4.3. Evaluation Metrics
To assess the predictive performance of the model, four performance metrics were chosen, including mean square error (MSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and R-squared (R2), as described by Equations (20)–(23). Additionally, the MSE serves as the loss function in this study.
MSE reflects the extent of deviation between predicted values and actual values. When the model performs well, the predicted values closely align with the true values, resulting in a smaller MSE value. Due to its sensitivity to data bias, the MSE can evaluate the model’s prediction performance at both peak and trough values. The calculation formula for the MSE is as follows:
The distinction between MAE and MSE lies in MAE reflecting the true error without squaring, making it an excellent metric for evaluating model prediction performance. Concerning model assessment, a smaller MAE value signifies a superior prediction performance of the model. The calculation formula is depicted as Equation (21):
MAPE measures the degree of deviation between the predicted values and the actual values. A lower value of the MAPE indicates a better fit between the predicted value curve and the true value curve, making it the most straightforward evaluation index. The calculation formula for the MAPE is as follows:
is a metric used to evaluate the quality of fit of a prediction model. It represents the proportion of the variance in the dependent variable that can be explained by the independent variables in the model. A higher value of
, closer to 1, indicates a better fit, meaning that the model can effectively account for the changes in the dependent variable. On the other hand, a value closer to 0 suggests that the model fails to explain the variations in the dependent variable adequately. It is calculated using Equation (23):
And, in order to further test the performance of proposed model, promoting mean square error (PMSE), promoting mean absolute error (PMAE), promoting mean absolute percentage error (PMAPE), and promoting R-squared (
) are also utilized; they are calculated as Equations (21)–(26):
In all the above equations, the number of samples is described as n, the predicted value of the model output is described as , the true value is described as , and the average value of the true value is described as .
4.4. Experimental Results Analysis
In this section, a variety of models, which are all classic deep learning and machine learning models in the field of time-series prediction, including TCN, LSTM, GRU, Conv-LSTM, Bi-LSTM, BIGRU, Bi-Conv-LSTM, RFR, and SVR models, have been selected as comparison models for roll angle prediction and pitch angle prediction tasks. To ensure a reliable comparison, the same hyper-parameters optimization method was employed in the comparison models. The detailed parameter setting is shown in
Table 4.
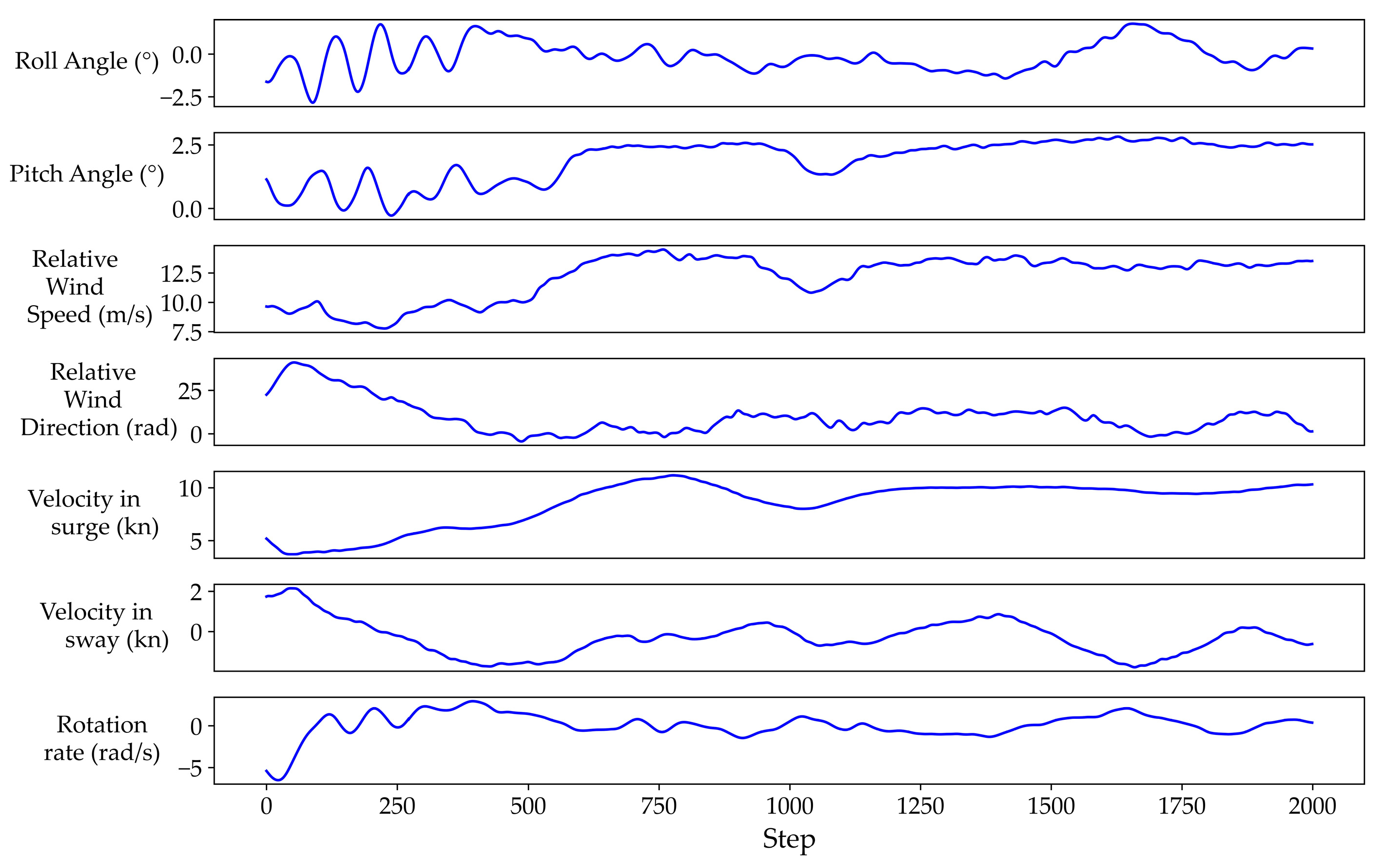
Figure 8 illustrates the USV roll angle prediction results of the TBT hybrid model in a 2000 step timeframe. The real roll angle is represented by a black sloid line, while the red solid line represents the predicted values generated by the TBT model. As depicted in
Figure 8, the USV roll angle exhibits clear non-stationarity and aperiodic behavior, posing a significant challenge in accurately capturing the trend of the true values and obtaining precise predictions. From
Figure 8, it can be seen that, due to its specially designed structure, the TBT hybrid model can adapt well to the non-periodic and non-stationary time-series characteristics of the roll angle. In the peak and trough regions, the TBT hybrid model is able to accurately predict the real roll angle. The subgraph in
Figure 8 displays the prediction results from steps in the range of 1750–1990, where the trend of the roll angle differs from that of most time periods. Remarkably, the TBT model still provides relatively accurate predictions, even amidst the uncertainty surrounding these changes in the real values. The ability of the TBT hybrid model to address this uncertainty and offer precise predictions in challenging circumstances further validates its effectiveness as a prediction model.
Figure 9 shows the prediction comparison results of different models. It can be observed that all models can generally track the changes in the real roll angle over time. However, during the continuous change in the true value curve, the GRU model and the LSTM model inaccurately predicted the changes in the true value, such as during steps in the range of 600–800. There is a significant error between the predicted value curve and the true value curve, which indicates that the pure RNN model can capture the temporal features well, but is unable to capture the spatial features that can enhance the prediction accuracy simultaneously. Similarly, the TCN model also faces the same issue, which indicates that the TCN model using only convolution operations and a non-recursive mode still struggles to make accurate predictions in multivariate input scenarios. At the pinnacle of the roll angle variation, the Conv-LSTM model demonstrates a superior performance compared to the LSTM and GRU models, as is evident for the interval including steps in the range of 1750–1850. It can be seen in
Figure 9 that, as variants of the LSTM, Conv-LSTM, GRU: Bi-LSTM, Bi-Conv-LSTM, and Bi-GRU models, their performance does not improve significantly; this illustrates that a bi-directional structure is not helpful for capturing temporal information more accurately under a multivariate input scenario. For two machine learning models, the RFR model exhibits the poorest performance at the peak and trough, particularly during the period of steps in the range of 1750–1850. Meanwhile, during steps in the range of 1250–1500, the SVR model tends to exhibit pronounced prediction errors when confronted with rapid changes in the roll angle.
Figure 10 shows the box plots of the prediction errors of various models in the roll angle prediction task; the prediction errors are calculated as
. Box plots utilize the interquartile range (IQR) to measure the dispersion of data, where a smaller IQR indicates a more concentrated data distribution, while a larger IQR signifies a more dispersed data distribution. The combination of the IQR with the median allows for a clear depiction of the distribution differences in prediction error data across different models.
It is apparent that the median error of the TBT hybrid model prediction error box plot is 0.041. In comparison, the medians of the other nine error box plots are 0.029, 0.076, 0.051, 0.046, 0.066, 0.056, 0.060, 0.074, and 0.071. At the same time, the IQR of the TBT hybrid model prediction error box plot is 0.028, while the IQRs of the other nine error box plots are 0.038, 0.101, 0.050, 0.057, 0.059, 0.038, 0.050, 0.076, and 0.071, indicating that the dispersion degree of the prediction error of the TBT hybrid model is the smallest. In other words, the TBT hybrid model prediction error is more concentrated, which means having a smaller error variation range and smaller prediction error.
In
Figure 10, the green dots represent the mean value of every box plot; as can be seen from the diagram, the mean value of the TBT hybrid model prediction error box plot is 0.044, while the mean values of other box plots are 0.077, 0.111, 0.067, 0.067, 0.074, 0.069, 0.076, 0.090, and 0.088. It is apparent that the mean of the RFR model is out of the box, due to the fact that the forecast errors in steps 1750–1850 increase the mean of RFR model’s errors.
Figure 11 displays the prediction results of the USV pitch angle using the TBT hybrid model. In
Figure 11, the real pitch angle is represented by a black solid line, while the red solid line represents the predicted value. In
Figure 11, it is clear that the pitch angle exhibits clearer periodic characteristics and is more stable when compared with the roll angle. Therefore, predicting the pitch angle is much less challenging than predicting the roll angle. As can be seen, the TBT hybrid model can accurately capture the changing trend of the true value and closely track the true value with minimal deviation throughout the prediction process. Especially at the extreme values that are significantly related to the USV motion attitude, the prediction value rarely shows large deviations from the true value.
Figure 12 shows the prediction results of different models in predicting the pitch angle. As depicted in
Figure 12, all models generally exhibit the ability to track the changes in the real pitch angle over time. However, during continuous changes in the true value curve, the LSTM model performs better than the GRU model; overall, the effects of the LSTM, GRU, and Conv-LSTM models exhibit similarities in pitch angle prediction tasks. The TCN model predicts well at peak points; however, there is a notable difference between the TCN model and the true value curve for trough points. The SVR model continued to struggle with accurately predicting the pitch angle under rapid changes in the ground truth value at extreme points. The performance of the RFR model is relatively better, but there is still a significant deviation between the predicted value and the real value, and the fluctuation in the real value cannot be accurately predicted. Similarly, for the pitch angle prediction, the bi-directional architectures of various RNN models did not demonstrate a superior performance at extreme points in comparison to the unidirectional counterparts.
Figure 13 shows the box plot of the prediction errors of several models for the pitch angle prediction task. It can be seen that the median of the TBT hybrid model prediction error box plot is the smallest at 0.007. In contrast, the medians of the other nine error box plots are 0.013, 0.017, 0.016, 0.015, 0.011, 0.024, 0.017, 0.016, and 0.010. At the same time, the IQR of the TBT hybrid model prediction error box plot is 0.008, while the IQRs of the other nine error box plots are 0.019, 0.019, 0.006, 0.011, 0.014, 0.013, 0.008, 0.017, and 0.010. Despite the IQR of the TBT model not being the smallest, the TBT hybrid model exhibits the smallest mean and median errors, along with the minimum and maximum error values. This suggests that the dispersion of prediction errors of the TBT hybrid model is minimized, demonstrating its superior performance in terms of error distribution. In other words, the TBT hybrid model prediction error is more concentrated, with a smaller error variation range and lower prediction error. As can be seen in
Figure 10, the mean value of the TBT hybrid model prediction error box plot is 0.008, while the mean values of the other models are 0.016, 0.019, 0.016, 0.016, 0.014, 0.023, 0.017, 0.017, and 0.012.
To further assess the prediction performance of different models,
Table 5 displays different evaluation metrics, including the MSE, MAE, MAPE, and
.
Additionally,
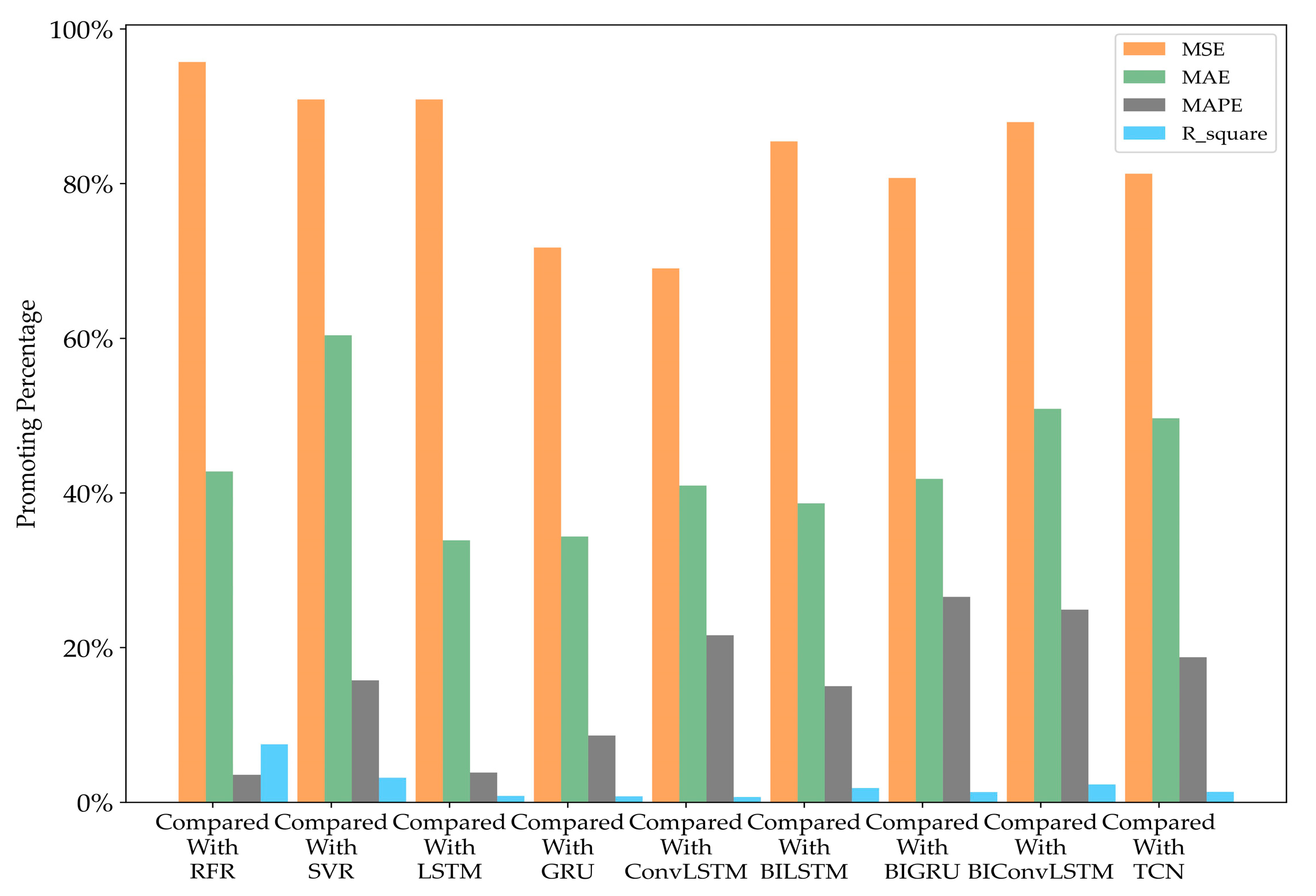
Table 6 illustrates the promotion percentage of the TBT hybrid model in comparison to other models across different evaluation metrics.
Table 5 and
Table 6 present the results of the evaluation indices, indicating that the TBT model outperforms other models in both roll angle and pitch angle prediction tasks. The proposed TBT hybrid model demonstrates significant advantages across all four evaluation indicators, showcasing improvements of at least 66.67%, 33.88%, 3.56%, and 0.58% compared to the other nine models on two different tasks. These substantial improvements can be attributed to its capability to simultaneously capture spatial and temporal features dynamically.
Based on the aforementioned analysis, the TBT hybrid model can effectively capture the time-series characteristics and spatial relationship of USV motion data, and accurately fits real data. Through the analysis of the experiment, it can be seen that the TBT hybrid model proposed in this study successfully captures the transformation of real motion data. The prediction effect is more accurate, stable, and dependable compared to the other models, thereby providing a solid foundation for a further analysis of its safe navigation capabilities.
4.5. Ablation Experiments
The purpose of this section is to compare the performance of different variants of the proposed model; concretely, the ablation experiments were performed to verify the contributions of the Conv-1D, TPA, and TCN-Bi-LSTM residual models to the improved outcomes of the TBT model. These experiments were conducted on the same datasets and environment, including the training and testing of different model variants.
Table 6 and
Table 7 represent the results of the ablation experiments. The ablation experiments involve the following variations:
A1: TBT model without the Conv-1D feature extractor at the end. Use fully connected layer to directly output predicted values.
A2: TBT model without the TPA mechanism. Pass the output of the preorder components directly to Conv-1D feature extractor and fully connected layer to obtain predicted values.
A3: TBT model without the TPA mechanism and Conv-1D feature extractor simultaneously. Only the basic TCN-Bi-LSTM residual structure is retained to obtain predicted values.
A4: TBT model without the TPA mechanism, Conv-1D feature extractor, or TCN module simultaneously (i.e., the Bi-LSTM model).
A5: The whole TBT model proposed in this paper.
In the ablation experiments, the parameters of each variant model were kept consistent with the full TBT model, the preprocessed multivariate USV motion data were input into several models separately, and the values of MSE, MAE, MAPE,
, and the corresponding promoting percentage are reported in
Table 7 and
Table 8.
As shown in
Table 7 and
Table 8, compared with the prediction results of the Bi-LSTM model (i.e., A4), the prediction accuracy of the TCN-Bi-LSTM residual model (i.e., A3), which is a combination of the Bi-LSTM model and the TCN, is significantly improved, with the roll angle and pitch angle prediction results obtaining an improvement of 3.67% and 13.50% in the key evaluation index, MAPE, respectively. Such an improvement can be attributed to the incorporation of the TCN as well as the introduction of the residual structure; the ability of the model to capture temporal features is improved accordingly. However, the model is still unable to carry out joint spatial-temporal feature extraction for the multiple coupled USV motion data input into the model, so the improvement in the prediction accuracy is very limited.
To further explore the effects of the Conv-1D model on the model’s performance, in A1, the model replaces the back-end Conv-1D layer with a fully connected layer; from the experimental results, the model’s performance of removing Conv-1D shows a certain degree of degradation, and compared with the complete TBT model, there are decreases in the key evaluation index, MAPE, by 2.76% and 32.11%. In addition, the other evaluation metrics of A1 are also slightly worse than the other cases, which may be caused by the fact that the removal of the local feature extraction capability of Conv-1D leads to a certain degree of decline in the model’s ability to finely perceive the trend of data changes, which will affect the model’s prediction accuracy near the extreme values, and thus manifests itself in evaluation metrics, such as the MSE, resulting in the value of these metrics to be substantially reduced.
In A2, the hidden states derived from the front component of the model are propagated through subsequent Conv-1D and fully connected layers, resulting in the computation of the final output. Based on the experimental findings, it is evident that the omission of the TPA mechanism has a more pronounced impact on the model compared to the exclusion of Conv-1D concerning the key evaluation metric, MAPE. This leads to the conclusion that the TPA mechanism plays a more crucial role in enhancing the prediction accuracy of the model as opposed to Conv-1D. One possible explanation for this observation is attributed to the TPA mechanism’s ability to capture spatial correlations present in the data. Furthermore, its adaptive allocation of different weights to individual input features contributes to reinforcing the model’s ability to characterize relationships among distinct variables, thereby further improving the accuracy of predictions.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}