Abstract
In scenarios such as nearshore and inland waterways, the ship spots in a marine radar are easily confused with reefs and shorelines, leading to difficulties in ship identification. In such settings, the conventional ARPA method based on fractal detection and filter tracking performs relatively poorly. To accurately identify radar targets in such scenarios, a novel algorithm, namely YOSMR, based on the deep convolutional network, is proposed. The YOSMR uses the MobileNetV3(Large) network to extract ship imaging data of diverse depths and acquire feature data of various ships. Meanwhile, taking into account the issue of feature suppression for small-scale targets in algorithms composed of deep convolutional networks, the feature fusion module known as PANet has been subject to a lightweight reconstruction leveraging depthwise separable convolutions to enhance the extraction of salient features for small-scale ships while reducing model parameters and computational complexity to mitigate overfitting problems. To enhance the scale invariance of convolutional features, the feature extraction backbone is followed by an SPP module, which employs a design of four max-pooling constructs to preserve the prominent ship features within the feature representations. In the prediction head, the Cluster-NMS method and α-DIoU function are used to optimize non-maximum suppression (NMS) and positioning loss of prediction boxes, improving the accuracy and convergence speed of the algorithm. The experiments showed that the recall, accuracy, and precision of YOSMR reached 0.9308, 0.9204, and 0.9215, respectively. The identification efficacy of this algorithm exceeds that of various YOLO algorithms and other lightweight algorithms. In addition, the parameter size and calculational consumption were controlled to only 12.4 M and 8.63 G, respectively, exhibiting an 80.18% and 86.9% decrease compared to the standard YOLO model. As a result, the YOSMR displays a substantial advantage in terms of convolutional computation. Hence, the algorithm achieves an accurate identification of ships with different trail features and various scenes in marine radar images, especially in different interference and extreme scenarios, showing good robustness and applicability.
1. Introduction
The continuous surveillance of ships within ports and designated navigational waterways represents a pivotal undertaking, serving to provide regulatory personnel and ship operators with instantaneous insights into the state of maritime passages [1]. As a widely deployed monitoring apparatus, a shore-based marine radar enables the continuous detection of ship targets in wide-ranging water areas under adverse weather conditions (e.g., rain or fog) and poor nighttime visibility. It offers expansive imaging coverage and demonstrates stable imaging performance at relatively close observation distances. Compared to detection methods like the Automatic Identification System (AIS) and Very High Frequency (VHF) radio, marine radar does not require a real-time response from ships, significantly improving the speed of obtaining navigation information. Consequently, marine radar has emerged as a critical means for ship identification in open water domains.
In the context of shore-based surveillance, marine radar systems intended for regulatory purposes commonly incorporate diverse tail display modes of varying lengths. By discerning the distinctive features of ship trails, maritime regulators and navigators can approximate absolute or relative speeds, enabling them to assess the existence of potential risks. Consequently, in this particular scenario, the prompt and effective detection of ship targets assumes paramount importance. The ship identification in marine radar images can be effectively categorized into two distinct classes, i.e., long-wake ship identification and short-wake ship identification. Long-wake ships typically display conspicuous spot and trail features that exhibit clear differentiation from the background, thereby facilitating their localization and feature extraction with relative ease. Conversely, short-wake ships present image characteristics akin to environmental elements like rocky formations and coastlines within the maritime domain. Therefore, the discriminative process for such targets becomes susceptible to numerous background interferences, resulting in substantial difficulties in their distinguishment.
In comparison to object classification conducted on natural images, ship detection in the context of marine radar introduces a relatively higher degree of complexity. Primarily, within congested waterways, only a small portion of the detected spots genuinely correspond to mobile ships, leading to a heightened presence of interference in marine radar images. This, in turn, exerts a significant influence on the precise classification and localization of ships, alongside the formidable challenges associated with clutter removal, encompassing the elimination of sea waves, atmospheric elements such as clouds and rain, as well as extraneous noise. Moreover, the observational angle between the radar system and the ships imparts a substantial impact on the resulting ship imaging, while the irregular shapes of ship trails and spots further impede the efficacy of ship identification efforts. Meanwhile, ship targets within radar images exhibit a relatively diminished occupancy of absolute pixels, usually numbering in the hundreds. This results in a reduced pool of discernible features. Furthermore, when ships draw closer to coastlines, the backscattered spot from ships and the coastal backdrop often prove indistinguishable. Thus, the extraction of effective features and subsequent detection of small-scale ships become pivotal areas of focus and complexity within the research domain. Additionally, given the widespread adoption of embedded devices within radar systems, ship identification methods designed for radar images necessitate careful consideration of the practical computational limitations imposed by the deployed hardware.
Traditional methodologies for ship detection in radar images encompass a range of techniques, including reference object calibration, filtering algorithms, and pattern identification methods. The investigation of reference object calibration approaches primarily capitalizes on image processing methods, such as thresholding and connected component extraction, to extract salient contour features pertaining to ships and the surrounding coastal boundaries. These extracted features are subsequently employed in tandem with target feature-matching techniques to effectuate the calibration of ships within the surveilled water domain [2,3]. Furthermore, filtering algorithms are judiciously applied to distill the authentic trajectories of ship spots from a multitude of traces within the image, thus enabling the acquisition of essential ship attributes encompassing temporal and positional information [4,5]. Based on an exact modeling of ship motion trajectories, the judicious application of filtering algorithms may yield efficacy. However, conventional filtering algorithms, prevalent in radar systems, may not be amenable to ship detection manifesting diminutive target scales, occlusions, or intricate environmental perturbations [6,7]. Conversely, pattern identification methods have engendered commendable results in the classification and localization of ship spots within marine radar images [8]. Notably, several non-probabilistic models have gained wide acclaim, engendering improvements in ship identification efficacy. Nevertheless, the efficacy of the aforementioned techniques may exhibit limitations when confronted with ship identification characterized by a paucity of pixel features, languid motion velocities, and formidable background interferences.
In recent times, the utilization of Convolutional Neural Networks (CNNs) in object detection algorithms has witnessed notable advancements, encompassing both single-stage algorithms [9,10,11,12] and two-stage algorithms [13,14]. These CNN-based techniques have demonstrated conspicuous advantages over traditional methodologies, particularly concerning the extraction of deep semantic information from images and the attainment of precise object localization [15]. Of particular significance, researchers have made seminal contributions to ship identification by harnessing the potential of CNNs within the domains of Synthetic Aperture Radar (SAR) and remote sensing images, yielding satisfactory outcomes [16,17]. The prevailing ship instances within the aforementioned contexts predominantly manifest as diminutive object types, invariably accompanied by the conspicuous presence of background interferences. This intrinsic similarity shared with ship identification in marine radar images thus furnishes invaluable inspiration for the formulation of the identification algorithm elucidated within this present research.
Presently, radar image-oriented ship identification methods grounded in CNN architectures have attained a moderate degree of advancement. The judicious design of backbone networks and attention mechanisms aids in suppressing clutter interferences and ameliorating ship confidence levels [18]. Concurrently, certain investigations have achieved an efficient extraction of pivotal ship features within radar images through the implementation of two-stage algorithms [19,20]. Nonetheless, the aforementioned approaches still exhibit inadequacies in effectively mitigating complex interferences and precisely identifying dense small-scale ships. Moreover, it is imperative to elucidate that models based on deep neural networks are conventionally deployed on high-performance computing devices, which entail elevated computational costs due to the excessive convolutional layers and parameters encompassed within. This predicament engenders a diminished sensitivity of higher-level features within the network towards diminutive targets, consequently yielding unsatisfactory outcomes in terms of feature extraction for small-scale objects. Ergo, the adoption of lightweight algorithms, characterized by optimized computational efficiency and a reduced number of convolutional layers [21,22], may be deemed more appropriate for small target identification, thereby augmenting the identification effectiveness pertaining to small-scale ship instances characterized by truncated wake signatures within marine radar images.
In light of the distinctive attributes associated with ship identification in marine radar images, this research designs a novel algorithm, denoted as YOSMR, which leverages a tailored lightweight convolutional network. This approach deviates significantly from prior research in several key aspects.
- [1]
- Adoption of a more efficient lightweight network for extracting crucial ship spot features;
- [2]
- Introduction of a deep feature enhancement method that integrates multi-scale receptive fields to enhance the generalization capability of the feature network;
- [3]
- Incorporation of convolution methods with higher parameter efficiency into a bidirectional feature fusion network, enabling effective learning of spatial and channel features from input data and facilitating the fusion of ship features at both micro and global levels;
- [4]
- Improvement of prediction box formation through advanced non-maximum suppression (NMS) and localization loss estimation, leading to improved ship localization accuracy in dense scenarios;
- [5]
- Design of a more robust ship identification method by utilizing a lightweight convolutional neural architecture to address the computational limitations of embedded devices in radar systems.
It is noteworthy that the ship detection undertaken in this effort is based on the output images from a shore-based radar system. As the imaging foundation, fundamental signal processing techniques within radar systems, including the CFAR (Constant False Alarm Rate) operating modes, will profoundly influence the resulting radar imaging quality. For the shore-based radar used in this research, the echo acquiring and processing technique has undergone targeted adjustments in prior work, with the aim of enhancing the efficiency and stability of the radar imaging in the specific region. It is only upon this foundation that the image-oriented ship detection method possesses true practical value. Additionally, traditional radar’s multi-target tracking generally employs the Track-While-Scan (TWS) model, wherein the core technologies are tracking filters and data association. Techniques such as Least Squares Filtering (LSF), Kalman Filtering (KF), Extended Kalman Filtering (EKF), and Unscented Kalman Filtering (UKF) have long played a pivotal role in tracking filters. For data association, the Nearest Neighbor algorithm is suitable for environments with low clutter interference, while for scenarios with medium to high-density clutter and multiple targets, the Joint Probabilistic Data Association (JPDA) algorithm and Multiple Hypothesis Tracking (MHT) algorithm have been proposed and utilized, though these methods also exhibit limitations in high real-time computational demands and large computational loads.
In this work and the upcoming research, we are exploring a novel image-based ship detection-tracking pipeline. Specifically, we will build upon the proposed YOSMR model and seamlessly integrate a customized tracking algorithm tailored for ship targets in radar images, which will enable the development of an innovative working paradigm for shore-based radar detection and tracking. This will serve as a complementary technique to the traditional TWS method, thereby enhancing the real-time performance, accuracy, and robustness of radar perception.
The subsequent sections of this manuscript are structured as follows: Section 2 elucidates a CNN-based customized ship identification algorithm. Section 3 juxtaposes and scrutinizes the experimental outcomes of diverse algorithms employed in marine radar images. Lastly, Section 4 encapsulates the principal contributions of the proposed method and deliberates upon prospective avenues for future advancement.
2. A Proposed Method
The overall framework of the proposed method is depicted in Figure 1, consisting primarily of a feature extraction network and a lightweight feature fusion network. The feature extraction network utilizes the MobileNetV3(Large) architecture [21], which possesses a deeper convolutional layer structure and demonstrates adaptable capability in extracting features at different levels from radar images. The lightweight design of the feature fusion network incorporates three prediction channels, each encompassing the identification process for ships at different scales. Additionally, this network employs depthwise separable convolutions (DSC) [23] as a replacement for standard 3 × 3 convolutions, significantly reducing the model’s parameter and computational complexity. Furthermore, an SPP module [24] is introduced between the feature extraction network and the feature fusion network. The SPP module employs multiple pooling layers to transform feature maps of arbitrary sizes into fixed-size feature vectors, which enhances the capability of extracting ship features and reduces overfitting issues. Lastly, in the prediction head of the algorithm, the non-maximum suppression process is improved using the Cluster-NMS method [25]. This enhancement elevates the accuracy and confidence level of the predicted boxes. Additionally, the α-DIoU loss function is introduced to optimize the calculation of position loss for the predicted boxes, thereby improving the convergence speed and accuracy of the predicted boxes [26].
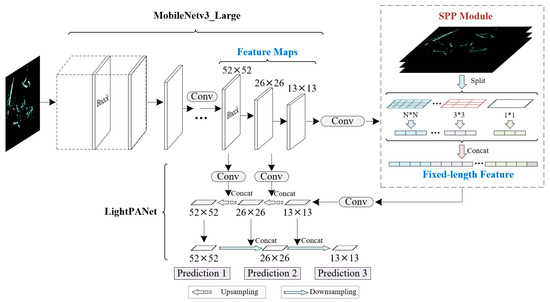
Figure 1.
The pipeline of the proposed algorithm. We present a novel detection algorithm grounded in the YOLO architecture, which we term YOSMR. The holistic architecture of YOSMR can be delineated into three core components: Backbone, Neck, and Head. Furthermore, the algorithm also encompasses loss functions and training strategies as pivotal elements. Relative to the standard YOLO framework, YOSMR has undertaken adaptive adjustments across its Backbone, Neck, Head, Loss function, and NMS components to better cater to the unique characteristics of radar-based applications. (a) Within the Backbone, YOSMR has integrated a mature feature extraction network, MobileNetV3(Large), and appended a feature enhancement module known as the Spatial Pyramid Pooling (SPP). (b) We leverage the efficient Depthwise Separable Convolution (DSC), a lightweight convolutional unit, to reconstruct the feature fusion network. This not only ensures the effective extraction of small-scale object features but also significantly reduces the convolution parameters. (c) In the Head structure, we have introduced three prediction channels of diverse scales to encompass the detection of various target types. (d) we have incorporated Cluster NMS and designed the α-DIoU loss to optimize the algorithm’s training and accelerate convergence.
2.1. Feature Extraction Network
MobileNetV3(Large) is a remarkable lightweight network renowned for its favorable identification performance on general datasets involving multiple object categories. It comprises 15 so-called Bneck modules with diminishing feature map sizes. In addition, the inverse residual structures within the network exhibit an increment in channel numbers and feature layer quantities. This architectural configuration effectively tackles the issue of feature networks losing object salient information in deep convolutional layers. The Bneck module, depicted in Figure 2, utilizes an inverse residual structure with linear bottlenecks to enhance model dimensionality. Meanwhile, it incorporates residual edge structures for convolutional feature fusion. Additionally, the module employs depthwise separable convolution and lightweight feature attention mechanisms to perform feature extraction, resulting in reduced parameter count and computational requirements. This approach enhances the network’s ability to capture significant features of small objects. Research [21] has demonstrated that MobileNetV3(Large) exhibits efficient convolutional computation capabilities and a relatively deep network architecture, enabling robust extraction of essential object features. Moreover, the network has significantly fewer parameters compared to general network architectures such as RCNN series, ResNet-101, SENet, and Darknet53, striking a good balance between accuracy and speed.
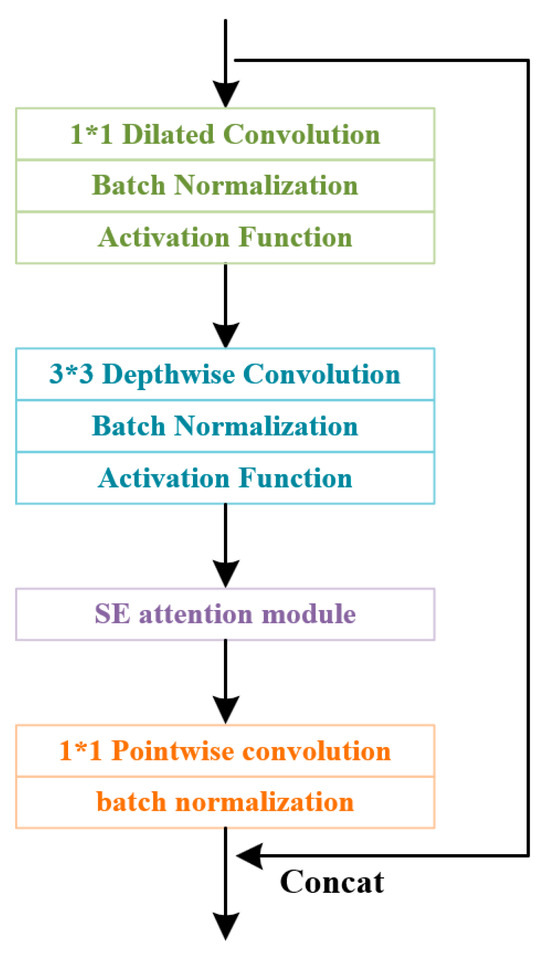
Figure 2.
Structure of the Bneck module. In the process of forward convolution, this module employs an attention calculation mechanism and a residual edge structure to enhance the extraction of crucial features relevant to the targets.
In marine radar images, the small scale of ship targets and their limited distinctive features result in the representation of only a limited number of abstract features in deep convolutional networks. This can give rise to the challenge of confounding ship features with background information. Therefore, ship identification in radar images imposes elevated demands on feature extraction networks. MobileNetV3(Large), with its efficient feature extraction architecture for small targets, can capture more comprehensive ship information and enhance accuracy. By incorporating convolutional heatmaps, it is observed that MobileNetV3(Large) primarily leverages the trailing features of ships for object localization. As shown in Figure 3, MobileNetV3(Large) is capable of effectively extracting ship features and accurately distinguishing ships from the background environment, even in scenarios involving minute scales or extreme conditions. This significantly improves ship detection performance and ensures increased accuracy with relatively fewer convolutional parameters.
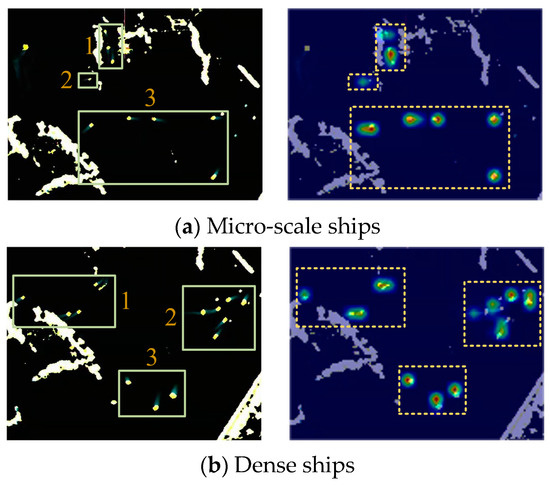
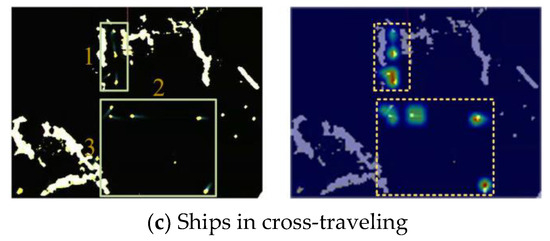
Figure 3.
Convolutional heatmaps. It is apparent that MobileNetV3(Large) leverages the detection of radar spot features to discern the validity of targets. The heatmaps substantiate the remarkable precision of the feature network in localizing ships while effectively mitigating false positives.
2.2. Receptive Field Expansion Module
When performing convolutional computations in the feature network for radar image inputs, variations in the input image size often necessitate operations like stretching and cropping, resulting in the loss of pixel information from the original image. Moreover, small-scale ships tend to have fewer preserved effective features in deep convolutions, leading to lower accuracy in their identification by the model. To address these challenges, concatenating an SPP module after the feature network can preserve more comprehensive image features. This is because SPP utilizes pyramid-like pooling operations, which increase the network’s receptive field without altering the resolution of the feature maps. Consequently, it better captures object-related features at different scales, thereby enhancing the model’s capability. The SPP structure, as depicted in Figure 4, employs the concatenation of multiple max pooling modules with different sizes to transform the multi-scale feature maps into fixed-size feature vectors [10]. Through numerous experiments, it has been observed that concatenating four max-pooling layers, with sizes of 1 × 1, 5 × 5, 9 × 9, and 13 × 13, yields optimized detection results for ship identification in radar images.
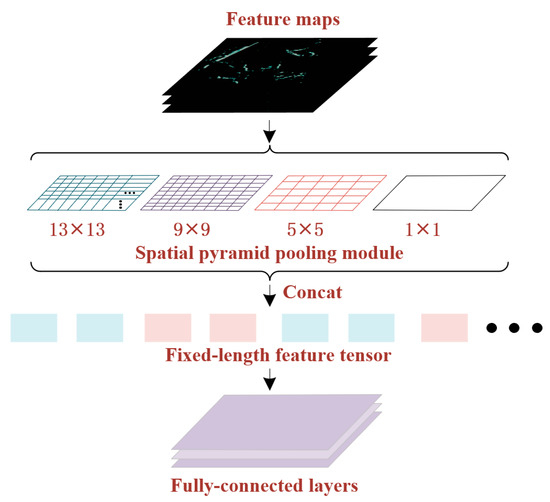
Figure 4.
Structure of the SPP. Through the concatenation of multiple scales of maximum pooling layers, this module captures the relatively prominent feature representations from diverse local regions of the feature map. This strategy ensures the positional invariance of the feature data and contributes to mitigating the risk of overfitting.
Drawing upon prior knowledge, it is widely acknowledged that the inclusion of the SPP module plays a critical role in effectively integrating features from diverse scales, thereby enhancing the identification efficacy for small targets and mitigating overfitting concerns. In ship detection using marine radar images, the dataset encompasses diverse scenes and scales of ships, which exert an influence on the complexity and learning capacity of the model, as well as the convergence of the feature network’s parameters. The SPP module, in addressing these challenges, enhances the extraction effectiveness of significant features from small-scale ships by expanding the receptive field range of the feature maps. This expansion, in due course, positively contributes to the overall practical capability of the model.
By conducting evaluations within an appropriate training environment and utilizing relevant radar images, the practical performance of the YOSMR algorithm with the incorporation of the SPP module was assessed. In certain marine radar images, a notable presence of ships with short wakes is observed. These ships are commonly considered small-scale targets, posing significant challenges for accurate identification, as depicted in Figure 5. Experimental observations indicate that in situations involving dense and intersecting ships, the SPP module demonstrates robust adaptability to various types of ship targets. It exhibits high precision in ship localization without any instances of mistakes. In contrast, when the SPP module is not utilized, the detection results fail to differentiate between densely packed ships and intersecting ships, leading to multiple erroneous results. Analysis suggests that the SPP module effectively mitigates the common issue of misidentification in small target detection, thus enhancing the actual effectiveness of the algorithm.
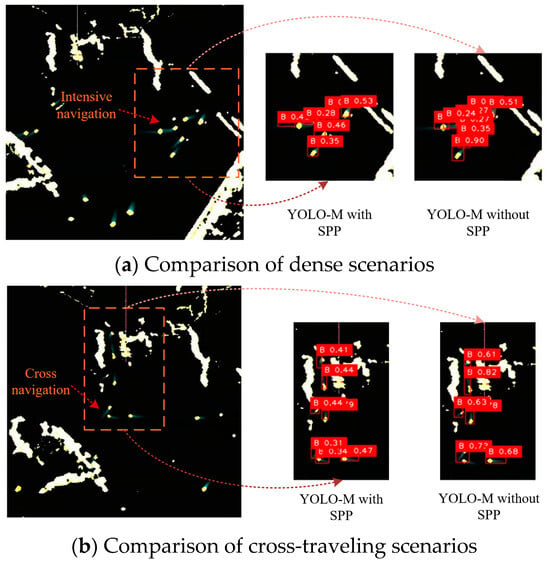
Figure 5.
Comparison of identification results with and without SPP. The SPP module, by extracting finer-grained target features, enables effective discrimination of adjacent spots in dense scenes, reducing the probability of misidentification and enhancing the model’s robustness.
2.3. Feature Fusion Network
In the field of ship detection and identification in marine radar images, it is typical to observe multiple ship spots with varying sizes and distinct shapes within a single image. Furthermore, the majority of these ships tend to possess relatively diminutive scales, thereby potentially leading to overlapping ship pixels or a striking resemblance to the background. These factors significantly compound the challenges associated with ship identification. To address these aforementioned issues, the extraction of salient features, such as ship contour morphology and the distinguishing characteristics of the bow and stern, can furnish the model with precise discriminative information. Consequently, this augmentation serves to enhance the accuracy and robustness of ship detection.
In general, within deep convolutional networks, shallow convolutions tend to possess higher resolution, capturing more detailed spatial information that aids in improving the precision of object localization. Conversely, deep convolutions have lower resolution but encapsulate stronger multi-scale and semantic information. This research aims to fully integrate feature information extracted from different scales of receptive fields in a single image, thereby devising a more efficient feature fusion network.
With the advancement of convolutional neural networks, feature fusion structures, exemplified by the standard Feature Pyramid Network (FPN) [27], often employ convolutional units that entail redundant computations. Moreover, a plethora of ineffective convolutional parameters can impede the extraction of salient features. Additionally, the single-level top-down feature fusion structure within the FPN architecture fails to concatenate shallow features with deep convolutions, leading to varying fusion effects for different levels of convolutional features. Therefore, the feature blending effect of certain prediction channels is compromised. Research has shown that when PANet [28] is employed as the feature fusion network, its bidirectional fusion structure facilitates a secondary fusion of convolutional features from different levels. This reinforces the outputs of each convolutional level, consequently enhancing the algorithm’s estimation and classification capabilities. Simultaneously, the feature fusion network devised in this research incorporates three prediction channels, encompassing the prediction processes for large, medium, and small-scale targets. Consequently, the convolutional computations of the feature fusion network far exceed those of a single prediction channel. This, in turn, leads to a more complex network structure with a larger parameter count and computational overhead, resulting in a surplus of redundant information. Experimental findings indicate that when PANet employs standard 3 × 3 convolutions, the identification model experiences a significant increase in ineffective parameters. Therefore, simplifying the convolutional computations of feature data serves as a direct approach to reduce the parameter count of the model and alleviate overfitting issues in deep networks.
It has been established through research that depthwise separable convolution profoundly simplifies the computational process of standard convolution while maintaining identical input and output dimensions [23]. Compared to standard convolution, depthwise separable convolution exhibits heightened precision in extracting features pertaining to small targets due to a substantial reduction in redundant parameters. In the context of marine radar images, diminutive-scale ships possess fewer discernible features that distinguish them from background pixel information within the convolutional network. Consequently, such targets gradually fade or even vanish within deep-level feature maps. In actuality, standard convolution tends to suppress the feature expression process of such targets, consequently influencing actual outcomes. Conversely, depthwise separable convolution augments the diversity of convolutional features, thereby ameliorating the algorithm’s proficiency in recognizing small-scale ships. Consequently, within the framework of feature fusion networks, this research enhances the PANet network by incorporating five modules of depthwise separable convolution, resulting in the design of the LightPANet network. This endeavor aims to curtail superfluous parameters within the network, enhance computational efficiency, and elevate identification performance for small targets. The LightPANet structure, as devised in this paper, is depicted in Figure 6.
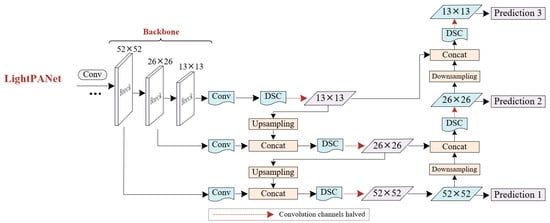
Figure 6.
Structure of the LightPANet. In this network, the employment of Depthwise Separable Convolution (DSC) results in a remarkable reduction in parameter count. By decomposing the convolution operation into depthwise convolution and pointwise convolution, DSC achieves a significant decrease in parameters, thereby reducing model complexity and computational demands. Moreover, the independent processing of each input channel during the depthwise convolution allows for the extraction of highly discriminative features. This facilitates the network’s ability to capture spatial information within the input data and enhances its generalization capabilities.
To compare the practical capabilities of LightPANet and PANet for ship detection in radar images, the aforementioned networks were employed as feature fusion networks within the YOSMR algorithm. While keeping other structures constant, their practical performance was assessed. Referring to the inference results of radar images in Figure 7, it was observed that the crossing of ship trajectories in regions 1 and 2 posed significant challenges, resulting in substantial interference with the algorithm. The PANet-based model encountered issues of misidentification, leading to a higher rate of false output for ships. Conversely, the LightPANet-based model achieved accurate localization of all ship spots. This experiment validates the detrimental impact of excessive convolution on the detection of small targets in radar images, impeding the effective acquisition of ship pixel features. In contrast, a lightweight feature fusion structure, such as LightPANet, effectively mitigates this issue.
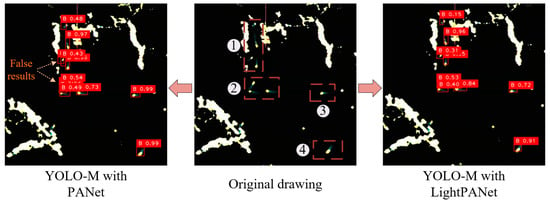
Figure 7.
Comparison of identification results between LightPANet and PANet. The utilization of the optimized feature fusion network, empowered by the integration of the DSC module, yields higher precision in localizing ship spots and enhances the accuracy of identifying small-scale targets. Consequently, this leads to a reduced occurrence of false positive predictions.
2.4. Non-Maximum Suppression
Within the YOSMR algorithm, this research employed the LightPANet network to construct a target prediction structure with three channels, enabling the presence of multiple bounding boxes for the same ship target. Typically, the non-maximum suppression (NMS) method is utilized to retain the optimal detection results by filtering out redundant predictions. In conventional algorithms, the IoU metric is commonly employed to filter out redundant predictions, preserving only the bounding box with the highest overlap ratio. However, the IoU metric solely considers the degree of overlap between target bounding boxes, neglecting other crucial target attributes such as shape, size, and orientation. Thus, in scenarios where similar but not entirely overlapping targets exist, the IoU metric may fail to accurately assess the similarity between targets. Moreover, when there is a significant difference in scale between targets, the IoU metric may inadequately measure the similarity between targets, leading to the selection of inappropriate bounding boxes during non-maximum suppression.
This research introduces Cluster-NMS [25] as a solution to the aforementioned issues, serving as a metric for performing non-maximum suppression. In comparison to the IoU metric, the Cluster-NMS method incorporates the DIoU metric [26] and prediction box fusion strategy [29] to achieve weighted adjustments of the bounding box positions and confidence values. This approach enhances the prediction accuracy for small-scale and dense ships. Particularly, the application of a weighted fusion strategy combines multiple prediction boxes, where the weight of each prediction box is determined based on its confidence score. Prediction boxes with higher confidence scores carry greater weights, thereby exerting a more significant influence on the final fusion result. This method better captures the position and shape information of targets, providing more accurate bounding boxes and improving the quality and accuracy of object detection.
As depicted in Figure 8, YOSMR generates multiple bounding boxes for a single ship. Conventional NMS or Soft-NMS methods solely filter the bounding boxes, which may result in lower localization accuracy for the retained boxes. In contrast, the Cluster-NMS method captures more precise ship position and shape information and performs a fusion of multiple prediction boxes. This enables the method to handle ships of different scales, shapes, and scenes, leading to a significant improvement in ship prediction accuracy.
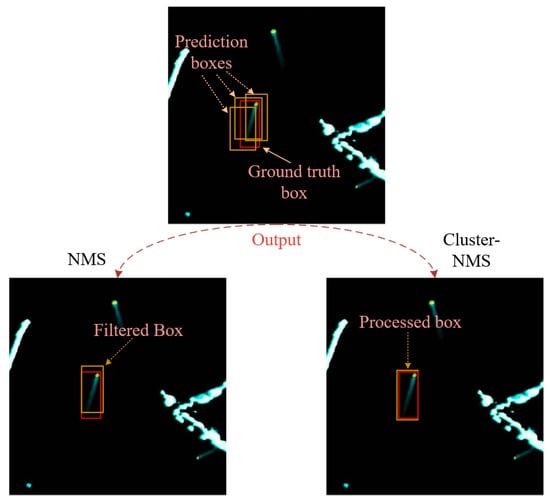
Figure 8.
Comparison between Cluster-NMS and other methods. By comparison, Cluster-NMS stands out by utilizing an innovative weighted fusion approach to process candidate prediction boxes, leading to satisfactory precision in target localization.
2.5. Position Loss Function
For the purpose of refining the localization accuracy of ship-bounding boxes, this research introduces the α-DIoU loss function as a computational measure for evaluating the positional error of predicted boxes. On general datasets, this method significantly outperforms standard loss functions such as IoU, DIoU, and CIoU. Moreover, in different scenarios, by adjusting the α coefficient, the detection model exhibits greater flexibility in achieving regression accuracy at various levels, making it easier to find more adaptive threshold settings. Experimental results demonstrate that the α-DIoU loss function exhibits stronger robustness to marine radar images and various types of noise. The overall calculation of the α-DIoU function is illustrated in Equations (1) and (2), with partially key metrics of the function also explained in Figure 9.
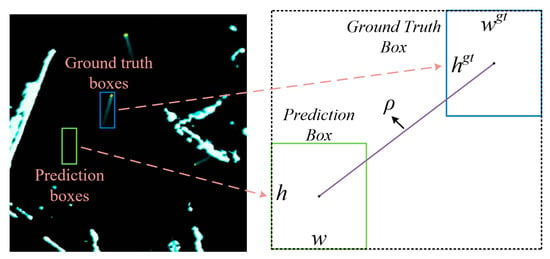
Figure 9.
Key indicators of α-DIoU function. Through separate adjustments of a hyperparameter, this method effectively modifies the impact weight of the center point distance metric compared to the standard DIoU metric. This adjustment, made during the loss calculation, facilitates faster convergence of prediction boxes for small-scale targets.
In this context, represents the Euclidean distance between the minimum bounding rectangles of the prediction box and ground truth bounding box, while denotes the Euclidean distance between their center points. After multiple tests, it has been observed that when the α coefficient is set to 1/2, the α-DIoU function is better suited for ship identification in radar images.
3. A Case Study
3.1. Dataset
The present research focuses on the waters adjacent to Mount Putuo in Zhoushan, China, a large coastal passenger terminal, where the primary ship types encompass passenger ships and maritime auxiliary craft. The JMA5300-MKII marine radar (source from Furuno Electric Co., Ltd., Hyogo, Japan) was selected as the data collection instrument. Following the preprocessing of raw data, a dataset named Radar3000 comprising 3000 images of high quality was constructed for the purpose of training and validating various algorithms. It is noteworthy that passenger terminals prohibit ship operation during inclement weather conditions like heavy rain, dense fog, and strong winds. As such, radar images acquired under these adverse environments would hold limited practical research value. Consequently, the Radar3000 dataset does not consider the aforementioned situations but instead includes other factors such as daytime, dusk, nighttime, and electromagnetic interference, which represent the majority of real-world scenarios. As depicted in Figure 10, the ships in the images can be primarily classified into two categories, i.e., long-wake ships and short-wake ships. The edge features of long-wake ships are more salient. Conversely, it is readily apparent that the pixel characteristics of short-wake ships bear resemblance to interferences such as islands and reefs. This issue is particularly pronounced during ships in dense environments, where mutual interference among short-wake ships tends to manifest.
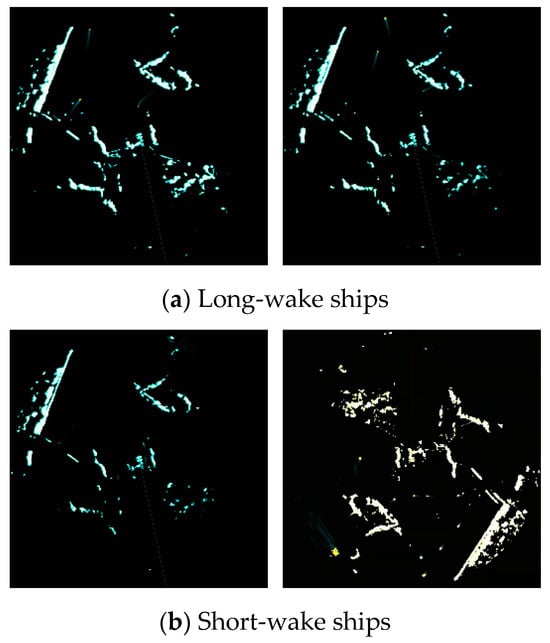
Figure 10.
Marine radar images. The radar spots present in the image are characterized by their minuscule scale, while small islands and atmospheric clusters, due to their high feature similarity, significantly interfere with the accurate recognition of actual ships.
Furthermore, the Radar3000 dataset encompasses a diverse range of complex background environments, including varying weather conditions, harbor settings, and imaging conditions. It also takes into account factors such as ship heading, distance variations in imaging, and angle transformations. Moreover, to address the issue of mistakes during cross-traveling and busy traffic environments of ships, the Radar3000 dataset incorporates an increased number of ship images specifically tailored to these scenarios. Given the highly similar characteristics exhibited by different ship types in marine radar images, all ships in the Radar3000 dataset have been uniformly labeled and designated as “B”, with corresponding XML annotation files generated to adhere to the format requirements of the Pascal VOC dataset.
In the entirety of experiments conducted in this research, all the images in the Radar3000 dataset were partitioned into training, validation, and testing sets in an 8:1:1 ratio. Various algorithms were trained on the training and validation sets, and the actual identification accuracy and effectiveness of the algorithms were evaluated on the testing set. Additionally, through K-means clustering analysis, it was discovered that the average size of the bounding boxes for ship targets was 21 × 25 pixels, accounting for approximately 0.05% of the entire image area. This finding indicates that ship targets in marine radar images predominantly belong to the categories of small-scale and miniature-scale objects.
3.2. Experimental Environment and Training Results
This research conducted algorithm training and testing using a computational platform equipped with an NVIDIA RTX3090 24G (source from NVIDIA Corporation, Santa Clara, CA, USA) graphics card, operating under the Ubuntu 20.04 operating system. The experimental comparisons encompassed conventional algorithms, the YOLO series, and the YOSMR algorithm. The experiments were conducted using the same set of ship images. Furthermore, transfer learning techniques were employed to optimize the training process of the different algorithms. Specifically, the pre-trained network weights of different YOLO models and MobileNetV3 on the ImageNet dataset were utilized as initial weights for algorithm training. Subsequently, several rounds of algorithm iterations were performed to improve training stability and enhance the learning capabilities of the algorithms in capturing ship features under different scenarios.
During model training, the input image size was set to 416 × 416 pixels, and the momentum was set to 0.9. In the transfer learning phase, where only the prediction layers were activated, the batch size was set to 10 for 15 iterations, with an initial learning rate of 10−4. When all convolutional layers were enabled, the batch size was set to 4, and the initial learning rate was again set to 10−4. This phase consisted of a total of 300 predetermined iterations. If the algorithm’s loss value did not decrease in 15 consecutive iterations, the training process was terminated early. Based on the aforementioned settings, the convergence of the loss during training for different algorithms is illustrated in Figure 11. Specifically, the YOLOv3, YOLOv4, YOLOv5(L)-6.0, and YOSMR algorithms underwent 141, 125, 137, and 133 iterations, respectively. The losses in the training set converged to 9.38, 8.55, 10.31, and 9.26, while the ones in the validation set converged to 10.02, 9.03, 9.82, and 9.4, respectively. It is evident that the training process of YOSMR exhibits smoother loss convergence, with a smaller difference between the two types of losses, thereby contributing to improved training efficacy of the algorithm.
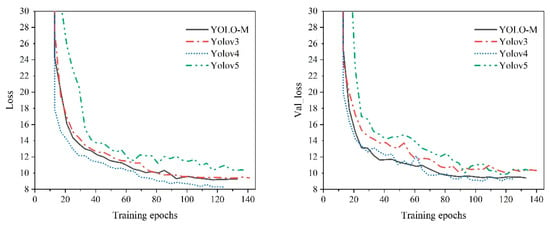
Figure 11.
Comparison of training processes of various algorithms. Throughout the entirety of the training process, the proposed algorithm exhibits an expedited and consistent convergence compared to standard methods, resulting in obviously lower overall loss computation values.
3.3. Comparisons and Discussion
This paper quantitatively evaluates the model using five metrics, namely recall, accuracy (Ac), precision (Pr), model parameters (PARAMs), and floating-point operations (FLOPs) [30]. Additionally, a series of experiments were devised to examine the identification performance of the YOSMR algorithm on ship images from marine radar. Firstly, based on the testing images from the Radar3000 dataset, comparative experiments were designed to scrutinize the actual performance of various algorithms across different evaluation metrics, thus validating the effectiveness of the YOSMR algorithm. Moreover, ablation experiments were devised to analyze the different improvement methods within YOSMR, thereby verifying the specific effects of each method. Lastly, by identifying ships from different scenarios, the adaptability of the YOSMR algorithm to different types of tasks was assessed.
- A.
- Experimental analysis of different algorithms
In the constructed Radar3000 dataset, a comparative analysis was undertaken to assess the performance of various generic algorithms in comparison to the proposed YOSMR algorithm in this paper. Uniformly, the algorithms were trained using the same approach and tested on an identical dataset. Furthermore, cross-validation was employed for all the algorithms, resulting in the recall, accuracy, and precision values being the average of three experimental runs. According to Table 1, the proposed YOSMR achieved a recall rate of 0.9308, accuracy of 0.9204, and precision of 0.9215 for the testing set images. Compared to the top-performing comparative algorithm, YOSMR exhibited a 0.64% increase in recall rate. This improvement can be attributed to YOSMR’s adequate ability to accurately identify dense and small-scale ships in radar images. Additionally, in relation to model parameter size and real-time computational consumption, YOSMR exhibited favorable performance, with figures of 12.4 M and 8.63 G, respectively. In comparison to the standard YOLOv3, YOSMR achieved significant reductions of 80.18% and 86.9% in the respective metrics mentioned earlier. Meanwhile, YOSMR has achieved an inference throughput of 122 frames per second (FPS) when deployed on a server equipped with a 3090 24 GB GPU (source from NVIDIA Corporation, Santa Clara, CA, USA) in our research lab. Furthermore, we have integrated the trained model into the existing radar-based surveillance system at Zhoushan Port, where a 1660 6 GB GPU (source from NVIDIA Corporation, Santa Clara, CA, USA) is utilized, delivering a real-time inference speed of 82 FPS and satisfying the requirements of real-time computation.

Table 1.
Specific experimental results of various algorithms.
The conventional methods [31,32], incorporating CV and GHFilter, exhibited a recall of 0.8910, accuracy of 0.8815, and precision of 0.8744 in the identification of ships from radar images. These figures were lower by 3.98%, 3.89%, and 4.71%, respectively, compared to the performance achieved by YOSMR. Analysis indicates that when dealing with small-scale ships, difficulties arise due to their diminutive dimensions, absence of prominent characteristics, and limited distinguishability from the surrounding background. These factors pose challenges in terms of target association and data integration, rendering the processes more intricate. Within complex backgrounds, traditional methods are susceptible to false or missed associations, resulting in imprecise detection outcomes. Therefore, experimental results demonstrate the advantages of CNN-based approaches in ship detection under marine radar images.
YOSMR attains a level of identification precision that closely rivals several YOLO algorithms, encompassing YOLOv3, YOLOv4, YOLOv5(L)-6.0, YOLOv7 [33], and YOLOv8(L) [34]. It closely approaches the performance of the best-performing YOLOv8(L) and even surpasses them in terms of recall. Furthermore, YOSMR outperforms YOLOv8(L) by a significant margin in terms of model parameter size and computational consumption. Compared to the lightweight YOLOv5(S) and YOLOv8(S) algorithms, YOSMR demonstrates an enhancement of 3.64% and 1.98% in the recall, respectively, while sustaining relatively superior overall performance. In comparison to optical images, radar images exhibit lower resolution and higher levels of noise. These factors hinder the clear depiction of details and features of small targets in radar images, posing challenges for standard YOLO algorithms in accurately localizing and recognizing such targets. Consequently, the experimental performance of YOLO algorithms in this context often falls short of the desired expectations. Conversely, the proposed YOSMR demonstrates competent capability in suppressing false targets, accurately distinguishing coastal objects, reefs, clouds, and other interferences that bear resemblance to ship features. This effectively reduces mistaken rates and enhances adaptability for radar images.
To extract more accurate ship features from radar images while simultaneously balancing identification capability and model parameter size, this experiment explored several combinations of lightweight feature networks with YOLO architecture. By utilizing the prediction head structure of YOLOv3, the MobileNetV3(Large), MobileNetV3(Small), and Ghostnet networks are successively employed to replace the original Darknet53 network, resulting in three categories of lightweight algorithms for comparison. As shown in Table 1, the YOLOv3-MobileNetV3(Large) algorithm achieved recall, accuracy, and precision rates of 0.9019, 0.9001, and 0.9127, respectively. It outperformed the YOLOv3-Ghostnet algorithm in all evaluation metrics and significantly outperformed the YOLOv3-MobileNetV3(Small) algorithm, particularly in terms of recall. This underscores its effectiveness across diverse radar images. Moreover, YOLOv3-MobileNetV3(Large) exhibits minimal deviation from various standard YOLO series in terms of detection precision in radar scenarios. Given its desirable performance in all aspects, YOLOv3-MobileNetV3(Large) has been selected as the benchmark algorithm in this research.
To validate the practical performance of the LightPANet network, the standard PANet network was applied as the feature fusion structure in YOSMR, resulting in the YOSMR(PANet) algorithm. It is worth noting that the only difference between YOSMR(PANet) and YOSMR lies in the feature fusion structure, while the other components remain consistent. According to the data in Table 1, YOSMR(PANet) exhibits a slight decline in overall performance compared to YOSMR, particularly in terms of recall and precision, which decreased by 0.64% and 1.2%, respectively. This suggests that excessive convolution calculations can lead to a noticeable decrease in the model’s accuracy in predicting ship-positive samples and discerning interference objects. The experiments confirm that reducing redundant convolutions is beneficial for improving the feature extraction of deep convolutional networks for small targets. Furthermore, in terms of convolution parameter count and real-time computational consumption, YOSMR achieves a reduction of 70.57% and 72.77%, respectively, compared to YOSMR(PANet). This provides evidence that the 3 × 3 convolutions in the PANet network contribute significantly to the presence of ineffective parameters in the model. In conclusion, the lightweight LightPANet significantly enhances the algorithm’s performance for ship detection in radar images and is better suited for designing lightweight algorithms.
Amidst the current lack of CNN or transformer-based ship detection algorithms specifically developed for marine radar images, through a comparative assessment, we have determined that the target features in SAR images exhibit similarities to the small-scale characteristics of ships in radar scenes. As such, we have selected two detection algorithms designed specifically for SAR images, namely SRDet [35] and AFSar [36], to benchmark against our proposed YOSMR, thereby validating the efficacy of our approach. The experimental results indicate that the comparative algorithms demonstrate unconvincing adaptability when applied to radar images. Although they exhibit better performance in sparse target detection, the precision, recall, and accuracy metrics for the identification of radar spots are markedly weaker in comparison to YOSMR. This disparity can be attributed to the fact that ship targets in SAR images primarily represent static objects in port or near-shore environments, which contrasts sharply with the dynamic characteristics of ships in radar scenes, thus accounting for their suboptimal real-world performance.
- B.
- Ablation Experiments
To further validate the practical performance of the proposed method, a decomposition validation was conducted on the constructed Radar3000 dataset to analyze the influence of each method on ship identification results. The experimental process primarily involved applying various improvement methods step by step on the basis of YOLOv3-MobileNetV3(Large) and testing their respective metrics. The ablation experiments for YOSMR are presented in Table 2.
Table 2.
Ablation experiments of YOSMR.
(1) The incorporation of the SPP module following the MobileNetV3(Large) network yields a noteworthy increase of 0.79% in the recall rate of ship targets in radar images. This enhancement signifies an improved capability of the algorithm to suppress false targets, reduce mistaken rates, and diminish the likelihood of ship omissions. Furthermore, through multiple experiments, it has been observed that the integration of the SPP module accelerates algorithm convergence, resulting in an average reduction of 11 iterations in the YOSMR training process. Additionally, the discrepancy between the training set loss and the validation set loss decreases from 0.7 to 0.14. The empirical findings unequivocally demonstrate that SPP significantly enhances the training quality of the algorithm and improves the identification ability of the model. Notably, in the later stages of algorithm training, the model loss continues to steadily decline with increasing training iterations. Therefore, the SPP module aids in mitigating the overfitting issue in YOSMR and enhances the model’s generalizability across diverse ship detection scenarios.
(2) This research focuses on optimizing two modules, namely non-maximum suppression (NMS) for bounding box prediction and the calculation of object localization loss, in the conventional YOLO’s prediction structure. Firstly, the Cluster-NMS method is introduced to optimize the candidate results of bounding boxes. By preserving more accurate ship prediction boxes, experimental results demonstrate improvements of 0.4% in recall, 1.04% in accuracy, and 1.29% in precision. Secondly, the α-DIoU loss function is incorporated to calculate the localization loss of bounding boxes, providing a more accurate evaluation of the positioning accuracy of predicted ships. Experimental findings reveal that this approach increases recall by 0.86% and accuracy by 1.02%.
(3) As previously elucidated, the application of depthwise separable convolutions to the feature fusion network presents a notable avenue for reducing convolutional parameters and computational costs, thus facilitating the development of lightweight algorithms. Analysis of the data in Table 2 reveals a significant enhancement in the identification capability of the YOSMR algorithm with the incorporation of the LightPANet network. In comparison to the original FPN network in YOLO, this architecture achieves a 1.18% increase in precision and a 0.79% improvement in recall. Theoretically, assigning higher impact factors to critical feature information is of paramount importance for the detection of small targets, such as ships, in marine radar images. Consequently, LightPANet effectively improves the representation of crucial target features by reducing redundant computations, ultimately bolstering the model’s ability to identify small-scale ships.
- C.
- Comparisons in radar images
Figure 12 presents the detection results of YOSMR for ships in marine radar images across different scenarios, with a specific focus on assessing its performance in recognizing ships with various wake features. As shown in the radar images, each real ship spot is accompanied by motion wake characteristics of varying lengths. In contrast, as the islands and coastline remain stationary in the shore-based radar, these targets do not exhibit any pronounced or extended wakes. By evaluating the wake features surrounding the spots, YOSMR can accurately differentiate between ship targets and confounding entities such as islands. Furthermore, during the image annotation process, we have precisely distinguished the true radar reflections from other objects, providing a robust guide for the algorithm training. This enables YOSMR to learn the salient features of the ship targets, ultimately facilitating accurate classification. From Figure 12a, it can be observed that YOSMR accurately identifies ships with long-wake features in various environments, indicating its strong identification capability for targets with distinctive features. This clearly demonstrates the algorithm’s ability to effectively address and mitigate the degradation of target localization accuracy caused by interruptions or changes in ship wake patterns. Figure 12b reveals that YOSMR achieves high identification accuracy for ships with short wake features in different radar conditions. It demonstrates robust feature extraction capabilities for small-scale ship targets, avoiding both missed detections and false results. This highlights its ability to effectively mitigate the influence of confounding factors, such as islands and weather patterns that exhibit similar features. Figure 12c demonstrates YOSMR’s precise detection of densely packed ships, exhibiting high ship localization accuracy. Moreover, YOSMR performs well even in extreme scenarios such as close-range encounters and crossing trajectories. The analysis suggests that YOSMR’s utilization of small-scale feature receptive fields enables it to capture pixel-level features and positional information of ships, even in situations where small targets are densely clustered.
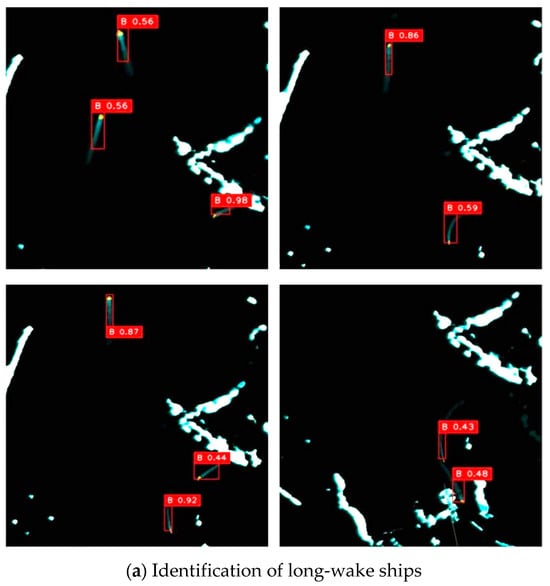

Figure 12.
The identification results of YOSMR for different marine radar images. Regardless of the ship scales, YOSMR exhibits remarkable efficiency in identifying ship spots, effectively capturing target information across various sizes. Moreover, in navigation-intensive environments, this model excels in accurately localizing targets and demonstrates a reduced occurrence of false positives.
Within the 3 nautical miles perceptual range, as depicted in the radar images presented in Figure 10, the proposed model demonstrates the ability to accurately identify ship signatures, as illustrated in Figure 12. It is well-established that as the radar detection range expands, the effective feature points of individual ships undergo a rapid diminution. We have also conducted experiments using radar images of varying scales, which have revealed that without increasing the training sample size, YOSMR can maintain an identification precision of approximately 83% for ship targets within the 3.5 nautical mile range. However, when tasked with detecting ships across larger radar-sensing domains, the model begins to exhibit a higher incidence of omission errors. Therefore, the current iteration of YOSMR has been calibrated to operate within an effective perceptual range of 3 nautical miles.
A salient point to note is that upon scrutinizing the radar images, we have observed that a minority of islands or reefs are accompanied by some short luminous streaks, which could impact the recognition accuracy for certain ship targets. Through experiments, we have found that in 1024 × 1024 resolution images, when the real wake associated with a ship occupies more than 120 pixels, YOSMR is consistently able to accurately identify the target. However, when the number of pixels occupied by the ship’s wake falls below this threshold, or when the luminous streaks surrounding islands approach this value, the model becomes prone to probabilistic misclassification.
- D.
- Comparisons under noise interference
Radar systems are susceptible to electromagnetic interference (EMI) with similar or adjacent frequencies, leading to anomalies in echo returns, which can subsequently impact radar imaging. The shore-based radar used in this study is equipped with countermeasures against co-frequency asynchronous interference, which can mitigate the effects of EMI at the source. However, to quantify the resilience of the proposed method against varying degrees of interference, we simulated different types and intensities of EMI using salt-and-pepper noise, speckle noise, and Gaussian noise, as outlined in Table 3, to assess their impact on ship detection in radar images.
Table 3.
Noise Generation Mechanisms.
In more detail, the salt-and-pepper noise adheres to a random distribution pattern, and its impact on real-world detection performance is relatively more pronounced. When the proportion of randomly occurring black and white noise pixels occupies less than 30% of the entire image, the proposed YOSMR can still detect the ship targets, though the confidence levels may be affected, and occasional misclassifications may occur. Regarding Gaussian noise, which follows a normal distribution, when the standard deviation is set below 25, the designed model can accurately identify the targets. However, when the standard deviation exceeds 25, more target omissions will arise. In comparison, speckle noise has a relatively less obvious influence on the existing image pixels. This is because the image features a predominately black pixel background surrounding the true ship targets, and this type of noise minimally interferes with the black pixels, thereby preserving the inherent pixel characteristics of the ship targets. Consequently, the performance of YOSMR remains largely unaffected by speckle noise.
Figure 13 presents the real detection results of YOSMR in radar images under various interference signals. The original images contain three types of targets, i.e., ships with short wakes, ships with long wakes, and dense ships, which are common and prevalent in radar images. The empirical investigation conducted on real images has revealed that salt-and-pepper noise significantly impacts radar images, resulting in substantial distortion of pixel characteristics for ships and other objects. In contrast, the influence of speckle noise and Gaussian noise on ship-specific pixel information is comparatively minimal. Empirical observations reveal that YOSMR achieves accurate detection of all ships under the influence of speckle noise and Gaussian noise, demonstrating commendable robustness against these forms of interference. However, when subjected to the interference of salt-and-pepper noise, YOSMR exhibits a slight decrease in confidence for ship identification and introduces one false positive in dense scenarios. Nonetheless, it maintains a satisfactory performance for other ships.
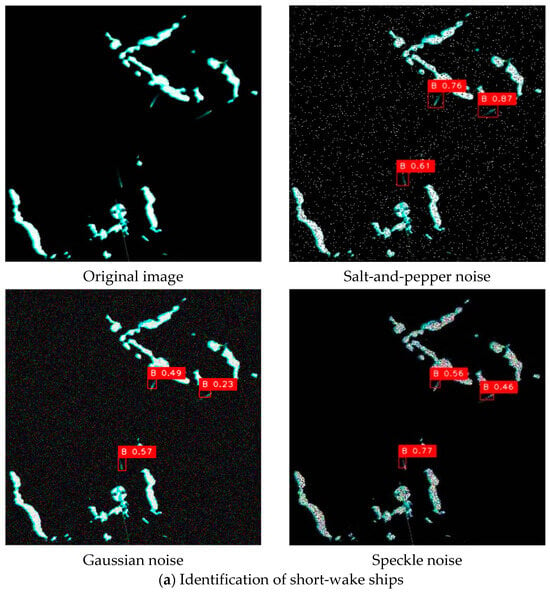
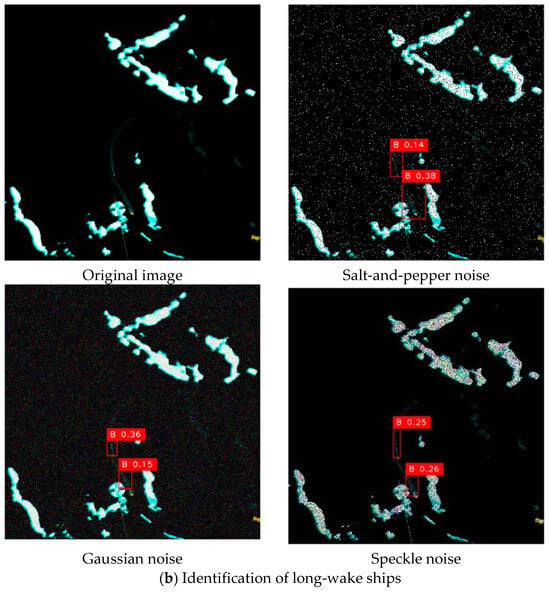
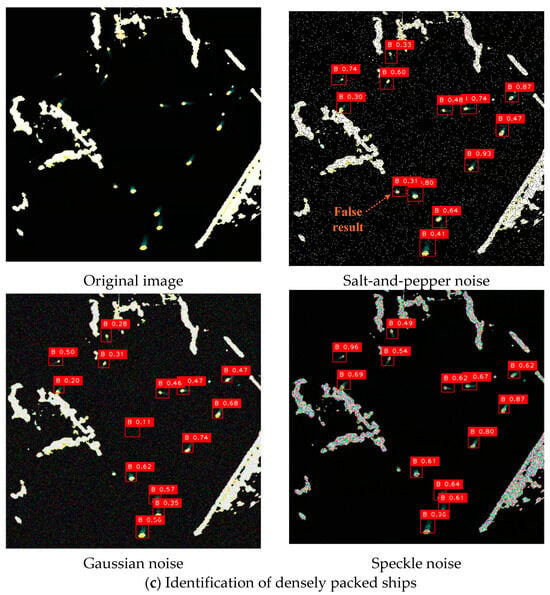
Figure 13.
Identification of YOSMR for different types of ships under various noises. YOSMR exhibits resilience to a certain degree of interference, as it can effectively discern and accurately locate the majority of authentic ship spots despite the varying impact on target confidence scores caused by different types of disturbances.
- E.
- Comparisons of small-scale ship identification
The identification of small targets has always been a focal point and challenge in various computer vision tasks, including ship detection in marine radar images. To evaluate the performance of YOSMR and other typical algorithms in detecting small-scale ships, an experiment was conducted using a dedicated subset of the Radar3000 dataset. This subset included two scenarios, i.e., cross-traveling and dense environment, both of which contained numerous small-scale, and even minuscule, ships with short wakes. The presence of interference objects, such as reefs, also had a noticeable impact on the model’s detection. For this experiment, we selected the commonly used YOLOv5(L) and YOLOv8(L) as the comparative algorithms, as they are widely recognized for their effectiveness in detecting small objects. The results, as shown in Table 4, revealed that YOSMR outperformed the comparison algorithms in all aspects, demonstrating its adequate effectiveness in detecting various small-scale ships.
Table 4.
Comparison of different algorithms in small-scale ship identifications.
In the context of small-scale ship identification, although YOSMR exhibits competent performance across various evaluation metrics compared to the comparative algorithms, it is still essential to validate its effectiveness on real radar images. To visualize this experiment, we have selected several representative images and presented them in Figure 14. As shown in the experimental results, YOLOv5(L) exhibits susceptibility to misidentification issues when dealing with tiny ship spots, whereas YOLOv8(L) is equally prone to misidentification in dense scenarios. This can be attributed to the utilization of relatively large receptive fields and deep convolutional layers in both methodologies, which may inadvertently diminish their sensitivity towards capturing intricate nuances of small-scale ships. As a consequence, the above models may erroneously categorize background elements or extraneous objects as ships. Conversely, YOSMR outperforms both the YOLOv5(L) and YOLOv8(L) in terms of ship localization precision. It demonstrates lower rates of mistakes and omission, indicating that the lightweight algorithm, through the construction of a rational network structure, can extract finer pixel and texture features, thereby enhancing the detection effect of small targets by the model.


Figure 14.
Comparison of different algorithms for small-scale ship identification. It should be noted that the image presented above has been appropriately cropped and magnified from the original radar image to provide a clearer visualization of the detection results of the spots. In the challenging context of identifying small-scale ships, typical models often produce a considerable number of false positive targets in their recognition outcomes. This issue persists even with advanced models such as YOLOv8 and the latest version of YOLOv5, which are widely acknowledged. However, through comparison, it becomes apparent that the proposed YOSMR exhibits remarkable detection performance, particularly in its ability to effectively suppress false positive targets.
- F.
- Comparative experiments on other datasets
Given the absence of publicly accessible marine radar datasets to assess the practical performance of the proposed YOSMR across alternative scenarios, we have selected a set of representative ship targets within SAR images to conduct corresponding experiments. This decision is informed by the distinctive characteristics of SAR scenes, which feature a high proportion of small targets and a rich diversity of contexts, posing notable challenges for target detection. Employing such a dataset provides a compelling means to evaluate the transferability of our method. The images utilized for model training, validation, and testing were sourced from the RSDD-SAR dataset [37], which encompasses a diverse array of imaging modalities and resolutions, totaling 7000 images and 10,263 ship instances, thereby offering broad representational coverage. The experimental findings reveal that YOSMR achieves recall and precision rates of 0.8612 and 0.8733, respectively, demonstrating considerable adaptability. However, the model also exhibits a comparatively elevated misidentification rate for small targets and densely populated ship scenes, consistent with its performance in radar-based scenarios. Accordingly, our subsequent efforts will focus on optimizing this specific shortcoming.
- G.
- Comparative Experiments with CFAR Methods
In order to more comprehensively evaluate the capabilities of various methods in suppressing clutter and accurately detecting real targets within the shore-based radar in port waters, we have designed a set of experiments to compare two categories of approaches. The first category comprises target detection algorithms tailored for radar echo signals, which have been extensively deployed in a myriad of practical applications, namely the CFAR method and its diverse improved variants. These methods endeavor to maximize the detection rate under a fixed false alarm probability by meticulously designing dynamic thresholds to filter the radar echo signals. The second category encompasses deep learning-based detection algorithms designed for radar images, such as the constructed YOSMR. As mentioned earlier, the prerequisite for the efficacious implementation of such methods is the pre-processing of radar echo signals to obtain radar images. In the present research, the radar image is generated based on a customized CFAR method for clutter suppression and a Kalman filtering-based target tracking approach, which have eliminated a certain proportion of clutter interference while preserving the majority of true targets.
For the specific experiments, within the traditional methods, we have selected two variants of the CFAR approach, namely CA-CFAR, and OS-CFAR, to be compared against the proposed YOSMR. Since the conventional methods are tailored for radar echo signals, we have chosen the Probability of Detection(PD) and Probability of False Alarm(PFA) as the evaluation metrics [38]. To ensure the uniformity of the evaluation criteria, the YOSMR will also be assessed based on these same metrics. The experimental data is derived from the same shore-based radar located at the Zhoushan passenger terminal, comprising both radar echo and image data collected at the same timestamps.
The experimental results, elucidated in Table 5 and Table 6, demonstrate YOSMR’s preferable performance in interference suppression compared to two conventional methods. The analysis suggests that while CA-CFAR exhibits commendable performance in scenarios with sparse targets and relatively low interference, it suffers from elevated miss-detection probabilities in ship-dense waters with pronounced clutter variations. Conversely, OS-CFAR showcases enhanced detection rates for multiple targets. As previously expounded, radar image, through efficacious suppression of clutter interference while maintaining satisfying detection rates, lays the groundwork for YOSMR’s image-oriented detection capabilities. The empirical data corroborates that YOSMR, by employing identification and localization of ship spots within images, further attenuates interference and mitigates target misidentification instances, consequently diminishing the Probability of False Alarm (PFA).
Table 5.
Probability of Detection of various CFAR methods under different PFA settings.
Table 6.
Probability of Detection and Probability of False Alarm of YOSMR under different PFA settings.
In summary, the detection methods that operate directly on the radar echoes tend to exhibit relatively higher target detection rates, yet also confront correspondingly elevated false alarm rates. Conversely, the detection approaches oriented towards radar images can effectively strike a balance between the detection rate and the false positive rates, with the capability to further reduce the false alarm rate in particular.
4. Conclusions and Discussion
This paper presents YOSMR, an algorithm for ship identification in marine radar images. YOSMR leverages the MobileNetV3(Large) network in its feature extraction module, which demonstrates satisfactory capabilities in extracting ship-specific features from radar images. Additionally, YOSMR employs lightweight design principles in its feature fusion network by replacing certain traditional convolutions with depthwise separable convolutions. This design significantly reduces the model’s parameter count and computational complexity while enhancing its ability to capture salient ship features. Moreover, YOSMR incorporates the SPP module after the feature network to enhance the extraction capabilities of deep convolution features. In the prediction structure, YOSMR optimizes NMS using the Cluster-NMS method and employs the α-DIoU loss function to improve the accuracy of predicted bounding boxes. The experimental results indicate that in the context of marine radar images, YOSMR exhibits a more satisfying performance than conventional approaches. It achieves accurate detection of both long-wake and short-wake ships in various scenarios, particularly excelling in extreme conditions such as recognizing tiny ships under complex navigation scenarios. YOSMR achieves recall, accuracy, and precision values of 0.9308, 0.9204, and 0.9215, respectively. Furthermore, YOSMR significantly reduces convolutional parameter count and real-time computational costs to 12.4 M and 8.63 G, respectively, compared to the standard YOLO series. The proposed YOSMR effectively balances model size and identification accuracy, making it suitable for deployment in embedded monitoring devices.
Considering the limited range of ship classes currently covered in the Radar3000 dataset, we plan to actively pursue the collection of radar images from typical inland waterways and coastal ports. This will enable the inclusion of a more diverse set of ship characteristics, such as cargo ships, container ships, tankers, and tugboats. Particular attention will be given to enhancing the detection of dense ship formations and small-scale ships. Moreover, the next explorations will integrate multi-object tracking algorithms to obtain comprehensive ship trajectory data, which will enable the analysis of ship traffic patterns and enhance safety monitoring in specific waterway scenarios, thereby expanding the practicality of this research.
Author Contributions
Conceptualization, Z.K., F.M. and C.C.; methodology, Z.K. and F.M.; software, Z.K.; validation, Z.K.; formal analysis, F.M. and C.C.; investigation, F.M.; resources, J.S.; data curation, J.S.; writing—original draft preparation, Z.K.; writing—review and editing, Z.K. and F.M.; visualization, Z.K.; supervision, F.M. and C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China, grant number 2021YFB1600400, and the National Natural Science Foundation of China, grant number 52171352.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We have made the dataset public on the following website: https://github.com/kz258852/dataset_M_Radar (Accessed on 30 July 2024).
Acknowledgments
We are deeply grateful to our colleagues for their exceptional support in developing the dataset and assisting with the experiments.
Conflicts of Interest
Author Jie Sun was employed by the company Nanjing Smart Water Transportation Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Chen, P.; Li, X.; Zheng, G. Rapid detection to long ship wake in synthetic aperture radar satellite imagery. J. Oceanol. Limnol. 2018, 37, 1523–1532. [Google Scholar] [CrossRef]
- Han, J.; Kim, J.; Son, N. Coastal navigation with marine radar for USV operation in GPS-restricted Situations. J. Inst. Control Robot. Syst. 2018, 24, 736–741. [Google Scholar] [CrossRef]
- Wen, B.; Wei, Y.; Lu, Z. Sea clutter suppression and target detection algorithm of marine radar image sequence based on spatio-temporal domain joint filtering. Entropy 2022, 24, 250. [Google Scholar] [CrossRef]
- Wu, C.; Wu, Q.; Ma, F.; Wang, S. A novel positioning approach for an intelligent vessel based on an improved simultaneous localization and mapping algorithm and marine radar. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2018, 233, 779–792. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, T.; Hu, R.; Su, H.; Liu, Y.; Liu, X.; Suo, J.; Snoussi, H. Multiple kernelized correlation filters (MKCF) for extended object tracking using x-band marine radar data. IEEE Trans. Signal Process. 2019, 67, 3676–3688. [Google Scholar] [CrossRef]
- Qiao, S.; Fan, Y.; Wang, G.; Mu, D.; He, Z. Radar target tracking for unmanned surface vehicle based on square root sage–husa adaptive robust kalman filter. Sensors 2022, 22, 2924. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Chen, Y.; Yan, X.; Chu, X.; Wang, J. Target recognition for coastal surveillance based on radar images and generalised bayesian inference. IET Intell. Transp. Syst. 2017, 12, 103–112. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 September 2023).
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Domain adaptation for semi-supervised ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Miao, T.; Zeng, H.; Yang, W.; Chu, B.; Zou, F.; Ren, W.; Chen, J. An improved lightweight retinanet for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4667–4679. [Google Scholar] [CrossRef]
- Mou, X.; Chen, X.; Guan, J.; Zhou, W.; Liu, N.; Yang, D. Clutter suppression and marine target detection for radar images based on INet. J. Radars 2020, 9, 640–653. [Google Scholar] [CrossRef]
- Chen, X.; Mu, X.; Guan, J.; Liu, N.; Zhou, W. Marine target detection based on marine-faster r-cnn for navigation radar plane position indicator images. Front. Inf. Technol. Electron. Eng. 2022, 23, 630–643. [Google Scholar] [CrossRef]
- Chen, X.; Su, N.; Huang, Y.; Guan, J. False-alarm-controllable radar detection for marine target based on multi features fusion via CNNs. IEEE Sens. J. 2021, 21, 9099–9111. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted boxes fusion: Ensembling boxes from different object detection models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Cao, S.; Zhao, D.; Liu, X.; Sun, Y. Real-time robust detector for underwater live crabs based on deep learning. Comput. Electron. Agric. 2020, 172, 105339. [Google Scholar] [CrossRef]
- Ma, F.; Wu, Q.; Yan, X.; Chu, X.; Zhang, D. Classification of automatic radar plotting aid targets based on improved fuzzy c-means. Transp. Res. Part C Emerg. Technol. 2015, 51, 180–195. [Google Scholar] [CrossRef]
- Ma, F.; Chen, Y.; Yan, X.; Chu, X.; Wang, J. A novel marine radar targets extraction approach based on sequential images and bayesian network. Ocean Eng. 2016, 120, 64–77. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G. YOLO by Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 21 February 2024).
- Lv, J.; Chen, J.; Huang, Z.; Wan, H.; Zhou, C.; Wang, D.; Wu, B.; Sun, L. An anchor-free detection algorithm for SAR ship targets with deep saliency representation. Remote Sens. 2022, 15, 103. [Google Scholar] [CrossRef]
- Wan, H.; Chen, J.; Huang, Z.; Xia, R.; Wu, B.; Sun, L.; Yao, B.; Liu, X.; Xing, M. AFSar: An anchor-free SAR target detection algorithm based on multiscale enhancement representation learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5219514. [Google Scholar] [CrossRef]
- Xu, C.; Su, H.; Li, J.; Liu, Y.; Yao, L.; Gao, L.; Yan, W.; Wang, T. RSDD-SAR: Rotated ship detection dataset in SAR images. J. Radars 2022, 11, 581–599. [Google Scholar] [CrossRef]
- Chen, X.; Liu, K.; Zhang, Z. A PointNet-based CFAR detection method for radar target detection in sea clutter. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3502305. [Google Scholar] [CrossRef]
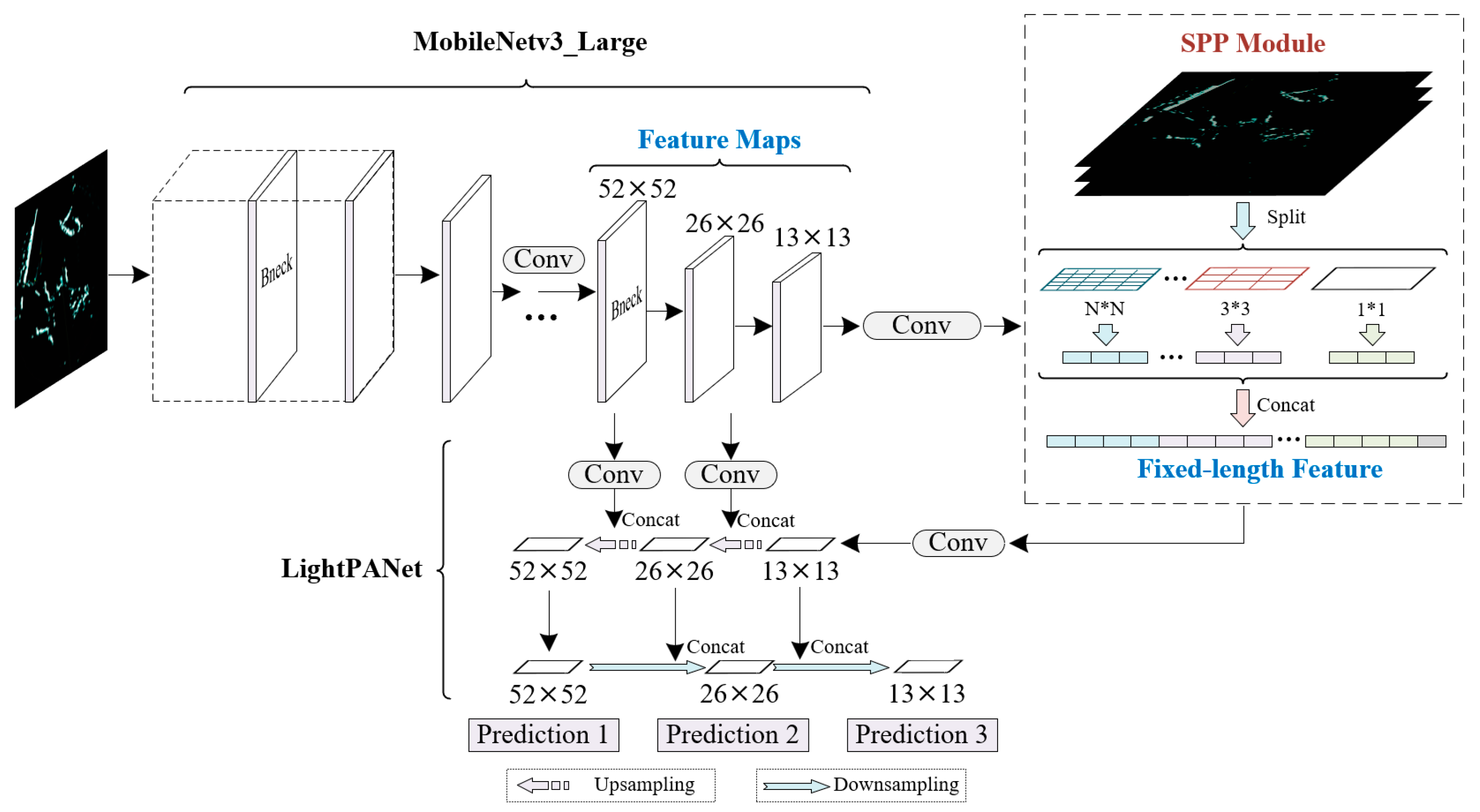
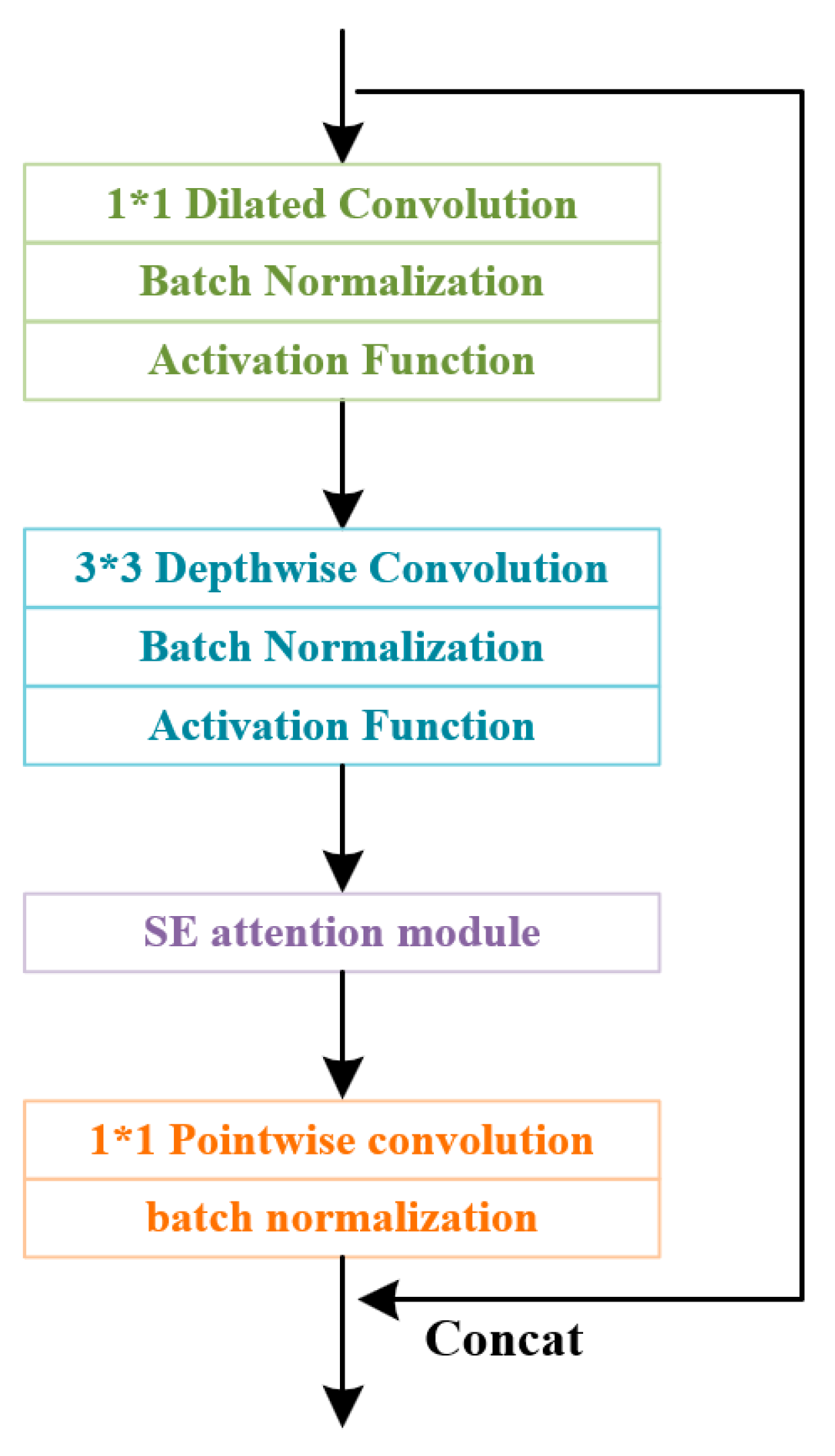
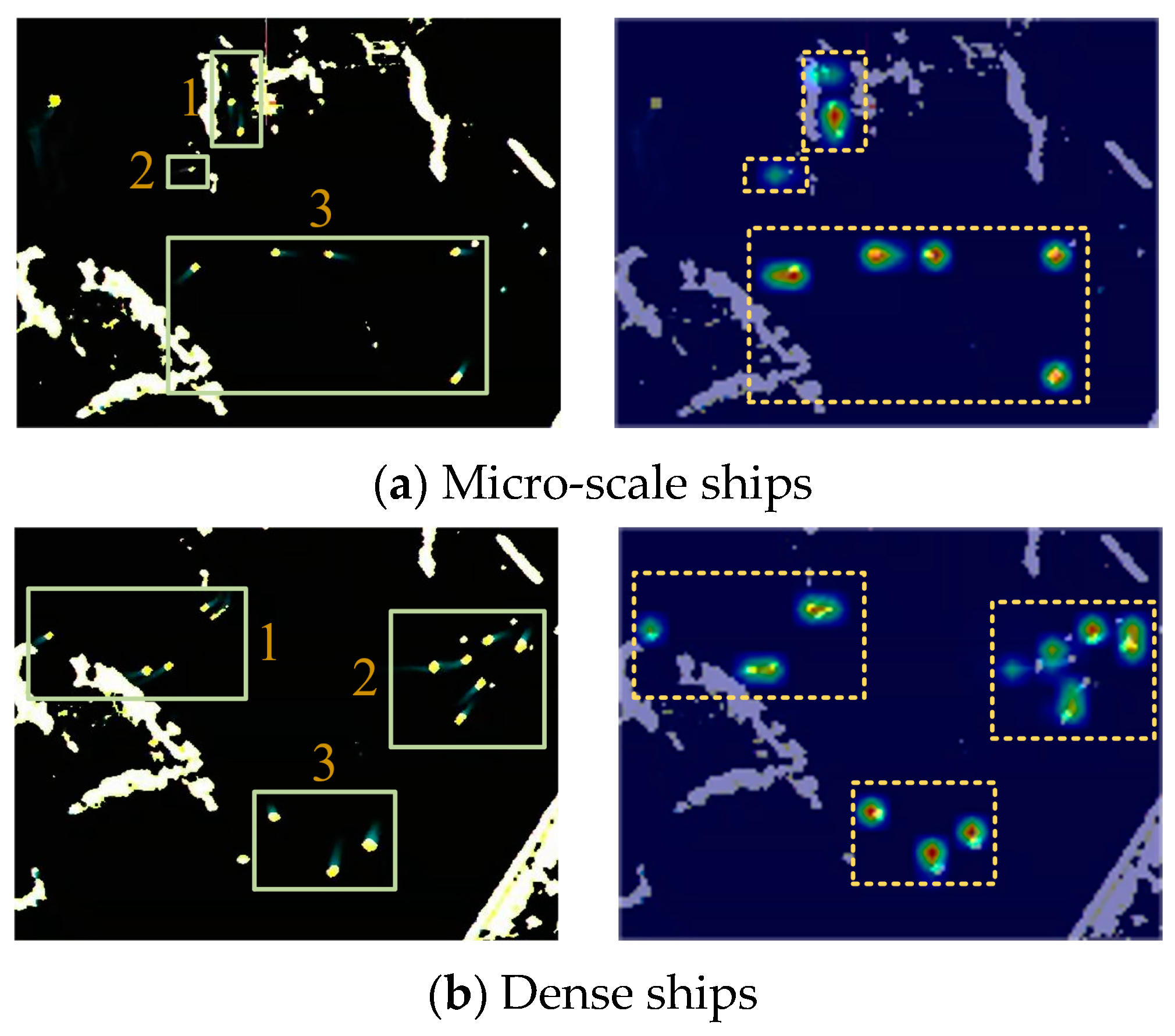
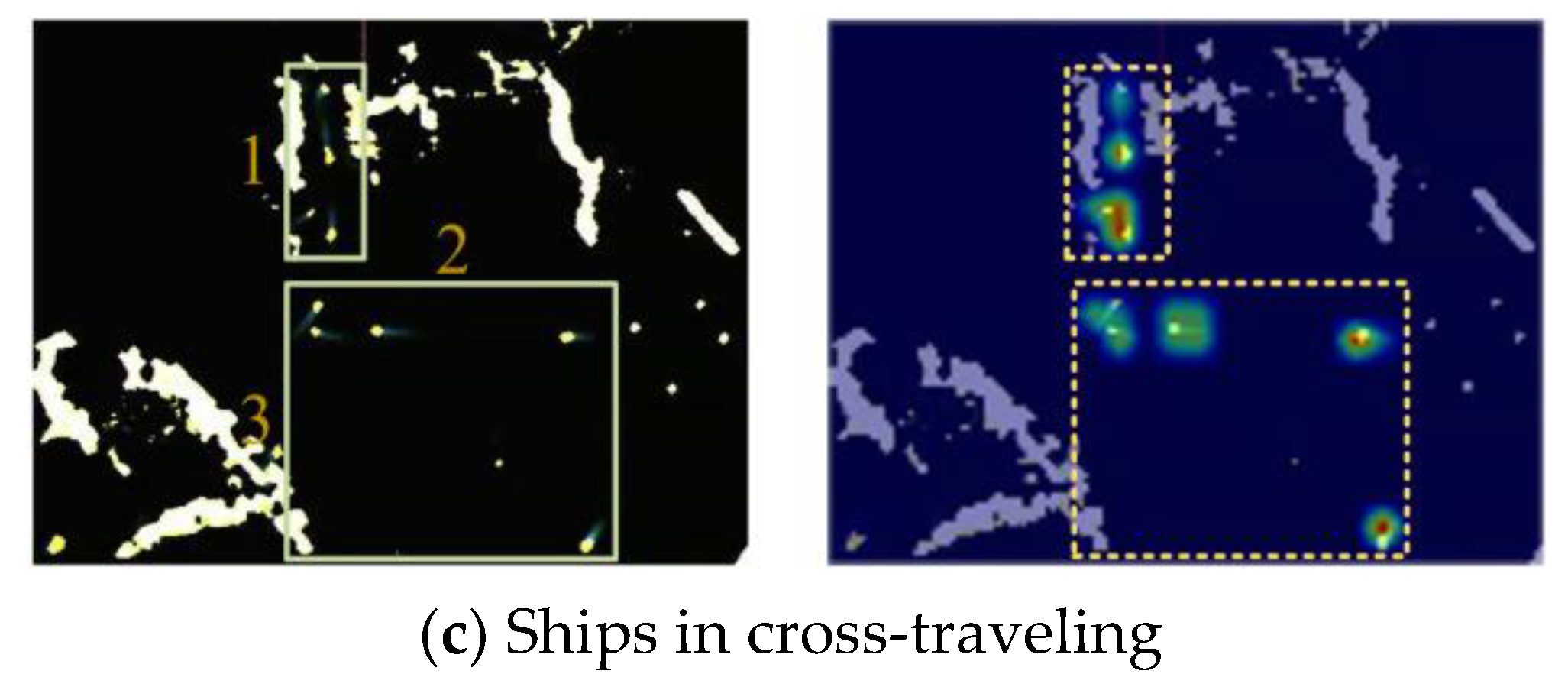
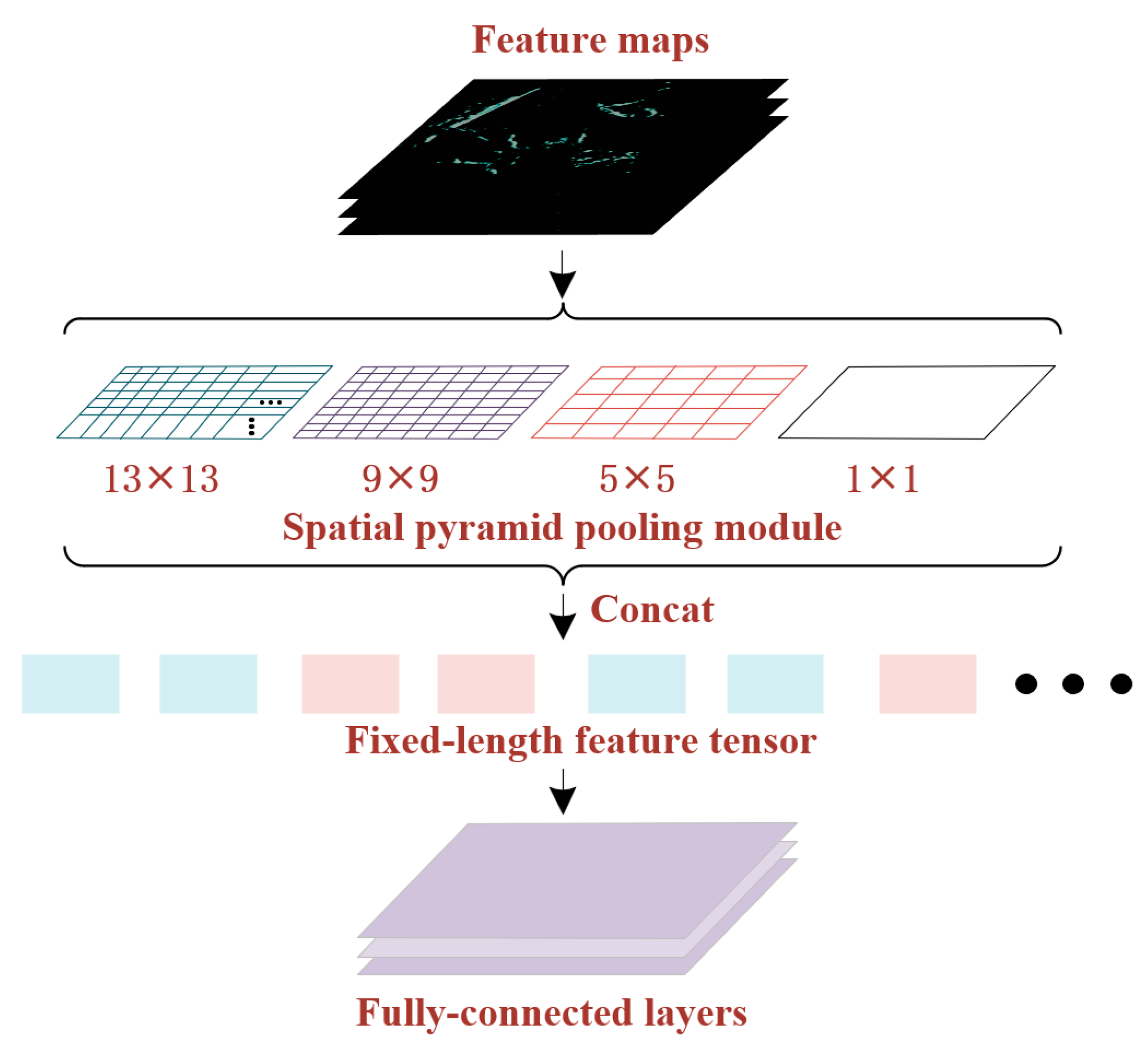
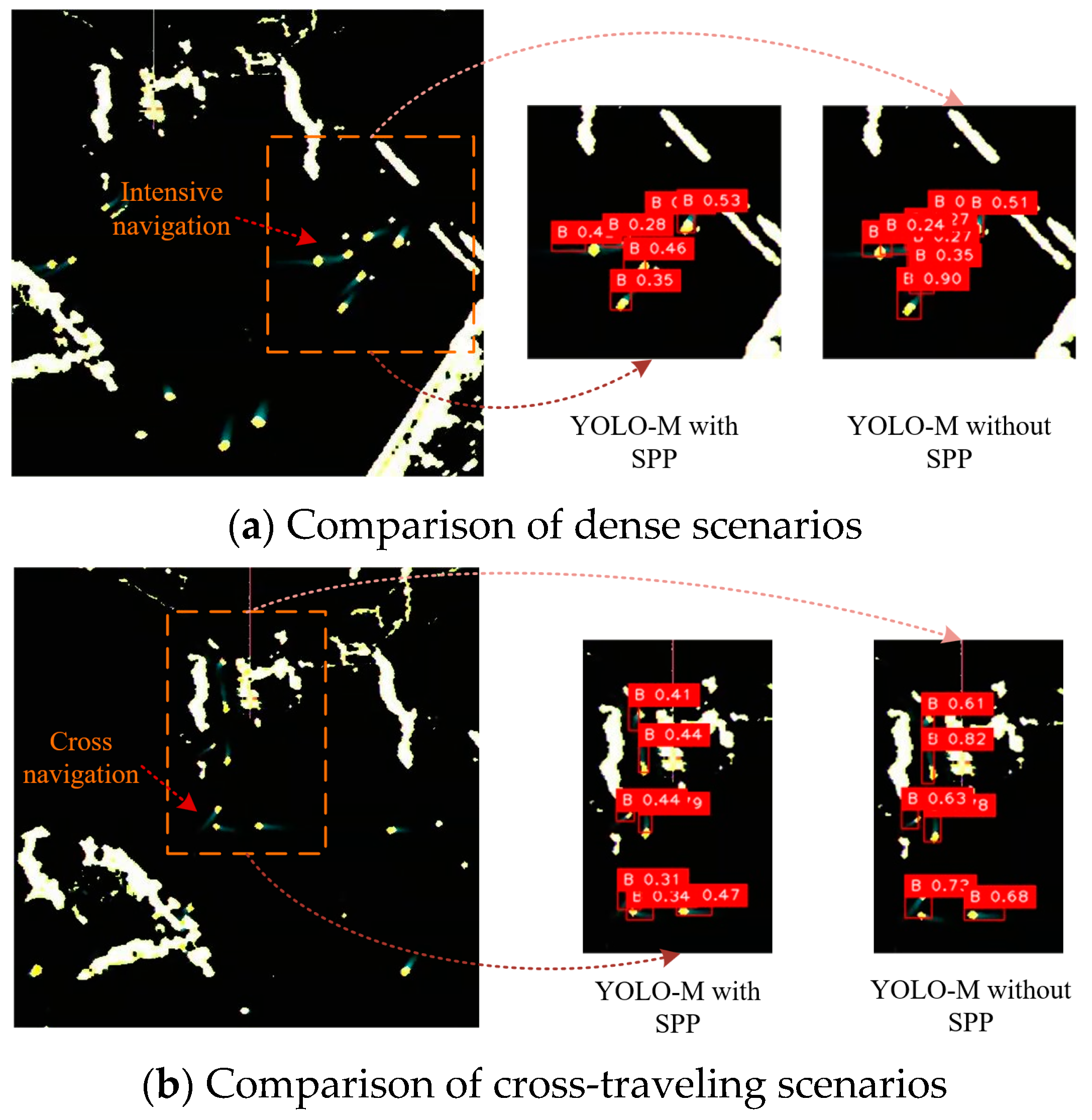
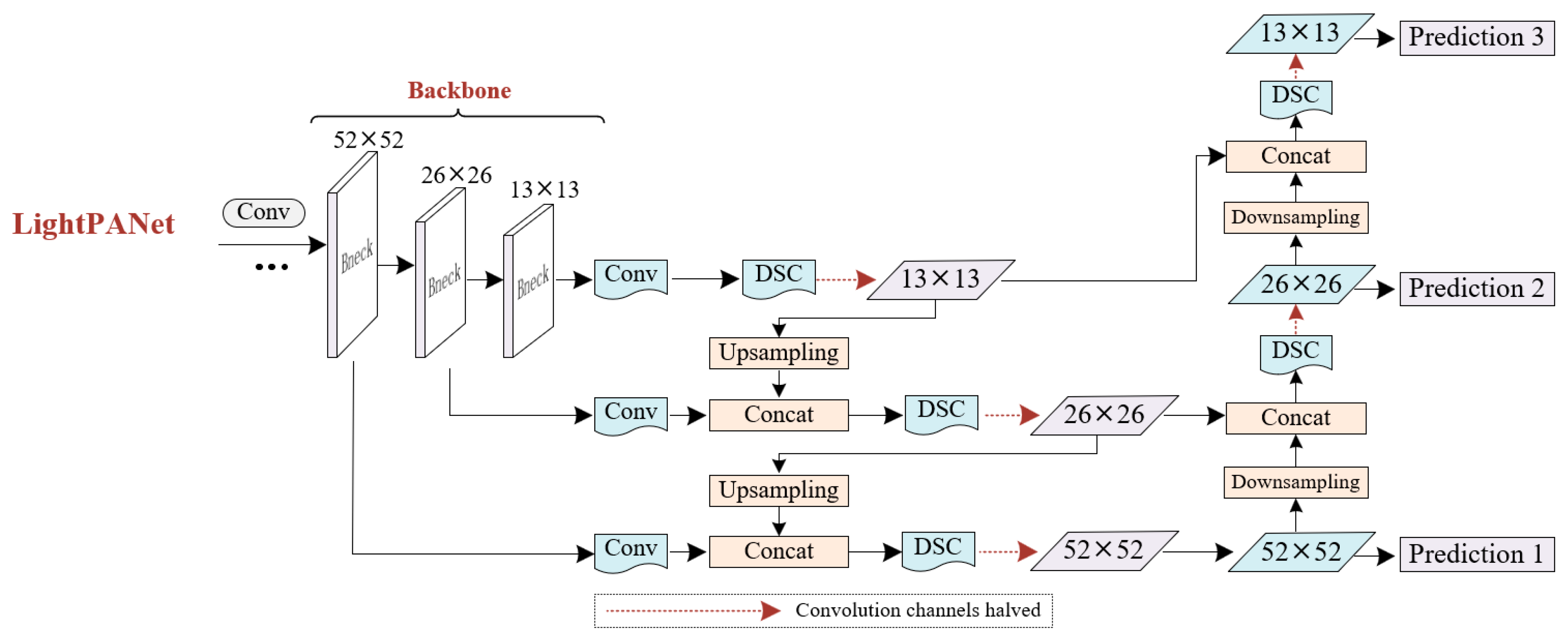
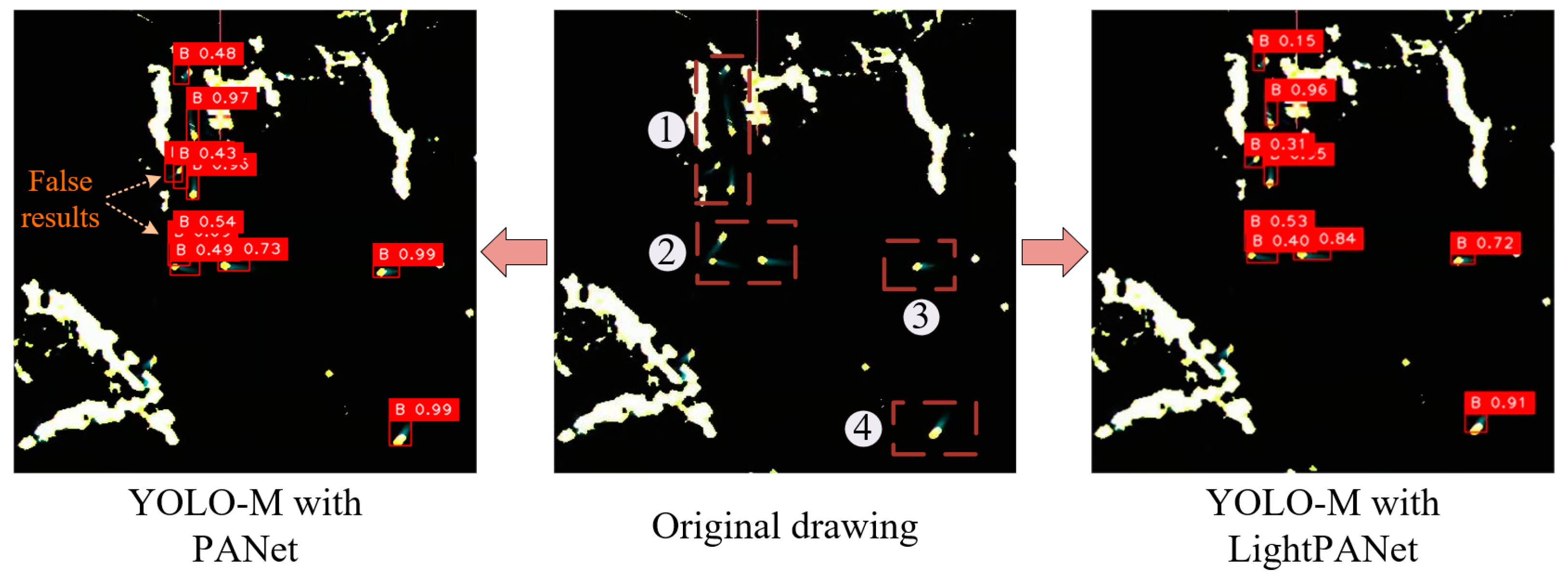
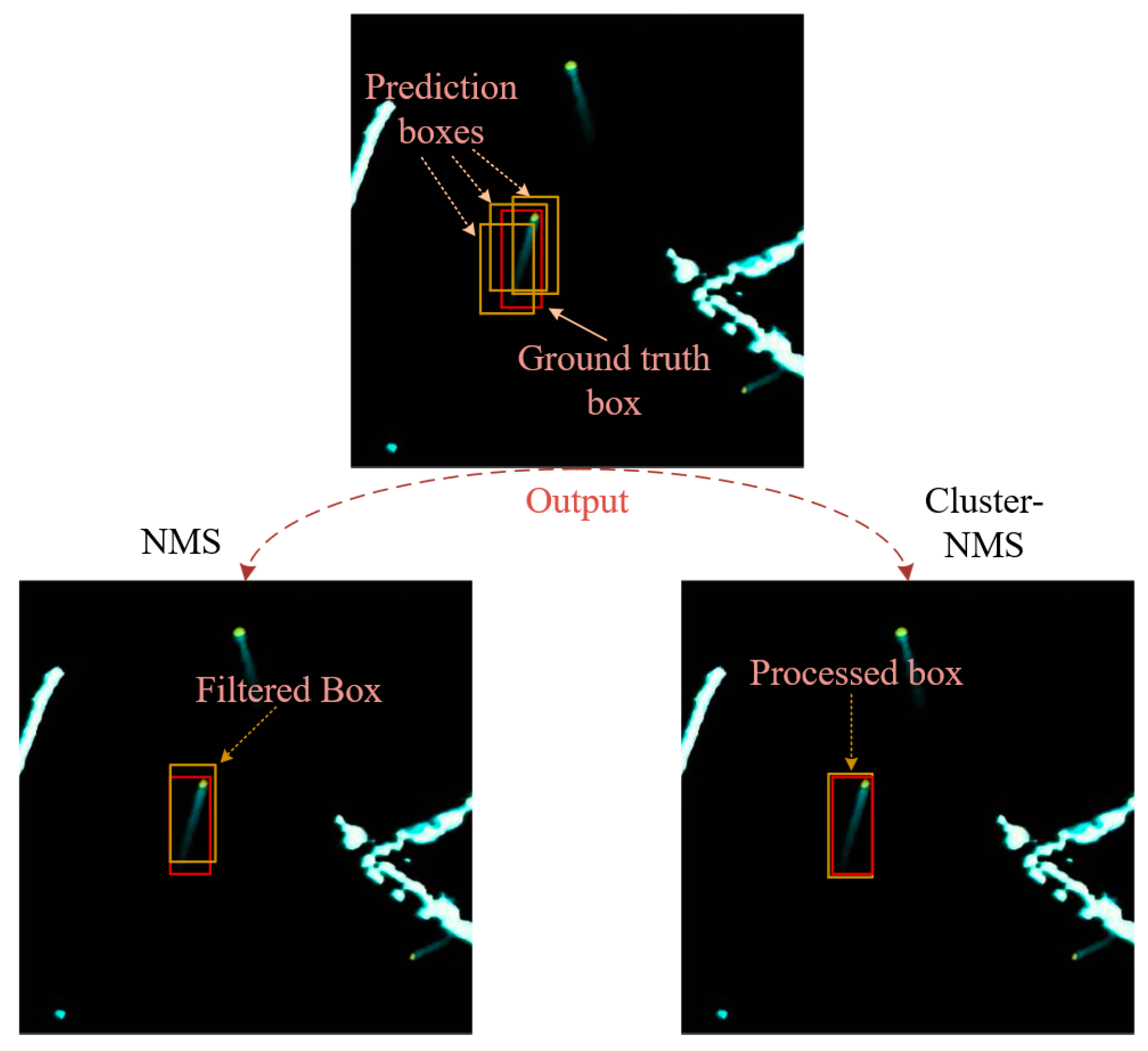
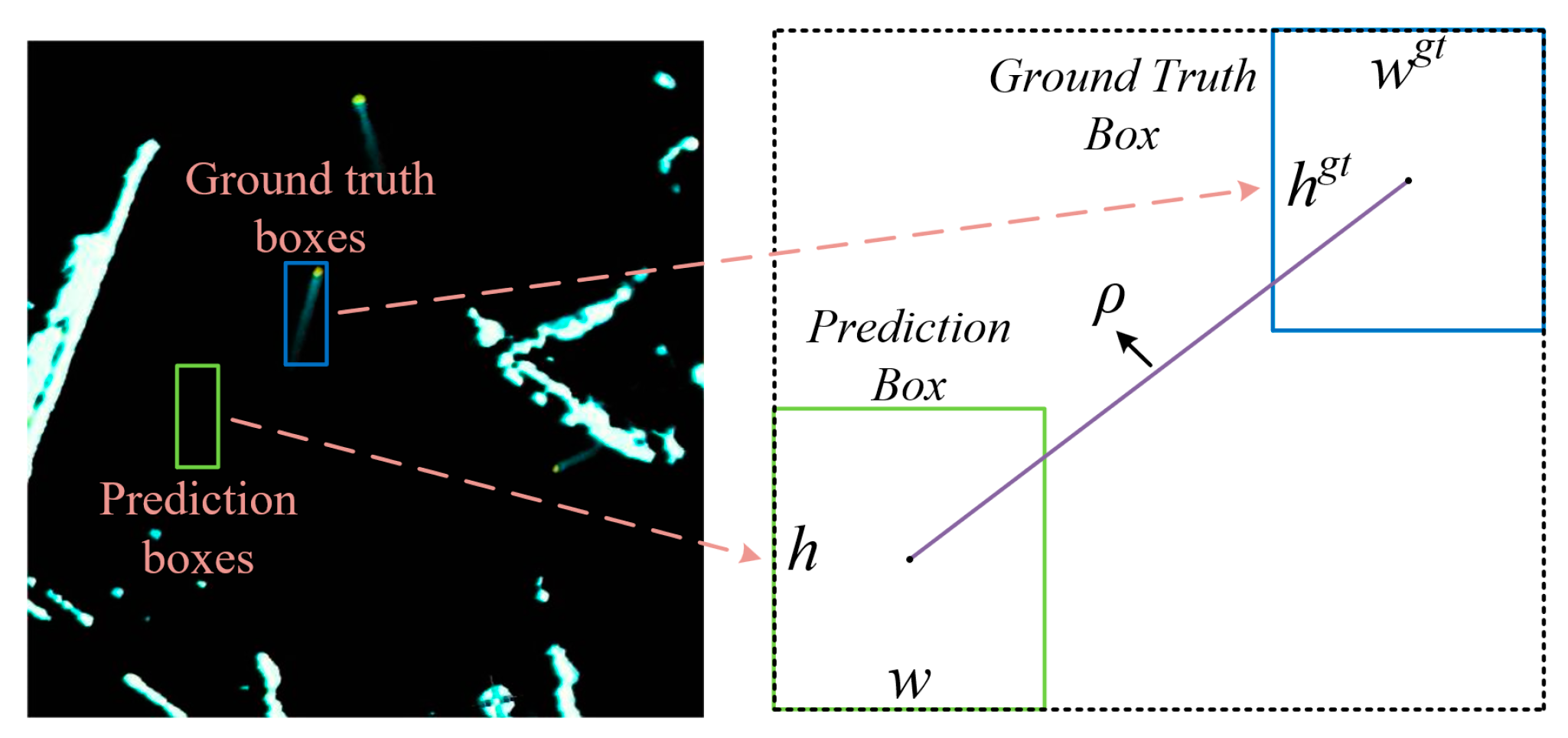
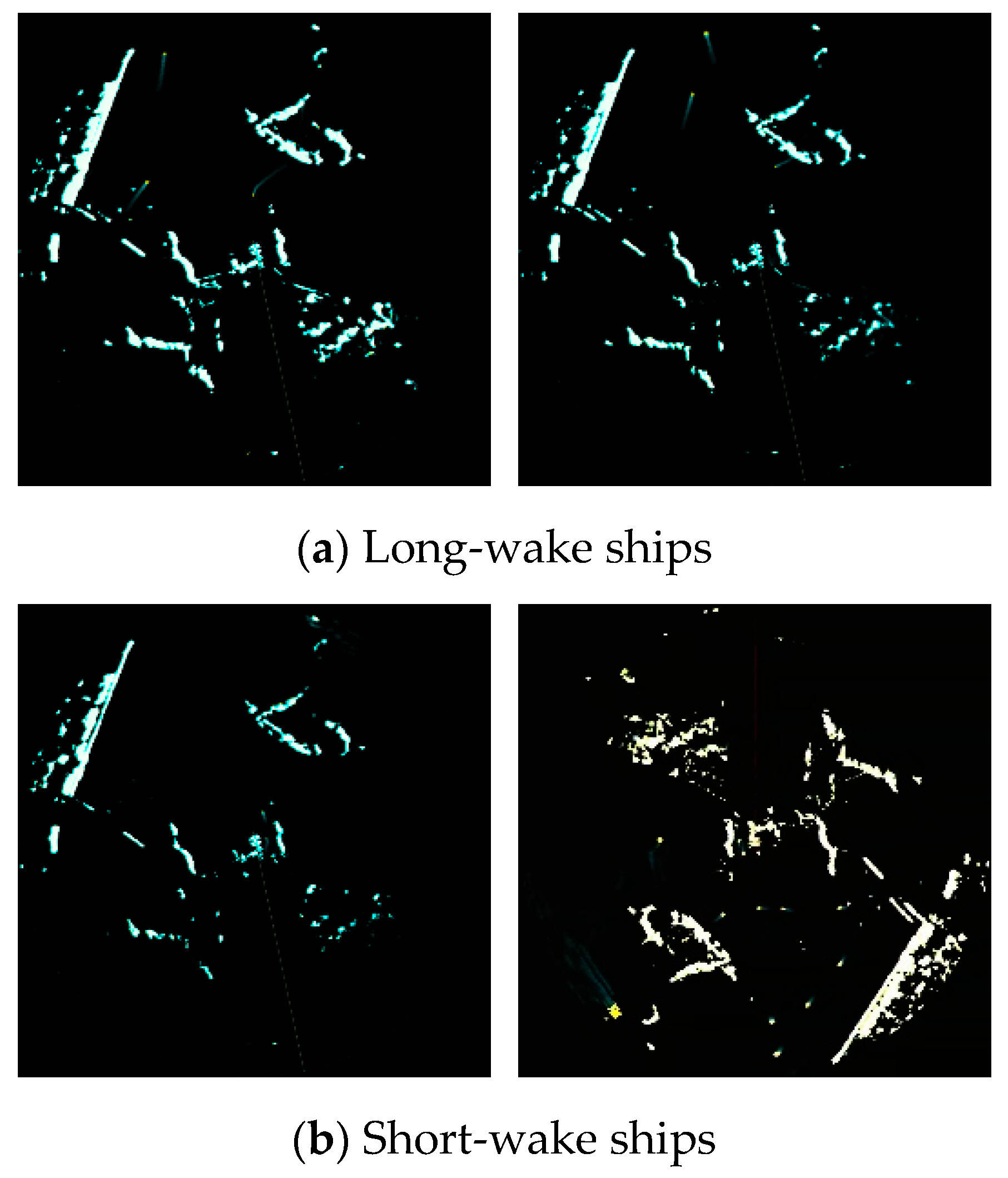
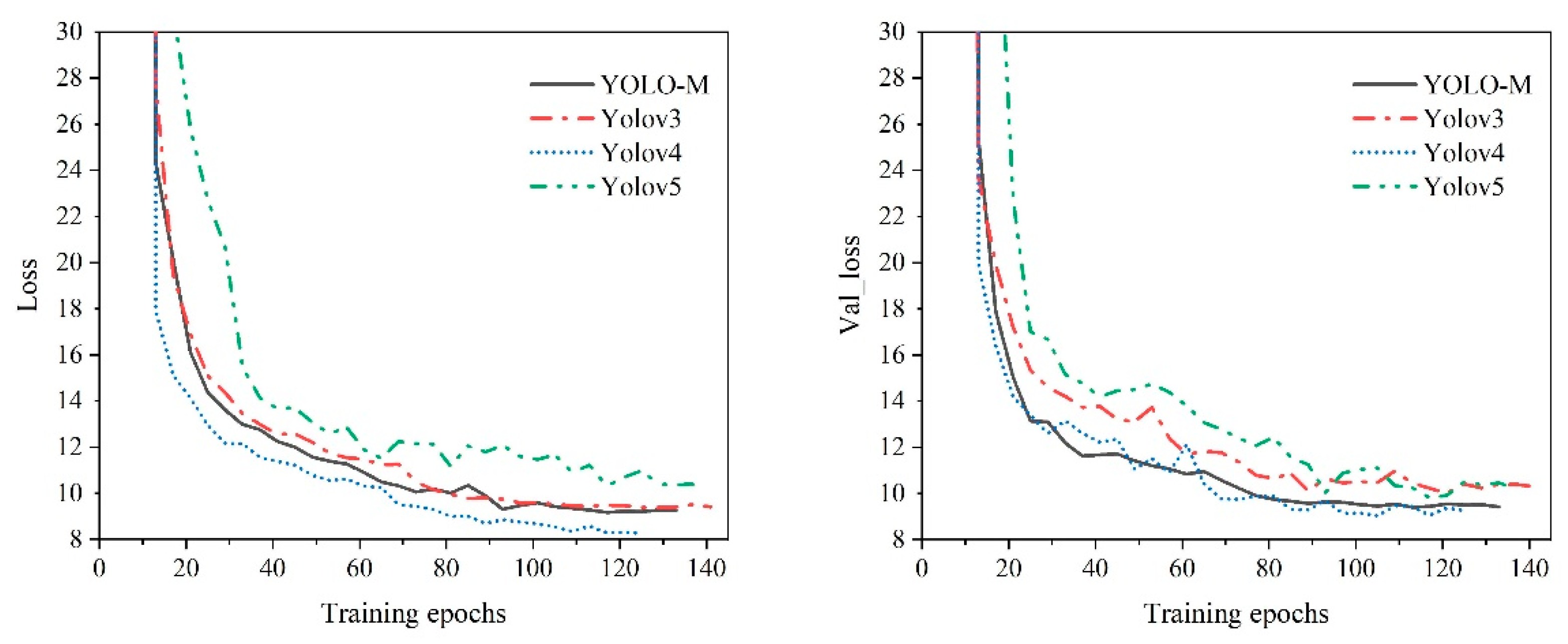
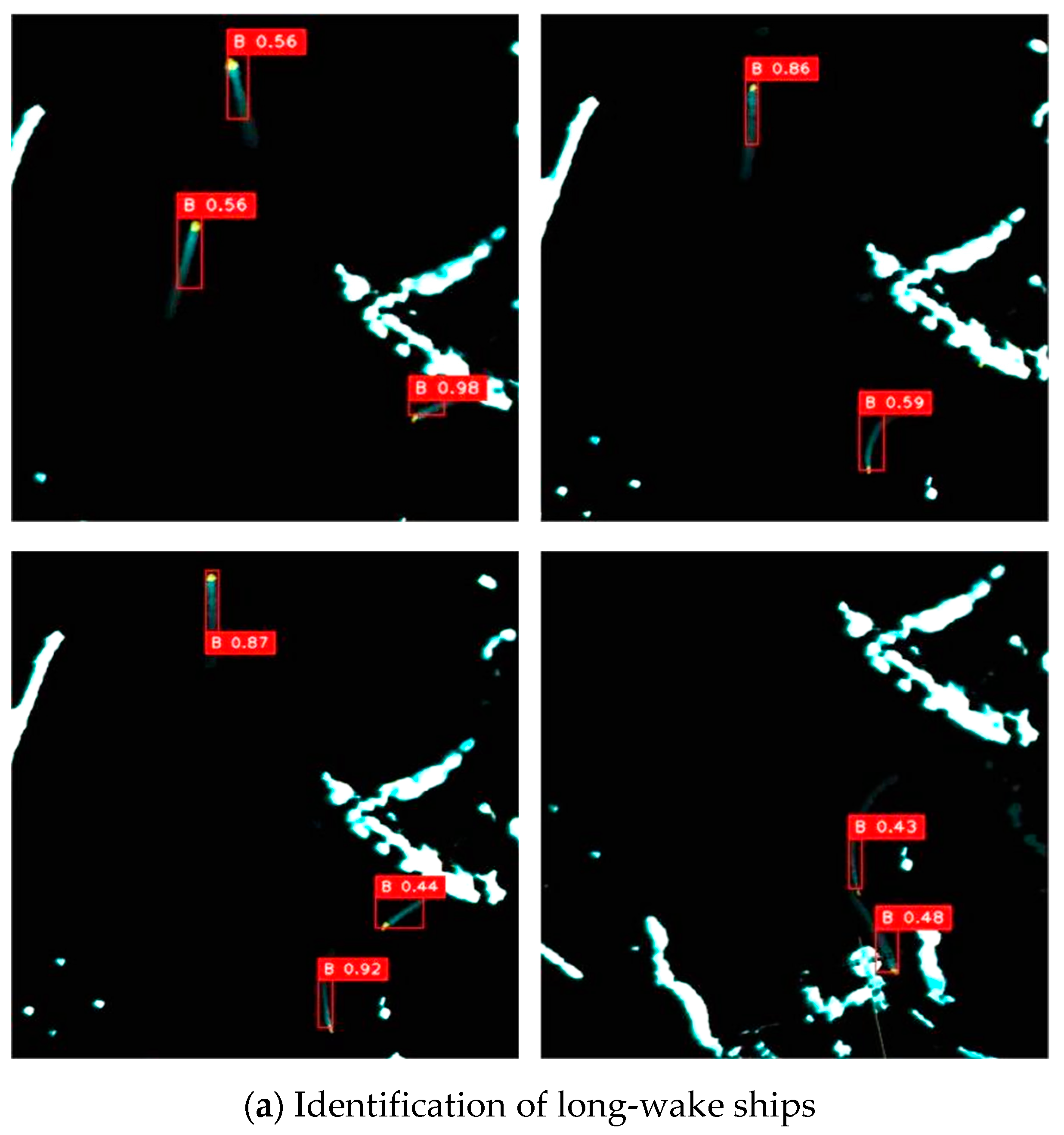

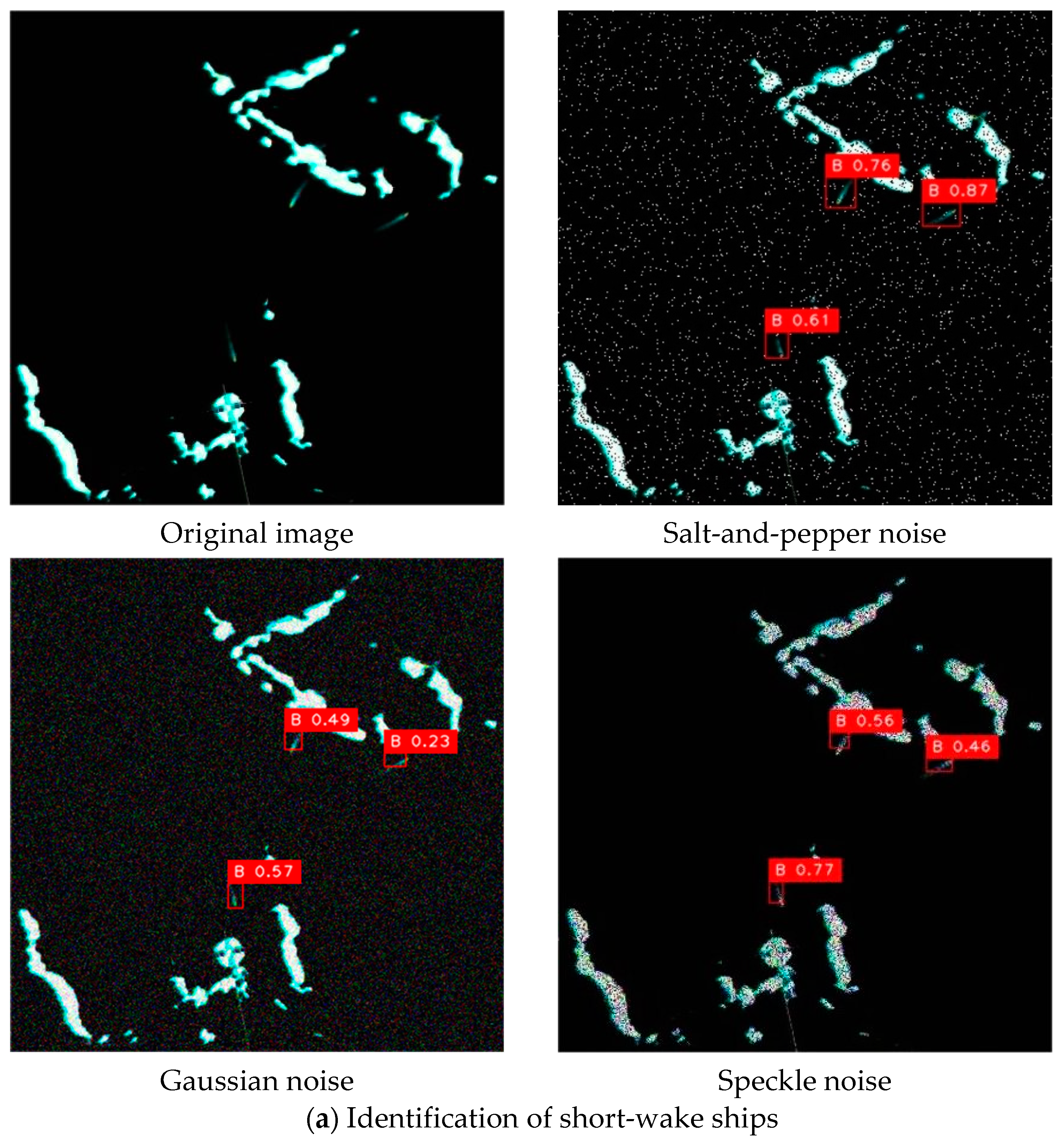



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).