
Underwater Unsupervised Stereo Matching Method Based on Semantic Attention


Abstract
1. Introduction
2. Related Work
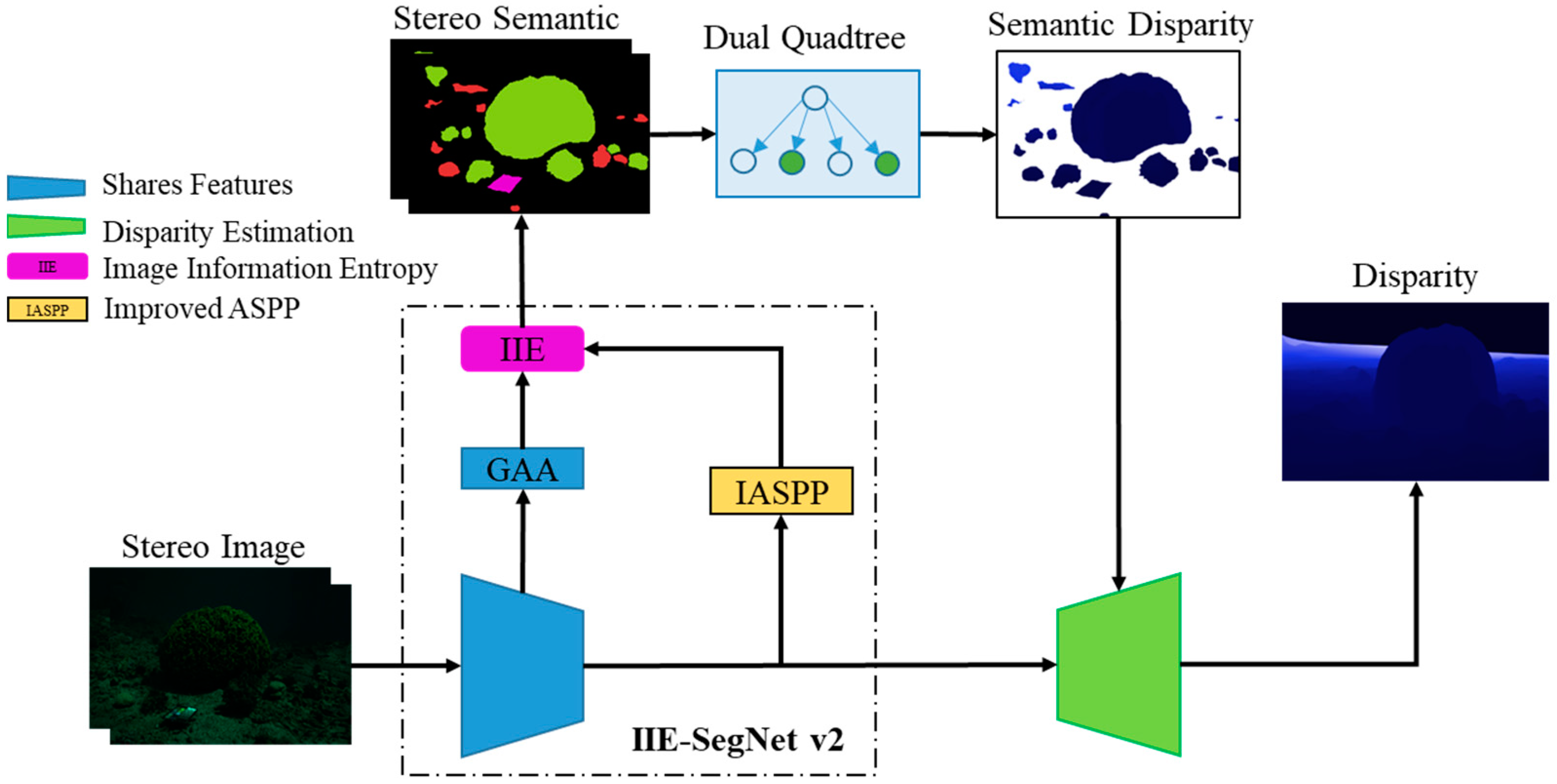
3. Research Methods
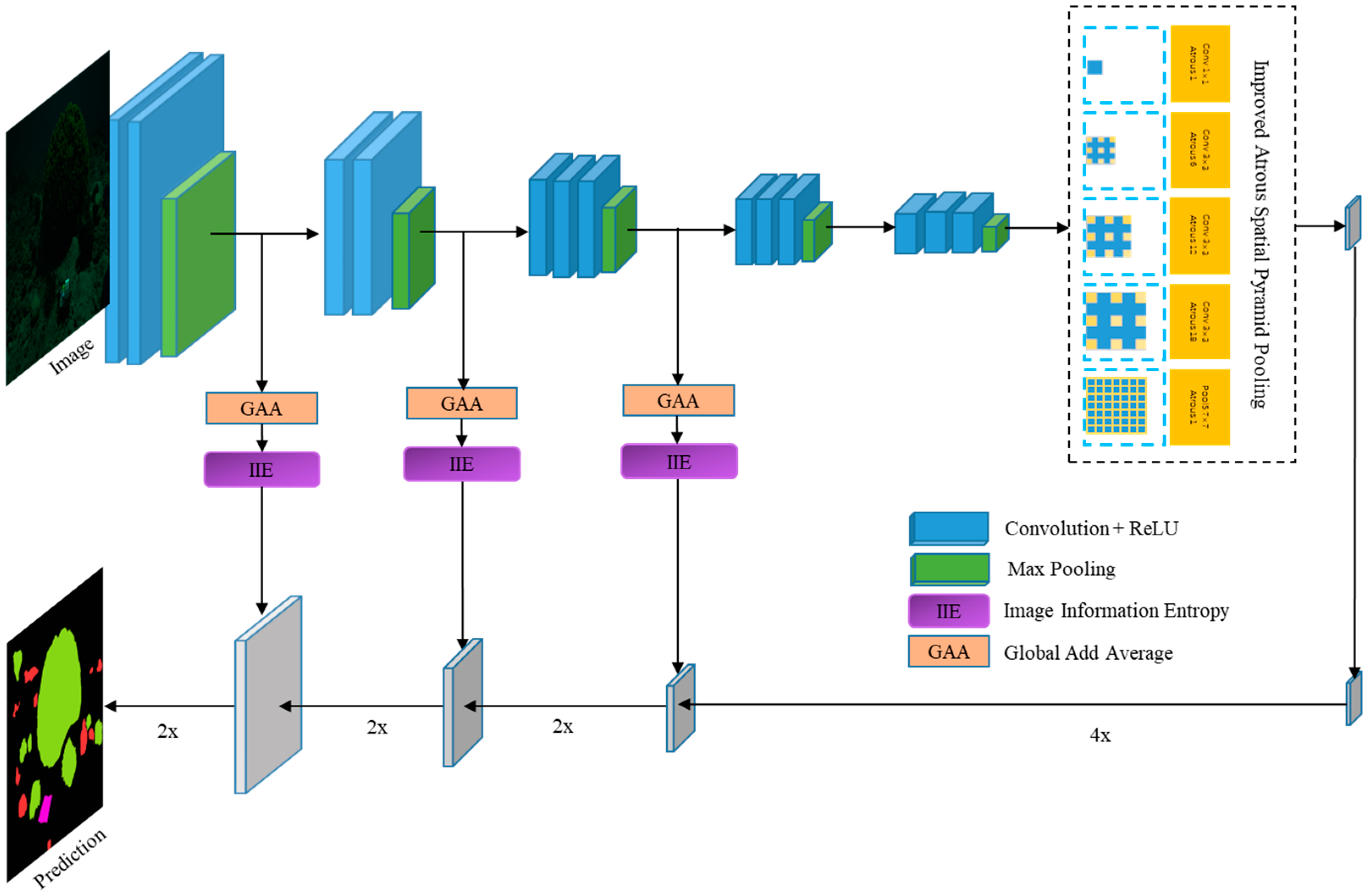
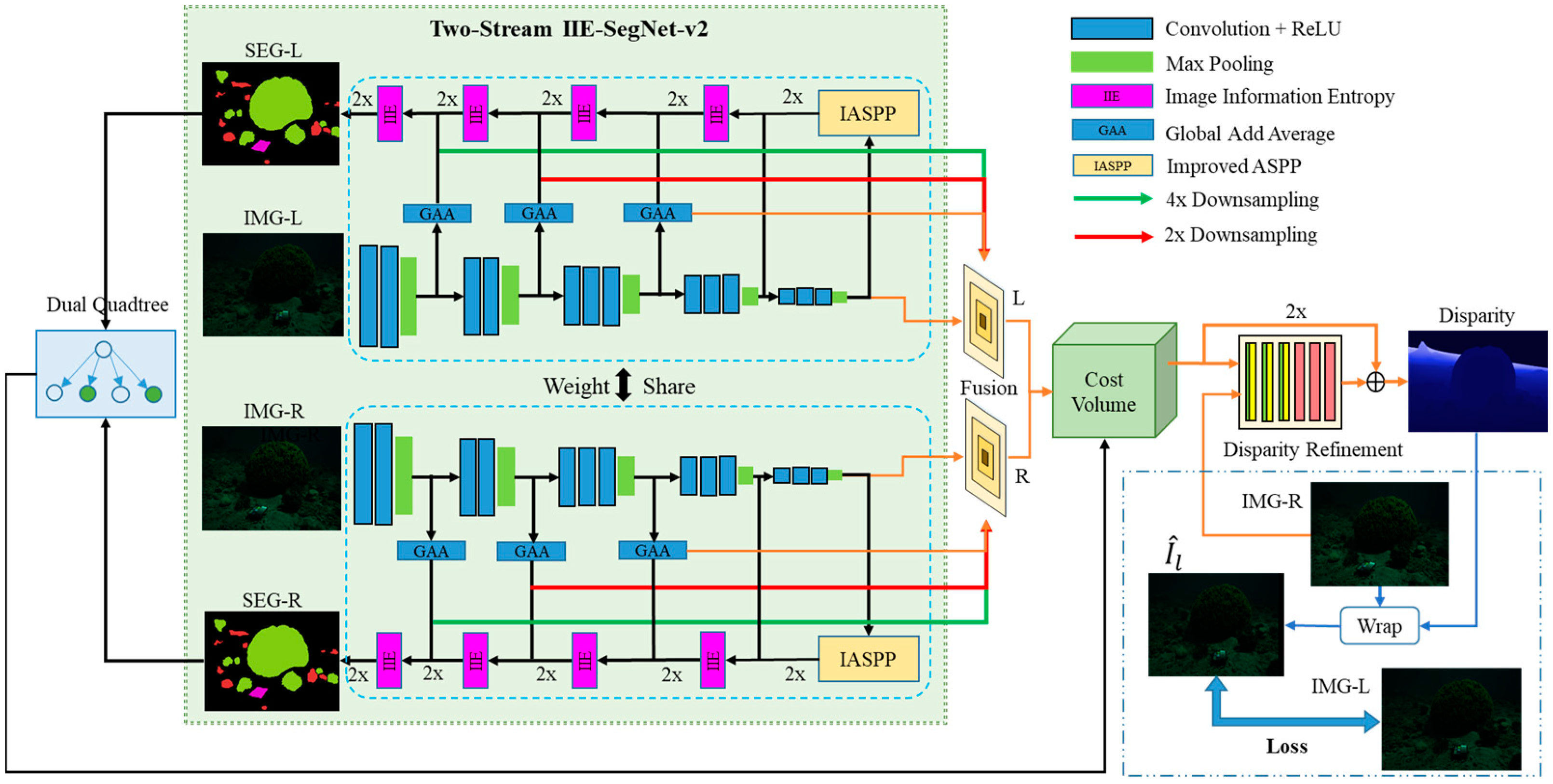
3.1. IIE-SegNet-v2
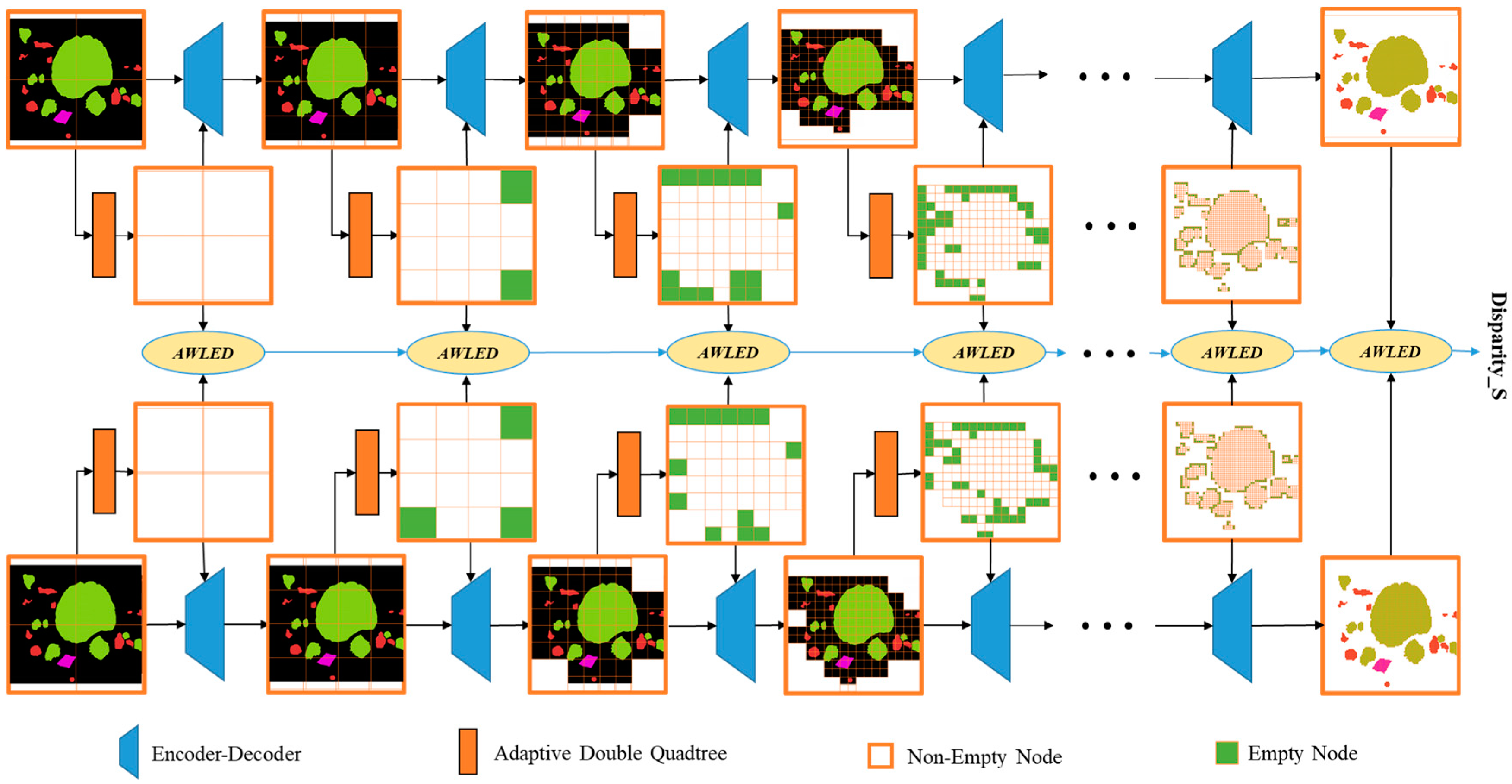
3.2. Adaptive Double Quadtree Attention Model
3.2.1. Quadtree
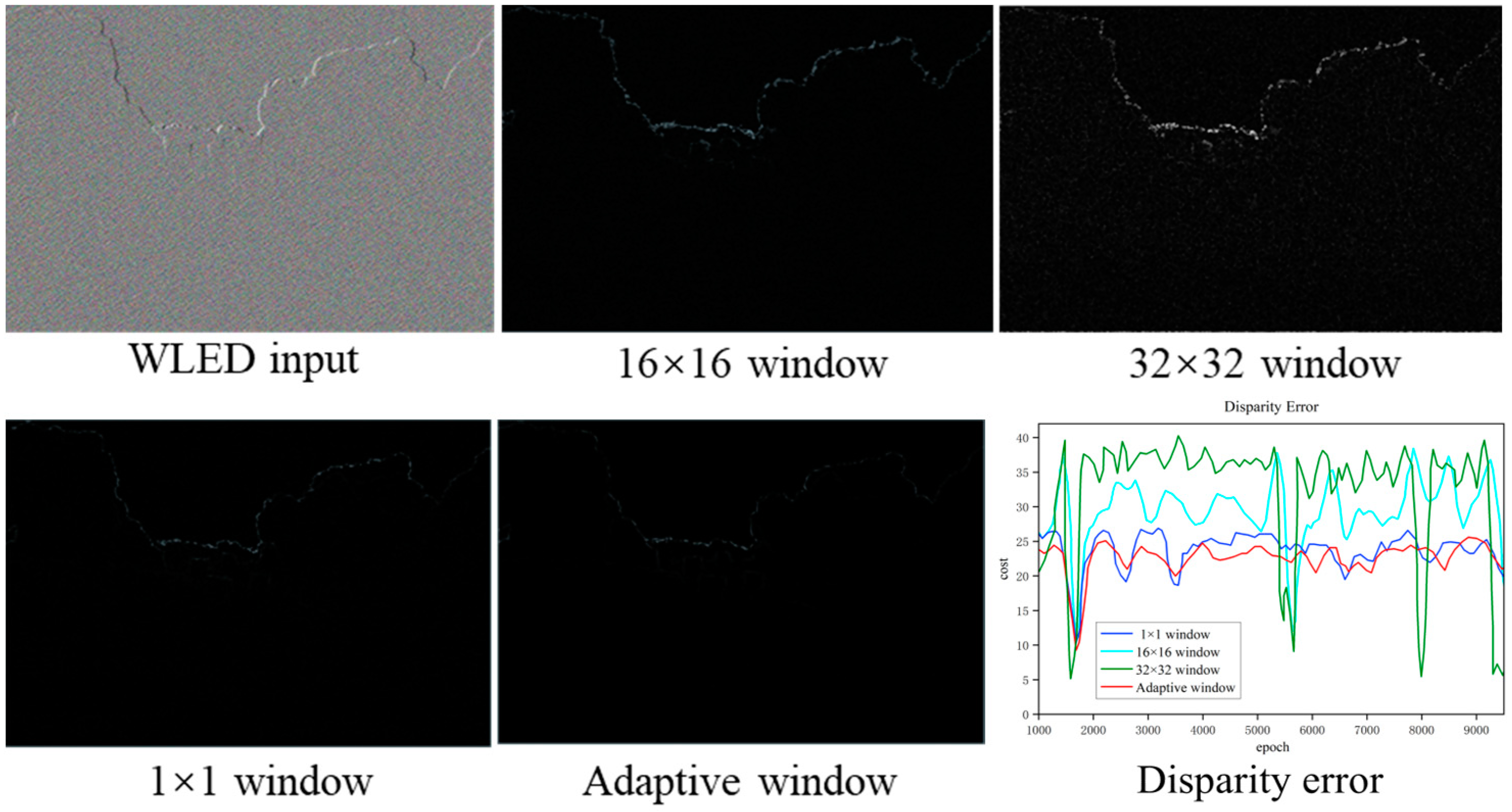
3.2.2. Adaptive Weighted Euclidean Distance
3.2.3. Adaptive Quadtree
3.3. Overall Network Structure
3.4. Unsupervised AWLED Semantic Loss
4. Experiment and Result Analysis
4.1. Underwater Stereo Matching Dataset
4.2. Network Training
4.3. Testing and Evaluation
4.3.1. Evaluation Indicators
- Avg All is the endpoint error (EPE) for all regions:
- 2.
- Evaluate all regions of the first frame image (D1 all):
4.3.2. Qualitative and Quantitative Evaluations
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kuppuswamy, R. Method to Profile the Maintenance Needs of a Fleet of Rotating Machine Assets using Partial Discharge Data. In Proceedings of the 2020 Electrical Insulation Conference (EIC), Knoxville, TN, USA, 22 June–3 July 2020; pp. 268–289. [Google Scholar]
- Corti, N.; Bonali, F.L.; Pasquaré Mariotto, F.; Tibaldi, A.; Russo, E.; Hjartardóttir, Á.R.; Einarsson, P.; Rigoni, V.; Bressan, S. Fracture Kinematics and Holocene Stress Field at the Krafla Rift, Northern Iceland. Geosciences 2021, 11, 101. [Google Scholar] [CrossRef]
- Hożyń, S.; Żak, B. Stereo Vision System for Vision-Based Control of Inspection-Class ROVs. Remote Sens. 2021, 13, 5075. [Google Scholar] [CrossRef]
- Gerlo, J.; Kooijman, D.G.; Wieling, I.W.; Heirmans, R.; Vanlanduit, S. Seaweed Growth Monitoring with a Low-Cost Vision-Based System. Sensors 2023, 23, 9197. [Google Scholar] [CrossRef]
- Zuo, Y.; Guan, H.; Duan, F.; Wu, T. A Light Field Full-Focus Image Feature Point Matching Method with an Improved ORB Algorithm. Sensors 2023, 23, 123. [Google Scholar] [CrossRef]
- Torkaman, H.; Fakhari, M.; Karimi, H.; Taheri, B. New Frequency Modulation Strategy with SHE for H-bridge Multilevel Inverters. In Proceedings of the 4th International Conference on Electrical Energy Systems (ICEES), Hangzhou, China, 5–7 July 2024; pp. 157–161. [Google Scholar]
- Madison, N.; Schiehll, E. The Effect of Financial Materiality on ESG Performance Assessment. Sustainability 2021, 13, 36–52. [Google Scholar] [CrossRef]
- Pan, Y.L.; Chen, J.C.; Wu, J.L. A Multi-Factor Combinations Enhanced Reversible Privacy Protection System for Facial Images. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Liu, J.; Yang, M.; Li, C.; Xu, R. Improving Cross-Modal Image-Text Retrieval with Teacher-Student Learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3242–3253. [Google Scholar] [CrossRef]
- Zuo, Y.; Yao, H.; Xu, C. Category-Level Adversarial Self-Ensembling for Domain Adaptation. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhang, T.; Ding, B.; Hu, Q.; Liu, Y.; Zhou, D.; Galo, W.; Fukuda, H. Research on Regional System Planning Method of Rural Habitat in Gully Regions of the Loess Plateau, under the Background of Rural Vitalization Strategy in China. Sustainability 2020, 12, 3317. [Google Scholar] [CrossRef]
- Shearmana, A.; Zendulkováa, D. Use of National and International Databases for Evaluation of International Project Award Potential. In Proceedings of the 14th International Conference on Current Research Information Systems, CRIS2018, Umeå, Sweden, 13–16 June 2019; pp. 102–111. [Google Scholar]
- Jeong, T.; Yun, J.; Oh, K.; Kim, J.; Woo, D.W.; Hwang, K.C. Shape and Weighting Optimization of a Subarray for an mm-Wave Phased Array Antenna. Appl. Sci. 2021, 11, 6803. [Google Scholar] [CrossRef]
- Amer, M.; Laninga, J.; McDermid, W.; Swatek, D.R.; Kordi, B. Very Light Pollution DC Flashover Characteristics of Short Samples of Polymer Insulators. In Proceedings of the 2020 IEEE Conference on Electrical Insulation and Dielectric Phenomena (CEIDP), Virtual, 18–30 October 2020; pp. 143–146. [Google Scholar]
- Hu, X.; He, C.; Walton, G.; Fang, Y. Face Stability Analysis of EPB Shield Tunnels in Dry Granular Soils Considering Nonuniform Chamber Pressure and a Dynamic Excavation Process. Int. J. Geomech. 2021, 21, 04021074. [Google Scholar] [CrossRef]
- Bynum, M.; Staid, A.; Arguello, B.; Castillo, A.; Knueven, B.; Laird, C.D.; Watson, J.-P. Proactive Operations and Investment Planning via Stochastic Optimization to Enhance Power Systems’ Extreme Weather Resilience. J. Infrastruct. Syst. 2021, 27, 04021004. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, H.; Yu, Y. Method for Calculating Text Similarity of Cross-Weighted Products Applied to Power Grid Model Search. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 3863–3867. [Google Scholar]
- Akkoyun, F.; Ercetin, A.; Aslantas, K.; Pimenov, D.Y.; Giasin, K.; Lakshmikanthan, A.; Aamir, M. Measurement of Micro Burr and Slot Widths through Image Processing: Comparison of Manual and Automated Measurements in Micro-Milling. Sensors 2021, 21, 4432. [Google Scholar] [CrossRef]
- Sousa, P.R.; Magalhães, L.; Resende, J.S.; Martins, R.; Antunes, L. Provisioning, Authentication and Secure Communications for IoT Devices on FIWARE. Sensors 2021, 21, 5898. [Google Scholar] [CrossRef]
- Moghimi, A.; Welzel, M.; Celik, T.; Schlurmann, T. A Comparative Performance Analysis of Popular Deep Learning Models and Segment Anything Model (SAM) for River Water Segmentation in Close-Range Remote Sensing Imagery. IEEE Access 2024, 12, 52067–52085. [Google Scholar] [CrossRef]
- da Silva Rocha, É.; Endo, P.T. A Comparative Study of Deep Learning Models for Dental Segmentation in Panoramic Radiograph. Appl. Sci. 2022, 12, 3103. [Google Scholar] [CrossRef]
- Afkir, Z.; Guermah, H.; Nassar, M.; Ebersold, S. Machine Learning Based Approach for Context Aware System. In Proceedings of the IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Napoli, Italy, 12–14 June 2019; pp. 43–48. [Google Scholar]
- Zhang, J.; Han, F.; Han, D.; Su, Z.; Li, H.; Zhao, W.; Yang, J. Object measurement in real underwater environments using improved stereo matching with semantic segmentation. Measurement 2023, 218, 113–147. [Google Scholar] [CrossRef]
- Ye, X.; Zhang, J.; Yuan, Y.; Xu, R.; Wang, Z.; Li, H. Underwater Depth Estimation via Stereo Adaptation Networks. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5089–5101. [Google Scholar] [CrossRef]
- Böer, G.; Gröger, J.P.; Badri-Höher, S.; Cisewski, B.; Renkewitz, H.; Mittermayer, F.; Strickmann, T.; Schramm, H. A Deep-Learning Based Pipeline for Estimating the Abundance and Size of Aquatic Organisms in an Unconstrained Underwater Environment from Continuously Captured Stereo Video. Sensors 2023, 23, 3311. [Google Scholar] [CrossRef]
- Xi, Q.; Rauschenbach, T.; Daoliang, L. Review of Underwater Machine Vision Technology and Its Applications. Mar. Technol. Soc. J. 2017, 51, 75–97. [Google Scholar] [CrossRef]
- Zhanga, X.; Zhangb, Z. Research on stereo matching algorithm of underwater binocular detection. In Proceedings of the Third International Conference on Computer Vision and Pattern Analysis (ICCPA), Hangzhou, China, 31 March–2 April 2023; Volume 12754, pp. 1–11. [Google Scholar]
- Liabc, Y.; Sun, K. Review of Underwater Visual Navigation and Docking: Advances and Challenges. In Proceedings of the Sixth Conference on Frontiers in Optical Imaging and Technology: Imaging Detection and Target Recognition, Nanjing, China, 22–24 October 2024; Volume 13156, pp. 1–8. [Google Scholar]
- Fayaz, S.; Parah, S.A.; Qureshi, G.J.; Kumar, V. Underwater Image Restoration: A state-of-the-art review. IET Image Process 2021, 15, 269–285. [Google Scholar] [CrossRef]
- Saad, A.; Jakobsen, S.; Bondø, M.; Mulelid, M.; Kelasidi, E. StereoYolo+DeepSORT: A Framework to Track Fish from Underwater Stereo Camera in Situ. In Proceedings of the International Conference on Machine Vision, Edinburgh, UK, 10–13 October 2024; Volume 13072, pp. 1–7. [Google Scholar]
- Ishibashi, S. The Stereo Vision System for an Underwater Vehicle. In Proceedings of the OCEANS 2009-EUROPE, Bremen, Germany, 11–14 May 2009; pp. 1–6. [Google Scholar]
- John, Y.; Ying, C.; Chen, C. Underwater Image Enhancement by Wavelength Compensation and Dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar]
- Deng, Z.; Sun, Z. Binocular Camera Calibration for Underwater Stereo Matching. J. Phys. Conf. Ser. 2020, 1550, 032047. [Google Scholar] [CrossRef]
- Zhuang, S.; Zhao, Q.; Wang, G.; Song, Y. Analysis of Binocular Visual Perception Technology of Underwater Robot. In Proceedings of the International Conference on Image Processing and Intelligent Control, Kuala Lumpur, Malaysia, 5–7 May 2023; Volume 12782, pp. 1–9. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–18. [Google Scholar]
- Zhuang, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16260–16270. [Google Scholar]
- Chen, L.; Dou, X.; Peng, J.; Li, W.; Sun, B.; Li, H. EFCNet: Ensemble Full Convolutional Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 9, 8011705. [Google Scholar] [CrossRef]
- Xu, L.; Ouyang, W.; Bennamoun, M.; Boussaid, F.; Xu, D. Multi-class Token Transformer for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4300–4309. [Google Scholar]
- Zhang, Z.; Wang, B.; Yu, Z.; Zhao, F. Attention Guided Enhancement Network for Weakly Supervised Semantic Segmentation. Chin. J. Electron. 2023, 32, 896–907. [Google Scholar] [CrossRef]
- Liu, F.; Fang, M. Semantic Segmentation of Underwater Images Based on Improved Deeplab. J. Mar. Sci. Eng. 2020, 8, 188. [Google Scholar] [CrossRef]
- Yang, X.; Feng, Z.; Zhao, Y.; Zhang, G.; He, L. Edge supervision and muti-scale cost volume for stereo matching. Image Vis. Comput. 2022, 117, 104336. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Wang, N.; Xin, G.; Hu, W. Underwater self-supervised depth estimation. Neurocomputing 2022, 514, 362–373. [Google Scholar] [CrossRef]
- Sharma, A.; Gupta, V. A novel approach for depth estimation using weighted Euclidean Distance in stereo matching. Comput. Vis. Image Underst. 2017, 162, 74–84. [Google Scholar]
- Gupta, S.; Sharma, R. An efficient image retrieval method based on standard Euclidean distance. J. Vis. Commun. Image Represent. 2018, 51, 166–175. [Google Scholar]
- Li, Q.; Wang, H.; Li, B.Y.; Yanghua, T.; Li, J. IIE-SegNet: Deep semantic segmentation network with enhanced boundary based on image information entropy. IEEE Access 2021, 9, 40612–40622. [Google Scholar] [CrossRef]
- Poggi, M.; Tonioni, A.; Tosi, F.; Mattoccia, S.; Di Stefano, L. Continual Adaptation for Deep Stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4713–4727. [Google Scholar] [CrossRef] [PubMed]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2822–2835. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Xu, Y.; Yang, X.; Jia, W.; Guo, Y. Bilateral Grid Learnimg for Stereo Matching Networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12492–12499. [Google Scholar]
- Skinner, K.A.; Zhang, J.; Olson, E.A.; Johnson-Roberson, M. UWStereoNet: Unsupervised learning for depth estimation and color correction of underwater stereo imagery. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7947–7954. [Google Scholar]
- Ye, X.; Li, Z.; Sun, B.; Wang, Z.; Xu, R.; Li, H.; Fan, X. Deep joint depth estimation and color correction from monocular underwater images based on unsupervised adaptation networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3995–4008. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | D1-All | EPE | 3px Error | Runtime |
|---|---|---|---|---|
| UWStereoNet [49] | 0.857 | 17.96 | 35.12 | 3200 ms |
| MUNet [50] | 0.594 | 9.76 | 12.87 | 1200 ms |
| BGNet [48] | 0.727 | 12.93 | 16.32 | 263 ms |
| MADNet [46] | 0.801 | 15.26 | 29.65 | 202 ms |
| Xchen Y, et al. [24] | 0.547 | 6.55 | 10.11 | 263 ms |
| Proposed method-basic | 0.672 | 5.98 | 15.69 | 232 ms |
| Proposed method-SS | 0.505 | 5.08 | 9.84 | 368 ms |
| Proposed method | 0.325 | 3.98 | 8.58 | 256 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Wang, H.; Xiao, Y.; Yang, H.; Chi, Z.; Dai, D. Underwater Unsupervised Stereo Matching Method Based on Semantic Attention. J. Mar. Sci. Eng. 2024, 12, 1123. https://doi.org/10.3390/jmse12071123
Li Q, Wang H, Xiao Y, Yang H, Chi Z, Dai D. Underwater Unsupervised Stereo Matching Method Based on Semantic Attention. Journal of Marine Science and Engineering. 2024; 12(7):1123. https://doi.org/10.3390/jmse12071123
Chicago/Turabian StyleLi, Qing, Hongjian Wang, Yao Xiao, Hualong Yang, Zhikang Chi, and Dongchen Dai. 2024. "Underwater Unsupervised Stereo Matching Method Based on Semantic Attention" Journal of Marine Science and Engineering 12, no. 7: 1123. https://doi.org/10.3390/jmse12071123
APA StyleLi, Q., Wang, H., Xiao, Y., Yang, H., Chi, Z., & Dai, D. (2024). Underwater Unsupervised Stereo Matching Method Based on Semantic Attention. Journal of Marine Science and Engineering, 12(7), 1123. https://doi.org/10.3390/jmse12071123