Bangla DeConverter for Extraction of BanglaText from Universal Networking Language


Abstract
:1. Introduction
obj(change(icl>occur,src>thing,obj>thing,gol>thing).@entry.@present.@complete,colour(icl>kind>thing,equ>color).@def)
obj(colour(icl>kind>thing,equ>color).@def,screen(icl>surface>thing).@def)
src(change(icl>occur,src>thing,obj>thing,gol>thing).@entry.@present.@complete,red(icl>adj,equ>crimson))
gol(change(icl>occur,src>thing,obj>thing,gol>thing).@entry.@present.@complete,green(icl>adj))
{/unl}
2. Related Works
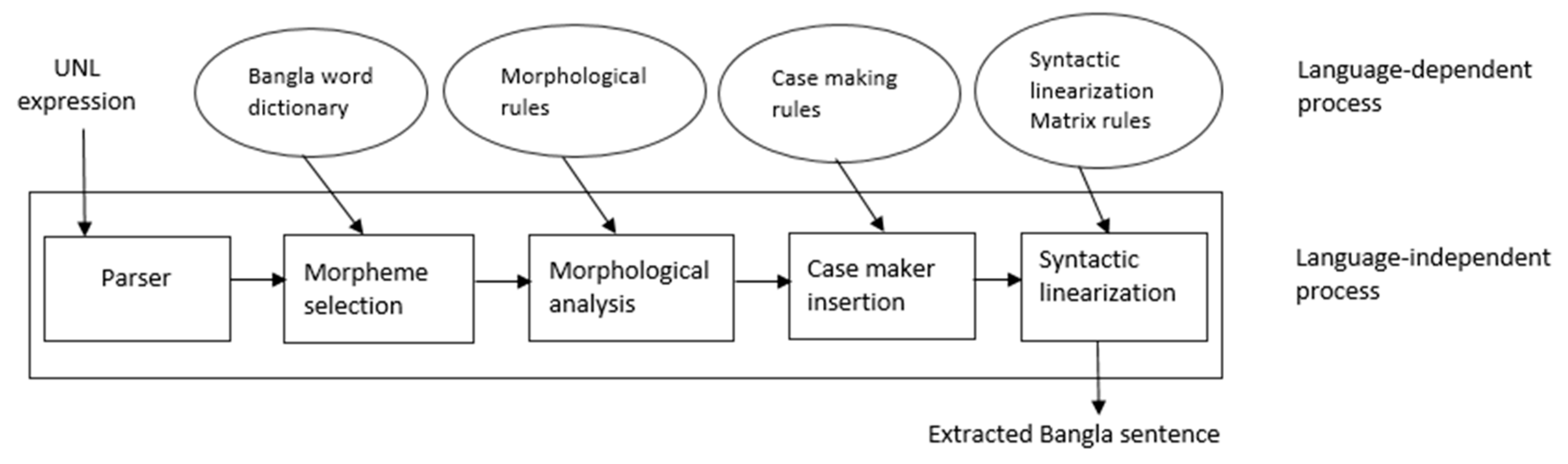
3. Architecture of Bangla DeConverter
agt(sing(icl>do).@entry.@past,girl(icl>child>person,ant>boy))
obj(sing(icl>do).@entry.@past,song(icl>musical_composition))
plc(sing(icl>do).@entry.@past,stage(icl>place))
{/unl}
UW: sing(icl>do,agt>living_thing,obj>song.@entry.@past)
Node2: Bangla word: ‘বালিকা’ pronounce as balika
UW: girl(icl>child>person,ant>boy))
Node3: Bangla word: ‘গান’ pronounce as gan
UW: song(icl>musical_composition))
Node4: Bangla word: ‘মঞ্চ’ pronounce as moncho
UW: stage(icl>place)
UW: sing(icl>do,agt>living_thing,obj>song.@entry.@past)
Node2: Bangla word: ‘বালিকা’ pronounce as balika
UW: girl(icl>child>person,ant>boy)
Node3: Bangla word: ‘গান’ pronounce as gan
UW: song(icl>musical_composition)
Node4: Bangla word: ‘মঞ্চ’ pronounce as moncho
UW: stage(icl>place)
UW: sing(icl>do,agt>living_thing,obj>song.@entry.@past)
Node2: Bangla word: ‘বালিকাটি’pronounce as balikati
UW: girl(icl>child>person,ant>boy)
Node3: Bangla word: ‘গান’pronounce as gan
UW: song(icl>musical_composition)
Node4: Bangla word: ‘মঞ্চে’ pronounce as monche
UW: stage(icl>place)
4. Phases of Bangla DeConverter
4.1. Parser Phase
4.2. Morpheme Selection Phase
4.3. Morphological Analysis Phase
| Root | + | Verbal Inflexion | = | Verb |
| খা | + | ইতেছি | ইতেছি | খাইতেছি |
| verb | + | suffix | = | verbal noun |
| চল | + | অন্ত | = | চলন্ত |
4.4. Case Maker Insertion Phase
- The first column (UNL relation name): This column stores the UNL relations’ name in which the rule is being made. For example; agt (agent relation), obj (object relation), etc.
- The second column (The case maker preceding the parent node): This column stores the case maker that can be inputted before the parent node of a given UNL relation in produced output.
- The third column (The case maker following the parent node): This column stores the case maker that can be inputted after the parent node of a given UNL relation in produced output.
- The fourth column (The case maker preceding the child node): This column stores the case maker that can be inputted before the child node of a given UNL relation in produced output.
- The fifth column (The case maker following the child node): This column stores the case maker that can be inputted after the child node of a given UNL relation in produced output.
- The sixth column (Positive condition for the parent node): This column stores attributes that need to be declared on the parent node for firing the rule.
- The seventh column (Negative conditions for the parent node): This column stores attributes that need to be declared on the parent node for firing the rule.
- The eighth column (Positive condition for the child node): This column stores attributes that need to be declared on the child node for firing the rule.
- The ninth column (Negative conditions for the child node): This column stores attributes that need to be asserted on the child node for firing the rule.
4.5. Syntactic Linearization Phase
5. Issues in Syntactic Linearization
5.1. Parent–Child Relation
agt(write(icl>do,equ>compose).@entry.@present.@progress,he(icl>person))
obj(write(icl>do,equ>compose).@entry.@present.@progress,letter(icl>text).@indef)
{/unl}
5.2. Matrix-Based Priority of Relations
6. Syntactic Linearization of Simple and Compound Sentences
6.1. Syntactic Linearization of Simple Sentence
agt(earn(icl>do).@entry.@present.@complete,she(icl>person))
qua(dollar(icl>monetary_unit).@pl,100)
obj(earn(icl>do).@entry.@present.@complete,dollar(icl>monetary_unit>thing).@pl)
{/unl}
UW: earn(icl>do,agt>person,obj>thing,ins>uw)
Node2: Bangla word: সে (মহিলা), pronounce as ‘se (mohila)
UW: she(icl>person)
Node3: Bangla word: ডলার, pronounce as dollar
UW: dollar(icl>monetary_unit>thing)
Node4: Bangla word: ১০০, pronounce as 100
UW: 100
6.2. Syntactic Linearization of Compound Sentence
{/org}
{unl}
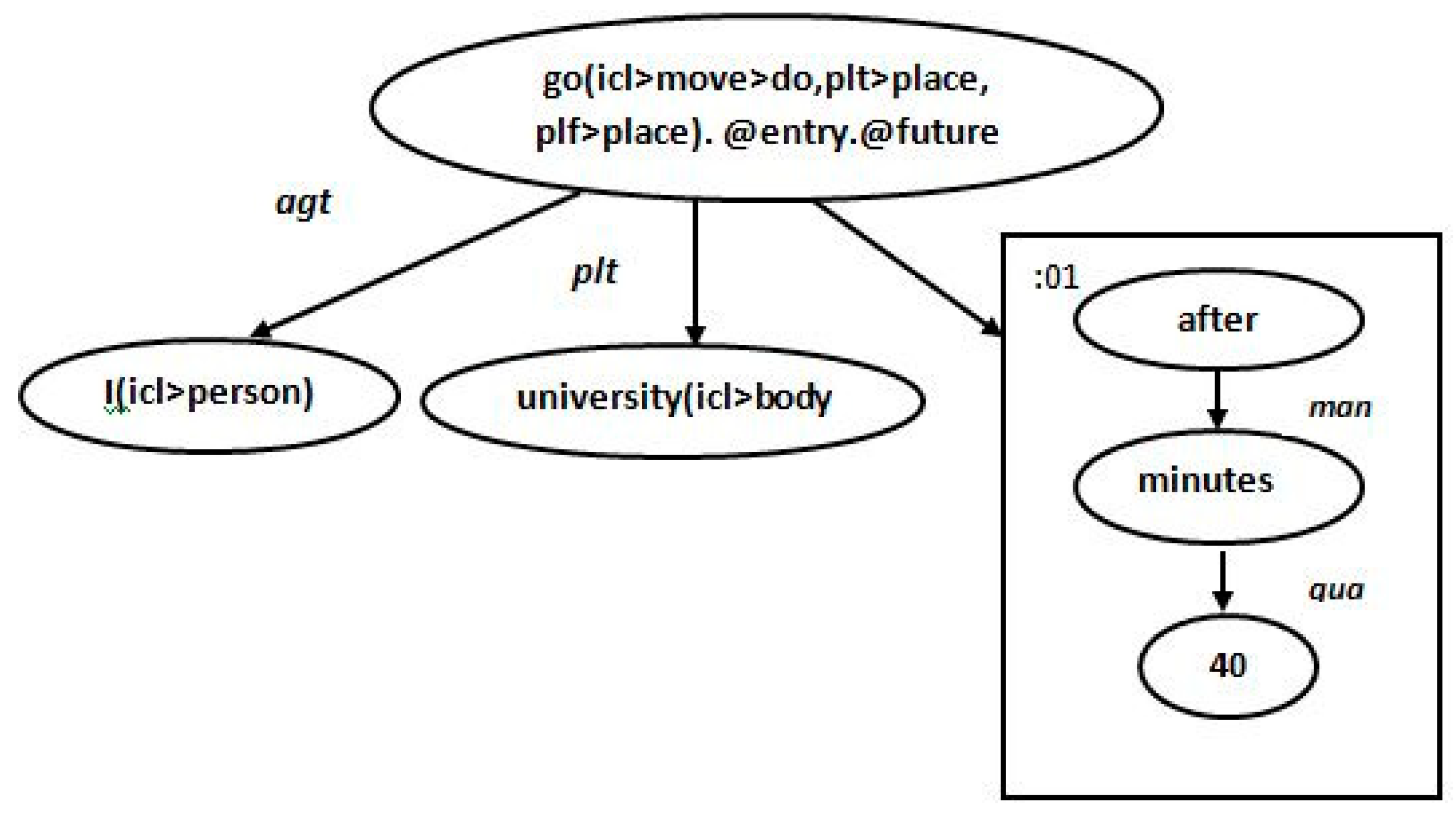
agt(go).@entry.@future,i(icl>person))
plt(go.@entry.@future,university(icl>body))
tim(go.@entry.@future,:01))
man:01(after,@entry, minutes)
qua:01(minute.@pl,40)
{/unl}
[/S]
7. Experimental Results and Discussions
7.1. Extraction of a Bangla Sentence
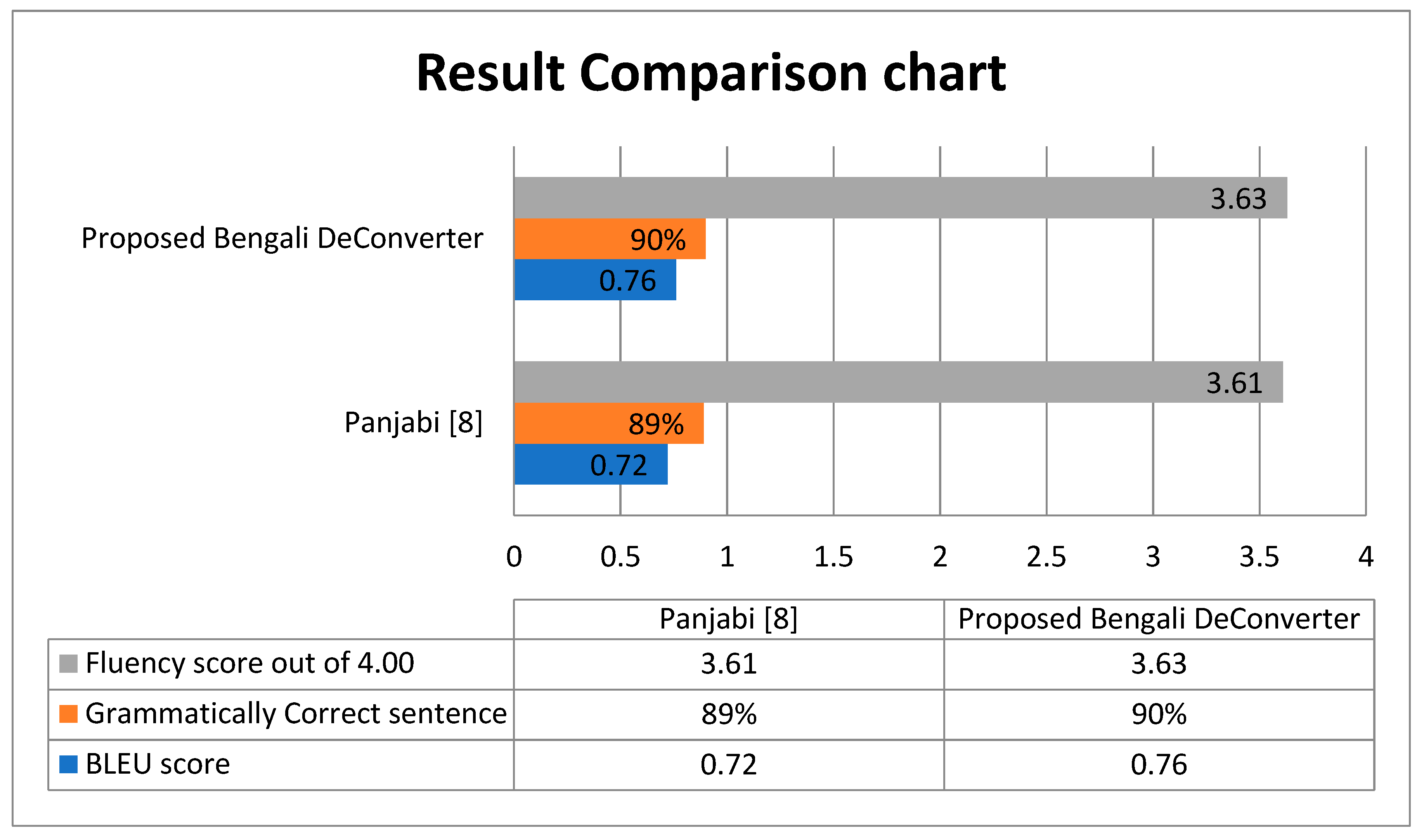
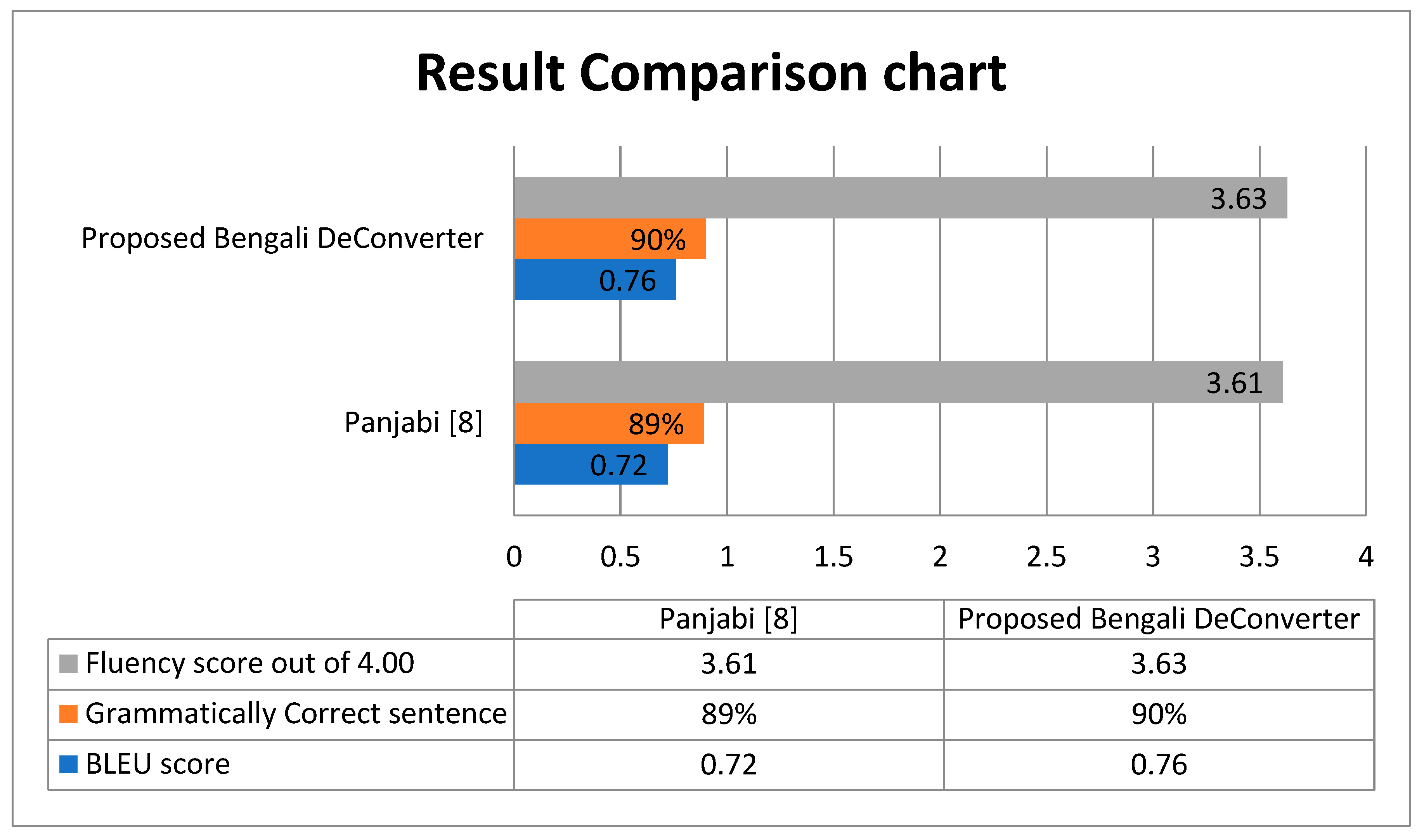
7.2. Results and Discussions
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Uchida, H.; Zhu, M.; Senta, T.C.D. Universal Networking Language, UNDL Foundation. Int. Environ. House 2005, 6. [Google Scholar]
- EnConverter Specification, Version 3.3; UNL Center/UNDL Foundation: Tokyo, Japan, 2002.
- Boguslavsky, I.; Frid, N.; Iomdin, L.; Kreidlin, L.; Sagalova, I.; Sizov, V. Creating a Universal Networking Language module within an advanced NLP system. In Proceedings of the 18th conference on Computational Linguistics, Saarbrücken, Germany, 31 July–4 August 2000; Volume 1, pp. 83–89. [Google Scholar]
- DeConverter Specification, Version 2.7; UNL Center, UNDL Foundation: Tokyo, Japan, 2002.
- Martins, R.T.; Hasegawa, R.; Rino, L.H.M.; Oliveira Junior, O.N.D.; Nunes, M.D.G.V. Specification of the UNL-Portuguese enconverter-deconverter prototype. 1997. Available online: https://bdpi.usp.br/item/000951455 (accessed on 21 October 2019).
- Dave, S.; Parikh, J.; Bhattacharyya, P. Interlingua-based English–Hindi Machine Translation and Language Divergence. Comput. Transl. 2001, 16, 251–304. [Google Scholar]
- Kumar, P.; Sharma, R.K. Punjabi DeConverter for generating Punjabi from Universal Networking Language. J. Zhejiang Univ. Sci. C 2013, 14, 179–196. [Google Scholar] [CrossRef]
- Blanc, E. About and around the French Enconverter and the French Deconverter. Univers. Netw. Lang. Adv. Theory Appl. 2005, 12, 157–166. [Google Scholar]
- Shi, X.; Chen, Y. A Unl Deconverter for Chinese; UNL Book: Instituto Politécnico Nacional, Mexico, 2005. [Google Scholar]
- Daoud, D.M. Arabic generation in the framework of the Universal Networking Language. Univers. Netw. Lang. Adv. Theory Appl. 2005, 12, 195–209. [Google Scholar]
- Keshari, B.; Bista, K. UNL Nepali DeConverter. In Proceedings of the 3rd International Conference on CALIBER, Cochin University of Science and Technology, Kochi, India, 2–4 February 2005; pp. 70–76. [Google Scholar]
- Singh, S.; Dalal, M.; Vachhani, V.; Bhattacharyya, P.; Damani, O.P. Hindi generation from Interlingua (UNL). In Proceedings of the Machine Translation Summit XI, Copenhagen, Denmark, 10–14 September 2007. [Google Scholar]
- Nalawade, A. Natural Language Generation from Universal Networking Language. Master’s Thesis, Indian Institute of Technology, Bombay/Mumbai, India, 2007. [Google Scholar]
- Vachhani, V. UNL to Hindi DeConverter. Bachelor’s Thesis, Dharamsinh Desai Institute of Technology, Nadiad, India, 2006. [Google Scholar]
- Dey, K.; Bhattacharyya, P. Universal Networking Language based analysis and generation of Bangla case structure constructs. Univers. Netw. Lang. Adv. Theory Appl. 2006, 12, 215–229. [Google Scholar]
- Vora, A. Generation of Hindi sentences from Universal Networking Language. Bachelor’s Thesis, Dharamsinh Desai Institute of Technology, Nadiad, India, 2002. [Google Scholar]
- Hrushikesh, B. Towards Marathi Sentence Generation from Universal Networking Language. Master’s Thesis, Indian Institute of Technology, Bombay/Mumbai, India, 2002. [Google Scholar]
- Ru: Russian and English Language Server. Available online: http://www.unl.ru (accessed on 18 August 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [আমি] { }“i(icl>person)”(PRO, HPRO,SUB,P1,SG) |
| [ভাত]{ } “rice(icl>grain>thing)”(N, OBJ, NCOM,CEN) |
| [খে]{ } “eat(icl>consume>do,agt>living_thing,obj>concrete_thing)” (ROOT,VEN,AGT,OBJ,VEG1) |
| [য়ে]{ }“VI” (VI,VEN,P1,PRE) |
| [ইউনিভার্সিটি]{ } “office(icl>body>thing)”(N, |
| [যা]{ } “go(icl>move>do,plt>place,plf>place,agt>thing)”(VR, VEN,AGT,PLT,PLF,P1) |
| [বো]{ }“VI” (VI,VEN,P1,FUT) |
| Rule 1: (Pronoun insertion) |
| :”HPRO,P1,SUB,^@pl,::agt:”{ROOT,VEN,^AL,#AGT,^p1:p1::} |
| Rule 2: R{:::}{SUB:::} |
| Rule 3: {SUB,^blk:blk::}”[],BLK:::”} |
| Rule 4: -R{:::}{SUB:::} |
| Rule 5: -R{SUB:::} {:::} |
| Rule 6: “N,^OBJ:OBJ::”{ROOT,VEN,#OBJ::} |
| Rule 7: R{PRO:::}{N:::} |
| Rule 8: R{N:::} {ROOT:::} |
| Rule 9: {ROOT,VEN,p1,@present,^@progress,^@complete,^vi:vi::}”[[VI]],VI,VEN,P1,PRE,^PRG,^CMPL:::”} |
| Rule 10: R{PRO:::}{N:::} |
| Rule 11: “N,^OBJ:OBJ::”{ROOT,VEN,#OBJ::}P7; |
| Rule 12: {SUB,^blk:blk::}”[],BLK:::”} |
| Rule 13: R{N:::}{:::} |
| Rule 14: {N:::} {ROOT,VEN,#OBJ::} |
| Rule 15: R{ROOT:::} {:::} |
| Rule 16: {ROOT,VEN,p1,@future,^@progress,^@complete,^vi:vi::}”[[VI]],VI,VEN,P1,FUT,^PRG,^CMPL:::”} |
| Rule 17: R{:::} {V:::} |
| Sentence No. | Input UNL Expressions | Bangla Sentences Produced by Bangla DeConverter |
|---|---|---|
| 1 | {unl} agt(spend(icl>pass>do,com>time,).@entry.@past,i(icl>person)) pos(holiday(icl>leisure>thing,equ>vacation),i(icl>person)) obj(spend(icl>pass>do,com>time).@entry.@past,holiday(icl>leisure>thing,equ>vacation)) plc(holiday(icl>leisure>thing,equ>vacation),paris(iof>national_capital>thing)) {/unl} | আমি ছুটির দিন পারিসে কাটিয়েছি Ami chhutir din parishe katiechhi I spent my holiday in Paris. |
| 2 | {unl} agt(perform_an_action(icl>do).@entry.@present,we(icl>group).@pl) pos(work(icl>activity>abstract_thing),we(icl>group).@pl) obj(perform_an_action(icl>do).@entry.@present,work(icl>activity>abstract_thing)) man(perform_an_action(icl>do).@entry.@present,perfectly(icl>how,equ>absolutely)) {/unl} | আমরা আমাদের কাজ সঠিকভাবে করি। Amra amader kaj shothikvabe kori We do our work perfectly |
| 3 | {unl} aoj(city(icl>administrative_district).@entry.@present,tokyo(iof>national_capital>thing)) man(beautiful(icl>adj,ant>ugly),very(icl>how,equ>extremely)) mod(city(icl>administrative_district).@entry.@indef.@present,beautiful(icl>adj,ant>ugly)) {/unl} | টকিও একটি সুন্দর শহর। Tokyo ekti shundor shohor Tokyo is a very beautiful city. |
| 4 | {unl} aoj(have(icl>be,equ>possess,obj>thing,aoj>thing).@entry.@present,i(icl>person)) obj(have(icl>be,equ>possess,).@entry.@present,tomorrow(icl>time,ant>yesterday)) aoj(meet(icl>join>be,cao>thing,aoj>thing).@progress,tomorrow(icl>time,,ant>yesterday)) {/unl} [/S] | আগামিকাল আমার একটা মিটিং আছে। Agamikal amar ekti meeting achhe I have a meeting tomorrow. |
| 5 | {unl} agt(go(icl>move>do,plt>place,plf>place,agt>thing).@entry.@present,they(icl>group).@pl) plt(go(icl>move>do,plt>place).@entry.@present,office(icl>organization,icl>place)) met(go(icl>move>do,plt>place).@entry.@present,car(icl>motor_vehicle>thing)) {/unl} | তারাএকটিগাড়িতেকরেঅফিসজায়। Tara ekti garite kore office jaye. They go to office by a car. |
| 6 | {unl} aoj(admit(icl>icl>give_access>be,plt>place).@entry.@past,he(icl>person)) plc(admit(icl>give_access>be,plt>place).@entry.@past,hospital(icl>medical_institution>)) rsn(admit(icl>give_access>be,plt>place).@entry.@past,illness(icl>ill_health>thing)) {/unl} | সে অসূস্ত হওয়ায় হাসপাতাল ভর্তি হয়েছে। Se oshusto howaye haspatale vorti hoyeche He admitted in a hospital due to illness |
| 7 | {unl} agt(go(icl>move>do,plt>place,plf>place,agt>thing).@entry.@present,i(icl>person)) plt(go(icl>move>do,plt>place).@entry.@present,australia(iof>country>thing)) via(australia(iof>country>thing),singapore(iof>island>thing)) {/unl} | আমি সিঙ্গাপুর হয়ে অস্ট্রেলিয়া জাই। Ami Singapore hoye Australia jai I go to Australia via Singapore. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.N.Y.; Rahman, M.L.; Sorwar, G. Bangla DeConverter for Extraction of BanglaText from Universal Networking Language. Information 2019, 10, 324. https://doi.org/10.3390/info10100324
Ali MNY, Rahman ML, Sorwar G. Bangla DeConverter for Extraction of BanglaText from Universal Networking Language. Information. 2019; 10(10):324. https://doi.org/10.3390/info10100324
Chicago/Turabian StyleAli, Md. Nawab Yousuf, Md. Lizur Rahman, and Golam Sorwar. 2019. "Bangla DeConverter for Extraction of BanglaText from Universal Networking Language" Information 10, no. 10: 324. https://doi.org/10.3390/info10100324
APA StyleAli, M. N. Y., Rahman, M. L., & Sorwar, G. (2019). Bangla DeConverter for Extraction of BanglaText from Universal Networking Language. Information, 10(10), 324. https://doi.org/10.3390/info10100324