1. Introduction
The Semantic Web is defined by Berners-Lee et al. [
1] as an extension of the current Web in which information is given a well-defined meaning, in order to allow computers and people to cooperate better than before. In this context, linked data is about creating typed links between data from different sources by using the current Web. More precisely, it is a “Web of Data” in Resource Description Format (RDF) [
2,
3].
Knowledge bases represent the backbone of the Semantic Web, and they also represent Web resources [
4]. Knowledge bases are being created by the integration of resources like Wikipedia and Linked Open Data [
5,
6] and have turned into a crystallization point for the emerging Web of Data [
7,
8]. Among the main knowledge bases on the Semantic Web, the DBpedia knowledge base represents structured information from Wikipedia, describes millions of entities, and it is available in more than a hundred languages [
9]. DBpedia uses a unique identifier to name each entity (i.e., Wikipedia page) and associates it with an RDF description that can be accessed on the Web via the URI dbr: (
http://dbpedia.org/resource/) [
10,
11]. Similarly, DBpedia is based on an ontology, represented in the namespace dbo: (
http://dbpedia.org/ontology/), that defines various classes that are used to type available entities (resources). DBpedia refers to and is referenced by several datasets on the LOD and it is used for tasks as diverse as semantic annotation [
12], knowledge extraction [
13], information retrieval [
14], querying [
15,
16] and question answering [
17].
Given the automatic extraction framework of DBpedia, along with its dynamic nature, several inconsistencies can exist in DBpedia [
18,
19,
20,
21]. One important quality problem is related to DBpedia types (classes). In fact, there exist invalid DBpedia types for some entities. For example, the DBpedia entity “dbr:Xanthine (
http://dbpedia.org/resource/Xanthine)” belongs to three DBpedia types: “dbo:ChemicalSubstance”(
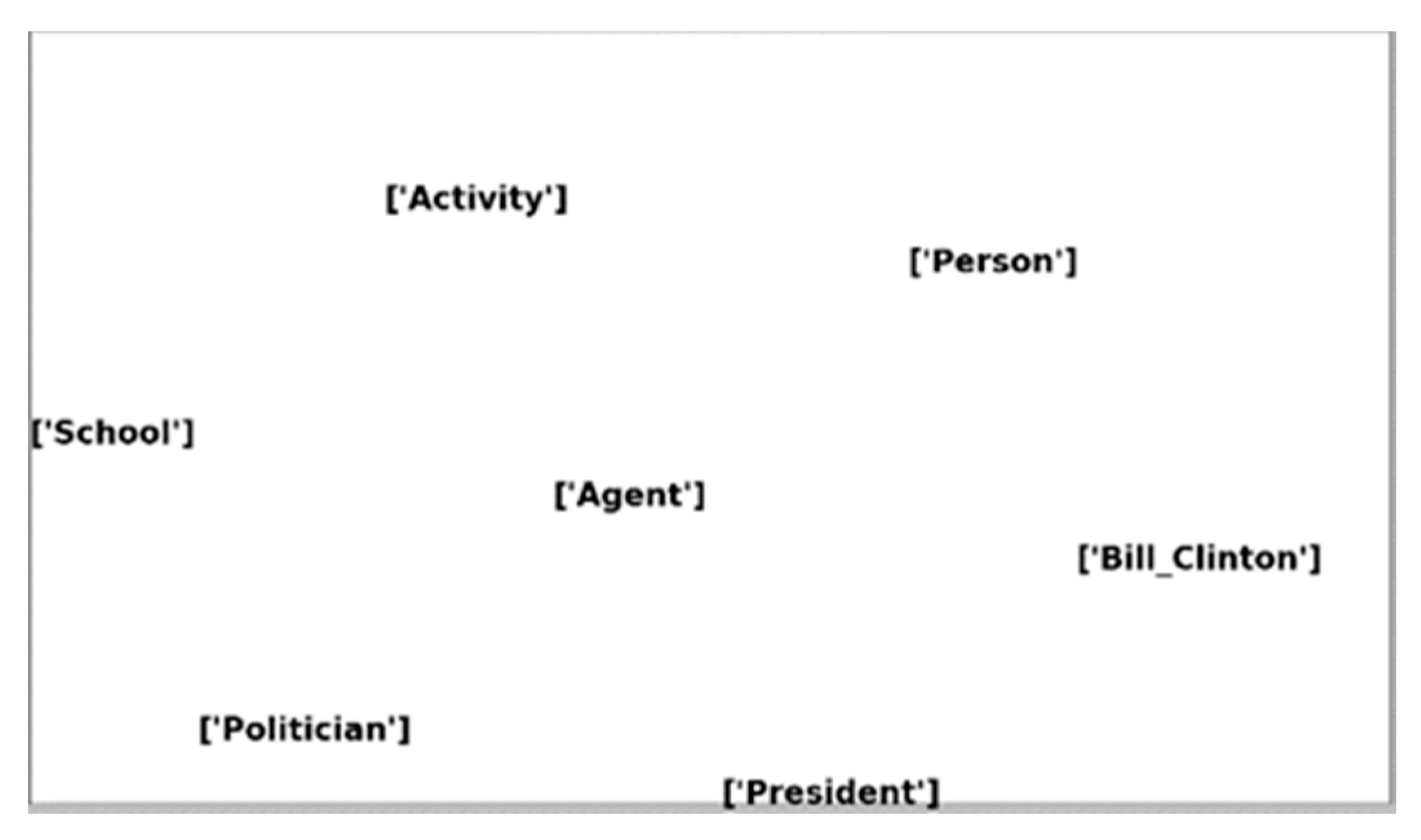
http://dbpedia.org/ontology/ChemicalSubstance), “dbo:ChemicalCompound,” and “dbo:Airport,” though “dbo:Airport” is an invalid type. Furthermore, given the size of DBpedia, type information is sometimes unavailable for some entities. Several entities are still un-typed, or not typed with all the relevant classes from the DBpedia ontology. For instance, one example of the missing type problem is the absence of the types “dbo:Politician” and “dbo:President” for the entity “dbr:Donald_Trump”. The only available types are “dbo:Person” and “dbo:Agent” which are not incorrect, but they are not specific enough. As well, another problem is that some of the available ontology classes still do not have any instances, such as “dbo:ArtisticGenre”, “dbo;TeamSport”, and “dbo:SkiResort”. Finally, invalid DBpedia entities may exist in the RDF description of an entity due to erroneous triples [
22]. Consequently, some entities are not correctly linked to other entities. For instance, the description of the DBpedia entity “dbr:Earthquake” contains the triple <dbr:Vanilla_Ice dbo:genre dbr:Earthquake>, which is an erroneous fact. Thus, “dbr:Vanilla_Ice” is considered an invalid entity in the resource description of “dbr:Earthquake”.
Identifying these invalid types and entities manually is unfeasible. In fact, the automatic enrichment and update of DBpedia with new type statements (through rdf:type) is becoming an important challenge [
23,
24]. In this paper, we rely on vector-based representations such as word embeddings and entity embeddings [
25,
26] to reach these objectives. Word embeddings are vector representations of word(s) [
27,
28,
29] that have several applications in natural language processing tasks, such as entity recognition [
30], information retrieval [
31], and question answering [
32]. Entity embeddings, as defined in this article, are similar to word embeddings [
27,
28,
29] but they differ in that they are based on vectors that describe the entity URIs instead of words [
25,
26].
In this article, we compare two vector-based representations that emerge from text, that is, n-gram models and entity embeddings models. Both types of representations are learned from Wikipedia text and represent n-grams and entities (URIs) using a vector space model. In fact, n-gram models have long been a strong baseline for text classification. The emergence of entity URIs from one side and word embeddings models from the other side represents a good opportunity for entity representation using a vector model and for the comparison of the performance of sparse vector space models with dense vectors in natural language processing tasks.
Overall, we aim at addressing the following research questions:
RQ1: How do entity embeddings compare with traditional n-gram models for type identification?
RQ2: How do entity embeddings compare with traditional n-gram models for invalid entity detection?
The article is structured as follows. In
Section 1, we discuss the motivation of this work, our goals and contributions.
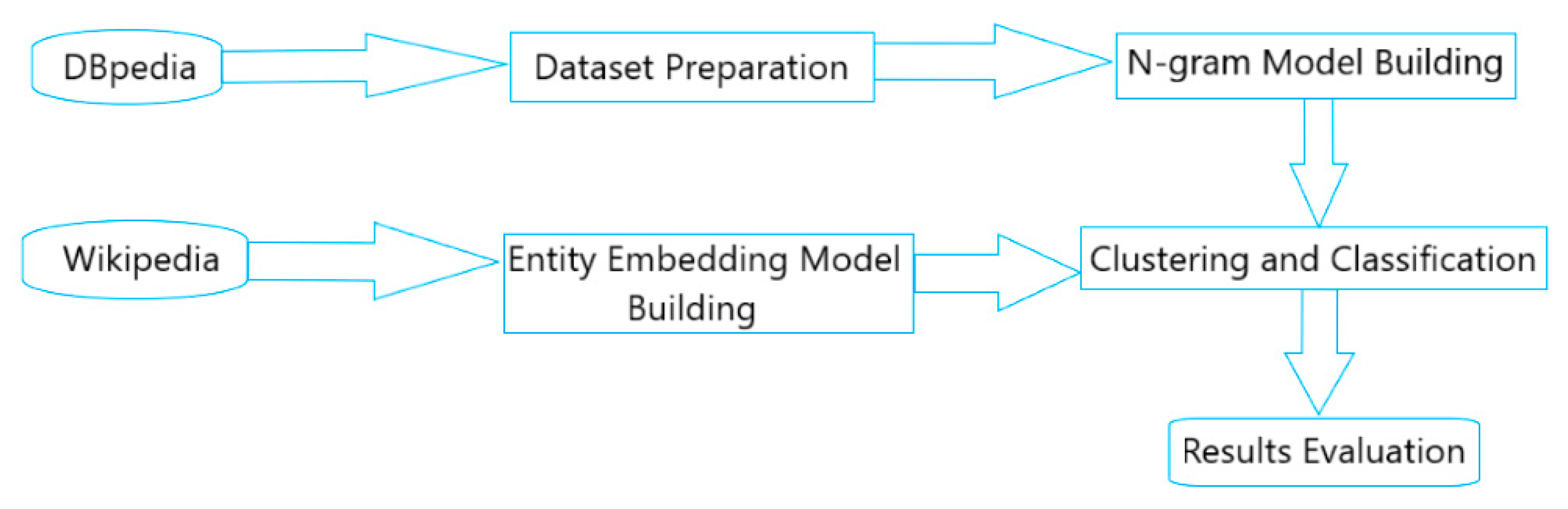
Section 2 presents background information about automatic type identification and erroneous information detection. In
Section 3, we discuss our work for collecting datasets, building entity embedding and n-gram models. Then, in
Section 4, we propose different clustering and classification methods to detect invalid DBpedia types, and complete missing types for 358 types from the DBpedia ontology. In
Section 5, we present our approach to detect invalid DBpedia resources using our own entity embedding and n-gram models. In
Section 6, we run our best trained models on the whole DBpedia, in order to see how many wrong type and invalid entities we find. In
Section 7, we conclude our work and contributions, and we discuss possible directions of work for the future. This article is an extended version of our published conference paper [
33]. In particular,
Section 4 of this article is based on the conference paper [
33].
5. DBpedia Invalid Entity Detection in Resources Description
This section describes the task of DBpedia invalid entity detection in resource description, including the methods and the experimental setups and detailed evaluation results for this task.
The task of DBpedia invalid entity detection in resource description is to detect invalid DBpedia entities in the DBpedia resource descriptions. For instance, consider the entity “dbr:Cake” where the resource description contains triples related to types of Food or ingredients. In the “dbr:Cake” description, we found one invalid entity “dbr:Ernest_Dichter”. “dbr:Ernest_Dichter” is a psychologist. Similarly, in “dbr:Farmer”, where entities are about “dbo:Agriculture”, we identified “dbr:Iowa_State_University” as an outlier, as it has the type “dbo:University” and is related to “dbo:School” and “dbo:Education” for instance.
At the time of our experiments, there were several outliers and invalid facts in some resource descriptions. However, DBpedia is a knowledge base that is updated and cleaned on a regular basis. Some of the invalid entities detected during our experiments were removed from DBpedia resources later. Based on our latest experiments, most (90%) of the DBpedia entities do not currently have any invalid entities. Thus, to be able to evaluate the interest of our approach, we built an artificial dataset by adding noisy/invalid triples in randomly selected entities. The objective of this task is to detect whether the clustering and classification algorithms can detect this external noise. For instance, in the “dbr:Cake” resource description, the external noise entities, such as “dbr:FreeBSD”, “dbr:Hydrazine”, “dbr:Johns_Hopkins_University”, etc., have indeed been detected as invalid entities. The original entities from the “Cake” resource description, such as “dbr:Cupcake”, “dbr:Butter”, “dbr:Sprinkles”, etc., have been detected as valid entities. Similarly, our approach has been able to discriminate, for the “dbr:Farmer” resource description, between invalid entities, such as “dbr:Solar_Wind”, “dbr:Linux”, and “dbr:Fibre_Channel”, and valid entities such as “dbr:Farm”, “dbr:Local_Food”, and “dbr:Agriculture”.
6. Evaluation on the Whole DBpedia Knowledge Base
In this section, we present the results of applying the Random Forest classification model on the whole DBpedia knowledge base. We performed several types of experiments: We experimented with the identification of new and similar types for entities in the DBpedia knowledge base to both ascertain the interest and accuracy of our classification procedure and the identification of wrong types for already available rdf:type statements.
Based on our experiments with the three clustering and six classification algorithms, we came to the conclusion that SVM had the best overall performance when coupled with the skip-grams model. Random Forest displayed good overall performance, and most of its results were close to Support Vector Machine. However, Support Vector Machine is slow compared to Random Forest. By taking into account both performance and efficiency, we decided to use the Random Forest classifier for our experiments on the whole DBpedia knowledge base.
There were around 4.7 million resources in DBpedia at the time of our experiments. We checked the availability of these entities in our embedding model. We found that 1.4 million of these entities were represented by a vector in our model, with a coverage rate of around 30%. Compared to the pre-built model that we first used, where only 0.22 million were available with a coverage around 5%, this is better and justifies the interest of our own word2vec model. Our explanation for absence of the remaining 3.3 million entities is the use of a threshold of 5 for taking into account an entity (an entity that occurs less than 5 times is ignored).
New types discovery. The first experiment on the whole DBpedia knowledge base tested how many entities have new types based on our methods. The experiment was processed as follows: for each DBpedia entity from the 1.4 million entities, we tested the entity with the 358 classifiers previously trained, then compared the classification results with the types already available in the DBpedia knowledge base for these entities. For example, “dbr:Donald_Trump” originally had two classes, “dbo:Person” and “dbo:Agent”, in the DBpedia knowledge base. Our classification procedure discovered four classes for the entity “dbr:Donald_Trump”: “dbo:Person”, “dbo:Agent”, “dbo:Politician”, and “dbo:President”, based on our experiment results. Thus, the new types are “dbo:President” and “dbo:Politician”. Based on the results on the whole DBpedia knowledge base, 80,797 out of 1,406,828 entities were associated with new types. There are around two new types per entity, on average. The percentage of entities with new types is 5.74%.
Table 19 shows the detailed results for the top five DBpedia classes that have the highest number of new DBpedia entities.
Below is a set of new rdf:type triples found by our classification experiments:
<dbr:Wright_R-540 rdf:type dbo:Aircraft>
<dbr:Asian_Infrastructure_Investment_Bank rdf:type dbo:Bank>
<dbr:Hernando rdf:type dbo:Place>
<dbr:Air_China_flight_129 rdf:type dbo:Airline>
<dbr:New_Imperial_Hotel rdf:type dbo:Hotel>
Type Confirmation. The second experiment counted how many entities had the same types as shown on DBpedia based on our methods. The experiment was processed as follows: for each DBpedia entity, we tested the entity with the 358 classifiers, then compared the classification results with the DBpedia knowledge base. For example, “dbr:Barack_Obama” originally had four classes: “dbo:Person”, “dbo:Agent”, “dbo:Politician”, and “dbo:President”. Based on our classification results, the four types were correctly mapped to the entity “dbr:Barack_Obama” using our classifiers. Based on the results on the whole DBpedia knowledge base, 1,144,719 out of 1,406,828 entities had the same types as those available in the DBpedia knowledge base. The percentage of the entities that have the same types is 81.37%. This shows the completeness of our classification methods and the interest of using our classifiers to automatically identify the types of new resources that will emerge in Wikipedia and DBpedia.
Table 20 shows the detailed results for the top five DBpedia classes that have the highest number of similar entities as DBpedia based on our methods.
Entity Extraction. The third experiment counted how many classes were related to new entities based on our methods. The experiment was processed as follows: for each DBpedia class, we tested the class with the entities from the whole DBpedia knowledge base using our 358 classifiers. Then we compared the classification results with the DBpedia knowledge base to find the number of classes with new entities. For example, the class “dbo:Politician” originally had more than a hundred thousand entities, such as “dbr:Barack_Obama”, “dbr:George_Bush”, “dbr:Bill_Clinton”, etc. Following our experiment, “dbr:Donald_Trump” and “dbr:Rex_Tillerson” were added as new entities to the class “dbo:Politician”. Based on the results on the whole DBpedia knowledge base, 358 out of 358 classes obtained new entities (100%).
Invalid RDF Triple Detection. The fourth experiment tested the number of invalid RDF triples through the predicate rdf:type based on our methods. The experiment was processed as follows: for each RDF triple using the predicate rdf:type:<Subject rdf:type Object> in the DBpedia knowledge base, we ran the 358 classifiers to classify the Subject and compared the output to the object. For example, based on our classification results, the Subject “dbr:Xanthine” is correctly classified with the Objects “dbo:ChemicalSubstance” and “ChemicalCompound”. Thus, the RDF triples <dbr:Xanthine rdf:type dbo:ChemicalSubstance> and <dbr:Xanthine rdf:type dbo:ChemicalCompound> are classified as valid RDF triples. However, the classification results do not find the type “dbo:Airport”. Thus, the RDF triple <dbr:Xanthine rdf:type dbo:Airport > is classified as an invalid RDF triple. Among the 4,161,452 rdf:type triples that were tested, 968,944 were detected as invalid triples. The overall percentage of invalid RDF triples is 23.28%.
The following examples show several invalid triples detected using our methods:
<dbr:Wright_R-540 rdf:type dbo:TelevisionShow>
<dbr:Asian_Infrastructure_Investment_Bank rdf:type dbo:University>
<dbr:African_Investment_Bank rdf:type dbo:University>
<dbr:Air_China_flight_129 rdf:type dbo:ArtificialSatellite>
<dbr:Lufthansa_Flight_615 rdf:type dbo:Band>
Table 21 shows the detailed results for the top five DBpedia classes that have the biggest number of invalid triples.
7. Conclusions and Future Work
In this article, we addressed the tasks of building our own entity embedding and n-gram models for DBpedia quality enhancement by detecting invalid DBpedia types, completing missing DBpedia types, and detecting invalid DBpedia entities in resources description. We compared the results of different clustering and classification algorithms, and the results of different entity embedding and n-gram models.
In the DBpedia entity type detection part (
Section 4), the experiments show that we can detect most of the invalid DBpedia types correctly, and can help us to complete missing types for un-typed DBpedia resources. In the DBpedia invalid entity detection part (
Section 5), our experimental results show that we can detect most of the invalid DBpedia entities correctly. In the experiments in both parts (
Section 4 and
Section 5), we chose the best models and algorithms, and we presented further detailed results for a sample of DBpedia types and entities. Overall, the Skip-gram entity embedding model has the best results among all of the entity embedding and the n-gram models. Given an accuracy greater than or equal to 96%, we are confident that our approach is able to complete and correct the DBpedia knowledge base.
Recalling the two research questions that we proposed at the beginning of this article:
RQ1: How do entity embeddings compare with traditional n-gram models for type identification?
The entity embeddings can help detect relevant types of an entity. Based on the results with Support Vector Machine, more than 98% of the relevant types of an entity can be detected with the Skip-gram entity embedding model. However, not all entity embedding models outperform traditional n-gram models. N-gram and uni-gram models performed better than the Continuous Bag-Of-Words (CBOW) entity embedding model.
RQ2: How do entity embeddings compare with traditional n-gram models for invalid entity detection?
All the entity embedding models (Skip-Gram, CBOW) performed better than the traditional n-gram models. Entity embeddings, and more precisely the Skip-Gram model, helped detect the relevant entities in the RDF description of a DBpedia resource. Based on our results with SVM, we showed that around 95% of the relevant entities in the RDF description of a DBpedia resource can be detected with the Skip-gram entity embedding model.
There are still some limitations to our approach. The first limitation is that vector representation of entities is the only feature for the description of DBpedia entities. Features based on the DBpedia knowledge base or extracted from the Wikipedia abstracts or complete pages could be used to enhance the performance of our classifiers. Another limitation is that our entity embedding models do not contain all of the DBpedia entities, even if they are more complete than the ones available in the state of the art. In terms of comparison with results obtained in the state of the art, our initial plan was to compare our methods with SDValidate and SDType [
41,
42]. However, we were not able to run the code provided despite repeated efforts. Similarly, the authors did not share their specific datasets extracted from DBpedia for us to be able to use the same gold standards.
Another limitation is that the approach for detecting the validity of an RDF triple in a resource description could be significantly enhanced. For example, we did not use the properties or predicates to identify the validity of an RDF triple. Most importantly, we relied on the available DBpedia descriptions as our gold standard. Given that these descriptions might contain incorrect statements, it is not clear how this impacts the discovery of invalid triples in unknown resources. Another limitation is that we only built classifiers based on 358 DBpedia classes. There are 199 DBpedia classes that do not have entities, and for which we cannot build classifiers based on our current method.
The first work for the future is to use more features rather than a single vector representation of entities. One important aspect would be to identify how properties can be exploited to assess the validity of an RDF triple rather than relying only on the semantic distance between the subject and object based on the obtained vectors. Furthermore, how to build classifiers for the 199 ontological classes without any entities in DBpedia is an important avenue for the future. Another important direction is to build larger entity embedding models to include more DBpedia entities, and also to explore how graph embeddings models such as node2vec [
52] can be used in similar experiments. In terms of the entity embedding model building, we also plan to try other entity embedding tools, such as GloVe [
53] to see if they can lead to better models.



{kind=link}
{kind=link}