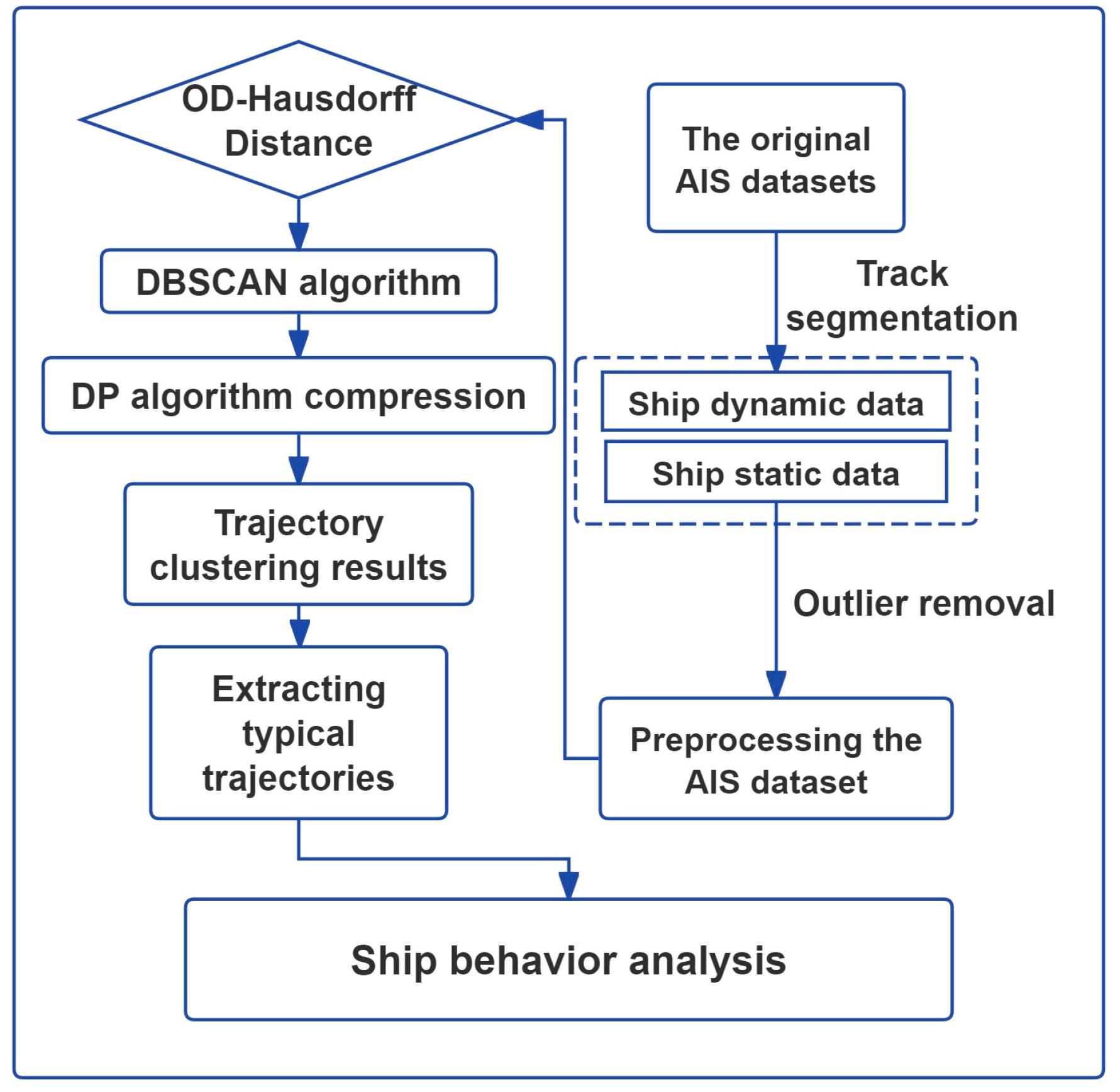
2.1. AIS Data Preprocessing
The collection of AIS data is primarily reliant on equipment installed on ships, base stations, and data centers. After the AIS data are collected, preprocessing becomes critical, including data cleaning, completion, and compression. Erroneous, inconsistent, or missing data are eliminated to ensure accuracy through data cleaning and completion. Information relevant to specific research or applications is extracted through data compression. Trajectory segment clustering heavily relies on trajectory compression. In areas with good signal reception, redundant data can result from the short upload intervals of AIS data due to the ship being in a stable navigation state with close position information. After cleaning the AIS data, removing outliers can inadvertently break continuous trajectories, especially when eliminating drift points. This removal may cause abnormal time and distance gaps between the remaining points, leading to their misidentification as fly points, thus wrongly splitting a continuous trajectory. To prevent this unintended trajectory fragmentation, it is crucial to restore these removed points to maintain trajectory continuity and integrity.
Specifically, cubic spline interpolation is used to fill in the missing latitude and longitude information caused by the outlier removal, ensuring spatial continuity of the trajectory. For speed and course corrections, linear interpolation is employed due to its simplicity and effectiveness in handling time series data, allowing for a better restoration of the vessel’s speed and course trends. This interpolation strategy effectively prevents trajectory fragmentation during outlier processing, ensuring accurate and reliable trajectory analysis. Cubic spline interpolation is a mathematical method used to construct a smooth curve through a set of discrete points. In AIS data processing, it is commonly used to repair abnormal or missing trajectory points because it provides a highly smooth curve while preserving the local characteristics of the data points.
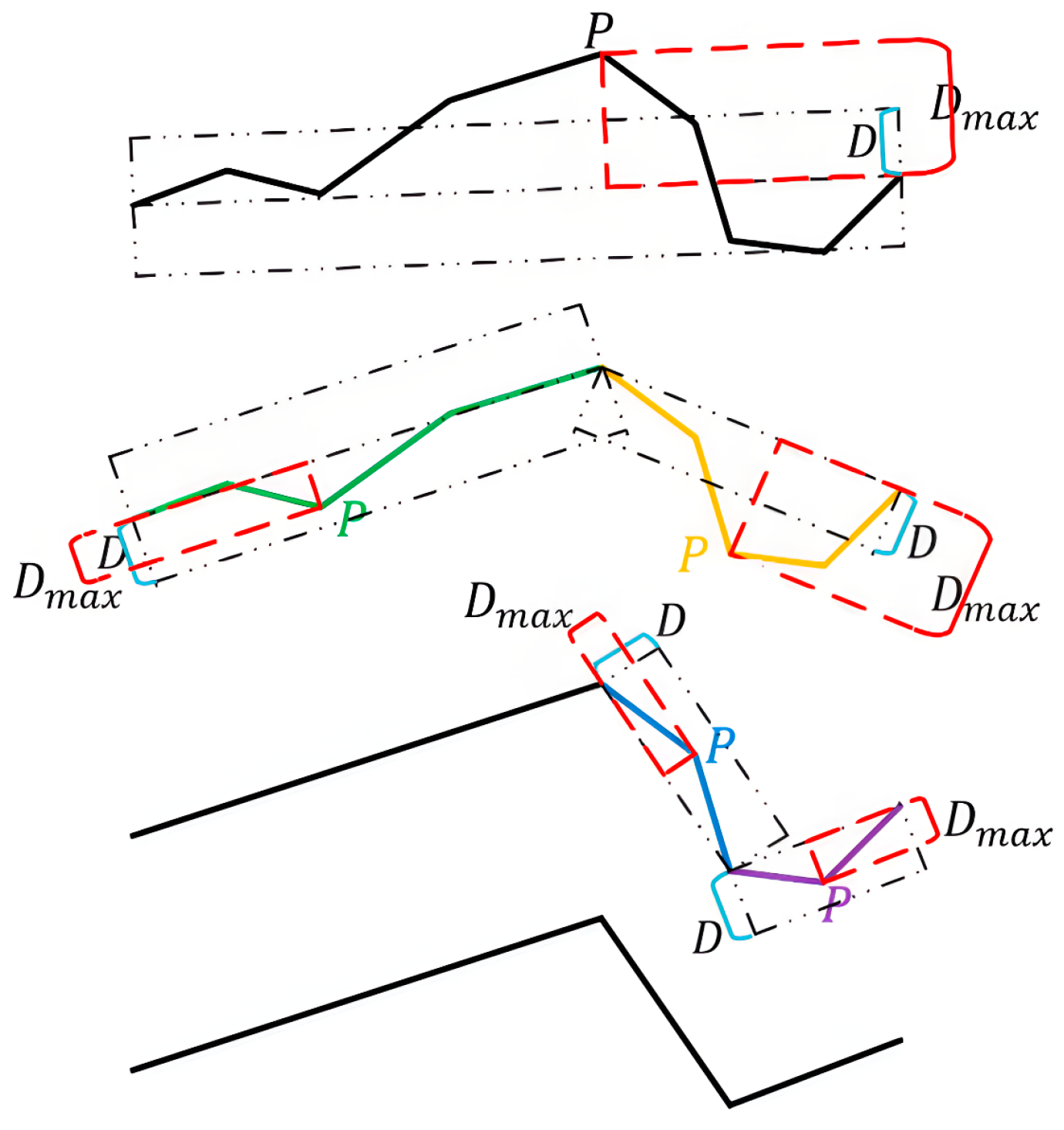
The number of points in the data is reduced while maintaining the shape characteristics of the trajectory using the Douglas–Peucker (DP) algorithm [
31]. Firstly, a distance threshold D is set for the trajectory composed of points. Secondly, the first and last points are connected by drawing a straight-line segment between them. Thirdly, the Euclidean distance from each point on the trajectory to the constructed line segment is calculated, and the maximum distance
Dmax is identified, with the point having the maximum distance marked as P. Fourthly, if
Dmax >
D, the trajectory is divided into two parts at point P. Fifthly, if
Dmax <
D, all points except the first and last points of the segment are deleted. These steps are repeated until the trajectory can no longer be divided. The resulting simplified trajectory is the compressed outcome. The effectiveness of the DP (Douglas–Peucker) compression algorithm is illustrated in
Figure 2. Clustering efficiency is significantly enhanced by this trajectory simplification, as essential features are preserved with fewer data points.
2.2. OD–Hausdorff Distance
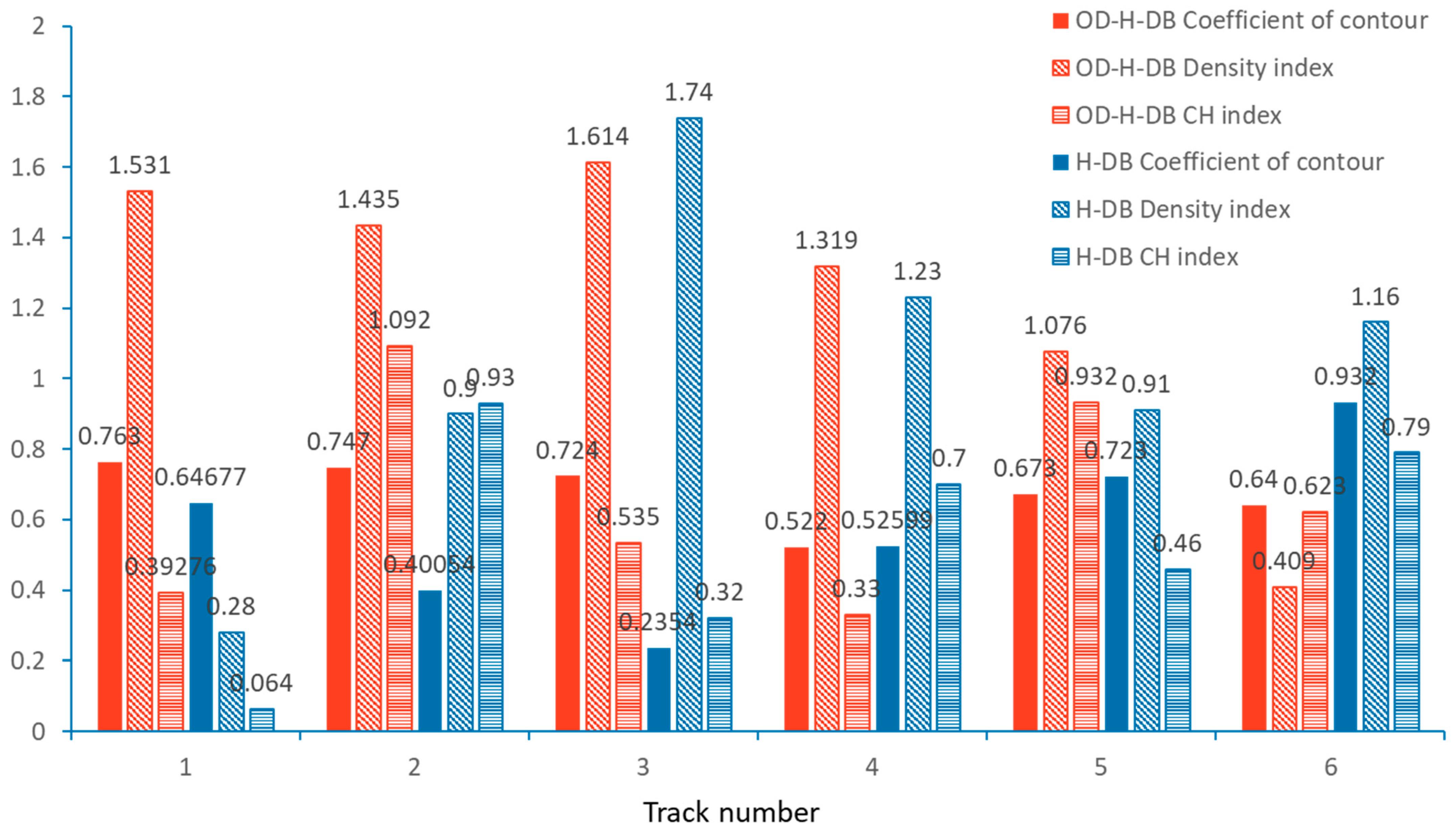
The traditional Hausdorff distance is used to measure the similarity between two sets of points by determining the greatest distance from a point in one set to the closest point in the other set. It is focused primarily on spatial distribution without considering dynamic characteristics like speed and heading, making it sensitive to outliers and small, local shape changes. In contrast, the OD–Hausdorff distance is designed as an improved version tailored for ship trajectories, particularly useful for analyzing the behavior of ships entering and leaving ports. This method involves the trajectory being divided into three segments: the overall trajectory, the port segment, and other segments. The average Hausdorff distance is measured for these segments, with more importance being given to the port segments where significant behavioral changes occur. By incorporating dynamic characteristics such as speed and heading, the OD–Hausdorff distance provides a more comprehensive and accurate similarity measure for trajectories, making it more robust to outliers and small shape changes.
The spatial distribution of trajectory points is primarily what is focused on by the traditional Hausdorff distance, while the core dynamic characteristics of ship behavior, such as heading and speed, are neglected. For example, ships traveling in opposite directions may be spatially close, but the similarity may be misjudged if the Hausdorff distance is calculated solely from positions. Significant measurement bias can be introduced due to missing points in the trajectory data caused by signal interference or equipment failure, to which the traditional Hausdorff distance is sensitive. Therefore, the Hausdorff distance needs to be improved from the perspective of dynamic information to reflect the actual movement patterns of ships more accurately.
The OD (Origin–Destination)–Hausdorff distance method was developed in this study to enhance the accuracy of clustering analysis, particularly for the specific behaviors of ships entering and leaving ports. Clustering performance is significantly improved by this method, as it accurately captures these behaviors. The trajectory is segmented into overall, port, and other parts, and each part is independently evaluated using an improved Hausdorff distance. A global view of the trajectory is provided by the overall part. The ship’s actions, such as accelerating, decelerating, and preparing to depart or dock, are focused on by the port part, capturing the key characteristics of ships entering and leaving ports. The similarity of ship trajectories is more comprehensively evaluated by setting different weighting factors to adjust the influence of these parts through the OD–Hausdorff distance.
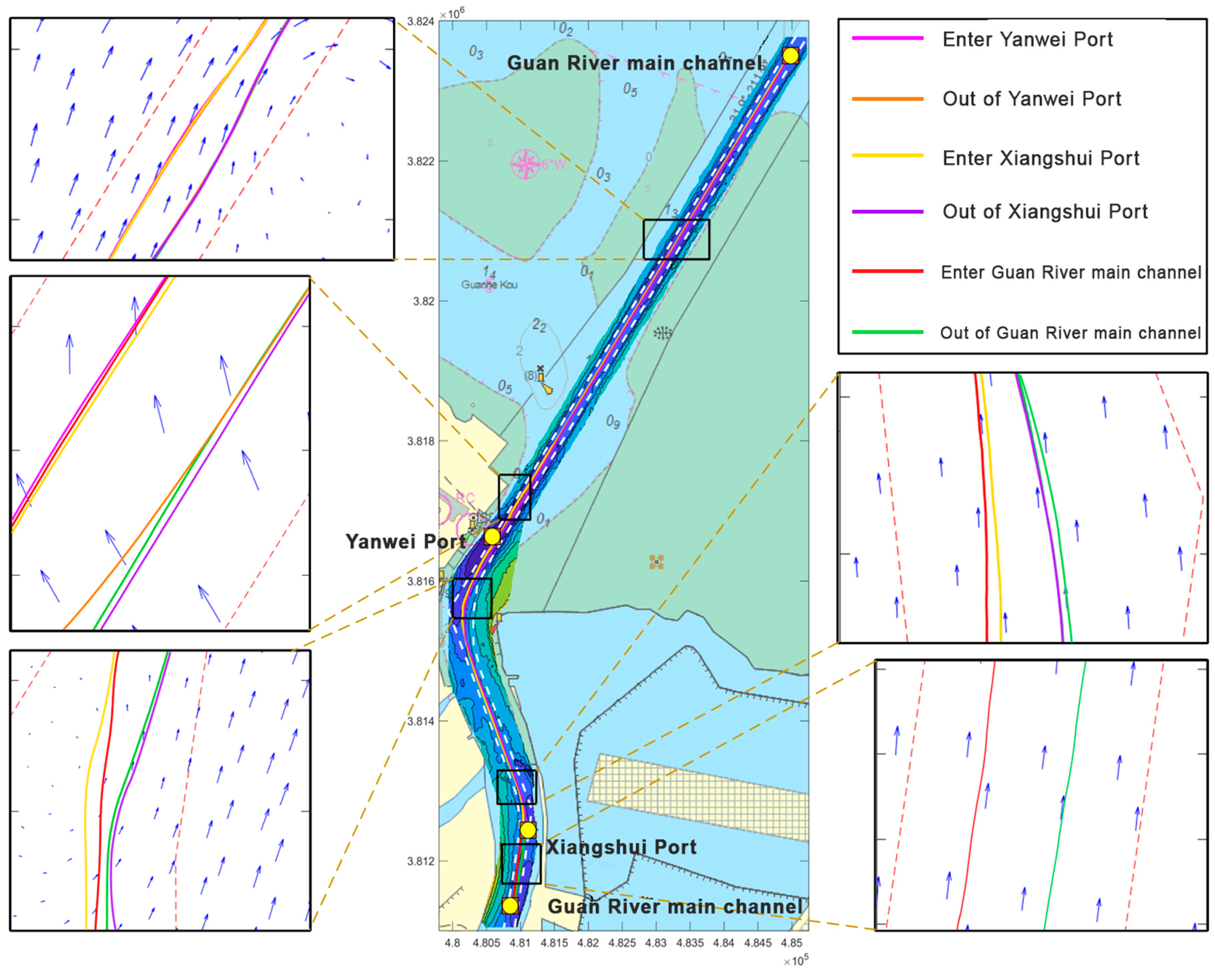
The principle of OD–Hausdorff distance measurement is shown in
Figure 3. Each inbound and outbound trajectory can be divided into three parts. The entire trajectory corresponds to
,
, the other parts corresponds to
,
, and the port part corresponds to
,
.
The normalization formula is
where
denotes normalization,
is the perpendicular intersection point of trajectory point
in trajectory
to trajectory
, with
,
,
,
corresponding to the latitude, longitude, speed, and course of
, respectively, and
,
, and
are the distance weight, speed weight, and course weight, respectively.
It is important to note that the OD–Hausdorff distance measures similarity using the Average Improved Hausdorff Distance (AIHD). The formula for the OD–Hausdorff similarity measurement is defined as
where
,
, and
represent the overall part, port part, and other parts, respectively, and the distances calculated using the above average distance measurement are defined as follows:
are the weight coefficients for the three parts. Substituting Formulas (1) into (3)–(5) yields the OD–Hausdorff similarity measurement.
In practical implementations, the OD–Hausdorff distance first conducts a temporal analysis of the trajectories, identifying and isolating the port segments. The improved Hausdorff distance is then calculated for the overall trajectory, port segments, and other parts. The final similarity is obtained as the weighted average of these three distances, with the weighting factors adjustable according to actual needs to suit different analytical scenarios.
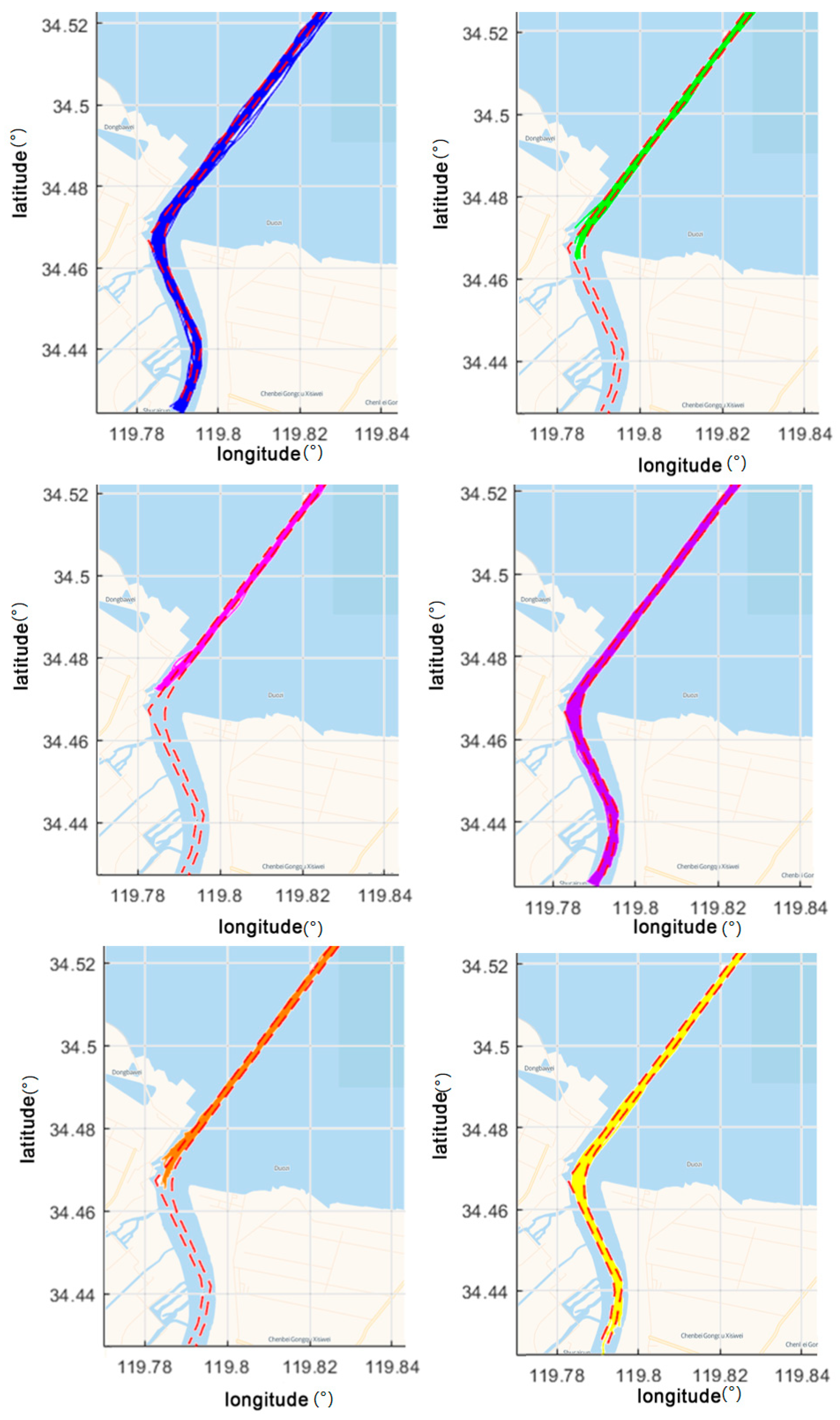
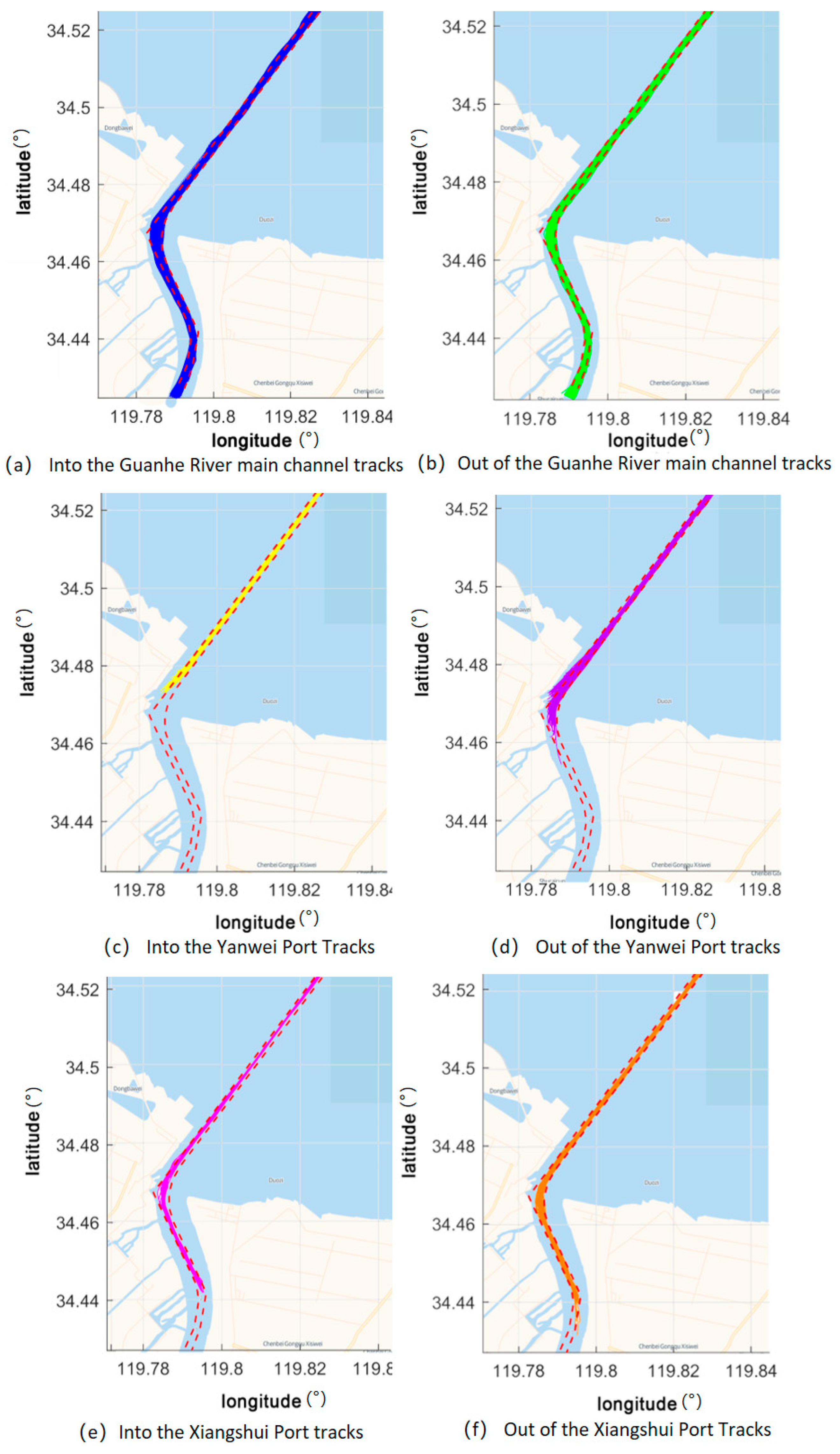
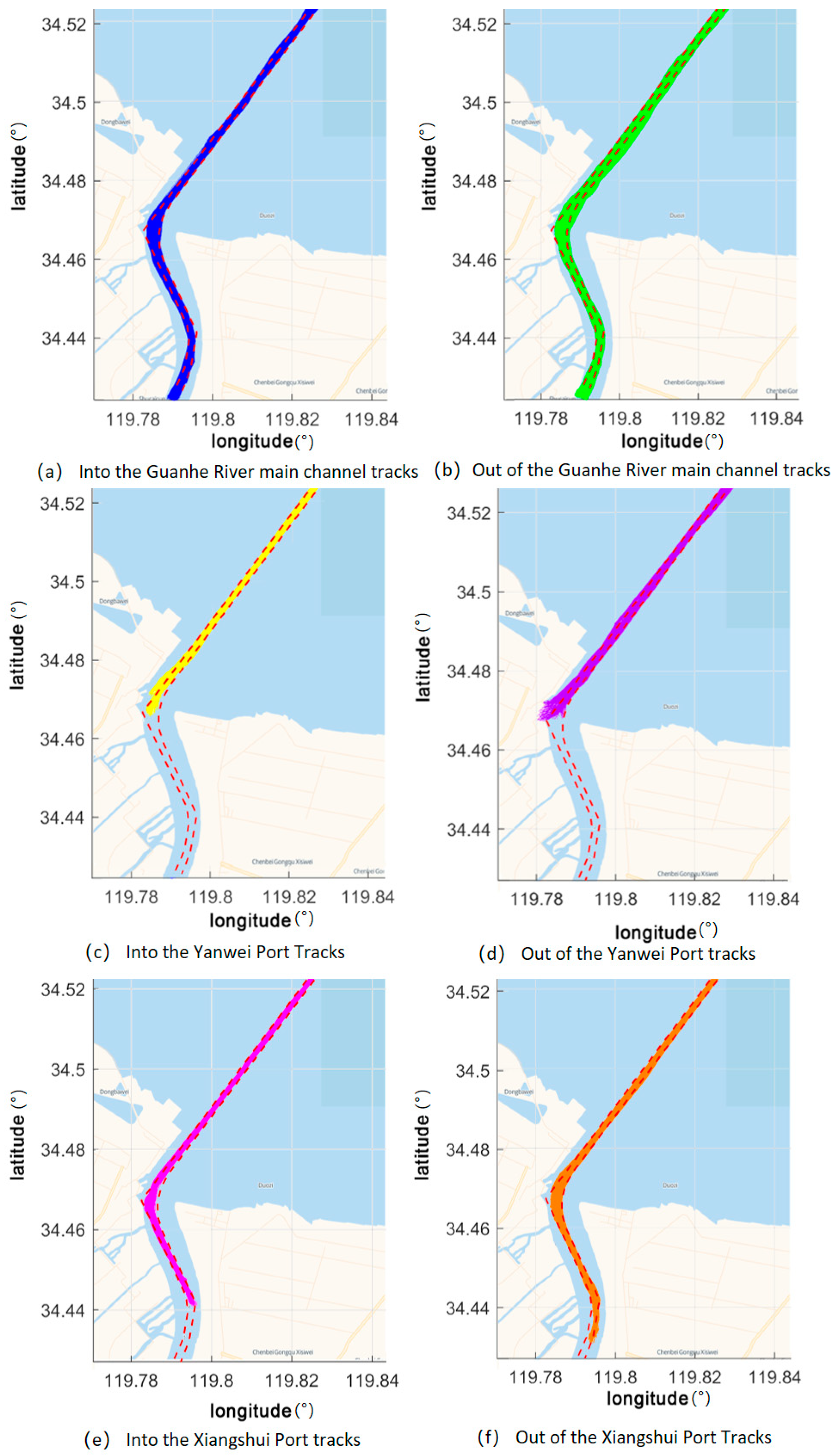
A method of clustering based on density is employed in this study for segments of ship trajectories. Among the density clustering methods, the algorithm DBSCAN is widely used for data from point sets. In this study, the application of DBSCAN is extended to the multidimensional data of ship trajectories. When the DBSCAN algorithm is applied, it is necessary first to standardize the data of ship trajectories into a uniform format, with each segment of trajectories consisting of points from several trajectories.
Given a trajectory
, its neighborhood is formally defined as
where
represents the neighborhood radius of the trajectory segment.
is the set of trajectories.
is the similarity distance between trajectory segments
and
.
The criterion for judging a
trajectory segment is given by Formula (7).
where
represents the minimum number of trajectories in the neighborhood. If Formula (7) is satisfied, the trajectory segment is considered a core trajectory segment. If Formula (6) is satisfied but Formula (7) is not, the trajectory segment is regarded as a border trajectory segment.
In the data space, if
where
is directly density-reachable from
. Clusters representing characteristics of different navigational behaviors are formed by connecting segments of core trajectories and linking them with segments of border trajectories.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}