1. Introduction
The International Maritime Organization (IMO), the global standard-setting authority for the maritime industry, has increased scrutiny of ships’ environmental performance. The IMO added a new annex to the International Convention for the Prevention of Pollution from Ships (MARPOL) in 1997, with a focus on minimizing airborne emissions from ships, mainly from sulfur oxides (SO
x), nitrogen oxides (NO
x), ozone-depleting substances (ODSs), and volatile organic compounds (VOCs), which began being enforced on 19 May 2005. Amendments made to MARPOL Annex VI in 2011 mandated technical and operational energy efficiency measures to reduce CO
2 emissions from maritime shipping. These measures adopted by the IMO were the first global mandatory GHG reduction regime for international industry [
1]. With the adoption of new amendments, emissions reductions have become the main focus of research by policymakers. The Energy Efficiency Design Index (EEDI) aimed to encourage the use of more energy-efficient machinery, thus lowering carbon emissions. Energy-saving devices (ESDs) have become standard applications for almost all newly constructed ships. In 2011, during the 72nd session of the Marine Environment Protection Committee, it was agreed to adopt the initial strategy for reducing GHG emissions from ships, with provisions to review this in 2023. The IMO’s initial target was focused on reducing CO
2 emissions per transport work by 70% by 2050 compared with 2008, and reducing the total annual GHG emissions by 50% by 2050 compared with the 2008 baseline. The IMO’s initial strategy, aligned with the Paris Agreement, was a wake-up call for the industry as it highlighted that while ESDs will help operators to comply with regulations in the short term, they are not the only long-term solution for the decarbonization of the maritime industry. Various alternatives are currently being implemented or researched, such as hybrid propulsion systems and the full electrification of ships, as well as alternative fuels, such as methanol, ammonia, and hydrogen. However, the maturity level and applicability of these alternatives changes greatly based on the ship type and size. The quality of marine fuels is crucial for efficient combustion in ships’ main engines, auxiliary generators, and boilers. It is important to understand the physicochemical properties of the fuel bunkers. Studies show that under consistent cyclic conditions, fuel supply variations can impact efficiency by up to 5% [
2]. Additionally, bunker analysis can provide guidance to ship operators when troubleshooting combustion-quality-related problems as well as combustion efficiency problems. While bunker samples are sent to laboratories for evaluation, it is also possible to carry out a multiparametric assessment of fuel quality results, which can be completed almost instantly [
3]. On the other hand, one of the greatly varying factors in ship efficiency is operations. The carbon intensity indicator (CII) is a measure of a ship’s energy efficiency and is described as the grams of CO
2 emitted per cargo-carrying capacity per nautical mile [
4].
As expressed above, a couple of factors can be controlled to reduce the carbon intensity of maritime operations. Annual fuel consumption can be controlled by means of energy-saving devices (ESDs) and efficient operations. As the maritime industry adapts to environmental regulations, the fatigue resistance of ships’ mechanical components, such as propellers and engines, is becoming increasingly critical. The implementation of ESDs, as well as efficient operations such as slow steaming, is pivotal for reducing emissions, although it necessitates a thorough understanding of the fatigue behavior of these components under operational loads [
5]. While it may seem easy, identifying inefficient operations and identifying anomalies requires a set of data, including normal and abnormal conditions. As the machinery operates within a certain operating range, it is not always easy to identify anomalies as they start to develop; most of the time, they only become evident when the equipment fails. Manufacturers set design ranges and alarm parameters, but those variables mainly focus on the safety aspect of machinery operation, so the efficiency of the machinery is considered secondary when designing the operating range for machinery. Similarly, machinery failures are fixed as soon as they are identified. Therefore, this introduces the problem of data imbalance. The data imbalance problem is frequently the bottleneck of performance classification. Data imbalance is the terminology used to describe the situation where the class distributions are not equal, i.e., when one class, which is called the majority class, far exceeds the other classes, which are called the minority classes. This is the case when different classes have a significantly different number of samples. Due to the data imbalance problem, the training algorithm gives more weight to the class(es) with the majority of samples, which results in biased classifiers. Despite its complexity, the algorithm’s prediction model needs a lot of data to understand the hidden data correlations for output prediction. This is attributed to the fact that the training of predictive algorithms relies on deciphering intricate patterns within historical data. The augmentation of data quantity corresponds to heightened precision in the predictive model.
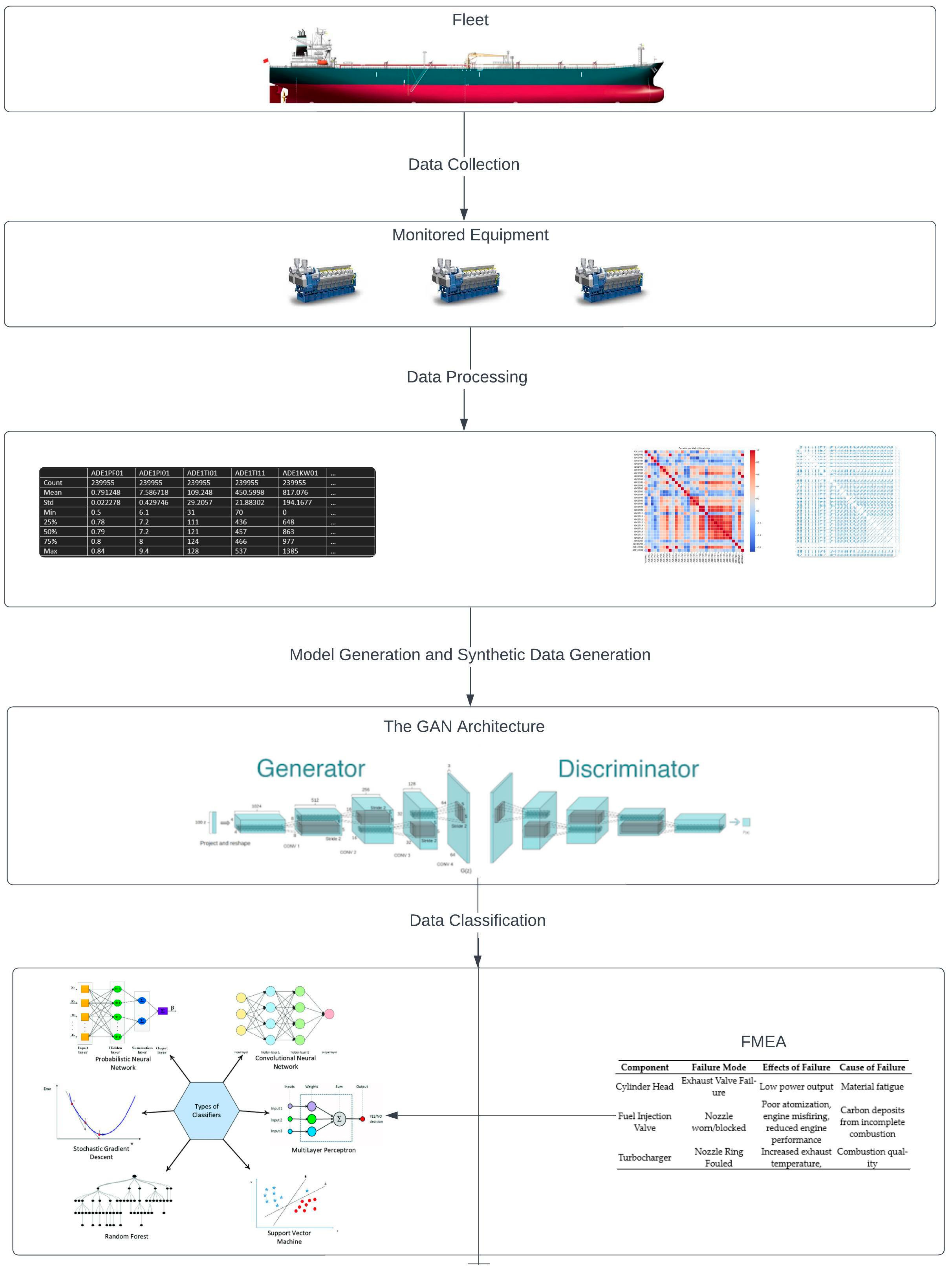
This is where generative adversarial networks (GANs) have emerged as a groundbreaking solution, enabling the generation of synthetic data that closely resemble real-world data. The ability to generate synthetic data that accurately capture the underlying distribution and statistical properties of real data has significant implications. generative adversarial networks offer a powerful solution by employing a dual architecture of generator and discriminator networks, enabling the generation of synthetic data that are remarkably similar to real data. This paper explores the utilization of GANs in ship machinery anomaly detection by using synthetic data generation, highlighting their potential to overcome data limitations and foster innovation across ship machinery anomaly detection.
GANs are powerful algorithms that utilize a dual training process, comprising a generator and a discriminator. The generator’s objective is to generate synthetic images that exhibit a high degree of realism, resembling real images. The discriminator is trained to differentiate between the generated images and real images. As GANs have evolved, they have made significant progress in unconditional image synthesis, generating images without any specific conditioning. Different types of GANs are deployed for different applications: realistic image generation [
6,
7], natural language processing [
8,
9], healthcare and medical imaging [
10], reinforcement learning [
11], etc. The use of GANs has primarily focused on computer vision and image generation; however, GANs have emerged as a promising solution for the generation of synthetic tabular data that exhibit similar statistical characteristics and patterns to the original data.
In this study, we focus on the prescriptive model of ship machinery monitoring based on GANs, supported by failure mode and effect analysis (FMEA) techniques. The proposed prescriptive model for ship machinery monitoring makes the following contributions to the literature.
First, generative adversarial networks have attracted significant attention and been applied to varying domains, including shipping. However, to the best of our knowledge, within the maritime domain, they are still not applied for machinery anomaly detection. GANs and their variants are used here for object detection and surveillance systems.
Second, data-driven approaches are integrated with FMEA for autonomous decision support systems (DSSs) for ship machinery systems.
Third, a comparison is made with six different classifiers trained with synthetic data and tested on real-life data for fault diagnosis. The model achieved 30–83% accuracy on real-life data for anomaly detection.
The rest of this study is organized as follows. In
Section 2, anomaly detection in the maritime industry is discussed; in
Section 3, the main tools used in this study, GAN and FMEA, are reviewed, followed by an explanation of the proposed prescriptive model.
Section 4 details the results of this study, and in
Section 5, the conclusions are discussed.
2. Literature Review
In recent years, data-driven approaches have garnered substantial attention in the maritime industry, a sector characterized by its historical significance and evolving technological landscape. The integration of advanced machine learning techniques, particularly in the realms of computer vision and natural language processing, has not only paralleled, but in some instances surpassed human performance in certain tasks [
12]. This paradigm shift towards data-centric methodologies in maritime operations is indicative of a broader trend in industry and academia alike.
With the ever-growing complexity of marine systems, the increasing maintenance demand and complexity of troubleshooting increases the need for decision support systems. Investigation reports indicate that 80% of accidents are caused by human error [
13].
The categorization of data-driven models into white, black, and gray box models offers a framework for understanding their applications and limitations [
14]. White box models, known for their transparency and explainability, are grounded in clear, underlying mechanisms. White box models are widely used, as they are characterized by their explicit mathematical equations and parameters, which have real-world interpretations. They are commonly used in reliability analyses [
15] and failure analyses [
16].
In contrast, black box models operate on statistical inferences, deriving conclusions from input–output relationships without explicitly revealing their internal workings. With the growing implementation of IoT devices and increases in the availability and accessibility of data, black box models are gaining significant momentum. In the maritime industry, black box models and data-driven algorithms are employed across a diverse range of applications. These applications include the prediction of fuel consumption by the main engine [
17], voyage optimization via vessel speed optimization [
18], and the prognostics and health management of ship machinery systems [
19]. Each of these applications’ predictive capabilities relies on data-driven models, which aim to enhance the ship’s operational efficiency and decision-making processes within the maritime sector. Gray box models represent a hybrid approach, enhancing the predictive capabilities of white box models by incorporating elements of black box models to address uncertainties. Gray box models, also called hybrid models, have gained attention as they aim to bridge the gap between white box models and black box models. They offer a valuable compromise between transparency and flexibility. By combining domain knowledge and data-driven insights, gray box models provide versatility and effectiveness to the predictive tools. They have been used for fuel consumption predictions [
20], remaining useful life predictions [
21], hull fouling predictions [
22], and engine performance predictions [
23].
Despite their advantages, a primary concern with the use of data-driven models in maritime applications is the autonomy of their decision-making. The reliance on purely data-driven methods can obscure the nuanced understanding that domain expertise provides. To bridge this gap, recent studies have advocated for a dual approach that synergizes data-driven techniques with domain knowledge [
24,
25,
26]. This involves integrating expert insights into black box models to enhance their relevance and applicability in real-world maritime scenarios.
In the context of maritime operations, anomaly detection plays a pivotal role in ensuring safety, security, and efficiency. Recent advancements in this area have been significantly influenced by the integration of cutting-edge technologies. The Internet of Things (IoT) has revolutionized data collection in maritime environments, offering real-time monitoring capabilities. When combined with machine learning algorithms, devices can provide instantaneous anomaly detection.
The integration of advanced data-driven approaches in anomaly detection within the maritime industry marks a significant stride towards modernizing and securing maritime operations. However, the successful implementation of these technologies necessitates a balanced approach, addressing the challenges mentioned earlier. One of the main challenges with classification problems is the lack of labeled data for the anomaly class. Many of the anomaly detection capabilities are rule-based, such that simple rules trigger an alarm [
27]. Additionally, the majority of diagnostics systems were found to rely on physics-based models [
28] and predictive models’ targeting to minimize prediction errors, which the prediction results mostly ignored [
29].
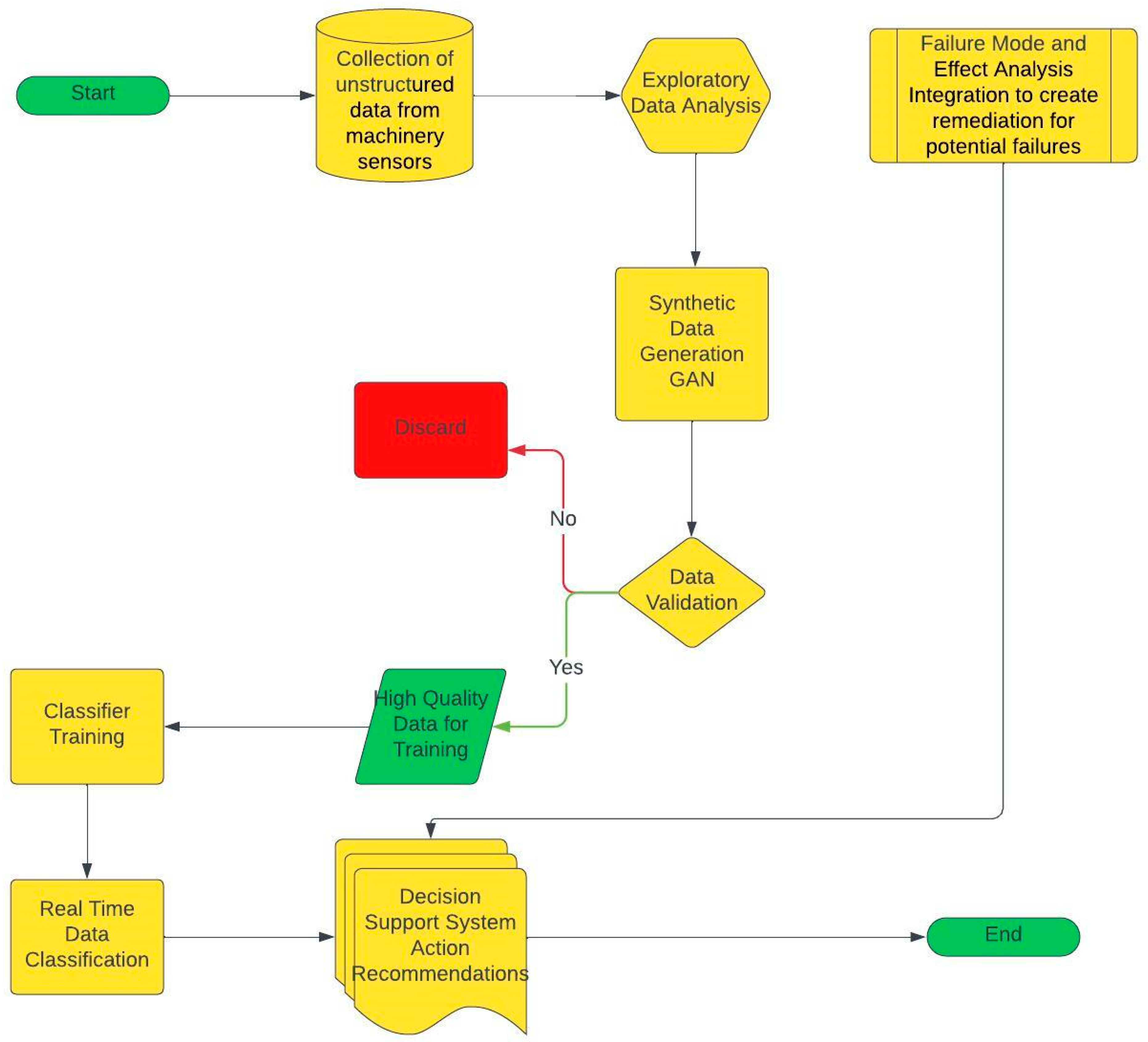
This study focuses on addressing the key challenges highlighted in anomaly detection in the maritime domain. The first problem we are tackling is the data imbalance problem via the implementation of GAN-based synthetic failure data generation. One of the primary methods used to address the imbalance in datasets is the use of various resampling techniques, such as undersampling, oversampling, and the synthetic minority oversampling technique (SMOTE) [
30]. However, where anomalies are rare, GANs can generate realistic examples of these events by improving the model’s ability to detect them.
Secondly, in order to overcome the lack of recommendations in predictive systems, we are proposing an effective FMEA-based DSS that leverages the systematic identification and prioritization of potential failure modes to guide the decision-making process.
4. Results and Discussion
The synthetic data that were generated resemble real data; then, the imbalanced dataset was classified according to the framework described in
Section 3.4.1. The specifications of the device used for modelling were established with an Intel Core i7-13700F 2.10 GHz processor, 16 GB of RAM, NVIDIA GeForce RTX 4070, and 1TB SSD hard disk. During the modelling process, TensorFlow 2.10.0 was utilized within a Python 3.9.18 programming environment. In order to generate the synthetic data, various hyperparameter tuning operations were performed throughout the GAN modelling phase, where the model underwent significant changes in its performance as the training process evolved. The GAN architecture integrates a discriminator with a total of four layers (512, 256, 128, and 1) and a generator comprising three layers (1024, 2048, and 4096), employing LeakyReLU as the primary activation function, and using intermediate layers and sigmoid in the final layer of the discriminator.
Table 13 and
Table 14 summarize the key hyperparameters used during modeling. Additionally, during performance optimization, we implemented Python packages Cprofiler and Snakeviz to visualize the computation time of the algorithm. The final computational performance of the GAN architecture is demonstrated in
Figure 8.
Synthetic data were generated and evaluated using various metrics before the best model for the GAN was chosen. These metrics included the discriminator’s accuracy when using real samples and generated samples, the F1 score, the precision score, and the recall score.
Table 15 presents the accuracy of the discriminator using the GAN model at different epochs.
The discriminator’s accuracy when using real data remained strong throughout the iterations, whereas its accuracy when using generated samples fluctuated significantly; it achieved a perfect accuracy of 100%, which indicates that the model was overfitted. Based on the accuracy of the discriminator, 100 and 200 epochs stand out as the best performers. However, accuracy, as a traditional metric, might provide misleading results [
74]. Therefore, an evaluation of additional metrics is required. In summary, the GAN model, at 100 epochs, achieves an F1 score of 67.18%, yielding the best results regarding the balance between precision and recall; thus, the GAN model with 100 epochs can be used for classification problems.
After the selection of the optimal GAN model, a comparative study was conducted to evaluate the performance of six different classifiers: AdaBoost, Random Forest, decision tree, Logistic Regression, KNN, and XGBoost. The performance of the classifiers in the classification algorithm was evaluated by several metrics, namely, accuracy, precision, recall, F1, and elements of the confusion matrix. These metrics offer a multifaceted view of each classifier’s performance, which is crucial for understanding their applicability to classification tasks.
Table 16 presents a summary of the classification results, along with the metrics used for evaluation.
Based on a comparative study of six classification algorithms, XGBoost emerged as the best classification algorithm, with an accuracy of 83.13% and an F1 score of 51.18%. This also indicates the effectiveness of the XGBoost algorithm for varying data distributions. However, logistic regression displayed significant limitations, with an 80.41% recall rate, suggesting that, while it can identify the majority of positive instances, it had a high rate of misclassification. AdaBoost and KNN classification algorithms achieved respective accuracies 81.84% and 80.48%; the increased number of false positives indicates a potential trade-off when aiming to achieve high sensitivity. Random Forest and decision tree classifiers also had an increased false positive rate, which demonstrates the overfitting problem that can occur with a given dataset. This indicates the need for feature selection in order to improve the model’s generalization ability.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}