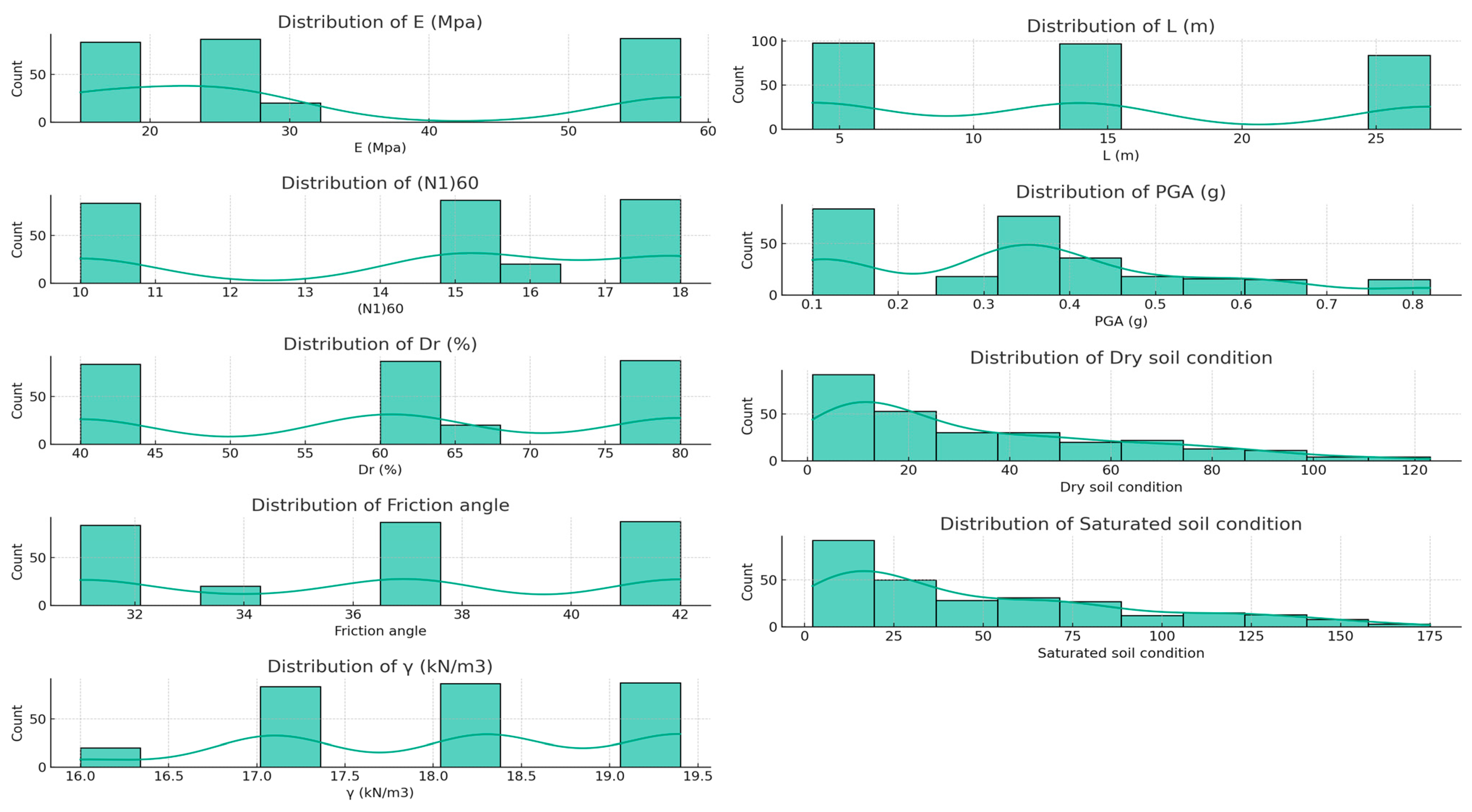
2.2.1. Data Cleaning and Missing Values
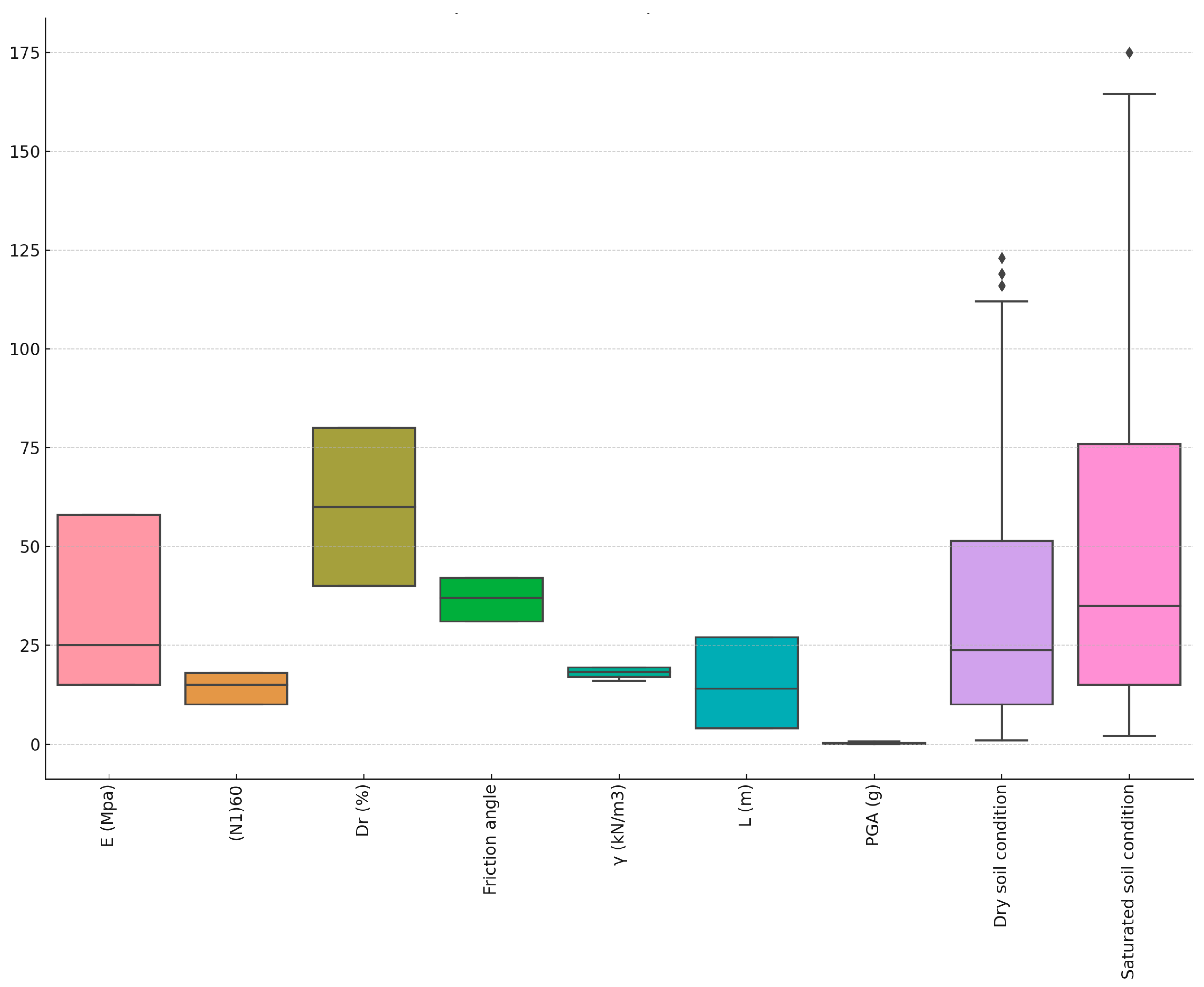
2.2.2. Outlier Identification and Removal
2.2.3. Feature Encoding
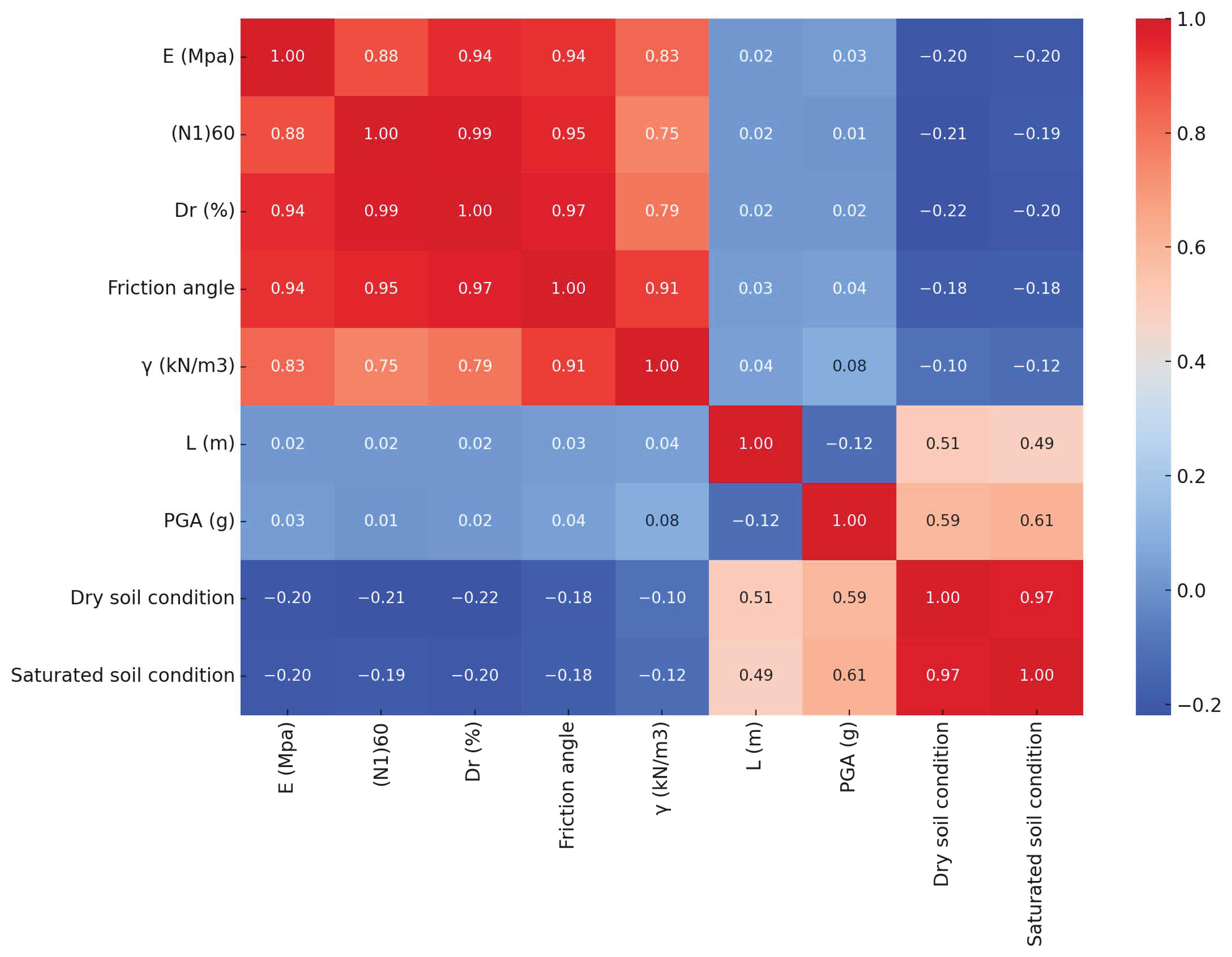
2.2.4. Correlation Heatmap
2.2.5. Stratified Train–Test Split
2.2.6. Model Optimization Scope
3. Model Development
3.1. Algorithm Selection
3.2. Tuning Fundamentals
3.3. Hyperparameter Setting
- Number of trees (n_estimators): Set to 500, a value that offers a good balance between model performance and computational load. More trees generally improve accuracy but increase computation time.
- Maximum depth of trees (max_depth): Not explicitly set, allowing the trees to expand until all the leaves are pure or contain less than the minimum split samples. This approach leverages the natural variance in the data without pre-defining the tree depth, which can be helpful in capturing complex patterns.
- Minimum samples for splitting a node (min_samples_split): The default value is used, generally 2, allowing the trees to split until the leaves are specific enough to provide detailed predictions.
- Random state (random_state): Set to a fixed value (e.g., 42) to ensure reproducibility of the results. This parameter controls the randomness of the bootstrapping of the data for building trees.
3.4. Hyperparameter Optimization
3.5. Model Training and Validation
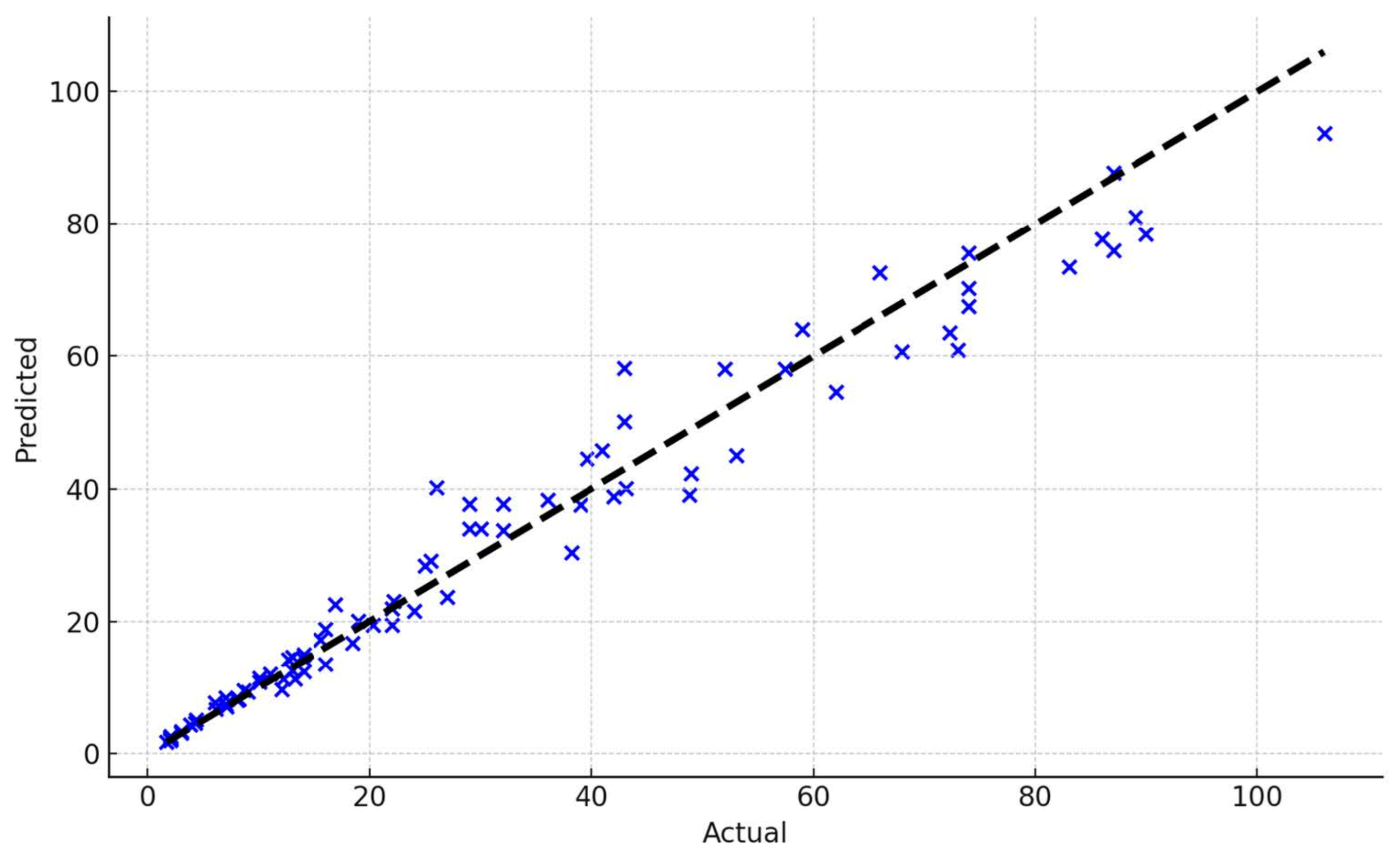
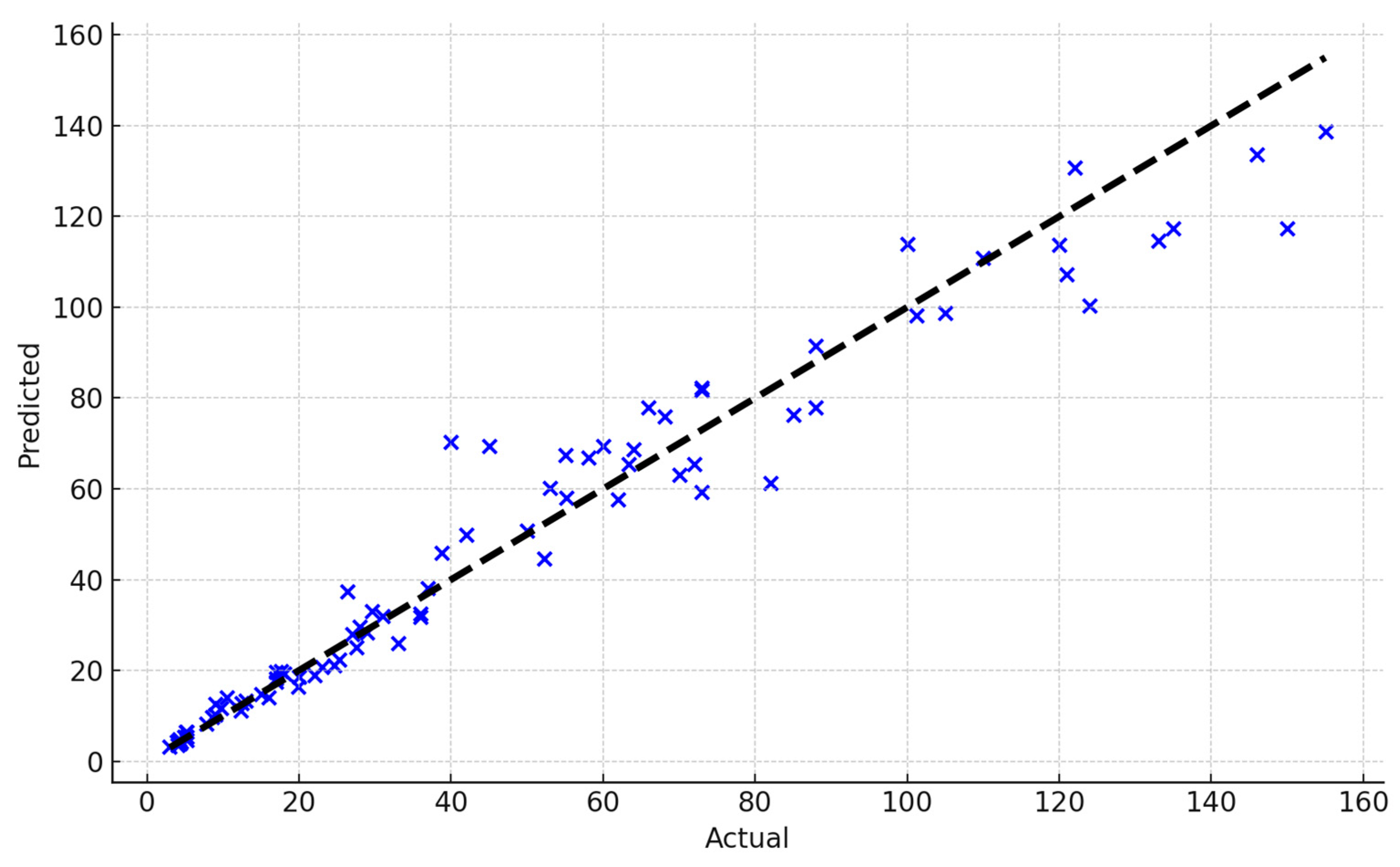
4. Performance Evaluation
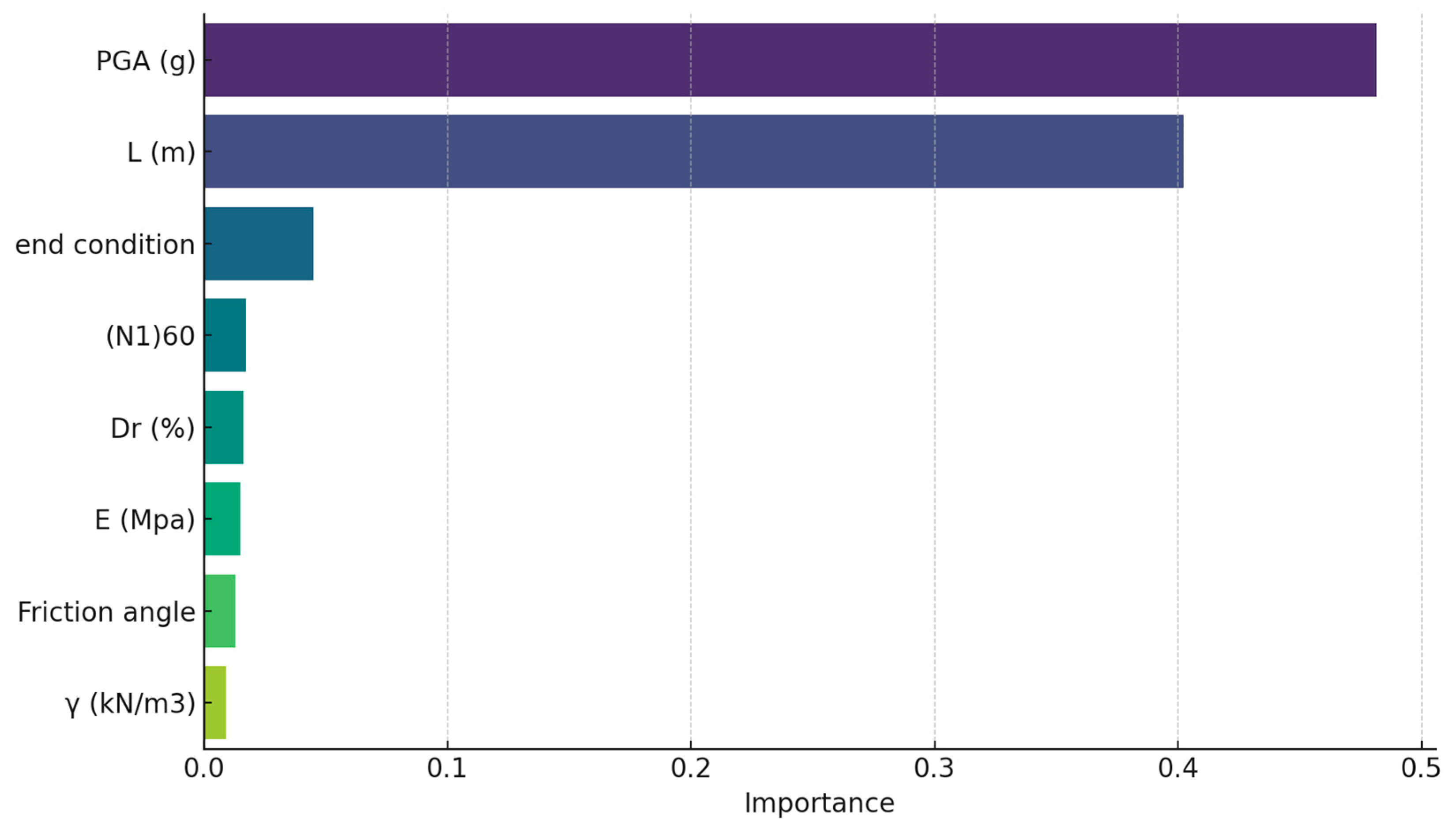
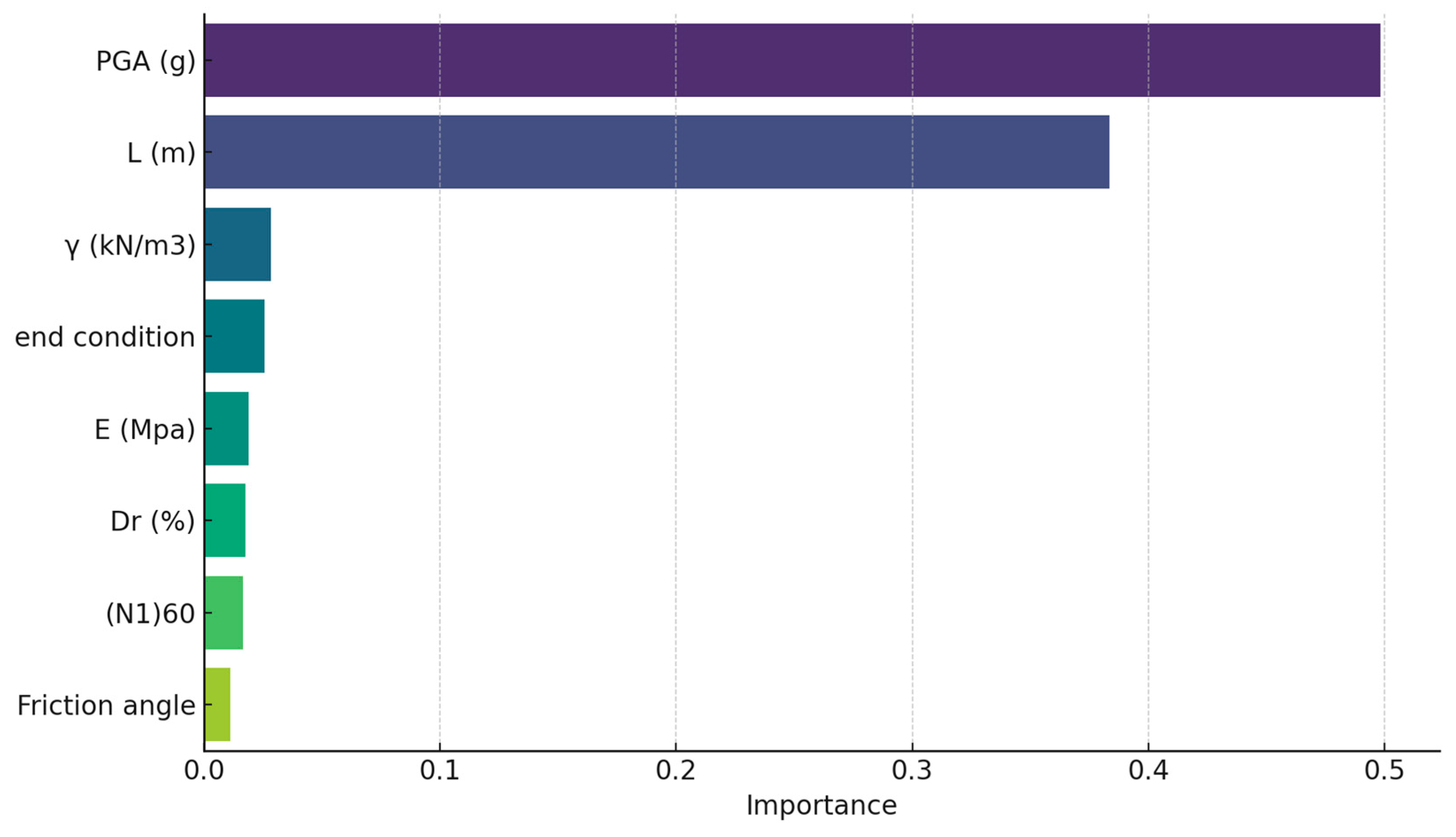
5. Interpretability Assessment
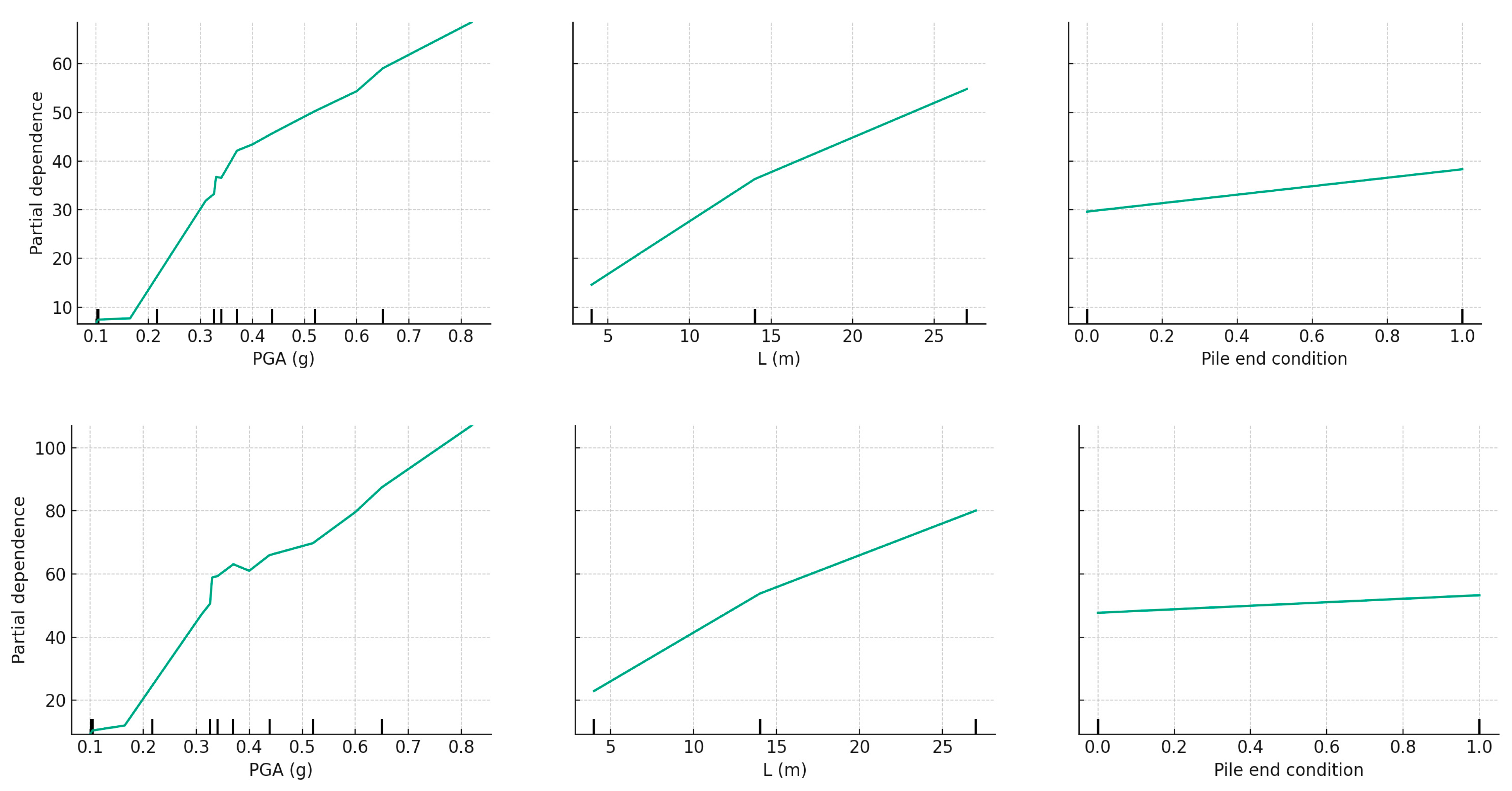
6. Partial Dependence Plots for the Top Features
7. Conclusions and Recommendations
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Random Forest Regression Code for Pile Settlement Prediction
References
- Xu, S.H.; Li, Z.W.; Deng, Y.F.; Bian, X.; Zhu, H.H.; Zhou, F.; Feng, Q. Bearing performance of steel pipe pile in multilayered marine soil using fiber optic technique: A case study. Mar. Georesources Geotechnol. 2022, 40, 1453–1469. [Google Scholar] [CrossRef]
- Abi, E.; Shen, L.; Liu, M.; Du, H.; Shu, D.; Han, Y. Calculation Model of Vertical Bearing Capacity of Rock-Embedded Piles Based on the Softening of Pile Side Friction Resistance. J. Mar. Sci. Eng. 2023, 11, 939. [Google Scholar] [CrossRef]
- Wang, Y.; Qi, Z.; Wei, T.; Bao, J.; Zhang, X.; Zhou, Y. Numerical Study on the Responses of Suction Pile Foundations under Horizontal Cyclic Loading Considering the Soil Stiffness Degradation. J. Mar. Sci. Eng. 2023, 11, 2336. [Google Scholar] [CrossRef]
- Wu, Q.; Ding, X.; Zhang, Y. Dynamic interaction of coral sand-pile-superstructure during earthquakes: 3D Numerical simulations. Mar. Georesour. Geotechnol. 2023, 41, 774–790. [Google Scholar] [CrossRef]
- Bhattacharya, S. Pile Instability during Earthquake Liquefaction. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2003. [Google Scholar]
- Barbosa, V.D.; Galgoul, N.S. Designing Piled Foundations with a Full 3D Model. Open Constr. Build. Technol. J. 2018, 12, 65–78. [Google Scholar] [CrossRef]
- Tehrani, F.S.; Han, F.; Salgado, R.; Prezzi, M.; Tovar, R.D.; Castro, A.G. Effect of surface roughness on the shaft resistance of non-displacement piles embedded in sand. Géotechnique 2016, 66, 386–400. [Google Scholar] [CrossRef]
- Al-Jeznawi, D.; Jais, I.B.M.; Albusoda, B.S.; Khalid, N. Numerical assessment of pipe pile axial response under seismic excitation. J. Eng. 2023, 29, 10, 1–11. [Google Scholar] [CrossRef]
- Hussein, A.F.; Hesham El Naggar, M. Seismic axial behaviour of pile groups in non-liquefiable and liquefiable soils. Soil Dyn. Earthq. Eng. 2021, 149, 106853. [Google Scholar] [CrossRef]
- Al-Jeznawi, D.; Khatti, J.; Al-Janabi, M.A.Q.; Grover, K.S.; Jais, I.B.M.; Albusoda, B.S.; Khalid, N. Seismic performance assessment of single pipe piles using three-dimensional finite element modeling considering different parameters. Earthq. Struct. 2023, 24, 455. [Google Scholar]
- Al-Jeznawi, D.; Jais, I.B.M.; Albusoda, B.S.; Alzabeebee, S.; Keawsawasvong, S.; Khalid, N. Numerical study of the seismic response of closed-ended pipe pile in cohesionless soils. Transp. Infrastruct. Geotechnol. 2023, 1–27. [Google Scholar] [CrossRef]
- Sarkhani Benemaran, R.; Esmaeili-Falak, M.; Javadi, A. Predicting resilient modulus of flexible pavement foundation using extreme gradient boosting based optimized models. Int. J. Pavement Eng. 2022, 24, 2095385. [Google Scholar] [CrossRef]
- Zhang, Q.; Afzal, M. Prediction of the elastic modulus of recycled aggregate concrete applying hybrid artificial intelligence and machine learning algorithms (retracted). Struct. Concr. 2021, 23, 2477–2495. [Google Scholar] [CrossRef]
- Huang, L.; Jiang, W.; Wang, Y.; Zhu, Y.; Afzal, M. Prediction of long-term compressive strength of concrete with admixtures using hybrid swarm-based algorithms. Smart Struct. Syst. 2022, 29, 433–444. [Google Scholar]
- Benemaran, R.S.; Esmaeili-Falak, M. Optimization of cost and mechanical properties of concrete with admixtures using MARS and PSO. Comput. Concr. 2020, 26, 309–316. [Google Scholar]
- Qu, X.-Q.; Wang, R.; Zhang, J.-M.; He, B. Influence of Soil Plug on the Seismic Response of Bucket Foundations in Liquefiable Seabed. J. Mar. Sci. Eng. 2023, 11, 598. [Google Scholar] [CrossRef]
- Poulos, H.G. Tall Building Foundation Design; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Zhang, Y.; Hu, X.; Tannant, D.D.; Zhang, G.; Tan, F. Field monitoring and deformation characteristics of a landslide with piles in the Three Gorges Reservoir area. Landslides 2018, 15, 581–592. [Google Scholar] [CrossRef]
- Lee, I.-M.; Lee, J.-H. Prediction of pile bearing capacity using artificial neural networks. Comput. Geotech. 1996, 18, 189–200. [Google Scholar] [CrossRef]
- Che, W.F.; Lok, T.M.H.; Tam, S.C.; Novais-Ferreira, H. Axial Capacity Prediction for Driven Piles at Macao using Artificial Neural Network; AA Balkema Publishers: Leiden, The Netherlands, 2003. [Google Scholar]
- Liu, H.; Li, T.J.; Zhang, Y.F. The Application of Artificial Neural Networks in Estimating the Pile Bearing Capacity; AA Balkema Publishers: Leiden, The Netherlands, 1997. [Google Scholar]
- Hanna, A.M.; Morcous, G.; Helmy, M. Efficiency of pile groups installed in cohesionless soil using artificial neural networks. Can. Geotech. J. 2004, 41, 1241–1249. [Google Scholar] [CrossRef]
- Shanbeh, M.; Najafzadeh, D.; Ravandi, S.A.H. Predicting pull-out force of loop pile of woven terry fabrics using artificial neural network algorithm. Ind. Textila 2012, 63, 37–41. [Google Scholar]
- Xu, B.; Deng, J.; Liu, X.; Chang, A.; Chen, J.; Zhang, D. A Review on Optimal Design of Fluid Machinery Using Machine Learning Techniques. J. Mar. Sci. Eng. 2023, 11, 941. [Google Scholar] [CrossRef]
- Wang, K.; Gaidai, O.; Wang, F.; Xu, X.; Zhang, T.; Deng, H. Artificial Neural Network-Based Prediction of the Extreme Response of Floating Offshore Wind Turbines under Operating Conditions. J. Mar. Sci. Eng. 2023, 11, 1807. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representation by error propagation. In Parallel Distributed Processing; Rumelhart, D.E., McClelland, J.L., Eds.; MIT Press: Cambridge, MA, USA, 1986; Chapter 8, Volume 1. [Google Scholar]
- Albinmousa, J.; Peron, M.; Jose, J.; Abdelaal, A.F.; Berto, F. Fatigue of V-notched ZK60 magnesium samples: X-ray damage evolution characterization and failure prediction. Int. J. Fatigue 2020, 139, 105734. [Google Scholar] [CrossRef]
- Marsavina, L.; Berto, F.; Radu, N.; Serban, D.A.; Linul, E. An engineering approach to predict mixed mode fracture of PUR foams based on ASED and micromechanical modelling. Theor. Appl. Fract. Mech. 2017, 91, 148–154. [Google Scholar] [CrossRef]
- Al-Jeznawi, D.; Jais, M.; Albusoda, B.S. A Soil-Pile Response under Coupled Static-Dynamic Loadings in Terms of Kinematic Interaction. Civ. Environ. Eng. 2022, 18, 96–103. [Google Scholar] [CrossRef]
- Song, W.; Liu, X.; Berto, F.; Razavi, S.M.J. Energy-based low cycle fatigue indicator prediction of non-load-carrying cruciform welded joints. Theor. Appl. Fract. Mech. 2018, 96, 247–261. [Google Scholar] [CrossRef]
- Qian, G.; Lei, W.-S.; Yu, Z.; Berto, F. Statistical size scaling of breakage strength of irregularly-shaped particles. Theor. Appl. Fract. Mech. 2019, 102, 51–58. [Google Scholar] [CrossRef]
- Lei, W.-S.; Qian, G.; Yu, Z.; Berto, F. Statistical size scaling of compressive strength of quasi-brittle materials incorporating specimen length to diameter ratio effect. Theor. Appl. Fract. Mech. 2019, 104, 102345. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Raman, C.D.; Bhattacharya, S.; Blakeborough, A. Settlement Prediction of Pile-Supported Structures in Liquefiable Soils During Earthquake. In Proceedings of the 14th World Conference on Earthquake Engineering, Beijing, China, 12–17 October 2008. [Google Scholar]
- Robinsky, E.I.; Morrison, C.F. Sand Displacement and Compaction around Model Friction Piles. Can. Geotech. J. 1964, 1, 81–93. [Google Scholar] [CrossRef]
- Beaty, M.H.; Byrne, P.M. UBCSAND Constitutive Model Version 904aR. Itasca UDM Web Site 2011, 69, 71. [Google Scholar]
- Mahmood, M.R.; Al-Helo, K.H.; AL-harbawee, A.M. Laboratory study of plug length development and bearing capacity of pipe pile models embedded within partially saturated cohesionless soils. In Advances in Analysis and Design of Deep Foundations: Proceedings of the 1st GeoMEast International Congress and Exhibition, Egypt 2017 on Sustainable Civil Infrastructures; Springer International Publishing: Cham, Switzerland, 2018; Volume 1, pp. 28–43. [Google Scholar] [CrossRef]
- Hussein, R. Experimental and Numerical Modeling of Piles under Combined Loading in Liquefied Sandy Soil with Improvement by Nanomaterials. PhD Thesis, University of Baghdad, Baghdad, Iraq, 2021. [Google Scholar]
- Namdar, A. Prediction of the settlement of a pile and assessment of seismic soil-pile interaction—An analytical investigation. Procedia Struct. Integrity 2020, 28, 311–322. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Qi, D. Indoor Thermal Stratification and Its Statistical Distribution. Indoor Air 2019, 29, 243–255. [Google Scholar] [CrossRef] [PubMed]
- Cao, G.; Wang, S.; Yoo, E.-H. A Statistical Framework of Data Fusion for Spatial Prediction of Categorical Variables. Stoch. Environ. Res. Risk Assess 2014, 28, 1785–1799. [Google Scholar] [CrossRef]
- Kohavi, R. Feature subset selection as search with probabilistic estimates. In Proceedings of the AAAI Fall Symposium on Relevance, Arlington, Virginia, 25–27 October 1994; pp. 122–126. [Google Scholar]
- Geisser, F.; Eddy, W. A predictive approach to model selection. J. Am. Stat. Assoc. 1979, 74, 153–160. [Google Scholar] [CrossRef]
- Ren, Z.; Sun, L.; Zhai, Q. Improved k-means and spectral matching for hyperspectral mineral mapping. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102154. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of rockburst in underground projects: Comparison of ten supervised learning methods. J. Comput. Civ. Eng. 2016, 30, 4016003. [Google Scholar] [CrossRef]
- Tao, H.; Jingcheng, W.; Langwen, Z. Prediction of Hard Rock TBM Penetration Rate Using Random Forests. In Proceedings of the IEEE Control and Decision Conference, Osaka, Japan, 15–18 December 2015. [Google Scholar]
- Rodriguez-Galiano, V.; Mendes, M.P.; Garcia-Soldado, M.J.; Chica-Olmo, M.; Ribeiro, L. Predictive modeling of groundwater nitrate pollution using Random Forest and multisource variables related to intrinsic and specific vulnerability: A case study in an agricultural setting (Southern Spain). Sci. Total Environ. 2014, 476, 189–206. [Google Scholar] [CrossRef]
- Ching, J.; Phoon, K.K. Constructing site-specific multivariate probability distribution model using Bayesian machine learning. J. Eng. Mech. 2019, 145, 04018126. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Soil #1 | Soil #2 | Soil #3 |
|---|---|---|---|
| Dr = 30% | Dr = 70% | Dr = 65% | |
| Poisson’s ratio (ν) | 0.33 | 0.33 | 0.3 |
| Ko | 0.47 | 0.426 | 0.45 |
| E (kPa) | 11,000 | 28,000 | 25,000 |
| Secant elastic modulus in shear hardening (kPa) | 5639 | 15,037 | 15,400 |
| Tangential stiffness primary oedometer test loading (Eoedref) (kPa) | 5639 | 15,038 | 15,400 |
| Elastic modulus at unloading (Eurref) (kPa) | 22,225 | 59,265 | 46,200 |
| (unitless) | 902 | 1093 | 1019 |
| (unitless) | 320 | 940 | 617 |
| (°) | 34 | 36 | 35 |
| Failure ratio (Rf) (%) | 0.9 | 0.9 | 0.9 |
| Porosity (%) | 0.8 | 0.6 | 0.77 |
| Øcv (°) | 32 | 35 | 34 |
| Dilatancy angle (ψ) (°) | 2 | 5 | 4 |
| Cohesion (c) (kPa) | 0.1 | 0.1 | 0.1 |
| Attribute | Mean | Std. | Min. | Max. | |
|---|---|---|---|---|---|
| Corrected SPT test blow count (N1)60 | 14.5 | 3.2 | 10 | 18 | |
| PGA (g) | 0.37 | 0.21 | 0.1 | 0.82 | |
| Soil unit weight (γ) (kN/m3) | 18.1 | 1.1 | 16 | 19.4 | |
| Closed-ended pile | (Pile settlement)Dry (mm) | 33.5 | 32.5 | 1 | 150 |
| (Pile settlement)Sat (mm) | 54.8 | 55.6 | 2.2 | 269 | |
| Open-ended pile | (Pile settlement)Dry (mm) | 44.2 | 41 | 1.6 | 211 |
| (Pile settlement)Sat (mm) | 64.6 | 65.5 | 3.3 | 423 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasheed, S.E.; Al-Jeznawi, D.; Al-Janabi, M.A.Q.; Bernardo, L.F.A. Data-Driven Prediction of Maximum Settlement in Pipe Piles under Seismic Loads. J. Mar. Sci. Eng. 2024, 12, 274. https://doi.org/10.3390/jmse12020274
Rasheed SE, Al-Jeznawi D, Al-Janabi MAQ, Bernardo LFA. Data-Driven Prediction of Maximum Settlement in Pipe Piles under Seismic Loads. Journal of Marine Science and Engineering. 2024; 12(2):274. https://doi.org/10.3390/jmse12020274
Chicago/Turabian StyleRasheed, Sajjad E., Duaa Al-Jeznawi, Musab Aied Qissab Al-Janabi, and Luís Filipe Almeida Bernardo. 2024. "Data-Driven Prediction of Maximum Settlement in Pipe Piles under Seismic Loads" Journal of Marine Science and Engineering 12, no. 2: 274. https://doi.org/10.3390/jmse12020274
APA StyleRasheed, S. E., Al-Jeznawi, D., Al-Janabi, M. A. Q., & Bernardo, L. F. A. (2024). Data-Driven Prediction of Maximum Settlement in Pipe Piles under Seismic Loads. Journal of Marine Science and Engineering, 12(2), 274. https://doi.org/10.3390/jmse12020274