
Observations on the Intertextuality of Selected Abhidharma Texts Preserved in Chinese Translation
Abstract
1. Introduction
Preliminary Remarks
2. Visualization of the Translation Canon of Xuanzang
- FastText Vector representations (Bojanowski et al. 2016) of individual tokens were created and averaged over a fixed window size in order to generate phrase representations.
- A k-nearest neighbors search was then used to find similar phrase representations within a fixed corpus. Continuous chains of similar phrase representations were merged together to form longer matches.
- Local alignment (the Smith–Waterman algorithm) was then used to find the exact beginning and end points of the detected matches.
| Dhātukāya (T1540) | Vijñānakāya (T1536) |
| 色為緣生於眼識,三和合故觸,觸為緣故受,受為緣愛。此中眼為增上、色為所緣,於眼所識色,諸貪等貪,執藏防護愛樂耽著, | 色為緣生眼識,三和合故觸,觸為緣故受,受為緣故愛。此中眼為增上、色為所緣,於眼所識色,諸貪等貪執藏防護耽著愛樂, |
| Dhātukāya (T1540) | Vijñānakāya (T1536) |
| 觸不相應十八界、十二處、五蘊。 | 復次於欲界繫十八界十二處五蘊諸法中諸貪等貪, |
3. Analysis of the Visualization
- The largest community, which consisted mainly of Sūtra translations in blue in the upper half of the visualization.
- The red community to the bottom left-hand side of community 1, which centered around the *Mahāvibhāṣā (T1545) and included the canonical Sarvāstivāda texts Dhātukāya (T1540), the Prakaraṇapāda (T1542), the Vijñanakāya (T1539), and Jñānaprasthāna (T1544).
- The purple community centering around the Abhidharmakośabhāṣya (T1558) to the bottom left of community 2. Apart from Saṅgabhadra’s commentaries, two Yogācāra works attributed to Vasubandhu, the Viṃśikā (T1590) and the Karmasiddhiprakaraṇa (T1609), were also included here.
- The dark orange community to the right of communities 2 and 3, which was dominated by the works attributed to Asaṅga, centering around the Abhidharmasamuccaya (T1605).
- The green community, which was dominated by the Yogācārabhūmi (T1579), above community 4 and to the right of community 2.
- The dark red community on the right side of the visualization, which consisted of the texts related to he Mahāyānasaṃgraha (T1594) and the *Buddhabhūmisūtraśāstra (T1530).
- The purple community at the bottom of the visualization, with the Chéng Wéishì Lùn 成唯識論 (T1585) and the Madhyāntavibhāgabhāsya (T1600) as its centers.
- Sūtra material tended to accumulate in community 1 at the top, while Śāstra material gathered in communities 2–7 at the bottom.
- The left side was dominated by Abhidharma works and the “Sautrāntika” Yogācāra works attributed to Vasubandhu in community 3, the middle by works ascribed to Asaṅga and the Yogācārabhūmi (T1579) in community 4 and 5, and the Maitreya texts and their respective commentaries were found on the right side of the visualization in community 6 and at the bottom in community 7.
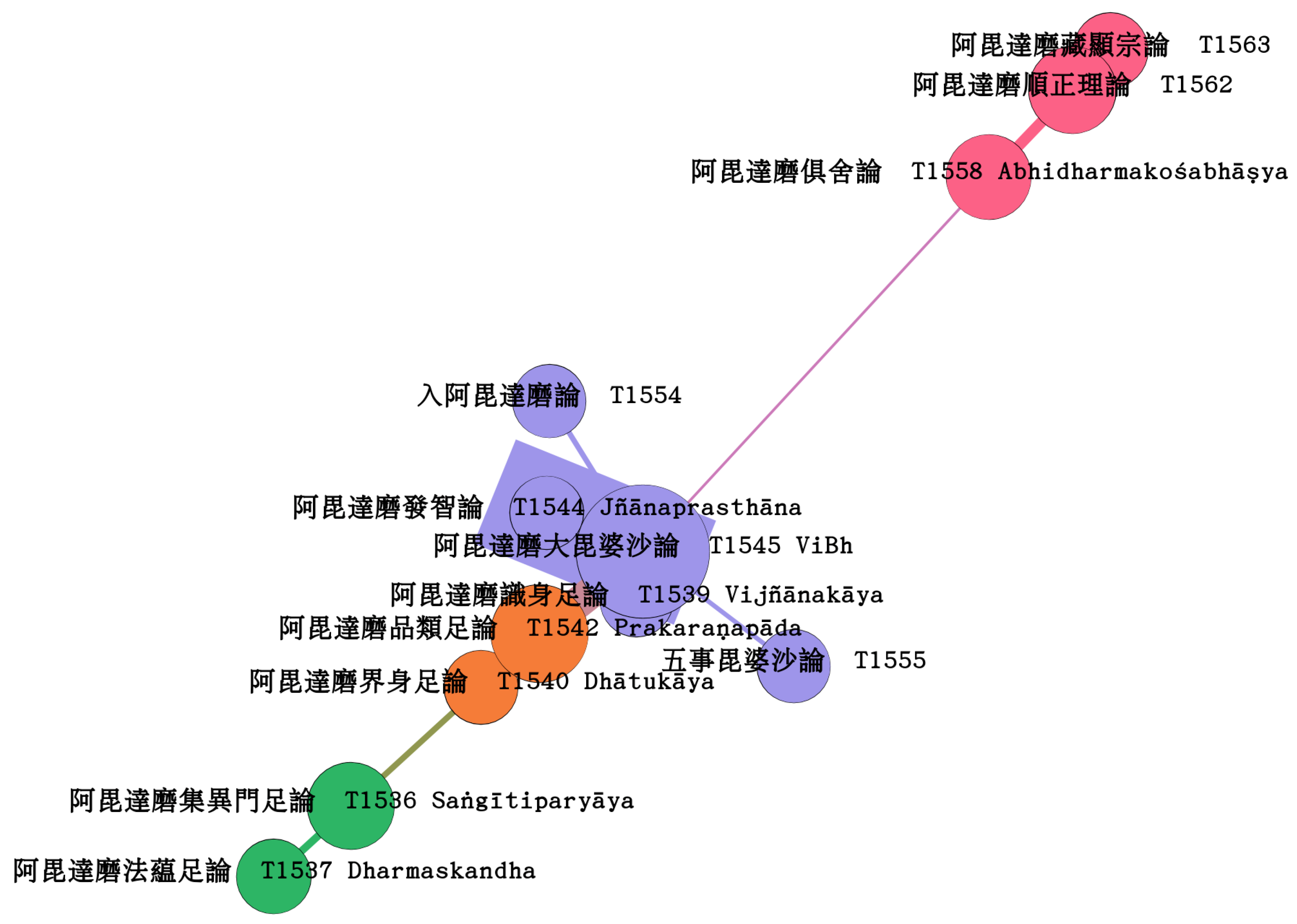
4. Maximum Spanning Tree Analysis of Selected Abhidharma Works
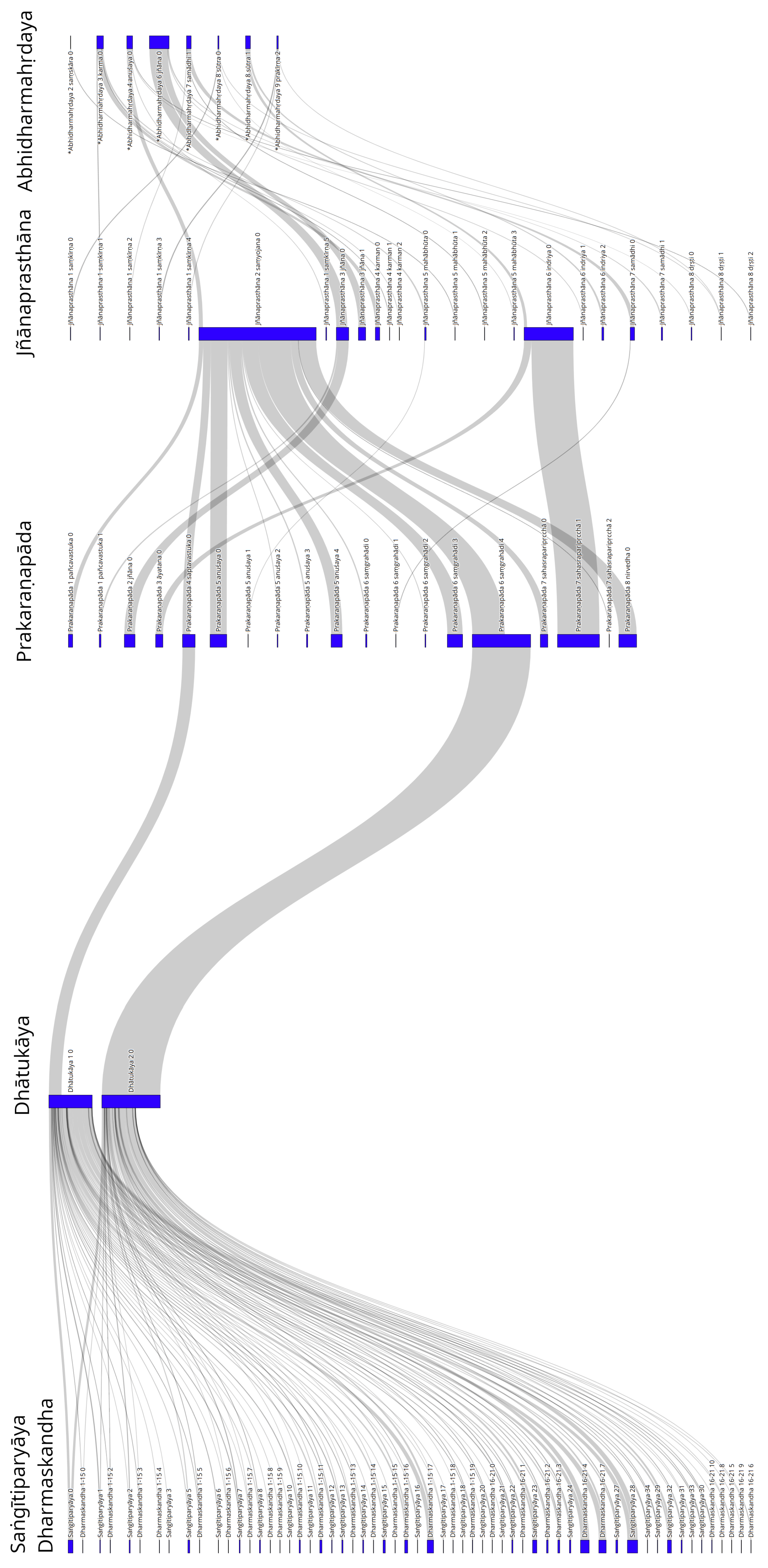
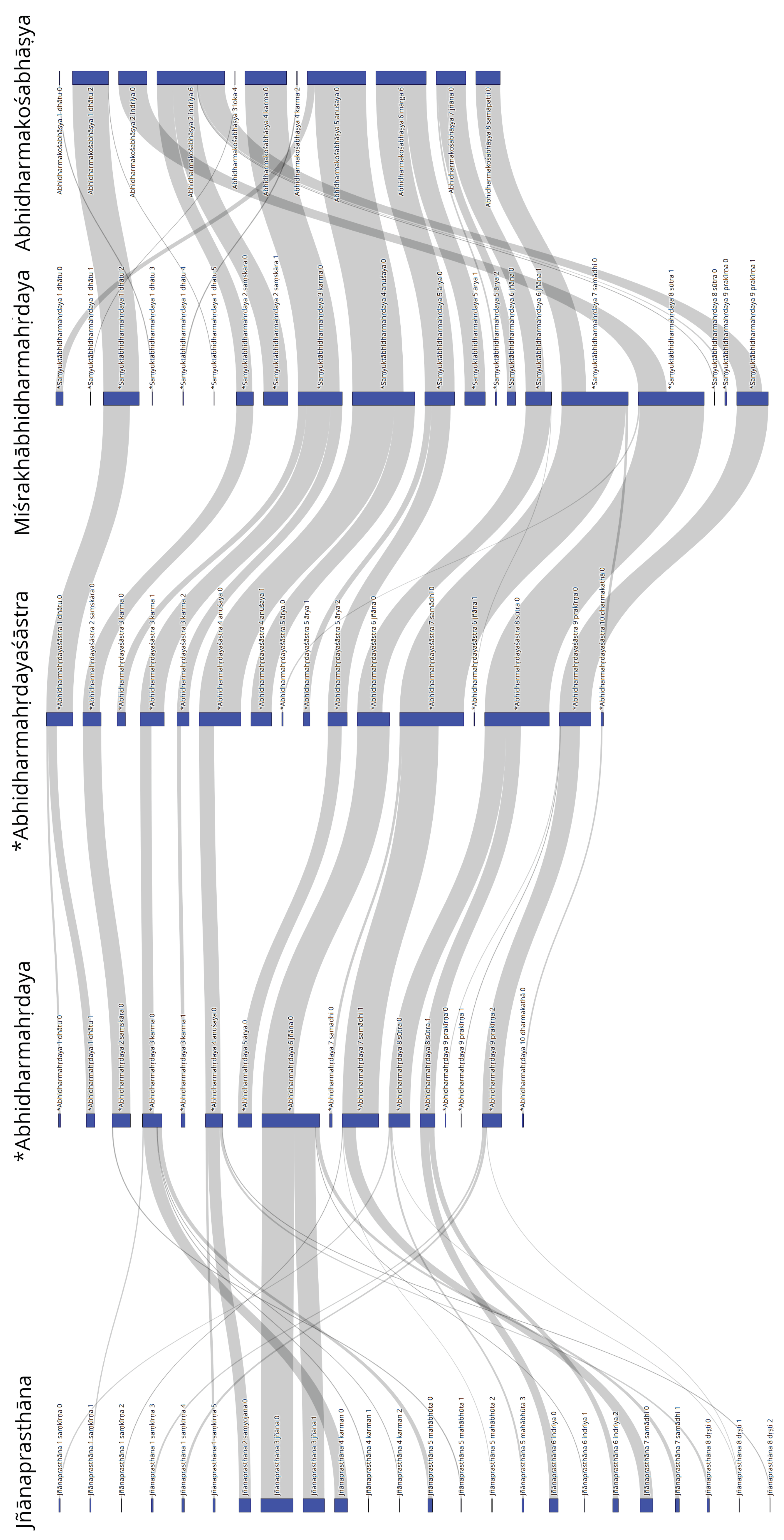
5. Visualization of the Relationships between Individual Sections of Selected Abhidharma Works
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | http://buddhanexus.net (accessed on 10 July 2023). |
| 2 | See Bronkhorst (2016), especially p. 38 ff. for a discussion on the importance of Gandhāran Abhidharma for the intellectual history of South Asia. |
| 3 | |
| 4 | This assumption is shared by Robert Kritzer (Kritzer 2005, p. XXXI). |
| 5 | |
| 6 | For this possible objection see (Cox 1998, p. 167). |
| 7 | Version number 0.9.2. Accessible at: https://gephi.org/users/download/ (accessed on 10 July 2023). |
| 8 | |
| 9 | As an example of this difficulty within Xuanzang’s translation corpus the relationship between the Dharmaskandha (T1537) and the Yuánqǐ jīng 緣起經 (T124) can be singled out. a plethora of common passages between these two texts shows how entangled their relationship is. |
| 10 | In Xuanzang’s translation these are the *Mahāyānasaṃgrahabhāṣya (T1597) and the Madhyāntavibhāgabhāsya (T1600). |
| 11 | Lambert Schmithausen has expressed his view of the relationship of the Maitreya commentaries and the Sautrāntika-Yogācāra works attributed to Vasubandhu at (Schmithausen 1987, p. 262) and reiterated this position at (Schmithausen 2014, p. 27). t’s important to note that the methodology of this study isn’t designed to identify authorship, and definitive answers to this question can’t be solely derived from network graph representations of textual reuse. However, the pattern that becomes visible at this point is that these two groups are indeed clearly separated. The likely reason for this is that the texts of the “Sautrāntika” Vasubandhu are part of a closely connected web of textual reuse that connects them with the texts of the Vaibhāṣika Abhidharma tradition, especially the *Mahāvibhāṣā, a situation that is not found to the same extent with regard to the Maitreya commentaries attributed to Vasubandhu. This could indicate a different educational background of the author(s) of the Sautrāntika-influenced works, who might have been more familiar with Vaibhāṣika positions than the author(s) of the Maitreya commentaries. |
| 12 | The relative arrangement of the Abhidharma texts up to the Abhidharmakośabhāṣya and their scholarly assessment will be discussed in this study below. For the relative chronology of the Yogācāra works see (Deleanu 2006, p. 195). The composition and compilation of the *Mahāvibhāṣā and the Yogācārabhūmi likely took many decades, maybe even centuries, and can therefore only be approximated in a rather simplistic manner here. |
| 13 | Frauwallner places it after the Dhātukāya, see (Frauwallner 1995, p. 28). Collet Cox describes their relative chronology as uncertain (Cox 1998, p. 206). Yin Shun places it after the Prakaraṇapāda and even the Jñānaprasthāna (Yin Shun (印順) 1968, p. 170a6-11). |
| 14 | This general grouping of the texts is widely discussed in modern research, see for example (Frauwallner 1995, p. 13), (Cox 1998, p. 171) and (Eltschinger and Honjō 2015, p. 95). |
| 15 | |
| 16 | In the first step of this method, a semantic relatedness graph is constructed based on the cosine similarity of the averages of the vector representations of each character of an individual sentence in each text. In the second step, maximum cliques are detected, and overlapping maximum cliques are merged together as representations of semantically coherent sections of text. In addition to this, the texts have been pre-segmented into chapters/parts if that information was available in the research literature. |
| 17 | This is broadly discussed in (Yin Shun (印順) 1968, p. 148a9 ff.). Yin Shun’s theory of placing the Prakaraṇapāda after the Jñānaprasthāna cannot be discussed in detail here. The MST analysis indicates general trends in the development of the literature and is not suited to give clear answers to such particular questions. |
| 18 | See (Frauwallner 1995, p. 33) and (Cox 1998, p. 218). |
| 19 | Frauwallner seems to base his assessment solely on the description in Tao-yen’s foreword to Buddhavarman’s Vibhāṣa and his application of the principle of lectio difficilior (Frauwallner 1995, p. 152). |
| 20 | In fact, Yin Shun argues that the *Abhidharmahṛdaya is based on the Abhidharmāmṛtarasaśāstra (T1553), which he sees as younger than the Jñānaprasthāna and *Mahāvibhāṣā (Yin Shun (印順) 1968, p. 479a9 ff.) |
| 21 | Yin Shun also observed the structural influence of the *Abhidharmahṛdaya on later treatises such as the Abhidharmakośabhāṣya but attributes the innovation to the *Abhidharmāmṛtarasa (甘露味論), which he claims to be older than the *Abhidharmahṛdaya (Yin Shun (印順) 1968, p. 493a6). If his theory should be right, the true innovation here has been achieved by the *Abhidharmāmṛtarasa. The question of whether the *Abhidharmāmṛtarasa pre- or postdates the *Abhidharmahṛdaya, while being very interesting, lies outside the scope of this article. |
References
- Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics 5: 135–46. [Google Scholar] [CrossRef]
- Brin, Sergey, and Lawrence Page. 1998. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Computer Networks and ISDN Systems 30: 107–17. [Google Scholar] [CrossRef]
- Bronkhorst, Johannes. 2016. Abhidharma and Indian Thinking. In Text, History, and Philosophy: Abhidharma across Buddhist Scholastic Traditions. Leiden: Brill, pp. 29–46. [Google Scholar]
- Cox, Collett. 1998. Kaśmira: Vaibhāṣika Orthodoxy. In Sarvāstivāda Buddhist Scholasticism. Leiden: Brill, pp. 138–254. [Google Scholar]
- Dessein, Bart. 1998. Bactria and Gandhāra. In Sarvāstivāda Buddhist Scholasticism. Leiden: Brill, pp. 255–85. [Google Scholar]
- Deleanu, Florin. 2006. The Chapter on the Mundane Path (Laukikamārga) in the Śrāvakabhūmi. Studia Philologica Buddhica Monograph Series. Tokyo: The International Institute for Buddhist Studies. [Google Scholar]
- Delhey, Martin. 2016. From Sanskrit to Chinese and Back Again. In Cross-Cultural Transmission of Buddhist Texts. Edited by Dorji Wangchuk. Hamburg: Indian and Tibetan Studies, vol. 5. [Google Scholar]
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for language understanding. Paper presented at the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MI, USA, June 2–7; pp. 4171–86. [Google Scholar]
- Eltschinger, Vincent, and Yoshifumi Honjō. 2015. Abhidharma. In Brill’s Encyclopedia of Buddhism. Volume One. Leiden: Brill, pp. 88–102. [Google Scholar]
- Frauwallner, Erich. 1995. Abhidharma Literature and the Origins of Buddhist Philosophical Systems. New York: State University of New York Press. [Google Scholar]
- Fukuhara Ryōgon (福原亮嚴). 1965. The Development of the Abhidharmaśāstras of the Sarvāstivāda School (有部阿毘達磨論書の発達). Kyoto: Nagata Bunshōdō (永田文昌堂). [Google Scholar]
- Glavaš, Goran, Federico Nanni, and Simone Paolo Ponzetto. 2016. Unsupervised Text Segmentation Using Semantic Relatedness Graphs. Paper presented at the Fifth Joint Conference on Lexical and Computational Semantics, Berlin, Germany, August 11–12; Berlin: Association for Computational Linguistics, pp. 125–30. [Google Scholar]
- Hellwig, Oliver. 2013. Googling the Rishi–Graph Based Analysis of Parallel Passages in Sanskrit Literature. Paper presented at Recent Researches in Sanskrit Computational Linguistics: Fifth International Symposium IIT Mumbai, Mumbai, India, January 4–6. [Google Scholar]
- Kimura Taiken (木村泰賢). 1937. A Study of the Abhidharma Treatises (阿毘達磨論の研究). Tokyo: Meiji Shoin (明治書院). [Google Scholar]
- Kramer, Jowita. 2014. Innovation and the Role of Intertextuality in the Pañcaskandhaka Related Yogācāra Work. Journal of the International Association of Buddhist Studies 37: 281–352. [Google Scholar]
- Kritzer, Robert. 2005. Vasubandhu and the Yogācārabhūmi. Studia Philologica Buddhica Monograph Series. Tokyo: The International Institute for Buddhist Studies. [Google Scholar]
- Kruskal, Joseph B. 1956. On the shortest spanning subtree of a graph and the traveling salesman problem. Proceedings of the American Mathematical Society 7: 48–50. [Google Scholar] [CrossRef]
- Nehrdich, Sebastian. 2020. A Method for the Calculation of Parallel Passages for Buddhist Chinese Sources Based on Million-scale Nearest Neighbor Search. Journal of the Japanese Association for Digital Humanities 5: 132–53. [Google Scholar] [CrossRef] [PubMed]
- Nicoll-Johnson, Evan. 2018. Drawing Out the Essentials: Historiographic Annotation as a Textual Network. Journal of Chinese Literature and Culture 5: 214–49. [Google Scholar] [CrossRef]
- Sakuma, Hidenori, and Ulrich Timme Kragh. 2013. Remarks on the Lineage of Indian Masters of the Yogācāra School. In The Foundation for Yoga Practitioners. Edited by Ulrich Timme Kragh. Harvard Oriental Series. Cambridge, MA: Harvard University Press, vol. 75. [Google Scholar]
- Schmithausen, Lambert. 1967. Sautrāntika-Vorausetzungen in Viṃśatikā und Triṃśikā. Wiener Zeitschrift für die Kunde Süd- und Ostasiens XI: 109–250. [Google Scholar]
- Schmithausen, Lambert. 1987. Ālayavijñāna. Tokyo: The International Institute for Buddhist Studies. [Google Scholar]
- Schmithausen, Lambert. 2014. The Genesis of Yogācāra-Vijñānavāda. Tokyo: The International Institute for Buddhist Studies of the ICPBS. [Google Scholar]
- Tharsen, Jeffrey, and Clovis Gladstone. 2020. Using Philologic For Digital Textual and Intertextual Analyses of the Twenty-Four Chinese Histories 二十四史. Journal of Chinese History 中國歷史學刊 4: 558–63. [Google Scholar] [CrossRef]
- Vierthaler, Paul, and Mees Gelein. 2019. A BLAST-based, Language-agnostic Text Reuse Algorithm with a MARKUS Implementation and Sequence Alignment Optimized for Large Chinese Corpora. Journal of Cultural Analytics 4: 1–25. [Google Scholar] [CrossRef] [PubMed]
- Yin Shun (印順). 1968. A Study on the Main Works and Masters of Abhidharma, with Special Focus on the Sarvāstivāda School (說一切有部為主的論書與論師之研究). CBETA 2023.Q1, Y36, No. 34. Available online: https://cbetaonline.dila.edu.tw/Y0034 (accessed on 10 July 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text A | Text B | Weight |
|---|---|---|
| Yogācārabhūmi (T1579) | Púsà jièběn 菩薩戒本 (T1501) | 5.91 |
| Prakaraṇapāda (T1542) | *Mahāvibhāṣa (T1545) | 3.46 |
| Prakaraṇapāda (T1542) | Dhātukāya (T1540) | 3.40 |
| Yogācārabhūmi (T1579) | Wángfǎ zhènglǐ lùn 王法正理論 (T1615) | 2.74 |
| Dhātukāya (T1540) | *Mahāvibhāṣa (T1545) | 2.59 |
| Text | PageRank Score |
|---|---|
| Yogācārabhūmi (T1579) | 0.028 |
| *Mahāvibhāṣa (T1545) | 0.027 |
| *Nyāyānusāriṇī (T1562) | 0.025 |
| *Samayapradīpikā (T1563) | 0.024 |
| Dharmaskandha (T1537) | 0.023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nehrdich, S. Observations on the Intertextuality of Selected Abhidharma Texts Preserved in Chinese Translation. Religions 2023, 14, 911. https://doi.org/10.3390/rel14070911
Nehrdich S. Observations on the Intertextuality of Selected Abhidharma Texts Preserved in Chinese Translation. Religions. 2023; 14(7):911. https://doi.org/10.3390/rel14070911
Chicago/Turabian StyleNehrdich, Sebastian. 2023. "Observations on the Intertextuality of Selected Abhidharma Texts Preserved in Chinese Translation" Religions 14, no. 7: 911. https://doi.org/10.3390/rel14070911
APA StyleNehrdich, S. (2023). Observations on the Intertextuality of Selected Abhidharma Texts Preserved in Chinese Translation. Religions, 14(7), 911. https://doi.org/10.3390/rel14070911