Attention-Based Joint Entity Linking with Entity Embedding

Abstract
:1. Introduction
- We present an entity embedding framework, which can effectively capture different information aspects.
- We are the first ones who use a CRF-based attention mechanism to capture the important text spans in the mention context, to improve the performance of our linking system.
- We take the coherence among mentions into consideration with the Forward-Backward algorithm, which is less time consuming than those graph-based models used in previous work.
- Based on the above three contributions, we build our global model. Our experimental results show that our model can achieve a competitive, or better, performance than state-of-the-art models.
2. Related Work
2.1. Encoding of Entity
2.2. Encoding of Mention Context
2.3. Modeling Coherence among Mentions
3. Definition
4. Model
4.1. Framework of Entity Embedding
4.1.1. Encoder for Entity Context
4.1.2. Encoder for Entity Description
4.1.3. Combine Different Information Aspects
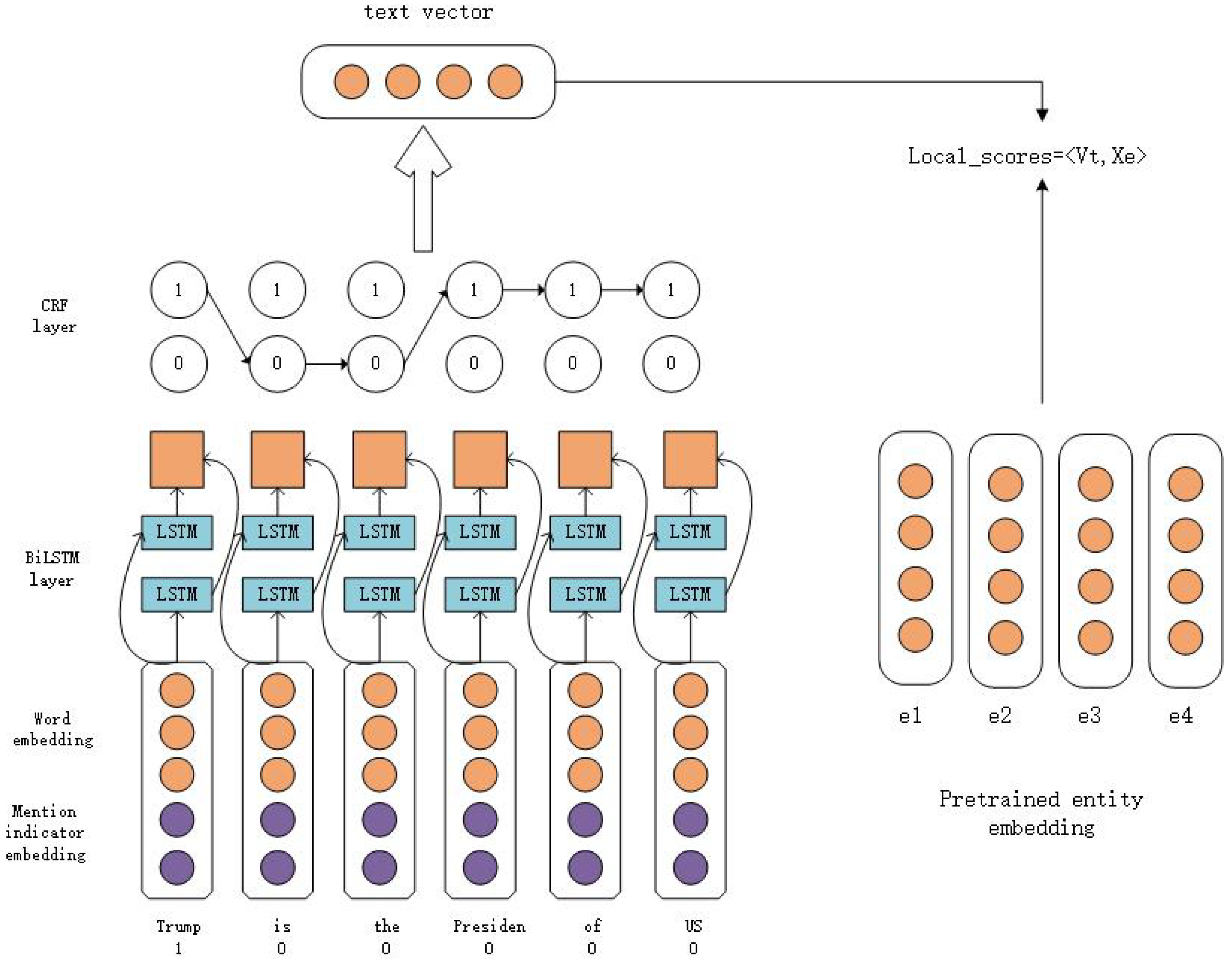
4.2. Attention-Based Local Model
4.3. Global Model
5. Experiments
5.1. Datasets
5.2. Candidate Generation
5.3. Disambiguation Step
5.3.1. Hyper-Parameters Setting
5.3.2. Evaluation Matrix
5.4. Case Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling mention, context and entity with neural networks for entity disambiguation. In Proceedings of the IJCAI’15 Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1333–1339. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective Entity Linking in Web Text: A Graph-based Method. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’11), Beijing, China, 24–28 July 2011; ACM: New York, NY, USA, 2011; pp. 765–774. [Google Scholar] [CrossRef]
- Zwicklbauer, S.; Seifert, C.; Granitzer, M. Robust and Collective Entity Disambiguation Through Semantic Embeddings. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’16), Pisa, Italy, 17–21 July 2016; ACM: New York, NY, USA, 2016; pp. 425–434. [Google Scholar] [CrossRef]
- Gupta, N.; Singh, S.; Roth, D. Entity Linking via Joint Encoding of Types, Descriptions, and Context. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2681–2690. [Google Scholar] [CrossRef]
- Guo, Z.; Barbosa, D. Robust Entity Linking via Random Walks. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM’14), Shanghai, China, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 499–508. [Google Scholar] [CrossRef]
- Chen, Z.; Tamang, S.; Lee, A.; Li, X.; Lin, W.; Snover, M.G.; Artiles, J.; Passantino, M.; Ji, H. CUNY-BLENDER TAC-KBP2010 Entity Linking and Slot Filling System Description. In Proceedings of the Third Text Analysis Conference, TAC 2010, Gaithersburg, MD, USA, 15–16 November 2010. [Google Scholar]
- Pappu, A.; Blanco, R.; Mehdad, Y.; Stent, A.; Thadani, K. Lightweight Multilingual Entity Extraction and Linking. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (WSDM’17), Cambridge, UK, 6–10 February 2017; ACM: New York, NY, USA, 2017; pp. 365–374. [Google Scholar] [CrossRef]
- Ganea, O.E.; Hofmann, T. Deep Joint Entity Disambiguation with Local Neural Attention. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2619–2629. [Google Scholar] [CrossRef]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, 11–12 August 2016; pp. 250–259. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Stajner, T.; Mladenic, D. Entity Resolution in Texts Using Statistical Learning and Ontologies. In Proceedings of the Semantic Web, Fourth Asian Conference, ASWC 2009, Shanghai, China, 6–9 December 2009; pp. 91–104. [Google Scholar] [CrossRef]
- Phan, M.C.; Sun, A.; Tay, Y.; Han, J.; Li, C. Pair-Linking for Collective Entity Disambiguation: Two Could Be Better Than All. CoRR 2018, abs/1802.01074. Available online: http://xxx.lanl.gov/abs/1802.01074 (accessed on 31 January 2019). [CrossRef]
- Wang, B.; Lu, W. Learning Latent Opinions for Aspect-level Sentiment Classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 5537–5544. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Francis-Landau, M.; Durrett, G.; Klein, D. Capturing Semantic Similarity for Entity Linking with Convolutional Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2016), San Diego, CA, USA, 12–17 June 2016; pp. 1256–1261. [Google Scholar]
- Association for Computational Linguistics (ACL). Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7–12, 2016, Berlin, Germany, Volume 1: Long Papers; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar]
- Moro, A.; Raganato, A.; Navigli, R. Entity Linking meets Word Sense Disambiguation: A Unified Approach. TACL 2014, 2, 231–244. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngomo, A.N.; Röder, M.; Gerber, D.; Coelho, S.A.; Auer, S.; Both, A. AGDISTIS—Graph-Based Disambiguation of Named Entities Using Linked Data. In Proceedings of the Semantic Web—ISWC 2014—13th International Semantic Web Conference, Riva del Garda, Italy, 19–23 October 2014; Part I. pp. 457–471. [Google Scholar] [CrossRef]
- Kulkarni, S.; Singh, A.; Ramakrishnan, G.; Chakrabarti, S. Collective annotation of Wikipedia entities in web text. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June 28–1 July 2009; pp. 457–466. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; A Meeting of SIGDAT, a Special Interest Group of the ACL. pp. 1746–1751. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust Disambiguation of Named Entities in Text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, John McIntyre Conference Centre, Edinburgh, UK, 27–31 July 2011; A Meeting of SIGDAT, a Special Interest Group of the ACL. pp. 782–792. [Google Scholar]
- Guo, Z.; Barbosa, D. Robust named entity disambiguation with random walks. Semant. Web 2018, 9, 459–479. [Google Scholar] [CrossRef]
- Gabrilovich, E.; Ringgaard, M.; Subramanya, A. FACC1: Freebase Annotation of ClueWeb Corpora, Version 1 (Release Date 2013-06-26, Format Version 1, Correction Level 0). 2013. Available online: https://www.researchgate.net/publication/267026725_FACC1_Freebase_annotation_of_ClueWeb_corpora_Version_1_Release_date_2013-06-26_Format_version_1_Correction_level_0 (accessed on 29 January 2019).
- Spitkovsky, V.I.; Chang, A.X. A Cross-Lingual Dictionary for English Wikipedia Concepts. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, LREC 2012, Istanbul, Turkey, 23–25 May 2012; pp. 3168–3175. [Google Scholar]
- Ratinov, L.; Roth, D.; Downey, D.; Anderson, M. Local and Global Algorithms for Disambiguation to Wikipedia. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1375–1384. [Google Scholar]
- Fang, W.; Zhang, J.; Wang, D.; Chen, Z.; Li, M. Entity Disambiguation by Knowledge and Text Jointly Embedding. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, 11–12 August 2016; pp. 260–269. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number Docs | Number Mentions |
|---|---|---|
| AIDA-train | 946 | 18,448 |
| AIDA-A (valid) | 216 | 4971 |
| AIDA-B (test) | 231 | 4485 |
| WNED-CWEB | 320 | 11,154 |
| ACE04 | 36 | 257 |
| AQUAINT | 50 | 727 |
| Datasets | Number Linkable Mentions | Gold Recall |
|---|---|---|
| AIDA-train | 18,143 | 0.98 |
| AIDA-A (valid) | 4665 | 0.97 |
| AIDA-B (test) | 4359 | 0.97 |
| WNED-CWEB | 233 | 0.90 |
| ACE04 | 10,983 | 0.93 |
| AQUAINT | 694 | 0.96 |
| Parameters | Search Space | Value |
|---|---|---|
| dim of ,, | {100,200,300} | 200 |
| dropout rate | {0.2,0.3,0.4,0.5} | 0.4 |
| batch size | {300,600,900,1200} | 600 |
| Parameters | Search Space | Value |
|---|---|---|
| dim of | {200,300,400} | 300 |
| dim of | {10,20,30,40} | 30 |
| dim of hidden state in Bi-LSTM | {50,100,150,200} | 100 |
| dropout rate | {0.2,0.3,0.4,0.5} | 0.4 |
| [0,0.2] with step size 0.04 | 0.1 | |
| [0,0.2] with step size 0.04 | 0.04 |
| Models | AIDA-B | AIDA-A |
|---|---|---|
| Hoffart et al., 2011 [22] | 81.8 | - |
| Landau et al., 2016 [16] | 85.5 | 86.9 |
| Gupta et al., 2017 [4] | 82.9 | 84.9 |
| LSTM-MEAN | 83.4 | 84.2 |
| LSTM-A | 83.8 | 89.7 |
| LSTM-A-R | 84.4 | 90.7 |
| Global Model C | 87.1 | 90.3 |
| Global Model D | 86.9 | 90.3 |
| Global Model CD | 87.6 | 91.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Li, F.; Sun, X.; Han, H. Attention-Based Joint Entity Linking with Entity Embedding. Information 2019, 10, 46. https://doi.org/10.3390/info10020046
Liu C, Li F, Sun X, Han H. Attention-Based Joint Entity Linking with Entity Embedding. Information. 2019; 10(2):46. https://doi.org/10.3390/info10020046
Chicago/Turabian StyleLiu, Chen, Feng Li, Xian Sun, and Hongzhe Han. 2019. "Attention-Based Joint Entity Linking with Entity Embedding" Information 10, no. 2: 46. https://doi.org/10.3390/info10020046